
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Physiol. , 20 July 2023
Sec. Computational Physiology and Medicine
Volume 14 - 2023 | https://doi.org/10.3389/fphys.2023.1200656
 Zhentao Huang1
Zhentao Huang1 Yahong Ma1*Jianyun Su2*Hangyu Shi2Shanshan Jia3
Yahong Ma1*Jianyun Su2*Hangyu Shi2Shanshan Jia3 Baoxi Yuan1Weisu Li1Jingzhi Geng4Tingting Yang4
Baoxi Yuan1Weisu Li1Jingzhi Geng4Tingting Yang4EEG-based emotion recognition through artificial intelligence is one of the major areas of biomedical and machine learning, which plays a key role in understanding brain activity and developing decision-making systems. However, the traditional EEG-based emotion recognition is a single feature input mode, which cannot obtain multiple feature information, and cannot meet the requirements of intelligent and high real-time brain computer interface. And because the EEG signal is nonlinear, the traditional methods of time domain or frequency domain are not suitable. In this paper, a CNN-DSC-Bi-LSTM-Attention (CDBA) model based on EEG signals for automatic emotion recognition is presented, which contains three feature-extracted channels. The normalized EEG signals are used as an input, the feature of which is extracted by multi-branching and then concatenated, and each channel feature weight is assigned through the attention mechanism layer. Finally, Softmax was used to classify EEG signals. To evaluate the performance of the proposed CDBA model, experiments were performed on SEED and DREAMER datasets, separately. The validation experimental results show that the proposed CDBA model is effective in classifying EEG emotions. For triple-category (positive, neutral and negative) and four-category (happiness, sadness, fear and neutrality), the classification accuracies were respectively 99.44% and 99.99% on SEED datasets. For five classification (Valence 1—Valence 5) on DREAMER datasets, the accuracy is 84.49%. To further verify and evaluate the model accuracy and credibility, the multi-classification experiments based on ten-fold cross-validation were conducted, the elevation indexes of which are all higher than other models. The results show that the multi-branch feature fusion deep learning model based on attention mechanism has strong fitting and generalization ability and can solve nonlinear modeling problems, so it is an effective emotion recognition method. Therefore, it is helpful to the diagnosis and treatment of nervous system diseases, and it is expected to be applied to emotion-based brain computer interface systems.
EEG is the overall reflection of nerve cells in the cerebral cortex or scalp surface of electrophysiological activities in the brain, which has the advantages of being non-invasive, easy to use, portable, and other advantages. It is often used in sleep staging, seizure detection and prediction, brain-computer interfaces (BCIs) and other fields. Data-driven machine learning or deep learning can simulate or even improve the clinical diagnosis of EEG. Emotion is an important part of human life, which reflects human emotions, thoughts, behaviors and further affects physical and behavioral states (Lu et al., 2020). Positive emotions can promote and enhance, while negative emotions can weaken and reduce human behavior. Severe negative emotion, such as depression, may cause serious damage to the physical and mental health of patients. Emotion plays a crucial role in all aspects, such as human communication and decision-making. Therefore, understanding and analyzing human emotions is very important, which can be used in many fields, such as intelligent driving systems (Nakisa et al., 2018), medical services (Mehmood et al., 2017), voice assistants (Liu et al., 2017), robots (Dai et al., 2017) etc., When treating patients with emotional problems, auto-recognition of real emotional states can help doctor to provide better medical care. Several psychological and physiological studies have found a strong correlation between emotion recognition and brain activity (Sammler et al., 2007; Mathersul et al., 2008; Knyazev et al., 2010). Emotion can be recognized through physical activity, body posture, speech, facial expression, etc. However, these external signs are easy to be disguised or concealed, great impact by subjective factors and it is difficult to reflect the true emotional state of the heart. Physiological signals have the advantages of universality, spontaneity and difficulty in disguising, which can reflect the real emotional state more accurately.
Physiological signals can reflect the state of the central and autonomic nervous systems (CNS and ANS) (Cannon, 1927) and indicate a subject’s potential emotional response (Shu et al., 2018). With advanced mobile computing technologies and miniaturized wearable sensors, physiological signals can be continuously monitored, which include electroencephalogram (EEG), electrocardiogram (ECG), electromyogram (EMG), electrodermal response (GSR), body temperature, respiratory rate (RR), and pulse blood oxygen measurement. EEG signals have been shown to provide important features for emotion recognition (Petrantonakis and Hadjileontiadis, 2011), which has excellent spatial and temporal resolution during emotional induction (Dale and Sereno, 1993). EEG has the advantage of non-invasive, fast, and economic. However, the complexity and nonlinearity of EEG signals lead to the suboptimal processing effect of many traditional methods, the steps of which contains feature extraction and classification. According to the EEG signal characteristics, obtaining the most prominent features is the most critical step. Common feature extraction methods include time domain, frequency domain, time-frequency analysis, and nonlinear analysis, etc. However, traditional machine learning methods require selecting electrode channels and manually extracting features, which are tedious, time-consuming and laborious, and easily lead to low accuracy of classification results. Deep learning has the advantages of strong learning ability and portability (Chen et al., 2021), thus EEG signal recognition and classification based on deep learning has become an important research direction. Jaiswal and Banka, (2017) proposed an artificial neural networks (ANN) model for feature-based EEG signal classification, which used local gradient patterns and neighborhood description patterns, and the final classification accuracy is 99.82%. Zhang et al. (2018) proposed a Spatial Temporal Recursive Neural Network (STRNN) for emotion recognition, the results of which shows that STRNN performed significantly better than SVM. Zheng and Lu (2015) used a short Fourier Transform to extract density entropy of multichannel EEG signals and used Deep Trust Network (DBN) to classify positive, negative, and neutral emotions with 86.65% accuracy.
Many researchers have devoted themselves to put forward various algorithms to improve the accuracy of emotion classification. For example, studies that selected representative spatial and temporal information can greatly optimize the classification of emotion, and studies that selected a minimum number of channels to determine the emotional state of EEG signals without compressing accuracy can be applied to portable EEG interface implants. EEG signals are time-varying and continuous, which is very useful for classifying emotional states. Therefore, a good combination of spatial temporal combination features can provide more information.
According to the characteristics of EEG signals and the shortcomings of existing methods, this paper proposes a CNN-DSC-Bi-LSTM-Attention (CDBA) model based on multi-branching feature fusion, which can achieve the feature extraction, feature selection and classification for emotional EEG. There are three channels to extract spatial and temporal features, including primary spatial features and advanced spatial features. According to the importance of EEG features, attention mechanisms are used to give different weights to each feature. Finally, Softmax function is used as a classifier to classify emotions and obtain triple or four categories results. Compared to existing research, the innovations of this paper can be summarized as follows:
(1) The use of raw EEG signals facilitates transplantation and application to brain interfaces.
(2) Bi-LSTM, Depthwise Separable Convolution (DSC), and Attention Mechanism are introduced to achieve high performance and lower model overhead by combining multiple features.
(3) Extensive experiments were conducted on both SEED datasets to verify and evaluate the model accuracy and credibility.
The organizational structure of this paper is as follows: section 2 describes the details of the data set, the classification model architecture, and the overall framework of this paper. section 3 introduces the results of this paper and compares them with other models. section 4 summarizes this paper and puts forward the future research direction.
SJTU Emotion EEG Dataset (SEED) is provided by the BCMI Laboratory of Shanghai Jiaotong University (Duan et al., 2013; Zheng and Lu, 2015). The data of SEED was from EEG recordings of 15 subjects. During the experiment, 15 Chinese film clips (positive, neutral, and negative emotions) were selected from a library of materials as stimuli used in the experiment. The total duration of the experiment should be short. Otherwise, subjects may feel tired. Film clips should be well understood, not clarified. Clips should stimulate single-goal emotions. It shouldn't contain mixed emotions. Each film has been edited to create coherent emotion and maximize emotional meaning. There were a total of 15 tests per experiment. Each clip is preceded by a 5-s reminder, 45 s for self-assessment, and 15 s to rest after each clip in a session. The order of screenings is such that two clips of the same emotion will not be shown consecutively. In response to feedback, participants were told to report their emotional reaction to each film clip by completing a questionnaire immediately after viewing each clip. SEED-IV (Zheng et al., 2018) was data from EEG recordings of 15 subjects, and 72 film clips were carefully selected for three experiments, which tended to induce feelings of happiness, sadness, fear, or neutrality, as SEED did. Table 1 gives some details of the film clips used in the SEED experiment.
