
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
DATA REPORT article
Front. Plant Sci. , 18 November 2022
Sec. Sustainable and Intelligent Phytoprotection
Volume 13 - 2022 | https://doi.org/10.3389/fpls.2022.1047356
This article is part of the Research Topic Robotics for Crop Care and Breeding View all 6 articles
 Nan Hu1†
Nan Hu1† Shuo Wang1†Xuechang Wang1Yu Cai1
Shuo Wang1†Xuechang Wang1Yu Cai1 Daobilige Su1*
Daobilige Su1* Purevdorj Nyamsuren2
Purevdorj Nyamsuren2 Yongliang Qiao3
Yongliang Qiao3 Yu Jiang4Bo Hai5
Yu Jiang4Bo Hai5 Hang Wei6
Hang Wei6With the development of robotics and artificial intelligence, various intelligent robots are being developed and deployed for different autonomous operations in agriculture. Specifically for robotic precision spray of pesticide and fertilizer, modern agricultural robots use various onboard cameras to detect and track various plants on farms. Accurate detection and reliable tracking of plants are of utmost importance for robots to carry out pinpoint spray action for delivering the chemicals to the relevant parts of plants. With the rapid development of artificial intelligence, specially with deep learning methods, robots are able to accomplish detection and tracking of plants using intelligent machine learning algorithms. However, the prerequisite of it is the large amount of labelled data to train, validate and test the machine learning models.
In recent years, many researchers have proposed various datasets to detect and localize fruits and vegetables (Jiang et al., 2019; Moreira et al., 2022). Bargoti and Underwood (2017) presented a fruit detection dataset collected by a robot travelling in fruit orchards. Images in the dataset include mangoes, almonds and apples. Koirala et al. (2019) provided a image dataset which was captured in a mango orchard. At the same time, they also presented a benchmark called ‘MangoYOLO’. Kusumam et al. (2017) collected three-dimensional point cloud data and RGB images of broccoli with their robots in Britain and Spain. Chebrolu et al. (2017) presented a large-scale agricultural dataset of sugar beet, which was collected by their robot traveling in a sugar beet farm near Bonn in Germany. The dataset contains approximately ten thousand images of plants and weeds labelled pixel by pixel, which can be used for semantic segmentation of crop and weed. Bender et al. (2020) utilized the agricultural robot Ladybird to collect a multimodal data including stereo RGB and hyperspectral images of crops and weeds, as well as the environment information. The dataset contains information of cauliflower and broccoli recorded over teen weeks. These datasets have made a significant contribution in the field of plant detection, localization and segmentation (Lottes et al., 2017; Milioto et al., 2018). However, these datasets cannot be directly used for tracking plants, due to the lack of correspondence of plants between consecutive images. Without tracking plants, robots cannot recognize the same plant which shows up in two consecutive images, and might spray it more than once.
More recently, Jong et al. (2022) presented APPLE MOTS, a dataset collected by a UAV and a wearable sensor platform which includes about 86000 manually annotated apple masks for detecting, segmenting and tracking homogeneous objects. They evaluated different MOTS (Voigtlaender et al., 2019; Xu et al., 2020) methods on the dataset, and provided benchmark values of apple tracking performance. This dataset can be used for detection, segmentation and tracking of apples. The trajectory of camera mostly follows a simple forward motion, and targets which have gone out of camera field of view do not re-appear again in the following images. However, for robotic precision spray application, robots might reverse back to avoid dynamic obstacles such as a working human. It might also temporarily move out of the row, e.g. to refill its battery, and return back to continue its spray work. In such cases, it will unavoidably encounter situations in which plants that have been previously observed and gone out of camera field of view re-appear again. The robots need to re-identify these plants and correlate them again with the same ones previously observed in order to spray each plant exactly once. Otherwise if these plants are identified as new plants, they will be sprayed more than once.
