 Lorenzo Valleggi
Lorenzo Valleggi Giuseppe Carella
Giuseppe Carella Rita Perria
Rita Perria Laura Mugnai
Laura Mugnai Federico Mattia Stefanini
Federico Mattia Stefanini
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Plant Sci., 20 July 2023
Sec. Sustainable and Intelligent Phytoprotection
Volume 14 - 2023 | https://doi.org/10.3389/fpls.2023.1117498
Plant pathogens pose a persistent threat to grape production, causing significant economic losses if disease management strategies are not carefully planned and implemented. Simulation models are one approach to address this challenge because they provide short-term and field-scale disease prediction by incorporating the biological mechanisms of the disease process and the different phenological stages of the vines. In this study, we developed a Bayesian model to predict the probability of Plasmopara viticola infection in grapevines, considering various disease management approaches. To aid decision-making, we introduced a multi-attribute utility function that incorporated a sustainability index for each strategy. The data used in this study were derived from trials conducted during the production years 2018-2020, involving the application of five disease management strategies: conventional Integrated Pest Management (IPM), conventional organic, IPM with substantial fungicide reduction combined with host-defense inducing biostimulants, organic management with biostimulants, and the use of biostimulants only. Two scenarios were considered, one with medium pathogen pressure (Average) and another with high pathogen pressure (Severe). The results indicated that when sustainability indexes were not considered, the conventional IPM strategy provided the most effective disease management in the Average scenario. However, when sustainability indexes were included, the utility values of conventional strategies approached those of reduced fungicide strategies due to their lower environmental impact. In the Severe scenario, the application of biostimulants alone emerged as the most effective strategy. These results suggest that in situations of high disease pressure, the use of conventional strategies effectively combats the disease but at the expense of a greater environmental impact. In contrast to mechanistic-deterministic approaches recently published in the literature, the proposed Bayesian model takes into account the main sources of heterogeneity through the two group-level effects, providing accurate predictions, although precise estimates of random effects may require larger samples than usual. Moreover, the proposed Bayesian model assists the agronomist in selecting the most effective crop protection strategy while accounting for induced environmental side effects through customizable utility functions.
Plasmopara viticola is a heterothallic oomycete that is the causal agent of downy mildew (DM), one of the most severe diseases of grapevines in many viticultural areas of the world (Wong et al., 2001). Its life cycle starts in autumn when oospores enter their overwintering stage in infected leaves on the ground. At the beginning of spring, zoospores, released by macrosporangia produced by oospore germination, are distributed by rain and wind on new leaves, shoots and later, clusters of the vine. New zoospores are produced by asexual reproduction, and this occurs throughout the growing season infecting new tissues, often leading to heavy economic losses (Gessler et al., 2011). To prevent DM infections, fungicide applications are usually required, many applications of fungicides are usually necessary to prevent DM infections, but some of those applied in agriculture can have a significant impact on the environment (Shunthirasingham et al., 2010) and human health (Kab et al., 2017). There is a heavy impact of fungicide strategies also in organic viticulture (ORG), where mainly copper-based products are applied (Dagostin et al., 2011), as copper can accumulate in the soil and damage the microflora and microfauna (Cavani et al., 2016). That is why, based on Regulation (EU) 2018/1981 of 13 December 2018, the use of copper is strictly limited. The EU is making many efforts to reduce the impact of fungicides on the environment. One of the strategies proposed in the literature enhances the resilience capacity of the grapevine to reduce the use of fungicides with a potential environmental impact.
Perria et al. (2022) promoted the use of “GreenGrapes” strategies, including integration or substitution of products based on plant, seaweed or yeast extracts that guarantee greater environmental sustainability in viticulture, with a good or acceptable protection level compared to conventional pesticides, both in ORG and IPM management. The latter context sees the integration of defense induction activity alongside the more frequently used direct antifungal activity, and the application of an efficient Vite.net system (a Decision Support System [DSS] developed by Horta s.r.l., providing daily information updates to aid careful scheduling of antifungal treatments). This system predicts the probability of infection events, leading to optimal scheduling of the strategies, enabling a move toward more environmental sustainability in viticulture.
Many simulation models to provide short-term and field-scale DM predictions have been developed in recent years, one of the most recent ones being proposed by Bove et al. (2020a). These authors developed the model considering all of the biological mechanisms of the disease process and the different phenological stages of the vines. They simulated the infection that occurred on healthy foliage, which generated a sporulation site producing the secondary infections. Also, the infection on clusters is simulated as a rate, the function of a specific transmission coefficient. This model reproduces the disease kinetic (number of diseased sites) based on tuning parameters, but as the authors declare, many simplifications were made, especially on cluster infections, due to the lack of information in the literature and the inherent complexity. Also, they considered a steady-state system, where plant structure and microclimatic conditions were stable. Brischetto et al. (2021) extended this simulation model using findings from previous studies [(Caffi et al., 2016), (Magarey et al., 2005), (Bove et al., 2020b), (Lalancette, 1988)] to develop a proper DSS, so that scouting of the vineyard and monitoring the environmental conditions could give information about the expected sporangia development, sporangia availability, and the relative severity of lesions, and thus determine secondary infection cycles. Other authors (Chen et al., 2020) compared statistical models and machine learning algorithms to predict infection by DM in terms of incidence and severity, using field scouting and climate variables as inputs. The results were used by the authors to evaluate the potential reduction in the number of fungicide applications.
In this work, we present a novel approach to address the challenge of predicting Plasmopara viticola incidence under different agronomic treatment strategies using Bayesian models and utility functions. This research aims to bridge a significant gap in the current literature, because the use of Bayesian models and utility functions is still not widespread in the agronomic field, especially in Plasmopara viticola studies. Our proposal assimilates expert knowledge at three levels: the first deals with the structure of the statistical model, and the second with the elicitation of prior distributions for model parameters. In the third level, the development of utility functions makes it possible to consider the preferences and priorities of decision-makers in a quantitative way, while evaluating treatment strategies. This novel aspect of our research empowers stakeholders to make more informed decisions about strategies by incorporating their subjective preferences, treatment efficiency and environmental implications at the same time.
All the details about the original experiment, such as vine age, vine spacing, pruning and training system, and also on products used, spraying schedule and dates, spraying equipment and volume per ha are reported in the paper by Perria et al. (2022), which aimed to evaluate five disease management strategies. These were: Integrated Pest Management (IPM) (“Strategy 1”), the IPM management modified by a reduction in fungicides and use of plant defense supporting biostimulants (IPM-GG) (“Strategy 2”), organic management (ORG) (“Strategy 3”), organic management with reduced copper application, and plant defense supporting biostimulants (ORG-GG) (“Strategy 4”) and only biostimulants application (“Strategy 5”). Strategy 5 was considered in this analysis as the experimental control because it did not include fungicides. These crop protection strategies were applied over three years from 2018 to 2020, in a cultivar Sangiovese vineyard located in the Chianti Classico wine district (Perria et al., 2022). The trial was applied to an area of 50,000 m2 which was divided into 5 blocks each 10,000 m2. These blocks were environmentally and pedologically homogeneous. For each strategy, four sub-plots with the size of eight vines were randomly selected at the beginning of the experiment, for a survey of disease symptoms on leaf and bunch.
The survey was conducted in each sub-plot, where 100 leaves and 100 bunches (if sufficient numbers were present) were sampled at different dates to measure the disease incidence and severity (EPPO guidelines). The survey was conducted from May to the end of July each year, but the analysis carried out in the present study considered only disease parameters obtained at the last time point in each year at the phenological phase BBCH 85-89.
A Bernoulli random variable describes the presence, , or absence, , of disease, i.e. if the observational unit is infected under strategy at the end of year , thus . Following Gelman and Hill notation (2007, chap. 14), a logistic regression model has been defined as:
where betas are (fixed) effects due to the strategy applied and their initial distribution is defined by marginally independent uniform distributions (see Gelman et al., 2006); the notation refers to an element in the vector of betas whose index depends on statistical unit i; the random fluctuation due to year t is described by ; alphas are normal and marginally independent in the initial distribution with , which is (half of) a Student-t distribution defined on positive reals, with 3 degree of freedom, location 0 and scale 2.5; gammas are random variables describing year-specific fluctuations of strategies around the average represented by betas (Gelman and Hill, 2007), and the initial distribution is defined by marginally independent components . The prior distributions for the standard deviation and its hyperparameters were weakly informative, so that data dominate on expert prior belief in the posterior distribution.
The above model features were discussed with the experts and it was recognized how the disease may start with different pressures every year due to the dependence on environmental conditions. Furthermore, leaves also change every year, thus important features of the statistical unit, the plant, represent a source of variability in the response to be taken into account. Similarly, each strategy may have slightly different effects across years, as described by the considered parameters gammas. The baseline (model intercept) is , i.e. Strategy 5 in the original study, whose components are only plant-defense-supporting biostimulants. The outputs of the model are the Odds ratios (ORs), which are the result of exponentiating the parameters in a logistic regression model. The latter represents the log odds of an event occurring (in this case, the disease event) compared to the probability of the event not occurring in a specific category (e.g., Strategies). ORs are actually the probability of an event occurring between two different categories (Strategy 1 vs Strategy 2). If the value is greater than 1, it means that the probability of the event is higher in the category at the numerator of the ratio, while if the value is less than 1, it indicates that the probability of the event is higher in the category at the denominator of the ratio.
