
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Plant Sci. , 18 January 2023
Sec. Sustainable and Intelligent Phytoprotection
Volume 13 - 2022 | https://doi.org/10.3389/fpls.2022.1075929
This article is part of the Research Topic Agricultural Sensors and Systems for Field Detection View all 21 articles
 Lijia Xu1†
Lijia Xu1† Yanjun Chen1†
Yanjun Chen1† Xiaohui Wang1†Heng Chen1
Xiaohui Wang1†Heng Chen1 Zuoliang Tang1Xiaoshi Shi1Xinyuan Chen2Yuchao Wang1*Zhilang Kang1
Zuoliang Tang1Xiaoshi Shi1Xinyuan Chen2Yuchao Wang1*Zhilang Kang1 Zhiyong Zou1Peng Huang1
Zhiyong Zou1Peng Huang1 Yong He3Ning Yang4*
Yong He3Ning Yang4* Yongpeng Zhao1*
Yongpeng Zhao1*The soluble solid content (SSC) is one of the important parameters depicting the quality, maturity and taste of fruits. This study explored hyperspectral imaging (HSI) and fluorescence spectral imaging (FSI) techniques, as well as suitable chemometric techniques to predict the SSC in kiwifruit. 90 kiwifruit samples were divided into 70 calibration sets and 20 prediction sets. The hyperspectral images of samples in the spectral range of 387 nm~1034 nm and the fluorescence spectral images in the spectral range of 400 nm~1000 nm were collected, and their regions of interest were extracted. Six spectral pre-processing techniques were used to pre-process the two spectral data, and the best pre-processing method was selected after comparing it with the predicted results. Then, five primary and three secondary feature extraction algorithms were used to extract feature variables from the pre-processed spectral data. Subsequently, three regression prediction models, i.e., the extreme learning machines (ELM), the partial least squares regression (PLSR) and the particle swarm optimization - least square support vector machine (PSO-LSSVM), were established. The prediction results were analyzed and compared further. MASS-Boss-ELM, based on fluorescence spectral imaging technique, exhibited the best prediction performance for the kiwifruit SSC, with the , and RPD of 0.8894, 0.9429 and 2.88, respectively. MASS-Boss-PLSR based on the hyperspectral imaging technique showed a slightly lower prediction performance, with the , , and RPD of 0.8717, 0.8747, and 2.89, respectively. The outcome presents that the two spectral imaging techniques are suitable for the non-destructive prediction of fruit quality. Among them, the FSI technology illustrates better prediction, providing technical support for the non-destructive detection of intrinsic fruit quality.
People love kiwifruit for its sweet and sour taste and rich nutritional value. Sugar is important in judging kiwifruit’s quality, affecting its taste. About 81% of kiwifruit’s solid soluble content (SSC) is sugar, so SSC is usually used to evaluate its sugar content. The traditional SSC detection methods use refractometer and other instruments, which are cumbersome to operate and also destroy the physical integrity of the detected object, and cannot achieve rapid detection. Therefore, realizing the non-destructive detection of kiwifruit SSC is of great practical importance.
Hyperspectral imaging (HSI) and fluorescence spectral imaging (FSI) technologies combine image and spectral information, which can quickly detect the quality parameters of the measured object without damage. In recent years, HSI technology has developed rapidly in the non-destructive detection of the intrinsic parameters of fruits, such as SSC, pH, hardness, etc. Pham et al. (Pham and Liou, 2022) used HSI to achieve online detection of jujube surface defects. They used principal component analysis (PCA) to extract feature variables from hyperspectral data in a spectral range of 468~950 nm to establish ANN and SVM models, illustrating accuracy rates of 95% and 94.6%, respectively. Li et al. (Li et al., 2022) used short-wave infrared HSI technology to predict the SSC in dried Hami jujube and established the FS-CNN model, where and RPD were 0.857 and 2.648, respectively. Gao et al. (Gao and Xu, 2022) predicted the SSC of red globe grape by combining HSI imaging technology with the PLSR model. They obtained the correlation coefficients of the calibration and prediction sets of 0.9775 and 0.9762, respectively.
FSI technology utilizes the fluorescence of different intensities emitted by excited molecules or atoms when certain substances are excited after being irradiated by light of specific wavelengths. Compared with HSI technology, FSI technology was applied later but achieved good progress in recent years. For example, Kim et al. (Kim et al., 2022) used FSI technology to detect aflatoxin in corn under 365 nm ultraviolet excitation rapidly, and the detection accuracy of the quadratic support vector machine (QSVM) reached 95.7%. Zhou et al. (Zhou et al., 2022) used FSI technology to detect the heavy metal lead in lettuce leaves, where a fluorescent filter of 475 nm was used to collect the fluorescence spectrum image in the spectral range of 480.46 nm~1001.61 nm, and , and RPD of the best prediction method (i.e., WT-MS-SAE-SVR) were 0.9802, 0.9467, and 3.273, respectively. Kang et al. (Kang et al., 2022) used FSI technology to detect the dry matter content of mango, and , , RMSEC and RMSEP of the best prediction method (i.e., CARS-RF-SPA-BPNN) were 0.9710, 0.9658, 0.1418 and 0.1526, respectively.
Although FSI technology has been widely used to detect agricultural products, most current studies are extended to detect mold, and less is applied to detect the intrinsic quality of agricultural products. In this study, the feasibility of FSI technology to predict kiwifruit SSC was examined, and the outcome was compared with HSI technology, where the feature extraction method was designed to establish a prediction model and the effects of two different imaging technologies on the performance of the prediction model were analyzed from the experimental results. Also, various regression prediction models were compared, and the performance differences between the two detection techniques led to the best method for detecting kiwifruit SSC.
90 samples of “Hongyang” kiwifruit with intact skin were selected from a kiwifruit base in Ya’an City, Sichuan Province. After the sample’s surface was cleaned with water, they were sequentially numbered and left at room temperature (25 ± 1 °C) for 24 h, and their hyperspectral and fluorescence spectral images were collected. After collecting the two spectral images of the samples, their SSC physicochemical values were determined immediately. According to the SSC measurement method of “NY/T 2637-2014”, the samples were washed and peeled around their equators, then the pulp was removed, and the juice was pressed. The fruit juice was introduced into the detection tank of the handheld glucose salinity refractor (i.e., YSK-107) with a resolution of 0.1% Brix, and the data were recorded as the SSC physicochemical values after the display data were stable. In order to reduce the operation error, each sample was measured twice, and the average value was taken as the SSC physicochemical value of the sample, with the unit of “Brix”.
Hyperspectral images of the kiwifruit samples were collected by Gaia sorter “Gaia” hyperspectral sorter in a spectral range of 387~1034 nm. The sorter mainly includes two groups of 4 LSTS-200 bromine tungsten lamps with a uniform light source, Image-Λ “spectral image” series CCD camera, an electronically controlled mobile platform and a computer with hyperspectral data acquisition software (SpaceView) powered by AC220V. The pixel and pixel size of the spectral camera are 1344 × 1024 and 6.45 × 6.45 μm, respectively. The overall structure of the Gaia sorter is shown in Figure 1A.
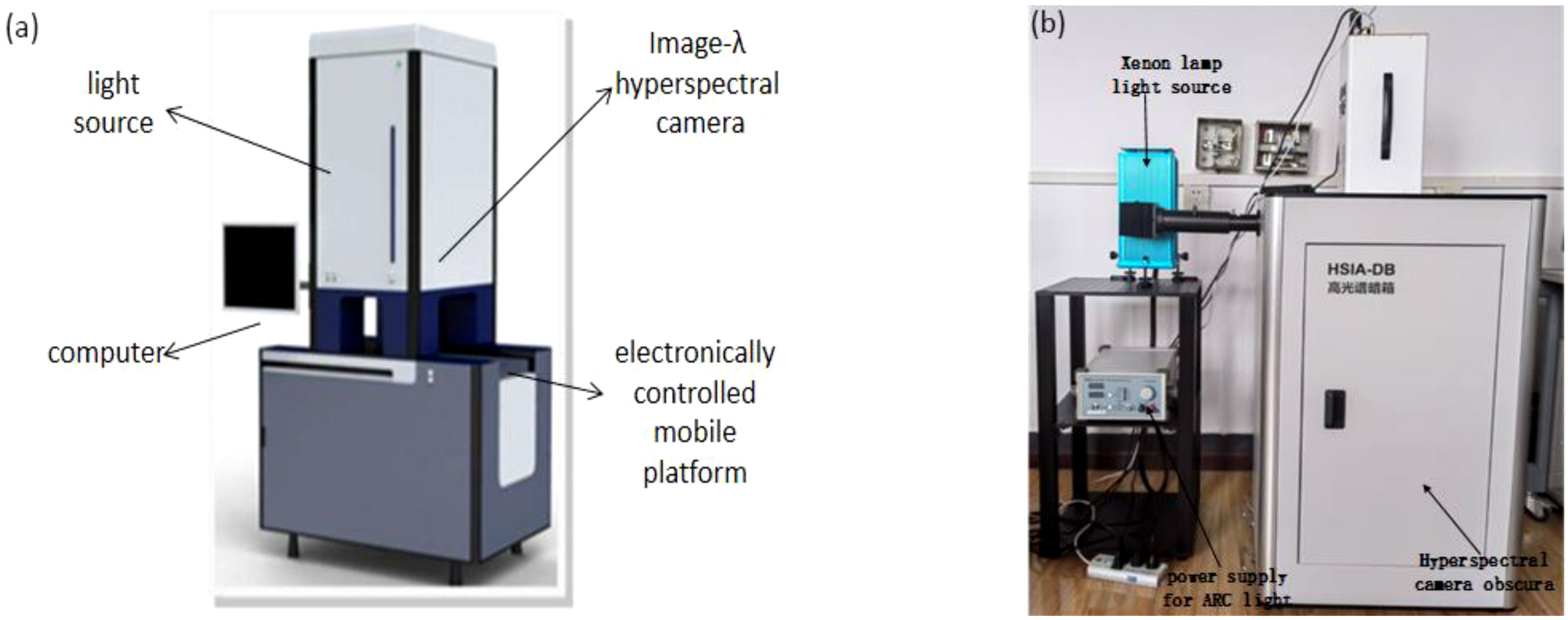
Figure 1 The overall equipment structure: (A) Gaia hyperspectral sorter; (B) Gaia fluorescence spectral detection system.
The GaiaFluo series fluorescence spectral detection system was utilized to collect the fluorescence images of kiwifruit samples. In the system, the camera is Gaiafluo-VN-HR, the spectrometer is a transmission grating (PGP) structure, the spectral range and resolution are 400-1000 nm and 2.8 nm, respectively, and the detector is the SCMOS with a pixel size of 6.5 μm. The system also includes an 80 × 80 × 100 cm Obscura and a 30 × 30 × 40 cm platform. In addition, it contains four 50 W reflective light sources, a 150 W xenon lamp light source, various excitation filters, fluorescent filters, and a computer equipped with spectrum acquisition software (spaceview). The overall structure of the fluorescence spectral detection system is shown in Figure 1B.
The HSI system was first warmed up for more than 30 min before the hyperspectral images of the samples were acquired and corrected in black and white after stabilizing the voltage. During acquisition, the sample platform was 170 mm away from the lens, the exposure time of the spectroscopic camera was 13.5 ms, the advancing distance of the electronically controlled platform was 110 mm, and the advancing and retracting speeds were 4.6 mm/s and 50 mm/s, respectively. Similarly, the FSI system was prewarmed for about 30 min, and suitable excitation and fluorescence filters were selected after stabilizing the voltage. A xenon lamp was selected as the excitation light source.
After the combination of different filters was tested, the excitation filter with a central wavelength of 390 nm and a bandwidth of 40 nm and the fluorescence filter with a central wavelength of 495 nm were finally selected. The system parameters were set as follows: the camera moving speed was 0.13 mm/s, the exposure time was 800 ms, and the distance between the spectral camera lens and the measured object was about 70 cm.
The HSI and FSI spectral images of the samples and their region of interest (ROI) are shown in Figures 2A–D, respectively. During the acquisition process of hyperspectral images, SpecView software was employed to perform black-and-white calibration on the hyperspectral images to reduce the interference of environmental factors, and ENVI 5.3 software was utilized to extract the ROI. The average spectrum in the ROI was taken as the raw spectral value of the samples.

Figure 2 Spectral image of a sample: (A) raw hyperspectral image; (B) raw fluorescence spectral image; (C) ROI of the raw hyperspectral image; (D) ROI of the raw fluorescence spectral image.
Collecting spectral image data is easily affected by the differences between samples, environmental noise, and baseline drift during detection. In order to reduce these interferences, selecting appropriate pre-processing methods for the raw spectral images is necessary. Among the common pre-processing methods, the standard normal variant transform (SNV) (Dong et al., 2022, Liu et al., 2022) eliminates the error caused by different scattering levels between samples. The detrend correction (DT) (Ai et al., 2022) reduces the influence of external noise on the spectral curve by subtracting the trend-fitting line of the noise. The Savitzky-Golay (SG) convolution smoothing (Ren et al., 2021) reduces the noise by smoothing the spectral data within the window. The Gaussian window smoothing (GWS), boxing smoothing (BS) and exponential smoothing (ES) methods can reduce the noise in different smoothing ways.
