 Miguel Angel Raffo
Miguel Angel Raffo Pernille Sarup
Pernille Sarup Jeppe Reitan Andersen
Jeppe Reitan Andersen Jihad Orabi
Jihad Orabi Ahmed Jahoor
Ahmed Jahoor Just Jensen
Just Jensen
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Plant Sci. , 02 September 2022
Sec. Plant Breeding
Volume 13 - 2022 | https://doi.org/10.3389/fpls.2022.939448
Multi-trait and multi-environment analyses can improve genomic prediction by exploiting between-trait correlations and genotype-by-environment interactions. In the context of reaction norm models, genotype-by-environment interactions can be described as functions of high-dimensional sets of markers and environmental covariates. However, comprehensive multi-trait reaction norm models accounting for marker × environmental covariates interactions are lacking. In this article, we propose to extend a reaction norm model incorporating genotype-by-environment interactions through (co)variance structures of markers and environmental covariates to a multi-trait reaction norm case. To do that, we propose a novel methodology for characterizing the environment at different growth stages based on growth degree-days (GDD). The proposed models were evaluated by variance components estimation and predictive performance for winter wheat grain yield and protein content in a set of 2,015 F6-lines. Cross-validation analyses were performed using leave-one-year-location-out (CV1) and leave-one-breeding-cycle-out (CV2) strategies. The modeling of genomic [SNPs] × environmental covariates interactions significantly improved predictive ability and reduced the variance inflation of predicted genetic values for grain yield and protein content in both cross-validation schemes. Trait-assisted genomic prediction was carried out for multi-trait models, and it significantly enhanced predictive ability and reduced variance inflation in all scenarios. The genotype by environment interaction modeling via genomic [SNPs] × environmental covariates interactions, combined with trait-assisted genomic prediction, boosted the benefits in predictive performance. The proposed multi-trait reaction norm methodology is a comprehensive approach that allows capitalizing on the benefits of multi-trait models accounting for between-trait correlations and reaction norm models exploiting high-dimensional genomic and environmental information.
Genomic selection (GS, Meuwissen et al., 2001) is an efficient selection method based on whole-genome prediction (WGP) that has been successfully applied for a variety of complex traits in animals and plants (De los Campos et al., 2009; Hayes and Goddard, 2010; Gianola and Rosa, 2015; Crossa et al., 2017). Over the last few decades, genomic models have been extended to accommodate greater availability of data from new technologies and increasing computational resources that allow incorporation of high dimensional data. In plant breeding, there has been an increasing interest in using multi-trait (MT) multi-environmental (ME) models over single-trait (ST) single-environmental models, as it may result in an improvement in accuracy of selection and prediction (Malosetti et al., 2007; Montesinos-Lopez et al., 2016; Montesinos-Lopez et al., 2019). MTME models combine the benefits of exploiting between-trait correlations from MT models and characterizing genotype-by-environment interactions (G×E) from ME evaluations. Efficient G×E modeling is required to counteract the negative impacts of climate change, either by selecting more resilient lines with decreased G×E or by developing lines well adapted to specific environments.
The advantages of MT models lie in that they can represent and exploit the correlation between traits, which can increase prediction accuracy and reduce bias in predictions compared to single-trait models (Henderson and Quaas, 1976; Pollak et al., 1984). The use of between-trait correlations is especially beneficial to enhance accuracy of predicted breeding values when genetic and environmental correlations are of opposite sign, and when MT models are used to infer low-heritability traits genetically correlated with high-heritability traits (Thompson and Meyer, 1986; Jia and Jannink, 2012; Jiang et al., 2015). However, MT models increase statistical complexity in the number of parameters to estimate, which could reduce the accuracy of estimation and their benefits for prediction (Haile et al., 2018; Lado et al., 2018). MT models are also useful for predicting genetic values of individuals not phenotyped for specific traits of interest but having phenotypic records for correlated traits. This may represent an additional advantage for the MT analysis, particularly if the trait of interest is difficult to measure or has high phenotyping cost.
Modeling G×E has been valuable for wheat genomic prediction (GP), as it has shown increases in prediction accuracy ranging from 10 to 40 % (reviewed by Crossa et al., 2017) and allows prediction of breeding values for lines not tested in the target environment, but genetically related with other tested lines. G×E can be identified in ME evaluations and incorporated into statistical models to detect the responses of genotypes to changing environments (also termed Macro-environmental sensitivity); the differential response of genotypes to environments is called the reaction norm (RN, Falconer, 1990; Falconer and Mackay, 1996; Calus and Veerkamp, 2003). The G×E can be modeled in an RN framework as a function of markers and environmental covariates (ECs) collected from weather stations (e.g., temperature, precipitation, solar radiation) and soil characterization (e.g., water storage capacity, sand content, hydraulic conductivity). However, given the high dimensional nature of genomic data and ECs, modeling marker × ECs interactions can lead to computational challenges.
A computationally efficient approach to quantify the G×E is using (co)variance structures. Burgueño et al. (2012) model G×E in a ME version of the genomic best linear unbiased predictor model (G-BLUP), where (co)variances structures of molecular markers and pedigree were used to represent genetic relationships within environments. The Burgueño et al. (2012) approach can also be seen as an MT methodology since environments were considered different traits, representing heterogeneous variance and covariances among environments. However, their approach did not include ECs to model G×E. Jarquin et al. (2014) developed an RN model, where the main and interaction effects of markers and ECs were introduced using high-dimensional (co)variance structures of markers and ECs. The ECs were specifically computed for different phenological stages summarizing water availability, temperature, and radiation. A similar definition of ECs has been implemented by Heslot et al. (2014), but the phenological stages were simulated using crop modeling instead of the empirical measure of phenology. Such approaches can be interpreted as RN models (Falconer, 1990; Falconer and Mackay, 1996; Calus and Veerkamp, 2003; Su et al., 2006) since phenotypes are -implicitly- linearly regressed on ECs. The RN model proposed by Jarquin et al. (2014) has been applied successfully in breeding programs of cotton and wheat (Pérez-Rodríguez et al., 2015; Crossa et al., 2016) and has recently been applied in combination with historical weather records and simulation to tackle the problem of predicting cultivars’ future performance under uncertain conditions (De Los Campos et al., 2020). Other methods have also been proposed to incorporate marker by environment interaction into the GS framework, for instance, models using Gaussian Kernel (Cuevas et al., 2016; Cuevas et al., 2017) or deep learning methodologies (Montesinos-Lopez et al., 2018) and have been successfully applied for GP.
Approaches for incorporating both MT and ME information in GS have been developed using different methodologies (Malosetti et al., 2007; Montesinos-Lopez et al., 2016; Montesinos-Lopez et al., 2019; Ward et al., 2019). However, to the best of our knowledge MT reaction norm models (MTRN) incorporating ECs information are lacking. In our study, we propose to extend a RN model incorporating G×E through high-dimensional (co)variance structures of markers and ECs (Jarquin et al., 2014; Pérez-Rodríguez et al., 2015; De Los Campos et al., 2020) to the MT case (MTRN). To do that, we propose a novel methodology for characterizing the environment at different growth stages based on growth degree-days (GDD) instead of phenological stages. Thus, GDD periods (e.g., computed each 100-GDD) encompassing the crop stages throughout the full season can be used. The GDD have been broadly recognized as one of the main forces driving phenology in wheat (Nuttonson, 1955; Slafer and Rawson, 1994; Salazar-Gutierrez et al., 2013; Aslam et al., 2017). We hypothesize that using GDD to define wheat growth periods can be useful for several reasons:
I. It simplifies the implementation of RN models since phenological records or crop simulations are no longer needed to infer the phenology of the lines. This may be convenient for wheat breeding because, in most cases, the full phenological stages are not recorded, or alternatively, it avoids the use of crop simulations that can represent a challenge for breeders since crop simulations are not commonly used in breeding programs.
II. GDD periods represent a convenient approach to deal with the differences in growth stages of breeding lines. Accurately capturing differences in the growth stages of breeding lines can be difficult using crop simulation because the critical periods for different breeding lines can occur at different moments within the same environment (year-location combinations). Nevertheless, this is no longer a problem when GDD periods are used.
III. Using GDD periods can be helpful when ECs is determined for traits where the relationships between the environmental conditions and resulting phenotype are not well established; while this may not represent a problem for wheat grain yield since these relationships have been extensively defined (Meynard and Sebillotte, 1994), it can be relevant for quality or diseases traits.
In addition, the proposed MTRN model using (co)variance structures to incorporate G×E represent a convenient choice to reduce the high demand on computational resources, which have often been a relevant restriction for developing MTME models. This study uses a large set of winter wheat breeding lines phenotyped for grain yield and protein content in multiple environments. The proposed models were evaluated for both traits using cross-validation (CV) and trait-assisted genomic prediction (TA-GP) in two prediction scenarios relevant to plant breeders: (i) predicting the performance of breeding lines that have been tested in some environments but not in others (CV1, leave-one-year-location-out), and (ii) predicting the performance of new lines across breeding cycles (CV2, leave-one-breeding-cycle-out). The TA-GP was performed considering the phenotypes of the additional trait to exploit between-trait correlations, which is intended to improve predictions of breeding values for the trait of interest.
In this study, 2,015 sixth-generation (F6) winter wheat lines (T. aestivum L.) from the breeding company Nordic Seed A/S were used; a subset of these data has been used in earlier studies (Cericola et al., 2017; Kristensen et al., 2018; Tsai et al., 2020; Raffo et al., 2022). The breeding lines came from seven breeding cycles (BC) tested in years 2014–2019, and each breeding cycle originated from approximately 60 parental line-crosses followed by five generations of selfing, including creating single seed descent (SSD) lines in generation F4. Each BC were composed of around 330 lines sown in one or 2 years (cycle 1: 2014, cycle 2: 2014–2015, cycle 3: 2015–2016, cycle 4: 2016–2017, cycle 5: 2017, cycle 6: 2018, cycle 7: 2019) at three locations in Denmark (DK): Odder (Central DK), Holeby (South DK), and Skive (North-west DK). For breeding cycles from 2014 to 2016 (cycle 2, 3 and 4) lines were tested in 2 years instead of one in order to have a quick construction of a reliable training population for genomic prediction. Each year the field trials were designed in 15 blocks of 46 line plots of 8.25 m2, having two replicates of 21 F6 lines and two checks randomly assigned per year-location combination. The traits analyzed were grain yield measured as kg per plot (8.25 m2) and protein content (%) determined by near-infrared spectroscopy (NIRS), and both traits were chosen according to their high relevance for breeding. Similar agronomic management was applied for all trials (e.g., sowing and assessment time, fertilization, application of treatments etc.).
A modified CTAB method was used to perform DNA extractions (Rogers and Bendich, 1985). The plant material was genotyped using the 15K Illumina Infinium iSelect HD Custom Genotyping BeadChip technology (Wang et al., 2014). Quality control was carried out by removing genotyped SNPs with minor allele frequency (MAF) lower than 5% and call rate lower than 0.90. In total, 12,893 SNPs remained after quality control.
Climatic variables were collected on a daily basis and described temperature, relative humidity, wind speed, vapour-pressure deficit, and global radiation from weather stations within 20 km from field trials; precipitation within 10 km; minimum and maximum temperature and potential evaporation from the closest weather stations located in Silstrup, Askov, and Flakkebjerg for Skive, Dyngby, and Holeby, respectively (Plauborg, pers. comm.). Soil information was available in each locality for depths 0–30, 30–60, 60–100, 100–200 cm and described texture (clay, sand, silt), carbon content, hydraulic conductivity and plant available water (Adhikari et al., 2013; Kotlar et al., 2020).
