 Xiaojing Chen
Xiaojing Chen Longyu Huang
Longyu Huang Jingchao Fan
Jingchao Fan Shen Yan
Shen Yan Guomin Zhou2,3
Guomin Zhou2,3
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Plant Sci., 17 January 2024
Sec. Plant Bioinformatics
Volume 14 - 2023 | https://doi.org/10.3389/fpls.2023.1293599
This article is part of the Research TopicMulti-omics and Computational Biology in Horticultural Plants: From Genotype to Phenotype, Volume IIView all 25 articles
KASP marker technology has been used in molecular marker-assisted breeding because of its high efficiency and flexibility, and an intelligent evaluation model of KASP marker primer typing results is essential to improve the efficiency of marker development on a large scale. To this end, this paper proposes a gene population delineation method based on NTC identification module and data distribution judgment module to improve the accuracy of K-Means clustering, and introduces a decision tree to construct the KASP-IEva primer typing evaluation model. The model firstly designs the NTC identification module and data distribution judgment module to extract four types of data, grouping and categorizing to achieve the improvement of the distinguishability of amplification product signals; secondly, the K-Means algorithm is used to aggregate and classify the data, to visualize the five aggregated clusters and to obtain the morphology location eigenvalues; lastly, the evaluation criteria for the typing effect level are constructed, and the logical decision tree is used to make conditional discrimination on the eigenvalues in order to realize the score prediction. The performance of the model was tested by the KASP marker typing test results of 2519 groups of cotton varieties, and the following conclusions were obtained: the model is able to visualize the aggregation and classification effects of the amplification products of NTC, pure genotypes, heterozygous genotypes, and untyped genotypes, enabling rapid and accurate KASP marker typing evaluation. Comparing and analyzing the model evaluation results with the expert evaluation results, the average accuracy rate of the four grades evaluated by the model was 87%, and the overall evaluation results showed an uneven distribution of the grades with significant differential characteristics. When evaluating 2519 KASP fractal maps, the expert evaluation consumes 15 hours, and the model evaluation only uses 8min27.45s, which makes the model intelligent evaluation significantly better than the expert evaluation from the perspective of time. The establishment of the model will further enhance the application of KASP markers in molecular marker-assisted breeding and provide technical support for the large-scale screening and identification of excellent genotypes.
Cotton is an important fiber crop in the world, and is also an important strategic material related to the national economy and people’s livelihood of China, with high economic value (Gu et al., 2020; Lu et al., 2023; Chen et al., 2024). A number of important agronomic traits of cotton are characterized by quantitative genetic features, which are easily disturbed by external environmental conditions and are genetically negatively correlated, resulting in a large workload and low selection efficiency in cotton variety selection (Li and Yuan, 2013). The traditional breeding methods of selection of low accuracy, long cycle, poor predictability, and molecular marker-assisted selection (MAS) can make up for these shortcomings. Molecular marker-assisted selection is a direct selection of genotypes for target traits with the help of molecular markers, which greatly shortens the breeding time and reduces the population planting scale, and is of great significance for the rapid breeding of new cotton materials and varieties (Abdelraheem et al., 2021; Gao et al., 2023).
At present, the commonly used molecular marker technologies mainly include RFLP, RAPD, AFLP, SSR, InDel, SNP, etc (Amiteye, 2021; Geng et al., 2021; Al-Khayri et al., 2022; Kumar et al., 2022), among which SNP (single nucleotide polymorphisms) markers have been designated as one of the priority recommended marker methods by the International Union for the Protection of New Plant Variety Rights (UPOV) BMT molecular testing guidelines (Nie et al., 2021), and KASP (kompetitive allele-specific PCR), as a mainstream SNP high-throughput typing technology, is a novel PCR-based homogeneous fluorescent SNP typing method. KASP has high analytical stability and accuracy, and KASP provides great flexibility in terms of the number of SNPs and samples used for the determination and can achieve high-precision dual-allele genotyping (SNPs and InDels) for a small number of target markers in large-scale segregating or natural populations (Yang et al., 2020; Wang et al., 2021; Zhao et al., 2021).
Some scholars at home and abroad are working on kompetitive allele-specific PCR studies in cotton and other crops. Guo et al. (2023) developed the M-1590 KASP marker to classify 90 kinds of cotton materials and used the grid lines of the coordinate axes to assist in visually inspecting the high and low signal values of the allele population, and the results showed that the marker could only classify four kinds of materials. Fan Tao (Fan et al., 2021) and others screened multiple spikes and long-grain wheat resources based on KASP marker technology, using two straight lines parallel to the axes to divide the area composed of the axes into four parts on average, and observing the high and low fluorescence values of the signal points and the size of the angle between the different genotypes, to evaluate whether the primers were able to type the different materials in the population well or not. Xu Biyu (Xu et al., 2023) and others used KASP to identify key variants or genes responsible for stem trichome traits in cotton stalks and confirmed that mutations co-segregated with the stem trichome phenotype by directly observing the relative independence of gene populations in allelic discrimination maps. Byers et al. (2012) and others transformed hundreds of putative allotetraploid cotton SNPs into functional SNPs. In the genotyping determination, the genotyping map of Fluidigm SNP analysis software was divided into tables to determine whether the heterozygote group was distinguished from the homozygote group, so as to evaluate the amplification and separation of the genotype group. Sheng et al. (2022) used the designed markers to genotype 86 kale crop materials at the target loci, and they verified the accuracy and applicability of the markers by outlining and observing the distribution trend lines of the signal points. Li Lihua (Li et al., 2022) and others designed KASP primers based on the results of pre-fiber strength association analysis and genotyped 376 land cotton materials, and they proposed that the population was classified into three categories by the marker, the pure and genotypes were close to the axes, and the heterozygous genotypes were located in the center of the typing diagram of the typing results could prove that the marker had DNA polymorphism in the group. Wang et al. (2022) used 48 KASP markers to genotype 348 grape germplasm for genotyping, observed the separation status of pure and heterozygous populations in the output genotyping map of LGC’s KASP detection technology platform, and finally screened out 46 markers with good fluorescence genotyping results. In the traditional KASP primer typing results validation, the evaluation of competitive primer combination status relies heavily on professional knowledge and long-term experience judgment. The expert visual evaluation requires that the evaluators in the relevant fields have a high degree of professionalism and data analysis ability, and the diversity of genotypic amplification signal patterns puts forward a higher demand for the expert’s ability to make judgments. The approach also suffers from highly subjective results, high physical effort, low precision and slow validation of large-scale materials.
With the development of high-throughput SNP genotyping technology, new molecular marker technologies have been continuously developed, and KASP genotyping technology has been gradually involved in selection tests to optimize the best technology to be applied in the field of crop breeding. For example, in order to compare the detection differences among TaqMan, KASP and rhAmp, Broccanello et al. (2018) utilized the indicators of distance of genotypic clusters to the NTC, cluster angle segregation and cluster spread to perform analysis of variance to quantitatively assess the typing effect by comparing the differences in the values of the indexes. On this basis, Ayalew et al. (2019) proposed to measure allelic discrimination by using the cluster separation angle, and cluster compactness by calculating the standard deviation of the distances between the data points in the clusters with the mean coordinate value of the clusters to realize the comparison of the three genotyping platforms in hexaploid wheat. Although this method provides a more scientific and statistical idea for evaluating the typing effect, it still has the problems of few evaluation indexes and low degree of intelligence, in addition, the method does not provide accurate evaluation standards and is only applicable to multi-detection technology difference comparison tests.
To summarize, most KASP studies mainly adopt the way of expert interpretation of primer typing diagrams, and some of them have used statistical analyses. There is a scarcity of studies on intelligent evaluation of typing effects, which makes it difficult to evaluate the amplification efficiency and specificity of competitive primers for crops on a large scale. In this study, in strict accordance with the grade evaluation criteria, based on the K-Means algorithm, we propose the NTC identification module and data distribution judgment module to improve the accuracy of gene population delineation, and design the decision tree for the grade evaluation of typing effect to construct the intelligent typing evaluation model for the KASP-IEva primers. Based on the results of kompetitive allele-specific PCR study, we organized experimental data, applied the KASP-IEva model to type the amplification products of 2519 groups of KASP markers, realized the classification of different genotypes of land cotton materials, constructed the evaluation decision tree according to the grade evaluation criteria, and intelligently and rapidly screened and identified the KASP markers with excellent typing effect, with the aim of providing data support for improving the success rate of KASP marker development and technical support for molecular marker-assisted breeding and other work.
In this study, the results of the KASP marker test of cotton variety resource materials were used as experimental data, which came from the Cotton Quality Supervision, Inspection and Testing Center of the Ministry of Agriculture and Rural Affairs of the Chinese Academy of Agricultural Sciences (CAAS) Cotton Research Institute, and the KASP marker test materials contained 450 resource varieties, 260 line materials and 1,200 audited varieties and 609 genetically segregated population materials. The content of the experimental data is 2519 groups of amplification product information, each group contains 46 or 94 DNA samples detection data and 2 NTC (negative control reaction without DNA samples added in the PCR assay) detection data, and each detection data includes SNP locus number, sample number, relative value of the sample HEX and FAM fluorescence signal magnitude, daughter plate serial number, mother plate serial number and genotype and other information, and so on. Only the first four items were involved in the experiment, and the specific data are shown in Table 1.
