 Siyu Quan1,2
Siyu Quan1,2 Jiajia Wang
Jiajia Wang- 1School of Computer Science and Technology, Xinjiang University, Urumqi, China
- 2Xinjiang Uygur Autonomous Region Signal Detection and Processing Key Laboratory, Xinjiang University, Urumqi, China
The rapid development of image processing technology and the improvement of computing power in recent years have made deep learning one of the main methods for plant disease identification. Currently, many neural network models have shown better performance in plant disease identification. Typically, the performance improvement of the model needs to be achieved by increasing the depth of the network. However, this also increases the computational complexity, memory requirements, and training time, which will be detrimental to the deployment of the model on mobile devices. To address this problem, a novel lightweight convolutional neural network has been proposed for plant disease detection. Skip connections are introduced into the conventional MobileNetV3 network to enrich the input features of the deep network, and the feature fusion weight parameters in the skip connections are optimized using an improved whale optimization algorithm to achieve higher classification accuracy. In addition, the bias loss substitutes the conventional cross-entropy loss to reduce the interference caused by redundant data during the learning process. The proposed model is pre-trained on the plant classification task dataset instead of using the classical ImageNet for pre-training, which further enhances the performance and robustness of the model. The constructed network achieved high performance with fewer parameters, reaching an accuracy of 99.8% on the PlantVillage dataset. Encouragingly, it also achieved a prediction accuracy of 97.8% on an apple leaf disease dataset with a complex outdoor background. The experimental results show that compared with existing advanced plant disease diagnosis models, the proposed model has fewer parameters, higher recognition accuracy, and lower complexity.
1 Introduction
As the population grows, the demand for food will increase dramatically, and it is particularly important to minimize food losses due to pests and diseases, which not only reduce food production but also affect biodiversity, food prices and human health, while trying to increase yields (Ristaino et al., 2021; Sileshi and Gebeyehu, 2021). Early prevention and control of plant diseases can recover some of the agricultural economic losses and improve the yield and quality of agricultural production and food safety (Savary et al., 2019; Gold, 2021). Thus, the diagnosis and control of crop diseases are crucial for food production. The traditional method of diagnosing plant pests and diseases is the visual observation by plant protection specialists or people with experience in planting. However, this approach relies heavily on experience and subjective cognition and is prone to bias, which can lead to misdiagnosis. (Bai et al., 2018; Barbedo, 2018). Moreover, in some underdeveloped or remote areas, there is often a shortage of experts. Therefore, one kind of portable, fast, and accurate plant disease automatic identification system is significant for the timely diagnosis of crop diseases.
Currently, the automatic diagnosis of plant diseases primarily relies on computer vision (CV) techniques. The predominant methods in this field can be categorized into two groups: machine learning-based approaches and deep learning-based approaches (Saeed et al., 2021; Uguz and Uysal, 2021). The widely used machine learning methods are the Bayesian model (BM), k-nearest neighbor (KNN), support vector machine (SVM), decision tree (DT), random forest tree (RF), etc. (Liakos et al., 2018; Chen et al., 2020). Within deep learning-based methods, many outstanding architectures such as ResNet, Inception, and DenseNet have achieved excellent results in image classification tasks. (Szegedy et al., 2015; He et al., 2016; Huang et al., 2017). Machine learning has made significant progress in the field of plant disease and pest recognition. However, it has a high degree of subjectivity, heavily relies on manual feature selection, is time-consuming, and has low efficiency (Li et al., 2021; Albattah et al., 2022b). In comparison, using deep learning methods is simpler and more efficient.
Recent studies demonstrated the effectiveness and feasibility of deep learning in plant disease classification tasks (Abbas et al., 2021; Deng et al., 2021; Elaraby et al., 2022). The end-to-end training approach avoids the drawbacks of manual feature extraction. Although there are many advanced deep CNN models for crop disease diagnosis, it is still difficult to promote this method on a large scale. The key reason is that complex models lead to high computational costs, making it difficult to deploy on simple mobile devices. In the agricultural field, using complex laboratory equipment with GPUs restricted the application and promotion of artificial intelligence, as growers cannot undertake the additional costs brought by complex equipment (Karthik et al., 2020; Chen et al., 2022a; Hassan and Maji, 2022). Therefore, lightweight models with fewer parameters, faster training speeds, and higher accuracy are a more promising research trend (Atila et al., 2021), which can further promote the popularization of automatic crop disease diagnosis methods. To address the aforementioned challenges, this paper proposes an improved MobileNetV3, which has low parameter count, high accuracy, and short training cycles. Specifically, we added two skip connections after the first bneck layer of the original feature extraction network. The low-level features extracted by the first bneck layer are used to compensate for the 7th and 11th bneck layers, thereby enriching the input features of the higher layers. Moreover, to achieve better results, different weights are assigned to the input feature maps of the skip connection parts, and the improved whale optimization algorithm is used to automatically adjust the weight parameters. Compared to manual hyperparameter tuning, the automatic optimization algorithm saves a significant amount of time and results in better model performance. The improved whale optimization algorithm enhances the search capability for global optimal parameters and convergence speed. Secondly, the Bias loss replaces the standard cross-entropy loss function. The Bias loss function can reduce the errors caused by redundant features during the model learning process. Another reason for the superior performance of the method proposed in this paper is the abandonment of the traditional ImageNet pre-training dataset. The constructed network is pre-trained on a large-scale plant classification task dataset. Transfer learning on similar objects further enhances the performance of the model. We refer to the re-formed lightweight network as MS-Net, which is mainly used for crop disease recognition. Experimental results demonstrate the effectiveness and feasibility of the proposed method. Compared to other SOTA models in the research field, MS-Net achieves the highest accuracy with lower parameter count, computational complexity, and memory size. The main contributions of this study are as follows.
1. We propose a new lightweight network, MS-Net. This network uses MobileNetV3 as the feature extraction network, embeds skip connections into the network, and adjusts the loss function, thereby improving the model’s accuracy and convergence speed.
2. The improved WOA (Whale Optimization Algorithm) is used to optimize the weight parameters in the skip connections.
3. Bias loss replaces the traditional cross-entropy loss, and this loss function can optimize the errors during the feature learning process, thereby enhancing the performance of the lightweight model.
4. The proposed model is pre-trained on a plant classification task dataset, which, compared to pre-training on ImageNet, can further improve the accuracy of crop disease recognition tasks.
The rest of this paper is organized as follows: The “Related Work” section introduces and summarizes recent work related to this research; the “Materials and Methods” section describes the materials used in the experiments, relevant concepts, and the proposed method, as well as summarizes the experimental procedure; the “Experimental Results and Discussion” section includes the experimental setup and results, and evaluates and compares the experimental results with other current advanced methods; finally, the “Conclusion” section summarizes this research and proposes future research directions.
2 Related work
In this section, various recent works related to this study are described, and relevant methods based on machine learning and deep learning for plant disease detection are summarized. Due to the limitations of machine learning methods and the flexibility of convolutional neural networks, deep learning approaches are more common in research.
Machine learning methods have fewer parameters, shorter training cycles, and do not require a large amount of training data, making them easier to deploy in practice (Albattah et al., 2022a). However, the challenges lie in complex data preprocessing and accurate manual feature extraction processes. Sharif et al. (2018) proposed a method for automatic detection and classification of citrus diseases based on optimized weighted segmentation and feature selection. The contrast of input images is enhanced using Top-hat filters and Gaussian functions, and the weighted segmentation method using chi-square distance and threshold functions is employed to extract the enhanced lesion points. The results show that the preprocessing method further improves the accuracy of lesion segmentation. Manually extracted features still contain many noisy features, Tan Nhat et al. (2020) used Adaptive Particle-Grey Wolf metaheuristic (APGWO) to screen extracted mango leaf pathology features and combined them with artificial neural networks (ANN) to detect early mango leaf diseases. Common types of features include texture features, geometric features, statistical features, etc., and multiple features can be used in combination. Pantazi et al. (2019) used the GrabCut algorithm to segment sample images and extracted histogram features of the segmented samples using Local Binary Patterns (LBP). Li et al. (2020) employed the Gray-Level Co-occurrence Matrix (GLCM) to extract texture features from multispectral images and constructed a Binary Logistic Regression (BLR) model for cotton root rot disease classification. Experiments showed that the spectral model is suitable for more severely infected cotton fields, while the spectral-texture model is more suitable for low or moderately infected cotton fields. Different classifiers can also be combined to further improve classification accuracy, Sahu and Pandey (2023) proposed a novel hybrid Random Forest Multi-Class Support Vector Machine (HRF-MCSVM) method for plant leaf disease detection. Experimental results on PlantVillage showed that this method performs better than popular standalone classifiers.
A series of deep learning methods, represented by convolutional neural networks, have attracted widespread attention from researchers. However, their inherent dependence on high-cost computational resources limits their development space. Fortunately, in recent years, many scholars have noticed such issues and started to study the application of lightweight networks in plant disease recognition. Nandhini and Ashokkumar (2022) used the improved Henry’s Law Constant Gas Solubility Optimization algorithm to optimize the hyperparameters of the pre-trained DenseNet-121, achieving a classification accuracy of 98.7% for various plant disease classification tasks on PlantVillage. Amin et al. (2022) utilized pre-trained EfficientNetB0 and DenseNet-121 to extract deep features from corn plant images. By extracting and fusing deep features from different CNNs to generate more complex feature sets, the limitations of single lightweight CNNs in feature extraction are compensated, thereby improving classification accuracy. Zhao et al. (2022) proposed a CNN that combines Inception, residual structures, and embedded attention mechanisms, and conducted training and testing on three plant disease image datasets in PlantVillage. With a model size of 19.1 MB, they achieved a classification accuracy of 99.55%. Chen et al. (2022b) proposed an improved ResNet-18 method for disease recognition in peanut leaf datasets and PlantVillage datasets. Channel attention mechanisms were inserted into the model to enhance feature extraction capabilities, and channel pruning techniques were used to remove unimportant channels to reduce model parameters and complexity. Compared to the baseline model, the compressed model’s parameter count was reduced by 57.85%. Wang et al. (2021) formed a trilinear convolutional neural network consisting of VGG-16, InceptionV3, and ResNeXt-101 through weight sharing methods and compared the effects of no sharing, partial sharing, and complete sharing on model performance. The weight sharing mechanism can reduce the parameter count of the fused network and improve network performance. In the PlantVillage dataset test, the fully shared method based on ResNeXt-101 achieved the highest accuracy of 99.7% with 361.24M parameters. Notably, the fully shared method based on InceptionV3 had a 0.1% lower accuracy than the former but had only 91.13M parameters, seemingly having more competitive potential. Moreover, lightweight models have limited feature extraction capabilities, and in cases with fewer data samples, the network’s few-shot learning ability is more challenging. Liu and Zhang (2023) proposed an improved InceptionV3 network for few-shot learning in the plant disease diagnosis domain, achieving a prediction accuracy of 99.45% with a total of 120 training samples in four apple disease categories.