The main contributions of the proposed dataset are as follow:
1. A dataset captured by the front downward facing camera of the VegeBot, an agricultural robot developed by China Agricultural University, in two growth stages of lettuce for joint plant detection and tracking research, is provided as shown in Figure 1. It contains around 5400 RGB images and their corresponding annotations in the widely used MOT format (Leal-Taixé et al., 2015; Milan et al., 2016; Dendorfer et al., 2020; Dendorfer et al., 2021). The dataset is publicly available at: https://mega.nz/folder/LlgByZ6Z#wmLa-TQ8NYGkPrJjJ5BfQw.
2. The proposed dataset fills the current shortage of plant detection and tracking agricultural dataset in which the challenging situation of re-identification of re-occurred plants exists. By tackling such a challenging problem, the agricultural robot ensures to spray each plant exactly once even if it observes the same plant more than once during back and forth motion, or it re-enters the same row in the farm. Four state-of-the-art MOT methods are tested on the proposed dataset, and the benchmark results are reported for comparison.
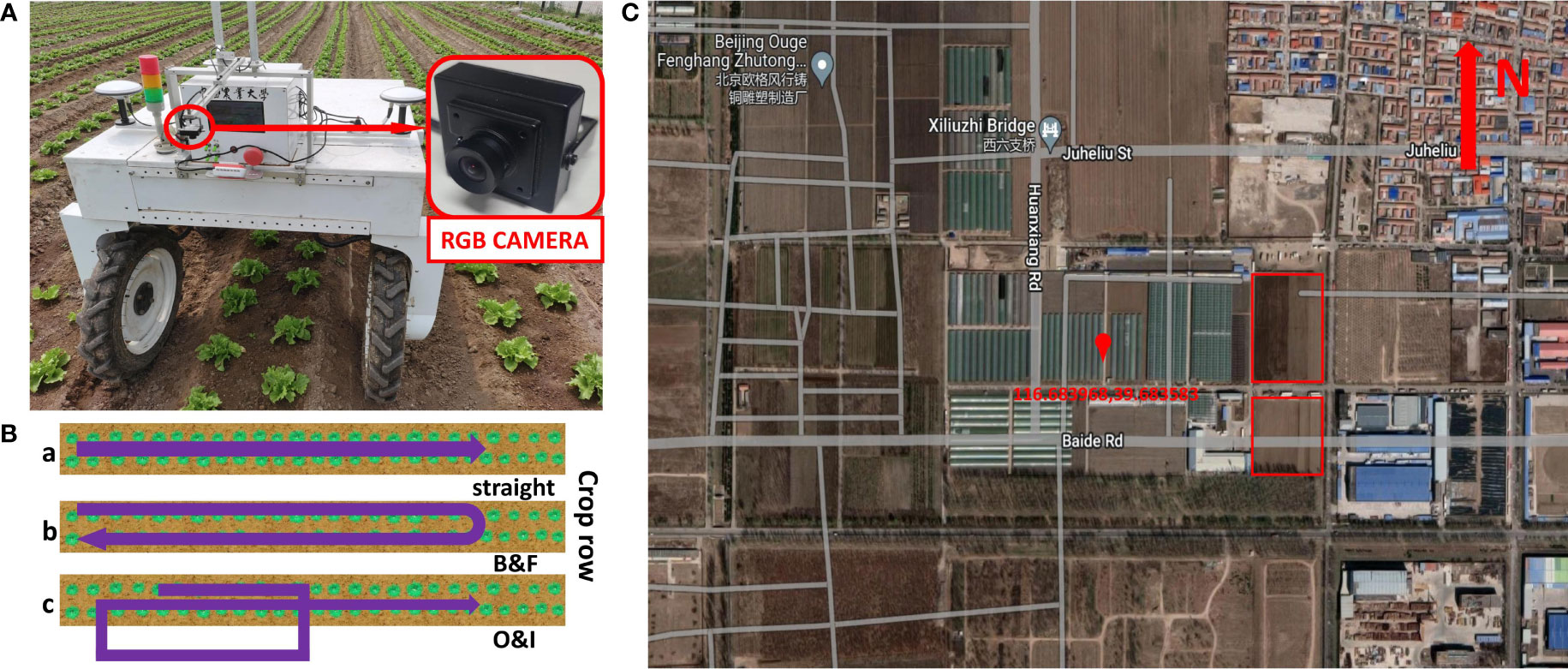
Figure 1 Details of data acquisition. (A) A RGB camera was installed in front of the VegeBot, an agricultural robot developed by China Agricultural University, and collected data in lettuce farm. (B) Three types of robot motions during image acquisition process. a, b and c correspond to straight, backward & forward, and turning out & turning in robot motions, respectively. (C) The location of the farm on satellite image. The red box is the place where the image is collected.
