
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Physiol. , 12 January 2021
Sec. Fractal Physiology
Volume 11 - 2020 | https://doi.org/10.3389/fphys.2020.612598
This article is part of the Research Topic The New Frontier of Network Physiology: From Temporal Dynamics to the Synchronization and Principles of Integration in Networks of Physiological Systems View all 65 articles
 Antonio Barajas-Martínez1,2
Antonio Barajas-Martínez1,2 Elizabeth Ibarra-Coronado2,3
Elizabeth Ibarra-Coronado2,3 Martha Patricia Sierra-Vargas4,5
Martha Patricia Sierra-Vargas4,5 Ivette Cruz-Bautista6
Ivette Cruz-Bautista6 Paloma Almeda-Valdes6
Paloma Almeda-Valdes6 Carlos A. Aguilar-Salinas2,6,7
Carlos A. Aguilar-Salinas2,6,7 Ruben Fossion2,3
Ruben Fossion2,3 Christopher R. Stephens2,3Claudia Vargas-Domínguez8Octavio Gamaliel Atzatzi-Aguilar8,9Yazmín Debray-García8Rogelio García-Torrentera10Karen Bobadilla8María Augusta Naranjo Meneses6Dulce Abril Mena Orozco6
Christopher R. Stephens2,3Claudia Vargas-Domínguez8Octavio Gamaliel Atzatzi-Aguilar8,9Yazmín Debray-García8Rogelio García-Torrentera10Karen Bobadilla8María Augusta Naranjo Meneses6Dulce Abril Mena Orozco6 César Ernesto Lam-Chung6
César Ernesto Lam-Chung6 Vania Martínez Garcés11
Vania Martínez Garcés11 Octavio A. Lecona1,2Arlex O. Marín-García2
Octavio A. Lecona1,2Arlex O. Marín-García2 Alejandro Frank2,3,12
Alejandro Frank2,3,12 Ana Leonor Rivera2,3*
Ana Leonor Rivera2,3*Currently, research in physiology focuses on molecular mechanisms underlying the functioning of living organisms. Reductionist strategies are used to decompose systems into their components and to measure changes of physiological variables between experimental conditions. However, how these isolated physiological variables translate into the emergence -and collapse- of biological functions of the organism as a whole is often a less tractable question. To generate a useful representation of physiology as a system, known and unknown interactions between heterogeneous physiological components must be taken into account. In this work we use a Complex Inference Networks approach to build physiological networks from biomarkers. We employ two unrelated databases to generate Spearman correlation matrices of 81 and 54 physiological variables, respectively, including endocrine, mechanic, biochemical, anthropometric, physiological, and cellular variables. From these correlation matrices we generated physiological networks by selecting a p-value threshold indicating statistically significant links. We compared the networks from both samples to show which features are robust and representative for physiology in health. We found that although network topology is sensitive to the p-value threshold, an optimal value may be defined by combining criteria of stability of topological features and network connectedness. Unsupervised community detection algorithms allowed to obtain functional clusters that correlate well with current medical knowledge. Finally, we describe the topology of the physiological networks, which lie between random and ordered structural features, and may reflect system robustness and adaptability. Modularity of physiological networks allows to explore functional clusters that are consistent even when considering different physiological variables. Altogether Complex Inference Networks from biomarkers provide an efficient implementation of a systems biology approach that is visually understandable and robust. We hypothesize that physiological networks allow to translate concepts such as homeostasis into quantifiable properties of biological systems useful for determination and quantification of health and disease.
Communication and interaction between physiological systems and organs are the essence of physiology (Ganong, 1969; Bashan et al., 2012; Bartsch et al., 2015; Ivanov et al., 2016). This integration of organisms as a whole results in an inherent complexity of physiological phenomena (Burggren et al., 2005) that has implications for the behavior of physiological systems in health and disease. For example, it has become clear that the simultaneous occurrence of diseases in the same individual (comorbidity) occurs more often than would be expected from the individual prevalence of each disease by chance alone (Alberti et al., 2009). Additionally, when a comorbid state is present, the clinical expression of each individual disease is usually more difficult to treat and associated with worsened outcomes (Wu et al., 2019). Although these observations are common in medical practice, relatively few health conditions are regarded with an extensive perspective. Some of the most common examples are the metabolic syndrome (Alberti et al., 2009), and the asthma-obesity-diabetes triad (Wu et al., 2019). Mainstream methodology in disease diagnosis and disease treatment employs a reductionist approach to physiology, where at most two variables are studied simultaneously. This presents an immediate challenge for the study of complex comorbidities where several physiological systems are involved. An emerging paradigm for this problem is the systems biology perspective, where the organism is visualized as an open system composed of interacting components (Von Bertalanffy, 1968). The integration of these body components generates physiological states that can be studied in health and disease through complexity approaches (Ivanov et al., 2016). A way of representing and conceptualizing systems is through networks. This approach facilitates the visualization and analysis of potentially large numbers of interactions (Pavlopoulos et al., 2011). Networks have been applied in very diverse fields of science, including economy, sociology, ecology, and they have been generalized recently for the study of biomedical sciences (Albert and Barabási, 2002; Boccaletti et al., 2006). Currently, most approaches to network analysis in biomedical science are restricted to homogeneous datasets, i.e., where all the variables and interactions are of the same kind, e.g., differential gene expression networks. However, physiology is not constructed from interactions between components that are all of the same kind. Some novel approaches to address physiological networks have been developed where physiological integration of different systems within the organism is demonstrated through time-series analysis (Ivanov and Bartsch, 2014). Multiple time scales may be involved in different physiological interactions and their measurements (Bartsch et al., 2014). For instance, some physiological interactions occur in seconds and are measured with great accuracy in fractions of seconds. Other physiological interactions occur in cycles of days or months and may only be quantified as isolated point measurements and not continuously as time series (Barajas-Martínez et al., 2020). Moreover, while networks are usually constructed through links that are associated with known, experimentally verified interactions, such as the Kyoto Encyclopedia of Genes and Genomes, KEGG (Ogata et al., 1999), it is likely that certain important interactions in biological systems remain unknown. The methodology of Complex Inference Networks allows the construction of networks where the links are inferred, instead of being directly observed. Correlation networks are a common and widespread method to make such inferences (Batushansky et al., 2016) that may be later verified through conventional mechanistic studies. A network approach provides also a new level of study where global properties of the system, that are not apparent at the local level, emerge from the interactions of the multiple components. These interactions are revealed by changes in topology and connectivity (Ivanov and Bartsch, 2014).
How to approach multivariate datasets to generate insight in physiology is an area under development. Principal Component Analysis (PCA) and network analysis are two current data analysis techniques that have been transferred to biology from other areas of science (Liu et al., 2015; Asada et al., 2016). The coupling between physiological variables can be explored through the change in the covariance observed in different samples (Hofer and Sliwinski, 2001). For correlation networks, an association would be found between those variables that interact directly or indirectly within the physiological network. Here, the physiological network is modeled as a continuous association of pairs of variables. For this correlation model, a correlation matrix was constructed for the chosen physiological parameters. These variables are often of different nature, ions in solution, mechanical forces and hormones. Their interactions are also of different kinds, direct and indirect, through very different physiological mechanisms. In summary, physiological variables are correlated along all their biologically plausible spectrum. In this scenario, the associations between parameters are present even for healthy values and represent a continuum. From the systems biology perspective, the network structure is a direct result of the coordination, or lack thereof, of components that are linked by homeostatic feedback (Goldstein, 2019). For example, in a simple negative feedback a change in a regulated variable is detected by a comparator in the organism that through effector variables counteracts the perturbation (Fossion et al., 2018). These variables, along with buffer variables, result in the covariance of multiple variables in biological systems.
The aim of this work is to generate a mainstream workflow for developing physiological networks from heterogeneous datasets including endocrine, mechanic, biochemical, anthropometric, vital signs, and cellular elements that are readily accessible and already being employed without a holistic perspective. In this contribution we have constructed a physiological network for control subjects (young adults, asymptomatic, clinically diagnosed as healthy) from physiological, biochemical, and anthropometric data.
The study was developed according to Good Clinical Practice guidelines and the Declaration of Helsinki. All procedures involving participants were in accordance with these ethical standards and followed the procedures required by the corresponding ethics committees. All the participants signed a written informed consent form with full knowledge of the interventions involved in this protocol. All databases employed here were constructed with authorization of the Ethics Committees as detailed below.
In the present contribution, 2 different datasets of multivariate and heterogeneous physiological data were analyzed (C22_14 and Project_42) allowing to compare the physiological networks obtained from different datasets and to confirm the robustness of the approach and the consistency of the results obtained. The C22_14 database comprised 81 variables of which 46 were unique; the Project_42 database recorded 55 variables of which 19 were unique; 36 variables were in common between both datasets (see Table 1). The physiological network corresponding to the 36 variables in common was also constructed to allow comparison between both datasets.

Table 1. Description of physiological variables.
This study was carried out in accordance with current regulation of the Mexican Official Normativity, NOM-012-SSA3-2012. The Ethics Committee of the “Instituto Nacional de Enfermedades Respiratorias” (INER) approved the procedures and protocols for this study as project C22_14, all the participants provided a written informed consent.
134 participants from Mexico City and surroundings were evaluated, corresponding to 43 men and 91 women with an age ranging from 25 to 67 years old (median age = 46 years old). Overweight and obesity were highly prevalent, being present in 42% and 39% of the participants, respectively. 81 independent variables were measured through anthropometry, bioimpedance, spirometry, complete blood count, blood chemistry and ELISA (see list of variables in Table 1). Several derived variables of common use in medical practice were calculated for the database (see list of derived variables in Table 2).
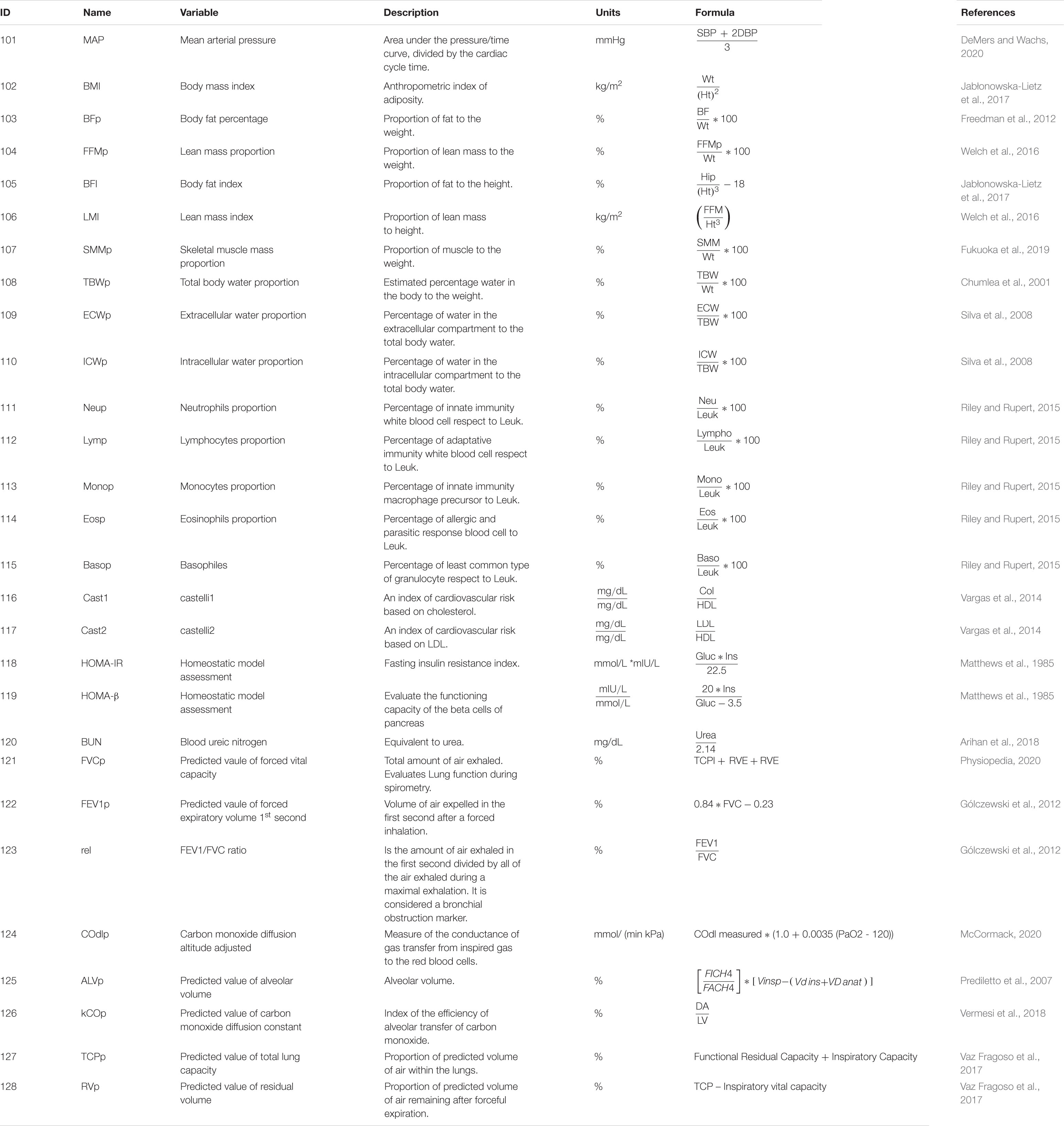
Table 2. Description of derived variables.
Approximately 10 mL of venous blood was taken from each participant in fasting conditions and stored in darkness throughout the biospecimen handling process. EDTA or heparin was used as an anticoagulant according to the determinations to be made. The samples were centrifuged, plasma was obtained and routine clinical analysis was performed to know the health state of individual subjects. The set of bioclinical tests included hematologic analyses, biochemistry, C-reactive protein, which were carried out in the local clinical laboratory in compliance with current quality standards. Additionally, analyses by ELISA were performed. Spirometry was carried out in the Clínica de Ayuda para dejar de Fumar at the INER.
This study was carried out in accordance with current regulation contained in the Mexican Official Normativity, NOM-012-SSA3-2012. The Ethics Committee of the Facultad de Medicina of the Universidad Nacional Autónoma de México (UNAM) approved the procedures and protocols for this study as project FM/DI/023/2014. All the participants provided a written informed consent.
