 Xiaofeng Wang
Xiaofeng Wang Jiameng Sun2
Jiameng Sun2 Yingying Su
Yingying Su- 1College of Mathematical and Physical Sciences, Chongqing University of Science and Technology, Chongqing, China
- 2College of Electrical Engineering, Chongqing University of Science and Technology, Chongqing, China
Unsupervised monocular depth estimation is challenging in ill-posed regions, such as weak texture scenes, projection occlusion, and redundant error of detail information, etc. In this paper, in order to tackle these problems, an improved unsupervised monocular depth estimation method for the ill-posed region is proposed through cascading training depth estimation network and pose estimation network by loss function. Firstly, for the depth estimation network, a feature extraction network using asymmetric convolution is designed instead of traditional convolution, which strengthens the extraction of the feature information and improves the accuracy of the weak texture scenes. Meanwhile, a feature extraction network integrating multi-scale receptive fields with the structure of different scale convolution and dilated convolution stack is designed to increase the underlying receptive field of the depth estimation network, which strengthens the fusion ability of the network for multi-scale detail information, and improves the integrity of the model output details. Secondly, a pose estimation network using an attention mechanism is presented to strengthen the pose detail information of keyframes and suppress redundant errors of the pose information of non-keyframes. Finally, a loss function with minimum reprojection error is adopted to alleviate the occlusion problem of the projection process between adjacent pixels and enhance the quality of the output depth images of the model. The experiments demonstrate that our method achieves state-of-the-art performance on KITTI monocular datasets.
1 Introduction
As an important research focus in the field of computer vision, monocular depth estimation aims to explore the mapping relationship between image and depth, and predict the depth information from a single image. Monocular depth estimation plays an important role in visual tasks, especially in intelligent fields such as autonomous driving, 3D map construction, AR (Augmented Reality) synthesis, etc.
At present, the mainstream way of monocular depth estimation task is to train the deep neural network by using a large number of marked real depth images as the training set, so as to obtain the depth value of the corresponding pixel from the image. In this way, deep neural networks are used to generate high-quality depth images with different optimization strategies [1–4]. However, supervised depth estimation methods need to collect a large amount of real-depth information data and require an immense amount of computing time in the training process, which greatly increases the difficulty and complexity of the algorithm. Comparatively speaking, unsupervised monocular depth estimation only requires monocular video sequences or stereo image pairs to realize the depth information estimation of each pixel of a single image [5–7]. In recent years, unsupervised monocular depth estimation have been favored by researchers [8–10]. Among them, Zhou [10] innovatively proposes an unsupervised training framework which cascades the depth estimation network and the pose estimation network through the loss function to predict the depth information of the image, improving the accuracy of model estimation and becoming one of the most dominant frameworks in current unsupervised monocular depth estimation.
However, current unsupervised monocular depth estimation studies, including Zhou’s method, still face great challenges in dealing with ill-posed regions problems, such as weak texture scenes, occlusion of pixel projections, and lack of detailed information in depth images, etc. As a result, the depth information obtained by the model cannot fully reflect the image-depth mapping relationship. To solve these problems, we propose an improved unsupervised monocular depth estimation which included a depth estimation network, pose estimation network, and the loss function. Firstly, in the depth estimation network, asymmetric convolution structure and multi-scale field structure are proposed to enhance the feature extraction capability of the network, to alleviate the influence of weak texture scenes. Secondly, in the pose estimation network, the redundant information of pose estimation of adjacent image frames is reduced by the attention mechanism structure. Finally, the minimum reprojection error is introduced into the loss function to reduce the influence of occluded pixels and inter-frame motion which results in out-of-bounds regions on depth information prediction during pixel projection. By improving the depth estimation network, pose estimation network, and loss function, the accuracy of the unsupervised monocular depth estimation model for depth information is improved, and the robustness and generalization performance of the model is enhanced.
The main contributions of our works are as follows:
We propose an unsupervised monocular depth estimation method improved for ill-posed regions by training a depth estimation network and a pose estimation network in cascade with loss functions.
We improve the unsupervised depth estimation network by using asymmetric convolution, multiscale perceptual field structure, SE structure and minimum reprojection error in ill-posed regions, such as weak texture scenes, pixel projection occlusion, lack of detailed information in depth images, and so on.
Our approach demonstrate state-of-the-art performance at KITTI monocular datasets.
2 Approach
At present, the unsupervised monocular depth estimation model takes video sequences as input and constructs an unsupervised learning framework for monocular depth and camera pose estimation based on unstructured video sequences. Specifically, an end-to-end learning method is used to jointly train a depth estimation network and a pose estimation network in an encoder-decoder manner, so as to obtain the depth information in a single frame of a video sequence in an unsupervised manner [11].
However, current unsupervised monocular depth estimation algorithms still have limitations when dealing with ill-posed regions, such as weak texture scenes, occlusion of pixel projection, detail information lack of depth images, and redundant errors of continuous image frames for pose information.
In order to further improve the unsupervised monocular depth estimation model and cope with the above complex scenes, this paper improves the unsupervised monocular depth estimation model, which consists of depth estimation network, pose estimation network, and the loss function. We predict the depth information and pose information of 2D images by cascading the depth estimation network and pose estimation network, then we take the pixel error between the reconstructed image and the input image as the supervised signal of the whole network to achieve the depth estimation of unsupervised monocular estimated images. Firstly, for the depth estimation network, inspired by Ding [11], the AC (Asymmetric Convolution) is designed to extract the features of the input image from vertical, horizontal, and overall directions, so as to alleviate the influence of weak texture scenes. Through RFB (Receptive Field Block) which is a multi-scale receptive field structure [12], the ability to obtain all and local information is enhanced in the receptive field area of different scales of the network. Secondly, for the pose estimation network, SE(Squeeze-and-Excitation) structure [13] is introduced to reduce the error region of pose estimation. Finally, for the loss function, the concept of minimizing reprojection error is introduced to reduce the impact of pixel projection occlusion in depth information estimation.
The overall structure of improved unsupervised monocular depth estimation network is shown in Figure 1. Firstly, multi-scale feature maps which is equivalent to 1/2, 1/4, 1/8, 1/16 resolution of the input image frame are generated in the improved depth estimation network, and then these features are mapped to the depth decoder with parameter sharing, and the estimated depth is restored to the same size as the resolution of the input image frame through the upsampling structure. Secondly, for the improved pose estimation network, the relative pose of 6 degrees of freedom which includes displacement with 3 degrees of freedom and spatial rotation with 3 degrees of freedom is generated by the pose estimation network. Finally, the depth information and pose information obtained by the improved depth estimation network and pose estimation network are jointly trained using the loss function.
