 Jia Li
Jia Li Jiangwei Li3
Jiangwei Li3 Fons J. Verbeek
Fons J. Verbeek Tanja Schultz
Tanja Schultz Hui Liu
Hui Liu- 1School of Software Engineering, Xi’an Jiaotong University, Xi’an, China
- 2Leiden Institute of Advanced Computer Science, Leiden University, Leiden, Netherlands
- 3Department of Geriatric Surgery, The Second Affiliated Hospital of Xi’an Jiaotong University, Xi’an, China
- 4MOE Key Lab of Intelligent Network and Network Security, Xi’an Jiaotong University, Xi’an, China
- 5Cognitive Systems Lab, University of Bremen, Bremen, Germany
As an important technique for data pre-processing, outlier detection plays a crucial role in various real applications and has gained substantial attention, especially in medical fields. Despite the importance of outlier detection, many existing methods are vulnerable to the distribution of outliers and require prior knowledge, such as the outlier proportion. To address this problem to some extent, this article proposes an adaptive mini-minimum spanning tree-based outlier detection (MMOD) method, which utilizes a novel distance measure by scaling the Euclidean distance. For datasets containing different densities and taking on different shapes, our method can identify outliers without prior knowledge of outlier percentages. The results on both real-world medical data corpora and intuitive synthetic datasets demonstrate the effectiveness of the proposed method compared to state-of-the-art methods.
1 Introduction
Massive and complex databases often contain numerous patterns. Most traditional data mining tasks find general patterns in the datasets and regard the outliers as noise, such as frequent pattern mining, classification, and clustering. What should not be overlooked is that outliers may embody more valuable information than general patterns, as they could imply abnormal behaviors or potential new patterns, which is consistent with real-life situations Liu and Schultz (2022). An outlier generally means a point that deviates greatly from others, typically generated by a different mechanism Atkinson and Hawkins (1980). Detecting outliers in a dataset is critical and beneficial for practical applications in various fields, such as fraud detection Fiore et al. (2019); Tseng et al. (2015), cyber-security, medical diagnostics Schlegl et al. (2017); Zhang et al. (2016), and others Kang et al. (2016). Outliers of physiological signals in the form of time series are often studied by statistical models, with the latest examples including self-similarity matrices Rodrigues et al. (2022) and subsequence search Folgado et al. (2022), while graph theory-based outlier detection algorithms shine in medical data composed of discrete points, the subject of this article.
Research on outlier detection has a long tradition. Following Hawkins’ classical definition of outliers Atkinson and Hawkins (1980), researchers have developed various outlier detection algorithms and schemes over the years. Generally speaking, these approaches fall into four major groups: distribution-based Zong et al. (2018), distance-based Amagata et al. (2021); Radovanović et al. (2015), density-based Schubert et al. (2014); Corain et al. (2021), and clustering-based Manzoor et al. (2016); Chawla and Gionis (2013); Wang et al. (2019). The main characteristic of the distribution-based method is that it fits datasets with a standard distribution, assuming that the underlying distribution of the dataset is known in advance. It identifies the outliers as the points that do not conform to a particular distribution that sums up most of the data points. Although effective for datasets with a known distribution, the distribution-based approach is not always advisable for real-world scenarios due to the unavailability of a priori distribution knowledge and the high cost of concluding an appropriate distribution Li et al. (2022). During the past 2 decades, distance-based methods have attracted much attention, finding points whose given distance range of neighbors contains less than a predetermined percentage of points of the whole dataset Knorr and Ng (1998). In addition to the unavoidable computational expense of the distances between all pairs, the configuration of the neighboring amount k significantly influences the detection quality. The density-based algorithm was proposed to cover the shortcoming of distance-based approaches, which often fail to detect local outliers. The local outlier factor (LOF) proposed by Markus is widely used to evaluate the outsiderness degree of a point Jahanbegloo and Jahanbegloo (2000), performing well in the dataset with different density distributions. LOF measures the difference between the samples’ local density and their k-nearest neighbors (k-NN) as the outlier factor. However, the choice of k can greatly influence performance. Clustering-based methods have gained popularity in the field of outlier detection as they can overcome the influence of parameters. Clustering divides the dataset into several clusters, making the intra-cluster distance much smaller than the inter-cluster distance. Outliers are identified as the points that are isolated from the resulted clusters. Many researchers have focused on combining clustering and outlier detection Wang et al. (2019); Degirmenci and Karal (2022); Liu et al. (2019). Clustering based on minimum spanning trees (MSTs) is widely adopted for its ability to identify clusters with irregular boundaries Wang et al. (2013). Unlike k-means, there is no assumption that the data points are grouped around centers or separated by a regular geometric curve. However, building an MST is time-consuming for large datasets and may not detect different density clusters effectively Li et al. (2019).
This article proposes a novel outlier detection method, called Mini-MST-based Outlier Detection (MMOD), which does not require specifying the number of outliers. For the emerging real-world data without ground truth, sometimes called black-box data, algorithms that do not require a predetermined number or proportion of outliers can often be straightforwardly plug-and-play. Our approach uses a new distance measure as the edge weight of MST, to better differentiate the clusters so that the outliers in datasets with various density clusters can be identified. To improve the efficiency, we compute some mini-MSTs with a small proportion of the whole dataset and delete the points added to the trees. Our method starts with constructing a Prim’s MST to find one data point in the densest cluster. Subsequently, some small mini-MSTs are computed from the densest point using a distance scaled by the termination threshold of Prim’s algorithm instead of the traditional Euclidean distance to represent the edge weight. The points in each mini-MST can be regarded as a cluster. We compute a termination condition for the MST construction so that the remaining points are outliers after all the mini-MSTs are constructed. The novelty of the proposed method includes a new distance measure to construct the MST to identify different density clusters and efficiency enhancement by employing the mini-MST structure and deleting the data points while constructing the trees. Compared with eight state-of-the-art outlier detection methods on various real-world medical datasets and five synthetic datasets, our method’s feasibility and effectiveness will be proven.
The remainder of the article is organized as follows. Section 2 discusses relevant work on outlier detection. Section 3 prepares the foundations of the preliminaries and definitions for subsequent tasks. Section 4 presents our mini-MST-based outlier detection method. Section 5 manifests the experimental results in comparison to the state-of-the-art technologies. Section 6 concludes our work and looks into the future.
