
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Plant Sci. , 09 March 2023
Sec. Technical Advances in Plant Science
Volume 14 - 2023 | https://doi.org/10.3389/fpls.2023.1106104
This article is part of the Research Topic Trait Mining and Genetic Enhancement of Millets and Potential Crops: Modern Prospects for Ancient Grains View all 9 articles
 Shweta Shekhar1†
Shweta Shekhar1† Archana S. Prasad1†
Archana S. Prasad1† Kalpana Banjare2†
Kalpana Banjare2† Abhijeet Kaushik2†
Abhijeet Kaushik2† Ajit K. Mannade1
Ajit K. Mannade1 Mahima Dubey3Arun Patil3Vinay Premi1Ashish K. Vishwakarma4
Mahima Dubey3Arun Patil3Vinay Premi1Ashish K. Vishwakarma4 Abhinav Sao5Ravi R. Saxena2†Amit Dubey6
Abhinav Sao5Ravi R. Saxena2†Amit Dubey6 Girish Chandel1*†
Girish Chandel1*†Little millet (Panicum sumatrense) a native of Chhattisgarh, belongs to the minor millet group and is primarily known as a climate-resilient and nutritionally rich crop. However, due to the lack of enough Omic studies on the crop, the scientific community has largely remained unaware of the potential of this crop, resulting in less scope for its utilization in crop improvement programs. Looking at global warming, erratic climate change, nutritional security, and limited genetic information available, the Little Millet Transcriptome Database (LMTdb) (https://igkv.ac.in/xenom/index.aspx) was conceptualized upon completion of the transcriptome sequencing of little millet with the aim of deciphering the genetic signatures of this largely unknown crop. The database was developed with the view of providing information about the most comprehensive part of the genome, the ‘Transcriptome’. The database includes transcriptome sequence information, functional annotation, microsatellite markers, DEGs, and pathway information. The database is a freely available resource that provides breeders and scientists a portal to search, browse, and query data to facilitate functional and applied Omic studies in millet crops.
An alarming increase in the Earth’s temperature, along with increasing water scarcity in recent years, is posing a threat to the future of global food security. In addition to this, addressing the issue of micronutrient deficiency in developing and underdeveloped nations is another formidable challenge faced by policymakers today. Enhancing the productivity and nutritional value of crops in the modern-day world is a concern that needs to be addressed efficiently to bridge the gap between demand and supply of food in the coming years. The nutritionally rich millets are low-maintenance, climate-resilient cereals that hold potential benefits for human health at minimal cost, thus providing a comprehensive solution for global food and nutritional security (Kumar et al., 2018). Nevertheless, despite the satisfaction that these crops bring to our table, sheer negligence has been observed in their cultivation and consumption (Himanshu et al., 2018). Also, the molecular aspects of stress tolerance in millets have largely remained unexplored (Babele et al., 2022).
Panicum sumatrense (Little millet) is one of the predominant yet lesser-studied, tetraploid species (2n = 4x = 36) of minor millets, essentially cultivated for its grain (Gomez and Gupta, 2003; Das et al., 2020). The crop is loaded with nutrients such as dietary fiber, protein, and minerals like iron (Fe = 32.20 ppm) and zinc (Zn = 32.40 ppm) (Girish et al., 2014; Vetriventhan et al., 2021) and performs exceptionally well under challenging environmental conditions and is invariably adapted to high temperature and moisture stress (Ajithkumar and Panneerselvam, 2014). Yet, to date, the crop has been considered an ‘orphan’ and has never fallen under the umbrella of extensive research until recent years. As a result of that, unlike rice, wheat, and other cereals, the crop has still not achieved breakthroughs in terms of gene discoveries, genetic improvement, and yield enhancement. Also, due to a lack of enough studies, ‘Omics’ information related to the crop has remained scarce (Natesan et al., 2020).
Transcriptomics is a promising approach that has transformed our outlook toward gene expression patterns at the cellular and molecular levels (Lowe et al., 2017). RNA-Seq, is one of the transcriptomic technologies and is known to resolve expression patterns of genes with exceptional clarity (Finotello and Di Camillo, 2015). It is evident from previous studies that, RNA-Seq has opened new opportunities for researchers and has played a pivotal role in mining a plethora of genes in a wide range of plant species, from parasitic to land plants and tree species. (Li et al., 2015; Howlader et al., 2020; Sobreiro et al., 2021). In millets as well, several genes, transcription factors, and metabolic pathways regulating biotic (Kulkarni et al., 2016) and abiotic stress tolerance (Das et al., 2020; Shivhare et al., 2020; Sun et al., 2020; Suresh et al., 2022), along with those involved in modulating metal-ion homeostasis (Chandra et al., 2020; Satyavathi et al., 2022) have also been tracked using RNA-Seq. This data-driven technology delivers enormous information upon intricate analysis and can help researchers if made publicly accessible. Foreseeing the potential of RNA-Seq data in understanding plants’ behavioral and developmental biology, scientific fraternities from all over the globe have been emphasizing to create web-based platforms which can be utilized to explore these information free of cost. FmMiRNADb, FmTFDb (Thulasinathan et al., 2022) Plant Public RNA-Seq Database (Yu et al., 2022), GRAND (Zhang et al., 2022), HpeNet (Sheng et al., 2020), TRANSNAP (Koshimizu et al., 2019), AgriSeqDB (Robinson et al., 2018), SeagrassDB (Sablok et al., 2018), and MOROKOSHI (Makita et al., 2015) are few of the popular plant expression databases developed for millets and other plants. Interestingly, even after a heedful screening, we were unable to detect any independent platform dedicated solely to little millet and this prompted us to create an interactive web-based transcriptomic resource for this non-model plant that can serve as a comprehensive guide to understanding the crop’s molecular biology. To our knowledge, the Little Millet Transcriptome Database version 1.0.0 (LMTdb v-1.0.0) is an exclusive, first-of-its-kind database made for little millet that runs on the Windows operating system. The database is an information-rich resource of transcriptome sequences and functions, plant metabolic networks, molecular markers, and differentially expressed genes of three tissue types, namely secondary leaf, flag leaf, and panicle under control and drought conditions, in which all data can be freely accessed for research purposes to attain global food and nutritional security.