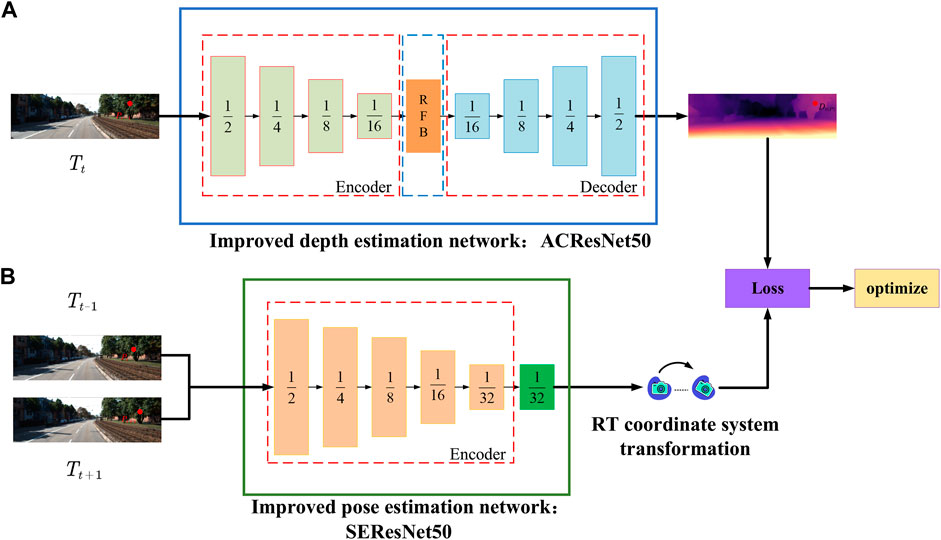
FIGURE 1. Structure diagram of unsupervised monocular depth estimation model: (A) Improved depth estimation network ACResNet50; (B) Improved pose estimation network SEResNet50.
2.1 The depth estimation network optimization
At present, most unsupervised monocular depth estimation algorithms cannot effectively deal with weak texture scenes and miss detailed information of the predicted depth image. In order to solve this problem, asymmetric convolution and multi-scale receptive field RFB are used in the depth estimation network to enhance the recognition of weak texture scenes and strengthen the acquisition of detailed information. The depth estimation network is improved accordingly.
2.1.1 Improved ACResNet50 depth estimation network
Weak texture regions are not distinct and significant features, which are prone to semantic ambiguity and lead to wrong depth estimation, so we deal with this problem in this paper. Our improved ACResNet50 depth estimation network is shown in Figure 2.
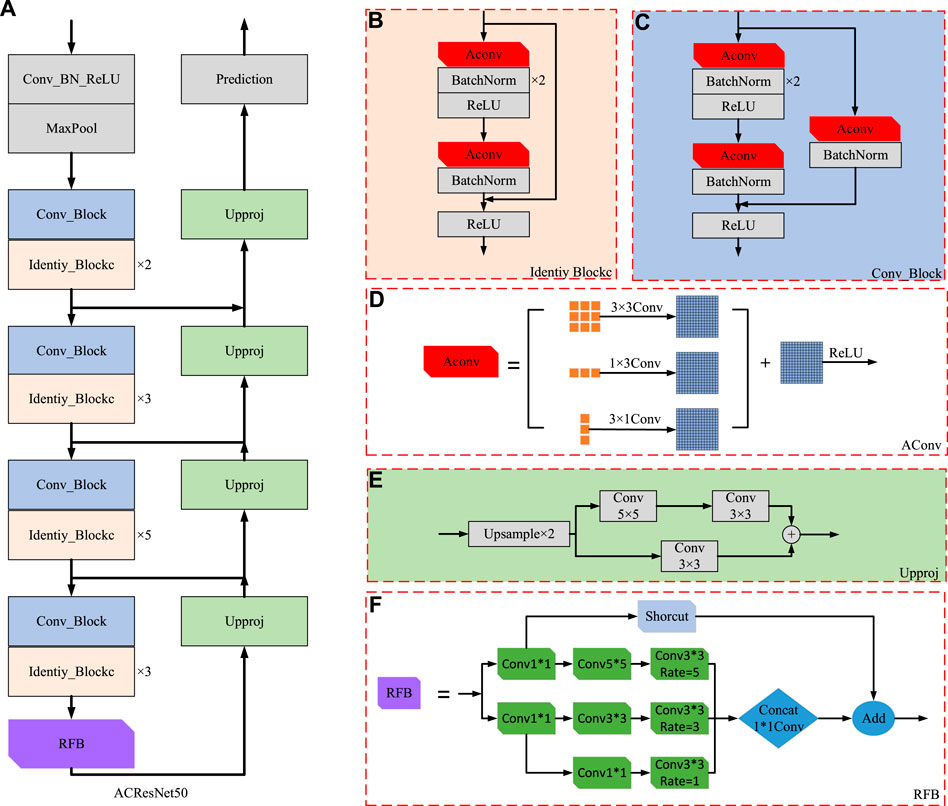
FIGURE 2. Depth estimation network model: (A) ACResNet50 structure; (B) Identiy_Block structure; (C) Conv_Block structure; (D) AConv structure; (E) Upproj structure; (F) RFB structure.
Firstly, in order to effectively mitigate the impact of weak texture scenes on the accuracy of depth estimation information, the traditional convolution method is replaced by AC, and each traditional convolution of ResNet50 network is replaced to strengthen its feature extraction ability, and the ACResNet50 network structure is formed. Secondly, in order to solve the problem of missing details, the RFB structure is connected to the last structure of ACResNet50. Based on the convolution of different sizes, the dilated convolution is added and its expansion rate is adjusted to ensure the network receptive field, so as to achieve the acquisition of high-resolution features. The fusion of global feature information and local feature information is strengthened. Finally, the deconvolution structure is used to restore the size of the output feature map to the size of the original feature image, and the prediction function of the entire network depth information is realized.
2.1.2 Asymmetric convolution
At present, the unsupervised monocular depth estimation network performs poorly on weak texture scenes. Most unsupervised monocular depth estimation networks use the ResNet50 network as the feature extraction backbone network in the encoding process of the image and extract the feature information of the image by feature superposition and refinement. Although the residual structure of ResNet50 can extract the feature information of the image to a certain extent, it is far from sufficient for the task of unsupervised monocular depth estimation that requires more accurate depth information. At the same time, the continuous superposition of the ResNet50 network and the deepening of the number of network layers will also lead to many problems, such as too many network parameters, difficult training, and the degradation of the whole network.
In order to obtain more feature information of the input image and alleviate the influence of weak texture scenes on unsupervised monocular depth estimation tasks, inspired by ACNet research, the traditional convolution method is improved, and we propose a novel depth estimation network based on ACNet. The feature extraction of the input image is carried out from the vertical, horizontal, and overall directions, which strengthens the feature information extraction ability of the feature extraction network and alleviates the influence of weak texture scenes on the depth information.