2 Related work
2.1 Distance-based outlier detection
Knorr and Ng advocated distance-based outlier detection (DOD) for the first time to soften the limitation of distribution-based methods on data distribution and prior information Knox and Ng (1998). The local distance-based outlier factor (LDOF) is one of the most known variants in distance-based approaches Zhang et al. (2009), which measures the outsiderness degree in scattered real-world datasets. The relative location of one point and its neighbors evaluates the deviation of the patterns, based on which the classical top-n strategy chooses outlier candidates. As the volume of data increases and the form of data diversifies, data streams are becoming popular, spawning many studies on in-stream outlier detection. Angiulli et al. presented three algorithms to detect distance-based outliers in a sliding-window model Angiulli and Fassetti (2010). A novel notion called the one-time outlier query identifies outliers in a targeted window at an arbitrary time. Milos Radovanovic et al., focusing on the effects of high-dimensional datasets, analyzed the relationship between antihubs and outliers taking into account the reverse nearest neighbor, that is, the point neighboring its k-NN Radovanović et al. (2015). Continuous outlier mining employs the sliding-window data structure to reduce time and memory costs, which is flexible in terms of input parameters Kontaki et al. (2016). Scaleable, distributed algorithms have been put forward for substantial data. MapReduce works for distributed tasks: A multi-tactic strategy for DOD is proposed, where data characteristics are considered in data partitioning Cao et al. (2017). The in-memory proximity graph copes with the memory problem of large datasets, analyzing the type of proximity graph for the algorithm Amagata et al. (2022).
2.2 Minimum spanning tree-based outlier detection
MST is an important and widely used data structure in clustering analysis. MST-based clustering finds inconsistent edges and deletes them to form reasonable and meaningful clusters. In the case of the existence of outliers, cutting inconsistent edges can result in isolated points or clusters, which can be utilized for outlier detection.
Jiang et al. proposed a two-phase outlier detection method based on k-means and MST, in which small clusters are selected and deemed outliers Jiang et al. (2001). There are two stages to this method. In the first phase, they used modified k-means clustering by assigning the far point as a new cluster center. In the second phase, an MST is constructed, and the longest edges are cut to find the small clusters, the tree with a few nodes. MST-based spatial outlier detection combines MST-based clustering constructed by the Delaunay triangle irregular net (D-TIN) and density-based outlier detection, performing effectively on the data of soil chemical elements Lin et al. (2008). Previous work also modified the k-means algorithm to construct a spanning tree efficiently Wang et al. (2012). Integrating MST-based clustering and density-based outlier detection improves the quality of detection. Meanwhile, the removal of outliers may lead to enhanced results of MST-based clustering Wang et al. (2013).
2.3 Summary of deficiencies
From the existing work in outlier detection, it can be concluded that.
• Distance-based models are weak in detecting local outliers. Furthermore, the boundary points in a sparse cluster may be misclassified as outliers.
• Density-based models are less effective at identifying global outliers because these outliers are usually scored low.
• Clustering-based models, ignoring the locations and conditions, can identify outliers that do not belong to any cluster, but are not robust to the presence of different density clusters.
We propose a novel method inspired by MST to tackle the shortcomings mentioned above.
3 Foundation
3.1 Preliminaries
Spanning tree. Given N n-dimensional data points (vertices) in Euclidean space, the spanning tree is a tree that includes all N vertices without closed loops, in which the number of edges is not greater than
Minimum spanning tree (MST). An MST is a spanning tree whose total weight is minimal among all spanning trees, which means that the number of edges in an MST is N − 1. The total weight is the sum of the weight of all edges of the tree. Generally speaking, the weight of an edge in a tree is the Euclidean distance between its two endpoints. Mahalanobis distance or other metrics can also be used as a measure.
Prim’s MST. Among the three traditional algorithms for constructing MST, Prim, Kruskal, and Boruvka, this work employs Prim Medak (2018), whose process can be briefly described as.
• Randomly choose one point in the dataset as the root of the tree;
• Compute the pairwise distances between the chosen point and other points to find the shortest edge;
• Add the shortest edge and the other endpoint of it to the tree;
• Repeat the steps above until all the data points are added to the tree.
Euclidean distance (d). Given two endpoints x1 and x2 of the ith edge ei of an MST in the n-dimensional Euclidean space, the Euclidean distance between x1 and x2 is
3.2 Definitions
Threshold of termination (Tt). A global termination threshold sets the stopping condition of the cluster computation to identify the remaining points as outliers, defined as
where
where the numerator accumulates all edges in the Prim’s MST.
Threshold-based Euclidean distance (ted). We put forward a weighted Euclidean distance to replace the traditional Euclidean, computed as
Tt is calculated based on all edges from the MST of the entire dataset, which enables the scaled distances to handle different density clusters by reducing the discrepancy of the edge weights.
Mini-MST generation. In this work, the mini-MST generation algorithm starts from a point in the densest cluster and computes the MST using ted. When an edge is supposed to be added to the tree, its weight is first compared to the adaptive exit condition defined below. If the former is greater, the other end of the current edge does not belong to the current cluster. Consequently, the computation of the current mini-MST terminates and a new construction starts.
Mini-edge weight set (MEW). A mini-edge weight set records the weight of the edges added to the mini-MST. Once an edge is added to the MST, its weight enters MEW.
The first value added to MEW, denoted as MEW1, defaults to d1, the length of the first edge added to mini-MST. The default value performs well on all real-world datasets applied in this work, as Section 5.2 manifests. In exceptional cases, like a significantly high value of d1, MEW1 can be tuned, such as for the synthetic “Two densities” and “Three clusters” datasets in Appendix, where MEW1 was set to 1.
Adaptive exit condition of mini-MST generation (aec). To improve efficiency, we repeatedly compute mini-MSTs and delete the points added to the MST, applying an adaptively updated exit condition that judges whether the mini-MST generation should terminate at the targeted edge ei:
where
MST-based outliers. MST-based outliers are the points not added to any generated mini-MSTs. Our method does not require a given number of outliers; Instead, aec and Tt differentiate the different density clusters and outliers. The construction of the mini-MSTs finishes when the weight of the next edge is greater than the threshold, so that the points in this current mini-MST can be regarded as a cluster with the same density. Furthermore, a sliding window is applied to the edge weight denoted by the Euclidean distance. If the mean value of such a window is greater than Tt, the remaining points that are not ready to be added to the tree should be deemed outliers.
4 Methods
4.1 MST generation details and an illustrative example
In response to traditional MST-clustering-based outlier detection’s weak performance on datasets with different densities, this work applies a novel distance measure scaled by the threshold of algorithm termination for better discrimination of normal points and outliers. Such a threshold could be considered a quasi-measure of noise in the dataset. The second algorithm improvement of this work targets efficiency: Mini-MSTs are built iteratively. Finishing a mini-MST generation in a cluster is followed by the deletion of processed points and a new construction procedure on the remaining points. An adaptive exit condition based on a progressively updated MEW qualifies the termination of the mini-MST building. A traditional MST algorithm, like Prim, is first applied to create an exact MST to find the point in the densest cluster. Subsequently, all edges are sorted in non-decreasing order to ensure that the first edge’s two endpoints are in the densest cluster because the higher the cluster’s density, the shorter the distances between its points. The edges between different density clusters are taken into account.
