 Xiaoxue Fan1
Xiaoxue Fan1 Xiaojuan Mao
Xiaojuan Mao Pingping Gu
Pingping Gu Hengrong Ju
Hengrong Ju- 1School of Information Science and Technology, Nantong University, Nantong, China
- 2Department of Respiratory Medicine, The Sixth People’s Hospital of Nantong, Affiliated Nantong Hospital of Shanghai University, Nantong, China
- 3Jiangsu Vocational College of Business, Nantong, China
- 4School of Transportation and Civil Engineering, Nantong University, Nantong, China
Data description and data reduction are important issues in sensors data acquisition and rough sets based models can be applied in sensors data acquisition. Data description by rough set theory relies on information granularity, approximation methods and attribute reduction. The distribution of actual data is complex and changeable. The current model lacks the ability to distinguish different data areas leading to decision-making errors. Based on the above, this paper proposes a neighborhood decision rough set based on justifiable granularity. Firstly, the rough affiliation of the data points in different cases is given separately according to the samples in the neighborhood. Secondly, the original labels are rectified using pseudo-labels obtained from the label noise data that has been found. The new judgment criteria are proposed based on justifiable granularity, and the optimal neighborhood radius is optimized by the particle swarm algorithm. Finally, attribute reduction is performed on the basis of risky decision cost. Complex data can be effectively handled by the method, as evidenced by the experimental results.
1 Introduction
In sensor data processing systems, researchers are often confronted with large amounts of multimodal and complex sensing data. To deal with these sensing data, data description and data reduction are pivotal process. For data acquisition, rough sets based models are considered as effective approaches in recent years [1, 2]. Rough set theory [3] was proposed in 1982 by Pawlak as a mathematical tool for analyzing and handling imprecise, inconsistent, and incomplete information. Traditional rough set theory lacks fault tolerance and does not take errors in the classification process into account at all. Pawlak et al. proposed the probabilistic rough set model to improve rough set theory using probabilistic threshold [4]. A probabilistic rough set model has been introduced to Bayesian decision theory by [5]. Further, Yao proposed a three-way decision theory on the basis of decision rough set theory [6].
Currently, many scholars have been improving the research on decision rough sets from different aspects. [7] proposed the theoretical framework of local rough set. [8] proposed local neighborhood rough set, which integrated the neighborhood rough set and local rough set. [9] combined Lebesgue and entropy measure, and proposed a novel attribute reduction approach. [10] introduced the pseudo-label into rough set, and proposed a pseudo-label neighborhood relationship, which can distinguish samples by distance measure and pseudo-labels.
As mentioned above, scholars proposed equivalent modifications to the neighborhood decision rough set approach from multiple perspectives. However, for complex sensor data processing, neighborhood decision rough set methods still face some challenges. For example, in practical applications, complex data distribution is often uneven. In addition, the presence of abnormal data can also greatly weaken the performance of rough models and cannot correctly classify abnormal data points. For the issues mentioned above, this paper proposes a local strategy to improve the calculation process of rough membership. Additionally, the neighborhood of sample is optimized by the particle swarm optimization method (PSO algorithm) to offer the optimal neighborhood granularity for the model and carry out attribute reduction.
The remainder of this paper is structured as follows. Section 2 introduces the relevant basic theories. Section 3 presents a decision rough calculation method based on justifiable granularity. Six datasets are chosen in Section 4 to evaluate the suggested methodology. Section 5 summarizes the full text.
2 Preliminary notion
2.1 Neighborhood relation and rough set
The construction of equivalence relations for numerical type data first requires the discretization of the original data, and this method will inevitably cause the loss of information. On the basis of neighborhood relations, a neighborhood rough set model was proposed by Hu et al. [11–13].
Assume that information system is expressed as
Definition 1. Suppose the information system is
where dis (•) represents the distance between any objects, using Euclidean distance commonly.