This sample was based on first and second year students at the School of Medicine at the UNAM, all living in Mexico City and its surroundings. 69% of the sample were women, with an age ranging from 18 to 28 years old (mean age of 20 ± 2 years-old). 54 independent variables were measured through anthropometry, bioimpedance, hematic biometry, blood chemistry (see list of variables in Table 1). Derived variables used commonly to characterize meaningful relations between variables are present in the database (see list of derived variables in Table 2).
After a medical check-up, all samples and anthropometric measurements were realized in fasting conditions from 7:00 to 9:00 h. Anthropometric measurements were performed employing the corresponding WHO guidelines. All participants were advised to abstain from alcohol and other substances 24 h prior to the measurements. All blood samples were stored at 4°C and processed the same day. A full description of the methods employed for this dataset is available in Barajas-Martínez et al. (2020).
Databases were constructed manually in excel and validated at random as quality control.
All the physiological variables obeyed asymmetric and leptokurtic distributions, such that the median value (Me) was considered to be the best measure of the distribution center, and the range (difference between maximum (Max) and (Min)) to be the best representation of the dispersion. For each variable from the data we obtained the normalized value xi applying the following normalization to the original data Vi :
Outliers and implausible data were screened using the ROUT method where Q = 1%. Given the leptokurtic distributions, both databases presented various outlying values. However, most of these outliers were within expected ranges of biological variability. In the C22_14 database no outliers were discarded. In the Project_42 database, 3 values each were discarded for waist circumference, systolic blood pressure, and glucose, 2 values for hip and 1 value each for creatinine, arm and wrist temperature.
All physiological variables were tested for normality using the Shapiro-Wilk test and they were screened as well for extreme values. Since the data sets were not normally distributed and presented outlying values within ranges of biological variability, the Spearman rank correlation ρ (Batushansky et al., 2016) was selected as a measure of correlation (Figures 1, 2). The Spearman rank correlation is a nonparametric measure of the statistical dependence between the rank values of the variables considering monotonic relationship (not necessarily linear) and is not affected by the normalization. For each pair of physiological variables, X and Y, rank (rkX, rkY, respectively) and standard deviation (σrk_X, σrk_Y) were evaluated, and the Spearman rank correlation was calculated as the ratio between covariance (coν) and deviations:
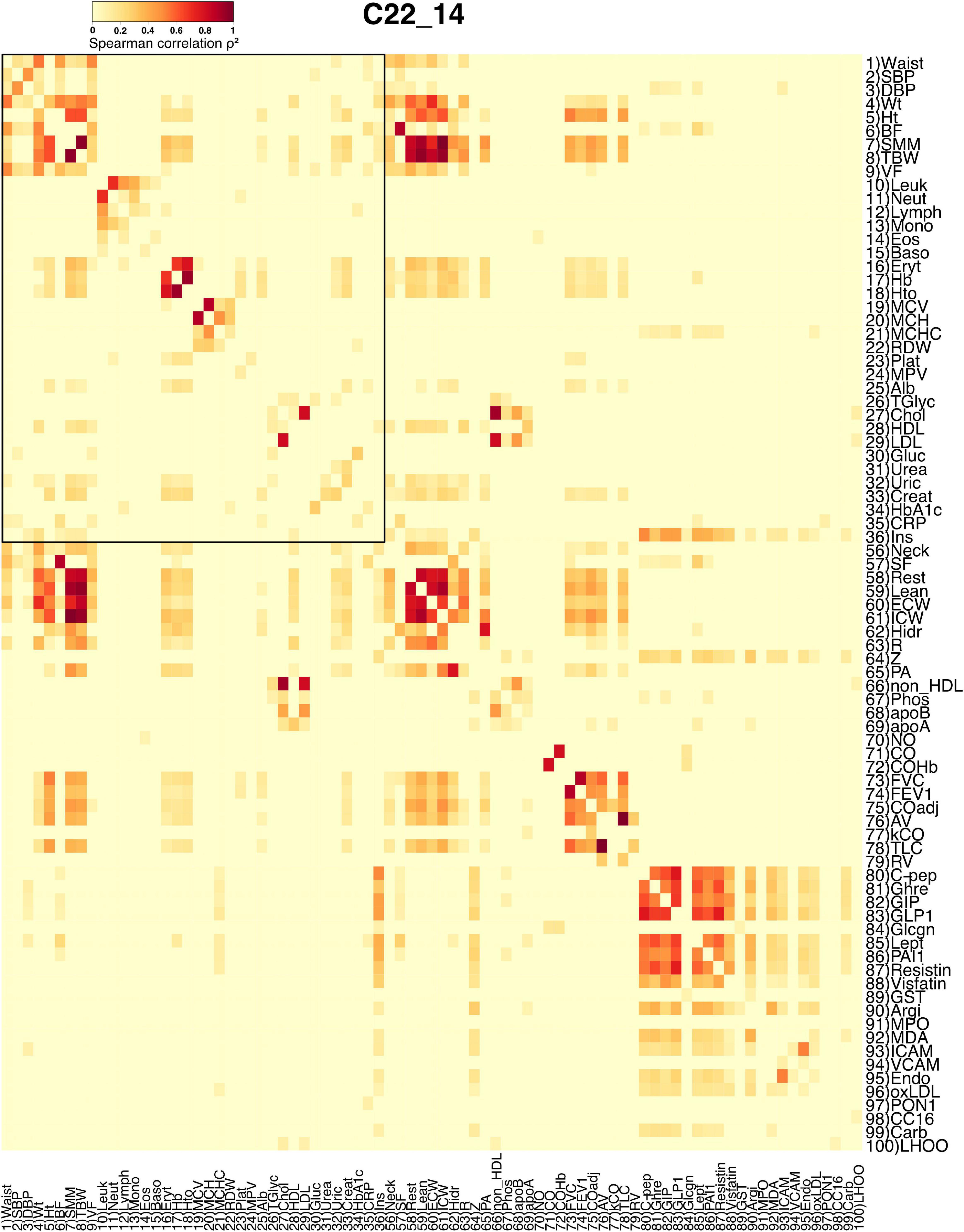
Figure 1. Adjacency matrix for the C22_14 database. Spearman correlation values were squared to obtain only positive values. The strength of each link is shown in the heatmap as a heat gradient. Numerical ID and short name are presented next to rows and below columns. The shared physiological variables between both databases are encased within the black rectangle in the upper left side of the heatmap.
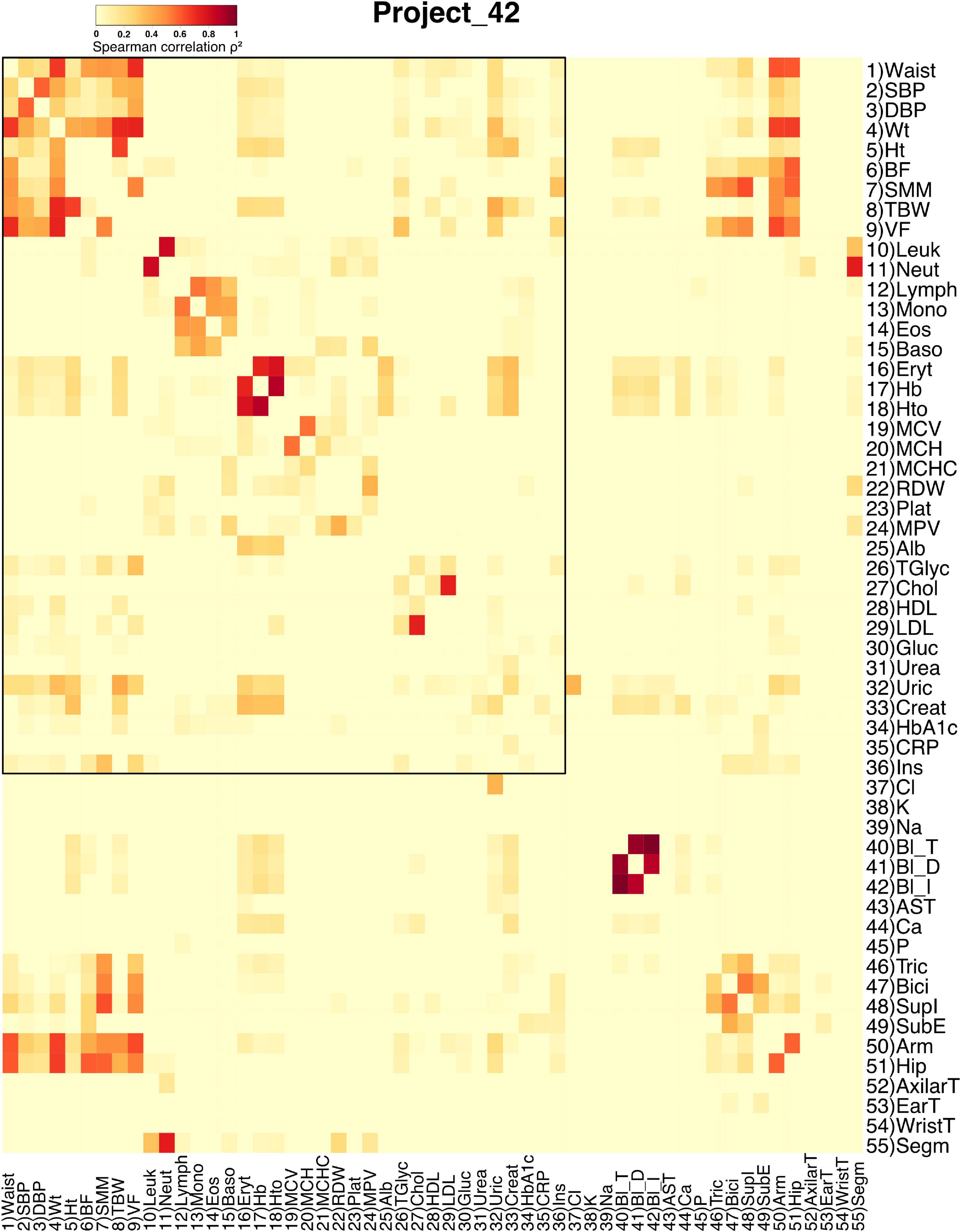
Figure 2. Adjacency matrix for the Project_42 database. Spearman correlation values were squared to obtain only positive values. The strength of each link is shown in the heatmap as a heat gradient. Numerical ID and short name are presented next to rows and below columns. The shared physiological variables between both databases are encased within the black rectangle in the upper left side of the heatmap.
To test if the Spearman rank correlation is significantly different from zero, a Student’s t-distribution with (n-2) degrees of freedom was employed. Significant correlations were established below a threshold value of p < 0.001, indicating that the relation does not support the null hypothesis that the independent and dependent variables are unrelated. The Spearman rank correlation coefficient ρ was squared in order to obtain only positive values (Figure 3). An adjacency matrix was constructed with matrix elements corresponding the ρ coefficients between each pair of physiological components such that the resulting network was weighted (Figure 3). Data-set normality testing, linear regression and chi-squared tests for trends were realized with Prism 8.1.2(277), GraphPad Software, La Jolla, CA, United States, www.graphpad.com. For the network construction RStudio, an R language programming suite and igraph package were employed (Csárdi et al., 2016; R Core Team, 2020; RStudio Team, 2020). A glossary of terms used in this paper is given in Table 3.
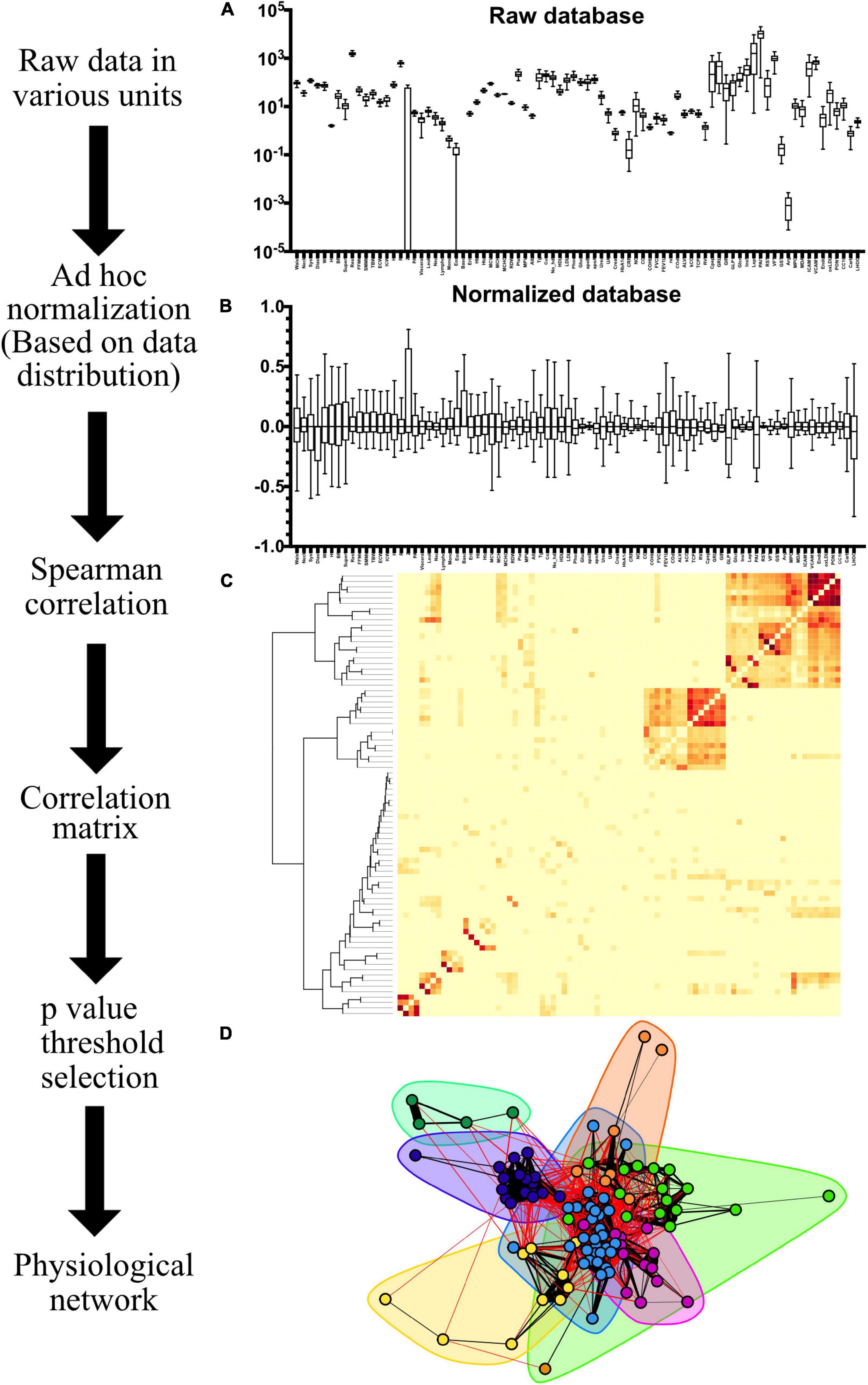
Figure 3. Network construction workflow. The range and distribution of values recorded in the raw database as Tukey box-plots are shown in (A). Variables are normalized, resulting in the box-plots shown in (B). The resulting Spearman ρ correlation matrix, with squared values to represent correlation between variables regardless of sign, is shown as an adjacency matrix heatmap in (C) with a hierarchical dendrogram on the left. After choosing a p-value threshold to discard insignificant links, a network can be constructed as illustrated in (D). Network structures can be enriched with several features, e.g., clusters (shadowed areas) and strength of the spearman correlation (width of the links).