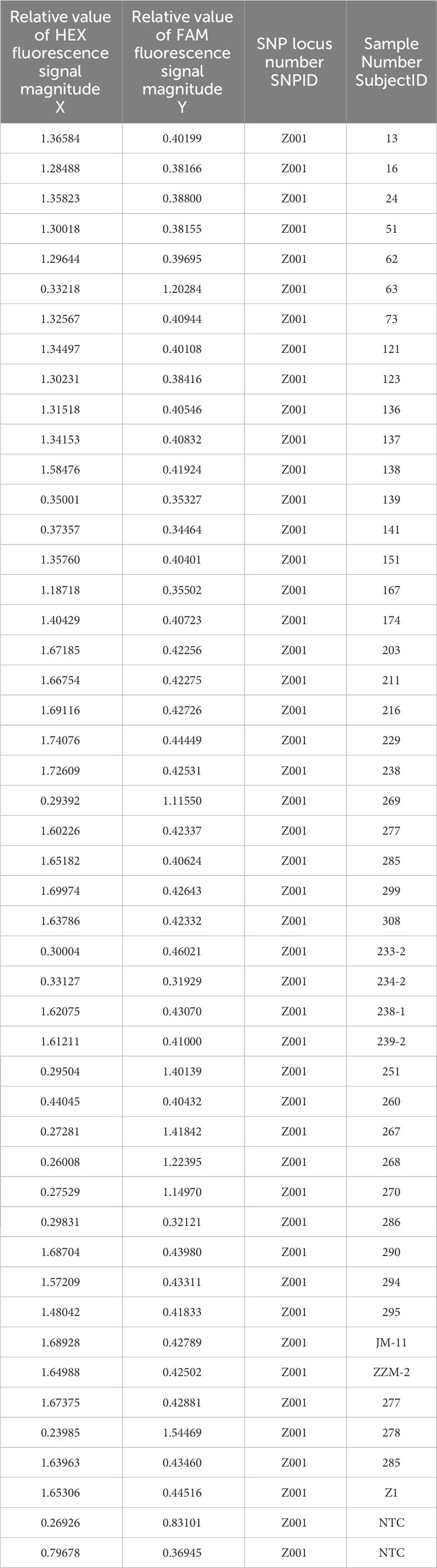
Table 1 Information of a set of 48 KASP-labeled amplification products.
In general, experts evaluate the typing effect based on the typing map results of the LGC-SNPline platform software by manual judgment based on experience, and there is a lack of unified typing effect evaluation standards and evaluation models. In order to quantify the evaluation criteria and meet the need for the model to be evaluated with higher precision and faster speed, this study constructs the KASP-IEva model by using the intelligent typing module and decision tree on the basis of more detailed evaluation criteria for the typing effect level, so that the factors within the typing diagram undergo a recursive process, and the precise calculation is performed at each intermediate node to classify the attributes. The research-constructed model uses unlabeled datasets for processing, groups the data based on the similarity of the underlying structure of the given dataset so that the typing results are in line with professional empirical perceptions, and then realizes score prediction through the computation of eigenvalues of genotypic amplification product classifications and combinations, which then realizes the typing evaluation intelligently.
The KASP-IEva primer intelligent typing evaluation model is mainly composed of four modules, namely, the NTC identification module, data distribution judgment module, K-Means clustering module, and typing effect evaluation, in which the typing effect evaluation module adopts the decision tree theory, and the structure of the model is shown in Figure 1. From the viewpoint of data distribution, there are four main types, namely, NTC data, untyped product data, heterozygous genotype data, and pure genotype data. The distribution of NTC data is characterized by no obvious boundaries, random degree of aggregation, and fixed quantity. The non-NTC data had some missing types, which were categorized into three categories: containing four types of data, not containing untyped data, and not containing heterozygous genotype data. The decentralized distribution of non-NTC data resulted in the boundary of different types of data not being easy to distinguish. Firstly, each group of fluorescence signal magnitude relative value data and sample number are read, NTC identification module controls the separation of NTC data from the rest of the data, and two different branches are used to perform clustering operation separately without destroying the connectivity of the final results, in order to improve the classification ability of the model to the target under the data mixing condition. Data distribution judgment module extracts different types of data by discriminating the location characteristics, and further splits the non-NTC data into 3 parts, which reduces the training time of the subsequent algorithms of the model and improves the distinguishability of the amplified signals. The machine learning algorithm in the K-Means module extracts the deep structure eigenvalues between amplification products on the basis of obtaining 5 aggregation clusters of different sizes in order to compute the evaluation indexes. The decision tree for the evaluation of the fractal effect categorizes the eigenvalue dataset through multiple conditional discriminative processes, the Based on the tree structure, the decision-making judgment of amplification efficiency and specificity of competitive primers is carried out, and the evaluation results of typing effect of each group are finally obtained. These four modules are described in detail below.
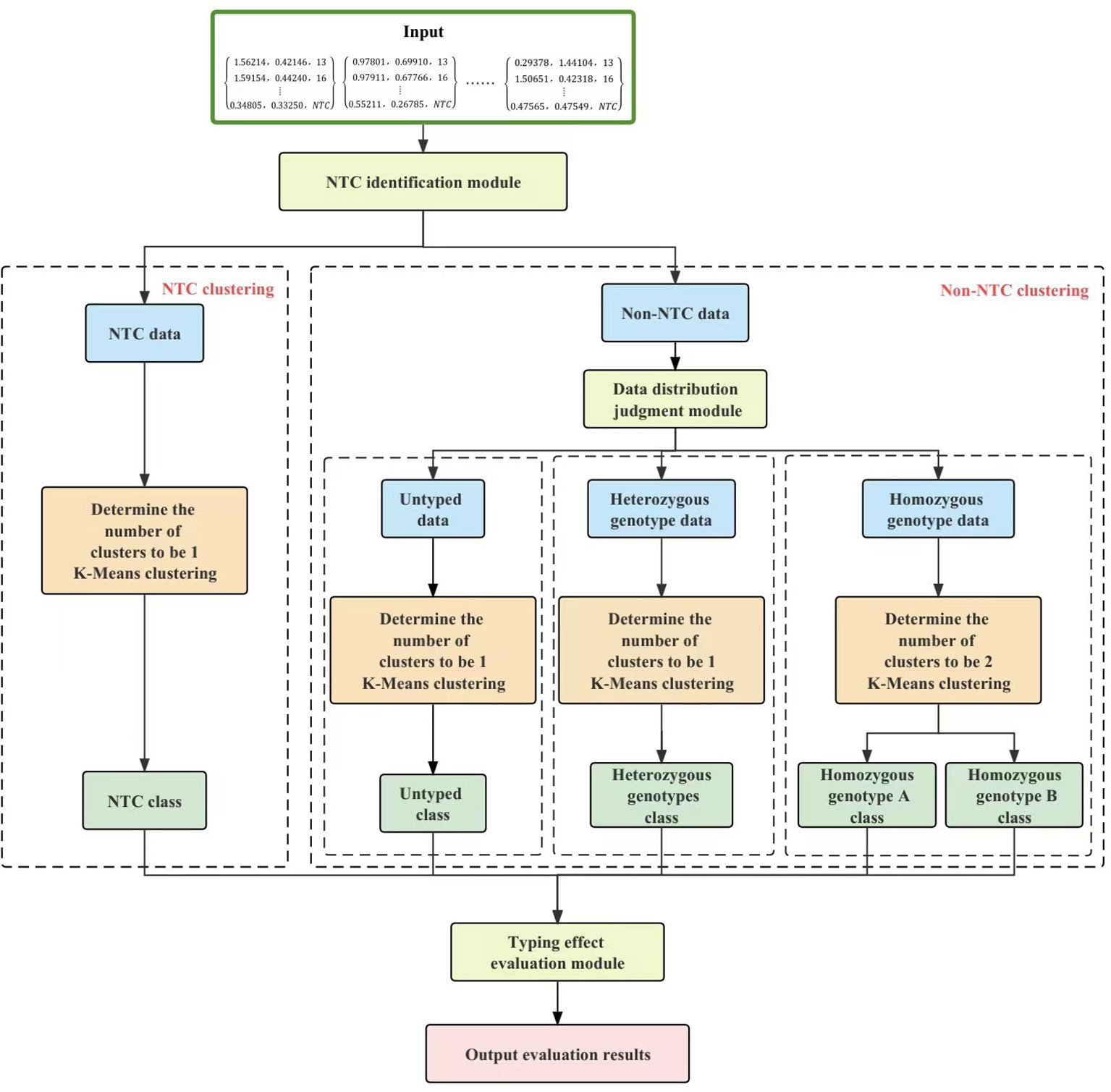
Figure 1 Overall structure of the KASP-IEva model.
Retrieval is performed within each set of data, and the elements at the corresponding positions of the NTC data are transformed to form a two-dimensional array A[M][N] of pairs of fluorescent signal magnitude relative-value tuples, in which each row represents the coordinates of a point.
