 Hui Zhang
Hui Zhang Lisa Dean
Lisa Dean Ming Li Wang
Ming Li Wang Phat Dang
Phat Dang Marshall Lamb5
Marshall Lamb5 Charles Chen
Charles Chen
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Plant Sci., 15 September 2023
Sec. Functional and Applied Plant Genomics
Volume 14 - 2023 | https://doi.org/10.3389/fpls.2023.1204415
Peanut flavor is a complex and important trait affected by raw material and processing technology owing to its significant impact on consumer preference. In this research, principal component analysis (PCA) on 33 representative traits associated with flavor revealed that total sugars, sucrose, and total tocopherols provided more information related to peanut flavor. Genome-wide association studies (GWAS) using 102 U.S. peanut mini-core accessions were performed to study associations between 12,526 single nucleotide polymorphic (SNP) markers and the three traits. A total of 7 and 22 significant quantitative trait loci (QTLs) were identified to be significantly associated with total sugars and sucrose, respectively. Among these QTLs, four and eight candidate genes for the two traits were mined. In addition, two and five stable QTLs were identified for total sugars and sucrose in both years separately. No significant QTLs were detected for total tocopherols. The results from this research provide useful knowledge about the genetic control of peanut flavor, which will aid in clarifying the molecular mechanisms of flavor research in peanuts.
Peanut, also known as goober or groundnut, is a globally important oilseed crop grown worldwide. Peanuts can be consumed in different formats, such as peanut butter, peanut oil, roasted peanuts, confections, and nutritional bars. The primary and popular means of consumption is roasted peanuts because of their unique, pleasant flavor and abundant nutrients although they can be amenable to various processes (Lykomitros et al., 2016). The improvement of peanut flavor, especially for roasted peanuts, is a long-term goal for the peanut industry. Research has shown that peanut flavor can be affected by genetic, environmental, and storage conditions (Neta et al., 2010). Plants can produce a large variety of flavor volatiles, and the perception of flavor, which includes aroma and taste, is the consequence of different aromatic volatile compound interactions (Zhang et al., 2015).
There are mainly two methods to check peanut flavor including descriptive sensory and analysis by instrument. Analysis by descriptive sensory, which is a forceful tool used to characterize food flavors, makes use of a panel trained in the use of lexicon to evaluate the various flavor characteristics (Meilgaard et al., 1999), while instrumental analysis mainly uses chemical methods to analyze seed composition contents, including moisture content, volatile extracts, tocopherols profile, fatty acids profile, and sugars profile. Moisture content has a significant effect on flavor development reactions. Peanuts have more carbohydrates and glucose in an environment with higher moisture contents (8.7-9.2%) than peanuts stored in an environment with lower humidity (6.2-6.3%) (Pattee et al., 1982). The volatile compositions and concentrations that are present in roasted peanuts determine the flavor although the specific aroma-active compounds responsible for peanut flavor remain elusive (Schirack et al., 2006). All of these seed composition contents can affect peanut flavor; however, the relationship among different contents and which content has the main effect on peanut flavor are still not clear.
The genetics and molecular foundation of flavor, especially volatiles are deficiently understood because of the complexity of flavor/aroma traits. High-throughput sequencing has paved the way for the QTL analysis of aroma components. Genome-wide association studies (GWAS), a powerful tool based on the linkage disequilibrium (LD) theory, are used to detect QTLs associated with complex agronomic traits (Kimani et al., 2020). In GWAS, the fundamental approach is to examine the relationships that exist among each genotyped single-nucleotide polymorphism (SNP) marker and the phenotypes of interest. GWAS does not require the creation of a mapping population, which is in contrast to linkage mapping. At a single locus, they are able to evaluate multiple alleles, and they are also able to offer a higher mapping resolution (Rafalski, 2010; Kimani et al., 2020). QTLs and genes related to tomato flavor have been identified through GWAS (Zhang et al., 2015), and they have been effectively utilized in peanuts to follow hereditary marks related to ionomic (Zhang H. et al., 2019) and agronomic traits (Pandey et al., 2014; Zhang H. et al., 2020), but there is no GWA study in peanut flavor-related traits.
Principal component analysis (PCA) is an effective method to extract a few and major information from complex components and retain most of the variation in the dataset (Ishikawa and Namikawa, 2004; Ringnér, 2008). PCA uses the dimensionality-reduction method to transform multiple correlated phenotypes into a smaller number of uncorrelated variables known as principal components (PCs), which can capture important data points (He et al., 2008). Numerous linkage analyses for correlated traits have utilized it successfully (Karasik et al., 2004; Adeyemo et al., 2005) since this method can decrease the likelihood of type 1 error rate and extract PCs that are closer to the normal distribution (Holberg et al., 2001; He et al., 2008). GWAS and PCA are a good combination when analyzing phenotypically complex traits and this approach has been validated as effective in detecting causal genes related to rice architecture (Yano et al., 2019).
Peanut breeders make the achievement of desirable flavor and quality characteristics as important breeding objective. Various traits can affect peanut flavor, but until now, little information is available on which trait has a bigger effect. Therefore, the aims of the present research were: 1) to explore correlations among moisture, oil content, tocopherols profile, sugars profile, and sensory attributes to identify the main traits that have a major effect on peanut flavor, 2) to determine genomic regions that are associated with main peanut flavor traits, and 3) to identify the candidate genes near the determined QTLs.
In this experiment, 102 accessions primarily from the U.S. peanut mini-core collection (Holbrook and Dong, 2005) were used (Table S1). These genotypes were grown in the field in Dawson, GA, between 2013 and 2014, and each accession with 20 seeds was planted in two-row 10-feet long plots. Prior to growing peanuts, corn-cotton-peanuts were planted on the site (Dothan sandy loam soil) as part of a crop rotation. Gypsum fertilizer was used to grow peanuts in both years in the same quantity (500 pounds/acre). Following the published method, the oil percentage was determined using a Maran pulse nuclear magnetic resonance (NMR, Resonance Instruments, Whitney Oxfordshire, UK) (Wang et al., 2010). The oil percentage was calculated using physiologically mature seeds (∼10 g) on a premise of zero water content by utilizing the equation [oil % * 100/(100 – H2O % * 100)]. Seed water contents were estimated, and the mass of the estimation was changed over completely to a percentage of the total weight of each example. All examples were estimated in three replicates.
A household coffee grinder (Krups International, Frankfurt am Main, Germany) was used to grind the raw peanut samples into a fine meal. Cheesecloth was used to wrap approximately 200 grams of the meal before it was loaded into the X. A hydraulic press (Model 2622-1, Carver, Inc., Wabash, IN) was used to extract the oil. The normal phase HPLC was used to analyze tocopherols in the oil (Hashim et al., 1993). In short, 200 mg of oil was weighed into a 2 mL autosampler vial and then 0.8 mL of hexane was added which contains 2% (v/v) isopropanol. The items in the vial were vortexed to blend and infused onto the HPLC (Agilent Model 110, Agilent Technologies, Santa Clara, CA). The mobile phase was adding 2% (v/v) isopropanol in hexane at 1.2 mL/min in an isocratic manner. The column was a Luna Silica, which was kept at a temperature of 30°C. UV was used for detection at 295nm. Hexane solutions of genuine tocopherols were tested simultaneously as standards. Sigma Chemical Corp. (St. Louise, MO) provided the standards of α, γ, and δ tocopherols, and Matreya LLC (State College, PA) provided β-tocopherol. Retention times and external standards for calculating tocopherol content were determined using standards. Triplicates were used for each analysis.
A Soxhlet apparatus was used to boil hexane to completely defat the recovered pressed paste for tocopherols. The remaining meal was broken down for sugars analysis as previously depicted (Pattee et al., 2000). In short, approximately 100 mg of defatted peanut meal was extracted with 15 mL of an aqueous solvent mix (chloroform/methanol/water 60/25/15 v/v/v). To extract approximately 100 mg of defatted peanut meal, 15 mL of an aqueous solvent mix was used. In order to pellet the remaining solid material, the samples were then centrifuged at 1000 rpm. In a vacuum oven with a solvent trap, the solvent layer was decanted into a small beaker and evaporated overnight. The evaporated buildup was carried with 1 ml of water containing 2.3 mM lactose and 1.2 mM cellobiose as inside principles. To get rid of free amino acids, the solution was diluted 40 times with water and filtered through a sulfonic acid column (Dionex On Guard IIH, Thermo-Dionex, Sunnyvale, CA). Then, HPLC with an ion exchange column and a pulsed amperometric detector (PAD) was used to analyze the solutions. A Dionex BioLC system with a Dionex PA-1 column (250 mm X 4.6 mm i.d.) and a detector using electrochemistry was used in the HPLC. At 1.0 mL/min, 200 mM sodium hydroxide in water served as the mobile phase. The segment was warmed to 30°C. For quantitation, a standard blend containing the interior principles of myo-inositol, glucose, fructose, sucrose, raffinose, and stachyose was utilized. Sigma Chemical Corp. (St. Louis, MO) supplied all of the standards. Each analysis was performed three times. Reaction factors in light of the inner guidelines were determined and utilized for the quantitation.
After harvest, the crude peanuts were first dried and precisely shelled at the USDA, ARS Public Nut Research facility in Dawson, GA. For analysis, the mature peanuts, which had been dried and shelled, were sent to the USDA-ARS Market Quality and Handling Research Unit in Raleigh, North Carolina. Using a colorimeter (Hunter Labs, Reston, VA), the raw peanut samples were roasted in a forced air oven (Model LXD, Despatch Industries, Minneapolis, MN) at 171°C until they reached a final color of L=48 ± 1 on the Hunter scale. A Robot Coupe Blixer 3 commercial food processor (Robot Coupe U.S.A., Inc., Ridgeland, MS) was used to ground samples to a paste. Any variation between seeds was eliminated by this preparation (Sanders et al., 1989).
An eight-member panel that was trained in the descriptive evaluation of peanut flavor and maintained by the USDA-ARS Market Quality and Handling Research Unit in Raleigh, North Carolina, received the pastes. The Spectrum® Flavor Descriptive Analysis Technique was taught to the panel (Meilgaard et al., 1999). Three-digit numbers were used to randomly present the samples. On a 15-point scale, the previously described flavor descriptors were evaluated (Sanders et al., 1989; Johnsen et al., 2004). The examples were introduced aimlessly in copy and scores were accounted as means.