The dataset in this paper were collected in a lettuce farm in Tongzhou District, Beijing, China in April and May 2022. The images of lettuce are captured during its two growth stages, which are namely rosette stage and heading stage, respectively. The distance between two adjacent lettuces in the same row is approximately 0.3-0.35 m, and the distance between two rows of lettuce is about 0.3 m. Due to regular weeding, the maximum weed density is 10 per square meter.
The images were collected by VegeBot when it traveled through different rows of the farm. VegeBot is a four-wheel-steer and four-wheel-drive agricultural robot developed by China Agricultural University, which is specifically designed for autonomous operations in vegetable farms. Key parameters of the robot are summarized in Table 1. The VegeBot is equipped with a RTK-GPS sensor for GNSS based global localization, a front downward facing USB RGB camera for the perception of vegetable plants, and a downward facing Intel RealSense D435i depth camera with IMU sensor for collecting additional depth and heading angle information. During the data collection process of this paper, only the front downward facing USB RGB camera was utilized. When collecting data, in order to ensure the quality of the collected data, the vision based autonomous navigation functionality of the robot was disabled, and it was manually driven with a remote controller on the farm. Since the velocities and steering angles of four wheels can be independently controlled, the motion of the robot can adopt different styles. When the robot traveled straight along the farm lane, it adopted the Ackerman motion style for smooth forward or backward motion with smaller angular velocity. When it turned and switched to another lane, it adopted four-wheel-steer motion to ensure a large rotation angle.

Table 1 Key parameters of VegeBot.
As shown in Figure 1, images are acquired by a RGB camera, which is installed approximately 1.5 m away from the ground. The model of camera is Vishinsgae SY011HD. It is equipped with a 1/2.7-inch AR0230CS digital image sensor, and the pixel size of it is 3 µm × 3 µm. The maximum resolution and maximum frame rate of the camera are 1920×1080 and 30 FPS, respectively. The manufacturer of the camera lens is Vishinsgae, and the f-number of 2.8 is utilized. The wide-angle of the camera lens is 130 degree. Images are cropped into the resolution of 810×1080 to remove unrelated area for better detection and tracking. The camera exposure time is automatically set by the camera. The images are captured under natural ambient light condition, and they are extracted from the original video format. The camera acquires images at the frequency of 10 FPS, with the average overlap between two consecutive images larger than 2/3 of the image.
During the data acquisition process, the robot follows three types of motions, i.e. straight, backward and forward, and turning out and turning in, as shown in Figure 1B. Among them, the data recorded with the robot motions backward and forward (denoted as B&F) and turning out and turning in (denoted as O&I) contains re-occurrence of lettuce plants after having gone out of the camera field of view. In comparison, plants will not re-appear again after having gone out of the camera field of view in the data recorded with the robot straight motion (denoted as straight). The speed of the robot is between 0.3 m/s to 0.4 m/s when it travels straight forward or backward, and between 0.1 m/s to 0.2 m/s when it turns.