Figure 3 is the operation process of asymmetric convolution. The ACNet network in the Figure 3 can be divided into two stages, training and test reasoning, with Figure 3A indicating the training stage and Figure 3B indicating the test reasoning stage. Firstly, we set up three parallel convolution kernels with sizes
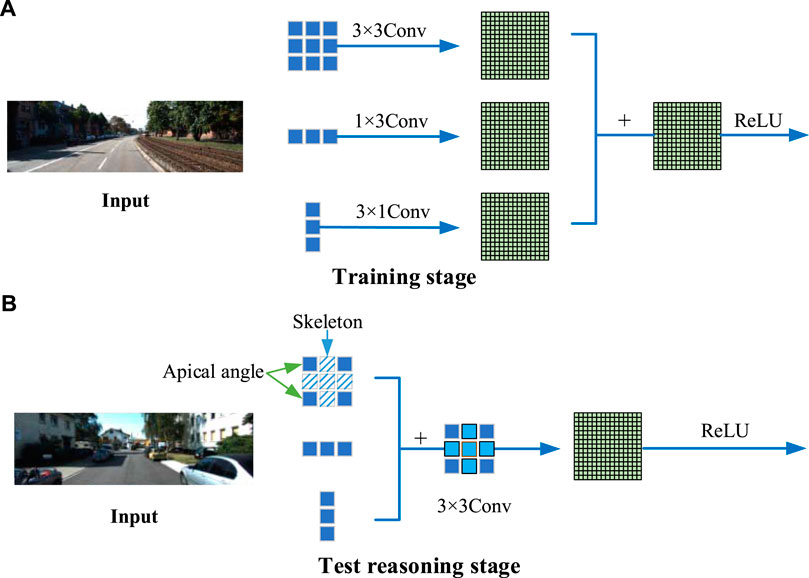
FIGURE 3. Asymmetric convolution structure:(A) The ACNet structure in the training stage; (B) The network structure in the test reasoning stage.
2.1.3 Multiscale receptive fields
The lack of details in depth maps has always been a difficulty for unsupervised monocular depth estimation. The reason is that in the theory of deep convolutional neural networks, the perceptual field of the network gradually increases with the number of layers of the network, Zhou [14] founds that the network’s ability of detail acquisition in the receptive field is reduced in deeper networks, leading to poor network learning. Moreover, in the traditional convolution process, convolution is used to continuously stack down sampling to extract abstract information, but continuous downsampling will lead to the loss of image details and local information. Zhao [15] points out that the fusion of global and different scale context information in semantic segmentation is beneficial to alleviate the loss of detail information and preserve the spatial structure of the image. Therefore, RFB is adopted to solve this problem in that the receptive field decreases in the unsupervised monocular depth estimation model, which leads to unsatisfactory context information fusion and missing details of the estimated depth map.
The RFB can achieve the acquisition of high-resolution features without repeated down-sampling and enhance the ability of network feature extraction and fusion [12]. At the same time, different receptive fields are obtained by adjusting different expansion rates of dilated convolution, so as to enhance the variability of network receptive field region size. By stacking in this way, the ability of interfusion between feature information at different scales of the network is enhanced, and the acquisition of full and local detail information is strengthened. The multiscale receptive field RFB structure is shown in Figure 4.
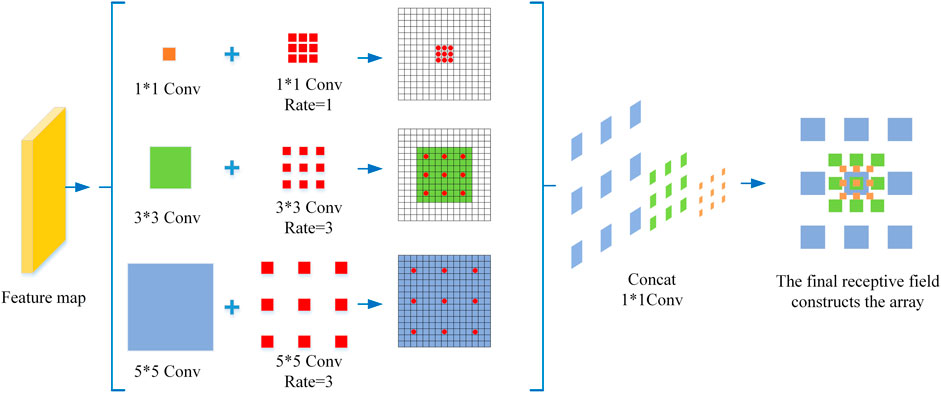
FIGURE 4. Multi-scale receptive field RFB structure.
In this paper, a multi-scale receptive field RFB structure is added after the last convolutional block of the ACResNet50 feature extraction network. Firstly, in the multi-branch convolution layer, convolution kernels of
2.2 Pose estimation network based on SEResNet50
The pose estimation network is crucial for accurately predicting depth information. However, in the design process of the pose estimation network, most unsupervised monocular depth estimation models directly use the pose information of consecutive image frames for model prediction, ignoring the redundant error of pose information, which leads to the reduction of the accuracy of the model prediction depth information.
In order to reduce the large redundant errors in pose estimation, we design the SE attention mechanism structure based on ResNet50 in the pose estimation network, which can focus on the important pose information of the image frame, suppress the unimportant pose information of the image frame, and reduce the large error redundancy. The improved pose estimation network is shown in Figure 5.
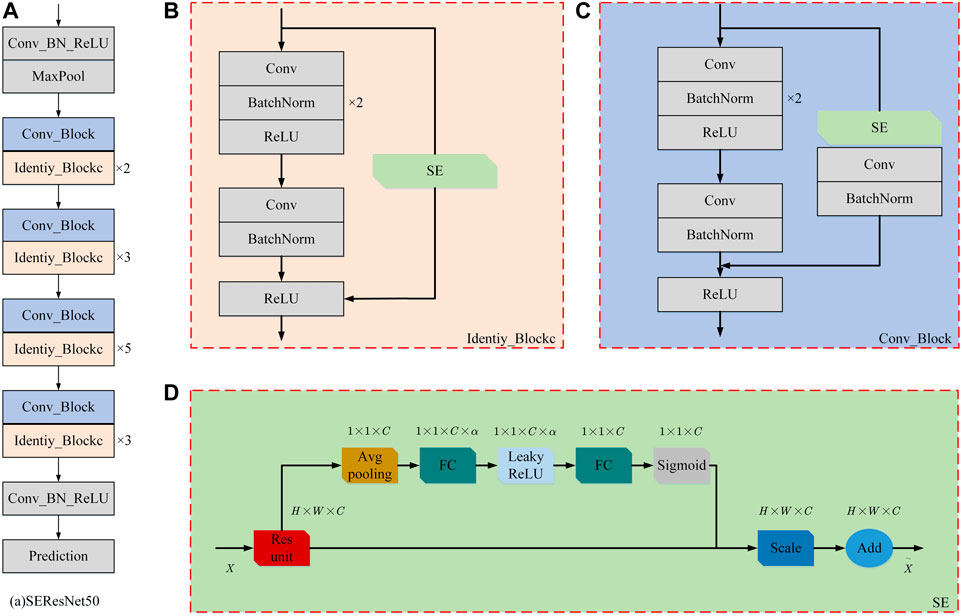
FIGURE 5. Improvement of pose estimation network model: (A) SEResNet50 structure; (B) Identiy_Block structure; (C) Conv_Block structure; (D) SE structure.
