 Junjun Mao
Junjun Mao Yuhao Chen
Yuhao Chen Luyang Xu1
Luyang Xu1 Weihuang Chen
Weihuang Chen Zhuo Fang
Zhuo Fang Mingkang Zhong
Mingkang Zhong- 1Department of Pharmacy, Huashan Hospital, Fudan University, Shanghai, China
- 2Department of Data and Analytics, WuXi Diagnostics Innovation Research Institute, Shanghai, China
Objective: The aim of this study was to identify the important factors affecting cyclosporine (CsA) blood concentration and estimate CsA concentration using seven different machine learning (ML) algorithms. We also assessed the predictability of established ML models and previously built population pharmacokinetic (popPK) model. Finally, the most suitable ML model and popPK model to guide precision dosing were determined.
Methods: In total, 3,407 whole-blood trough and peak concentrations of CsA were obtained from 183 patients who underwent initial renal transplantation. These samples were divided into model-building and evaluation sets. The model-building set was analyzed using seven different ML algorithms. The effects of potential covariates were evaluated using the least absolute shrinkage and selection operator algorithms. A separate evaluation set was used to assess the ability of all models to predict CsA blood concentration. R squared (R2) scores, median prediction error (MDPE), median absolute prediction error (MAPE), and the percentages of PE within 20% (F20) and 30% (F30) were calculated to assess the predictive performance of these models. In addition, previously built popPK model was included for comparison.
Results: Sixteen variables were selected as important covariates. Among ML models, the predictive performance of nonlinear-based ML models was superior to that of linear regression (MDPE: 3.27%, MAPE: 34.21%, F20: 30.63%, F30: 45.03%, R2 score: 0.68). The ML model built with the artificial neural network algorithm was considered the most suitable (MDPE: −0.039%, MAPE: 25.60%, F20: 39.35%, F30: 56.46%, R2 score: 0.75). Its performance was superior to that of the previously built popPK model (MDPE: 5.26%, MAPE: 29.22%, F20: 33.94%, F30: 51.22%, R2 score: 0.68). Furthermore, the application of the most suitable model and the popPK model in clinic showed that most dose regimen recommendations were reasonable.
Conclusion: The performance of these ML models indicate that a nonlinear relationship for covariates may help to improve model predictability. These results might facilitate the application of ML models in clinic, especially for patients with unstable status or during initial dose optimization.
1 Introduction
Cyclosporine (CsA) is a potent calcineurin inhibitor widely used to prevent allograft rejection in solid organ transplantation (Fahr, 1993; Meier-Kriesche et al., 2006). Given its narrow therapeutic index and large inter- and intra-individual pharmacokinetic/pharmacodynamic (PK/PD) variabilities, conducting routine therapeutic drug monitoring (TDM) is essential to optimize CsA dosage regimens and minimize adverse effects (Shaw et al., 1987).
Currently, the pre-dose (C0) and 2 h post-dose concentrations (C2) of CsA are conventionally monitored during clinical follow-up. Population PK (popPK) models combined with maximum a posteriori Bayesian estimators (MAP-BE) are used to establish a dose titration guide, which is more precise than the prescription depending only on the personal experiences of physicians (Asberg et al., 2010). With the advances in computer technology, precision dosing based on pharmacogenetics and PK/PD models has been suggested to improve patient care (Mizuno et al., 2020).
Based on the compartmental model theory, popPK models can describe the drug PK behavior of individuals by applying statistical mixed effect methods with PK parameters (Sheiner et al., 1977; Sheiner and Beal, 1980). In a previous study, we attempted to identify factors that explain the variability of the CsA PK properties and characterize the time-varying clearance (CL/F) by comprehensively analyzing the CsA PK process using popPK modeling (Mao et al., 2021). Although more theoretical mechanisms were considered to improve model transferability, describing the drug in vivo process was challenging in patients with unstable conditions. In addition, in the context of the rapidly changing clinical status and inflammatory state of renal transplant recipients, the assumptions of the structural model may be inaccurate or overly simplistic.
Contrary to PK-based approaches, which aims to describe the physiological phenomena involved in the drug in vivo process and its variability between individuals, machine learning (ML) models are accuracy-centered, data-driven approaches that eliminate the need for mechanistic assumptions (Badillo et al., 2020). A traditional ML algorithm can be something as simple as linear regression. They use a variety of statistical techniques to interpret the existing data without having to be programmed explicitly. Moreover, artificial neural network (ANN) is a specialized subset of ML algorithms, which describes algorithms that analyze data with a logical structure similar to how a human would draw conclusions. Inspired by the biological neural network of the human brain, ANN uses a layered structure of algorithms to learn a set of complex relationships between the variables, leading to a learning process that is far more capable than that of traditional ML algorithms (Popescu et al., 2009).