The image labeling and annotation tool DarkLabel1 is utilized to label the collected images. The images are labeled with the MOT format (Leal-Taixé et al., 2015; Milan et al., 2016; Dendorfer et al., 2020; Dendorfer et al., 2021), which is denoted as follow,
where frameidis the ID number of the frame, id is the ID number of the target, x and y are the coordinates of the upper left corner of the annotated box, and w and h represent the width and height of the box. The last three numbers in the label format are not used in our dataset, and therefore they are all filled with ones. A sample image and its corresponding annotation are shown in Figure 2A. The dataset consists of eight parts, with each growth stage containing four parts, and contains 5466 RGB images in total. Each growth stage consists of two straight parts, one B&F part and one O&I part. There are 2745 RGB images in the rosette stage and 2721 RGB images in the heading stage. The details of the dataset are summarized in Table 2. Wherein, Tracks and Boxes refer to the total number of objects and the total number of bounding boxes in an image sequence, respectively.

Figure 2 Details of the dataset. (A) Sample images and their corresponding annotations. The direction of the red arrow indicates the order of images. (B) The file structure of the dataset.
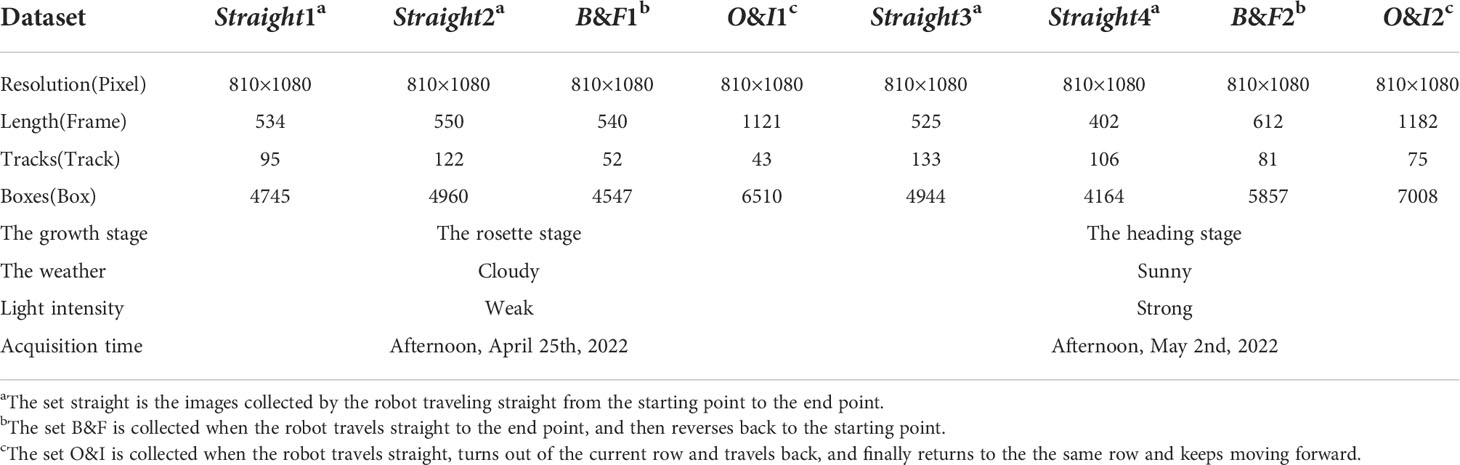
Table 2 Summary of eight parts of the dataset.
The structure of the dataset is shown in Figure 2B. The eight parts of dataset are stored in eight folders, each of which contains two folders, i.e. img and gt. The images captured by the robot are contained in the img folder, whose corresponding annotations are contained in the gt.txt file in the gt folder. All image files are named by their numerically orders and are in PNG format.
Four state-of-the-art MOT methods are tested on the proposed dataset, which are ByteTrack (Zhang et al., 2021a), ByteTrack with NSA Kalman filter (Du et al., 2021), FairMOT (Zhang et al., 2021b), and SORT (Bewley et al., 2016)2. They are finetuned on our dataset using their default hyperparameters. The results are summarized in Table 3. straight2 and straight4 are used to train each model and inference is performed on the other six parts. All training and testing are carried out on a NVIDIA RTX 2080Ti GPU. It can be seen from Table 3 that ByteTrack with NSA Kalman filter performs better than the other three methods on the test sets. FairMOT performs poorly when objects are very similar due to the application of appearance features. Therefore, it is easier to obtain better results by using motion features on our dataset. However, due to the lack of the ability to re-identify re-occurred objects in these methods, the performance metrics, e.g. the IDSW, on B&F and O&I are generally poor, where lettuces go out of the camera field of view and re-occur later. To tackle such a challenging tracking problem, successful MOT methods can potentially try to extract unique feature of each lettuce plant, e.g. the color feature of its surrounding soil or the graph structure of the target lettuce with its neighbors. By matching the composed unique feature, a successful MOT method should search from all targets in history, and find out the correct targets for the re-occurred objects.
