 Bo Liu
Bo Liu Shusen Wei
Shusen Wei Fan Zhang1,2
Fan Zhang1,2 Hongyu Fan
Hongyu Fan Wei Yao
Wei Yao- 1College of Information Science and Technology, Hebei Agricultural University, Baoding, China
- 2Hebei Key Laboratory of Agricultural Big Data, Baoding, China
Introduction: Tomato leaf diseases can cause major yield and quality losses. Computer vision techniques for automated disease recognition show promise but face challenges like symptom variations, limited labeled data, and model complexity.
Methods: Prior works explored hand-crafted and deep learning features for tomato disease classification and multi-task severity prediction, but did not sufficiently exploit the shared and unique knowledge between these tasks. We present a novel multi-task distillation learning (MTDL) framework for comprehensive diagnosis of tomato leaf diseases. It employs knowledge disentanglement, mutual learning, and knowledge integration through a multi-stage strategy to leverage the complementary nature of classification and severity prediction.
Results: Experiments show our framework improves performance while reducing model complexity. The MTDL-optimized EfficientNet outperforms single-task ResNet101 in classification accuracy by 0.68% and severity estimation by 1.52%, using only 9.46% of its parameters.
Discussion: The findings demonstrate the practical potential of our framework for intelligent agriculture applications.
1 Introduction
Tomato is one of the most widely cultivated vegetables in the world, with its versatility extending to various applications such as a culinary ingredient (Kumar et al., 2022), an industrial raw material (Botineştean et al., 2015), a component in cosmetics (Septiyanti and Meliana, 2020), and medicinal uses (Kumar et al., 2012). However, tomato diseases can rapidly spread through a field if not identified and managed in a timely manner, leading to substantial losses in both yield and quality of the crop (Zhang et al., 2022). As symptoms of many tomato diseases can appear on the leaves, leveraging computer vision techniques for automated recognition of leaf diseases has attracted widespread attention from researchers (Boulent et al., 2019; Habib et al., 2020; Nanehkaran et al., 2020; Roy and Bhaduri, 2021; Albahli and Nawaz, 2022; Harakannanavar et al., 2022). Although these techniques effectively improve the accuracy and speed of disease diagnosis, they also present challenges. These include variations in disease symptoms and lighting conditions (Zhang et al., 2018a), difficulty in collecting enough disease samples (Zhang et al., 2021), varying levels of disease severity (Wang et al., 2021), and limitations in computing power (Bi et al., 2022). Such factors potentially influence the applicability of the learning models.
Most of the computer vision-based leaf disease recognition methods are mainly divided into two categories: hand-crafted feature-based methods and deep learning-based methods. Traditionally, hand-crafted features refer to the manual extraction of specific features such as textures, colors, shapes, and sizes from leaf images. These features are then used as input for training a classifier to identify the presence of plant diseases. The utilization of classical classifiers, such as support vector machines (SVM) (Cortes and Vapnik, 1995) and random forests (RF) (Breiman, 2001), has been instrumental in leaf disease identification, owing to their robust nature in handling high-dimensional, noisy, and missing data (Patil et al., 2017). Consequently, the research community has significantly focused on developing improved methods for feature extraction to enhance recognition performance. Mokhtar et al. (2015) employed geometric features and histogram features for classifying two tomato leaf viruses, achieving the highest accuracy of 91.5% using the Quadratic kernel function. Meenakshi et al. (2019) improved plant leaf disease identification using exact Legendre moments shape descriptors, with a high accuracy of 99.1% on three tomato diseases (early and late blight and mosaic). In Rahman et al. (2022), texture features from tomato leaf images were analyzed using a gray level co-occurrence matrix (GLCM). In addition to single-type features, hybrid features have been well-studied. Sharif et al. (2018) proposed a hybrid method for automatic detection and classification of six types of diseases in citrus plants, which used color, texture, and geometric features combined in a codebook and selected by PCA score, entropy, and skewness-based covariance vector before being fed to a multi-class SVM. Similarly, Basavaiah and Arlene Anthony (2020) recognized four main diseases in tomato plants through the fusion of multiple features, including color histograms, Hu Moments, Haralick, and local binary pattern, resulting in 94% accuracy achieved by a RF classifier. In summary, hand-crafted feature-based methods are highly valued for their simplicity and interpretability, as well as they have demonstrated satisfactory performance on small to medium-sized datasets. However, they struggle to scale up large and diverse datasets, and fall short in coping with biases and noises in the data distribution, leading to decreased accuracy and robustness in real-world applications.
Recently, deep learning has revolutionized the field of computer vision, resulting in significant improvements in detecting leaf diseases (Sujatha et al., 2021; Shoaib et al., 2022). For instance, a novel tomato leaf disease recognition framework was proposed, which used binary Wavelet transform for image preprocessing to remove noise, and both-channel residual attention network (B-ARNet) for identification (Sujatha et al., 2021). Other types of attention mechanisms are also incorporated to enhance the model’s recognition capability. In Zhao et al. (2021), to adaptively recalibrate channel-wise feature responses, a squeeze-and-excitation (SE) module (Hu et al., 2018) is integrated into a ResNet50 network (He et al., 2016), with an average identification accuracy of 96.81% on the publicly available PlantVillage dataset (Hughes et al., 2015).
Additionally, Bhujel et al. (2022) compared the performance and computational complexity of different attention modules and found that the convolutional block attention module (CBAM) (Woo et al., 2018) was the most effective in enhancing classification performance, resulting in an average accuracy of 99.69%. Despite the successes of these deep learning-based methods, they face limitations such as the need for large amounts of labeled data and substantial computational resources. To address these challenges, researchers have proposed a series of strategies for constructing lightweight networks, such as depthwise separable convolutions (MobileNet (Howard et al., 2017)), channel shuffling (ShuffleNet (Zhang et al., 2018a)), and a combination of network scaling and architecture search (EfficientNet (Tan and Le, 2019)). For example, Zeng et al. (2022) developed a lightweight CNN model named LDSNet, which uses an improved dense dilated convolution (IDDC) block and coordinated attention scale fusion (CASF) mechanism to identify corn leaf diseases in complex backgrounds. Similarly, Janarthan et al. (2022) utilized a simplified MobileNetV2 architecture and an empirical method for creating class prototypes, requiring low processing power and storage space. Li et al. (2023) explored a hybrid transformer-based architecture by integrating shuffle-convolution and a lightweight transformer encoder. While compact models achieve computational efficiency gains by reducing the parameters, these gains may come at the cost of decreased accuracy (Atila et al., 2021; Thai et al., 2023).
In addition to identifying the presence of a plant disease, it is also crucial to estimate the severity of the disease, providing a quantitative assessment for disease diagnosis (Ilyas et al., 2022; Ji and Wu, 2022). The precise localization, size, and distribution of infected regions in plant leaves can significantly enhance the accuracy of disease classification, especially in field images with complex backgrounds (Barbedo, 2019). Moreover, these factors are vital for severity grading, disease progression monitoring, and assessment of treatment efficacy. The process of estimating the level of leaf diseases often involves two main steps: segmentation and grading. Segmentation refers to the operation of separating infected regions from healthy areas of the leaf or plant. This can be achieved through various methods such as morphological operations (Gupta, 2022), k-means clustering and thresholding (Karlekar and Seal, 2020; Singh et al., 2021), and deep learning-based semantic segmentation (Wang et al., 2021; Liu et al., 2022; Deng et al., 2023). Grading then assigns a numerical score or rating to the severity of the disease, based on proportional area measurement (Wu et al., 2022) or ordinal categories (Ozguven and Adem, 2019; Pal and Kumar, 2023). Considering the complementary nature of disease classification and severity estimation, there is an emerging trend toward multi-task learning. This approach aims to jointly optimize both tasks by leveraging shared representations and correlations between them. For example, Ji et al. (2020) presented a set of binary relevance-CNNs that can simultaneously recognize 7 crop species, classify 10 crop diseases (including healthy), and estimate 3 disease severity levels, achieving the best test accuracy of 86.70% for recognition and 92.93% for severity estimation. Other techniques, such as alternating training (Jiang et al., 2021) and weighting adjustment (Wang et al., 2022), have been explored to enhance the accuracy of the combined task. Although multi-task learning can lead to better performance than individual tasks, it may also introduce increased computational effort and suboptimal solutions due to the difficulty in balancing tasks.
To address these challenges, we propose a novel multi-task distillation learning framework for tomato leaf disease diagnosis (MTDL). Unlike traditional distillation learning (Hinton et al., 2015) that relies on one-to-one and one-way knowledge transfer from a teacher model to a student model. Instead, our framework considers tomato disease category identification and severity prediction as a multi-task model that can be optimized simultaneously, as well as two single-task models that can be mutually informative. Accordingly, we develop a learning process for knowledge decoupling and reorganization, facilitating the efficient transfer of knowledge between the two tasks. Furthermore, this process is designed to be integrated with deep networks of varying complexity and architecture, making it adaptable to different disease identification scenarios with diverse computational power configurations and performance requirements.
Specifically, MTDL uses a multi-task model that contains disease classification and severity estimation as the baseline. It adopts a multi-stage learning strategy, including knowledge disentanglement, single-task mutual learning, and knowledge integration, In this process, the goal of knowledge disentanglement is to transfer the shared knowledge from the original multi-task model to the corresponding single-task models. This enables the specialization of task-specific models and avoids negative transfer of knowledge between tasks. For mutual learning between tasks, the goal is to fully exploit the complementarity between different learning objectives. Finally, through knowledge integration, the disentangled and mutually learned knowledge components are re-combined and unified to produce the refined high-quality multi-task model.
Furthermore, considering that multi-stage distillation learning will lead to a dependency of the current student model on the teacher model from the previous stage, we propose a decoupled teacher-free knowledge distillation (DTF-KD) strategy to simplify the training process. DTF-KD introduces a virtual teacher, replacing the traditional teacher model in the distillation process. This approach allows for increased adaptability by applying different learning intensities to target and non-target knowledge. In the context of the classification problem addressed in this paper, the target knowledge corresponds to the correct classification assignment of the ground truth.
The main contributions of this paper are summarized as follows:
1. We propose a novel multi-task distillation learning (MTDL) framework for leaf disease identification. This framework progressively decomposes and integrates the inherent knowledge from two tasks: tomato disease classification and severity prediction, through a distillation process, thereby generating a robust multi-task model for comprehensive disease diagnosis.
2. We propose a decoupled teacher-free knowledge distillation (DTF-KD) method to simplify MTDL by reducing the reliance on teacher models during the learning process. A virtual teacher is introduced to guide the learning process by providing separate instructions for the correct class and non-correct classes.
3. The experimental results demonstrate that the proposed framework effectively leverages the complementary characteristics of tomato disease category identification and severity prediction, reducing the model size while improving the performance.
2 Materials and methods
2.1 Dataset
The dataset employed in this study is aggregated from three distinct sources.The first source is drawn from the AI Challenger 2018 Crop Leaf Disease Challenge (Dataset AI Challenger, 2018), encompassing 11 types of plants and 27 types of diseases. Some of these diseases are further categorized into general and severe degrees, resulting in a total of 61 categories. Specifically, the dataset includes instances of leaf diseases for the following plants: apple (2,765), grape (3,144), peach (2,146), potato (3,246), citrus (4,577), pepper (1,929), strawberry (1,263), cherry (939), maize (3,514), pumpkin (1,465), and tomato (11,610). For the purposes of our study, we focus on the tomato subset. However, as the dataset contains only three samples of Canker disease, we decide to exclude this category from our analysis. The second source, the PlantDoc dataset (Singh et al., 2020), consists of 2,598 data samples that involve 13 types of plants and 27 categories (17 diseases, 11 healthy). These samples were mainly obtained from the internet and manually annotated, with the tomato subset containing 8 categories. The third source is the Taiwan Tomato Disease dataset (Huang and Chang, 2020), which is originally comprising 622 samples, was first employed in the study detailed in Thuseethan et al. (2022). In addition, it encompasses six distinct categories, namely Bacterial Spotted (110), Leaf Mold (67), Gray Spot (84), Health (106), Late Blight (98), and Powdery Mildew (157). We choose this dataset for its diverse disease conditions and combine it with larger datasets like AI Challenger 2018 and PlantDoc to further enrich the diversity of our data. Figure 1 shows examples of different tomato leaf diseases.

Figure 1 Examples of tomato diseases from the datasets.
2.2 Data preprocessing
For the AI Challenger dataset, given the scarcity of data for the canker disease category (only 3 instances), we excluded this data. The dataset provided severity labels for most of the data, categorized into three levels: healthy, moderate, and severe. In addition, we supplemented the dataset with severity labels for the tomato spotted wilt virus. For the PlantDoc dataset, due to the complexity of the leaf background, we manually cropped the tomato leaf subset to meet the needs of the disease identification task. Each image was cropped to retain the main area of a single leaf while preserving some background information from the plant. For the Taiwan Tomato dataset, we used all the original data. For all three datasets, we applied consistent severity labeling. Specifically, we hired five agricultural experts to manually annotate the severity of the disease. The final severity level was determined by a majority vote. Table 1 summarizes the information about the three datasets used in this study.