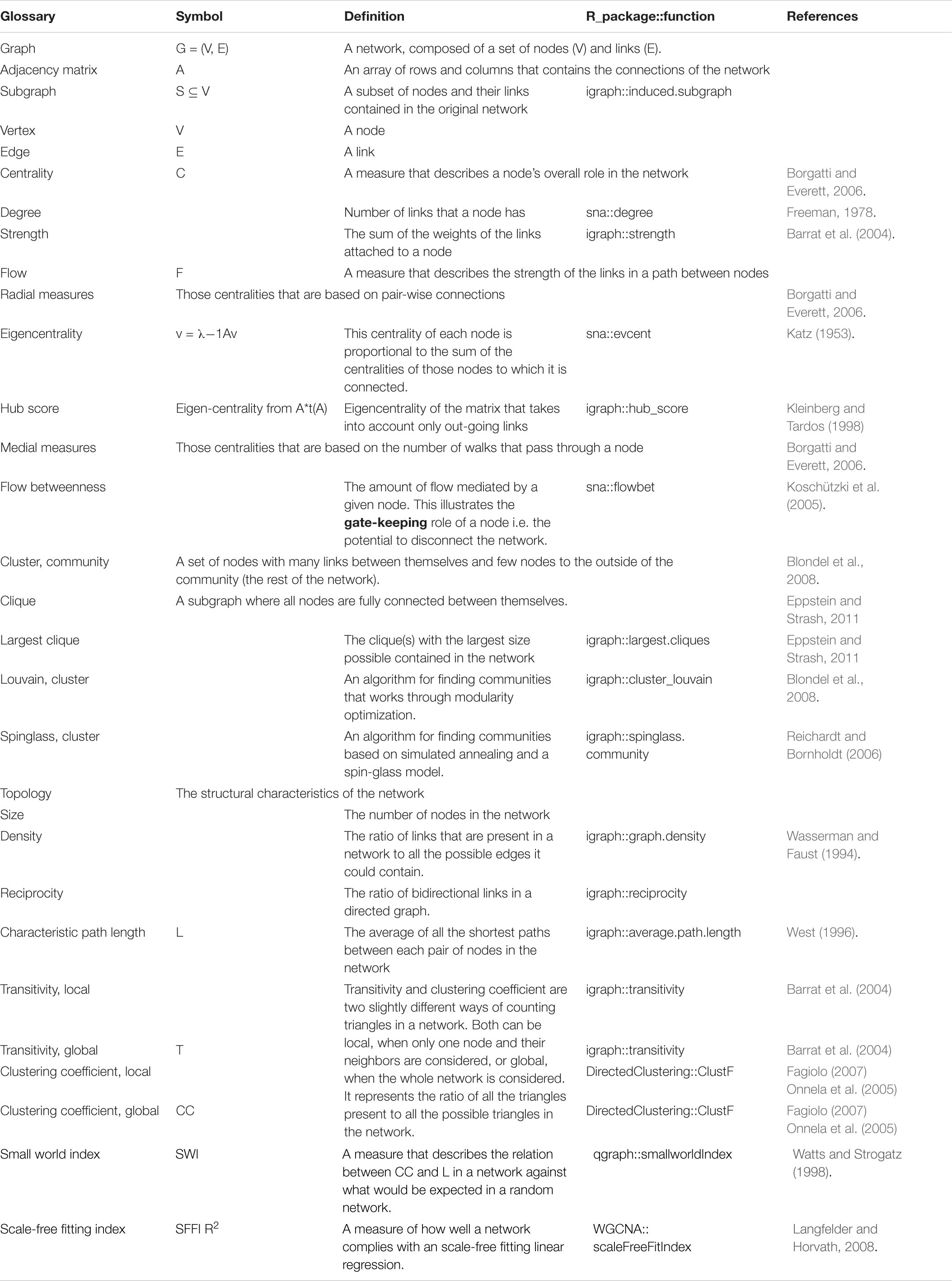
Table 3. Glossary. A brief description for quick reference of network’s specialized terms.
Nodes within a network can be ranked according to several centrality definitions that fall into two main groups, radial measures and medial measures. These centrality values allow for a direct comparison of either the influence of nodes (radial measure) or gatekeeping (medial measure) within the network (Borgatti and Everett, 2006). Eigencentrality corresponds to the value of the first eigenvector of the graph adjacency matrix and was interpreted as a measure of influence within the undirected networks. Inferring causality exclusively from centrality within networks requires caution, although eigencentrality has been found to be the best centrality measurement for this purpose, especially for small networks with less than 30 nodes (Dablander and Hinne, 2019). Furthermore, eigencentrality is resilient to incomplete sampling of the underlying network (Costenbader and Valente, 2003). For radial measures eigenvectors were selected for the undirected networks and hubscores for the directed networks, whereas for medial measures flow betweenness was used. Flow betweenness was used as a measurement of intermediation within the network. These values were obtained using the SNA package (Butts, 2019). Univariate conditionally uniform graph tests (CUG test), more in particular the cug.test function from the SNA package, were employed in order to test whether the eigencentrality and flow betweenness values obtained would be seen in a random graph with the same number of vertices, edges or dyads. Assortativity of these centralities, i.e., the tendency of nodes with similar centrality to link together, was calculated. NetSwan package was used for studying network robustness, resilience, and vulnerability. Differences were assessed with a paired Friedman’s test using Dunn’s post hoc test. Topological properties were assessed as follows: density, reciprocity and characteristic path length of the networks were calculated using the igraph package. For the calculation of the weighted transitivity and the clustering coefficient in directed and undirected weighted networks the DirectedClustering package was employed (Clemente and Grassi, 2018). CUG tests were also performed for network density, efficiency, transitivity and characteristic path length. The small world index and smallworldness as calculated by qgraph, were used as a summary metric of the network topology (Watts and Strogatz, 1998). Scale-free fitting index was calculated to show fit to scale-invariant distribution using WGCNA package (Langfelder and Horvath, 2008).
In order to generate a common layout to both networks the edge lists of both networks were merged. The resulting network contained all 100 nodes from both datasets with their corresponding edges. This network was outlined with Fruchterman-Reingold force-directed layout (Fruchterman and Reingold, 1991). As a result of this procedure, the relative position of each of the shared nodes between the different networks was the same. This allowed an easy side-by-side contrast between networks. When clusters were collapsed into nodes, they were placed in the location of the node with greatest strength in each cluster to retain the general arrangement of the network.
Determining whether a natural division of nodes is present in a network entails practical and useful insight of the studied system that is not accessible in reductionist approaches. A cluster is a set of nodes with many edges inside and few edges outside the cluster. This condition must also meet the requisite of surpassing what would be expected in an equivalent network where links are placed at random (Newman, 2006). This is tested through positive values of modularity in a network. Clusters can be detected by using a suitable algorithm, that groups vertices within a graph that are more densely connected to one another than to other vertices (Figure 3; Csárdi et al., 2016). There are several alternative algorithms for discovering communities of vertices within graphs. In the present contribution, 2 clustering algorithms were employed that are included in the igraph package, Louvain and MAP (Blondel et al., 2008; Rosvall and Bergstrom, 2008). The results were compared using the igraph::compare function for the calculation of the Rand Index (Rand, 1971) and variation of information (Meilă, 2007). The results of this unsupervised clustering were then examined against current literature to find the functional systems that best described the nodes.
Communities may also be found through walks, simulated annealing, or greedy algorithms, that are supposed to converge iteratively to the best result. 2 clustering algorithms were employed that are included in the igraph package, Louvain, a greedy algorithm, and MAP, a method based on walks and information theory (Blondel et al., 2008; Rosvall and Bergstrom, 2008). The Louvain algorithm optimizes modularity, the ratio between density of links inside the community, compared to the links between communities. To do so, at first, each node is a community of its own. With each step, nodes are re-assigned to communities in a local greedy way. Each node is placed in the community where modularity is increased most. When all nodes are assigned, each community follows the same merging and relocating procedure until modularity cannot be further optimized (Blondel et al., 2008). In contrast, InfoMap clustering tries to minimize the description length of a random walker’s movements on a network (Rosvall and Bergstrom, 2008). To increase the detail of the generated clusters, each cluster subgraph was clustered as an independent network, generating subclusters. Additionally, force-directed layouts such as a Linear logarithmic layout (Linlog) and a Fruchterman-Reingold layout may complement the representation of the community structure of a network (Noack, 2009).
The reliability of the present approach was tested by checking whether data normalization or a variation in the p-value threshold resulted in substantial changes in the network topology or in the centrality of individual variables (Figures 4, 5). Spearman correlation matrices resulted to be very similar and largely independent form of data treatment. This is an indication of the robustness of the correlations between variables. As intuitively expected, without a threshold, the result is a fully connected network. However, by lowering the p-value required to indicate a significative relationship between two variables, the topology of the network changed abruptly, until reaching a value p < 0.05 (Figures 4A,C, 5A,C). For constructing physiological networks, connectivity is a desirable feature, since little can be said of isolated nodes. On the other hand, also a deletion of redundant links is needed because correlations arise from collinearity of the variables. The best compromise between these needs was p < 0.001. This was remarkable because the density of the network continued to decrease exponentially whereas the strength of the nodes did not decrease at the same rate. This indicated that lowering the p-value of the network removed preferentially the weakest links. As a result, the efficiency of the network increased, and the connectedness only decreased slightly until p < 0.001, where connectedness and efficiency began to decrease (Figures 4A, 5A). Characteristic path length (L) increased with the p-value threshold (Figures 4B, 5B). At p < 0.001 some relatively stable value of transitivity and clustering coefficient was obtained (Figures 4B, 5B). Moreover, although transitivity and characteristic path length remained similar, small world index increased steadily (Figures 4E, 5E). This indicated that the underlying topology of the network is not a product of the threshold but is actually a phenomenon of high significance. The R2 value for fitting a scale-free network was above 90% until p < 10–6, when it decreased abruptly (Figure 4F). Regarding centrality measurements, eigenvectors were stable across all the range of p-values, making it a centrality measure robust to any data processing. On the other hand, betweenness centralities were dependent on walks, paths or flows that, being macro-scale properties, relied on the overall structure of the network. As such, flow betweenness was more variable. The best Freeman centralization for the flow betweenness was also reached at p < 0.001. Despite the similarity of the correlation matrices of raw and normalized data, modularity was visibly improved by normalization procedures. This indicated an increase in intra-cluster correlations and decrease of inter-cluster correlations. It was concluded that data normalization provided the best results to find community structures in these networks.
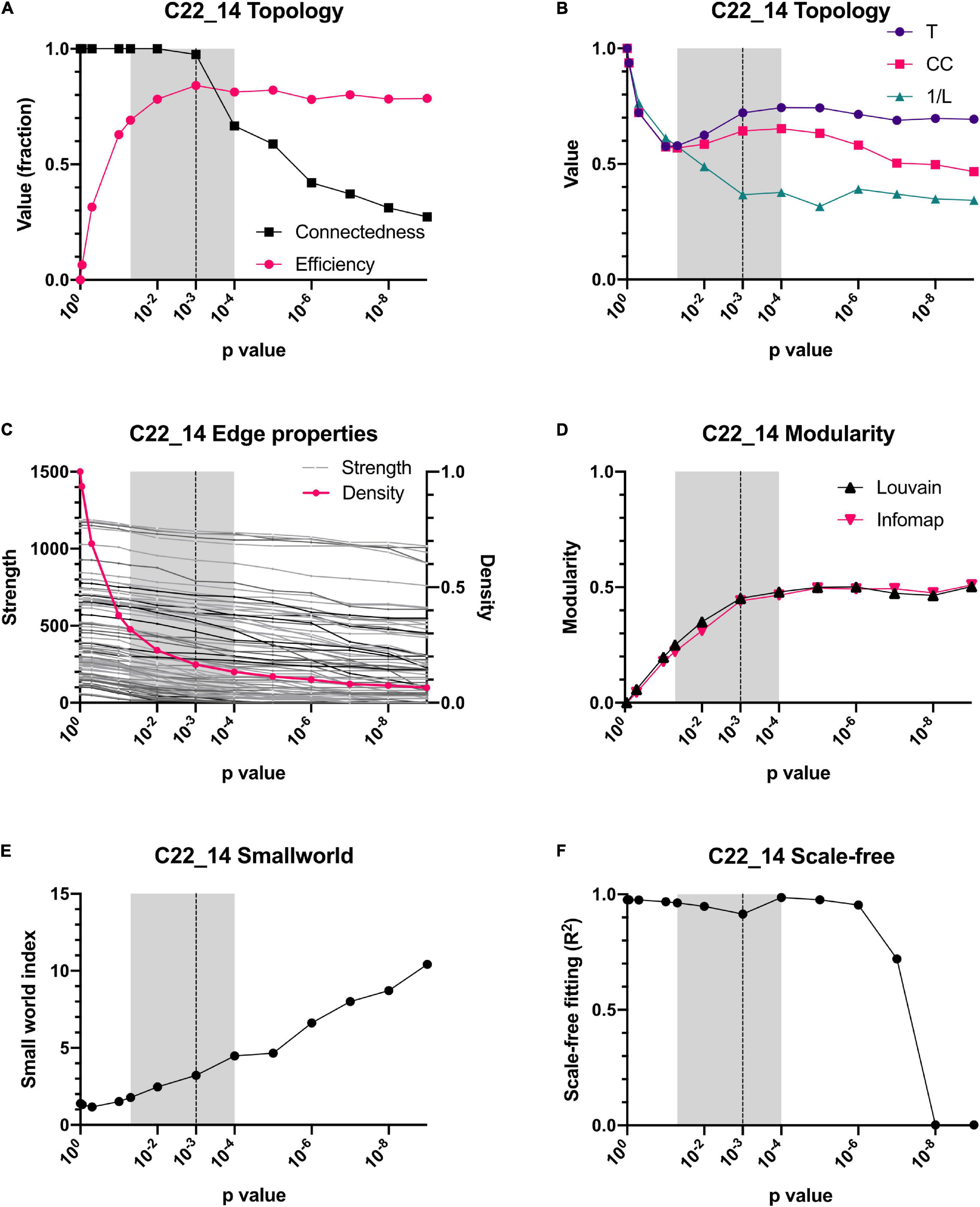
Figure 4. Dependence of topology on the p-value threshold for the C22_14 database. For all panels, shadowed areas show the windows employed for examining the networks, from p < 0.05 to p < 0.0001. Our selected threshold, p < 0.001, is shown as a vertical dotted line. Relationship of connectedness and efficiency of the network is shown in (A). Topology indicators such as characteristic path length (L), global Barrat’s weighted transitivity (T) and clustering coefficient (CC) are shown in (B). A comparison between density (number of connections) and strength (sum of weights of links for each node) is presented in (C). Modularity quantified by 2 different clustering strategies, Louvain clustering and InfoMAP, increases as a function of the p-value threshold (D). Small-world index increase with p-value threshold (E). Node’s degree frequency distribution fitting to a scale-free model is shown in (F).