As ML models can capture the complex relationships between variables and analyze high-dimensional data in clinical practice, these have been used in clinical pharmacology in recent years. For example, Woillard et al. used ML models to estimate the glomerular filtration rate of intensive care unit patients, based on sparse iohexol PK data (Woillard et al., 2021c). This approach was also used to predict the exposure of tacrolimus (Woillard et al., 2021b) and mycophenolic acid (Woillard et al., 2021a). Moreover, Tang et al. combined popPK and ML models to improve the prediction of individual clearance of renally cleared drugs in neonates (Tang et al., 2021).
According to our previous study, the incorporation of nonlinear kinetics during the modeling process can improve the predictive performance of popPK models for CsA in adult renal transplant recipients (Mao et al., 2020). Furthermore, rather than defining a structural model to describe the observed data, ML models use algorithmic modeling of multiple variables linked by complex interactions to obtain nonlinear relationships that predict clinical outcomes with high accuracy (Badillo et al., 2020; Gautier et al., 2021). In pharmacokinetics, these methods can estimate clearance through characteristics of the patient, such as demographic characteristics, pathophysiological indexes, disease status, and associated medications.
In this study, we aimed to identify the important covariates of the CsA concentration based on retrospective data and estimate the CsA concentration using multiple ML models. We compared the predictions obtained in this study with those of the previously developed popPK model (Mao et al., 2021). Then, the most suitable ML and popPK models were applied to guide personalized medicine.
2 Materials and methods
2.1 Study group and data collection
We recruited 183 renal transplant patients (122 males and 61 females) at Huashan Hospital. Patients were administered combined immunosuppressive therapy, including a CsA microemulsion (Neoral; Novartis Pharma Schweiz AG, Emberbach, Germany), mycophenolate mofetil (MMF; CellCept; Roche Pharma Ltd., Shanghai, China), and steroids. The detailed therapeutic regimens are described in Supplementary Text S1.
The inclusion criteria were as follows: patients 1) aged ≥18 years, 2) who had received their first allograft renal transplantation and 3) who had received a CsA-based triple immunosuppressive regimen. The exclusion criteria were as follows: those who 1) received the conventional, oral formulation of CsA, 2) underwent dialysis treatment, and 3) had missing covariate data required for analyses.
The study protocols were approved by the Ethics Committee of Huashan Hospital and conducted in accordance with the Declaration of Helsinki. All patients provided written informed consent and agreed to the anonymous use of their samples in this study.
We retrospectively collected PK samples of CsA C0 and C2 from the enrolled patients during follow-up TDM. All samples were stored at −20°C for CsA concentration determination, biochemical assay, and pharmacogenetic tests. Details regarding to the determination of CsA concentration and genotyping are presented in Supplementary Text S2 and S3 respectively.
2.2 Machine learning model development
Seven ML models including six traditional models and an ANN model were applied to describe the relationship between variables and CsA concentration.
Our study comprised the following steps:
Step 1:. Covariate selection was performed using the least absolute shrinkage and selection operator (LASSO).
Step 2:. Seven ML algorithms were used to construct the prediction models.
Step 3:. The predictability of the ML models and that of the previously built popPK model were evaluated.
Step 4:. The most suitable ML model and the previously built popPK model were used to guide precision dosing.The flowchart of these procedures is shown in Figure 1.
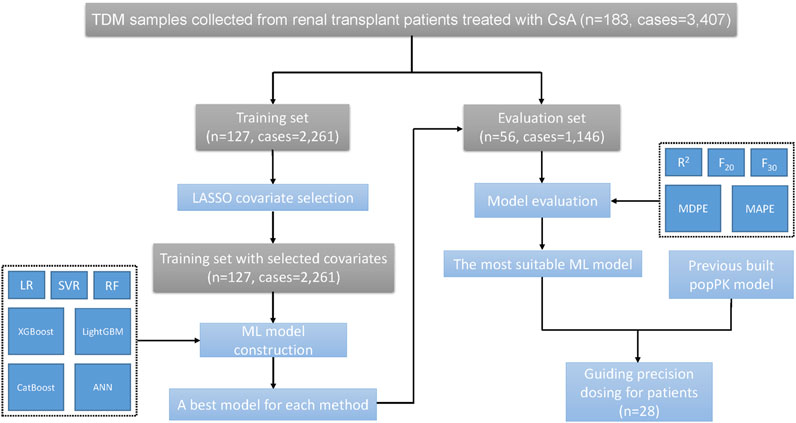
FIGURE 1. The flowchart of study procedures.