The climatic variables were used to compute ECs summarizing environmental descriptors linked to water availability, radiation, and temperature at different crop stages (see Figure 1 and Table 1), which together with the soil information, were used to describe the environments at the level of year-location. The crop stages were defined each 100 GDD, where GDD were estimated as the thermal sum of daily average temperature over 0°C (McMaster and Wilhelm, 1997; Salazar-Gutierrez et al., 2013) from sowing date until August 15 (estimated end of harvest season in Denmark). The 100-GDD stages were intended to summarize environmental conditions in short periods of days that encompass the crop phases throughout the full crop period. In total, 17 climatic variables were computed for each GDD stage, and seven soil variables specific for each locality were defined for four depths (0–30, 30–60, 60–100, 100–200 cm). Quality control of ECs was performed by removing variables with more than 10% of missing values (NA) or 30% of repeated values as indicated in Jarquin et al. (2014). After quality control, 300 climatic ECs from the first to the 27 GDD stages remained for each year-location combination plus 23 soil ECs (300 climatic ECs + 23 soil ECs = 323 ECs; see Supplementary material 1 for a complete description of variables obtained after quality control). Climatic ECs for GDD stages above 2,700 GDD did not pass quality control due to presenting more than 10% on NA values. The maturity date was simulated for the different environments following Pullens et al. (2021), and it was confirmed that all relevant growth stages until maturity were within the 27 GDD stages obtained after quality control.
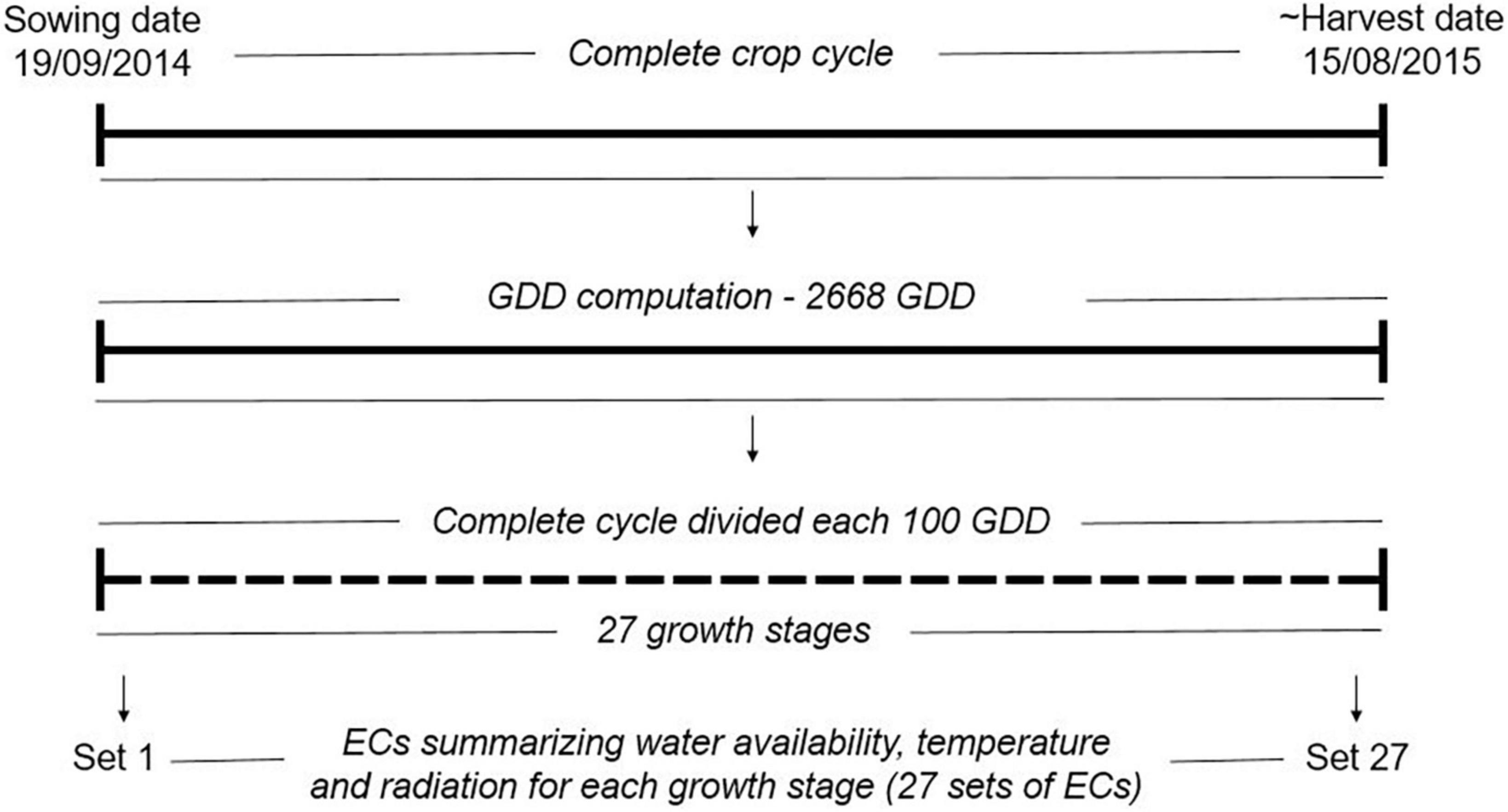
Figure 1. Computation of growth stages and environmental covariates (ECs) for year 2014 in the locality of Skive. In total, the complete crop cycle was divided into 27 shorter periods of 100 GDD (27 growth stages). For each growth stage, a set of ECs summarizing environmental descriptors linked to water availability, radiation and temperature were computed as described in Supplementary material 1. The same approach was used for all year-location combinations. GDD: growth degree days, the GDD were estimated as the thermal sum of daily average temperature over 0°C.

Table 1. Environmental covariates (ECs) description, modified from Lecomte (2005) and Heslot et al. (2014).
In this study, five models were proposed to evaluate the effect of including G×E interaction and MT modeling for grain yield and protein content. The full data set was used for VCs estimation to obtain estimates as accurate as possible. First, a baseline mixed model without genomic information (M1) was used as a starting point for constructing the other models; a similar baseline model has been used in earlier works with Nordic Seed A/S data (Cericola et al., 2017; Tsai et al., 2020). Second, the baseline model was extended by a genomic [SNPs] effect (M2), capturing the main additive genetic effects (Habier et al., 2007; VanRaden, 2008). Third, a G×E effect based on genomic [SNPs] by ECs interactions extended M2 to the RN framework (M3). Lastly, M2 and M3 were extended to the MT case (M4 and M5, respectively), considering grain yield and protein content. A detailed model description is provided below.
The M1 (Equation 1) is a mixed model considering the main sources of variability affecting the data and the experimental design. It was defined as:
where yn is the vector of phenotypes for grain yield (n = 1) or protein content (n = 2); X and Zn(n = 1, 2, 3) are design matrices for fixed and random effects, respectively; b is the vector of fixed trial effects nested within year-location-breeding cycle, which is intended to capture the variation due to overall effects of year, location, the interaction between year and location as well as effects of the spatial location of the trial within the field.; l is a vector of line effect with , where I is an identity matrix and is the variance due to uncorrelated line effects; f is a vector of line × environment interaction (L×E) with , where is the variance due to uncorrelated L×E effects; s is a vector of spatial effect, which follows a multivariate normal density (MVN) with , where S is a spatial relationship matrix and is the spatial effect variance. The spatial effect was defined as the combination of 9-spatial sub-components, where one sub-component is the spatial effect for the square centered on the plot of the observation (i.e., target plot), and the eight remaining sub-components are the spatial effects for the square centered on the eight plots surrounding the target plot (Figure 2). Virtual plots were added over trial borders and into empty spaces of the X by Y grid to control border effects and ensure all plots have eight surrounding plots. The spatial effects were identified by assigning a unique id given by its X (row) and Y (column) coordinates. The spatial relationship matrix S was computed as , where Xn× q is a n × q matrix, with n = number of observations (i.e., number of real plots), and q = number of real plus virtual plots. The Xn× q is an indicator matrix relating observations to spatial effects in S. A heatmap of the S matrix for a subset of the data (Dyngby, 2017) is shown in Figure 3. Additional explanations for the modeling of the spatial effect can be found in Tsai et al. (2020), where the spatial effect was equivalently modeled by the first time, but with the difference that for our case we used the relationship matrix S, and they used the regression of the 9-spatial covariates for each plot observation directly as random effects. However, although these two implementations are mathematically equivalent, our implementation is computationally faster. The e is a vector of random residuals with , where is the residual variance.
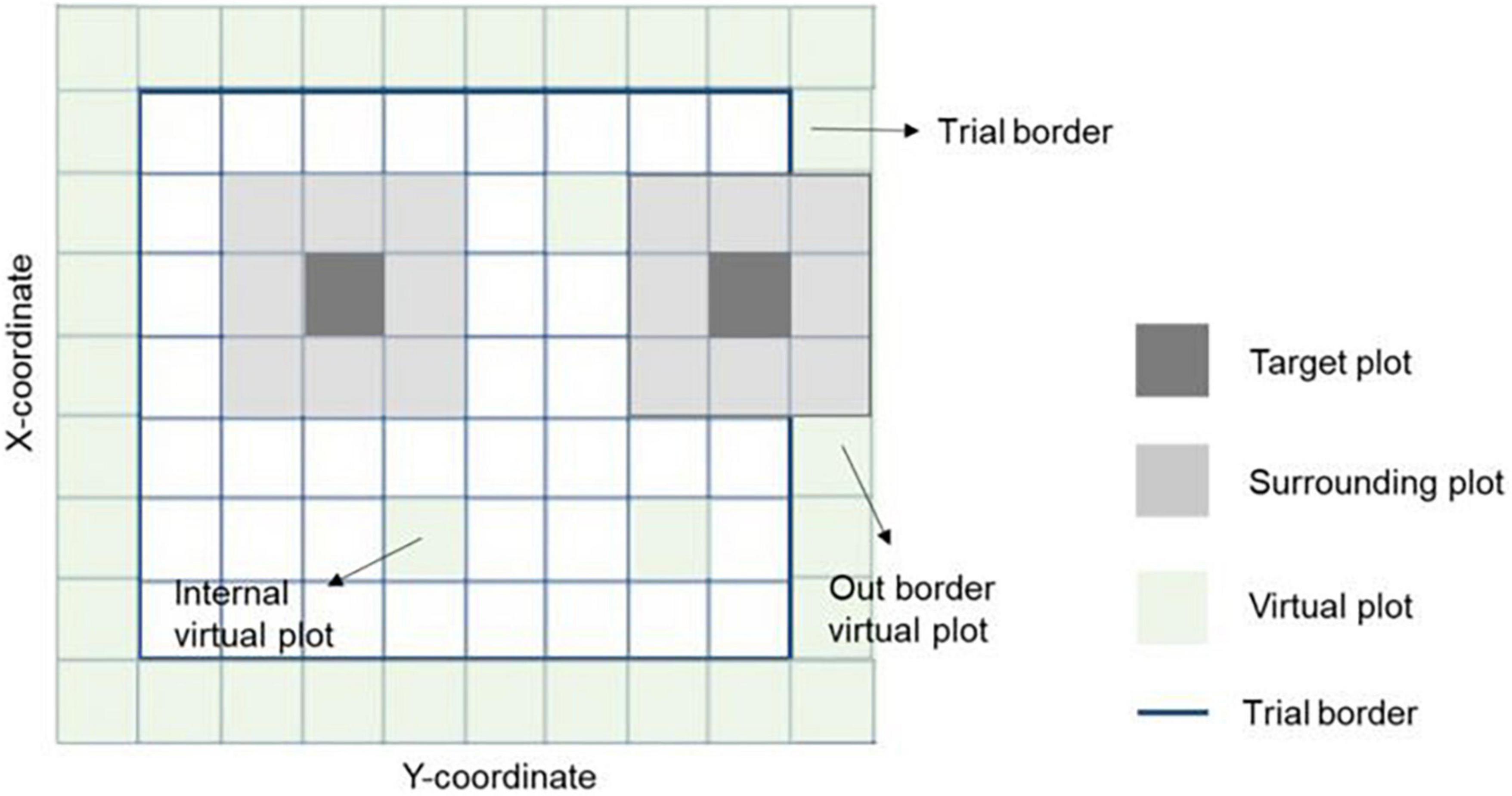
Figure 2. Representation of spatial information in a field trial. The target and eight surrounding plots were used together to correct the spatial variability across the field. The trial borders’ effect was considered by adding virtual plots to complete the eight surrounding plots for all observations. Virtual plots were also added in empty X-Y coordinates (with no plot observation registered) to ensure all plots have the eight surrounding plots. Hence, the spatial effects on an individual plot is the sum of effects with the square centered on the plot itself plus the effects of the eight surrounding plots with a square centered on those plots.