Using SPSS Statistics Version 24 (IBM SPSS, IBM Corp, Armonk, NY, USA), the phenotypic data were subjected to statistical analysis. SPSS factor dimension reduction was used in the PCA analysis. The analysis of variance components was assessed utilizing the restricted maximum likelihood (REML) method, and the standard GLM method was used to do the univariate variance analyses. The broad-sense heritability for every trait (with the exception of sensory analysis) across the two environment experiments was determined based on the estimated variance components with the accompanying equation: , where , , and represent the genotypic variance, the interaction between 102 genotypes and environment variance, and the error (residual) variance component, respectively. r is the number of environment trials and n is the number of replications in each environment trial (Holland et al., 2003).
For DNA extraction, field-grown plant leaves were collected and stored at -80°C. The genomic DNA was extracted using a modified CTAB method (Porebski et al., 1997). For the purpose of analysis, the purified DNA was dissolved in TE buffer. The Nanodrop 2000 was used to measure the DNA’s quantity and quality.
At GeneSeek (Lincoln, Nebraska, USA), the SNP array (Affymetrix 2) was used for the genotyping. No samples were excluded for low call rate (< 0.95) or low quality. After removing SNPs with genotyping error, a call rate of less than 0.95, or a minor allele frequency of less than 0.05, a total of 12,526 SNP markers were retained. STRUCTURE 2.2.3 was used to analyze the population structure of the 102 accessions (Pritchard et al., 2000). In a previous study, the markers’ density and heterozygosity were reported (Zhang H. et al., 2019).
The filtered SNP data was used to calculate the linkage disequilibrium (LD) with the PopLDDecay program (Zhang C. et al., 2019). Standardized disequilibrium coefficients (D’) and squared correlations (r2) were figured. Based on the means of distances between SNP pairs and r2 values, LD decay plots were created.
To detect the association between SNPs and flavor-related traits in peanuts, statistical analyses were performed using three different methods: (1) TASSEL 5.0: the PCA (first five PCs) + GLM module (general linear model, GLM) was utilized in the TASSEL software (Bradbury et al., 2007). (2) GAPIT 3.0: association mapping was implemented in R utilizing the MLM module (mixed linear model), Y = Xβ + Zu + e (Lipka et al., 2012). (3) BLUP analysis with mrMLM software (Zhang YW et al., 2020).
The TASSEL module matched the data better than the MLM module, as shown by the Q-Q plots. The TASSEL was used to analyze the phenotype and genotype data. LD pruning was accomplished by PLINK (Purcell et al., 2007) using the indep-pairwise function with a step size of 50, a variant count of 5, and r2 threshold of 0.5, which generates 2,363 independent SNPs and LD blocks for this population. Based on the number of independent SNPs and LD blocks, the P-value threshold for significant and suggestive QTLs was calculated (Zhou et al., 2017). The LD block was defined as a collection of adjacent SNPs with a pairwise r2 value of at least 0.50 (Gu et al., 2011). A total of 2,363 independent SNPs and LD blocks were retained after LD pruning. Thus, the threshold for significant QTLs was 0.05/2363 = 2.12e−5 with − log10 (P value) = 4.67. Major or significant QTLs were defined as QTLs that met the significant threshold. In a genome-wide test, “suggestive association” permits one false-positive effect, indicating that the threshold p-value was 1/2363 = 4.23e−4 with − log10 (P value) = 3.37. Suggestive QTLs were defined as QTLs that were lower than the significant threshold but up to the suggestive threshold. Using qqman, Manhattan plots of the p-value results were created (Turner, 2014).
Genes within the ±80 kb region of the significant and suggestive SNPs associated with peanut flavor were detected from the Tifrunner genome sequences (https://peanutbase.org/). The Tifrunner genome annotation file was used to annotate the identified genes. RNA-Seq data under BioProject PRJNA573070 were downloaded from the NCBI Sequence Read Archive (SRA) database and used for differential expressed genes (DEGs) analysis. Four seed developmental stages (yellow, orange, brown, and black) of four genotypes (AABB, aaBB, AAbb, and aabb) of F8 breeding lines were used for RNA-Seq. For details, see the paper by Zhang et al. (2021).
A total of 102 U.S. peanut mini-core accessions planted in 2013 and 2014 were used in this research. Thirty-three traits associated with flavor, which includes moisture, oil content, tocopherol (total tocopherols, alpha-tocopherol, beta-tocopherol, gamma-tocopherol, and delta-tocopherol), sugars (inositol, glucose, fructose, sucrose, raffinose, stachyose, and total sugars), and descriptive quality (roast peanut, sweet aromatic, raw beany, dark roast, woody hulls skins, earthy musty, cardboardy, plastic chemical, painty, fruity fermented, metallic, spice, sour, sweet, salty, bitter, tongue-throat burn, astringent, and ashy) were measured. Significant variability was identified for these traits among the accessions (Table 1). The total sugars varied significantly (ranging from 22502.56 to 40462.04 mcg/g on average 29297.07 mcg/g). Among the total sugars, variation in sucrose ranged from 19999.40 to 37097.90 mcg/g with an average of 25280.23 mcg/g. In addition, the amounts of total tocopherols (293.49-493.25 mcg/g) and gamma-tocopherol (99.38-276.68 mcg/g) also showed significant variation. There is no significant difference in the traits of descriptive quality.
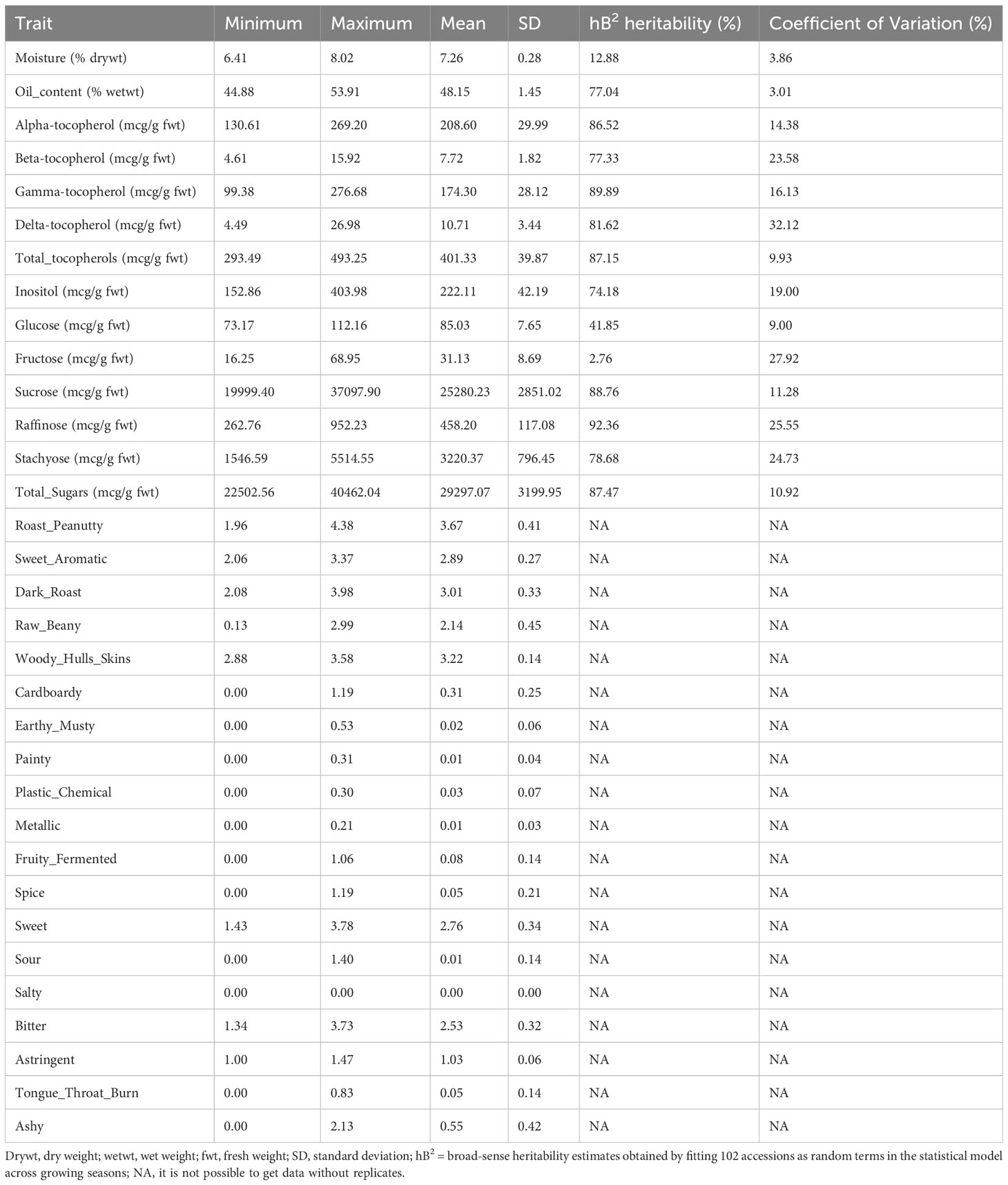
Table 1 Variability of flavor-related traits within the U.S. peanut mini-core collection.
To investigate the relationships and the main factors underlying trait variation, Pearson correlation and PCA were conducted. For the results of the Pearson correlation, salty has no significant relationship with other traits (Dataset 1). PCA results revealed that each PC can only explain a small variance, such as PC1 explaining 18.11% and PC2 explaining 15.32% of total variance (Table 2A; Dataset 2). This indicated that all of the PCs contributed to total variance without significant difference, so we performed condensed PCA selecting one or two traits from each of the 10 PCs according to the first PCA results. Condensed PCA included 13 traits resulting in five PCs and they explained 68.89% of total variance (Table 2B; Dataset 3). Considering the normal distribution and component percentage of the phenotype data, three traits (total sugars, sucrose, and total tocopherols) were selected for the following GWAS analysis.
