
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Pharmacol., 11 August 2022
Sec. Drugs Outcomes Research and Policies
Volume 13 - 2022 | https://doi.org/10.3389/fphar.2022.804566
This article is part of the Research TopicMedication Safety and Interventions to Reduce Patient Harm in Low- and Middle-Income CountriesView all 20 articles
 Wu Xingwei1,2†Chang Huan1†Li Mengting1†Qin Lv3†Zhang Jiaying4Long Enwu1,2Zhu Jiuqun1,2*
Wu Xingwei1,2†Chang Huan1†Li Mengting1†Qin Lv3†Zhang Jiaying4Long Enwu1,2Zhu Jiuqun1,2* Tong Rongsheng1,2*
Tong Rongsheng1,2*Potentially inappropriate prescribing (PIP), including potentially inappropriate medications (PIMs) and potential prescribing omissions (PPOs), is a major risk factor for adverse drug reactions (ADRs). Establishing a risk warning model for PIP to screen high-risk patients and implementing targeted interventions would significantly reduce the occurrence of PIP and adverse drug events. Elderly patients with cardiovascular disease hospitalized at the Sichuan Provincial People’s Hospital were included in the study. Information about PIP, PIM, and PPO was obtained by reviewing patient prescriptions according to the STOPP/START criteria (2nd edition). Data were divided into a training set and test set at a ratio of 8:2. Five sampling methods, three feature screening methods, and eighteen machine learning algorithms were used to handle data and establish risk warning models. A 10-fold cross-validation method was employed for internal validation in the training set, and the bootstrap method was used for external validation in the test set. The performances were assessed by area under the receiver operating characteristic curve (AUC), and the risk warning platform was developed based on the best models. The contributions of features were interpreted using SHapley Additive ExPlanation (SHAP). A total of 404 patients were included in the study (318 [78.7%] with PIP; 112 [27.7%] with PIM; and 273 [67.6%] with PPO). After data sampling and feature selection, 15 datasets were obtained and 270 risk warning models were built based on them to predict PIP, PPO, and PIM, respectively. External validation showed that the AUCs of the best model for PIP, PPO, and PIM were 0.8341, 0.7007, and 0.7061, respectively. The results suggested that angina, number of medications, number of diseases, and age were the key factors in the PIP risk warning model. The risk warning platform was established to predict PIP, PIM, and PPO, which has acceptable accuracy, prediction performance, and potential clinical application perspective.
With the rapid aging of the global population, countries around the world are currently facing a serious problem of an aging population and the health problems of the elderly. It is estimated that by 2050, the number of people aged over 60 years will reach 2.1 billion worldwide (Phillips, 2017), and the proportion will be more than 20% (Biritwum et al., 2013). The elderly have poor physical function and often suffer from comorbidities (Vermunt et al., 2017). Costs related to comorbidities are a significant economic burden to patients and healthcare systems (King and Giedrimiene, 2021). During recent years, there has been a growing interest in the study of disease associations in aging patients. Accumulated evidence has suggested that cardiovascular diseases are the most common comorbid condition in older people with multimorbidities (Manckoundia et al., 2020). In addition, cardiovascular diseases are considered a leading cause of death, and the rate reached 10%–30% in the LifeLines Cohort Study (Van der Ende et al., 2017). Importantly, this becomes even more pronounced in the elderly population (Hamilton-Craig et al., 2015; Valdés et al., 2018).
Moreover, elderly patients usually have several comorbidities that leads to polypharmacy, increasing the risk of potentially inappropriate prescribing (PIP) (Corsonello et al., 2010; Gallagher et al., 2011; D'Cruz et al., 2012; Chen et al., 2014; Hyttinen et al., 2019b), especially leading to an increase in adverse drug reactions (ADRs) (Maaroufi et al., 2021). Additionally, PIP includes potentially inappropriate medications (PIM) and potential prescribing omissions (PPO), which is a key factor influencing the occurrence of ADR in elderly patients (O’Mahony and Gallagher, 2008). PIM is very common in elderly patients with cardiovascular disease (Sheikh-Taha and Dimassi, 2017; Maaroufi et al., 2021). 98.2% of elderly patients, who were admitted to medical or cardiovascular ICUs in a large tertiary teaching hospital in Brazil, had at least one PIM (Galli et al., 2016). According to a multicenter, prospective cohort study that recruited 1,280 patients (median age of 82 years) in England, PIM contributed to ADR in 12% of elderly patients (Parekh et al., 2019).
Currently, there are various criteria for assessing PIP (Petrovic et al., 2016; Lopez-Rodriguez et al., 2020); for instance, the Beers criteria developed in the United States (By the 2019 American Geriatrics Society Beers Criteria® Update Expert Panel, 2019) and the STOPP/START criteria developed in Ireland (O’Mahony et al., 2015). Although these criteria are currently in wide use for post-event evaluation, there are some shortcomings, such as the inability to provide advance warning of the risk of PIP in elderly patients. Through early warning of PIP, physicians or pharmacists will be able to identify patients at risk of PIP and adopt individualized interventions to reduce the risk of ADR.
Some studies have shown that PIP in elderly patients can be identified using the frailty index (Cullinan et al., 2016) and the new Croatian tool (Matanović and Vlahović-Palčevski, 2014). However, these approaches were not convenient enough, as they would require a lot of time and effort. In recent years, with the rise of artificial intelligence, machine learning algorithms have been increasingly applied to develop predictive models (Badet et al., 2021; Fralick et al., 2021; Hossain et al., 2021; Lin et al., 2021; Mišić et al., 2021; Pinaire et al., 2021). Multiple studies reported that machine learning algorithms could predict severe hypoglycemia in hospitals, identify genetic risk factors for the progression and survival of colorectal cancer, etc. Patel et al. used machine learning algorithms to develop predictive models to identify predictors of inappropriate use of non-steroidal anti-inflammatory drugs (NSAIDs) of PIP in elderly patients with osteoarthritis (Patel et al., 2020).
However, the following problems remain to be resolved: 1) Fewer data pre-processing methods are used. Our previous study (Wu et al., 2020) has demonstrated that different data pre-processing methods (p < 0.05) are important in choosing an optimal data pre-processing method. 2) Fewer machine learning algorithms are used. Our previous study (Wu et al., 2020) used 14 machine learning algorithms, and the results showed the variability between different machine learning algorithms. Each machine learning algorithm applies in different conditions. At most two machine learning algorithms in the above studies were used, which was not sufficient. 3) Fewer platforms for risk prediction. Risk warning platforms can output the risk of PIP in elderly patients with cardiovascular disease, which might alert physicians or pharmacists to review the medicines.