2.2.1 SE attention mechanism
For the pose estimation network, its task is to accurately predict the camera motion trajectory between adjacent frames in the video sequence, so as to obtain the rotation matrix and translation matrix. Then, the image is reconstructed by combining the internal parameter matrix of the camera and the depth information predicted by the depth estimation network. However, in the pose estimation network, the camera pose motion estimation in the image between two highly adjacent frames is highly approximate. If the network trains all the pose information of the video sequence frames and predicts the camera pose, it will not only increase the amount of information processed by the network but also lead to an increase in redundancy error in the pose estimation.
SE structure focuses on exploring the relationship between different channels in feature information, and this exploration method has a good performance in balancing the importance of feature channels and learning global feature information [13]. In the pose estimation network, the SE structure can be used to pay more attention to the important pose information in the continuous image frames of the video sequence, suppress the unimportant pose information, and effectively enhance the network’s prediction of the camera pose motion trajectory between image frames, and improve the ability of pose estimation.
Figure 6 shows the attention mechanism structure of SE channel. Firstly, given a feature input
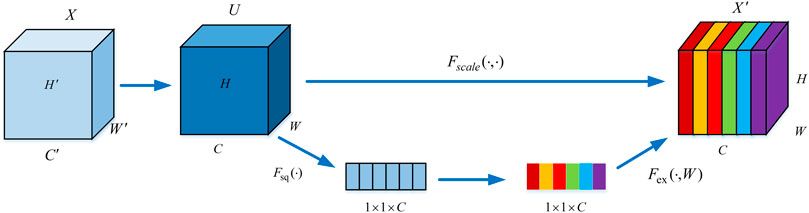
FIGURE 6. SE channel attention mechanism.
2.2.2 Residual network with attention mechanism
There are multiple block structures in the original ResNet50 feature extraction network, and each block realizes the extraction of image features by stacking each other. The original ResNet50 backbone feature extraction network does not consider the relationship between different channels in the feature information. Such a way will lead to the lack of ability to distinguish the main and secondary channel feature information, resulting in a weak performance in global feature information extraction ability.
However, the SE channel attention mechanism makes full use of the weights of different feature channel information importance to enhance the information acquisition of important feature channel. In this paper, the attention mechanism is introduced into the backbone feature extraction network to strengthen the extraction performance of global feature information. Its improved residual network with attention mechanism is shown in Figure 7.
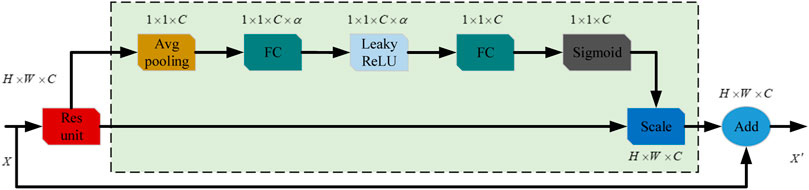
FIGURE 7. SE+ Residual blocks structure.
This paper designs the channel attention mechanism SE in each block structure of the ResNet50 feature extraction network. Firstly, the feature map of height
2.3 Design of the loss function
In the design of the loss function, since the whole unsupervised monocular depth estimation network consists of two parts: the depth estimation network and the pose estimation network, which are used together to predict the depth of a pixel. Therefore, the constraint term of the loss function is derived from the pixel difference between the reconstructed image and the input image after information predicted by the depth estimation network and the pose estimation network. In the inference of the loss function, let the three adjacent frames of images at time
In the process of image reconstruction, each pixel
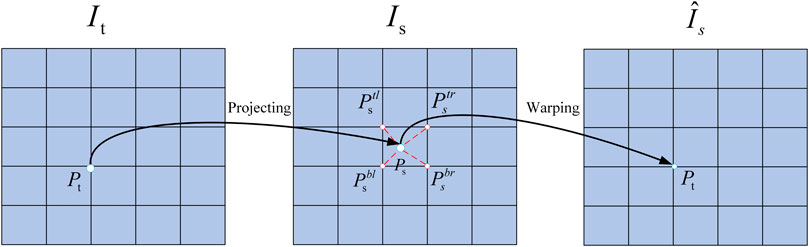
FIGURE 8. Differentiable image warping process.
For the flush coordinate
where
In this case, let the target image
Since the premise assumptions of invisible change and static scene need to be satisfied in network construction, if one of the assumptions is not met, the gradient will be destroyed and the inhibition of training will occur. In response to these factors, in order to improve the robustness of the network, the output confidence weight
In the original algorithm, the ill-posed region is solved by adding a smoothing constraint when obtaining the depth map, and the depth of each pixel is solved by global optimization. However, this method is to average the reprojection error of multi-source images, which may lead to problems of pixels which are visible in the target image and invisible in the source image. If the network predicts the correct depth of a pixel, then the corresponding color in the blocked source image has a high probability of mismatch with the target, resulting in a high photometric error. There are two reasons for this problem. One is pixels which are on the edge of the image and are out of view due to motion between frames. The other is the occluded pixels.
In this paper, we use the concept of minimum reprojection error to deal with the problem of out-of-bounds caused by occluded pixels and inter-frame motion. At each pixel, the photometric error of all source images is no longer averaged, but simply the minimum value is used, which can effectively alleviate the pixels that are visible in the target image and invisible in the source image in the process of pixel projection, and solve the occlusion problem caused by pixel projection. Therefore, the calculation process of the minimum reprojection loss function
Among them, SSIM (Structural Similarity Index Measurement) is the structural similarity index,
Finally, the minimum reprojection error constraint is introduced into the overall loss function to reduce the impact of pixel occlusion on the model during pixel projection and ensure the accuracy of the model in predicting depth information. The final loss function of the model
3 Experiments
In our experiment, video images of real scenes are utilized as training data set and test data set, such as urban areas and highways in KITTI data set. In order to ensure the consistency of the experiment, the image resolution is uniformly cropped to a size of 640
3.1 The ablation experiment
To verify the reliability of the proposed scheme, we validated the proposed scheme on the KITTI dataset and performed ablation experiments and compared the proposed method in this paper with the scheme of Zhou [10], and the experimental scheme and results are shown in Table 1.