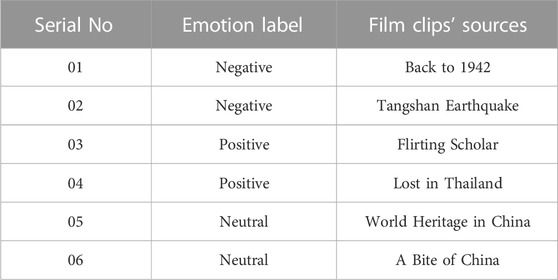
TABLE 1. Examples of the movie clips of Positive, Negative and Neutral emotions (Duan et al., 2013; Zheng and Lu, 2015; Zheng et al., 2018).
Similarly, the DREAMER database (Gabert-Quillen et al., 2015; Katsigiannis and Ramzan, 2017) consists of multichannel EEG signals collected from 23 healthy subjects (9 women and 14 men). In this database, each subject’s mood was induced by playing 18 movie clips. Each film clip considered nine emotional categories, such as anger, fear, calm, entertainment, sadness, surprise, disgust, happiness, and excitement. EEG signals were recorded with 14 electrodes (using a standard 10–20 electrode system) and sampled at 128 Hz.
The SEED dataset was tested in three stages for each subject. The interval between each experiment was 1 week or more. This process ensures a stable pattern of neural activity at different stages and in different individuals. Record both facial video and EEG. Subjects sat in front of large screens showing movie clips. The data were collected via 62 channels which are placed according to 10–20 system, down-sampled to 200 Hz, a bandpass frequency filter from 0–75 Hz was applied and presented as MATLAB “.mat” files. In total, 45 sessions of EEG data was recorded. The labels are given according to the clip contents (−1 for negative, 0 for neutral and 1 for positive). To test the superiority of the model for emotional recognition, we used only the original EEG signals of SEED and SEED-IV for test training. Due to the large volume of data, we extracted 1,000 consecutive datasets from each person in the experiment in the middle of each video segment, so SEED and SEED-IV were extracted for 15 people × 15 videos × 1,000 = 225,000 and 15 people × 24 videos × 1,000 = 360,000.
The same DREAMER was created by 23 subjects each watching 18 movie clips, producing 23 × 18 = 414 EEG files. Each subject was given a score between 1 and 5 based on valence, arousal, and dominance levels, and the Valence classifications was used as a label in the paper. We extract 1,000 consecutive data sets from each person in the experiment in the middle of each video clip, so the extraction DREAMER is 23 people x 18 videos × 1,000 = 414,000.
The importance of each feature in the emotion classification is different, a CDBA model for emotion recognition is proposed in this paper. The structure of the CDBA model is shown in Figure 1.
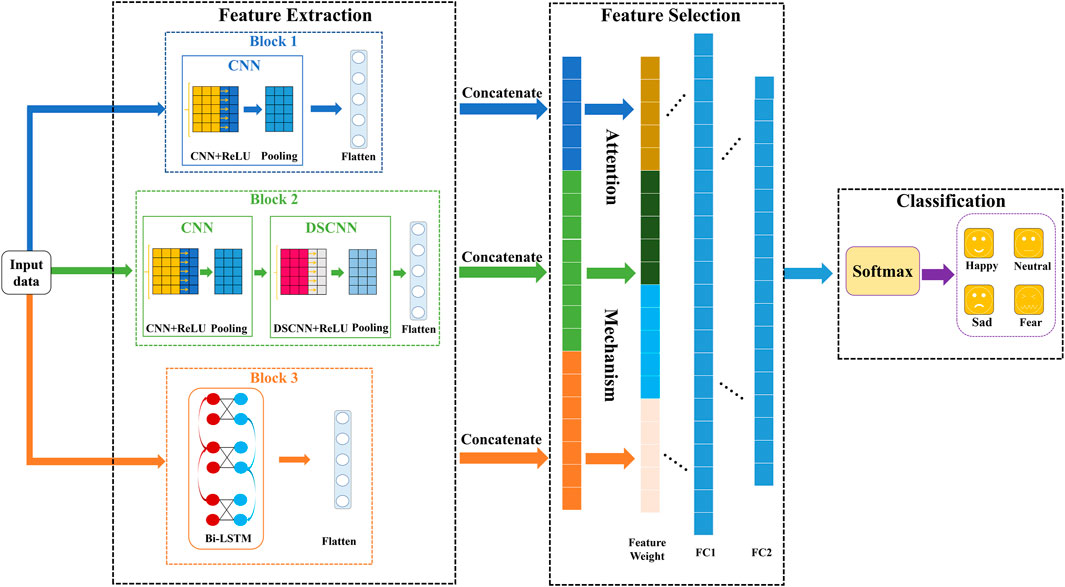
FIGURE 1. CDBA structure.
It can be seen from Figure 1, the CDBA model can achieve the feature extraction, feature selection and classification for emotional EEG. There are three parallel channels to extract spatial and temporal features, including primary spatial features and advanced spatial features. The raw EEG signals are first normalized and then input simultaneously to the three Blocks. Block 1 consists of a convolution layer with ReLU activation function, a max pooling layer, and a flatten layer. The reason for choosing ReLU activation function is that it abandons complex computation to improve the operation speed, which helps to solve the convergence problem of deep networks. And it is more in line with the characteristics of biological neurons and is easy to learn and optimize. Block 2 added a deeply separable network to Block 1. Depth separable convolution (DSCNN) can be divided into deep and separable convolution, mainly obtains the interaction information between physiological signal space and characteristic channels. In the depth convolution part, all the connected channels of each sample point are convolved. In the separable convolution part, each sample point channel convolution is performed on the basis of deep convolution. 64 unit Bi-LSTM and flatten layers are used in Block 3, which is solves the long term dependence of cyclic neural network RNN. The unique “gate” structure avoids gradient explosion and gradient disappearance and has the advantage of strong long term memory. Bi-LSTM considers forward and backward time series information in the time dimension to make the prediction more comprehensive and accurate. CNN is suitable for extracting local spatial features, and Bi-LSTM combines bidirectional time-series information to analyze emotional characteristics more thoroughly from spatial-temporal characteristics and improve the fit of predictive results. The primary spatial features, the advanced spatial features and the time series features are extracted from the three blocks, respectively. And then they are concatenated together into a sequence. The attention mechanism layer will weigh the concatenated sequence, assign weight values to each channel, further extract features and reduce dimensions through two fully connected layers, and then categorize the final prediction results through the Softmax function. Parameters of the CDBA architecture are shown in Table 2.
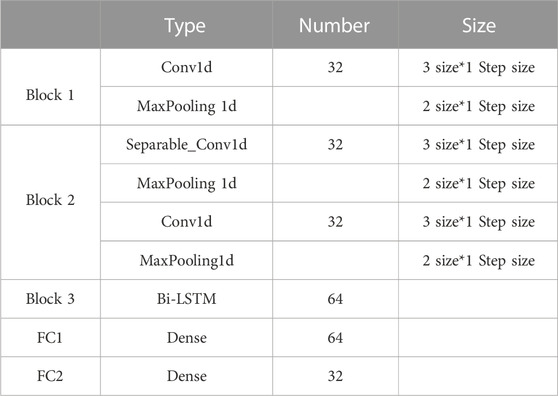
TABLE 2. Parameters of the CDBA architecture.
CNN is a deep learning model that automatically learns to classify objects from images, numbers or videos, which generally consists of convolution, pooling and full connection layers. The convolution layer contains 32 convolution nuclei and performs convolution calculations on input signals. Then the non-linearization of the convolution results is performed by using the activation function. By optimizing the weight parameters of each filter, the algorithm minimizes classification errors and can learn from input data. The EEG data used in this paper is one-dimensional, so only one-dimensional convolution neural networks are used, the diagram of which is shown in Figure 2. Rectifying linear activation units (ReLU) were used in the one-dimensional convolution layer. The pooling layer, also known as the down-sampling layer, performs pool operations on the output of the convolution layer to preserve higher-level representation. The advanced features are usually fed into the full connection layer for final classification. Assuming the input is two-channel data, the kernel is also a two-dimensional two-column filter, with the first convolution output calculated as Eq. 1.
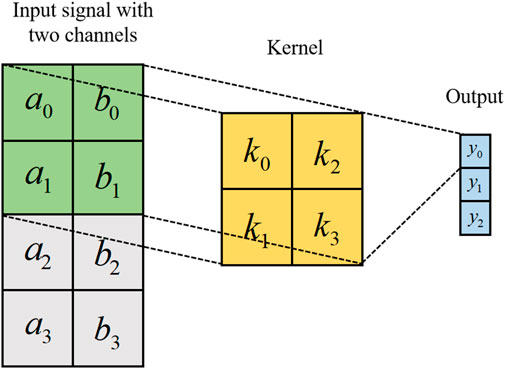
FIGURE 2. Two channels one-dimensional convolution.