The final distribution (also called a-posteriori distribution) of model parameters after learning from field data has been approximated by Markov Chain Monte Carlo simulation (Van de Schoot et al., 2021), see results. Four strategies (Strategies 1-4) were compared to the reference strategy (Strategy 5) and expected values and credible intervals of these effects were calculated. Nevertheless, side effects specific to each strategy may reduce/increase the appeal of strategies, for example, because of the magnitude of secondary effects induced in the soil. For this reason, a utility function has been defined in order to support the choice of strategy in future fieldwork.
A utility function was defined to find the optimal phytosanitary strategy for crop protection in a hypothetical next year by joint evaluation of the probability of infection for one leaf and the sustainability of the selected strategy. A number of attributes were selected to describe the future consequences of a selected strategy and the uncertainty on the value taken by the attributes in the following year was described by predictive and prior-predictive distributions. The Simple Multi-Attribute Rating Technique (SMART) (Edwards, 1977) is the multi-attribute framework adopted here to define a utility function that compares alternative crop protection strategies by rating attributes on a natural scale. The value of each sub-utility function dealing with attribute under crop protection strategy k was multiplied by weight wj, where weights are subject to . The importance of an attribute is reflected in a high value of its weight wj. The utility value of the crop protection strategy k is calculated by a linear additive model of all sub-utility functions and normalized to range from 0 to 1:
where 0 is the worst and 1 is the best value of .
The first attribute () is the probability of infection of one leaf in the next year. Subsequent attributes () describe the sustainability in terms of environmental impact and toxicological effects, in particular they are:
● ɑ2: the Human Tox score that defines the impact of toxic substances on human health;
● ɑ3: the Treatment Frequency Index, determined by the absolute frequency of fungicide applications;
● ɑ4: the Carbon Footprint, based on the amount of greenhouse gases produced;
● ɑ5: the Carbon sequestration index, which is the amount of carbon seized by plant tissues;
● ɑ6: the Ecological Footprint, which quantifies the biologically productive land and aquatic surface needed to provide resources and absorb emissions for the production of a certain good or service;
● ɑ7: the Eco Tox Score, to evaluate the eco-toxicological risk on the health of the aquatic and terrestrial ecosystems, due to synthetic chemicals used in the field;
● ɑ8: the Water Footprint, which is based on the water consumption of the production process;
Details on the above attributes are contained in Perria et al. (2022).
The sample space of each environmental index (listed above) was divided into four classes from 0 to 3, where the best class is labeled as 0 and the worst as 3. The sub-utility function u1 depends on , which is the probability of infection for one leaf next year under strategy k
as described by the Bayesian predictive distribution conditioned to observed data. The sub-utility function u1 has been elicited as a negative exponential function:
where is a positive tuning parameter chosen by the expert. The value of modifies the rate at which the utility decreases with increasing probability of infection (); if it implies a faster decrease while if it implies a slower decrease in utility value. More conservative experts tend to set values greater than 1 to prioritize strategies with high protection. In this case, we set =0.4, which was deemed a suitable value for this analysis. A threshold of 0.1 was established such that when the percentage of infected leaves exceeds 10% (based on a sample of 100 leaves), the utility of the attribute representing the probability of infection is set to zero. This threshold was determined based on input from our expertise, who believed that strategies under consideration would not enable recovery of the vineyard if the infected leaf percentage exceeded this threshold. This threshold is subjective and can be adjusted by agronomists depending on the disease’s potential for spread and on personal evaluation of risk. In order to achieve this threshold, indicating function was defined (), which becomes zero when the probability of infection exceeds the threshold, and otherwise becomes 1. The elicitation of additional sub-utility functions was not performed in the same manner as the primary utility function, as a simple rescaling of their values to a range from 0 to 1 was judged flexible enough by the expert:
where is the maximum and the minimum for attribute on the original scale.
The weights were defined as follows: and for each attribute after the first.
In order to rank the five considered strategies in terms of utility, expected values were calculated for each strategy given the collected data , and the best strategy in a given scenario was found as the value k determining the expected utility maximum:
where the expectation of is calculated with respect to the distribution of the attributes describing the consequences of the adopted strategy in the future:
where is the elicited prior-predictive distribution of the future score for attribute j under strategy k: these are members of the Multinomial-Dirichlet family of distributions with parameter vector (see below); is the predictive distribution for the future probability of infection of one leaf under strategy k given the experimental data. Equivalently, equation (2) may be expanded as follows:
thus is the strategy that the decision-maker (in this case the agronomist) should apply in the following year of grapevine production Smith, 2010).
Markov Chain Monte Carlo simulation was performed using rstan and brms packages (Bürkner, 2017b; Carpenter et al., 2017) in order to fit a Bayesian Linear Mixed Model (GLMM) using a No-U-Turn sampler, which is an adaptive version of Hamiltonian Monte Carlo sampling (HMC) (Bürkner, 2017a). The predictive probability of infection for each year and strategy was estimated using kernel density curves, which were used to perform a predictive check. The graphs depict the comparison between the predicted probability of infection by the model and the observed average. This comparison is performed to assess the compatibility of the predicted mean of the new observations with the observed one, and to examine the distribution of the new observations. The highest density interval (HDI) was also computed, which indicates the range of values that are most plausible for a given parameter based on the posterior distribution. In this case, the HDI represents the range with 80% of the posterior density. Model quality and fit were evaluated using trace plots, which were among the output diagnostic tools used. Continuous residuals were obtained by calculating residuals using the DHARMa R package which uses the inverse of the cumulative distribution function of the standard normal to evaluate the residuals in the generalized mixed linear model (Gelman et al., 1995; Dunn and Smyth, 1996). Traceplot is a graphical diagnostic tool applied to each parameter of the posterior sample generated in Bayesian statistical analysis, and is commonly used to check the validity and reliability of the posterior estimates generated by the MCMC algorithm. The main use of traceplot is to assess the convergence and mixing properties of the MCMC algorithm. If the MCMC algorithm has converged, the traceplot should show a stable pattern over time, with little variability in the posterior samples. Additionally, traceplot can also help to identify any potential issues with the MCMC 8 algorithm, such as poor mixing, which can affect the accuracy of the posterior estimates (Van de Schoot et al., 2021). A complete list of all packages used in this work is available in the Supplementary Material.
The proposed Bayesian model can be exploited to predict the probability of infection at the end of the season each year for one randomly sampled leaf, given a selected strategy among those investigated. As a relevant amount of variability depends on features specific to each year, several scenarios may be defined. In particular, two main scenarios were selected: in the first one, average environmental fluctuations to represent an average disease pressure for DM development were considered, while in the second scenario, the best environmental fluctuations for DM development to represent a high pressure were selected, which corresponds to the worst situation for the farmer. Through the estimation of the group-level parameters, it was possible to predict infection probability under each strategy. Each scenario refers to a value of parameter , where for average pressure, and in particular for high disease pressure. The average pressure scenario could have been associated to but, given the limited number of considered years, we preferred to set to the value estimated in the year 2020, which is the closest value to zero among the three available years.
Descriptive statistics were calculated to summarize the distributions of DM over the years of observation. In Figure 1, a bar plot of counts of infected and non-infected leaves by strategy is shown, from 2018 to 2020.
