
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Physiol. , 28 September 2018
Sec. Systems Biology Archive
Volume 9 - 2018 | https://doi.org/10.3389/fphys.2018.01355
 Cheng Zhang1*
Cheng Zhang1* Gholamreza Bidkhori1
Gholamreza Bidkhori1 Rui Benfeitas1
Rui Benfeitas1 Sunjae Lee1
Sunjae Lee1 Muhammad Arif1
Muhammad Arif1 Mathias Uhlén1
Mathias Uhlén1 Adil Mardinoglu1,2,3*
Adil Mardinoglu1,2,3*Genome-scale metabolic models (GEMs) are comprehensive descriptions of cell metabolism and have been extensively used to understand biological responses in health and disease. One such application is in determining metabolic adaptation to the absence of a gene or reaction, i.e., essentiality analysis. However, current methods do not permit efficiently and accurately quantifying reaction/gene essentiality. Here, we present Essentiality Score Simulator (ESS), a tool for quantification of gene/reaction essentialities in GEMs. ESS quantifies and scores essentiality of each reaction/gene and their combinations based on the stoichiometric balance using synthetic lethal analysis. This method provides an option to weight metabolic models which currently rely mostly on topologic parameters, and is potentially useful to investigate the metabolic pathway differences between different organisms, cells, tissues, and/or diseases. We benchmarked the proposed method against multiple network topology parameters, and observed that our method displayed higher accuracy based on experimental evidence. In addition, we demonstrated its application in the wild-type and ldh knock-out E. coli core model, as well as two human cell lines, and revealed the changes of essentiality in metabolic pathways based on the reactions essentiality score. ESS is available without any limitation at https://sourceforge.net/projects/essentiality-score-simulator.
Genome-scale metabolic models (GEMs) are congregations of biochemical reactions that occur in an organism or cell/tissue (Mardinoglu and Nielsen, 2015). GEMs have become one of the denominators in systems biology and have been extensively and successfully used in metabolic engineering, synthetic biology, antibiotic design, understanding diseases, biomarker discovery, and drug target identification (Zhang and Hua, 2015; Benfeitas et al., 2017; Bosley et al., 2017; Uhlén et al., 2017; Mardinoglu et al., 2018; Turanli et al., 2018). GEMs for hundreds of gut microbiota, healthy tissues and tumor samples have been generated in AGORA (Magnúsdóttir et al., 2017), Human Metabolic Atlas (Pornputtapong et al., 2015) and Human Pathology Atlas (HPA) (Uhlén et al., 2015, 2017) efforts, respectively. These resources may provide information for investigating the metabolic capability with species or individual-tumor resolution, but also raise the challenge of comparing and stratifying GEMs in large-scale studies.
There are number of ways to compare GEMs, such as network topology parameters (Doncheva et al., 2012; Vinayagam et al., 2016). For instance, betweenness and degree centrality are two topology parameters frequently used for comparing node importance in a network (Koschützki and Schreiber, 2008). However, topological analyses of GEMs neglect stoichiometric balance and likely miss the required input or output of a metabolic system (Zhang and Hua, 2015). A possible solution would be weighting the stoichiometric properties for each reaction/gene using Essentiality Analysis (EA) (Palumbo et al., 2005, 2007). However, EA only provides binary information about the essentiality of the reaction, and this is insufficient for complex GEMs since there would be too little essential reactions. In this case, a higher degree of EA such as Synthetic Lethality Analysis (SLA) is necessary to provide additional information about non-essential reactions/genes. Generally, it is very difficult to interpret the results of SLA, since thousands to millions of synthetic lethal (SL) combinations may be involved. An option for interpretation of SLA result is using Degree of Essentiality (DoE) (Suthers et al., 2009), but DoE scores ignore the difference between reactions/genes involves in single and multiple SL combinations.
In this study, we present Essentiality Score Simulator (ESS), a tool that uses SLA's results as input to calculate reaction-/gene-specific Essentiality Score (EScore). Unlike topology based methods, ESS relies on the highly valuable biochemical stoichiometric information embedded in GEMs to evaluate the structural properties of reactions/genes. In addition, compared to the DoE, ESS makes the complete use of SLA results and provides higher resolution scores for each reaction/genes.
