 Nathan Gold
Nathan Gold Martin G. Frasch
Martin G. Frasch Christophe L. Herry
Christophe L. Herry Bryan S. Richardson4
Bryan S. Richardson4- 1Department of Mathematics and Statistics, York University, Toronto, ON, Canada
- 2Department of Obstetrics and Gynecology, University of Washington, Seattle, WA, United States
- 3Dynamical Analysis Laboratory, Clinical Epidemiology Program, Ottawa Hospital Research Institute, Ottawa, ON, Canada
- 4Department of Obstetrics and Gynecology, London Health Sciences Centre, Victoria Hospital, London, ON, Canada
Experimentally and clinically collected time series data are often contaminated with significant confounding noise, creating short, noisy time series. This noise, due to natural variability and measurement error, poses a challenge to conventional change point detection methods. We propose a novel and robust statistical method for change point detection for noisy biological time sequences. Our method is a significant improvement over traditional change point detection methods, which only examine a potential anomaly at a single time point. In contrast, our method considers all suspected anomaly points and considers the joint probability distribution of the number of change points and the elapsed time between two consecutive anomalies. We validate our method with three simulated time series, a widely accepted benchmark data set, two geological time series, a data set of ECG recordings, and a physiological data set of heart rate variability measurements of fetal sheep model of human labor, comparing it to three existing methods. Our method demonstrates significantly improved performance over the existing point-wise detection methods.
1. Introduction
Various biological and medical settings require constant monitoring, collecting massive volumes of data in time series typically containing confounding noise (Grassberger and Procaccia, 1983; Sugihara and May, 1990; Barahona and Poon, 1996). This noise, as well as natural fluctuations in the biological system, create non-stationary time series, known as piecewise locally stationary time series, which are difficult to analyze in real time (Bodenstein and Praetorius, 1977; Corge and Puech, 1986; Dowse, 2007; Ndukum et al., 2011). Immensely important in clinical and experimental decision making is the accurate and timely detection of pathological changes in the observed time series as they occur. Statistically, this may be interpreted as a change point detection problem for piecewise locally stationary time series (Adak, 1998; Ombao et al., 2001; Davis et al., 2006).
The heavy contamination of noise due to measurement error and naturally varying phenomena, however, make the detection of change points challenging, as existing techniques will often observe non-pathological changes, resulting in false-alarms and mistrust of detection techniques (O'Carrol, 1986; Beneken and Van der Aa, 1989; Lawless, 1994)—the so-called cry-wolf effect. Extracting meaningful change points from naturally occurring fluctuations and noisy corruptions remains a challenge.
The detection of change points in a non-stationary time series is a well-studied problem, which has produced many techniques (Basseville and Nikiforov, 1993; Adak, 1998; Takeuchi and Yamanishi, 2006; Adams and MacKay, 2007; Last and Shumway, 2008). Some of the first work in change point detection is due to Basseville and Nikiforov (1993), where changes were detected by comparing probability distributions of time series samples over past and present intervals. This work was extended by Takeuchi and Yamanishi (2006) (method TY), who proposed a scoring procedure along with outlier detection, to compare past and present probability distributions in real-time. The scoring method is based on an automatically updating autoregressive model, known as the sequentially discounting autoregressive (SDAR) model. Points with scores above a user-defined threshold are declared as change points.
Non-stationary time series may also be viewed as segments of piecewise locally stationary time series (Adak, 1998). We follow this spirit in our work for the Delta point method. In Adak (1998), the locally stationary segments are broken into small pieces and the distance between power spectra for two adjacent pieces are calculated. A variety of distance measures between power spectra exist such as the Kolmogorov–Smirnov distance looking at the distance between cumulative power spectra, and the Cramer-Von Mises distance between power spectra used by Adak (1998). An extension was proposed by Last and Shumway (2008) where the Kullback–Liebler discrimination information between power spectra is used to identify change points. These power spectra methods are particularly well-suited for time series with periodic structure, as they compare power spectra in the frequency domain. Additionally recent advances in real-time change point detection have been made in the machine learning community with promising results, such as relative density ratio estimation method of Liu et al. (2013). Relative density ratio estimation uses a divergence measure to estimate the divergence between subsequent time series samples' density ratios.
As the current change point detection methodology we consider operates in a point-wise manner, temporal information of change points is lost, such as how often they can be expected to occur, and if they should occur in quick succession or not. Especially in physiological time series, where temporal information and patterns of change points may be highly relevant to practitioners, a point-wise approach may be ill-suited to these time series containing noise. To rectify this problem, we propose a novel change point detection method to analyse the pattern of change points and their inter-arrival times in a small time window so as to observe additional information that may be missed using a point-wise approach. It is our intention this method will reduce the cry-wolf effect (Lawless, 1994) of declaring all of the detected change points as change points relevant to the user. Our method is designed for univariate, piecewise stationary time series, where we seek to correctly classify change points as false alarms or true changes depending on the domain-specific application. The structure of the possibly detected change points may be a shift in mean, change in variance, or the introduction of a new trend to the time series.
While the existing methods (Basseville and Nikiforov, 1993; Adak, 1998; Takeuchi and Yamanishi, 2006; Adams and MacKay, 2007; Last and Shumway, 2008), can determine the location of change points, they are not able to extract meaningful change points in time series with piecewise locally stationary structure that contain minor changes and large noise corruption. Our novel method, termed the Delta point method, extends the Bayesian online change point detection method of Adams and MacKay (2007) and later Turner (2011), to allow a meaningful change point to be extracted. Our method uses fixed time intervals to construct the joint distribution of the number of change points per interval, and the average length of time between change points in each interval. We demonstrate the effectiveness of the Delta point method on three simulated time series of our own design inspired by existing literature, the widely used Donoho–Johnstone Benchmark curves (Donoho and Johnstone, 1994), nuclear magnetic resonance recordings from well-log measurements (Ó Ruanaidh et al., 1994), annual lowest water levels of the Nile River (Beran, 1994) an ECG recordings from clinical setting (Chen et al., 2015), and an experimental physiological data set of recordings of fetal sheep heart rate variability during experiments mimicking human labor (Frasch et al., 2009a; Ross et al., 2013; Wang et al., 2014). The fetal sheep data set contains short time series with large amounts of measurement noise, while the ECG dataset consists of short time series, with varying features.
2. Methods
In this section, we will describe the underlying change point detection methodology our Delta point method extends, as well as the theoretical background of these methodologies. We begin with a notation section for the reader to refer to, and subsequently describe the Bayesian online change point detection methodology introduced by Adams and MacKay (2007). Following this, we describe the Gaussian process time series model of Turner (2011), which is used as a predictive model for the Bayesian online change point method, and then introduce our Delta point method. The section concludes with a description of the statistical techniques used to analyse the data sets used for testing and our results.
Notation
Throughout the remainder of the article, we use the following notation (we omit descriptions in this section). Vectors are denoted in bold, e.g., y. rt is the run length of the change point detection algorithm. y1:t is a vector of time series observations from time s = 1, …, s = t, with the component yt the observation at time t. y(r) denotes the vector of time series observations since the previous change point. τ ∈ [1, t − 1] is a time index denoting the time since the last change point. p(·) represents the probability of an event occurring, with p(·, ·) denoting a joint probability, and p(·|·) a conditional probability. f ~ GP(μ, k) represents a function drawn from a Gaussian process, with μ the mean function, and k(·, ·) is the covariance function or kernel for a Gaussian process. c = c[ti,tj] denotes the number of change points in an interval [ti, tj]. represents the average run length of the change points in the interval [ti, tj]. α is a computation parameter, and ℓ is a computation parameter for the input length scale. ϵt is Gaussian white-noise, and σ2 is the standard deviation of the noise. k* is a vector computed by the covariance function, and K is a matrix computed by the covariance function.
Bayesian Online Change Point Detection
We begin with a review of the Bayesian online change point detection (BOCPD) algorithm (Adams and MacKay, 2007). Briefly, BOCPD is a recently introduced change point detection methodology that employs Bayes' rule to progressively update the probability of observing a change point in time series data while using a predictive model of the time series to make next time step ahead predictions of the time series. The predicted value is then compared with the observed value of the time series to determine if a change-point has occurred.
