
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Plant Sci. , 08 November 2017
Sec. Plant Breeding
Volume 8 - 2017 | https://doi.org/10.3389/fpls.2017.01916
 Ao Zhang1,2‡
Ao Zhang1,2‡ Hongwu Wang2,3‡Yoseph Beyene4Kassa Semagn4†Yubo Liu1,2Shiliang Cao5Zhenhai Cui1Yanye Ruan1
Hongwu Wang2,3‡Yoseph Beyene4Kassa Semagn4†Yubo Liu1,2Shiliang Cao5Zhenhai Cui1Yanye Ruan1 Juan Burgueño2
Juan Burgueño2 Felix San Vicente2Michael Olsen4Boddupalli M. Prasanna4
Felix San Vicente2Michael Olsen4Boddupalli M. Prasanna4 José Crossa2Haiqiu Yu1*
José Crossa2Haiqiu Yu1* Xuecai Zhang2*
Xuecai Zhang2*Genomic selection is being used increasingly in plant breeding to accelerate genetic gain per unit time. One of the most important applications of genomic selection in maize breeding is to predict and select the best un-phenotyped lines in bi-parental populations based on genomic estimated breeding values. In the present study, 22 bi-parental tropical maize populations genotyped with low density SNPs were used to evaluate the genomic prediction accuracy (rMG) of the six trait-environment combinations under various levels of training population size (TPS) and marker density (MD), and assess the effect of trait heritability (h2), TPS and MD on rMG estimation. Our results showed that: (1) moderate rMG values were obtained for different trait-environment combinations, when 50% of the total genotypes was used as training population and ~200 SNPs were used for prediction; (2) rMG increased with an increase in h2, TPS and MD, both correlation and variance analyses showed that h2 is the most important factor and MD is the least important factor on rMG estimation for most of the trait-environment combinations; (3) predictions between pairwise half-sib populations showed that the rMG values for all the six trait-environment combinations were centered around zero, 49% predictions had rMG values above zero; (4) the trend observed in rMG differed with the trend observed in rMG/h, and h is the square root of heritability of the predicted trait, it indicated that both rMG and rMG/h values should be presented in GS study to show the accuracy of genomic selection and the relative accuracy of genomic selection compared with phenotypic selection, respectively. This study provides useful information to maize breeders to design genomic selection workflow in their breeding programs.
Genomic selection (GS) is being used increasingly in plant breeding to accelerate genetic gain (Crossa et al., 2010; Zhang et al., 2015; Roorkiwal et al., 2016; Edriss et al., 2017). In GS, a training population is used for estimating the effects of markers based on prior phenotypic and marker data. The marker effects estimated from the training population are then used to predict the genomic estimated breeding value (GEBV) of individuals in the prediction population, which have been genotyped but not phenotyped (Meuwissen et al., 2001). Breeders then select individuals from the prediction population based on the GEBV to advance to the next cycle (generation) to shorten the length of the selection cycle and increase the genetic gain per unit time (Heffner et al., 2009; Lorenz et al., 2011; Guo et al., 2012; Newell and Jannink, 2014).
In plant breeding, several studies have implemented GS to develop improved germplasm, evaluate the genetic gain of GS (Poland et al., 2012; Battenfield et al., 2016; Marulanda et al., 2016), and compare the genetic gains from GS with marker assisted selection or pedigree selection methods (Asoro, 2013; Combs and Bernardo, 2013; Beyene et al., 2015; Rutkoski et al., 2015; Zhang et al., 2017). Using recombinant inbred lines derived from a cross between B73 and Mo17, Massman et al. (2013) showed that GS produced from 14 to 50% higher genetic gains for stover and grain yield than marker assisted recurrent selection for several traits in a maize biparental population. This result was then verified in tropical maize (Beyene et al., 2015; Vivek et al., 2017). Beyene et al. (2015) found that the average genetic gain per year across eight tropical maize populations of GS was three times higher than that of pedigree based phenotypic selection in drought stress conditions. Vivek et al. (2017) pointed that two cycles of GS produced 4–43% higher grain yield than two cycles of pedigree-based phenotypic selection in two bi-parental populations. In a multi-parental tropical maize population, Zhang et al. (2017) reported that the realized genetic gain of GS per year was 1.2%, when the total breeding time was estimated from making the initial cross to harvesting the last selection cycle. The average genetic gain per selection cycle was 2.8%, when only the selection cycles were considered as the total breeding time.
Prediction accuracy (rMG), defined as the correlation between the true breeding value and the GEBV, is used to evaluate the effectiveness of genomic selection, rMG value must be high enough for GS to be time and cost effective (Combs and Bernardo, 2013). Highly variable levels of rMG values have been reported in plants depending on prediction models, breeding schemes, training population size, the relationship between the training and the prediction populations, trait complexities, marker densities, and genotyping platforms (Jia and Jannink, 2012; Zhao et al., 2012; Crossa et al., 2013; Lian et al., 2014; Spindel et al., 2015; Battenfield et al., 2016; Bernardo, 2016). Previous studies showed that the rMG value is increased as the increase of trait heritability, size of training population, and marker density. The rMG value also could be improved, when the relationship between the training population and the prediction population is close (Sonah et al., 2015). Modeling genotyping by environment interactions and incorporating known marker-trait associations into prediction model is also beneficial increasing the rMG value (Crossa et al., 2014; Zhang et al., 2015; Bian and Holland, 2017; Cao et al., 2017). Lian et al. (2014) showed that the rMG is difficult to be predicted in advance, but r2(Nh2)1/2 had a strong association with the prediction accuracy value, where r2 refers to the linkage disequilibrium between a marker and a quantitative trait locus, N is the training population size, and h2 is the trait heritability. Further GS studies are still required to understand the factors that affect the prediction accuracy, and how to maximum the prediction accuracy to streamline GS schemes in a breeding program.
One of the most important applications of GS in maize breeding is to predict and identify the best untested lines from bi-parental populations, when the training and prediction populations are derived from the same cross. Moderate-to-high rMG values have been reported in biparental populations due to the close relationship between the training and prediction populations, and the maximum linkage disequilibrium between a marker and a quantitative trait locus (Zhang et al., 2015). In this study, 22 bi-parental tropical maize populations including 4,120 segregating lines were phenotyped with six trait-environment combinations and each lines were genotyped with 162 to 283 SNPs (single nucleotide polymorphisms) (Semagn et al., 2014; Ertiro et al., 2015). The main objectives of this study were to: (1) evaluate the rMG value of the six trait-environment combinations in 22 bi-parental tropical maize populations; (2) assess the effect of trait heritability, training population size (TPS) and marker density (MD) on rMG estimation in bi-parental populations; (3) identify the most important factor affecting rMG estimation and provide useful information to breeders for implementing GS in their breeding programs; and (4) assess the predictions accuracy between pairwise half-sib populations.