The pre-processed spectral data exhibited a multicollinearity problem, so it was necessary to find the feature variables beneficial to the prediction results and eliminate the invalid variables. In this study, the Bootstrapping soft shrinkage (Boss) algorithm (Deng et al., 2016; Ouyang et al., 2021), the competitive adaptive reweighted sampling (CARS) algorithm (Zhang et al., 2019; Shicheng et al., 2021), the iteratively variable subset optimization (IVSO) algorithm (Sun et al., 2021), the Interval Variable Iterative Space Shrinkage Approach (IVISSA) (Cheng et al., 2020; Hao et al., 2022) and the Model adaptive space shrinkage (MASS) (Wen et al., 2016) methods were used to extract the spectral data.
Extreme learning machines (ELM) is a single-hidden layer feedforward neural network with fast training speed and strong generalization ability. It is widely used in various classification and regression scenarios (Jiang et al., 2018; Cheng et al., 2022). The partial least squares regression (PLSR) model combines principal components analysis (PCA) with maximum correlation analysis to fit the distribution of random variables into linear equations. It is widely used in mathematics, statistics, and finance (Guo et al., 2021; Ma et al., 2021). Least square support vector machine (LSSVM) replaces the complex secondary optimization problem in the traditional SVM by solving primary linear equations, simplifying the model and improving its operation speed (Feng et al., 2018; Zhang et al., 2020).
Five indicators, namely the coefficient of determination of the calibration set (), the root mean square error of the calibration set (RMSEC), the coefficient of determination of the prediction set (), the root mean square error of the prediction set (RMSEP), and the residual prediction deviation (RPD) were selected to evaluate the prediction capabilities of the developed models (Sharma et al., 2022). These evaluation indexes were calculated using the following Eqs. (1)-(3).
where R2 represents the correlation between the predicted and actual values, and the closer R2 is to 1, the better the predictive stability and the fit of the model. RMSE represents the difference between the predicted and actual values, and a smaller RMSE indicates better model prediction performance. RPD is the ratio of the sample’s standard deviation, and its root means square error (Saeys et al., 2005). RPD< 1.4 indicates a poor model prediction, 1.4 ≤ RPD ≤ 2 indicates an average model prediction and RPD ≥ 2 indicates a good model prediction.
The particle swarm optimization (PSO) algorithm was originally proposed by Eberhart and Kennedy in 1995 and used commonly to solve optimization problems (Bhandari et al., 2015; Bonah et al., 2020). Its principle indicates that the position of each particle corresponds to the optimal vector of the problem to be solved, and a population X of m particles in a D-dimensional space is set. The position Xi and the moving speed Vi of the ith particle in the population corresponds to (Xi1,Xi2,Xi3,…XiD) and (Vi1,Vi2,Vi3,…ViD) , respectively, and Pibest is (Pi1,Pi2,Pi3,…PiD) , representing the optimal position sought by the individual particles. At this time, the global optimal position of the whole population is Gbest, which is (Pg1,Pg2,Pg3,…PgD) . Each particle continuously updates Pbest and Gbest through a given fitness function until the optimal solution is found or the number of iterations is reached. The velocity and position of the dth-dimension of the ith particle are updated as follows (Eqs (4) and (5)).
where c1 and c2 are learning factors which adjust the maximum step size of learning, r1 and r2 are random numbers in the range of 0~1, and w is the inertia weight that adjusts the searchability of the solution space. This study used the PSO algorithm to optimize the LSSVM model parameters.
The raw spectral curves of the 90 kiwifruit samples are shown in Figure 3. Figure 3A is the original hyperspectral data in a wavelength range of 387.15 nm~1034.99 nm with 256 spectral bands. Figure 3B is the original fluorescence spectral data in a wavelength range of 376.80 nm~1011.05 nm with 125 spectral bands.
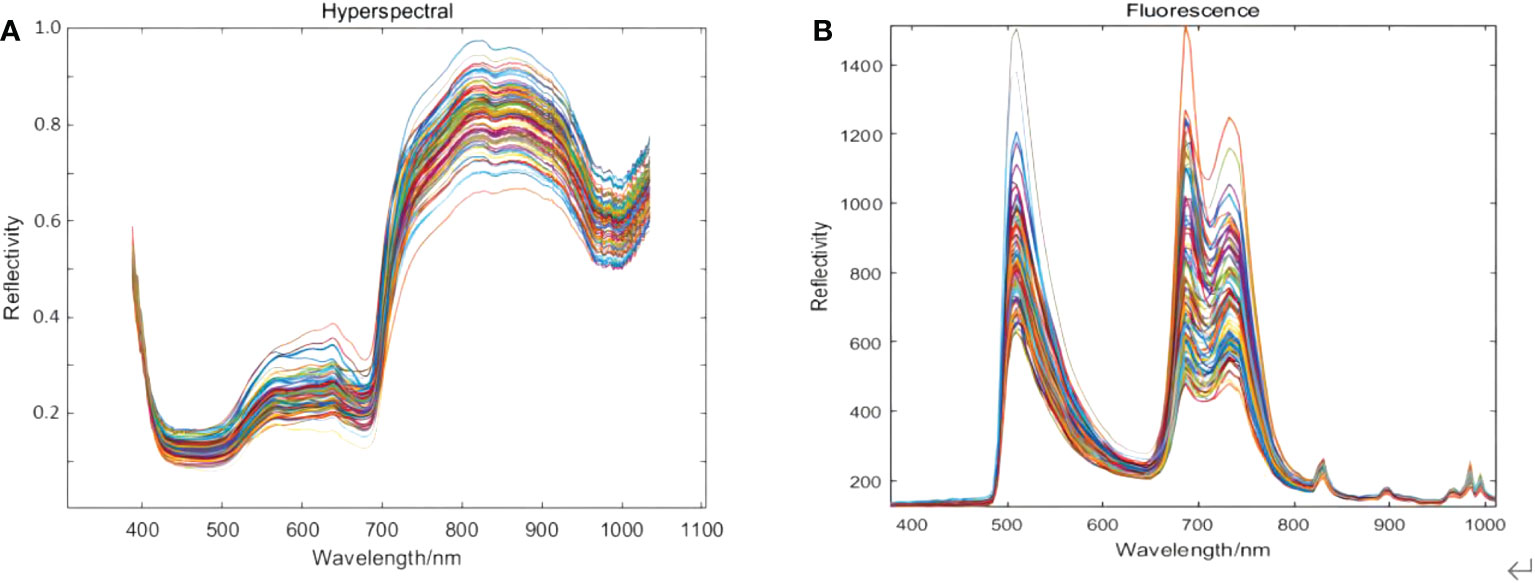
Figure 3 Spectral data of kiwifruit acquired by using (A) hyperspectral imaging and (B) fluorescence imaging.
It can be seen from Figure 3A that the bands at the beginning and the end of the original hyperspectral image data are significantly affected by noise. The spectral range of 420 nm~1000 nm was selected as the useful wavelength for the original hyperspectral image, with a total of 229 spectral bands. From Figure 3A, the troughs at 450 nm and 670 nm could be due to chlorophyll and other pigments in the cell wall. In comparison, the trough absorption peak at 980 nm is attributed to the tertiary and secondary frequencies of the C-H and O-H bonds in kiwifruit SSC (Chu, 2016). The first and last bands of the original fluorescence spectral images were also affected by noise, so the spectral range of 400~900 nm was selected as the effective wavelength of the original fluorescence spectral images, with a total of 102 spectral bands. From Figure 3B, after using the excitation filters with a central wavelength of 390 nm and 495 nm, obvious peaks appear near 510 nm, 690 nm, and 740 nm.
Dividing samples are beneficial to the stability and accuracy of the model prediction. Kennard Stone (KS) (Wei et al., 2020; Huang et al., 2021) algorithm was applied to divide 90 samples into a training set of 60 samples and a prediction set of 30 samples in a ratio of 2:1. The SSC values were collected by a handheld YSK-107 Brix salinity refractometer. The statistical results of the training and prediction sets of HSI and FSI are listed in Table 1.

Table 1 Statistical results of training and prediction data sets of SSC (unit:/Brix).
From Table 1, the ranges of each statistical parameter for the SSC values of the training set and prediction set samples corresponding to the HSI data are 6.50~14.9 and 8.70~15.35, respectively, and the standard deviations of the two samples are 1.79 and 1.44, respectively. Although the data range of the prediction set exceeds the training set, only occasional individual data at the front and back ends of the data exist. By comparing the standard deviations, the data of the prediction set are more concentrated, conforming to the principle of independent and identical distribution, indicating that the distribution of the two is relatively consistent. The statistical parameters of the SSC values of the training set and the prediction set corresponding to the FSI data ranged from 6.50 to 15.35 and 8.70 to 14.90, respectively. The above results illustrate that the sample division is reasonable and representative.
The raw effective spectral image data were pre-processed by the above six methods, and the prediction results of each pre-processing method were compared through the PLSR model, from which the optimal pre-processing method was selected. The prediction results of PLSR are listed in Table 2. The number of latent variables (lvs) in Table 2 was determined by the cross-sectional analysis. 1 to n potential variables were used to establish the model and the number of lvs with the best prediction was selected.
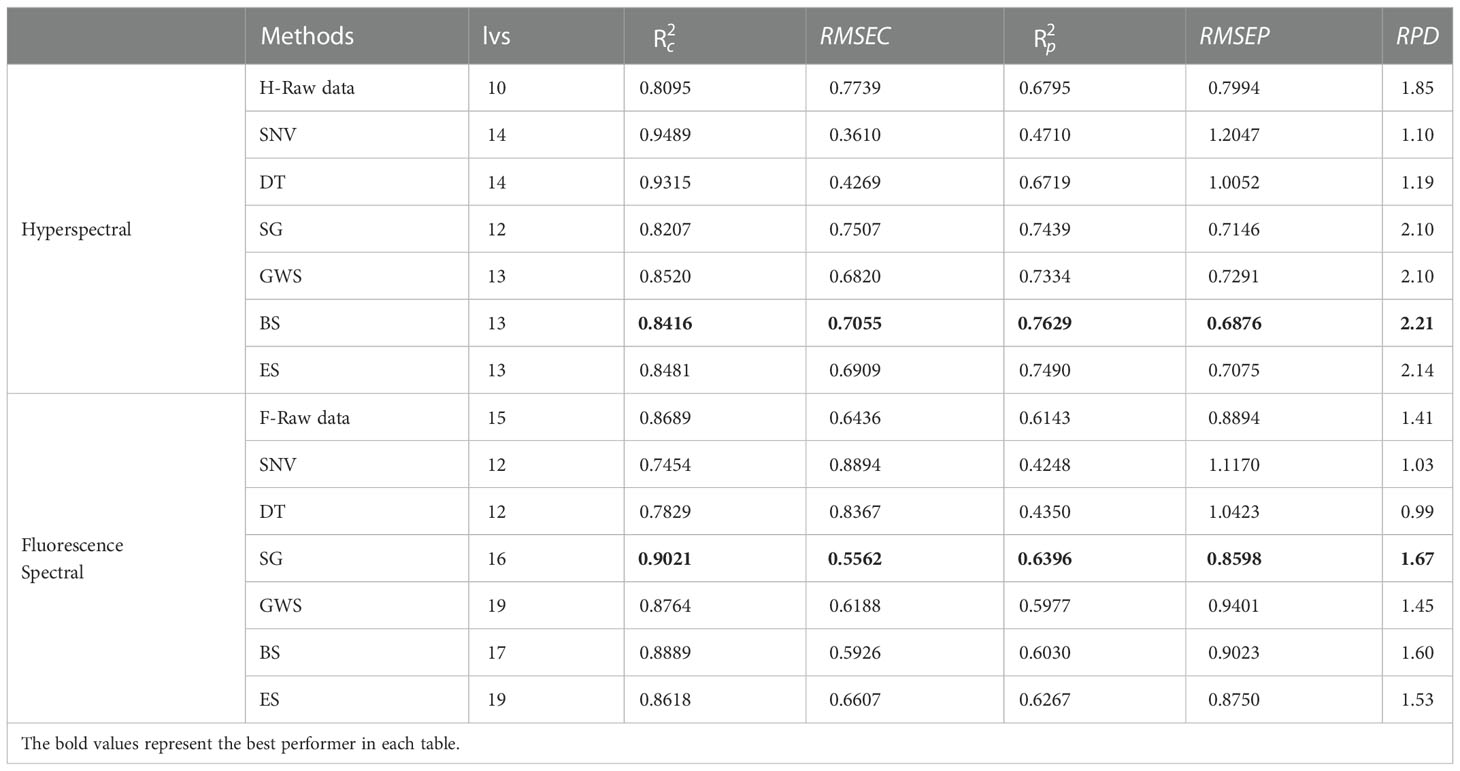
Table 2 The prediction results of PLSR based on different pre-processing methods.
During pre-processing of the hyperspectral data, the RPD values of SG, GWS, BS and ES were above 2.1 (Table 2), among which BS-PLSR exhibited the best prediction performance. The of BS-PLSR is 0.8416, which is not the optimal value, but its and RPD are 0.7629 and 2.21, respectively, the best values observed among all the methods. Hence BS was selected as the pre-processing method for raw hyperspectral image data. During pre-processing of the fluorescence spectral data, the RPD values of SG, BS, and ES were higher than the original fluorescence spectral data, with a value of 1.41. Among them, SG-PLSR showed the best prediction performance, and its were 0.9021, 0.6396, and 1.67, respectively. SG was selected as the pre-processing method for raw fluorescence spectral image data.