There is a complex nonlinear correlation between amplification products, and the relative value of fluorescence signal magnitude of each data point affects each other to different degrees, so this paper tries to add a data distribution judgment module into the model to make the amplification product characteristic information more distinguishable. This module is based on the maximum value, minimum value, and manually adjusted segmentation value of the data set to quantitatively divide the range of the region, and proposes the extraction method of grouped data, i.e., the target point in the experimental data that is in the same region as the partitioning result is inputted into a two-dimensional array as the data of this genotype. The specific process of the setup is as follows:
For the division of the distribution region of heterozygous genotypes, the segmentation of the value along the horizontal and vertical coordinate axes, respectively, is used to obtain the maximum and minimum values of the relative value of the fluorescence signal level in all non-NTC data, and after calculating the appropriate distance that needs to be intercepted within the interval of the coordinate axes, the relative value of the fluorescence signal level of the data whose horizontal and vertical coordinates meet the requirements of the region is put into the two-dimensional array B[M][N], and the calculation process is represented by Equations 1–7.
Where: Xi and IBx denote the relative values of HEX fluorescence signal magnitude of experimental data points of non-NTC, Yi and IBy denote the relative values of FAM fluorescence signal magnitude of experimental data points of non-NTC, XBD is the distance of heterozygous genes’ distribution region from the ends along the horizontal direction, and YBD is the distance of heterozygous genes’ distribution region from the ends along the vertical direction.
For the division of the distribution region of the untyped product, the same method as described above is used to obtain the maximum and minimum values of the remaining relative values of the fluorescence signal magnitude after the extraction of the NTC data and the heterozygous genotype data, calculate the appropriate interception distance within the range of the coordinate axes, and form a two-dimensional array of the relative values of the fluorescence signal magnitude satisfying the condition of being in the interception region into a two-dimensional array C[M][N], and the remaining data can be expressed directly as D[M][N], and the calculation process is represented by Equations 8–14:
Where: Xj and ICx denote the relative values of HEX fluorescence signal magnitude for unfractionated and pure amplification product data points, Yj and ICy denote the relative values of FAM fluorescence signal magnitude for unfractionated and pure amplification product data points, XCD is the horizontal distance from the distribution area of unfractionated amplification products, and YCD is the vertical distance from the distribution area of unfractionated amplification products.
Based on the K-Means machine learning algorithm to complete the modeling process of the fractal model, the clustering idea is used to mine the potential correlation of the genotype data, and the data are grouped categorized, and visualized. The K-Means algorithm was proposed by the Lloyd scholars in 1982, and the algorithm is one of the most classical and commonly used unsupervised learning algorithms to solve the clustering problem (Chakraborty et al., 2020; Sinaga and Yang, 2020). It divides the set of samples into K-class clusters and uses Euclidean distance to measure the similarity between the samples, which results in high similarity within clusters of the same class and low similarity between clusters of different classes (Mirzal, 2020). The K-Means algorithm process is as follows:
Randomly select K samples from a set of sample sets as the initial center of mass, calculate the Euclidean distance between each sample point and the K clustering centers, and use this as the basis for assigning all sample points to their nearest clustering centers; in order to reduce the sum of squares of the error of the dataset, calculate the mean vector of the cluster Ci as the new center of mass of the cluster; the smaller the squared error SSE is, the greater the similarity of the samples within the cluster is, and repeat the training of each cluster center, until the cluster center position and the size of SSE value no longer change significantly, to get the final clustering results (Chou, 2016; Yin et al., 2022). The calculation process is represented by equations Equations 15–18:
Where: x is the data object, Ci denotes the ith clustering center, k denotes the number of clustering centers, m is the dimension of the data object, xj is the attribute value of the jth dimension of the data object x, and Cij is the attribute value of the jth dimension of the clustering center Ci.
As can be seen from the above calculation process, before starting the clustering process, the K-Means algorithm will randomly select a certain number of data points as the initial center of mass. The way of selecting the random initial center of mass will directly affect the final results of the clustering, and if the initial selection of the clustering center is not ideal, the approach may fall into an unreasonable local optimal solution, so it is proposed that based on the previously mentioned data distribution judgment module to limit the initial Clustering center selection range, NTC data, heterozygous genotype data, untyped product data and pure genotype data were clustered separately, and the K used for input was 1, 1, 1, and 2 in order. In this study, we inherited the form of Euclidean distances to represent the inter-individual similarity indexes of the amplification product points proposed by the classical K-Means clustering method, and at the end of the clustering process, the order of the clustering results was fixed and different colors of fluorescent light were displayed. NTC data were shown in black, the amplification products with FAM sequence tags were shown in red, those with HEX sequence tags were shown in blue, the untyped amplification products were in pink, the heterozygous genotypes were in green, and the sequence numbers of the clusters for non-NTC data were fixed to 1, 2, 3, and 4 in order.
The typing map contains a large amount of quantifiable positional and morphological feature information, and the center coordinates, center distances, radius eigenvalues, and axes maximum values of K-Means clustering of the experimental data of all groups to form aggregated clusters are obtained to provide data support for the evaluation of the typing effect in the next step.
The purpose of the validation of primer typing results is to evaluate KASP markers and screen and identify KASP markers with excellent typing effect. After classifying and partitioning the experimental data, the model in this paper will intelligently evaluate the partitioning results. The evaluation of the KASP primer typing effect is characterized by many evaluation indexes, strong intrinsic correlation, great difficulty in evaluation, etc. In order to overcome the subjectivity of the expert evaluation method which scores by visually inspecting the unmeasurable abstract indexes, we propose the hierarchical evaluation method based on the decision tree to improve the performance of evaluation and perform data statistics and analysis of the characteristic values such as the radius of the clusters, the center position and the center relative distance to ensure the objectivity and science of the hierarchical evaluation.
According to a large amount of experimental data, if NTC did not show a significant fluorescence signal, it indicated that the PCR primer amplification was normal and the test results were credible, and the grading of the typing effect was classified as grade 0, grade 1, grade 2, and grade 3 according to the status of the combination of the red competitive primer and the status of the combination of the blue competitive primer in descending order. The grading is independent of the cluster number, and the criteria for the classification of each grade are shown in Table 2. If the NTC showed a significant fluorescence signal, it was evaluated as grade 2 according to its amplification product combination status if it was not classified as grade 3.
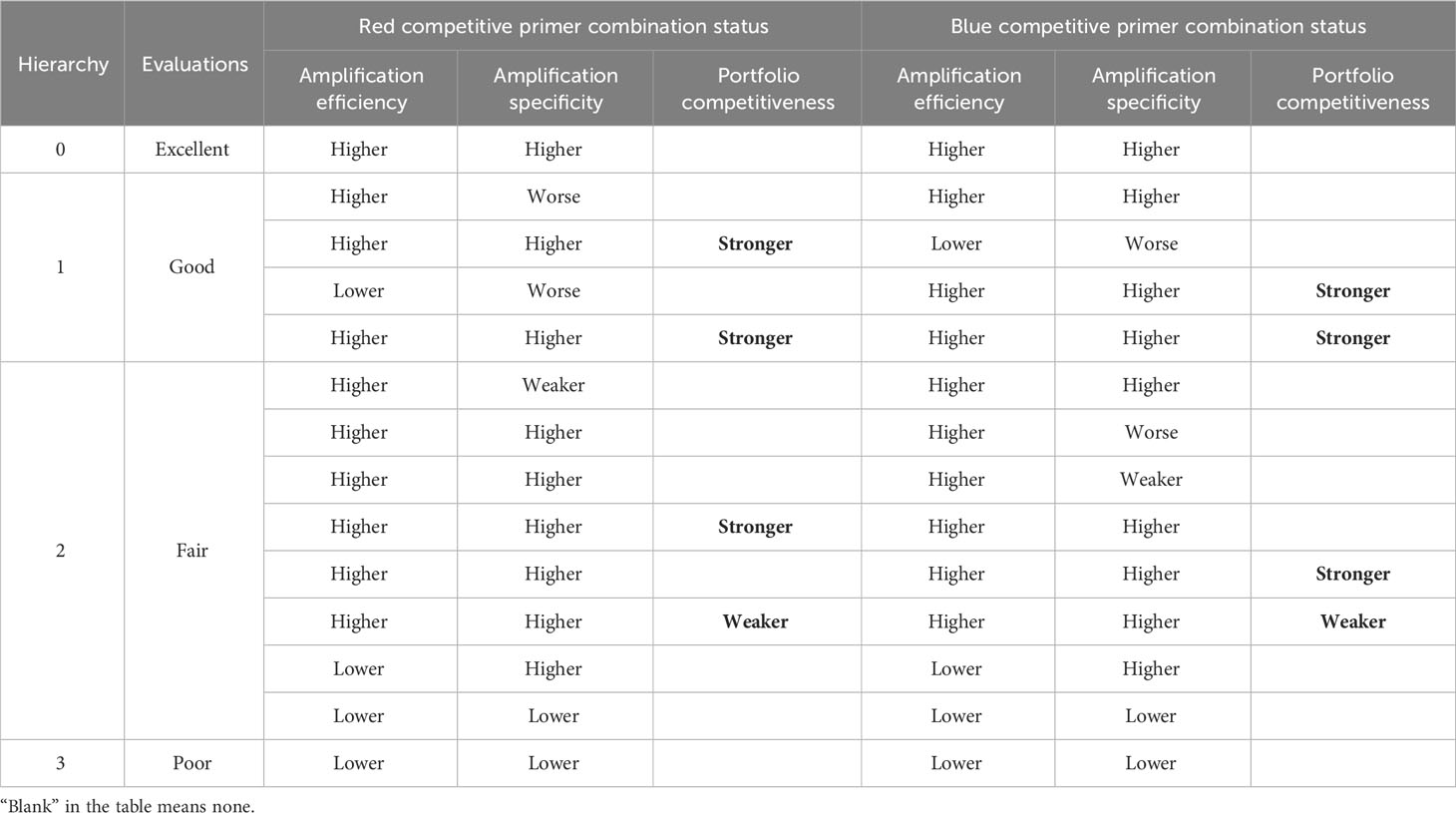
Table 2 Classification criteria of KASP primer typing effect level.