This study comprised a total of 4,120 lines derived from 22 bi-parental populations. Sixteen of the 22 bi-parental populations were developed in 2009 as part of the Water Efficiency Maize for Africa project, and the other six bi-parental populations were developed as part of the Drought Tolerant Maize for Africa project in 2008. Details on population development and phenotyping were described in previous studies (Beyene et al., 2015; Zhang et al., 2015; Wallace et al., 2016). In brief, all the populations were derived from crosses between CIMMYT drought-tolerant donors and CIMMYT inbred lines currently in commercial use in eastern and southern Africa. The F1 crosses formed with two inbred line parents were advanced to the BC1F2:3, F2:3, or F7:8 generations for each population (details showed in the previous studies). Testcross hybrids of each population were generated by crossing the individual family with a single-cross tester from a complementary heterotic group. The testcrosses along commercial checks were planted under four well-watered (WW) environments and three to four water-stressed (WS) environments in Kenya, Zambia, and Zimbabwe during 2010 and 2011 (Semagn et al., 2013). The WW trials were planted during the rainy season, and supplemental irrigation was provided as needed. The WS trials were planted during the dry (rain-free) season by withdrawing irrigation starting from 2 weeks before flowering through harvest.
Parameter information of each population including pedigree code, tester, number of families in each population, number of polymorphic SNPs in each bi-parental population, mean, and standard deviation of all trait-environment combinations is summarized in Table 1. In total, 28 inbred lines were used as the parents to form the 22 bi-parental populations. Six testers were used in making testcrosses, of which 10 populations share tester T1, 6 populations share T2, 3 populations share T3, and the remaining 3 populations were testcrossed with T4, T5, or T6 (Table 1). The number of polymorphic SNPs in each population ranged from 162 to 283, with a mean of 206.
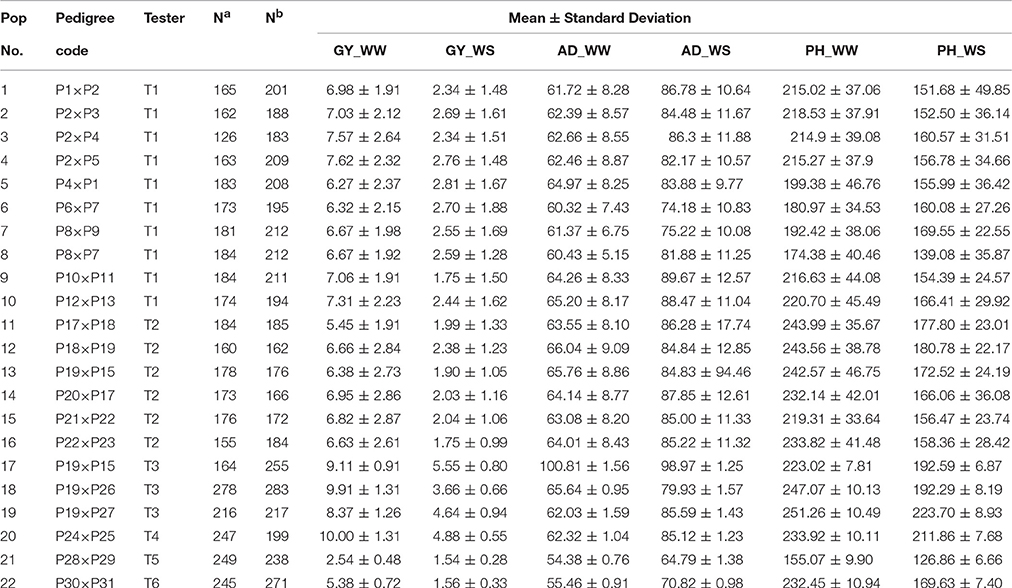
Table 1. Summary of 22 bi-parental populations used in the present study, including pedigree code, tester, number of families (Na) and number of polymorphic SNPs (Nb) of all populations, mean and standard deviation of all target trait-environment combinations (GY, grain yield; AD, anthesis date; PH, plant height; WW, well-watered environments; WS, water-stressed environments).
All the testcross hybrids in each population were evaluated up to 17 different traits, but only grain yield (GY), anthesis date (AD), and plant height (PH) were selected as the main target traits in the present study. GY was measured as dry shelled grain yield at 12.5% moisture content. AD was measured as the number of days from planting to when 50% of the plants had shed pollen. PH was measured as the distance from the base of the plant to the height of the first tassel branch. In total, six trait-environment combinations (that is, GY_WW, AD_WW, PH_WW, GY_WS, AD_WS and PH_WS) were considered, GY_WW and GY_WS were treated as complex traits, and the other four trait-environment combinations were treated as less complex traits in the present study.
The experimental design in each environment was an α-lattice incomplete block design with two replications per location. At all locations, entries were planted in one-row plot with 5 m long, 0.75 m between rows and 0.25 m between hills. For each population, combined trial analyses were performed within WW and WS environments, respectively.
MEATA-R software (http://hdl.handle.net/11529/10201) was used to conduct multi-location trial analysis using a mixed linear model with all factors set as random effects. Best linear unbiased prediction (BLUP) value of genotypes, variance components and broad-sense heritability were obtained. Broad-sense heritability of the target trait was calculated as the ratio of total genetic to total phenotypic variance. In multi-location trial analysis, broad-sense heritability was calculated as
Where are the genotypic, genotype-by-environment interaction, and error variance components, respectively, and e and r are the number of environments and of replicates within each environment included in the corresponding analysis, respectively. According to the h2 value of each trait-environment combination, the 22 populations were sorted in an ascending order and divided into 4 subgroups for estimating the relationship between h2 and genomic prediction accuracy. Subgroup 1 (lowest heritability subgroup) had six populations, and the other three subgroups each had five populations.
The 16 populations developed for the Water Efficiency Maize for Africa project were genotyped by the Monsanto Company using a TaqMan assay (http://www.appliedbiosystems.com), while the 6 populations developed for the Drought Tolerant Maize for Africa project were genotyped at LGC genomics (http://www.lgcgenomics.com/genotyping/kasp-genotyping-chemistry) using a KASP assay (Semagn et al., 2014). For each family in each population, equal amount of leaf tissue from 15 plants were bulked for DNA extraction and genotyping. For each segregating SNP, a χ2 goodness-of-fit analysis was performed to test for deviation from the expected segregation ratio. Only SNPs passed the segregation distortion tested were used for further analyses.
Genome-wide prediction was performed using the rrBLUP package for R version 3.2.5 (Endelman, 2011). In order to test the effects of TPS and MD on genomic prediction accuracy, four levels of TPS (i.e., 30, 50, 70, and 90) and three levels of MD (i.e., 50 SNPs, 100 SNPs, and all SNPs) were considered to evaluate the prediction accuracy of each trait-environment combination within each bi-parental population. Different with the 5-fold cross-validation method reported previously (Zhang et al., 2015; Cao et al., 2017), fixed number of lines were randomly sampled 100 times from each bi-parental population to develop the prediction model. Approximate 16, 28, 39, and 50% of the entire population were selected to build the training population, when the TPS was 30, 50, 70, and 90, respectively. All the predictions were replicated for 100 times, the average value of the Pearson correlations between the phenotype and the genomic estimated breeding values was defined as the genomic prediction accuracy (rMG). For each trait-environment combination, value of rMG/h was calculated to compare the breeding efficiency between phenotypic selection and genomic selection, where h was the square root of the heritability of the target trait-environment combination, and the accuracy of phenotypic selection was measured by h. In total, we did prediction on 1,584 scenarios, when all the possible recombination were considered among 22 populations, 6 trait-environment combinations, 4 levels of TPS, and 3 levels of MD.