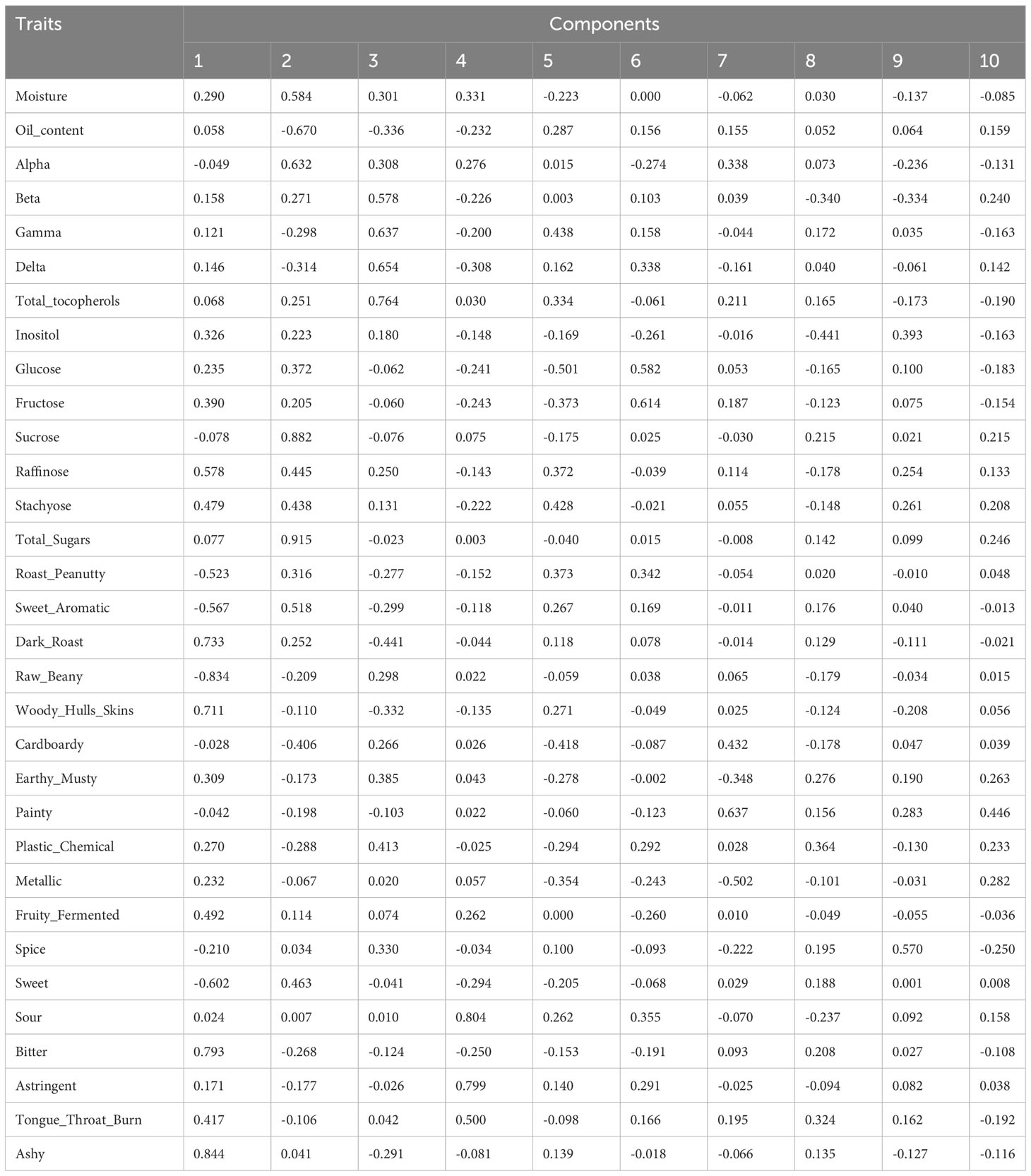
Table 2A Principal component scores of the first 10 PCs for 32 traits (A) and first 5 PCs for 13 traits (B) in the dataset of 102 peanut accessions.
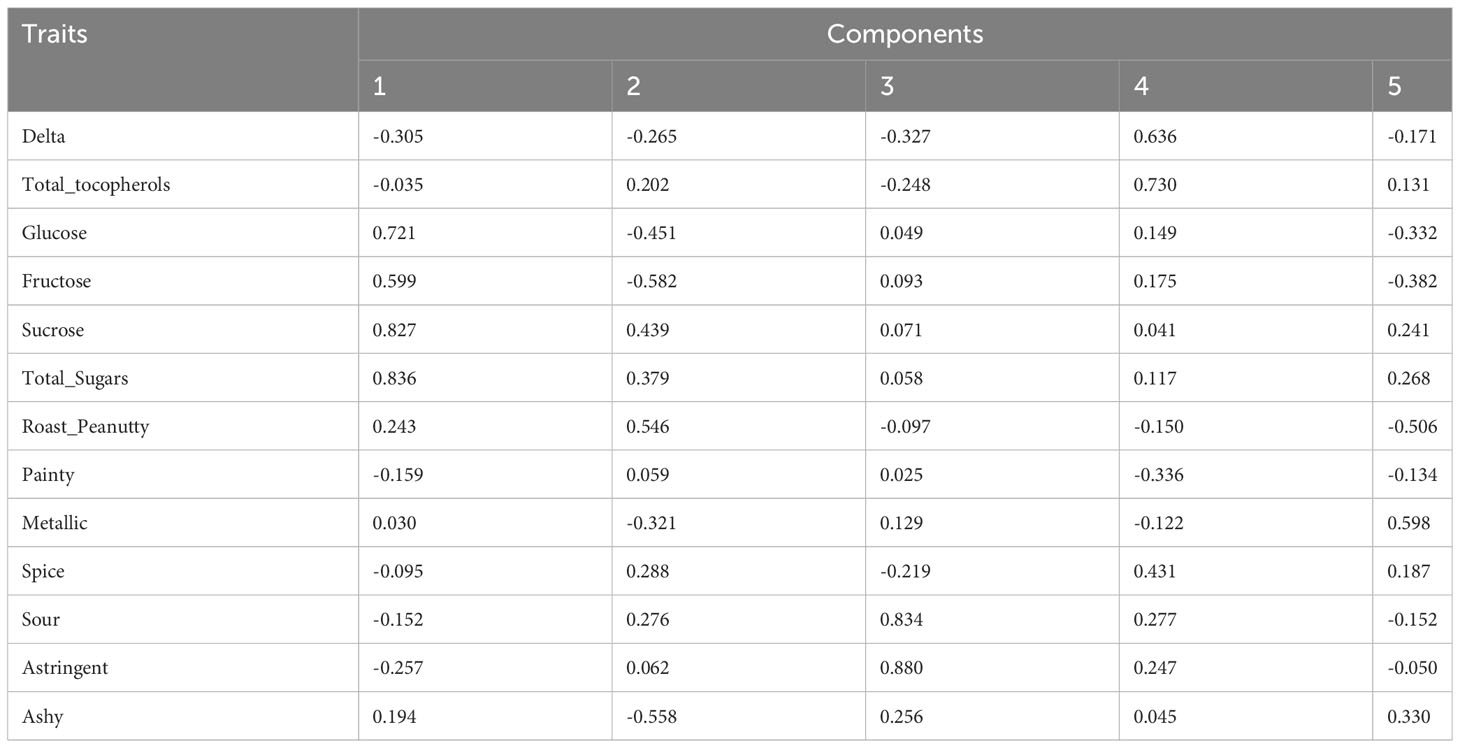
Table 2B
After removing SNPs with genotyping error, a call rate of less than 0.95, or a minor allele frequency of less than 0.05, 12,526 SNP markers were retained. No samples were excluded because of low call rates (< 0.95) or poor quality. Population structure results indicated that the 102 mini-core accessions were grouped into primarily two subpopulations according to the delta K (Figure 1A), which was in line with our previous study (Zhang H. et al., 2019). Under K = 2, Group 1 contains 52 mini-core genotypes, most of which belong to hypogaea, while Group 2 mainly includes fastigiata (Figure 1B). Linkage disequilibrium (LD) was estimated from r2 (r2< 0.2 was considered unlinked) against distances between each marker in the 102 U.S. mini-core collections. In this population, the LD decay was approximately 0.16 Mb and the r2 was 0.2 (Figure 1C).
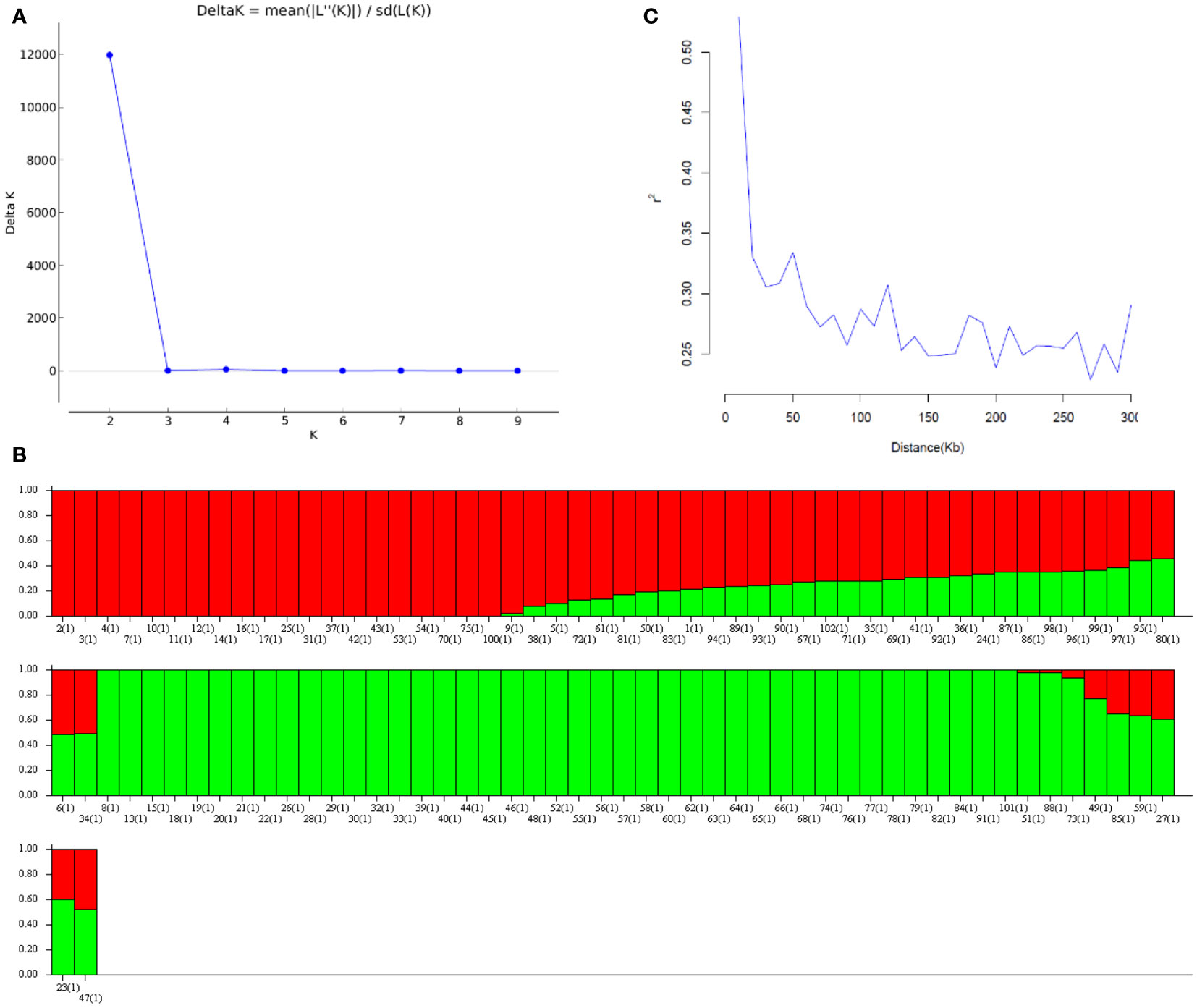
Figure 1 The genetic structure of 102 genotypes mainly comes from the U.S. peanut mini-core collection. (A) Δ K information from STRUCTURE analysis of the U.S. peanut mini-core collection. (B) Population structure inferred by STRUCTURE analysis. The bar plot for K = 2 was created from 102 accessions and was ordered by Q values. A single vertical line represents each collection and each color represents one cluster. (C) Linkage disequilibrium (LD) decade over distance.