Figure 1 illustrates a simplified case that embodies four clusters with different densities and six outliers. C1 is the densest cluster with the smallest average weight of edges. A Prim’s MST is constructed first to find the point in the densest cluster, as Figure 1A demonstrates. The shortest edge can be identified by sorting the edges in Prim’s MST in non-decreasing order. Let s denote the start point of the shortest edge in C1, from which a mini-MST is computed. Like Prim, the shortest edge is repeatedly added to the mini-MST until the next edge’s weight is larger than the exit condition aec (see Eq. (5)). The points in the built mini-MST are labeled normal and removed from the dataset. The above steps are repeated from the point of the next densest cluster, which in this example is C2, and the whole procedure ends with the adaptive exit condition being satisfied. The remaining points are considered outliers.
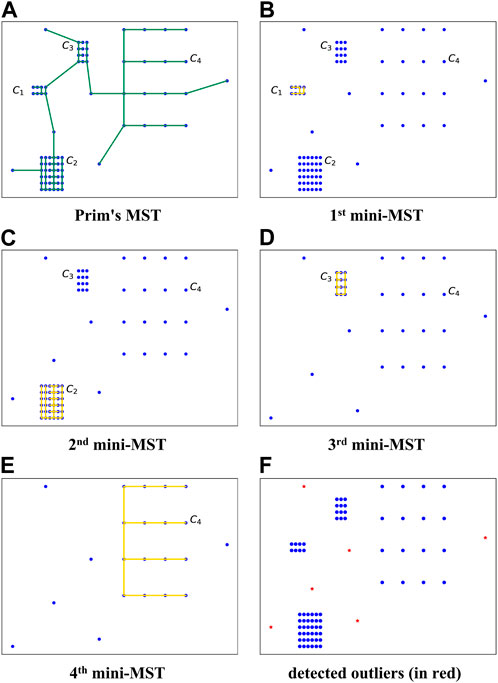
FIGURE 1. An intuitive example of the adaptive mini-minimum spanning tree-based outlier detection (MMOD) method. C1, C2, C3, and C4: four clusters of different densities; (A) Prim’s MST on the original dataset; (B)–(E) procedure of iterative mini-MST construction; (F) detected outliers (in red).
4.2 Adaptive mini-minimum spanning tree-based outlier detection (MMOD)
As can be observed from the example in Section 4.1, the proposed method is centered on the iterative computation of mini-MSTs. Similarly to Prim, two arrays, labeled_data and unlabeled_data, are used to record data points added or not added to the tree, initialized by an empty set and all points, respectively. Unlike the traditional exact MST, the MST in our algorithm is constructed according to the data density, and an exit condition is added to obtain a mini-MST for efficiency. The edge weight of the mini-MST is a threshold-based Euclidean distance in place of the conventional Euclidean distance (see Eq. 4). s denotes the start point of the mini-MST. Aside from the MST array used in Prim’s MST, an additional ted_arr records the threshold-based distance between all data points. Algorithm 1 details the mini-MST construction.
Algorithm 1.Mini-minimum spanning tree construction
Require: a set of N data points, R; start point, s; labeled_data; unlabeled_data
Ensure: an MST
1: Let MEW denote mini edge weight set
2: Let result_set denote the generated MST
3: Let ted_arr denote N − 1 threshold-based Euclidean distances
4: Let edge_arr denote the parents of the N data points
5: for i ← 1: N do
6: edge_arr [i] ← s
7:
8: end for
9: choose another point p from R which is the nearest point to s
10: add the edge denoted by s, p, ted_arr [s] to result_set
11: move p from unlabeled_data to labeled_data
12: initialize MEW with distance (s, p)
13: while True do
14: initialize min _ted with ∞;
15: for q in unlabeled_data do
16: last_weight ← ted (p, q)
17: if last_weight < ted_arr [q] then
18: update ted_arr with the last_weight
19: update edge_arr with the index of p
20: min _ted ← last_weight
21: end if
22: end for
23: compute aec (ei) according to Equation 5
24: if min _ted > aec (ei) then break
25: end if
26: choose point r with smallest ted in ted_arr
27: add the edge denoted by p, r, ted_arr [p] to result_set
28: move r from unlabeled_data to labeled_data
29: update p with r
30: add ted_arr [p] to MEW
31: end while
32: return result_set, edge_arr and ted_arr
Least number. To be noted, the number of points in the cluster falls within a certain range. A cluster containing too few points is considered an outlier cluster. least_number distinguishes normal clusters from outlier clusters:
where the ROUND function finds the closest integer to the parameter; N and n are the size and dimension of the dataset, respectively. If the number of edges of a mini-MST is less than least_number, the points belonging to the tree are marked as outliers.
Since the algorithm starts building MSTs from the densest cluster, it keeps outliers until all mini-MSTs have been generated. Therefore, the threshold of termination Tt (see Eq. 2) can be applied to stop finding normal points. To compare with Tt, a window filled with the weights of the current edge and the following five edges is used: If the mean value of this window is greater than Tt (see Eq. 2), the remaining data points will be treated as outliers.
Algorithm 2 provides the pseudocode of the proposed adaptive mini-MST-based outlier detection, which takes the input of the dataset R with N data points and its corresponding Prim’s MST denoted by the edges. Each edge of the MST consists of a starting point, an endpoint, and an edge weight.
Algorithm 2.Adaptive mini-minimum spanning tree-based outlier detection
Require: dataset R
Ensure: a label array, labels
1: labels ← [−1]*N
2: compute a Prim’s MST using Prim algorithm
3: sort the Prim’s MST in non-decreasing order
4: compute Tt according to Equation 2
5: compute the least_number according to Equation 6
6: for edge in MST do
7: s ←start point of edge
8: if one of the two ends of the edge is in labeled_data then
9: continue
10: end if
11: window ← the weight of the current edge and the next 5 edges;
12: edge_threshold ← the mean value of window
13: if edge_threshold < Tt then mini_mst ← Mini_MST (DS, s, labeled_data, unlabeled_data)
14: if len (mini_mst)
15: labeled the two ends of the edges in mini_mst as normal
16: end if
17: else
18: break
19: end if
20: end for
21: return labels
5 Experimental results and evaluation
5.1 Applied datasets
Ten experiments were conducted on different real-world datasets, as summarized in Table 1, to demonstrate MMOD’s applicability on the benchmark Campos et al. (2016). The datasets will be introduced in detail in Section 5.4, along with the results of the experiments carried out on them.