Predictions between pairwise half-sib populations were performed, when two populations shared one common parental line, and one population was used as training population to predict the other population. In the prediction population, the Pearson correlations value between the phenotype and the genomic estimated breeding values was defined as rMG. In total, 204 predictions were made on the six trait-environment combinations between all the 34 pairwise half-sib populations, only the common markers shared between the pairwise half-sib populations were used for prediction. Due to lack of common markers, predictions across different genotyping platforms (TaqMan assay and KASP assay) were not conducted.
Correlation and variance analyses were performed across all the 22 bi-parental populations to see the importance of the three factors (i.e., h2, TPS, and MD) on affecting rMG, correlation coefficient between rMG and three factors across all the 22 bi-parental populations were estimated in R version 3.2.5 (R Development Core Team, 2013) on all the six trait-environment combinations.
In the variance analysis, rMG was set as response variable, and h2, TPS and MD were set as predictor variables, where the importance of the three factors will be assessed on all the six trait-environment combinations across all the 22 bi-parental populations.
For all the 22 bi-parental populations, the phenotypic mean and standard deviation of the six trait-environment combinations were showed in Table 1. Phenotypic mean of GY and PH were consistently higher under WW condition than under WS condition in all the populations. Phenotypic mean of GY ranged from 2.54 to 9.91 t/ha, with an average value of 6.99 t/ha under WW condition, while the mean of GY ranged from 1.54 to 4.88 t/ha, with an average value of 2.68 t/ha under WS condition. For PH_WW, the phenotypic mean ranged from 155.07 to 251.26 cm, and have an average value of 218.47 cm across all the populations. For PH_WS, the phenotypic mean ranged from 126.86 to 223.7 cm, and have an average value of 168 cm across all the populations. Phenotypic mean of AD was consistently lower under WW condition than under WS condition in all the populations. Phenotypic mean of AD ranged from 54.38 to 100.81 days, with an average value of 64.23 days under WW condition, while the mean of AD ranged from 64.79 to 98.97 days, with an average value of 83.29 days under WS condition across all the populations. The phenotypic mean distribution of all the six trait-environment combinations was either normal or approximately normal for all the 22 bi-parental populations (data not shown). Standard deviation of GY were consistently greater under WW condition than under WS condition in all the populations, while standard deviation of the less complex traits, i.e., AD and PH, were consistently smaller under WW condition than under WS condition.
Broad-sense heritability of the six trait-environment combinations in all the 22 bi-parental populations was shown in Figure 1 and Table S1. h2 of the complex trait (GY) were consistently lower than those of less complex traits (AD and PH) under both WW and WS conditions. For the same trait, h2 under WW conditions were consistently higher than under WS conditions in almost all the populations. Under WW condition, h2 across populations had a mean value of 0.38, 0.55 and 0.59 for GY, AD, and PH, respectively. Under WS condition, h2 across populations had a mean value of 0.27, 0.47, and 0.37 for GY, AD, and PH, respectively.
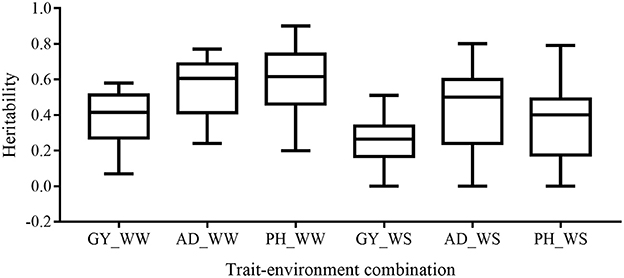
Figure 1. Distribution of heritability of all the target trait-environment combinations across all the populations.
The mean, range and standard deviation of rMG differed among the six trait-environment combinations (Figure 2, Table S2). In general, trait-environment combination with higher h2 had a higher rMG. Mean of rMG of complex trait (GY) was consistently lower than those of less complex traits (AD and PH) under both WW and WS conditions. For the same trait, rMG mean under WW condition was consistently higher than under WS condition. The rMG mean was lowest for GY_WS and highest for PH_WW. For example, when TPS equaled to 90 and all the SNPs were used for prediction, rMG across populations under WW condition had a mean value of 0.33, 0.34, and 0.38 for GY, AD, and PH, respectively (Figure 2, Table S2). The rMG across populations under WS condition had a mean value of 0.18, 0.28, and 0.25 for GY, AD, and PH, respectively (Figure 2, Table S2). For the same trait, the standard deviation of rMG under WW condition was similar with that under WS condition. Similar trends were observed, when other TPS and MD combinations were used for prediction (Figures 3, 4).
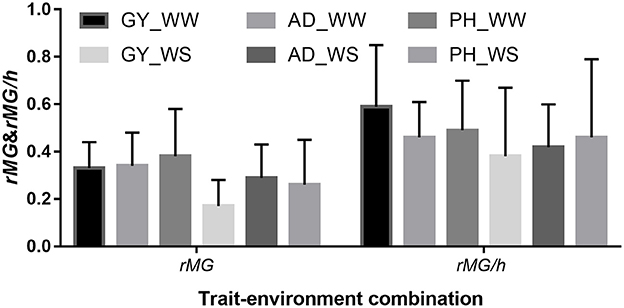
Figure 2. Mean and standard deviation (SD) of rMG and rMG/h of all the target traits across all the 22 bi-parental populations. Values of rMG in each population were estimated, when training population size equaled to 90 and all the SNPs were used for prediction.
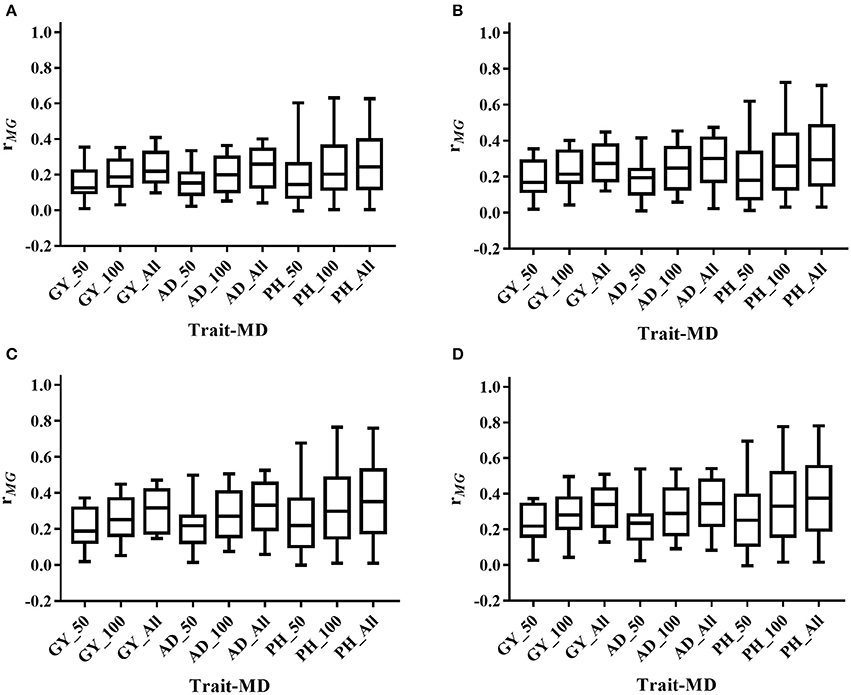
Figure 3. Distribution of rMG across all the populations for all the target traits evaluated under WW condition under all the possible training population size (TPS) and marker density (MD) combinations. (A) TPS = 30; (B) TPS = 50; (C) TPS = 70; (D) TPS = 90. Three levels of MD, i.e., 50 SNPs, 100 SNPs and All SNPs, were used for prediction.
