
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Phys. , 15 March 2018
Sec. Interdisciplinary Physics
Volume 6 - 2018 | https://doi.org/10.3389/fphy.2018.00020
This article is part of the Research Topic Coordination and Cooperation in Complex Adaptive Systems: Theory and Application View all 14 articles
 Shin-Ichiro Kumamoto*
Shin-Ichiro Kumamoto* Takashi Kamihigashi
Takashi KamihigashiMany phenomena with power laws have been observed in various fields of the natural and social sciences, and these power laws are often interpreted as the macro behaviors of systems that consist of micro units. In this paper, we review some basic mathematical mechanisms that are known to generate power laws. In particular, we focus on stochastic processes including the Yule process and the Simon process as well as some recent models. The main purpose of this paper is to explain the mathematical details of their mechanisms in a self-contained manner.
Many phenomena with power laws have been observed in various fields of the natural and social sciences: physics, biology, earth planetary science, computer science, economics, and so on. These power laws can be interpreted as the macro behaviors of the systems that consist of micro units (i.e., agents, individuals, particles, and so on). In other words, the ensemble of dynamics of these micro units is observed as the behavior of the whole system such as a power law1. To obtain a deep understanding of the phenomenon for the system, we must first observe the behavior on the macro side, then assume the stochastic dynamics on the micro side, and finally reveal the theoretical method connecting both sides. Thus, the mechanisms generating power laws have been studied as the second and final steps in the study of power laws.
Next, we mathematically define the power law. When the probability density function p(x) for a continuous random variable2 is given by
we say that satisfies the power law. The exponent α is called the exponent of power law, C is the normalization constant, and xmin is the minimum value that x satisfies the power law. The power law is the only function satisfying the scale-free property [1]
Then we define the cumulative distribution function P>(x) as
When the probability density function satisfies the power law p(x) = Cx−α,
The behavior of the cumulative distribution function with the power law is a straight line in a log–log plot for x ≥ xmin (Figure 1).
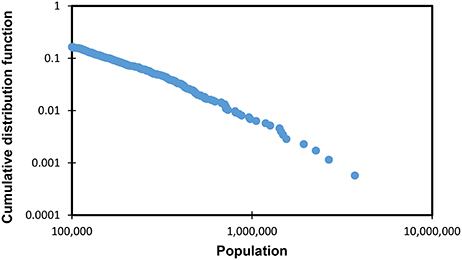
Figure 1. Log–log plot for the cumulative distribution function of the populations of Japanese cities in 2015, with xmin ≃ 100, 000. Data from the basic resident register.
Next, we list some examples of power laws in various phenomena.
(a) Populations of cities [2].
(b) Frequency of use of words [3, 4].
(c) Number of papers published by scientists [5].
(d) Number of citations received by papers [6].
(e) Number of species in biological genera [7, 8].
(f) Number of links on the World Wide Web [9].
(g) Individual wealth and income [10].
(h) Sizes of firms (the number of employees, assets, or market capitalization) [11–17].
(i) Sizes of earthquakes [18].
(j) Sizes of forest fires [19].
Furthermore, we partly list the generating mechanisms that are important for applications, and the phenomena to which they are applied in the above list, such as “mechanism ⇒ phenomena.”
• Growth and preferential attachment:
- Yule process [20] ⇒ (e);
- Simon process [21] ⇒ (a), (b), (c), (e), and (g);
- Barabási–Albert (BA) model [22] ⇒ (d) and (f).
• Stochastic models based on Geometric Brownian motion (GBM):
- GBM with a reflecting wall [23] ⇒ (a), (g), and (h);
- GBM with reset events [24, 25] ⇒ (g).
- Kesten process [26]⇒ (g).
- Generalized Lotka–Volterra (GLV) model [27–29] ⇒ (g);
- Bouchaud–Mézard (BM) model [30] ⇒ (g).
• Combination of exponentials (change of variable) [31] ⇒ (b).
• Self-organized criticality [32] ⇒ (i) and (j).
• Highly optimized tolerance [33, 34] ⇒ (j).
Though there are many other generating mechanisms besides them3, the mechanisms of the above list are particularly well known and widely applied to phenomena in various fields.
In this paper, we focus on the generating mechanisms with the stochastic processes in the above list4: the growth and preferential attachment and the stochastic models based on the GBM, which, in particular, are widely applied in social science. In addition, we explain about the combination of exponentials that is related to the mechanism of the Yule process. We mainly give full details of the mathematical formalisms for these mechanisms in self-contained manner, because understanding them is important for researchers in any field to create new models generating power laws in empirical data. The necessary mathematical supplements to understand these mechanisms are given in the Appendix at the end of this paper.
As the name suggests, this mechanism consists of the two characteristics: growth and preferential attachment. In the example of a city, the meanings of growth and preferential attachment are as follows.
• Growth: The number of cities increases.
• Preferential attachment: The more populated cities become, the higher the probability that the population will increase. Namely, it is “the rich get richer” process5.
In this section, we deal with the Yule process, the Simon process, and the BA model, which all have these two characteristics. The Yule process generates the power law about the number of species within genera in biology. The Simon process generates the power laws about the frequency of use of a word in a text, the population of cities, and so on (see the list in the Introduction for details). The BA model generates the power law about the number of edges incident to nodes in the network. We now explain in detail how these three mechanisms mathematically generate the power laws.
The Yule process [20] was invented to model stochastic population growth with the preferential attachment process for the model of speciation in biology. In this process, new species and genera are born by biological mutations that are interpreted as the branchings from the lines of existing species in the evolutionary tree (Figures 2, 3).