The existing research achievements of machine learning and deep learning in plant disease detection and classification are shown in Table 1. Although the aforementioned studies tend to favor relatively lightweight network models, it is still difficult to achieve an ideal balance between accuracy and size. These studies generally use complex networks or fused networks to achieve higher accuracy and employ network compression techniques to reduce the model’s parameter count(Wang et al., 2021; Zhao et al., 2022; Zhu et al., 2022). However, network compression is a highly challenging task, making it difficult to effectively balance accuracy and latency(Hinton et al., 2015; Garg et al., 2023).
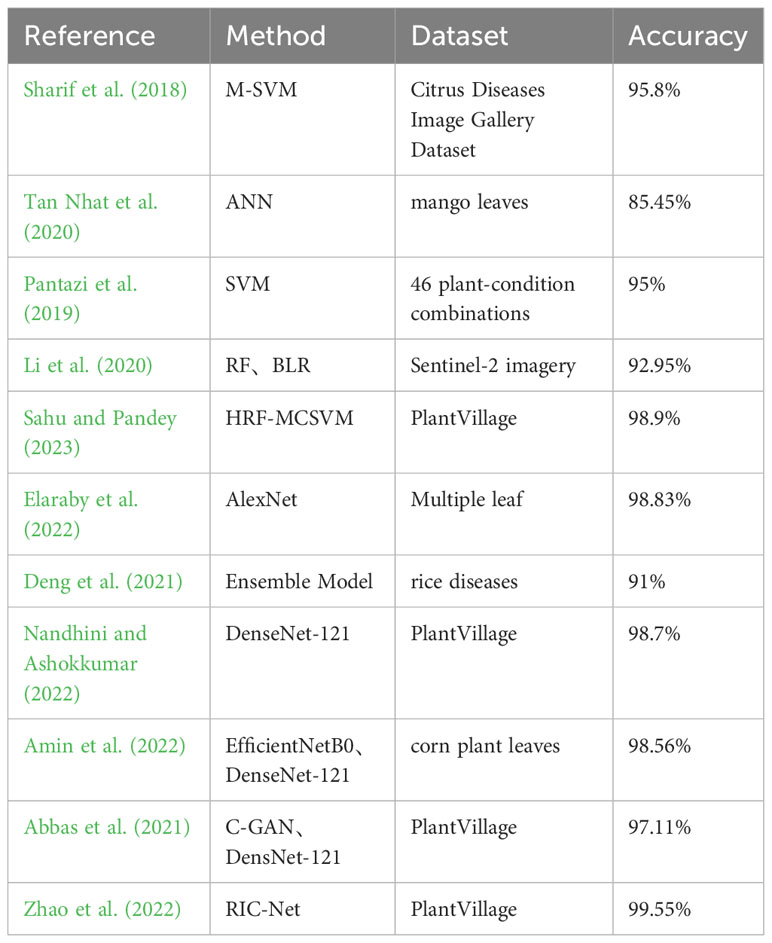
Table 1 Research related to machine learning and deep learning in plant disease identification.
3 Materials and methods
3.1 Dataset and pre-processing
Three datasets were selected for the experiment: the PlantVillage (PV) (Hughes and Salathe, 2015), the Plant Pathology 2020 - FGVC7 (Thapa et al., 2020) apple leaf dataset, and Pl@ntNet-300K (Garcin et al., 2021). The PV dataset is popular in the plant disease classification task. It consists of healthy and diseased images of 14 crops with 38 different categories and 54,305 images. The dataset was captured in a controlled environment where the images were stripped of complex backgrounds, and only the individual leaves were retained. Therefore, the apple leaf dataset from the Plant Pathology 2020-FGVC7 Kaggle competition was used to further evaluate the model’s performance in a realistic field environment. This dataset consists of 3651 high-quality images of symptoms of multiple apple leaf diseases and contains four states of apple black star disease, cedar apple rust, multiple diseases, and healthy leaves. All images were taken in outdoor environments containing complex background conditions; each image has multiple leaves. According to the official description, this dataset has 1821 labeled images for training and testing, and the remaining unlabeled images are used to evaluate the participants’ performance. Therefore, only the 1821 annotated images from the FGVC7 Apple Leaf dataset were used as the experimental dataset in this work. The proposed model is pre-trained on Pl@ntNet-300K, a plant species dataset built from the Pl@ntNet citizen observatory database, which consists of 306,146 plant images covering 1,081 species, but excluding plant diseases.
A portion of the PV dataset and the FGVC7 apple leaf dataset are shown in Figure 1, and the dataset was expanded using preprocessing techniques such as horizontal flipping, rotating, cropping, and resizing to prevent the model from over-fitting during training. In practical training, the image size of the apple leaf dataset is cropped to 512×512, while the PV dataset is cropped to 224×224.

Figure 1 Example images of PlantVillage dataset and Plant Pathology 2020 - FGVC7 apple leaf disease dataset.
3.2 Lightweight model
Existing lightweight models include EfficientNet, ShuffleNet, MobileNet, Xception, DenseNet, etc. On the ImageNet classification task, EfficientNet-B1 achieved 78.8% accuracy with 7.8M parameters, EfficientNet-B3 achieved 81.1% accuracy with 12M parameters (Tan and Le, 2019), MobileNet with 4.2M parameters 70.6% accuracy (Howard et al., 2017), and Xception achieved 79% accuracy with 22M number of parameters (Chollet, 2017). These deep learning models have fewer parameters and excellent performance, making them more suitable for deployment on mobile devices.
MobileNet with more balanced performance is a lightweight model designed by the Google team for mobile or embedded application scenarios, where the number of parameters and computations are reduced not only by the shallow network structure, but more importantly by using a depth-separable convolutional structure to replace the traditional standard convolutional structure.
Since some of the convolution kernels for deep convolution in MobileNetV1 may be empty after training, the Inverted Residuals structure is proposed in MobileNetV2 to solve this problem. Sandler et al., 2018 realized that when using the ReLU function, more information is lost when the dimensionality of the input features is relatively low, while more information is retained when the dimensionality of the input features is high, so the expansion layer is added to boost the input features before deep convolution. After the deep convolution is completed, a 1×1 convolution kernel is used to reduce the dimensionality of the output features. In addition, linear bottleneck have been proposed in MobileNetV2 to replace some of the ReLU with linear activation functions (Sandler et al., 2018). MobileNetV3 improves upon MobileNetV2 by renaming the basic network unit bottleneck to bneck, incorporating the squeeze-and-excite (SE) attention mechanism, utilizing Network Architecture Search (NAS) to optimize the model structure, and redesigning the time-consuming structure. In the ImageNet classification task, MobileNetV3-Large 1.0 achieved a Top-1 accuracy of 75.2% with 5.4 million parameters (Howard et al., 2019).
3.3 Transfer learning
Deep learning requires massive amounts of sample data to train the model, which can lead to limited model performance improvement and overfitting if the labeled dataset used to train the model is poor. However, collecting massive, labeled datasets is challenging, and manually labeling samples is time consuming and costly. Using transfer learning can solve these problems by retraining the pre-trained model from a large dataset on a small target dataset, which not only reduces the training time but also enhances the performance of the model (Chen et al., 2020; Jiang et al., 2021; Krishnamoorthy et al., 2021). In addition, Lee et al. (2020) indicated that models for plant disease classification could improve the network’s performance and reduce the effects of overfitting if they are pre-trained using plant datasets, but this approach may not apply to simpler, shallower networks. In this work, comparison experiments were conducted using pre-trained models on ImageNet and pre-trained models on Pl@ntNet-300K to verify the effectiveness of this method for the lightweight model proposed in this study. The architecture of the transfer learning workflow is shown in Figure 2.
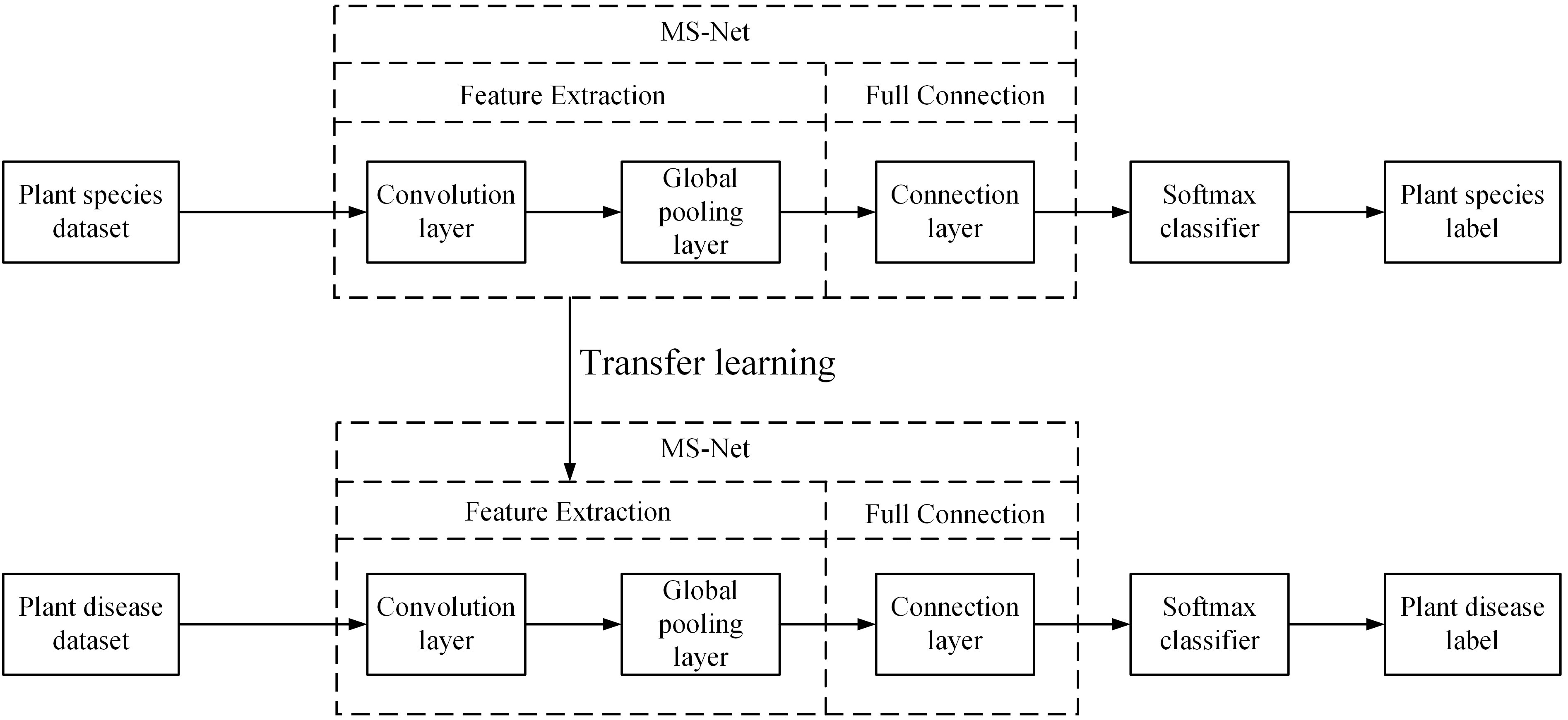
Figure 2 Flow chart of transfer learning of the proposed method.