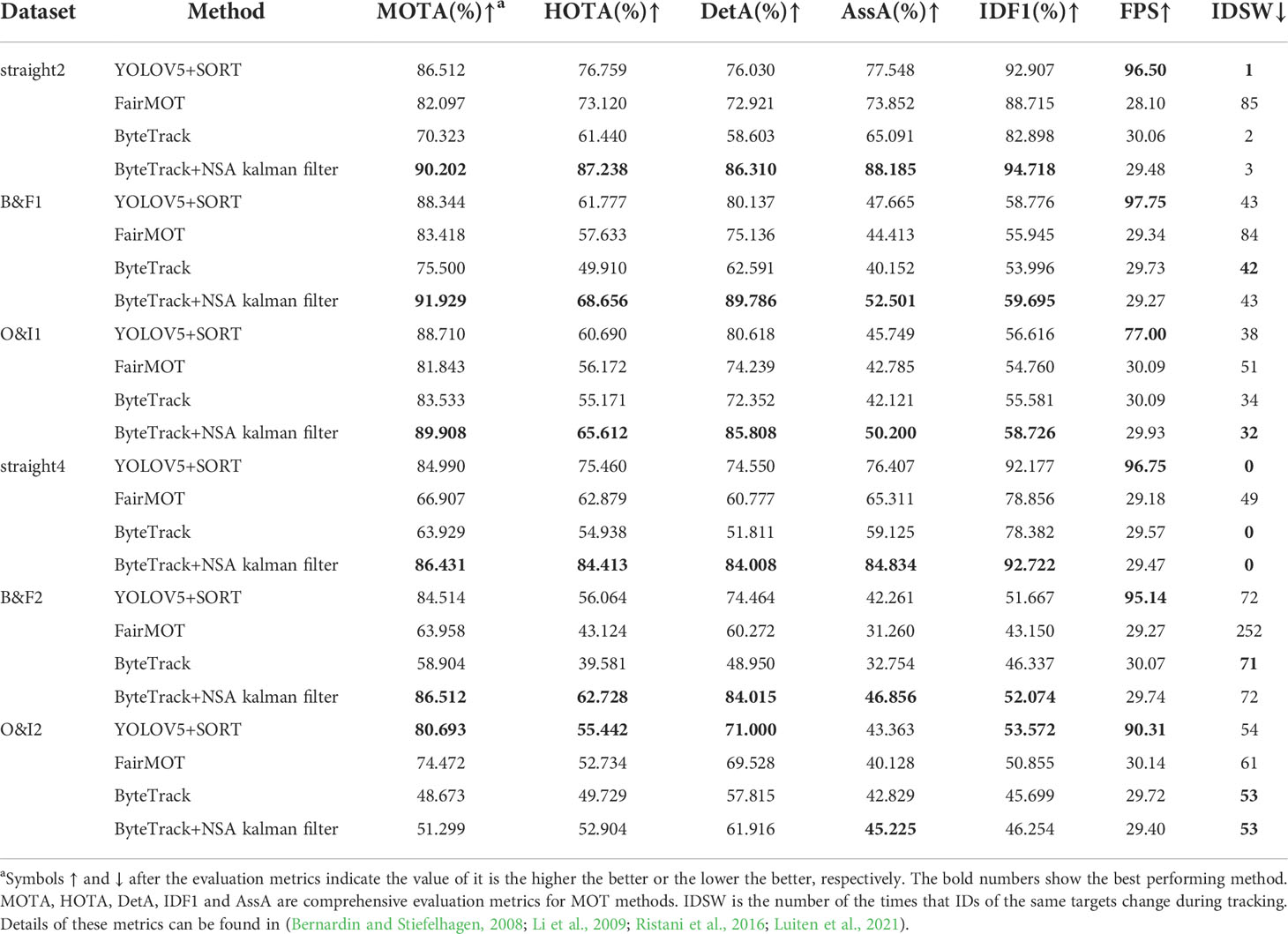
Table 3 Performance of four MOT methods with the proposed LettuceMOT.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: The direct link to the data is https://mega.nz/folder/LlgByZ6Z\#wmLa-TQ8NYGkPrJjJ5BfQw. The name of the repository is ‘LettuceMOT’.