Definition 2. Suppose the information system is
where
Definition 3. Suppose the information system is
The following definitions apply to the positive, negative, and boundary regions of X in B:
From the above definition, it can be found that the conditions on which the neighborhood rough set is based in taking both acceptance and rejection decisions are too severe and lack a certain degree of fault tolerance. Only elements that are completely correctly classified are grouped into the positive domain. Alternatively, only elements that are completely misclassified are classified in the negative domain. The result of such a definition makes the boundary domain too large.
2.2 Rough set with neighborhood decision
The rough set model for decision-making put forth by Yao et al. [5] lacks the ability to directly process numerical data. In order to address this weakness, a rough set model of decision theory based on neighborhood was proposed by Li et al. [14] through the integration of the neighborhood rough set and the decision rough set.
The decision rough set has two important elements:
In addition, Yao proposed three decision theories based on decision rough set model [5], including P rule, N rule and B rule.
Definition 4. Suppose the information system
3 Neighborhood decision rough set model based on justifiable granularity
To solve the problems discussed above, this article first introduces the local neighborhood rough set model to eliminate the interference of some noise data on the approximate set.
3.1 Local rough neighborhood decision model
Definition 5. Suppose the information system
The following definitions apply to the positive, negative, and boundary regions of X in B:
The most significant difference between the local neighborhood rough set model and the neighborhood rough set model is the different search scope when finding the upper and lower approximation sets. In the neighborhood rough set model, finding the approximation set for each decision category requires traversing all the data points in the data set. However, in the local neighborhood rough set model, the focus is on the data points of the same category, and only the data points of the same decision category need to be traversed. This greatly reduces the computational effort and increases the computational speed [14]. This model not only improves computational efficiency, but also eliminates the interference of noisy points.In addition, the traditional method of calculating rough affiliation does not take into account the complexity of the data. In this paper, the calculation process of affiliation degree is improved for the affiliation degree, and the process is as follows:Suppose
(1)
(2)
(3)
Algorithm 1. The upper and lower approximation sets of local neighborhood rough set.
Input:
Output: lower approximate
1: Segmentation of the entire dataset by tag categories
2: Using the cost matrix, the threshold value
3: For
4: Compute the
5: end
6: If
7:
8:
9: End
10: If
11:
12:
13:
14: End
15: If
16:
17: End
18: If
19:
20: If
21:
22: End
23: End
24: Return
Algorithm 1 detects outliers and labeled noisy points, as well as enables the detection of data points for high-density areas. In fact, some samples are not always considered as outlier data or noise, and their decisions sometimes depend on the choice of neighborhood radius.
3.2 Selection of neighborhood information granularity based on justifiable granularity
According to the above-mentioned rough set model, a smaller neighborhood radius contains very little information, while a larger radius may cause the next approximate set to be an empty set. This paper introduces the justifiable granularity criterion [15, 16]. There are generally two functions in the construction of information granules, namely, covering function and particularity function.
The coverage function describes how much data is in the constructed information granule. This paper designs the coverage index function as shown below:
where
The coverage index function mentioned above is considered from two perspectives, namely, neighborhood information granularity and approximate set. In terms of specificity criteria, the smaller the neighborhood radius, the better. Therefore, the specificity function can be designed as:
Obviously, the two are contradictory. Therefore, the function for optimized performance can be written as the multiplication of specificity and coverage, which is:
In this way, the optimal neighborhood about
To achieve the optimal
Moreover, to update the dataset, one can utilize the noise identification strategy along with the set of predicted pseudo-decision labels. The main steps are described in Algorithm 2.
Algorithm 2. Update of rough approximation set in label noise injection environment.
1: Obtain the optimal neighborhood radius
2: Execute Algorithm 1 to obtain the approximation set, the set of outlier points, the set of labeled noise points, and the pseudo-tags of labeled noise points;
3: Updating decision labels for noisy data based on pseudo-labels;
4: Update the approximation set using the modified decision system.
3.3 Attribute reduction based on neighborhood decision rough set model
In this paper the risky decision cost will be used to reduce the attributes. It comes from the Bayesian decision process, which is comparable to the classical rough set. Risky decision costs for P, N and B rule can be separately expressed as:
As discussed above, the cost of making a risky decision for all decision rules can be obtained as:
Obviously, the higher
Definition 6. Suppose the information system
A scheme based on neighborhood decision rough sets is designed for forward search to achieve the optimal reduction. Its specific steps are shown in Algorithm 3.