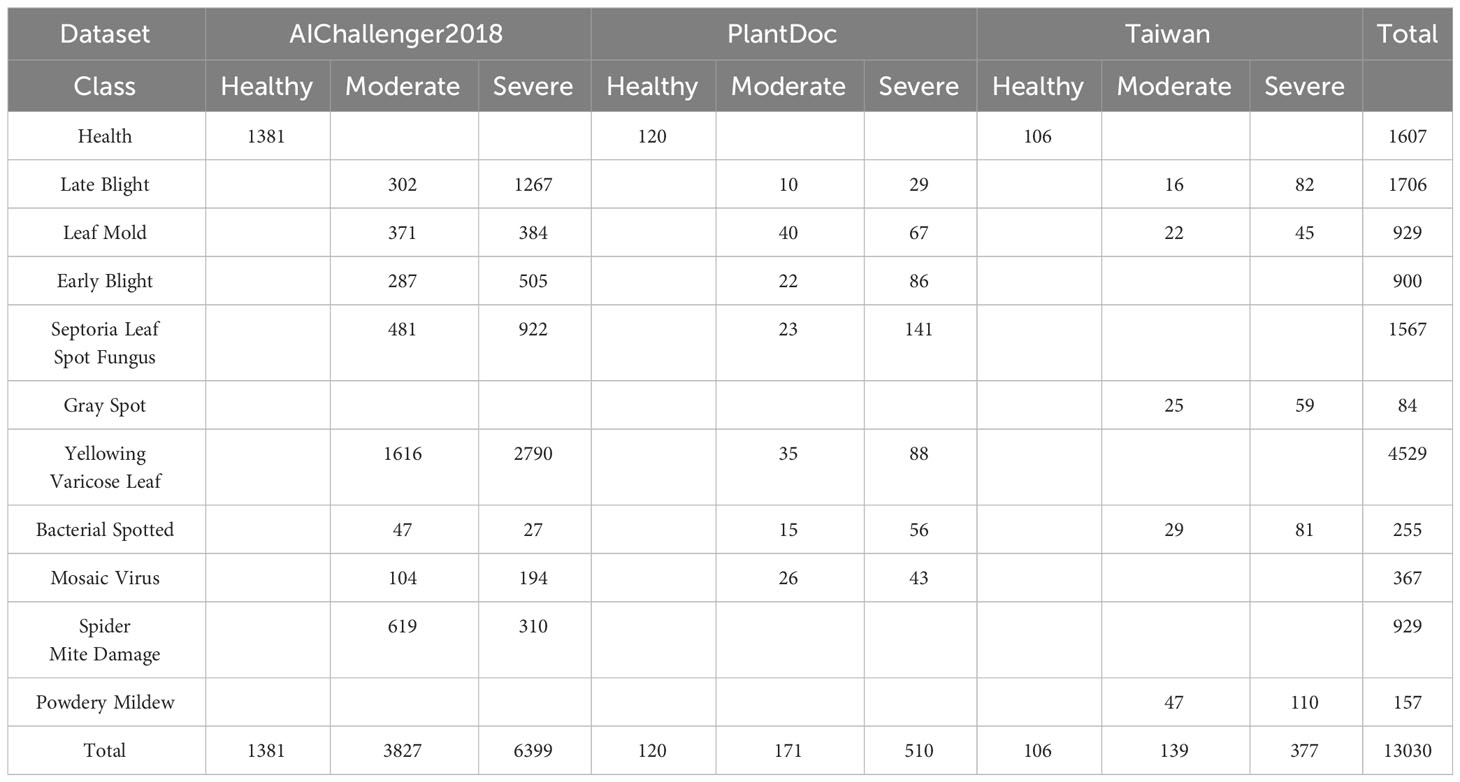
Table 1 Summary of main datasets used in the study.
We divide the dataset into training, validation, and test sets in an 8:1:1 ratio, ensuring a balanced and representative distribution for each set. The division is performed randomly to maintain fairness and diversity. Furthermore, we rigorously validate both the results reported in the paper and the determination of hyperparameters through 10-fold cross-validation.
2.3 Multi-task distillation framework
The proposed MTDL for tomato leaf disease diagnosis is comprised of three components: two single-task models, one for disease recognition and the other for severity prediction, and a hybrid model that integrates these two tasks. As illustrated in Figure 2, the MTDL pipeline enables mutual knowledge transfer between the two individual tasks, facilitating knowledge disentanglement and integration to enhance performance. In traditional distillation learning processes (Hinton et al., 2015), a powerful teacher model transfer knowledge to a lightweight student model. However, our MTDL framework emphasizes bidirectional knowledge transfer between teacher and student models, allowing for greater flexibility in their selection.
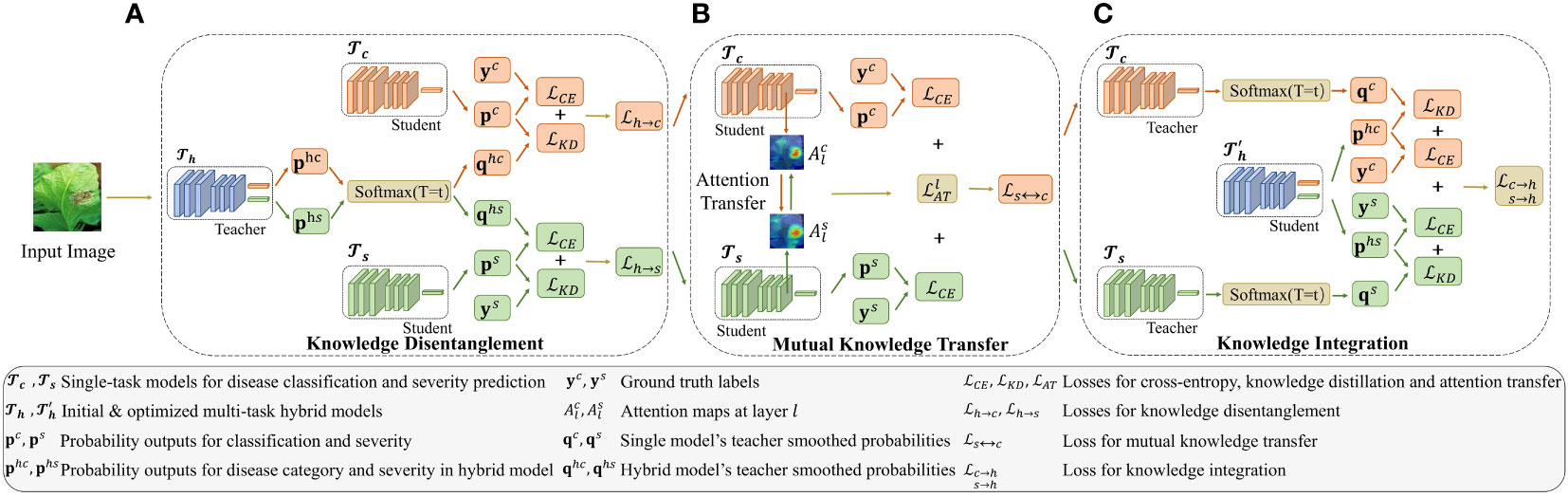
Figure 2 Architecture of the multi-task distillation learning (MTDL). The MTDL framework uses a three-stage distillation process involving single-task models and , and a multi-task model . Initially, knowledge from is transferred to the single-task models. Then, and share knowledge. Finally, their knowledge is integrated back into , creating an improved multi-task model . For simplicity, sample indices are omitted from the symbols in the figure. Additionally, the temperature parameter T in KD is fixed at t during the learning process. (A) Knowledge Disentanglement, (B) Mutual Knowledge Transfer, (C) Knowledge Integration.
2.3.1 Problem formulation
Given a leaf disease dataset containing N images, where is the i-th leaf image with C, H, and W denoting the number of channels, height, and width of the image, respectively. Each image is labeled with two types of annotations: is the disease category label, with Kc being the number of disease categories, and is the disease degree label, with Ks being the number of severity levels.
In MTDL, there are three basic tasks denoted as for disease category recognition, for severity estimation, and for the hybrid task that jointly performs and . As shown in Figure 2, each task uses a standard ResNet50 (He et al., 2016) as the backbone for feature extraction. In particular, the two single tasks and , each uses a multi-layer perceptron (MLP) to output the logits of its corresponding task, denoted as and , respectively. For , two separate MLPs are used to perform two tasks simultaneously on a shared backbone, and the output is denoted as , where and corresponding to the logits for the disease category and severity, respectively. Usually, a softmax function is applied to the output of each task to produce the predicted probabilities, , and , respectively. Guided by these three basic tasks, MTDL employs a designed knowledge routing mechanism to build a tomato disease diagnosis model. The process begins with the distillation of multi-task knowledge from back to the corresponding task models and (as shown in Figure 2A). These two models then engage in mutual learning (as shown in Figure 2B). Finally, the knowledge from these two models is integrated to output an enhanced multi-task model, namely (as shown in Figure 2C). The detailed learning process is described in the following sections, including, knowledge decomposition (Section 2.3.2), mutual knowledge tranfer (Section 2.3.3), and knowledge integration (Section 2.3.4).
2.3.2 Knowledge disentanglement
Multi-task learning has demonstrated its advantages in leveraging shared information among related tasks to improve performance on individual tasks. However, directly training a multi-tasking model can be suboptimal, as the tasks may have different levels of difficulty. For instance, the task of severity estimation is more challenging than the leaf disease classification task because it typically necessitates a finer analysis of the leaf and disease spot attributes (Wang et al., 2017). Therefore, given a multi-task model pre-trained on dataset D, as shown in Figure 2A, it is reasonable to disentangle the shared knowledge and transfer it back to the single-task models, i.e., and , using knowledge distillation (Hinton et al., 2015). Specifically, when distilling knowledge from to , we first soften the probability by:
where T is the temperature hyperparameter that controls the sharpness of , is the j-th element of , and denotes the softened probability distribution of the j-th class for the i-th input data. The formulation of the knowledge distillation process from to involves minimizing the loss function , which is defined as follows:
where is the cross-entropy loss, which measures the dissimilarity between the predicted probability distribution and the one-hot ground-truth label vector for the single-task model . It can be written as shown in Equation 3:
And , the knowledge distillation loss, which quantifies the divergence between and , is defined as shown in Equation 4:
Similar to Equation 2, we can define a loss function from
to , denoted as , which is given by:
where is the probability distribution obtained by softening the severity prediction output from (referred to in Equation 1), and is the output from .
2.3.3 Mutual knowledge transfer
Upon completing the knowledge disentanglement process, the shared knowledge from the hybrid tasks is individually transferred back to the corresponding subtasks, i.e., for disease species classification and for disease severity identification. We then employ mutual distillation to further investigate the complementarity of the two subtasks. Here, we assume that and use the same backbones, such as ResNet50. Motivated by Komodakis and Zagoruyko (2016), as shown in Figure 2B, the commonality of knowledge between subtasks is reflected in the consistency of attention maps from the middle layer. Specifically, given two feature mappings, and , which are the outputs of layer l of the models and , respectively, we can calculate the attention maps, and , as shown in Equation 6:
where Ci is the number of channels in the feature mappings of
and , and (k,x,y) specifies the location and channel of an activation value within the feature mapping. The attention maps and are computed by averaging the activation values across the channels of the respective feature mappings, and . For stability of optimization, we first reshape the and into a vector form as and , where vec(.) is an operation that transforms a matrix into a vector by concatenating its columns. Then, we normalize the vectors using l2 norm as shown in Equation 7:
The attention transfer loss for layer l is written as shown in Equation 8:
And the total loss for mutual learning between subtasks is defined as follows:
where L denotes the number of layers considered for attention transfer loss.
2.3.4 Knowledge integration
The primary objective of the proposed MTDL is to enhance multi-task learning capabilities. In the final step of this learning framework, we consider the two sub-tasks after mutual learning, and , and reintegrate them into the original multi-tasking model, denoted as … As shown in Figure 2C, this reintegration process results in an enhanced multi-task model .The knowledge integration loss is formulated as follows:
where and represent the output of softened probability distributions of and , respectively, which are obtained by applying the process described in Equation 1. The whole process of MTDL is summarized in Algorithm 1.

Algorithm 1 MTDL process.
2.4 Teacher-free based MTDL
In the staged learning process of MTDL, the current stage can be considered the teacher model for subsequent stages. While this approach fully utilizes the process of knowledge transfer, it also leads to a dependency on the teacher model, thereby reducing the flexibility of the framework. To overcome this limitation, inspired by the work of Yuan et al. (2020) and Zhao et al. (2022), we propose a decoupled teacher-free KD (DTF-KD) method. In the following sections, we first present the general form of the DTF-KD, and then demonstrate how it can be applied to MTDL.
In the absence of a teacher model, we introduce a virtual teacher. We define the output of this virtual teacher as a categorical distribution, vi,j, given by:
where α is a predefined constant, typically ≥ 0.95, t is the correct class or target class for the i-th sample, K is the total number of classes, j represents the class index, and \t denotes all classes except the correct class t. This definition ensures that the virtual teacher assigns the highest probability to the correct class, while distributing the remaining probability equally among the incorrect classes.