The main purpose of ESS is to qualitatively evaluate the essentiality of reactions/genes based on stoichiometric balance. The input for ESS includes a constrain based model either in COBRA (Schellenberger et al., 2011) or RAVEN format (Agren et al., 2013), the objective function and the maximal level of SLA (denoted as level n hereafter) sought by the user. An n = 1 implies targeting of a single reaction/gene, whereas n > 1 test for combinations of reactions/genes after excluding single lethal reactions/genes. With these inputs, ESS identifies all essential and synthetic lethal reactions/genes internally using an adapted FastGeneSL (Pratapa et al., 2015; Zhang et al., 2015), and then uses a unique algorithm to calculate the ES for each reaction/gene based on the SLA results.
Figure 1 provides examples of level 2 ESS calculations for two sample cases to elucidate the concept. The first pathway (Figure 1A), with 5 reactions and an objective reaction, shows that every non-objective reaction could be essential or synthetic lethal in 4 cases for level 2 SLA (i.e., single C knockout, or double knockouts CA, CB, or CD). For instance, reaction C is not essential per se, but double knockout of CD would be essential. As a result of the weighted scores, the ESS of C is 0.25. In this case, only the true SL combinations would be considered in order to eliminate redundancy, and that is why CA was neglected since single deletion of A would be lethal. It should be noted that the EScore for an essential reaction (e.g., reaction A) is always 1 regardless of the level of ESS. Figure 1B shows that reaction D has an EScore that is higher than reaction B and C. This is because reaction D is overrepresented and involved in two SL pairs, while reactions B and C are only involved in one. In other words, ESS could identify the hot-spots in the model. This also explains why reaction D has a higher EScore in Figure 1B than in Figure 1A. As topological view, it can also be explained by the shortest path to the objective function.
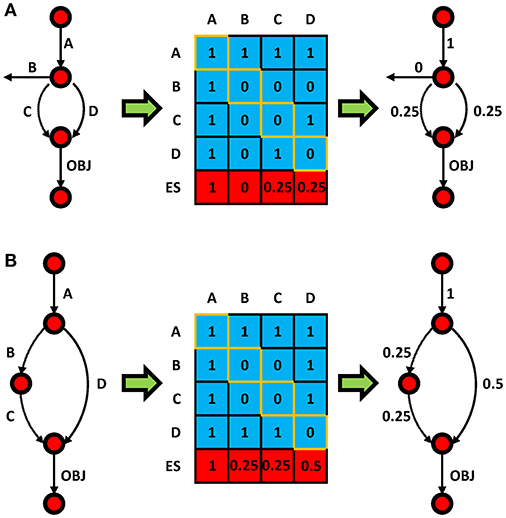
Figure 1. Toy model examples (A,B) showing the principal of ESS. Circles and arrows represent metabolites and reactions, respectively. The value in the ith row and jth column of the blue matrix is 1 if knockout of reaction i and j lead to zero flux OBJ reaction; otherwise it is 0. Diagonal elements (orange) represent single gene essentialities; all others represent double knockouts. The ES for each reaction (red row) is presented in the matrix and mapped to the pathway (right).
It is noteworthy that, this principle could be applied to higher level SLA. The increase of SLA level could give a higher resolution of the EScore. Furthermore, the principle could be implemented for calculation of EScore for genes. To calculate EScore for a specific reaction/gene in any level, all possible synthetic lethal combinations involving a reaction/gene should be introduced for normalization purpose. For example, in the case of the 4 reaction/gene model of Figure 1A, the number of possible combination for reaction/gene A in level 2 ESS is 4 [A(A), AB, AC, and AD]. For level 3 ESS it would then be 16 [A(AA), A(A)B, A(A)C, A(A)D, … AD(A), ADB, ADC, and AD(D)]. Note that, there are repetition in the population [e.g., A(A)D and AD(A)], and this give weight to different combination. Since this number is the same for every reaction/gene in the same model for a given n, we could calculate EScore of a reaction as follows:
where ESi represents the EScore of reaction/gene i, yij represents the number of combination that reaction/gene i is SL (or essential) at level j. X represents number of reactions/genes in the model. In this equation, ESi for an essential reaction/gene is always 1 since for any j > 1, yij would be 0; otherwise, ESi is always no more than 1. In addition, a comparison of EScore among different models is possible since EScore is normalized by the model's X. We used level 3 ESS throughout this study considering the balance between accuracy and computational cost.