The selected traits (total sugars, sucrose, and total tocopherols) displayed near-normal distribution for both years (Figure 2). In general, the distributions of each trait varied little from year to year. For total sugars and sucrose, the ratings ranged from 20000 to 45000 and 15000 to 40000, respectively, in both years 2013 and 2014. For total tocopherols, the ratings ranged from 250 to 550 in 2013 and 250 to 500 in 2014. The median of rating scores for every trait in various years is displayed in Figure S1. The estimated broad-sense heritability of total sugars, sucrose, and total tocopherols was 87.47%, 88.76%, and 87.15%, respectively (Table 1).
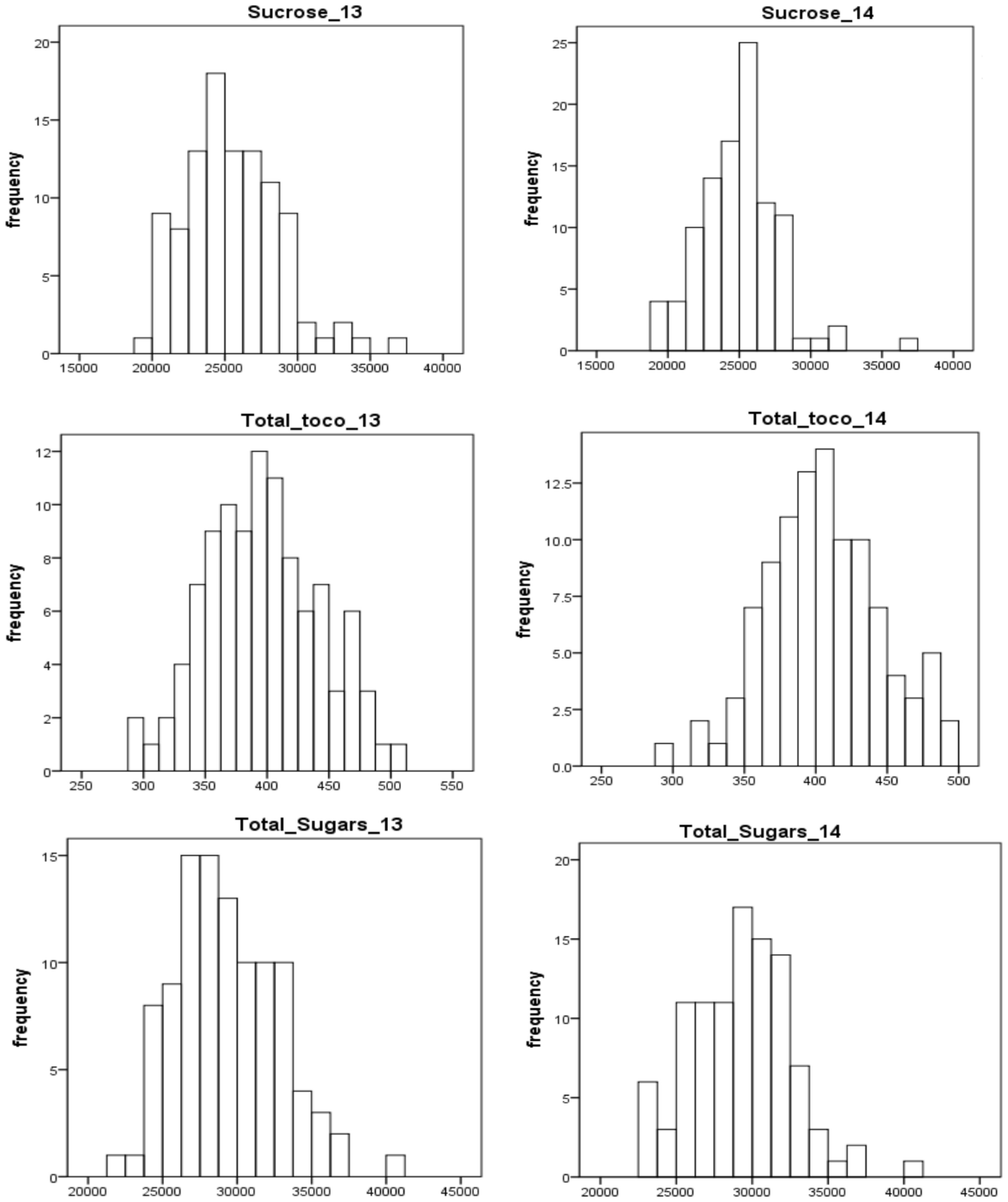
Figure 2 Frequency distribution of total sugars, sucrose, and total tocopherols in peanuts in years 2013 and 2014.
To choose the most suitable model for GWAS analysis of the selected traits in the population, the PCA + GLM and MLM models were tested. Quantile-quantile (Q-Q) plots suggested that the PCA + GLM model provided a better fit with the expected distribution (Figures 3, S2, S3). Therefore, the PCA + GLM model was chosen for subsequent analysis. In total, 67, 91, and 20 QTLs were identified for total sugars, sucrose, and total tocopherols, respectively (Table 3). Among them, there were seven significant QTLs for total sugars and 22 for sucrose; however, significant QTLs were not identified for total tocopherols. A total of 178 QTLs were found to be distributed in over 15 chromosomes; 81 QTLs were found to be distributed in over six chromosomes of the A sub-genome, and 97 QTLs were found to be mapped in over nine chromosomes of the B sub-genome (Table S2). Of the 29 significant QTLs, 12 were situated on the A sub-genome and 17 were on the B sub-genome (Table S3). ChrB04 had a maximum of 28 QTLs, followed by ChrA04 with 26 QTLs, and ChrA01, ChrA07, ChrA08, ChrA10, and ChrB07 had no QTLs (Table S2). ChrB04 and ChrB05 had the same number of significant QTLs, which is seven (Table S3). In addition, two stable significant QTLs (AX-176797514 and AX-176812379) associated with total sugars were identified in both years and both of them explained 16.13% of the phenotypic variance (Table 4). Similarly, three stable significant QTLs (AX-147248761, AX-176796778, and AX-147248574) located on ChrB04, and two stable significant QTLs (AX-176797514 and AX-176812379) located on ChrB05 were detected to be related to sucrose. On ChrB05, two significant QTL regions (AX-176797514 and AX-176812379) were found to be related to sucrose and total sugars, respectively. More importantly, QTL AX-147221247 on ChrA04 was significantly associated with sucrose and total sugars. For this QTL, our analysis indicated that the C/C genotype had higher sucrose and total sugars contents, while the T/C or T/T genotype had lower sucrose and total sugars contents (Figure 4).
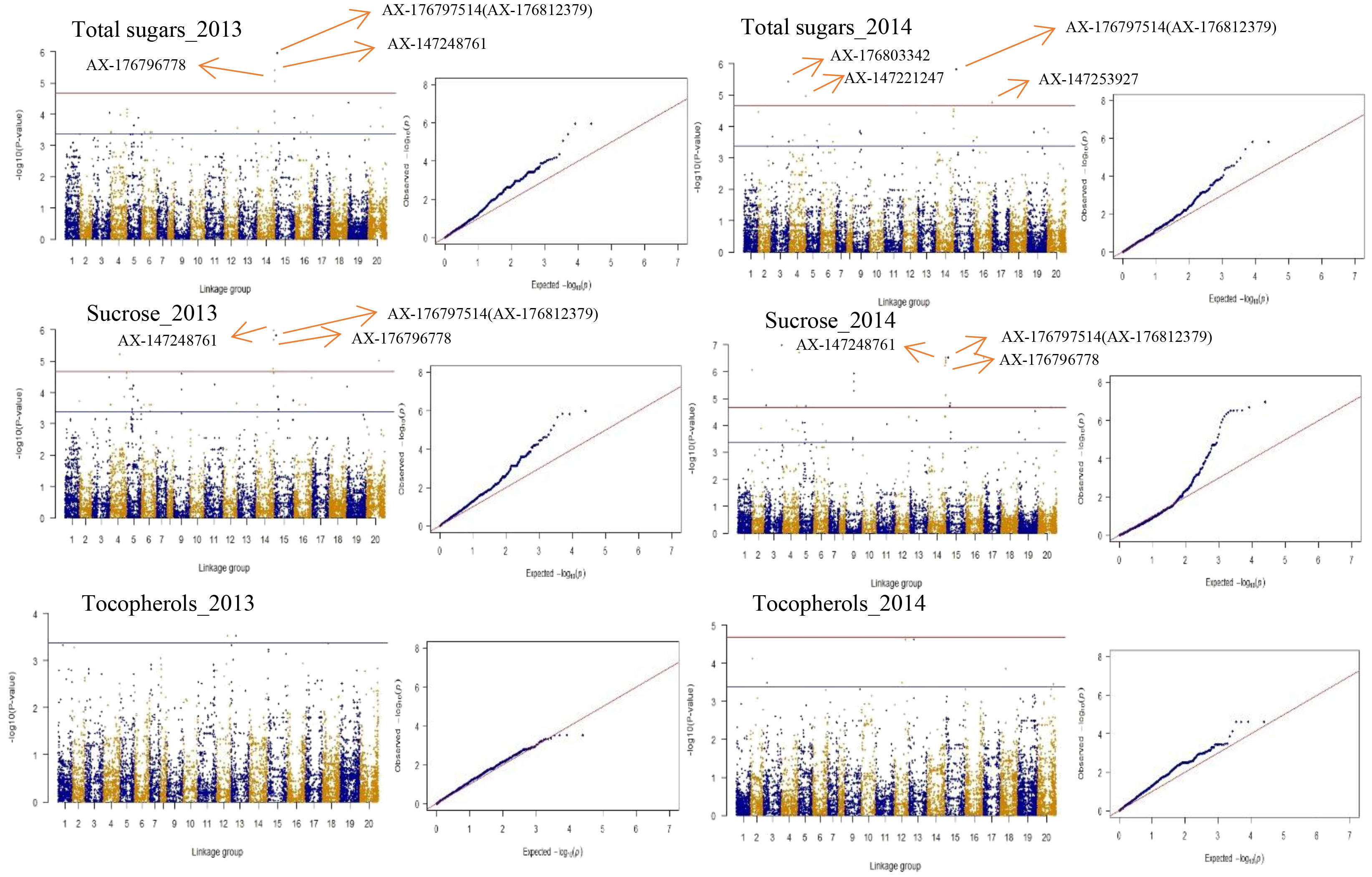
Figure 3 Presentation of Manhattan and Q-Q plots for total sugars, sucrose, and total tocopherols in peanut. The red horizontal line indicates the genome-wide significant threshold: − log10 (Pvalue) = 4.67. The blue horizontal line indicates the threshold for the significance of “suggestive association”: − log10 (Pvalue) = 3.37.