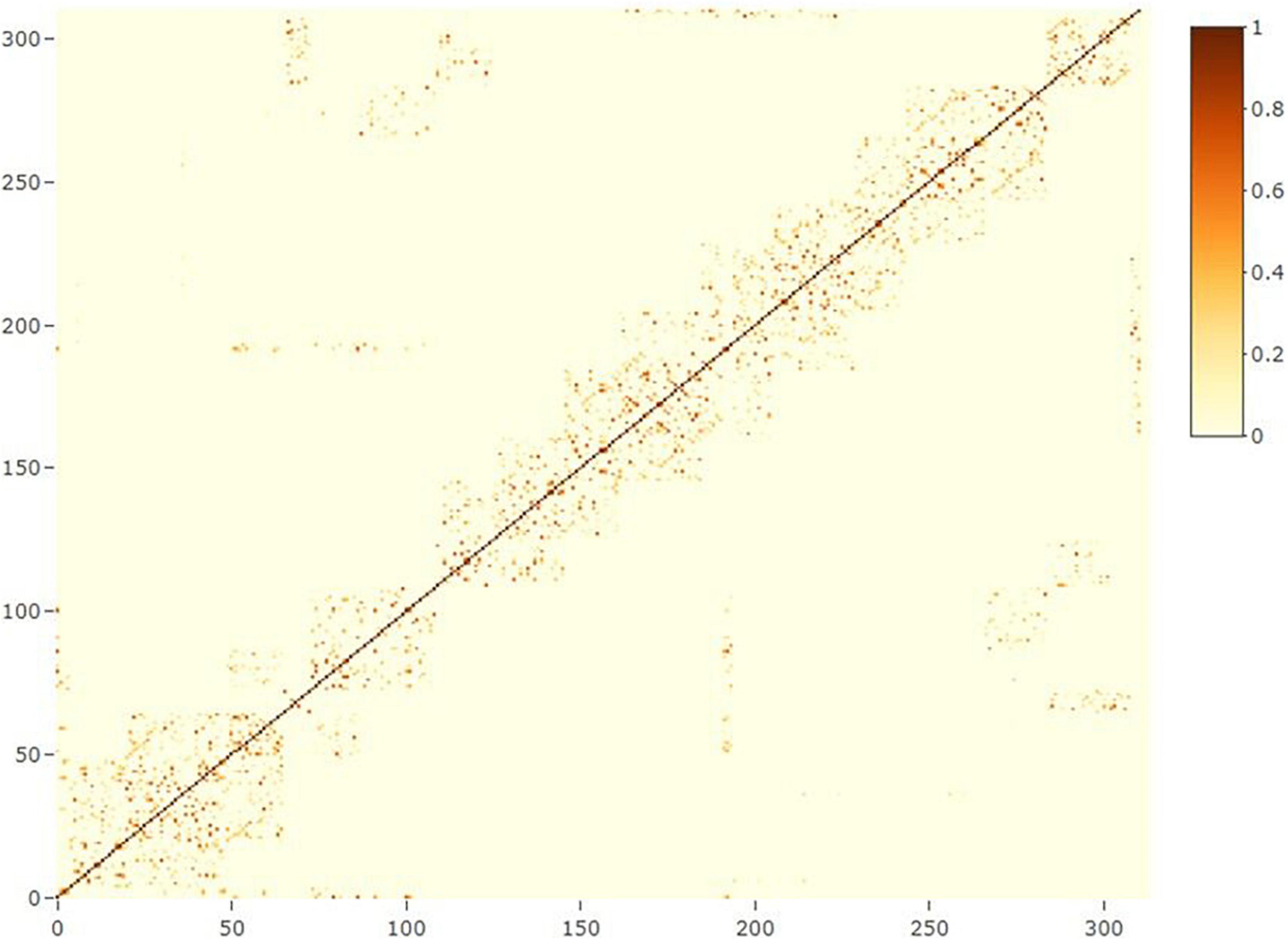
Figure 3. Heatmap of the spatial relationship matrix for locality Dyngby in the year 2017. A total of 311 plots were observed at Dyngby 2017, and the spatial relationship between plots are represented. Higher to lower relationships are represented from yellow to light-blue colors; the dark blue represents a lack of relationship between plots (not neighboring connections).
The M2 (Equation 2) extend M1 by adding a genomic [SNP] additive effect using the VanRaden (2008) genomic relationship matrix as (co)variance structure, and therefore, M2 can be seen as a G-BLUP model (Habier et al., 2007; VanRaden, 2008). M2 was defined as:
where yn, X, Zn, b, l, f, s, and e were defined as in M1; g is a vector of the genomic additive breeding values (GEBVs), with , is the genomic additive variance, and G is the genomic relationship matrix (GRM) based on the first method proposed by VanRaden (2008): , where pi is the minor allele frequency (MAF) of the ithSNP;Z is M−P; M is a SNP matrix coded −1, 0, 1, and P is a matrix with the MAF of SNP i calculated as 1(2(pi−0.5)) for column i.
The line effect (l) was kept in all genomic models since it is intended to capture non-additive variance and additive variance not captured by SNPs in the genomic effect; therefore, this model definition helps to improve the characterization for the specific additive genomic variance captured by the SNPs.
The narrow (h2) and broad-sense (H2) plot heritabilities were estimated for M2 as and , where d(G) is the mean diagonal value of G with d(G) = 1.869, the d(G) value can be interpreted as 1 plus the average genomic inbreeding coefficient for the population (VanRaden, 2008); and are the genomic estimated additive and line variance as defined for M2 and M1, respectively; is the estimated phenotypic variance of the plot calculated as: , with , d(G), , , , and as defined previously in M2 and M1. Note that h2 and H2 were reported at the plot level and not for family means as sometimes are used in plant breeding.
The M3 (Equation 3) is the most developed model in terms of definition of effects as it extends M2 by including a genomic [SNPs] × ECs interaction effect (gw), and therefore, it can be viewed as a linear RN model where the genetic and environmental gradients are specified as regressions on markers and ECs. As pointed in Jarquin et al. (2014) and Pérez-Rodríguez et al. (2015), the M3 uses the (co)variance patterns induced by linear-by-linear reaction norm, where the intercept of the reaction norm are implicitly in the main effects of lines and environment and the slope in the genomic [SNPs] × ECs interaction effect. The M3 was defined as:
where yn, X, Zn, b, l, f, s, g, and e were defined as in M1 and M2; gw is a vector of genomic [SNPs] additive × ECs interaction values with , where Zg is a design matrix connecting phenotypic observations with cultivars, G is the GRM, andΩ is the (co)variance matrix computed as in De Los Campos et al. (2020) and derived from ECs as , where Wnxq is a matrix of centered and scaled ECs with n rows (number of phenotypic observations) and q columns (number of ECs). The operator “°” represents the cell-by-cell (or Hadamard) product between matrices, and is the variance term associated with the genomic [SNPs] × ECs interaction effect.
Note that the inclusion of the line × environment interaction (f) and the genomic [SNPs] × ECs interaction effects together in M3 is justified since ECs do not capture all the environmental variability, and therefore, this definition of interactions with the environment contribute to specifying what is not captured by ECs. A similar concept is also extended to the main line effect (L) effect, which are present in all the defied models and are intended to cover the misspecification of the SNPs on genetic effects. The inclusion of an additional model term defining the main effect of ECs have also been used in previous works (Jarquin et al., 2014; Pérez-Rodríguez et al., 2015; De Los Campos et al., 2020); however, such an effect is not possible to estimate in our case since the main environmental effect is implicitly defined and estimated by the fixed effects of our models.
All models presented so far have been implemented in a single-trait (ST) approach for grain yield and protein content. In the following section we summarize the extension of ST models to the MT case.
The M2 and M3 were extended to the MT case by M4 and M5 (Equation 4), respectively. The MT models considered grain yield and protein content in a bivariate analysis. The MT methodology allows exploiting between traits (co)variances for the different model effects, which modified the definition of the random effects from ST models. Following, we present the definition of the effects for the M5 (the most developed model in terms of effects and traits included):
where yn, X, Zn, b, l, f, s, g, gw are the same as defined in the previous models for grain yield and protein content, except for the random effect variances which under the MT framework becomes: ∼NIID(0,I⊗L), where ⊗ denotes the Kronecker product, and L the line (co)variance matrix ∼NIID(0,I⊗F) with F the line × environment (co)variance matrix ; ∼MVN(0,S⊗H) with H the spatial (co)variance matrix ; ∼MVN(0,G⊗K) with K the genomic (co)variance matrix ; with P the genomic [SNPs] × ECs (co)variance matrix , and ∼NIID(0,I⊗R) with R the residual (co)variance matrix . Moreover, for MT models (M4-M5), we calculated the between-trait correlation for all model effects; for example, the genetic correlation was: , where COVg12 is the between-trait covariance for the genomic effect, and and are the variances associated to grain yield and protein content, respectively.
A summary of the effects included in the models and the ST or MT case is presented in Table 2. All proposed models were developed under the context of a multivariate normal distribution assuming Gaussian priors for random effects and the analyses were performed using the BGLR R package (Pérez and de los Campos, 2014) with 50,000 iterations, burn-in of 10,000, and a thinning of 10. The initial specifications in BGLR were set to an R2 = 0.90 to approximate the R2 expected of our models (known from previous data analysis using Average Information Restricted Maximum Likelihood, Cericola et al., 2017; Raffo et al., 2022) and degree of freedom (df) = 0.0001 to set uninformative priors. The posterior standard deviation (PSD) for VCs estimates was computed. In addition, the convergence on parameter estimation was analyzed using the package CODA in R (R Core Team, 2014) by estimating the Monte Carlo standard errors (MCMC error), effective sample (ESS) and by graphical analysis of Markov chains trace plots and posterior density plot. The convergence analysis is presented in Supplementary material 2.
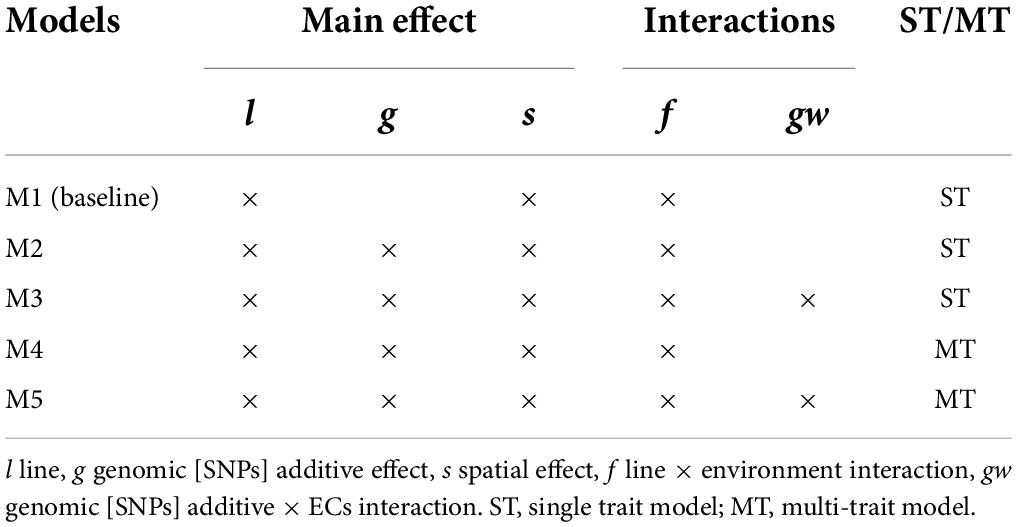
Table 2. Summary of the effect included in the models and single-trait (ST) or multi-trait (MT) case.