3.4 Whale optimization algorithm
The Whale Optimization Algorithm (WOA) is a meta-heuristic optimization algorithm that finds the optimal solution by mimicking the spiral bubble net feeding of humpback whale populations in nature. The algorithm includes three types of predation behaviors of humpback whale populations: encircling prey, bubble netting to enclose prey, and randomly searching for prey. By continuously updating the position of the whale population in space through these three behaviors to achieve the search for the globally optimal solution (Mirjalili and Lewis, 2016), the algorithm has fewer parameters and is more capable of searching for the optimal global solution.
In searching for prey, the whale needs to assume the current best search agent (prey) first since the location of the prey is not known a priori, and the other search agents (whales) will update their locations to the best search agent. This behavior can be expressed as Eq. (2).
Where, is the current number of iterations, and are the coefficient vectors, is the current position of the best search agent, is the position of the present agent, is the updated position, and will be updated after each iteration if there is a position closer to the optimal solution. and are calculated using Eq. (3) and Eq. (4).
Where, decreases linearly from 2 to 0 during the iteration and is a random vector in .
In addition, whale populations also employ the bubble-net strategy to surround prey, consisting of constrictive encirclement and spiral swimming around the prey. The mathematical modeling equation for the constrictive encirclement behavior follows Eq. (2) for the prey encirclement process, but the value of in this process is limited to . The position search between the whale and the prey is updated using a spiral path while swimming around the prey. This can be expressed as Eq. (5).
Where, the distance between the whale and the prey is denoted by , is a constant that defines the shape of the spiral, and is a random number in the range . The whale has two behaviors in the process of enclosing the prey, contraction and encirclement and spiral swimming around the prey. Assuming that the probabilities of these two behaviors are equal, this process can be represented by Eq. (6).
When the range of does not belong to during the contraction envelope, the humpback whale will search for its prey randomly. The current whale will choose a random whale in the whale population to approach to update its position, which will enhance the algorithm’s global search ability. The mathematical expression of this behavior can be represented by Eq. (7) and Eq. (8).
Where, is the location of the random whale.
To further enhance the global search capability of the algorithm, the Lévy flight strategy is used to update the position of an individual whale again after it has updated its position, and the mathematical expression can be represented as Eq. (9).
Where, takes values in the range , in this work, each component of and follows the normal distribution as described in Eq. (10) and Eq. (11).
Where, denotes the component of and denotes the component of . The process of the whale optimization algorithm is demonstrated in Figure 3.
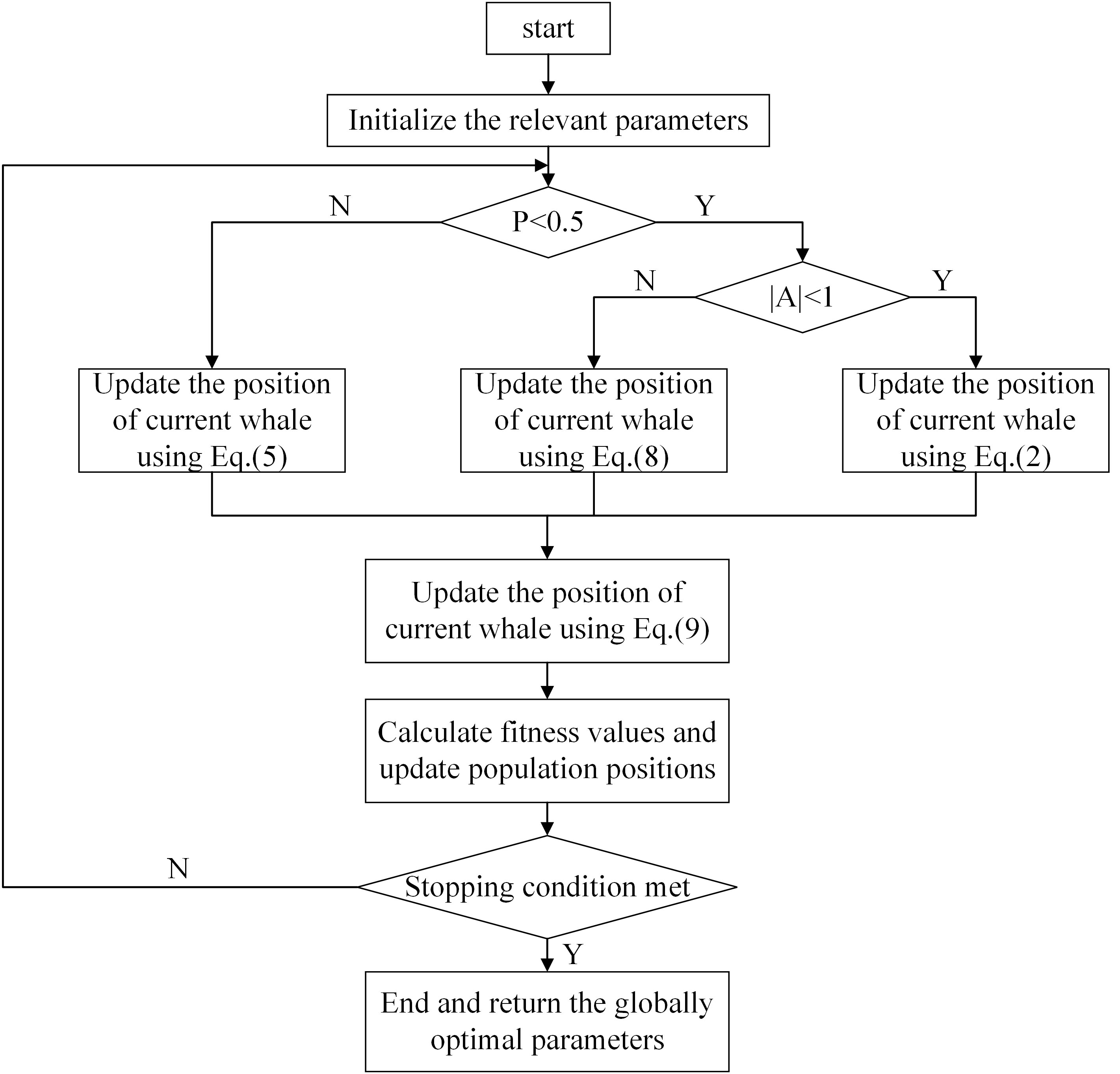
Figure 3 Flowchart of the Whale Optimization Algorithm.
Two skip blocks, s1 and s2, are embedded in the proposed network architecture as shown in Figure 4. To achieve better fusion, different weights are assigned to the input feature maps of each jump connection and the weight parameters are automatically adjusted using the whale optimization algorithm.
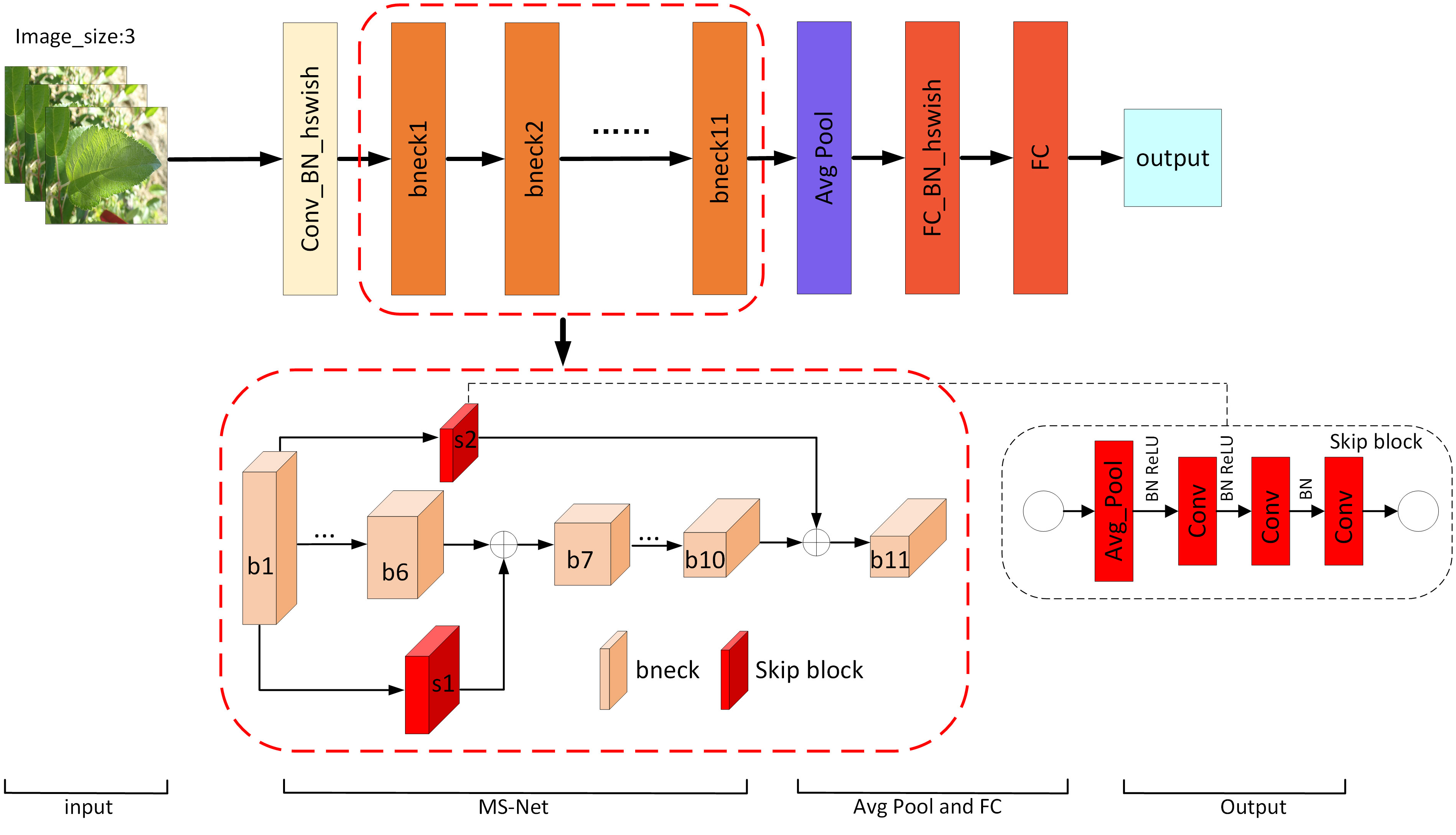
Figure 4 The proposed MS-Net architecture.