Regarding the Bidkhori et al. method (Bidkhori et al., 2018), we generated directed Metabolite-Metabolite network (MMN), directed Reaction-Reaction network (RRN), and directed Gene-Gene network from GEMs (GGN). The currency metabolites (Khosraviani et al., 2016) such as cofactors, coenzymes and H2O were removed before generating RRN and GGN. The importance of the nodes (metabolites in MMN, reactions in RRN and genes in GGN) was scored by computing centrality topological parameters i.e., betweenness, eccentricity, closeness, and degree (Bidkhori et al., 2018). The nodes were ranked in the basis of each node's topological measures. The ranking and scoring were calculated for each node in the largest connected component in each generated network.
Genome-wide CRISPR gene essentiality scores (CERES) were retrieved from Avana public datasets 18Q2 (Meyers et al., 2017). In brief, essentiality of each gene in cancer cell lines were tested using lentiviral vectors expressing the Cas9 nuclease and calculated by a computational method developed in that study. The CERES scores are used to benchmark the computationally estimated EScore in this study.
The E. coli core model was reconstructed based on a previous study (Orth et al., 2010) and retrieved from BiGG database (King et al., 2016). The original constraints and objective function are used for simulations of wild-type E. coli. The model for ldh knockout E. coli mutant is obtained by removing the reaction “LDH_D” in the wild-type model. The EScore of “LDH_D” for mutant model is set the same as in wild-type model for fair comparison with the wild-type model. The reaction “ATPM” is excluded from the ESS calculation since it is a pseudo reaction that presents a mandatory function of the model.
Cell line specific GEMs, iIPC298 and iNCIH1299, were reconstructed based on the RNAseq gene expression data downloaded from CCLE public dataset 18Q2 as RPKM (Barretina et al., 2012) and using a previously developed task-driven model reconstruction (tINIT) algorithm in RAVEN toolbox (Agren et al., 2014). The tINIT algorithm employs defined metabolic tasks for imposing constraints on the functionality of the reconstructed models. In this specific case, we changed the input of the growth task from Ham's media to RPMI1640 which was used in the experiments. The constraints for the cell GEMs calculated based on the RPMI1640 composition are provided as supplementary (Table S1). The adapted metabolic tasks, the RNA-Seq data and a generic GEM for human cancer from our previous study (Uhlén et al., 2017) were used as inputs for the tINIT algorithm, and as a result, cell line specific GEMs have been generated.
All linear programming and mixed integer linear programming problems are solved by the freely available “mosek” solver version 8 obtained from https://www.mosek.com/downloads/. All computational times reported in this paper are for a single core CPU with 6 GB RAM in server.
ESS is a method build in Matlab (version R2017b) environment, and the source code and models (including the cell line models) are available at https://sourceforge.net/projects/essentiality-score-simulator/. In addition, SBMLlib (Bornstein et al., 2008) and COBRA/RAVEN toolbox (Schellenberger et al., 2011; Agren et al., 2013) are also required to import SBML format GEMs.