Algorithm 3. Attribute reduction based on neighborhood decision rough set model.
1: RED =
2: For
3: Calculate
4: End
5: Select
6: If
7:
8: Else
9: Break.
10: End
11: Return RED
3.4 Evaluation index
To assess the effectiveness of the suggested approach, this article discusses the following two evaluation indicators: the lower approximation and information granularity.
Approximation quality (AQ): Given decision information system
The
Neighborhood number(NN):
The larger value of
4 Experiment analysis
In this section, six UCI datasets are utilized to illustrate the feasibility and validity of the suggested methodology. Table 1 describes the relevant information of the datasets.

TABLE 1. Dataset description.
Parameter setting of PSO algorithm, initialize the particle swarm size to 300, a maximum of 100 iterations is permitted, the individual experience learning factor
where
Figure 1 show the performance of
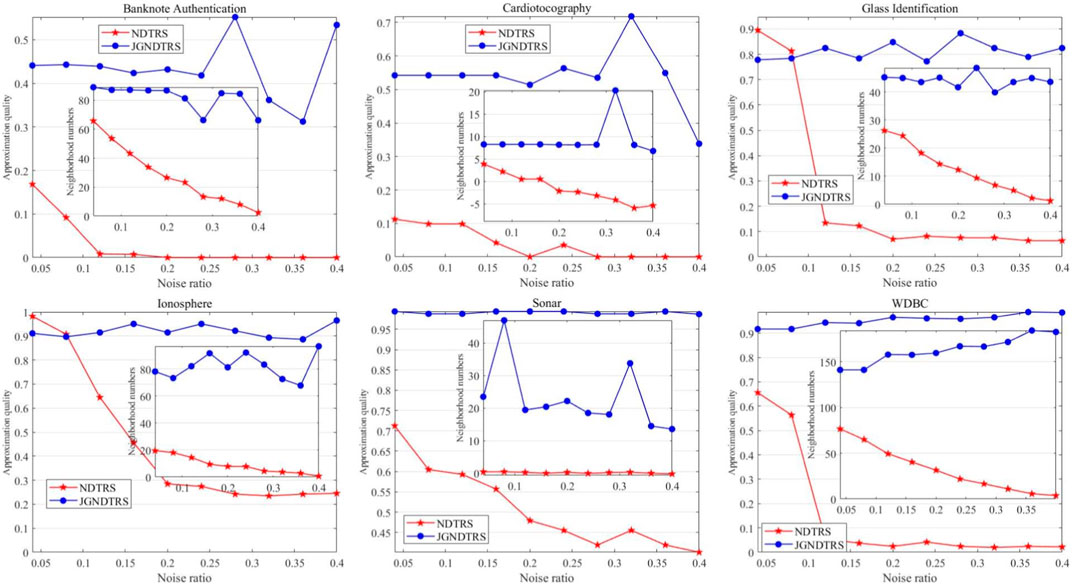
FIGURE 1. Comparison of AQ and NN with different noise ratios.
Figure 2 shows the comparison of the cost of JGNDTRS and NDTRS when performing attribute reduction. A dataset is represented by each subplot, and various Universe sizes are shown on the x-axis. Through closer observation, we can conclude that the decision cost of both JGNDTRS and NDTRS shows a decreasing trend as the size of Universe increases. In each dataset, the decision cost of JGNDTRS is always lower than that of NDTRS, regardless of the value of the Universe size. This indicates that JGNDTRS has a superior performance with less cost used in performing attribute reduction.