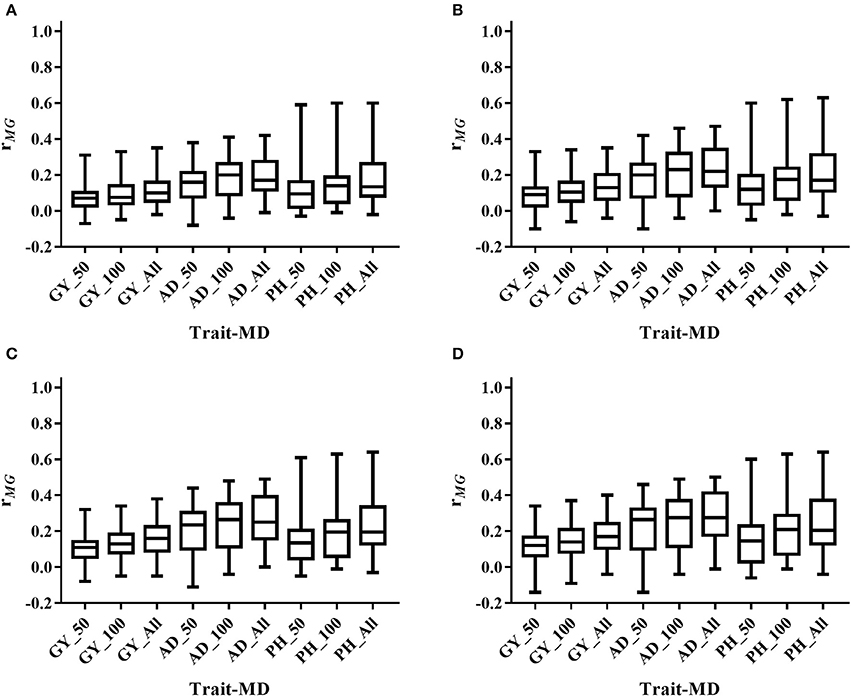
Figure 4. Distribution of rMG across all the populations for all the target traits evaluated under WS condition under all the possible training population size (TPS) and marker density (MD) combinations. (A) TPS = 30; (B) TPS = 50; (C) TPS = 70; (D) TPS = 90. Three levels of MD, i.e., 50 SNPs, 100 SNPs and All SNPs, were used for prediction.
For each trait-environment combination, the rMG differed among populations, where populations with higher h2 had higher rMG values (Figure 5). For all the six trait-environment combinations, rMG mean estimated under combinations of TPS = 90 and MD = All SNPs were used as example and to show the correlations between rMG and h2, where 22 populations were divided into 4 subgroups sorted by the h2 of each trait-environment combination from low to high. In general, the rMG value increased with the increase of h2 for all the trait-environment combinations, but the trends differed among trait-environment combination. For the complex traits (GY_WW and GY_WS), slight increase was observed with the increase of h2 among subgroups. Slight decrease was observed from subgroup 1 to subgroup 2, due to sampling variation/error in both rMG and h2 in subgroup 1, it indicated that other factors, i.e., TPS and MD, are important for further improvement on rMG estimation of GY. For less complex trait AD, the increase in rMG began to plateau once a high h2 was reached (subgroups 3 and 4). For less complex trait PH, the rMG continuously increased with the increase of h2 from subgroup 1 to subgroup 4, it indicated that further improvement on rMG of PH could be obtained by increasing the h2.
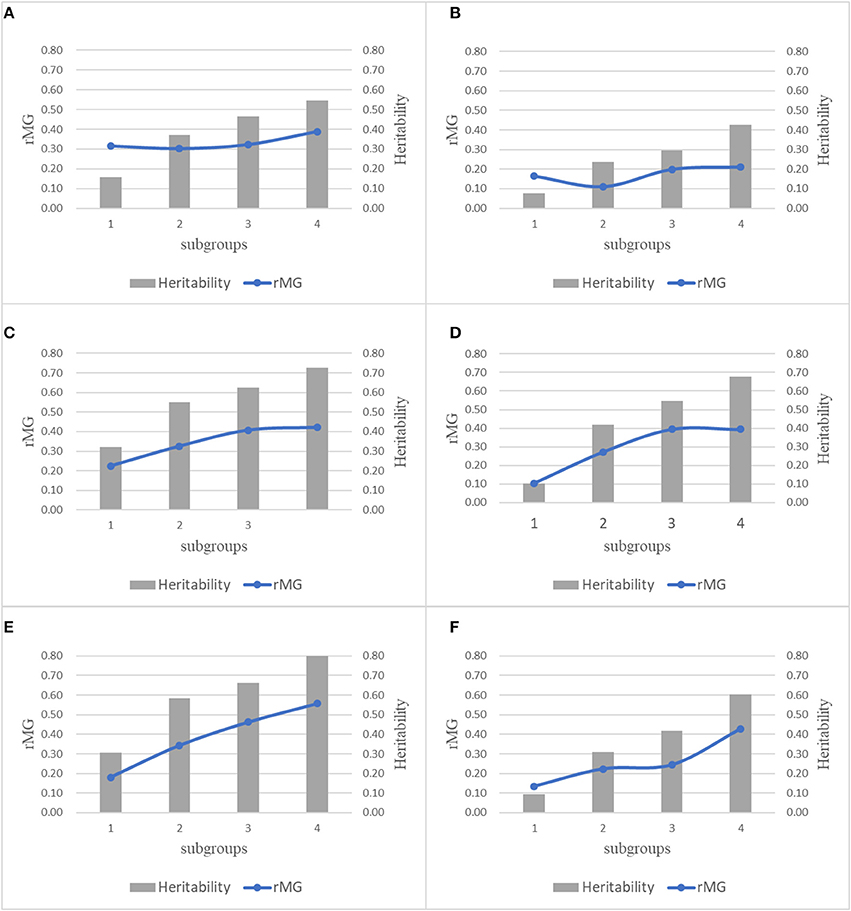
Figure 5. Combination plot of rMG and h2 of all the 6 trait-environment combinations, all the 22 populations were divided into 4 subgroups sorted by the h2 of target traits from low to high, mean rMG of each subgroup was estimated under combinations of TPS = 90 and MD = All SNPs. (A) GY_WW; (B) GY_WS; (C) AD_WW; (D) AD_WS; (E) PH_WW; (F) PH_WS.