The mathematical expressions for the input features of the bneck7 and bneck11 network base units are as follows.
Where, denotes the input features, denotes the output features, denotes the weight parameters of different feature maps and satisfies , .
3.5 Proposed approach
Considering the superior performance of MobileNetV3 with the inclusion of the SE attention mechanism and optimized with NAS, MobileNetV3-Small is used as the feature extraction network in this work. The small version of the feature extraction network consists of 11 bnecks, which has fewer parameters compared to the large version, but the performance is also degraded. In this paper, the classical MobileNetV3-Small is modified by adding two skip blocks of different sizes after the first bneck to pass the extracted low-level features to the 7th and 11th bneck, enriching their input feature information and thus improving the classification performance of the model. Abrahamyan et al. (2021) proposed skip block to enhance the performance of compact CNNs. To achieve skip connectivity in the network, adaptive average pooling operation and convolution operation are used in the skip block to reduce the spatial size of feature information and retain key features (Ahmed et al., 2022). In addition, to achieve better feature fusion, different weights are assigned to the input feature maps of the skip connected parts, and the whale optimization algorithm is used to search for globally optimal parameters. The newly generated network model is called MS-Net, and the network structure is shown in Figure 4.
Abrahamyan et al. (2021) note that in compact CNNs, the limited number of parameters always makes it unlikely for the model to obtain rich features, and some irrelevant and redundant data may negatively affect the optimization process of the model and affect the final performance. There is no way to avoid this effect in the standard cross-entropy loss function, which gives equal weight to all data, and the standard cross-entropy loss is mathematically defined by Eq. (14).
Where, represents the number of samples, and represents the number of categories. represents the probability that sample belongs to category . is a one-hot encoding; if sample belongs to category , then the value of is 1, otherwise, it is 0.
Abrahamyan et al. (2021) proposed bias loss to mitigate this negative consequence. The variance is applied to measure the feature diversity contained in the sample data and to weight each data point to prevent samples with poor feature diversity from influencing the optimization process. The mathematical representation of bias loss is given by Eq. (15)-Eq. (18).
Where, and are adjustable contribution parameters, which can generally be set to and . The variable represents the proportional variance of the output characteristics of the ith data point in the batch. The denotes the output of the convolutional layer, while stands for the batch size. Additionally, , where corresponds to the number of input channels, and and represent the tensor width and height, respectively.
In this paper, bias loss is used to replace the conventional cross-entropy loss to minimize the impact of redundant data in the samples on MS-Net performance. Based on the transfer learning approach, the proposed network model was first pre-trained on the plant species dataset Pl@ntNet-300K, and then the completed pre-trained model was fine-tuned on the PlantVillage dataset and the FGVC7 apple leaf dataset.
4 Results and discussion
4.1 Experimental setup
To fully evaluate the model’s performance, experiments were conducted on the PlantVillage and the FGVC7 Apple leaf datasets, and the following quality metrics: Accuracy, Precision, Recall, F1-score (F1), and confusion matrix were used. Where Accuracy is the percentage of correctly predicted samples out of the total samples, Precision is the probability of being genuinely positive out of all samples predicted to be positive, and Recall is the probability of being predicted to be positive out of the genuinely positive samples, and F1-score is a combined measure of Accuracy and Recall. The mathematical definitions of these metrics as Eq. (19)-Eq. (22).
Where TP, TN, FP, and FN represent true positive, true negative, false positive, and false negative, respectively.
The experimental platform used in this research: the hardware environment was Intel(R) Xeon(R) Silver 4314 CPU 2.40GH, 64G RAM, NVIDIA GeForce RTX 3090 GPU; the software environment was Ubuntu 20.04 system, Python3.9, and PyTorch1.11.0.
4.2 Experiments on the FGVC7
To evaluate the performance of the ImageNet pre-trained model and the Pl@ntNet-300K pre-trained model on the FGVC7 apple leaf dataset with a realistic field background, two pre-training schemes of MobileNetV3 Small were used for ablation experiments. To approximate the 1,000 classes found in the ImageNet dataset, a random selection of classes was excluded from the Pl@ntNet-300K dataset, resulting in a total of 966 classes. These classes were then divided into training and validation sets in a 4:1 ratio. The pre-trained model was run for 15 epochs on the FGVC7 apple leaf dataset, Figure 5 depicts the training performance of MobileNetV3 utilizing the two pre-training methods on the apple leaf dataset with a realistic field background, and Table 2 summarizes the performance of the models with different pre-training approaches on the test set.
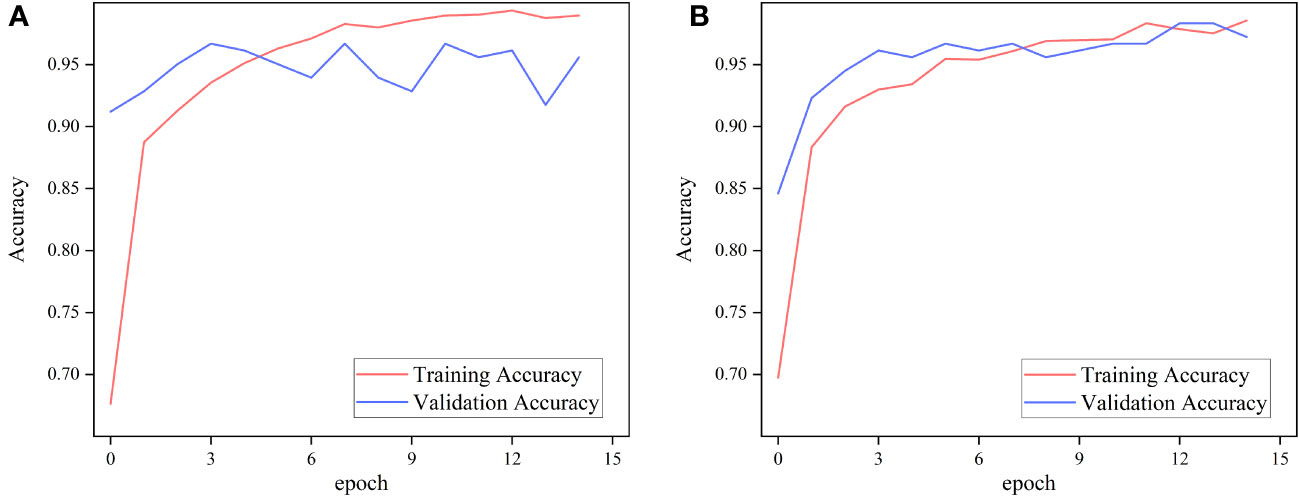
Figure 5 Performance of MobileNetv3 on FGVC7 apple leaf disease dataset using different pre-training methods. (A) ImageNet and (B) Pl@ntNet-300K.
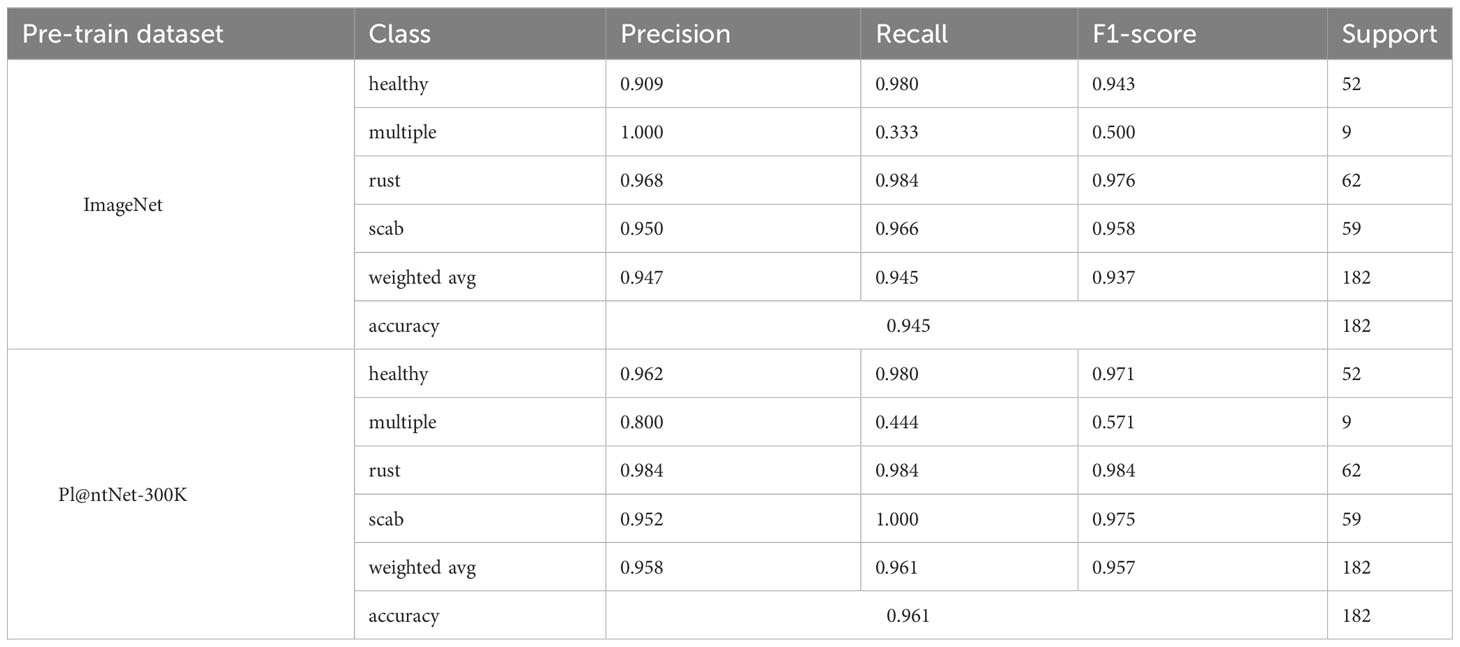
Table 2 Recognition results under two pre-training methods.