The decision tree classification algorithm has the advantages of fast speed, low computational cost, clear classification rules, and high accuracy (Adibi, 2019; Zhang et al., 2023). Each internal node in the decision tree represents a judgment on an attribute, each branch represents the output of a judgment result, and finally, each leaf node represents a classification result (Che et al., 2011; Charbuty and Abdulazeez, 2021; Huang et al., 2022). In this paper, we use cluster 1 to denote the pure genotype with FAM sequence tag, cluster 2 to denote the pure genotype with HEX sequence tag, cluster 3 to denote the untyped amplification product, and cluster 4 to denote the heterozygous genotype and construct a complete decision tree with a maximum depth of 7 for the morphology location eigenvalues such as radius, center position and relative distance from the center obtained by clustering, and the structure is shown in Figure 2. Layer 1 uses “module start” as the root node of the decision tree, layer 2 mainly judges whether there is cluster 4 data in the typing diagram, and filters the input data set of the subsequent recursive conditions, layer 3 is the evaluation index layer, which is the factor condition to discriminate the state of primer combinations expressed by the eigenvalues, and also the core of the decision tree. The main task of layer 4 is to quantify the formula of the indicators, and the formula will help to transform the evaluation indicators into numerical calculation forms for better comparison and analysis. Layer 5 is mainly used to classify the cases in which the eigenvalues satisfy each indicator item, and two layers of logical decision-making for judging the degree of dispersion among the groups of amplification products have been included in the strategic paths existing in the cluster 4 data, which can further ensure the reasonableness of the classification of the evaluation results. Finally, the classification results of each index item were combined to determine the evaluation grade of typing effect.
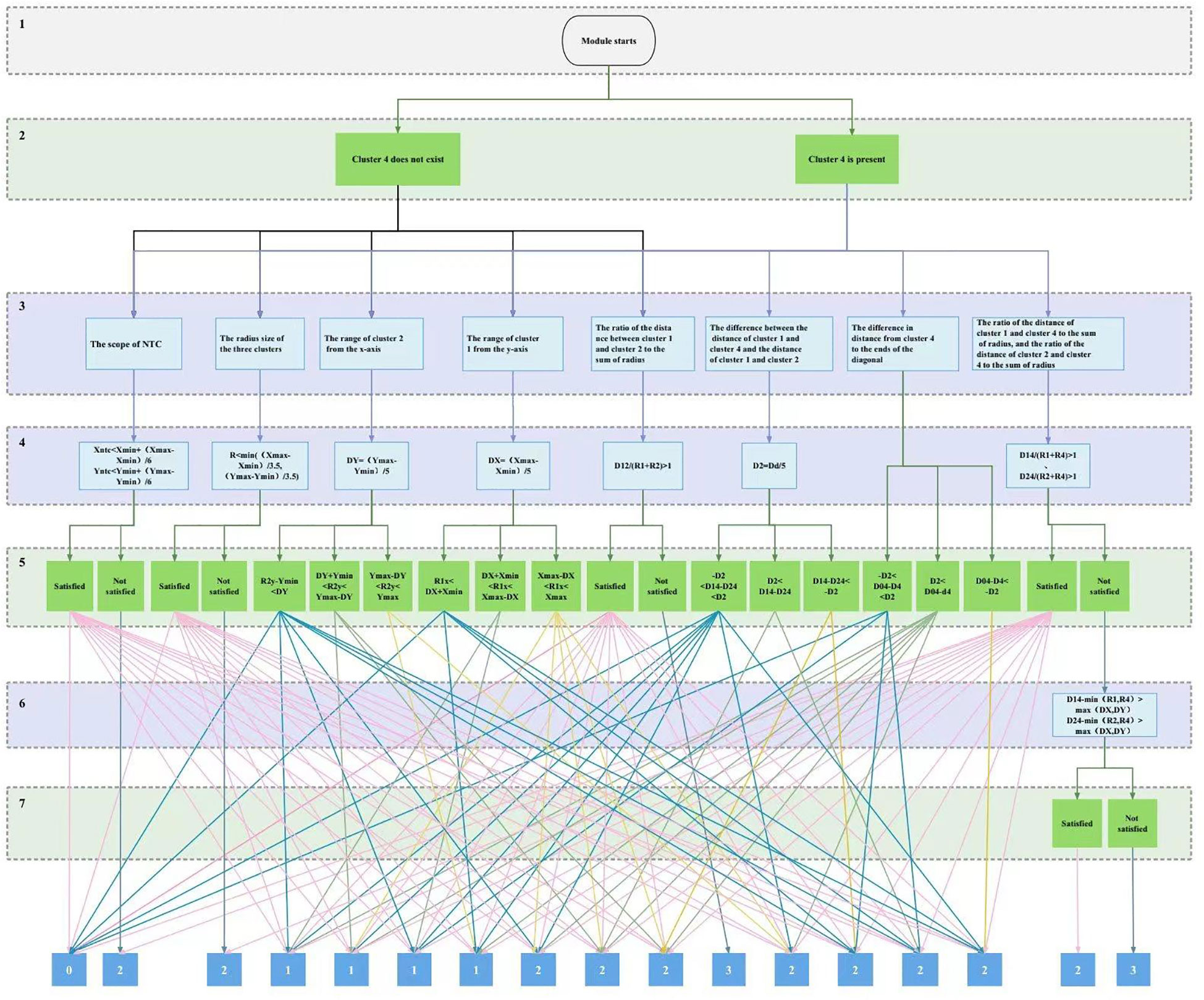
Figure 2 Decision tree rank evaluation module structure. Where: Xntc and Yntc are x and y coordinate values of NTC clustering centers, Xmax and Xmin are maximum and minimum values of the X-axis, Ymax and Ymin are the same as above, R denotes the radius of the three genotypes clusters, R2y denotes the y coordinate value of the center of cluster 2, D12, D14, D24, and D04 denote the distances of cluster 1 and 2 centers, cluster 1 and 4 centers, cluster 2 and 4 centers and the cluster 4 centers to the origin, respectively, R1, R2, and R4 denote the radii of clusters 1, 2, and 4, respectively, and Dd denotes diagonal distance.
The operating system environment for this experiment is Windows 11 with a 12th Gen Intel (R) Core (TM) i5-12500 3.00 GHz CPU, 32.0 GB of RAM on board, NVDIA GeForce RTX 3080 GPU, and 10 GB of RAM. The environment is configured for Python 3.8.3.
Input the KASP marker test data of cotton variety resource materials in the KASP-IEva model to verify the typing ability of the model. As shown in Figure 3A, the model first read the relative value of signal magnitude and sample number of each group of amplification products, and then extracted the NTC data, heterozygous genotype data, untyped product data, and pure genotype data, which were temporarily stored in a two-dimensional array, and then classified and combined the amplification product data and output the characteristic values. The results showed that the KASP-labeled pure genotype amplification products, heterozygous genotype amplification products, and untyped detection data could be successfully classified and analyzed using this model, and the final typing effect is shown in Figure 3B.