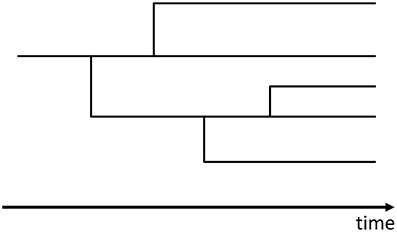
Figure 2. An example of the evolutionary tree of species in the Yule process.
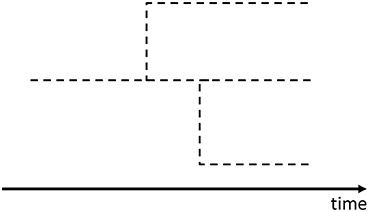
Figure 3. An example of the evolutionary tree of genera in the Yule process.
These branchings occur as Poisson processes and add lines of new genera or species to the evolutionary tree. The Yule process mathematically corresponds to the stochastic process that the numbers of genera and species increase independently by following the linear birth processes (see Appendix A.3)6. In other words, we consider the evolutionary tree of species (Figure 2) and that of genera (Figure 3) separately.
In short, the Yule process is the combination of the stochastic processes for the numbers of species and genera (Figure 4) [41, 49, 50].
• The number of species within a genus increases as the linear birth process with the Poisson rate λsns, where λs is a positive constant and ns is the number of species within the genus at that time.
• The number of genera within a family increases as the linear birth process with the Poisson rate λgng, where λg is a positive constant and ng is the number of genera within the family at that time.
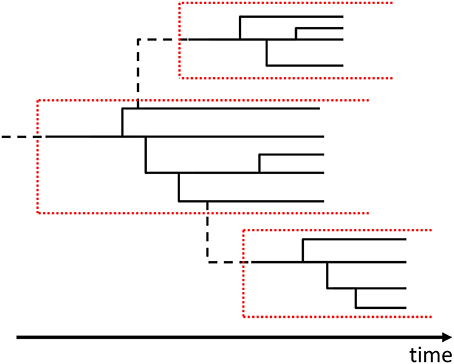
Figure 4. An example of the evolutionary tree for the Yule process. The black solid lines show the branchings of species. The black broken lines show the branchings of genera. One genus is represented by the part surrounded by the red dotted lines. In this figure, though, the probability of branching for a new genus seems to depend on the number of species in the original genus and, in fact, the Poisson rate for branching of a genus is constant in the Yule process.
To obtain the probability distribution of the number of species within genera at a large time7, we need the conditional probability distribution of the number of species included in the genus whose age (i.e., the time intervals elapsed since the birth) is t. Let us use rs(n, t) to denote its conditional probability distribution, where n (∈ ℕ) is the number of species and t (∈ ℝ) is the age of the genus.
First, rs(1, t) is equivalent to the probability that no new species is born in (a, a + t] after the genus is born8 at an arbitrary time a. Accordingly, we obtain rs(1, t) from (A.2) as
where is the number of species born in (0, t] by the Poisson process with the Poisson rate λs.
Second, we calculate rs(2, t). It is equivalent to the probability that one new species is born in (a, a + t] after the genus is born at an arbitrary time a. Then we assume that one new species is born in the infinitesimal time interval [a + τ1, a + τ1 + dτ1). From (A.2) and (A.3), we obtain the probabilities for one birth or no birth in each of the three divided time intervals:
Integrating the product of these probabilities with respect to τ1, we obtain
Similarly, rs(3, t) is given by
Finally, repeating the same procedure, we obtain rs(n, t), that is, the conditional probability distribution of the number of species included in the genus at the age of t:
Next, let ℓg(t) be the probability distribution function for the age of genera at a large time in the linear birth process. It is given by (A.15) as
Consequently, the probability density of the number of species within genera at a large time, denoted by q(n), is given by integrating the product of the conditional probability distribution of the number of species within genera and the probability density function for the age of genera at a large time:
where the beta function B(a, b) is defined as
When b takes a large value, the beta function is approximately
Therefore, for a large number of species, the probability distribution of the number of species within genera at a large time satisfies the power law as
where the exponent of power law is .
The Simon process [21] is interpreted as a discrete-time stochastic process for the growth in the numbers of urns and balls contained in those urns: an urn and the number of balls in the urn correspond to a word and the number of times that the word is used. In this stochastic process, a certain number of balls are newly added and stochastically distributed to the existing urns containing some balls at each time step. After that, one urn containing a certain number of balls (it need not be the same as the number of balls added above) is also added newly. Repeating this procedure, the number of balls and urns grows stochastically.
We calculate the stationary probability distribution of balls contained in urns at a large time.
First, we define all quantities for the Simon process by using the following notation:
• t (= 0, 1, 2, ⋯ ), discrete time;
• k0, number of balls contained in each urn in the initial state (before balls are added);
• m, number of balls added at each time step;
• B(t) (= B(0) + t(m + k0)), total number of balls before balls are distributed at t;
• U(t) (= U(0) + t), number of urns before balls are distributed at t;
• group-(k), group of all the urns containing k balls;
• , number of urns belonging to the group-(k) before balls are distributed at t.
Next, we provide the detailed procedure with the stochastic rule as follows (Figure 5).
1. There are U(0) urns containing k0 balls at the initial time9 t = 0.
2. The m balls are newly added at each time step10.
3. Each of the m balls is distributed once for each group-(k) with the probability 11.
4. Then the balls distributed to the group-(k) are further distributed to the urns within the group with arbitrary probabilities12 with the assumption that each urn can only get up to one ball at each time step13.
5. At the end of each time step, one urn containing k0 balls is added.
6. We repeat steps 2–5.

Figure 5. An example of the Simon model with k0 = 2, U(0) = 4, and m = 3.