The predictive performance of the proposed models was evaluated using two CV approaches. The CV1 (leave-one-year-location-out) was carried out by masking the phenotypes of one year-location in the validation set and using the remaining phenotyped lines to predict the masked lines (Supplementary material 3). This process was repeated n times (n = number of year-locations = 17) until predictions for all year-locations were obtained. The CV1 simulates the prediction problem where breeding lines have been tested in some environments but not in others, and the genetic values for lines in the untested environment are desired. The CV2 (leave-one-breeding-cycle-out) was carried out by masking the phenotypes of one BC in the validation set and using the remaining phenotyped lines to predict the masked lines (Supplementary material 3). This process was repeated n-times (n = no. of breeding cycles = 7) until all BCs were predicted. The CV2 simulates the prediction problem where a new generation (newly developed lines) is predicted from parental and historical records. In addition, the MT models (M4-M5) were evaluated using TA-GP, where the phenotypic data in CV1 and CV2 was masked only for one of the traits in the validation set, and the phenotypes for the second trait were available for all lines.
The predictive ability (PA, ) of the models was calculated as the Pearson correlation between the average value of lines in each year-location after correcting by fixed effects and the vector of predictions [ and ]. The fixed effects were estimated for each model using the full dataset in order to obtain as accurate estimates as possible. The lines corrected by fixed effects were computed subtracting the fixed effects from each corresponding plot observation, and averaging the resulting lines values within year-locations. The PA was obtained for predictions of the main additive effect [] of M2, M3, M4, and M5, and for predictions of the main additive effect plus the genomic [SNPs] × ECs interactions effect [] for M3 and M5. We used an ordinary non-parametric bootstrap with replacement based on full sample size (n = 2,015), and 10,000 replicates to obtain PA standard errors. The PA between models was contrasted using a two-tailed paired t-test (critical P-value = 0.01). The maximum PA was calculated for g and g + gw predictions in the different models; for M2, M4 it was calculated as , where n was the average number of lines repetitions within year-location, was the family-based heritability and hence is affected by the experimental design (number of replications). For M3 and M5 it was calculated using the same formula but substituting with the proportion of total variance explained by the genomic additive plus the genomic interaction effects (genomic [SNPs] × ECs interaction).
A test for variance inflation in the predicted genetic effects was performed as the slope of the regression of predicted values obtained with whole information (subscript w, estimations with complete phenotypic information for all genotypes) on the estimated with partial information (subscript p, predictions for all genotypes from CVs when their phenotypes were masked): (Legarra and Reverter, 2018).
The descriptive statistics for grain yield and protein content are shown in Table 3. In total, 2,015 lines and 14,430 plot observations were obtained, and normal distribution was observed for both traits. Grain yield had an average value of 8.85 kg grain/8.25 m2 with a coefficient of variation of 11.63%. Protein content had an average value of 9.84%, with a coefficient of variation of 8.11%. The between traits correlation based on the observed phenotypes was in general negative for the different breeding cycles and had an average of −0.18 (Table 3). The variance for descriptive statistics was 1.06 for grain yield and 0.64 for protein content.
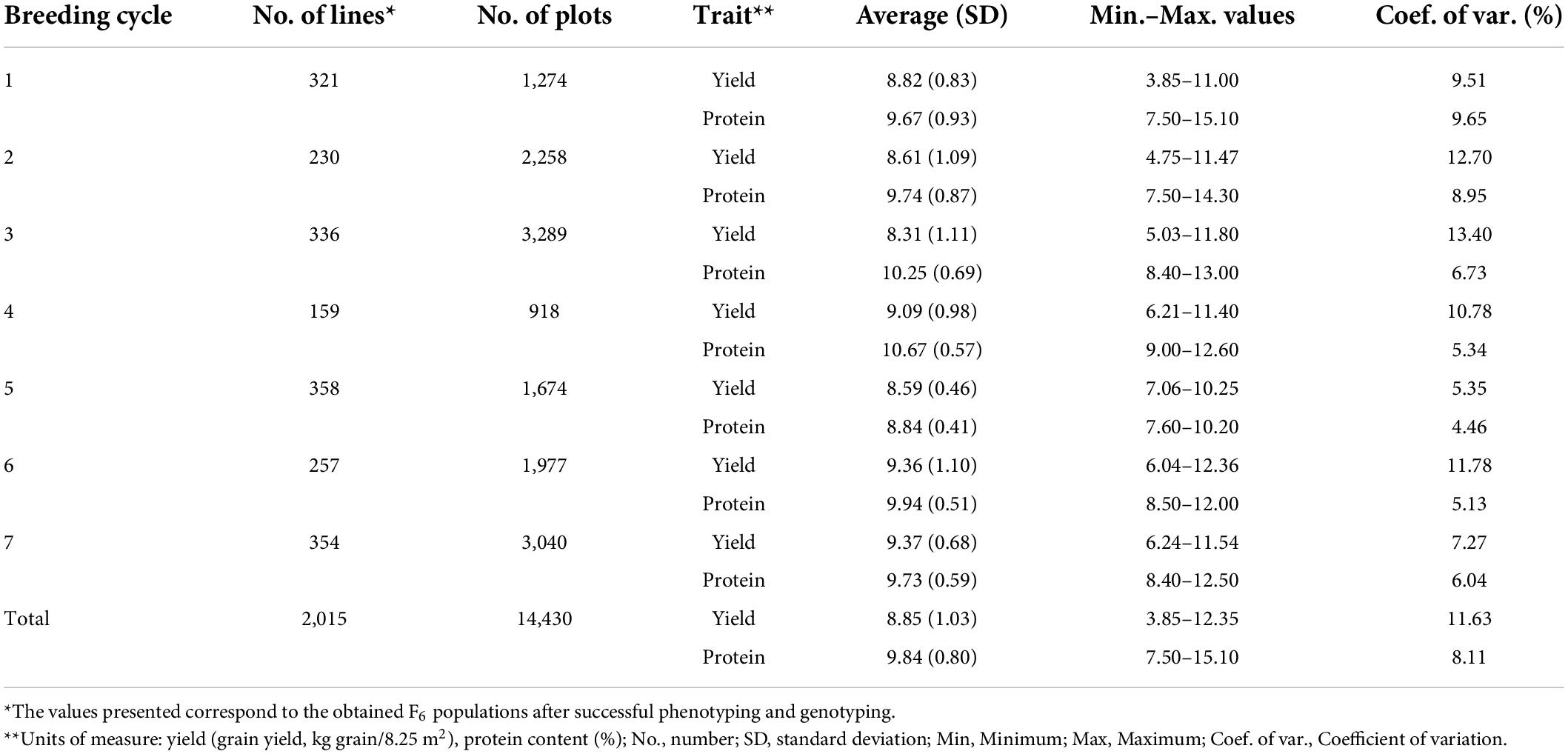
Table 3. Descriptive statistics for the grain yield and protein content of F6 wheat breeding lines.
Five proposed models differing in the incorporation (M2–M5) or not (M1) of genomic information, the incorporation of genomic [SNPs] × ECs interaction (M3 and M5), and the single-trait (M1, M2 and M3) or multi-trait case (M4 and M5) were used to estimate VCs for grain yield (Table 4) and protein content (Table 5).
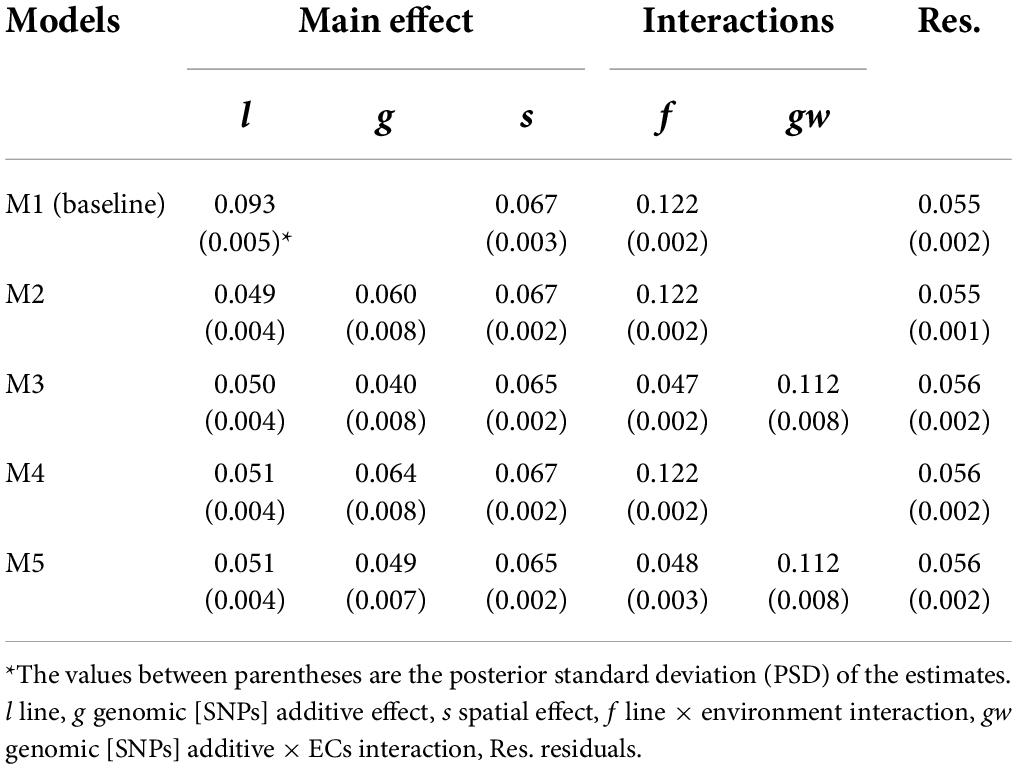
Table 4. Posterior mean of variance components for grain yield (kg grain/8.25 m2).
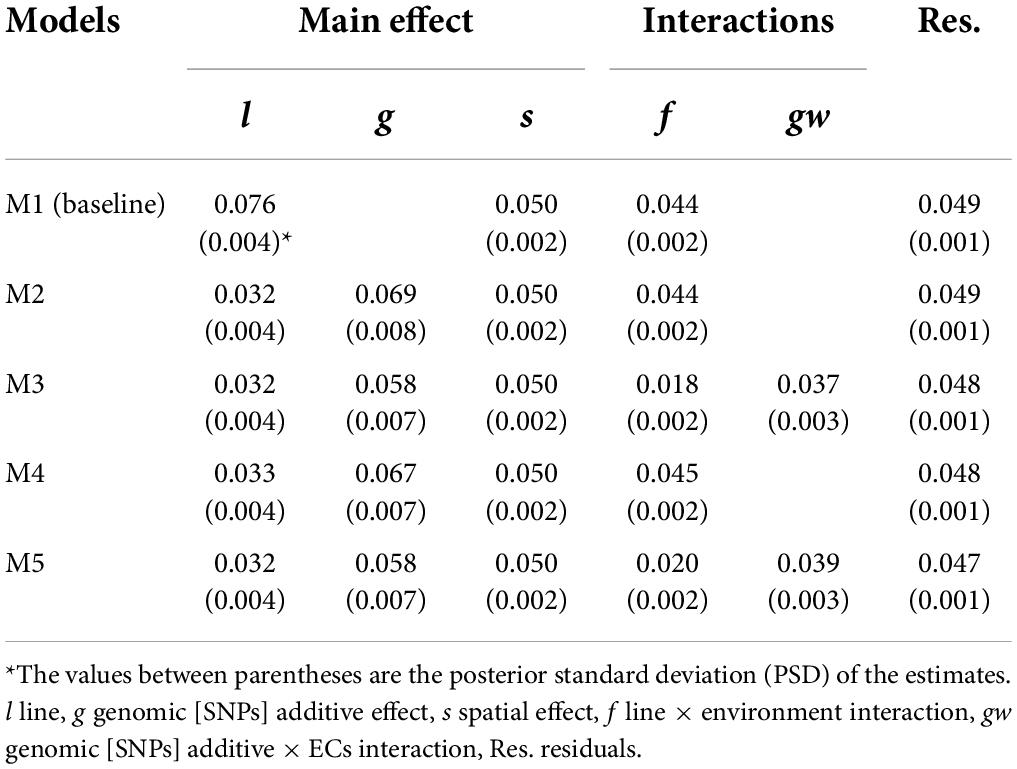
Table 5. Posterior mean of variance components for protein content (%).