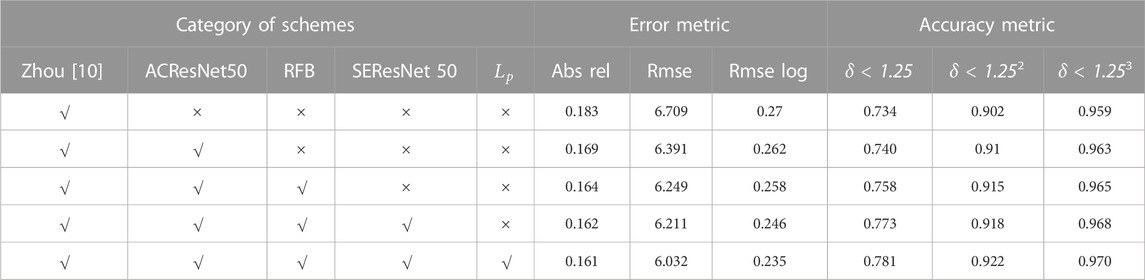
TABLE 1. Ablation experimental design protocol and comparison of experimental results.
3.2 The depth estimation network
3.2.1 Verification of asymmetric convolution structure
In order to verify AC, we conduct comparative experiments between ACResNet50 in this paper and Zhou’s method.
From the quantitative and qualitative analysis of the relevant evaluation indicators in Table 1 and Figure 9, our method works better than Zhou’s method for weak texture scenes in the ill-posed regions of the billboard in row 2 and the columnar objects in rows 2 to 3. Only using the asymmetric convolution structure designed to replace the traditional convolution structure has a certain improvement in the accuracy of the estimated depth value of the network. The experimental results show that the improved asymmetric convolution can effectively enhance the ability of the network to obtain feature information for the color two-dimensional image, strengthen the feature extraction of the input image, and make the unsupervised monocular depth estimation network output depth images with rich textures and clear edges.
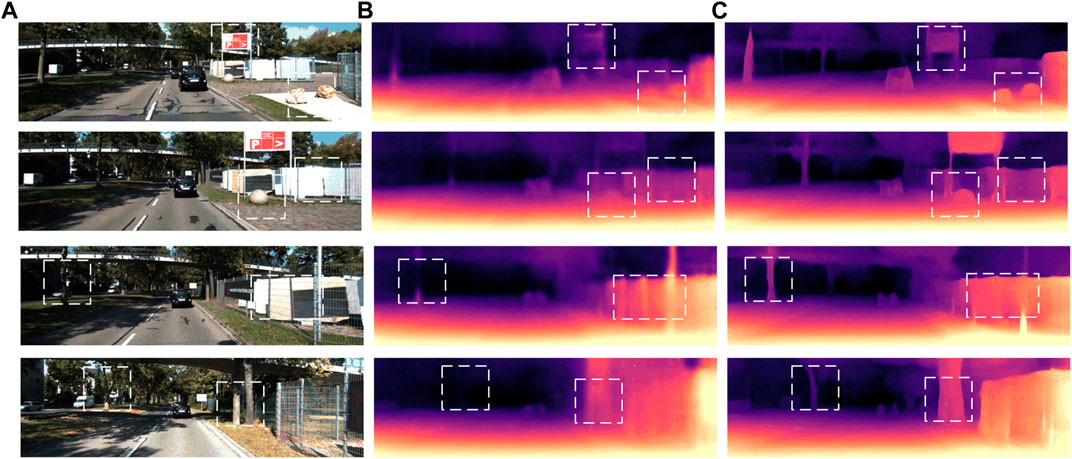
FIGURE 9. Comparative experimental results of asymmetric convolution module visualization on KITTI dataset: (A) represents the color image input by the model; (B) represents the depth map result predicted by Zhou et al.; (C) The ACResNet50 prediction of asymmetric convolution to the depth map results.
3.2.2 Validation of ACResNet50+ RFB structure
In order to verify the RFB structure, the ACResNet50 + RFB is compared with Zhou [10].
The relevant quantity and quality evaluation metrics are analyzed in Table 1 and Figure 10. In this paper, RFB is introduced into the last module of the ACResNet50 network, so that the model can obtain the context information of image features at different scales. The obtained feature information is more continuous and the detail information is more complete, which ensures the continuity and integrity of the spatial structure of the output depth image of the network. In Figure 10, our method is able to retain more detailed information of vehicle contours, which is significantly better than Zhou’s method. Experimental results show that the proposed multi-scale receptive field enhanced RFB structure outperforms Zhou’s algorithm in depth map detail information and spatial structure presentation. It can effectively avoid the lack of details in the unsupervised monocular image depth estimation task, strengthen the control of the model for detailed information. At the same time, it can further obtain multi-scale information and rich context information in two-dimensional color images, and improve the overall prediction accuracy and generalization performance of the model. The results show that the method can effectively alleviate the redundancy error problem of detail information in the ill-posed regions.
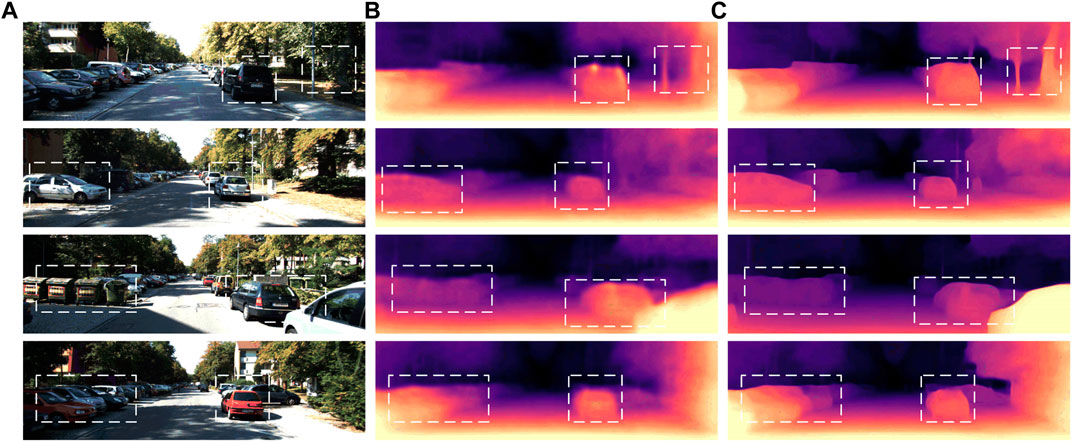
FIGURE 10. Comparative experimental results of multi-scale receptive field RFB visualization on KITTI dataset: (A) The color images input by the model; (B) The depth map results predicted by Zhou et al.; (C) The depth map results predicted by ACResNet50+ RFB structure.
3.3 Pose estimation network
In order to verify the actual effect of the pose estimation network SEResNet50 embedded with the attention mechanism designed in this paper, the method in this paper is compared with Zhou [10].