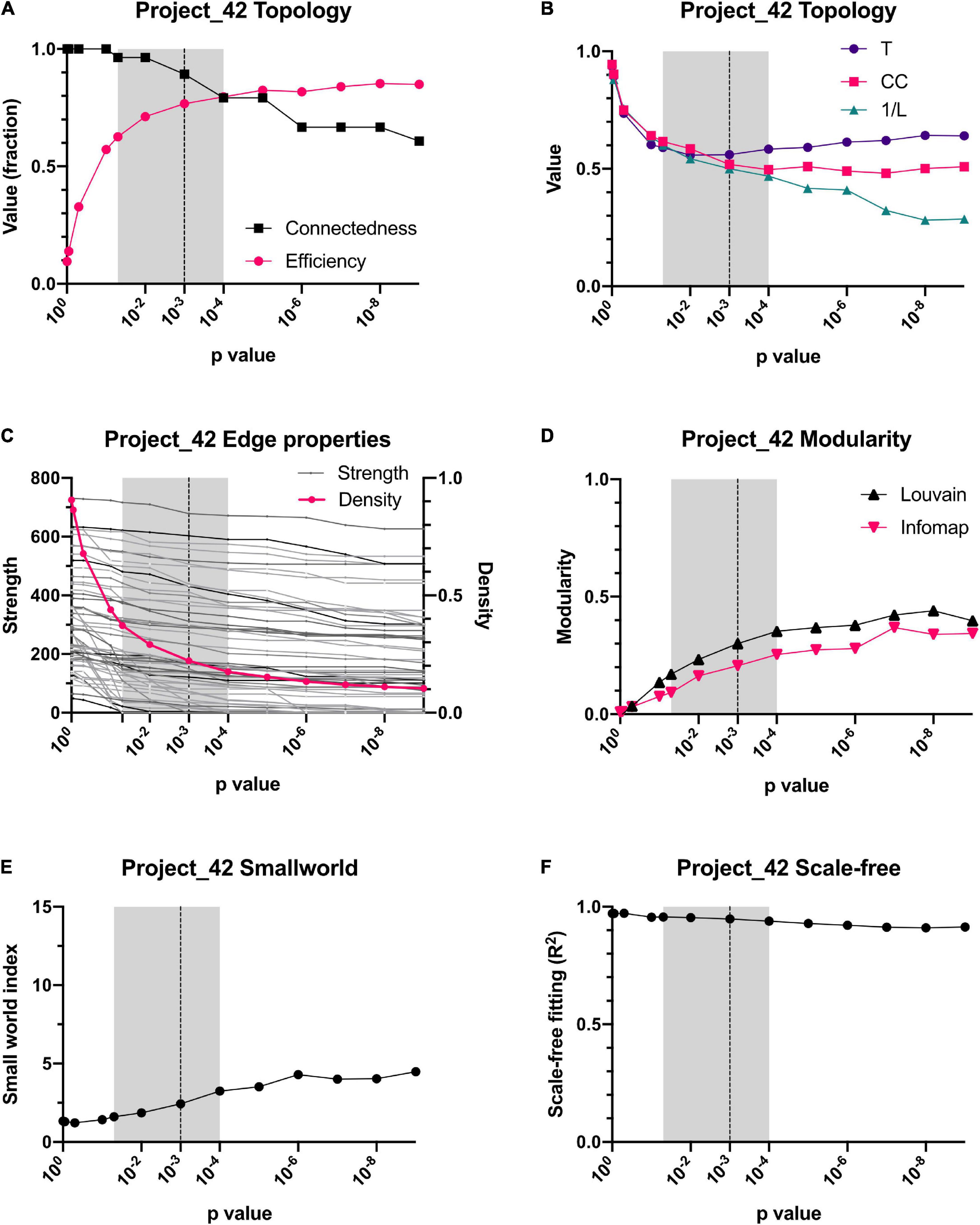
Figure 5. Dependence of topology on the p-value threshold for the Project 42 database. For all panels, shadowed area shows the window we employed for examining networks, from p < 0.05 to p < 0.0001. Our selected threshold, p < 0.001, is shown as a vertical dotted line. Relationship of connectedness and efficiency of the network is shown in (A). Topology indicators such as characteristic path length (L), global Barrat’s weighted transitivity (T) and clustering coefficient (CC) are shown in (B). The decrease of networks number of connections (density) is contrasted against the sum of the links weight for each node (strength) is presented in (C). Modularity increase with p-value threshold is presented in through 2 clustering strategies, Louvain clustering and InfoMAP (D). Small-world index increase with p-value threshold is presented in (E). Node’s degree frequency distribution fitting to a scale-free model is shown in (F).
At the selected significance threshold of p < 0.001, C22_14 database resulted in a correlation matrix with 523 links, while Project_42 had 368 links. Overall, links in C22_14 database were stronger, but this difference was small (mean difference 8 ± 1.4, p < 0.0001). In contrast, node strength (weighted degree, the sum of links weight) was greater in Project_42 (mean difference 131 ± 46, p < 0.001). However, strength of both nodes and edges were highly correlated in the 36 nodes and 80 links that both networks had in common (Spearman’s rho = 0.69, p < 0.0001 for nodes and Spearman’s rho = 0.5, p < 0.0001 for edges).
To test whether node centrality measures were similar between networks the values obtained in the full networks and in the shared network were compared, built from the common subset of variables studied in both databases. For full networks eigencentrality values were similar for both datasets (Spearman’s rho = 0.74, p < 0.0001) while flow betweenness was dependent on the specific network (Spearman’s rho = 0.03, p = 0.8, see Figures 6A,B). Similar to the comparison of the full networks, when comparing networks comprising only shared nodes large correlations were found for eigencentrality (Spearman’s rho = 0.77, p < 0.0001) while there was no correlation for flow betweenness (Spearman’s rho = 0.22, p = 0.2, see Figures 6C,D). These shared networks with the same number of nodes were directly comparable. The Quadratic Assignment Procedure (QAP) test showed a significant correlation which was not observed in networks with shuffled rows and columns (Figure 6E). Clusterings obtained with the Louvain method were compared with igraph::compare for the Rand Index (0.74) and variation of information (1.5), without differences using the Wilcoxon paired ranked test (T = 174, W = −6, p = 0.9414) and significant spearman correlation (r = 0.49, C.I. [0.18, 0.71], p = 0.002, pairs = 36). Therefore, both networks had consistent clusters as well as high correlation. This is in spite that the correlation between networks was only moderate (gcor = 69%). Nonetheless, this correlation was greater than expected from permuted networks by QAP test, indicating that this similitude was not a product of chance (Figure 6E). Differences between networks may be expected by the decrease in transitivity that we have observed with age and/or disease (Barajas-Martínez et al., 2020).
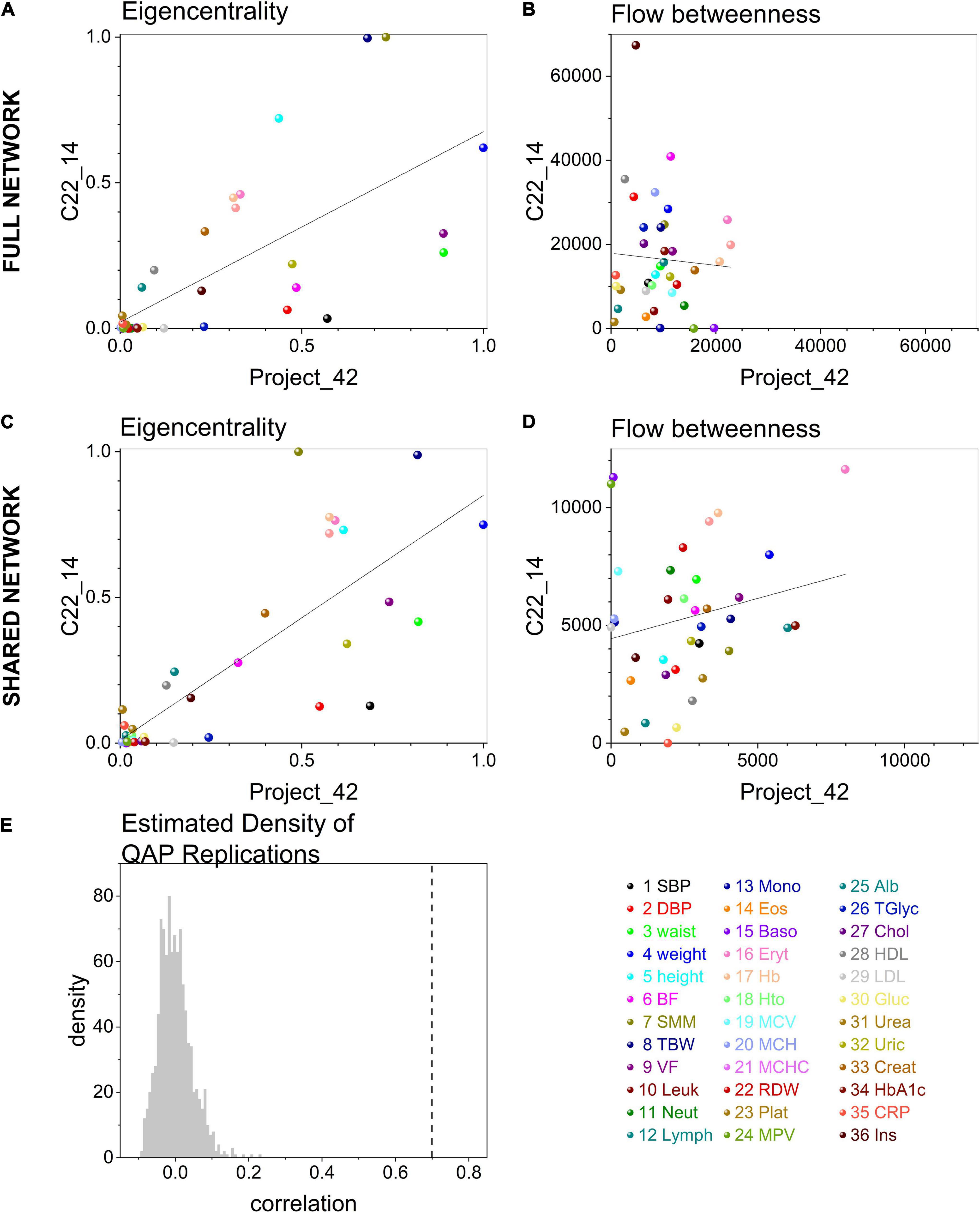
Figure 6. Matching between centrality measures in networks. Centrality measures, eigencentrality and flow betweenness, correlation between C22_14 and Project 42 full networks are shown in (A) and (B) respectively. After extracting the subgraph of the matching 36 shared physiological variables in both datasets the comparison was repeated in (C) and (D). Linear regression (continuous curves) with 95% confidence intervals (dashed curves) are shown together with the values of all physiological variables (dots). The color of the dot indicates the specific variable. The density of the distribution of Montecarlo draws for correlation between networks in Quadratic Assignment Procedure test (QAP test) is presented in (E). The dashed line indicates the correlation values between C22_14 and Project_42 shared networks.
Several community detection algorithms for networks were tested and evaluated through their modularity scores. Seven clusters were identified within the network (Figures 7, 8). The first cluster included anthropometric, bioimpedance and spirometry variables related with body size. This cluster has most of the nodes with high eigencentrality in the network. Most of these nodes with high influence belong to bioimpedance and spirometry variables. Three subclusters are identifiable here. First, bioimpedance and anthropometric variables, along with four biomarkers, uric acid, CRP, PON-1 and HDL. The second subcluster comprises spirometry variables, while the third includes blood biomarkers like hematocrit, erythrocytes, platelets, albumin, urea and creatinine. In contrast, only few nodes in this cluster have high flow betweenness. Platelets, erythrocytes and CRP numbers were prominent in this regard. The second cluster includes elements of endocrine regulation such as the hormones of the adipoinsular axis and endothelial activation biomarkers. Eigencentrality values in this cluster are low, with insulin as the most influential node. This cluster has two nodes with high flow betweenness, insulin and arginase activity. Only one bioimpedance parameter is included here, the impedance value (Z). A third cluster, comprising lipidic biomarkers as well as club cell protein 16 (CC16), is present and exhibits a very low eigencentrality overall. The fourth cluster includes white blood cells and the two glycemic variables, glucose and HbA1c. This cluster has many high flow betweenness nodes. Eosinophils, lymphocytes and leukocytes were important intermediaries in the network. The fifth cluster involves the four red cell indices. From these, MCHC has a high flow betweenness. A sixth cluster around carbon monoxide is present. As this node is mostly peripheral in the network, glucagon and GST had high flow betweenness by linking these variables to the main component. For the Project_42 database network there was one main difference related to the variable set that was employed (Figure 8). The cluster encompassing the red cells indices cluster is merged with the immune cells cluster. Figures and tables for each cluster described here are provided in supplementary material (Supplementary Figures 1–11).