DS, PN, YQ, YJ, BH and HW contributed to the design of the data acquisition. NH, SW, XW, and YC collected the experimental data. NH, SW and XW organized and labelled the data. NH, SW and DS wrote the first draft of the manuscript. PN, XW, YQ and YJ wrote sections of the manuscript. All authors contributed to manuscript revision, read, and approved the submitted version.
This research was financially supported by the National Natural Science Foundation of China (Grant No. 3217150435), and China Agricultural University with Global Top Agriculture related Universities International Cooperation Seed Fund 2022.
We would like to thank the editor and reviewers for their valuable input, time, and suggestions to improve the quality of the manuscript.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Bargoti, S., Underwood, J. (2017). “Deep fruit detection in orchards,” in In 2017 IEEE International Conference on Robotics and Automation (ICRA 2017). 3626–3633.
Bender, A., Whelan, B., Sukkarieh, S. (2020). A high-resolution, multimodal data set for agricultural robotics: A ladybird’s-eye view of brassica. J. Field Robotics 37, 73–96. doi: 10.1002/rob.21877
Bernardin, K., Stiefelhagen, R. (2008). Evaluating multiple object tracking performance: The clear mot metrics. EURASIP J. Image Video Process. 2008, 246309. doi: 10.1155/2008/246309
Bewley, A., Ge, Z., Ott, L., Ramos, F. T., Upcroft, B. (2016). “Simple online and realtime tracking,” in In 2016 IEEE International Conference on Image Processing (ICIP 2016). 3464–3468.
Chebrolu, N., Lottes, P., Schaefer, A., Winterhalter, W., Burgard, W., Stachniss, C. (2017). Agricultural robot dataset for plant classification, localization and mapping on sugar beet fields. Int. J. Robotics Res. 36, 1045–1052. doi: 10.1177/0278364917720510
Dendorfer, P., Osep, A., Milan, A., Schindler, K., Cremers, D., Reid, I. D., et al. (2021). Motchallenge: A benchmark for single-camera multiple target tracking. Int. J. Comput. Vision 129, 845–881. doi: 10.1007/s11263-020-01393-0
Dendorfer, P., Rezatofighi, H., Milan, A., Shi, J. Q., Cremers, D., Reid, I. D., et al. (2020). Mot20: A benchmark for multi object tracking in crowded scenes. ArXiv.
Du, Y., Wan, J.-J., Zhao, Y., Zhang, B., Tong, Z., Dong, J. (2021). “Giaotracker: A comprehensive framework for mcmot with global information and optimizing strategies in visdrone 2021,” in In 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW 2021). 2809–2819. doi: 10.1109/ICCVW54120.2021.00315
Jiang, Y., Li, C., Paterson, A. H., Robertson, J. S. (2019). Deepseedling: deep convolutional network and kalman filter for plant seedling detection and counting in the field. Plant Methods 15, 141. doi: 10.1186/s13007-019-0528-3
Jong, S. D., Baja, H., Tamminga, K., Valente, J. (2022). Apple mots: Detection, segmentation and tracking of homogeneous objects using mots. IEEE Robotics Automation Lett. 7, 11418–11425. doi: 10.1109/LRA.2022.3199026
Koirala, A., Walsh, K. B., Wang, Z., McCarthy, C. (2019). Deep learning for real-time fruit detection and orchard fruit load estimation: benchmarking of ‘mangoyolo’. Precis. Agric. 20, 1107–1135. doi: 10.1007/s11119-019-09642-0
Kusumam, K., Krajník, T., Pearson, S., Duckett, T., Cielniak, G. (2017). 3d-vision based detection, localization, and sizing of broccoli heads in the field. J. Field Robotics 341505–1518 doi: 10.1002/rob.21726
Leal-Taixé, L., Milan, A., Reid, I. D., Roth, S., Schindler, K. (2015). Motchallenge 2015: Towards a benchmark for multi-target tracking. ArXiv.