In our proposed DTF-KD method, we divide the information distillation process into two parts: teacherfree based correct class KD (CC-KD) and teacher-free based non-correct class KD (NCC-KD). CC-KD focuses on the learning of target knowledge. It aims to transfer knowledge that is particularly important or challenging for the student model. In CC-KD, according to Equation 11, the binary probability outputs the virtual teacher for the correct class t and the K−1 non-correct classes are denoted as . These outputs are calculated using:
Correspondingly, for the student model, we can obtain , defined as:
where zi,j represents the logit for the j-th class of i-th instance of the student model. Therefore, combining Equations 12 and 13, the loss function of CC-KD can be written as:
In NCC-KD, we consider the probability outputs for the K−1 non-correct classes, denoted as for the virtual teacher and for the student model. For each m ∈ {1, 2,…,K}\{t}, we calculate these outputs as follows:
where vi,m is defined in Equation 11, and zi,m represents the logit for the m-th class of the i-th instance from the student model. According to Equation 15, the NCC-KD loss function is then defined as:
Combining Equations 14 and 16, the total loss of DTF-KD is
According to DTF-KD, we propose two variants of the MTDL framework. The first variant, as shown in Figure 3A which we call partially teacher-free MTDL (MTDL-PTF), eliminates the knowledge disentanglement stage from the MTDL process, thereby removing the dependency on the initial multi-task teacher model, known as . To compensate for the absence of , we introduce two virtual teacher models corresponding to the two learning tasks of disease category recognition and severity estimation, denoted as and , respectively. For , as described in Equations 12, 13 and 15, we obtain and for the distillation outputs for the correct class, as well as and and the non-correct classes. Similarly, for , we can obtain and for the correct severity level. For the non-correct severity levels, we can also obtain and . Therefore, the mutual knowledge transfer process in MTDL-PTF is given as shown in Equation 18:
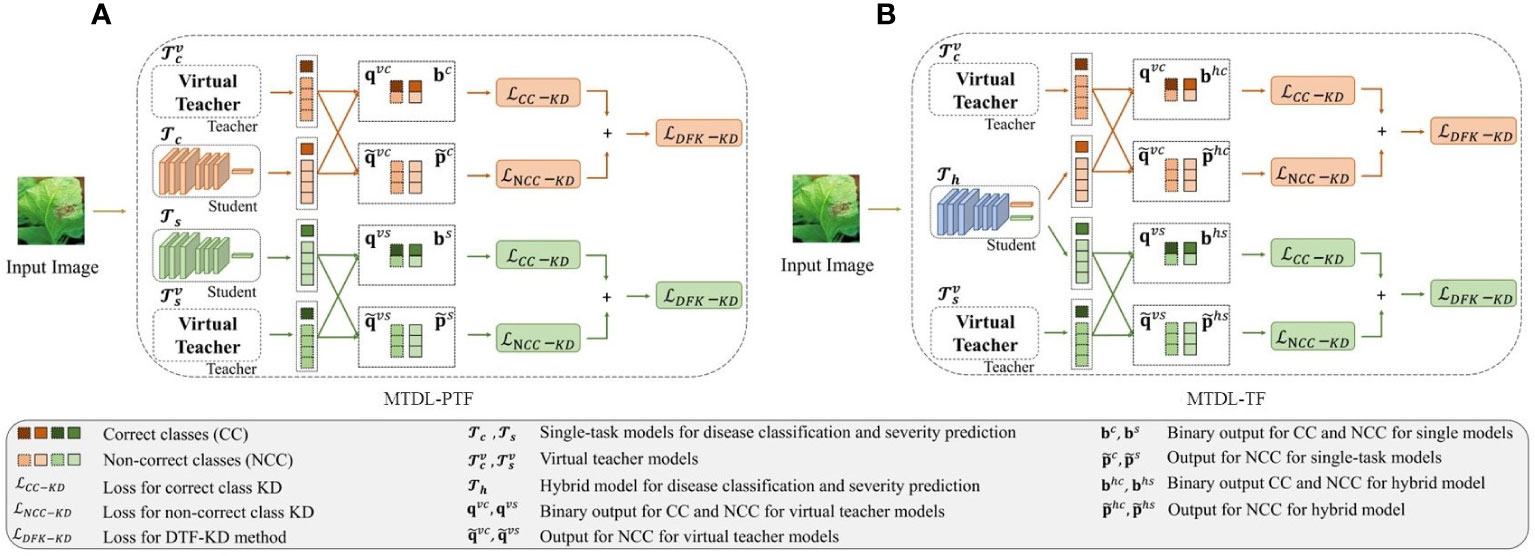
Figure 3 Overview of the decoupled teacher-free (DTF) based MTDL. (A) Partially teacher-free MTDL (MTDL-PTF): Eliminating dependency on the multi-task teacher model in the knowledge disentanglement stage. (B) Teacher-Free MTDL (MTDL-TF): Simplifying MTDL to only retain the final knowledge integration stage with virtual teachers.
where and LDFK-KD are defined in Equations 9 and 17, respectively.
In the second variant of MTDL, named teacher-free MTDL (MTDL-TF), we completely abandon the teacher model. The process of MTDL-TF is illustrated in Figure 3B. Instead, we directly introduce the distillation information from the virtual teacher models and into , which is defined as shown in Equation 19:
where and are two binary probability outputs corresponding to the correct class and non-correct classes for the disease category recognition and severity estimation tasks, respectively, in the hybrid model . They can be obtained via and using Equation 13. Accordingly, the output for the non-correct classes in , and , can be calculated by Equation 15.
3 Experimental results and discussion
3.1 Experimental setup
3.1.1 Model training
The MTDL framework consists of three main components: knowledge disentanglement, subtask mutual learning, and knowledge integration. To ensure simplicity and generality of the framework, we employ a consistent training strategy for different learning components. Specifically, the framework is trained using the SGD optimizer with a batch size of 32 and a momentum of 0.9. The initial learning rate is set to 0.001, and it is reduced by a factor of 0.1 every 20 epochs. The weight decay is set to 1e-4. The maximum number of training epochs is set to 100, and an early stopping strategy is used based on the validation performance. If the validation loss does not improve for 5 consecutive epochs, the training process is stopped.
3.1.2 Hyperparameter settings
The MTDL framework involves three main stages of knowledge distillation, which correspond to the objective functions in Equations 2, 9, and 10. During the process, we use a temperature parameter T to smooth the output of the teacher model. This hyperparameter is determined through cross-validation using the validation set. A comprehensive analysis of hyperparameter selection can be found in Section 3.3.4.
3.1.3 Evaluation metrics
To evaluate the performance of the proposed MTDL method, we employ four commonly used evaluation metrics, namely Accuracy, Precision, Recall, and F1-score. Given true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN), the specific definitions of these metrics are as shown in Equations 20 and 21:
3.1.4 Baseline methods
The MTDL framework is a flexible knowledge distillation approach designed for tomato disease diagnosis. It aims to improve the performance of recognition models while reducing their parameter size and can be combined with various existing neural network architectures. To ensure the versatility of the MTDL framework, we incorporate four conventional network models, including ResNet101 (He et al., 2016), ResNet50 (He et al., 2016), DenseNet121 (Huang et al., 2017), and VGG16 (Simonyan and Zisserman, 2014), as well as four lightweight network models such as EfficientNet (Tan and Le, 2019), ShuffleNetV2 (Zhang et al., 2018b), MobileNetV3 (Howard et al., 2019), and SqueezeNet (Iandola et al., 2016). Detailed information about these models can be found in Table 2. These backbone models serve as the learning components in different stages of the MTDL framework. We use the original classification results of these models as a baseline and compare the results before and after the multi-task distillation process to validate the effectiveness of the proposed framework.
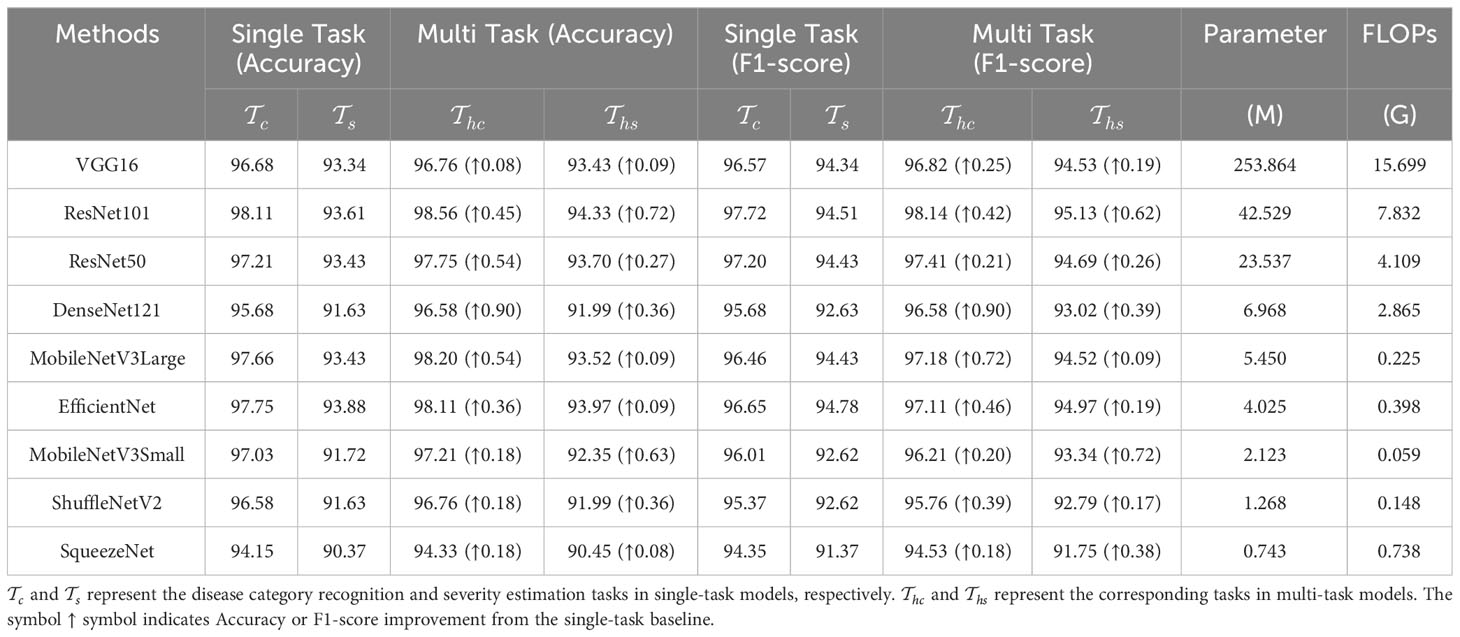
Table 2 Baseline results of single and multi-task models.
3.2 Results
3.2.1 Performance comparison
In this section, we report the results from two experimental settings. The first setting, referred to as unified MTDL, employs the same network architecture for teacher and student modules. This setting aims to verify the effectiveness of the multi-stage distillation architecture proposed in this paper. The second setting, termed heterogeneous MTDL, involves using lightweight network architectures for all student models within the MTDL framework. This setting is designed to demonstrate the advantages of the proposed architecture in achieving a balance between performance and efficiency. As a reference, Table 2 lists the baseline results of the initial two single tasks and , as well as the multi-task model , where and correspond to the results of for disease classification and severity estimation tasks, respectively. The results in Table 2 demonstrate that the multi-task learning approach effectively enhances performance across various network architectures.
The results for MTDL with a unified architecture are presented in Table 3. We can observe that all models show improvement when using MTDL for knowledge learning. This indicates that the MTDL framework effectively leverages the staged learning of knowledge and the complementarity between different tasks. In terms of specific models, ResNet101 achieves the highest performance in both tasks under the MTDL setting, with Accuracy scores of 98.92% for and 95.32% for , respectively. The corresponding F1-scores are 98.78% and 96.32%, respectively. These results can be attributed to both the ResNet101’s powerful feature extraction capabilities and MTDL’s effective multi-task learning strategy. On the other hand, SqueezeNet shows significant improvement with an increase of 1.08% and 2.53% in Accuracy of and respectively, and an increase of 0.68% and 2.26% in F1-scoref or each task. This suggests that the MTDL allows the lightweight model to learn more robust and comprehensive features. Furthermore, Table 3 also provides a comparison between the MTDL, MTDL-PTF, and MTDL-TF methods across various architectures. The results indicate that while the overall performance of MTDL-PTF and MTDL-TF decreases when the dependence on the teacher model is reduced, the introduction of a virtual teacher model significantly improves the accuracy of both methods compared to the original multitask learning. This indeed validates the effectiveness of the decoupled teacher-free knowledge distillation approach that we proposed. We also display the confusion matrices for results using ResNet50 as the backbone. As shown in Figure 4, it is evident that our proposed MTDL method either maintains or improves performance across all individual classes for both disease classification and severity estimation tasks. This demonstrates MTDL’s ability to achieve a balanced enhancement in both overall performance and category-specific outcomes.