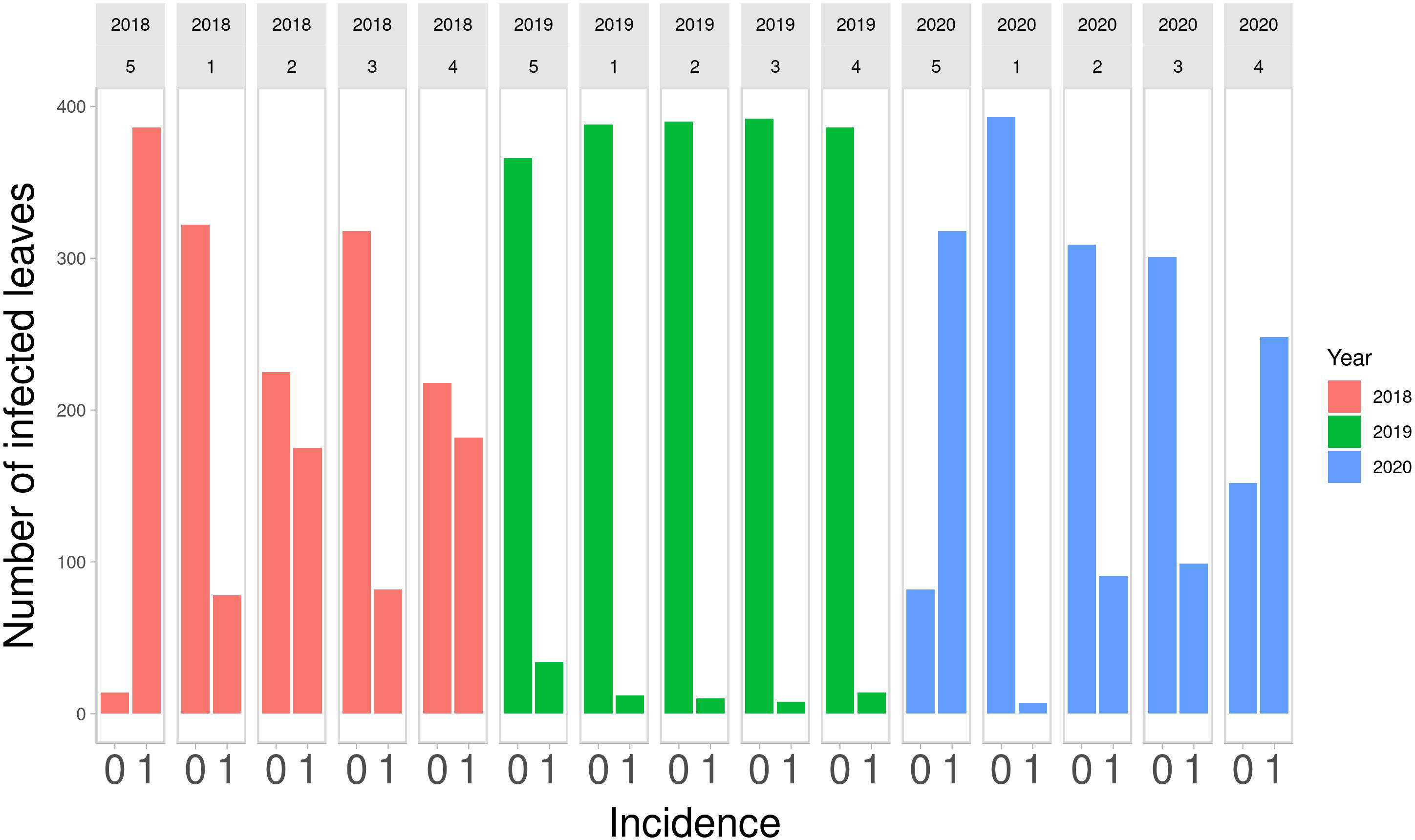
Figure 1 Number of infected leaves out of 400 monitored in the final field survey on Strategy 5 (control), and on other 4 strategies in the 3 years of study. 0, symptom absent; 1, symptom present.
The number of infected leaves varies across years. 2018 Strategy 4 and Strategy 2 had a similar number of infected and non-infected leaves, as was the case for Strategy 1 and Strategy 3. Strategy 5 had the highest number of infected leaves. In 2019, there were few infected leaves for all the strategies. Strategy 5 had the highest number of infected leaves. In 2020, Strategy 1 had the lowest number of infected leaves, Strategy 2 and Strategy 3 had a similar number of infected leaves and Strategy 4 had more infected leaves than non-infected leaves. Strategy 5, as expected, had the highest number of infected leaves. The numbers of infected and non-infected leaves are reported quantitatively in Table 1. These numbers highlight that Strategy 1 showed the lowest number of infected leaves.
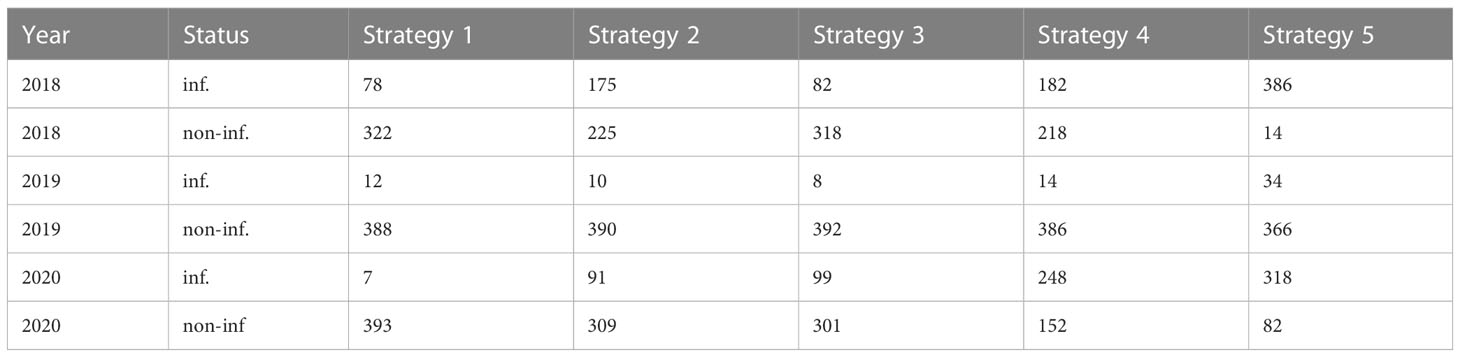
Table 1 Absolute frequency of infected (inf) and non-infected (non-inf) leaves observed in each year and strategy.
The a-posteriori parameter values are reported in Table 2, where betas with indexes from 1 to 4 are reported as odds ratios (OR) and the baseline was Strategy 5, while represents the odds between the probability of being infected or not for Strategy 5.
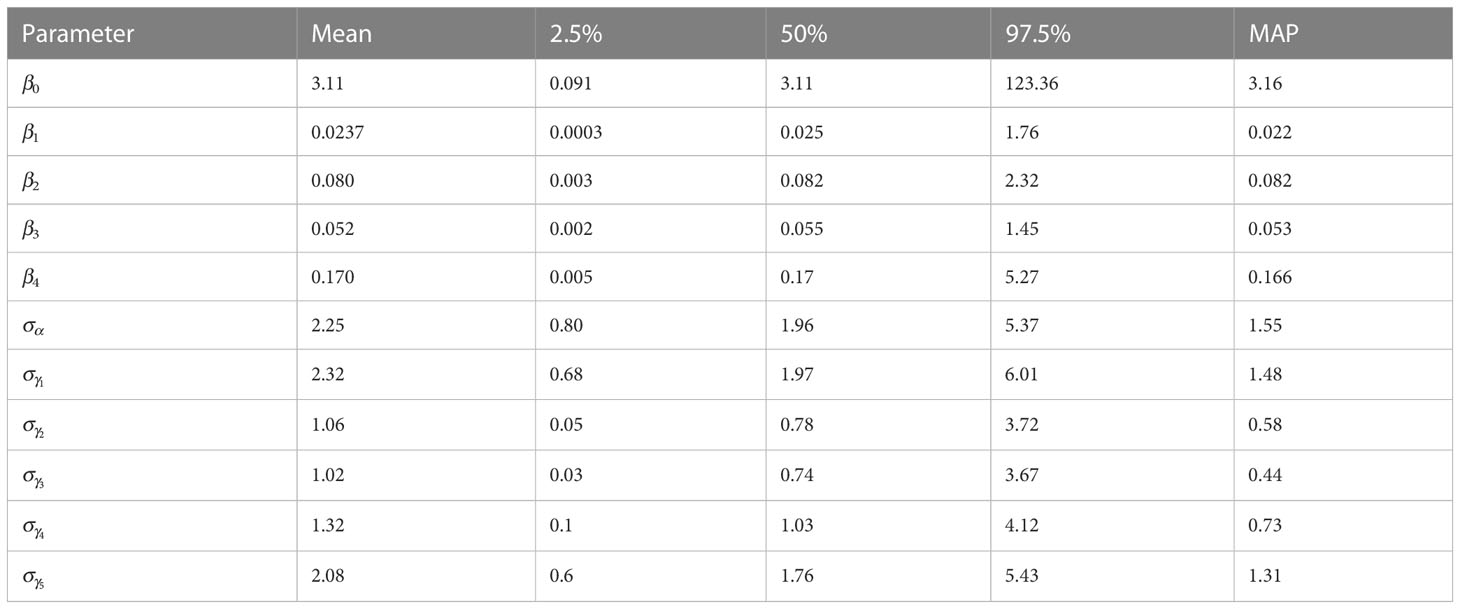
Table 2 Summary of marginal a-posteriori distributions for each model parameter are shown: mean, quantile 0.025, quantile 0.975, median and highest Maximum A Posteriori (MAP) density estimate.
The parameter is the standard deviation of the random parameter that describes a group effect that evaluates how the strategy effect changes every year, while the parameter is the standard deviation of the random parameter that describes a group effect that evaluates the year effect changes in the study. For each parameter the mean, quantile at , quantile at , the median and the highest Maximum A Posteriori (MAP) probability estimate are reported.