The mean, range and standard deviation of rMG/h differed among the six trait-environment combinations (Figure 2). However, the trend observed in rMG/h different with the trend observed in rMG for the different trait-environment combinations. The highest rMG/h mean was observed on complex trait GY under WW condition. In contrast, complex trait GY had the lowest rMG/h mean among the three traits evaluated under WS condition. For the same trait, rMG/h mean value under WW condition was consistently higher than under WS condition. When TPS equaled to 90 and all the SNPs were used for prediction, rMG/h value across populations under WW condition had a mean of 0.59, 0.46, and 0.49 for GY, AD, and PH, respectively. Under WS condition, rMG/h value across populations had a mean of 0.38, 0.42, and 0.46 for GY, AD, and PH, respectively.
Prediction accuracy increased as the TPS increased for all the trait-environment combinations, when the MD was constant (Figures 3, 4, Table S2). When all the SNPs were used for prediction, the rMG of GY_WW was 0.24 with TPS = 30, 0.28 with TPS = 50, 0.31 with TPS = 70, and 0.33 with TPS = 90. The rMG mean of AD_WW was 0.24 with TPS = 30, 0.29 with TPS = 50, 0.32 with TPS = 70, and 0.34 with TPS = 90. The rMG mean of PH_WW was 0.27 with TPS = 30, 0.32 with TPS = 50, 0.36 with TPS = 70, and 0.38 with TPS = 90. The similar trend was observed with MD = 50 and MD = 100. The rMG mean of the target traits evaluated under WS condition also increased as the TPS increased, when the MD was constant.
Prediction accuracy increased as the MD increased for all the trait-environment combinations, when the TPS was constant (Figures 3, 4, Table S2). When TPS equaled to 90, the rMG mean of GY_WW was 0.24 with MD = 50, 0.29 with MD = 100, and 0.33 with MD = all of markers. The rMG mean of AD_WW was 0.24 with MD = 50, 0.31 with MD = 100, and 0.34 with MD = all of markers. The rMG mean of PH_WW was 0.27 with MD = 50, 0.34 with MD = 100, and 0.38 with MD = all of markers. The similar trend was observed with TPS = 30, TPS = 50 and TPS = 70. The rMG mean of the target traits evaluated under WS condition also increased as the MD increased, when the TPS was constant.
Number of markers used for predictions between the pairwise half-sib populations ranged from 44 to 100, with a mean of 71 (Table S3). The observed rMG values between the pairwise half-sib populations were centered around zero for all the six trait-environment combinations (Figure 6). Out of the 204 predictions, 100 (49%) had rMG values above zero. The maximum rMG value of the target traits evaluated under WW condition was 0.32, 0.14, and 0.18 for GY, AD, and PH, respectively. While the maximum rMG value of the target traits evaluated under WS condition was 0.25, 0.30, and 0.14 for GY, AD, and PH, respectively (Table S3).
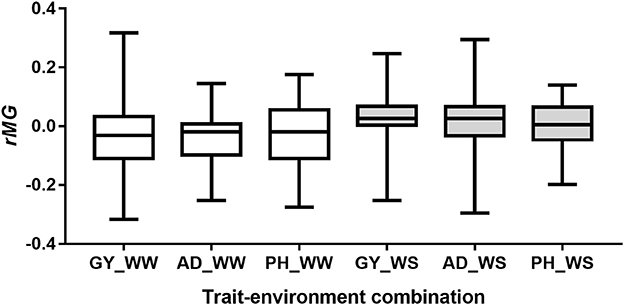
Figure 6. Distribution of rMG values of predictions between the pairwise half-sib populations.
Correlation analysis results between rMG and individual factor (h2, TPS, and MD) were showed in Table 2, which differed among the different trait-environment combinations. The rMG was most strongly associated with h2 for all the trait-environment combinations except for GY_WW. The second strongly associated factor was TPS for all the trait-environment combinations except for GY_WS. The rMG was least associated with MD for all the trait-environment combinations except for GY_WS. Compared with the less complex traits (AD and PH), the correlation values between rMG and h2 of the complex traits (GY) were lower, it indicated that all the three factors have to be considered simultaneously for further improvement on rMG estimation for GY. For the less complex traits, h2 of the predicted trait was the most important factor for rMG estimation improvement.
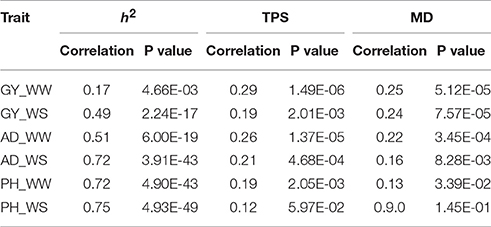
Table 2. Correlation between rMG and the three factors (h2, TPS and MD) for all the trait-environment combinations.
Variance analysis results between the rMG and all three factors together were shown in Table 3. Total variance explained by the three factors were lower for complex traits than less complex traits. In the regression model, the total variance explained by the three factors was 17.69, 39.18, and 58.85% for traits of GY, AD, and PH evaluated under WW condition, while the total variance explained by the three factors was 32.51, 57.68, and 58.62% for GY, AD, and PH evaluated under WS condition. For the same trait, the percentage of total variance explained was higher or similar under WS condition than under WW condition. Among the three factors, h2 explained the greatest percentage of the total variance for all the trait-environment combinations except GY_WW, and MD explained the least percentage of the total variance for all the trait-environment combinations except GY_WS and PH_WW. Variance analysis results were consistent with the results observed in correlation analysis.
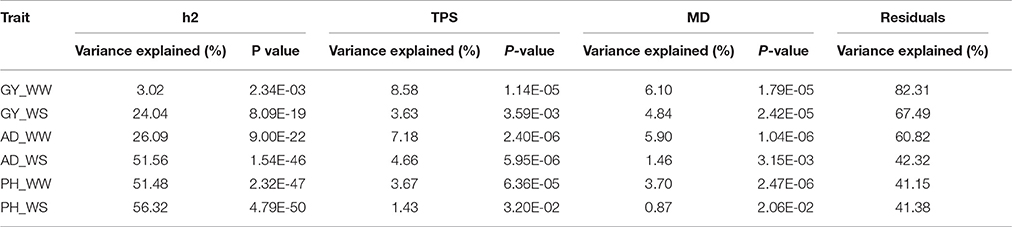
Table 3. Variance analysis between rMG and the three factors (h2, TPS and MD) for all the trait-environment combinations.
In maize breeding, one of the most promising applications of GS is to predict and select the best un-phenotyped lines in a bi-parental population, when a subset of this population has been phenotyped and genotyped as a training population, moderate-to high rMG value for various traits could be obtained using different TPS and MD combinations (Crossa et al., 2014; Zhang et al., 2015). In the present study, 22 bi-parental tropical maize populations were used to assess the effect of h2, TPS, and MD on rMG estimation. Results showed that rMG value increase with an increase in h2, TPS, and MD. The correlation between h2 and rMG was significant for all the trait-environment combinations. Trait-environment combinations with higher h2 had higher rMGvalues, and rMG mean of less complex trait was consistently higher than that of complex trait under both conditions. For the same trait, rMG mean under WW condition was consistently higher than that under WS condition, and populations with higher h2 of the target trait-environment combination also had higher rMG values than that of populations with lower h2. Variance analysis also showed that h2 is the most important factors on rMG estimation, and h2 explained the greatest percentage of the total variance for all the trait-environment combinations, only except for GY_WW. Our results agree with the previous studies that increase in h2 of the target trait results in an increase in rMG (Combs and Bernardo, 2013; Lian et al., 2014). When the breeders design the GS pipeline in their breeding programs, they should consider that the heritability of the target traits in training population must be high to achieve good prediction accuracy values by increasing the number of locations and replications in phenotyping trials.