Thus, the present study analyzed the information on PIP, PIM. and PPO of cardiovascular disease in elderly patients, and established a prediction platform using multiple machine learning algorithms to predict the risk of PIP, PIM, and PPO in elderly patients with cardiovascular disease.
Participants who were discharged from the Department of Geriatric Cardiology at Sichuan Provincial People’s Hospital from January 2017 to June 2018 were included in this study. Their clinical information, including prescription information, medical record information, and results of laboratory tests, were collected from the electronic medical record. The following inclusion criteria were used for the selection of the study participants: 1) age ≥65 years; 2) the duration of hospitalization between 3 and 60 days; and 3) diagnosed with at least one cardiovascular disease (hypertension, myocardial infarction, angina pectoris, hyperlipidemia, peripheral vascular disease, and indication for antithrombotic therapy, which was determined by cardiovascular physicians). The patient selection flowchart is shown in Figure 1.
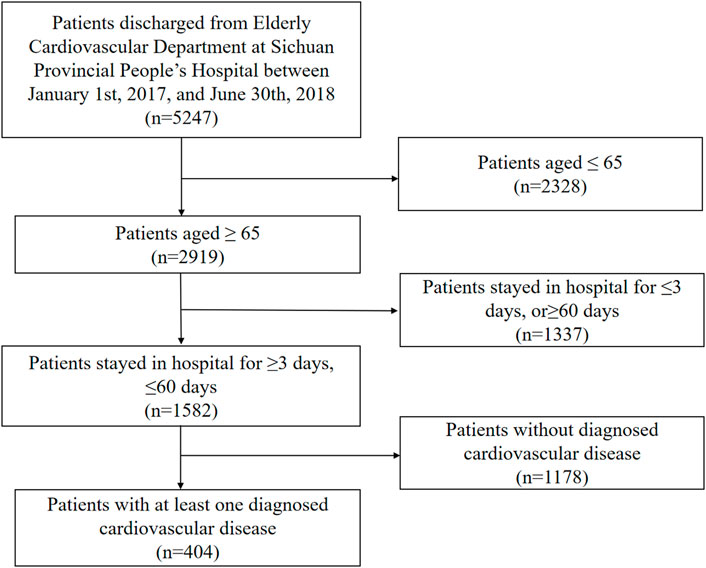
FIGURE 1. Flowchart of patient selection.
The STOPP/START criteria (version 2) for the cardiovascular system and antiplatelet/anticoagulant drugs were used to identify PIP prescriptions in elderly patients, including 24 PIM criteria (13 for cardiovascular system and 11 for antiplatelet/anticoagulant drugs) and 8 PPO criteria for the cardiovascular system. Each electronic medical record was independently reviewed by three pharmacists, Wu Xingwei, Zhang Jiaying, and Xiong Huan, who had received training from the chief pharmacists (Tong Rongsheng and Long Enwu) to ensure the accuracy of the results. All disagreements were resolved by consulting the chief physician of internal medicine.
The patient’s ID number, name, home address, and telephone number were anonymous during the data acquisition for ethical reasons. As this is a retrospective study without intervention, the ethics committee considered it unnecessary to obtain informed consent from patients. All variables were coded (X1, X2, … , Xn) to allow blinded analysis of patient data.
Data pre-screening included three processes: 1) deleting columns with more than 90% missing data; 2) deleting columns with a single value occupying more than 90%; and 3) deleting columns with coefficient of variation less than 0.01. Variables meeting one of the abovementioned conditions would be considered less informative.
To minimize the adverse impact of data imbalance on prediction performance, the following data sampling methods were used: 1) no sampling; 2) random upsampling, which duplicates minority class samples to create additional minority class samples; 3) random undersampling, which randomly selects samples from the initial dataset to create a new smaller dataset; 4) synthetic minority oversampling technique (SMOTE), which achieves upsampling by linear interpolation between a small number of class samples and their nearest neighbors; and 5) borderline SMOTE upsampling, which improves the SMOTE method by upsampling only the border samples of a small number of classes, thus improving the class distribution of the samples.
Three feature selection methods were used for feature screening: 1) no screening; 2) the Lasso screening method which evaluates the importance of variables and output the results by introducing a penalization parameter penalizing and discarding unimportant variables (variables with coefficients near zero); and 3) the Boruta screening method which is a feature selection algorithm to identify the minimal set of relevant variables.
Fifteen datasets were generated by five data sampling methods and three feature screening methods, and 18 machine learning algorithms were used on each dataset, respectively, to develop a total of 270 models. Machine learning algorithms in this study included logistic regression, decision tree, Gaussian naive bayes, Bernoulli naive bayes, multinomial naive bayes, passive aggressive, AdaBoost, bagging, gradient boosting, eXtreme gradient boosting (XGBoost), K-nearest neighbor (KNN), linear discriminant analysis (LDA), quadratic discriminant analysis (QDA), random forest, stochastic gradient descent (SGD), support vector machine (SVM), extra tree, and ensemble learning (Wu et al., 2020). These abovementioned algorithms were commonly used and were suitable for binary classification. In comparison to single classification algorithms, ensemble algorithms always prove to be more effective and stable in prediction models.
The whole process of model development could be described as follows:
(1) The data set was divided into a training set and a test set in a ratio of 8:2 (according to our sample size, a ratio of 8:2 would be more suitable than 9:1 or 7:3)
(2) Models were trained in the training set so that the loss function was minimized. Internal validation was performed by the ten-fold cross-validation method.
(3) Test set data were passed into the trained model for assessing model prediction performance. Bootstrapping was employed for external validation.
(4) The model with the best performance was selected.
The area under the receiver operating characteristic curve (AUC), accuracy, precision, recall, and F1 score were adopted as quantitative metrics to evaluate the performance of models, and the candidate model achieving the best performance was selected as the optimal prediction model. The contribution of each variable to the predictive model was estimated with SHapley Additive exPlanation (SHAP). The modeling process is shown in Figure 2.