A total of 4 samples from three different tissue types of little millet genotype RLM-37 namely secondary leaf under drought conditions and secondary leaf, flag leaf, and panicle under control conditions, were undertaken for RNA isolation. The extracted mRNAs were examined for their quality and quantity and were sequenced using the Illumina HiSeq Platform followed by quality check with the help of Trimmomatic-0.39 and de novo transcriptome assembly utilizing the Trinity v 2.4.0 (Figure 1) (Unpublished data). The unigenes of de novo transcriptome assembly were annotated using BLASTx (blast.ncbi.nlm.nih.gov) against NCBI non-redundant protein database (www.ncbi.nlm.nih.gov) followed by Gene Ontology mapping utilizing Blast2GO (www.blast2go.com) and motif identification using InterProScan (www.ebi.ac.uk/interpro/search/sequence/). Based on the read counts and expression values of each transcript differentially expressed genes (DEGs) were identified using edgeR. In addition, the KEGG database (www.genome.jp/kegg/) was employed for metabolic pathway annotation, and finally, MISA (www.bio.tools/misa) was undertaken for the identification of simple sequence repeats (SSRs). Also, to identify similar sequences BLASTn was performed against Reference RNA sequences (refseq_rna) database.
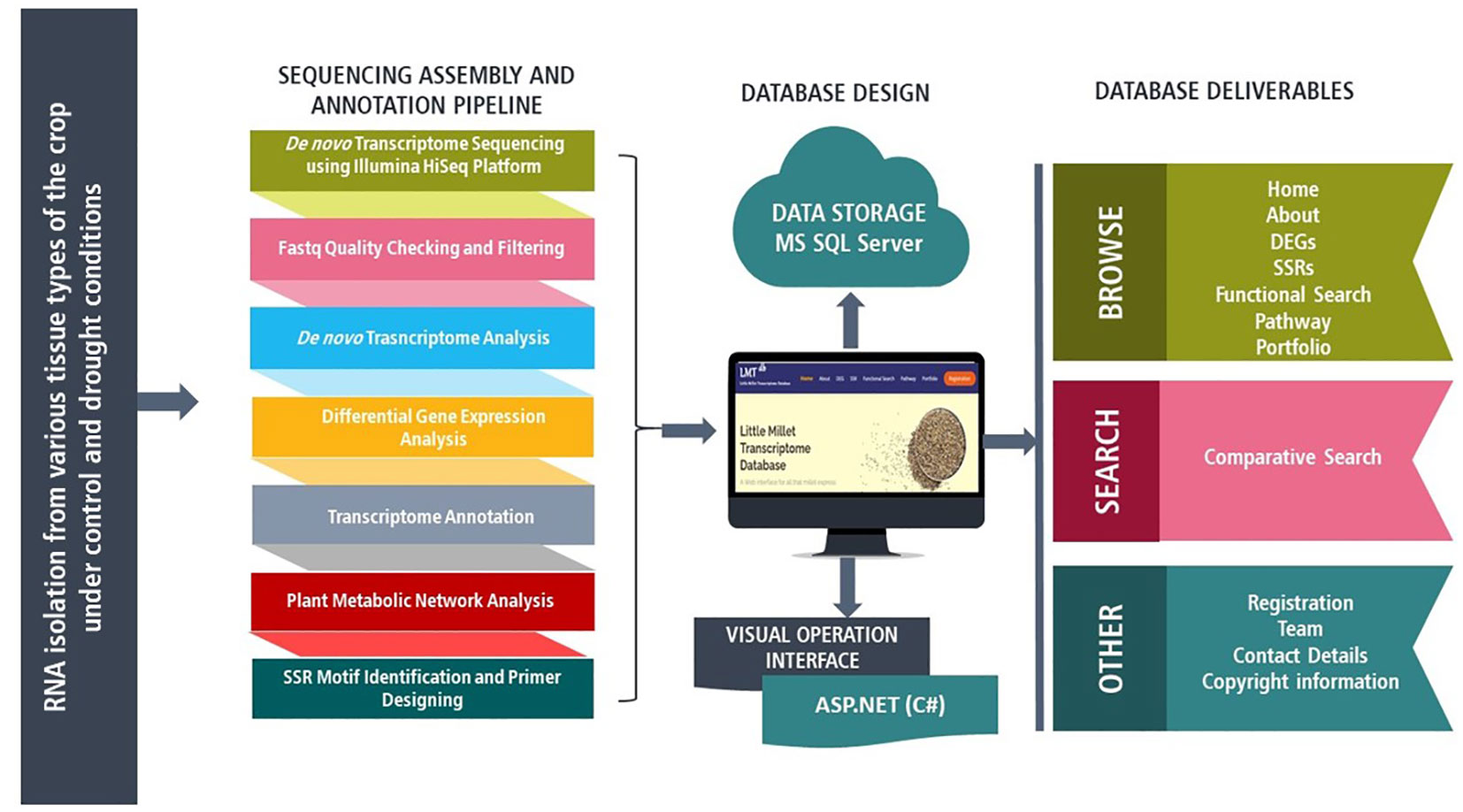
Figure 1 Schematics of Little Millet transcriptome database (LMTdb v.1.0.0) structure and web interface features along with transcriptome sequencing, assembly, and annotation pipeline.