The rest of the output is calculated by sliding the kernel in a vertical direction, that is, time-stamp direction. Thus, vectors can be obtained from each filter, which is connected by columns to obtain a two-dimensional feature diagram and further processed by continuous convolution operations. Through multiple convolution operations until the abstract features of the signal are extracted.
DSCNN can be divided into depthwise convolution and pointwise convolution, which are mainly used for feature extraction. A convolution kernel of depthwise convolution is responsible for a channel, and a channel is convolved by only a convolution kernel, and this process produces exactly the same number of feature map channels as the input number. Point convolution applies standard convolution operations to the intermediate features using multiple 1 × 1 convolution cores to obtain multiple outputs of the same height and width as the input data. Finally, the output of all the convolution kernels is spliced to get its final output. Depthwise separable convolution can significantly reduce the number of parameters and computation, thus further improving the identification efficiency. Figure 3 shows the one-dimensional convolution process for DSCNN.
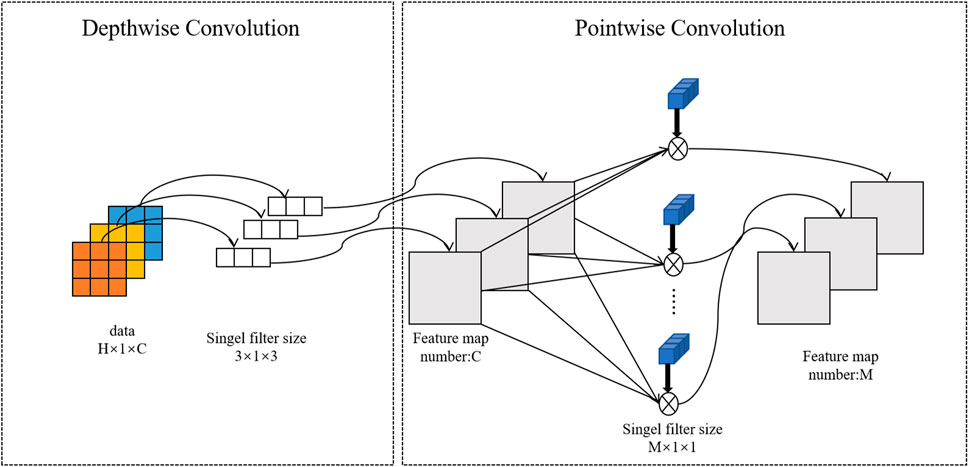
FIGURE 3. Convolution process of one-dimensional depthwise separable convolution.
Suppose the size of the input data is H × W × C, in which H, W, and C are the height, width, and number of channels, respectively. In our experiment, W = 1. Each channel is deeply convoluted with a convolution core of 3 × 3, the parameters of which are calculated as shown in Formula (2)
For point-by-point convolution, the output channel of the feature map generated by deep convolution is expanded by M convolution nuclei of 1 × 1 size. Formula (3) for calculating point-by-point convolution parameters is:
Therefore, the calculation of depth can be divided into convolution weights of depth convolution and point convolution, shown in Formula (4)
For standard convolution, the parameters are calculated as follows, Formula (5)
By comparing Formulas (4) and (5), it can be seen that the ratio of standard convolution to parameter calculations of deeply divisible convolution is (M × 9)/(M + 9) and the required parameters are reduced by the use of depthwise separable convolution compared to ordinary convolution (Hou et al., 2022).
The most important thing is that the depthwise separable convolution can change the channel and region of the previous common convolution operation. Convolution first considers the region and then the channel. The separation of channels and regions was achieved.
A recurrent Neural Network (RNN) is a neural network that can analyze data sequences relying on previous calculation result. This leads to the possibility of gradient disappearance and the explosion of RNN, limiting its availability in long input sequence analysis. Therefore, we used Bi-directional Long Short Term Memory Network (Bi-LSTM) in this paper, which is an improved circular neural network and can learn long term information. Figure 4 shows the structure of the Bi-LSTM network and LSTM cell structure.
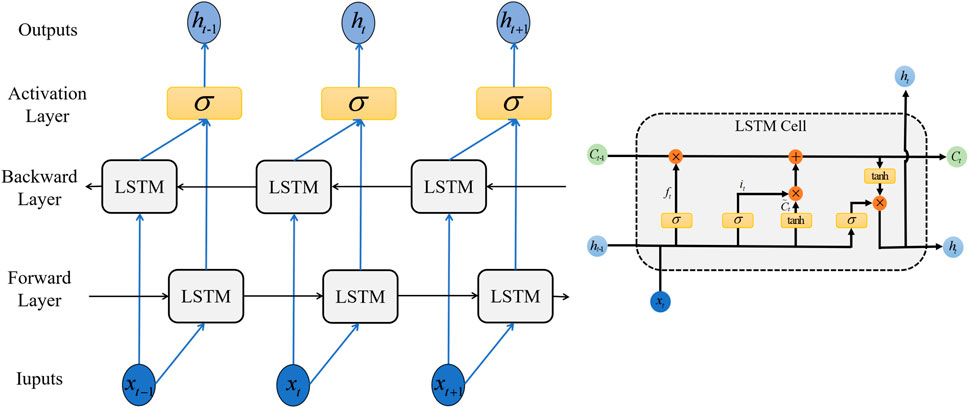
FIGURE 4. Bi-LSTM Structure and LSTM cell structure.
The special structure of LSTM network avoids the long term dependencies caused by complex repetitive chain modules. The parameters of LSTM are shown respectively in Formulas (6–11). The LSTM network consists of input gates, forgotten gates, and output gates that update and delete information into storage units. Cell state Ct and “gate” structures are key parameters of LSTM. In particular, the forgotten Gate decides whether or not to delete past information from the cell state. In these formulas, xt and ht-1 are determined by the output of hidden layer and sigmoid activation function σ, and W represents the corresponding weight matrix. b is network bias. ft, it and Ot are the state of the forgotten gate, the input gate and the output gate, respectively. Ct stands for the temporary state of input at the moment of t, tanh () is the unit output.
In a one-way long short term memory network, the network does not consider the follow-up information and drives the follow-up information by learning from the previous information. However, in many cases, prediction often requires sufficient contextual information to extract key features. Unlike LSTM, which consists of two LSTMs that send opposing messages in a looped diagram, the network connects not only the past but also the future, making the model more robust. Bi-LSTM processes two LSTMs, which consider the values before and after input and then combine the outputs. In this way, for each piece of data, LSTM can learn about the impact of previous data and the impact of subsequent data. Therefore, unlike normal LSTM, the Bi-LSTM calculation is performed by the values of two layers, which can learn long-term dependencies and effectively compensate for disappearing gradients (Zheng and Chen, 2021).
Attention mechanism is a resource allocation mechanism that mimics the attention of the human brain, which focuses on areas that need concentration at a particular moment, reducing or even ignoring attention to other areas for more detailed information. For a given target, by generating a weighted summation of the input to identify which features in the input are important for the target and which are not. The attention mechanism improves the accuracy of the model by paying sufficient attention to the key information and highlighting the impact of the key information by means of probability distribution. It can effectively improve the time series too long to lose information and replace the original method of randomly assigning weights with probabilities.
In this study, frequently used indicators in the classification were used to assess the validity and robustness of our framework from different perspectives including five indicators: accuracy, precision, recall, F1-score, and Matthews’ correlation coefficient. These evaluation indicators were defined as follows: TP, FN, TN, and FP represent true positive, false negative, true negative, and false positive, respectively.
In this experiment, to prevent a high correlation of EEG data and to make the results more reasonable and accurate, the experimental on SEED dataset was divided into 80% (12 individuals, training set) and 20% (3 individuals, testing set), and the experimental on DREAMER dataset was divided into18 individuals training set and 5 individuals testing set. The experiment conducted 150 rounds of training using the Adam optimizer, with the Batch size set at 1,024. To further verify the performance of the model, a 10-fold cross-validation experiment was performed which used mean values as the model evaluation criteria. While ensuring the same data distribution between the training and test sets, setting all pre-training data to the same random seed, randomly scrambling, and transferring to the network model. CDBA and other comparative network models were implemented and modeled using the same parameter settings on GeForce RTX 2080Ti.