To demonstrate the advantage of ESS compared to topology based method, we firstly employed the core metabolic model of E. coli with 95 reactions as a proof of concept case. We calculated and compared the EScores and betweenness centralities (BCs) which is one of the most used topology based method for all reactions in the core model (Table S2). Within the 95 reactions, there are 10 reactions that display zero scores for both EScores and BCs, and 49 reactions that have non-zero scores for both EScores and BCs. Spearman correlation between EScores and BCs for the 49 reactions was found substantially low (r = 0.0994; P > 0.1), suggesting inconsistency between two metrics although both methods classify these reactions as essential to a certain extent. There are 16 reactions that have non-zero EScores and zero BCs, and 15 of them are responsible for exchanging of very important or essential metabolites, including carbon dioxide, oxygen, glucose, ethanol, formate, lactate, proton, ammonium, phosphate, and succinate. Moreover, among these exchange reactions, those for glucose, proton and ammonium exchange have the maximum EScores (equal to one), which means they are essential for growth of E. coli in the given condition. This highlights the limitation of topology based methods which missed uptake of glucose as essential because of neglecting stoichiometric info as previously reported (Zhang and Hua, 2015). In addition, there is also another reaction, RPI (ribose-5-phosphate isomerase), that is also missed by betweenness (BC = 0), and this reaction has been already experimentally validated as essential in E. coli in previous study (Neidhardt and Curtiss, 1999) which further proves the advantage of ESS compared to betweenness. On the other hand, there are 20 reactions that showed non-zero scores uniquely in betweenness analysis. These reactions are mainly involved in glycolysis and TCA cycle, including FBP (fructose-bisphosphatase), AKGDH (2-oxogluterate dehydrogenase) and SUCOAS (succinyl-CoA synthetase). The observation that other reactions show both significantly higher BCs and EScores (Student t-test; P < 0.05) suggests that these 20 reactions are possibly not metabolically important. Moreover, some of them have been reported to be non-essential experimentally, which is the case of FBP in E. coli (Fujita et al., 1998).
In order to further test the efficiency and accuracy of ESS in actual genome-scale model cases, we reconstructed two novel human cell line specific GEMs for IPC298 and NCIH1299, named iIPC298 and iNCIH1299, respectively. We selected these two cell lines based on availability of transcriptomic data and experimentally derived CRISPR essentiality scores (CERES algorithm, see section Materials and Methods), and both are cultured in the same medium, RPMI1640. The iIPC298 includes 3414 reactions, 2102 metabolites, and 1827 genes, whereas iNCIH1299 includes 3550 reactions, 2117 metabolites and 1906 genes. Then, we applied level 3 ESS to these two human cancer cell line GEMs to calculate EScores for genes. The computational costs for this analysis were much lower compared to greedy search which was used in most EA analysis (Table 1). We also applied several frequently used topology methods to these two GEMs including Betweenness Centrality, Closeness Centrality, Eccentricity Centrality and Degree (Table S3). To check how much ESS can identify experimentally derived gene essentialities, we calculated the Spearman's correlation between all in silico predicted essentiality or centrality scores and the CRISPR derived CERES scores for all genes with non-zero EScores (Table 2).
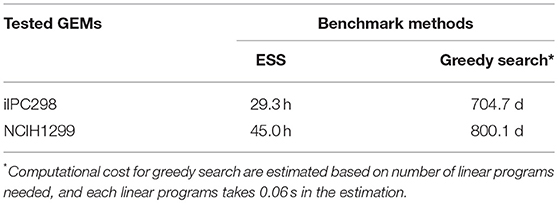
Table 1. Computational costs of ESS and greedy search for level 3 synthetic lethality analysis for human cell line GEMs.
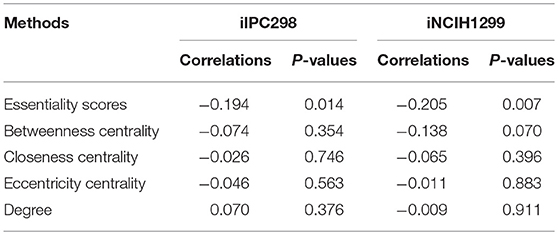
Table 2. Spearman correlation between experimentally derived CERES scores and the in silico methods.
CERES scores are normalized essentiality scores of genes where the median values for essential and non-essential genes are −1 and 0, respectively. Therefore, the correlation between EScores and CERESs should be negative if they agree with each other. Indeed, the respective correlations between EScores and CERESs for iPC298 and iNCIH1299 are −0.194 and −0.205, and both of them being statistically significant (P < 0.05), whereas, as shown in Table 1, the correlations between network topology based parameters for these genes and CERESs for iPC298 or NCIH1299 could not meet the same statistical significance. These suggest that the EScores calculated by ESS are accurate and correlate better with experimental data compared to topology based method.