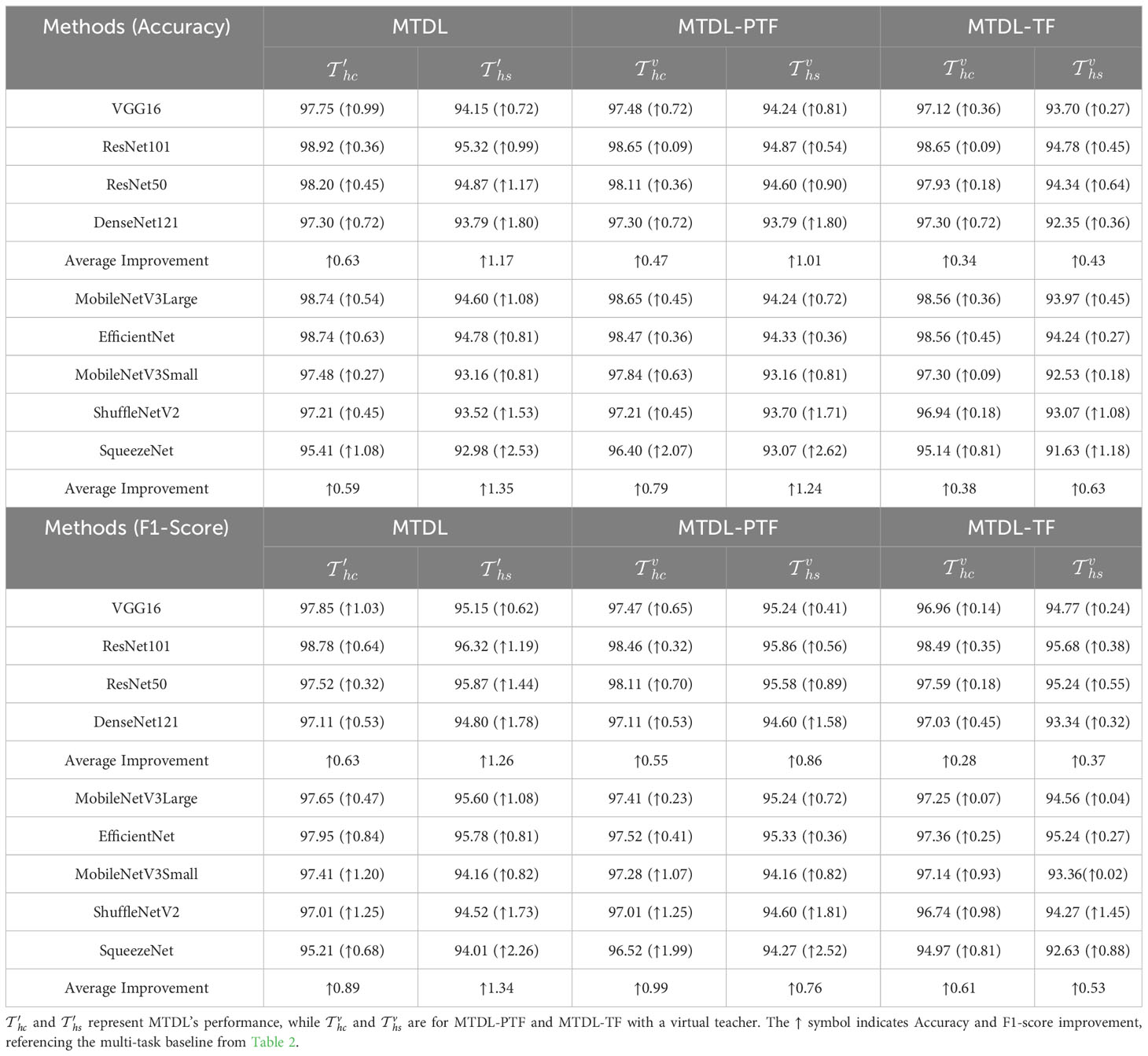
Table 3 Performance of MTDL and its variants in a unified architecture.
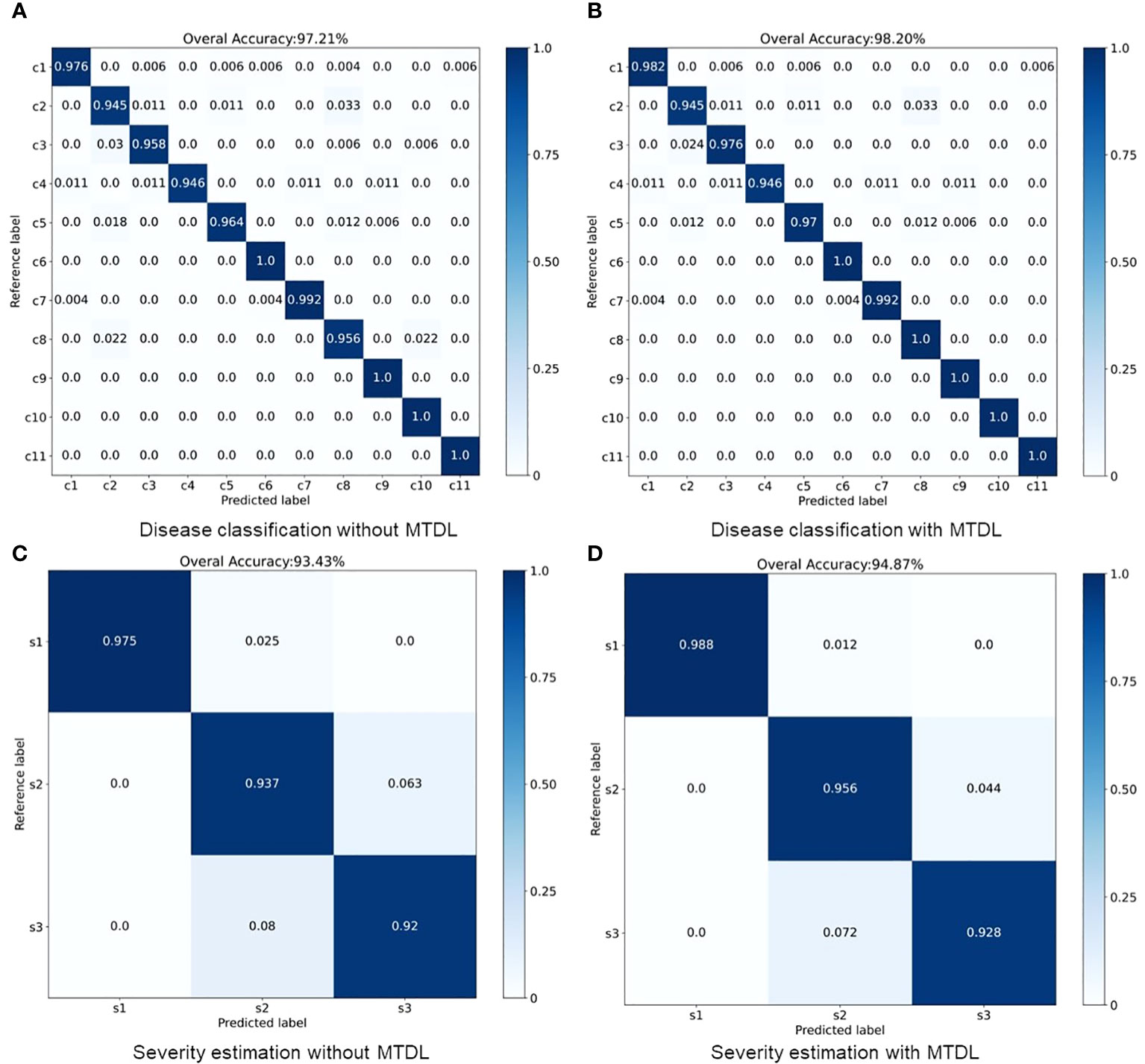
Figure 4 Performance improvement through multi-stage distillation in MTDL. (A) Disease classification without MTDL, (B) Disease classification with MTDL, (C) Severity estimation without MTDL, (D) Severity estimation with MTDL.
Furthermore, to investigate the impact of using teacher and student models with different architectures on the performance of the MTDL framework, we employ complex models like DenseNet121 for the teacher and lightweight models such as EfficientNet for the student. The results presented in Table 4 substantiate the effectiveness of this heterogeneous MTDL approach. For instance, when using ResNet101 as the teacher model, the SqueezeNet student model shows an improvement of 1.95% and 3.07% in and respectively, which are higher than the result obtained under the unified architecture MTDL setting. These results suggest that a more powerful teacher model enriches the student model’s learning.
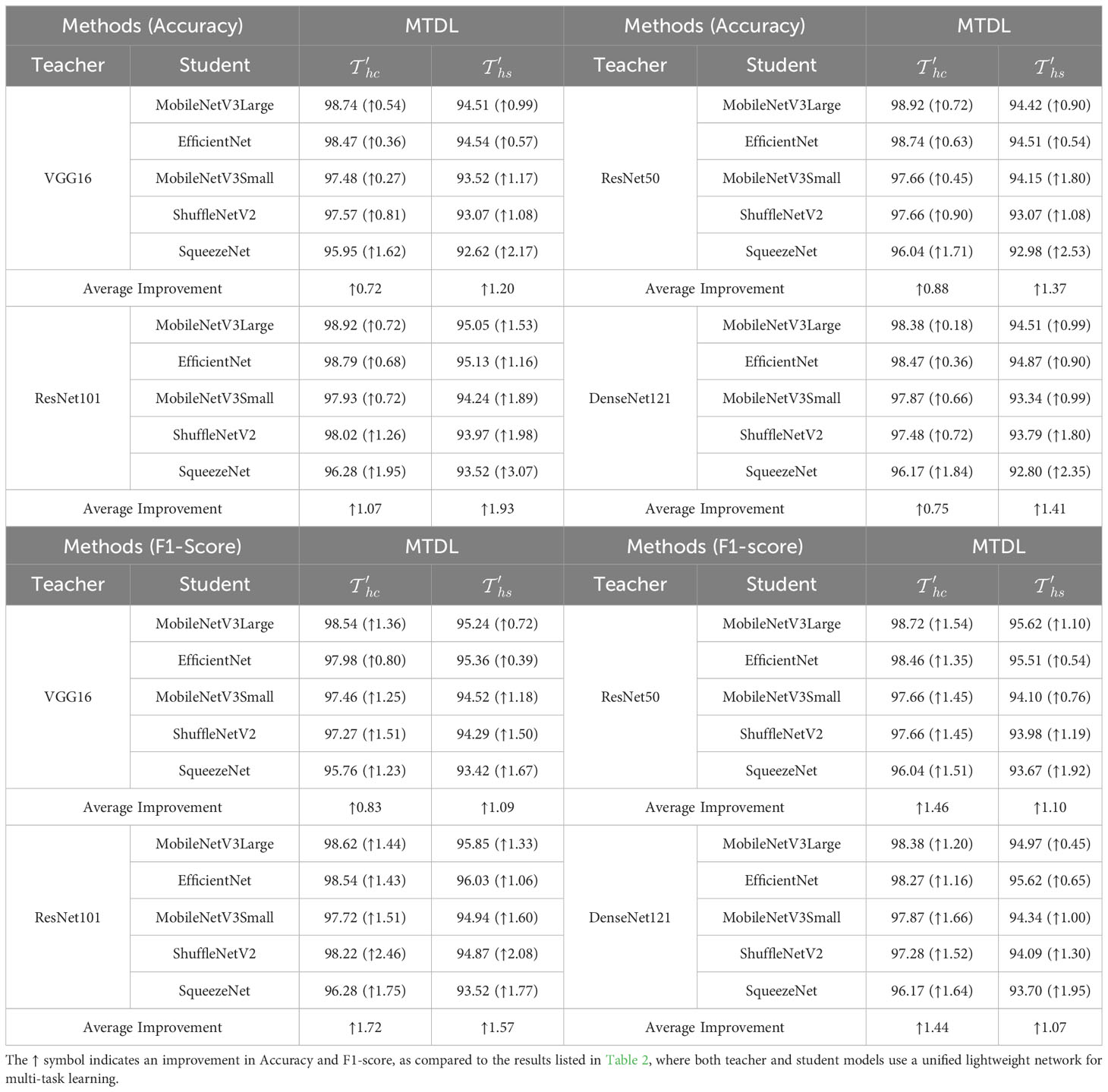
Table 4 Performance evaluation of MTDL under a heterogeneous setting.
Finally, to ensure the effectiveness of our proposed method, we conduct a comprehensive comparison with four well-established approaches in the field to validate its performance:
(a) Dual-stream hierarchical bilinear pooling (DHBP) (Wang et al., 2022): As a multi-task method initially developed for crops and diseases classification, we adapt DHBP for both disease classification and severity prediction tasks. This comparison allows us to evaluate the performance of our MTDL approach against a specialized multi-task learning method within the same domain.
(b) Traditional knowledge distillation (KD) (Ghofrani and Toroghi, 2022) and decouple knowledge distillation (DKD) (Zhao et al., 2022): These two methods represent the knowledge distillation category. We apply KD and its enhanced version, DKD, to our disease recognition and severity estimation tasks, providing a direct comparison with standard and advanced distillation techniques.
(c) Attention transfer (AT) (Komodakis and Zagoruyko, 2016): Differing from KD and DKD that focus on distilling knowledge through predicted outcomes, AT utilizes attention maps to transfer knowledge between the teacher and student models. Including AT in our comparison allows us to assess the efficacy of a distinct transfer learning approach.
To ensure fair comparisons among KD, DKD, AT, and MTDL, we consistently used ResNet-101 as the teacher and MobileNetV3Small as the student model. This approach enables a reliable assessment of knowledge distillation efficacy. Additionally, we present MTDL results using ResNet-101 as both teacher and student, aligning with DHBP’s backbone, to effectively demonstrate its multi-tasking capabilities.