Boss used WBS technology to establish a sub-model to extract feature variables randomly from the pre-processed spectral data; thus, there was certain randomness. In the experiment, Boss was repeated several times to reduce the influence of randomness. During the extraction of hyperspectral data, the number of latent variables was set to 17 through cross-validation, the cross-folding was 5 layers, and the number of sampling was 1000. Meanwhile, 19 feature variables were extracted, accounting for 8.3% of the total hyperspectral variables. Similarly, the same extraction process was performed for the fluorescence spectrum data. The number of latent variables was set to 20, other parameters were the same as above, and 31 characteristic variables were finally extracted, accounting for 30.4% of the total fluorescence spectral variables. The distribution of the feature variables extracted by Boss is shown in Figure 4.
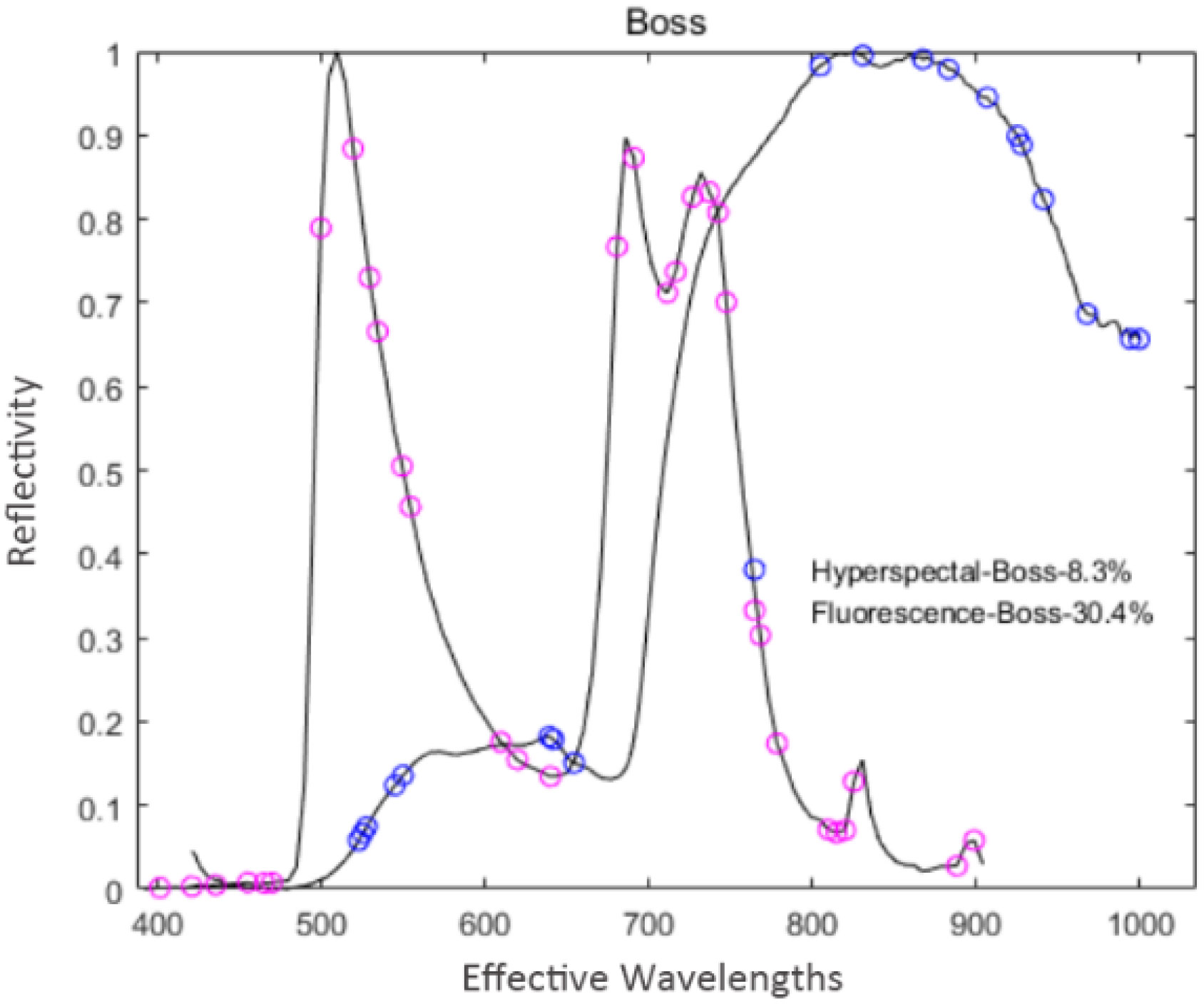
Figure 4 Distribution of the feature variables extracted by Boss.
As shown in Figure 4, the number and distribution of feature variables extracted by the Boss for the two spectral data differ. For hyperspectral data, the distribution of feature variables was mainly concentrated in the intervals of 500~650 nm and 800~1000 nm. In contrast, the feature variables were mainly concentrated in the wave peaks and troughs for the fluorescence spectral data.
CARS was used to extract the feature variables from the pre-processed spectral data. The same parameters were set for both spectral data: a maximum principal component of 18, the cross-validation of 5 times, and the Monte Carlo sampling 100 times. The extraction process of two feature variables from the spectral data by CARS is shown in Figures 5, 6, respectively.
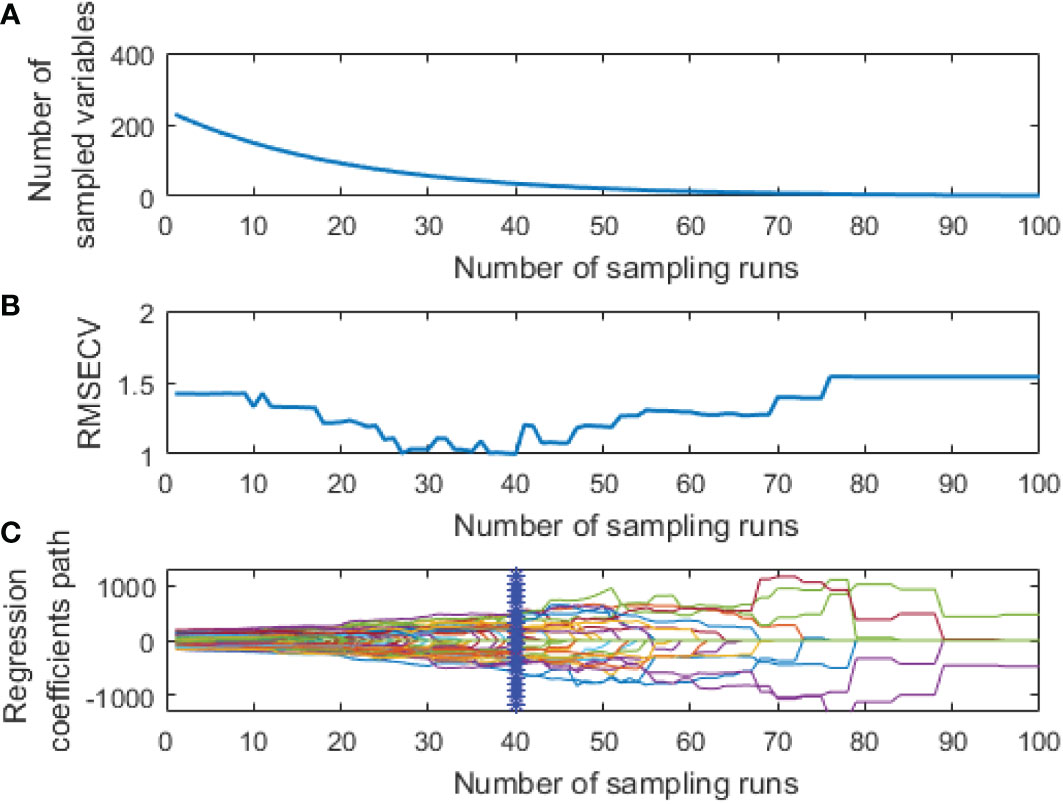
Figure 5 Extraction process of hyperspectral feature variables by CARS: (A) The number of feature variables reserved; (B) RMSECV; (C) The change of regression coefficient of each characteristic variable.
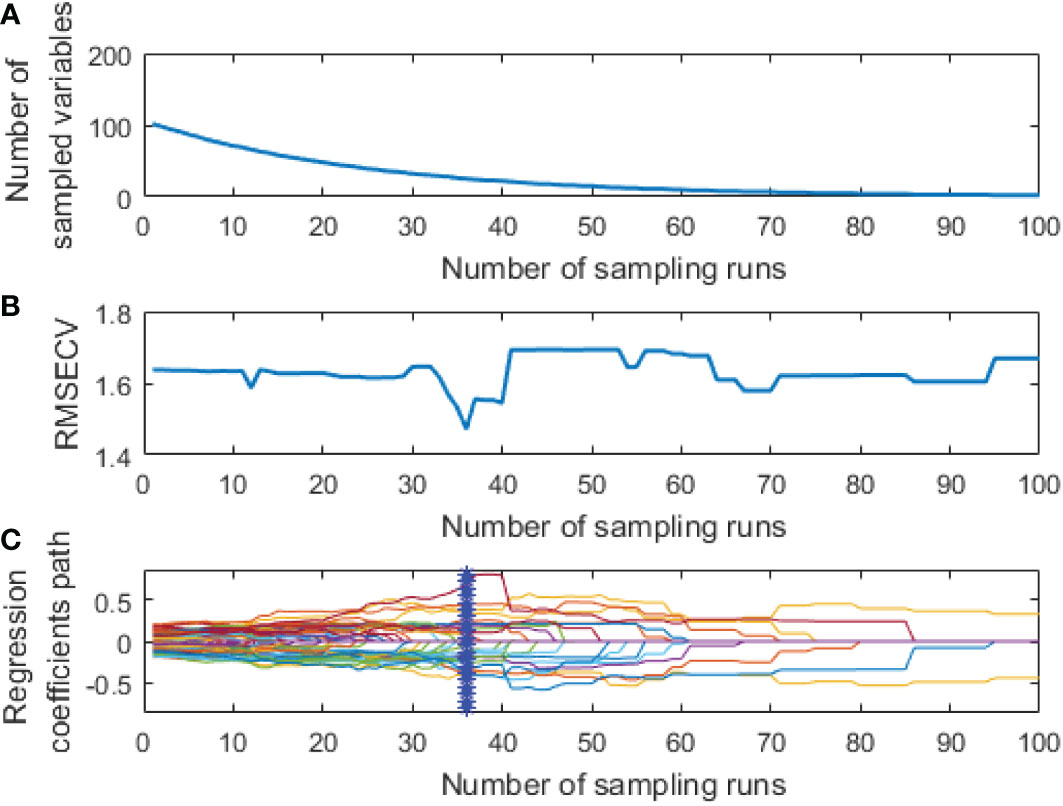
Figure 6 Extraction process of fluorescence spectral feature variables by CARS: (A) The number of feature variables reserved; (B) RMSECV; (C) The change of regression coefficient of each characteristic variable.
As shown in Figures 5A, B, the number of retained feature variables showed a fast and then slow continuous decreasing trend with the increase of sampling times, while the RMSECV value showed a decreasing and then an increasing trend. This could be due to the elimination of many redundant variables at the initial extraction stage. However, the excessive deletion of variables at the later extraction stage led to a decline in the model’s prediction performance.
The curve in Figure 5C represents changes in the regression coefficient of each feature variable with the increase of the sampling times. The blue “*” indicates the Monte Carlo sampling times when RMSECV had a minimum value. The model prediction performance was optimal at this time, and the corresponding number of samples was 40. Also, the trend of Figure 6 is similar to Figure 5, and the corresponding number of samples was 36 when RMSECV had the minimum value. Finally, the numbers of feature variables of hyperspectral data and fluorescence spectral data extracted by CARS were 35 and 25, respectively, accounting for 15.3% and 24.5% of the total original spectral variables. The distribution of feature variables extracted by CARS is shown in Figure 7.