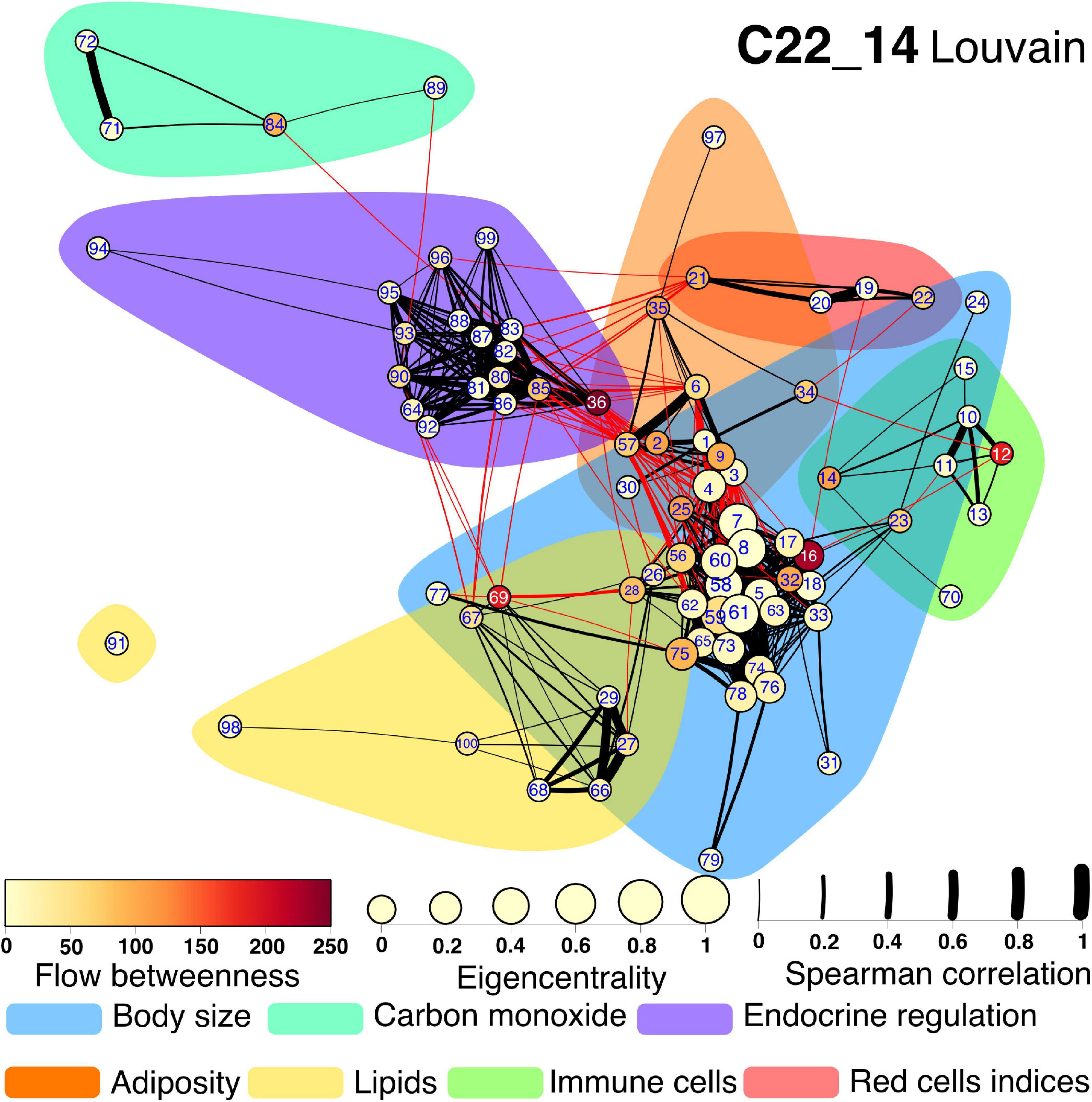
Figure 7. Physiological network for C22_14 database. The physiological network constructed from the correlation matrix once the p-value discards connections without statistical significance. Clusters are presented as shadowed areas. Links within the same cluster are black while links between clusters are red. Node centrality is represented as size for the eigencentrality and color for the flow betweenness. Edge width represents the weight of the Spearman correlation. Nodes are labeled according to Table 1 numerical ID.
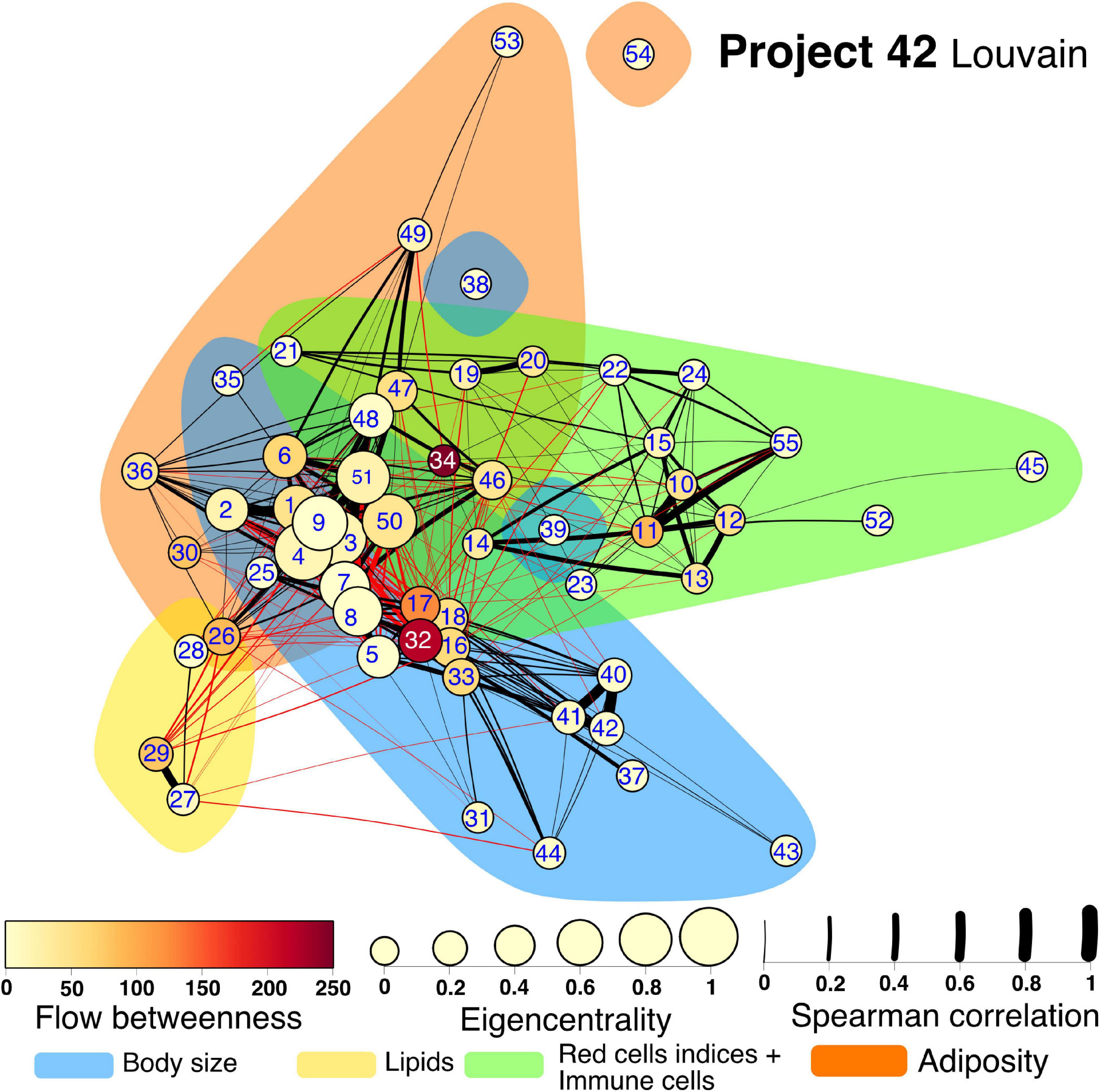
Figure 8. Physiological network for Project 42 database. The physiological network constructed from the correlation matrix once the p-value discards connections without statistical significance. Clusters are presented as shadowed areas. Links within the same cluster are black while links between clusters are red. Node centrality is represented as size for the eigencentrality and color for the flow betweenness. Edge width represents the weight of the Spearman correlation. Nodes are labeled according to Table 1 numerical ID.
Next, to highlight inter-cluster connections, that reflect the coordination between different systems within the organism, nodes inside the same cluster were contracted into a single node (Figure 9). For both networks, the body size cluster (C1) and the visceral adiposity cluster (C6) were the most closely interrelated. For the C22_14 network, the endocrine regulation cluster (C2) is closely related to the visceral adiposity cluster (C6), the red blood cells indices (C3) and the lipids cluster (C5). For Project_42 network, the immune cells cluster (C4) and C5 are densely connected with C1 and C6. Novel interactions between physiological systems were found. For instance, the connections between C2 and C3 in C22_14 network represent correlations with a single red cell index, the mean corpuscular hemoglobin concentration (MCHC). Salient inter-cluster connections present in both networks were diastolic blood pressure (DBP) relation to insulin and body weight, and HbA1c correlation with total lymphocytes and red cell distribution width (RDW). Nodes that had a high number of inter-cluster connections were waist, body fat, DBP, weight, HDL and triglycerides (Figure 9). This suggests that these physiological variables are located at the crossroads between the physiological modules. This observation is reinforced by the position of waist circumference, body fat, weight, and HDL for C22_14 and insulin for Project_42 in the spaces between topological clusters in the Linlog Layout (Supplementary Figures 12, 13).
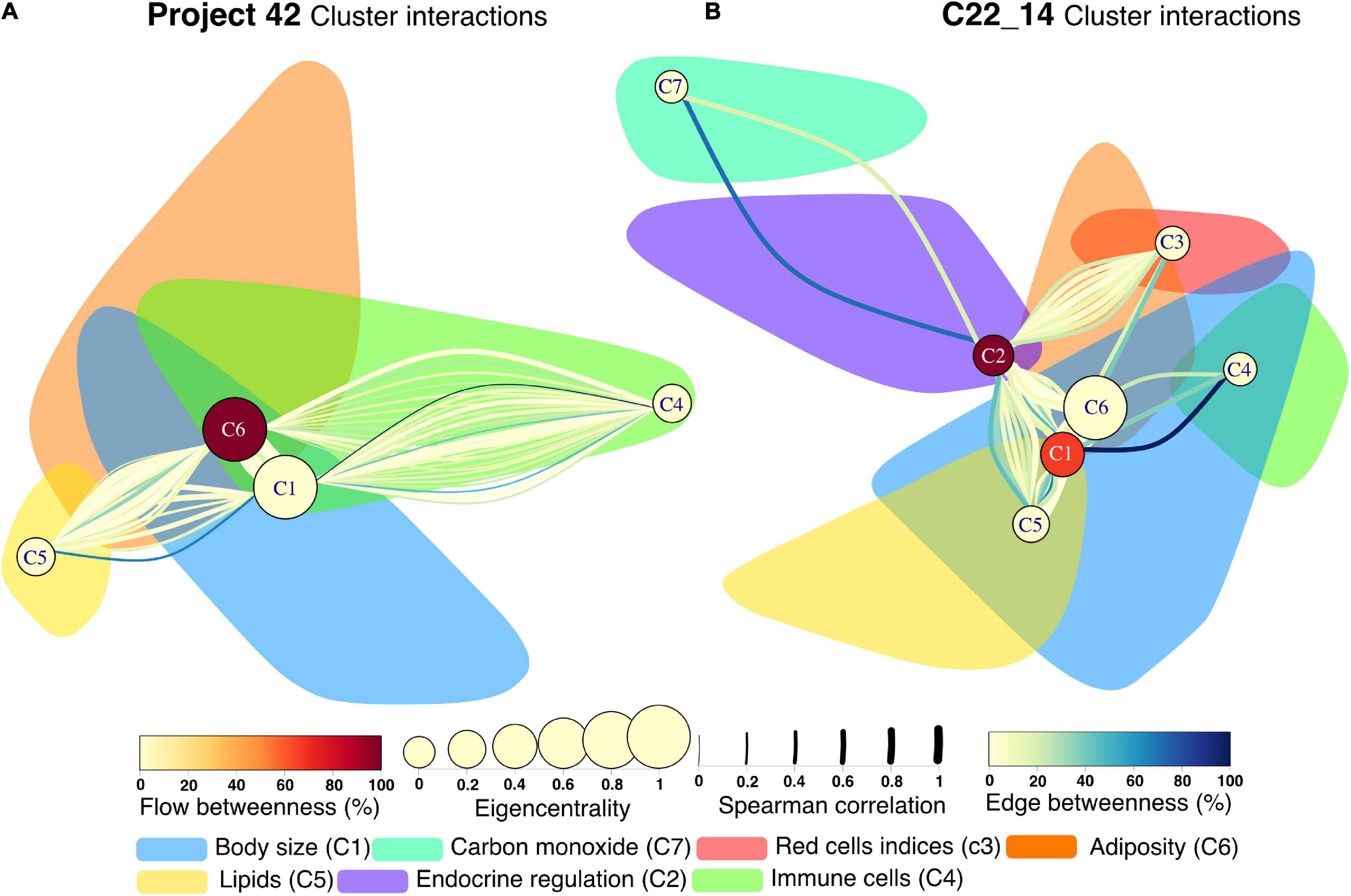
Figure 9. Cluster interactions network for Project 42 (A) and C22_14 (B). Interactions between clusters are presented as a multigraph, where more than one link between two given nodes are possible. All nodes within a cluster are contracted into a single node whereas all individual links remain displayed. This new node is placed in the position of the node with greatest strength in the original network. The shadow of the original cluster remains in place for comparison with the physiological networks presented previously. The edge betweenness – the number of shortest paths that pass through a link- is presented with the color of the link, while the width represents the strength of the Spearman correlation. The new nodes centrality and flow betweenness are presented by node size and color, respectively.