The experimental results show that for classifying multiple apple leaf diseases with a realistic background in the field, the accuracy of the model pre-trained using ImageNet is 94.47% on the test set, while the pre-trained model on Pl@ntNet-300K achieves an accuracy of 96.13%. The model pre-trained with Pl@ntNet-300K outperforms the model pre-trained with ImageNet, improving the accuracy by 1.66%. Figure 5 also illustrates that the model pre-trained with Pl@ntNet-300K has better data convergence and fit during the training process compared to the model pre-trained with ImageNet. The reason for the better pre-training results on the plant classification task dataset may be that utilizing datasets within similar domains can provide richer feature information for the compact CNN during pre-training compared to the more broadly generalized ImageNet dataset, allowing the model to learn more features about similar target tasks. Consequently, the proposed MS-Net will be pre-trained on Pl@ntNet-300K and then fine-tuned on the FGVC7 apple leaf dataset. To further evaluate the performance of the proposed method on the FGVC7 apple leaf dataset, MobileNetV2, MobileNetV3, EfficientNet-B3, Xception, and DenseNet-121 are used to perform comparative experiments on the FGVC7 apple leaf dataset. All networks were obtained pre-trained weights from ImageNet and trained for 15 epochs. Figure 6 depicts the performance of the proposed method compared to other lightweight models. Table 3 summarizes the test accuracy, F1 score, parameter count, FLOPs, memory size, and training time for all models. Table 4 s shows the prediction results of the models on the test set, and Figure 7 presents the confusion matrix of the models on the test set.
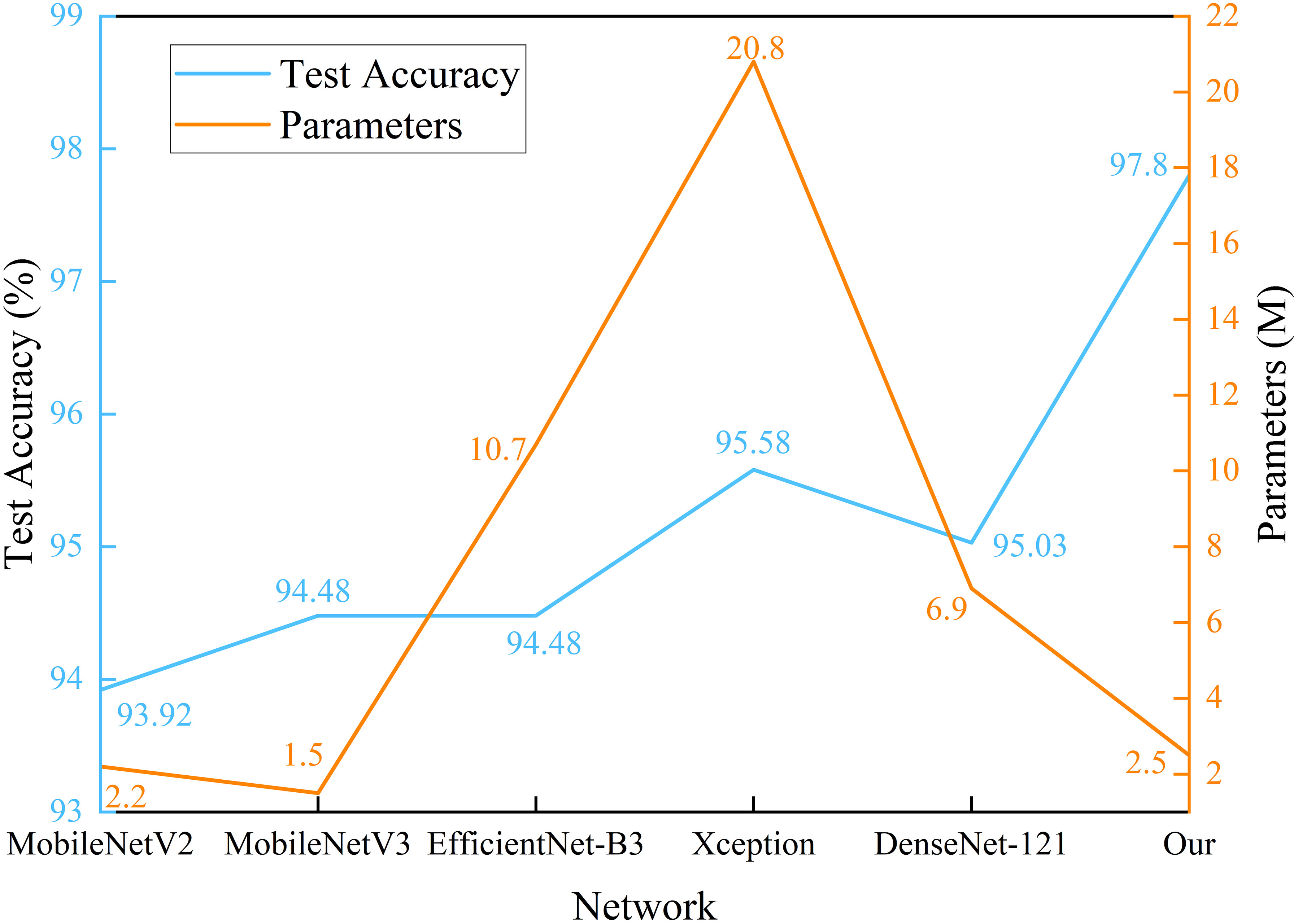
Figure 6 Parameters and test accuracy of identification models for apple disease identification.
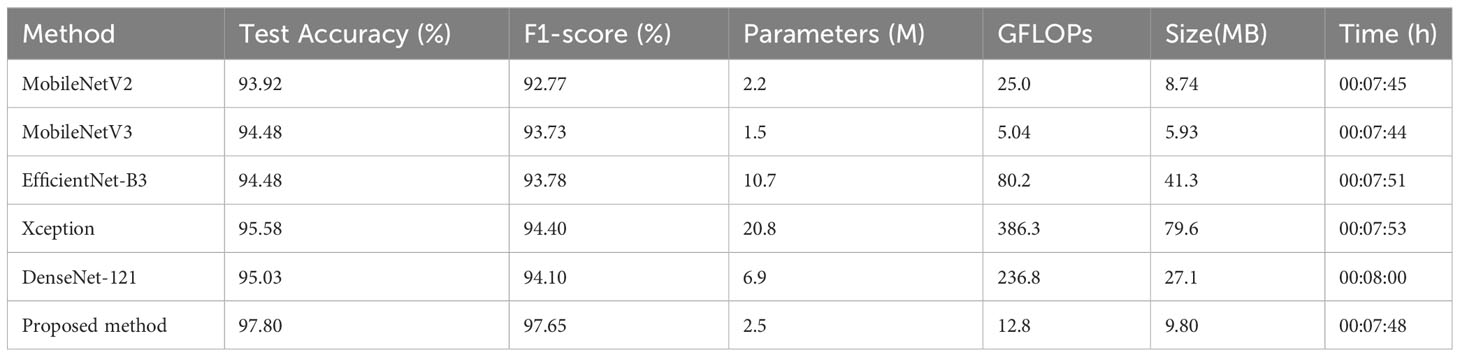
Table 3 Experimental results of the proposed method and existing models on the Apple dataset.
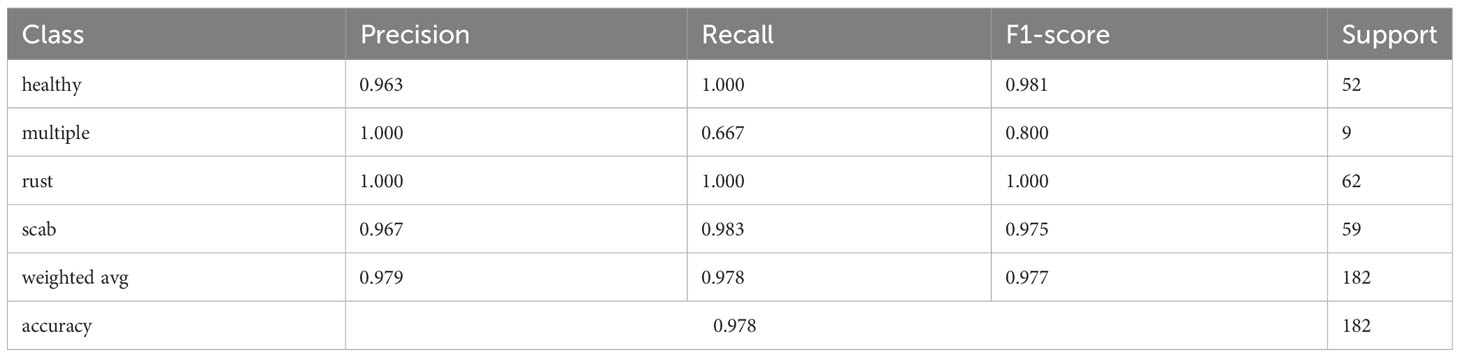
Table 4 The recognition results of different apple diseases.
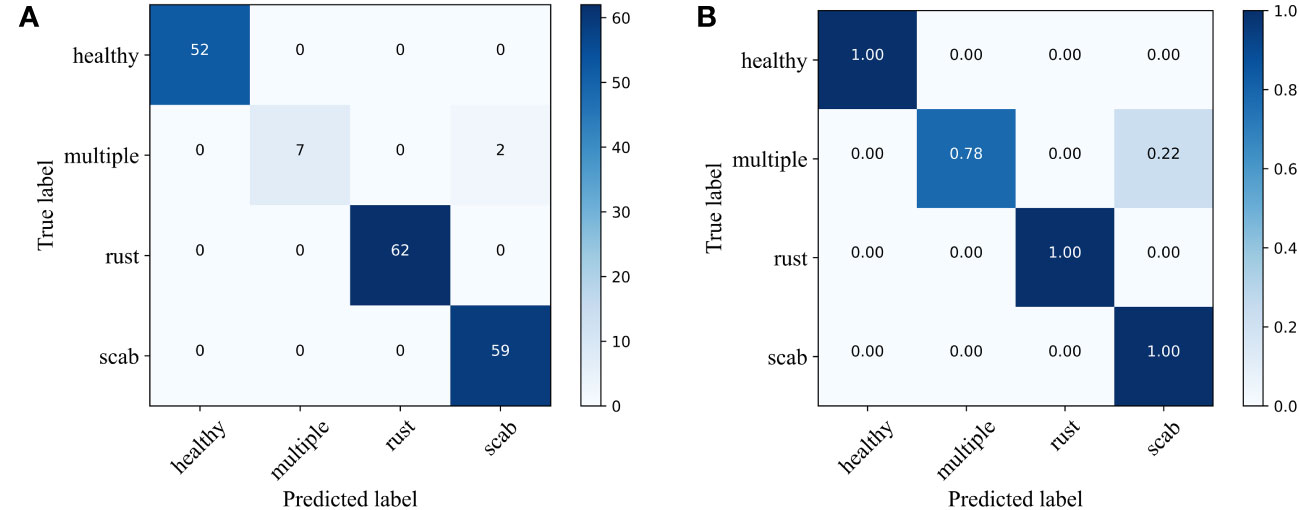
Figure 7 Confusion matrix of different apple diseases. (A) number of classes and (B) probabilities of classes.