In detail, BOCPD uses a combination of a predictive model of future observations of the time series, an integer quantity, rt, known as the run length, or the time since the last change point, and a hazard function p(rt|rt−1), which calculates the probability of a change point occurring with respect to the last change point, to calculate the probability of a change point occurring. Bayes' rule is used to compute the posterior or past distribution of the run length as
where y1:t is a vector of past observations of the time series, p(rt, y1:t) is the joint likelihood of the cumulative run length and observations, calculated at each step, and p(y1:t) is the marginal likelihood of the observations. The joint distribution p(rt, y1:t) is computed with each new observation using a message passing algorithm,
where p(rt|rt−1) is the hazard function, p(yt|rt−1, y(r)) is the prediction model with observations y(r) since the last change point, and p(rt−1, y1:t−1) is the previous iteration of the algorithm.
Once the online message passing algorithm of Equation (2) is computed, the probability of a change point having occurred or not is given by,
respectively.
Gaussian Process Time Series
The performance of the BOCPD algorithm is highly dependent on the choice of predictive model for the next time step ahead prediction of the time series data. State of the art performance for the BOCPD algorithm was recently achieved by the use of a Gaussian process time series predictive model (Turner, 2011). With this in mind, we selected the Gaussian process time series predictive model to be used as the predictive model for the BOCPD algorithm.
A Gaussian process is a Gaussian distribution over functions—that is, the distribution of the possible values of the function follows a multivariate Gaussian distribution (Rasmussen and William, 2006). Gaussian processes are flexible and expressive priors over functions, allowing patterns and features to be learned from observed data. A Gaussian process is completely specified by a mean function, μ(·), and a positive definite covariance function, or kernel, k(·, ·), which determines the similarity between different observations. The covariance function generates properties of the function drawn from the Gaussian process, such as smoothness and shape. In our work, we used the rational quadratic covariance function (Rasmussen and William, 2006),
where α is a computing parameter, and ℓ is the input scale, or distance between inputs y and y′, which determines the smoothness of the functions. These parameters are set by an Empirical Bayes procedure or Type-II Maximum Likelihood estimation where the marginal likelihood of the observations given these parameters is maximized via gradient descent techniques. For full details of this procedure, see Chapter 5 of Rasmussen and William (2006). The performance of Gaussian process models is indeed dependent upon properly setting these parameters, and this remains an active area of research in the machine learning community.
In the Gaussian process time series model we used, the time index t is used as the input to the function f drawn from the Gaussian process, and the time series observation yt is the output. This is collected in the model,
where is white-noise in the regression model, and f ~ GP(0, k) denotes that the function f is drawn from a GP with mean 0 and covariance function k.
To predict future observations of the time series, we appeal to Bayes' rule, using the GPTS predictive model as a prior over functions. By the rules of conditioning Gaussian distributions (Rasmussen and William, 2006), the predictive distribution for the next time series observation used in the BOCPD model (Equation 2) is given by a Gaussian predictive distribution, , where
where k* = k(y(r), yt) is an (τ − 1) × 1 vector, where τ is the time since the last change-point, K = k(y(r), y(r)) is an (τ − 1) × (τ − 1) matrix, and k*.* = k(yt, yt). The mean and covariance of the Gaussian predictive distribution, given above in Equations (7) and (8), respectively, are derived by conditioning the previous Gaussian distributed observations on the current observation, which due to the Gaussian process model also follows a Gaussian distribution. For a formal derivation of these formulae, see Bishop (2006).
The GPTS predictive model was then used as the predictive model for the BOCPD algorithm to make next time step ahead predictions of the time series.
Delta Point Method
Now that we have reviewed the previous change point detection method and Gaussian process time series predictive model, we can introduce the newly proposed Delta point method. The BOCPD algorithm with the Gaussian process time series predictive model returns a vector of change points. We term the change points stored in this returned vector suspected change points. The BOCPD algorithm with the Gaussian process time series predictive model is typically effected by confounding noise in the time series, which in real-world applications is often due to sensor movement or other corrupting sources. Considering the predictive mean and variance from the Gaussian process time series model, Equations (7) and (8), respectively, noise in the observed time series will highly influence the accuracy of predictions. The covariance matrices and vectors in the Gaussian process model are computed on past observations of the time series to be used for forecasting. Highly varied time series observations will thus result in extremely varied future forecast values. The Hazard function in the change point algorithm, p(rt|rt−1), is then updated in the message-passing scheme (Equation 2) with highly varying information. The probability of change points occurring, as computed by the posterior run length distribution given by Equation (1), will be set artificially high due to this, thus resulting in over-detection of change points.
The Delta point method is designed to classify, with highest probability, from a vector of suspected change points, the change point most representative of a significant change in the generative process of the time series, and not those given by confounding noise.
The method consists generally of dividing the time series into intervals of user-specified, domain specific length for which a suspected change point may be contained. The number of change points and average run length of the change points in each interval containing a declared change point is then computed, and the interval with the fewest change points and longest average run length is selected as the interval with the highest probability of containing the change point most relevant to the user—the Delta point.
Given a vector of suspected change points from the BOCPD algorithm, we can view the observed change points as a realization of a doubly stochastic point process, that is, a point process where the intensity rate determining inter-arrival times of events is itself a stochastic process. As the Delta point method is concerned with determining the probability of finding the fewest number of change points and longest average run length in an interval, the point process view is natural to take. This framework allows us to determine explicit probabilities of each suspected change point being the change point of interest, by computing the probabilities of a specific number of change points occurring in each interval. Rather than following a homogeneous point process with a constant and deterministic intensity rate, the Delta point method must have a stochastic intensity rate. The doubly stochastic term arises naturally from the intensity function of the change point process being generated from the BOCPD algorithm, which returns a probability of change points occurring.
Let {N(t)}t⩾0 be a counting process representing the number of change points which are declared by the BOCPD algorithm. For clarity of exposition, we begin with a rapid review of the Poisson counting process. A Poisson process with rate or intensity λ is a counting process {N(t)}t⩾0 with independent increments, and for which the number of events in a time interval of length t follows a Poisson distribution, Poisson(λt). As we mention above, since the BOCPD method declares change points in a probabilistic fashion, the change point intensity rate must be stochastic, giving rise to a doubly stochastic Poisson process. Thus we assume that {Nt}t⩾0 is a doubly stochastic Poisson process, where the intensity {Λ(t)}t⩾0 is itself a stochastic process (Lefebvre, 2007; Diggle et al., 2013). Thus, for t2 ⩾ t1 ⩾ 0, we have
where,
The probability distribution of the intensity process, {Λ(t)}t⩾0, is given by the posterior run length distribution p(rt|y1:t). Since the intensity process is a continuous stochastic process, we need a continuous version of the posterior run length distribution from the BOCPD algorithm, which is given by combining Equations (1) and (2). This is given as,
In the time interval (ti, ti+1], where where M is the length of the time series, and j is the length of each time interval, the probability of observing k change points is,
The expected value of a doubly stochastic point process {N(t)}t⩾0 is computed as in a standard Poisson process, however there is a complication due to the stochastic intensity rate {Λ(t)}t⩾0. Consider the doubly stochastic point process N(t)|{Λ(t), 0 ⩽ s ⩽ t}. The expectation of a point process is given by the rate of intensity multiplied by the duration of the interval being considered. Therefore, from the stochastic intensity rate,
For the Delta point algorithm, the length j of the time interval (ti, ti+1] as defined above is user-defined. Let Ci be the number of change points in the interval (ti, ti+1]. Thus, Ci = N(ti+1) − N(ti), where {N(t)} is the doubly stochastic point process defined above. The average run length of each interval is computed by the arithmetic mean,
where rn is the run length associated with each change point in the interval.
Following the average run length computation, we then consider the joint probability distribution of Ci and , for each interval (ti, ti+1]. The average run length is conditioned by the probability of observing Ci many change-points in the interval (ti, ti+1],
The conditioned averaged run length probability is computed for each interval. Due to the Gaussian process predictive model properties, for a noisy time series, once a change point has been observed in an interval, the probability of more change points being detected in that interval increases. Further, the average run length of that interval decreases accordingly. In the traditional point-wise methods, this will result in many false positives. To avoid this difficulty, we take the opposite approach by observing that the interval with the fewest number of change points and the longest average run length has the highest probability of containing a representative change in the system, and not erroneous change points introduced by noise; that is, it contains a Delta point.