The phenotypic variances () for the different models represented a proportion of 31.9–35.8 % and 34.1–38.4 % of the descriptive statistical variance for grain yield and protein content, respectively. The difference between the variance from descriptive statistics and can be attributed to the considerable amount of variation captured by the fixed effects. The M1 (model without genomic information) captured lower variance related to the main genetic effect than models including the additive genomic [SNPs] term. For example, comparing line variance from M1 to line plus genomic variance from M2, the M2 captured around 17 and 33 % more genetic variance for grain yield and protein content, respectively; this is attributed to correctly accounting for covariances among lines when the additive genomic [SNPs] effect is included in the models. The narrow- and broad-sense heritabilities at plot level were estimated using M2, and higher values were observed for protein content: h2 = 0.282 (PSD = 0.025) and H2 = 0.414 (PSD = 0.017) than for grain yield: h2 = 0.168 (PSD = 0.020), H2 = 0.307 (PSD = 0.153). The G×E variability was accounted for the line × environment (f) and genomic [SNPs] × ECs interaction (gw) effects, and a higher amount of G×E variance was observed for grain yield (~40% of ) than for protein content (~ 17% of ).
The VCs estimates for single-trait models M2 and M4 were similar to MT models M3 and M5, respectively. The between-trait correlations were analyzed for all terms in M3 and M5 (Table 6), and negative correlations were observed for all the effects. High negative between-trait correlations (>0.40) were observed for the main genetic model effects [line (l), additive (g)], and the interaction effects (line × environment (f), and genomic [SNPs] × ECs interaction (gw).
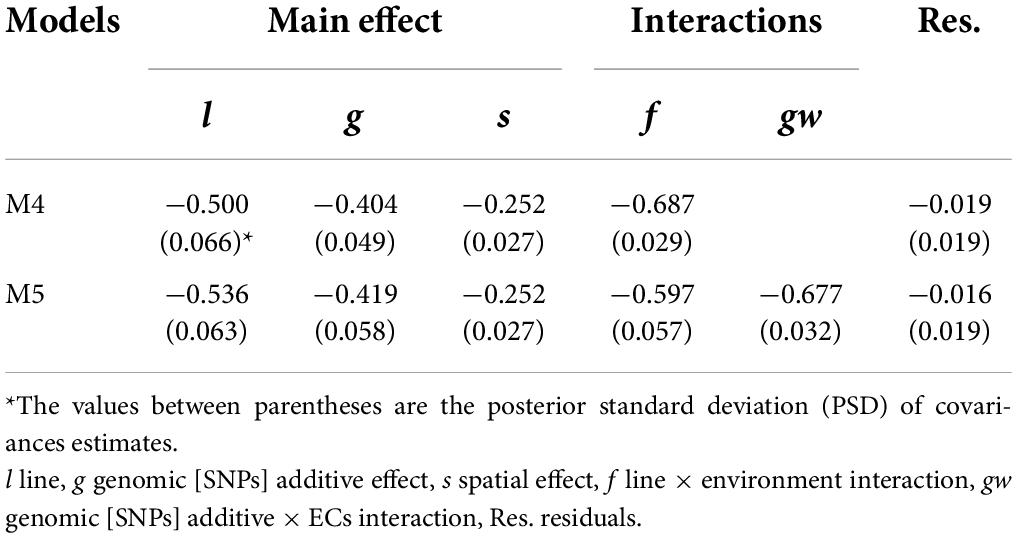
Table 6. Between-trait correlations for model effects of multi-trait models (M4 and M5).
The MCMC errors, effective sample (ESS), and graphical analysis of trace and posterior density plots were performed as control of convergence for VCs estimates (Supplementary material 2). The parameters estimated for all models had good convergence as revealed by the MCMC error in the order of 1 × 10–4 or lower, the high ESS, and the appropriate trace and posterior density plots.
The PAs () of M2 to M5 in leave-one-year-location-out (CV1) and leave-one-breeding-cycle-out (CV2) are shown in Figure 4 for grain yield and Figure 5 for protein content.
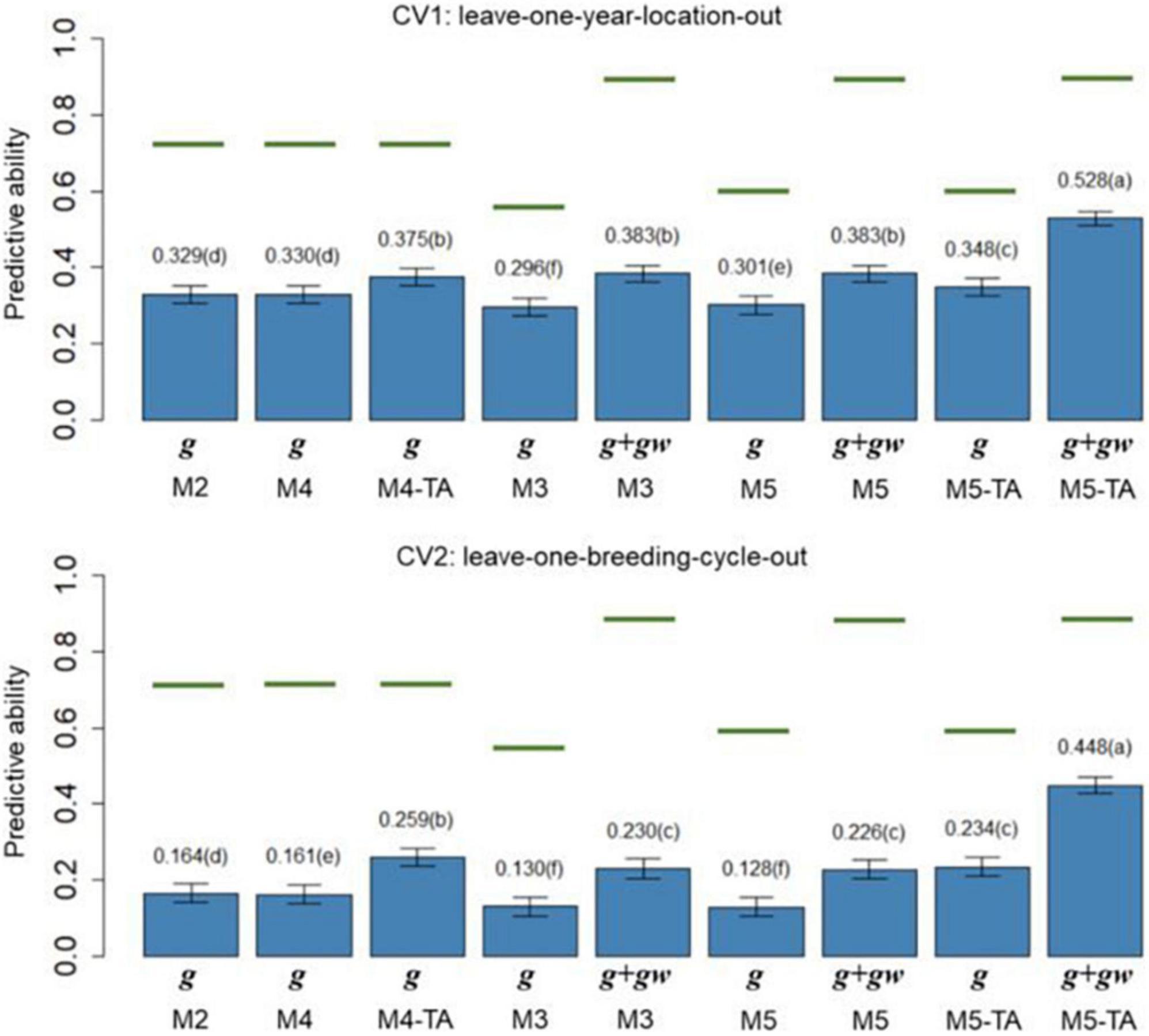
Figure 4. Barplot of predictive abilities (PAs) for grain yield in leave-one-year-location-out (CV1, upper panel) and leave-one-breeding-cycle-out (CV2, lower panel) cross-validations. M2: line + genomic [SNPs] additive effect + spatial effect + line × environment interaction. M3 expand M2 by adding a genomic [SNPs] additive × ECs interaction. M4 expand M2 to the multi-trait case. M4-TA is the M4 using trait-assisted (TA) genomic prediction. M5 expand M3 to the multi-trait case. M5-TA is the M4 using TA genomic prediction. Black bars are the 95% confidence interval. Differences in the letter above the bar represent significant differences between models (P-value < 0.01). Green lines are the theoretical maximum PAs.
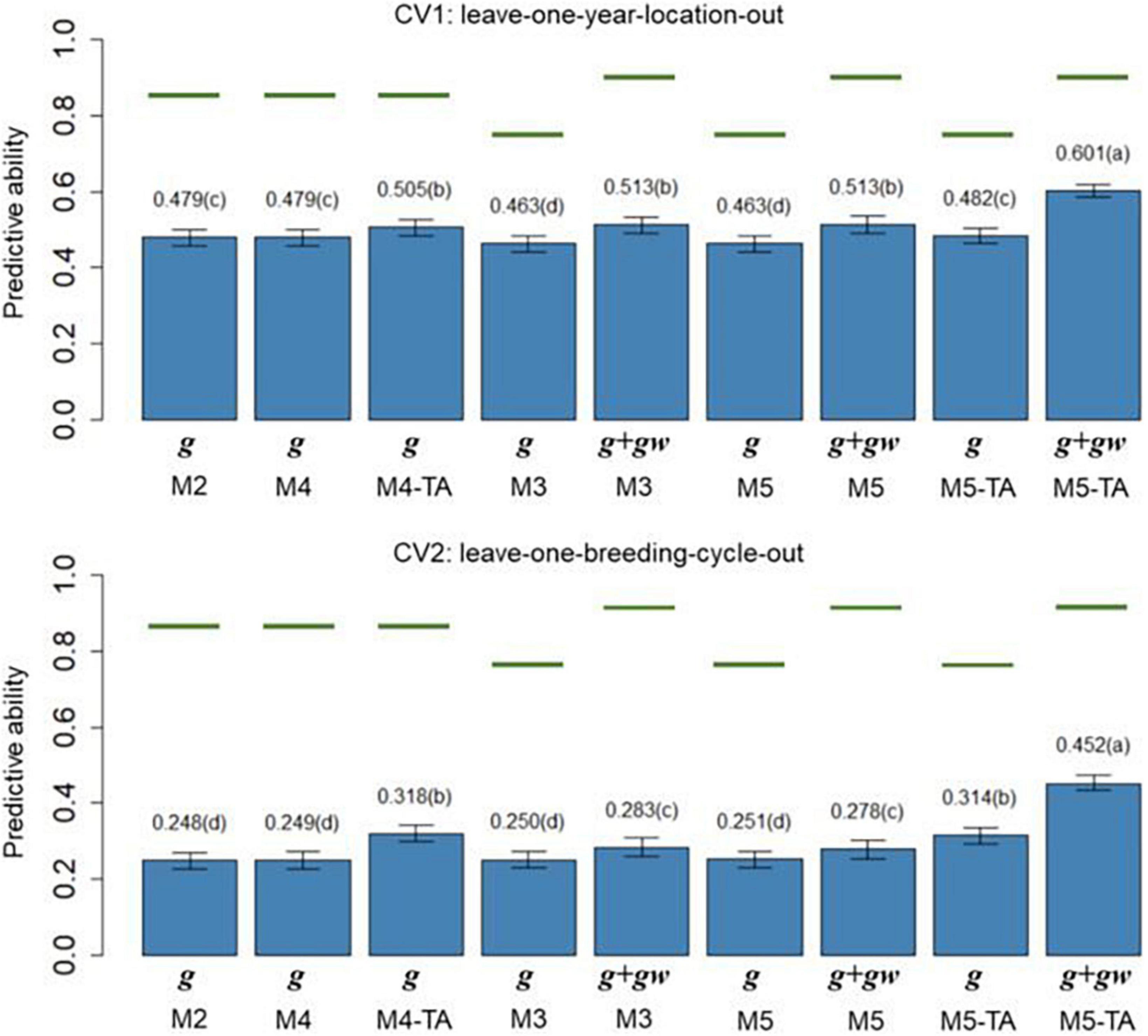
Figure 5. Barplot of predictive abilities (PAs) for protein content in leave-one-year-location-out (CV1, upper panel) and leave-one-breeding-cycle-out (CV2, lower panel) cross-validations. M2: line + genomic [SNPs] additive effect + spatial effect + line × environment interaction. M3 expand M2 by adding a genomic [SNPs] additive × ECs interaction. M4 expand M2 to the multi-trait case. M4-TA is the M4 using trait-assisted (TA) genomic prediction. M5 expand M3 to the multi-trait case. M5-TA is the M4 using TA genomic prediction. Black bars are the 95% confidence interval. Differences in the letter above the bar represent significant differences between models (P-value < 0.01). Green lines are the theoretical maximum PAs.