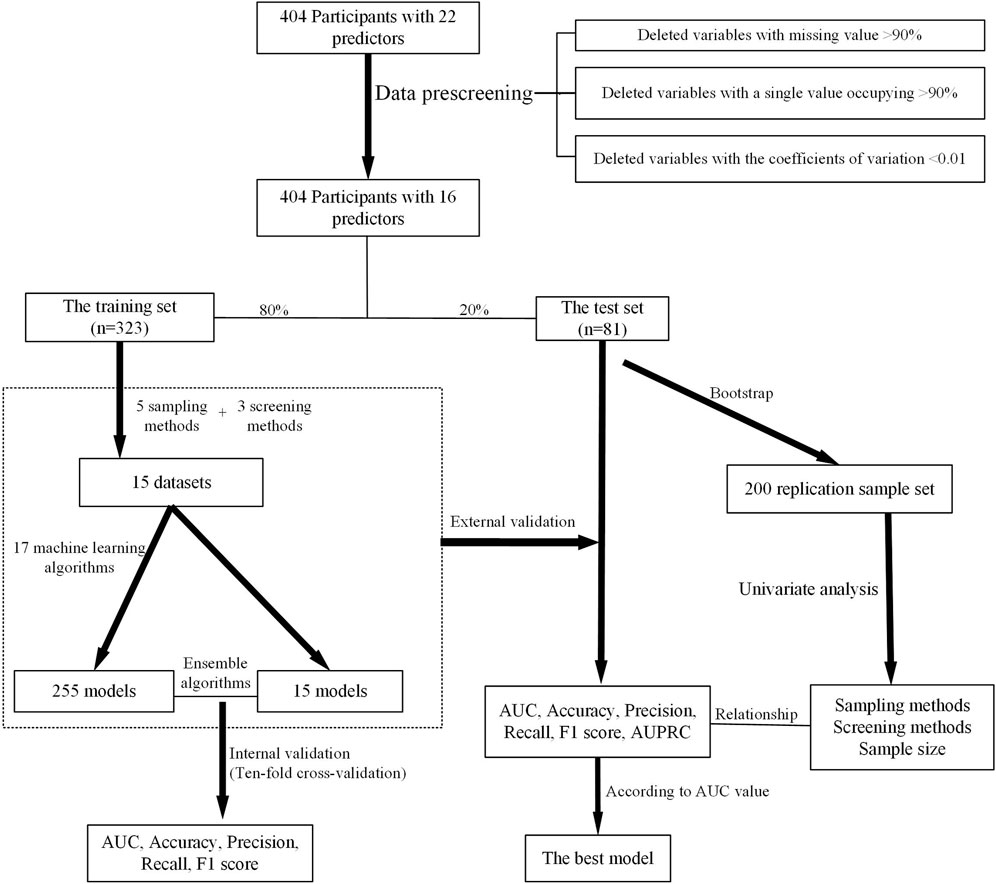
FIGURE 2. Overview of the modeling method.
A total of 270 prediction models were developed based on different sampling methods and feature screening methods. On the test set, the model with the highest AUC value was selected and used to establish the prediction platform for PIP, PIM, and PPO.
To train the best model, the bootstrap method was used to randomly select 10%, 20%, 30%,......100% of the resampling data from the training set, and the test set was used to test the predictive ability of the model. The AUC values of the best models of PIP, PPO, and PIM were estimated. The above process was repeated 100 times, and the results were plotted on a line graph. We judged the contribution of the sample size to improve the prediction performance of models according to the inflection point change of the line graph.
Categorical data were described by frequency (percent), and continuous data were statistically described by mean and standard deviation (Mean ± SD). Analysis of variance (ANOVA) and rank sum test were used for univariate analysis.
Statistical analysis was performed using stats in Python 3.8, and model development was implemented using sklearn in Python 3.8. The front-end of the PIP prediction platform was written in JavaScript, and the back-end was written in Python 3.8.
A total of 404 elderly patients with cardiovascular diseases were eligible for this study. The mean age of the patients was 79.1 years, and 59.9% were male. Participants identified as PIP, PIM, and PPO were 318 (78.7%), 112 (27.7%), and 273 (67.6%), respectively. The most frequent PIPs were antiplatelet agents simultaneously used with vitamin K antagonists, direct thrombin inhibitors, or factor inhibitors in patients (37 instances, accounting for 21.5% of total PIPs). Table 1 shows detailed patient demographic information and clinical information as the independent variables, with PIP, PIM, and PPO as the dependent variables.
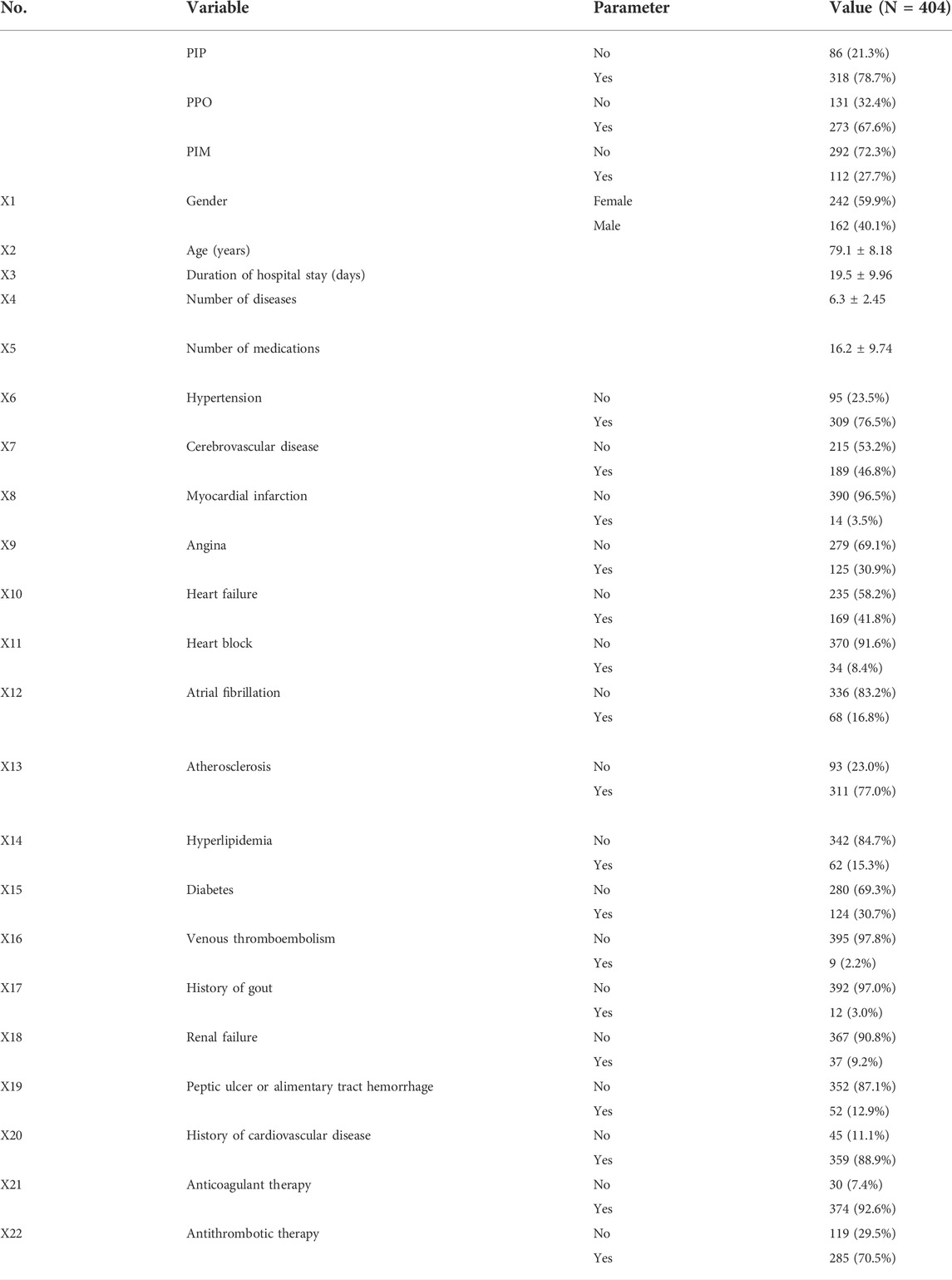
TABLE 1. Information of PPO, PIP, PIM, and characteristics in the participants.