To verify the classification performance of the proposed CDBA model in EEG emotion detection, the model was combined with Deep Neural Network (DNN), Convolution Neural Network (CNN), Gated Recurrent Unit (GRU), Recurrent Neural Network (RNN), Long Short Term Memory Network (LSTM) and Bi-directional Long Short Term Memory Network (Bi-LSTM). And their combined models CNN-RNN, CNN-LSTM, CNN-Bi-LSTM, DSCNN-RNN, DSCNN-LSTM and DSCNN-Bi-LSTM. 1D Convolutional Auto-Encode (CAE) is composed of two convolutional layers replacing the fully connected layers, and the symbols of the input are down-sampled to provide a potential representation of smaller dimensions. 1D InceptionV1 is compared. 1D InceptionV1 is the replacement of InceptionV1 two-dimensional convolution nuclei with one-dimensional convolution nuclei. In addition to comparing the model to other deep learning models, we compared it to four popular traditional machine learning types: Adaboost, Bayes, Decision Tree and XGBoost. Traditional machine learning methods have also been widely used in many computer fields. Traditional machine learning feature extraction relies on manual methods that are simple, efficient and explainable for particularly simple tasks. The advantage of deep learning is that features can be extracted automatically. The CDBA model validates test set results on a three, four and five category task, as shown in Figures 5–7. As can be seen from these figures, the CDBA model has fast convergence speed and good performance.
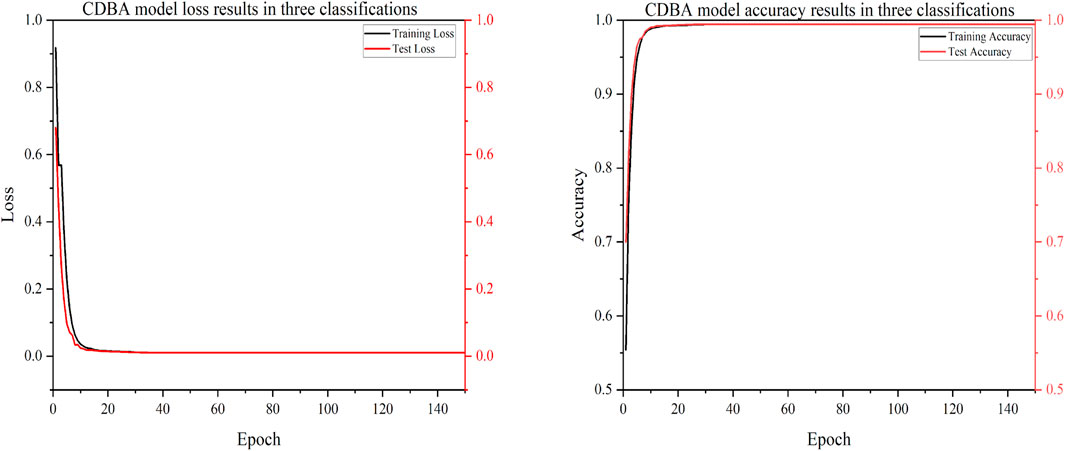
FIGURE 5. Test results of CDBA model based on three-classifications.
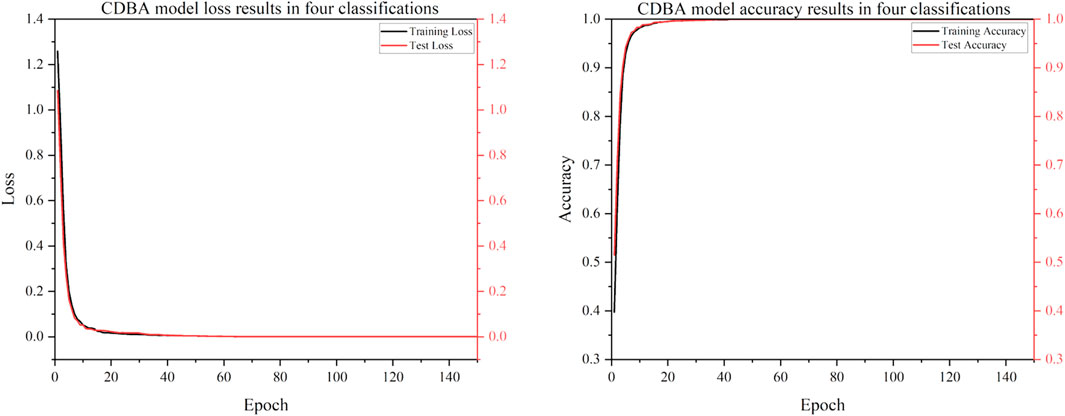
FIGURE 6. Test results of CDBA model based on four-classifications.
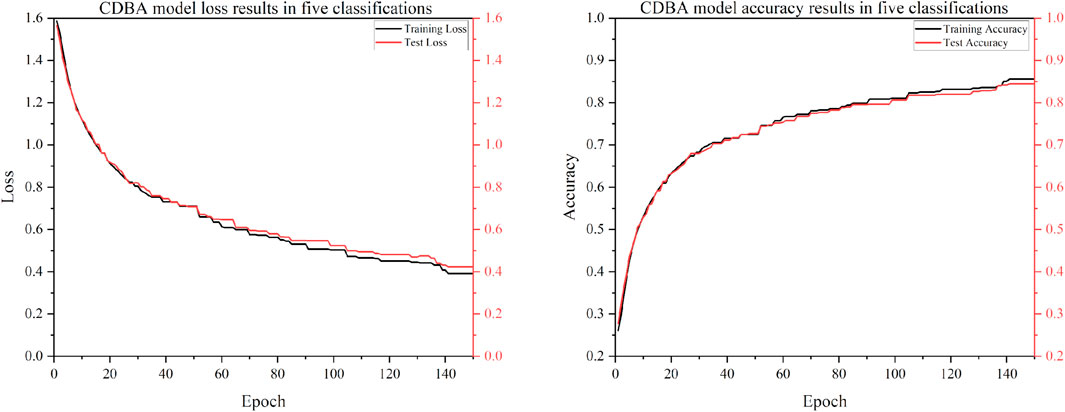
FIGURE 7. Test results of CDBA model based on five-classifications.
The results of the validation experiments for the triple-category and four-category test sets are shown in Tables 3, 4, with three classification labels representing positive, neutral and negative emotions, respectively. Four categories of labels represent feelings of happiness, sadness, fear and neutrality. Of all the comparison models, the CDBA presented here performed best in three categories, with 99.44% accuracy, 99.45% precision, 99.44% recall, 99.44% F1-score, and 99.17% MCC. The four categories were 99.99% accuracy, 99.98% precision, 99.98% recall, 99.98% F1-score and 99.98% MCC. The 1D CAE model was 95.92% accuracy, 95.92% precision, 95.92% recall, 95.91% F1-score, and 93.88% MCC for all three categories of tasks. The DSCNN-LSTM model had 88.87% accuracy, 88.87% precision, 88.87% recall, 88.87% F1-score and 85.17% MCC across the four categories. These two models are second only to CDBA models in the three and four classification tasks. Of the four traditional machine learning models, XGBoost and Decision Tree performed best in the three and four categories, respectively, while Bayes performed worst in the three and four categories.