Once this interval has been determined, the interval is then searched to look up the associated run length with each interval. The declared change point with the longest average run length rn is declared as the Delta point.
The only parameter in the Delta point method is the user-defined length of the interval (ti, ti+1], or j, as defined above. In this way, the length of the interval generalizes the pointwise change point detection methods, as one can recover the point-wise detection methods by setting the interval length to 1. Conversely, setting the interval length to the length of the time series M, will result in selecting the declared change point with the longest run length as the delta point. This follows immediately from taking the arithmetic average of the run lengths. Our method is quite robust to changes in this value, however the best results will be achieved by incorporating expert domain level knowledge to best set the length of the interval, deciding over with time course is of most interest.
In future work, we will explore the structure of the doubly stochastic Poisson process of declared change points in greater detail. As the intensity function is determined predominately by the predictive model, the kernel of the Gaussian process is a natural place to begin investigation. Further, we aim to derive rigorous results on the interval length for optimal performance.
3. Results
We tested the Delta point method on several simulated and real world time series data sets. The simulated time series consist of three synthetic time series of our own design, and two widely used benchmark curves. The real world data sets are made up of well-log recordings from geophysical drilling measurements, annual water levels of the Nile river and 100 clinical ECG recordings. We compared the Delta point method to three competing non-stationary change point detection algorithms, namely Takeuchi and Yamanishi (TY) (Takeuchi and Yamanishi, 2006), Last and Shumway (LS) (Last and Shumway, 2008), and Liu et al. (L) (Liu et al., 2013) which were discussed in the Introduction section as popular existing change point detection methods. It is not possible to do a direct comparison with the proposed Delta point methodology and the BOCPD method itself, as the BOCPD method returns a vector of suspected change points, without information as to whether or not the suspected change points are the change point of interest to the user. Hence, it is not feasible to make a direct comparison between the two methods, as we would have to manually select from the vector of suspected change points given by BOCPD the change point of interest, rather than do so in an algorithmic fashion. The Delta point method gives such a way to determine the change point of interest.
Statistical Analysis
To compare the Delta point method to competing methods, we performed several statistical tests on declared change points from each method. For the simulated data, we computed the mean square error (MSE) for each method, taking the absolute temporal difference between the user labeled change point and the declared change point. We then performed two-sided t-tests to compare the mean absolute detection times of each method to the Delta point method, with the null hypothesis that the mean detection times of other methods will not differ from the Delta point method's time. For the clinical ECG recording data set, we computed the absolute differences in detection times for each method between the user-labeled change points, and the MSE for each method. We also performed two-sided t-tests to compare the mean absolute detection times between methods with the null hypothesis that the mean detection times of other methods will not differ from the Delta point method's time. For the experimental data sets, we performed a Fisher's exact test to compare successful change point detection for each method. In addition, we generated Bland-Altman plots for the fetal sheep physiological data set to compare the accuracy of each method to the user defined change point of interest and the declared change point.
Simulation
To test the efficacy of the Delta point method, we produced 1,000 simulations of three different time series, each 500 data points in length. Each time series was designed to simulate change points that may be seen in real world settings, and to have a specific change point that is of more interest than others in the time series. By change point of interest we are are referring to either a change in mean in the case of simulated Series 1 and Series 2, and the introduction of a linear trend in the data in Series 3. These cases are chosen so as to be representative of changes that may occur in real world settings such as sensor failure, or a changing physiological condition.
Series 1 has two change points, with the change point of interest occurring at t = 150. This time series simulated the change from a scaled random walk to an autoregressive model, and then back to a scaled random walk. This is a relatively subtle change point to detect, and was inspired from Last and Shumway (2008). Series 1 is given as,
where ϵt ~ N(0, 1), is Gaussian noise, and ρ1 values are uniformly sampled from [0,1].
Series 2 is a simulated autoregressive model with a large jump, and then a return back to the original process. The change point of interest was chosen as the onset of the jump (t = 175). This time series was used to simulate sensor shocks or faults, or a change in the generative parameters of the time series distribution. Series 2 is given as,
where, ϵt ~ N(0, 1), is Gaussian noise, and ρ2 values are uniformly sampled from [0,1].
Series 3 is a simulated autoregressive moving average model with an introduced linear trend and subsequent return to the autoregressive moving average model. The change point of interest was chosen as the beginning of the linear trend (t = 225). This is a difficult change point to detect, as the noise added to the data obscured the introduction of the trend. This time series simulated the accumulation of some product in a system. Series 3 is given as,
where, ϵt ~ N(0, 1), is Gaussian noise, and ρ3 values are uniformly sampled from [0,1].
Simulated time series from Series 1–Series 3 are displayed in Figures 1–3, respectively. The parameter values used for the simulation are ρ1 = 0.7, ρ2 = 0.4, and ρ3 = 0.5.
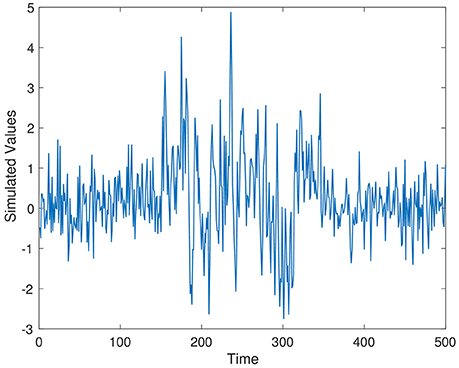
Figure 1. Simulation time series 1, ρ1 = 0.7.
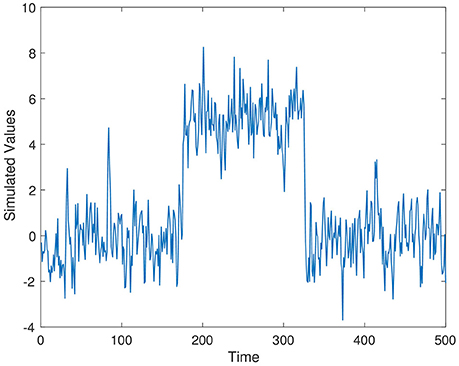
Figure 2. Simulation time series 2, ρ2 = 0.4.
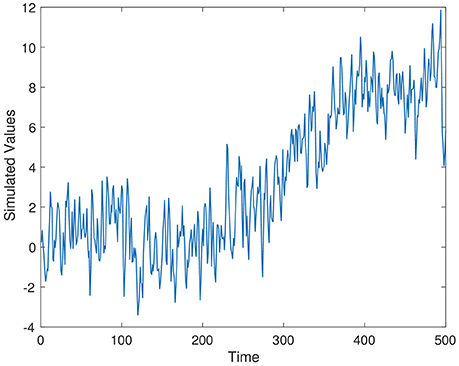
Figure 3. Simulation time series 3, ρ3 = 0.5.
The BOCPD method learned parameter values through training, so we only list the values we used to initiate the method. For Series 1, Series 2, and Series 3, we used a training set of 200 data, taken at the beginning of the time series. The Gaussian process model used a non-biased parameter initialization, with an assumed standard normal distribution prior for Series 1, Series 2, and Series 3. The hazard rate parameter used for the hazard function for initial training for each time Series is θh = −3.982. The Delta point interval length for each time series was set at 40 for training, as this should protect against the BOCPD possibly declaring too many erroneous change points, by being set too short. Setting the interval length to longer should produce similar results. The techniques TY, LS, and L all require a threshold value above which a change point will be declared. We performed cross-validation of several threshold values for each method, choosing the value for each time series that allows the most accurate detection of the change point of interest. We select the change point declared by each method that is closest to the significant change point described above.