After removing columns that met the deleting criteria, 16 variables were retained and 6 variables were deleted (X8 myocardial infarction, X11 heart block, X16 venous thromboembolism, X17 history of gout, X18 renal failure, and X21 anticoagulant therapy).
After data pre-screening and data sampling, the variables were screened using the Lasso method and the Boruta method, as shown in Supplementary Figure S1. The results showed that the five most important variables in the PIP model were angina, atherosclerosis, heart failure, diabetes, and number of medications (Supplementary Figure S1A). In the PPO model, the five most important variables were number of medications, angina, atherosclerosis, and history of cardiovascular diseases (Supplementary Figure S1B). The most important variables in the PIM model were number of medications, number of diseases, duration of hospitalization (days), age, and heart failure (Supplementary Figure S1C).
Internal validation was performed using the 10-fold cross-validation method. Fifteen datasets were created using five data sampling methods and three feature screening methods. Two hundred and fifty-five models for predicting PIP, PPO, and PIM respectively, were built using 18 machine learning algorithms. Different data sampling methods and different machine learning algorithms in the PIP model were significantly affected by the prediction performance of the PIP model (p < 0.0001). Details are listed in Supplementary Table S1.
As shown in Supplementary Table S2, different data sampling methods and different machine learning algorithms showed significant differences in the prediction performance of the PPO model (p < 0.0001), but the different feature screening methods were not significant (p > 0.05).
The results of the PIM prediction model were similar to those of the PPO prediction model. Significant differences between different data sampling methods and machine learning algorithms on the prediction performance of the PIM model are shown in Supplementary Table S3.
Applying 18 machine learning algorithms, 270 machine learning models were developed for each output. External validation of the models was performed by bootstrapping 200 samples in the test set. Different data sampling methods, different feature screening methods, and different machine learning algorithms in the PIP models had a significant effect (p < 0.0001) on prediction performance (list in Supplementary Table S1).
As presented in Supplementary Tables S1, S3, the results of the external validation of the PIM and PPO models were consistent with the PIP models. Data sampling methods, feature screening methods, and machine learning algorithms showed statistically significant differences in the prediction performance of the PIM and the PPO model.
The data from 200 bootstrapping samples were entered in the PIP, PIM, and PPO models. The contribution of each variable to the prediction performance in the different models is shown in Supplementary Figure S2 by the averaged AUC value when the variable was included in the prediction model. The five most important variables in the PIP model were cerebrovascular disease, history of cardiovascular disease, number of medications, duration of hospitalization (days), and age, while diabetes, gastrointestinal bleeding, hypertension, and angina were the least important (Supplementary Figure S2A). In the PPO model, the five most important variables were diabetes, hyperlipidemia, heart failure, duration of hospitalization (days), and gastrointestinal bleeding, while the five least important variables were hypertension, cerebrovascular disease, antithrombotic therapy, and atrial fibrillation (Supplementary Figure S2B). The most important variable in the PIM model were diabetes, antithrombotic therapy, duration of hospitalization (days), age, and hypertension, while gastrointestinal bleeding, hyperlipidemia, history of cardiovascular disease, and atrial fibrillation were unimportant (Supplementary Figure S2C).
AUC, accuracy, precision, recall, F1 score, and the area under the precision-recall curve (AUPRC) were used to evaluate the predictive performance of models, and the best models according to the AUC value are presented in Figure 3. The prediction performance of the PIP model achieved an AUC of 0.8341 and an AUPRC of 0.9556 (Figure 3A). As presented in Figure 3B, the best performing PPO model had the highest AUC (0.7007) and AUPRC (0.7992). The best prediction performance of the PIM model provided an AUC of 0.7061 and an AUPRC of 0.4268 (Figure 3C). The best predictive performance metrics of PIP, PIM, and PPO are presented in Figure 3D.