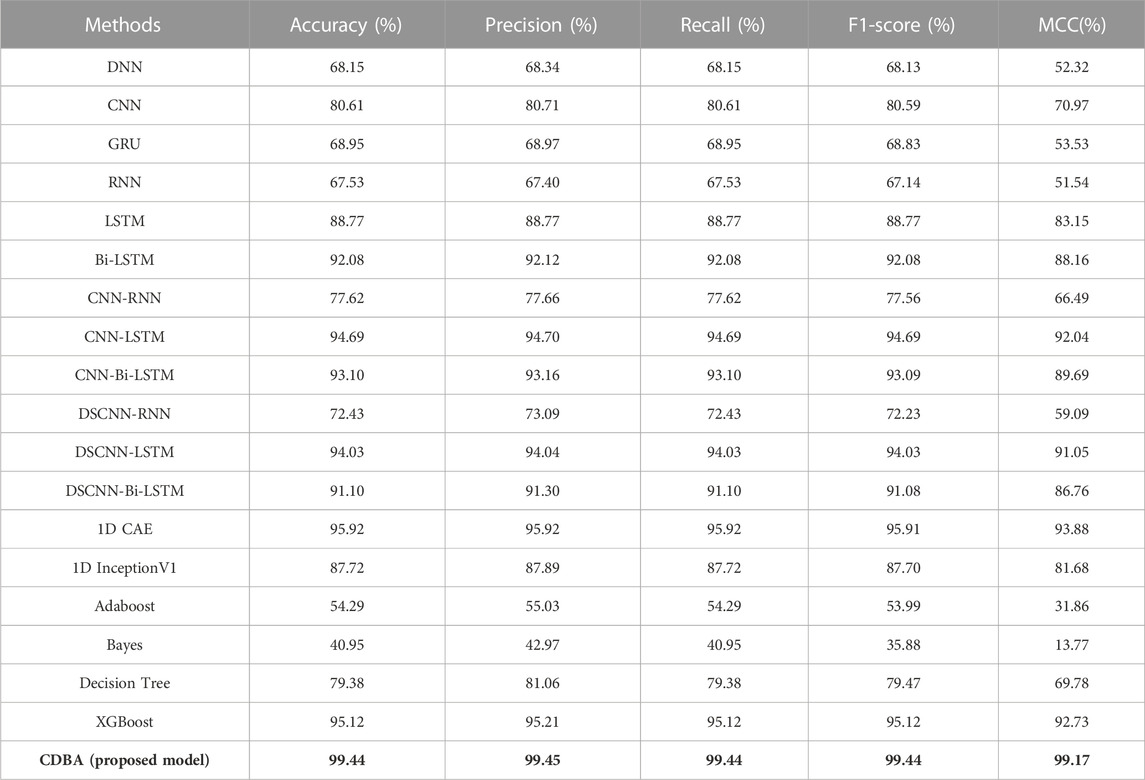
TABLE 3. The performance of CDBA model on three-category of task test sets.
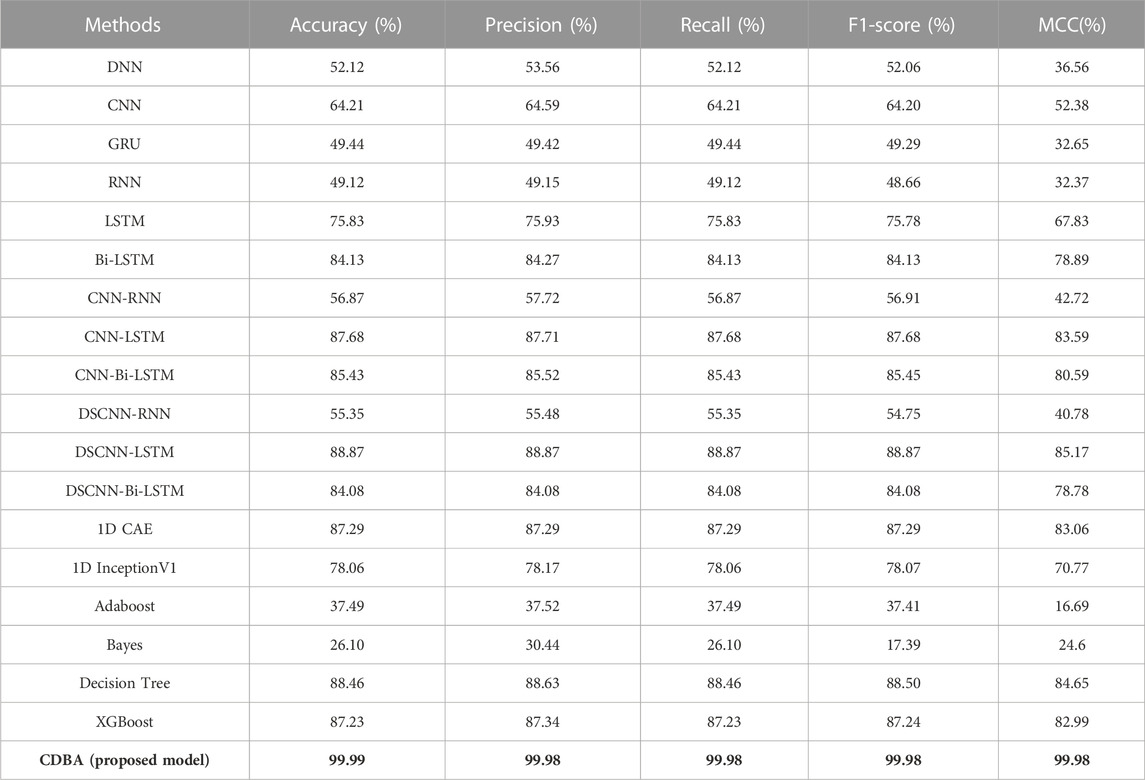
TABLE 4. The performance of CDBA model on four-category of task test sets.
The experimental results of five classifications on DREAMER dataset are shown in Table 5, and the CDBA model is still the best performance, with 84.49% accuracy, 84.81% precision, 84.07% recall, 84.38% F1-score, and 80.38% MCC for all five categories of tasks. Bayes method performs the worst. The results show that the CDBA model proposed in this paper is superior to other models. The three-block parallel structure can extract the characteristics of the input signal simultaneously, and can extract the temporal and spatial features from the original features, thus to improve the accuracy of the model.
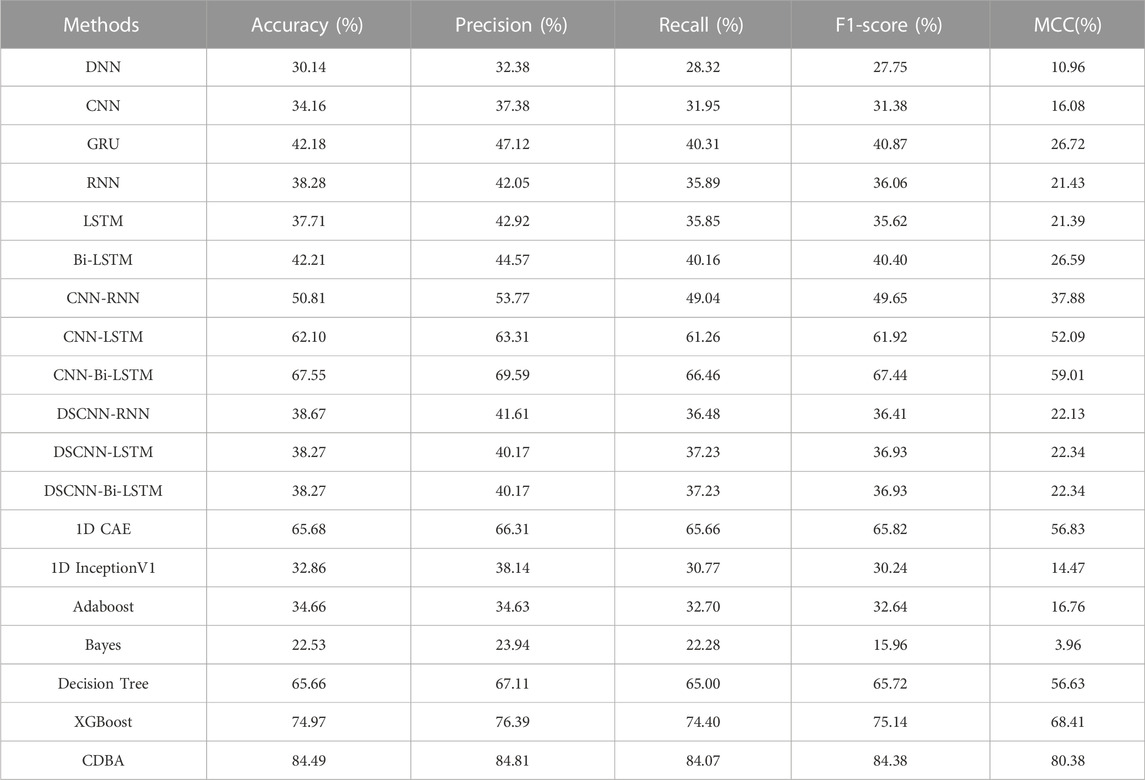
TABLE 5. The performance of CDBA model on five-category of task test sets.