The results of each method are displayed in Table 1. We report results for ρ1 = 0.7, ρ2 = 0.4, and ρ3 = 0.5, respectively; the results for different values are ρ1, ρ2, and ρ3 are not significantly different. For Series 1, the Delta point method significantly (p < 0.001) outperformed methods TY and LS in the mean absolute difference (absolute difference) of detection time, and had a significantly lower MSE. This difference in performance is confirmed by a two sided t-test with a null hypothesis that other methods do not have a significant mean absolute difference from the Delta point method. In our simulations, method L had a slightly smaller mean absolute difference (8.953) compared to the Delta point method (9.718), however the distribution of declared change points had a larger standard deviation (12.783 compared to 9.881). As well, the Delta point method had a lower MSE. The two sided t-test confirmed that both methods had indistinguishable performance (p = 0.135). For Series 2, the Delta point method significantly (p < 0.001) outperformed all methods. For Series 3, method TY performed the best, with the lowest mean absolute difference. Figures 4–6 display box plots of the results of each method for Series 1–3, respectively.
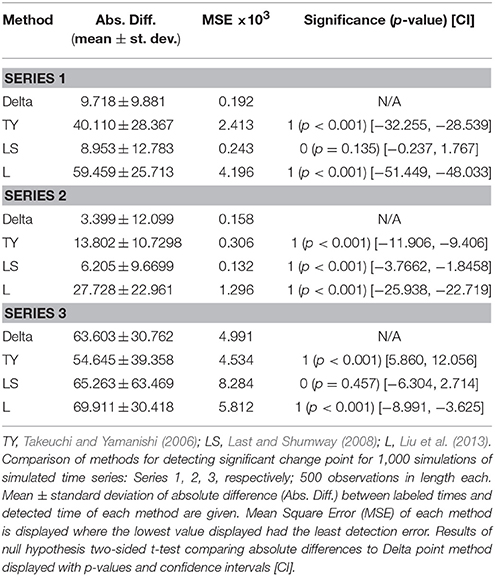
Table 1. Simulation results.
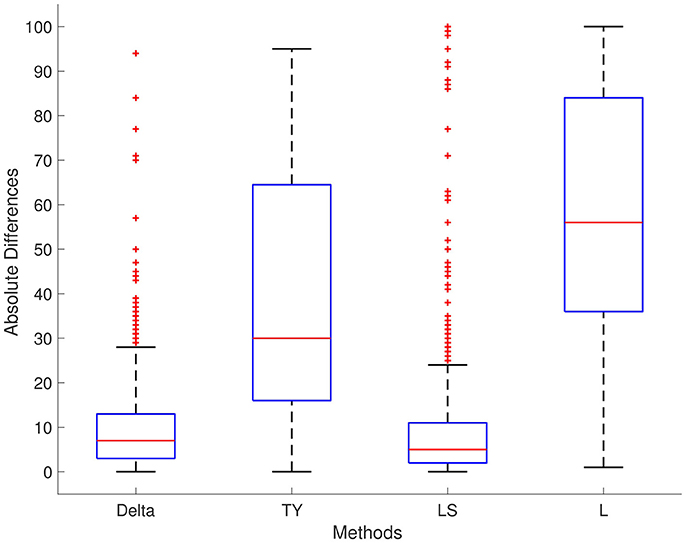
Figure 4. Simulation series 1 boxplot. TY, Takeuchi and Yamanishi (2006); LS, Last and Shumway (2008); L, Liu et al. (2013). Boxplot of absolute differences of detected change points for 1,000 simulations of simulation data set Series 1. The true change point location is located at 0.
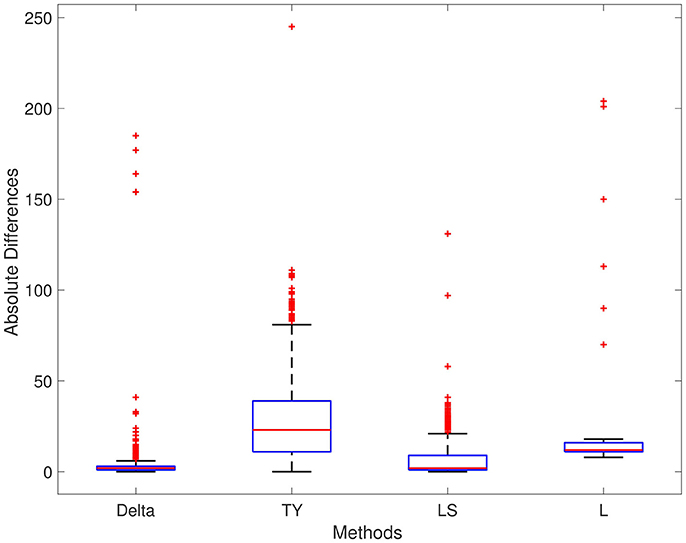
Figure 5. Simulation series 2 boxplot. TY, Takeuchi and Yamanishi (2006); LS, Last and Shumway (2008); L, Liu et al. (2013). Boxplot of absolute differences of detected change points for 1,000 simulations of simulation data set Series 2. The true change point location is located at 0.
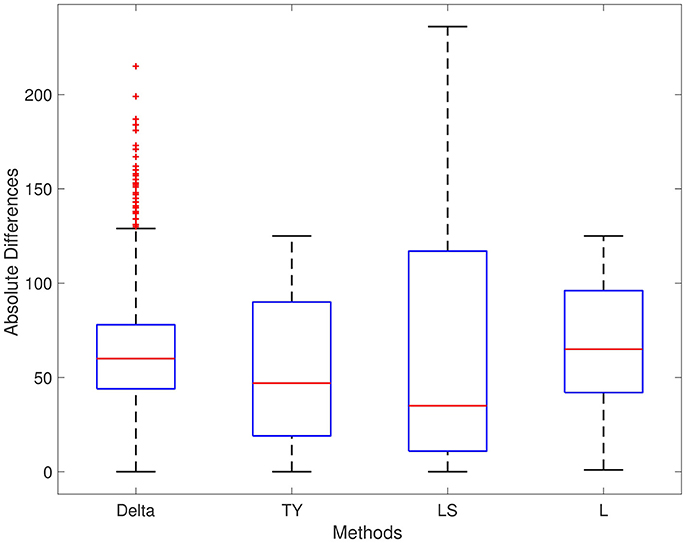
Figure 6. Simulation series 3 boxplot. TY, Takeuchi and Yamanishi (2006); LS, Last and Shumway (2008); L, Liu et al. (2013). Boxplot of absolute differences of detected change points for 1,000 simulations of simulation data set Series 3. The true change point location is located at 0.
Donoho-Johnstone Benchmark
To further analyse the performance of the Delta point method, we tested it and the existing methods on the Donoho-Johnstone Benchmark non-stationary time series (Donoho and Johnstone, 1994). The Donoho-Johnstone Benchmark is a classic collection of four non-stationary time series designed as a test for neural network curve fitting. The curves are known as the Block, Bump, Doppler, and Heavisine, and are 2,048 data points in length each. We adapted the curves with the introduction of noise to test for change point detection. As the Delta point method is not designed to function with time varying periodic data, rather piecewise locally stationary time series, we did not test with the Doppler and Heavisine curves.
For training for the Delta point method, we used a standard normal distribution prior for the Gaussian process, and hazard rate parameter θh = −3.982. We set the Delta point interval to 50 for the Bump curve and the Block curve. We selected 50 time points for the interval length so that we could observe sufficient temporal structure for the doubly stochastic Poisson process. The training set consisted of the first 800 data of each curve, to correspond to the rule of thumb of using the first 35–40% of time series data for training (Turner, 2011).
The results of the methods for the Bump and Block curves are displayed in Table 2. The Delta point method performed very well in these cases, declaring the change point of interest very close to the user-labeled point. The Bump curve was a more difficult curve to detect change points in, due to noise. The Delta point method and LS curve have about the same performance for the bump curve (absolute difference of 5 and 4, respectively). The Delta point method outperformed methods TY, LS, and L for accurate detection in the Block curve (absolute difference compared to 17, 22, and 24, respectively).