2.2.1 Data preparation and covariate selection
The patients were divided into training and evaluation sets, as described in our previous study (Mao et al., 2021). The samples collected were used for model construction and evaluation. For each CsA concentration, the two latest CsA doses before measurement were identified as the major predictors. Furthermore, 57 other variables (e.g., demographics, pathophysiological characteristics, concomitant medications, and pharmacogenomic information) were identified as covariates. An integrated abbreviation list of all variables and their corresponding explanations is provided in Supplementary Table S1.
After data separation, the training set included 127 patients with complete data of all variables, whereas the evaluation set had missing genetic information from 16 of 56 patients. The missing data were imputed using the genotype with the highest frequency among the remaining subjects. Numerical variables were scaled to 0–1. Covariate selection was conducted using LASSO (Alhamzawi and Ali, 2018).
LASSO was used to obtain the predictor subset that minimized the prediction error (PE) for the variables. LASSO applied a constraint on the model parameters by using a generalized linear model via penalized maximum likelihood, shrinking the regression coefficients of some variables toward zero. Variables with regression coefficients equal to zero were excluded from the model. The R software package glmnet was used for the LASSO analysis, and the model was evaluated using a 10-fold cross-validation procedure (Friedman et al., 2022).
Specifically, the training data were split into 10 independent folds of approximately equal size. The models were trained using nine folds of the data and then tested using the remaining fold; this procedure was repeated for each of the 10 training and testing fold combinations.
2.2.2 Six traditional machine learning modeling
Along with the selected variables, six traditional ML algorithms, including linear regression (LR), support vector regression (SVR), random forest (RF), XGBoost, LightGBM, and CatBoost were used for model building (Mahabub, 2019). These ML models were implemented using the “scikit-learn” (sklearn) module in Python 3.6 (Pedregosa et al., 2011). Similarly, a 10-fold cross-validation procedure was performed for the parameter tuning and performance evaluation of each method in the training set. Root mean square error (RMSE) was used to select the best parameter combinations. The model built with the fine-tuned parameters was used as the final model for each method.
2.2.3 Artificial neural network modeling
A multilayer perceptron (MLP) is a fully connected class of feedforward ANN. It consists of at least three layers of nodes: an input layer, a hidden layer, and an output layer (Popescu et al., 2009). The input layer receives the input signal to be processed. The required task, such as prediction or classification, is performed by the output layer. An arbitrary number of hidden layers that are placed in between the input and output layers are the true computational engine.
In this study, an MLP neural network model, which consisted of an input layer, two hidden layers, and an output layer, was constructed for CsA concentration prediction using the “keras” module in Python 3.6 (Gulli A, 2017). To obtain the best generalization performance, we induced a dropout layer behind each hidden layer and applied an early stop strategy to stop model learning before overfitting.
The patients in the training set were randomly divided into model building (including 70% of the patient samples) and model validation (including the remaining 30% of the patient samples) sets. The hyper-parameters, including the number of neurons in the hidden layer, activation function, dropout rate, and batch sizes, the values of which were used to control the learning process, were fine-tuned using the model building set and evaluated using the model validation set.
The mean squared error was used as the loss function metric, and Adam was used as the optimizer. The model with the highest R2 value in the model validation set was selected as the most suitable model. Using all samples in the training set, the associated combination of hyper-parameters was used to construct the final model.
2.3 Model evaluation
Each model of different algorithms was validated using samples from an independent evaluation dataset. The coefficient of determination R2 scores, prediction-based PE (Eq. 1), median prediction error (MDPE), and median absolute prediction error (MAPE) were used to compare the accuracy and precision of model predictive performance (Sheiner and Beal, 1981). R2 is the squared correlation between predicted and observed CsA concentrations, with higher values indicating better predictability. The model with the highest R2 values and the lowest MDPE and MAPE values was considered the most suitable model.
The percentages of PE within 20% (F20) and 30% (F30) were used as the combination index of both accuracy and precision. Furthermore, the prediction performance of the ML models was compared with that of the previously developed popPK model in the same evaluation dataset (Mao et al., 2021).