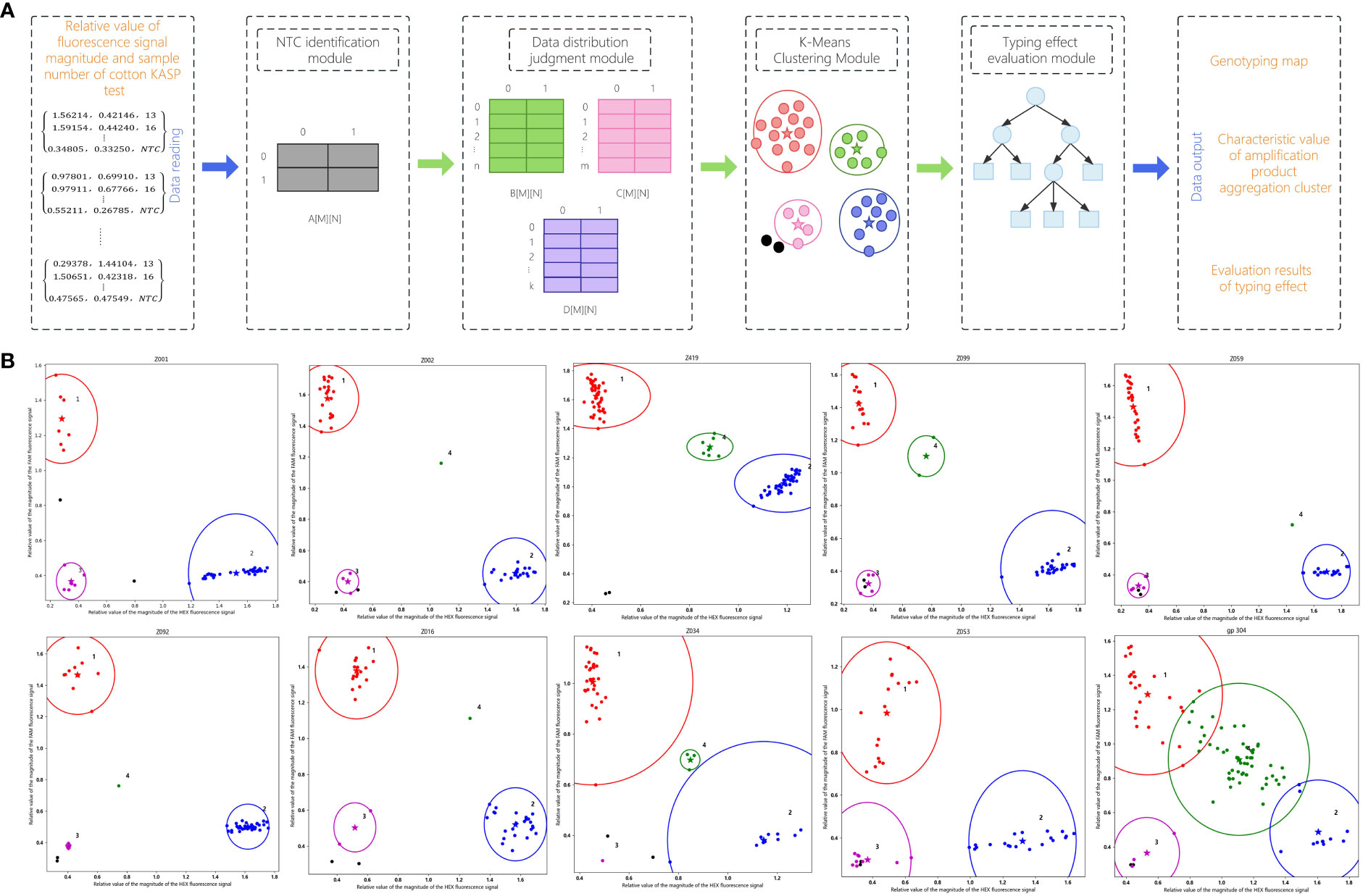
Figure 3 KASP-IEva model typing display. (A) Model composition schematic. (B) Different typing effects.
The horizontal and vertical coordinates indicate the relative values of HEX and FAM fluorescence signal magnitudes, respectively. From the NTC typing results, the NTC identification module can accurately identify the detection data of negative control samples, and the model is indicated by the use of black dots. From the non-NTC data typing results, the data distribution judgment module can correctly classify the data categories, the pure genotype group is divided into cluster 1 and cluster 2, the HEX signal of the amplification product of the pure allele genotypes close to the horizontal axis is significantly high, and the FAM signal is not obvious, which is shown in red, and the FAM signal of the amplification product of the pure allele genotypes close to the vertical axis is significantly high, and the HEX signal is not obvious, which is shown in blue; The dots in the pink circle with the serial number labeled 3 indicate unsuccessfully typed DNA samples; the green population located in the middle position of the typing diagram can detect both FAM and HEX signals, indicating a heterozygous amplification product containing both alleles, with the serial number labeled 4. In summary, in terms of classification, the KASP-IEva model can aggregate and categorize the amplification product data into the correct distributions that accurately reflect the relationship between homozygous and heterozygous alleles. Morphologically, the KASP-IEva model uses stars and circles to represent the center position and range of the amplification signal clusters of each genotype, which makes the effect of distinguishing and clustering genotypes more obvious, and better expresses the amplification efficiency and specificity of competitive primers for crops. The characteristic values of the aggregation cluster information of each genotype produced by the model are shown in Table 3, which can provide data support for evaluating the typing effect.
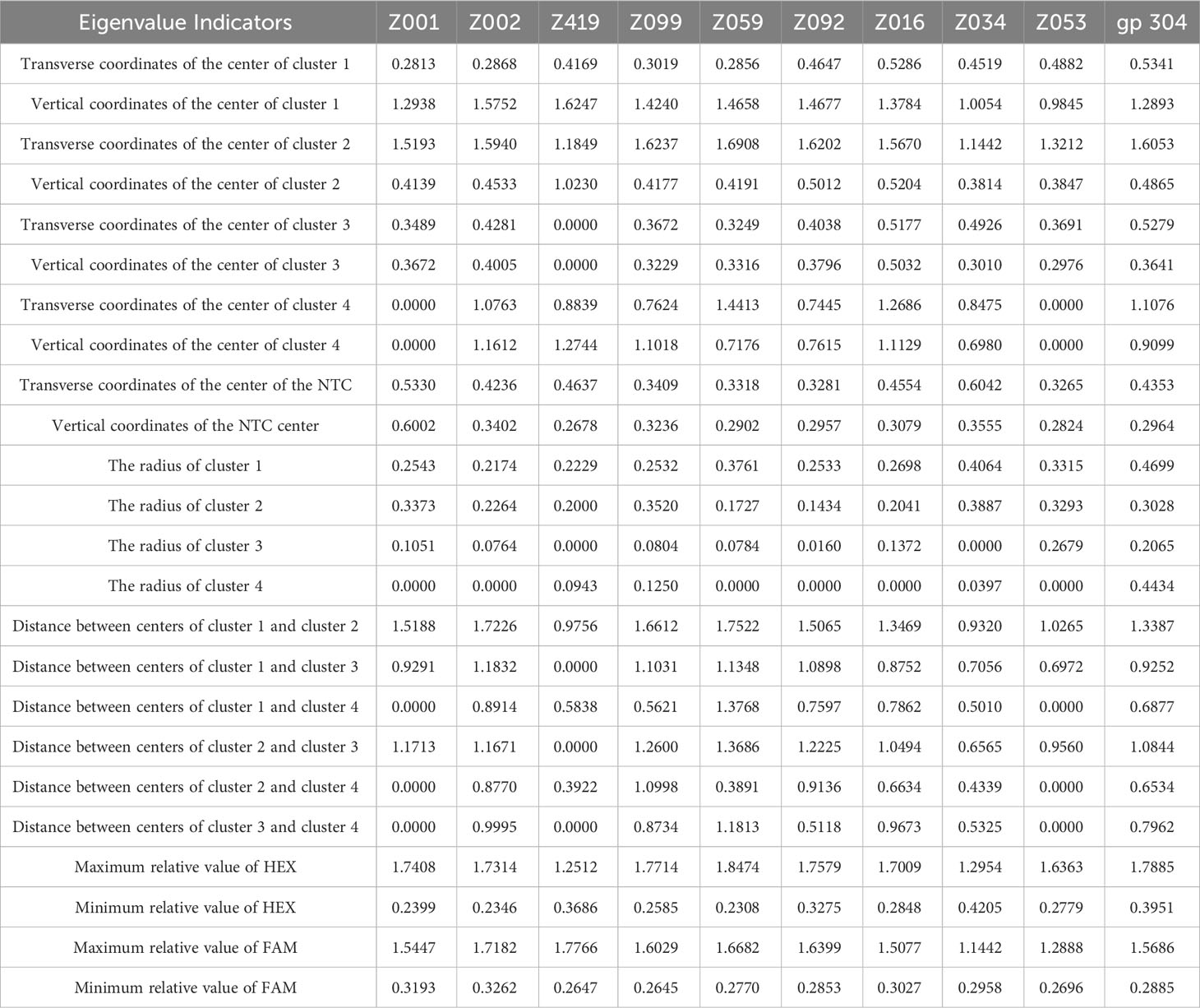
Table 3 Eigenvalue information corresponding to different typing effects.
The KASP-IEva model evaluates the typing effect by calculating the eigenvalues of each genotypic aggregation cluster information in 2519 cotton KASP marker typing result maps, and some of the evaluation results are shown in Table 4. As shown in the first set of samples in the table, the original data are X=0.43932, 0.43774, 0.84223……0.41968, 0.50936, 0.48568, Y=1.39457, 1.44224, 1.04104……1.63594, 0.28467, 0.29018, and the modeling process yields eigenvalues 0.4503,1.4939, 1.7889……0.3965, 1.6608, 0.2847, using the expert evaluation grade scores as the standard, the model evaluation results are compared and analyzed with the expert evaluation results. It can be seen that the evaluation scores of the model are the same as the expert evaluation scores, indicating that the model has good accuracy and reliability in evaluating the effect of typing.