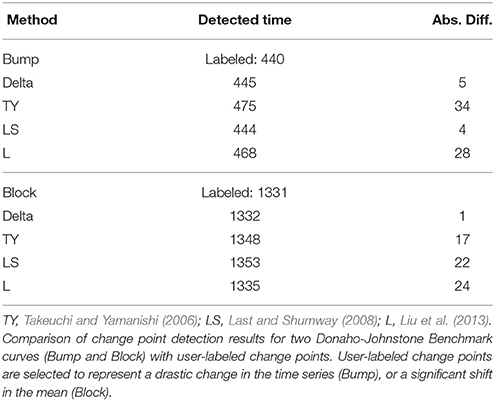
Table 2. Donaho-Johnstone Benchmark curves results.
Well-Log and Nile Recordings
The well-log data set consists of 4,050 nuclear magnetic resonance measurements obtained during the drilling of a well (Ó Ruanaidh et al., 1994). These data are used to deduce the geophysical structures of the rock surrounding the well. Variations in the mean reflect differences in stratification of the Earth's crust (Adams and MacKay, 2007). The well-log data set is a well studied time series for change point detection (Ó Ruanaidh et al., 1994; Adams and MacKay, 2007; Turner, 2011). We selected the largest jump in the mean of the time series as the most significant change point (i = 1,070).
The Nile river time series consists of a record of the lowest annual water levels between 622 and 1,284 CE, recorded on the Island of Roda, near Cairo, Egypt (Beran, 1994). The Nile river data set has been used extensively in change point detection (Turner, 2011), making it an effective benchmark for the Delta point method. Geophysical records suggest the installation of the Nilometer in 715 CE, a primitive device for more accurate water level measurements. As such, we selected this as the change point of significance.
For training for the Delta point method for both time series, we used a standard normal distribution prior for the Gaussian process, and hazard rate parameter θh = −3.982. For the well-log data, the Delta point interval was chosen as 30 due to the length of the time series and sensor noise, and for the Nile river time series, the Delta point interval was chosen to be 50, as the curve is smoother. The training set consisted of the first 1,000 data for the well-log series, and first 250 data for the Nile river set.
The results of each method are displayed in Table 3. The Delta point method performed better than the other methods TY, LS, and L for the well-log data set (absolute difference 2 compared to 13, 15, and 33, respectively). For the Nile river data set, all methods performed well, with declared change points of interest very close to the labeled installation of the Nilometer in 715 CE. The Delta point method for the well-log set is displayed in (Figure 7, Top panel), and the Delta point method for the Nile river data set is displayed in (Figure 7, Bottom panel).
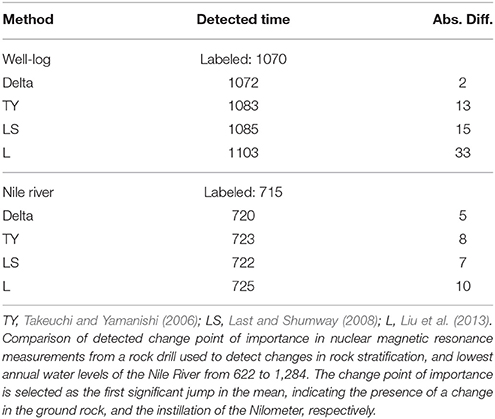
Table 3. Well-log and Nile River results.
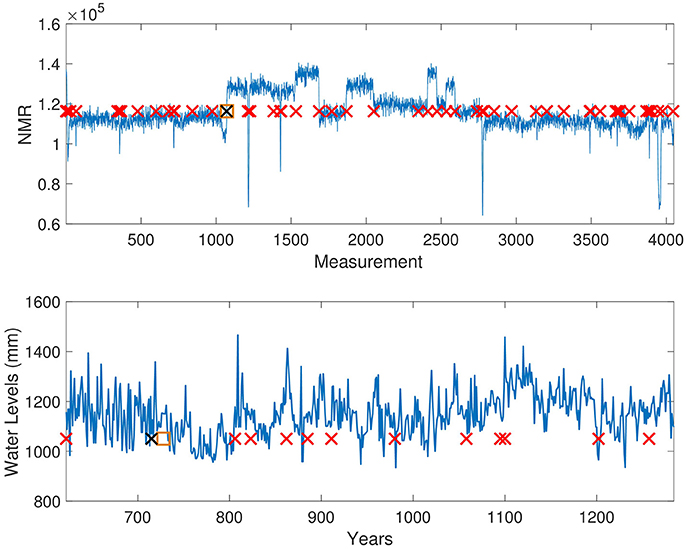
Figure 7. Well-log and Nile River level Delta point method. Top: Delta point method for Well-log data set. The y-axis denotes NMR reading during well digging, and the x-axis denotes the measurement instance. Suspected change points are denoted with red crosses, the user-labeled change point with a black cross (1070), and the detected Delta point with an orange box (1072). Bottom: Delta point method for annual lowest levels of Nile River. The y-axis denotes the water level (mm), and the x-axis denotes the years. Suspected change points are denoted with red crosses, the installation of the Nilometer (715) with a black cross, and the detected Delta point with an orange box (720).
ECG Recordings
The ECG dataset consists of short time series, with varying features. It is comprised of 100 clinical ECG recordings, each 136 data in length taken from a 67 year old patient Chen et al. (2015). Each recording contains one QRS complex for the patient, with the onset of the QRS complex user-labeled. To determine the effectiveness of the Delta point method in detecting a significant change point in short time series, we tested each method's accuracy in detecting the QRS complex, and the difference between the labeled beginning and detected time. As each time series is short, and the QRS complex rapidly begins and ends in the recording, accurate detection of the change point was considered very important.
For training for the Delta point method, we used a standard normal distribution prior for the Gaussian process, and hazard rate parameter θh = −3.982. Due to the short nature of these time series, the training set length was selected to be the first 30 data points; the training set never included the QRS complex for any of the 100 instances. The Delta point interval was set to 5, as the QRS complex is very short, and occurs rapidly in the series. The time series rapidly changes here, so a shorter interval performed best.
The performance of each method is displayed in Table 4. The Delta point method significantly outperformed the TY and LS method in mean absolute difference from the labeled detection times of the complex (p < 0.001 CI = [−2.138, −1.002] and [−0.1339, −0.0611], respectively). Method L had indistinguishable performance from the Delta point method (p = 0.954 CI = [−0.709, 0.609]). The Delta point method had the lowest MSE of all methods (14.13 compared to 32.2, 26.31, and 22.73, respectively). A box plot of the absolute difference of all of the methods is displayed in Figure 8.
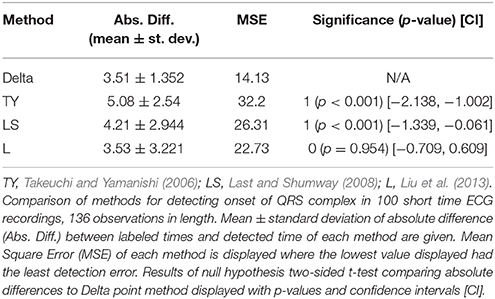
Table 4. ECG (ECGFiveDays) QRS complex results.
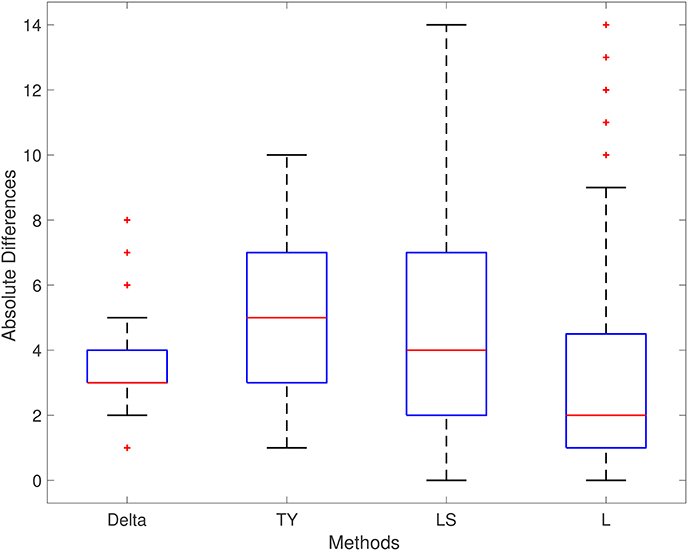
Figure 8. ECG (ECGFiveDays) boxplot. TY, Takeuchi and Yamanishi (2006); LS, Last and Shumway (2008); L, Liu et al. (2013). Boxplot of absolute differences of detected QRS complexes for 100 short time series of ECG recordings. The true change point is located at 0.