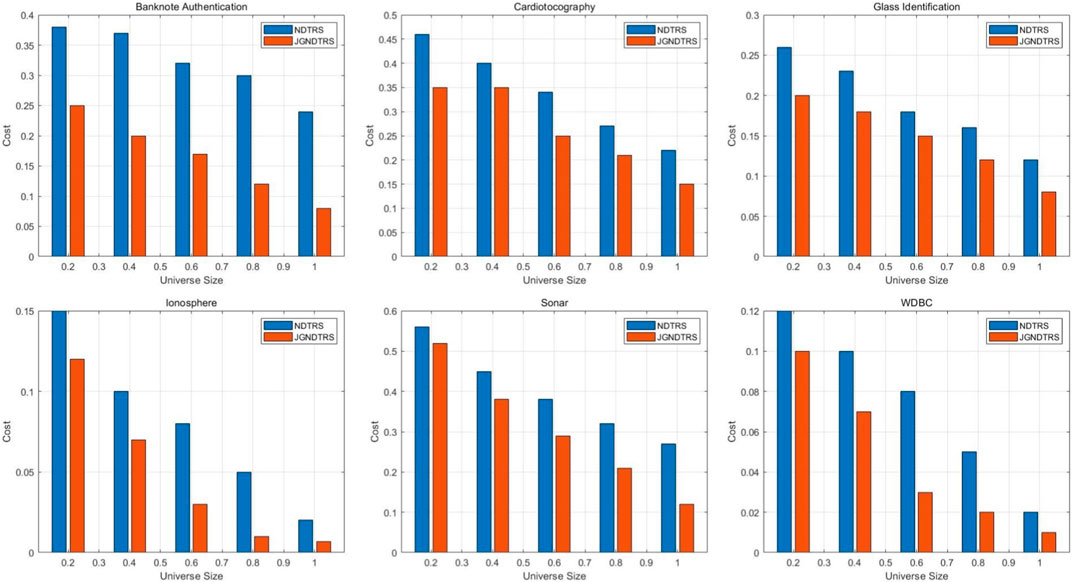
FIGURE 2. The cost of attribute reduction comparison under different universe sizes.
5 Conclusion
The proposed neighborhood decision rough set model compensates the lack of fault tolerance of classical rough sets. However, there are some challenges in the existing models when dealing with complex data. In this paper, we propose a neighborhood decision rough set model based on justifiable granularity. Firstly, the calculation of rough affiliation is improved according to the number of data points in the neighborhood and the corresponding decision label categories. Secondly, to rectify the original labels, provide pseudo-labels for the noisy data points that are found. A justifiable granularity criterion is introduced and the optimal neighborhood radius is obtained by PSO algorithm. Finally, the risky decision cost is used for attribute reduction. The results of the experiments demonstrate that the neighborhood decision rough set model based on justifiable granularity has significant performance in identifying abnormal data points and can enhance classification performance. In the future work, the attribute reduction of the neighborhood decision rough set based on justifiable granularity will be further investigated.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding authors.
Author contributions
The idea was proposed by PG and HJ; XF and XM simulated the algorithm, wrote the paper and polish the English, TC and YS analysed the data designed the experiments. All authors contributed to the article and approved the submitted version.