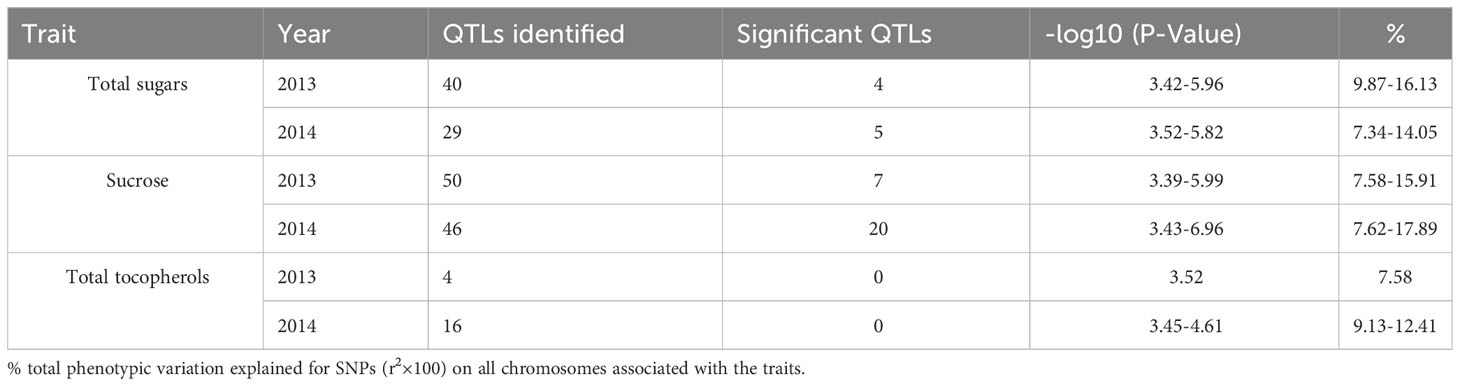
Table 3 Summary of QTLs associated with total sugars, sucrose, and total tocopherols in peanuts.
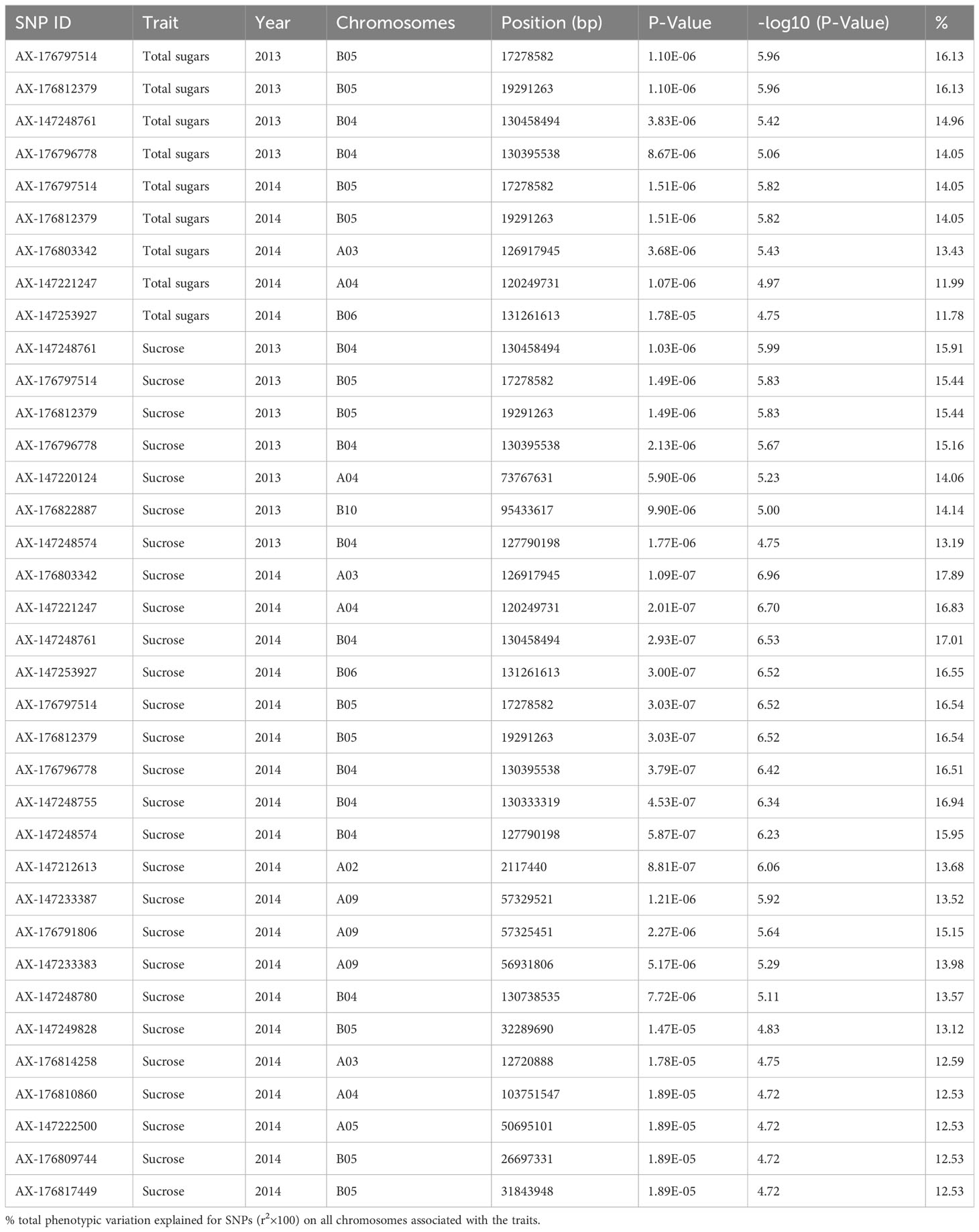
Table 4 Details of SNPs near significant QTLs identified for total sugars and sucrose.
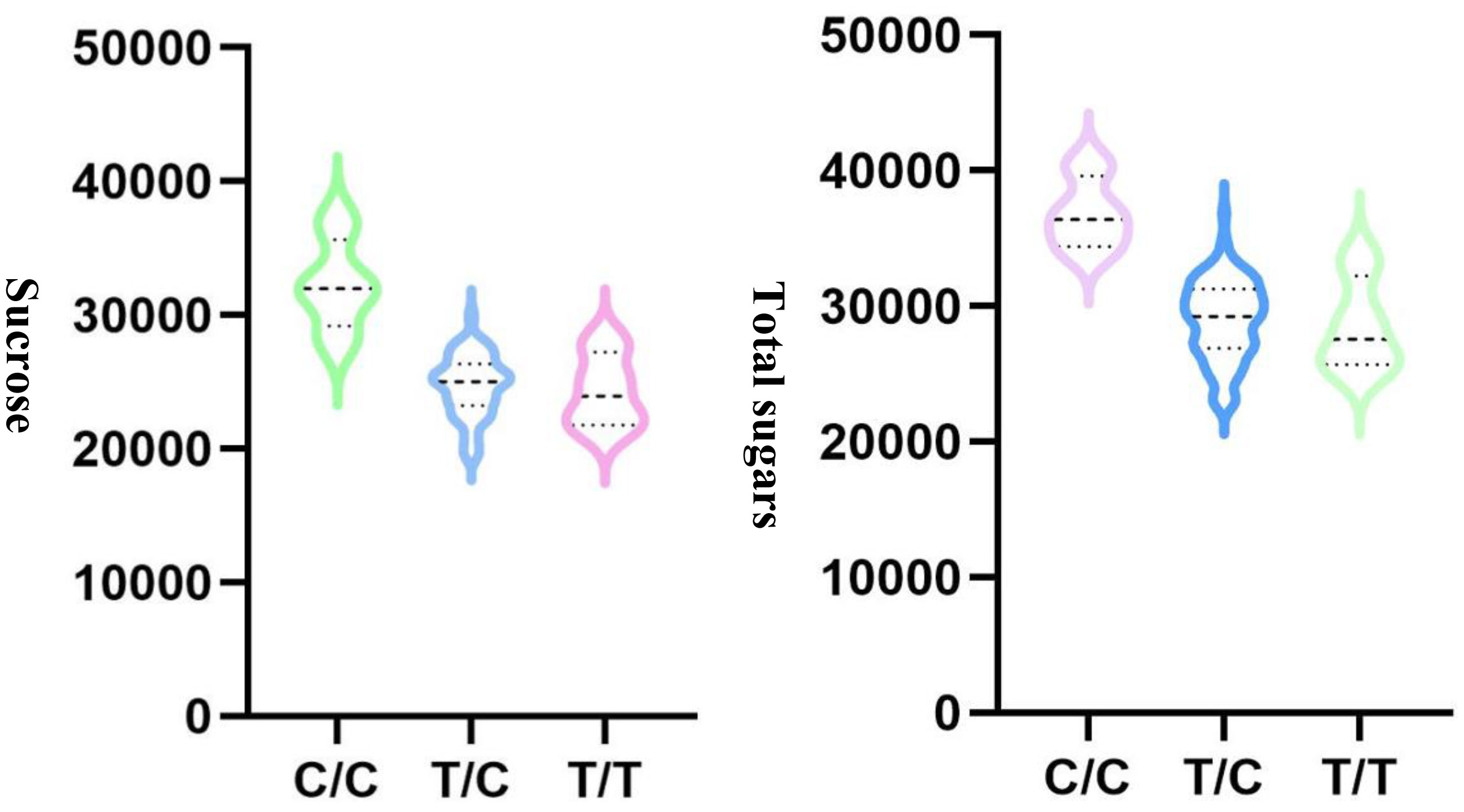
Figure 4 QTL analysis for AX-147221247 located on ChrA04 that is associated with sucrose and total sugars.