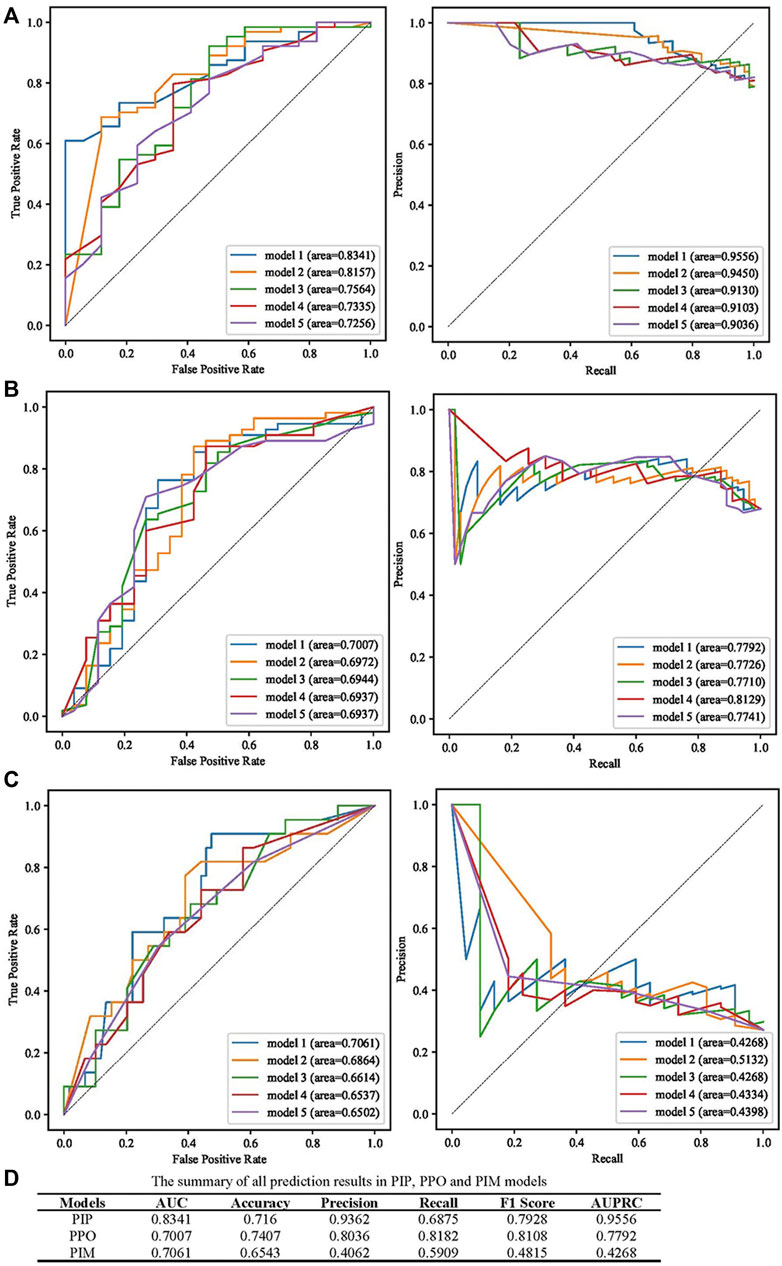
FIGURE 3. Summary of the performance of PIP, PPO, and PIM model. (A) The results of AUC and AUPRC in the best five PIP model. (B) The results of AUC and AUPRC in the best five PPO model. (C) The results of AUC and AUPRC in the best five PIM model. (D) The summary of AUC, accuracy, precision, recall, F1 score, AUPRC in the best PIP, PPO, and PIM model.
SHAP can interpret the output of any machine learning model. The contribution of variables in the PIP model is explained by SHAP, and the results are shown in Figure 4. As illustrated in Figure 4A, SHAP estimated the contribution of each feature value in each sample to the prediction. Cerebrovascular disease, heart failure, age, hyperlipidemia, and hypertension provided a positive contribution to the SHAP value, while duration of hospital stay (days), myocardial infarction, and gender provided a negative contribution. Cerebrovascular disease was the most important variable.
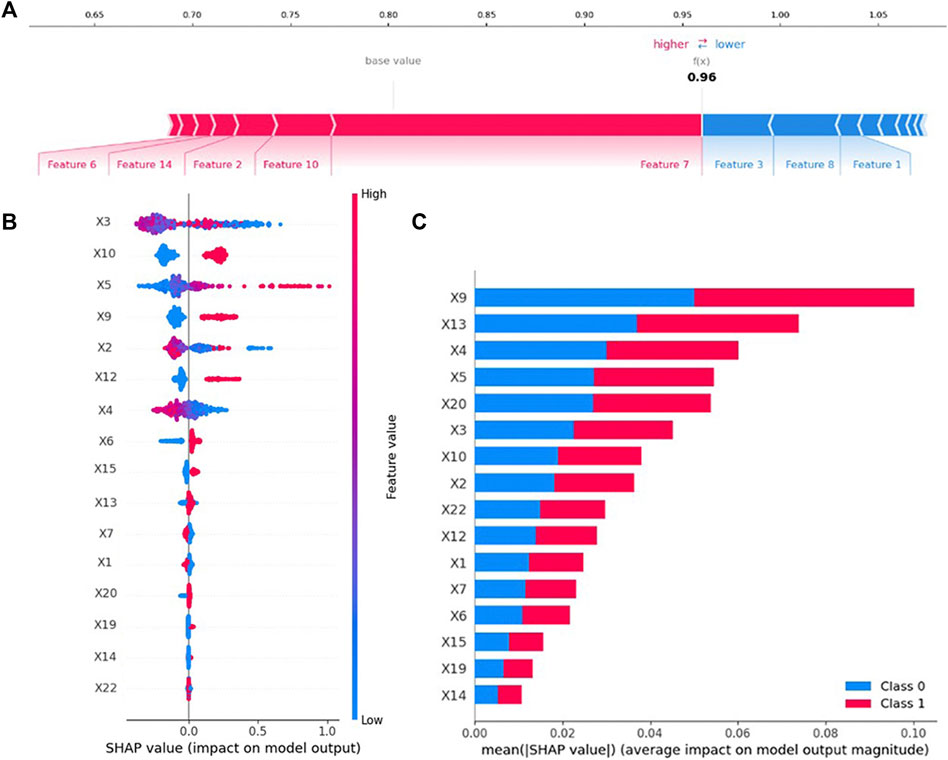
FIGURE 4. Variable contribution to the PIP model by SHAP Value. (A) Contribution of each feature value in one sample. (B) Summary of SHAP value of each variable. (C) Absolute average of SHAP value of each variable.
As presented in Figure 4B, the SHAP value of each feature in each sample was calculated and plotted. Variables were ranked in descending order by summarizing the SHAP values of each sample. For example, the higher the values of duration of hospital stay (days), lower the value of SHAP.
The mean of the absolute value of the SHAP value of each variable, which was regarded as of feature importance, was plotted as shown in Figure 4C. The top five most important variables in the PIP model were angina, atherosclerosis, number of diseases, number of medications, and history of cardiovascular disease.
The adequacy of the sample size was verified using the resampling bootstrapping method, and the results are plotted in Supplementary Figure S3. In the PIP model, the AUC gradually increased and the dispersion of the AUC value decreased as the percentage of sample size increased. When the sample size reached 70%, the curve flattened. The results indicated that the performance of the PIP model might be affected when expanding the sample size (Supplementary Figure S3A). In both the PPO model and the PIM model, both the curves showed an upward trend. These results indicate that the performance of the PPO and PIM models might be improved even further with the addition of samples (Supplementary Figures S3B,C).
Based on the parameters of the best models of PIP, PPO, and PIM, the prediction platform was established for individualized intervention. The input interface will be used to receive information on key variables in each patient (Figure 5A), and the output interface will show the risk rate of PIP, PIM, and PPO (Figure 5B). The software has obtained the Computer Software Copyright Registration Certificate (No. 7960815) received from the National Copyright Administration of the PRC (Supplementary Figure S4).