The PA in CV1 varied from 0.296 to 0.528 for grain yield and 0.463 to 0.601 for protein content. A significant improvement in PA was observed for using predictions of the main additive effect plus the genomic [SNPs] × ECs interaction effect (g + gw) compared to using only predictions from the main additive effect (g). The inclusion of the gw effect represented a significant increase of 16.4% for grain yield and 7.1% for protein content (M3 compared to M2). The MT models performing TA-GP (M4 and M5) showed a significant improvement in PA compared to the ST models and MT models without TA-PA. The TA-GP showed a significant PA increase of 37.9% for grain yield and 17.2% for protein content (M5 compared to M3). The highest PAs were obtained for both traits when combined TA-GP and G×E modeling through the genomic [SNPs] × ECs interaction effect in M5 (grain yield PA: 0.528, protein content PA: 0.601).
In CV2, the PA showed similar trends as CV1. A significant PA improvement was observed for models using the g + gw predictions compared to models using only predictions from the g effect. Using g + gw predictions represented a significant increase of 40.2% for grain yield and 14.1% for protein content (M3 compared to M2). The TA-GP for MT models provided a significant increase compared to the ST models and MT models without TA-PA, revealing a PA increase of 94.8% for grain yield and 59.7% for protein content (M5 compared to M3). The highest PA was obtained for both traits when TA-GP and G×E modeling through the genomic [SNPs] × ECs interaction effect in M5 (grain yield PA: 0.448, protein content PA: 0.452). In comparison, the CV2 had lower PA than CV1 for both traits, and higher benefits were observed in CV2 for modeling G×E and using TA-GP.
The maximum potential PA followed a similar trend for both traits, and the highest values were observed for the models accounting for genomic [SNPs] × ECs predictions (M3 and M5). The M1 (baseline) was not included in this section because such a model has no PA in CVs due to independence between lines is assumed.
The estimates for variance inflation (bw,p) of the predicted genetic effects (Legarra and Reverter, 2018) for CV1 and CV2 are shown in Table 7 for grain yield and Table 8 for protein content.

Table 7. Slope of regression (bw,p) of estimated genetic values with whole information on genetic values with partial information for grain yield in leave-one-year-location-out and leave-one-breeding-cycle-out cross-validations.

Table 8. Slope of regression (bw,p) of estimated genetic values with whole information on genetic values with partial information for protein content in leave-one-year-location-out and leave-one-breeding-cycle-out cross-validations.
Predictions for the main additive effect (g) did not present variance inflation in CV1 since bw,p values were close to one for both analyzed traits. The bw,p for predictions of the genomic [SNPs] × ECs interaction effect (gw) indicated a moderate over-dispersion for M3 (bw,p = 0.87) and M5 (bw,p = 0.85, without TA-GP) for grain yield. The use of TA-GP resulted in a reduction of over-dispersion in predictions of the gw effect for grain yield (M5-TA-GP: bw,p = 0.92). For protein content the bw,p values for predictions of the gw effect varied from 0.92 to 1.0, revealing lower over-dispersion than grain yield.
CV2 had higher variance inflation of predicted values than CV1, and trends were similar for both analyzed traits. The predictions of the main additive effect (g) presented the highest variance inflation for M2 (grain yield: bw,p = 0.80, protein content bw,p = 0.80) and the MT model M4 without TA-GP (grain yield: bw,p = 0.80, protein content bw,p = 0.81). A systematic improvement in the variance inflation for predictions of the main additive effect (g) was observed for both traits when the genomic [SNPs] × ECs interaction was included in the models (bw,p from 0.80 in M2 to 0.89 in M3 for both traits). The bw,p for predictions of the genomic [SNPs] × ECs interaction effect (gw) varied from 0.79 to 0.98 for grain yield and 0.86 to 0.98 for protein content, where in general, the lowest values were associated in both traits to M3 and the MT model M4 without TA-GP, and the highest bw,p to the M5 using TA-GP.
In this study, we proposed a growth degree-day (GDD) based reaction norm (RN) methodology to introduce genomic [SNPs] × environmental covariates (ECs) interactions via (co)variance structures in single-trait (ST) and multi-trait (MT) frameworks. The developed models were used for VCs estimation and genomic prediction of grain yield and protein content in a large set of advanced wheat breeding lines from the commercial company Nordic Seed A/S. The proposed models were evaluated using cross-validation (CV) analysis and trait-assisted genomic prediction (TA-GP) in two prediction problems relevant for plant breeding: (i) predicting breeding values for lines that have been tested in some environments but not in others (CV1, leave-one-year-location-out), and (ii) predicting breeding values for new lines across breeding cycles (CV2, leave-one-breeding-cycle-out). In CV1, the RN developed models have the potential to predict in environments where no lines have been tested, and thus, it could be used either to retrieve information from lines whose phenotyping has failed in a target environment or to predict for a completely new environment where no phenotyping has been performed before. Combining the proposed RN methodology and TA-GP proved to be an efficient approach to improve the predictive ability (PA) and reduce variance inflation of grain yield and protein content predictions in both CVs.
The VCs were estimated for the different models in ST and MT scenarios for grain yield (Table 4) and protein content (Table 5). A significant proportion of genetic variance was captured for both traits, as it can be observed in the narrow-sense (h2) and broad-sense (H2) heritabilities for M2. In agreement with previous studies using Nordic Seed A/S data, higher heritability for protein content than grain yield was observed (Kristensen et al., 2018; Kristensen et al., 2019; Guo et al., 2020; Raffo et al., 2022). The M2 was extended in order to better account for G×E interactions, and the genomic [SNPs] × ECs interaction term (gw) was included in M3. The gw effect captured a significant proportion of variance for grain yield, and models including the G×E interaction terms f (line × environment) and gw (M3 and M5) captured higher proportion of G×E variance than models only including the f effect (M1, M2 and M4). The higher G×E variance captured by M3 and M5 can be likely attributed to better accounting for genetic and environmental covariances between lines. The trends were similar for protein content, but the variance for G×E interaction was considerably lower than for grain yield. As reported in previous studies (Jarquin et al., 2014; Pérez-Rodríguez et al., 2015; De Los Campos et al., 2020), the modeling of gw explain a limited proportion of G×E variance. It can happen due to SNPs and ECs not fully capturing the additive genetic effects (due to incomplete LD of QTLs and SNPs) and the environmental variation (e.g., due to distance between weather stations and the test field), respectively. To deal with this issue, the line × environment interaction effect is defined in the models to account for the mentioned misspecifications. In addition, another model term specifying genomic [SNPs] × environment interactions have been considered in the models; however, no significant contribution was observed and data has not been displayed since such an effect does not have the capacity of performing predictions in CV1. The inclusion of an additional term defining the main effect of ECs has been used in previous studies (Jarquin et al., 2014; Pérez-Rodríguez et al., 2015; De Los Campos et al., 2020); nevertheless, such an effect was not possible to estimate in our case as the main environmental effect is already defined at the level of fixed effects. Lastly, a significant proportion of spatial variance () was observed for both traits, revealing a high spatial variability in the experimental fields. Our proposed methodology for modeling spatial effects has the advantage of not assuming any gradient or specific pattern across the field, allowing for spatial heterogeneity in any direction. This can present an advantage compared to previous methodologies that use X and Y coordinates (row-columns) as covariates to model spatial variation, as they may assume a gradient in X and Y directions (Bernal-Vasquez et al., 2014; Cericola et al., 2017); however, although it can be practical given its simplicity, the spatial variation can generally vary randomly without following a gradient across the field. The estimate obtained for of grain yield in our study was consistent with the observed for a similar dataset and spatial effect definition in Raffo et al. (2022), and it was higher than in Cericola et al. (2017), where spatial effects were modeled in a row-column setting for a subset of our data. The differences between studies could be, at least in part, attributed to the mentioned differences in model assumptions. Given the significant proportion observed for in our study, the inclusion of spatial effects in selection models is justified as it may help to improve the model specification.
The MT models showed similar VCs estimates to ST models. In general, high negative between-trait correlations were observed for the different model effects (Table 6). From a breeding perspective, the negative genetic correlation between grain yield and protein content implies an unfavorable response in one trait when selecting on another (Falconer and Mackay, 1996). The negative genetic trait correlations can be due to pleiotropy or tight gene linkage disequilibrium (Chen and Lübberstedt, 2010). Understanding the genetic basis for the negative correlation can help to define an appropriate breeding program and avoid affecting long-term breeding prospects. Note that for pleiotropic gene effect it can be recommended to select against those genes, while for undesirable linkage between genes the strategy would aim to break the linkage through recombination (Falconer and Mackay, 1996; Lynch and Walsh, 1998).
The PA of the proposed models (Figures 4, 5) was calculated as the correlation between the average value of lines in each year-location after correcting by fixed effects and the vector of predictions (prediction of g effect for M2 to M5; predictions of g + gw effects for M3 and M5). The predictions for the main additive effect (g) had the lowest values of PAs, and they were significantly outperformed by the models accounting for the genomic [SNPs] × ECs interaction when the sum of g + gw effects was used. In CV1, using the sum of g + gw effects results in an increase of 16.4% for grain yield and 7.1% for protein content (comparing M3 to M2). Predictions for g + gw in CV1 are year-location specific and cannot be generalized to future years. In CV2, similar trends to CV1 were observed, but the increments for including the gw predictions were considerably higher than in CV1, representing a 40.2% and 14.1% increase for grain yield and protein content, respectively (comparing M3 to M2). As shown in Figures 4, 5, the PAs were higher for protein content than for grain yield. These results could be related to the underlying architecture of the traits (Momen et al., 2018) and the differences found in h2, where for the lower h2 values as in grain yield, lower PA is expected (Wimmer et al., 2013; Muranty et al., 2015).