The comparison between the OR of , which represents Strategy 1, against the OR of , which represents Strategy 2, gives 0.30, indicating the decreased occurrence of disease presence using Strategy 1. The comparison between the OR of , which represents Strategy 3, against the OR of , which represents Strategy 4, gives 0.31, indicating the decreased occurrence of disease presence using Strategy 3. The comparison between the OR of against the OR of , gives 0.46, indicating the decreased occurrence of disease presence using Strategy 1. The comparison between the OR of against the OR of , gives 0.14, indicating the decreased occurrence of disease presence using Strategy 1. The comparison between the OR of against the OR of , gives 1.54, indicating the increased occurrence of disease presence using Strategy 2. The comparison between the OR of against the OR of , gives 0.47, indicating the decreased occurrence of disease presence using Strategy 2. The 95% intervals range from 0.0003 to 1.76 for , from 0.003 to 2.32 for , from 0.002 to 1.45 for and from 0.005 to 5.27 for . In Figure 2 the boxplot of the a-posteriori distributions of logodds of each parameter are reported. The density distributions were symmetric—indeed, the median and mean had similar values. The standard deviation of , reported as , had an expected value of 2.25 and its interval ranges from 0.80 to 5.37 and represents the heterogeneity of the year effect. The heterogeneity of each strategy effect is expressed through the parameters , which are reported in Table 2. Strategy 1 had the highest heterogeneity—the expected value of its standard deviation was 2.32, followed by Strategy 5 with an the expected value of 2.08, Strategy 4 with an expected value of 1.32, Strategy 2 with an expected value of 1.06 and then Strategy 3 with an expected value of 1.02. The density distributions of standard deviations are reported in Figure 2, where it is possible to see that the values are positively skewed. MAP for strategy effect was similar to their expected values, while the MAP of group effect variances was smaller than their expected values, except for the group effect variance of Strategy 5 (control). Summary statistics about group effects and their density distributions are reported as Supplementary Material.
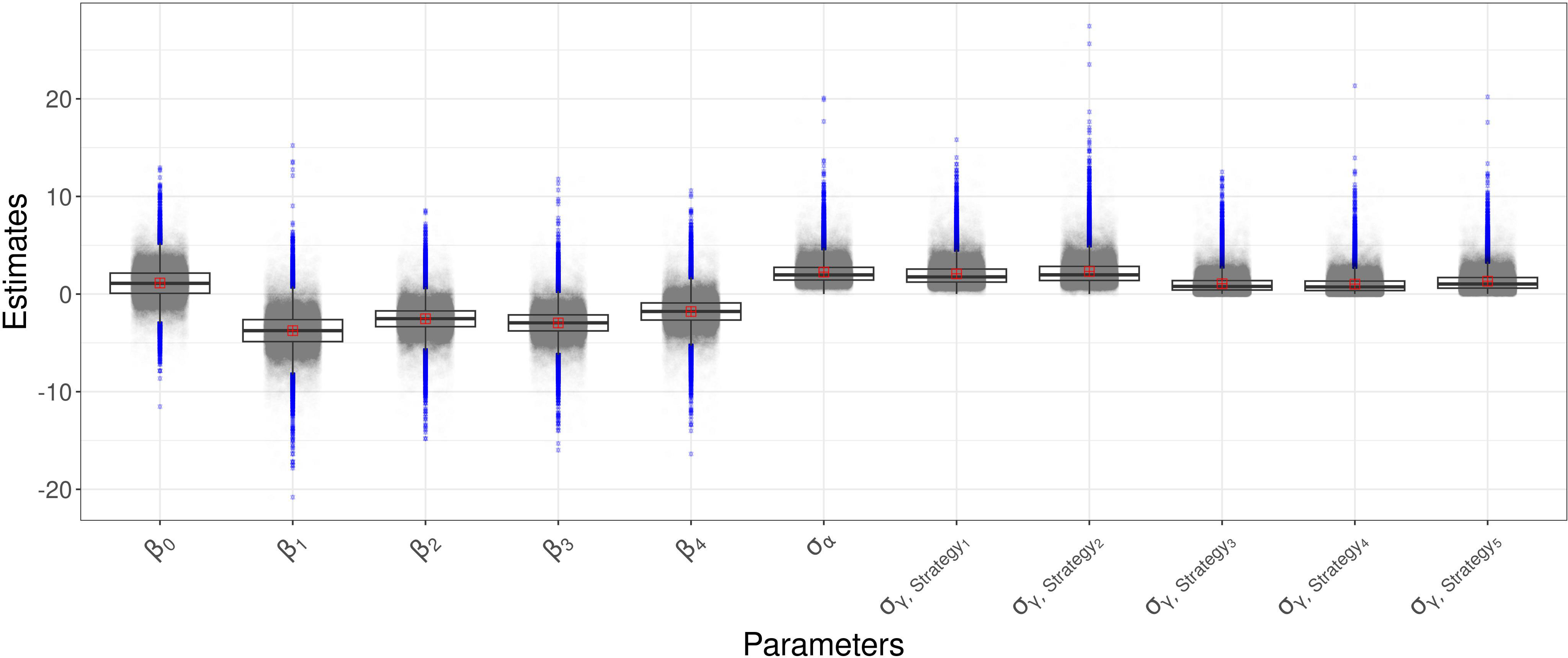
Figure 2 Boxplot of the a-posteriori marginal distributions of model parameters.
to represent the fixed effects of the disease management strategies (the Strategy 1-4), is the baseline and corresponds to the Strategy5, is the standard deviation of random effect describing the random fluctuation due to year, and is the standard deviation of random effect describing year-specific fluctuations of strategies around the average.
The predictions were obtained for each considered strategy. Below, figures of the estimated predicted probability density functions are shown together with the Highest posterior Density Interval (HDI) at 80%. In Figure 3, the median and the HDI of the predictions for all strategies, and infection probabilities for the Average scenario (green line) and the Severe scenario (red line), are reported. Under the conditions of Strategy 1, infection probability for the Average scenario (green line) ranges from about 0 to about 0.24 (HDI at 80%) with a mean of 0.15. The Severe scenario (red line) infection probability ranges from about 0.35 to about 1 (HDI at 80%) with a mean of 0.68. With Strategy 2, in the Average scenario (green line), infection probability ranges from about 0.002 to about 0.41 (HDI at 80%) with a mean of 0.26. Infection probability for the Severe scenario (red line) ranges from about 0.72 to about 1 (HDI at 80%) with a mean of 0.84. With Strategy 3, in the Average scenario (green line) infection probability ranges from about 0.003 to about 0.3 (HDI at 80%) with a mean of 0.20. The Severe scenario (red line) infection probability ranges from about 0.6 to about 1 (HDI at 80%) with a mean of 0.8. With Strategy 4, in the Average scenario (green line) infection probability ranges from about 0.0007 to about 0.63 (HDI at 80%) with a mean of 0.40. The Severe scenario (red line) infection probability ranges from about 0.82 to about 1 (HDI at 80%) with a mean of 0.90.
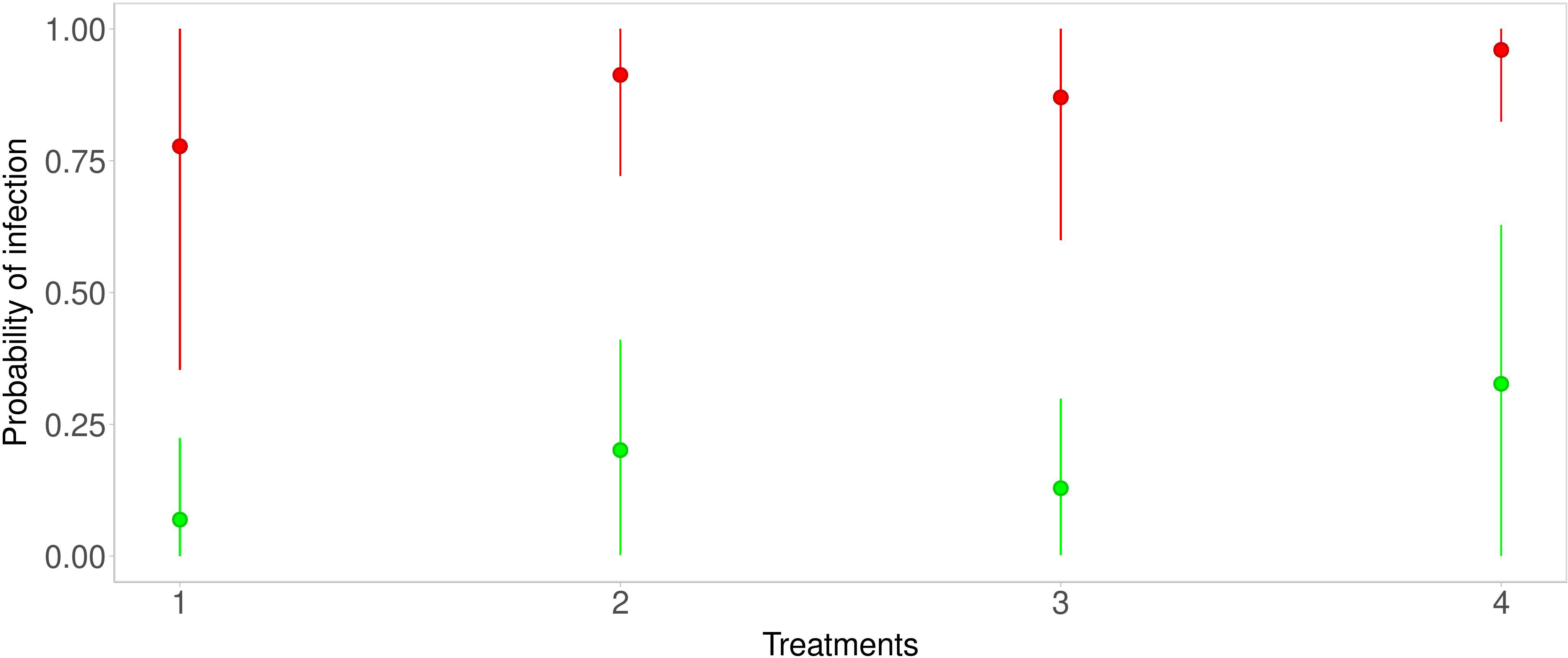
Figure 3 Predictive distributions for each strategy—green points and lines are related to the Average scenario, while red points and lines are related to the Severe scenario.