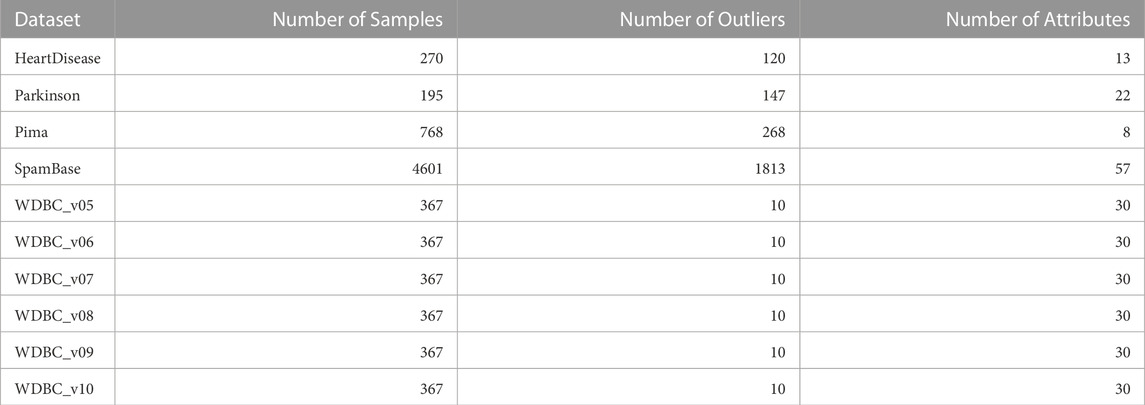
TABLE 1. Description of the applied real-world datasets.
As a supplement, experiments on five synthetic two-dimensional datasets with different morphologies are added to demonstrate MMOD’s parameter tuning and its availability on manually generated data; plus, the two-dimensional visualization is intuitive and well-readable (see Appendix).
5.2 State-of-the-art methods for comparison
MMOD’s experimental results were compared with eight algorithms from the Python outlier detection package Zhao et al. (2019), including four classical algorithms, k-NN Ramaswamy et al. (2000), LOF Jahanbegloo and Jahanbegloo (2000), angle-based outlier detection (ABOD) Pham and Pagh (2012), and histogram-based outlier score (HBOS) Goldstein and Dengel (2012), as well as four recent algorithms, one class support vector machine (OCSVM) Erfani et al. (2016), lightweight online detector of anomalies (LODA) Pevný (2016), locally selective combination of parallel outlier ensembles (LSCP), and multiple-objective generative adversarial active learning (MOGAAL) Liu et al. (2019) Zhao et al. (2018). LOF and k-NN are classical density-based and distance-based methods, respectively. ABOD is developed for high-dimensional feature space datasets to alleviate the “curse of dimensionality,” an efficient version of which was used in our experiments. HBOS is an unsupervised outlier detection method that computes the outsiderness degree by building histograms. OCSVM is an extension of the support vector algorithm that learns a kernel function called the decision boundary, distinguishing outliers from inliers. LODA is operative for data streams and real-time applications. LSCP, also unsupervised, chooses the competent detectors by using the local region of the data points. The newly presented MOGAAL is based on a generative adversarial active learning neural network.
To generate a fair comparison reference, the kthreshold value for each state-of-the-art method being compared was set to 7, a typical value setting. Literature such as Campos et al. (2016) records the performance of other kthreshold values on most reference methods. The outlier percentage is calculated as the number of outliers divided by the size of the dataset. All experiments were run through Python 3.6.5 on a computer with an Intel® Core™ 3.2 GHz i5-3470 CPU and 4 GB RAM.
5.3 Evaluation metrics
Conventional evaluation metrics precision, recall, and F-measure were applied to analyze and compare the experimental results on real-world datasets. Let m denote the number of correct outliers returned by the detector, n denote the total number of all outliers returned by the detector, and o denote the number of ground-truth outliers. The precision P is the proportion of correct outliers in all outliers identified by the detector:
The recall R is the proportion of correct outliers that the detector returns in all ground-truth outliers:
The F-measure is the harmonic mean of precision and recall:
5.4 Results on real-world datasets
Applying real-world datasets can demonstrate the effectiveness of the proposed method straightforwardly. Since medical data are one of the most prominent application scenarios of outlier detection, nine widely investigated open-source medical datasets are utilized for experiments. A spam dataset is additionally brought into the experiment as a case for other domain applications. On each real-world dataset, default MMOD parameter settings or formulas defined in Section 3.2 were adopted, such as the MEW’s first added value MEW1, the threshold-based Euclidean distance ted, and the exit condition aec, which evidences the broad applicability of MMOD without parameter tuning. The precision, recall, and F-measure values of MMOD’s and the experimental results of the peer methods’ are entirely recorded in Tables 1–3, of which the statistics are plotted in Figures 2–4 for visual comparison.
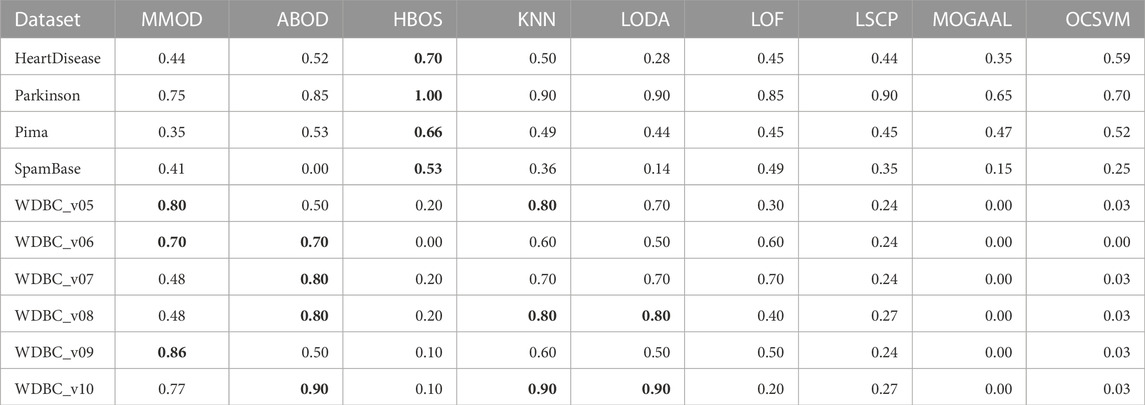
TABLE 2. The precisions of experimental results from MMOD and eight state-of-the-art algorithms on the real-world datasets. The best performance on each dataset is indicated in bold.