The relevant evaluation indicators in Table 1 and Figure 11 are analyzed quantitatively and qualitatively. In this paper, the attention mechanism SE structure is designed to reduce the redundant error caused by using the pose information of consecutive frames to predict the pose information of the next frame in the pose estimation process. The attention mechanism SE can pay attention to the important information in a single frame and suppress the unimportant information, so as to effectively reduce the redundant error generation and improve the overall prediction accuracy of the model. From Figure 11, we can find that our method works well when targeting the projected occlusion region of bicycle pedestrians and car outline. The experimental results show that the attention mechanism SE structure designed in this paper can reduce the redundant error of camera pose estimation in the pose estimation network. In terms of the accuracy of predicting the depth value, the three indicators have a corresponding improvement, where
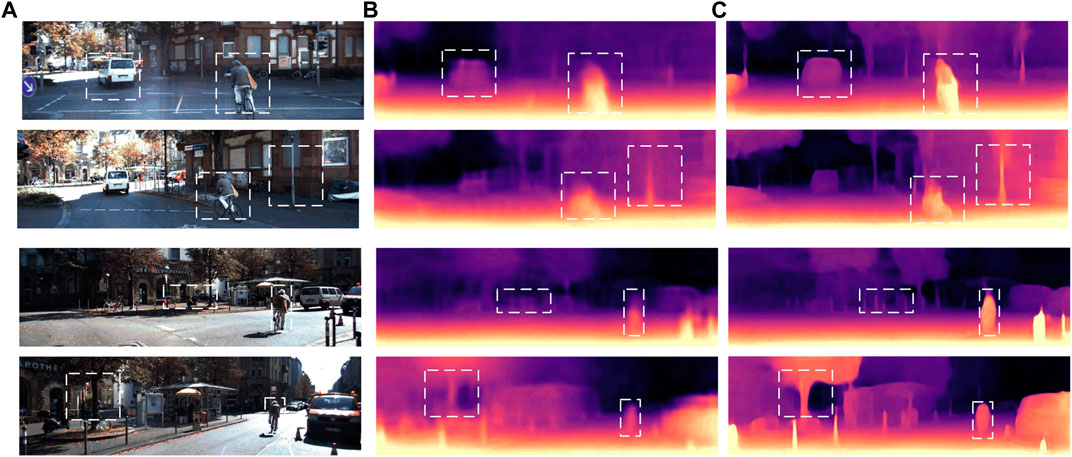
FIGURE 11. Comparative experimental results of attention mechanism SE module visualization on KITTI dataset: (A) The color image input by the model; (B) The depth map results predicted by Zhou et al.; (C) The depth map predicted by SEResNet50 embedded attention mechanism in the pose estimation network.
At the same time, in order to further verify the absolute trajectory error estimated as the pose information, the prediction results are tested through the pose estimation test data Seq.9 and Seq.10 provided by the KITTI dataset official website, as shown in Table 2.
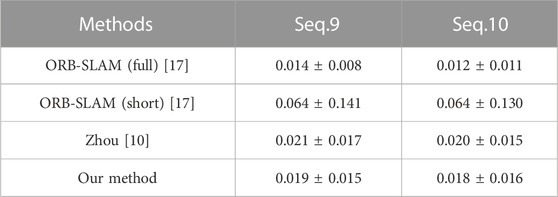
TABLE 2. Absolute trajectory error for validating positional estimation on KITTI test set.
As can be seen from Table 2, after designing the attention mechanism in the pose estimation network, the error of pose estimation on the KITTI test set is smaller than that of ORB-SLAM (short) and Zhou’s method, but larger than that of ORB-SLAM (full). Therefore, the attention mechanism used in the pose estimation network can effectively reduce the redundant error caused by the superposition of consecutive multi-frame image information and improve the robustness of the model.
3.4 Minimum reprojection error loss function
In order to verify the experimental effect of introducing the minimum reprojection error loss function. The model introduced with the minimum reprojection error loss function designed in this paper is compared with the method of Zhou [10].
The relevant evaluation indicators in Table 1 and Figure 12 are analyzed quantitatively and qualitatively. In this paper, a constraint term of minimum reprojection error is added to the loss function, which is beneficial for the prediction of depth information, and can effectively improve the occlusion problem in the projection process of adjacent pixels.
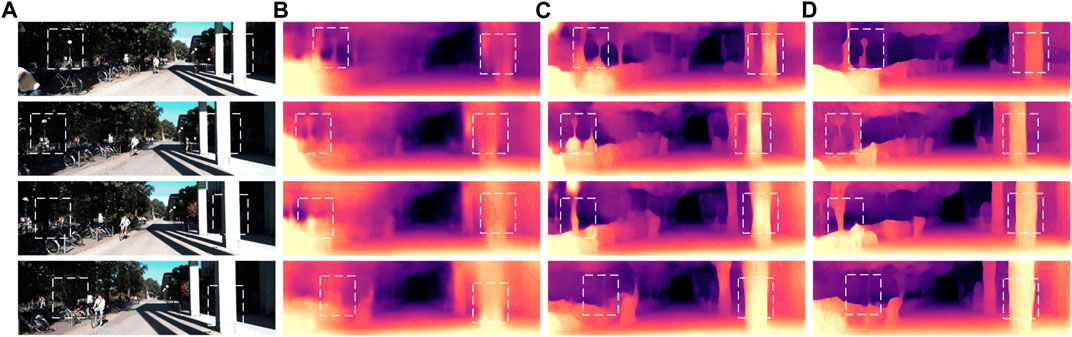
FIGURE 12. Comparative experimental results of the per-pixel minimum reprojection error visualized in the KITTI dataset: (A) The color image input by the model; (B) The depth map result predicted by Zhou et al.; (C) The depth map predicted by the whole network structure after improvement; (D) The depth map predicted by the whole model after using the minimum reprojection error loss function.
Experimental results show that after using the minimum reprojection error as a constraint term, each error index is reduced accordingly. It improves the problem of occlusion during the projection of adjacent pixels and enhances the prediction accuracy of depth information of the model. At the same time, the robustness and generalization performance of the model are improved.
3.5 KITTI contrast experiment
At the same time, in order to verify the effectiveness and generalization of the proposed method, we make qualitative and quantitative comparison analysis with the research algorithms in related fields. In order to verify the effectiveness of the method in this paper, the comparative experiments are based on the KITTI dataset, verify the generalization of the method in this paper, the cityscapes dataset is used, but the error of the model increases slightly when dealing with data sets other than KITTI.