The predictive performance of a candidate model was considered satisfactory given the following values: MDPE ≤ ± 15%, MAPE ≤30%, F20 > 35%, and F30 > 50% (Mao et al., 2018). Among all models, the one associated with the best prediction performance was selected as the most suitable ML model. The scatter plots of the predicted versus reference CsA concentrations and the distribution plots of percentage prediction errors were drawn for visualization.
2.4 Model application
The most suitable ML model and the previously built popPK model were used to guide precision dosing, and the dose regimens suggested by these two models were compared. Patients in the evaluation dataset with information on the early stages of transplantation were used for dosage adjustments. For each patient, we selected the first sample from postoperative day (POD) 10–15, based on our hypothesis that the concentrations of these samples were at steady state.
The most suitable ML and popPK models were used to optimize the initial dose of these patients. Target C0 values of 200–350 ng ml−1 and target C2 values of 1000–1500 ng ml−1 were suggested for the first month of CsA treatment (Shi and Yuan, 2016). For the ML model, a series of CsA dosages was input into the model to fit the upper and lower limits of recommended target C0 and C2, respectively. Then, the lower and upper limits of CsA dosage were recommended for each patient. Using the popPK model, we conducted Monte Carlo simulations as previously published (Mao et al., 2021). Time-concentration profiles were simulated based on 1000 hypothetical individuals. The C0/C2 value of the CsA doses was simulated from 50 mg q12h to 300 mg q12 h for each patient. The median and the 25th to 75th percentiles of a steady-state C0/C2 value were calculated, and the optimal dosing regimen was selected according to the target concentration. Finally, the rationality of the suggested dose regimens was assessed.
3 Results
3.1 Patients