The results are shown in Table 5. In our experiments, MTDL with ResNet-101 as both teacher and student models achieve the best results, outperforming DHBP in disease classification by 0.53% in Accuracy and 0.29% in F1-score, and in severity prediction by 0.86% in Accuracy and 1.08% in F1-score. These improvements validate MTDL’s phased multi-task learning approach. Moreover, when compared under the same teacher-student model setup with other distillation methods (KD, DKD, AT), MTDL excelled, particularly surpassing DKD by 0.37% in Accuracy and 0.16% in F1-score for disease classification, and by 0.62% in Accuracy and 0.38% in F1-score for severity prediction. This indicates the effectiveness of MTDL’s proposed mutual distillation learning between teachers and students.
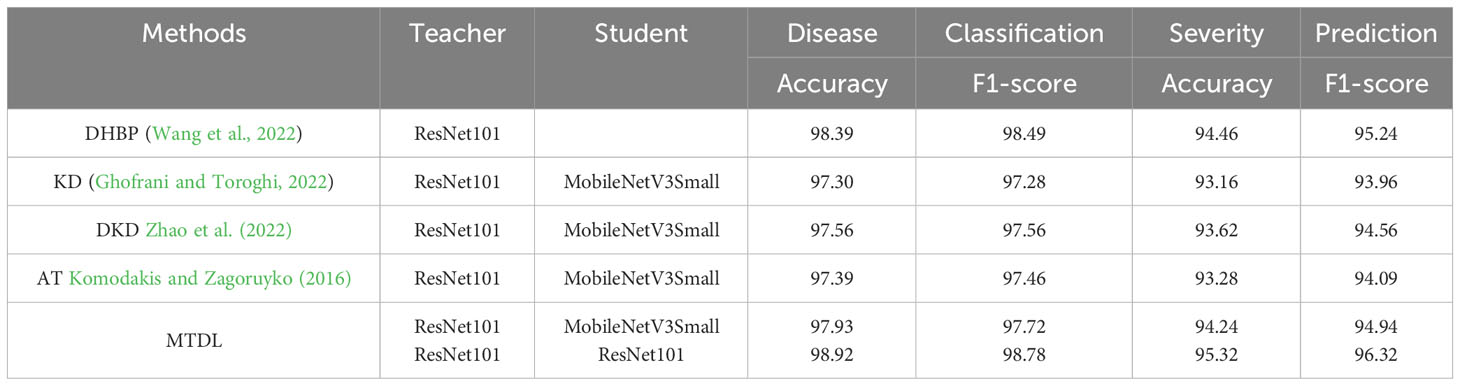
Table 5 Comparative performance analysis of MTDL with other distillation-based and multi-task learning methods for disease classification and severity prediction.
3.2.2 Significance analysis
In this subsection, we conduct a Wilcoxon Signed-Rank Test (Corder and Foreman, 2014) to evaluate the significance of the performance improvements across all CNN architectures. We provide the detailed significance analysis corresponding to the results originally presented in Tables 3 and 4 in the following Table 6 and 7. In Table 6, we present a comparison of the performance of our MTDL model and its variants against several baseline CNN architectures. This table focuses on scenarios within our MTDL framework where both the teacher and student models utilize identical architecture. The results from this table demonstrate statistically significant improvements across all comparisons in both disease classification and severity prediction tasks. The p-values obtained are consistently well below the 0.05 threshold, indicating robust enhancements attributed to our MTDL approach. Similarly, Table 7 showcases the results in a heterogeneous setting, where the MTDL model employs a more complex architecture as the teacher model and a lightweight network as the student model. In these comparisons, the results again confirm significant improvements across all evaluated aspects.
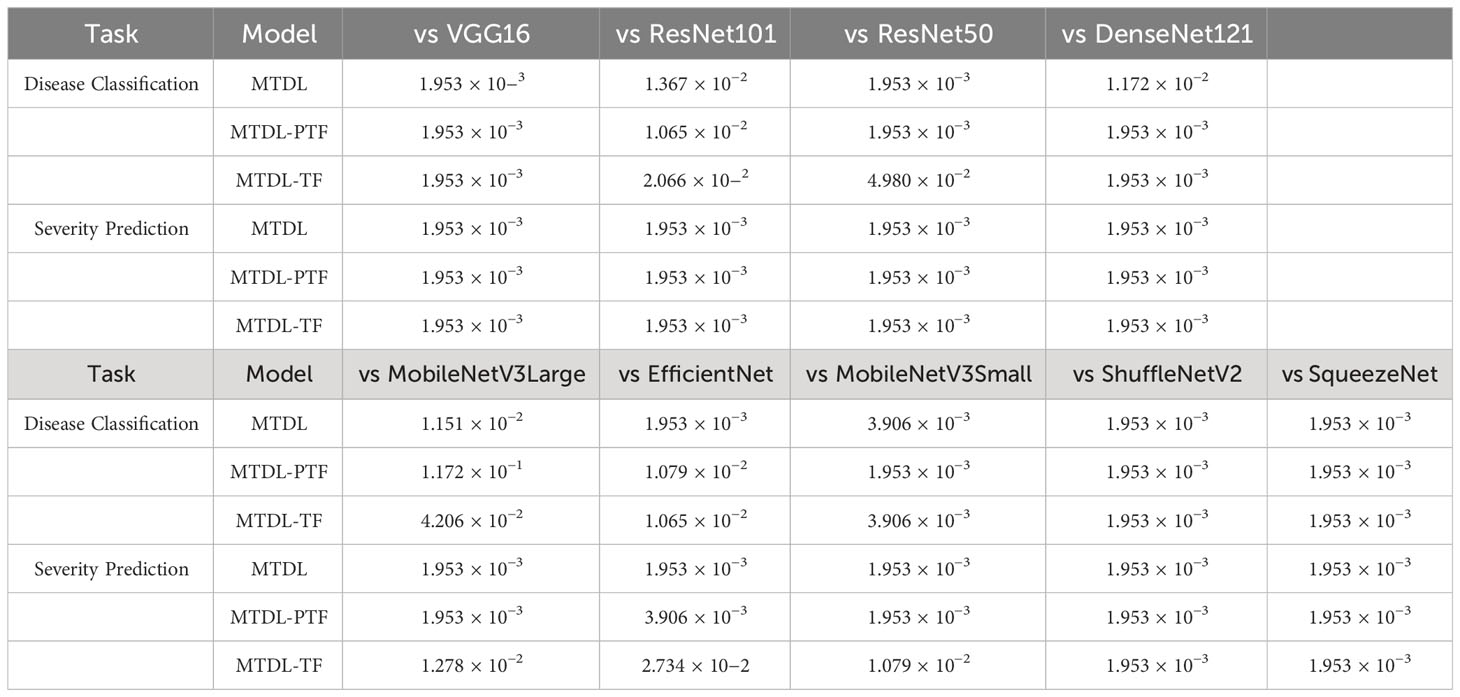
Table 6 Wilcoxon Signed-Rank Test results for MTDL variants’ Accuracy in a unified architecture.
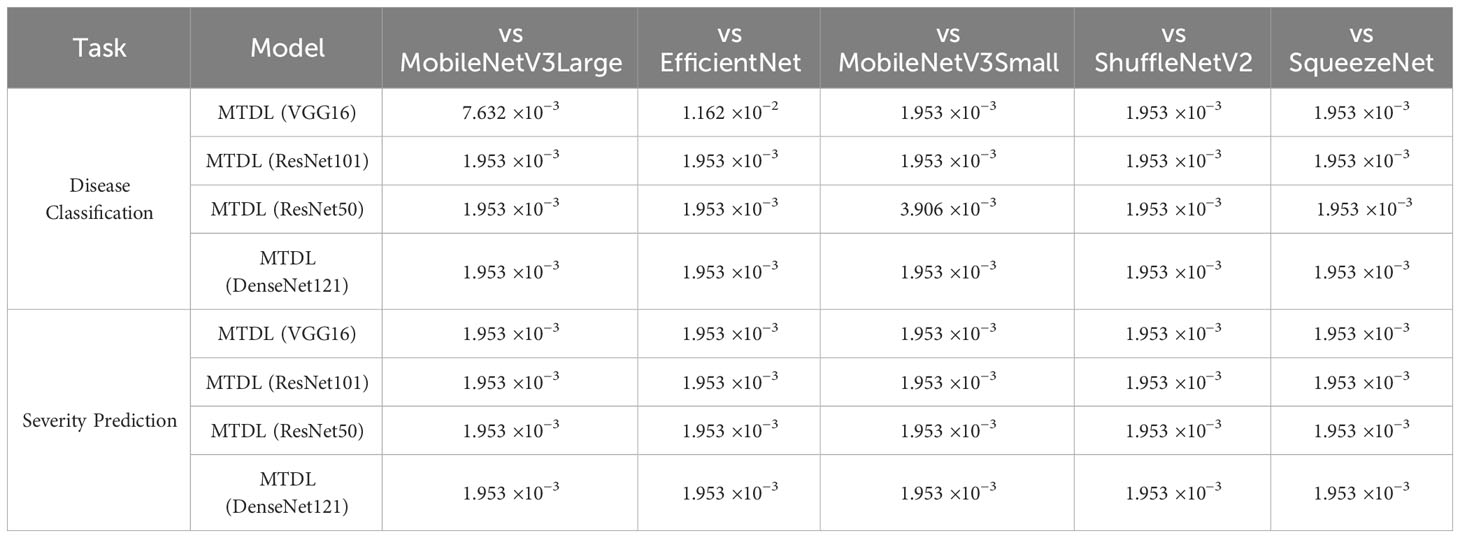
Table 7 Wilcoxon Signed-Rank Test results for MTDL variants’ Accuracy under heterogeneous settings (‘()’ indicate teacher models).
In addition, we also perform the significance of the results in comparison with other multi-task and distillation learning methods. with the results recorded in Table 8. It can be seen that in most cases, the MTDL framework shows statistically significant differences when compared with methods like DHBP, KD, DKD, and AT, with p-values well beneath the 0.05 significance threshold. However, there is one exception to note: in the case of MTDL (ResNet101-MobileNetV3Small) vs DHBP for severity prediction, the p-value is slightly above the conventional threshold for significance. This exception likely stems from MTDL employing lightweight MobileNetV3Small as the distillation target, whereas DHBP uses the more substantial ResNet101 as its base model.

Table 8 Results of the Wilcoxon Signed-Rank Test for MTDL and its variants versus other methods (The first in ‘()’ is the teacher model and the second is the student model).
3.3 Discussion
3.3.1 The effectiveness of multi-stage distillation learning
We assess the effectiveness of the three stages in our MTDL framework: knowledge disentanglement, mutual knowledge transfer, and knowledge integration. To do so, we employ single-task and multi-task models as our baselines and incorporate the results obtained after each stage of learning. As illustrated in Figure 5, the results in terms of Accuracy and F1-score align with our expectations. The results clearly demonstrate that each stage of learning contributes to the final performance improvement, thereby validating the effectiveness of staged distillation in the MTDL framework.
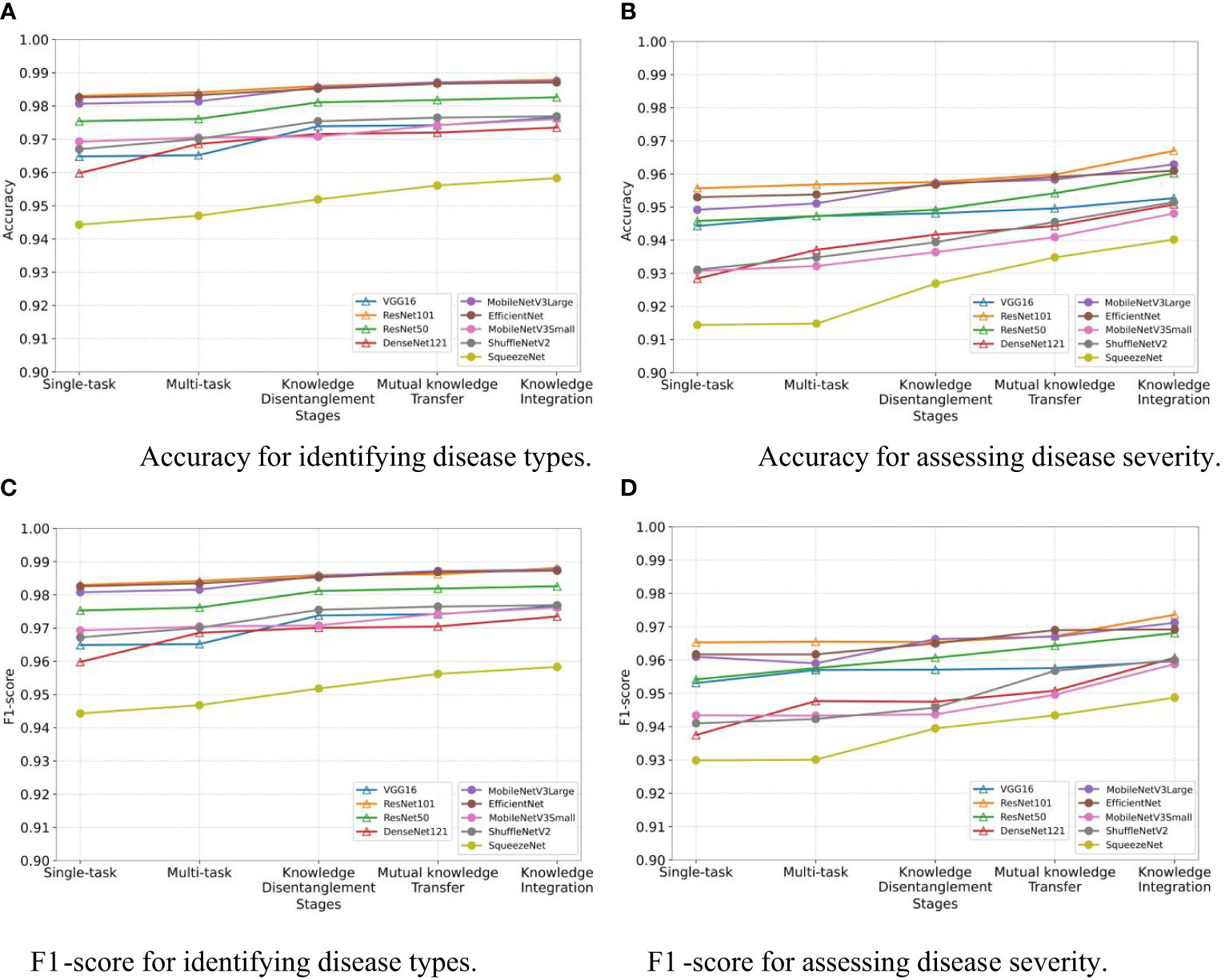
Figure 5 Performance improvement through multi-stage distillation in MTDL. (A) Accuracy for identifying disease types, (B) Accuracy for assessing disease severity, (C) F1-score for identifying disease types, (D) F1-score for assessing disease severity.