In Table 3, k is the KITTI dataset, CS is the Cityscapes dataset, and supervision (Y, N) indicates whether it is an unsupervised and supervised monocular depth estimation task. The relevant evaluation indicators in Table 3 and Figure 13 are analyzed quantitatively and qualitatively. The algorithm designed in this paper is .022, .677, and .035 lower than Zhou in AbsRel (Absolute Relative error), RMS (Root Mean Square error), and LogRMS (Log Root Mean Square error), respectively. In the three depths value accuracy evaluation indicators of
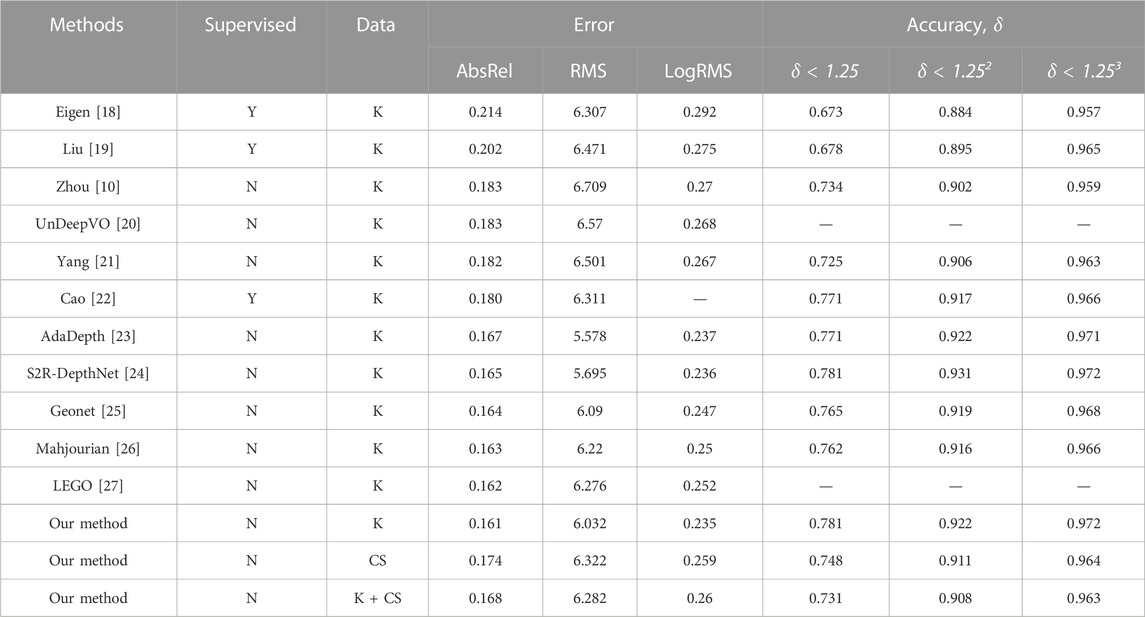
TABLE 3. Comparison of experimental results with other related research algorithms.
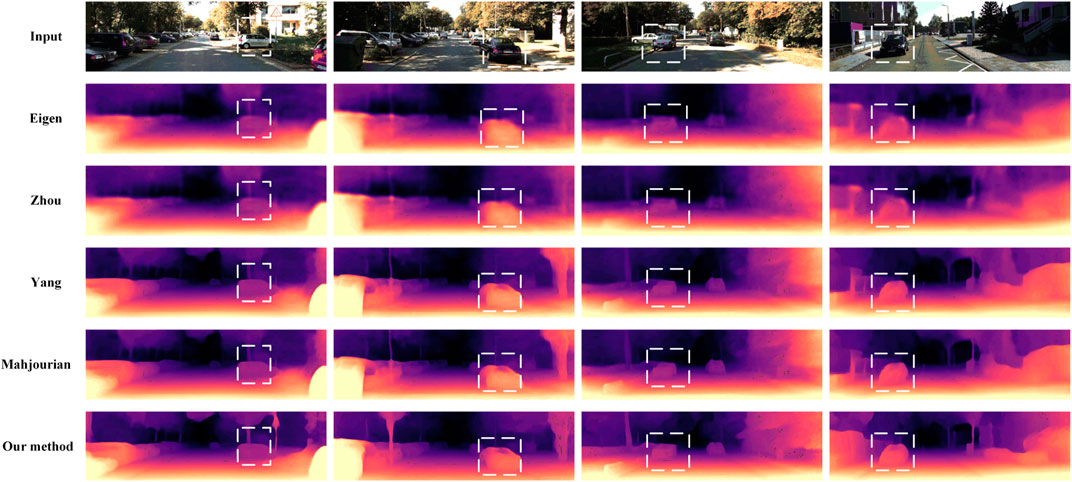
FIGURE 13. Visual comparison experimental results with other related research algorithms on the KITTI dataset: the first row is the input two-dimensional color image; rows 2 to 6 show the depth maps predicted by Eigen, Zhou, Yang, Mahjourian et al. and our method, respectively.
The method designed in this paper has good performance in various evaluation indicators compared with the previous research work. Among them, compared with the supervised method of Eigen [18], Liu [19] and Cao [22], the accuracy of the predicted depth value is greatly improved. Compared with the unsupervised monocular depth estimation proposed by Zhou [10], the three indexes in this paper are increased by .047, .020, .013 respectively, and the error index is reduced accordingly. Compared with the recent work of Yang [21], AdaDepth [23], S2R-DepthNet [24], etc. which studied the unsupervised monocular depth estimation task, the proposed method performs better in all indicators. At the same time, from the depth images predicted by each algorithm in Figure 13, the proposed algorithm has good performance in the texture information, detail information, and spatial structure of the output depth map.
The experimental results show that the improved unsupervised monocular depth estimation algorithm designed in this paper can effectively alleviate the impact of weak texture scenes on the model, solve the lack of detail of the input image, reduce the redundant error of pose information, reduce the occlusion problem in the process of pixel projection, and ensure the prediction accuracy of the unsupervised monocular depth estimation model. From the analysis of the above indicators, the unsupervised monocular depth estimation network has a certain competitive advantage in depth prediction, and can accurately estimate the depth information of images or video frames.
4 Conclusion
Currently, supervised monocular image depth estimation tasks require a large amount of real depth data for training, which greatly increase the development cost of the model and the difficulty of landing the model. The improved unsupervised monocular depth image estimation task designed in this paper only uses continuous video sequences to complete the depth prediction of each pixel of a single image, which greatly reduces the model development cost and accelerates the model implementation process. It can effectively improve the influence of weak texture scene on depth prediction, reduce the lack of details of the model predicted depth image, and reduce the occlusion problem of the model due to the pixel projection process. Through the improvement of this paper, the prediction accuracy of the unsupervised monocular image depth estimation model on depth information is strengthened, which makes the depth image predicted by the model richer in texture information, clearer in detail information, and more continuous in spatial structure, thus enhancing the structure of the predicted depth image and improving the resolution of the output image. The robustness and generalization performance of the unsupervised monocular depth estimation model are improved.