Detailed demographics and clinical statistics are presented in Table 1. In total, 183 renal transplantation recipients were recruited for this study. Furthermore, 3,407 whole-blood CsA measurements were available, with 1,621 C0 and 1,786 C2. Concentrations below the lower quantification limit were not included in the analysis.
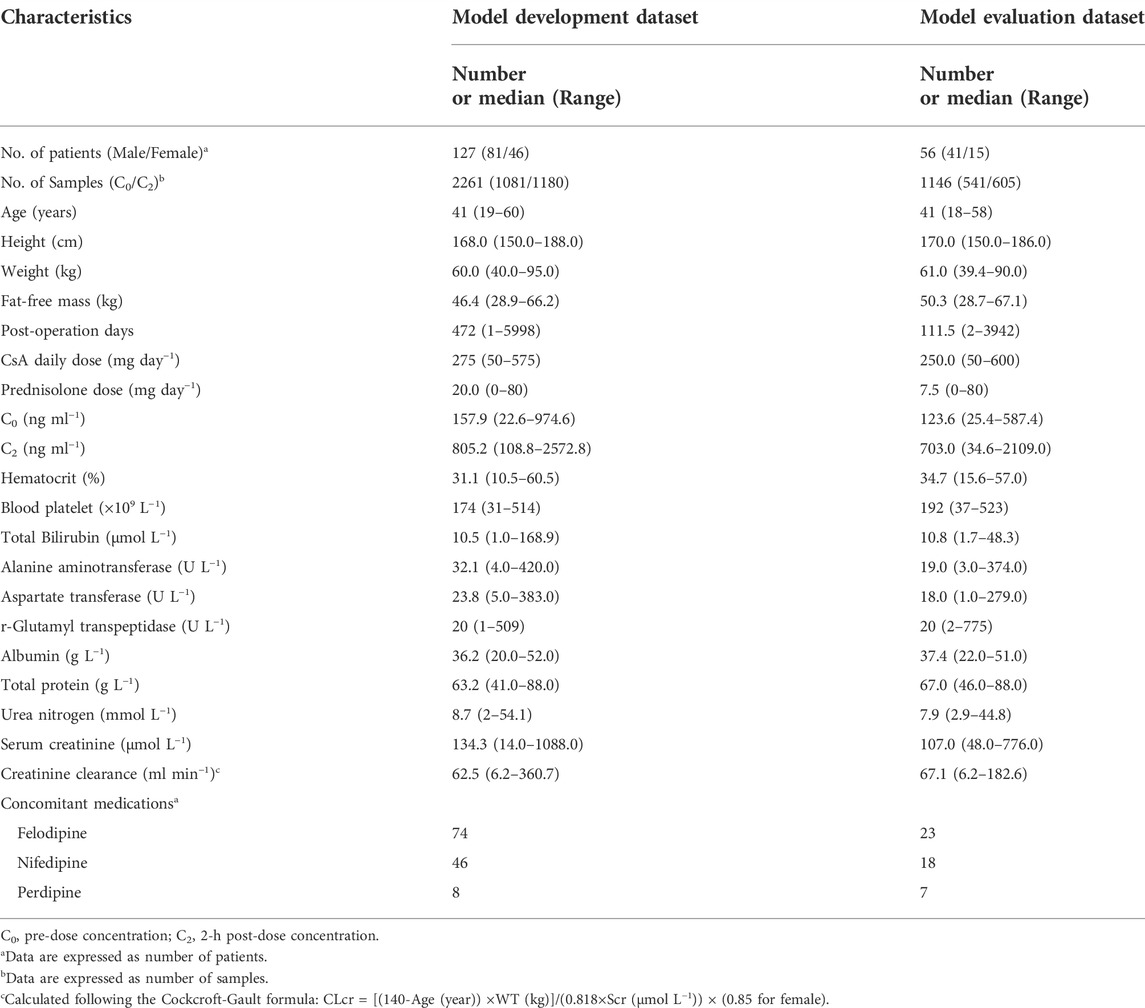
TABLE 1. Patients demographics used to develop and evaluate models.
All observed genotypic distributions of CYP3A4*1G, CYP3A5*3, and ABCB1 genetic polymorphisms were in accordance with the Hardy-Weinberg equilibrium (Supplementary Table S2). Only haplotypes with frequencies and patient proportions ≥8% were analyzed (Supplementary Table S3).
3.2 Covariate selection
Sixteen variables with non-zero coefficients and minimal prediction errors were selected using LASSO as the most important covariates (Supplementary Table S4), which were subsequently used for model construction with seven different ML algorithms: sampling time (C0 or C2), the two latest CsA doses before each sampling time, height, POD, white blood cell (WBC), hematocrit (HCT), blood platelet (PLT), total bilirubin (TBIL), r-glutamyl transpeptidase (rGT), urea nitrogen (UN), creatinine (CR), creatinine clearance rate (CLCR), acyclovir (ACI) use, norvasc (NOR) use, and MDR1 haplotypes CGC. Out of 16 covariates selected by LASSO, only three covariates (POD, HCT, and MDR1 haplotype CGC) were consistent with those of the previously built popPK model based on the same dataset (Mao et al., 2021).
3.3 Model construction and evaluation
The best-tuned parameters for six traditional ML models (i.e., LR, SVR, RF, XGBoost, LightGBM, and CatBoost) and the hyper-parameters selected for the ANN model are presented in Supplementary Table S5. The prediction performance of all models in the evaluation dataset is presented in Table 2. The previously developed popPK model was also included for comparison (Mao et al., 2021). The predicted CsA concentrations vs. observed concentrations for each method, along with the R2 scores of all models, are presented in Figure 2.
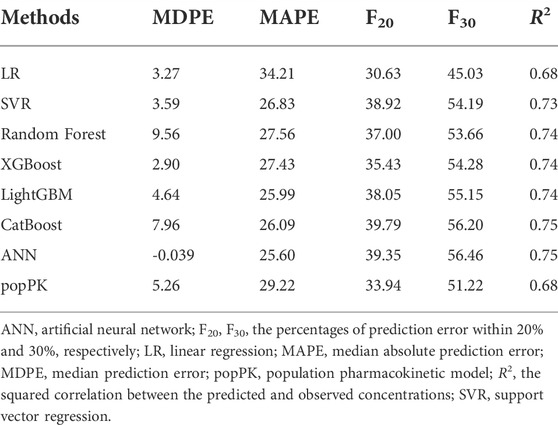
TABLE 2. Predictive performance of seven ML models and previously built popPK model in the evaluation dataset.