Then we can obtain the expectation values of from the above stochastic rule as
At a large time t, we can make an approximation for k ≥ k0 and obtain
The probability distribution of the number of balls in urns, denoted by p(k, t), can be represented by :
Consequently, the master equation for p(k, t) is given by
We are interested in only the stationary distribution function p(k) that is defined as p(k, t) in the limit of large time:
Then, considering
and taking the limit t → ∞ for Equation (18), we obtain
We can solve these equations recursively:
For the large k, the stationary probability distribution of the number of balls in urns satisfies the power law as
where the exponent of power law is .
The BA model [22] is one of the scale-free network models for the growth in the number of nodes and edges. Mathematically, the BA model can be interpreted as a special case of the Simon model. In particular, the nodes and edges in the BA model correspond to the urns and balls in the Simon model, respectively (Figure 6). In this model, one node with a certain number of edges are newly added at each time step. Then following a stochastic rule, the edges of new node are connected to the existing nodes. Repeating this procedure, the number of nodes and edges grows stochastically.
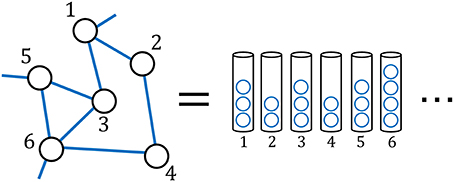
Figure 6. An example of equivalence between a networks and the urns containing balls.
We calculate the stationary probability distribution of edges connecting to nodes at a large time. First, we define all quantities for the BA model by using the following notation:
• t (= 0, 1, 2, ⋯ ), discrete time;
• k0, number of edges that the additional new node has;
• B(t) (= B(0) + 2tk0), total number of degrees in the network before the new node is added at t;
• U(t) (= U(0) + t), number of nodes in the network before the new node is added at t;
• , number of nodes with the degree k before the new node is added at t;
• , number of the edges of node-i (where i is the label of the node) before the new node is added at t.
Next, we give the detailed procedure with the stochastic rule for the BA model as follows (Figure 7).
1. At the initial time t = 0, there is an arbitrary connected network with U(0) nodes that are all connected to nodes other than themselves14.
2. One new node with k0 edges is added15.
3. The k0 edges of the new node are connected to the existing nodes following the stochastic rule16,17: the probability that one edge is connected to the existing node-i is under the assumption that each node can only connect to one node at each time step18.
4. We repeat steps 2 and 3.
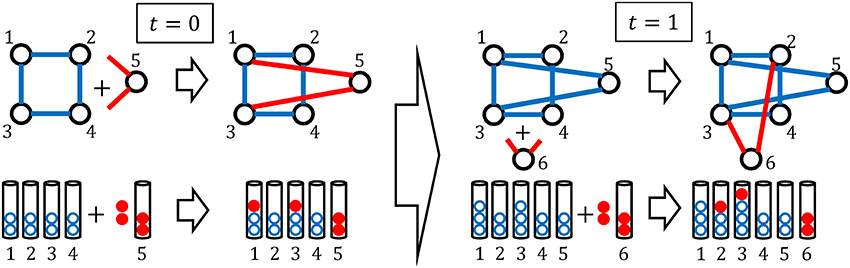
Figure 7. An example of the BA model with k0 = 2 and U(0) = 4 and the Simon model equivalent to it.
Consequently, we obtain the same master equation for the probability distribution of edges as (18) with m = k0:
We can solve this master equation and obtain the stationary distribution function for the large k from Equations (21–23):
where the exponent of power law is 3.
In this section we look at five stochastic processes, generating power laws, which can be represented by the stochastic differential equations (SDEs). They all are mathematically based on the GBM and accompanied by a constraint (i.e., additional condition) or additional terms to the SDE. The constraints correspond to a reflecting wall19 as a boundary condition [23], and reset events (i.e., birth and death process20) [25]. The stochastic processes with additional terms to the SDE of GBM are the Kesten process, the GLV model, and the BM model. Though the effect of additional term to the GMB in the Kesten process is similar to a reflecting wall, those of the GLV model and BM model correspond to the interactions between particles, agents, or individuals. We mainly explain the mathematical formalisms and properties of these qualitatively different stochastic processes.
The GBM, on which many models for power laws are based, is one of the most important stochastic processes. It is mathematically defined by the SDE
where is a standard Brownian motion, μ is the drift, and σ is the volatility.
The SDE (Equation 26) gives us the partial differential equation (PDE), that is, the Fokker–Planck equation (FPE) [51]:
where p(x, t) is the probability density function. The solution of Equation (27) with the initial distribution p(x, 0) = δ(x − x0) is
where x0 is the initial position of the particle. This solution is the log-normal distribution where the expectation value and variance are
In the limit t → ∞, the log-normal distribution never converges to the stationary solution. To obtain it, therefore, we need to impose some additional conditions on the SDE (Equation 26) or modify the SDE itself. We introduce the conditions and modifications in the following sections.
We consider the GBM with the reflecting wall (see Appendix A.5 for details). The stationary solution p(x) for the FPE (Equation 27) is defined by
which is equivalent to the second-order ordinary differential equation (ODE):
As a result, we obtain the first-order ODE:
where D is an arbitrary constant. We take D = 0 to obtain a normalizable power-law probability distribution. The solution of Equation (32) with D = 0 is
where x0 is an arbitrary constant. For this stationary solution p(x) to exist, it must satisfy the normalization condition:
We set the reflecting wall at x = xmin(> 0) and take xmax = ∞. The existence of the reflecting wall is mathematically equivalent to the conditions and p(x) = 0 for x < xmin. Then we assume α > 1. The normalization condition
determines the constant C as
Thus, we have the normalized stationary solution
where the exponent of power law is .