Although our approach does not require labeling of real depth images as supervised methods do, the framework lacks explicit estimation of scene dynamics in 3D scene understanding. In future work, we would like to explore methods for modeling scene dynamics through motion segmentation to improve the performance of unsupervised monocular depth estimation in dynamic scenes.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
Conceptualization, XW; methodology, XW and JS; software, YS; validation, JY, YS, and ZS; formal analysis, XW; writing—original draft preparation, YY; writing—review and editing, XW; supervision, XW and HQ. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the Natural Science Foundation of Chongqing (CSTB2022NSCQ-MSX0398, CSTB2022NSCQ-MSX1425), Science and Technology Foundation of the Education Department of Chongqing (KJQN202101510).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Zhao C, Sun Q, Zhang C, Tang Y, Qian F. Monocular depth estimation based on deep learning: An overview. Sci China Technol Sci (2020) 63(9):1612–27. doi:10.1007/s11431-020-1582-8
2. Ming Y, Meng X, Fan C, Yu H. Deep learning for monocular depth estimation. A Review Neurocomputing (2021) 438:14–33.
3. Liu X, Xue N, Wu T. Learning auxiliary monocular contexts helps monocular 3D object detection. Proc AAAI Conf Artif Intelligence (2022) 36:1810–8. doi:10.1609/aaai.v36i2.20074
4. Luo S, Dai H, Shao L, Ding Y. M3dssd: Monocular 3d single stage object detector. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE (2021). p. 6145–54.
5. Bhattacharyya S, Shen J, Welch S, Chen C. Efficient unsupervised monocular depth estimation using attention guided generative adversarial network. J Real-Time Image Process (2021) 18(4):1357–68. doi:10.1007/s11554-021-01092-0
6. Ye X, Fan X, Zhang M, Xu R, Zhong W. Unsupervised monocular depth estimation via recursive stereo distillation. IEEE Trans Image Process (2021) 30:4492–504. doi:10.1109/tip.2021.3072215
7. Sun Q, Tang Y, Zhang C, Zhao C, Qian F, Kurths J. Unsupervised estimation of monocular depth and VO in dynamic environments via hybrid masks. IEEE Trans Neural Networks Learn Syst (2021) 33(5):2023–33. doi:10.1109/tnnls.2021.3100895
8. Garg R, Bg VK, Carneiro G, Reid I. Unsupervised cnn for single view depth estimation: Geometry to the rescue. In: European conference on computer vision. Cham: Springer (2016). p. 740–56.
9. Godard C, Mac Aodha O, Brostow GJ. Unsupervised monocular depth estimation with left-right consistency. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). IEEE (2017). p. 270–9.
10. Zhou T, Brown M, Snavely N, Lowe DG. Unsupervised learning of depth and ego-motion from video. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). IEEE (2017). p. 1851–8.
11. Ding X, Guo Y, Ding G, Han J. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks. In: Proceedings of the IEEE/CVF international conference on computer vision (ICCV); October 2019. IEEE (2019). p. 1911–20.
12. Liu S, Huang D. Receptive field block net for accurate and fast object detection. In: Proceedings of the European conference on computer vision (ECCV). IEEE (2018). p. 385–400.
13. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). IEEE (2018). p. 7132–41.
14. Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning deep features for discriminative localization. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR); December 2016. IEEE (2016). p. 2921–9.
15. Zhao H, Shi J, Qi X, Wang X, Jia J. Pyramid scene parsing network. In: Proceedings of the IEEE conference on computer vision and pattern recognition(CVPR). IEEE (2017). p. 2881–90.
16. Liu C, Zhu L, Belkin M. Loss landscapes and optimization in over-parameterized non-linear systems and neural networks. Appl Comput Harmonic Anal (2022) 59:85–116. doi:10.1016/j.acha.2021.12.009
17. Mur-Artal R, Montiel JMM, Tardos JD. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans robotics (2015) 31(5):1147–63. doi:10.1109/tro.2015.2463671
18. Eigen D, Puhrsch C, Fergus R. Depth map prediction from a single image using a multi-scale deep network. Adv Neural Inf Process Syst (2014) 27:2366–74.
19. Liu M, Salzmann M, He X. Discrete-continuous depth estimation from a single image. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); June 2014; Columbus, OH, USA. IEEE (2014). p. 716–23.
20. Li R, Wang S, Long Z, Gu D. Undeepvo: Monocular visual odometry through unsupervised deep learning. In: Proceedings of the 2018 IEEE international conference on robotics and automation (ICRA); May 2018; Brisbane, QLD, Australia. IEEE (2018). p. 7286–91.
21. Yang Z, Wang P, Xu W, Zhao L, Nevatia R. Unsupervised learning of geometry from videos with edge-aware depth-normal consistency. Proc AAAI Conf Artif Intelligence (2018) 32:12257. doi:10.1609/aaai.v32i1.12257
22. Dovesi PL, Poggi M, Andraghetti L, Martí M, Kjellström H, Pieropan A, Mattoccia S. Real-time semantic stereo matching. In: Proceedings of the 2020 IEEE international conference on robotics and automation (ICRA); Paris, FranceMay 2020. IEEE (2020). p. 10780–7.
23. Kundu JN, Uppala PK, Pahuja A, Babu RV. Adadepth: Unsupervised content congruent adaptation for depth estimation. In: Proceedings of the IEEE conference on computer vision and pattern recognition; March 2018. IEEE (2018). p. 2656–65.
24. Chen X, Wang Y, Chen X, Zeng W. S2r-depthnet: Learning a generalizable depth-specific structural representation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; June 2021; Nashville, TN, USA. IEEE (2021). p. 3034–43.
25. Yin Z, Shi J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In: Proceedings of the IEEE conference on computer vision and pattern recognition; June 2018. IEEE (2018). p. 1983–92.
26. Mahjourian R, Wicke M, Angelova A. Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR); June 2018. IEEE (2018). p. 5667–75.
Keywords: unsupervised monocular depth estimation, asymmetric convolution, multi-scale receptive field, attention mechanism, ill-posed regions
Citation: Wang X, Sun J, Qin H, Yuan Y, Yu J, Su Y and Sun Z (2023) Accurate unsupervised monocular depth estimation for ill-posed region. Front. Phys. 10:1115764. doi: 10.3389/fphy.2022.1115764
Received: 04 December 2022; Accepted: 29 December 2022;
Published: 12 January 2023.
Edited by:
Huafeng Li, Kunming University of Science and Technology, ChinaReviewed by:
Yiwen Chen, Wuhan University, ChinaShuanglin Yan, Nanjing University of Science and Technology, China
Jinting Zhu, Massey University, New Zealand
Jian Pang, China University of Petroleum, China
Copyright © 2023 Wang, Sun, Qin, Yuan, Yu, Su and Sun. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xiaofeng Wang, eGZ3YW5nODI4QDEyNi5jb20=