The goal of the utility function U(k) was to identify the crop protection strategy k* against DM infection that achieved the maximum of the expected value with respect to a multi-attribute description of consequences due to the strategy. In Tables 3 and 4 the expected values of U(k) for each considered strategy k and scenario are reported.

Table 3 Utility of the crop protection strategies.

Table 4 Utility of the crop protection strategies after considering the environmental indexes.
Results suggest that Strategy 1 was the most effective against DM infection for both scenarios. In the Average scenario, Strategy 3 was more effective than Strategy 2, and the least effective strategy against DM infection was Strategy 4. In the Severe scenario, Strategy 2 was more effective than Strategy 3, and the least effective strategy against DM infection was Strategy 4.
Strategy 1 was still the most effective in the Average scenario, followed by Strategy 3. In the Severe scenario, among those considered here, the biostimulants strategy was the most effective in terms of expected utility. It is important to emphasize that the optimal decision depends heavily on the expert-specific definition of the utility function. Indeed, by changing its parameters different results can be achieved. In this case it seems that after reaching a specified threshold, the best decision to take is simply to support plant vigor.
But the results change fully after the introduction of the environmental component utility values, which showed that the strategies were closer to each other. Indeed, utilities of Strategy 1 and Strategy 3 were 0.461 vs 0.455 instead of 0.576 vs 0.380 and utilities of Strategy 2 and Strategy 4 were 0.311 vs 0.281 instead of 0.380 vs 0.138. It would seem that the environmental components gave a boost in terms of utility to strategies that had a lower environmental impact. Indeed Strategy 1 utility decreased (0.576 to 0.461) and Strategy 3 utility increased (0.380 to 0.455).
Graphical diagnostics were calculated in order to assess model performances—posterior predictive probability and their HDI are shown in Figure 4. The curves represent the probability of infection drawn from the model; the red line in each panel represents the observed mean of infection; while blue lines and blue areas represent the HDI.
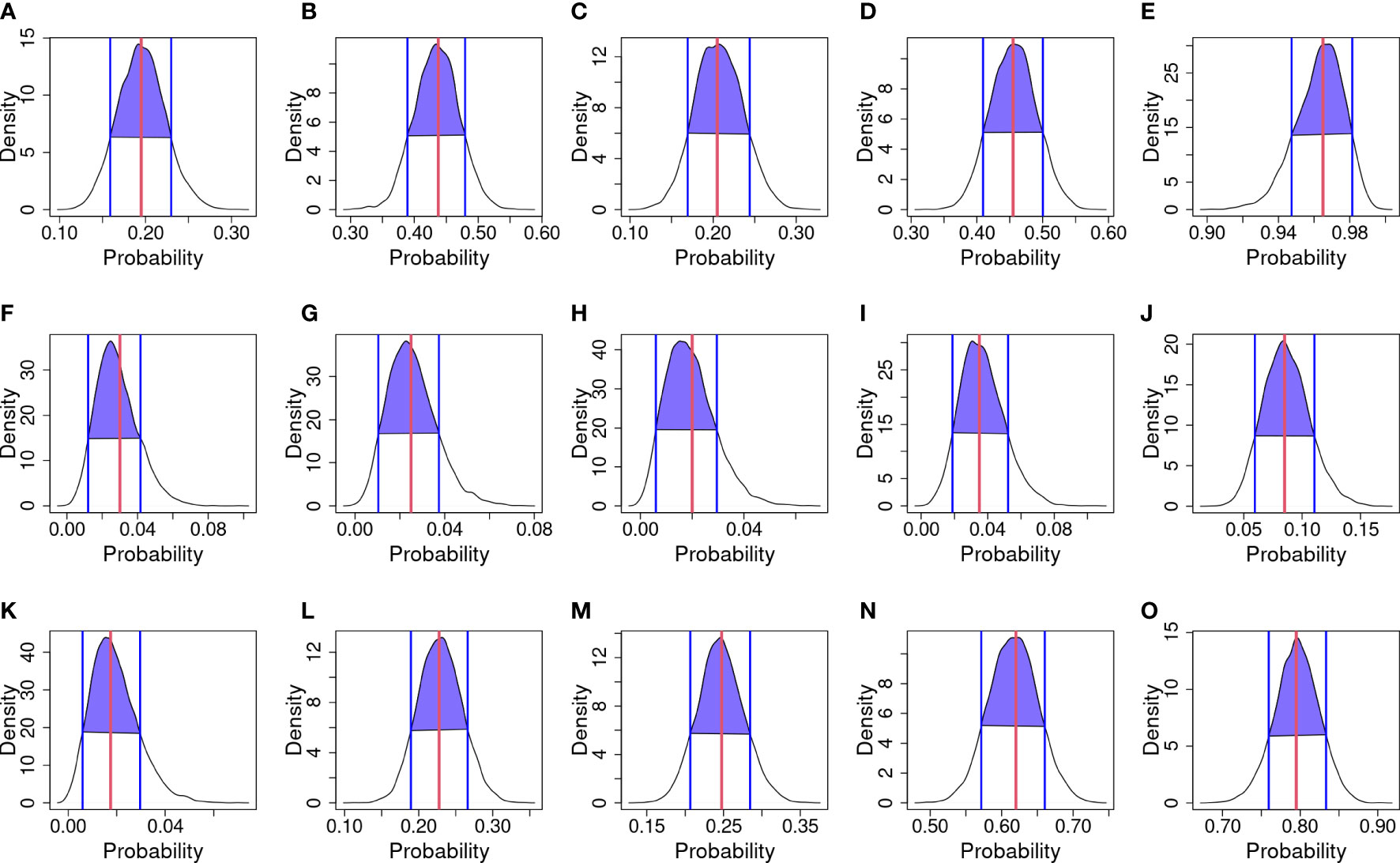
Figure 4 Posterior predictive checks. The black curve line represents the kernel density of predicted probabilities of infection for each year and strategy; blue vertical lines and purple area are the Highest density interval (HDI) at 80%; and the red vertical line is the infection probability observed. (A) 2018 & Strategy 1. (B) 2018 & Strategy 2. (C) 2018 & Strategy 3. (D) 2018 & Strategy 4. (E) 2018 & Strategy 5. (F) 2019 & Strategy 1. (G) 2019 & Strategy 2. (H) 2019 & Strategy 3. (I) 2019 & Strategy 4. (J) 2019 & Strategy 5. (K) 2020 & Strategy 1. (L) 2020 & Strategy 2. (M) 2020 & Strategy 3. (N) 2020 & Strategy 4. (O) 2020 & Strategy 5.
Considering 2018 (Figures 4A–E) observed mean matches the mean of draws, except for Strategy 3 where a bimodal trend in kernel density is observed. In 2019 (Figures 4F–J), kernel densities are shifted to the left to respect the observed mean. In 2020 (Figures 4K–O), the observed mean matches the mean of draws. Considering the HDI for Strategy 1, in 2018 (Figure 4A) the interval ranges from about 0.16 to 0.24; in 2019 (Figure 4F) the interval ranges from about 0.015 to 0.04; and in 2020 (Figure 4K) the interval ranges from about 0.01 to 0.025. Considering the HDI for Strategy 2, in 2018 (Figure 4B) the interval ranges from about 0.38 to 0.48; in 2019 (Figure 4G) the interval ranges from about 0.015 to 0.04; and in 2020 (Figure 4L) the interval ranges from about 0.18 to 0.26. Considering the HDI for Strategy 3, in 2018 (Figure 4C) the interval ranges from about 0.16 to 0.24; in 2019 (Figure 4H) the interval ranges from about 0.01 to 0.03; and in 2020 (Figure 4M) the interval ranges from about 0.20 to 0.28. Considering the HDI for Strategy 4, in 2018 (Figure 4D) the interval ranges from about 0.41 to 0.50; in 2019 (Figure 4I) the interval ranges from about 0.02 to 0.05; and in 2020 (Figure 4N) the interval ranges from about 0.57 to 0.60. Considering the HDI for Strategy 5 in 2018 (Figure 4E), the interval ranges from about 0.95 to 0.98; in 2019 (Figure 4J) the interval ranges from about 0.06 to 0.11; and in 2020 (Figure 4O) the interval ranges from about 0.75 to 0.84.