From Figure 6, it can be observed that the proposed method has superior performance. Meanwhile, as shown in Table 3, after 15 epochs, the method proposed in this paper achieves the best accuracy with fewer parameters, FLOPs, and memory size. Compared to the unimproved original MobileNetV3 network, the method proposed in this paper slightly increases network complexity but achieves a significant improvement in accuracy, with almost the same training time and no significant increase in memory size. In addition, most baseline models have relatively large FLOPs, and the baseline models chosen in this study are popular lightweight networks. The reason for this phenomenon is that the dataset size is relatively large. The original pixel size of the apple leaf dataset is 2048×1365. To preserve image features as much as possible, we resize it to 512×512, but this still brings a considerable amount of computational overhead. It is worth noting that even though all models have significant complexity differences, there is no noticeable difference in the time consumed by all models when training for only 15 epochs. If the training cycles are increased, the differences in the time consumed by the models will be further magnified. As can be seen from Table 4 and Figure 7, the classification results of the “multiple” class have a significant impact on the quality indicators of the model. Analysing the dataset reveals that this phenomenon is caused by the uneven distribution of categories in the FGVC7 apple leaf dataset. Among the 1821 images, there are only 91 in the “multiple” class. The limited number of training samples and the presence of multiple disease features always constrain the performance improvement of the model. If the amount of data for this class is increased or some advanced data augmentation methods (such as Generative Adversarial Networks) are used to expand the multi-disease category dataset, the overall performance of the model can be further improved.
4.3 Experiments on the PlantVillage
To test the performance of the proposed method under different disease conditions in different crops and to compare it with other state-of-the-art methods, the proposed method is verified in this work on the publicly available PlantVillage dataset. Ablation experiments were performed using ImageNet and Pl@ntNet-300K pre-trained MobileNetV3 Small to verify whether transfer learning in similar domains is effective on the PlantVillage dataset. The two pre-trained models were trained for 30 epochs each, and Figure 8 depicts the performance of the two models on the PlantVillage dataset.
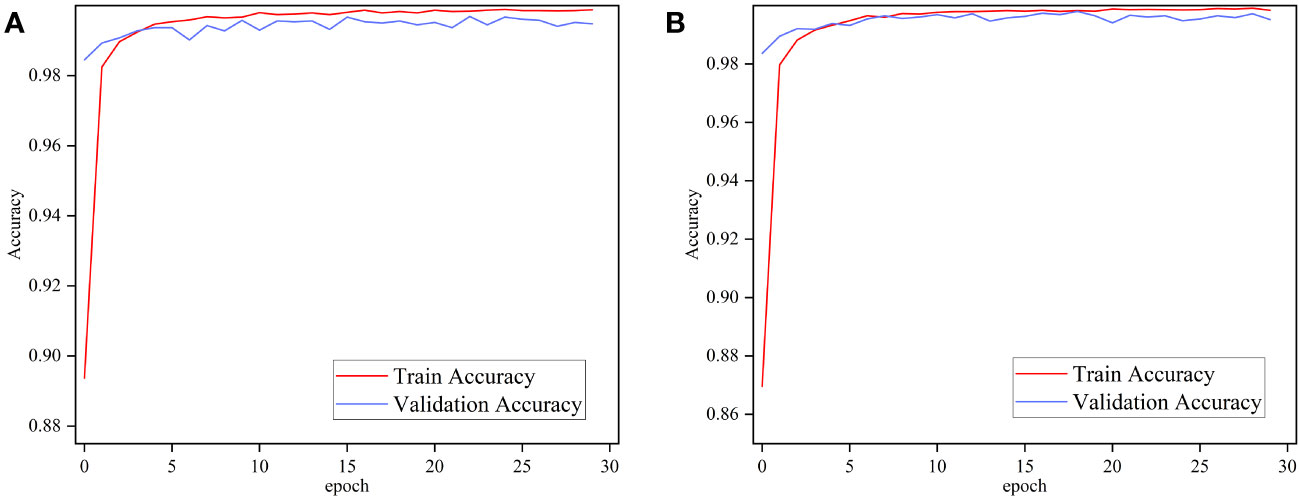
Figure 8 Performance of MobileNetv3 on PlantVillage dataset using different pre-training methods. (A) ImageNet and (B) Pl@ntNet-300K.
Figure 8 demonstrates that the performance difference between MobileNetV3 pre-trained with ImageNet and Pl@ntNet-300K is minimal. The pre-trained networks using these two methods achieve 99.65% and 99.76% classification accuracy on the test set, respectively. The transfer learning method using similar domains on the FGVC7 Apple Leaf dataset exhibited significant performance gains, the reason for which is attributed to the fact that the two datasets are too different. As shown in Figure 1, the PlantVillage dataset was captured under controlled conditions without complex backgrounds and multiple leaves, and the images contained only individual plant leaves, so the models achieved similar performance in both pre-training conditions. Comparison of the aforementioned work leads to the conclusion that transfer learning on similar domain datasets enhances the robustness of the model and can further improve the performance of plant disease diagnostic models.
To evaluate the performance of the method proposed in this paper on PlantVillage, we also conducted comparative experiments with the other five lightweight models mentioned earlier, which obtained pre-trained weights from ImageNet. All networks were trained for 30 epochs, and the performance of each network is shown in Figure 9. Table 5 summarizes the accuracy, parameter count, F1 score, FLOPs, memory size, and training time of all models on the PlantVillage dataset.
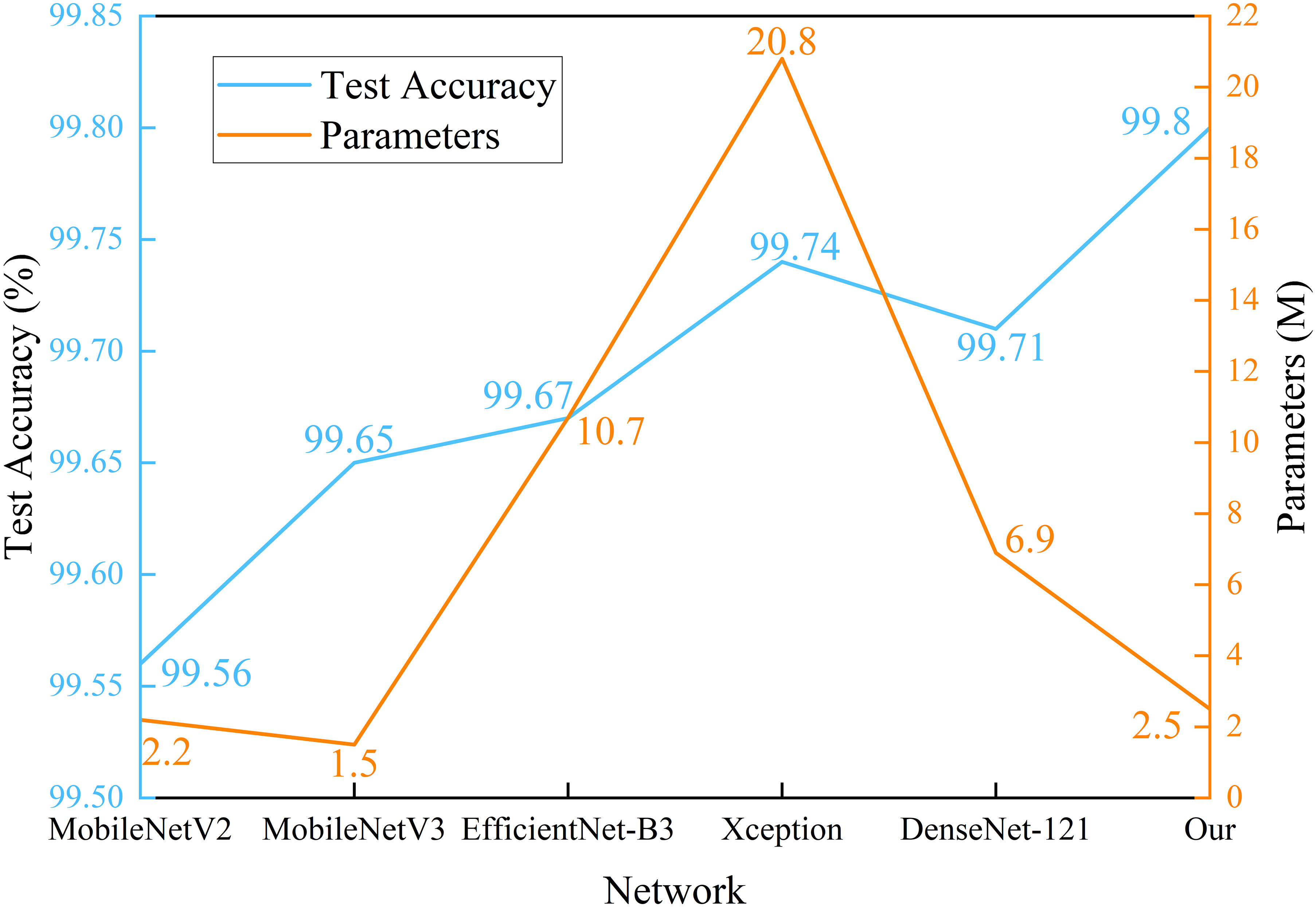
Figure 9 Parameters and test accuracy of multiple disease identification models.
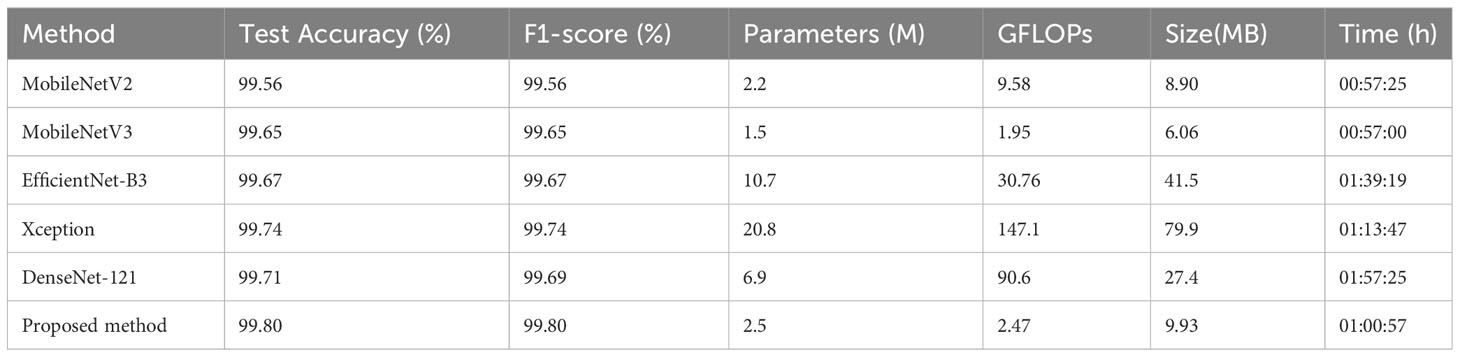
Table 5 Experimental results of the proposed method and existing models on the PlantVillage dataset.