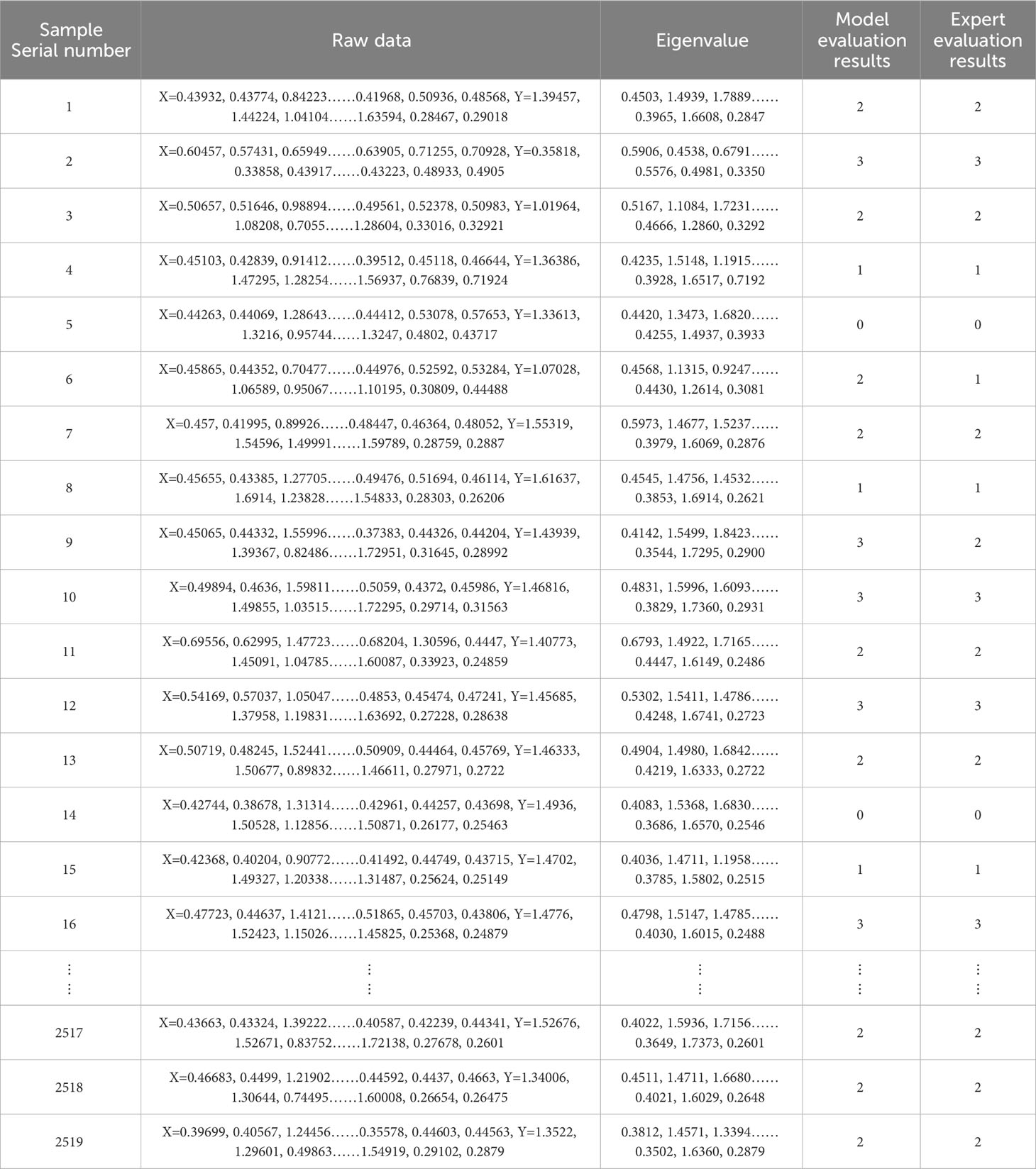
Table 4 Results of the evaluation of the effect of partial subtyping.
In order to effectively assess the computational accuracy of the KASP-IEva primer intelligent typing evaluation model for 2519 sets of experimental materials, the accuracy measure of the evaluation results was performed by constructing a confusion matrix. As shown in Figure 4, the rows of the confusion matrix, i.e., the real labels, represent the expert evaluation levels, the columns, i.e., the prediction labels, represent the model evaluation levels, the diagonal elements represent the correct rate of judgment of each level of the KASP-IEva primer intelligent typing evaluation model, and the off-diagonal elements are the proportion of judgment errors, which are calculated by dividing the number of evaluation errors of the level by the total number of samples. It can be seen that a higher diagonal value indicates a higher evaluation accuracy and a better performance of the model for grade evaluation. After analysis, it can be seen that the average accuracy of the four evaluation levels is 87%, and the evaluation accuracy of levels 0, 2, and 3 is 91%, 80%, and 95%, respectively, which indicates that the model judgment ability is better for these three types of typing diagrams, and the evaluation accuracy of level 1 is 72%. The reason for this is, on the one hand, the number of experimental data of this kind of sample is small, on the other hand, considering the influence of human subjective factors, the description of NTC not showing significant fluorescent signals in the class classification standard of primer typing effect is ambiguous, and the reasonable distribution area of NTC is not strictly defined in the process of expert evaluation, which results in the interpretation of the 2-level typing effect as 1-level. In comparison, the evaluation results of the intelligent model based on the principle of the decision tree machine algorithm are more objective and reasonable.
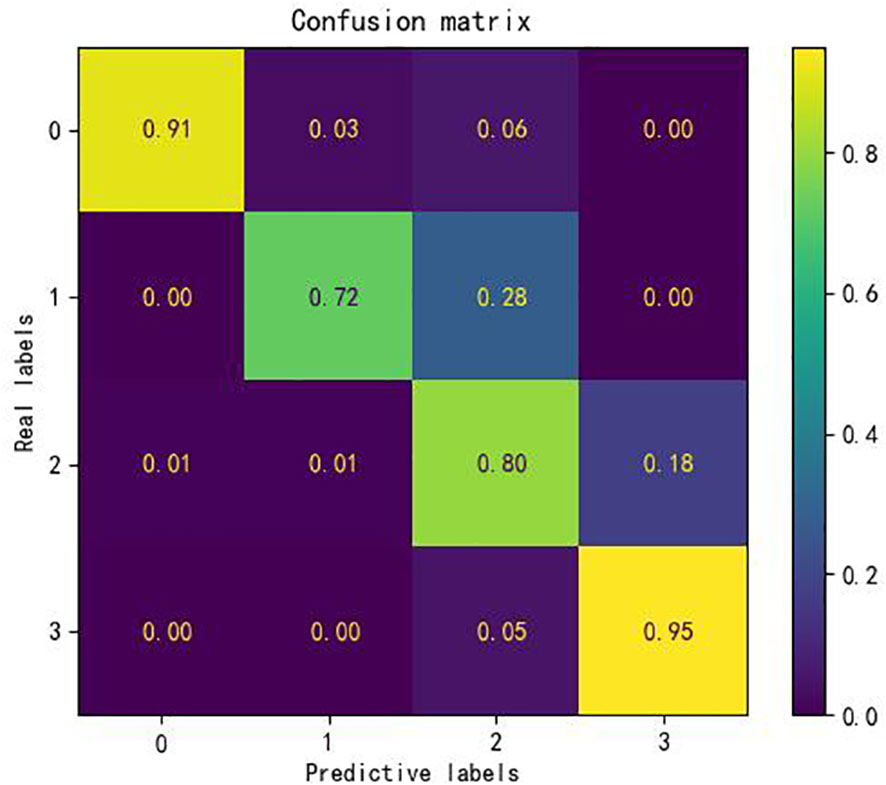
Figure 4 Detection effect of KASP-IEva primer intelligent typing evaluation model.
As can be seen from the counting statistics of the intelligent evaluation results of the experimental data in Figure 5, among the 2519 test samples, the proportion of level 2 and 3 fractal effects is significantly higher, reaching 48.55% and 41.23%, respectively, and the proportion of level 0 and 1 fractal maps are both smaller, 6.74% and 3.47%, respectively. In the model evaluation results, 42.39% of the samples were grade 2, 47.98% of the samples were grade 3, and the proportion of grade 1 was the least, only 3.08%. The overall evaluation results of the model showed an uneven distribution of grades, with significant differential characteristics, which basically reflected the low success rate of KASP marker development in the batch of experimental data, and was in line with the actual grade distribution. The fact that the number of level 3 results obtained from the model evaluation exceeded that of the expert evaluation was due to the fact that the eigenvalue indexes selected in the decision tree algorithm had certain limitations on the representativeness of the clustering pattern (Sagi and Rokach, 2020), which potentially introduced bias in the branching structure for calculating the degree of dispersion among the groups of amplification products.