Figure 3 depicts the Manhattan plots of the GWAS results. The genes near significant and suggestive QTLs within ± 80 kb regions are shown in Table 5, Dataset 4, and Dataset 5. A total of four potential candidate genes associated with total sugars near significant QTLs were detected, including one stable gene arahy.BXRJ0F, which spans a genomic region between 19,236,308 and 19,239,067 bp on ChrB05 encoding nucleotide-diphospho-sugar transferase superfamily protein (Table 5). The functional annotation of the other three genes in major QTL regions incorporates two genes (arahy.V3ZQ6H and arahy.94J2Q8) that encode UDP-glycosyltransferase and one gene (arahy.0B2YB3) that encodes acyl-CoA thioesterase. For sucrose, within the significant associated region, eight genes were found, including nucleotide-diphospho-sugar transferase superfamily protein (arahy.BXRJ0F), Gag-pol polyprotein n (arahy.0KX8XR), probable polygalacturonase (arahy.ETW0X5), acyl-CoA thioesterase (arahy.0B2YB3), UDP-glycosyltransferase (arahy.V3ZQ6H), UDP-Glycosyltransferase superfamily protein (arahy.94J2Q8), ATP-binding/protein serine/threonine kinase (arahy.8E8ZZ7), and lysosomal alpha-mannosidase-like (arahy.X2JSTS). The stable gene arahy.BXRJ0F related to sucrose was also detected in both years. In addition, four genes (arahy.BXRJ0F, arahy.V3ZQ6H, arahy.94J2Q8, and arahy.0B2YB3) near significant QTL regions were associated with both total sugars and sucrose, which includes one stable gene (arahy.BXRJ0F).
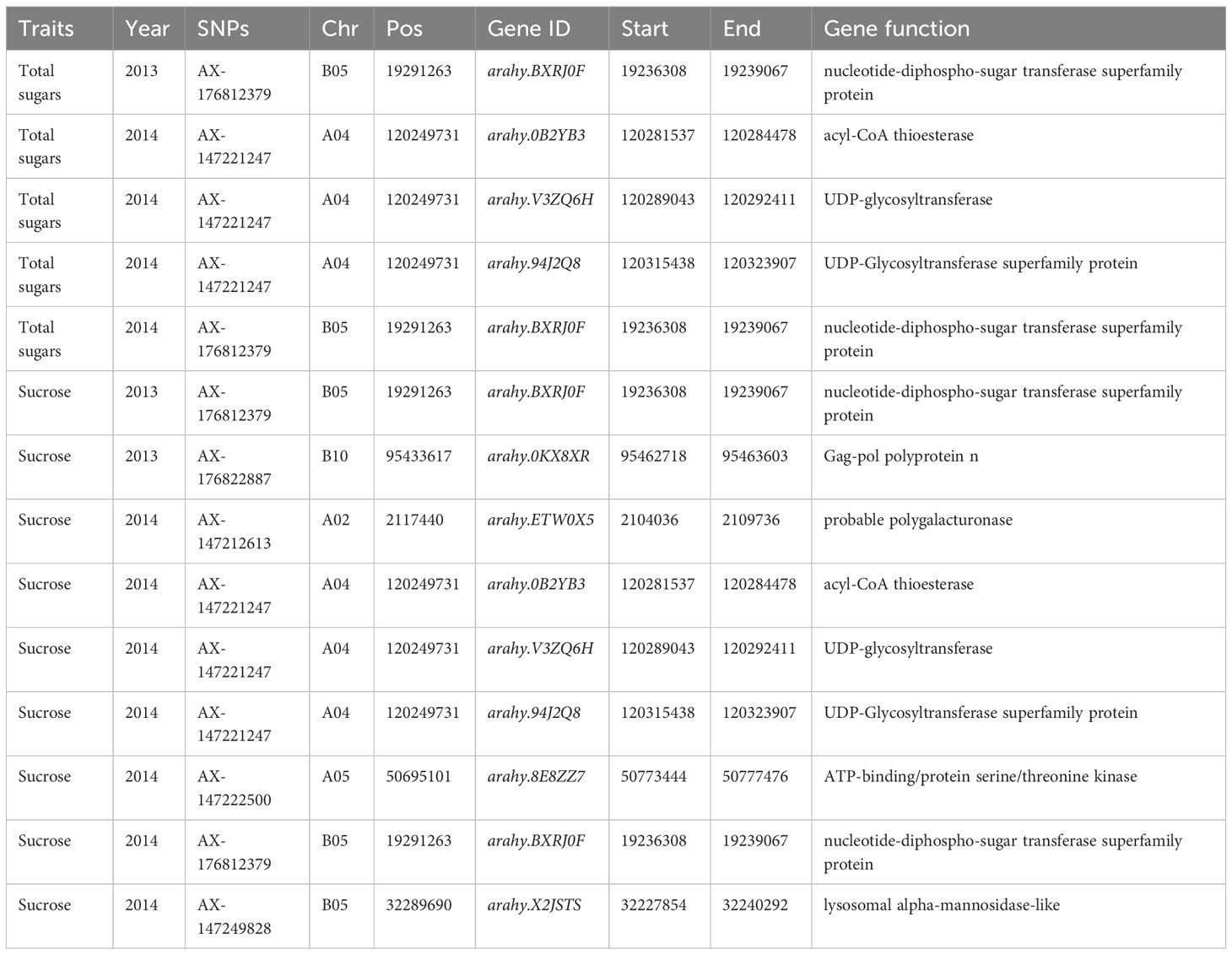
Table 5 The potential candidate genes’ association with total sugars and sucrose detected from GWAS.
PCA is a useful method to extract main factors from complex traits that are highly correlated, which covers eigenvectors, standard deviation, and covariance (Karamizadeh et al., 2013). Correlation coefficients were calculated from all 33 investigated traits (Dataset 1). Salty was proved to have no significant correlation with other traits. Total sugars and total tocopherols are not significantly correlated with each other; however, both of them have a significantly positive relationship with moisture and a negative relationship with oil content. Moisture and oil contents have a significantly negative relationship with each other. After Pearson correlation calculation, 32 correlated traits were selected to conduct PCA. Each of the traits contributed to a small variance and the first three PCs can only explain 43.91% of phenotype variance during the first PCA. Then, the condensed PCA was performed to reduce the PCs, and finally, three traits (total sugars, sucrose, and total tocopherols) were selected which can explain the most variance of peanut flavor. In addition, for descriptive analysis, astringent, sour, metallic, and roast_peanutty also need to be considered when detecting peanut flavor. From the Pearson correlation and PCA study, we know which traits have bigger effects on flavor.
GWAS is an effective method to identify QTLs that are linked to the interest traits. However, many variables can affect the consequences of association mapping, which includes genetic diversity, linkage disequilibrium (LD), population structure and size, density of markers, and errors in phenotyping and genotyping data (Gordon and Finch, 2005). At least two methodologies can be used to validate the reliability of GWAS results including approving the QTLs related to the characteristic in various populations and mutual validation through combining association mapping with genetic mapping in Recombinant Inbred Line (RIL) or F2 groups. Abundant genetic diversity, rapid LD decay within a diverse population, and higher density of markers could increase the mapping resolution. In our study, a total of 102 U.S. peanut mini-core accessions were used, and it covered all peanut botanical varieties (var. fastigiata, var. vulgaris, var. hypogaea, var.aequatoriana, var. peruviana, and var.hirsuta) (Table S1). Population structure analysis revealed that although the principal component analysis plot did not show any distinct clusters, the mini-core collections were primarily divided into two subpopulations (Figure S4). Population structure, allele frequency, recombination rate, and selection could also influence the precision of GWAS by affecting the LD decay (Liu et al., 2020). In this panel, the LD decay was around 160 kb for the entire genome, which is consistent with a former report (Zhang et al., 2020). GWAS has been extensively utilized in peanut research including different traits, such as ionomic (Zhang H. et al., 2019), leaf spots (Zhang et al., 2020), domestication (Zhang et al., 2017), and yield-related traits (Wang et al., 2019); however, no reports concerning GWAS of peanut flavor-related traits have been reported. The findings from this study will have the potential to be used in the genetic improvement of peanuts, as well as provide important information for flavor research.
Peanut flavor is a complex agronomic trait influenced by many factors. Peanut seed ingredients including free amino acids, reducing sugars, and amino acids released during protein denaturation are important precursors for flavor development through the Maillard reaction pathway. The scoring test and the hedonic scale method are the two most widely used sensory evaluation methods (Oupadissakoon and Young, 1984). An evaluation sheet for peanuts’ off-flavor and texture was developed by Holaday et al. (Holaday et al., 1964), and Thomas et al. (Thomas et al., 1968) utilized the rank preference test to evaluate peanuts’ quality. Arthur D. Little Co. (Cairncross and Sjöström, 2004) first developed a method for descriptive flavor profile analysis and applied it to foods. Professionally trained panelists were hired to evaluate the peanut flavor by eating peanuts; however, this approach is subjective, time and energy-wasting, and not very accurate. In addition, it is impractical to screen for a variety of flavor chemicals and to select for good flavor by tasting a large number of peanuts. With the rapid advances in molecular breeding tools and QTLs/genes discovery, marker-assisted selection could be used to select peanut with desired flavor.