The RNA-Seq data obtained from little millet was utilized for creating Little Millet Transcriptome Database version 1.0.0 (LMTdb v-1.0.0). High quality reads generated after trimming of raw reads from secondary leaf under drought conditions (SLS), and secondary leaf (SLC), flag leaf (FLC), and panicle (PC) under control conditions were undertaken for de novo transcriptome assembly (Table S1; Table 1). Further, after functional annotation of the assembled transcripts, a total of 128,963 unigenes were pinned down, and via. KEGG we identified metabolic network pathways corresponding to these unigenes. In addition, the data also includes 1,434 differentially expressed genes under control and drought conditions followed by 10,317 differentially expressed genes across three tissue types. For the identification of significant DEGs, stringent parameters such as a p-value (0.05), log2FC (± 2), and false discovery rate (FDR < 0.001) were applied. Apart from the above information, we have also identified a sum of 13,496 SSRs useful for functional genomic studies.

Table 1 A summary of RNA-Seq data.
The first version of the Little Millet Transcriptome Database (LMTdb v-1.0.0) is an MS SQL database, designed and built to run on the Windows operating system with a DOTNET framework. The proposed transcriptome database algorithms are implemented in a C# environment on a 4 core processor Intel Xeon Gold 6152 CPU remote cloud server. The standard 3 Tier architecture is used as client-server architecture for the development of the project (Figure 1). MS SQL server version 2017 is used as a backend for storing transcriptome sequence and annotation data. The proposed system is designed to allow its end-users to query the database through a web-based interface developed using ASP.NET, HTML5, and CSS3. The system is cleared black box test based on test cases built around the specifications and requirements of the application.
The incomparable tolerance of millets toward abiotic stresses including drought, salinity, and heat along with their efficiency to sequester and load minerals from the soil to the grains make them an amenable system to understand the plant’s stress-responsive behavior and metal homeostasis at cellular, molecular and physiological levels (Bandyopadhyay et al., 2017). Next-generation sequencing approaches have been successfully harnessed to comprehend the stress and nutrition biology of both major and minor millets (Lata, 2015; Prabha et al., 2017; Pujar et al., 2020). In little millet, the de novo transcriptome analysis has recently been leveraged to identify genes involved in drought and salinity tolerance mechanisms (Das et al., 2020) Attempts have also been made to identify grain nutrient related and moisture stress-responsive gene orthologous (Chandel et al., 2017; Sushmitha et al., 2018) and genic microsatellite markers in little millet (Desai et al., 2021). Further, the chloroplast genome of little millet has been sequenced and employed to investigate the crop’s phylogenetic relationship with other members of Poaceae (Sebastin et al., 2018). However, the crop is still undermined as not much is known about molecular mechanisms that govern metal homeostasis and several other functions.
It is noteworthy that over the past decade gene discovery via transcriptomic approaches has been much more frequently observed than that through genomic approaches. Transcriptomics allows us to track changes in gene expression patterns over tissue types, environmental conditions, and developmental stages with great precision. With this idea, several researchers across the globe have developed open-access transcriptomic portals or databases for minor millets which are currently being explored for mining genes associated with biotic and abiotic stress tolerance, metal homeostasis, and also for yield and quality improvement. However, to our knowledge, no such unified browsing platform has been specifically designed and developed for little millet posing restrictions in employing forward genetic approaches to penetrate deeper into the molecular architecture of the crop. To bridge this gap, we developed the Little Millet transcriptome database (https://igkv.ac.in/xenom/index.aspx), encompassing extensive information on transcriptome assembly and annotation of little millet under one umbrella.
LMTdb v-1.0.0 is a compendium of the expressed parts of the little millet’s genome. It has a comprehensive yet methodical representation of transcriptome data and has been proficiently designed to provide absolute ease to its end-users while browsing and searching for desired information in the database (Figure 1). The database encompasses transcriptome information for three different tissue types (secondary leaf, flag leaf, and panicle) under drought and control conditions. It also provides a brief description of the tools and frameworks that have been utilized for designing the database which shall guide researchers willing to design a similar kind of repository for some other crop. Structurally, the database comprises eight key tabs namely: Home, About, DEGs, SSRs, Functional Search, Pathway, Portfolio, and Registration (Figure 2A). The ‘home’ page has been designed in a way that makes browsing effortless and intuitive for its end-users, with key elements of the database being accessible from all the relevant locations throughout the home page. As LMTdb is one of the first databases designed precisely for little millet, we have also provided a brief description regarding the crop and its importance in the modern world in the ‘About’ section of the website. The platform provides browse and search functions for transcriptomic information including, gene expression profiles (DEGs) genomic variations (SSRs), and functional and metabolic pathway annotation.