3.3.2 Trade-off between performance and efficiency
We investigate the balance between performance and efficiency within the context of our MTDL framework. Performance is measured by Accuracy, while efficiency is represented by the number of parameters and floating-point operations (FLOPs). We use the single-task ResNet101 model and the multi-task ResNet101 model as baselines due to their superior performance across all single-task and multi-task models, as shown in Table 3. The results are presented in Figure 6, and the size of each model’s marker in the figure represents the number of parameters used by the model.
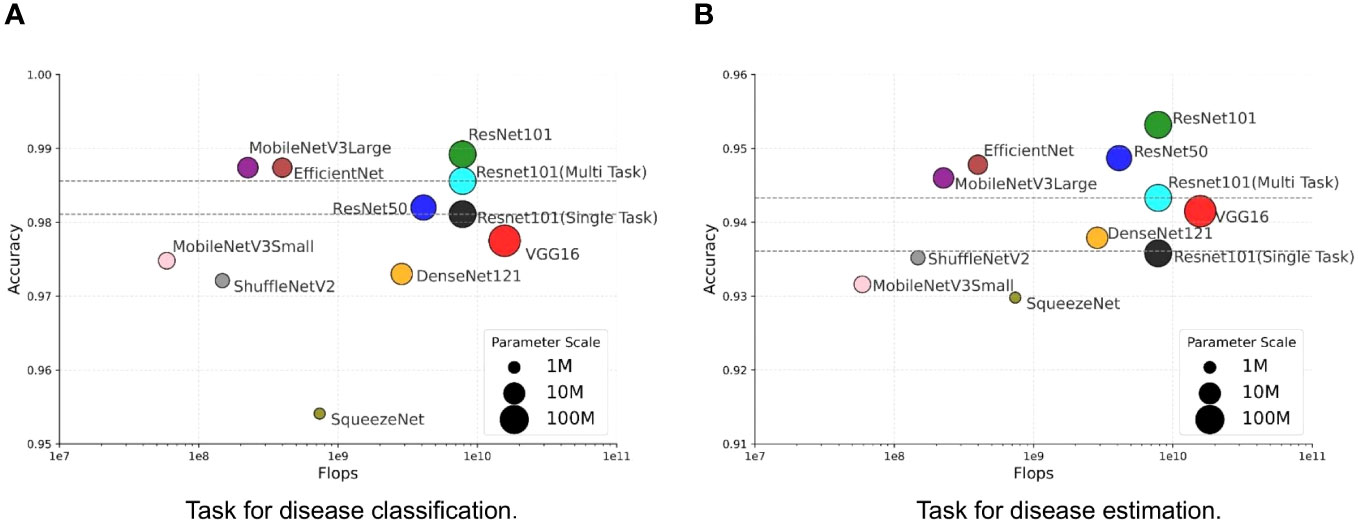
Figure 6 Trade-off between performance and efficiency. (A) Task for disease classification, (B) Task for disease estimation.
It can be observed that there is a similar trend in both task of disease classification (Figure 6A) and disease severity estimation (Figure 6B). Our MTDL-enhanced ResNet101 notably surpasses the single-task baseline with an Accuracy improvement of 0.81% for disease classification and 1.71% for severity estimation, and it outperforms the multi-task baseline with 0.36% and 0.99% improvements respectively. When using MobileNetV3Large as the MTDL-optimized model, we achieved significant performance gains with reduced parameter count and FLOPs, while still enhancing Accuracy over both baselines. For example, the MobileNetV3Large model, enhanced by our MTDL framework, outperforms the ResNet101 baseline by 0.63% and 1.44% in the two tasks, respectively. Remarkably, this is achieved with only 12.81% of the parameters (5.450M vs. 42.529M) and 2.87% of the FLOPs (0.225G vs. 7.832G). These findings highlight the MTDL framework’s capability to improve performance significantly while maintaining computational efficiency, thereby reinforcing its advantage over conventional models.
Therefore, we need to select the appropriate distillation model for each specific scenario. The choice depends on balancing computational resources and performance. Typically, complex teachers like ResNet101 outperform compact students such as MobileNet, owing to deeper architectures. MTDL promotes mutual learning between teachers and students, simultaneously enhancing both models. With abundant resources, an MTDL-optimized teacher offers substantial performance gains. In contrast, for limited-resource scenarios like mobile inference, MTDL can distill a lightweight yet performant student model. Additionally, the teacher-free MTDL-TF variant reduces dependency on complex teachers, offering an alternative when resources are constrained.
3.3.3 Visual analysis for multi-task learning
In this section, we use Grad-CAM (Selvaraju et al., 2017) for visual analysis to gain deeper insights into the learning process of our MTDL framework. We examine three severity levels of Early Blight: healthy, general, and severe. Visualizations for single-task and multi-task models, as well as for each stage of MTDL learning, are provided. Figure 7 shows that the model’s attention shifts toward task-relevant areas as it learns. For healthy leaves, the MTDL-enhanced model more precisely identifies the leaf as a whole, aligning with human visual systems. For leaves at a general severity level, the model focuses on localized disease spots for classification but expands its attention to surrounding regions for severity estimation. In cases of severe disease levels, the disease spots typically exhibit a widespread distribution across the leaf area. The knowledge integration model, in its pursuit to accurately recognize both the disease type and severity, tends to produce a Grad-CAM sensitivity map covering the entire leaf area. This comprehensive coverage contrasts with the single-task model, which primarily focuses on localized diseased regions, and the multi-task model, which, although it expands the area of interest, does not distribute sensitivity intensity as effectively. Moreover, the distribution of sensitivity intensity in the knowledge integration model offers a more realistic representation of the disease’s extensive impact, thereby enhancing the model’s explanatory power for Severe Early Blight. This analysis highlights the MTDL framework’s adaptability in shifting its focus based on the task and severity, thereby improving performance and interpretability.
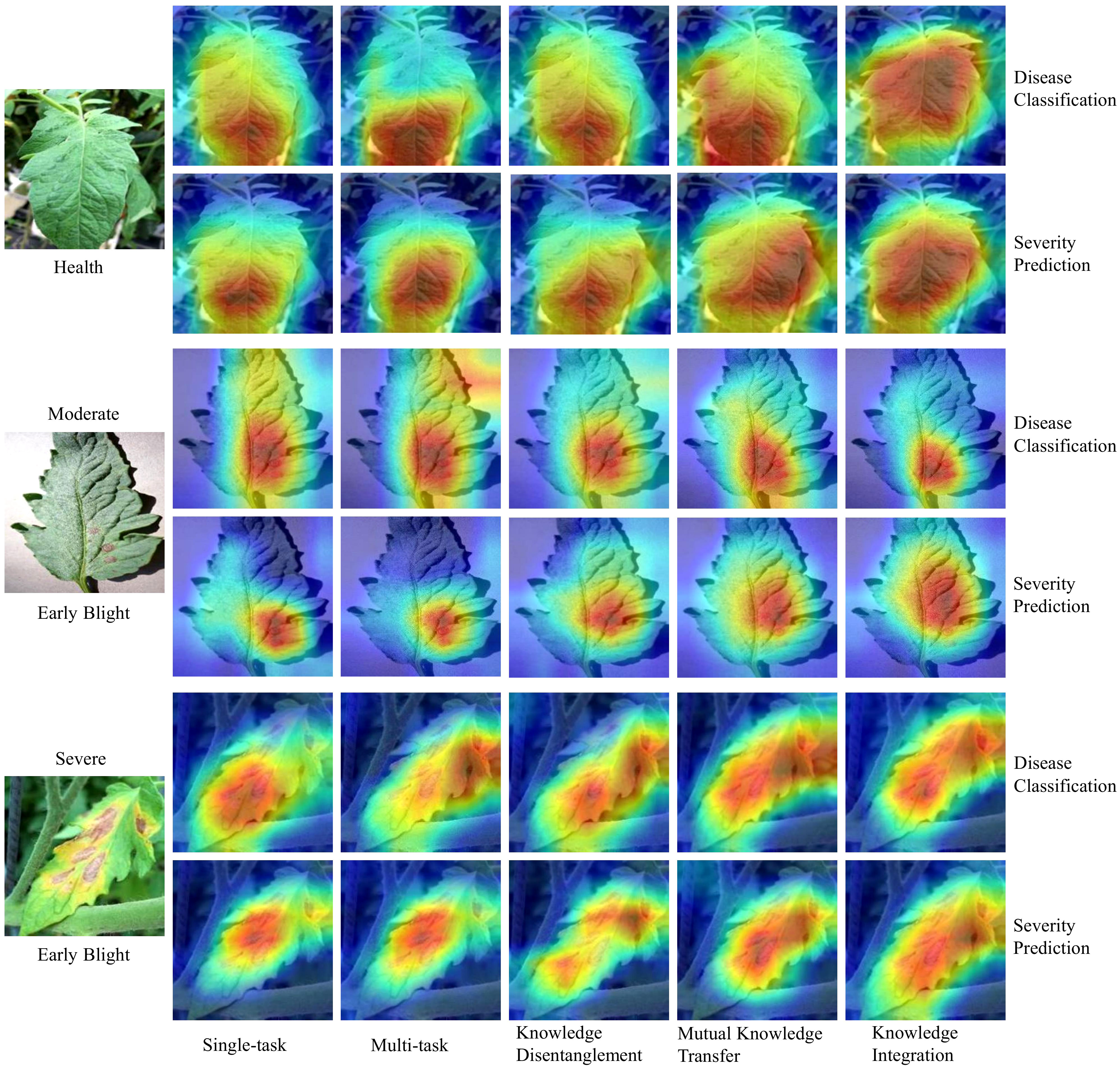
Figure 7 Visual analysis of attention shifts in MTDL framework across severity levels.
3.3.4 Parameter sensitivity analysis
The temperature parameter T adjusts the softmax output in the neural network, smoothing the probability distribution and revealing more nuanced information about the model’s predictions. This is crucial for knowledge distillation, where it aids in transferring detailed information from a teacher to a student model. This concept is introduced and utilized in Equation 1. To assess the sensitivity of our model to T, we vary T within the interval [0.1,50] and record the Accuracy of the disease classification and severity estimation tasks for each value. The results of nine common network architectures are shown in Figure 8. Despite the differences in architecture, a similar trend is observed: as T increases, the model’s performance improves, but rapidly declines when T exceeds 10. Notably, the model’s performance remains relatively stable for T within the interval [3,8]. This indicates that our model is robust to the choice of T within this range, providing flexibility in practical applications.