Fetal Sheep Model of Human Labor
We applied the Delta point method to a data set consisting of 14 experimental time series of a measure of fetal heart rate variability (HRV) known as the root mean square of successive differences (RMSSD) of R-R intervals of ECG recorded during umbilical cord occlusions (UCO) (Frasch et al., 2007, 2009b). The RMSSD may be used a measure to study the relationship between fetal systemic arterial blood pressure (ABP) and fetal heart rate in a fetal sheep model of human labor (Frasch et al., 2009a; Ross et al., 2013; Wang et al., 2014). RMSSD is a sensitive measure of vagal modulation of HRV, and is known to increase with worsening acidemia, a dangerous condition that may occur during labor (Frasch et al., 2007, 2009b; Durosier et al., 2014; Xu et al., 2014).
During UCO mimicking human labor, a hypotensive blood pressure response to the occlusions manifests as the introduction of a new trend in the recorded time series. This response is induced by the vagal nerve activation triggered by worsening acidemia during UCO as discussed in Frasch et al. (2015). These points are detected by expert visual detection and are known as ABP sentinel points. These sentinel points are defined as the time between the onset of blood pressure responses and the time when pH nadir (ph < 7.00) is reached. A change point detection algorithm should be able to detect these sentinel points from the non-invasively obtainable fetal heart rate derived RMSSD signal in an online manner to assist in clinical decision making.
The experimental time series are short—<200 observations—and confounded with a large amount of noise due to experimental conditions and measurement error. The time series are piecewise locally stationary, and contain naturally occurring biological fluctuations due, for example, to non-linear brain-body interactions (Berntson et al., 1997). These factors make the detection of the expert sentinel point difficult for existing change point techniques (Grassberger and Procaccia, 1983; Barahona and Poon, 1996).
To avoid false alarms, we defined a clinical region of interest (ROI) of 20 min before the sentinel point where a declared change point of interest is determined to be a success. We also took into account detections that are at most 3 min posterior to the sentinel point, as this is one experimental cycle late. The defined region of interest is to assist clinicians in decision making, as it provides a feasible window of time to provide clinical evaluation, as well as reject false alarm. For training for the Delta point method, we used a standard normal distribution prior for the Gaussian process, and hazard rate parameter θh = −3.982. We trained the Delta point method with 48 data points per time series, corresponding to 2 h of recording. The Delta point interval was set at 10 data, which corresponded to 25 min of experiment time. This interval was chosen to coincide with the clinical ROI.
The Delta point method significantly outperformed competing methods, with 11 of 14 declared change points in the ROI, compared to 3 of 14 for TY with Fisher's exact test statistic 0.007028, 5 of 14 for LS with Fisher's exact test statistic 0.054238, and 2 of 14 for L with Fisher's exact test statistic 0.001838. The Delta point method applied to one animal from the data set (ID473378) is displayed in Figure 9, and the results and detection times of each method are shown in Table 5.
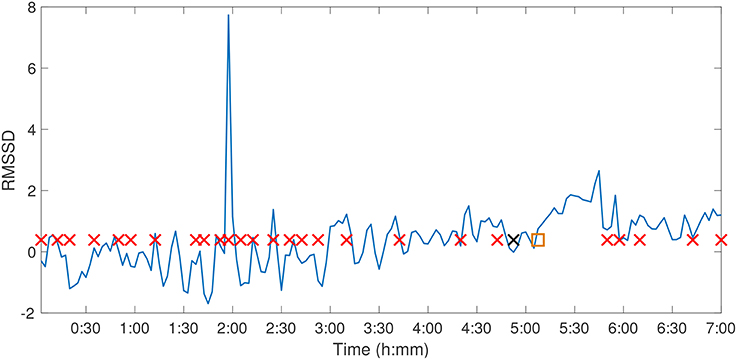
Figure 9. Fetal Sheep ID473378 Delta point method. Delta point method for Fetal Sheep ID473378 RMSSD time series. The y-axis denotes the RMSSD of the animal over the experimental course, and the x-axis denotes experimental time. Suspected change points are denoted with red crosses, the expert sentinel value with a black cross (6:13), and the detected Delta point with an orange box (6:24).
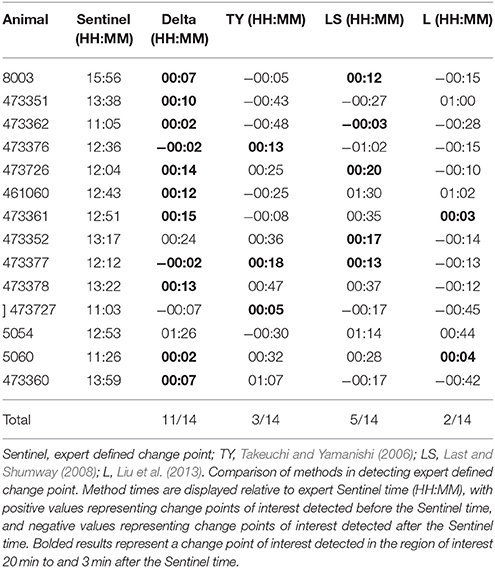
Table 5. Fetal sheep experiment results.
We also computed Bland-Altman plots for the experimental time series to compare the Delta point method to each other method. In Figure 10A, we display the Bland-Altman plot for the Delta point method and TY with mean difference (6.93 ± 89.03). Figure 10B displays the Bland-Altman plot for the Delta point method and LS, with mean difference (−1.36 ± 62.6). Figure 10C displays the Bland-Altman plot for the Delta point method and L, with mean difference (14.4 ± 59.9). In Figure 10D, we display a modified Bland-Altman plot of the differences in detection times for each method, along with the upper and lower ROI.
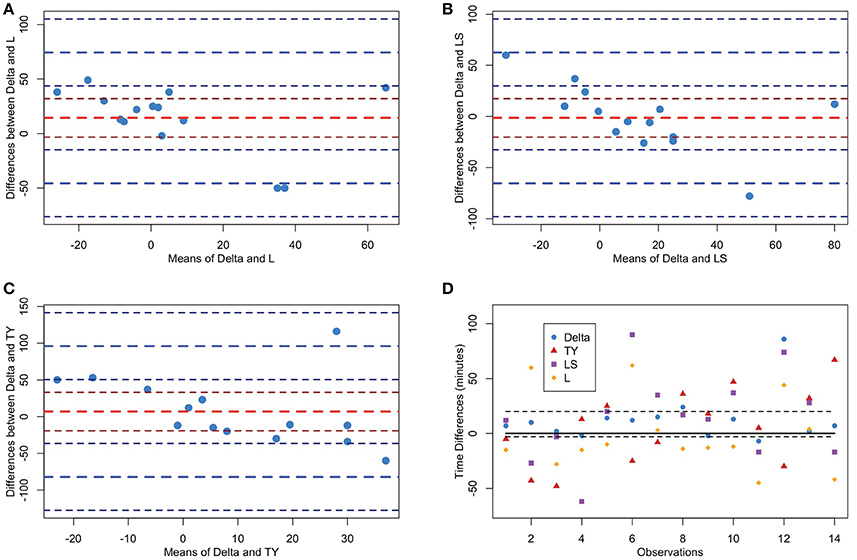
Figure 10. Bland-Altman plots of methods for Fetal Sheep dataset. TY, Takeuchi and Yamanishi (2006); LS, Last and Shumway (2008); L, Liu et al. (2013). (A–C) Bland-Altman plot comparing Delta point method to TY, LS, L, respectively. The y-axis displays the differences in the detection times, and x-axis displays the means of detection times for the two methods for each observation. The means (red) and two standard deviations (blue) are displayed with associated confidence intervals (maroon;navy). (D) Modified Bland-Altman plot of difference of each method and expert labeled sentinel time. Dashed black lines 20 min above and 3 min below sentinel time denote the clinical region of interest. Observations within this region are classified as a success.