Next, we generalize this formalism from the GBA to the Itô process which can have the stationary solution [52]:
The stationary solution (see Appendix A.5 for details) is given by
where C is the normalization constant. Following Yakovenko and Rosser [53] and Banerjee and Yakovenko [54], we take a(x) and b(x) as
which is interpreted as a kind of qualitative combination of the generalized Wiener process21 and GBM. Consequently, we obtain the stationary solution
For x ≪ x*, the stationary solution becomes the exponential distribution while for the large x, it satisfies the power law as
where the exponent of power law is .
We consider the particles that follow the GBM with the reset events, that is, the birth and death events22. For simplicity, we assume that particles can disappear with a certain probability by following a Poisson process and immediately appear at a point so that the number of particles is conserved. By these reset events, the FPE (Equation 27) is changed into
where η is the probability for a particle in [x, x + dx) to disappear per the time interval dt, and the particle reappears immediately at x = x*(> 0). Accordingly, we obtain the second-order ODE for the stationary solution p(x):
which is held except for x = x*. To solve this equation easily, we change the variable x into y: = logx. The new probability density function q(y) is determined by
Then we obtain the ODE for q(y):
except for y = y* (y*: = logx*). The general solution of this second-order ODE is
where C1 and C2 are the arbitrary constants determined by the normalization condition:
To normalize the solution (Equation 47), we impose the boundary conditions q(∞) = q(−∞) = 0, which result in C1 = 0 for y ≥ y* and C2 = 0 for y < y*, that is,
Accordingly, the normalization condition
and the continuous condition at y = y*, namely, give us the normalized solution of Equation (46) as
Consequently, we obtain the solution of Equation (44):
which is called the double Pareto distribution [25]. The exponents of the power law are 1 − λ1 and 1 − λ2.
Next, we derive the probability density function (Equation 52) by another method as follows [56]. The lifetimes of particles are independently distributed with the exponential distribution as , because the death events occur as a Poisson process, with rate η, which have the time-reversal symmetry property. Accordingly, the ages of particles (i.e., the time intervals elapsed since the birth of them) at a large time are also independently distributed with the exponential distribution:
The probability density function of particles of age t as the conditional probability distribution is given by the log-normal distribution (Equation 28) with . Consequently, the probability density function of the coordinate of particle at a large time, denoted by p(x), is given by integrating the product of Equations (53) and (28):
We can calculate this with the change of variable u2: = t and the identity [35]
Thus, we obtain the same result with Equation (52)23 without solving the ODE (Equation 44).
The Kesten process [26] is defined as a stochastic process whereby an additional term is added to the SDE of the GBM; namely, the SDE is represented by
where ĉ, in the additional term, is a random variable. We can expect that the additional term prevents from decreasing toward −∞ in a similar way as the reflecting wall in section 3.2
Here, we simply take ĉ as a positive constant: ĉ = c (> 0). We then obtain the FPE for the probability density function:
The ODE for the stationary solution p(x) is given by
Consequently, we obtain the normalized stationary solution of Equation (58)24:
where Γ(α) is the gamma function defined in Equation (12). For the large x, the stationary solution satisfies the power law given as
where the exponent of the power law is . Although c, in the additional term, achieves the stationary state, it is independent of the exponent. It is worth noting that the exponent of the power law is affected not by the constant c of the additional term, but by the drift μ and volatility σ of the GBM. The additional term affects only the lower tail of the probability density function. Even for c as a random variable, these properties are invariant.
The GLV model was introduced for the analysis of individual income distribution. We consider the dynamical system composed of N agents (individuals) with incomes that grow by the GBM process and have the interactions for the redistribution of wealth [27–29]. The GLV model is represented by the system of SDEs called the GLV equations:
where is the individual income of agent i (i = 1, 2, ⋯ , N) at t, and Û(t) is the average income for the whole system. To keep , the third term in RHS of Equation (61) redistributes a fraction of the total income for the whole system. This term can be interpreted as the effect of a tax or social security policy. The fourth term controls the growth of whole system and can be interpreted as the effect of finiteness of resources, technological innovations, wars, natural disasters, and so on.
The GLV equations have no stationary solution, and the total income for the entire system is not constant with time. Here, we introduce the new random variable as the relative value:
Then we obtain the SDEs for Ŷi(t) as
where the last term in the second row is of the order , because the standard deviation of is of the order .
We then take the large N limit as the mean field approximation and obtain the new system of SDEs:
which has the same form as the SDE of Equation (56) in the Kesten process. We can use the result of Equation (59) to obtain the normalized stationary probability density:
For large y, the stationary solution satisfies the power law as follows:
where the exponent of the power law is . Consequently, by a change of variables, and the mean field approximation, the GLV model with interactions gives us the same result as that obtained by the Kesten process without interactions.
The BM model was introduced for the analysis of wealth distribution [30, 57–59]. We suppose there is an economic network composed of N agents (individuals) with wealth that grows by the GBM process and is redistributed by the exchanges between agents. The BM model is represented by the system of SDEs as follows:
where is the individual wealth of agent i at t, and aij is the positive exchange rate between agent i and j. The wealth is exchanged by the third term in RHS of Equation (67), which can be interpreted as a kind of trading in the economic network.
For simplicity, we take aij as the constant in preparation for the mean field approximation. Here, we again introduce the new random variables as the average of wealth and the relative value:
We then obtain the SDEs for Ŷi(t) in the mean field approximation:
which has the same form as the SDE of Equation (64) in the LV model. Consequently, we obtain the normalized stationary solution:
For large y, the stationary solution satisfies the following power law:
where the exponent of the power law is . It is worth noting that though the forms of the additional terms in the GLV model and BM model are quantitatively different from those of the Kesten process, the results are eventually the same in the mean field approximation.