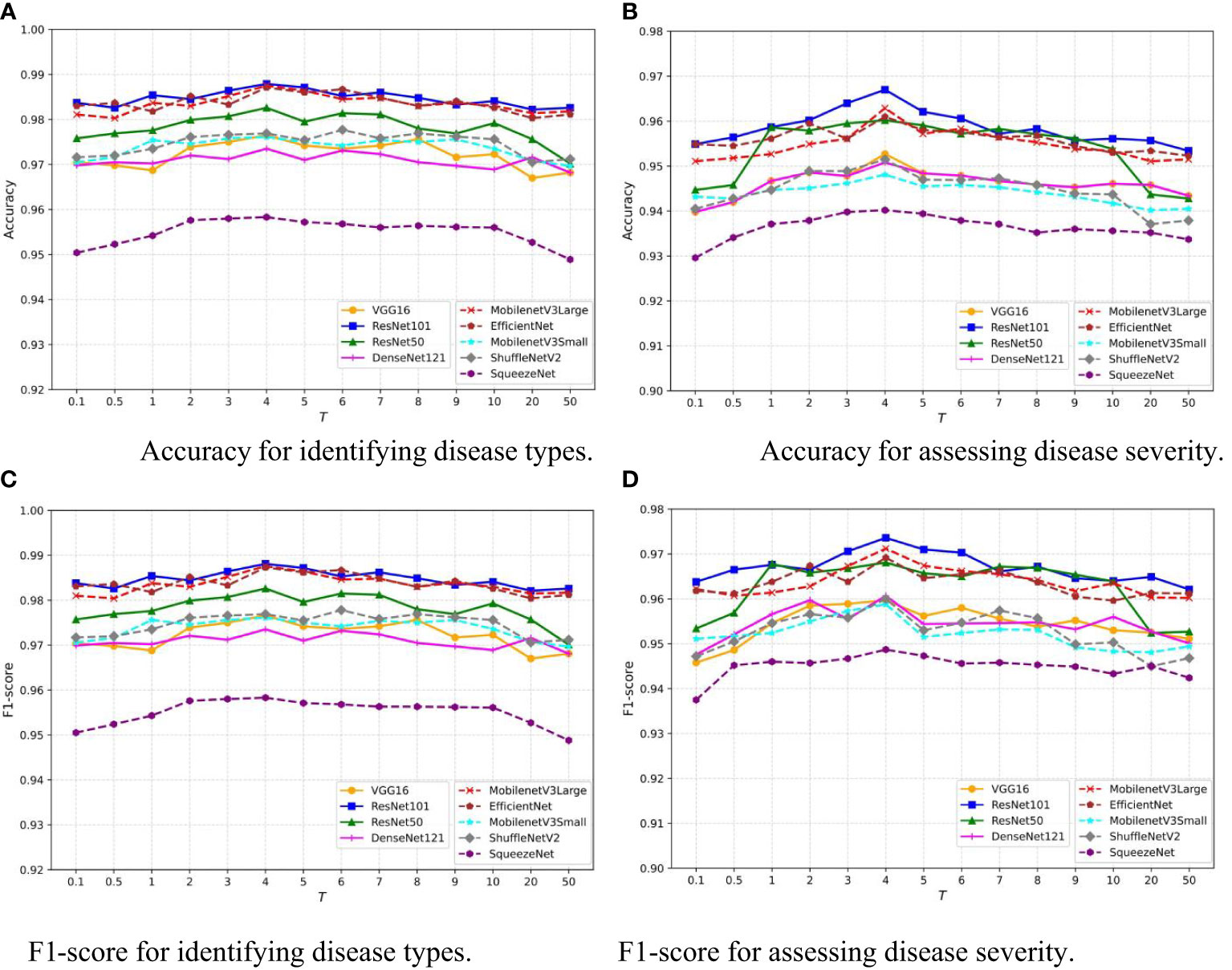
Figure 8 Sensitivity analysis of temperature hyperparameter T in MTDL framework. (A) Accuracy for identifying disease types, (B) Accuracy for assessing disease severity, (C) F1-score for identifying disease types, (D) F1-score for assessing disease severity.
One the other hand, the selection of a batch size of 32, momentum of 0.9, and learning rate decay factor of 0.1 was guided by a combination of empirical conventions and experimental validation aimed at striking a balance between computational efficiency and model performance. To validate the impact of different parameter settings on performance, we analyzed MTDL and its variants on the validation set for varying batch sizes (Figures 9A, B), momentum (Figures 9C, D), and learning rate decay factors (Figures 9E, F), detailing their effects on Accuracy. We can see that Accuracy remains relatively stable across batch sizes that varies (8, 16, 32, 64, 128), with the optimal average Accuracy achieved at 32. This is likely because a moderate batch size balances gradient estimation Accuracy and the beneficial noise of stochasticity, optimizing learning. As momentum increases from 0.1 to 0.9, Accuracy generally improves. A higher momentum, like 0.9, effectively uses past gradients to accelerate convergence and navigate through local minima, leading to better performance compared to a lower setting like 0.1. Moreover, increasing decay factors tend to lower Accuracy, potentially due to a swift reduction in the learning rate and premature convergence. An optimal decay factor is one that slowly decreases the learning rate, facilitating precise adjustments as the model converges to the best solution.
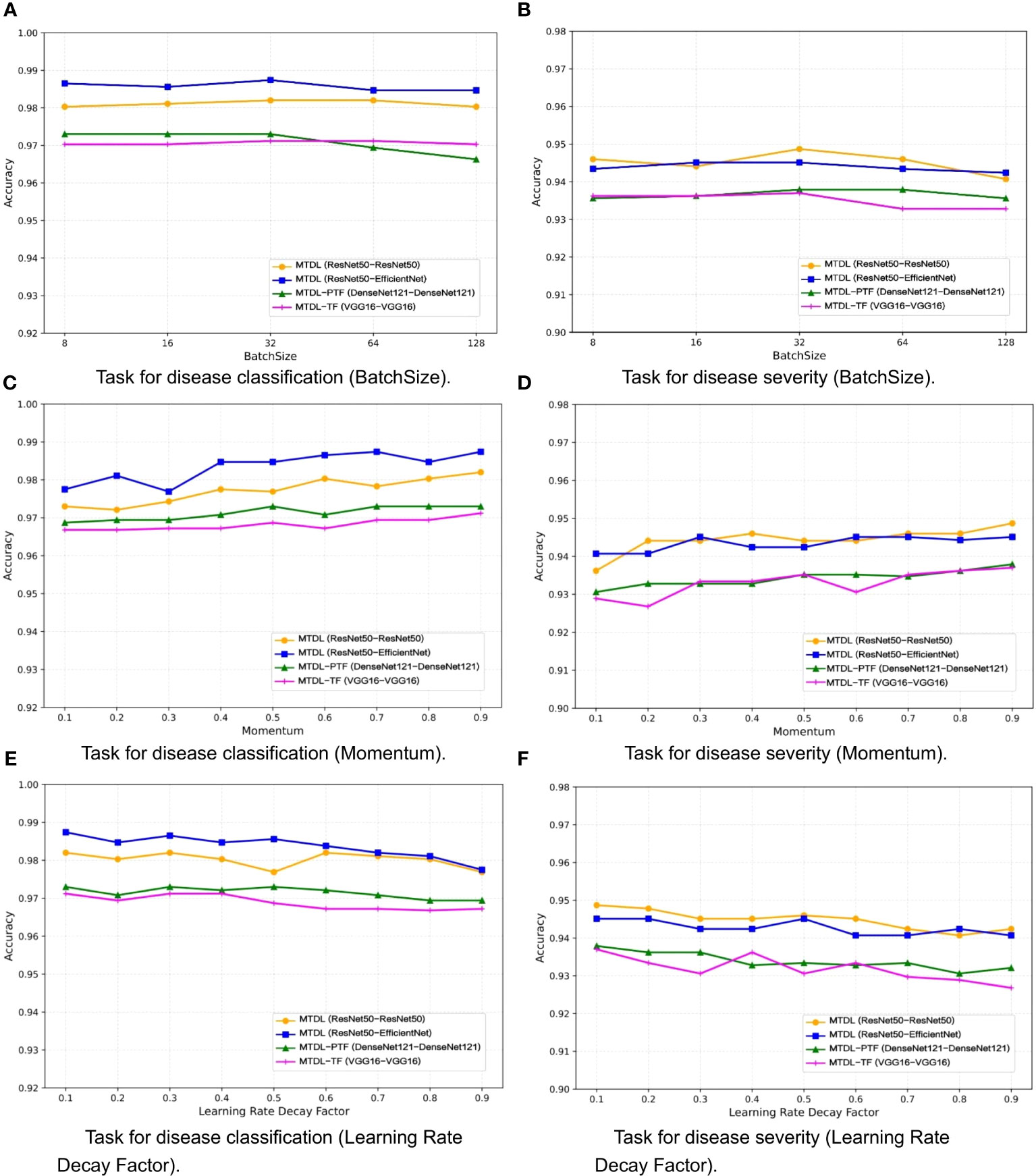
Figure 9 Effect of different parameters on model performance. (A) Task for disease classification (BatchSize), (B) Task for disease severity (BatchSize), (C) Task for disease classification (Momentum), (D) Task for disease severity (Momentum), (E) Task for disease classification (Learning Rate Decay Factor), (F) Task for disease severity (Learning Rate Decay Factor).
4 Conclusion
In this work, we present the multi-task distillation learning (MTDL) framework, a specialized solution for diagnosing tomato diseases. The framework comprises three key stages: knowledge disentanglement, mutual knowledge transfer, and knowledge integration. Using this staged learning approach, we leverage the complementary aspects of different tasks to enhance performance across various network architectures. Moreover, our framework adeptly balances performance with efficiency, underlining its potential for practical applications. Although MTDL enhances traditional knowledge distillation with bidirectional knowledge transfer between teacher and student models, it extends training time due to a progressive, multi-stage learning approach. To mitigate this, we introduce MTDL-PTF and MTDL-TF variants for efficiency, though they may slightly underperform compared to the original MTDL.
Furthermore, our current framework has some limitations. First, although the framework is designed for outdoor environments, it has stringent requirements for the subject being photographed, focusing mainly on recognizing single subjects in images. Second, the severity level classification is relatively basic, encompassing only three levels, including a healthy state. In future work, we plan to integrate object localization techniques into the distillation process to facilitate the identification of multiple leaves in images. Additionally, we aim to refine the classification of disease severity levels, focusing especially on the early detection of diseases. These planned enhancements will contribute to the development of more sophisticated and nuanced solutions in the field of tomato disease diagnosis, offering a robust framework for sustainable and intelligent agriculture.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
BL: Conceptualization, Methodology, Writing – original draft. SW: Data curation, Formal analysis, Software, Writing – review & editing. FZ: Funding acquisition, Methodology, Writing – review & editing. NG: Formal analysis, Validation, Writing – review & editing. HF: Data curation, Formal analysis, Validation, Writing – review & editing. WY: Project administration, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the National Natural Science Foundation of China (No. 61972132), the S&T Program of Hebei (Nos. 20327404D, 21327404D, 21327407D), the Natural Science Foundation of Hebei Province, China (Nos. F2020204009, C2023204069), and the Research Project for Self-cultivating Talents of Hebei Agricultural University (No. PY201810).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Albahli, S., Nawaz, M. (2022). Dcnet: Densenet-77-based cornernet model for the tomato plant leaf disease detection and classification. Front. Plant Sci. 13, 957961. doi: 10.3389/fpls.2022.957961
Atila, Ü, Ucar, M., Akyol, K., Ucar, E. (2021). Plant leaf disease classification using efficientnet deep learning model. Ecol. Inf. 61, 101182. doi: 10.1016/j.ecoinf.2020.101182
Barbedo, J. G. A. (2019). Plant disease identification from individual lesions and spots using deep learning. Biosyst. Eng. 180, 96–107. doi: 10.1016/j.biosystemseng.2019.02.002
Basavaiah, J., Arlene Anthony, A. (2020). Tomato leaf disease classification using multiple feature extraction techniques. Wireless Pers. Commun. 115, 633–651. doi: 10.1007/s11277-020-07590-x
Bhujel, A., Kim, N.-E., Arulmozhi, E., Basak, J. K., Kim, H.-T. (2022). A lightweight attention-based convolutional neural networks for tomato leaf disease classification. Agriculture 12, 228. doi: 10.3390/agriculture12020228
Bi, C., Wang, J., Duan, Y., Fu, B., Kang, J.-R., Shi, Y. (2022). Mobilenet based apple leaf diseases identification. Mobile Networks Appl. 27, 172–180. doi: 10.1007/s11036-020-01640-1
Botineştean, C., Gruia, A. T., Jianu, I. (2015). Utilization of seeds from tomato processing wastes as raw material for oil production. J. Material Cycles Waste Manage. 17, 118–124. doi: 10.1007/s10163-014-0231-4
Boulent, J., Foucher, S., Theau, J., St-Charles, P.-L. (2019). Convolutional neural networks for the automatic identification of plant diseases. Front. Plant Sci. 10, 941. doi: 10.3389/fpls.2019.00941
Corder, G. W., Foreman, D. I. (2014). Nonparametric statistics: A step-by-step approach (John Wiley & Sons).
Cortes, C., Vapnik, V. (1995). Support-vector networks. Mach. Learn. 20, 273–297. doi: 10.1007/BF00994018
Dataset AI Challenger (2018) AI Challenger 2018 Datasets. Available at: https://github.com/AIChallenger/AI_Challenger_2018 (Accessed Nov. 1, 2022).