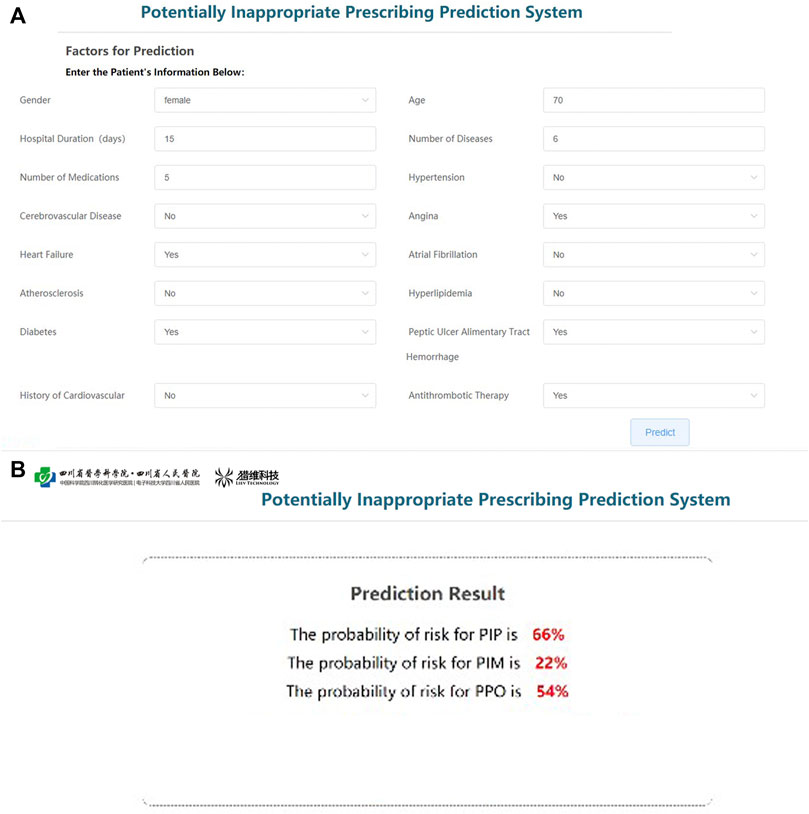
FIGURE 5. Operation interface of PIP warning platform. (A) User input interfaces. (B) User output interfaces.
In this study, a total of 404 elderly patients with cardiovascular disease who were hospitalized for 3–60 days were included. Five data sampling methods and three feature screening methods were used to construct 15 datasets, and 270 machine learning models were developed using 18 machine learning algorithms. AUC, accuracy, precision, recall, F1 Score, and AUPRC were used to evaluate the performance of the models. The PIP prediction platform was developed based on the parameters in the best model (the AUCs of the PIP, PPO, and PIM models were 0.8341, 0.7007 and 0.7061, respectively).
One study reported that length of stay, comorbidities, and age were associated with PIP in elderly patients (Abegaz et al., 2018). Muhlack et al. (2018) found that elderly patients with multiple diseases, frailty, and cognitive impairment were more likely to have PIM. Meanwhile, the study showed that elderly patients with lower levels of education, those taking multiple medications, and unplanned hospitalization were more likely to have PIM. Previous research suggested that the number of medications prescribed was associated with the occurrence of PIM (Nieves-Pérez et al., 2018; Ma et al., 2019). Maaroufi et al. (2021) found significant correlations between PIM and the number of medications used (at home), gender, unauthorized medications, and the number and type of comorbidities, with information on the number of medications used. Multiple results showed that comorbidities and the number of medications were key risk factors for developing PIP in the elderly. Moreover, a recent study showed that the prevalence of PIP was related to the days of hospitalization (Xu et al., 2020). According to the electronic medical record in the hospital, patients whose duration of hospitalization was between 3 and 60 days were included in the study. Patients whose length of stay was less than 3 days might die following hospitalization or have a few examinations after hospitalization and should be excluded. In this study, we found that angina, atherosclerosis, heart failure, diabetes, and the number of medications used were more strictly associated with the development of PIP in elderly patients with cardiovascular disease. These results suggest that patients with the above variables need additional care and attention. Furthermore, using these variables in similar studies may be interesting in the future.
Similar to this study, Patel et al. (2020) built prediction models using cross-validated logistic regression (CVLR) and XGBoost to screen predictors of potentially inappropriate osteoarthritis in the elderly with NSAIDs. The machine learning algorithms used in this study included two machine learning algorithms used by Patel et al. (2020). Compared to this study, Patel et al. (2020) reported a better predictive performance with an AUC of 0.8341 and an accuracy of 0.7160. However, Patel’s study did not perform external validation and had poor generalization ability. In this study, external validation was performed. Additionally, the ensemble algorithms summarized the output of the five best models (assessed by AUC) among the trained models and generated output according to the voting principle, which could help to improve the prediction performance of models. The results suggested that the model in the present study had a stronger generalization ability and higher prediction accuracy.
This study had a number of limitations. First, this study was based on data from a single medical center in China. We are not certain if our results can also be generalized to other hospitals with a large elderly population. Second, according to the sample size results of this study and the results of other studies (Black et al., 2018; Rose et al., 2018; Hyttinen et al., 2019a; Hyttinen et al., 2019b), a larger sample size is needed to further optimize the model in the future. Third, this study was a retrospective analysis, so there were cases of incomplete data or missing records. For example, educational status has previously been demonstrated to be associated with the development of PIP. However, we lacked such data.
In summary, we developed a risk warning platform for potentially inappropriate prescriptions in elderly patients with cardiovascular disease who are over 65 years of age and with hospitalization between 3 and 60 days. We explored various combinations of different sampling methods, feature selection methods, and algorithms. Additionally, the contribution of variables was demonstrated by several methods. The risk warning platform could conveniently inform clinicians about the risk of PIP, which is key to the development of effective and personalized treatment strategies.
The original contributions presented in the study are included in the article Supplementary Material; further inquiries can be directed to the corresponding authors.
WX was involved in reviewing prescriptions, model design, and data analysis. CH, LM, and QL contributed to writing and approval of the final manuscript. LE assisted in reviewing prescriptions. TR and ZJ were responsible for revising the research. All authors agreed to be accountable for the content of the work.
This study was funded by the National Natural Science Foundation of China (grant no. 72004020), the Key Research and Development Program of the Science and Technology Department of Sichuan Province (grant no. 2019YFS0514), the Postgraduate Research and Teaching Reform Project of the University of Electronic Science and Technology of China (grant no. JYJG201919), and the Research Subject of Health Commission of Sichuan Province (grant no. 19PJ262).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphar.2022.804566/full#supplementary-material
Supplementary Figure S1 | Results of feature screening in different models. (A) In the PIP model. (B) In the PPO model. (C) In the PIM model. (The importance of each variable was summarized and shown with the mean of the 15 datasets. The variable names are shown in Supplementary Table S1).