The residuals are reported in Figure 5. In the left panel, the QQ plot of the residual was reported, and no problems were highlighted since residuals follow the red line, meaning that there was no relevant difference between observed and expected values. In the right panel, standardized residuals were plotted vs model predictions, but no trend was observed since regression lines (black line) were almost parallel. Traceplots of the HMC sampler are reported in Figure 6. All traceplots showed the same behavior, so there is little reason to call into question the performance of the algorithm. Therefore only two traceplots are reported here.
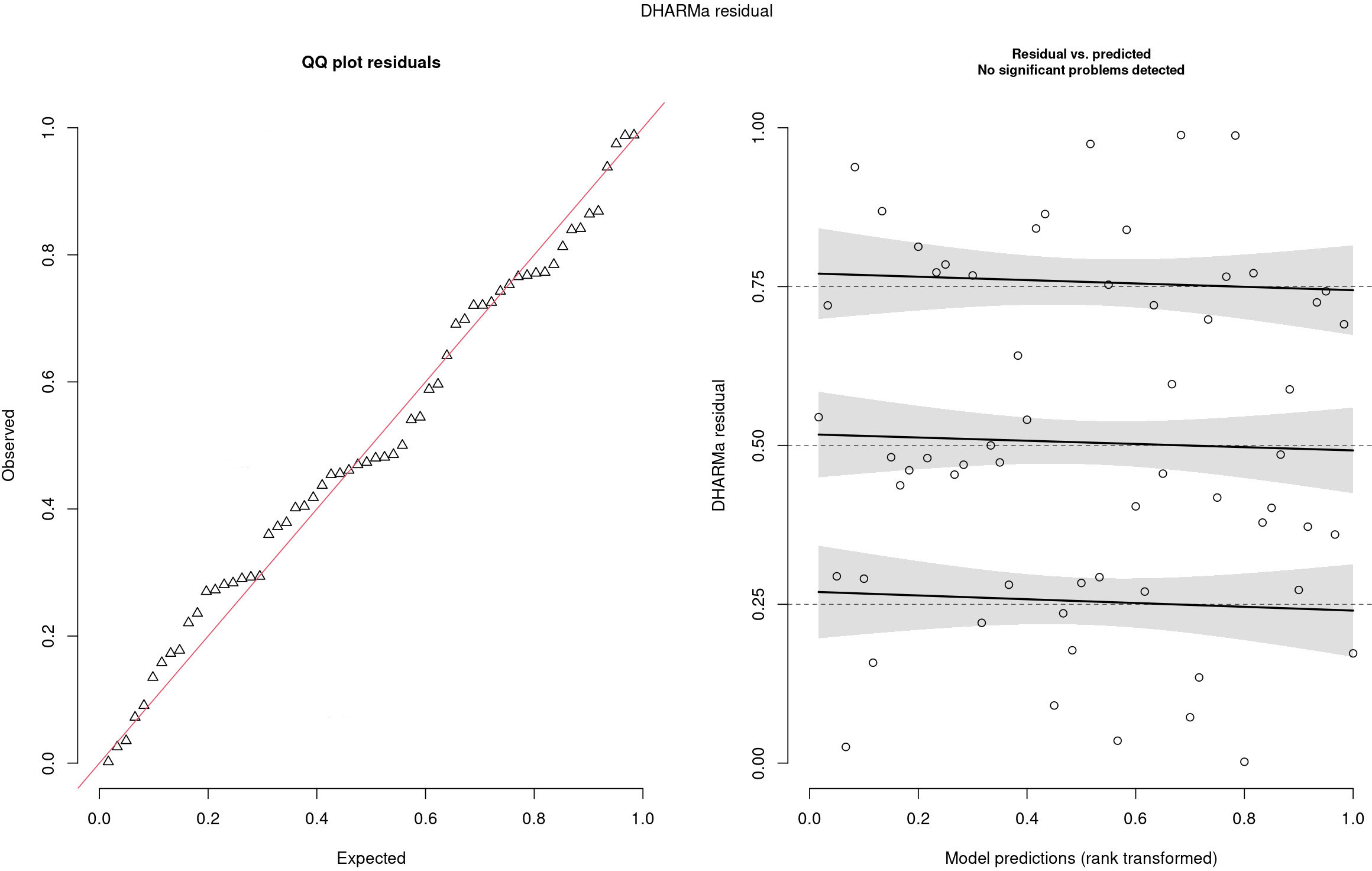
Figure 5 Analysis of DHARMa residuals.
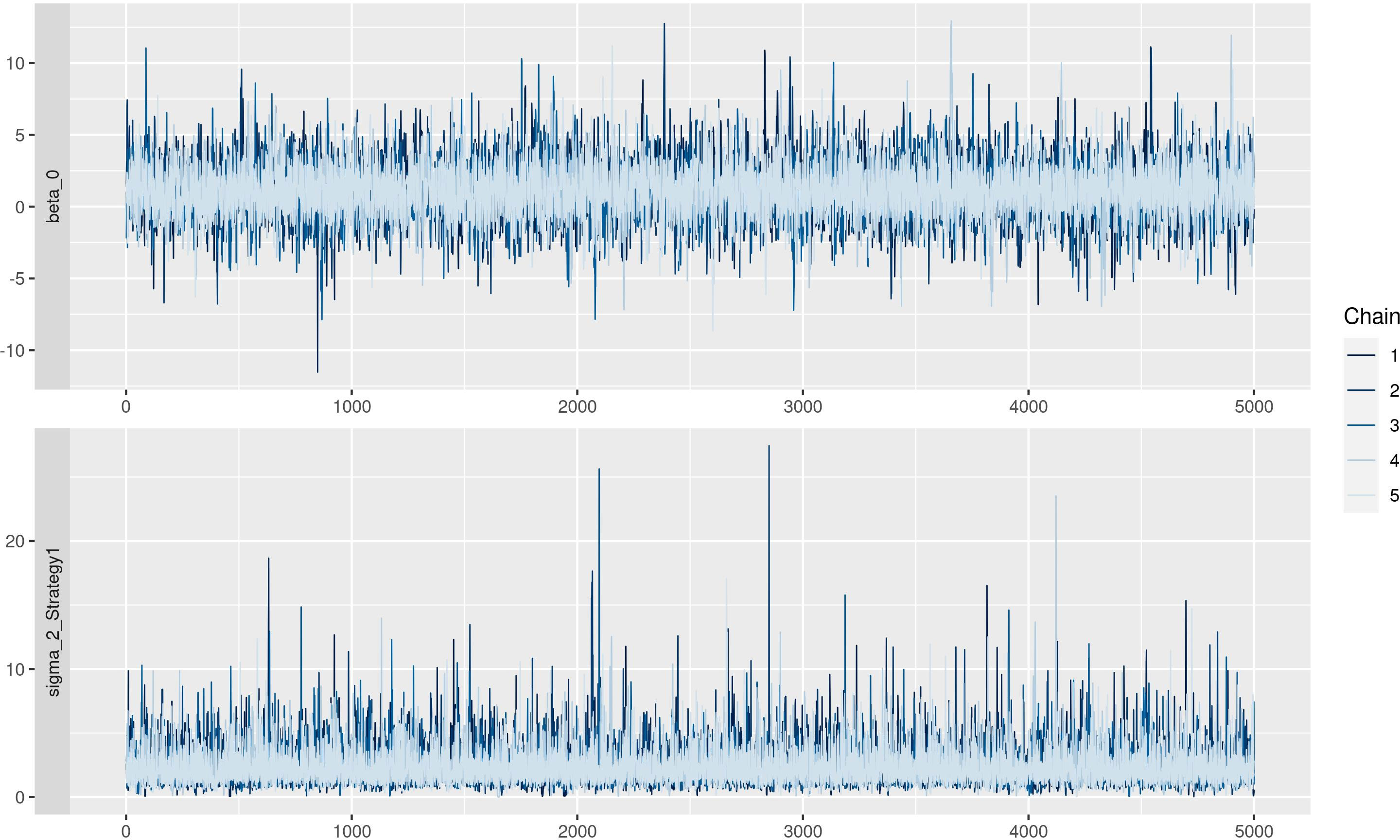
Figure 6 Traceplot of Markov Chain Monte Carlo simulations.