Figure 2 Schematic representation and screenshots of Little Millet transcriptome database (LMTdb v.1.0.0). (A) Representation of key elements (DEGs, SSRs, Functional Search, Pathway, and Portfolio) of the database as displayed on the database homepage. (B) Functional Search page displaying information related to CYP71A1 like gene (TRINITY_DN6320_c0_g1_i4). (C) BLAST details for CYP71A1 like gene (TRINITY_DN6320_c0_g1_i4) (D) Comparative search for CYP71A1 like gene under DEG module. (E) Downregulation of CYP71A1 like gene in secondary under drought stress. (F) Representation of SSRs information for CYP71A1 like gene. (G) Primer details corresponding to CYP71A1 like gene. (H) Metabolic pathway information with enzymes and pathway IDs corresponding to different transcripts.
The transcriptomic information stored in the database is freely accessible to the public and can be browsed under the module names DEGs, SSR, Functional Search, Pathway, and Portfolio on the database home page. The corresponding information for each of these modules is represented in a tabular format and can be visualized upon clicking directly on the module name. The data under the module DEG can be browsed under seven key attributes: a unique transcript identifier as Transcript ID, Tissue type or Treatment information, Fold Change (FC) value; Logarithm of Fold Change (logFC), Logarithm of Counts Per Million Reads (logCPM), Probability value (p-value) and False Discovery Rate (FDR) (Figure 2D). Information related to gene expression patterns (upregulation or downregulation) can be retrieved by clicking through Transcript IDs (Figure 2E). This information can further be analyzed to obtain a clear picture of candidate genes involved in stress tolerance and also for various developmental processes of the plant. In a similar fashion information about genomic variations i.e. SSRs can be browsed under 6 attributes, namely: Transcript ID, Sequence Length (in base pairs), SSR Motifs (classified based upon motif length as di, tri, tetra, penta, hexa, hepta, octa, and nona), Motif Repetition, and Start and End Positions of each marker (Figure 2F). Primer details, including marker ID, forward and reverse primer sequences in base pairs along with their melting temperatures and product size in base pairs can be accessed by clicking on the desired transcript IDs (Figure 2G). This information can be employed to track SSRs based genetic variation across species and also for marker-trait association studies for crop improvement. Apart from these, one can browse through the Functional Search and Pathway tabs to gain insights into the molecular functions and metabolic network pathways of the assembled transcripts. The functional search depicts the information related to functions of the transcript sequences under the attributes: Description, GO IDs, GO Names, Enzyme Codes, Enzyme Names, and InterPro, inclusive of Panther, Prosite, Gene3D, and Pfam IDs (Figure 2B). In addition to this, the functional search tab also provides BLAST details for given transcripts, which can be retrieved upon clicking the BLAST option (Figure 2C). Similarly, the Pathway tab displays information regarding plant metabolic networks under the attributes: Pathway Name, Pathway IDs, EC Number of enzymes, and Total Number of Enzymes involved in each respective pathway (Figure 2H). Users can access detailed pathway information from the KEGG database (https://www.genome.jp/kegg/) using the pathway IDs provided. Additionally, the database also has a portfolio section that serves as a collection of pathway maps, heat maps, and gene distribution graphs obtained as an outcome of transcriptome analysis. The section has been curated to make data interpretations visually appealing and uncomplicated for our end-users.
LMTdb allows users to perform a comparative search under the DEGs module. A web interface for DEGs is divided into two sections, the filter and the result section (Figure 2D). The filter section allows filtering comparative data by checking or unchecking the check box. The comparative search options comprise (i)Flag leaf vs. Panicle under control condition, (ii) Secondary leaf vs. Flag leaf under control condition, and (iii) Secondary leaf under control condition vs. Secondary leaf under drought stress condition. Based upon comparative search, the data will be updated in the result section in tabular format. Users after making a registration (https://igkv.ac.in/xenom/index.aspx) can retrieve transcriptome information free of cost. Apart from this, ‘Search by Transcript ID’ allows feasible exploration of robust data-set based on transcript IDs.
Plants under drought or dehydration stress elicit several enzymatic and hormonal responses involved in ROS scavenging, ion uptake and transportation, and accumulation of osmoprotectants (Shinozaki and Yamaguchi-Shinozaki, 2007). Cytochrome P450s (CYPs) are a member of the class oxidoreductase and are known to be one of the largest gene families in angiosperms. CYPs catalyze NADPH-and or/O2-dependent hydroxylation reactions in living systems and have been extensively studied in various plant species with an aim to discern their roles in response to biotic and abiotic stress (Pandian et al., 2020).