Supplementary Figure S2 | Contribution of each variable to prediction performance in different models. (A) In the PIP model. (B) In the PPO model. (C) In the PIM model. (The importance of each variable was summarized when the variable was included in the models. The variable names are shown in Supplementary Table S1).
Supplementary Figure S3 | Results of sample size validation (A) In the PIP model. (B) In the PPO model. (C) In the PIM model.
Supplementary Figure S4 | Computer Software Copyright Registration Certificate.
Abegaz, T. M., Birru, E. M., and Mekonnen, G. B. (2018). Potentially inappropriate prescribing in Ethiopian geriatric patients hospitalized with cardiovascular disorders using START/STOPP criteria. PLoS One 13, e0195949. doi:10.1371/journal.pone.0195949
Badet, T., Fouché, S., Hartmann, F. E., Zala, M., and Croll, D. (2021). Machine-learning predicts genomic determinants of meiosis-driven structural variation in a eukaryotic pathogen. Nat. Commun. 12, 3551. doi:10.1038/s41467-021-23862-x
Biritwum, R. B., Mensah, G., Minicuci, N., Yawson, A. E., Naidoo, N., Chatterji, S., et al. (2013). Household characteristics for older adults and study background from SAGE Ghana Wave 1. Glob. Health Action 6, 20096. doi:10.3402/gha.v6i0.20096
Black, C. D., Thavorn, K., Coyle, D., Smith, G., and Bjerre, L. M. (2018). Health system costs of potentially inappropriate prescribing in ontario, Canada: a protocol for a population-based cohort study. BMJ Open 8, e021727. doi:10.1136/bmjopen-2018-021727
By the 2019 American Geriatrics Society Beers Criteria® Update Expert Panel (2019). American geriatrics society 2019 updated AGS beers criteria® for potentially inappropriate medication use in older adults. J. Am. Geriatr. Soc. 67, 674–694. doi:10.1111/jgs.15767
Chen, Y. C., Fan, J. S., Chen, M. H., Hsu, T. F., Huang, H. H., Cheng, K. W., et al. (2014). Risk factors associated with adverse drug events among older adults in emergency department. Eur. J. Intern. Med. 25, 49–55. doi:10.1016/j.ejim.2013.10.006
Corsonello, A., Pedone, C., and Incalzi, R. A. (2010). Age-related pharmacokinetic and pharmacodynamic changes and related risk of adverse drug reactions. Curr. Med. Chem. 17, 571–584. doi:10.2174/092986710790416326
Cullinan, S., O'Mahony, D., O'Sullivan, D., and Byrne, S. (2016). Use of a frailty index to identify potentially inappropriate prescribing and adverse drug reaction risks in older patients. Age Ageing 45, 115–120. doi:10.1093/ageing/afv166
D'Cruz, S., Sachdev, A., and Tiwari, P. (2012). Adverse drug reactions & their risk factors among Indian ambulatory elderly patients. Indian J. Med. Res. 136, 404–410.
Fralick, M., Dai, D., Pou-Prom, C., Verma, A. A., and Mamdani, M. (2021). Using machine learning to predict severe hypoglycaemia in hospital. Diabetes Obes. Metab. 23, 2311–2319. doi:10.1111/dom.14472
Gallagher, P., Lang, P. O., Cherubini, A., Topinková, E., Cruz-Jentoft, A., Montero Errasquín, B., et al. (2011). Prevalence of potentially inappropriate prescribing in an acutely ill population of older patients admitted to six European hospitals. Eur. J. Clin. Pharmacol. 67, 1175–1188. doi:10.1007/s00228-011-1061-0
Galli, T. B., Reis, W. C., and Andrzejevski, V. M. (2016). Potentially inappropriate prescribing andthe risk of adverse drug reactions in critically ill older adults. Pharm. Pract. 14, 818. doi:10.18549/PharmPract.2016.04.818
Hamilton-Craig, I., Colquhoun, D., Kostner, K., Woodhouse, S., and d'Emden, M. (2015). Lipid-modifying therapy in the elderly. Vasc. Health Risk Manag. 11, 251–263. doi:10.2147/vhrm.S40474
Hossain, M. J., Chowdhury, U. N., Islam, M. B., Uddin, S., Ahmed, M. B., Quinn, J. M. W., et al. (2021). Machine learning and network-based models to identify genetic risk factors to the progression and survival of colorectal cancer. Comput. Biol. Med. 135, 104539. doi:10.1016/j.compbiomed.2021.104539
Hyttinen, V., Jyrkkä, J., Saastamoinen, L. K., Vartiainen, A. K., and Valtonen, H. (2019b). Patient- and health care-related factors associated with initiation of potentially inappropriate medication in community-dwelling older persons. Basic Clin. Pharmacol. Toxicol. 124, 74–83. doi:10.1111/bcpt.13096
Hyttinen, V., Jyrkkä, J., Saastamoinen, L. K., Vartiainen, A. K., and Valtonen, H. (2019a). The association of potentially inappropriate medication use on health outcomes and hospital costs in community-dwelling older persons: a longitudinal 12-year study. Eur. J. Health Econ. 20, 233–243. doi:10.1007/s10198-018-0992-0
King, R., and Giedrimiene, D. (2021). Primary care physician services and the frequency of comorbidities in patients with acute myocardial infarction. Eur. J. Prev. Cardiol. 28. doi:10.1093/eurjpc/zwab061.265
Lin, Y., Wu, J. Y., Lin, K., Hu, Y. H., and Kong, G. L. (2021). Prediction of intensive care unit readmission for critically ill patients based on ensemble learning. Beijing Da Xue Xue Bao Yi Xue Ban. 53, 566–572. doi:10.19723/j.issn.1671-167X.2021.03.021
Lopez-Rodriguez, J. A., Rogero-Blanco, E., Aza-Pascual-Salcedo, M., Lopez-Verde, F., Pico-Soler, V., Leiva-Fernandez, F., et al. (2020). Potentially inappropriate prescriptions according to explicit and implicit criteria in patients with multimorbidity and polypharmacy. Multipap: a cross-sectional study. PLoS One 15, e0237186. doi:10.1371/journal.pone.0237186
Ma, Z., Zhang, C., Cui, X., and Liu, L. (2019). Comparison of three criteria for potentially inappropriate medications in Chinese older adults. Clin. Interv. Aging 14, 65–72. doi:10.2147/cia.S190983
Maaroufi, A., Zahidi, H., Abouradi, S., Choukrani, H., and Habbal, R. (2021). Potentially inappropriate home medications among older patients with cardiovascular disease in a moroccan population. Eur. J. Prev. Cardiol. 28. doi:10.1093/eurjpc/zwab061.442