We also validated the performance of each model with a 10-fold cross-validation. The 10 cross-validation sessions divided the dataset into 10 segments, with 9 as the training set, 1 as the test set, and the mean value of the 10 cross-validation sessions as an estimate of the algorithm’s accuracy. The results of the CDBA model with 10-fold cross-validation are respectively shown in Figures 8–10. Tables 6–8 show the results of the average 10-fold cross-validation. Of all the comparison models, the CDBA model presented here continues to perform best, with 99.40% accuracy, 99.41% precision, 99.40% recall, 99.40% F1-score, and 99.11% MCC across all three categories of tasks. The four categories of tasks were 99.51% accuracy, 99.51% precision, 99.51% recall, 99.51% F1-score, and 99.36% MCC. The five categories of tasks were 82.30% accuracy, 82.50% precision, 81.95% recall, 82.16% F1-score, and 77.63% MCC. The CNN-LSTM model was 93.28% accuracy, 93.29% precision, 93.27% recall, 93.28% F1-score, and 89.92% MCC for all three categories of tasks. The 1D CAE model was 83.20% accuracy, 83.26% precision, 83.20% recall, 83.20% F1-score, and 77.63% MCC for all four categories of tasks. The Decision Tree model was 77.81% accuracy, 77.60% precision, 77.55% recall, 77.58% F1-score, and 71.96% MCC for all five categories of tasks. These two models were second only to CDBA models in the three, four and five classification tasks. The worst-performing model was the Bayes model, with 41.79% accuracy, 42.23% precision, 41.79% recall, F1-score of 38.82%, and MCC of 13.75% in the three-category task. The four-category task had an accuracy rate of 25.77%, precision of 28.84%, recall rate of 25.77%, F1-score of 17.34%, and MCC score of 16.60%. The five-category task had an accuracy rate of 21.88%, precision of 21.19%, recall rate of 21.11%, F1-score of 13.76%, and MCC score of 2.24%. As can be seen from the results of single validation and 10-fold cross-validation, the model presented in this paper has the best performance of all comparison models.
FIGURE 8. The accuracy of CDBA model based on ten-fold cross-validation three-classification task.
FIGURE 9. The accuracy of CDBA model based on ten-fold cross-validation four-classification task.
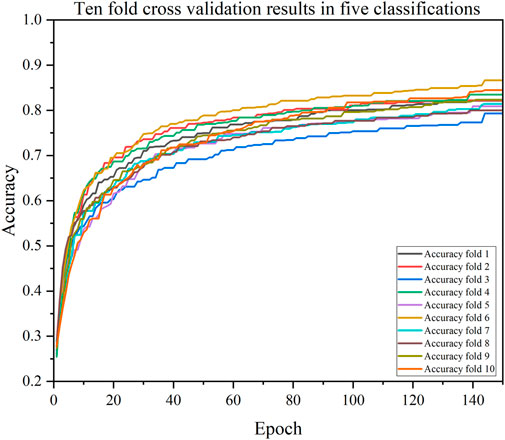
FIGURE 10. The accuracy of CDBA model based on ten-fold cross-validation five-classification task.
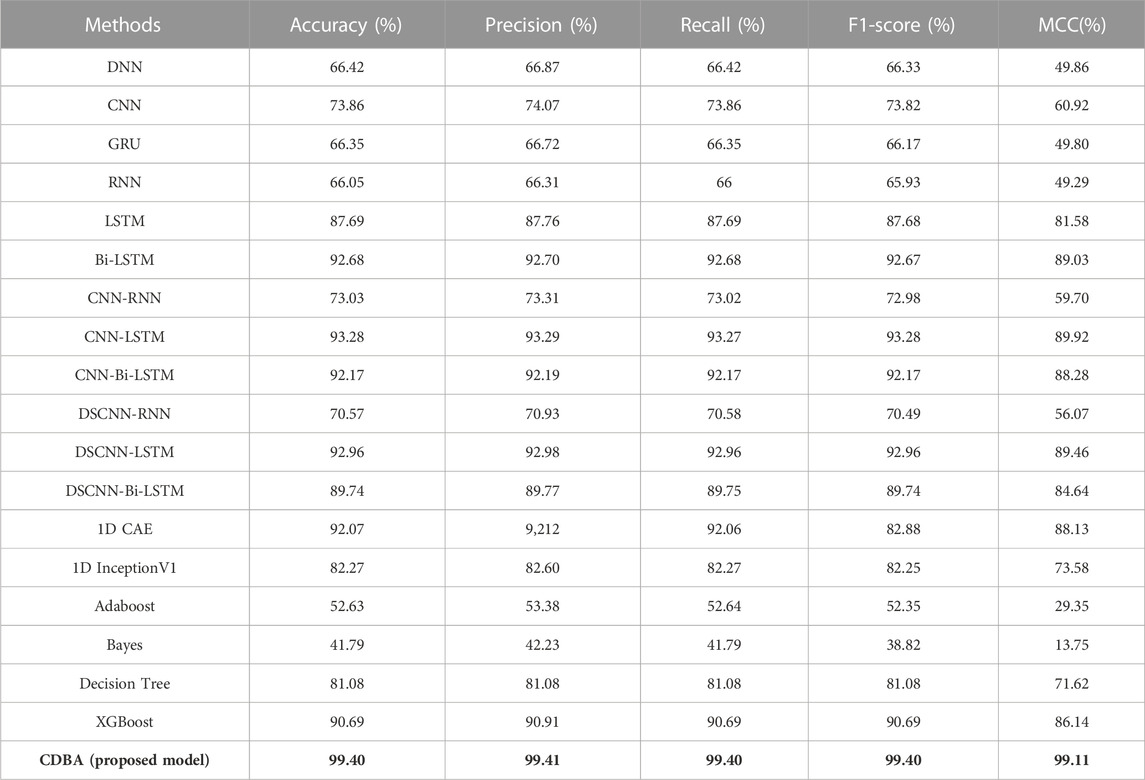
TABLE 6. The performance of CDBA model based on ten-fold cross-validation (three-classification task).
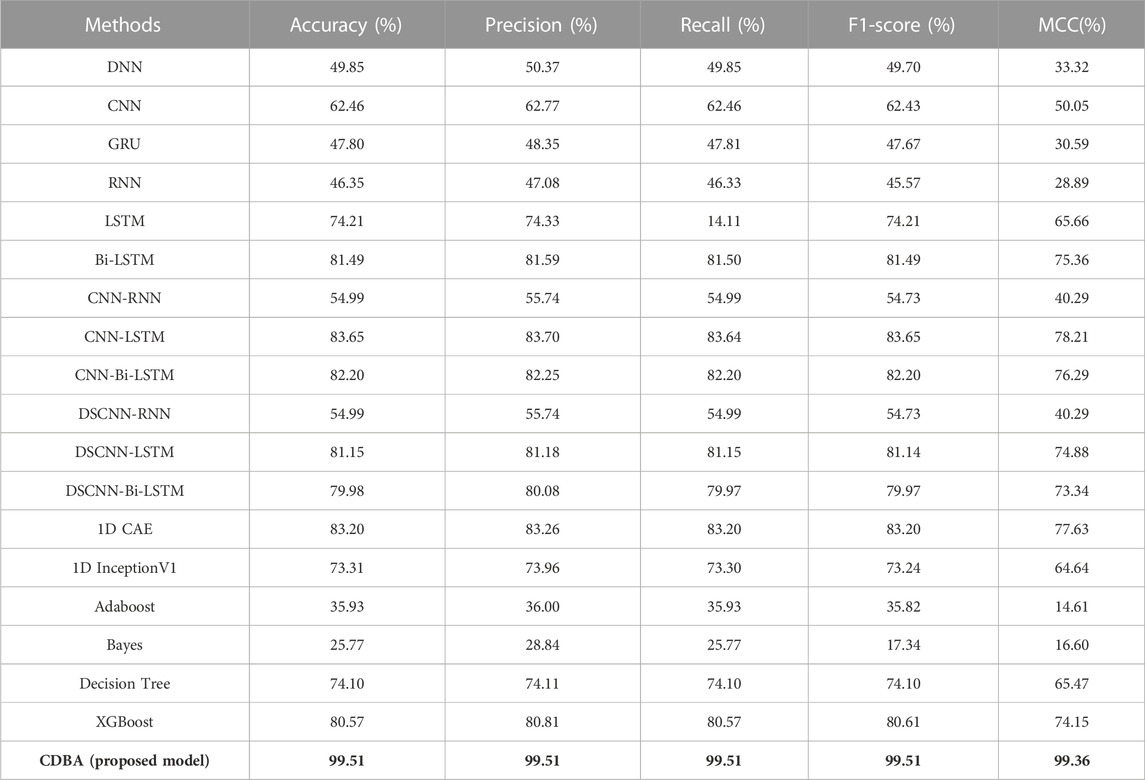
TABLE 7. The performance of CDBA model based on ten-fold cross-validation (four-classification task).