4. Discussion
We observed that the Delta point method is effective at finding change points of interest in piecewise locally stationary time series of different types. For the simulated time series of our own design, the Delta point method performed better or indistinguishably from the best performing methods for Series 1 and Series 2. For Series 1, the Delta point method had the lowest MSE, which suggested it is accurately identifying change points of interest. For Series 2, the Delta point method significantly outperformed the competing methods in terms of mean absolute difference in detection time for labeled change points of interest. Although method LS had a lower MSE for this series, its mean detection difference is closer to 0. In Series 3, method L performed the best, with the smallest mean absolute difference in detection time, and MSE. Series 3 consisted of the introduction of the linear trend to the autoregressive moving average model, of which the introduction of the trend was obscured by added noise. Since method L compares density ratios of the time series, its good performance on this time series is likely due to noticing these changing ratios before other methods noticed the trend.
For the Donoho-Johnstone Bump curve, the Delta point method performed nearly as well as the best performing method—method LS—with a smaller absolute difference in detection time compared to the other methods, TY and L. The Delta point method performance for the Donaho-Johnstone Block curve was better than the other methods, exemplifying the strength of the Delta point method for piecewise locally stationary time series. Our test results for the well-log data set also provides evidence of the performance of the Delta point method for piecewise locally stationary time series. For the Nile river data set, as the installation of the Nilometer is the most significant change point in the time series, and can even be noticed visually, we expected that all methods should accurately detect this change point with little variation. Indeed, our results confirm this hypothesis.
For the clinical ECG data set, ECGFiveDays, the Delta point method performs significantly better than methods TY and LS, however has an indistinguishable performance difference with method L, although the Delta point method has the lowest MSE. Due to the rapidly varying nature of the time series when the QRS complex begins, the ability of method L to compare density ratios between components of the time series is beneficial and improves its performance compared to other methods.
With regards to the fetal sheep experimental data set, the early detection of acidemia is better than late detection from a clinical perspective. Hence, we defined the clinical ROI according to expert physician input. The 20 min window before the expert-labeled sentinel point provides adequate warning to clinicians to increase monitoring, or expedite delivery, while the 3 min window posterior to the expert-labeled sentinel point is sufficiently close to be included in the experimental procedure. In clinical settings, we believe that earlier detection is better, as it provides longer decision making time, and justification for increased monitoring.
The novelty of the current work is that our method permits statistical-level predictions about concomitant changes in individual bivariate time series, simulated or physiological such as HRV measure RMSSD and ABP in an animal model of human labor. Our method is able to predict cardiovascular de-compensation by identifying ABP responses to UCO, a sensitive measure of acidosis. These predictions are reliable even in the instances when the signals are noisy. This is based on our observation that here, to mimic the online recording situation, no artifact correction for RMSSD was undertaken as is usually done for HRV offline processing (Seely et al., 2011). The 2 h training time used for the Delta point method is also acceptable for delivery room settings, due to the typical time length of human labor between 6 and 8 h on average (Albers, 1999). To our knowledge, no comparable statistical methods exist. Another benefit of the Delta point method is the ability to automatically extract the change point of interest with minimal user interaction, as opposed to other methods which require user specific thresholds and criteria.
Although the Delta point method performs well in settings with noise, the method is not designed to work accurately for time series that exhibit periodic structure. Due to the Gaussian process time series predictive model that is used for updating predictions, the accuracy or predictions and thus detected change points by the BOCPD algorithm depends on the kernel selected by the user. Indeed, periodic kernels do exist, as shown in Rasmussen and William (2006), however to be as general as possible, we did not implement them. Another possible limitation of the Delta point methodology is that the length of the interval for change point identification is required to be set by the user. In future work, we propose to establish an optimal window length, however this is a difficult task, as the window length should be determined both by the features of the time series, as well as the time scales over which interesting phenomena occur.
We have intentionally focused our analysis on the change point detection time, due to our interest in early detection of possibly negative phenomena in biological systems. For this reason, our analysis focuses only on the sensitivity of the method. Other methods may be more ideally suited for analysis with a certain specificity in mind. Additionally, it may be interesting to consider different time series predictive models, such as the dynamical Bayesian inference models of Duggento et al. (2012) which allow for adaptations in real-time to changes, or Gaussian process based Kalman filters given by Turner (2011). These methods provide an interesting direction for future research as they may be able to make better predictions of the time series data.
5. Conclusion
We have developed a novel, change point detection method for effectively isolating a change point of interest in short, noisy, non-stationary, and non-periodic time series. Our method is able to effectively extract clinically relevant changes in the time series, allowing informed decision making, an essential challenge posed by Seely and co-authors for the future of intelligent monitoring (Seely et al., 2011; Seely, 2014). By considering the joint distribution of the change points and the number of change points in disjoint intervals, the Delta point method remains robust to signal artifacts and confounding noise. We demonstrated our method on three simulated time series of our own design inspired by existing literature, curves from the Donoho-Johnstone benchmark curve data set, nuclear magnetic resonance reading from well-log measurements of geophysical drilling, annual water levels of the Nile river, a clinical ECG recording data set, and a physiological data set of fetal sheep recordings mimicking human labor. We compared the performance of the Delta point method to three existing change point detection methods. The Delta point method displays useful performance benefits in accurately extracting a meaningful change point to the user from a vector of suspected change-points.
Availability of Data and Materials
Data and codes associated with the manuscript may be found at the following sources: BOCPD code: https://sites.google.com/site/wwwturnercomputingcom/software/ThesisCodeAndData.zip?attredirects=0&d=1
Donoho-Johnstone data: ftp://ftp.sas.com/pub/neural/data/dojo_medium.txt
Well-log data: http://mldata.org/repository/data/viewslug/well-log/
Nile river data: http://mldata.org/repository/data/viewslug/nile-water-level/
ECGFiveDays: http://www.cs.ucr.edu/~eamonn/time_series_data/
Simulation data: https://github.com/ngold5/fetal_data
Ethics Statement
The human ECG dataset (Chen et al., 2015) was collected in agreement with the ethics procedures of the group Physical Activity Monitoring for Aging People, https://www.pamap.org. The animal research followed the guidelines of the Canadian Council on Animal Care and the approval by the University of Western Ontario Council on Animal Care.
Author Contributions
Conception and design: XW, MGF, and NG; Acquisition of data: MGF and NG; Analysis and interpretation of data: NG, MGF, XW, CLH, and BSR; Drafting the manuscript: NG, MGF, and XW; Revising it for intellectual content: NG, MGF, XW, CLH, and BSR; Final approval of the completed manuscript: NG, MGF, XW, CLH, and BSR.
Funding
This work was funded by CIHR (to MGF), FRQS (to MGF), Canada Research Chair Tier 1 in Fetal and Neonatal Health and Development (BSR); Women's Development Council, London Health Sciences Centre (London, ON, Canada) (to BSR and MGF).
Conflict of Interest Statement
BSR and MGF are inventors of related patent applications entitled “EEG Monitor of Fetal Health” including U.S. Patent Application Serial No. 12/532.874 and CA 2681926 National Stage Entries of PCT/CA08/0058 filed March 28, 2008, with priority to US provisional patent application 60/908,587, filed March 28, 2007 (US 9,215,999).
The other authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors gratefully acknowledge technical support by Dr. Qiming Wang and Dr. Michael Last. We would also like to thank Ms. Patrycja Jankowski and Ms. Dana Gurevich for excellent artwork assistance. We also gratefully acknowledge the referees, whose comments greatly improved the manuscript.
References
Adak, S. (1998). Time-dependent spectral analysis of nonstationary time series. J. Am. Stat. Assoc. 93, 1488–1501. doi: 10.2307/2670062
Adams, R. P., and MacKay, D. J. C. (2007). Bayesian online changepoint detection. arXiv:0710.3742v1.
Barahona, M., and Poon, C.-S. (1996). Detection of nonlinear dynamics in short, noisy time series. Nature 381, 215–217.
Basseville, M., and Nikiforov, I. V. (1993). Detection of Abrupt Changes: Theory and Application. Upper Saddle River, NJ: Prentice-Hall, Inc.