In both correlation and variance analyses, results showed that the rMG was significantly associated with TPS for all the trait-environment combinations, only except for PH_WS. This result also agrees with the previous studies that increase in TPS results in an increase in rMG (Zhang et al., 2015; Cao et al., 2017). Optimal TPS for running GS within a bi-parental population is also of interest of maize breeder. Cao et al. (2017) reported that relative high rMG with the smallest standard error were observed when 50% of the total genotypes were used as a training population. Different with the 5-fold cross-validation method reported previously, fixed number of lines were randomly sampled 100 times to evaluate the rMG value of different target trait-environment combinations in the present study. Our results also confirm that moderate-to high rMG values of a wide range of target trait-environment combinations obtained, when half of the population is used to build the prediction model. However, the rMG value could vary depending the genetic complexity of the target traits and the total population size used for sampling training population.
Among the three factors, the rMG was least associated with MD for most of the trait-environment combinations, although the rMG increases as the MD increases. In the correlation analysis, the correlation values between rMG and MD of the complex traits were higher as compared with the less complex traits under both the WW and WS conditions, which indicated higher MD is still required to obtain good rMG values for complex traits with relative low h2. The variance analysis showed that the MD explained greater variance in complex traits than in less complex traits, which indicated that MD plays a more important role on improving the rMG value of the complex traits. Our results are consistent with the previous studies, good rMG values could be obtained in bi-parental maize populations, when the h2 of the target trait is high and the genome is covered with sufficient markers, i.e., mean distance between markers is < 10–20 cM or around 150 markers evenly distributed the whole genome (Albrecht et al., 2011; Windhausen et al., 2012; Gorjanc et al., 2016). Higher MD is required to achieve good rMG values in bi-parental populations for complex traits with relative low h2 and strong genotype by environment interaction (Lorenzana and Bernardo, 2009; Lian et al., 2014; Zhang et al., 2015). In the previous studies, either rMG or rMG/h was used to assess the prediction ability (Crossa et al., 2014; Bernardo, 2016), the accuracy of GS is measured by rMG (the average value of the Pearson correlations between the phenotype and the genomic estimated breeding values), and the accuracy of phenotypic selection is measured by h (the square root of heritability of the predicted trait). The relative accuracy of GS compared with phenotypic selection represents by the value of rMG/h. In this study, both rMG and rMG/h values were presented. However, the trend observed in rMG differed with the trend observed in rMG/h for the different trait-environment combinations. Under WW condition, GY had a lowest rMG mean and a highest rMG/h mean among all the three traits, and it indicated that GS is more effective for complex trait improvement than phenotypic selection. In contrast, GY becomes the most ineffective trait for GS due to the lowest rMG and rMG/h means among all the three traits evaluated under WS condition. Lowest rMG and rMG/h of GY_WS are mainly caused by its relative low h2, which indicates the importance of improving the h2 of the predicted trait in training population.
Genomic prediction also could be improved by pooling multiple related bi-parental populations into the training sets or using multi-parental populations (Schulz-Streeckab et al., 2012; Zhang et al., 2015). However, only predictions between pairwise half-sib populations were performed in the present study, pooling multiple related populations as training population to predict the other related or un-related populations were not applied. Because the low-density markers were used to genotype each bi-parental population, and only few number of markers shared among the multiple populations. Predictions between pairwise half-sib populations showed that the rMG values for all the six trait-environment combinations were centered around zero, it indicated that the predictions between pairwise half-sib populations does not work well, especially with less number of shared markers among populations. Good predictions by pooling multiple related populations as training population require genotyping all the populations with high-density markers to have enough number of common markers among all the populations.
High-throughput and cost-effective genotyping platforms are required to implement GS routinely in the breeding programs. Recently advances in bar-coded multiplexed sequencing technologies, such as genotyping-by sequencing (GBS), provide the capacity to genotype a large number of breeding lines at low costs (Elshire et al., 2011; Wu et al., 2016). GBS multiplexed 96 to 384 samples into one sequencing lane has a similar cost with the low density SNPs obtained from the single-plex arrays. GBS becomes a competitive alternative for increasing the number of markers many folds economically for running GS on crop improvement, several previous studies showed that GBS could improve genomic prediction accuracy compared with the low density SNPs at similar costs (Crossa et al., 2013; Zhang et al., 2015). In this study, our results showed that high-density genotyping platforms are required, when the predictions are applied on complex traits with low heritability or by pooling multiple related bi-parental populations as training population. rAmpSeq (repeat Amplification Sequencing; (Buckler et al., 2016) was developed recently for large-scale genomic selection projects, this technology allows hundreds to thousands of markers to be scored for less than US$ 5 per sample. CIMMYT in collaborations with Cornell University is testing how to implement genomic prediction on untested double haploid lines using rAmpSeq technology. Cost benefit analysis and genomic prediction accuracy results of this initiative will be reported in the near future.
The main objectives of this study were to evaluate the rMG value of the six trait-environment combinations in 22 bi-parental tropical maize populations genotyped with low-density SNPs and assess the effect of h2, TPS, and MD on rMG estimation in bi-parental populations. Results of this study are clear, moderate rMG means obtained for different trait-environment combinations, when 50% of the total genotypes was used as training population and ~200 SNPs were used for prediction. Architecture of predicted trait affects the rMG value estimation, complex traits had lower rMG means than those of less complex traits, and rMG mean of the same predicted trait was higher in WW condition than in WS condition. For all the trait-environment combinations, rMG value increased as the increase of h2, TPS, and MD. Both correlation and variance analyses showed that h2 is the most important factor on rMG estimation. Among the three factors, h2 most significantly correlates with rMG and explains the greatest percentage of the total variance of rMG for almost all the target trait-environment combinations. Among the three factors, the MD was least associated with rMG estimation for most of the trait-environment combinations, good rMG values could be obtained in bi-parental maize populations, when the h2 of target trait is high and the genome is covered with sufficient markers (mean distance between markers is < 10–20 cM or around 150 markers evenly distributed the whole genome). Higher MD is required to achieve good rMG values in bi-parental populations for complex traits with relative low h2 and strong genotype by environment interaction. Predictions between pairwise half-sib populations showed that the rMG values for all the six trait-environment combinations were centered around zero, high-density and cost-effective genotyping platforms are required to apply genomic predictions across populations and implement GS routinely in the breeding programs. The trend observed in rMG differed with the trend observed in rMG/h for the different trait-environment combinations, which indicated that both rMG and rMG/h values should be presented in the GS studies to show the accuracy of GS and the relative accuracy of GS compared with phenotypic selection on various target predicted traits.