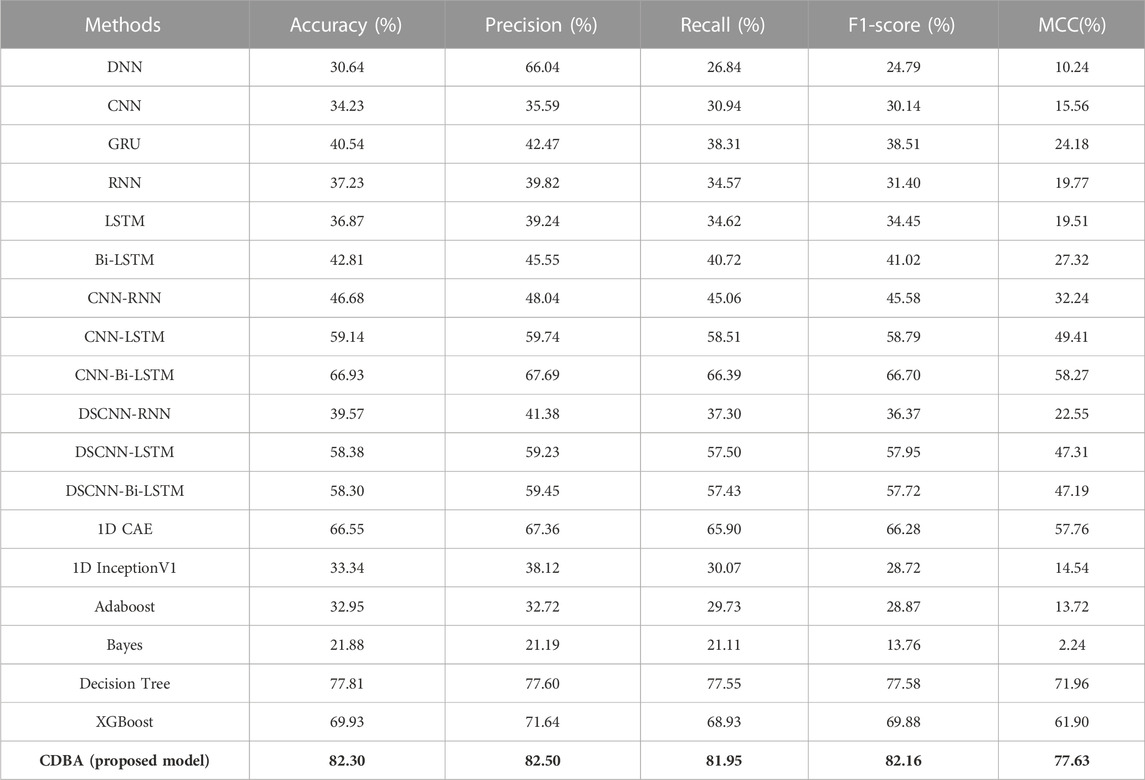
TABLE 8. The performance of CDBA model based on ten-fold cross-validation (five-classification task).
To validate the proposed CDBA model, we performed ablation experiments on SEED and DREAMER datasets. Feature extraction is a multi-channel structure, which is the most important module in the whole model, so only the feature extraction module is changed and the rest of the module remains the same. Results from the SEED dataset ablation experiments are shown in Table 9. It can be seen that the classification performance of the model on both datasets shows the same trend in channel selection. The Block3 model performs best in single-channel triage and quadrangle tasks based on ten-fold cross-validation, due to BI-LSTM’s expertise in extracting time-series signature data such as EEG. Block1 and Block2 perform best when combined with Block3 in dual channels, as it extracts spatiotemporal features simultaneously. Combining these two features, emotional recognition models perform better. Ablation experimental performance in the DREAMER dataset was similar to that in the SEED dataset as shown in Table 10, but the Block1 + Block2 model performed best in the two-channel model, suggesting that spatial features were more pronounced for the DREAMER dataset. However, our model is still the best of all ablation experimental comparison models, which further proves the validity of the proposed method.
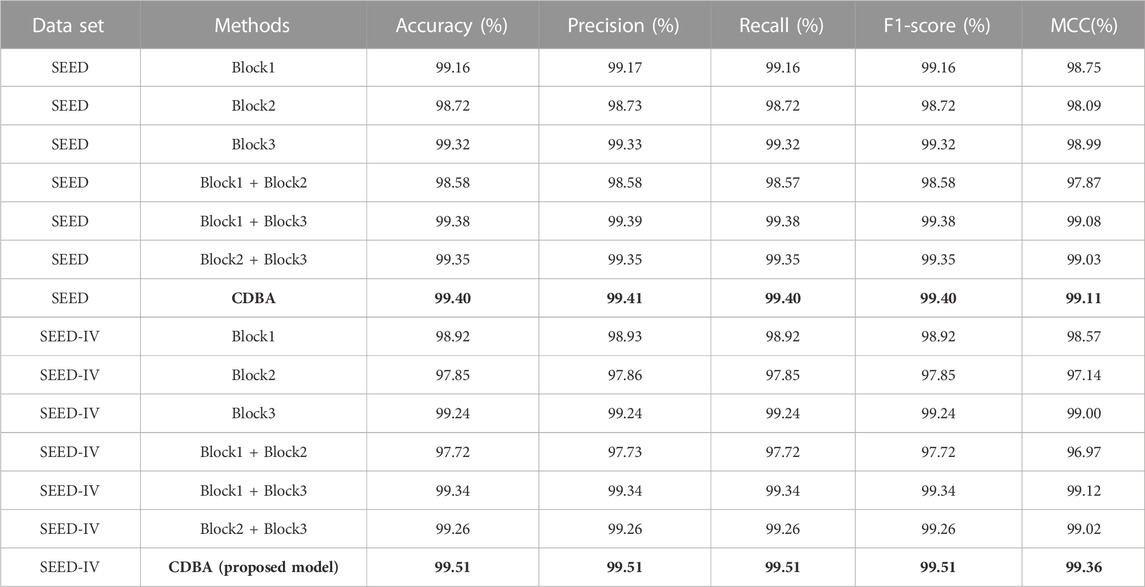
TABLE 9. Ablation experiments of CDBA model based on ten-fold cross-validation (three-classification task) and (four-classification task).
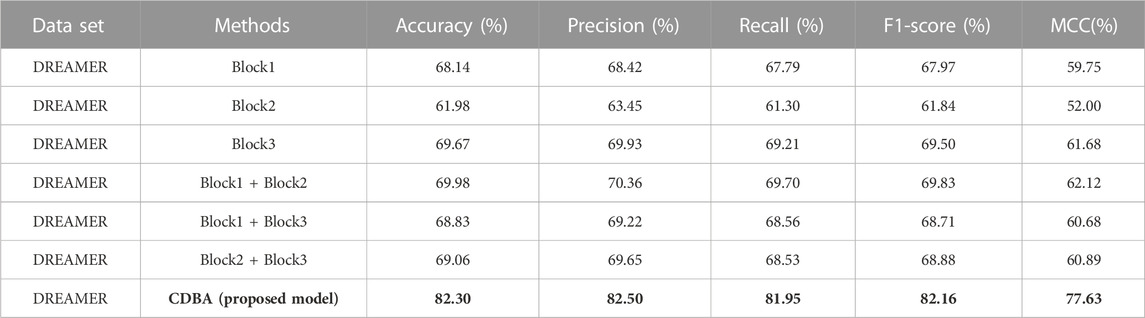
TABLE 10. Ablation experiments of CDBA model based on ten-fold cross-validation (five-classification task).
Automatic emotion recognition is an important application area of artificial intelligence. In this study, a multi-branching feature fusion model based on an attention mechanism is proposed for EEG emotional recognition network. The model framework includes spatial feature extraction based on CNN and DSCNN, temporal feature extraction based on Bi-LSTM, and feature weight allocation based on attention mechanisms, and is then classified in a fully connected layer. The method requires only normalized preprocessing of the raw data, which is then fed into the CDBA model to obtain the predicted results. For the three-class task, the accuracy of the single test set was 99.44%, for the four-class task, the accuracy of the single test set was 99.99%, and for the five-class task, the accuracy of the single test set was 84.49%. The average ten-fold cross-validation accuracy of the method was 99.40% for three classifications, 99.51% for four classification tasks and 82.30% for five classification tasks. The experimental results show that the proposed multi-channel feature fusion method has better accuracy than other single-channel model and traditional machine learning model. This is because the proposed CDBA model for EEG emotion classification can simultaneously extract low-level spatial features, high-level spatial features, and time-series features, and filter out the features with the most significant expression of emotion through attention mechanisms. And from the experimental results, it can be seen that the model combining spatial features and time features will get better results than the single model. Therefore, the CDBA model proposed in this paper is the most suitable for emotion prediction compared with other models. Physiological signals like EEG have the advantages of universality, spontaneity, and difficulty in camouflage (Zali-Vargahan et al., 2023), and human cognitive behavior and mental activity have a strong correlation with EEG signals. Therefore, physiological signals are a good choice to recognize emotions (Liu et al., 2020). The CDBA model proposed in this paper provides a new idea for decoding human emotions based on EEG, and can also be used for other EEG classification tasks, such as sleep phase classification and motor imagination. The model needs only simple preprocessing to obtain high accuracy, and can be easily transplanted into EEG equipment. In the future, we plan to identify and classify human emotions more accurately by combining EEG, ECG, and EMT signals.