When we have a probability density or distribution function for a random variable, we can obtain a new distribution by a change of variable. In particular, we can obtain a power law function from an exponential distribution by taking a new variable as the exponential function of the original variable. This mechanism was used to interpret the observed power law for the frequency of use of words with the assumption of random typings on a typewriter [31]. In this section, firstly we formalize this mechanism. Then we give the examples of applications to the Yule process and critical phenomena in physics.
Suppose the probability density function for a continuous random variable x is given by
We change the variable x into the new variable y as
Thus the new probability density function q(y) is obtained as
where the exponent of power law is .
Similarly, when the x is a discrete random variable, the new probability distribution function q(y) is obtained as
where the exponent of power law is .
The power law of the Yule process can be interpreted using a combination of exponentials with a rough approximation [41]. Firstly, by changing the Poisson rate λs into λg in (A.15), the probability density function of the age of genera at a large time is obtained as
Then, from (A.12) with ns0 = 1, we approximately obtain the number of species within the genus of age t as
Finally, taking A = λg, a = −λg, B = 1, and b = λs in Equation (74), the probability density function of the number of species within genera is
where the exponent of power law is . This exponent coincides with Equation (14). Thus the generating mechanism of power law in the Yule process can be roughly interpreted as a combination of exponentials as well.
It is well-known that in certain critical phenomena, some physical quantities (e.g., correlation length, susceptibility, and specific heat) take the form of power functions of the reduced temperature near the critical temperature Tc. By the renormalization group analysis [60], this property can be interpreted as emerging from a combination of exponentials [41].
We consider two physical quantities x and y whose scaling dimensions are dx and dy, respectively. When we perform the scale transformation (i.e., renormalization group transformation) by the scaling factor b near the critical point, we suppose that x and y are multiplied by λx and λy, respectively. By the dimensional analysis, we obtain
Then we obtain geometric progressions for the transformed x and y:
where x0 and y0 are the initial values of the transformation. Let us denote x and y transformed n times by xn and yn, respectively. Accordingly, xn and yn are defined as
which constitute a combination of exponentials. Therefore, taking A = y0, a = logλy, B = x0, and b = logλx in Equation (75), we can write down yn as a function of xn as
where the exponent of power law is . We emphasize that this is a simple consequence of the dimensional analysis.
Furthermore, if y : = p(x), the two geometric progressions (Equation 80) lead to
which satisfies the scale-free property (Equation 2) with b = λx and f(b) = λy. Namely, the two geometric progressions, equivalent to a combination of exponentials by the scale transformation, assures that the scale-free property holds25.
We have reviewed nine generating mathematical mechanisms of power laws (i.e., Yule process, Simon process, Barabási–Albert model, geometric Brownian motion with a reflecting wall and reset events, Kesten process, Generalized Lotka–Volterra model, and Bouchaud–Mézard model, and the combination of exponentials) that are widely applied in the social sciences. Since these mechanisms are only prototypes, the exponents of the power laws derived from them may not match those of real phenomena (e.g., number of links on the WWW, and so on). As explained in this paper, however, these mechanisms have been improved so that the exponents match those of real phenomena, while the basic principles of the improved mechanisms remain the same. Though many power laws as macro behaviors of systems have been studied, the mechanisms generating them from micro dynamics are not yet completely understood. In physics, however, the understanding of thermodynamics of macro behavior from quantum mechanics of micro dynamics has been advanced considerably based on statistical mechanics. A similar development may also be possible in the study of power laws.
TK: Designed the overall direction of this review paper, and found out the existing models, which are highly applicable from the viewpoint of the Computational Social Science; S-IK: Surveyed existing model studies and summarized the mathematical mechanisms of those models; S-IK and TK: Wrote the manuscript.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The authors greatly appreciate stimulating discussions about the scale-free property in critical phenomena with Prof. Ken-Ichi Aoki. Financial support from the Japan Society for the Promotion of Science (JSPS KAKENHI Grant Number 15H05729) is gratefully acknowledged.
1. ^For the example of a city, the micro dynamics correspond to immigration, emigration, births, and deaths, and the macro behavior is the distribution of the population.
2. ^The hat of Ô means that Ô is a random variable.
3. ^Readers interested in more phenomena with power laws and their generating mechanisms should refer to the reviews and textbooks by Mitzenmacher [35], Newman [1], Sornette [36], Hayashi et al. [37], Farmer and Geanakoplos [38], Gabaix [39, 40], Simkin and Roychowdhury [41], Pinto et al. [42], Piantadosi [43], Machado et al. [44], and Slanina [45].
4. ^Though the multiplicative process [46] is also the stochastic process, it is not explained in this paper because the multiplicative process is interpreted as the discrete-time version of the GBM of the continuous-time stochastic process. Namely, the multiplicative process is essentially equivalent to the GBM (see Appendix A.4).
5. ^Preferential attachment is also called the Matthew effect [47] or the cumulative advantage [48].
6. ^The characteristic of growth is the increase in the number of genera. The characteristic of preferential attachment is that the more species within a genus, the more new species are born.
7. ^We consider the probability distribution only at a large time for the stationary state.
8. ^This new genus is equivalent to the first species born in its own genus. Therefore, the new genus is counted as one for the number of species.
9. ^Since we finally take the limit t → ∞, the initial state does not actually affect the stationary state. However, to make it easier to imagine the procedure, we set the initial state in this manner.
10. ^This shows the characteristic of growth.
11. ^This shows the characteristic of preferential attachment.
12. ^When distributing balls in the group-(k), we do not set the probability that each urn in the group gets one ball. To obtain a master equation later, we only have to know the number of the balls distributed to the group-(k) under the condition that each urn can only get one ball at most. Namely, setting those probabilities is equivalent to imposing too strong a condition to obtain the master equation.