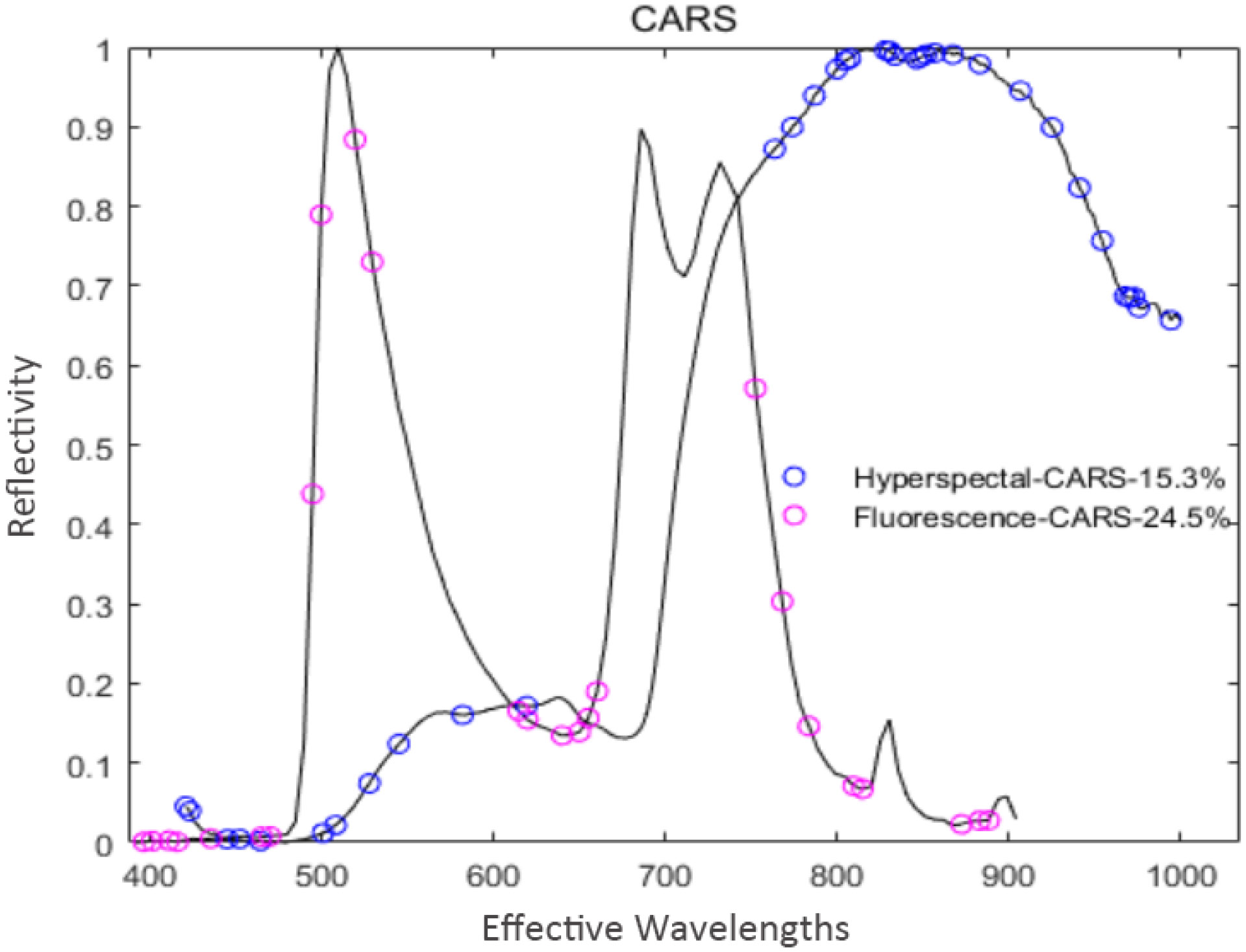
Figure 7 Distribution of the feature variables extracted by CARS.
As shown in Figure 7, the hyperspectral feature variables extracted by CARS were mainly concentrated in two spectral ranges of 430~610 nm and 800~1000 nm. In comparison, the fluorescence spectral feature variables extracted by CARS were mainly concentrated in three spectral ranges of 400~500 nm, 600~680 nm, and 770~900 nm.
IVSO was used to extract feature variables from the pre-processed spectral data. During the extraction process of hyperspectral data and fluorescence spectral data, the maximum numbers of PC cross-validation were set to 14 and 16, the cross-validation numbers were set to 9 and 7, and the running number of WBMS was set to 1000.
In the extraction process of hyperspectral data, IVSO was iterated 9 times. At this time, RMSECV reached a minimum value of 0.807, and 44 feature variables were extracted at the third iteration. In the fluorescence spectral data extraction process, RMSECV reached a minimum value of 0.940, and 23 feature variables were extracted. The distribution of feature variables extracted by IVSO is shown in Figure 8, where the hyperspectral feature variables are mainly distributed around 520 nm and 820 nm. In contrast, the distribution of the fluorescence spectral characteristic variables is relatively uniform.
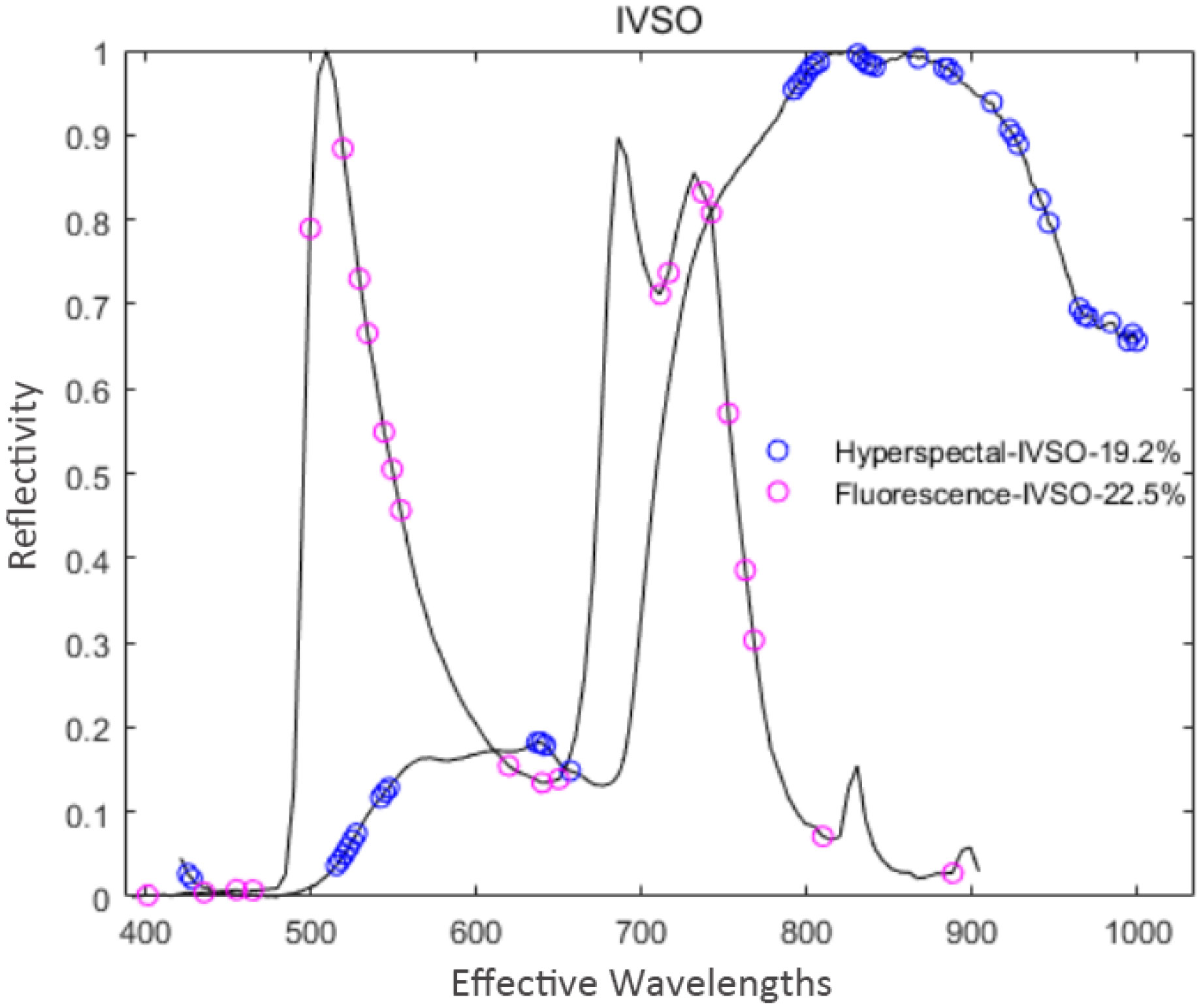
Figure 8 Distribution of the feature variables extracted by IVSO.
IVISSA was used to extract feature variables from the pre-processed spectral data. During the extraction processes of hyperspectral and fluorescence spectral data, the maximum number of latent variables was set to 19 and 17, respectively. Through cross-validation optimization, the number of cross-validation was 10, and the number of binary matrix sampling was 1000. In the extraction process of hyperspectral data, IVISSA iterated a total of 29 times, and RMSECV reached a minimum value of 0.7559. At this time, 70 feature variables were extracted, accounting for 30.6% of the total spectral variables. In the fluorescence spectral data extraction process, IVISSA iterated 19 times, and RMSECV reached a minimum value of 0.6923. 41 feature variables were extracted at that time, accounting for 40.2% of the total spectral variables. The distribution of feature variables extracted by IVISSA is shown in Figure 9.
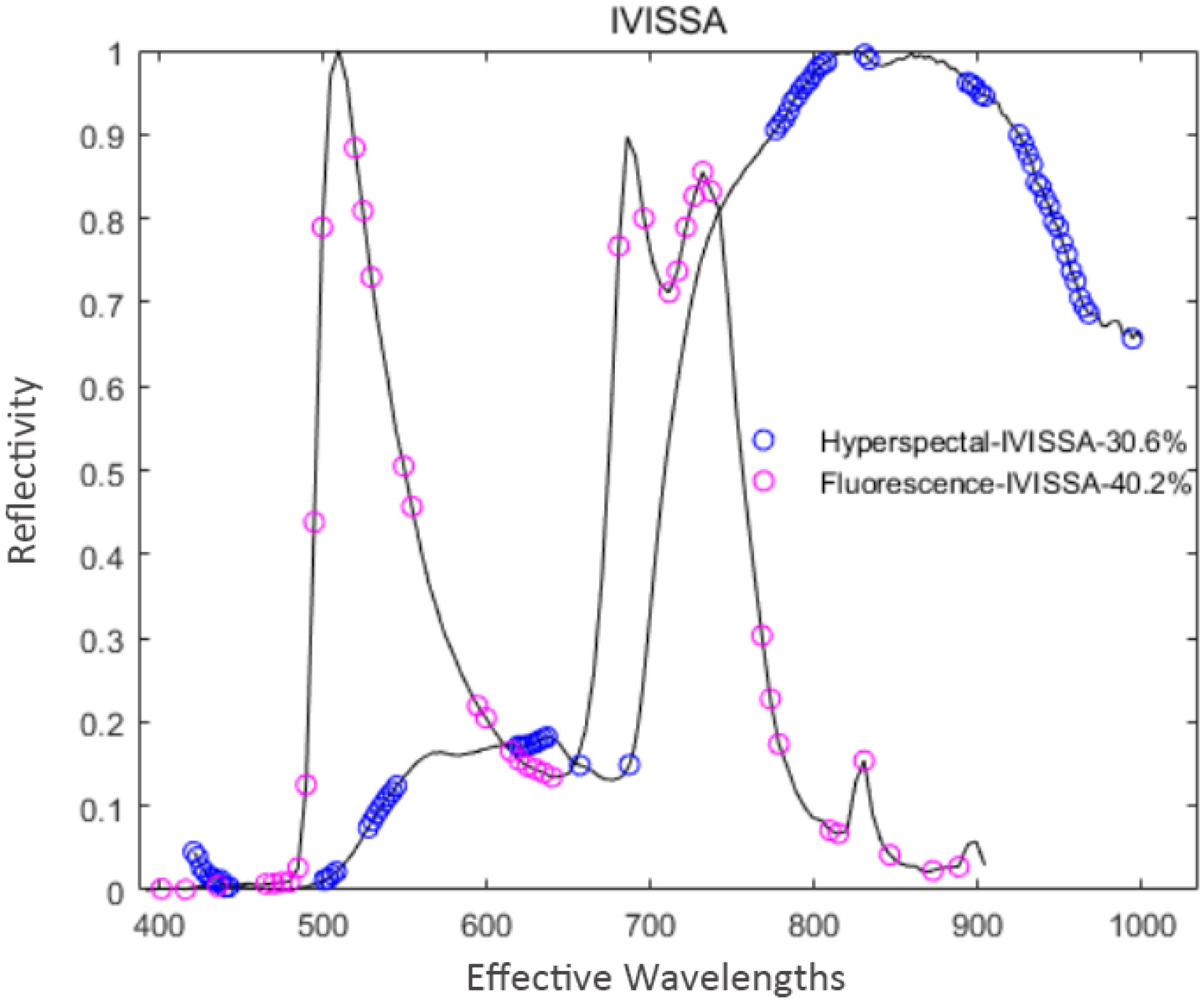
Figure 9 Distribution of feature variables extracted by IVISSA.
As shown in Figure 9, the numbers of two spectral feature variables extracted by the IVSO algorithm are relatively large, and the number of hyperspectral feature variables is much higher than the fluorescence spectral feature variables. Among them, the fluorescence spectral feature variables are distributed uniformly in the whole spectral range, while the hyperspectral feature variables are densely distributed at 450 nm, 540 nm, 620 nm, 810 nm, and 950 nm.
MASS was used to extract feature variables from the pre-processed spectral data. During the extraction processes of hyperspectral and fluorescence spectral data, the maximum number of latent variables was set to 13 and 14, respectively. Through cross-validation optimization, the number of cross-validation was 5, and the number of binary matrix sampling was 1000. In the extraction process of hyperspectral data, MASS iterated 36 times, and 53 feature variables were extracted, accounting for 23.1% of the total hyperspectral variables. In the extraction process of fluorescence spectral data, MASS iterated 22 times, and 29 feature variables were extracted, accounting for 28.4% of the total fluorescence spectral variables. The distribution of feature variables extracted by MASS is shown in Figure 10.