The correlation matrix of the 81 unique variables studied from C22_14 database has 523 correlations (of the possible 3240 = 80∗81/2) with p < 0.001, resulting in a network density of 16% (Table 4 and Figure 1). The correlation matrix of Project_42 database has 55 unique variables studied has 368 correlations (of the possible 1485 = 54∗55/2) with p < 0.001 (Table 5 and Figure 2), resulting in a network density of 25% (Table 4 and Figure 1). Only myeloperoxidase (MPO) was found to be disconnected from the main component of the network for the C22_14 network, and serum phosphorus for the Project_42 network. With a threshold p < 0.01 this variable is correlated with Club cell protein 16 (CC16) and malondialdehyde (MDA). The physiological networks had an efficiency of 84% and 75%, greater than would be expected from a random network of the same size. Despite the low density of the network, it has a high transitivity of 72% and 52%, larger than would be expected in a random network with the same size, density, or number of dyads (Supplementary Figures 14, 15). Characteristic path length of 3 and 2, respectively, was higher than a random network with the same size, density, or number of dyads (Supplementary Figures 14, 15). Network architecture was evaluated for small world and scale invariance properties (Tables 4, 5). The physiological network has a small world index of 3.2, and 2 with a smallworldness of 1.9 and 1.2. Scale-free fitting index, employed as a scale invariance measurement, shows both networks approach this fitting (Tables 4, 5). As expected for a network with these topological properties, eigencentrality has a high assortativity, while flow betweenness has a low assortativity (Table 4). In turn, this assortativity, while making the network very robust against random errors, results in large susceptibility to directed attacks, particularly cascading attacks (Figures 10A,B). The elevated modularity of the physiological network results in susceptibility to betweenness-directed attacks but implies robustness to degree-directed attacks (10A and 10B). It can also be observed that the physiological network follows a scale-free distribution (Figures 10C,D). Taken altogether, the physiological network has a complex structure that satisfies the biological requirements of robustness and adaptability.
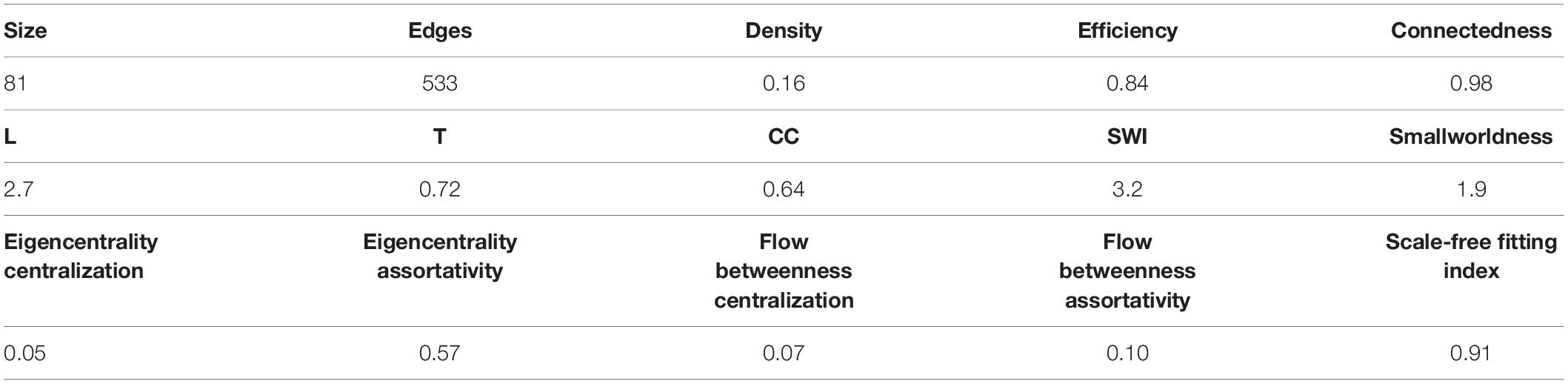
Table 4. Network topology summary for C22_14 database.
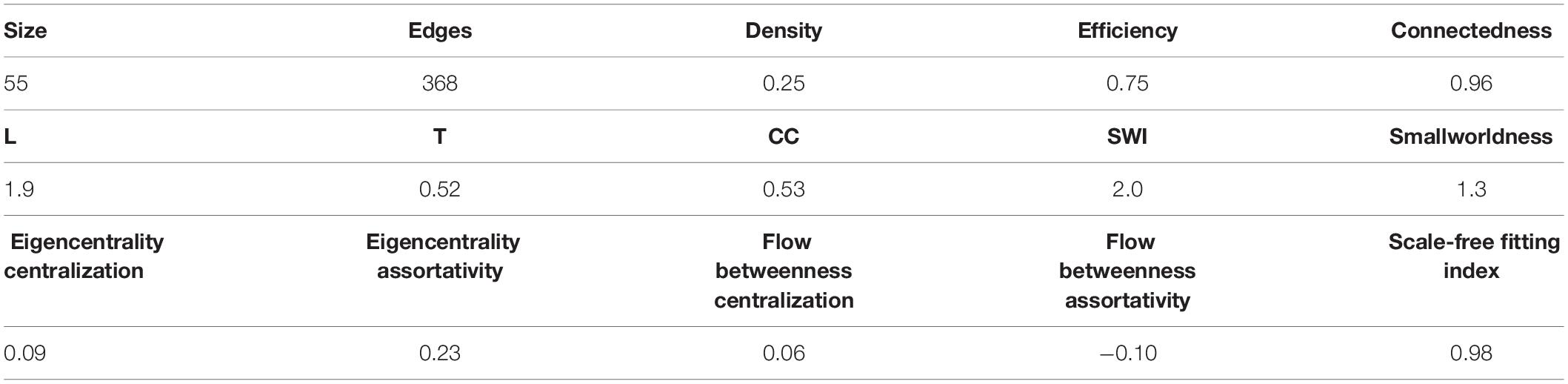
Table 5. Network topology summary for Project_42 database.
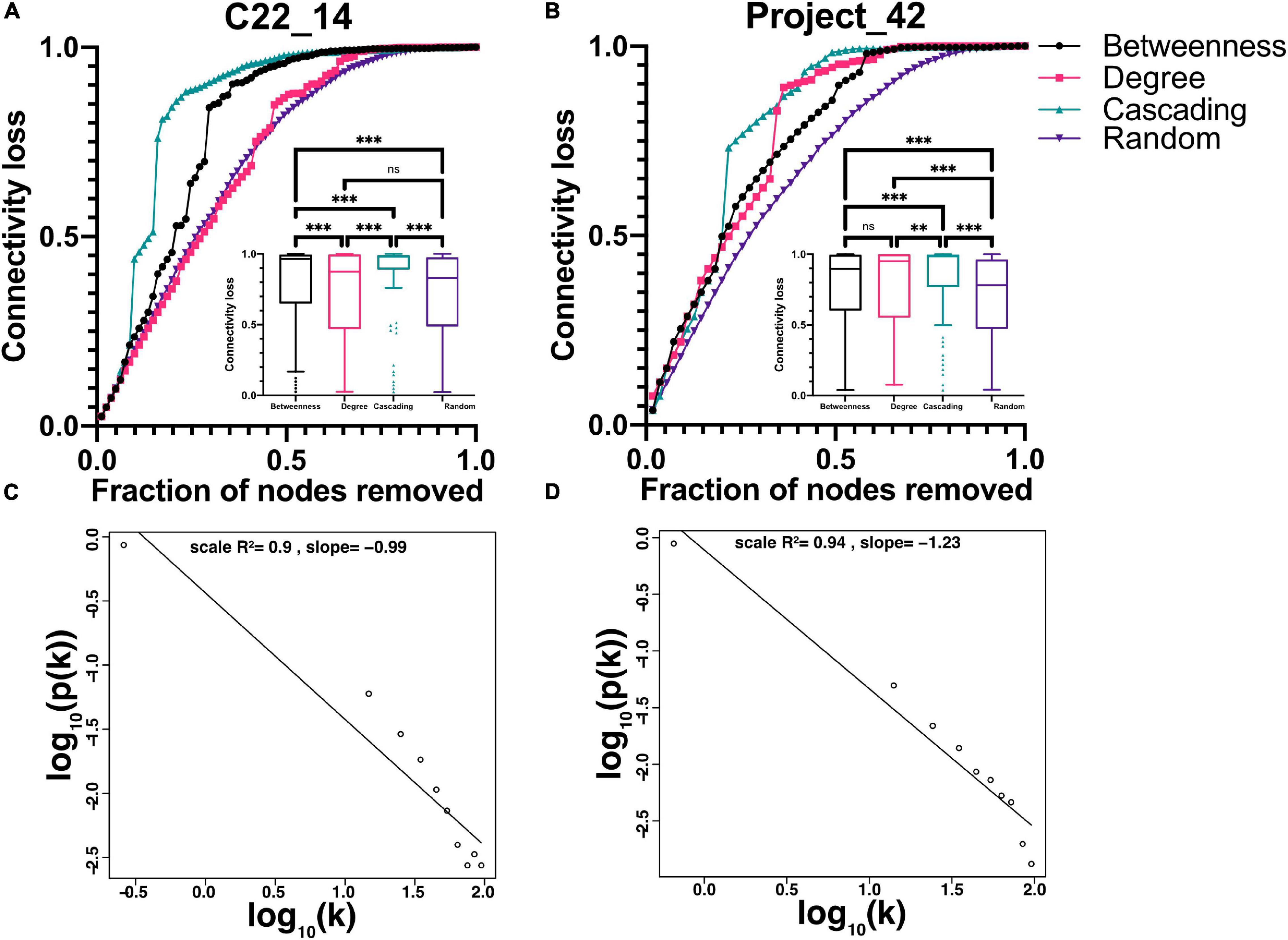
Figure 10. Topological characteristics of the networks. Analysis of network strengths and weaknesses is presented in (A) and (B) showing the difference between connectivity decrease in random failure (purple inverted triangles) against three different attacks, cascading (green upward triangles), betweenness (black circles) and degree (pink squares). Encased in each figure is the Tukey’s box and whiskers presentation of the data, with the Friedman’s test with Dunn’s post hoc test significance between groups. ** indicates p < 0.01, *** p < 0.0001. Node degree frequency distribution fitting to a scale-free model is shown in (C) and (D) for networks constructed with p-value thresholds of 0.001. Panel (A) and (C) for C22_14 and (B) and (D) for Project_42.
Physiological networks are an area of increasing interest for the study of biological systems. These networks relate inferred interactions between systems that may be constructed from co-occurrence of observations. This co-occurrence may be observed in time, as in networks constructed from time series for dynamical understanding of physiology (Liu et al., 2015), within populations through point measurements as is the case of our networks (Barajas-Martínez et al., 2020), but also between individuals as shared characteristics to generate phenotypic clusters (Mihaicuta et al., 2017). While most networks in biomedical sciences are constructed of nodes and links of the same nature, our network is closer to classical physiological interactions between systems. In human physiology, hormones (and other regulatory systems) exert effects over a wide array of variables regulated variables -blood pressure, electrolytes, protein expression, cellular responses etc., in response to internal needs and to external perturbations. These interactions are very different from usual network approach where only genes, proteins or metabolites are considered, or in the case of neurosciences where different channels of FMRI or EEG are used to construct functional networks. Here we propose a general framework for approaching multivariate datasets of physiological nature that are commonly analyzed through conventional approaches.
Networks are information-rich representations where meaningful characteristics are present in the network topology, layout, clustering, node centrality and edge characteristics. This provides a rich context for interpretation of physiological data. We show that there are robust interactions (links) between physiological variables (nodes), that are preserved between datasets and have very high significances, even for relatively small samples. The analysis of these networks results in similar clustering even when networks are constructed from different datasets. These clusters are not a product of random chance, but are rather built from related variables with underlying mechanisms related to specific functions. Clustering approaches have been used before in the literature, where at least two strategies have been well described. Nodes may be conglomerated through force-directed layouts to generate topological clusters, and through modularity optimization algorithms (Noack, 2009). For an adequate analysis and successful rendering of functional clusters network filtering is critical (Mihaicuta et al., 2017). Here we use the p-value, a widely validated strategy to sort significant correlations between variables, to filter the physiological network. Through a modularity optimization algorithm, we clustered physiological variables into functional groups.
The variables within this cluster are related to the size of the organism (Supplementary Figures 1, 2). One of the main drivers of body size differences in humans is sexual dimorphism. Males tend to have larger bodies than females with immediate mechanical consequences. For instance, body compartments are larger, including thoracic dimensions, and all the spirometry measurements where anatomic size is important (FVC, FEV1, COadj, AV, kCO, TLC, RV). A larger body also increases some anthropometric characteristics (neck, height, and weight), and bioimpedance measurements (skeletal muscle mass, lean body mass, total body water and intracellular water). Furthermore, a relation between pulmonary function and bioimpedance measurements is present only for lean mass measurements but not for body fat measurements (Park et al., 2012). Sex association with size has also a hormonal context that results in differences in complete cell count and chemistry (HDL, hemoglobin, hematocrit, albumin, and platelets). For the Project_42 database bilirubin measurements are also present in this cluster, as they are product of degradation of the hemoglobin. Finally, a large lean mass also implies an increased number of metabolites associated with protein and aminoacid replacement (urea, uric acid, and creatinine). These parameters are subject to a hormonal context as they are altered with chronic abuse of androgenic hormones (Navidinia and Ebadi, 2017).
This cluster contains nodes related to endocrine regulation. The adipoinsular axis comprehends incretins (Ghrelin, GIP, GLP-1), that signal the food bolus composition, and adipokines, that signal storage state of the adipose tissue (leptin, resistin, visfatin), to tailor the homeostatic response of the pancreatic islet (Kieffer and Habener, 2000). Embedded in this modulation environment, pancreatic beta cells secrete the only hormone that lowers glucose in hyperglycemia (insulin, equimolarly with c peptide), and pancreatic alpha cells secrete a contra-regulatory hormone in hypoglycemia (glucagon). Visceral fat accumulation induces a pro-inflammatory state, resulting in endothelial activation (PAI-1, ICAM-1, VCAM-1, endothelin-1) which allows for circulating immune cells diapedesis (passage from the blood to the tissues) where arrival perpetuates the pro-inflammatory state and produces insulin resistance (Meigs et al., 2004). These closely related functional interactions result in a dense endocrine regulation cluster for the C22_14 network (Supplementary Figure 3).
Erythrocyte characteristics are summarized in clinical settings through red cell indices. Of these, the red cell blood distribution width (RDW) is one of the most recent indices (Salvagno et al., 2015). Mean corpuscular volume (MCV), mean corpuscular hemoglobin concentration (MCHC) and mean corpuscular hemoglobin (MCH) represent average values of volume and hemoglobin content, whereas RDW is a variability-based metric (Sarma, 1990). Together these four parameters allow for classification of anemic disease and provide clinical orientation and are found clustered in the C22_14 network (Supplementary Figure 4).