To demonstrate the applications of the current version of LMTdb, we performed a case study undertaking CYP71A1 gene from the Cytochrome P450 superfamily. The CYP71A1 gene codes for tryptamine 5-hydroxylase enzyme involved in plant serotonin/melatonin biosynthesis pathway (Bhowal et al., 2021). In the past few years, the gene has reportedly been studied to understand biotic (Lu et al., 2018), and abiotic stress tolerance (Zhang et al., 2012) in rice. To assess the role of CYP71A1 gene in little millet under drought stress, we tried exploring LMTdb. To decipher the function of this gene, the functional search option on the database home page was carefully screened, and the putative function of CYP71A1 like gene along with its unique transcript ID (TRINITY_DN6320_c0_g1_i4) was located (Figure 2B). BLAST details for the given transcript showed the highest similarity with Panicum hallii cytochrome P450 71A1-like mRNA with a percent identity of 93.87%, and a score of 1373 bits(743) (Figure 2C). This transcript ID was then used to screen the ‘DEG’ module under secondary leaf control and drought stress comparative search option. Under the DEG module, downregulation of CYP71A1 gene (logFC -1.76431407043982 and p-value 1.06E-0) in secondary leaf under drought conditions was observed (Figures 2D, E). Further, we also identified two different SSRs, each with one primer, for the given transcript ID (Figures 2F, G). A similar workflow can be utilized by researchers for tracking transcriptomic information related to their genes of interest (Figure 3).
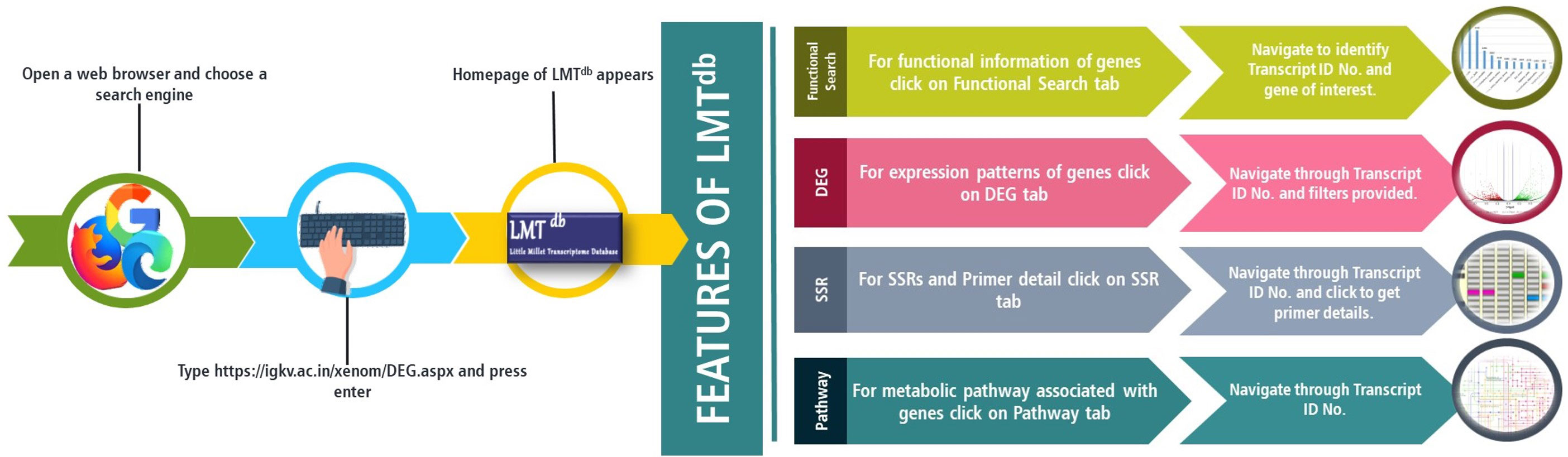
Figure 3 Schematics regarding access, browse and search gene functions in Little Millet transcriptome database (LMTdb v.1.0.0).
To understand the relevance of LMTdb v.1.0.0 for millet research in the current scenario, we compared our database with one of the advanced databases in millet i.e. MOROKOSHI: pTranscriptome Database in Sorghum bicolor (Makita et al., 2015) (Figure 4) (http://sorghum.riken.jp/Home.html). The look and feel of MOROKOSHI seems quite similar to our database with key tabs featuring Home, About, Search, Graph, Download, and Contact (Figure 4A), and the transcriptome information in both databases appear as static web pages. However, a major difference in terms of browse and search functions can be seen between both databases. In LMTdb, transcriptome information is available in a tab-wise (DEG, SSR, Pathway, and Functional Search) manner whereas, in MOROKOSHI gene/character-wise information is available (Figure 4B). It is noteworthy that, both the databases are at par in terms of outcomes of gene annotation comprising functional annotation, Uniprot, Pfam, Panther, GO, and KEGG IDs for the genes (Figure 4C). Nevertheless, there are a few differences that we encountered while comparing the two. LMTdb provides a comprehensive detail of microsatellite markers which is apparently not available in MOROKOSHI. On the contrary, MOROKOSHI provides additional features like orthologs, RNA-Seq expression profile, and co-expression network which we are yet to add in LMTdb. Another key difference that we noticed was MOROKOSHI runs on a Linux-based OS platform whereas, LMTdb uses a Windows-based OS platform for the same. Although MOROKOSHI provides more information with respect to analysis and cataloging compared to LMTdb it is crucial to note that little millet is still understudied compared to sorghum. We expect that with the additional data to be added shortly, we can upgrade the information content of our database in near future in the upcoming version.