Funding
This work was supported the National Natural Science Foundation of China under Grant 62006128, Jiangsu Innovation and Entrepreneurship Program.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Liu J, Lin Y, Du J, Zhang H, Chen Z, Zhang J . Asfs: A novel streaming feature selection for multi-label data based on neighborhood rough set. Appl Intell (2023) 53:1707–24. doi:10.1007/s10489-022-03366-x
2. Wang W, Guo M, Han T, Ning S. A novel feature selection method considering feature interaction in neighborhood rough set. Intell Data Anal (2023) 27:345–59. doi:10.3233/IDA-216447
4. Pawlak Z, Wong S, Ziarko W. Rough sets: Probabilistic versus deterministic approach. Int J Man Mach Stud (1988) 29:81–95. doi:10.1016/S0020-7373(88)80032-4
5. Yao Y, Wong S. A decision theoretic framework for approximating concepts. Int J Man Mach Stud (1992) 37:793–809. doi:10.1016/0020-7373(92)90069-W
6. Yao Y. Three-way decisions with probabilistic rough sets. Inf Sci (2010) 180:341–53. doi:10.1016/j.ins.2009.09.021
7. Qian Y, Liang X, Wang Q, Liang J, Liu B, Skowron A, et al. Local rough set: A solution to rough data analysis in big data. Int J Approx Reason (2018) 97:38–63. doi:10.1016/j.ijar.2018.01.008
8. Wang Q, Qian Y, Liang X, Guo Q, Liang J. Local neighborhood rough set. Knowl Based Syst (2018) 153:53–64. doi:10.1016/j.knosys.2018.04.023
9. Sun L, Wang L, Ding W, Qian Y, Xu J. Neighborhood multi-granulation rough sets-based attribute reduction using lebesgue and entropy measures in incomplete neighborhood decision systems. Knowl Based Syst (2020) 192:105373. doi:10.1016/j.knosys.2019.105373
10. Yang X, Liang S, Yu H, Gao S, Qian Y. Pseudo-label neighborhood rough set: Measures and attribute reductions. Int J Approx Reason (2019) 105:112–29. doi:10.1016/j.ijar.2018.11.010
11. Hu Q, Liu J, Yu D. Mixed feature selection based on granulation and approximation. Knowl Based Syst (2008) 21:294–304. doi:10.1016/j.knosys.2007.07.001
12. Hu Q, Yu D, Liu J, Wu C. Neighborhood rough set based heterogeneous feature subset selection. Inf Sci (2008) 178:3577–94. doi:10.1016/j.ins.2008.05.024
13. Lin Y, Hu Q, Liu J, Chen J, Duan J. Multi-label feature selection based on neighborhood mutual information. Appl Soft Comput (2016) 38:244–56. doi:10.1016/j.asoc.2015.10.009
14. Li W, Huang Z, Jia X, Cai X. Neighborhood based decision-theoretic rough set models. Int J Approx Reason (2016) 69:1–17. doi:10.1016/j.ijar.2015.11.005
15. Pedrycz W, Homenda W. Building the fundamentals of granular computing: A principle of justifiable granularity. Appl Soft Comput (2013) 13:4209–18. doi:10.1016/j.asoc.2013.06.017
16. Wang D, Liu H, Pedrycz W, Song W, Li H. Design Gaussian information granule based on the principle of justifiable granularity: A multi-dimensional perspective. Expert Syst Appl (2022) 197:116763. doi:10.1016/j.eswa.2022.116763
17. Cui Y, Meng X, Qiao J. A multi-objective particle swarm optimization algorithm based on two-archive mechanism. Appl Soft Comput (2022) 119:108532. doi:10.1016/j.asoc.2022.108532
18. Deng H, Liu L, Fang J, Yan L. The application of SOFNN based on PSO-ILM algorithm in nonlinear system modeling. Appl Intell (2023) 53:8927–40. doi:10.1007/s10489-022-03879-5
19. Hu X, Cercone N. Learning in relational databases: A rough set approach. Comput Intell (1995) 11:323–38. doi:10.1111/j.1467-8640.1995.tb00035.x
Keywords: justifiable granularity, sensor data, local neighborhood decision rough set model, attribute reduction, granular computing
Citation: Fan X, Mao X, Cai T, Sun Y, Gu P and Ju H (2023) Sensor data reduction with novel local neighborhood information granularity and rough set approach. Front. Phys. 11:1240555. doi: 10.3389/fphy.2023.1240555
Received: 15 June 2023; Accepted: 10 July 2023;
Published: 28 July 2023.
Edited by:
Xukun Yin, Xidian University, ChinaReviewed by:
Jing Ba, Jiangsu University of Science and Technology, ChinaKe Lu, Nanjing University of Information Science and Technology, China
Heng Du, Nanjing Institute of Technology (NJIT), China
Copyright © 2023 Fan, Mao, Cai, Sun, Gu and Ju. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xiaojuan Mao, MTAxNzI4NDgzNEBxcS5jb20=; Pingping Gu, Z3VwaW5ncGluZ0BudHUuZWR1LmNu; Hengrong Ju, anVoZW5ncm9uZ0BudHUuZWR1LmNu