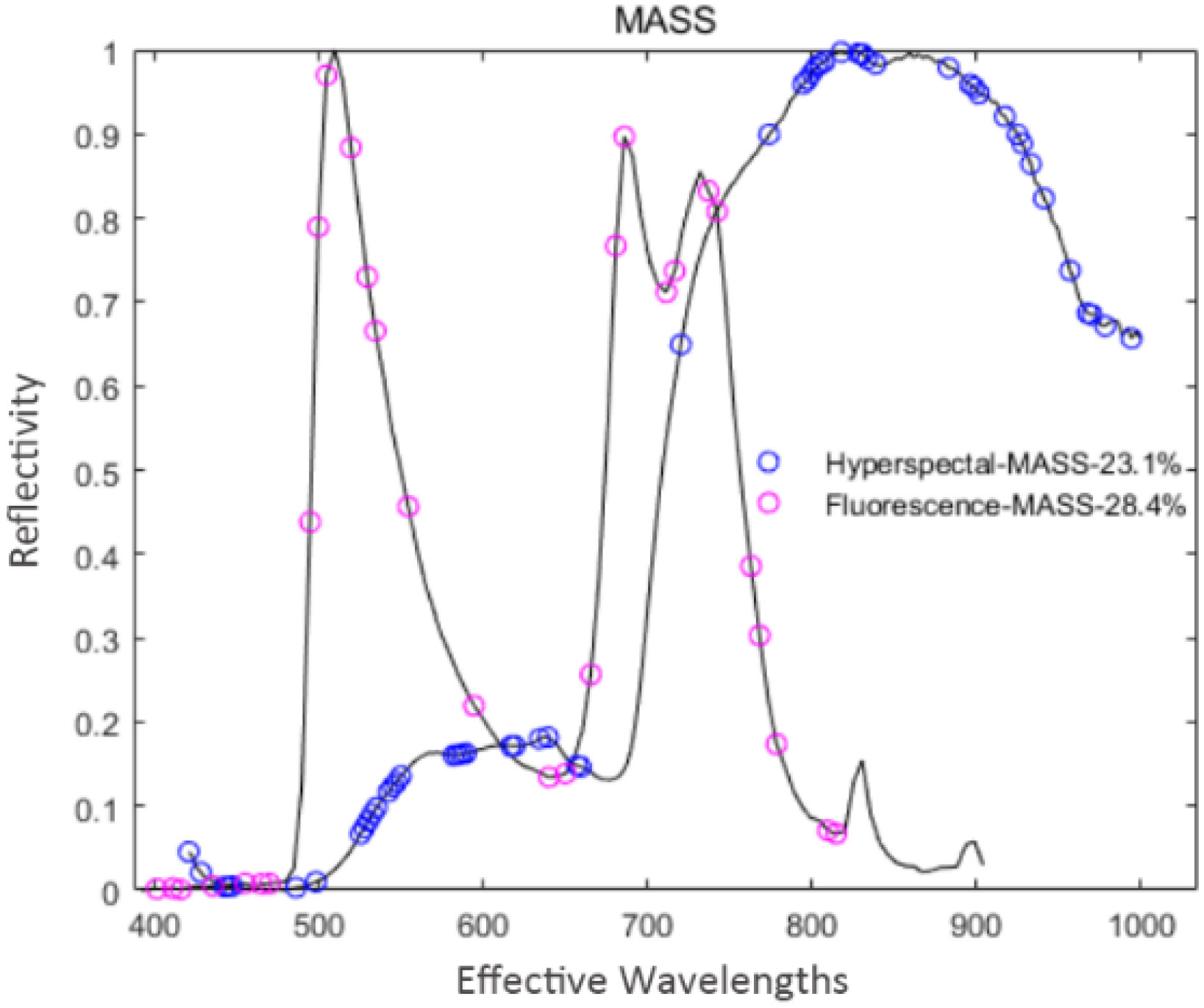
Figure 10 Spectral feature variable distribution map based on MASS.
From Figure 10, the number of feature variables extracted by MASS for the two types of spectral data are 23.10% and 28.4%, respectively. The extracted fluorescence spectral feature variables are distributed uniformly in the whole range, while the hyperspectral feature variables are concentrated in the former and latter two spectral ranges.
The first feature extraction could reduce some redundant and collinear variables in the original feature variables. However, the proportion of first-extracted feature variables is still high, with a few redundant variables. In order to further improve the prediction performance of the model, secondary feature extraction was adopted. Boss could greatly minimize the number of feature variables compared to the other four algorithms. Therefore, combining CARS, MASS, and IVISSA with the Boss algorithm for secondary feature extraction could combine the advantages of different feature extraction algorithms and further reduce the number of feature variables. The number of feature variables after the secondary extraction is listed in Table 3.
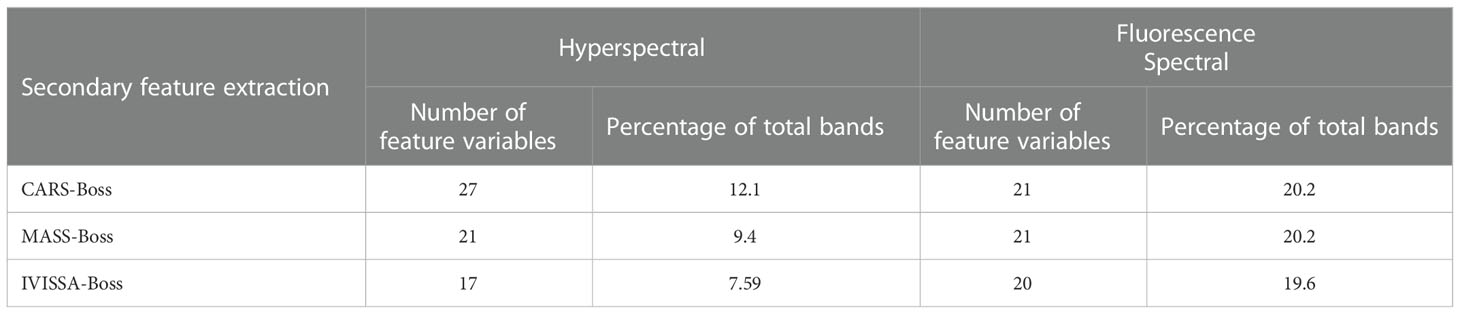
Table 3 The results of secondary feature extraction.
The specific feature variables obtained by the above three secondary feature extraction methods are listed in Table 4.
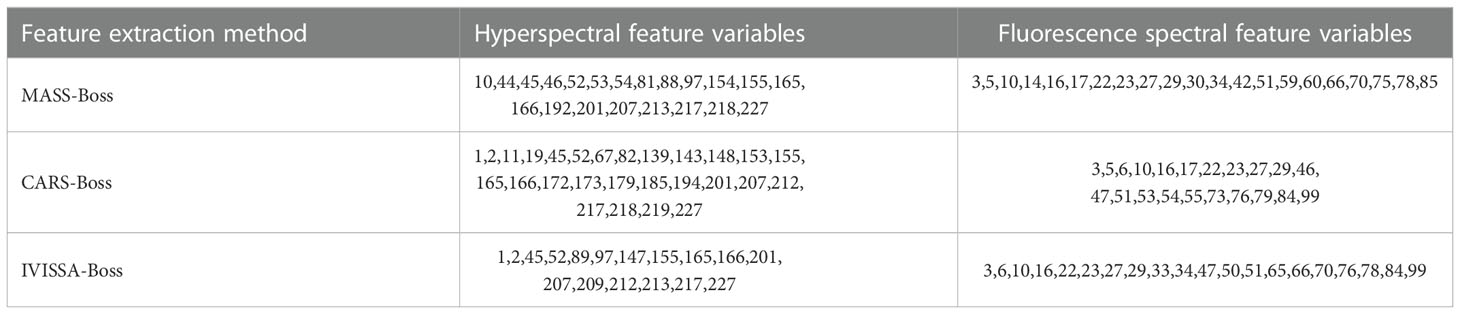
Table 4 Spectral variables obtained by different secondary feature extraction methods.
The numbers of feature variables obtained by the above eight feature extraction methods are shown in Figure 11.
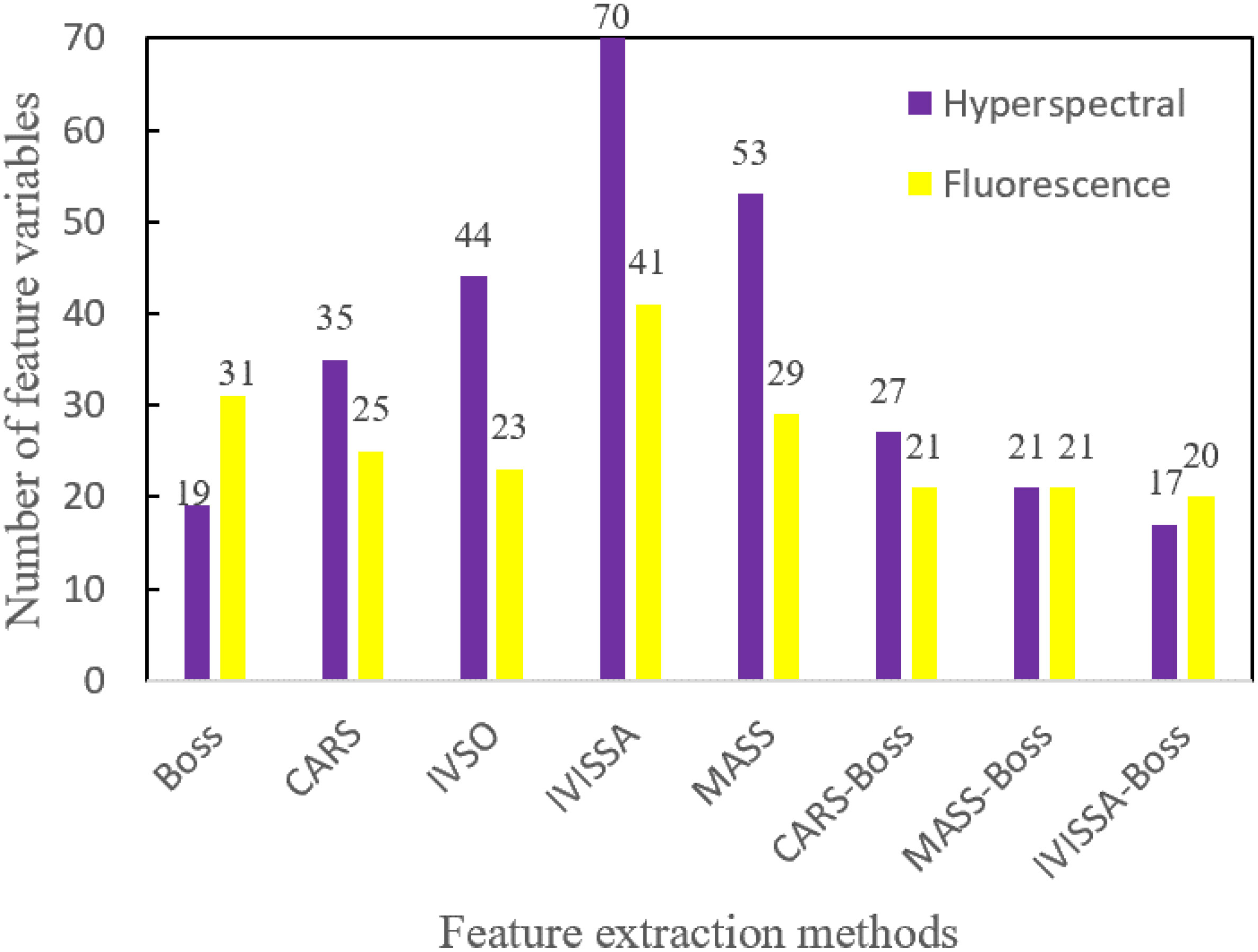
Figure 11 The number of variables extracted by different feature extraction methods.
From Figure 11, for hyperspectral data, the number of extracted feature variables ranged from 17 to 70. Among them, the number of feature variables extracted by IVISSA-Boss is the least, and the number of feature variables extracted by IVISSA is the largest. For the fluorescence spectral data, the number of the extracted feature variables ranged from 20 to 41. Among them, the number of feature variables extracted by IVISSA-Boss is the least, and the number of feature variables extracted by IVISSA is the largest. In addition, the number of feature variables after secondary feature extraction decreased, indicating that secondary feature extraction could further remove the redundant variables.
The extreme learning machine (ELM), the partial least squares regression (PLSR), and the least squares support vector machine optimized by the particle swarm optimization (PSO-LSSVM) prediction models were established for the above-indicated 8 types of feature variables extracted. The differences in the prediction performance of the two spectral image data for the SSC value of kiwifruit were analyzed and compared.
The “sig” function was selected as the activation function, and the number of neurons in the hidden layer was set from 1 to 100. The prediction results of ELM based on hyperspectral and fluorescence spectral feature variables are listed in Tables 5, 6, respectively.