By using PCA and GWAS, three important flavor chemicals were detected to have major positive effects on peanut flavor, and sugars are the major contributors to peanut flavor. The related QTLs and genes were obtained, and the function of the potential candidate genes detected from this research is related to the covalent addition and transfer of sugars. Within the genomic region of 160 kb, gene arahy.V3ZQ6H (120289043-120292411 bp) and arahy.94J2Q8 (120315438-120323907 bp), coding for UDP-Glycosyltransferase superfamily, were found to be located on chromosome A04, which catalyzes the covalent addition of sugars from nucleotide UDP-sugar donors to functional groups (amine, hydroxyl, or carboxyl) on an expansive scope of lipophilic molecules (Meech et al., 2019). Glycosyltransferases include multiple gene families that play a role in a process called glycosylation in plant secondary metabolites, which is necessary for the maintenance of cellular homeostasis (Yu et al., 2017). The potential polygalacturonase is encoded by gene arahy.ETW0X5 plays a role in the biosynthesis of carbohydrates. Some other candidate genes including arahy.BXRJ0F (nucleotide-diphospho-sugar transferase superfamily), arahy.0KX8XR (Gag-pol polyprotein), arahy.0B2YB3 (acyl-CoA thioesterase), arahy.8E8ZZ7 (ATP-binding/protein serine/threonine kinase), and arahy.X2JSTS (lysosomal alpha-mannosidase) were found participating in carbohydrate metabolism near significant QTLs regions. In addition, gene expression analysis indicated that most of these genes were involved in the carbohydrate metabolic process and were mainly expressed at the early seed development stages, such as genes arahy.X2JSTS, arahy.BXRJ0F, arahy.ETW0X5, and arahy.94J2Q8. There was no significant difference for gene arahy.0B2YB3 at different seed development stages in four peanut genotypes (Figure 5).
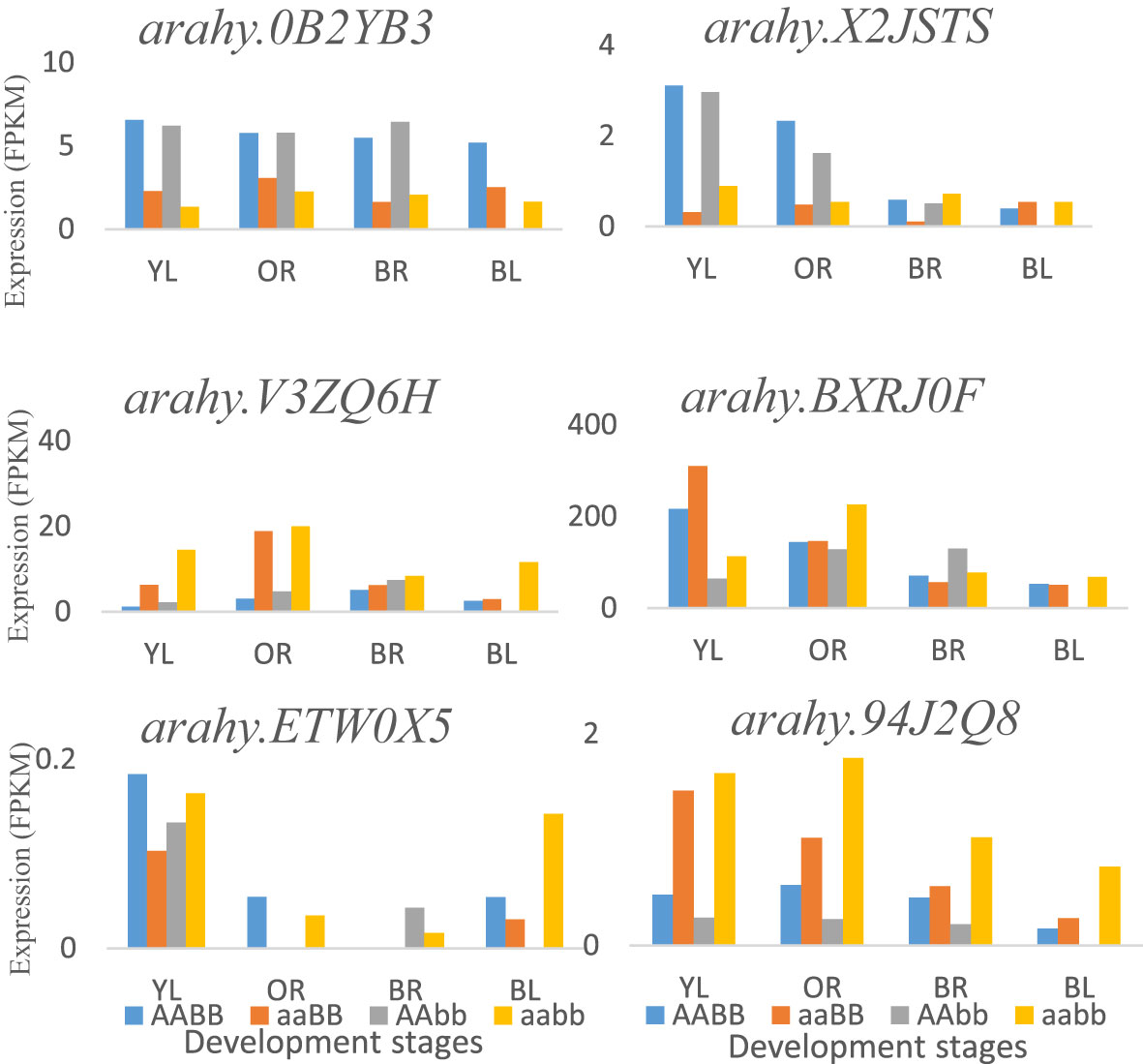
Figure 5 The potential flavor-related DEGs that are around significant QTLs and expressed at different development stages in four peanut genotypes: AABB, aaBB, AAbb, and aabb. YL, Yellow; OR, Orange; BR, Brown; and BL, Black.
Haplotype analysis was conducted for the identified genes; however, no SNPs were detected in the gene regions due to the limitation of the SNP numbers. In this research, the SNPs were from the SNP array, not genome resequencing, which limited the analysis. In addition, the number of accessions also had an influence on the results. To address these problems, whole genome resequencing and multi-environment joint GWAS via 3VmrMLM should be conducted in the future, and the candidate genes should be further confirmed by haplotype analysis and multi-omics analysis.
To the best of our knowledge, this is the first research on peanut flavor using genome-wide association analysis. The relationships among 33 traits affecting flavor were studied by Pearson correlation. According to our PCA results, three traits (total sugars, sucrose, and total tocopherols) were selected to have major effects on flavor than the other traits, and then GWAS was conducted for these three traits. The use of two-environment, two-year phenotypic data revealed QTL stability across environments. Seven significant QTLs associated with total sugars were identified including two stable QTLs and 22 significant QTLs related to sucrose were detected which also includes two stable QTLs. A total of four promising candidate genes, including arahy.BXRJ0F, arahy.V3ZQ6H, arahy.94J2Q8, and arahy.0B2YB3 were selected showing that nearby significant QTL regions control both total sugars and sucrose, and arahy.BXRJ0F is a stable gene. These findings can provide valuable information for future studies on peanut flavor, and further qTR-PCR or gene function-related experiments will be needed to verify the potential candidate QTLs/genes.
The original contributions presented in the study are included in the article/Supplementary Material. Further inquiries can be directed to the corresponding authors.
HZ conducted the statistical analysis and prepared the manuscript. LD collected GWAS data and revised the manuscript. MW and PD prepared the samples and phenotypic data. ML was involved in experiment design and manuscript revising. CC supervised the whole study and provided assistance for manuscript preparation. All authors read and approved the final manuscript.
This project was supported by the “Double first-class discipline promotion project” of South China Agricultural University (grant number 2021B10564001) and The Peanut Research Foundation (grant number 04-833-17).
The Peanut Foundation, National Peanut Board, Alabama Peanut Producers Association, the USDA-NIFA hatch fund, and the “Double first-class discipline promotion project” of South China Agricultural University funded this work. For their dedicated assistance with managing field experimental plots at the Wiregrass Research and Extension Center and the E.V. Smith Research Center, we are indebted to Sam Hilton, Brian Gamble, Larry Wells, and Jason Burkett. Additionally, we are indebted to Joseph Powell and the other members of the USDA-ARS National Peanut Research Lab at Dawson, GA, for their assistance with the research’s experimental components.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2023.1204415/full#supplementary-material
Adeyemo, A. A., Johnson, T., Acheampong, J., Oli, J., Okafor, G., Amoah, A., et al. (2005). A genome wide quantitative trait linkage analysis for serum lipids in type 2 diabetes in an African population. Atherosclerosis 181, 389–397. doi: 10.1016/j.atherosclerosis.2004.12.049
Bradbury, P. J., Zhang, Z., Kroon, D. E., Casstevens, T. M., Ramdoss, Y., Buckler, E. S. (2007). TASSEL: software for association mapping of complex traits in diverse samples. Bioinformatics 23, 2633–2635. doi: 10.1093/bioinformatics/btm308
Cairncross, S. E., Sjöström, L. B. (2004). Flavor profiles: a new approach to flavor problems. In Descriptive Sensory Analysis in Practice, M.C. Gacula (Ed.). doi: 10.1002/9780470385036.ch1b
Gordon, D., Finch, S. J. (2005). Factors affecting statistical power in the detection of genetic association. J. Clin. Invest. 115, 1408–1418. doi: 10.1172/JCI24756
Gu, X., Feng, C., Ma, L., Song, C., Wang, Y., Da, Y., et al. (2011). Genome-wide association study of body weight in chicken F2 resource population. PloS One 6, e21872. doi: 10.1371/journal.pone.0021872
Hashim, I. B., Koehler, P. E., Eitenmiller, R. R. (1993). Tocopherols in runner and virginia peanut cultivars at various maturity stages. J. Am. Oil Chem. Soc 70, 633–635. doi: 10.1007/BF02545333
He, L.-N., Liu, Y.-J., Xiao, P., Zhang, L., Guo, Y., Yang, T.-L., et al. (2008). Genomewide linkage scan for combined obesity phenotypes using principal component analysis. Ann. Hum. Genet. 72, 319–326. doi: 10.1111/j.1469-1809.2007.00423.x
Holaday, C. E., Cecil, S., Bartlett, R. P. (1964). Quality evaluation of mechanically cured peanuts. Proc. Natl. Peanut Res. Conf. 3rd 1964, 91–99.