From Figure 9 and Table 5, the method proposed in this paper performs better when considering both performance and parameter count. After 30 epochs of training, the proposed method achieves the best accuracy of 99.80%. It can be observed that MobileNetV3, with the smallest parameter count, has the shortest training time. Comparing MobileNetV2 and the proposed method, it can be concluded that the impact of small changes in parameter count on training time is almost negligible. However, DenseNet-121, which also has a relatively low parameter count, takes the longest training time. The reason is that this network has a larger number of FLOPs, resulting in a high computational load. In the design of compact CNNs, not only the parameter count of the network should be considered, but also the computational complexity of the network should be given attention. Interestingly, Xception, which has more parameters and FLOPs, has a shorter training time than DenseNet-121. The reason is that DenseNet-121 uses standard convolution, while Xception uses depthwise separable convolution, which reduces the number of multiplications and additions required, thus shortening the training time. Furthermore, it can be seen that the difference in test accuracy between the method proposed in this paper and other lightweight baseline models is not significant, and almost all models achieve excellent test accuracy on the PV dataset. As we mentioned earlier, the PV dataset was created in a laboratory environment, with each sample image having a complex background removed and centered in the frame, which also results in a high similarity in the distribution of samples within the same class in the dataset. This is precisely why we want to test our method on the apple dataset, which has a more complex outdoor background and stronger random distribution. Combined with Table 3, our method has stronger robustness and achieves the best prediction accuracy in field tests. In the proposed method, due to the addition of skip connections, the higher layers of the network obtain richer features with a smaller increase in network parameters. Using the bias function instead of the traditional cross-entropy loss function further reduces the impact of redundant features on compact networks during the learning process.
Table 6 summarizes the existing research results on the PlantVillage dataset. Compared to other current advanced methods, the proposed method achieves the highest accuracy of 0.998 and performs equally well in other evaluation metrics characterizing lightweight models. Among them, the performance of CACPNET is closest to our method. CACPNET further reduces the model’s complexity and memory size based on channel pruning (Chen et al., 2022b). Channel pruning is a highly challenging task that requires calculating the weights of each channel and sorting them, as well as a certain degree of manual adjustment to achieve the desired performance. Moreover, CACPNET has the longest training cycles among all methods. Other methods are trained for about 30 epochs, while CACPNET requires 200 epochs of training. Our method can be simply understood as expanding based on a small model, with easy operations and the ability to easily generalize to other smaller lightweight models. In addition, the T-CNN model achieves similar classification accuracy with a much larger parameter count. The reason is that integrating multiple models can indeed easily improve classification accuracy, but at the same time, it also increases the overall parameter count of the model (Wang et al., 2021). It is worth noting that although the accuracy of the L-CSMS model is not as high as other methods, the resource consumption of this network is extremely low, making it a more viable option in extreme situations (Xiang et al., 2021).
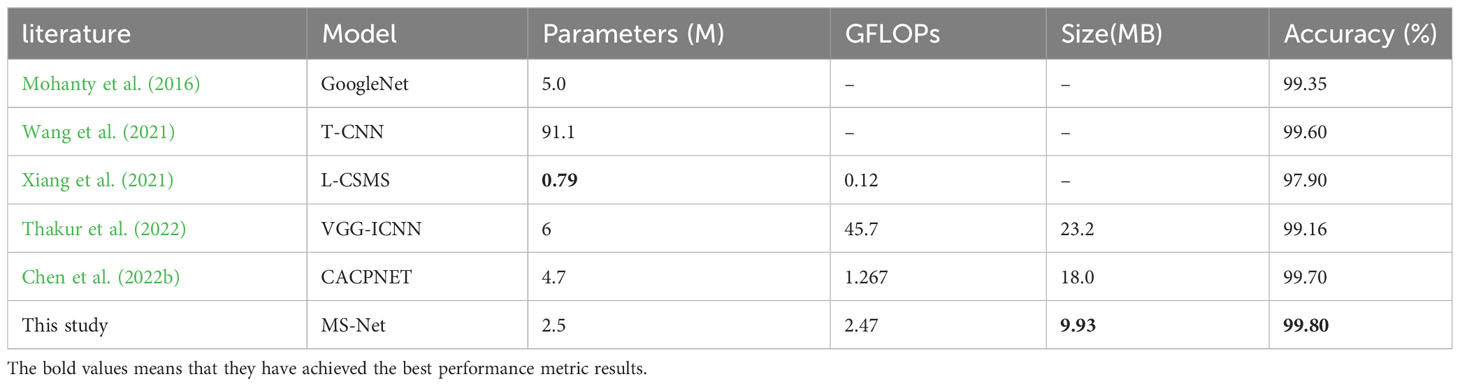
Table 6 Comparison with other current state-of-the-art methods in the literature.
5 Conclusion
The research on lightweight models with fewer parameters, lower complexity, and higher accuracy can further promote the popularization of automatic crop disease diagnosis methods. This study proposes a novel lightweight convolutional neural network for plant disease recognition, which has low parameter count and high accuracy. This is achieved by embedding skip blocks in the front end of the feature extraction network and optimizing the weight parameters in the skip connections using the improved whale algorithm. Bias loss replaces the traditional cross-entropy loss, reducing the negative impact of redundant data in limited features on the model learning process. At the same time, pre-training the proposed model on a plant species dataset further enhances the model’s performance and robustness. Experimental results show that, compared to the traditional transfer learning method, the proposed pre-training method improves the prediction accuracy on the apple leaf dataset by 1.6%. Compared to the original model, the prediction accuracy of the proposed method is increased by only 3.32% and 0.15% on the FGVC7 apple leaf dataset and PlantVillage dataset, respectively. The method proposed in this paper has strong robustness and achieves better performance on the apple leaf dataset with complex outdoor backgrounds, reaching the highest test accuracy with lower resource requirements. Compared to recent advanced techniques, the method proposed in this paper has lower parameter count, FLOPs, memory size, and higher recognition accuracy. Our research is beneficial for plant disease diagnosis in resource-constrained scenarios, low-resource, high-accuracy models can reduce the cost of hardware equipment and promote the development of automatic crop disease diagnosis solutions in the agricultural field. It should be noted that our method still has some shortcomings. Compared to other advanced methods, the FLOPs performance of the model is not outstanding. For the future research, we plan to analyse the training efficiency of the model, reduce the computational resources of the network, and develop a portable handheld device for plant disease diagnosis, deploying the proposed model on the device for practical applications in automatic plant disease diagnosis scenarios.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: https://zenodo.org/record/5645731#.YeGDOdvjKWh (Pl@ntNet-300K), https://github.com/spMohanty/PlantVillage-Dataset/tree/master/raw/color (PlantVillage), https://www.kaggle.com/competitions/plant-pathology-2020-fgvc7/data (FGVC7 Apple Leaf).
Author contributions
JW: Conceptualization, Funding acquisition, Writing – review & editing. SQ: Conceptualization, Methodology, Supervision, Visualization, Writing – original draft. ZJ: Methodology, Supervision, Writing – review & editing. MY: Investigation, Methodology, Software, Writing – review & editing. QX: Data curation, Investigation, Methodology, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Science and Technology Innovation 2030 - Major Project (No. 2022ZD0115802).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abbas, A., Jain, S., Gour, M., Vankudothu, S. (2021). Tomato plant disease detection using transfer learning with C-GAN synthetic images. Comput. Electron. Agric. 187, 106279. doi: 10.1016/j.compag.2021.106279
Abrahamyan, L., Ziatchin, V., Chen, Y., Deligiannis, N. (2021). “Bias loss for mobile neural networks,” in 2021 IEEE/CVF International Conference on Computer Vision (ICCV)). 6536–6546. doi: 10.1109/ICCV48922.2021.00649
Ahmed, S., Srinivasu, P., Alhumam, A., Alarfaj, M. (2022). AAL and internet of medical things for monitoring type-2 diabetic patients. Diagnostics 12 (11), 2379. doi: 10.3390/diagnostics12112739
Albattah, W., Javed, A., Nawaz, M., Masood, M., Albahli, S. (2022a). Artificial intelligence-based drone system for multiclass plant disease detection using an improved efficient convolutional neural network. Front. Plant Sci. 13. doi: 10.3389/fpls.2022.808380
Albattah, W., Nawaz, M., Javed, A., Masood, M., Albahli, S. (2022b). A novel deep learning method for detection and classification of plant diseases. Complex Intelligent Syst. 8, 507–524. doi: 10.1007/s40747-021-00536-1
Amin, H., Darwish, A., Hassanien, A. E., Soliman, M. (2022). End-to-end deep learning model for corn leaf disease classification. IEEE Access 10, 31103–31115. doi: 10.1109/ACCESS.2022.3159678
Atila, U., Ucar, M., Akyol, K., Ucar, E. (2021). Plant leaf disease classification using EfficientNet deep learning model. Ecol. Inf. 61, 101182. doi: 10.1016/j.ecoinf.2020.101182
Bai, X., Cao, Z., Zhao, L., Zhang, J., Lv, C., Li, C., et al. (2018). Rice heading stage automatic observation by multi-classifier cascade based rice spike detection method. Agric. For. Meteorology 259, 260–270. doi: 10.1016/j.agrformet.2018.05.001
Barbedo, J. G. A. (2018). Factors influencing the use of deep learning for plant disease recognition. Biosyst. Eng. 172, 84–91. doi: 10.1016/j.biosystemseng.2018.05.013
Chen, J. D., Chen, W. R., Zeb, A., Yang, S. Y., Zhang, D. F. (2022a). Lightweight inception networks for the recognition and detection of rice plant diseases. IEEE Sensors J. 22, 14628–14638. doi: 10.1109/JSEN.2022.3182304
Chen, J. D., Chen, J. X., Zhang, D. F., Sun, Y. D., Nanehkaran, Y. A. (2020). Using deep transfer learning for image-based plant disease identification. Comput. Electron. Agric. 173, 105393. doi: 10.1016/j.compag.2020.105393
Chen, R., Qi, H., Liang, Y., Yang, M. (2022b). Identification of plant leaf diseases by deep learning based on channel attention and channel pruning. Front. Plant Sci. 13. doi: 10.3389/fpls.2022.1023515
Chollet, F. (2017). “Xception: deep learning with depthwise separable convolutions,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Honolulu, HI, USA: IEEE). 1800–1807. doi: 10.1109/CVPR.2017.195
Deng, R. L., Tao, M., Xing, H., Yang, X. L., Liu, C., Liao, K. F., et al. (2021). Automatic diagnosis of rice diseases using deep learning. Front. Plant Sci. 12. doi: 10.3389/fpls.2021.701038
Elaraby, A., Hamdy, W., Alruwaili, M. (2022). Optimization of deep learning model for plant disease detection using particle swarm optimizer. Cmc-Computers Materials Continua 71, 4019–4031. doi: 10.32604/cmc.2022.022161
Garcin, C., Joly, A., Bonnet, P., Lombardo, J.-C., Affouard, A., Chouet, M., et al. (2021). “Pl@ntNet-300K: a plant image dataset with high label ambiguity and a long-tailed distribution,” in NeurIPS 2021 - 35th Conference on Neural Information Processing Systems (Virtual: MIT Press). doi: 10.5281/zenodo.5645731
Garg, S., Zhang, L., Guan, H. (2023). Structured pruning for multi-task deep neural networks. Arxiv doi: 10.48550/arXiv.2304.06840
Gold, K. M. (2021). Plant disease sensing: studying plant-pathogen interactions at scale. Msystems 6 (6), e01228-21. doi: 10.1128/mSystems.01228-21
Hassan, S. M., Maji, A. K. (2022). Plant disease identification using a novel convolutional neural network. IEEE Access 10, 5390–5401. doi: 10.1109/ACCESS.2022.3141371
He, K., Zhang, X., Ren, S., Sun, J. (2016). “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Las Vegas, NV, USA: IEEE). 770–778. doi: 10.1109/CVPR.2016.90
Hinton, G., Vinyals, O., Dean, J. (2015) Distilling the knowledge in a neural network. Available at: https://arxiv.org/abs/1503.02531.