As a proof of concept, we applied the method to the core metabolic model of E. coli of wide-type and ldh knockout mutant and calculated the EScores for all reactions in both models to demonstrate the usage of ESS in model comparison. The full results of level 3 ESS for wild-type and mutant E. coli core model are provided as Table S4. First of all, we found 48 and 4 reactions which respectively display larger and lower EScores in the knockout, and the average EScore is increased after ldh knockout. This suggests that the mutant metabolic model is less robust in terms of growth, which is expected since deletion of metabolic genes probably decreases the metabolic potential of the bacteria. Moreover, the metabolic pathways with the highest increases in EScore increases are acetaldehyde dehydrogenase (ACALD), oxidative phosphorylation (NADH16 and CYTBD), uptake of oxygen (EX_o2_e and O2t) and formate transportation (FORt2 and EX_for_e). ACALD and formate transportation are key alternatives for LDH_D in the model which explains these EScore increases. In addition, LDH_D is an important reaction for anaerobic growth, and therefore its deletion will surely increase the importance of aerobic metabolic function. This explains why oxidative phosphorylation and oxygen uptake have the highest increase in EScore since they are key pathways in aerobic growth for E. coli. On the other hand, the reactions with top EScore decreases are D_LACt2 and EX_lac__D_e, both of which are responsible for transportation of lactate. These two reactions are downstream of LDH_D in the model, and their EScores decreased since they become dead-end reactions in the mutant model.
In this study, we proposed a novel method name ESS, which shows as an accurate and efficient method for quantifying reaction and gene EScores. This method was implemented in Matlab and that requires standard constraint-based modeling toolboxes (COBRA or RAVEN). While gene and reaction essentiality have extensively been examined using GEMs, we here introduce a comprehensive scoring system for determining essentiality for single and combined reactions or genes. ESS employs logical transformation of model to refine the gene-protein-reaction relationships, avoiding the potential problem caused by redundant enzymes during the essentiality analysis. We benchmarked ESS against topology based methods and using experimentally derived essentiality scores for reference pan-essential and non-essential genes, and observed that ESS displays higher accuracy than topology-based methods. It should be noted that essentiality in GEMs is dependent on the inputs and objective function. Therefore, EScores could be different for the same GEMs given different inputs and/or objective function. As we showed in the last case study, the proposed method could be easily used to compare GEMs generated from the same reference model. Therefore, it could be a promising tool for future studies that investigate the relationships among gut microbiota, different cells and tissues using resources such as AGORA and HPA where models were generated from a common reference. In this context, we are confident that ESS will have a great application in biotechnology and systems medicine.
AM and CZ conducted the study. CZ developed the method. SL, RB, GB, MA and MU helped in development of the method. CZ performed most of the analysis and GB helped in the analysis. CZ wrote the paper and all authors were involved in editing the paper.
This work was funded by the Knut and Alice Wallenberg Foundation. We thank the National Genomics Infrastructure and Swedish National Infrastructure for Computing at UPPMAX and C3SE for providing assistance in computational infrastructure.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphys.2018.01355/full#supplementary-material
Table S1. The contraints for exchange reactions to simulate the input from RPMI medium.
Table S2. EScores and BCs for E. coli core model.
Table S3. CERES, EScores and all other topological parameters calculated for cell line specific GEMs.
Table S4. The full results of level 3 ESS for wild-type and mutant E. coli core model.