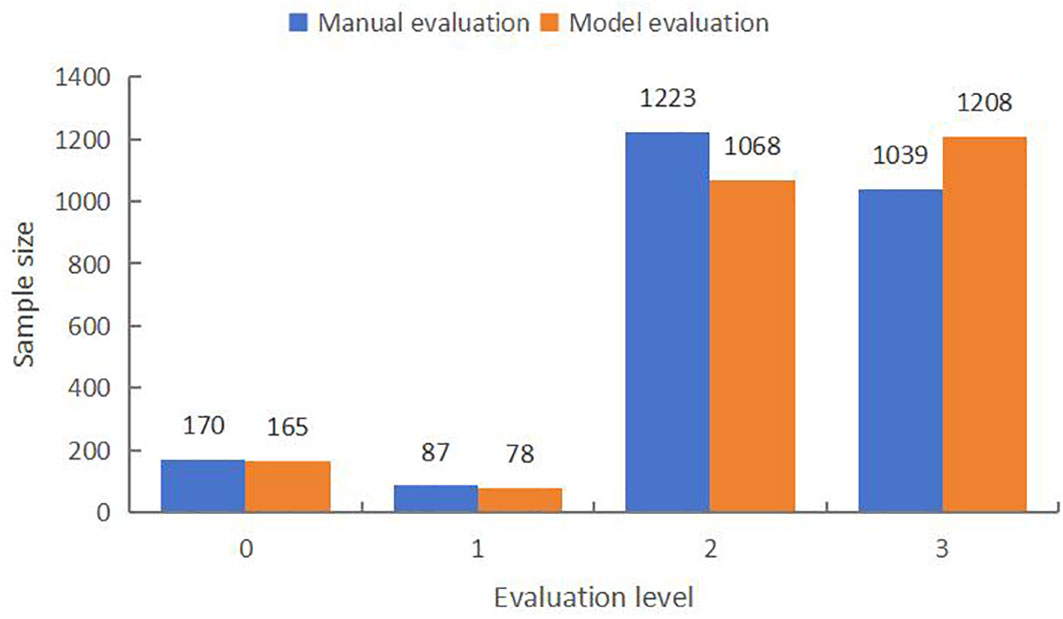
Figure 5 Comparative results of typing effect evaluation.
The speed of the expert and model evaluation methods was tested, and the comparison test of different groups was selected. The results are shown in Table 5. From the table, it can be seen that only for the evaluation of 1 group of KASP amplification product typing effect, the expert evaluation computation time is 3s, the KASP-IEva model computation time is 0.28s, the model is shorter than the time of the expert visual inspection method, the evaluation of the 2519 KASP typing diagrams, the expert evaluation consumes 15hour, the model evaluation is only 8min27.45s, the model intelligent evaluation shows more advantages, on the one hand, because the model front data distribution judgment module shortens the K-Means algorithm training time, the decision tree algorithm computational complexity is not high, and the output is fast, on the other hand, there are many influencing factors in the process of the expert evaluation, and the inefficiency of evaluation in a long period of time may lead to omitted evaluation, wrong evaluation, checking and repeated evaluation consume a lot of time. Therefore, from the perspective of time, the model evaluation in this paper is significantly better than the expert evaluation.
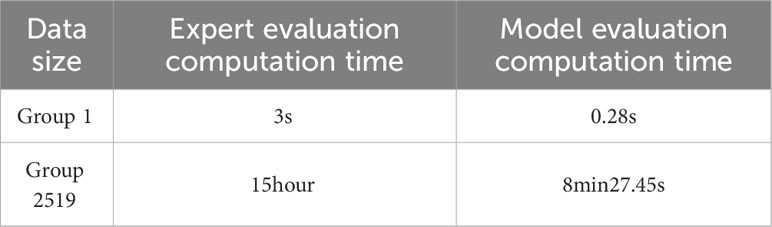
Table 5 Comparison of computation time between expert and model evaluation methods.
KASP markers are considered to be an efficient and flexible high-throughput typing technology in the field of molecular marker-assisted breeding. In the traditional validation of KASP primer typing results, due to the dependence of the manual visual inspection method on professional knowledge and long-term experience, high precision and rapid evaluation of large quantities of primer typing results are not possible, however, intelligent evaluation of KASP marker primer typing results has not yet been widely discussed in the industry. Therefore, in this study, the NTC identification module and the data distribution judgment module were combined with the K-Means algorithm and decision tree theory to propose an intelligent typing evaluation model for KASP-IEva primers, and the model was tested by using the results of the kompetitive allele-specific PCR test of the 2519 groups of cotton varietal resource materials, and the following conclusions were obtained:
(1) The KASP-IEva Primer Intelligent Typing Evaluation Model limits the initial clustering center selection range based on the data distribution judgment module, which effectively improves the reasonableness of genotype group typing. The model is able to visualize and display the data aggregation and classification effects of the amplification products of pure genotypes, heterozygous genotypes, and untyped genotypes, and at the same time, it can extract the positional morphology eigenvalues, which provides powerful data support for the evaluation decision.
(2) The typing effect rating evaluation criteria was constructed, and an intelligent typing effect evaluation model based on a logical decision tree was created on the basis of which the model predicts the scores for the calculation of eigenvalues of genotype classification and aggregation, realizing a fast and accurate typing evaluation of KASP markers, which is used to screen KASP markers with excellent typing effect.
(3) The typing effect evaluation test of 2519 groups of KASP markers was carried out, and the model evaluation results were compared and analyzed with the expert evaluation results. From the results of the comparative analysis, of 2519 groups of KASP markers, the model typing effect evaluation is correct, the average accuracy rate is 87%, and the evaluation results show the uneven distribution of the grades, with significant differential characteristics, basically can reflect the low success rate of the development of the KASP markers in the experimental data of the batch of the low success rate of the KASP markers, in line with the actual distribution of the grades; for the evaluation of the 2519 KASP typing diagrams, the expert evaluation consumes 15 hours, and the model evaluation only uses 8min27.45s, from the perspective of time, the model intelligent evaluation is obviously better than the expert evaluation. Therefore, the KASP-IEva model has good evaluation performance.
(4) The research method in this paper provides an intelligent evaluation idea for the KASP primer typing effect. The model is not only applicable to the results of the cotton KASP test but also can be used to evaluate the KASP typing effect of resource data of varieties including wheat, soybean, and corn.
In the study of this paper, we designed an intelligent KASP marker primer typing evaluation model to realize the rapid typing evaluation of KASP markers for 2519 sets of cotton varietal resource materials. First, the separation of NTC data from the rest of the data was controlled by the NTC identification module to enhance the classification ability of the target under data mixing conditions. In addition, the data distribution judgment module further classifies the data types to improve the distinguishability of amplified signals. The K-Means machine learning algorithm is introduced to analyze the potential association between amplification products and extract the deep structure feature values. Finally, the typing effect is evaluated based on the decision tree, which overcomes the subjectivity of the existing expert evaluation method that scores by visual inspection of unmeasurable abstract indicators. The average accuracy of the four levels of model evaluation was 87%, and the model evaluation took only 8min27.45s compared to the expert evaluation which took 15hour, all the tests and results show that the model has good performance and enough speed to be used for screening KASP markers with excellent typing results at scale. In the subsequent application research, the introduction of deep learning optimization evaluation method will be considered to further improve the evaluation accuracy, with a view to realizing the application of the KASP-IEva intelligent evaluation model in the field of KASP marker testing.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
XC: Conceptualization, Methodology, Software, Validation, Visualization, Writing – original draft, Writing – review & editing. LH: Writing – review & editing. JF: Writing – review & editing. SY: Writing – review & editing. GZ: Writing – review & editing. JZ: Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the National Key R&D Program of China (2022YFF0711805); the National Science Foundation of China (31971792, 32160421); Innovation Project of Chinese Academy of Agricultural Sciences (CAAS-ASTIP-2023-AII, ZDXM23011); Special Project for Basic Research Operating Costs of Central Public Welfare Scientific Research Institutes (JBYW-AII-2023- 06, Y2022XK24, Y2022QC17, JBYW-AII-2022-14); Special Project on Southern Prosperity for the National Institute of Southern Prosperity, Chinese Academy of Agricultural Sciences, Sanya (YBXM2312, YDLH01, YDLH07, YBXM10); the Project of Sanya Yazhou Bay Science and Technology City(SCKJ-JYRC-2023-45, SCKJ-JYRC-2022-62).