White blood cells (leukocytes) are the cellular component of the immune system that flows through the blood. These cell types are orchestrated in several immune responses but have been more or less well categorized in specialized functions and are clustered in the C22_14 network (Supplementary Figure 5). For instance, neutrophils and monocytes are part of the innate immune response. An “always ready” system for immediate deterrence of infectious pathogens. On the other hand, lymphocytes, eosinophils and basophils participate in the adaptative immune response. A tailored cellular response to effectively resolve infectious processes that have overcome responses of the innate immune system. For the Project_42 network, Cluster 3 physiological variables are included in this cluster, along with platelets and mean platelet volume (MPV), comprising al cellular components in the blood (Supplementary Figure 6). These physiological parameters have been related to cardiovascular risk, placing them in the context of a wider set of interactions beyond infection response (Hansen et al., 1990; Madjid and Fatemi, 2013). Nitric oxide in exhaled breath is present in this cluster and relates to eosinophils, as expected since eosinophils are a major source of NO in asthma (MacPherson et al., 2001).
Lipids present in blood, and their associated carrier proteins, are classical biomarkers of cardiovascular risk and were clustered in both networks (Supplementary Figures 7, 8). Triglycerides and total cholesterol were first identified. Later, cholesterol was separated into fractions according to weight, unveiling a transport system composed of lipoproteins that carry lipids from their storage depots to the cells, VLDL, IDL, and LDL, and lipoproteins that carry lipids from the cells into the storage depots, HDL (Ito and Ito, 2020). In epidemiological studies HDL levels have shown to be protective against cardiovascular disease, while LDL levels represent a risk factor. ApoA and ApoB, the protein envelopes that carry the lipids in these fractions, showed better predictive results. However, upon increasing knowledge of the physiopathology of vascular disease new biomarkers have been assessed such as lipoperoxidation products, serum phospholipids and oxidized LDL (Ngoc-Anh, 2009). As Project_42 has less lipidic variables this cluster comprises only LDL, HDL and cholesterol.
Visceral adiposity is the main driver of metabolic disease. It has been measured through several proxies including body weight and waist circumference either as individual measurements or as composed indices (BMI, height/waist ratio), and by indirect measurement using bioimpedance (total body fat, visceral fat, fat free mass, body fat, superficial body fat). These variables are clustered in both networks (Supplementary Figures 9, 10). Over time, excess of visceral adipose tissue triggers a low-grade chronic pro-inflammatory state, as revealed by high sensitivity but low specificity C reactive protein, an acute phase pentraxin produced in the liver (Pettersson-Pablo et al., 2019). Increased visceral adiposity is also related to high blood pressure (systolic and diastolic blood pressure) through several mechanisms even in young adulthood (Takeoka et al., 2016). The variables in this cluster share the property of being very stable over time. Body fat deposits, resting blood pressure and glucose levels are rather stable variables that vary only over very long periods of time. For Project_42 anthropometric measurements, such as hip and arm circumference, as well as all skinfolds of plicometry, are located in this cluster (Supplementary Figure 10).
Carbon monoxide cluster. There is a final cluster that comprises the relation between exhaled carbon monoxide (CO) and hemoglobin irreversibly bound to CO in blood (COHb) (Wald et al., 1981). As none of the participants in the C22_14 dataset were smokers this cluster is relatively well isolated from the network (Supplementary Figure 11). Nonetheless, breath profiles including CO and NO have been proposed for monitorization of whole body states (Maiti et al., 2019).
The inter-cluster correlations manifest the integration between these different functional systems within the organism, as well as some physiological variables placed as intermediaries in the network between clusters (Figure 9). As force-directed algorithms may work as energy-models (Noack, 2009), location of the nodes within the layout is also informative of the role nodes may have in the functional cluster, either deep inside or in the periphery (Supplementary Figures 12, 13). The robust agreement between the present network approach and medical knowledge invites us to extend network analysis to physiological phenomena. It has been suggested previously that topology characteristics of a network have functional implications that are not observable by reductionist approaches (Ivanov and Bartsch, 2014). A network framework for physiological understanding may facilitate immediate comprehension of distant interactions and emergent properties of living systems.
Living systems are neither completely random nor fully ordered. This property has been noted at multiple levels of observation. For example, from a time-series perspective, the analysis of continuous heart rate data reveals that balance between robustness and adaptability of the cardiovascular system is an important biomarker of health (Rivera et al., 2018). For networks, this is the essence of a complex topology, such as small world or scale-free, since they feature patterns of connection between their elements that are neither purely regular nor purely random. In Figure 10 we show that both networks have a scale-free topology (with some degree of both random and orderly structure). In summary, the complex behavior of living systems in time series appears to be reflected also in network physiology.
The limitation of our study is the small size of our datasets, nevertheless our methodology combines parameters that are not usually related to build a physiological network. Moreover, the physiological network constructed is robust and similar for both datasets.
Textbooks on basic physiology present homeostatic regulation of cardiovascular, respiratory, metabolic and other subsystems as if they were independent mechanisms coordinating the dynamics of closely related variables in order to create a stable local environment that can be studied from the perspective of separate medical disciplines (Ganong, 1969; Hall, 2011). This is of course a coarse approximation because it is implicit that the different subsystems must interact in order to assure a system-wide homeostatic state, remaining outside the scope of the reductionist approach to physiology. Systems biology, on the other hand, suggests that systemic homeostasis “emerges” from an underlying network and interactions between variables that span the whole system (Goldstein, 2019). Figures 7–9 show 6 distinct clusters, where the intra-cluster interactions between related variables may well represent the textbook examples of local subsystem homeostasis, whereas the inter-cluster interactions between very distinct variables most probably convey new and unexplored information of how homeostasis is established at the system level in the optimal conditions of youth and health, and how the loss of homeostasis arises with aging and/or disease.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by The Ethics Committee of the “Instituto Nacional de Enfermedades Respiratorias” (INER) approved the procedures and protocols for this study under project C22_14. The Ethics Committee of the Facultad de Medicina of the Universidad Nacional Autónoma de México (UNAM) approved the procedures and protocols for this study under project FM/DI/023/2014. The patients/participants provided their written informed consent to participate in this study.
AB-M, EI-C, and ALR performed data analysis, network modeling, and wrote this work. CRS did the conceptualization of the project for dataset of Project_42 and funding acquisition. AB-M participated in methodology and data collection. MPS-V did the conceptualization of the project for dataset C22_14, funding acquisition, and resources. OGA-A and YD-G did the data curation. OGA-A and MPS-V did the investigation. CV-D, RG-T, KB, OGA-A, and MPS-V did the methodology. ALR, EI-C, RF, VMG, OAL, AOM-G, and AF participated in the complexity interpretation and analysis of the results. MANM, DAMO, CEL-C, IC-B, PA-V, and CAA-S participated in data analysis and medical interpretation in this work. All authors contributed with the manuscript revision, read and approved the submitted version.
This work was partially supported by the CONACyT through the grants FORDECYT-PRONACES/610285/2020, Fronteras grants FC-2015-2/1093, Fondo Sectorial de Investigación en Salud y Seguridad Social, grant SALUD-2014-1-233950 and by the Universidad Nacional Autónoma de México through DGAPA Programa de Apoyo a Proyectos de Investigación e Innovación Tecnológica (PAPIIT) AG101520, IV100120, IN113619, and PAPIME PE103519. We also acknowledge support from SECTEI CDMX grant SECIT/093/2018 and a donation from Academic Relations, Microsoft Corporation.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
We appreciate the services to carry out respiratory function tests provided by the Clínica de Ayuda para dejar de Fumar at the Instituto Nacional de Enfermedades Respiratorias. We thank the participation of Kathia Marie Pellerin Flores, José Eduardo Hernández Paniagua, Roxana Stephanie García Sotelo, and Claudia Karen Gómez Romero from the national program of Medical Social Service, and of Itzel Abigail Corona Galván from the master’s program in Health Sciences, Romel Calero and Juan Antonio López-Rivera for computational aid.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphys.2020.612598/full#supplementary-material
Albert, R., and Barabási, A. L. (2002). Statistical mechanics of complex networks. Rev. Mod. Phys. 74:47. doi: 10.1103/RevModPhys.74.47
Alberti, K. G. M. M., Eckel, R. H., Grundy, S. M., Zimmet, P. Z., Cleeman, J. I., Donato, K. A., et al. (2009). Harmonizing the metabolic syndrome: a joint interim statement of the international diabetes federation task force on epidemiology and prevention; National heart, lung, and blood institute; American heart association; World Heart Federation; International Atherosclerosis Society; and International Association for the Study of Obesity. Circulation 120, 1640–1645. doi: 10.1161/CIRCULATIONAHA.109.192644
Arihan, O., Wernly, B., Lichtenauer, M., Franz, M., Kabisch, B., Muessig, J., et al. (2018). Blood Urea Nitrogen (BUN) is independently associated with mortality in critically ill patients admitted to ICU. PLoS One 13:e0191697. doi: 10.1371/journal.pone.0191697
Asada, T., Aoki, Y., Sugiyama, T., Yamamoto, M., Ishii, T., Kitsuta, Y., et al. (2016). Organ system network disruption in nonsurvivors of critically Ill patients. Crit. Care Med. 44, 83–90. doi: 10.1097/CCM.0000000000001354
Barajas-Martínez, A., Easton, J. F., Rivera, A. L., Tapia, R. J. M., De la Cruz, L., Cabrera, A. R., et al. (2020). Metabolic physiological networks: the impact of age. Front. Physiol. 11:587994. doi: 10.3389/fphys.2020.587994
Barrat, A., Barthelemy, M., Pastor-Satorras, R., and Vespignani, A. (2004). The architecture of complex weighted networks. Proc. Natl. Acad. Sci. U.S.A. 101, 3747–3752. doi: 10.1073/pnas.0400087101
Bartsch, R. P., Liu, K. K., Bashan, A., and Ivanov, P. C. (2015). Network physiology: how organ systems dynamically interact. PLoS One 10:e0142143. doi: 10.1371/journal.pone.0142143
Bartsch, R. P., Liu, K. K., Ma, Q. D., and Ivanov, P. C. (2014). Three independent forms of cardio-respiratory coupling: transitions across sleep stages. Comput. Cardiol. 41, 781–784.
Bashan, A., Bartsch, R. P., Kantelhardt, J. W., Havlin, S., and Ivanov, P. C. (2012). Network physiology reveals relations between network topology and physiological function. Nat. Commun. 3, 1–9. doi: 10.1038/ncomms1705
Batushansky, A., Toubiana, D., and Fait, A. (2016). Correlation-based network generation, visualization, and analysis as a powerful tool in biological studies: a case study in cancer cell metabolism. Biomed. Res. Intern. 2016, 1–9. doi: 10.1155/2016/8313272
Blondel, V. D., Guillaume, J.-L. L., Lambiotte, R., and Lefebvre, E. (2008). Fast unfolding of communities in large networks. J. Statist. Mech. 2008, 1–12. doi: 10.1088/1742-5468/2008/10/P10008
Boccaletti, S., Latora, V., Moreno, Y., Chavez, M., and Hwang, D. U. (2006). Complex networks: structure and dynamics. Phys. Rep. 424, 175–308. doi: 10.1016/j.physrep.2005.10.009
Borgatti, S. P., and Everett, M. G. (2006). A Graph-theoretic perspective on centrality. Soc. Netw. 28, 466–484. doi: 10.1016/J.SOCNET.2005.11.005
Burggren, W. W., Monticino, M. G., and Oliveras, D. (2005). Assessing physiological complexity. J. Exp. Biol. 208(Pt 17), 3221–3232. doi: 10.1242/jeb.01762
Butts, C. T. (2019). Sna: Tools for Social Network Analysis (R Package Version 2.5). Available online at: https://cran.r-project.org/package=sna (accessed April 14, 2020).
Chumlea, W. C., Guo, S. S., Zeller, C. M., Reo, N. V., Baumgartner, R. N., Garry, P. J., et al. (2001). Total body water reference values and prediction equations for adults. Kidney Int. 59, 2250–2258. doi: 10.1046/j.1523-1755.2001.00741.x
Clemente, G. P., and Grassi, R. (2018). Directed clustering in weighted networks: a new perspective. Chaos Solitons Fract. 107, 26–38. doi: 10.1016/j.chaos.2017.12.007
Costenbader, E., and Valente, T. W. (2003). The stability of centrality measures when networks are sampled. Soc. Netw. 25, 283–307.
Csárdi, G., Nepusz, T., and Airoldi, E. M. (2016). Statistical Network Analysis with Igraph. Berlin: Springer.
Dablander, F., and Hinne, M. (2019). Node centrality measures are a poor substitute for causal inference. Sci. Rep. 9:6846. doi: 10.1038/s41598-019-43033-9
DeMers, D., and Wachs, D. (2020). Physiology, Mean Arterial Pressure: StatPearls. StatPearls Publishing. Available online at: http://www.ncbi.nlm.nih.gov/books/NBK538226/ (accessed August 4, 2020). D. DeMers and D. Wachs (2020). “Physiology, mean arterial pressure,” in StatPearls, (Treasure Island, FL: StatPearls Publishing).
Eppstein, D., and Strash, D. (2011). Listing all Maximal Cliques in Large Sparse Realworld Graphs. arXiv [Preprint]. Available online at: https://arxiv.org/abs/1103.0318 (accessed August 15, 2020).
Fagiolo, G. (2007). Clustering in complex directed networks. Phys. Rev. E 76:026107. doi: 10.1103/PhysRevE.76.026107
Fossion, R., Rivera, A. L., and Estañol, B. (2018). A physicist’s view of homeostasis: how time series of continuous monitoring reflect the function of physiological variables in regulatory mechanisms. Physiol. Meas. 39:084007. doi: 10.1088/1361-6579/aad8db
Freedman, D. S., Thornton, J. C., Pi-Sunyer, F. X., Heymsfield, S. B., Wang, J., Pierson, R. N., et al. (2012). The body adiposity index (hip circumference ÷ height(1.5)) is not a more accurate measure of adiposity than is BMI waist circumference or hip circumference. Obesity 20, 2438–2444. doi: 10.1038/oby.2012.81
Freeman, L. C. (1978). Centrality in social networks conceptual clarification. Soc. Netw. 1, 215–239. doi: 10.1016/0378-8733(78)90021-7
Fruchterman, T. M. J., and Reingold, E. M. (1991). Graph drawing by force-directed placement. Softw: Pract. Exper. 21, 1129–1164. doi: 10.1002/spe.4380211102
Fukuoka, Y., Narita, T., Fujita, H., Morii, T., Sato, T., Sassa, M. H., et al. (2019). Importance of physical evaluation using skeletal muscle mass index and body fat percentage to prevent sarcopenia in elderly Japanese diabetes patients. J. Diabetes Invest. 10, 322–330. doi: 10.1111/jdi.12908
Ganong, W. F. (1969). Review of Medical Physiology, 4th Edn, New York, NY: Lange Medical Publications.