The CV2 had lower PAs for all models. The decline in PA can be explained by the higher genetic/pedigree distance between the training and validation population in CV2 (Habier et al., 2007; Wolc et al., 2011); while in CV1, the same line can be present in different year-locations folds, and full sibs are included in the training and validation sets, for CV2, the replication of the same line or close relatives are not shared between training and validation sets. This fact can also be evidenced in the average genomic relationships between reference and validation sets for CV1 and CV2. For example, the average of genomic relationships for reference/validation sets in CV2 was −0.009 with a standard deviation (SD) of 0.002; the negative value of relationships can be interpreted as lines less related than average. Conversely, in CV1, lines from the same breeding cycle were included in reference/validation sets, and the average genomic relationship within breeding cycles was 0.055 (SD: 0.015). The positive value obtained for relationships within breeding cycles can be interpreted as lines more related than average. As reported by Habier et al. (2007), the decline in PA can result from the break-up of linkage disequilibrium between SNPs and QTL between the training and validation populations when relationships become more distant.
The MT models were evaluated for GP with and without TA-GP. The PAs of MT models without TA-GP were similar to ST models for the two CVs and traits (Figures 4, 5). Similar results have been found for wheat (Lado et al., 2018; Kristensen et al., 2019), and other species (Jia and Jannink, 2012; Schulthess et al., 2016), and it has been associated with high trait complexity and low traits heritabilities (Jia and Jannink, 2012; Lado et al., 2018). Conversely, MT models with TA-GP significantly improve PA compared to ST models and MT models without TA-GP. The superior performance of MT models with TA-GP can be explained by the use of “borrowed” information from the trait with complete phenotypic records, which is possible due the use of the between-trait correlations. The highest benefits for TA-GP were observed for grain yield PA, where it significantly increased (P-value < 0.01) by 14.0% (M2 compared to M4-TA) and 37.9% (M3 compared to M5-TA) for CV1, and by 57.9% (M2 compared to M4-TA) and 94.8% (M3 compared to M5-TA) for CV2. For protein content, the benefits provided by TA-GP were lower but still significant (P-value < 0.01), increasing PA by 5.4% (M2 compared to M4-TA) and 14.3% (M3 compared to M5-TA) for CV1, and by 28.2% (M2 compared to M4-TA) and 59.7% (M3 compared to M5-TA) for CV2. As reported by Jia and Jannink (2012) and Guo et al. (2014), the highest benefits conferred by the MT approach are expected for low heritability traits when they are used together with high heritability traits. Accordingly, our study empirically addressed this issue by combining a low heritability trait as grain yield with an intermediate to high heritability trait as protein content in bivariate analysis. Our results were consistent with the literature, revealing the highest benefits for the lowest heritability trait in all scenarios. Another factor contributing to the large benefit observed in TA-GP is the substantial correlation observed between grain yield and protein content (from −0.404 to −0.687 for genetic and G×E effects, Table 6). High between-trait correlations are statistically useful since measurements of one trait can more informative on the genetic values of the other correlated traits (Henderson and Quaas, 1976; Schaeffer, 1984; Thompson and Meyer, 1986; Montesinos-Lopez et al., 2016).
The variance inflation (bw,p) for prediction of the main additive (g) and the genomic [SNPs] × ECs (gw) interaction effects in CV1 and CV2 are shown in Tables 7, 8. The CV1, did not present variance inflation for g predictions as expected due to the high information in the training population for the g effect. However, gw predictions revealed over-dispersion in CV1. A possible explanation for this can be associated with the design of CV1, where no phenotypes for the environment predicted are kept in the training population, and therefore, differences in the QTL effect/expression in the specific environment may not be captured by SNPs, resulting in inflation of the predicted effects. In CV2, over-dispersion was observed in g and gw predictions for both traits. This was expected as the genetic relationships between training and validation population are low, and over-dispersion due to genomic erosion by recombination can occur (Dekkers et al., 2021). Despite this, as described in the “Result” section, the over-dispersion of g predictions was reduced when the gw effect was included in the models. In addition, a reduction in the over-dispersion of g and gw predictions was observed for both traits in the two CVs when TA-GP was used in MT models. The benefits of using TA-GP can be related to a reduction of genomic erosion since phenotypic records of the additional trait are complete, and multi-trait modeling allows to indirectly capture the genetic effects for the trait of interest via the between-trait genetic correlations. The reduction in variance inflation conferred by TA-GP is consistent with previous studies, as reported by Pollak et al. (1984); Jia and Jannink (2012), Hayes et al. (2017), and Lado et al. (2018).
The proposed GDD based methodology provides a simplified approach to incorporate environmental information into prediction models and assists in the implementation of multi-trait reaction norm models. Our study showed that the weather and soil information was efficiently exploited without explicitly linking it to specific critical crop periods, which might open an opportunity to work with traits and species where the relationships between the environmental conditions and resulting phenotype are not fully established. A future avenue for developing the proposed models could be exploiting the potentiality of reaction norms in predicting G×E for future years (e.g., using average weather or soil variables to infer future years). The developed models work under the Bayesian Ridge Regression (BRR) framework and assume Gaussian distribution for random effects, implying no specific QTLs or ECs with large effects. Further studies exploring alternative methodologies capable of performing differential shrinkage or variable selection for genetic and environmental effects is warranted.
In this study, we proposed a growth degree-day (GDD) based reaction norm methodology to introduce genomic [SNPs] × environmental covariates interactions through (co)variance structures in a single-trait or multi-trait framework. The growth degree-day based methodology provides a simplified approach to introduce environmental information in prediction models and assists in the implementation of multi-trait reaction norm models. The modeling of genomic [SNPs] × environmental covariates interactions, and the use of trait-assisted genomic prediction in multi-trait models, significantly enhanced the predictive ability and reduced variance inflation in the predicted genetic values for grain yield and protein content in leave-one-year-location-out (CV1) and leave-one-breeding-cycle-out (CV2) cross-validations. The genotype by environment interaction modeling via genomic [SNPs] × environmental covariates interactions, combined with trait-assisted genomic prediction, boosted the benefits in predictive performance.
The original contributions presented in this study are publicly available. This data can be found here: https://doi.org/10.7910/DVN/WEXJWW.
JJ, MR, PS, and JA: conceptualization. MR, JA, PS, and JO: data curation. MR: formal analysis. JJ, MR, JA, JO, and AJ: funding acquisition. MR and JJ: investigation, methodology, and project administration. JJ and PS: resources and supervision. MR: software, validation, visualization, and writing—original draft. JJ, PS, JA, JO, and AJ: writing—review and editing. All authors contributed to the article and approved the submitted version.
This research received funding from the National Research and Innovation Agency (ANII) of Uruguay (POS_EXT_ 2018_1_154284) and the IFD RadiBooster project (9090-00052A) for funding contributions of JJ. We would like to thank Aarhus University for financial support for MR and JJ, and the commercial partner Nordic Seed A/S for PS, JA, JO, and AJ funding and for providing the data. The authors declare that this study also received funding from Nordic Seed A/S. The funder had the following involvement in the study: experimental design, data collection and analysis, and reviewing of previous manuscript versions.
We would like to thank the two reviewers for their insightful comments and suggestions on earlier versions of the manuscript. We would also like to thank the Danish Meteorological Institute and Dr. Finn Plauborg, Dr. Mette Balslev Greve, and Dr. Johannes Pullens from the Department of Agroecology of Aarhus University for providing climatic data, soil data, and simulated maturity dates, respectively.
PS, JA, JO, and AJ were employed by Nordic Seed A/S.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2022.939448/full#supplementary-material
Adhikari, K., Kheir, R. B., Greve, M. B., Bøcher, P. K., Malone, B. P., Minasny, B., et al. (2013). High-resolution 3-D mapping of soil texture in Denmark. Soil Sci. Soc. Am. J. 77, 860–876.
Aslam, M. A., Ahmed, M., Stöckle, C. O., Higgins, S. S., and Hayat, R. (2017). Can growing degree days and photoperiod predict spring wheat phenology? Front. Environ. Sci. 5:57. doi: 10.3389/fenvs.2017.00057
Bernal-Vasquez, A.-M., Möhring, J., Schmidt, M., Schönleben, M., Schön, C.-C., and Piepho, H.-P. (2014). The importance of phenotypic data analysis for genomic prediction-a case study comparing different spatial models in rye. BMC Genom. 15:646. doi: 10.1186/1471-2164-15-646
Burgueño, J., de Los Campos, G., Weigel, K., and Crossa, J. (2012). Genomic Prediction of Breeding Values when Modeling Genotype × Environment Interaction using Pedigree and Dense Molecular Markers. Crop. Sci. 52, 707–719. doi: 10.2135/cropsci2011.06.0299
Calus, M. Á, and Veerkamp, R. (2003). Estimation of environmental sensitivity of genetic merit for milk production traits using a random regression model. J. Dairy Sci. 86, 3756–3764.
Cericola, F., Jahoor, A., Orabi, J., Andersen, J. R., Janss, L. L., and Jensen, J. (2017). Optimizing Training Population Size and Genotyping Strategy for Genomic Prediction Using Association Study Results and Pedigree Information. A Case of Study in Advanced Wheat Breeding Lines. PLoS One 12:e0169606. doi: 10.1371/journal.pone.0169606
Chen, Y., and Lübberstedt, T. (2010). Molecular basis of trait correlations. Trends Plant Sci. 15, 454–461.
Crossa, J., de los Campos, G., Maccaferri, M., Tuberosa, R., Burgueño, J., and Pérez-Rodríguez, P. (2016). Extending the Marker × Environment Interaction Model for Genomic-Enabled Prediction and Genome-Wide Association Analysis in Durum Wheat. Crop. Sci. 56, 2193–2209. doi: 10.2135/cropsci2015.04.0260
Crossa, J., Perez-Rodriguez, P., Cuevas, J., Montesinos-Lopez, O., Jarquin, D., de Los Campos, G., et al. (2017). Genomic Selection in Plant Breeding: Methods, Models, and Perspectives. Trends Plant Sci. 22, 961–975. doi: 10.1016/j.tplants.2017.08.011
Cuevas, J., Crossa, J., Montesinos-Lopez, O. A., Burgueno, J., Perez-Rodriguez, P., and de Los Campos, G. (2017). Bayesian Genomic Prediction with Genotype x Environment Interaction Kernel Models. G3 7, 41–53. doi: 10.1534/g3.116.035584
Cuevas, J., Crossa, J., Soberanis, V., Perez-Elizalde, S., Perez-Rodriguez, P., Campos, G. L., et al. (2016). Genomic Prediction of Genotype x Environment Interaction Kernel Regression Models. Plant Genome 9, 1–20. doi: 10.3835/plantgenome2016.03.0024
De los Campos, G., Naya, H., Gianola, D., Crossa, J., Legarra, A., Manfredi, E., et al. (2009). Predicting quantitative traits with regression models for dense molecular markers and pedigree. Genetics 182, 375–385. doi: 10.1534/genetics.109.101501
De Los Campos, G., Pérez-Rodríguez, P., Bogard, M., Gouache, D., and Crossa, J. (2020). A data-driven simulation platform to predict cultivars’ performances under uncertain weather conditions. Nat. Commun. 11:4876.
Dekkers, J., Su, H., and Cheng, J. (2021). Predicting the accuracy of genomic predictions. Genetics Selection Evolution 53:55.
Falconer, D. (1990). Selection in different environments: Effects on environmental sensitivity (reaction norm) and on mean performance. Genet. Res. 56, 57–70.