In our analysis, we applied a Bayesian model developed for the vineyard under study, or any other vineyard with similar environmental characteristics. The model is suited to comparing different protection protocol strategies against Plasmopara viticola, and to predicting the probability of infection after strategy, providing key information for selecting the best crop strategy among the following: IPM, IPM-GG, ORG, ORG-GG or application of biostimulant products alone. The latter was used as the control strategy of this study, not only because a full negative control (no intervention of any type) was absent due to the large size of each plot, but also because the application of biostimulants is intended to stimulate plant immune systems to become more effective against pathogens, and therefore by definition they do not have a direct effect on pathogen growth itself [(Shahrajabian et al., 2021, Bertrand et al., 2021 and La Spada et al., 2021)]
The Bayesian model was applied while taking into account the main sources of heterogeneity of the phenomenon. Indeed, in the model specification, two group-level effects were considered. As described in Model specification, αt was specified to take into account the different disease pressure on plants each year. This can be observed also in Figure 1 and Table 1 in Strategy 5 bars and columns—indeed, in 2018 the proportion of infected leaves was 96.5%, in 2019 this figure was 8.5%, and in 2020 it was 79.5%. Considering that sporangia are a typical component of the airborne microflora, these differences in the infection percentage could be due to meteorological conditions (Brischetto et al., 2020). Indeed, weather data from Perria et al. (2022) showed that 2018 was particularly positive for DM development—more than in 2019—due to the fewer leaf wetness hours, which is very important for DM development. Since the model did not include data from meteorological conditions, the estimation of αt and its standard deviation (σα = 2.25) could provide for the variability of disease pressure due to favorable or unfavorable meteorological conditions, acting as a proxy variable which describes the disease pressure. For the same reason, we specified a parameter γk,t to take into account the variability of the protocols affect every year. Considering the assignment of strategies to plots, we were constrained by the experimental design originally defined for an already performed experiment. Our reanalysis is in any case suited to the quite large area considered because local experts clearly stated that this specific vineyard is reasonably homogeneous, with the same type of soil, the same slope, and the same exposure. We obviously agree that randomization is to be preferred in general, but we maintain that is not crucial point here. No data about microclimate or soil analyses were collected, thus we considered a model with subplots as random effects in order to estimate the standard deviation. In the analysis, such a model was considered, but estimated standard deviations of random effects for each strategy in each subplot were quite low (see Table S2 for results). The leave-one-out (LOO) cross-validation (Vehtari et al., 2017), was used to compare the considered models, and it confirmed that introducing subplots did not improve the predictive performance of the model, which is why subplots have been removed from the final model. Therefore, following the LOO, as well as the degree of belief of our expert, we peacefully stated that our vineyard is quite homogeneous. In any case, our statement should not be interpreted as a (bad) suggestion of avoiding randomization or even neglecting heterogeneity at all in general. The comparisons in terms of LOO between the model with and without the subplots as predictors are reported in Table S3. As reported in Forecasting of future infection, Strategy 1, which corresponds to IPM, gave the best prediction in both scenarios. Indeed, its predictive probability mass was concentrated around 15% in the Average scenario and 68% in the Severe scenario. Figure 3 highlights that probability distributions had a high dispersion, especially in the Severe scenario, in which high uncertainty of prediction is inherent. This could be due to the behavior of the disease in the 3-year study. Indeed as reported in Descriptive statistics, in 2019 a very low amount of disease was observed (8.5%). Moreover, high dispersion could be due to the absence of meteorological variables in the model specification. This could be confirmed by Chen et al. (2020) who used GLM (with a frequentist approach) to predict DM on leaves. Their results suggest that data about rainfall, especially recorded in March and April, were important to predict occurrence of the disease on leaves. The oospore germination process leading to macrosporangia production, which is the disease inoculum responsible for primary infections, is strongly inhibited where dry springs occur. Despite the relevant importance of the meteorological variable, in the discussion section, the authors recommend the usage of GLM where only the dates of disease onset detected by monitoring were used as an explanatory variable. In the case of Chen et al. (2020), meteorological variables were not available before June but despite this, their absence in the model specification did not compromise model performances. So, even if the disease is a function of meteorological data, the observation of its actual development in the field is enough to overcome the missing climatic information. This conjecture supports our approach based on group-level parameters as proxy variables that quantify differences in disease pressure and therefore explain the variability of the disease pressure due to favorable-unfavorable meteorological conditions discussed above.
Despite the fact that the predictive probability of infection is a key value in selecting the best strategies, nowadays it is more and more important to take a decision after also considering the environmental impact of the strategy and further possible side effects. In the last part of this work, a multi-attribute approach has been proposed, where variables that describe the environmental impact and the potential of causing human diseases jointly contribute to the optimal decision, namely the selection of the best crop protection strategy. It is important to note that the probability of infection for one future leaf has been calculated using a Bayesian predictive distribution conditional on collected data, while the future environmental impact and side effects were accounted for by a prior-predictive distribution (Multinomial-Dirichlet) mostly dependent on accumulated expert knowledge instead of on extensive data. In the prior-predictive approach, the mean of the only two observed scores per year was considered as the future modal value of the score, and indeed the vector α led to the concentration of probability mass on that observed value. The selected classes belong to the year 2020, because it was considered our average year (Average scenario) compared to the others.
The utility function elicited for presence of the disease depends on a parameter, δ, that was set to 0.4, but that value can be changed according to how fast the utility is increased by increasing the probability of a healthy leaf, i.e. by expert judgment: if the δ is less than 1 then the resulting value decreases quickly while if the δ is greater than 1 the result decreases slowly, as flexibility is required to adapt to expert-specific evaluations and differences in vineyards. In this work, the numerical weights assigned to the various attributes were determined based on their relevance for utility, which can vary depending on the purpose of the study and the preferences of the decision-makers. Indeed, Lavik et al. (2020) applied the SMART approach in an agronomic context and studied many scenarios with a different set of numerical weights, showing that changing weights can strongly change the outcome. In this work, results from expected utility show that the inclusion of the environmental attributes had an impact on the outcome: indeed when they were excluded, the IPM strategy dominated all other strategies in the average scenario. On the other hand, when they were included, utility values between IPM and IPM-GG became closer because of the low environmental impact of the “Green Grapes” version, especially for the Eco Tox score. Since both ORG and ORG-GG increased their utility values after including environmental attributes, the distance in terms of utility was the same, meaning that there were no differences in terms of sustainability, but only in terms of predictive disease detection. The observation of individual attributes highlighted that there were actually some differences. Indeed ORG-GG had a higher utility value for Carbon footprint and Carbon sequestration (data not shown), but a lower value for the Human tox score compared to ORG. However, the overall utility for the environmental components was the same. In the Severe scenario, a biostimulants-only approach (Strategy 5) was the best strategy—a result suggesting that when disease pressure is very high due to favorable climatological conditions then the use of the other strategies is not enough to counter the disease, without a high environmental impact. The latter result is strictly dependent on the elicitation of the sub-utility functions. Indeed, changing the tuning parameters, for instance by increasing the threshold of the sub-utility function describing future infections, might decrease the dominance of Strategy 5 in the Severe scenario. Therefore, since there is no unique-natural utility function, different agronomists can customize the sub-utility functions according to their attitude to risk, their evaluation of environmental side effects, as well as current regulatory dispositions, and thus leading to different optimal decisions. Despite IPM and ORG being the best strategies in the Average scenario, their utilities were not dominant, therefore an agronomist could change weights further to reward the “GreenGrapes” strategy that guarantees greater environmental sustainability of viticulture. These results can contribute greatly to a more targeted approach in disease control management, by selecting products with lower environmental impact based on risk assessment, aligning with current European guidelines for plant protection. Instead of synthetic products that have a high environmental impact, the use of substances that induce plant defense, basic compounds, and plant strengtheners with low environmental impact is recommended. However, the application of these alternatives, especially under a lower disease pressure, benefits considerably from the support of models in interpreting risk and guiding the selection of these less potent yet environmentally friendly products.
In contrast to mechanistic-deterministic approaches recently published in the literature which are based on differential equations, we have proposed a statistical approach grounded in accumulated real-world expertise and probabilistic evaluation of uncertainty. This key feature, besides enabling more flexibility in the analysis, also entails certain limitations. First, the quality of predictions strongly depends on sample size and on the extent of the natural variability in collected data. In a full Bayesian approach, variability is almost never neglected, thus bold overconfident statements are typically not a risk, but at the same time large samples are needed to reduce uncertainty to a practically useful degree. Second, in our work we exploited expert knowledge while defining assumptions for our model, but we did not use highly informative prior distributions for model parameters. Nevertheless, an analysis in which an experienced expert defines highly informative prior distributions remains a possibility for future work, given that in our case we have chosen to let data “speak aloud”. Third, uncertainty in prediction was not always small, a feature that we tend to prefer compared to the alternative of artificial overprecision and risky decisions. Fourth, our model did not consider the mechanistic features of the underlying causal data-generating process. We conjecture that the proposed statistical model could almost surely be improved by combining mechanistic and statistical approaches into a unified framework: deterministic models could play the role of anchors while defining structural causal models task that is likely to require specifically planned studies, as we have stated previously in our recent work Stefanini and Valleggi (2022).
Plasmopara viticola is the causal agent of downy mildew, one of the most damaging diseases of grapevines. A model able to select the best strategy against downy mildew could be a suitable tool in order to choose the optimal strategy based on the local characteristics of the vineyard, in terms of disease pressure and spread. In this work, a Bayesian decisional approach was used in order to combine different sources of information and select the best strategy for the next year of grapevine production, considering at the same time the efficiency of the strategy and its environmental impact. Thanks to the proposed utility function, the agronomist may consider several attributes on a very easily interpretable scale. Furthermore, it is also possible to change the emphasis of the analysis choosing weights to obtain the best balance between environmental attributes and strategy efficiency as a result of risk attitude and interest in sustainability that characterizes the decision maker.