Figure 4 Comparative representation of Little Millet transcriptome database (LMTdb v.1.0.0) and MOROKOSHI database. (A) A view of home page in Little Millet Transcriptome Database (LMTdb v.1.0.0) vs MOROKOSHI Database. (B) Comparative search options available at Little Millet Transcriptome Database (LMTdb v.1.0.0) vs MOROKOSHI Database. (C) Information about gene annotation in Little Millet Transcriptome Database (LMTdb v.1.0.0) vs MOROKOSHI Database.
The current version of LMTdb has some limitations for example, the database lacks hyperlinks to other web-based bioinformatic tools and we have planned to upgrade this in upcoming versions of the database.
LMTdb provides its end-users a web interface to access various information related to the expressed part of little millet’s genome, such as DEGs, microsatellite markers, gene functions, and plant metabolic pathway information. The above data can be browsed, analyzed, and even downloaded upon registration, free of cost, and can contribute to functional as well as comparative Omic studies elucidating evolutionary and developmental biology of the crop. The information in this database is highly useful for the identification and characterization of novel genes, understanding the drought and tissue-specific gene expression patterns, and also in designing SSR-based fingerprinting studies in little millet as well as in other related minor millets. The database will serve as a comprehensive resource for breeders and scientists involved in addressing global food and nutritional security through crop improvement programs. In the forthcoming versions of LMTdb, hyperlinks to various bioinformatic tools will be added along with information related to SNP, Indels, protein-protein interaction, and gene families making it an even more extensive platform for Omic studies.
The original contributions presented in the study are publicly available. This data can be found here: NCBI accession PRJNA718414.
GC conceptualized the idea. GC, AP, SS, KB, AK, and RS curated, and formatted the data and worked on the design and development of the database. AS provided the experimental material. GC AM, MD, ArP, VP, and AV carried out the preliminary wet-lab experiments and data analysis. GC, AP, SS, KB, AK, and RS drafted the original manuscript. All authors contributed to the article and approved the submitted version.
The financial support for this work was provided by the Government of Chhattisgarh under the RKVY (Rashtriya Krishi Vikas Yojana) project.
We sincerely acknowledge the contributions of A.R. Rao and Shikha Mittal, Indian Agricultural Statistics Research Institute, SciGenom Labs, and AgriGenome Labs for assisting in sequencing, assembly, and downstream analysis.
Authors MD and ArP are employed by VNR Seeds Private Limited at present and were Ph.D. students at the Department of Plant Molecular Biology and Biotechnology, IGKVV during the course of study.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2023.1106104/full#supplementary-material
Ajithkumar, I. P., Panneerselvam, R. (2014). ROS scavenging system, osmotic maintenance, pigment,t, and growth status of Panicum sumatrense roth. under drought stress. Cell Biochem. Biophys. 68, 587–595. doi: 10.1007/s12013-013-9746-x
Babele, P. K., Kudapa, H., Singh, Y., Varshney, R. K., Kumar, A. (2022). Mainstreaming orphan millets for advancing climate smart agriculture to secure nutrition and health. Front. Plant Sci. 13. doi: 10.3389/fpls.2022.902536
Bandyopadhyay, T., Muthamilarasan, M., Prasad, M. (2017). Millets for next generation climate-smart agriculture. Front. Plant Sci. 8. doi: 10.3389/fpls.2017.01266
Bhowal, B., Bhattacharjee, A., Goswami, K., Sanan-Mishra, N., Singla-Pareek, S. L., Kaur, C., et al. (2021). Serotonin and melatonin biosynthesis in plants: genome-wide identification of the genes and their expression reveal a conserved role in stress and development. Int. J. Mol. Sci. 22, 11034. doi: 10.3390/ijms222011034
Chandel, G., Dubey, M., Gupta, S., Patil, A. H., Rao, A. R. (2017). Identification and characterization of a grain micronutrient-related OsFRO2 rice gene ortholog from micronutrient-rich little millet (Panicum sumatrense). 3 Biotech. 7, 1–9. doi: 10.1007/s13205-017-0656-2
Chandra, A. K., Pandey, D., Tiwari, A., Sharma, D., Agarwal, A., Sood, S., et al. (2020). An omics study of iron and zinc homeostasis in finger millet: biofortified foods for micronutrient deficiency in an era of climate chan? OMICS 24, 688–705. doi: 10.1089/omi.2020.0095
Das, R. R., Pradhan, S., Parida, A. (2020). De-novo transcriptome analysis unveils differentially expressed genes regulating drought and salt stress response in Panicum sumatrense. Sci. Rep. 10, 1–14. doi: 10.1038/s41598-020-78118-3
Desai, H., Hamid, R., Ghorbanzadeh, Z., Bhut, N., Padhiyar, S. M., Kheni, J., et al. (2021). Genic microsatellite marker characterization and development in little millet (Panicum sumatrense) using transcriptome sequencing. Sci. Rep. 11, 1–14. doi: 10.1038/s41598-021-00100-4
Finotello, F., Di Camillo, B. (2015). Measuring differential gene expression with RNA-seq: challenges and strategies for data analysis. Brief Funct. Genomics 14, 130–142. doi: 10.1093/bfgp/elu035
Girish, C., Meena, R. K., Mahima, D., Mamta, K. (2014). Nutritional properties of minor millets: neglected cereals with potentials to combat malnutrition. Curr. Sci. 107, 1109–1111.