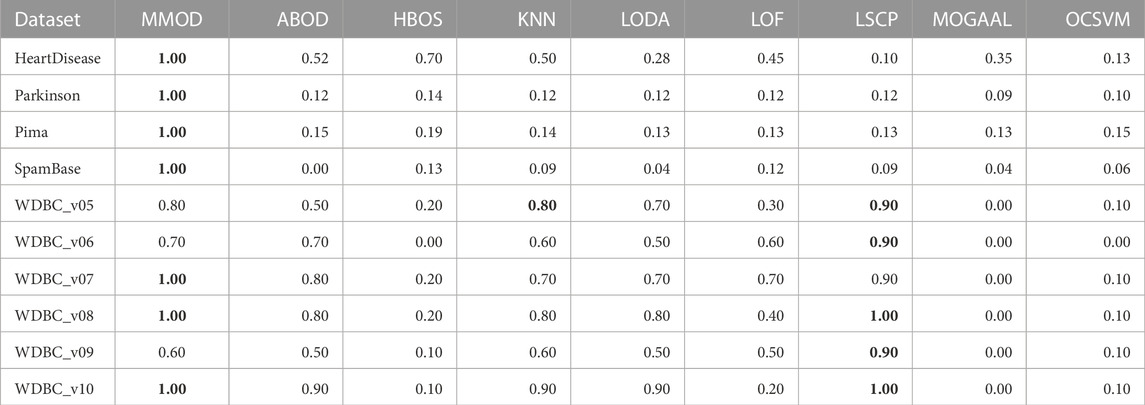
TABLE 3. The recalls of experimental results from MMOD and eight state-of-the-art algorithms on the real-world datasets. The best performance on each dataset is indicated in bold.
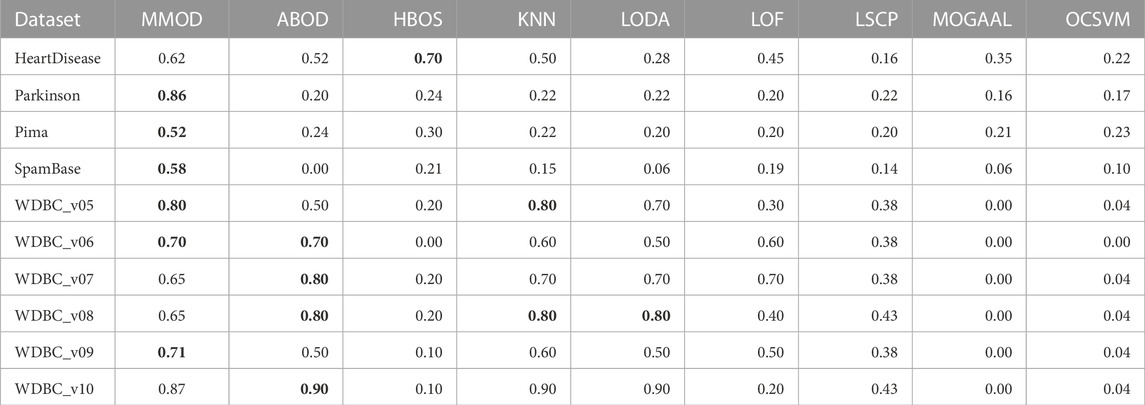
TABLE 4. The F-measures of experimental results from MMOD and eight state-of-the-art algorithms on the real-world datasets. The best performance on each dataset is indicated in bold.
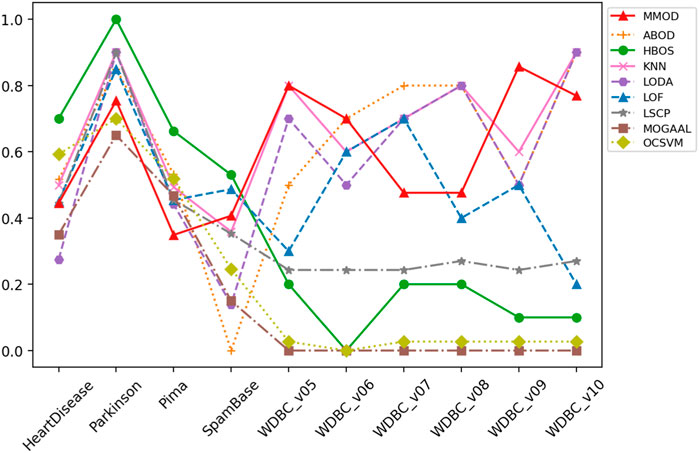
FIGURE 2. The precision of MMOD’s and peer methods’ experimental results on the real-world datasets.
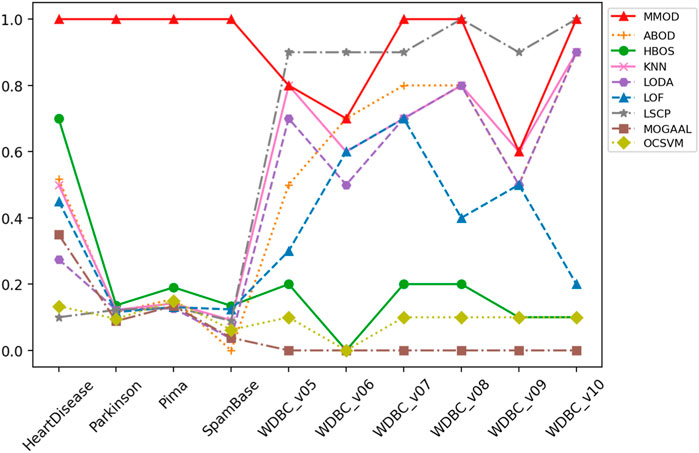
FIGURE 3. The recall of MMOD’s and peer methods’ experimental results on the real-world datasets.
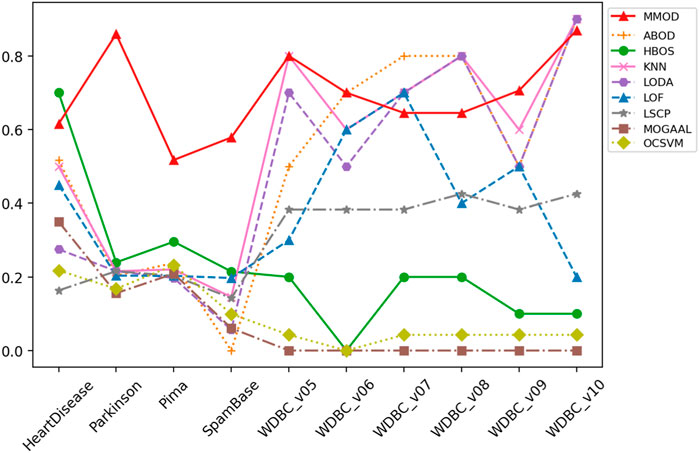
FIGURE 4. The F-measure of MMOD’s and peer methods’ experimental results on the real-world datasets.