13. ^Though one urn can get two or more balls, this possibility is small enough in the limit of large time. This is because the number of urns is large enough in a large time so that this possibility is ignored. Similarly, though more balls can be distributed than the number of urns in a group-(k), this possibility is also small enough in the limit of large time.
14. ^Since we finally take the limit t → ∞ as in the Simon model, the initial state does not actually affect the stationary state.
15. ^This shows the characteristic of growth.
16. ^This shows the characteristic of preferential attachment.
17. ^This setting of probability is equivalent to the balls distributed to the group-(k) being further distributed to the urns within the group with equal probabilities in step 4 in the Simon model. That is, the stochastic rule for the BA model is stronger than that of the Simon model as a condition.
18. ^Though one node can actually connect two or more nodes, this possibility is small enough in the limit of large time. This is because the number of nodes is large enough in a large time so that this possibility is ignored.
19. ^The reflecting wall means that there is the minimum value for a random variable (e.g., population of a city).
20. ^The birth and death process means that a new unit (e.g., city or firm) can be born at a rate and die at the same rate.
21. ^The SDE of generalized Wiener process is represented by where a and b are constants.
22. ^Following Gabaix [39] and Toda [55], we derive the stationary probability density function.
23. ^The two solutions in Equation (52) result from for (0 < x < x*), and for (x* ≤ x).
24. ^Following Slanina [45], we solve the ODE.
25. ^We thank Prof. Ken-Ichi Aoki for pointing out this observation.
26. ^Strictly speaking, the Poisson rate is not constant at Λs(n − 1) in (t, t + h], that is, the Poisson rate change into Λs(n) from Λs(n − 1) when the birth occurs. Therefore, the accurate probability is , where t + j (0 < j < h) is the time of the birth. However, since we take the limit h → 0 at the end, even if we deal with the probability this strictly, the time evolution equation of the final result will be the same.
27. ^Even if we precisely consider the changing Poisson rate with births, this probability will eventually be o(h). Therefore, we do not need the precise values for the exact Poisson rate and the probabilities that k(≥ 2) species are born in (t, t + h].
28. ^Though this process is also called the Yule–Furry process, we call it the linear birth process in this paper to distinguish it from the Yule process that generates a power law.
29. ^We consider only the probability in a large time, because we are interested in only the power-law distribution as the stationary state at a large time.
30. ^In the Stratonovich convention this SDE is represented by .
31. ^Though the existence of the stationary solution is nontrivial, we assume it here.
1. Newman ME. Power laws, Pareto distributions and Zipf's law. Contemp Phys. (2005) 46:323–51. doi: 10.1016/j.cities.2012.03.001
2. Auerbach F. Das Gesetz der Bevölkerungskonzentration. In: Petermanns Geographische Mitteilungen (1913) 59:74–76. Available online at: http://pubman.mpdl.mpg.de/pubman/item/escidoc:2271118/component/escidoc:2271116/Auerbach_1913_Gesetz.pdf
4. Zipf G. Human Behavior the Principle of Least Effort: An Introduction to Human Ecology. Reading, MA: Addison-Wesley (1949).
5. Lotka AJ. The frequency distribution of scientific productivity. J Wash Acad Sci. (1926) 16:317–23.
8. Willis JC, Yule GU. Some statistics of evolution and geographical distribution in plants and animals, and their significance. Nature (1922) 109:177–9. doi: 10.1038/109177a0
11. Ijiri Y, Simon HA. Skew Distributions and the Sizes of Business Firms. Vol. 24. Amsterdam: North-Holland Publishing Company (1977).
12. Stanley MH, Buldyrev SV, Havlin S, Mantegna RN, Salinger MA, Stanley HE. Zipf plots and the size distribution of firms. Econ Lett. (1995) 49:453–7.
13. Axtell RL. Zipf distribution of US firm sizes. Science (2001) 293:1818–20. doi: 10.1126/science.1062081
14. Gabaix X, Landier A. Why has CEO pay increased so much? Q J Econ. (2008) 123:49–100. doi: 10.1162/qjec.2008.123.1.49
15. Luttmer EG. Selection, growth, and the size distribution of firms. Q J Econ. (2007) 122:1103–44. doi: 10.1162/qjec.122.3.1103
16. Fujiwara Y. Zipf law in firms bankruptcy. Phys A Stat Mech Appl. (2004) 337:219–30. doi: 10.1016/j.physa.2004.01.037
17. Okuyama K, Takayasu M, Takayasu H. Zipf's law in income distribution of companies. Phys A Stat Mech Appl. (1999) 269:125–31.
18. Gutenberg B, Richter CF. Frequency of earthquakes in California. Bull Seismol Soc Am. (1944) 34:185–8.
19. Malamud BD, Morein G, Turcotte DL. Forest fires: an example of self-organized critical behavior. Science (1998) 281:1840–2.
20. Yule GU. A mathematical theory of evolution, based on the conclusions of Dr. JC Willis, FRS. Philos Trans R Soc Lond Ser B (1925) 213:21–87.
24. Manrubia SC, Zanette DH. Stochastic multiplicative processes with reset events. Phys Rev E (1999) 59:4945.
25. Reed WJ. The Pareto, Zipf and other power laws. Econ Lett. (2001) 74:15–19. doi: 10.1016/S0165-1765(01)00524-9
26. Kesten H. Random difference equations and renewal theory for products of random matrices. Acta Math. (1973) 131:207–48.