Gomez, M., Gupta, S. Oxford (2003). “Millets,” in Encyclopedia of food sciences and nutrition, 2nd ed. Oxford: Academic Press 3974–3979. doi: 10.1016/B0-12-227055-X/00791-4
Himanshu, K., Chauhan, M., Sonawane, S. K., Arya, S. S. (2018). Nutritional and nutraceutical properties of millets: a review. Clin. J. Nutr. Diet 1, 1–10.
Howlader, J., Robin, A. H. K., Natarajan, S., Biswas, M. K., Sumi, K. R., Song, C. Y., et al. (2020). Transcriptome analysis bRNAnA–seq rRNAals genes related to plant height in two sets of parent-hybrid combinations in Easter lily (Lilium longiflorum). Sci. Rep. 10, 1–15. doi: 10.1038/s41598-020-65909-x
Koshimizu, S., Nakamura, Y., Nishitani, C., Kobayashi, M., Ohyanagi, H., Yamamoto, T., et al. (2019). TRANSNAP: A web database providing comprehensive information on Japanese pear transcriptome. Sci. Rep. 9, 1–8. doi: 10.1038/s41598-019-55287-4
Kulkarni, K. S., Zala, H. N., Bosamia, T. C., Shukla, Y. M., Kumar, S., Fougat, R. S., et al. (2016). De novo transcriptome sequencing to dissect candidate genes associated with pearl millet-downy mildew (Sclerospora graminicola sacc.) interaction. Front. Plant Sci. 7. doi: 10.3389/fpls.2016.00847
Kumar, A., Tomer, V., Kaur, A., Kumar, V., Gupta, K. (2018). Millets: a solution to agrarian and nutritional challenges. Agric. Food Secur. 7, 1–15. doi: 10.1186/s40066-018-0183-3
Lata, C. (2015). Advances in omics for enhancing abiotic stress tolerance in millets. Proc. Indian Natl. Sci. Acad. 81, 397–417. doi: 10.16943/ptinsa/2015/v81i2/48095
Li, Y., Wang, X., Chen, T., Yao, F., Li, C., Tang, Q., et al. (2015). RNA-Seq based de novo transcriptome assembly and gene discovery of Cistanche deserticola fleshy stem. PloS One 10, 125722. doi: 10.1371/journal.pone.0125722
Lowe, R., Shirley, N., Bleackley, M., Dolan, S., Shafee, T. (2017). Transcriptomics technologies. PloS Comput. Biol. 13, 1005457. doi: 10.1371/journal.pcbi.1005457
Lu, H. P., Luo, T., Fu, H. W., Wang, L., Tan, Y. Y., Huang, J. Z., et al. (2018). Resistance of rice to insect pests mediated by suppression of serotonin biosynthesis. Nat. Plants 4, 338–344. doi: 10.1038/s41477-018-0152-7
Makita, Y., Shimada, S., Kawashima, M., Kondou-Kuriyama, T., Toyoda, T., Matsui, M. (2015). MOROKOSHI: transcriptome database in Sorghum bicolor. Plant Cell Physiol. 56, e6. doi: 10.1093/pcp/pcu187
Natesan, S., Venugopalan, G., Selvamani, S. B., Angamuthu, N. (2020). Characterization of little millet (Panicum sumatrense) varieties using morphological descriptors and SSR based DNA fingerprinting. J. Phytol. 12, 29–34. doi: 10.25081/jp.2020.v12.6317
Pandian, B. A., Sathishraj, R., Djanaguiraman, M., Prasad, P. V., Jugulam, M. (2020). Role of cytochrome P450 enzymes in plant stress response. Antioxid. 9, 454. doi: 10.3390/antiox9050454
Prabha, V. V., Varanavasiappan, S., Raveendran, M., Jeyakumar, P. (2017). Analysis of iron and zinc homeostasis in barnyard millet through transcriptome and ionome approach. Can. J. Biotech. 1, 209. doi: 10.24870/cjb.2017-a194
Pujar, M., Gangaprasad, S., Govindaraj, M., Gangurde, S. S., Kanatti, A., Kudapa, H. (2020). Genome-wide association study uncovers genomic regions associated with grain iron, zinc, and protein content in pearl millet. Sci. Rep. 10, 1–15. doi: 10.1038/s41598-020-76230-y
Robinson, A. J., Tamiru, M., Salby, R., Bolitho, C., Williams, A., Huggard, S., et al. (2018). AgriSeqDB: An online RNA-seq database for functional studies of agriculturally relevant plant species. BMC Plant Biol. 18, 1–8. doi: 10.1186/s12870-018-1406-2
Sablok, G., Hayward, R. J., Davey, P. A., Santos, R. P., Schliep, M., Larkum, A., et al. (2018). SeagrassDB: An open-source transcriptomics landscape for phylogenetically profiled seagrasses and aquatic plants. Sci. Rep. 8, 1–10. doi: 10.1038/s41598-017-18782-0
Satyavathi, C. T., Tomar, R. S., Ambawat, S., Kheni, J., Padhiyar, S. M., Desai, H., et al. (2022). Stage specific comparative transcriptomic analysis to reveal gene networks regulating iron and zinc content in pearl millet [Pennisetum glaucum (L.) r. br.]. Sci. Rep. 12, 1–13. doi: 10.1038/s41598-021-04388-0