Gólczewski, T., Lubiński, W., and Chciałowski, A. (2012). A mathematical reason for FEV1/FVC dependence on age. Respir. Res. 13:57. doi: 10.1186/1465-9921-13-57
Goldstein, D. S. (2019). How does homeostasis happen? Integrative physiological, systems biological, and evolutionary perspectives. Am. J. Physiol. Regul. Integr. Comp. Physiol. 316, R301–R317. doi: 10.1152/ajpregu.00396.2018
Hall, J. E. (2011). Guyton and Hall Textbook of Medical Physiology, 12th Edn, Philadelphia: Saunders Elsevier.
Hansen, L. K., Grimm, R. H. Jr., and Neaton, J. D. (1990). The relationship of white blood cell count to other cardiovascular risk factors. Int. J. Epidemiol. 19, 881–888. doi: 10.1093/ije/19.4.881
Hofer, S. M., and Sliwinski, M. J. (2001). Understanding ageing. An evaluation of research designs for assessing the interdependence of ageing-related changes. Gerontology 47, 341–352. doi: 10.1159/000052825
Ito, F., and Ito, T. (2020). High-Density Lipoprotein (HDL) triglyceride and oxidized HDL: new lipid biomarkers of lipoprotein-related atherosclerotic cardiovascular disease. Antioxidants 9:362. doi: 10.3390/antiox9050362
Ivanov, P. C., and Bartsch, R. P. (2014). “Network physiology: mapping interactions between networks of physiologic networks,” in Networks of Networks: The Last Frontier of Complexity. Understanding Complex Systems, eds G. D’Agostino and A. Scala (Cham: Springer), doi: 10.1007/978-3-319-03518-5_10
Ivanov, P. C. H., Liu, K. K. L., and Bartsch, R. P. (2016). Focus on the emerging new fields of network physiology and network medicine. New J. Phys. 18:100201.
Jabłonowska-Lietz, B., Wrzosek, M., Włodarczyk, M., and Nowicka, G. (2017). New indexes of body fat distribution, visceral adiposity index, body adiposity index, waist-to-height ratio, and metabolic disturbances in the obese. Kardiol. Pol. 75, 1185–1191. doi: 10.5603/KP.a2017.0149
Katz, L. (1953). A new status index derived from sociometric analysis. Psychometrika 18, 39–43. doi: 10.1007/BF02289026
Kieffer, T. J., and Habener, J. F. (2000). The adipoinsular axis: effects of leptin on pancreatic beta-cells. Am. J. Physiol. Endocrinol. Metab. 278, E1–E14. doi: 10.1152/ajpendo.2000.278.1.E1
Kleinberg, J., and Tardos, É (1998). Approximations for the disjoint paths problem in high-diameter planar networks. J. Comput. Syst. Sci. 57, 61–73. doi: 10.1006/jcss.1998.1579
Koschützki, D., Lehmann, K. A., Peeters, L., Richter, S., Tenfelde-Podehl, D., and Zlotowski, O. (2005). “Centrality indices,” in Network Analysis. Lecture Notes in Computer Science, eds U. Brandes and T. Erlebach (Berlin: Springer).
Langfelder, P., and Horvath, S. (2008). WGCNA: an R package for weighted correlation network analysis. BMC Bioinform. 9:559. doi: 10.1186/1471-2105-9-559
Liu, K., Bartsch, R. P., Ma, Q., and Ivanov, P. C. (2015). Major component analysis of dynamic networks of physiologic organ interactions. J. Phys. 640:012013. doi: 10.1088/1742-6596/640/1/012013
MacPherson, J. C., Comhair, S. A., Erzurum, S. C., Klein, D. F., Lipscomb, M. F., Kavuru, M. S., et al. (2001). Eosinophils are a major source of nitric oxide-derived oxidants in severe asthma: characterization of pathways available to eosinophils for generating reactive nitrogen species. J. Immunol. 166, 5763–5772. doi: 10.4049/jimmunol.166.9.5763
Madjid, M., and Fatemi, O. (2013). Components of the complete blood count as risk predictors for coronary heart disease: in-depth review and update. Texas Heart Instit. J. 40, 17–29.
Maiti, K. S., Lewton, M., Fill, E., and Apolonskiy, A. (2019). Human beings as islands of stability: Monitoring body states using breath profiles. Sci. Rep. 9:16167. doi: 10.1038/s41598-019-51417-0
Matthews, D. R., Hosker, J. P., Rudenski, A. S., Naylor, B. A., Treacher, D. F., and Turner, R. C. (1985). Homeostasis model assessment: insulin resistance and beta-cell function from fasting plasma glucose and insulin concentrations in man. Diabetologia 28, 412–419. doi: 10.1007/BF00280883
McCormack, M. (2020). “Diffusing capacity for carbon monoxide,” in UpToDate, eds J. K. Stoller and H. Hollingsworth, Available online at: https://www.uptodate.com/contents/diffusing-capacity-for-carbon-monoxide (accessed August 7, 2020).
Meigs, J. B., Hu, F. B., Rifai, N., and Manson, J. E. (2004). Biomarkers of endothelial dysfunction and risk of type 2 diabetes mellitus. JAMA 291, 1978–1986. doi: 10.1001/jama.291.16.1978
Meilă, M. (2007). Comparing clusterings—an information based distance. J. Multiv. Analys. 98, 873–895. doi: 10.1016/j.jmva.2006.11.013
Mihaicuta, S., Udrescu, M., Topirceanu, A., and Udrescu, L. (2017). Network science meets respiratory medicine for OSAS phenotyping and severity prediction. Peerj 5:e3289. doi: 10.7717/peerj.3289
Navidinia, M., and Ebadi, P. (2017). Medical consequences of long-term anabolic-androgenic steroids (AASs) abuses in athletes. Biomed. Res. Tokyo 28, 5693–5701.
Newman, M. (2006). Modularity and community structure in networks. Proc. Natl. Acad. Sci. U.S.A. 103, 8577–8582. doi: 10.1073/pnas.0601602103
Ngoc-Anh, L. (2009). Oxidized lipids and lipoproteins: indices of risk or targets for management. Clin. Lipidol. 4, 41–54. doi: 10.2217/17584299.4.1.41
Noack, A. (2009). Modularity clustering is force-directed layout. Phys. Rev. E 79:102. doi: 10.1103/physreve.79.026102
Ogata, H., Goto, S., Sato, K., Fujibuchi, W., Bono, H., and Kanehisa, M. (1999). KEGG: kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 27, 29–34. doi: 10.1093/nar/27.1.29
Onnela, J.-P., Saramäki, J., Kertész, J., and Kaski, K. (2005). Intensity and coherence of motifs in weighted complex networks. Phys. Rev. E 71:065103. doi: 10.1103/PhysRevE.71.065103
Park, J. E., Chung, J. H., Lee, K. H., and Shin, K. C. (2012). The effect of body composition on pulmonary function. Tubercul. Respir. Dis. 72, 433–440. doi: 10.4046/trd.2012.72.5.433
Pavlopoulos, G. A., Secrier, M., Moschopoulos, C. N., Soldatos, T. G., Kossida, S., Aerts, J., et al. (2011). Using graph theory to analyze biological networks. Biodata Min. 4:10. doi: 10.1186/1756-0381-4-10
Pettersson-Pablo, P., Nilsson, T. K., Breimer, L. H., and Hurtig-Wennlöf, A. (2019). Body fat percentage is more strongly associated with biomarkers of low-grade inflammation than traditional cardiometabolic risk factors in healthy young adults - the Lifestyle, Biomarkers, and Atherosclerosis study. Scand. J. Clin. Lab. Invest. 79, 182–187. doi: 10.1080/00365513.2019.1576219
Physiopedia (2020). Available online at: https://www.physio-pedia.com/home/ (accessed August 7, 2020).
Prediletto, R., Fornai, E., Catapano, G., and Carli, C. (2007). Assessment of the alveolar volume when sampling exhaled gas at different expired volumes in the single breath diffusion test. BMC Pulm. Med. 7:18. doi: 10.1186/1471-2466-7-18
R Core Team (2020). R: A Language and Environment for Statistical Computing (4.0.1). Vienna: R Foundation for Statistical Computing.
Rand, W. M. (1971). Objective criteria for the evaluation of clustering methods. J. Am. Statist. Assoc. 66, 846–850. doi: 10.1080/01621459.1971.10482356
Reichardt, J., and Bornholdt, S. (2006). Statistical mechanics of community detection. Phys. Rev. E 74:016110. doi: 10.1103/PhysRevE.74.016110
Riley, L. K., and Rupert, J. (2015). Evaluation of Patients with Leukocytosis. Am. Fam. Phys. 92, 1004–1011.
Rivera, A. L., Estañol, B., Robles-Cabrera, A., Toledo-Roy, J. C., Fossion, R., and Frank, A. (2018). “Looking for biomarkers in physiological time series,” in Quantitative Models for Microscopic to Macroscopic Biological Macromolecules and Tissues, eds L. Olivares-Quiroz and O. Resendis-Antonio (Cham: Springer International Publishing), 111–131. doi: 10.1007/978-3-319-73975-5_6
Rosvall, M., and Bergstrom, C. T. (2008). Maps of random walks on complex networks reveal community structure. Proc. Natl. Acad. Sci. U.S.A. 105, 1118–1123. doi: 10.1073/pnas.0706851105
Salvagno, G. L., Sanchis-Gomar, F., Picanza, A., and Lippi, G. (2015). Red blood cell distribution width: a simple parameter with multiple clinical applications. Crit. Rev. Clin. Lab. Sci. 52, 86–105.
Sarma, P. R. (1990). “Chapter 152: red cell indices,” in Clinical Methods: The History, Physical, and Laboratory Examinations, 3rd Edn, eds H. K. Walker, W. D. Hall, and J. W. Hurst (Boston: Butterworths).
Silva, A. M., Heymsfield, S. B., Gallagher, D., Albu, J., Pi-Sunyer, X. F., Pierson, R. N., et al. (2008). Evaluation of between-methods agreement of extracellular water measurements in adults and children. Am. J. Clin. Nutr. 88, 315–323. doi: 10.1093/ajcn/88.2.315
Takeoka, A., Tayama, J., Yamasaki, H., Kobayashi, M., Ogawa, S., Saigo, T., et al. (2016). Intra-abdominal fat accumulation is a hypertension risk factor in young adulthood: a cross-sectional study. Medicine 95:e5361. doi: 10.1097/MD.0000000000005361
Vargas, H. O., Nunes, S. O., Barbosa, D. S., Vargas, M. M., Cestari, A., Dodd, S., et al. (2014). Castelli risk indexes 1 and 2 are higher in major depression but other characteristics of the metabolic syndrome are not specific to mood disorders. Life Sci. 102, 65–71. doi: 10.1016/j.lfs.2014.02.033
Vaz Fragoso, C. A., Cain, H. C., Casaburi, R., Lee, P. J., Iannone, L., Leo-Summers, L. S., et al. (2017). Spirometry, static lung volumes, and diffusing capacity. Respir. Care 62, 1137–1147. doi: 10.4187/respcare.05515
Vermesi, I., Restuccia, F., Walker, C., and Rein, G. (2018). Carbon monoxide diffusion through porous walls: evidence found in incidents and experimental studies. Front. Built Environ. 4:44. doi: 10.3389/fbuil.2018.00044
Wald, N. J., Idle, M., Boreham, J., and Bailey, A. (1981). Carbon monoxide in breath in relation to smoking and carboxyhaemoglobin levels. Thorax 36, 366–369. doi: 10.1136/thx.36.5.366
Wasserman, S., and Faust, K. (1994). Social Network Analysis: Methods and Applications. Cambridge: Cambridge University Press.
Watts, D. J., and Strogatz, S. H. (1998). Collective dynamics of “small-world” networks. Nature 393, 440–442. doi: 10.1038/30918
Welch, A. A., Kelaiditi, E., Jennings, A., Steves, C. J., Spector, T. D., and MacGregor, A. (2016). Dietary magnesium is positively associated with skeletal muscle power and indices of muscle mass and may attenuate the association between circulating C-reactive protein and muscle mass in women. J. Bone Miner. Res. 31, 317–325. doi: 10.1002/jbmr.2692
Keywords: physiological networks, complex inference network, homeostasis, anthropometric measures, blood test biomarkers
Citation: Barajas-Martínez A, Ibarra-Coronado E, Sierra-Vargas MP, Cruz-Bautista I, Almeda-Valdes P, Aguilar-Salinas CA, Fossion R, Stephens CR, Vargas-Domínguez C, Atzatzi-Aguilar OG, Debray-Garcí Y, García-Torrentera R, Bobadilla K, Naranjo Meneses MA, Mena Orozco DA, Lam-Chung CE, Martínez Garcés V, Lecona OA, Marín-García AO, Frank A and Rivera AL (2021) Physiological Network From Anthropometric and Blood Test Biomarkers. Front. Physiol. 11:612598. doi: 10.3389/fphys.2020.612598
Received: 30 September 2020; Accepted: 16 December 2020;
Published: 12 January 2021.
Edited by:
Plamen Ch. Ivanov, Boston University, United StatesReviewed by:
Stefano Finazzi, Mario Negri Pharmacological Research Institute, ItalyCopyright © 2021 Barajas-Martínez, Ibarra-Coronado, Sierra-Vargas, Cruz-Bautista, Almeda-Valdes, Aguilar-Salinas, Fossion, Stephens, Vargas-Domínguez, Atzatzi-Aguilar, Debray-García, García-Torrentera, Bobadilla, Naranjo Meneses, Mena Orozco, Lam-Chung, Martínez Garcés, Lecona, Marín-García, Frank and Rivera. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ana Leonor Rivera, YW5hLnJpdmVyYUBudWNsZWFyZXMudW5hbS5teA==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.