27. Solomon S, Richmond P. Stable power laws in variable economies; Lotka-Volterra implies Pareto-Zipf. Eur Phys J B (2002) 27:257–61. doi: 10.1140/epjb/e20020152
28. Richmond P, Solomon S. Power laws are disguised Boltzmann laws. Int J Modern Phys C (2001) 12:333–43. doi: 10.1142/S0129183101001754
29. Malcai O, Biham O, Richmond P, Solomon S. Theoretical analysis and simulations of the generalized Lotka-Volterra model. Phys Rev E (2002) 66:031102. doi: 10.1103/PhysRevE.66.031102
30. Bouchaud JP, Mézard M. Wealth condensation in a simple model of economy. Phys A Stat Mech Appl. (2000) 282:536–45. doi: 10.1016/S0378-4371(00)00205-3
32. Bak P, Tang C, Wiesenfeld K. Self-organized criticality: an explanation of the 1/f noise. Phys Rev Lett. (1987) 59:381.
33. Carlson JM, Doyle J. Highly optimized tolerance: a mechanism for power laws in designed systems. Phys Rev E (1999) 60:1412.
34. Carlson JM, Doyle J. Highly optimized tolerance: robustness and design in complex systems. Phys Rev Lett. (2000) 84:2529. doi: 10.1103/PhysRevLett.84.2529
35. Mitzenmacher M. A brief history of generative models for power law and lognormal distributions. Int Math. (2004) 1:226–51. doi: 10.1080/15427951.2004.10129088
36. Sornette D. Critical Phenomena in Natural Sciences: Chaos, Fractals, Selforganization and Disorder: Concepts and Tools. Heidelberg: Springer Science & Business Media (2006).
37. Hayashi Y, Ohkubo J, Fujiwara Y, Kamibayashi N, Ono N, Yuta K, et al. Network Kagaku No Dougubako [Tool Box of Network Science]. Tokyo: Kindaikagakusya (2007).
38. Farmer JD, Geanakoplos J. Power Laws in Economics and Elsewhere. Technical Report, Santa Fe Institute (2008).
39. Gabaix X. Power laws in economics and finance. Annu Rev Econ. (2009) 1:255–94. doi: 10.3386/w14299
40. Gabaix X. Power laws in economics: an introduction. J Econ Perspect. (2016) 30:185–205. doi: 10.1257/jep.30.1.185
41. Simkin MV, Roychowdhury VP. Re-inventing willis. Phys Rep. (2011) 502:1–35. doi: 10.1016/j.physrep.2010.12.004
42. Pinto CM, Lopes AM, Machado JT. A review of power laws in real life phenomena. Commun Nonlinear Sci Numer Simul. (2012) 17:3558–78. doi: 10.1016/j.cnsns.2012.01.013
43. Piantadosi ST. Zipf's word frequency law in natural language: a critical review and future directions. Psychon Bull Rev. (2014) 21:1112–30. doi: 10.3758/s13423-014-0585-6
44. Machado JT, Pinto CM, Lopes AM. A review on the characterization of signals and systems by power law distributions. Signal Process. (2015) 107:246–53. doi: 10.1016/j.sigpro.2014.03.003
48. Price DdS. A general theory of bibliometric and other cumulative advantage processes. J Assoc Inform Sci Technol. (1976) 27:292–306.
49. Bacaër N. Yule and evolution (1924). In: A Short History of Mathematical Population Dynamics. London: Springer (2011). p. 81–8. Available online at: http://www.springer.com/gb/book/9780857291141
50. Kimmel M, Axelrod DE. Branching Processes in Biology. New York, NY: Springer Publishing Company, Incorporated (2016).
51. Risken H. Fokker-planck equation. In: The Fokker-Planck Equation. Berlin: Springer (1996). p. 63–95. Available online at: http://www.springer.com/la/book/9783540615309
52. Richmond P. Power law distributions and dynamic behaviour of stock markets. Eur Phys J B (2001) 20:523–26. doi: 10.1007/PL00011108
53. Yakovenko VM, Rosser Jr JB. Colloquium: statistical mechanics of money, wealth, and income. Rev Mod Phys. (2009) 81:1703. doi: 10.1103/RevModPhys.81.1703
54. Banerjee A, Yakovenko VM. Universal patterns of inequality. N J Phys. (2010) 12:075032. doi: 10.1088/1367-2630/12/7/075032
55. Toda AA. Zipf's Law: A Microfoundation (2017). Available online at: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2808237
56. Reed WJ. The Pareto law of incomes–an explanation and an extension. Phys A Stat Mech Appl. (2003) 319:469–86. doi: 10.1016/S0378-4371(02)01507-8
57. Marsili M, Maslov S, Zhang YC. Dynamical optimization theory of a diversified portfolio. Phys A Stat Mech Appl. (1998) 253:403–18.
58. Solomon S. Stochastic lotka-volterra systems of competing auto-catalytic agents lead generically to truncated pareto power wealth distribution, truncated levy distribution of market returns, clustered volatility, booms and craches. arXiv preprint cond-mat/9803367 (1998).
59. Malcai O, Biham O, Solomon S. Power-law distributions and Levy-stable intermittent fluctuations in stochastic systems of many autocatalytic elements. Phys Rev E (1999) 60:1299.
60. Wilson KG. Renormalization group and critical phenomena. I. Renormalization group and the Kadanoff scaling picture. Phys Rev B (1971) 4:3174.
61. Pinsky M, Karlin S. An Introduction to Stochastic Modeling. Cambridge, MA: Academic Press (2010).
62. Osaki S. Applied Stochastic System Modeling. Heidelberg: Springer Science & Business Media (1992).
Some mathematical supplements are given in this appendix.