Deng, Y., Xi, H., Zhou, G., Chen, A., Wang, Y., Li, L., et al. (2023). An effective image-based tomato leaf disease segmentation method using mc-unet. Plant Phenomics 5, 0049. doi: 10.34133/plantphenomics.0049
Ghofrani, A., Toroghi, R. M. (2022). Knowledge distillation in plant disease recognition. Neural Computing Appl. doi: 10.1007/s00521-021-06882-y
Gupta, A. (2022). A segmentation algorithm for the leaf area identification in plant’s images. Sci. Technol. Asia, 171–178. doi: 10.14456/scitechasia.2022.33
Habib, M. T., Majumder, A., Jakaria, A., Akter, M., Uddin, M. S., Ahmed, F. (2020). Machine vision based papaya disease recognition. J. King Saud University-Computer Inf. Sci. 32, 300–309. doi: 10.1016/j.jksuci.2018.06.006
Harakannanavar, S. S., Rudagi, J. M., Puranikmath, V. I., Siddiqua, A., Pramodhini, R. (2022). Plant leaf disease detection using computer vision and machine learning algorithms. Global Transitions Proc. 3, 305–310. doi: 10.1016/j.gltp.2022.03.016
He, K., Zhang, X., Ren, S., Sun, J. (2016). “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA. (Piscataway, NJ: IEEE), 770–778.
Hinton, G. E., Vinyals, O., Dean, J. (2015). Distilling the knowledge in a neural network. Available at: https://arxiv.org/abs/1503.02531.
Howard, A., Sandler, M., Chu, G., Chen, L.-C., Chen, B., Tan, M., et al. (2019). Searching for mobilenetv3. Proc. IEEE/CVF Int. Conf. Comput. vision. 2019, 1314–1324. doi: 10.1109/ICCV.2019.00140
Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., et al. (2017). “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Korea (South). (Piscataway, NJ: IEEE).
Hu, J., Shen, L., Sun, G. (2018). “Squeeze-and-excitation networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA. (Piscataway, NJ: IEEE).
Huang, G., Liu, Z., van der Maaten, L., Weinberger, K. Q. (2017). “Densely connected convolutional networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, USA. (Munich, Germany), 4700–4708.
Hughes, D., Salathé, M. (2015). An open access repository of images on plant health to enable the development of mobile disease diagnostics. Available at: https://arxiv.org/abs/1511.08060.
Iandola, F. N., Han, S., Moskewicz, M. W., Ashraf, K., Dally, W. J., Keutzer, K. (2016). Squeezenet: Alexnet-level accuracy with 50x fewer parameters and 0.5 mb model size. Available at: https://arxiv.org/abs/1602.07360.
Ilyas, T., Jin, H., Siddique, M. I., Lee, S. J., Kim, H., Chua, L. (2022). Diana: A deep learning-based paprika plant disease and pest phenotyping system with disease severity analysis. Front. Plant Sci. 13, 983625. doi: 10.3389/fpls.2022.983625
Janarthan, S., Thuseethan, S., Rajasegarar, S., Yearwood, J. (2022). P2op—plant pathology on palms: A deep learning-based mobile solution for in-field plant disease detection. Comput. Electron. Agric. 202, 107371. doi: 10.1016/j.compag.2022.107371
Ji, M., Wu, Z. (2022). Automatic detection and severity analysis of grape black measles disease based on deep learning and fuzzy logic. Comput. Electron. Agric. 193, 106718. doi: 10.1016/j.compag.2022.106718
Ji, M., Zhang, K., Wu, Q., Deng, Z. (2020). Multi-label learning for crop leaf diseases recognition and severity estimation based on convolutional neural networks. Soft Computing 24, 15327–15340. doi: 10.1007/s00500-020-04866-z
Jiang, Z., Dong, Z., Jiang, W., Yang, Y. (2021). Recognition of rice leaf diseases and wheat leaf diseases based on multi-task deep transfer learning. Comput. Electron. Agric. 186, 106184. doi: 10.1016/j.compag.2021.106184
Karlekar, A., Seal, A. (2020). Soynet: Soybean leaf diseases classification. Comput. Electron. Agric. 172, 105342. doi: 10.1016/j.compag.2020.105342
Komodakis, N., Zagoruyko, S. (2016). Paying more attention to attention: improving the performance of convolutional neural networks via attention transfer. In. Available at: https://arxiv.org/abs/1612.03928.
Kumar, M., Chandran, D., Tomar, M., Bhuyan, D. J., Grasso, S., Sá, A. G. A., et al. (2022). Valorization potential of tomato (solanum lycopersicum l.) seed: nutraceutical quality, food properties, safety aspects, and application as a health-promoting ingredient in foods. Horticulturae 8, 265. doi: 10.3390/horticulturae8030265
Kumar, K. S., Paswan, S., Srivastava, S. (2012). Tomato-a natural medicine and its health benefits. J. Pharmacognosy Phytochem. 1, 33–43.
Li, X., Li, X., Zhang, S., Zhang, G., Zhang, M., Shang, H. (2023). Slvit: Shuffle-convolution-based lightweight vision transformer for effective diagnosis of sugarcane leaf diseases. J. King Saud University-Computer Inf. Sci. 35, 101401. doi: 10.1016/j.jksuci.2022.09.013
Liu, B.-Y., Fan, K.-J., Su, W.-H., Peng, Y. (2022). Two-stage convolutional neural networks for diagnosing the severity of alternaria leaf blotch disease of the apple tree. Remote Sens. 14, 2519. doi: 10.3390/rs14112519
Meenakshi, K., Swaraja, K., Ch, U. K. (2019). “Grading of quality in tomatoes using multi-class svm,” in 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC) (Erode, India: Surya Engineering College, IEEE). 104–107.
Mokhtar, U., Ali, M. A., Hassanien, A. E., Hefny, H. (2015). “Identifying two of tomatoes leaf viruses using support vector machine,” in Information Systems Design and Intelligent Applications: Proceedings of Second International Conference INDIA 2015 (Kalyani, India), Vol. 1. 771–782.
Nanehkaran, Y., Zhang, D., Chen, J., Tian, Y., Al-Nabhan, N. (2020). Recognition of plant leaf diseases based on computer vision. J. Ambient Intell. Humanized Computing 2020, 1–18. doi: 10.1007/s12652-020-02505-x
Ozguven, M. M., Adem, K. (2019). Automatic detection and classification of leaf spot disease in sugar beet using deep learning algorithms. Physica A: Stat. Mechanics its Appl. 535, 122537. doi: 10.1016/j.physa.2019.122537
Pal, A., Kumar, V. (2023). Agridet: Plant leaf disease severity classification using agriculture detection framework. Eng. Appl. Artif. Intell. 119, 105754. doi: 10.1016/j.engappai.2022.105754
Patil, P., Yaligar, N., Meena, S. (2017). “Comparision of performance of classifiers-svm, rf and ann in potato blight disease detection using leaf images,” in 2017 IEEE International Conference on Computational Intelligence and Computing research (ICCIC) Tamil Nadu, India. (Piscataway, NJ: IEEE), 1–5.
Rahman, S. U., Alam, F., Ahmad, N., Arshad, S. (2022). Image processing based system for the detection, identification and treatment of tomato leaf diseases. Multimedia Tools Appl. 82, 9431–9445. doi: 10.1007/s11042-022-13715-0
Roy, A. M., Bhaduri, J. (2021). A deep learning enabled multi-class plant disease detection model based on computer vision. AI. 2 (3), 413–428. doi: 10.3390/ai2030026
Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D. (2017). Grad-cam: Visual explanations from deep networks via gradient-based localization. Proc. IEEE Int. Conf. Comput. Vision 2017, 618–626. doi: 10.1109/ICCV.2017.74
Septiyanti, M., Meliana, Y. (2020). Characterization of nanoemulsion gotukola, mangosteen rind, cucumber and tomato extract for cosmetic raw material. J. Physics: Conf. Ser. (IOP Publishing) 1442, 012046. doi: 10.1088/1742-6596/1442/1/012046
Sharif, M., Khan, M. A., Iqbal, Z., Azam, M. F., Lali, M. I. U., Javed, M. Y. (2018). Detection and classification of citrus diseases in agriculture based on optimized weighted segmentation and feature selection. Comput. Electron. Agric. 150, 220–234. doi: 10.1016/j.compag.2018.04.023
Shoaib, M., Hussain, T., Shah, B., Ullah, I., Shah, S. M., Ali, F., et al. (2022). Deep learning-based segmentation and classification of leaf images for detection of tomato plant disease. Front. Plant Sci. 13, 1031748. doi: 10.3389/fpls.2022.1031748
Simonyan, K., Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. Available at: https://arxiv.org/abs/1409.1556.
Singh, D., Jain, N., Jain, P., Kayal, P., Kumawat, S., Batra, N. (2020). Plantdoc: A dataset for visual plant disease detection. Proc. 7th ACM IKDD CoDS 25th COMAD, 249–253. doi: 10.1145/3371158.3371196
Singh, P., Verma, A., Alex, J. S. R. (2021). Disease and pest infection detection in coconut tree through deep learning techniques. Comput. Electron. Agric. 182, 105986. doi: 10.1016/j.compag.2021.105986
Sujatha, R., Chatterjee, J. M., Jhanjhi, N., Brohi, S. N. (2021). Performance of deep learning vs machine learning in plant leaf disease detection. Microprocessors Microsystems 80, 103615. doi: 10.1016/j.micpro.2020.103615
Tan, M., Le, Q. V. (2019). “Efficientnet: Rethinking model scaling for convolutional neural networks,” in International conference on machine learning (PMLR) 2019, 6105–6114.
Thai, H.-T., Le, K.-H., Nguyen, N. L.-T. (2023). Formerleaf: An efficient vision transformer for cassava leaf disease detection. Comput. Electron. Agric. 204, 107518. doi: 10.1016/j.compag.2022.107518
Thuseethan, S., Vigneshwaran, P., Charles, J., Wimalasooriya, C. (2022). Siamese network-based lightweight framework for tomato leaf disease recognition. Available at: https://arxiv.org/abs/2209.11214.
Wang, C., Du, P., Wu, H., Li, J., Zhao, C., Zhu, H. (2021). A cucumber leaf disease severity classification method based on the fusion of deeplabv3+ and u-net. Comput. Electron. Agric. 189, 106373. doi: 10.1016/j.compag.2021.106373
Wang, G., Sun, Y., Wang, J. (2017). Automatic image-based plant disease severity estimation using deep learning. Comput. Intell. Neurosci. 2017, 2917536. doi: 10.1155/2017/2917536
Wang, D., Wang, J., Ren, Z., Li, W. (2022). Dhbp: A dual-stream hierarchical bilinear pooling model for plant disease multi-task classification. Comput. Electron. Agric. 195, 106788. doi: 10.1016/j.compag.2022.106788
Woo, S., Park, J., Lee, J.-Y., Kweon, I. S. (2018). “Cbam: Convolutional block attention module,” in Proceedings of the European conference on computer vision (ECCV). (Munich, Germany, Berlin: Springer), 3–19.
Wu, J., Wen, C., Chen, H., Ma, Z., Zhang, T., Su, H., et al. (2022). Ds-detr: A model for tomato leaf disease segmentation and damage evaluation. Agronomy 12, 2023. doi: 10.3390/agronomy12092023
Yuan, L., Tay, F. E., Li, G., Wang, T., Feng, J. (2020). “Revisiting knowledge distillation via label smoothing regularization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. (Virtual, Piscataway, NJ: IEEE), 3903–3911.
Zeng, W., Li, H., Hu, G., Liang, D. (2022). Lightweight dense-scale network (ldsnet) for corn leaf disease identification. Comput. Electron. Agric. 197, 106943. doi: 10.1016/j.compag.2022.106943
Zhang, S., Griffiths, J. S., Marchand, G., Bernards, M. A., Wang, A. (2022). Tomato brown rugose fruit virus: An emerging and rapidly spreading plant rna virus that threatens tomato production worldwide. Mol. Plant Pathol. 23, 1262–1277. doi: 10.1111/mpp.13229
Zhang, J.-H., Kong, F.-T., Wu, J.-Z., Han, S.-Q., Zhai, Z.-F. (2018a). Automatic image segmentation method for cotton leaves with disease under natural environment. J. Integr. Agric. 17, 1800–1814. doi: 10.1016/S2095-3119(18)61915-X
Zhang, J., Rao, Y., Man, C., Jiang, Z., Li, S. (2021). Identification of cucumber leaf diseases using deep learning and small sample size for agricultural internet of things. Int. J. Distributed Sensor Networks 17, 15501477211007407. doi: 10.1177/15501477211007407
Zhang, X., Zhou, X., Lin, M., Sun, J. (2018b). “Shufflenet: An extremely efficient convolutional neural network for mobile devices,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Munich, Germany, (Munich, Germany). 6848–6856.
Zhao, B., Cui, Q., Song, R., Qiu, Y., Liang, J. (2022). “Decoupled knowledge distillation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA. (Piscataway, NJ: IEEE), 11953–11962.
Keywords: multi-task learning, knowledge distillation, tomato leaf diseases, disease classification, severity prediction
Citation: Liu B, Wei S, Zhang F, Guo N, Fan H and Yao W (2024) Tomato leaf disease recognition based on multi-task distillation learning. Front. Plant Sci. 14:1330527. doi: 10.3389/fpls.2023.1330527
Received: 31 October 2023; Accepted: 28 December 2023;
Published: 30 January 2024.
Edited by:
Dun Wang, Northwest A&F University, ChinaReviewed by:
Olarik Surinta, Mahasarakham University, ThailandGuoxiong Zhou, Central South University Forestry and Technology, China
Copyright © 2024 Liu, Wei, Zhang, Guo, Fan and Yao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wei Yao, WWFvV2VpLWhlYmF1QGhvdG1haWwuY29t