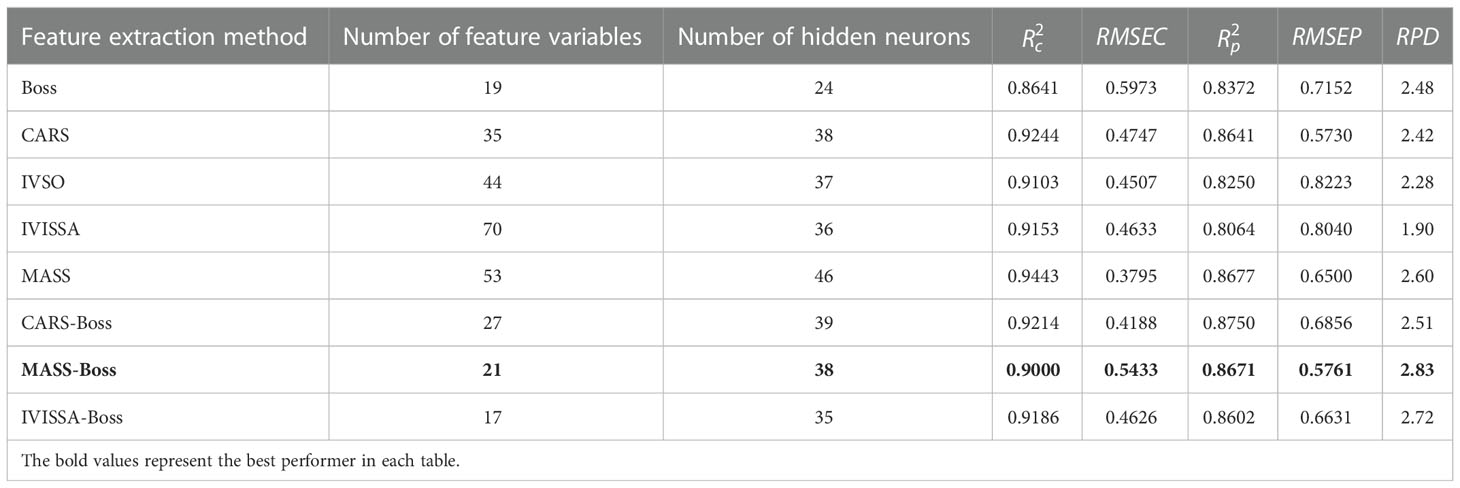
Table 5 Prediction results of ELM based on hyperspectral data.
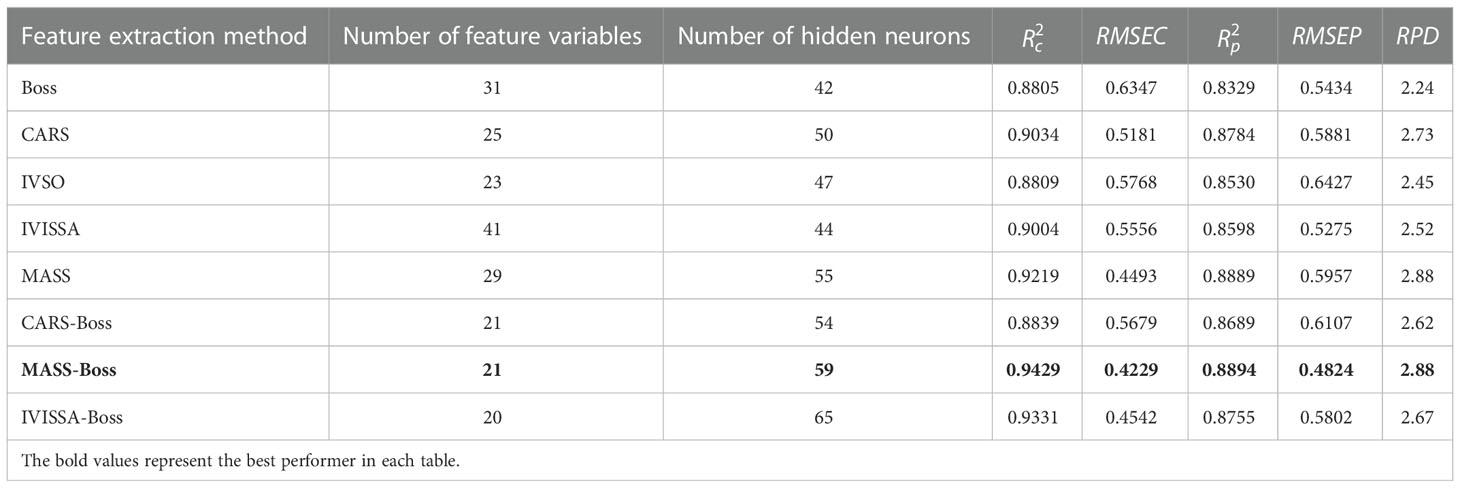
Table 6 Prediction results of ELM based on fluorescence spectral data.
As shown in Table 5, the RPD value of ELM established by 8 types of hyperspectral feature variables ranged from 1.90 to 2.83, and its and were higher than 0.86, presenting that the overall prediction effect of ELM is stable. IVISSA-ELM exhibited the worst prediction effect due to more redundant variables in its retained feature variables. The prediction effect of ELM after secondary feature extraction was improved, among which MASS-Boss-ELM showed the best prediction effect with , and RPD of 0.8671, 0.9000, and 2.83, respectively.
Table 6 illustrates that the RPD value of ELM established by 8 types of fluorescence spectral feature variables ranged from 2.24 to 2.88. Among them, the prediction performance of Boss-ELM is slightly worse, and its RPD is only 2.24. Compared with CARS-ELM, the RPD of CARS-Boss-ELM decreased slightly, and it was estimated that some effective feature variables were excluded in the secondary feature extraction process. The prediction performance of MASS-Boss-ELM was relatively optimal, with , , RPD of 0.8894, 0.9429, and 2.88, respectively.
From Tables 5, 6, the ranges of and of the ELM established by 8 types of hyperspectral feature variables were 0.8064~0.8750 and 0.8641~0.9443, respectively. For the feature variables of fluorescence spectra, the ranges of and corresponding to ELM were 0.8329~0.8894 and 0.8805~0.9429, respectively. Therefore, the overall prediction performance of ELM based on fluorescence spectral data is superior. MASS-Boss-ELM was optimal for both hyperspectral and fluorescence spectral data, verifying that the method reveals the strongest generalization ability.
The cross-validation method was used to determine the number of PLSR latent variables, and the optimal latent variables were selected as the final. The prediction results of PLSR based on hyperspectral and fluorescence spectral feature variables are listed in Tables 7, 8, respectively.
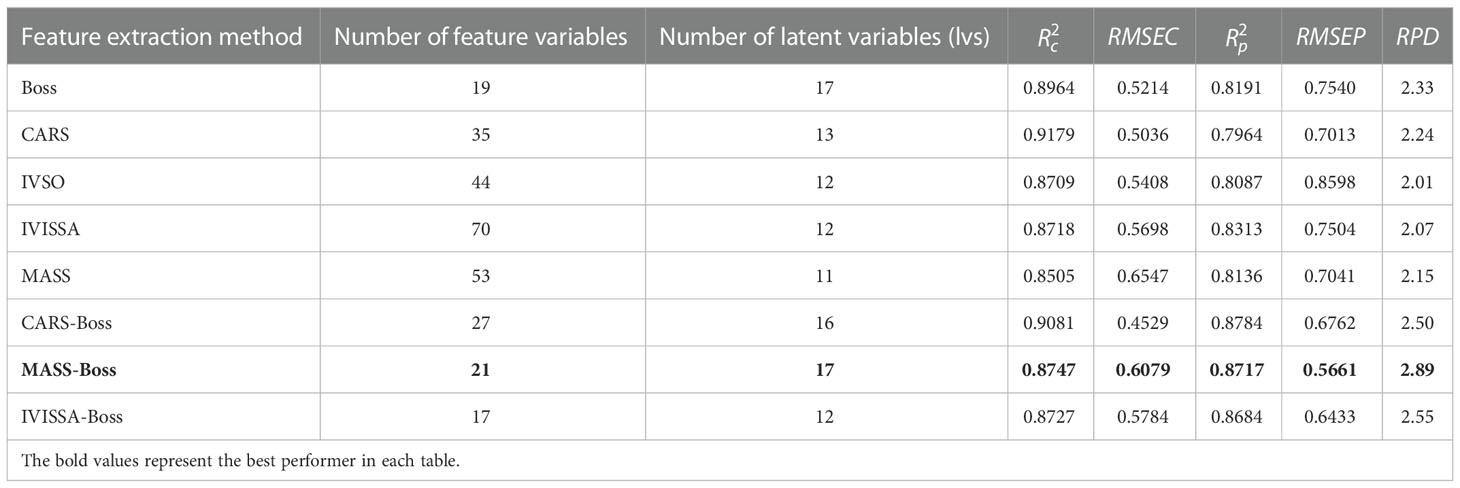
Table 7 Prediction results of PLSR based on hyperspectral data.
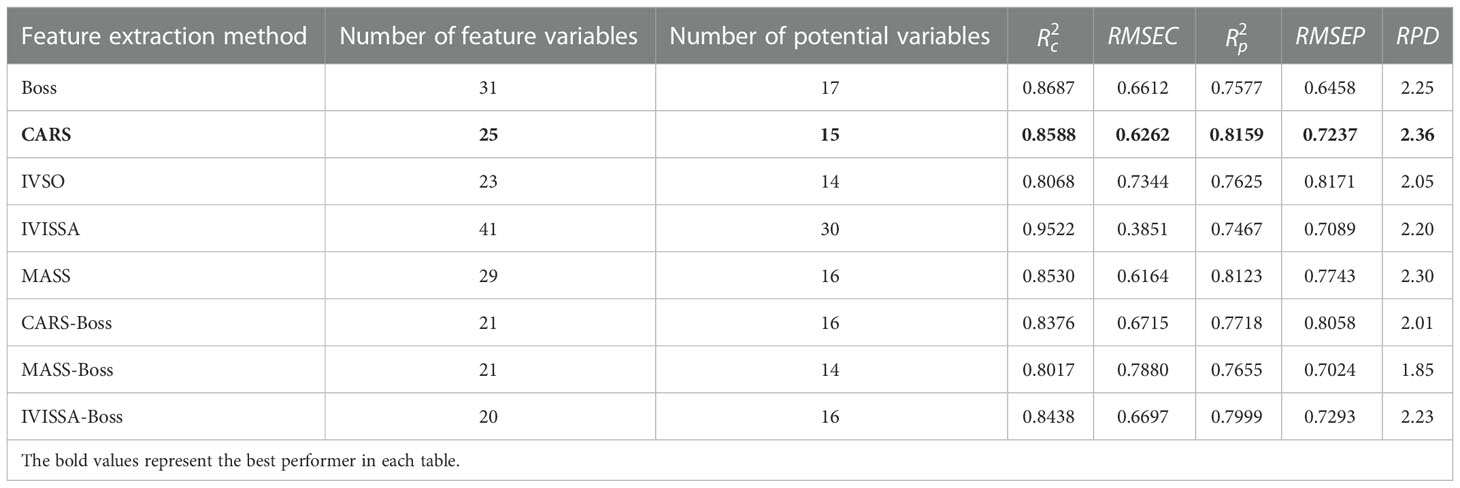
Table 8 Prediction results of PLSR based on fluorescence spectral data.
From Table 7, the PLSR established by 8 types of hyperspectral feature variables performed well in the prediction performance of kiwifruit SSC, and the RPD values exceeded 2.0; the highest RPD value reached 2.89. Compared with PLSR based on first feature extraction, the prediction performance of PLSR after secondary feature extraction was generally improved, indicating that secondary feature extraction could effectively filter out redundant variables. Among them, the prediction results of MASS-Boss-PLSR are relatively the best, with , and RPD of 0.8717, 0.8747 and 2.89, respectively.
As shown in Table 8, while comparing with the PLSR after only SG pre-processing, the prediction performance of PLSR displays improvements in the range of 1.85 to 2.36 after both the first and secondary feature variable extraction, both of which are higher than 1.67 of the SG-PLSR without feature extraction (Table 2). Among them, the prediction result of MASS-Boss-PLSR is the worst as the secondary feature extraction algorithm eliminates part of the key feature variables. The prediction performance of CARS-PLSR is relatively optimal, with , , and RPD of 0.8159, 0.8588, and 2.36, respectively.
By comparing Table 7, 8, the ranges of and of PLSR based on hyperspectral data are 0.7964~0.8784 and 0.8505~0.9179, respectively. The ranges of and of PLSR based on fluorescence data are 0.7467~0.8159 and 0.8017~0.9522, respectively. By combining Tables 4, 7, there is variability in the performance of the prediction models based on hyperspectral and fluorescence spectral data, in which MASS-Boss-ELM based on fluorescence spectral data is the optimal prediction method, and its , and RPD are 0.8894, 0.9429 and 2.88, respectively.
The radial basis function (RBF) was selected as the kernel function of LSSVM, and the prediction performance of the model was easily affected by the regularization parameter γ and the kernel parameter σ2 of RBF. The two parameters were optimized by the particle swarm optimization (PSO) algorithm (Bhandari et al., 2015; Bonah et al., 2020). In the training process, the population number, the iteration number, and the initial value of the inertia factor were set to 20,100, and 0.90, respectively, and both the learning factors c1 and c2 were 2. PSO-LSSVM was tested, and its prediction results are listed in Tables 9, 10, respectively.