Howard, A., Sandler, M., Chen, B., Wang, W., Chen, L. C., Tan, M., et al. (2019). “Searching for mobileNetV3,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (Seoul, Korea: IEEE). 1314–1324. doi: 10.1109/ICCV.2019.00140
Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., et al. (2017) MobileNets: efficient convolutional neural networks for mobile vision applications (Honolulu, HI, USA: IEEE). Available at: https://arxiv.org/abs/1704.04861.
Huang, G., Liu, Z., Maaten, L. V. D., Weinberger, K. Q. (2017). “Densely connected convolutional networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). (Honolulu, HI, USA: IEEE) 2261–2269. doi: 10.1109/CVPR.2017.243
Hughes, D. P., Salathe, M. (2015) An open access repository of images on plant health to enable the development of mobile disease diagnostics. Available at: https://arxiv.org/abs/1511.08060.
Jiang, Z. C., Dong, Z. X., Jiang, W. P., Yang, Y. Z. (2021). Recognition of rice leaf diseases and wheat leaf diseases based on multi-task deep transfer learning. Comput. Electron. Agric. 186, 106184. doi: 10.1016/j.compag.2021.106184
Karthik, R., Hariharan, M., Anand, S., Mathikshara, P., Johnson, A., Menaka, R. (2020). Attention embedded residual CNN for disease detection in tomato leaves. Appl. Soft Computing 86, 105933. doi: 10.1016/j.asoc.2019.105933
Krishnamoorthy, N., Prasad, L. V. N., Kumar, C. S. P., Subedi, B., Abraha, H. B., Sathishkumar, V. E. (2021). Rice leaf diseases prediction using deep neural networks with transfer learning. Environ. Res. 198. doi: 10.1016/j.envres.2021.111275
Lee, S. H., Goeau, H., Bonnet, P., Joly, A. (2020). New perspectives on plant disease characterization based on deep learning. Comput. Electron. Agric. 170, 105220. doi: 10.1016/j.compag.2020.105220
Li, X. R., Yang, C. H., Huang, W. J., Tang, J., Tian, Y. Q., Zhang, Q. (2020). Identification of cotton root rot by multifeature selection from sentinel-2 images using random forest. Remote Sens. 12 (21), 3504. doi: 10.3390/rs12213504
Li, L., Zhang, S., Wang, B. (2021). Plant disease detection and classification by deep learning—A review. IEEE Access 9, 56683–56698. doi: 10.1109/ACCESS.2021.3069646
Liakos, K. G., Busato, P., Moshou, D., Pearson, S., Bochtis, D. (2018). Machine learning in agriculture: A review. Sensors 18 (8), 2674. doi: 10.3390/s18082674
Liu, K., Zhang, X. (2023). PiTLiD: identification of plant disease from leaf images based on convolutional neural network. IEEE/ACM Trans. Comput. Biol. Bioinf. 20, 1278–1288. doi: 10.1109/TCBB.2022.3195291
Mirjalili, S., Lewis, A. (2016). The whale optimization algorithm. Adv. Eng. Software 95, 51–67. doi: 10.1016/j.advengsoft.2016.01.008
Mohanty, S. P., Hughes, D. P., Salathe, M. (2016). Using deep learning for image-based plant disease detection. Front. Plant Sci. 7. doi: 10.3389/fpls.2016.01419
Nandhini, S., Ashokkumar, K. (2022). An automatic plant leaf disease identification using DenseNet-121 architecture with a mutation-based henry gas solubility optimization algorithm. Neural Computing Appl. 34, 5513–5534. doi: 10.1007/s00521-021-06714-z
Pantazi, X. E., Moshou, D., Tamouridou, A. A. (2019). Automated leaf disease detection in different crop species through image features analysis and One Class Classifiers. Comput. Electron. Agric. 156, 96–104. doi: 10.1016/j.compag.2018.11.005
Ristaino, J. B., Anderson, P. K., Bebber, D. P., Brauman, K. A., Cunniffe, N. J., Fedoroff, N. V., et al. (2021). The persistent threat of emerging plant disease pandemics to global food security. Proc. Natl. Acad. Sci. U. S. A. 118 (23), e2022239118. doi: 10.1073/pnas.2022239118
Saeed, F., Khan, M. A., Sharif, M., Mittal, M., Goyal, L. M., Roy, S. (2021). Deep neural network features fusion and selection based on PLS regression with an application for crops diseases classification. Appl. Soft Computing 103, 107164. doi: 10.1016/j.asoc.2021.107164
Sahu, S. K., Pandey, M. (2023). An optimal hybrid multiclass SVM for plant leaf disease detection using spatial Fuzzy C-Means model. Expert Syst. Appl. 214, 118989. doi: 10.1016/j.eswa.2022.118989
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L. C. (2018). “MobileNetV2: inverted residuals and linear bottlenecks,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition). 4510–4520. doi: 10.1109/CVPR.2018.00474
Savary, S., Willocquet, L., Pethybridge, S. J., Esker, P., Mcroberts, N., Nelson, A. (2019). The global burden of pathogens and pests on major food crops. Nat. Ecol. Evol. 3, 430–43+. doi: 10.1038/s41559-018-0793-y
Sharif, M., Khan, M. A., Iqbal, Z., Azam, M. F., Lali, M. I. U., Javed, M. Y. (2018). Detection and classification of citrus diseases in agriculture based on optimized weighted segmentation and feature selection. Comput. Electron. Agric. 150, 220–234. doi: 10.1016/j.compag.2018.04.023
Sileshi, G. W., Gebeyehu, S. (2021). Emerging infectious diseases threatening food security and economies in Africa. Global Food Security-Agriculture Policy Economics Environ. 28, 100479. doi: 10.1016/j.gfs.2020.100479
Szegedy, C., Wei, L., Yangqing, J., Sermanet, P., Reed, S., Anguelov, D., et al. (2015). “Going deeper with convolutions,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Boston, MA, USA: IEEE). 1–9. doi: 10.1109/CVPR.2015.7298594
Tan, M., Le, Q. (2019). “EfficientNet: rethinking model scaling for convolutional neural networks,” in Proceedings of the 36th International Conference on Machine Learning (Long Beach, CA, USA: PMLR). 97.
Tan Nhat, P., Ly Van, T., Son Vu Truong, D. (2020). Early disease classification of mango leaves using feed-forward neural network and hybrid metaheuristic feature selection. IEEE Access 8, 189960–189973. doi: 10.1109/access.2020.3031914
Thakur, P. S., Sheorey, T., Ojha, A. (2022). VGG-ICNN: A Lightweight CNN model for crop disease identification. Multimedia Tools Appl 82 (1), 497–520. doi: 10.1007/s11042-022-13144-z
Thapa, R., Zhang, K., Snavely, N., Belongie, S., Khan, A. (2020). The Plant Pathology Challenge 2020 data set to classify foliar disease of apples. Appl. Plant Sci. 8, e11390. doi: 10.1002/aps3.11390
Uguz, S., Uysal, N. (2021). Classification of olive leaf diseases using deep convolutional neural networks. Neural Computing Appl. 33, 4133–4149. doi: 10.1007/s00521-020-05235-5
Wang, D. F., Wang, J., Li, W. R., Guan, P. (2021). T-CNN: Trilinear convolutional neural networks model for visual detection of plant diseases. Comput. Electron. Agric. 190, 106468. doi: 10.1016/j.compag.2021.106468
Xiang, S., Liang, Q. K., Sun, W., Zhang, D., Wang, Y. N. (2021). L-CSMS: novel lightweight network for plant disease severity recognition. J. Plant Dis. Prot. 128, 557–569. doi: 10.1007/s41348-020-00423-w
Zhao, Y., Sun, C., Xu, X., Chen, J. G. (2022). RIC-Net: A plant disease classification model based on the fusion of Inception and residual structure and embedded attention mechanism. Comput. Electron. Agric. 193, 106644. doi: 10.1016/j.compag.2021.106644
Keywords: deep learning, plant disease recognition, convolutional neural network (CNN), transfer learning, lightweight networks
Citation: Quan S, Wang J, Jia Z, Yang M and Xu Q (2023) MS-Net: a novel lightweight and precise model for plant disease identification. Front. Plant Sci. 14:1276728. doi: 10.3389/fpls.2023.1276728
Received: 12 August 2023; Accepted: 11 October 2023;
Published: 27 October 2023.
Edited by:
Kejian Lin, Chinese Academy of Agricultural Sciences (CAAS), ChinaReviewed by:
Parvathaneni Naga Srinivasu, Prasad V. Potluri Siddhartha Institute of Technology, IndiaXiujun Zhang, Chinese Academy of Sciences (CAS), China
Copyright © 2023 Quan, Wang, Jia, Yang and Xu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jiajia Wang, d2pqeGpAeGp1LmVkdS5jbg==