5.4.1 The HeartDisease dataset
HeartDisease contains 270 instances, of which 120 outliers represent patients, and the rest describe healthy individuals, showing a close number of normal samples and outliers. Normalized, unduplicated data were used for the experiments of the nine algorithms. Overall, all methods did not perform ideally on this dataset. The highest precision and recall were generated by HBOS and MMOD, respectively. Regarding the F-measure, MMOD came in second place, slightly below HBOS, while the rest of the methods did not exceed 0.6. It is worth noting that MMOD’s perfect recall. In terms of dataset composition, HeartDisease is the only one from all participating datasets with normal samples and outliers close to half-and-half. With such a high percentage of outliers (only lower than Parkinson), there are only 13 attributes used for detection (the second fewest), which evidences the difficulty of detection. Nevertheless, MMOD detected all outliers without any missing, despite causing many false identifications. In contrast, although HBOS has a higher F-measure than MMOD with a 0.80 gap, it has a recall loss of 0.30, which is too high a leakage rate, being insensitive for disease detection.
5.4.2 The Parkinson dataset
To evaluate MMOD’S effectiveness on a large percentage of outliers, we use the normalized, unduplicated Parkinson dataset, consisting of 195 instances, among which 147 are Parkinson’s disease patients as outliers. Due to the outlier percentage being larger than 50%, no parameters were passed to the eight peer algorithms. All methods performed acceptably in terms of precision, but MMOD is the only one standing out in terms of recall, contributing to its far-leading F-measure. For comparison, the F-measures of all peer algorithms are below 0.5. Compared to HeartDisease, Parkinson has a substantially higher percentage of outliers, over three-quarters, the highest among all datasets applied. Meanwhile, its total number of attributes is sizably greater than HeartDisease, at 22. Regarding Parkinson’s detection, MMOD’s perfect recall means no miss.
5.4.3 The Pima dataset for diabetes
Another normalized, unduplicated medical dataset, Pima, contains 768 cases, including 268 diabetic patients as outliers. Each sample is composed of 8 attributes. MMOD works imperfectly in terms of precision, although all methods are not bright; however, MMOD’s recall and F-measure are highlights. Table 1 implies that Pima contains exactly 500 normal samples, which makes the proportion of outliers about 34.90%, roughly one-third of the total data, for which the number of attributes used to describe the samples is the lowest of all the datasets. MMOD succeeded in detecting all diabetic cases but resulted in a certain number of false positives. Similar to Parkinson, on the F-measure, which indicates the overall performance, MMOD outperformed the other methods by a large margin, as none of the others exceeded 0.30.
5.4.4 The WDBC corpus and its variation sets for breast cancer
WDBC describes the nuclear characteristics of a breast cancer diagnosis, whose different variation datasets used in our experiments are randomly downsampled from the original classification dataset for outlier detection Zhang et al. (2009). Each variation of WDBC contains 367 samples, among which there are 10 outliers representing malignant cancers, while other instances indicate benign cancers. Therefore, the outlier proportion of the five WDBC datasets is uniform and tiny, about 2.72%, much smaller than others. Nevertheless, a relatively higher number of attributes are used to characterize the samples, reaching 30, the second highest. The nine algorithms, including MMOD, were experimented on the WDBC dataset’s six unnormalized, unduplicated subsets. For all applied WDBC datasets, MOGAAL was unable to identify any outliers, quitting the competition early.
For WDBC_v05, the proposed MMOD achieves the highest precision of 0.8, along with KNN, followed by LODA with 0.7. None of the other methods achieves a precision greater than 0.5 in this dataset. Regarding recall, LSCP achieves 0.9, while MMOD and KNN are 0.8. Nonetheless, LSCP’s F-measure is underperforming due to its low precision, while MMOD and KNN win at F-measure. MMOD on WDBC_v06 and WDBC_v09 also yielded similar situations of “optimal precision, suboptimal recall, and best F-measure,” just that ABOD replaced KNN as the joint winner on WDBC_v06, while MMOD alone performed best on WDBC_v09. It is noteworthy that besides MOGAAL, HBOS and OCSVM also failed on WDBC_v06. MMOD’s performance metrics on WDBC_v07, WDBC_v08, and WDBC_v10 are similar: perfect recalls with non-optimal precisions and F-measures.
A perfect recall of 1 means that all true malignancies are found without missing, while suboptimal precision represents the presence of a false positive chance. Overall, MMOD has a relatively high recall on WDBC, slightly inferior to LSCP (MMOD is higher only on WDBC_v06, while on par or lower at rest). Still, given LSCP’s inferior precision, it can be claimed that MMOD works well overall on WDBC_v05–WDBC_v10, as evidenced also by the F-measures. It can also be observed from Figure 4 that MMOD’s F-measure performance is relatively stable among a group of algorithms.
5.4.5 The SpamBase dataset
Additionally, an email dataset beyond medical scenarios, SpamBase, was applied, which consists of 4,601 objects of 57 attributes, 1,813 of which are spam emails as outliers. It is considerably formidable to detect outliers in such a dataset. Like in WDBC, MOGAAL did not manage to work. MMOD ranks third in precision, while its recall is again far ahead, leading to the winning F-measure. In addition to having the most significant number of samples and attributes, SpamBase has a large outlier quantity, accounting for 39.40%. This relatively “big” data witnessed MMOD’s report card of not missing any spam. All other algorithms have weak F-measures worse than 0.21.
5.5 Comprehensive performance analysis and discussion
MMOD has perfect or nearly perfect recalls on most datasets, which should be attributed to its ability to greatly retain possible outliers, enabled by the adaptive exit condition. Such an adaptive termination mechanism also improves the efficiency of the algorithm. LSCP’s recall performance is comparable to MMOD on WDBS, but on the one hand, its recall is extremely worse than MMOD on the other datasets; on the other hand, its precision on WDBS is also significantly inferior to MMOD. Regarding precision, HBOS works well on four datasets, but is overall unstable and particularly poor on the other six. MMOD is optimal in three datasets and at an average level globally.