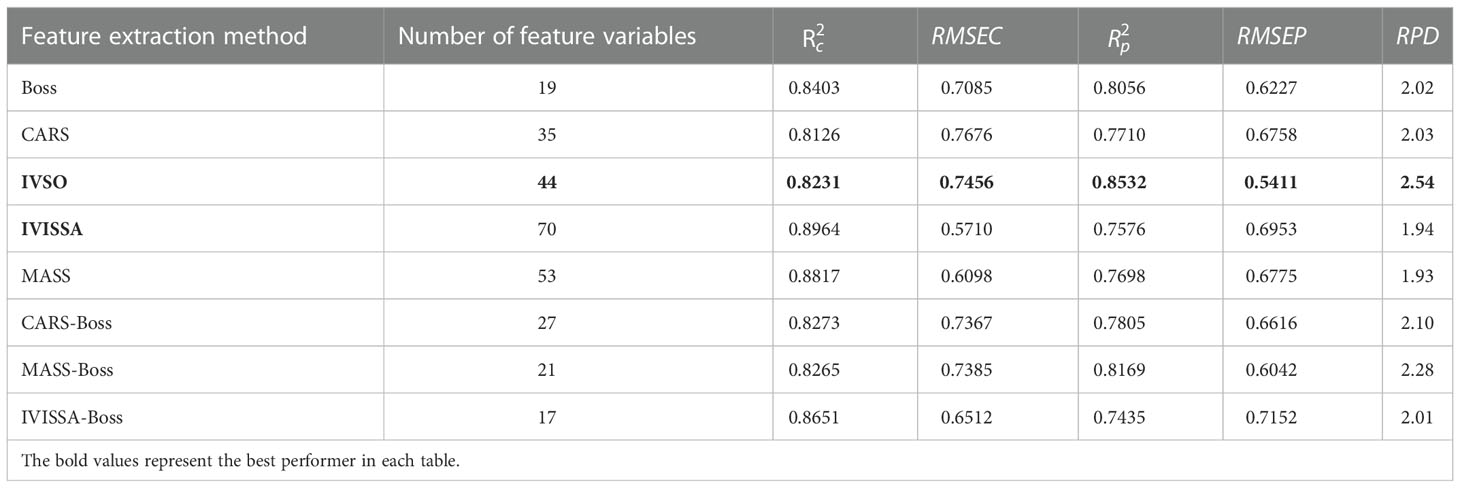
Table 9 Prediction results of PSO-LSSVM based on hyperspectral data .
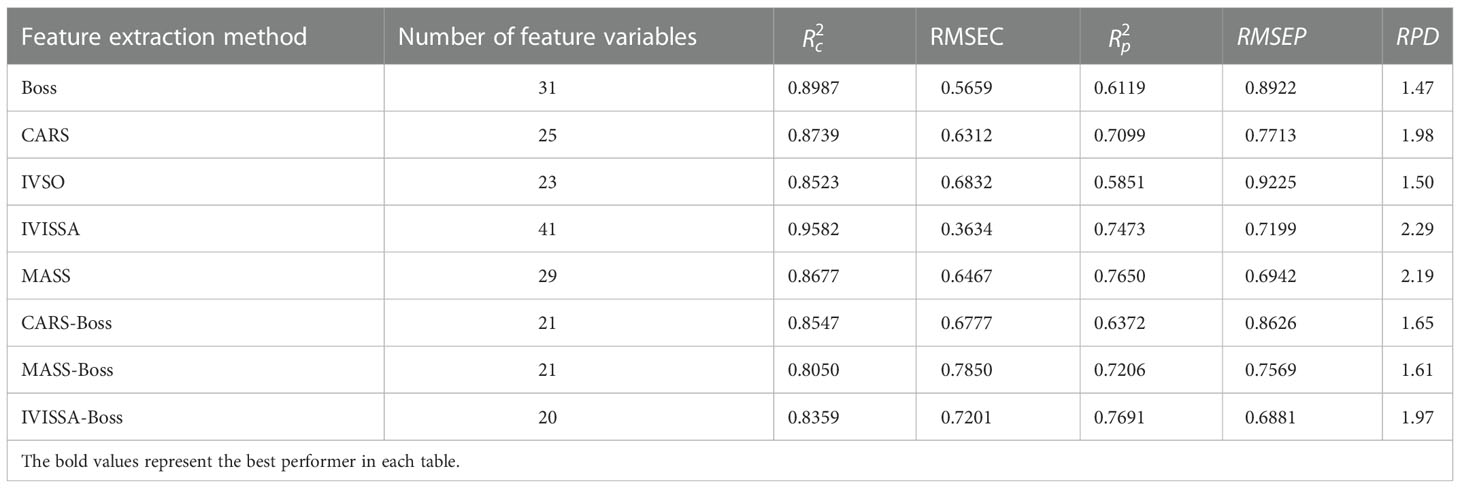
Table 10 Prediction results of PSO-LSSVM based on fluorescence spectral data.
As exhibited in Table 9, the prediction effect of PSO-LSSVM based on 8 types of hyperspectral feature variables performed well, and the RPD and are generally higher than 2.0 and 0.8, respectively, and ranged from 0.74 to 0.85, indicating that PSO-LSSVM presents good prediction performance for the SSC of kiwifruit. Among them, MASS-Boss-PSO-LSSVM illustrates the relatively best prediction results, with , , and RPD of 0.8169, 0.8265, and 2.28, respectively.
The prediction effect of PSO-LSSVM based on fluorescence spectral feature variables is significantly different, and the RPD values ranged from 1.47 to 2.29 (Table 10). Among them, IVISSA-PSO-LSSVM exhibits the relatively best prediction results, with the , , and RPD of 0.7473, 0.9582 and 2.29, respectively. The prediction performance of PSO-LSSVM is reduced after IVISSA-Boss secondary extraction, indicating that the valid variables among them were over-screened. In addition, the and of all methods differed significantly, specifying that the stability of PSO-LSSVM needs further improvements.
Among these, the best optimization parameters of PSO in the superior predicted models for the two spectra data are listed in Table 11.

Table 11 The best PSO optimization parameters.
The methods with relatively superior prediction results based on hyperspectral data and fluorescence spectral data were hyperspectral-BS-MASS-Boss-ELM, fluorescence spectral-SG-MASS-Boss-ELM, hyperspectral-BS-MASS-Boss-PLSR and fluorescence spectral-SG-CARS-PLSR, hyperspectral-BS-MASS-Boss-PSO-LSSVM, and fluorescence spectral-SG-IVISSA-PSO-LSSVM, respectively. The prediction results of the above six methods are shown in Figure 12 and are listed in Table 12.
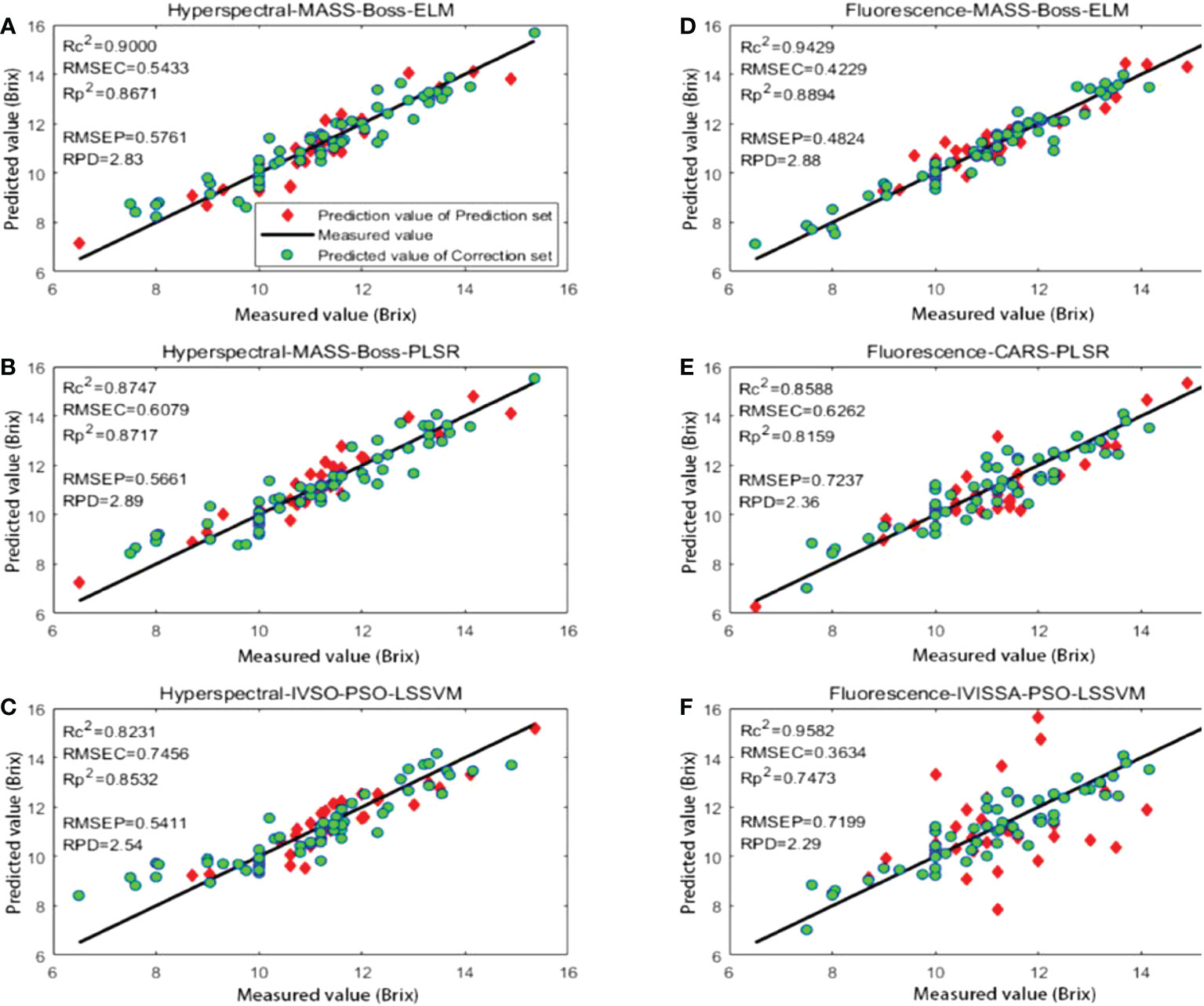
Figure 12 Prediction results of different optimal methods: (A) hyperspectral-MASS-Boss-ELM; (B) hyperspectral-MASS-Boss-PLSR; (C) hyperspectral-IVSO-PSO-LSSVM; (D) fluorescence-MASS-Boss-ELM; (E) fluorescence-CARS-PLSR; (F) fluorescence-IVISSA-PSO-LSSVM.
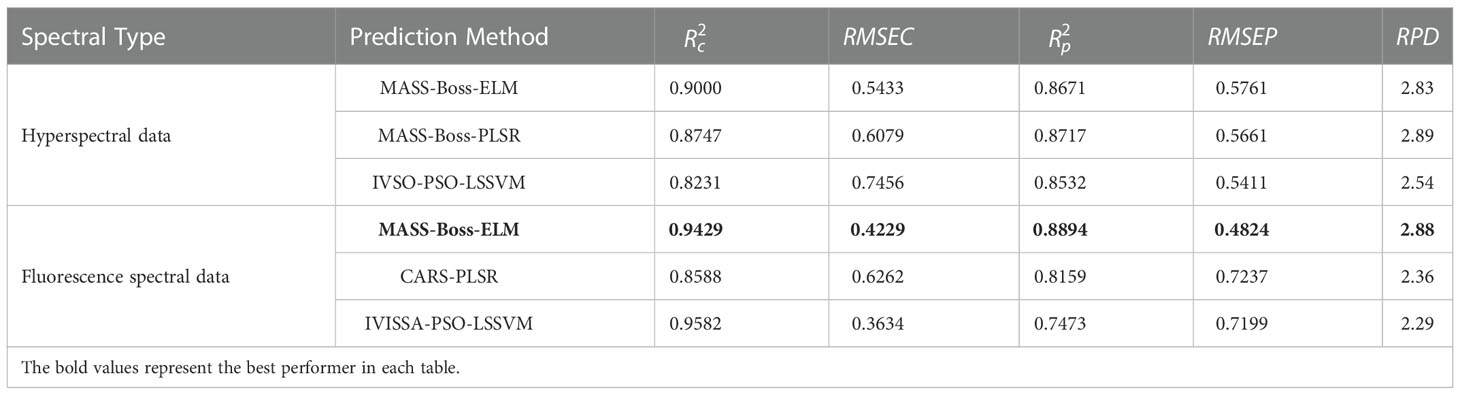
Table 12 Comparison of optimal results based on different feature extraction methods and models.
Figure 12 shows the regression chart of the prediction results for the above six methods. Comparing the prediction results with the other five methods, the prediction results of IVISSA-PSO-LSSVM based on fluorescence spectral data are quite different, and the prediction results are the worst. This is due to the excessive PSO algorithm parameters and the small number of samples, leading to an overfitting tendency in the training set. Compared with MASS-Boss-PLSR based on hyperspectral data, MASS-Boss-ELM and IVSO-PSO-LSSVM based on hyperspectral data exhibited relatively poor prediction results on the test set. Among them, the predicted results of MASS-Boss-ELM based on fluorescence spectral data illustrated the best generalization ability.
Table 12 presents that among the prediction results based on hyperspectral data, both MASS-Boss-ELM and MASS-Boss-PLSR show superior prediction performance, indicating that the MASS-Boss secondary extraction method could effectively filter out the feature variables, which could well represent the spectral data. Among them, MASS-Boss-PLSR exhibited a slightly superior RMSEP and RPD to MASS-Boss-ELM could be considered the most suitable prediction method for kiwifruit SSC based on hyperspectral data. The optimal prediction method for kiwifruit SSC based on fluorescence spectral data is MASS-Boss-ELM, whose prediction indicators far exceeded the IVISSA-PSO-LSSVM and CARS-PLSR.
The method followed in this study was compared with those reported in the literature, and the comparison results are listed in Table 13. It can be seen from Table 13 that Moen et al. (Moen et al., 2021) used different machine learning technologies to study the correlation between kiwifruit spectral information and its SSC, and found that the best prediction method was UVE-PLS, with the RMSEP of 1.047 and the of 0.39. Benelli et al. (Benelli et al., 2022) used the PLS model based on hyperspectral imaging technology to evaluate the maturity of “Hayward” kiwifruit, with the was in the range of 0.85~0.94, and RMSE was in the range of 1.10-0.73. The best prediction method in this study was MASS-Boss-ELM based on fluorescence spectral data, and its , RMSEP and RPD were 0.8894, 0.4824 and 2.88, respectively. Compared with the previous studies, the obtained in this study has not been improved significantly, but the RMSEP is the lowest, specifying that the MASS-Boss-ELM is superior.