XZ, BP, MO, FS, and YB designed, led, and coordinated the overall study. YB performed and coordinated the field experiments. KS performed and coordinated the genotyping work. AZ, HW, YL, SC, ZC, YR, JB, and JC carried out the analysis. XZ, AZ, HW, and HY wrote the manuscript.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The authors thank all collaborators in Africa who were involved in conducting the extensive bi-parental multi-environment trials. The authors gratefully acknowledge the financial support from the Water Effective Maize for Africa (WEMA) project, the Drought Tolerant Maize for Africa (DTMA) project, Cornell-CIMMYT Genomic Selection project, Genomics Open-source Breeding Informatics Initiative (GOBII) and the CGIAR Research Program (CRP) MAIZE funded by the Bill & Melinda Gates Foundation, the Howard G. Buffett Foundation, and the United States Agency for International Development. The National Key Research and Development Program of China (Grant No. 2016YFD0101803), the National Natural Foundation of China (Grant No. 31771880), Shenyang City Key Laboratory of Maize Genomic Selection and the Liaoning Province Key Scientific and Technological Research and Development Projects (Grant No. 2011208001) provide a finance support to AZ to perform this research.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2017.01916/full#supplementary-material
Albrecht, T., Wimmer, V., Auinger, H. J., Erbe, M., Knaak, C., Ouzunova, M., et al. (2011). Genome-based prediction of testcross values in maize. Theor. Appl. Genet. 123, 339–350. doi: 10.1007/s00122-011-1587-7
Asoro, F. (2013). Comparison of genomic, marker-assisted, and pedigree-BLUP selection methods to increase beta-glucan concentration in elite oat germplasm. Crop Sci. 53, 1894–1906. doi: 10.2135/cropsci2012.09.0526
Battenfield, S. D., Guzmán, C., Gaynor, R. C., Singh, R. P., Peña, R. J., Dreisigacker, S., et al. (2016). Genomic selection for processing and end-use quality traits in the CIMMYT spring bread wheat breeding program. Plant Genome 9, 1–12. doi: 10.3835/plantgenome2016.01.0005
Bernardo, R. (2016). Bandwagons I, too, have known. Theor. Appl. Genet. 129, 2323–2332. doi: 10.1007/s00122-016-2772-5
Beyene, Y., Semagn, K., Mugo, S., Tarekegne, A., Babu, R., Meisel, B., et al. (2015). Genetic gains in grain yield through genomic selection in eight bi-parental maize populations under drought stress. Crop Sci. 55, 154–163. doi: 10.2135/cropsci2014.07.0460
Bian, Y., and Holland, J. B. (2017). Enhancing genomic prediction with genome-wide association studies in multiparental maize populations. Heredity 118, 585–593. doi: 10.1038/hdy.2017.4
Buckler, E. S., Ilut, D. C., Wang, X., Kretzschmar, T., Gore, M., and Mitchell, S. E. (2016). rAmpSeq: using repetitive sequences for robust genotyping. bioRxiv. doi: 10.1101/096628
Cao, S., Loladze, A., Yuan, Y., Wu, Y., Zhang, A., Chen, J., et al. (2017). Genome-wide analysis of tar spot complex resistance in maize using genotyping-by-sequencing SNPs and whole-genome prediction. Plant Genome 10, 1–14. doi: 10.3835/plantgenome2016.10.0099
Combs, E., and Bernardo, R. (2013). Accuracy of genomewide selection for different traits with constant population size, heritability, and numbers of markers. Plant Genome 6, 1–7. doi: 10.3835/plantgenome2012.11.0030
Crossa, J., Beyene, Y., Kassa, S., Perez, P., Hickey, J. M., Chen, C., et al. (2013). Genomic prediction in maize breeding populations with genotyping-by-sequencing. G3 Genes Genom. Genet. 3, 1903–1926. doi: 10.1534/g3.113.008227
Crossa, J., de los Campos, G., Perez, P., Gianola, D., Burgueno, J., Araus, J. L., et al. (2010). Prediction of genetic values of quantitative traits in plant breeding using pedigree and molecular markers. Genetics 186, 713–724. doi: 10.1534/genetics.110.118521
Crossa, J., Perez, P., Hickey, J., Burgueno, J., Ornella, L., Ceron-Rojas, J., et al. (2014). Genomic prediction in CIMMYT maize and wheat breeding programs. Heredity 112, 48–60. doi: 10.1038/hdy.2013.16
Edriss, V., Gao, Y., Zhang, X., Jumbo, M. B., Makumbi, D., Olsen, M. S., et al. (2017). Genomic prediction in a large african maize population. Crop Sci. 57, 2361–2371. doi: 10.2135/cropsci2016.08.0715
Elshire, R. J., Glaubitz, J. C., Sun, Q., Poland, J. A., Kawamoto, K., Buckler, E. S., et al. (2011). A robust, simple genotyping-by-sequencing (GBS) approach for high diversity species. PLoS ONE 6:e19379. doi: 10.1371/journal.pone.0019379
Endelman, J. B. (2011). Ridge regression and other kernels for genomic selection with R Package rrBLUP. Plant Genome 4, 250–255. doi: 10.3835/plantgenome2011.08.0024
Ertiro, B. T., Ogugo, V., Worku, M., Das, B., Olsen, M., Labuschagne, M., et al. (2015). Comparison of kompetitive allele specific PCR (KASP) and genotyping by sequencing (GBS) for quality control analysis in maize. BMC Genomics 16:908. doi: 10.1186/s12864-015-2180-2
Gorjanc, G., Jenko, J., Hearne, S. J., and Hickey, J. M. (2016). Initiating maize pre-breeding programs using genomic selection to harness polygenic variation from landrace populations. BMC Genomics 17:30. doi: 10.1186/s12864-015-2345-z
Guo, Z. G., Tucker, D. M., Lu, J. W., Kishore, V., and Gay, G. (2012). Evaluation of genome-wide selection efficiency in maize nested association mapping populations. Theor. Appl. Genet. 124, 261–275. doi: 10.1007/s00122-011-1702-9
Heffner, E. L., Sorrells, M. E., and Jannink, J. L. (2009). Genomic selection for crop improvement. Crop Sci. 49, 1–12. doi: 10.2135/cropsci2008.08.0512
Jia, Y., and Jannink, J. L. (2012). Multiple-trait genomic selection methods increase genetic value prediction accuracy. Genetics 192, 1513–1522. doi: 10.1534/genetics.112.144246
Lian, L., Jacobson, A., Zhong, S. Q., and Bernardo, R. (2014). Genomewide prediction accuracy within 969 maize biparental populations. Crop Sci. 54, 1514–1522. doi: 10.2135/cropsci2013.12.0856
Lorenz, A. J., Chao, S. M., Asoro, F. G., Heffner, E. L., Hayashi, T., Iwata, H., et al. (2011). Genomic selection in plant breeding: knowledge and prospects. Adv. Agron. 110, 77–123. doi: 10.1016/B978-0-12-385531-2.00002-5
Lorenzana, R. E., and Bernardo, R. (2009). Accuracy of genotypic value predictions for marker-based selection in biparental plant populations. Theor. Appl. Genet. 120, 151–161. doi: 10.1007/s00122-009-1166-3
Marulanda, J. J., Mi, X. F., Melchinger, A. E., Xu, J. L., Wurschum, T., and Longin, C. F. H. (2016). Optimum breeding strategies using genomic selection for hybrid breeding in wheat, maize, rye, barley, rice and triticale. Theor. Appl. Genet. 129, 1901–1913. doi: 10.1007/s00122-016-2748-5
Massman, J. M., Gordillo, A., Lorenzana, R. E., and Bernardo, R. (2013). Genomewide predictions from maize single-cross data. Theor. Appl. Genet. 126, 13–22. doi: 10.1007/s00122-012-1955-y
Meuwissen, T. H. E., Hayes, B. J., and Goddard, M. E. (2001). Prediction of total genetic value using genome-wide dense marker maps. Genetics 157, 1819–1829.