Gianola, D., and Rosa, G. J. M. (2015). One Hundred Years of Statistical Developments in Animal Breeding. Annu. Rev. Anim. Biosci. 3, 19–56. doi: 10.1146/annurev-animal-022114-110733
Guo, G., Zhao, F., Wang, Y., Zhang, Y., Du, L., and Su, G. (2014). Comparison of single-trait and multiple-trait genomic prediction models. BMC Genetics 15:30. doi: 10.1186/1471-2156-15-30
Guo, X., Svane, S. F., Füchtbauer, W. S., Andersen, J. R., Jensen, J., and Thorup-Kristensen, K. (2020). Genomic prediction of yield and root development in wheat under changing water availability. Plant methods 16:90. doi: 10.1186/s13007-020-00634-0
Habier, D., Fernando, R. L., and Dekkers, J. C. (2007). The impact of genetic relationship information on genome-assisted breeding values. Genetics 177, 2389–2397. doi: 10.1534/genetics.107.081190
Haile, J. K., N’Diaye, A., Clarke, F., Clarke, J., Knox, R., Rutkoski, J., et al. (2018). Genomic selection for grain yield and quality traits in durum wheat. Mol. Breed. 38:75.
Hayes, B., and Goddard, M. (2010). Genome-wide association and genomic selection in animal breeding. Genome 53, 876–883.
Hayes, B., Nieuwhof, G., and Haile Mariam, M. (2017). “A multi-trait approach to incorporating foreign phenotypes and genotypes in genomic predictions to increase accuracy and reduce bias,” in Proceedings Australian Association of Animal Breeding and Genetics, (Townsville), 265–268.
Henderson, C., and Quaas, R. (1976). Multiple trait evaluation using relatives’ records. J. Anim. Sci. 43, 1188–1197.
Heslot, N., Akdemir, D., Sorrells, M. E., and Jannink, J. L. (2014). Integrating environmental covariates and crop modeling into the genomic selection framework to predict genotype by environment interactions. Theor. Appl. Genet. 127, 463–480. doi: 10.1007/s00122-013-2231-5
Jarquin, D., Crossa, J., Lacaze, X., Du Cheyron, P., Daucourt, J., Lorgeou, J., et al. (2014). A reaction norm model for genomic selection using high-dimensional genomic and environmental data. Theor. Appl. Genet. 127, 595–607. doi: 10.1007/s00122-013-2243-1
Jia, Y., and Jannink, J.-L. (2012). Multiple-trait genomic selection methods increase genetic value prediction accuracy. Genetics 192, 1513–1522.
Jiang, J., Zhang, Q., Ma, L., Li, J., Wang, Z., and Liu, J. (2015). Joint prediction of multiple quantitative traits using a Bayesian multivariate antedependence model. Heredity 115, 29–36. doi: 10.1038/hdy.2015.9
Kotlar, A. M., van Lier, Q. D. J., Andersen, H. E., Nørgaard, T., and Iversen, B. V. (2020). Quantification of macropore flow in Danish soils using near-saturated hydraulic properties. Geoderma 375:114479.
Kristensen, P. S., Jahoor, A., Andersen, J. R., Cericola, F., Orabi, J., Janss, L. L., et al. (2018). Genome-Wide Association Studies and Comparison of Models and Cross-Validation Strategies for Genomic Prediction of Quality Traits in Advanced Winter Wheat Breeding Lines. Front. Plant Sci. 9:69. doi: 10.3389/fpls.2018.00069
Kristensen, P. S., Jahoor, A., Andersen, J. R., Orabi, J., Janss, L., and Jensen, J. (2019). Multi-trait and trait-assisted genomic prediction of winter wheat quality traits using advanced lines from four breeding cycles. Crop. Breed. Genet. Genom. 1:e1900010.
Lado, B., Vázquez, D., Quincke, M., Silva, P., Aguilar, I., and Gutiérrez, L. (2018). Resource allocation optimization with multi-trait genomic prediction for bread wheat (Triticum aestivum L.) baking quality. Theor. Appl. Genet. 131, 2719–2731. doi: 10.1007/s00122-018-3186-3
Lecomte, C. (2005). L’évaluation expérimentale des innovations variétales. Proposition d’outils d’analyse de l’interaction génotype-milieu adaptés à la diversité des besoins et des contraintes des acteurs de la filière semences, INAPG. Paris: AgroParisTech.
Legarra, A., and Reverter, A. (2018). Semi-parametric estimates of population accuracy and bias of predictions of breeding values and future phenotypes using the LR method. Genet. Sel. Evol. 50:53. doi: 10.1186/s12711-018-0426-6
Lynch, M., and Walsh, B. (1998). Genetics and Analysis of Quantitative Traits. Sunderland, MA: Sinauer Associates, Inc.
Malosetti, M., Ribaut, J. M., Vargas, M., Crossa, J., and van Eeuwijk, F. A. (2007). A multi-trait multi-environment QTL mixed model with an application to drought and nitrogen stress trials in maize (Zea mays L.). Euphytica 161, 241–257. doi: 10.1007/s10681-007-9594-0
McMaster, G. S., and Wilhelm, W. (1997). Growing degree-days: One equation, two interpretations. Agricult. Forest Meteorol. 87, 291–300.
Meuwissen, T. H. E., Hayes, B. J., and Goddard, M. E. (2001). Prediction of total genetic value using genome-wide dense marker maps. Genetics 157, 1819–1829.
Meynard, J. M., and Sebillotte, M. (1994). L’élaboration du rendement du blé, base pour l’étude des autres céréales à talles. Paris: INRA Editions.
Momen, M., Mehrgardi, A. A., Sheikhi, A., Kranis, A., Tusell, L., Morota, G., et al. (2018). Predictive ability of genome-assisted statistical models under various forms of gene action. Sci. Rep. 8:12309. doi: 10.1038/s41598-018-30089-2
Montesinos-Lopez, A., Montesinos-Lopez, O. A., Gianola, D., Crossa, J., and Hernandez-Suarez, C. M. (2018). Multi-environment Genomic Prediction of Plant Traits Using Deep Learners With Dense Architecture. G3 8, 3813–3828. doi: 10.1534/g3.118.200740
Montesinos-Lopez, O. A., Montesinos-Lopez, A., Crossa, J., Cuevas, J., Montesinos-Lopez, J. C., Gutierrez, Z. S., et al. (2019). A Bayesian Genomic Multi-output Regressor Stacking Model for Predicting Multi-trait Multi-environment Plant Breeding Data. G3 9, 3381–3393. doi: 10.1534/g3.119.400336
Montesinos-Lopez, O. A., Montesinos-Lopez, A., Crossa, J., Toledo, F. H., Perez-Hernandez, O., Eskridge, K. M., et al. (2016). A Genomic Bayesian Multi-trait and Multi-environment Model. G3 (Bethesda) 6, 2725–2744. doi: 10.1534/g3.116.032359
Muranty, H., Troggio, M., Sadok, I. B., Rifaï, M. A., Auwerkerken, A., Banchi, E., et al. (2015). Accuracy and responses of genomic selection on key traits in apple breeding. Horticult. Res. 2:15060. doi: 10.1038/hortres.2015.60
Nuttonson, M. Y. (1955). Wheat-Climate Relationships And The Use Of Phenology In Ascertaining The Thermal And Photo-Thermal Requirements Of Wheat Based On Data Of North America And Of Some Thermally Analogous Areas Of North America In The Soviet Union And In Finland. Washington, DC: American Institute of Crop Ecology.
Pérez, P., and de los Campos, G. (2014). BGLR: A statistical package for whole genome regression and prediction. Genetics 198, 483–495. doi: 10.1534/genetics.114.164442
Pérez-Rodríguez, P., Crossa, J., Bondalapati, K., De Meyer, G., Pita, F., and Campos, G.D.l (2015). A pedigree-based reaction norm model for prediction of cotton yield in multienvironment trials. Crop. Sci. 55, 1143–1151.
Pollak, E., Van der Werf, J., and Quaas, R. (1984). Selection bias and multiple trait evaluation. J. Dairy Sci. 67, 1590–1595.
Pullens, J. W., Sørensen, C. A., and Olesen, J. E. (2021). Temperature-based prediction of harvest date in winter and spring cereals as a basis for assessing viability for growing cover crops. Field Crops Res. 264:108085.
R Core Team (2014). R: A Language and Environment for Statistical Computing. Available online at: http://www.R-project.org
Raffo, M. A., Sarup, P., Guo, X., Liu, H., Andersen, J. R., Orabi, J., et al. (2022). Improvement of genomic prediction in advanced wheat breeding lines by including additive-by-additive epistasis. Theor. Appl. Genet. 135, 965–978. doi: 10.1007/s00122-021-04009-4
Rogers, S. O., and Bendich, A. J. (1985). Extraction of DNA from milligram amounts of fresh, herbarium and mummified plant tissues. Plant Mol. Biol. 5, 69–76. doi: 10.1007/BF00020088
Salazar-Gutierrez, M., Johnson, J., Chaves-Cordoba, B., and Hoogenboom, G. (2013). Relationship of base temperature to development of winter wheat. Int. J. Plant Produc. 7, 741–762.
Schaeffer, L. (1984). Sire and cow evaluation under multiple trait models. J. Dairy Sci. 67, 1567–1580.
Schulthess, A. W., Wang, Y., Miedaner, T., Wilde, P., Reif, J. C., and Zhao, Y. (2016). Multiple-trait-and selection indices-genomic predictions for grain yield and protein content in rye for feeding purposes. Theor. Appl. Genet. 129, 273–287. doi: 10.1007/s00122-015-2626-6
Slafer, G. A., and Rawson, H. (1994). Sensitivity of wheat phasic development to major environmental factors: Are-examination of some assumptions made by physiologists and modellers. Funct. Plant Biol. 21, 393–426.
Su, G., Madsen, P., Lund, M. S., Sorensen, D., Korsgaard, I. R., and Jensen, J. (2006). Bayesian analysis of the linear reaction norm model with unknown covariates. J. Anim. Sci. 84, 1651–1657. doi: 10.2527/jas.2005-517
Thompson, R., and Meyer, K. (1986). A review of theoretical aspects in the estimation of breeding values for multi-trait selection. Livest. Product. Sci. 15, 299–313.
Tsai, H.-Y., Cericola, F., Edriss, V., Andersen, J. R., Orabi, J., Jensen, J. D., et al. (2020). Use of multiple traits genomic prediction, genotype by environment interactions and spatial effect to improve prediction accuracy in yield data. PLoS One 15:e0232665. doi: 10.1371/journal.pone.0232665
VanRaden, P. M. (2008). Efficient methods to compute genomic predictions. J. Dairy Sci. 91, 4414–4423.
Wang, S., Wong, D., Forrest, K., Allen, A., Chao, S., Huang, B. E., et al. (2014). Characterization of polyploid wheat genomic diversity using a high-density 90 000 single nucleotide polymorphism array. Plant Biotechnol. J. 12, 787–796.
Ward, B. P., Brown-Guedira, G., Tyagi, P., Kolb, F. L., Van Sanford, D. A., Sneller, C. H., et al. (2019). Multienvironment and Multitrait Genomic Selection Models in Unbalanced Early-Generation Wheat Yield Trials. Crop Sci. 59, 491–507. doi: 10.2135/cropsci2018.03.0189
Wimmer, V., Lehermeier, C., Albrecht, T., Auinger, H.-J., Wang, Y., and Schön, C.-C. (2013). Genome-wide prediction of traits with different genetic architecture through efficient variable selection. Genetics 195, 573–587. doi: 10.1534/genetics.113.150078
Keywords: genomic prediction, multi-trait, multi-environment, reaction norm, genotype by environment interaction
Citation: Raffo MA, Sarup P, Andersen JR, Orabi J, Jahoor A and Jensen J (2022) Integrating a growth degree-days based reaction norm methodology and multi-trait modeling for genomic prediction in wheat. Front. Plant Sci. 13:939448. doi: 10.3389/fpls.2022.939448
Received: 09 May 2022; Accepted: 08 August 2022;
Published: 02 September 2022.
Edited by:
Yusheng Zhao, Leibniz Institute of Plant Genetics and Crop Plant Research (IPK), GermanyReviewed by:
Wenxin Liu, China Agricultural University, ChinaCopyright © 2022 Raffo, Sarup, Andersen, Orabi, Jahoor and Jensen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Miguel Angel Raffo, bXJhZmZvQHFnZy5hdS5kaw==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.