Table 13 Comparison of the prediction results with the other methods.
This study explored the efficient prediction of hyperspectral and fluorescence spectral data for nondestructive detection of kiwifruit SSC (soluble solid content). Combining the six pretreatment methods and the PLSR model, the best pre-processing methods for hyperspectral and fluorescence spectral data were BS (boxing smoothing) and SG (Savitzky-Golay), respectively. Then, five primary and three secondary feature extraction algorithms were used to reduce the pre-processed spectral data. Three prediction models have been established: ELM, PLSR, and PSO-LSSVM. The prediction results of PLSR and ELM based on the hyperspectral and fluorescence spectral datasets were better. The best prediction method corresponding to the hyperspectral dataset was MASS-Boss-PLSR, and its , and RPD were 0.8717, 0.8747 and 2.89, respectively. The best prediction method corresponding to the fluorescence spectral dataset was MASS-Boss-ELM, and its , and RPD were 0.8894, 0.9429 and 2.88, respectively. Whereas PSO-LSSVM displayed the worst prediction results. In conclusion, the MASS-Boss-ELM method based on the fluorescence spectral dataset was the best non-destructive prediction method for kiwifruit SSC.
The research methods followed in this study could be improved further. For example, the optimal pre-processing methods for the two types of spectral datasets are different, and the best prediction models for each kind of spectral dataset are also different, which is not conducive to the follow-up research and development of non-destructive testing devices for agricultural products. Therefore, more spectral feature extraction algorithms and different models need to be studied further to find the best prediction model suitable for the different spectral datasets and apply it to the non-destructive testing of other parameters, such as pH and the hardness of kiwifruit.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
LX: Conceptualization, Data curation, Methodology, Writing – original draft, Writing – review & editing, Investigation, Validation, Formal analysis. YC: Data curation, Methodology, Writing – original draft, Writing – review & editing, Investigation, Validation, Formal analysis. XW: Methodology, Writing – original draft, Writing – review & editing, Investigation, Validation, Formal analysis. HC: Data curation, Formal analysis. ZT: Data curation, Formal analysis. XS: Data curation, Formal analysis. YW: Data curation, Formal analysis, Supervision. ZK: Data curation, Formal analysis. ZZ: Formal analysis. PH: Formal analysis. YH: Supervision, NY: Conceptualization, Supervision, Funding acquisition, Resources. YZ: Conceptualization, Supervision, Funding acquisition, Resources. All authors contributed to the article and approved the submitted version.
This study was funded by the Science and Technology Innovation Cultivation Project of Department of Science and Technology of Sichuan province(Grant No. 2021JDRC0091), the Key R & D project of Department of Science and Technology of Sichuan province(Grant No. 2020YFN0025). Natural Science Foundation of Sichuan Province(Grant No. 23NSFSC0568).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The reviewer ZG declared a shared affiliation with the author NY to the handling editor at the time of review. The handling editor JP declared a shared affiliation with the author YH at the time of review.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Ai, W., Liu, S., Liao, H., Du, J., Cai, Y., Liao, C., et al. (2022). Application of hyperspectral imaging technology in the rapid identification of microplastics in farmland soil. Sci. Total Environ. 807, 151030. doi: 10.1016/j.scitotenv.2021.151030
Benelli, A., Cevoli, C., Fabbri, A., Ragni, L. (2022). Ripeness evaluation of kiwifruit by hyperspectral imaging. Biosyst. Eng. 223, 42–52. doi: 10.1016/j.biosystemseng.2021.08.009
Bhandari, A. K., Kumar, A., Singh, G. K. (2015). Modified artificial bee colony based computationally efficient multilevel thresholding for satellite image segmentation using kapur’s, otsu and tsallis functions. Expert Syst. Appl. 42, 1573–1601. doi: 10.1016/j.eswa.2014.09.049
Bonah, E., Huang, X., Yi, R., Aheto, J. H., Yu, S. (2020). Vis-NIR hyperspectral imaging for the classification of bacterial foodborne pathogens based on pixel-wise analysis and a novel CARS-PSO-SVM model. Infrared Phys. Technol. 105. doi: 10.1016/j.infrared.2020.103220
Cheng, L., Liu, G., He, J., Wan, G., Ma, C., Ban, J., et al. (2020). Non-destructive assessment of the myoglobin content of tan sheep using hyperspectral imaging. Meat Sci. 167, 107988. doi: 10.1016/j.meatsci.2019.107988
Cheng, J., Sun, J., Yao, K., Xu, M., Wang, S., Fu, L. (2022). Development of multi-disturbance bagging extreme learning machine method for cadmium content prediction of rape leaf using hyperspectral imaging technology. Spectrochim. Acta A Mol. Biomol. Spectrosc. 279, 121479. doi: 10.1016/j.saa.2022.121479
Chu, X. L. (2016). Practical manual of near infrared spectroscopic analysis technology (Beijing: China Machine Press).
Deng, B. C., Yun, Y. H., Cao, D. S., Yin, Y. L., Wang, W. T., Lu, H. M., et al. (2016). A bootstrapping soft shrinkage approach for variable selection in chemical modeling. Anal. Chim. Acta 908, 63–74. doi: 10.1016/j.aca.2016.01.001
Dong, C., An, T., Yang, M., Yang, C., Liu, Z., Li, Y., et al. (2022). Quantitative prediction and visual detection of the moisture content of withering leaves in black tea (Camellia sinensis) with hyperspectral image. Infrared Phys. Technol. 123, 104118. doi: 10.1016/j.infrared.2022.104118
Feng, X., Yu, C., Shu, Z., Liu, X., Yan, W., Zheng, Q., et al. (2018). Rapid and non-destructive measurement of biofuel pellet quality indices based on two-dimensional near infrared spectroscopic imaging. Fuel 228, 197–205. doi: 10.1016/j.fuel.2018.04.149
Gao, S., Xu, J.-h. (2022). Hyperspectral image information fusion-based detection of soluble solids content in red globe grapes. Comput. Electron. Agric. 196. doi: 10.1016/j.compag.2022.106822
Guo, W., Li, X., Xie, T. (2021). Method and system for nondestructive detection of freshness in penaeus vannamei based on hyperspectral technology. Aquaculture 538. doi: 10.1016/j.aquaculture.2021.736512
Hao, J., Dong, F., Li, Y., Wang, S., Cui, J., Zhang, Z., et al. (2022). Investigation of the data fusion of spectral and textural data from hyperspectral imaging for the near geographical origin discrimination of wolfberries using 2D-CNN algorithmsInfrared physics & technology 125. doi: 10.1016/j.infrared.2022.104286
Huang, H., Hu, X., Tian, J., Jiang, X., Luo, H., Huang, D. (2021). Rapid detection of the reducing sugar and amino acid nitrogen contents of daqu based on hyperspectral imaging. J. Food Compos. Anal. 101. doi: 10.1016/j.jfca.2021.103970
Jiang, J., Cen, H., Zhang, C., Lyu, X., Weng, H., Xu, H., et al. (2018). Nondestructive quality assessment of chili peppers using near-infrared hyperspectral imaging combined with multivariate analysis. Postharvest Biol. Technol. 146, 147–154. doi: 10.1016/j.postharvbio.2018.09.003
Kang, Z., Geng, J., Fan, R., Hu, Y., Sun, J., Wu, Y., et al. (2022). Nondestructive testing model of mango dry matter based on fluorescence hyperspectral imaging technology. Agriculture 12 (9), 1337. doi: 10.3390/agriculture12091337
Kim, Y.-K., Baek, I., Lee, K.-M., Qin, J., Kim, G., Shin, B. K., et al. (2022). Investigation of reflectance, fluorescence, and raman hyperspectral imaging techniques for rapid detection of aflatoxins in ground maize. Food Control 132. doi: 10.1016/j.foodcont.2021.108479
Li, Y., Ma, B., Li, C., Yu, G. (2022). Accurate prediction of soluble solid content in dried hami jujube using SWIR hyperspectral imaging with comparative analysis of models. Comput. Electron. Agric. 193. doi: 10.1016/j.compag.2021.106655
Liu, Y., Long, Y., Liu, H., Lan, Y., Long, T., Kuang, R., et al. (2022). Polysaccharide prediction in ganoderma lucidum fruiting body by hyperspectral imaging. Food Chem. X. 13, 100199. doi: 10.1016/j.fochx.2021.100199
Ma, C., Ren, Z., Zhang, Z., Du, J., Jin, C., Yin, X. (2021). Development of simplified models for nondestructive testing of rice (with husk) protein content using hyperspectral imaging technology. Vib. Spectrosc. 114. doi: 10.1016/j.vibspec.2021.103230
Moen, J. E., Nilsen, V., Saidi, K. B., Kohmann, E., Devassy, B. M., George, S. (2021). Hyperspectral imaging and machine learning for the prediction of SSC in kiwi fruits. Norsk IKT-konferanse forskning og utdanning. (1), 86–98.
Ouyang, Q., Wang, L., Park, B., Kang, R., Chen, Q. (2021). Simultaneous quantification of chemical constituents in matcha with visible-near infrared hyperspectral imaging technology. Food Chem. 350, 129141. doi: 10.1016/j.foodchem.2021.129141
Pham, Q. T., Liou, N. S. (2022). The development of on-line surface defect detection system for jujubes based on hyperspectral images. Comput. Electron. Agric. 194, 106743. doi: 10.1016/j.compag.2022.106743
Ren, G., Liu, Y., Ning, J., Zhang, Z. (2021). Assessing black tea quality based on visible–near infrared spectra and kernel-based methods. J. Food Compos. Anal. 98. doi: 10.1016/j.jfca.2021.103810
Saeys, W., Mouazen, A. M., Ramon, H. (2005). Potential for onsite and online analysis of pig manure using visible and near infrared reflectance spectroscopy. Biosyst. Eng. 91 (4), 393–402. doi: 10.1016/j.biosystemseng.2005.05.001
Sharma, S., Sumesh, K. C., Sirisomboon, P. (2022). Rapid ripening stage classification and dry matter prediction of durian pulp using a pushbroom near infrared hyperspectral imaging system. Measurement 189. doi: 10.1016/j.measurement.2021.110464
Shicheng, Q., Youwen, T., Qinghu, W., Shiyuan, S., Ping, S. (2021). Nondestructive detection of decayed blueberry based on information fusion of hyperspectral imaging (HSI) and low-field nuclear magnetic resonance (LF-NMR). Comput. Electron. Agric. 184. doi: 10.1016/j.compag.2021.106100
Sun, J.-J., Yang, W.-D., Feng, M.-C., Xiao, L.-J., Sun, H., Kubar, M.-S. (2021). Adaptive variable re-weighting and shrinking approach for variable selection in multivariate calibration for near-infrared spectroscopy. Chin. J. Anal. Chem. 49, e21079–e21086. doi: 10.1016/s1872-2040(21)60102-0
Wei, X., He, J., Zheng, S., Ye, D. (2020). Modeling for SSC and firmness detection of persimmon based on NIR hyperspectral imaging by sample partitioning and variables selection. Infrared Phys. Technol. 105. doi: 10.1016/j.infrared.2019.103099
Wen, M., Deng, B., Cao, D., Yun, Y., Yang, R., Lu, H., et al. (2016). The model adaptive space shrinkage (MASS) approach: A new method for simultaneous variable selection and outlier detection based on model population analysis. Analyst 141, 5586–5597. doi: 10.1039/c6an00764c
Zhang, D., Xu, Y., Huang, W., Tian, X., Xia, Y., Xu, L., et al. (2019). Nondestructive measurement of soluble solids content in apple using near infrared hyperspectral imaging coupled with wavelength selection algorithm. Infrared Phys. Technol. 98, 297–304. doi: 10.1016/j.infrared.2019.03.026
Zhang, M., Zhang, B., Li, H., Shen, M., Tian, S., Zhang, H., et al. (2020). Determination of bagged ‘Fuji’ apple maturity by visible and near-infrared spectroscopy combined with a machine learning algorithm. Infrared Phys. Technol. 111. doi: 10.1016/j.infrared.2020.103529
Keywords: hyperspectral, fluorescence spectral, non-destructive detection, kiwifruit, ssc
Citation: Xu L, Chen Y, Wang X, Chen H, Tang Z, Shi X, Chen X, Wang Y, Kang Z, Zou Z, Huang P, He Y, Yang N and Zhao Y (2023) Non-destructive detection of kiwifruit soluble solid content based on hyperspectral and fluorescence spectral imaging. Front. Plant Sci. 13:1075929. doi: 10.3389/fpls.2022.1075929
Received: 21 October 2022; Accepted: 28 December 2022;
Published: 18 January 2023.
Edited by:
Jianfeng Ping, Zhejiang University, ChinaReviewed by:
Naveen Kumar Mahanti, Dr.Y.S.R. Horticultural University, IndiaCopyright © 2023 Xu, Chen, Wang, Chen, Tang, Shi, Chen, Wang, Kang, Zou, Huang, He, Yang and Zhao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yuchao Wang, d2FuZ3ljMDkxOEB5YWhvby5jby5qcA==; Ning Yang, eWFuZ25pbmc3NDEwQDE2My5jb20=; Yongpeng Zhao, emhhb3lwQHNpY2F1LmVkdS5jbg==
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.