Beneken, J. E., and Van der Aa, J. J. (1989). Alarms and their limits in monitoring. J. Clin. Monit. 5, 205–210.
Beran, J. (1994). Statistics for Long-Memory Processes, Vol. 61 of Monographs on Statistics and Applied Probability. Boca Raton, FL: Chapman & Hall.
Berntson, G., Nagaraja, H. K., Porges, S. W., and Saul, P. (1997). Heart rate variability: origins, methods, and interpretive caveats. Psychophysiology 34, 623–648.
Bishop, C. (2006). Pattern Recognition and Machine Learning. New York, NY: Springer-Verlag + Business Media, LLC.
Bodenstein, G., and Praetorius, H. M. (1977). Feature extraction from electroencephalogram by adaptive segmentation. Proc. IEEE 65, 642–652.
Chen, Y., Keogh, E., Hu, B., Begum, N., Bagnall, A., Mueen, A., et al. (2015). The UCR Time Series Classification Archive. Available online at: www.cs.ucr.edu/~eamonn/time_series_data/
Corge, J., and Puech, F. (1986). “Analyse du rythme cardiaque foetal par des methodes de detection de ruptures,” in 7th INRIA Int. Conf. Analysis and Optimization of System (Antibes), 853–866.
Davis, R. A., Lee, T. C. M., and Rodriguez-Yam, G. A. (2006). Structural break estimation for nonstationary time series models. J. Am. Stat. Assoc. 101, 223–239. doi: 10.1198/016214505000000745
Diggle, P., Moraga, P., Rowlingson, B., and Taylor, B. (2013). Spatial and spatio-temporal log-gaussian cox processes: extending the geostatistical paradigm. Stat. Sci. 28, 542–563. doi: 10.1214/13-STS441
Donoho, D. L., and Johnstone, I. M. (1994). Ideal spatial adaptation via wavelet shrinkage. Biometrika 81, 425–455.
Dowse, H. B. (2007). “Statistical analysis of biological rhythm data,” in Circadian Rhythms: Methods and Protocols, Vol. 362, ed E. Rosato (Totowa, NJ: Humana Press), 29–45.
Duggento, A., Stankovski, T., McClintock, P. V. E., and Stefanovska, A. (2012). Dynamical bayesian inference of time-evolving interactions: from a pair of coupled oscillators to networks of oscillators. Phys. Rev. E 86:061126. doi: 10.1103/PhysRevE.86.061126
Durosier, L. D., Green, G., Batkin, I., Seely, A. J., Ross, M. G., Richardson, B. S., et al. (2014). Sampling rate of heart rate variability impacts the ability to detect acidemia in ovine fetuses near-term. Front. Pediatr. 2:38. doi: 10.3389/fped.2014.00038
Frasch, M. G., Durosier, L. D., Gold, N., Cao, M., Matushewski, B., Keenliside, L., et al. (2015). Adaptive shut-down of eeg activity predicts critical acidemia in the near-term ovine fetus. Physiol. Rep. 3:e12435. doi: 10.14814/phy2.12435
Frasch, M. G., Mansano, R. Z., McPhaul, L., Richardson, B. S., and Ross, M. G. (2009a). Measures of acidosis with repetitive umbilical cord occlusions leading to fetal asphxyia in the near-term ovine fetus. Am. J. Obstet. Gynecol. 200:200.e1-7. doi: 10.1016/j.ajog.2008.10.022
Frasch, M. G., Muller, T., Weiss, C., Lohle, M., Schwab, K., Schubert, H., et al. (2007). Fetal body weight and the development of the control of the cardiovascular system in fetal sheep. J. Physiol. 579(Pt 3), 893–907. doi: 10.1113/jphysiol.2006.124800
Frasch, M. G., Müller, T., Weiss, C., Schwab, K., Schubert, H., and Schwab, M. (2009b). Heart rate variability analysis allows early asphyxia detection in ovine fetus. Reprod. Sci. 16, 509–517. doi: 10.1177/1933719108327597
Grassberger, P., and Procaccia, I. (1983). Measuring the strangeness of strange attractors. Phys. D 9, 189–208.
Last, M., and Shumway, R. (2008). Detecting abrupt changes in a piecewise locally stationary time series. J. Multivar. Anal. 99, 191–214. doi: 10.1016/j.jmva.2007.06.010
Lawless, S. T. (1994). Crying wolf: false alarms in a pediatric intensive care unit. Crit. Care Med. 22, 981–986.
Lefebvre, M. (2007). Applied Stochastic Processes. New York, NY: Springer Science + Business Media, LLC.
Liu, S., Yamada, M., Collier, N., and Sugiyama, M. (2013). Change-point detection in time-series data by relative density-ratio estimation. Neural Netw. 43, 72–83. doi: 10.1016/j.neunet.2013.01.012
Ndukum, J., Fonseca, L. L., Voit, E. O., and Datta, S. (2011). Statistical inference methods for sparse biological time series data. BMC Syst. Biol. 5:57. doi: 10.1186/1752-0509-5-57
Ó Ruanaidh, J. J., Fitzgerald, W. J., and Pope, K. J. (1994). “Recursive bayesian location of a discontinuity in time series,” in 4th IEEE International Conference on Acoustics, Speech, and Signal Processing (Adelaide, SA), 513–516.
Ombao, H. C., Raz, J. A., Von Sachs, R., and Malow, B. A. (2001). Automatic statistical analysis of bivariate nonstationary time series, in memory of Jonathan A. Raz. J. Am. Stat. Assoc. 96, 543–560. doi: 10.1198/016214501753168244
Rasmussen, C. E., and William, C. K. I. (2006). Gaussian Processes for Machine Learning. Cambridge, MA: The MIT Press.
Ross, M. G., Jessie, M., Amaya, K., Matushewski, B., Durosier, L. D., Frasch, M. G., et al. (2013). Correlation of arterial fetal base deficit and lactate changes with severity of variable heart rate decelerations in the near-term ovine fetus. Am. J. Obstet. Gynecol. 205, 281–286. doi: 10.1016/j.ajog.2012.10.883
Seely, A. J., Green, G. C., and Bravi, A. (2011). Continuous multiorgan variability monitoring in critically ill patients–complexity science at the bedside. Conf. Proc. IEEE Eng. Med. Biol. Soc. 2011, 5503–5506. doi: 10.1109/IEMBS.2011.6091404
Seely, A. J. E. (2014). Data intelligence is the future of monitoring. J. Clin. Monit. Comput. 28, 325–327. doi: 10.1007/s10877-014-9561-y
Sugihara, G., and May, R. M. (1990). Nonlinear forecasting as a way of distinguishing chaos from measurement error in time series. Nature 344, 734–741.
Takeuchi, J., and Yamanishi, K. (2006). A unifying framework for detecting outliers and change points from time series. IEEE Trans. Knowl. Data Eng. 18, 482–492. doi: 10.1109/TKDE.2006.1599387
Turner, R. D. (2011). Gaussian Processes for State Space Models and Change Point Detection. Ph.D. thesis, University of Cambridge, Engineering Department.
Wang, X., Durosier, L. D., Ross, M. G., Richardson, B. S., and Frasch, M. G. (2014). Online detection of fetal acidemia during labour by testing synchronization of EEG and heart rate: a prospective study in fetal sheep. PLoS ONE 9:e108119. doi: 10.1371/journal.pone.0108119
Keywords: machine learning, change point detection, non-stationary noisy time series, Bayesian methods, Gaussian processes
Citation: Gold N, Frasch MG, Herry CL, Richardson BS and Wang X (2018) A Doubly Stochastic Change Point Detection Algorithm for Noisy Biological Signals. Front. Physiol. 8:1112. doi: 10.3389/fphys.2017.01112
Received: 17 July 2017; Accepted: 15 December 2017;
Published: 05 January 2018.
Edited by:
Ahsan H. Khandoker, Khalifa University, United Arab EmiratesReviewed by:
Philip Thomas Clemson, Lancaster University, United KingdomFelix Putze, University of Bremen, Germany
Copyright © 2018 Gold, Frasch, Herry, Richardson and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Nathan Gold, ngold5@my.yorku.ca
†These authors have contributed equally to this work.