Newell, M. A., and Jannink, J. L. (2014). Genomic selection in plant breeding. Methods Mol. Biol. 1145, 117–130. doi: 10.1007/978-1-4939-0446-4_10
Poland, J., Endelman, J., Dawson, J., Rutkoski, J., Wu, S. Y., Manes, Y., et al. (2012). Genomic selection in wheat breeding using genotyping-by-sequencing. Plant Genome 5, 103–113. doi: 10.3835/plantgenome2012.06.0006
R Development Core Team. (2013). R: A language and Environment for Statistical Computing. Vienna, R Foundation for Statistical Computing.
Roorkiwal, M., Rathore, A., Das, R. R., Singh, M. K., Jain, A., Srinivasan, S., et al. (2016). Genome-enabled prediction models for yield related traits in chickpea. Front. Plant Sci. 7:66. doi: 10.3389/fpls.2016.01666
Rutkoski, J., Singh, R. P., Huerta-Espino, J., Bhavani, S., Poland, J., Jannink, J. L., et al. (2015). Efficient use of historical data for genomic selection: a case study of stem rust resistance in wheat. Plant Genome 8, 1–10. doi: 10.3835/plantgenome2014.09.0046
Schulz-Streeckab, T., Ogutua, J. O., Karamanc, Z., Knaakb, C., and Piepho, H. P. (2012). Genomic selection using multiple populations. Crop Sci. 52, 2453–2461. doi: 10.2135/cropsci2012.03.0160
Semagn, K., Babu, R., Hearne, S., and Olsen, M. (2014). Single nucleotide polymorphism genotyping using kompetitive allele specific PCR (KASP): overview of the technology and its application in crop improvement. Mol. Breed. 33, 1–14. doi: 10.1007/s11032-013-9917-x
Semagn, K., Beyene, Y., Warburton, M. L., Tarekegne, A., Mugo, S., Meisel, B., et al. (2013). Meta-analyses of QTL for grain yield and anthesis silking interval in 18 maize populations evaluated under water-stressed and well-watered environments. BMC Genomics 14:313. doi: 10.1186/1471-2164-14-313
Sonah, H., O'Donoughue, L., Cober, E., Rajcan, I., and Belzile, F. (2015). Identification of loci governing eight agronomic traits using a GBS-GWAS approach and validation by QTL mapping in soya bean. Plant Biotechnol. J. 13, 211–221. doi: 10.1111/pbi.12249
Spindel, J., Begum, H., Akdemir, D., Virk, P., Collard, B., Redona, E., et al. (2015). Correction: Genomic selection and association mapping in rice (Oryza sativa): effect of trait genetic architecture, training population composition, marker number and statistical model on accuracy of rice genomic selection in elite, tropical rice breeding lines. PLoS Genet. 11:e1005350. doi: 10.1371/journal.pgen.1005350
Vivek, B. S., Krishna, G. K., Vengadessan, V., Babu, R., Zaidi, P. H., Kha, L. Q., et al. (2017). Use of genomic estimated breeding values results in rapid genetic gains for drought tolerance in maize. Plant Genome 10, 1–8. doi: 10.3835/plantgenome2016.07.0070
Wallace, J. G., Zhang, X., Beyene, Y., Semagn, K., Olsen, M., Prasanna, B. M., et al. (2016). Genome-wide association for plant height and flowering time across 15 tropical maize populations under managed drought stress and well-watered conditions in Sub-Saharan Africa. Crop Sci. 56, 2365–2378. doi: 10.2135/cropsci2015.10.0632
Windhausen, V. S., Atlin, G. N., Hickey, J. M., Crossa, J., Jannink, J. L., Sorrells, M. E., et al. (2012). Effectiveness of genomic prediction of maize hybrid performance in different breeding populations and environments. G3 Genes Genom. Genet. 2, 1427–1436. doi: 10.1534/g3.112.003699
Wu, Y., San Vicente, F., Huang, K., Dhliwayo, T., Costich, D. E., Semagn, K., et al. (2016). Molecular characterization of CIMMYT maize inbred lines with genotyping-by-sequencing SNPs. Theor. Appl. Genet. 129, 753–765. doi: 10.1007/s00122-016-2664-8
Zhang, X., Perez-Rodriguez, P., Burgueno, J., Olsen, M., Buckler, E., Atlin, G., et al. (2017). Rapid cycling genomic selection in a multiparental tropical maize population. G3 Genes Genom. Genet. 7, 2315–2326. doi: 10.1534/g3.117.043141
Zhang, X., Perez-Rodriguez, P., Semagn, K., Beyene, Y., Babu, R., Lopez-Cruz, M. A., et al. (2015). Genomic prediction in biparental tropical maize populations in water-stressed and well-watered environments using low-density and GBS SNPs. Heredity 114, 291–299. doi: 10.1038/hdy.2014.99
Keywords: maize, genomic selection, trait heritability, training population size, marker density
Citation: Zhang A, Wang H, Beyene Y, Semagn K, Liu Y, Cao S, Cui Z, Ruan Y, Burgueño J, San Vicente F, Olsen M, Prasanna BM, Crossa J, Yu H and Zhang X (2017) Effect of Trait Heritability, Training Population Size and Marker Density on Genomic Prediction Accuracy Estimation in 22 bi-parental Tropical Maize Populations. Front. Plant Sci. 8:1916. doi: 10.3389/fpls.2017.01916
Received: 27 August 2017; Accepted: 23 October 2017;
Published: 08 November 2017.
Edited by:
Thomas Miedaner, University of Hohenheim, GermanyReviewed by:
Deniz Akdemir, Cornell University, United StatesCopyright © 2017 Zhang, Wang, Beyene, Semagn, Liu, Cao, Cui, Ruan, Burgueño, San Vicente, Olsen, Prasanna, Crossa, Yu and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xuecai Zhang, WEMuWmhhbmdAY2dpYXIub3Jn
Haiqiu Yu, aGFpcWl1eXVAMTYzLmNvbQ==
†Present Address: Kassa Semagn, Department of Agricultural, Food and Nutritional Science, University of Alberta, Edmonton, Canada
‡These authors have contributed equally to this work.
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.