Manckoundia, P., Rosay, C., Menu, D., Nuss, V., Mihai, A. M., Vovelle, J., et al. (2020). The prescription of vitamin K antagonists in a very old population: a cross-sectional study of 8696 ambulatory subjects aged over 85 years. Int. J. Environ. Res. Public Health 17, E6685. doi:10.3390/ijerph17186685
Matanović, S. M., and Vlahović-Palčevski, V. (2014). Potentially inappropriate prescribing to the elderly: comparison of new protocol to beers criteria with relation to hospitalizations for ADRs. Eur. J. Clin. Pharmacol. 70, 483–490. doi:10.1007/s00228-014-1648-3
Mišić, V. V., Rajaram, K., and Gabel, E. (2021). A simulation-based evaluation of machine learning models for clinical decision support: application and analysis using hospital readmission. NPJ Digit. Med. 4, 98. doi:10.1038/s41746-021-00468-7
Muhlack, D. C., Hoppe, L. K., Stock, C., Haefeli, W. E., Brenner, H., Schöttker, B., et al. (2018). The associations of geriatric syndromes and other patient characteristics with the current and future use of potentially inappropriate medications in a large cohort study. Eur. J. Clin. Pharmacol. 74, 1633–1644. doi:10.1007/s00228-018-2534-1
Nieves-Pérez, B. F., Hostos, S. G., Frontera-Hernández, M. I., González, I. C., and Muñoz, J. J. H. (2018). Potentially inappropriate medication use among institutionalized older adults at nursing homes in Puerto Rico. Consult. Pharm. 33, 619–636. doi:10.4140/TCP.n.2018.619
O'Mahony, D., and Gallagher, P. F. (2008). Inappropriate prescribing in the older population: need for new criteria. Age Ageing 37, 138–141. doi:10.1093/ageing/afm189
O'Mahony, D., O'Sullivan, D., Byrne, S., O'Connor, M. N., Ryan, C., Gallagher, P., et al. (2015). STOPP/START criteria for potentially inappropriate prescribing in older people: version 2. Age Ageing 44, 213–218. doi:10.1093/ageing/afu145
Parekh, N., Ali, K., Davies, J. G., and Rajkumar, C. (2019). Do the 2015 beers criteria predict medication-related harm in older adults? analysis from a multicentre prospective study in the United Kingdom. Pharmacoepidemiol. Drug Saf. 28, 1464–1469. doi:10.1002/pds.4849
Patel, J., Ladani, A., Sambamoorthi, N., LeMasters, T., Dwibedi, N., Sambamoorthi, U., et al. (2020). A machine learning approach to identify predictors of potentially inappropriate non-steroidal anti-inflammatory drugs (NSAIDs) use in older adults with osteoarthritis. Int. J. Environ. Res. Public Health 18, E155. doi:10.3390/ijerph18010155
Petrovic, M., Somers, A., and Onder, G. (2016). Optimization of geriatric pharmacotherapy: role of multifaceted cooperation in the hospital setting. Drugs Aging 33 (3), 179–188. doi:10.1007/s40266-016-0352-7
Phillips, C. (2017). Lifestyle modulators of neuroplasticity: how physical activity, mental engagement, and diet promote cognitive health during aging. Neural Plast. 2017, 3589271. doi:10.1155/2017/3589271
Pinaire, J., Chabert, E., Azé, J., Bringay, S., and Landais, P. (2021). Sequential pattern mining to predict medical in-hospital mortality from administrative data: application to acute coronary syndrome. J. Healthc. Eng. 2021, 5531807. doi:10.1155/2021/5531807
Rose, A. J., Bernson, D., Chui, K. K. H., Land, T., Walley, A. Y., LaRochelle, M. R., et al. (2018). Potentially inappropriate opioid prescribing, overdose, and mortality in Massachusetts, 2011-2015. J. Gen. Intern. Med. 33, 1512–1519. doi:10.1007/s11606-018-4532-5
Sheikh-Taha, M., and Dimassi, H. (2017). Potentially inappropriate home medications among older patients with cardiovascular disease admitted to a cardiology service in USA. BMC Cardiovasc. Disord. 17, 189. doi:10.1186/s12872-017-0623-1
Valdés, Á., Treuer, A. V., Barrios, G., Ponce, N., Fuentealba, R., Dulce, R. A., et al. (2018). NOX inhibition improves β-adrenergic stimulated contractility and intracellular calcium handling in the aged rat heart. Int. J. Mol. Sci. 19, E2404. doi:10.3390/ijms19082404
Van der Ende, M. Y., Hartman, M. H., Hagemeijer, Y., Meems, L. M., de Vries, H. S., Stolk, R. P., et al. (2017). The LifeLines Cohort Study: prevalence and treatment of cardiovascular disease and risk factors. Int. J. Cardiol. 228, 495–500. doi:10.1016/j.ijcard.2016.11.061
Vermunt, N., Harmsen, M., Westert, G. P., Olde Rikkert, M. G. M., and Faber, M. J. (2017). Collaborative goal setting with elderly patients with chronic disease or multimorbidity: a systematic review. BMC Geriatr. 17, 167. doi:10.1186/s12877-017-0534-0
Wu, X. W., Yang, H. B., Yuan, R., Long, E. W., and Tong, R. S. (2020). Predictive models of medication non-adherence risks of patients with T2D based on multiple machine learning algorithms. BMJ Open Diabetes Res. Care 8, e001055. doi:10.1136/bmjdrc-2019-001055
Keywords: cardiovascular diseases, potentially inappropriate prescribing, potentially inappropriate medications, potential prescribing omissions, machine learning, predictive models
Citation: Xingwei W, Huan C, Mengting L, Lv Q, Jiaying Z, Enwu L, Jiuqun Z and Rongsheng T (2022) A machine learning-based risk warning platform for potentially inappropriate prescriptions for elderly patients with cardiovascular disease. Front. Pharmacol. 13:804566. doi: 10.3389/fphar.2022.804566
Received: 29 October 2021; Accepted: 11 July 2022;
Published: 11 August 2022.
Edited by:
Johanna Catharina Meyer, Sefako Makgatho Health Sciences University, South AfricaReviewed by:
Roger E. Thomas, University of Calgary, CanadaCopyright © 2022 Xingwei, Huan, Mengting, Lv, Jiaying, Enwu, Jiuqun and Rongsheng. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zhu Jiuqun, NTQ1NjYyMjUxQHFxLmNvbQ==; Tong Rongsheng, MzE4MDA0MDMxQHFxLmNvbQ==
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.