In order to improve this tool, more than three years of study are required due to the presence of high seasonal variability. For example, in 2019 very low numbers of infected leaves were observed due to unfavorable meteorological conditions for the pathogen. The natural next step of this framework would be an extension of the proposed utility function where more attributes are considered, in particular by introducing attributes describing the quality and the disease incidence of grapes, the economic aspect of each strategy, and also considering the joint assessment of utility value over attributes, e.g. considering utility dependence within some subsets of attributes.
The original contributions presented in the study are publicly available. This data can be found here: source data can be downloaded from DataVerse at UNIMI https://dataverse.unimi.it/dataverse/unimi/?q=stefanini, dataset and R code: https://github.com/federico-m-stefanini.
LV: Writing – original draft, Visualization, Software, Methodology, Formal analysis, Conceptualization. GC: Writing – review & editing, Validation, Resources, Investigation. RP, LM: Writing – review & editing, Validation, Supervision, Resources, Investigation. FS: Writing – review & editing, Supervision, Methodology, Conceptualization.
Original data were collected under LIFE EU Life Green Grapes Project “New approaches for protection in a modern sustainable viticulture: from nursery to harvesting”, grant number “LIFE16 ENV/IT/000566, 2017”.
The authors would like to thank Horta Srl for the useful discussion which led the development of the utility function.
The authors declare that the research was conducted in theabsence of any commercial or financial relationships that could beconstrued as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2023.1117498/full#supplementary-material
Bertrand, C., Gonzalez-Coloma, A., Prigent-Combaret, C. (2021). Plant metabolomics to the benefit of crop protection and growth stimulation. Adv. Botanical Res. 98, 107–132. doi: 10.1016/bs.abr.2020.11.002
Bove, F., Savary, S., Willocquet, L., Rossi, V. (2020a). Designing a modelling structure for the grapevine downy mildew pathosystem. Eur. J. Plant Pathol. 157, 251–268. doi: 10.1007/s10658-020-01974-2
Bove, F., Savary, S., Willocquet, L., Rossi, V. (2020b). Simulation of potential epidemics of downy mildew of grapevine in different scenarios of disease conduciveness. Eur. J. Plant Pathol. 158, 599–614. doi: 10.1007/s10658-020-02085-8
Brischetto, C., Bove, F., Fedele, G., Rossi, V. (2021). A weather-driven model for predicting infections of grapevines by sporangia of Plasmopara viticola. Front. Plant Sci. 0. doi: 10.3389/fpls.2021.636607
Brischetto, C., Bove, F., Languasco, L., Rossi, V. (2020). Can spore sampler data be used to predict Plasmopara viticola infection in vineyards? Front. Plant Sci. 11. doi: 10.3389/fpls.2020.01187
Bürkner, P. C. (2017a) Advanced bayesian multilevel modeling with the r package brms. Available at: http://arxiv.org/abs/1705.11123.
Bürkner, P. C. (2017b). Brms: an r package for Bayesian multilevel models using Stan. J. Stat. Software 80, 1–28. doi: 10.18637/jss.v080.i01
Caffi, T., Legler, S. E., González-Domínguez, E., Rossi, V. (2016). Effect of temperature and wetness duration on infection by Plasmopara viticola and on post-inoculation efficacy of copper. Eur. J. Plant Pathol. 144, 737–750. doi: 10.1007/s10658-015-0802-9
Carpenter, B., Gelman, A., Hoffman, M. D., Lee, D., Goodrich, B., Betancourt, M., et al. (2017). Stan: A probabilistic programming language. J. Stat. Software 76, 1–32. doi: 10.18637/jss.v076.i01
Cavani, L., Manici, L. M., Caputo, F., Peruzzi, E., Ciavatta, C. (2016). Ecological restoration of a copper polluted vineyard: long-term impact of farmland abandonment on soil bio-chemical properties and microbial communities. J. Environ. Manage. 182, 37–47. doi: 10.1016/j.jenvman.2016.07.050
Chen, M., Brun, F., Raynal, M., Makowski, D. (2020). Forecasting severe grape downy mildew attacks using machine learning. PloS One 15, e0230254. doi: 10.1371/journal.pone.0230254
Dagostin, S., Schärer, H.-J., Pertot, I., Tamm, L. (2011). Are there alternatives to copper for controlling grapevine downy mildew in organic viticulture? Crop Prot. 30, 776–788. doi: 10.1016/j.cropro.2011.02.031
Dunn, P. K., Smyth, G. K. (1996). Randomized quantile residuals. J. Comput. Graphical Stat 5, 236–244.
Edwards, W. (1977). How to use multiattribute utility measurement for social decisionmaking. IEEE Trans. Systems Man Cybernetics 7, 326–340. doi: 10.1109/TSMC.1977.4309720
European and Mediterranean Plant Protection Organisation (2017) EPPO standards for the efficacy evaluation of plant protection products. Available at: https://www.eppo.int/RESOURCES/eppo.
Gelman, A., Carlin, J. B., Stern, H. S., Rubin, D. B. (1995). Bayesian Data analysis (New York: Chapman, Hall/CRC). doi: 10.1201/9780429258411
Gelman, A., Hill, J. (2007). Data analysis using regression and multilevel/hierarchical models (Cambridge, New York: Cambridge University Press).
Gelman, A., Jakulin, A., Su, Y.-S., Pittau, M. G. (2006). A default prior distribution for logistic and other regression models. Technical report. (Columbia University).
Gessler, C., Pertot, I., Perazzolli, M. (2011). A review of knowledge on downy mildew of grapevine and effective disease management Phytopathol. Mediterr 50, 3–44. doi: 10.14601/PhytopatholMediterr-9360
Kab, S., Spinosi, J., Chaperon, L., Dugravot, A., Singh-Manoux, A., Moisan, F., et al. (2017). Agricultural activities and the incidence of parkinson’s disease in the general French population. Eur. J. Epidemiol. 32, 203–216. doi: 10.1007/s10654-017-0229-z
Lalancette, N. (1988). Development of an infection efficiency model for Plasmopara viticola on american grape based on temperature and duration of leaf wetness. Phytopathology 78, 794. doi: 10.1094/Phyto-78-794
La Spada, F., Aloi, F., Coniglione, M., Pane, A., Cacciola, S. O. (2021). Natural biostimulants elicit plant immune system in an integrated management strategy of the postharvest green mold of orange fruits incited by penicillium digitatum. Front. Plant Sci. 12. doi: 10.3389/fpls.2021.684722
Lavik, M. S., Hardaker, J. B., Lien, G., Berge, T. W. (2020). A multi-attribute decision analysis of pest management strategies for Norwegian crop farmers. Agric. Syst. 178, 102741. doi: 10.1016/j.agsy.2019.102741
Magarey, R. D., Sutton, T. B., Thayer, C. L. (2005). A simple generic infection model for foliar fungal plant pathogens. Phytopathology® 95, 92–100. doi: 10.1094/PHYTO-95-0092
Perria, R., Ciofini, A., Petrucci, W. A., D’Arcangelo, M. E. M., Valentini, P., Storchi, P., et al. (2022). A study on the efficiency of sustainable wine grape vineyard management strategies. Agronomy 12, 392. doi: 10.3390/agronomy12020392
Shahrajabian, M. H., Chaski, C., Polyzos, N., Petropoulos, S. A. (2021). Biostimulants application: a low input cropping management tool for sustainable farming of vegetables. Biomolecules 11, 698. doi: 10.3390/biom11050698
Shunthirasingham, C., Oyiliagu, C. E., Cao, X., Gouin, T., Wania, F., Lee, S.-C., et al. (2010). Spatial and temporal pattern of pesticides in the global atmosphere. J. Environ. Monit. 12, 1650–1657. doi: 10.1039/C0EM00134A
Smith, J. Q. (2010). Bayesian Decision analysis: principles and practice (Cambridge: Cambridge University Press).
Stefanini, F. M., Valleggi, L. (2022). A Bayesian causal model to support decisions on treating of a vineyard. Mathematics 10, 4326. doi: 10.3390/math10224326
Van de Schoot, R., Depaoli, S., King, R., Kramer, B., Märtens, K., Tadesse, M. G., et al. (2021). Bayesian Statistics and modelling. Nat. Rev. Methods Primers 1, 1–26. doi: 10.1038/s43586-020-00001-2
Vehtari, A., Gelman, A., Gabry, J. (2017). Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Stat. Comput. 27, 1412–1432. doi: 10.1007/s11222-016-9696-4
Keywords: disease modeling, pesticides reduction, downy mildew, Bayesian modeling, utility function, sustainability
Citation: Valleggi L, Carella G, Perria R, Mugnai L and Stefanini FM (2023) A Bayesian model for control strategy selection against Plasmopara viticola infections. Front. Plant Sci. 14:1117498. doi: 10.3389/fpls.2023.1117498
Received: 06 December 2022; Accepted: 29 June 2023;
Published: 20 July 2023.
Edited by:
Roberto Mancinelli, University of Tuscia, ItalyReviewed by:
Antonio Vicent, Valencian Institute for Agricultural Research (IVIA), SpainCopyright © 2023 Valleggi, Carella, Perria, Mugnai and Stefanini. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Lorenzo Valleggi, bG9yZW56by52YWxsZWdnaUB1bmlmaS5pdA==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.