Two of the advanced aspects of MMOD are that it does not require the number of outliers as input and that it is outlier quantity and proportion insensitive. Such a characteristic was well reflected in the experimental results. The applied datasets include various outlier percentages, such as a small portion of outliers, a large percentage of outliers, and a close proportion of outliers and normal samples. Evidently, most of the peer methods are affected by such setups. For datasets with a high percentage of outliers, such as HeartDisease, Parkinson, Pima, and SpamBase, HBOS has high precision values; however, for cases with a low percentage of outliers, HBOS’s precision almost hits rock bottom. Worse, its recalls are always poor, no matter the outlier percentage. k-NN, LODA, and LSCP are almost the opposite. k-NN and LODA’s precision and recall on datasets with a low percentage of outliers are significantly better than the case with a high percentage of outliers. LSCP’s recall is excellent when the percentage of outliers is low; for the high percentage of outliers, LSCP is almost incapable, not to mention its unsatisfying precision all the time. As a comparison, MMOD’s performance is more consistent regardless of the outlier percentage, without dramatically poor metric values. Its recall is especially consistently splendid, its precision is in the middle of the pack, and its F-measure is relatively robust, all verifying that MMOD, which does not take outlier numbers or percentages as inputs, works insensitively to outlier quantity and proportion.
Which one of recall and precision is more valued during outlier detection is relevant to the application scenario. For medical data, especially disease diagnosis, recall is related to whether cases with real diseases will be missed. The preliminary validation experiments of MMOD’s method suggest its usability on medical data.
6 Conclusion
Outlier detection is an important approach to data mining, which is widely studied in medical scenarios. MST has been widely applied to clustering and outlier detection as an essential data structure in graph theory. In order to overcome the problems in distance-based and density-based outlier detection, an adaptive mini-minimum spanning tree-based outlier detection (MMOD) method was proposed in this article, employing threshold-based Euclidean distances as the edge weight and adaptive exit conditions of mini-MST generation, to improve efficiency. MMOD does not require the outlier percentage as an input parameter, which peer outlier detection algorithms usually need. Moreover, MMOD can detect outliers in datasets with different densities and is insensitive to the outlier proportion and distribution. A series of experiments in real-world medical datasets manifested the promising results of MMOD; additional spam and five synthetic datasets further validated its applicability. Topics on MST-based outlier detection methods, such as the quantitative measurement of outsiderness degree, remain research values in the future.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://github.com/laetella/MMOD.
Author contributions
Conceptualization, methodology, implementation, and experiment, JL; validation, JwL, TS, and HL; investigation, JwL; visualization, JL and HL; analysis and discussion, JL, JwL, and HL; writing—original draft preparation, JL and HL; writing—review and rewriting, JL and HL; supervision, CW, FV, and HL; funding acquisition, HL and CW; All authors contributed to the article and approved the submitted version.
Funding
The APC was funded by the Open Access Initiative of the University of Bremen and the DFG via SuUB Bremen. The research is partially supported by the National Natural Science Foundation of China (No. 62272379) and the Natural Science Basic Research Plan in Shaanxi Province (2021JM-018).
Acknowledgments
We extend our sincere gratitude to Xiaochun Wang for her help in conceptualization and methodology. This work was started with the support of Fund 2020JM-046, for which she is responsible.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphys.2023.1233341/full#supplementary-material
References
Amagata D., Onizuka M., Hara T. “Fast and exact outlier detection in metric spaces: A proximity graph-based approach,” in Proceedings of the 2021 International Conference on Management of Data, Virtual Event China, June 2021, 36–48.
Amagata D., Onizuka M., Hara T. (2022). Fast, exact, and parallel-friendly outlier detection algorithms with proximity graph in metric spaces. VLDB J, 31. doi:10.1007/s00778-022-00729-1
Angiulli F., Fassetti F. (2010). Distance-based outlier queries in data streams: the novel task and algorithms. Data Min. Knowl. Discov. 20, 290–324. doi:10.1007/s10618-009-0159-9
Atkinson A. C., Hawkins D. M. (1980). Identification of outliers. Biometrics 37, 860. doi:10.2307/2530182
Campos G. O., Zimek A., Sander J., Campello R. J. G. B., Micenková B., Schubert E., et al. (2016). On the evaluation of unsupervised outlier detection: measures, datasets, and an empirical study. Data Min. Knowl. Discov. 30, 891–927. doi:10.1007/s10618-015-0444-8
Cao L., Yan Y., Kuhlman C., Wang Q., Rundensteiner E. A., Eltabakh M. “Multi-tactic distance-based outlier detection,” in Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, April 2017, 959–970.
Chawla S., Gionis A. (2013). k -means–: A unified approach to clustering and outlier detection. https://epubs.siam.org/doi/pdf/10.1137/1.9781611972832.21.
Corain M., Garza P., Asudeh A. “Dbscout: A density-based method for scalable outlier detection in very large datasets,” in Proceedings of the ICDE (IEEE), Chania, Greece, April 2021, 37–48. doi:10.1109/icde51399.2021.00011
Degirmenci A., Karal O. (2022). Efficient density and cluster based incremental outlier detection in data streams. Inf. Sci. 607, 901–920. doi:10.1016/j.ins.2022.06.013
Erfani S. M., Rajasegarar S., Karunasekera S., Leckie C. (2016). High-dimensional and large-scale anomaly detection using a linear one-class svm with deep learning. Pattern Recognit. 58, 121–134. doi:10.1016/j.patcog.2016.03.028
Fiore U., Santis] A. D., Perla F., Zanetti P., Palmieri F. (2019). Using generative adversarial networks for improving classification effectiveness in credit card fraud detection. Inf. Sci. 479, 448–455. doi:10.1016/j.ins.2017.12.030
Folgado D., Barandas M., Antunes M., Nunes M. L., Liu H., Hartmann Y., et al. (2022). Tssearch: time series subsequence search library. SoftwareX 18, 101049. doi:10.1016/j.softx.2022.101049
Goldstein M., Dengel A. (2012). Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm. KI-2012 Poster Demo Track.
Jahanbegloo R., Jahanbegloo R. (2000). Lof: identifying density-based local outliers. SIGMOD 26, 1–22. doi:10.1145/335191.335388
Jiang M. F., Tseng S. S., Su C. M. (2001). Two-phase clustering process for outliers detection. Pattern Recognit. Lett. doi:10.1016/S0167-8655(00)00131-8
Kang M., Islam M. R., Kim J., Kim J., Pecht M. (2016). A hybrid feature selection scheme for reducing diagnostic performance deterioration caused by outliers in data-driven diagnostics. IEEE Trans. Industrial Electron. 63, 3299–3310. doi:10.1109/TIE.2016.2527623
Knorr E. M., Ng R. T. “Algorithms for mining distance-based outliers in large datasets,” in Proceedings of the 24rd International Conference on Very Large Data Bases, San Francisco, CA, United States, August 1998, 392–403.