Agren, R., Liu, L., Shoaie, S., Vongsangnak, W., Nookaew, I., and Nielsen, J. (2013). The RAVEN toolbox and its use for generating a genome-scale metabolic model for Penicillium chrysogenum. PLoS Comput. Biol. 9:e1002980. doi: 10.1371/journal.pcbi.1002980
Agren, R., Mardinoglu, A., Asplund, A., Kampf, C., Uhlen, M., and Nielsen, J. (2014). Identification of anticancer drugs for Hepatocellular Carcinoma through personalized genome-scale metabolic modeling. Mol. Syst. Biol. 10:721. doi: 10.1002/msb.145122
Barretina, J., Caponigro, G., Stransky, N., Venkatesan, K., Margolin, A. A., Kim, S., et al. (2012). The cancer cell line encyclopedia enables predictive modelling of anticancer drug sensitivity (vol 483, pg 603, 2012). Nature 492, 290–290. doi: 10.1038/nature11735
Benfeitas, R., Uhlen, M., Nielsen, J., and Mardinoglu, A. (2017). New challenges to study heterogeneity in cancer redox metabolism. Front. Cell Dev. Biol. 5:65. doi: 10.3389/fcell.2017.00065
Bidkhori, G., Benfeitas, R., Elmas, E., Kararoudi, M. N., Arif, M., Uhlen, M., et al. (2018). Metabolic network-based identification and prioritization of anticancer targets based on expression data in Hepatocellular Carcinoma. Front. Physiol. 9:916. doi: 10.3389/fphys.2018.00916
Bornstein, B. J., Keating, S. M., Jouraku, A., and Hucka, M. (2008). LibSBML: an API library for SBML. Bioinformatics 24, 880–881. doi: 10.1093/bioinformatics/btn051
Bosley, J., Boren, C., Lee, S., Grøtli, M., Nielsen, J., Uhlen, M., et al. (2017). Improving the economics of NASH/NAFLD treatment through the use of systems biology. Drug Discov. Today 22, 1532–1538. doi: 10.1016/j.drudis.2017.07.005
Doncheva, N. T., Assenov, Y., Domingues, F. S., and Albrecht, M. (2012). Topological analysis and interactive visualization of biological networks and protein structures. Nat. Protoc. 7, 670–685. doi: 10.1038/nprot.2012.004
Fujita, Y., Yoshida, K., Miwa, Y., Yanai, N., Nagakawa, E., and Kasahara, Y. (1998). Identification and expression of the Bacillus subtilis fructose-1, 6-bisphosphatase gene (fbp). J. Bacteriol. 180, 4309–4313.
Khosraviani, M., Saheb Zamani, M., and Bidkhori, G. (2016). FogLight: an efficient matrix-based approach to construct metabolic pathways by search space reduction. Bioinformatics 32, 398–408. doi: 10.1093/bioinformatics/btv578
King, Z. A., Lu, J., Dräger, A., Miller, P., Federowicz, S., Lerman, J. A., et al. (2016). BiGG models: a platform for integrating, standardizing and sharing genome-scale models. Nucleic Acids Res. 44, D515–D522. doi: 10.1093/nar/gkv1049
Koschützki, D., and Schreiber, F. (2008). Centrality analysis methods for biological networks and their application to gene regulatory networks. Gene Regul. Syst. Biol. 2, 193–201. doi: 10.4137/GRSB.S702
Magnúsdóttir, S., Heinken, A., Kutt, L., Ravcheev, D. A., Bauer, E., Noronha, A., et al. (2017). Generation of genome-scale metabolic reconstructions for 773 members of the human gut microbiota. Nat. Biotechnol. 35, 81–89. doi: 10.1038/nbt.3703
Mardinoglu, A., Boren, J., Smith, U., Uhlen, M., and Nielsen, J. (2018). Systems biology in hepatology: approaches and applications. Nat. Rev. Gastroenterol. Hepatol. 15, 365–377. doi: 10.1038/s41575-018-0007-8
Mardinoglu, A., and Nielsen, J. (2015). New paradigms for metabolic modeling of human cells. Curr. Opin. Biotechnol. 34, 91–97. doi: 10.1016/j.copbio.2014.12.013
Meyers, R. M., Bryan, J. G., Mcfarland, J. M., Weir, B. A., Sizemore, A. E., Xu, H., et al. (2017). Computational correction of copy number effect improves specificity of CRISPR-Cas9 essentiality screens in cancer cells. Nat. Genet. 49, 1779–1784. doi: 10.1038/ng.3984
Neidhardt, F. C., and Curtiss, R. (1999). Escherichia coli and Salmonella: Cellular and Molecular Biology. Washington, DC: ASM Press.