We thank all the participants in this study.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Abdelraheem, A., Kuraparthy, V., Hinze, L., Stelly, D., Wedegaertner, T., Zhang, J. (2021). Genome-wide association study for tolerance to drought and salt tolerance and resistance to thrips at the seedling growth stage in US Upland cotton. Ind. Crops Products 169, 113645. doi: 10.1016/J.INDCROP.2021.113645
Adibi, M. A. (2019). Single and multiple outputs decision tree classification using bi-level discrete-continues genetic algorithm. Pattern Recognition Lett. 128, 190–196. doi: 10.1016/j.patrec.2019.09.001
Al-Khayri, J. M., Mahdy, E. M., Taha, H. S., Eldomiaty, A. S., Abd-Elfattah, M. A., Abdel Latef, A. A. H., et al. (2022). Genetic and morphological diversity assessment of five kalanchoe genotypes by SCoT, ISSR and RAPD-PCR markers. Plants 11 (13), 1722. doi: 10.3390/plants11131722
Amiteye, S. (2021). Basic concepts and methodologies of DNA marker systems in plant molecular breeding. Heliyon 7 (10). doi: 10.1016/j.heliyon.2021.e08093
Ayalew, H., Tsang, P. W., Chu, C., Wang, J., Liu, S., Chen, C., et al. (2019). Comparison of TaqMan, KASP and rhAmp SNP genotyping platforms in hexaploid wheat. PloS One 14 (5), e0217222. doi: 10.1371/journal.pone.0217222
Broccanello, C., Chiodi, C., Funk, A., McGrath, J. M., Panella, L., Stevanato, P. (2018). Comparison of three PCR-based assays for SNP genotyping in plants. Plant Methods 14, 1–8. doi: 10.1186/s13007-018-0295-6
Byers, R. L., Harker, D. B., Yourstone, S. M., Maughan, P. J., Udall, J. A. (2012). Development and mapping of SNP assays in allotetraploid cotton. Theor. Appl. Genet. 124, 1201–1214. doi: 10.1007/s00122-011-1780-8
Chakraborty, S., Paul, D., Das, S., and Xu, J. (2020). Entropy weighted power kmeans clustering, Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, 26–28.
Charbuty, B., Abdulazeez, A. (2021). Classification based on decision tree algorithm for machine learning. J. Appl. Sci. Technol. Trends 2 (01), 20–28. doi: 10.38094/jastt20165
Che, D., Liu, Q., Rasheed, K., Tao, X. (2011). Decision tree and ensemble learning algorithms with their applications in bioinformatics. Adv. Exp. Med. Biol. 696, 191–199. doi: 10.1007/978-1-4419-7046-6_19
Chen, T., Li, Y., Rong, E., Wu, Y. (2024). Identification of traits and floral organ transcriptomic analysis of artificial allotetraploid progeny of the genus Cotton. Acta Agronomica Sin. 50 (02), 325–339. doi: 10.3724/SP.J.1006.2023.34061
Fan, T., Li, Z., Jiang, Q., Chen, S., Ou, X., Chen, Y., et al. (2021). Development and effect evaluation of KASP markers closely linked to major QTLs of spike number per unit area and grain length in wheat. Scientia Agricultura Sin. 54 (14), 2941–2951. doi: 10.3864/j.issn.0578-1752.2021.14.002
Gao, W., Chen, Q., Fu, J., Jiang, H., Sun, F., Geng, S., et al. (2023). Using association mapping and local interval haplotype association analysis to improve the cotton drought stress response. Plant Sci. 335, 111813. doi: 10.1016/j.plantsci.2023.111813
Geng, X., Qu, Y., Jia, Y., He, S., Pan, Z., Wang, L., et al. (2021). Assessment of heterosis based on parental genetic distance estimated with SSR and SNP markers in upland cotton (Gossypium hirsutum L.). BMC Genomics 22 (1), 1–11. doi: 10.1186/s12864-021-07431-6
Gu, Q., Ke, H., Liu, Z., Lv, X., Sun, Z., Zhang, M., et al. (2020). A high-density genetic map and multiple environmental tests reveal novel quantitative trait loci and candidate genes for fibre quality and yield in cotton. Theor. Appl. Genet. 133, 3395–3408. doi: 10.1007/s00122-020-03676-z
Guo, Y., Chen, Q., Qu, Y., Deng, X., Zheng, K., Wang, N., et al. (2023). Development and identification of molecular markers of GhHSP70-26 related to heat tolerance in cotton. Gene 874, 147486. doi: 10.1016/j.gene.2023.147486
Huang, H., Wang, W., Li, C., Hou, K., Zheng, Y., Chen, Q. (2022). The maximum Lyapunov exponent and Elman-Decision tree based fault warning diagnosis method. China Rural Water Hydropower 2), 168–173.
Kumar, S. J., Susmita, C., Sripathy, K. V., Agarwal, D. K., Pal, G., Singh, A. N., et al. (2022). Molecular characterization and genetic diversity studies of Indian soybean (Glycine max (L.) Merr.) cultivars using SSR markers. Mol. Biol. Rep. 49, 2129–2140. doi: 10.1007/s11033-021-07030-4
Li, L., Sun, Z., Ke, H., Gu, Q., Wu, L., Zhang, Y., et al. (2022). Development and effect evaluation of KASP markers for fiber strength in Gossypium hirsutum L. J. Agric. Sci. Technol., 1–10. doi: 10.13304/j.nykjdb.2022.0818
Li, F. G., Yuan, Y. L. (2013). Cotton molecular breeding (Beijing: China: Agricultural University Press).
Lu, Z., Huang, S., Zhang, X., Yang, W., Zhu, L., Huang, C. (2023). Intelligent identification on cotton verticillium wilt based on spectral and image feature fusion. Plant Methods 19 (1), 1–16. doi: 10.1186/s13007-023-01056-4
Mirzal, A. (2020). Statistical analysis of microarray data clustering using NMF, spectral clustering, Kmeans, and GMM. IEEE/ACM Trans. Comput. Biol. Bioinf. 19 (2), 1173–1192. doi: 10.1109/TCBB.2020.3025486
Nie, X. H., Wang, Z. H., Liu, N. W., Song, L., Yan, B. Q., Xing, Y., et al. (2021). Fingerprinting 146 Chinese chestnut (Castanea mollissima Blume) accessions and selecting a core collection using SSR markers. J. Integr. Agric. 20 (5), 1277–1286. doi: 10.1016/s2095-3119(20)63400-1
Sagi, O., Rokach, L. (2020). Explainable decision forest: Transforming a decision forest into an interpretable tree. Inf. Fusion 61, 124–138. doi: 10.1016/j.inffus.2020.03.013
Sheng, X., Shen, Y., Yu, H., Wang, J., Zhao, Z., Gu, H. (2022). ). Development and application of KASP marker of BoCAL gene related to curd development in cauliflower. Acta Agriculturae Zhejiangensis 34 (6), 1183–1192. doi: 10.3969/j.issn.1004-1524.2022.06.09
Sinaga, K. P., Yang, M. S. (2020). Unsupervised K-means clustering algorithm. IEEE Access 8, 80716–80727. doi: 10.1109/ACCESS.2020.2988796
Wang, F. Q., Fan, X. C., Zhang, Y., Lei, S., Liu, C. H., Jiang, J. F. (2022). Establishment and application of an SNP molecular identification system for grape cultivars. J. Integr. Agric. 21 (4), 1044–1057. doi: 10.1016/S2095-3119(21)63654-7
Wang, P., Tian, Z., Kang, C., Li, Y., Wang, H., Yang, C., et al. (2021). Establishment and application of a tomato KASP genotyping system based on five disease resistance genes. Acta Hortic. Sin. 48 (11), 2211–2226. doi: 10.16420/j.issn.0513-353x.2020-0913
Xu, B., Zhang, J., Shi, Y., Dai, F., Jiang, T., Xuan, L., et al. (2023). GoSTR, a negative modulator of stem trichome formation in cotton. Plant J. 116 (2), 389–403. doi: 10.1111/tpj.16379
Yang, S., Yu, W., Wei, X., Wang, Z., Zhao, Y., Zhao, X., et al. (2020). An extended KASP-SNP resource for molecular breeding in Chinese cabbage (Brassica rapa L. ssp. pekinensis). PloS One 15 (10), e0240042. doi: 10.1371/journal.pone.0240042
Yin, Z., Chen, J., Shen, Z., Fu, Y., Zheng, Z., Wang, Y. (2022). Identification algorithm of distribution Network transformer winding material based on Kmeans clustering. J. North China Electric Power Univ. (Natural Sci. Edition), 1–9.
Zhang, Y., Zhang, W., Xu, K., Li, J. (2023). Phenological phase identification of oilseed rape (Brassica napus L.) Using typical stokes parameters. Geomatics Inf. Sci. Wuhan Univ. 48 (8), 1322–1330. doi: 10.13203/j.whugis20210394
Zhao, Y., Chen, W., Cui, Y., Sang, X., Lu, J., Jing, H., et al. (2021). Detection of candidate genes and development of KASP markers for Verticillium wilt resistance by combining genome-wide association study, QTL-seq and transcriptome sequencing in cotton. Theor. Appl. Genet. 134, 1063–1081. doi: 10.1007/s00122-020-03752-4
Keywords: intelligent evaluation, KASP marker, decision tree, genotyping, cotton, molecular marker-assisted selection
Citation: Chen X, Huang L, Fan J, Yan S, Zhou G and Zhang J (2024) KASP-IEva: an intelligent typing evaluation model for KASP primers. Front. Plant Sci. 14:1293599. doi: 10.3389/fpls.2023.1293599
Received: 13 September 2023; Accepted: 27 December 2023;
Published: 17 January 2024.
Edited by:
Muhammad Aamir Manzoor, Shanghai Jiao Tong University, ChinaReviewed by:
Emre Sevindik, Adnan Menderes University, TürkiyeCopyright © 2024 Chen, Huang, Fan, Yan, Zhou and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jianhua Zhang, emhhbmdqaWFuaHVhQGNhYXMuY24=; Longyu Huang, aHVhbmdsb25neXUxQDE2My5jb20=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.