Li, Y., Huang, C., Nevatia, R. (2009). “Learning to associate: Hybridboosted multi-target tracker for crowded scene,” in In 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2009). 953–2960.
Lottes, P., Hörferlin, M., Sander, S., Stachniss, C. (2017). Effective vision-based classification for separating sugar beets and weeds for precision farming. J. Field Robotics 34, 1160–1178. doi: 10.1002/rob.21675
Luiten, J., Osep, A., Dendorfer, P., Torr, P. H. S., Geiger, A., Leal-Taixé, L., et al. (2021). Hota: A higher order metric for evaluating multi-object tracking. Int. J. Comput. Vision 129, 548–578. doi: 10.1007/s11263-020-01375-2
Milan, A., Leal-Taixé, L., Reid, I. D., Roth, S., Schindler, K. (2016). Mot16: A benchmark for multi-object tracking. ArXiv.
Milioto, A., Lottes, P., Stachniss, C. (2018). “Real-time semantic segmentation of crop and weed for precision agriculture robots leveraging background knowledge in cnns,” in In 2018 IEEE International Conference on Robotics and Automation (ICRA 2018). 2229–2235.
Moreira, G., Magalhães, S. A., Pinho, T., dos Santos, F. N., Cunha, M. (2022). Benchmark of deep learning and a proposed hsv colour space models for the detection and classification of greenhouse tomato. Agronomy 12, 356. doi: 10.3390/agronomy12020356
Ristani, E., Solera, F., Zou, R. S., Cucchiara, R., Tomasi, C. (2016). “Performance measures and a data set for multi-target, multi-camera tracking,” in In 2016 European Conference on Computer Vision (ECCV 2016). 17–35.
Voigtlaender, P., Krause, M., Osep, A., Luiten, J., Sekar, B. B. G., Geiger, A., et al. (2019). “Mots: Multi-object tracking and segmentation,” in In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019). 7934–7943.
Xu, Z., Zhang, W., Tan, X., Yang, W., Huang, H., Wen, S., et al. (2020). “Segment as points for efficient online multi-object tracking and segmentation,” in 2020 European Conference on Computer Vision (ECCV 2020). 264–281.
Zhang, Y., Sun, P., Jiang, Y., Yu, D., Yuan, Z., Luo, P., et al. (2021a). Bytetrack: Multi-object tracking by associating every detection box. ArXiv. doi: 10.1007/978-3-031-20047-2_1
Keywords: dataset, agriculture, robotics, deep learning, MOT, lettuce, detection, tracking
Citation: Hu N, Wang S, Wang X, Cai Y, Su D, Nyamsuren P, Qiao Y, Jiang Y, Hai B and Wei H (2022) LettuceMOT: A dataset of lettuce detection and tracking with re-identification of re-occurred plants for agricultural robots. Front. Plant Sci. 13:1047356. doi: 10.3389/fpls.2022.1047356
Received: 18 September 2022; Accepted: 01 November 2022;
Published: 18 November 2022.
Edited by:
Yuzhen Lu, Mississippi State University, United StatesReviewed by:
Jiajun Xu, Gachon University, South KoreaCopyright © 2022 Hu, Wang, Wang, Cai, Su, Nyamsuren, Qiao, Jiang, Hai and Wei. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Daobilige Su, c3VkYW9AY2F1LmVkdS5jbg==
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.