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding authors.
Conceptualization, data curation, investigation, methodology, validation, visualization, writing—original draft, ZH and YM; data curation, project administration, resources, supervision YM and JS; supervision, writing—review and editing YM and JS; investigation, HS, SJ, BY, WL, JG, and TY. All authors contributed to the article and approved the submitted version.
This work is supported by the General Projects of Shaanxi Science and Technology Plan (No. 2023-JC-YB-504), the Shaanxi province innovation capacity support program (No. 2018KJXX-095), the Xijing University special talent research fund (No. XJ17T03), the Research Project of Affiliate Children’s Hospital of Xi’an Jiaotong University in 2020 (No.2020C13) and the General Projects of Shaanxi Science and Technology Plan (No. 2017SF-292).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Cannon, W. B. (1927). The james-lange theory of emotions: A critical examination and an alternative theory. Am. J. Psychol. 39 (1/4), 106–124. doi:10.2307/1415404
Chen, B., Liu, Y., Zhang, Z., Li, Y., Lu, G., et al. (2021). Deep active context estimation for automated COVID-19 diagnosis. ACM Trans. Multimedia Comput. Commun. Appl. (TOMM) 17 (3), 1–22. doi:10.1145/3457124
Dai, Y., Wang, X., Zhang, P., and Zhang, W. (2017). Wearable biosensor network enabled multimodal daily-life emotion recognition employing reputation-driven imbalanced fuzzy classification. J. Meas. 109, 408–424. doi:10.1016/j.measurement.2017.06.006
Dale, A. M., and Sereno, M. I. (1993). Improved localizadon of cortical activity by combining EEG and meg with mri cortical surface reconstruction: A linear approach. J. cognitive Neurosci. 5 (2), 162–176. doi:10.1162/jocn.1993.5.2.162
Duan, R. N., Zhu, J. Y., and Lu, B. L. (2013). “Differential entropy feature for EEG-based emotion classification[C],” in 2013 6th International IEEE/EMBS Conference on Neural Engineering (NER), San-Diego, California, 6-8 November 2013 (IEEE), 81–84.
Gabert-Quillen, C. A., Bartolini, E. E., Abravanel, B. T., and Sanislow, C. A. (2015). Ratings for emotion film clips. Behav. Res. methods 47, 773–787. doi:10.3758/s13428-014-0500-0
Hou, L., Liu, L., and Mao, G. (2022). Machine Fault diagnosis method using lightweight 1-D separable convolution and WSNs with sensor computing. IEEE Trans. Instrum. Meas. 71, 1–8. doi:10.1109/tim.2022.3206764
Jaiswal, A. K., and Banka, H. (2017). Local pattern transformation based feature extraction techniques for classification of epileptic EEG signals. Biomed. Signal Process. Control 34, 81–92. doi:10.1016/j.bspc.2017.01.005
Katsigiannis, S., and Ramzan, N. (2017). Dreamer: A database for emotion recognition through EEG and ECG signals from wireless low-cost off-the-shelf devices. IEEE J. Biomed. health Inf. 22 (1), 98–107. doi:10.1109/JBHI.2017.2688239
Knyazev, G. G., Slobodskoj-Plusnin, J. Y., and Bocharov, A. V. (2010). Gender differences in implicit and explicit processing of emotional facial expressions as revealed by event-related theta synchronization. Emotion 10 (5), 678–687. doi:10.1037/a0019175
Liu, Y., Ding, Y., Li, C., Cheng, J., Song, R., Wan, F., et al. (2020). Multi-channel EEG-based emotion recognition via a multi-level features guided capsule network. Comput. Biol. Med. 123, 103927. doi:10.1016/j.compbiomed.2020.103927
Liu, Y. J., Yu, M., Zhao, G., Song, J., Ge, Y., and Shi, Y. (2017). Real-time movie-induced discrete emotion recognition from EEG signals. IEEE Trans. Affect. Comput. 9 (4), 550–562. doi:10.1109/taffc.2017.2660485
Lu, Y., Wang, M., Wu, W., Han, Y., Zhang, Q., and Chen, S. (2020). Dynamic entropy-based pattern learning to identify emotions from EEG signals across individuals. Measurement 150, 107003. doi:10.1016/j.measurement.2019.107003
Mathersul, D., Williams, L. M., Hopkinson, P. J., and Kemp, A. H. (2008). Investigating models of affect: Relationships among EEG alpha asymmetry, depression, and anxiety. Emotion 8 (4), 560–572. doi:10.1037/a0012811
Mehmood, R. M., Du, R., and Lee, H. J. (2017). Optimal feature selection and deep learning ensembles method for emotion recognition from human brain EEG sensors. IEEE Access 5, 14797–14806. doi:10.1109/access.2017.2724555
Nakisa, B., Rastgoo, M. N., Tjondronegoro, D., and Chandran, V. (2018). Evolutionary computation algorithms for feature selection of EEG-based emotion recognition using mobile sensors. Expert Syst. Appl. 93, 143–155. doi:10.1016/j.eswa.2017.09.062
Petrantonakis, P. C., and Hadjileontiadis, L. J. (2011). A novel emotion elicitation index using frontal brain asymmetry for enhanced EEG-based emotion recognition. IEEE Trans. Inf. Technol. Biomed. 15 (5), 737–746. doi:10.1109/TITB.2011.2157933
Sammler, D., Grigutsch, M., Fritz, T., and Koelsch, S. (2007). Music and emotion: Electrophysiological correlates of the processing of pleasant and unpleasant music. Psychophysiology 44 (2), 293–304. doi:10.1111/j.1469-8986.2007.00497.x
Shu, L., Xie, J., Yang, M., Li, Z., Li, Z., Liao, D., et al. (2018). A review of emotion recognition using physiological signals. Sensors 18 (7), 2074. doi:10.3390/s18072074
Zali-Vargahan, B., Charmin, A., Kalbkhani, H., and Barghandan, S. (2023). Deep time-frequency features and semi-supervised dimension reduction for subject-independent emotion recognition from multi-channel EEG signals. Biomed. Signal Process. Control 85, 104806. doi:10.1016/j.bspc.2023.104806
Zhang, T., Zheng, W., Cui, Z., Zong, Y., and Li, Y. (2018). Spatial-temporal recurrent neural network for emotion recognition. IEEE Trans. Cybern. 49 (3), 839–847. doi:10.1109/TCYB.2017.2788081
Zheng, W. L., Liu, W., Lu, Y., Lu, B. L., and Cichocki, A. (2018). EmotionMeter: A multimodal framework for recognizing human emotions. IEEE Trans. Cybern. 49 (3), 1110–1122. doi:10.1109/TCYB.2018.2797176
Zheng, W. L., and Lu, B. L. (2015). Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks. IEEE Trans. Aut. Ment. Dev. 7 (3), 162–175. doi:10.1109/tamd.2015.2431497
Keywords: convolution neural network (CNN), depthwise separable convolution (DSC), electroencephalogram (EEG), bi-directional long short term memory (Bi-LSTM), attention mechanism, emotion recognition
Citation: Huang Z, Ma Y, Su J, Shi H, Jia S, Yuan B, Li W, Geng J and Yang T (2023) CDBA: a novel multi-branch feature fusion model for EEG-based emotion recognition. Front. Physiol. 14:1200656. doi: 10.3389/fphys.2023.1200656
Received: 05 April 2023; Accepted: 10 July 2023;
Published: 20 July 2023.
Edited by:
Lisheng Xu, Northeastern University, ChinaReviewed by:
Liu Yi, National University of Defense Technology, ChinaCopyright © 2023 Huang, Ma, Su, Shi, Jia, Yuan, Li, Geng and Yang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yahong Ma, bWF5YWhvbmdAeGlqaW5nLmVkdS5jbg==; Jianyun Su, ZG9jdG9yc3UxMjE4MTdAMTYzLmNvbQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.