We consider the Poisson process [61, 62] with the Poisson rate λ (a positive constant), that is, the events occur on average λ times per unit time. The probability that an event occurs n times in (t, t + h] follows the Poisson distribution:
where denotes the number of times that the events occur in (0, t]. When h is the infinitesimal time interval, the probabilities of event occurrence can be expressed by o(hk). The probability that no event occurs in (t, t + h] is
Similarly, the probability that one event occurs is
and the probability that more than two events occur is
We generalize the Poisson process so that the Poisson rate depends on the number of times that the events have already occurred. To apply this generalized Poisson process to the evolution model in biology, we interpret the occurrence of events as the births of new species without deaths [61, 62].
First, we are interested in the probability that the number of species becomes n (∈ ℕ) at time t (∈ ℝ) with the initial number of species ns0 at time 0. It is denoted by , where is the number of species at time t. Then, we derive the time evolution equation of p(n, t). The probability p(n, t + h) is given as the sum of the following probabilities:
• the probability that and no birth occurs in (t, t + h] with rate Λs(n);
• the probability that and one birth occurs in (t, t + h] with rate26 Λs(n − 1);
• the probability that and two births occur in27 (t, t + h];
⋮
• the probability that and k births occur in (t, t + h];
⋮
where Λs(n) is the Poisson rate when the number of species is n. Accordingly, we obtain
From equations (A.2), (A.3), and (A.4), the probabilities on the right-hand side of (A.5) are expressed respectively as the orders of h:
We combine (A.5) with (A.6), and obtain the difference equation:
We take the limit h → 0 and obtain the ODEs with the initial conditions:
which are called the Kolmogorov's forward equations. The ODEs (A.8) can be solved and yield
Next, we consider the linear birth process [61, 62] that is mathematically defined as a special case of the pure birth process. When the Poisson rate Λs(n) is proportional to the number of species n,
where λs is a positive constant, this pure birth process is called the linear birth process28. Then, we can interpret the birth of new species in this process as the occurrence of branching in the evolutionary tree (Figure 2). In particular, the linear birth process means that the branchings occur independently on each line of a species as the Poisson processes with the Poisson rate λs, which is common for all existing species.
The solutions of (A.9) for the Yule process can be recursively calculated and yield
Then, the expectation value and the variance of the number of species at time t is given by
Let Ps{0 < age ≤ t at τ} be the probability of the species whose age, that is, the time intervals elapsed since the birth, is t or less at time τ (> t). This probability is given by
where the approximately equal symbol holds only for a large time29 τ. Therefore, it no longer depends on τ. Let us use ℓs(s) to denote the probability density function for the age s of species at a large time. By the probability of the species whose age is t or less at a large time, it is defined as
Differentiating both sides of (A.14) with respect to t, we obtain
The multiplicative process is the discrete-time stochastic process defined as
where , for all times t, are independent and equally-distributed random variables with and . This process is essentially equivalent to the GBM because both probability density functions are identically the log-normal distributions in the large time limit.
We can easily obtain the solution of (A.16) in the logarithmic form as follows:
where x0 is the initial value of . We then define the new variable Ŷ(t) as
By the central limit theorem, we obtain the probability density function of Ŷ(t) in the time limit t → ∞:
which is the normal distribution. Consequently, by a change of variables, we obtain the probability density function of as follows:
which is the same as the log-normal distribution as (28) of the GBM with .
Here we provide a stationary solution of the FPE with reflecting wall [23, 39, 55].
The SDE30 of an Itô process for the random variable is given by
where is a standard Brownian motion; . This SDE is equivalent to the Langevin equation [51]:
where the noise term satisfies
We can obtain the FPE for the random variable with the probability density p(x, t) as
Then we define the flux J(x, t) as
so that we can interpret (A.24) as the continuity equation
When a(x, t) and b(x, t) are the time-independent functions, that is, a(x, t) = a(x) and b(x, t) = b(x), the stationary solution p(x) is defined by the condition31
that is equivalent to
where J(x) is the stationary flux. Accordingly, the stationary flux J(x) must be constant.
When the stationary flux J(x) takes a nonzero value, the stationary state means that particles flow in from one side of infinity and out the other side. This situation causes the stationary probability density function p(x) to be nonzero at x = ±∞. Consequently, the nonzero stationary flux cannot give us a power-law probability density function that can be normalized, because any power function blows up at one side of infinity. In contrast, when the stationary flux J(x) vanishes anywhere, we can set the reflecting wall at x = xmin so that the stationary probability density function p(x) vanishes outside of the wall. The reflecting wall enables us to obtain a power-law probability density function that can be normalized, because we can cut out the side of infinity where the power function blows up. For this reason, we consider only the case that the flux vanishes at a boundary, that is, the reflecting wall.
In this case, we obtain the second-order ODE
that the stationary solution p(x) satisfies.
The stationary solution is obtained as the solution of (A.29):
where x0(≥ xmin) is an arbitrary constant. If a(x) and b(x) are the power functions that satisfy the condition
namely,
we obtain the stationary solution as the power function of x:
This stationary solution p(x) must satisfy the normalization condition
where we set the reflecting wall at x = xmin(> 0) and assume α > 1. The normalization condition
determines the constant C as
Thus, we have the stationary solution
Keywords: power law, Zipf's law, Pareto's law, preferential attachment, geometric brownian motion
Citation: Kumamoto S-I and Kamihigashi T (2018) Power Laws in Stochastic Processes for Social Phenomena: An Introductory Review. Front. Phys. 6:20. doi: 10.3389/fphy.2018.00020
Received: 13 October 2017; Accepted: 14 February 2018;
Published: 15 March 2018.
Edited by:
Isamu Okada, Sōka University, JapanReviewed by:
Francisco Welington Lima, Federal University of Piauí, BrazilCopyright © 2018 Kumamoto and Kamihigashi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Shin-Ichiro Kumamoto, a3VtYW1vdG9AcmllYi5rb2JlLXUuYWMuanA=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.