Knox E. M., Ng R. T. “Algorithms for mining distance-based outliers in large datasets,” in Proceedings of the international conference on very large data bases, San Francisco, CA, United States, August 1998, 392–403.
Kontaki M., Gounaris A., Papadopoulos A. N., Tsichlas K., Manolopoulos Y. (2016). Efficient and flexible algorithms for monitoring distance-based outliers over data streams. Inf. Syst. doi:10.1016/j.is.2015.07.006
Li J., Wang X., Wang X. (2019). A scaled-MST-based clustering algorithm and application on image segmentation. J. Intelligent Inf. Syst. doi:10.1007/s10844-019-00572-x
Li Z., Zhao Y., Hu X., Botta N., Ionescu C., Chen G. (2022). Ecod: unsupervised outlier detection using empirical cumulative distribution functions. IEEE Trans. Knowl. Data Eng. doi:10.48550/arXiv.2201.00382
Lin J., Ye D., Chen C., Gao M. “Minimum spanning tree based spatial outlier mining and its applications,” in Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Chengdu, China, May 2008.
Liu H., Li J., Wu Y., Fu Y. (2019a). Clustering with outlier removal. IEEE Trans. Knowl. data Eng. 33, 2369–2379. doi:10.1109/TKDE.2019.2954317
Liu H., Schultz T. “How long are various types of daily activities? Statistical analysis of a multimodal wearable sensor-based human activity dataset,” in Proceedings of the 15th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2022), Online Streaming, February 2022. doi:10.5220/0010896400003123
Liu Y., Li Z., Zhou C., Jiang Y., Sun J., Wang M., et al. (2019b). Generative adversarial active learning for unsupervised outlier detection. IEEE Trans. Knowl. Data Eng., 1. doi:10.1109/tkde.2019.2905606
Manzoor E., Milajerdi S. M., Akoglu L. “Fast memory-efficient anomaly detection in streaming heterogeneous graphs,” in Proceedings of the Acm Sigkdd International Conference on Knowledge Discovery & Data Mining, San Francisco California USA, August 2016.
Medak J. (2018). Review and analysis of minimum spanning tree using prim’s algorithm. Int. J. Comput. Sci. Trends Technol. (IJCST) 6.
Pevný T. (2016). Loda: lightweight on-line detector of anomalies. Mach. Learn. 102, 275–304. doi:10.1007/s10994-015-5521-0
Pham N., Pagh R. “A near-linear time approximation algorithm for angle-based outlier detection in high-dimensional data,” in Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining, Beijing China, August 2012. doi:10.1145/2339530.2339669
Radovanović M., Nanopoulos A., Ivanović M. (2015). Reverse nearest neighbors in unsupervised distance-based outlier detection. IEEE Trans. Knowl. Data Eng. 27, 1369–1382. doi:10.1109/TKDE.2014.2365790
Ramaswamy S., Rastogi R., Shim K. (2000). Efficient algorithms for mining outliers from large data sets. ACM SIGMOD Rec. 29, 427–438. doi:10.1145/342009.335437
Rodrigues J., Liu H., Folgado D., Belo D., Schultz T., Gamboa H. (2022). Feature-based information retrieval of multimodal biosignals with a self-similarity matrix: focus on automatic segmentation. Biosensors 12, 1182. doi:10.3390/bios12121182
Schlegl T., Seeböck P., Waldstein S. M., Schmidt-Erfurth U., Langs G. (2017). “Unsupervised anomaly detection with generative adversarial networks to guide marker discovery,” in Information processing in medical imaging. M. Niethammer, M. Styner, S. Aylward, H. Zhu, I. Oguz, P.-T. Yapet al. (Cham, Germany: Springer International Publishing), 146–157.
Schubert E., Zimek A., Kriegel H. P. “Generalized outlier detection with flexible kernel density estimates,” in Proceedings of the SIAM International Conference on Data Mining 2014, April 2014, 542–550. doi:10.1137/1.9781611973440.63
Tseng V. S., Ying J., Huang C., Kao Y., Chen K. “Fraudetector: A graph-mining-based framework for fraudulent phone call detection,” in Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney NSW Australia, August 2015, 2157–2166.
Wang X., Wang X. L., Chen C., Wilkes D. M. (2013). Enhancing minimum spanning tree-based clustering by removing density-based outliers. Digit. Signal Process. 23, 1523–1538. doi:10.1016/j.dsp.2013.03.009
Wang X., Wang X. L., Wilkes D. M. (2012). “A minimum spanning tree-inspired clustering-based outlier detection technique,” in Icdm (Berlin, Germany: Springer), 209–223. doi:10.1007/978-3-642-31488-9_17
Wang Y. F., Jiong Y., Su G. P., Qian Y. R. (2019). A new outlier detection method based on OPTICS. Sustain. Cities Soc. 45, 197–212. doi:10.1016/j.scs.2018.11.031
Zhang K., Hutter M., Jin H. “A new local distance-based outlier detection approach for scattered real-world data,” in Proceedings of the Advances in Knowledge Discovery and Data Mining, Bangkok, Thailand, April 2009, 813–822.
Zhang L., Li X., Liu H., Mei J., Hu G., Zhao J., et al. “Probabilistic-mismatch anomaly detection: do one’s medications match with the diagnoses,” in Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, December 2016, 659–668.
Zhao Y., Hryniewicki M. K., Nasrullah Z., Li Z. (2018). Lscp: locally selective combination in parallel outlier ensembles. https://arxiv.org/abs/1812.01528.
Zhao Y., Nasrullah Z., Li Z. (2019). Pyod: A python toolbox for scalable outlier detection. J. Mach. Learn. Res. 20, 1–7.
Keywords: minimum spanning tree, outlier detection, cluster-based outlier detection, data mining, medical data
Citation: Li J, Li J, Wang C, Verbeek FJ, Schultz T and Liu H (2023) Outlier detection using iterative adaptive mini-minimum spanning tree generation with applications on medical data. Front. Physiol. 14:1233341. doi: 10.3389/fphys.2023.1233341
Received: 01 June 2023; Accepted: 20 September 2023;
Published: 13 October 2023.
Edited by:
Michael Döllinger, University Hospital Erlangen, GermanyReviewed by:
Stefan Schoder, Graz University of Technology, AustriaEamonn John Keogh, University of California, Riverside, United States
Copyright © 2023 Li, Li, Wang, Verbeek, Schultz and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fons J. Verbeek, Zi5qLnZlcmJlZWtAbGlhY3MubGVpZGVudW5pdi5ubA==; Hui Liu, aHVpLmxpdUB1bmktYnJlbWVuLmRl