Orth, J. D., Fleming, R. M., and Palsson, B. (2010). Reconstruction and use of microbial metabolic networks: the core Escherichia coli metabolic model as an educational guide. EcoSal Plus 4. doi: 10.1128/ecosalplus.10.2.1
Palumbo, M. C., Colosimo, A., Giuliani, A., and Farina, L. (2005). Functional essentiality from topology features in metabolic networks: a case study in yeast. FEBS Lett. 579, 4642–4646. doi: 10.1016/j.febslet.2005.07.033
Palumbo, M. C., Colosimo, A., Giuliani, A., and Farina, L. (2007). Essentiality is an emergent property of metabolic network wiring. FEBS Lett. 581, 2485–2489. doi: 10.1016/j.febslet.2007.04.067
Pornputtapong, N., Nookaew, I., and Nielsen, J. (2015). Human metabolic atlas: an online resource for human metabolism. Database (Oxford) 2015:bav068. doi: 10.1093/database/bav068
Pratapa, A., Balachandran, S., and Raman, K. (2015). Fast-SL: an efficient algorithm to identify synthetic lethal sets in metabolic networks. Bioinformatics 31, 3299–3305. doi: 10.1093/bioinformatics/btv352
Schellenberger, J., Que, R., Fleming, R. M., Thiele, I., Orth, J. D., Feist, A. M., et al. (2011). Quantitative prediction of cellular metabolism with constraint-based models: the COBRA Toolbox v2.0. Nat. Protoc. 6, 1290–1307. doi: 10.1038/nprot.2011.308
Suthers, P. F., Zomorrodi, A., and Maranas, C. D. (2009). Genome-scale gene/reaction essentiality and synthetic lethality analysis. Mol. Syst. Biol. 5:301. doi: 10.1038/msb.2009.56
Turanli, B., Grøtli, M., Boren, J., Nielsen, J., Uhlen, M., Arga, K. Y., et al. (2018). Drug repositioning for effective prostate cancer treatment. Front. Physiol. 9:500. doi: 10.3389/fphys.2018.00500
Uhlén, M., Fagerberg, L., Hallström, B. M., Lindskog, C., Oksvold, P., Mardinoglu, A., et al. (2015). Tissue-based map of the human proteome. Science 347:1260419. doi: 10.1126/science.1260419
Uhlén, M., Zhang, C., Lee, S., Sjöstedt, E., Fagerberg, L., Bidkhori, G., et al. (2017). A pathology atlas of the human cancer transcriptome. Science 357:eaan2507. doi: 10.1126/science.aan2507
Vinayagam, A., Gibson, T. E., Lee, H. J., Yilmazel, B., Roesel, C., Hu, Y., et al. (2016). Controllability analysis of the directed human protein interaction network identifies disease genes and drug targets. Proc. Natl. Acad. Sci. U.S.A. 113, 4976–4981. doi: 10.1073/pnas.1603992113
Zhang, C., and Hua, Q. (2015). Applications of genome-scale metabolic models in biotechnology and systems medicine. Front. Physiol. 6:413. doi: 10.3389/fphys.2015.00413
Keywords: constraint-based modeling, gene essentiality, genome-scale metabolic models, reaction essentiality, systems biology
Citation: Zhang C, Bidkhori G, Benfeitas R, Lee S, Arif M, Uhlén M and Mardinoglu A (2018) ESS: A Tool for Genome-Scale Quantification of Essentiality Score for Reaction/Genes in Constraint-Based Modeling. Front. Physiol. 9:1355. doi: 10.3389/fphys.2018.01355
Received: 08 June 2018; Accepted: 07 September 2018;
Published: 28 September 2018.
Edited by:
Matteo Barberis, University of Amsterdam, NetherlandsReviewed by:
Alessandro Giuliani, Istituto Superiore di Sanità (ISS), ItalyCopyright © 2018 Zhang, Bidkhori, Benfeitas, Lee, Arif, Uhlén and Mardinoglu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Cheng Zhang, Y2hlbmcuemhhbmdAc2NpbGlmZWxhYi5zZQ==
Adil Mardinoglu, YWRpbG1Ac2NpbGlmZWxhYi5zZQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.