Sebastin, R., Lee, G. A., Lee, K. J., Shin, M. J., Cho, G. T., Lee, J. R., et al. (2018). The complete chloroplast genome sequences of little millet (Panicum sumatrense Roth ex roem. and Schult.)(Poaceae). Mitochondrial DNA B. Resour. 3, 719–720. doi: 10.1080/23802359.2018.1483771
Sheng, M., She, J., Xu, W., Hong, Y., Su, Z., Zhang, X. (2020). HpeNet: Co-expression network database for de novo transcriptome assembly of Paeonia lactiflora pall. Front. Genet. 11. doi: 10.3389/fgene.2020.570138
Shinozaki, K., Yamaguchi-Shinozaki, K. (2007). Gene networks involved in drought stress response and tolerance. J. Exp. Bot. 58, 221–227. doi: 10.1093/jxb/erl164
Shivhare, R., Lakhwani, D., Asif, M. H., Chauhan, P. S., Lata, C. (2020). De novo assembly and comparative transcriptome analysis of contrasting pearl millet (Pennisetum glaucum l.) genotypes under terminal drought stress using illuminaina sequencing. Nucleus 63, 341–352. doi: 10.1007/s13237-020-00324-1
Sobreiro, M. B., Collevatti, R. G., Dos Santos, Y. L., Bandeira, L. F., Lopes, F. J., Novaes, E. (2021). RNA-Seq reveals different responses to drought in Neotropical trees from savannas and seasonally dry forests. BMC Plant Biol. 21, 1–17. doi: 10.1186/s12870-021-03244-7
Sun, M., Huang, D., Zhang, A., Khan, I., Yan, H., Wang, X., et al. (2020). Transcriptome analysis of heat stress and drought stress in pearl millet based on pacbio full-length transcriptome sequencing. BMC Plant Biol. 20, 1–15. doi: 10.1186/s12870-020-02530-0
Suresh, B. V., Choudhary, P., Aggarwal, P. R., Rana, S., Singh, R. K., Ravikesavan, R., et al. (2022). De novo transcriptome analysis identifies key genes involved in dehydration stress response kodo millet (Paspalum scrobiculatum l.). Genomics 114, 110347. doi: 10.1016/j.ygeno.2022.110347
Sushmitha, B., Arun, P. H., Dubey, M., Chandel, G. (2018). Transcript analysis of the known moisture stress responsive gene orthologs among different genotypes of little millet, Panicum sumatrense. Biosc. Biotech. Res. Commun. 11, 335–346. doi: 10.21786/bbrc/11.2/21
Thulasinathan, T., Jain, P., Yadav, A. K., Kumar, V., Sevanthi, A. M., Solanke, A. U. (2022). “Current status of bioinformatics resources of small millets,” in Omics of climate resilient small millets (Singapore: Springer), 221–234.
Vetriventhan, M., Upadhyaya, H. D., Azevedo, V. C., Allan, V., Anitha, S. (2021). Variability and trait-specific accessions for grain yield and nutritional traits in germplasm of little millet (Panicum sumatrense roth. ex. roem. & schult.). Crop Sci. 61, 2658–2679. doi: 10.1002/csc2.20527
Yu, Y., Zhang, H., Long, Y., Shu, Y., Zhai, J. (2022). Plant public RNA-seq database: a comprehensive online database for expression analysis of~ 45 000 plant public RNA-seq libraries. Plant Biotechnol. J. 20, 806–808. doi: 10.1111/pbi.13798
Zhang, H. W., Pan, X. W., Li, Y. C., Wan, L. Y., Li, X. X., Huang, R. F. (2012). Comparison of differentially expressed genes involved in drought response between two elite rice varieties. Mol. Plant 5, 1403–1405. doi: 10.1093/mp/sss053
Keywords: transcriptome, database, Little Millet, LMTdb, DEGs, SSRs, functional annotation, metabolic pathway
Citation: Shekhar S, Prasad AS, Banjare K, Kaushik A, Mannade AK, Dubey M, Patil A, Premi V, Vishwakarma AK, Sao A, Saxena RR, Dubey A and Chandel G (2023) LMTdb: A comprehensive transcriptome database for climate-resilient, nutritionally rich little millet (Panicum sumatrense). Front. Plant Sci. 14:1106104. doi: 10.3389/fpls.2023.1106104
Received: 23 November 2022; Accepted: 21 February 2023;
Published: 09 March 2023.
Edited by:
Salej Sood, Indian Council of Agricultural Research (ICAR), IndiaReviewed by:
Supriya Ambawat, ICAR-AICRP, IndiaCopyright © 2023 Shekhar, Prasad, Banjare, Kaushik, Mannade, Dubey, Patil, Premi, Vishwakarma, Sao, Saxena, Dubey and Chandel. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Girish Chandel, Z2hjaGFuZGVsQGdtYWlsLmNvbQ==
†These authors contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.