Holberg, C. J., Halonen, M., Solomon, S., Graves, P. E., Baldini, M., Erickson, R. P., et al. (2001). Factor analysis of asthma and atopy traits shows 2 major components, one of which is linked to markers on chromosome 5q. J. Allergy Clin. Immunol. 108, 772–780. doi: 10.1067/mai.2001.119158
Holbrook, C. C., Dong, W. (2005). Development and evaluation of a mini core collection for the US peanut germplasm collection. Crop Sci. 45, 1540–1544. doi: 10.2135/cropsci2004.0368
Holland, J. B., Nyquist, W. E., Cervantes-Martínez, C. T. (2003). Estimating and interpreting heritability for plant breeding: an update. Plant Breed. Rev. 22, 9–112. doi: 10.1002/9780470650202
Ishikawa, A., Namikawa, T. (2004). Mapping major quantitative trait loci for postnatal growth in an intersubspecific backcross between C57BL/6J and Philippine wild mice by using principal component analysis. Genes Genet. Syst. 79, 27–39. doi: 10.1266/ggs.79.27
Johnsen, P. B., Civille, G. V., Vercellott, J. R., Sanders, T. H., Dus, C. A. (2004). Development of a lexicon for the description of peanut flavor. Descr. Sens. Anal. Pract., 533–542. doi: 10.1002/9780470385036.ch6f
Karamizadeh, S., Abdullah, S. M., Manaf, A. A., Zamani, M., HoOman, A. (2013). An overview of principal component analysis. J. Signal Inf. Process. 04, 173–175. doi: 10.4236/jsip.2013.43B031
Karasik, D., Cupples, L. A., Hannan, M. T., Kiel, D. P. (2004). Genome screen for a combined bone phenotype using principal component analysis: the Framingham study. Bone 34, 547–556. doi: 10.1016/j.bone.2003.11.017
Kimani, W., Zhang, L.-M., Wu, X.-Y., Hao, H.-Q., Jing, H.-C. (2020). Genome-wide association study reveals that different pathways contribute to grain quality variation in sorghum (Sorghum bicolor). BMC Genomics 21, 112. doi: 10.1186/s12864-020-6538-8
Lipka, A. E., Tian, F., Wang, Q., Peiffer, J., Li, M., Bradbury, P. J., et al. (2012). GAPIT: genome association and prediction integrated tool. Bioinformatics 28, 2397–2399. doi: 10.1093/bioinformatics/bts444
Liu, H., Zhan, J., Li, J., Lu, X., Liu, J., Wang, Y., et al. (2020). Genome-wide Association Study (GWAS) for Mesocotyl Elongation in Rice (Oryza sativa L.) under Multiple Culture Conditions. Genes 11, 49. doi: 10.3390/genes11010049
Lykomitros, D., Fogliano, V., Capuano, E. (2016). Flavor of roasted peanuts (Arachis hypogaea)-Part I: Effect of raw material and processing technology on flavor, color and fatty acid composition of peanuts. Food Res. Int. 89, 860–869. doi: 10.1016/j.foodres.2016.09.024
Meech, R., Hu, D. G., McKinnon, R. A., Mubarokah, S. N., Haines, A. Z., Nair, P. C., et al. (2019). The UDP-glycosyltransferase (UGT) superfamily: new members, new functions, and novel paradigms. Physiol. Rev. 99, 1153–1222. doi: 10.1152/physrev.00058.2017
Meilgaard, M. C., Carr, B. T., Civille, G. V. (1999). Sensory evaluation techniques. (CRC Press. Boca Taton). doi: 10.1201/9781003040729
Neta, E. R., Sanders, T., Drake, M. A. (2010). Understanding peanut flavor: a current review. Handb. Fruit Veg. Flavors, 985. doi: 10.1002/9780470622834.ch51
Oupadissakoon, C., Young, C. T. (1984). Modeling of roasted peanut flavor for some Virginia-type peanuts from amino acid and sugar contents. J. Food Sci. 49, 52–58. doi: 10.1111/j.1365-2621.1984.tb13667.x
Pandey, M. K., Upadhyaya, H. D., Rathore, A., Vadez, V., Sheshshayee, M. S., Sriswathi, M., et al. (2014). Genomewide association studies for 50 agronomic traits in peanut using the ‘reference set’ comprising 300 genotypes from 48 countries of the semi-arid tropics of the world. PloS One 9, e105228. doi: 10.1371/journal.pone.0105228
Pattee, H. E., Isleib, T. G., Giesbrecht, F. G., McFeeters, R. F. (2000). Investigations into genotypic variations of peanut carbohydrates. J. Agric. Food Chem. 48, 750–756. doi: 10.1021/jf9910739
Pattee, H. E., Young, C. T., Pearson, J. L., Singleton, J. A., Giesbrecht, F. G. (1982). Storage and moisture effects on peanut composition and roasted flavor. Peanut Sci. 9, 98–101. doi: 10.3146/i0095-3679-9-2-14
Porebski, S., Bailey, L. G., Baum, B. R. (1997). Modification of a CTAB DNA extraction protocol for plants containing high polysaccharide and polyphenol components. Plant Mol. Biol. Rep. 15, 8–15. doi: 10.1007/BF02772108
Pritchard, J. K., Stephens, M., Donnelly, P. (2000). Inference of population structure using multilocus genotype data. Genetics 155, 945–959. doi: 10.1093/genetics/155.2.945
Purcell, S., Neale, B., Todd-Brown, K., Thomas, L., Ferreira, M. A. R., Bender, D., et al. (2007). PLINK: A tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 81, 559–575. doi: 10.1086/519795
Rafalski, J. A. (2010). Association genetics in crop improvement. Curr. Opin. Plant Biol. 13, 174–180. doi: 10.1016/j.pbi.2009.12.004
Ringnér, M. (2008). What is principal component analysis? Nat. Biotechnol. 26, 303–304. doi: 10.1038/nbt0308-303
Sanders, T. H., Vercellotti, J. R., Crippen, K. L., Civille, G. V. (1989). Effect of maturity on roast color and descriptive flavor of peanuts. J. Food Sci. 54, 475–477. doi: 10.1111/j.1365-2621.1989.tb03110.x
Schirack, A. V., Drake, M., Sanders, T. H., Sandeep, K. P. (2006). Impact of microwave blanching on the flavor of roasted peanuts. J. Sens. Stud. 21, 428–440. doi: 10.1111/j.1745-459X.2006.00075.x
Thomas, M. C., Lyman, C. M., Langley, B. C., Senn, V. J. (1968). Some factors that affect quality in peanut products as determined by organoleptic evaluation. Food Technol. 22, 108–112.
Turner, S. D. (2014). qqman: an R package for visualizing GWAS results using Q-Q and manhattan plots. bioRxiv, 005165. doi: 10.1101/005165
Wang, M. L., Chen, C. Y., Davis, J., Guo, B., Stalker, H. T., Pittman, R. N. (2010). Assessment of oil content and fatty acid composition variability in different peanut subspecies and botanical varieties. Plant Genet. Resour. 8, 71–73. doi: 10.1017/S1479262109990177
Wang, J., Yan, C., Li, Y., Li, C., Zhao, X., Yuan, C., et al. (2019). GWAS discovery of candidate genes for yield-related traits in peanut and support from earlier QTL mapping studies. Genes 10, 803. doi: 10.3390/genes10100803
Yano, K., Morinaka, Y., Wang, F., Huang, P., Takehara, S., Hirai, T., et al. (2019). GWAS with principal component analysis identifies a gene comprehensively controlling rice architecture. Proc. Natl. Acad. Sci. 116, 21262–21267. doi: 10.1073/pnas.1904964116
Yu, J., Hu, F., Dossa, K., Wang, Z., Ke, T. (2017). Genome-wide analysis of UDP-glycosyltransferase super family in Brassica rapa and Brassica oleracea reveals its evolutionary history and functional characterization. BMC Genomics 18, 474. doi: 10.1186/s12864-017-3844-x
Zhang, H., Chu, Y., Dang, P., Tang, Y., Jiang, T., Clevenger, J. P., et al. (2020). Identification of QTLs for resistance to leaf spots in cultivated peanut (Arachis hypogaea L.) through GWAS analysis. Theor. Appl. Genet. 133, 2051–2061. doi: 10.1007/s00122-020-03576-2
Zhang, C., Dong, S.-S., Xu, J.-Y., He, W.-M., Yang, T.-L. (2019). PopLDdecay: a fast and effective tool for linkage disequilibrium decay analysis based on variant call format files. Bioinformatics 35, 1786–1788. doi: 10.1093/bioinformatics/bty875
Zhang, H., Li Wang, M., Dang, P., Jiang, T., Zhao, S., Lamb, M., et al. (2021). Identification of potential QTLs and genes associated with seed composition traits in peanut (Arachis hypogaea L.) using GWAS and RNA-Seq analysis. Gene 769, 145215. doi: 10.1016/j.gene.2020.145215
Zhang, Y. W., Tamba, C. L., Wen, Y. J., Li, P., Ren, W. L., Ni, Y. L., et al. (2020). mrMLM v4. 0.2: an R platform for multi-locus genome-wide association studies. Genom. proteom bioinf. 18 (4), 481–487. doi: 10.1016/j.gpb.2020.06.006
Zhang, H., Wang, M. L., Schaefer, R., Dang, P., Jiang, T., Chen, C. (2019). GWAS and coexpression network reveal ionomic variation in cultivated peanut. J. Agric. Food Chem. 67, 12026–12036. doi: 10.1021/acs.jafc.9b04939
Zhang, X., Zhang, J., He, X., Wang, Y., Ma, X., Yin, D. (2017). Genome-wide association study of major agronomic traits related to domestication in peanut. Front. Plant Sci. 8. doi: 10.3389/fpls.2017.01611
Zhang, J., Zhao, J., Xu, Y., Liang, J., Chang, P., Yan, F., et al. (2015). Genome-wide association mapping for tomato volatiles positively contributing to tomato flavor. Front. Plant Sci. 6, 1042. doi: 10.3389/fpls.2015.01042
Zhou, T., Liu, S., Geng, X., Jin, Y., Jiang, C., Bao, L., et al. (2017). GWAS analysis of QTL for enteric septicemia of catfish and their involved genes suggest evolutionary conservation of a molecular mechanism of disease resistance. Mol. Genet. Genomics 292, 231–242. doi: 10.1007/s00438-016-1269-x
Keywords: flavor, PCA, GWAS, peanuts, QTL
Citation: Zhang H, Dean L, Wang ML, Dang P, Lamb M and Chen C (2023) GWAS with principal component analysis identify QTLs associated with main peanut flavor-related traits. Front. Plant Sci. 14:1204415. doi: 10.3389/fpls.2023.1204415
Received: 12 April 2023; Accepted: 24 August 2023;
Published: 15 September 2023.
Edited by:
Gregory Thyssen, Agricultural Research Service (USDA), United StatesReviewed by:
Chengsong Zhu, University of Texas Southwestern Medical Center, United StatesCopyright © 2023 Zhang, Dean, Wang, Dang, Lamb and Chen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hui Zhang, aHVpemhhbmdAc2NhdS5lZHUuY24=; Charles Chen, Y3ljMDAwMkBhdWJ1cm4uZWR1
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.