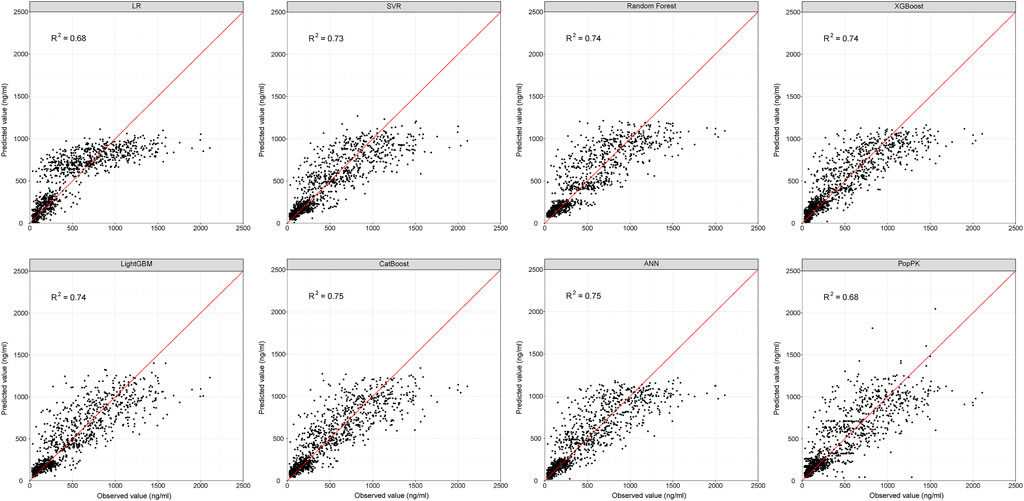
FIGURE 2. Scatter plots showing the reference and predicted cyclosporine concentrations from the evaluation dataset for ML and popPK models. Red line represents the reference line. ANN, artificial neural network; ML, machine learning; popPK, population pharmacokinetic model; R2, the squared correlation between the predicted and observed concentrations; LR, linear regression; SVR, support vector regression.
All ML models besides linear regression were developed based on nonlinear methods. The predictive performance of nonlinear-based ML models met the aforementioned criteria (i.e., MDPE ≤ ± 15%, MAPE ≤30%, F20 > 35% and F30 > 50%), except the linear regression model, which had an MDPE of 3.27%, MAPE of 34.21%, F20 of 30.63%, and F30 of 45.03%. This indicated that considering the nonlinear relationship of patient covariates may help improve model predictability.
With R2 as the assessment metrics, the popPK model was slightly superior to the linear regression model but was inferior to other ML models. The percentages of samples with prediction errors within 10%, 30%, and 50% are shown in Figure 3. Among these models, the highest percentages were consistently achieved with the ANN model. Here, the predicted CsA concentrations within the prediction errors of 10%, 30%, and 50% were 20.24%, 56.46%, and 77.31%, respectively. In both accuracy and precision, the ANN model was considered the most suitable ML model with an MDPE of -0.039%, MAPE of 25.60%, F20 of 39.35%, F30 of 56.46%, and R2 score of 0.75.
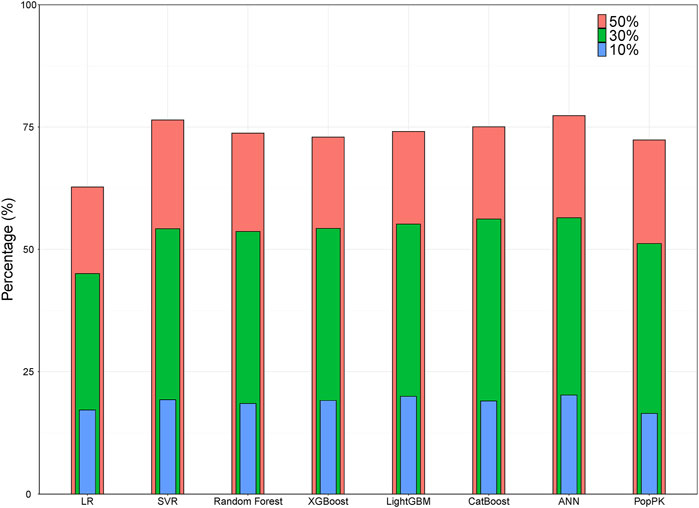
FIGURE 3. Bar plot showing the percentages of prediction error within 10%, 30%, and 50% for ML and popPK models. ANN, artificial neural network; ML, machine learning; popPK, population pharmacokinetic model; LR, linear regression; SVR, support vector regression.
3.4 Model application
Twenty-eight patients from the evaluation dataset were selected for dosage adjustment. In C0, subtherapeutic and supratherapeutic CsA concentrations were observed in 53.6% and 3.6% of patients, respectively. In C2, subtherapeutic and supratherapeutic CsA concentrations were observed in 67.9% and 3.6% of patients, respectively. The median POD of these TDM values was 11, indicating the need for an initial dose design.
The results of the dosing regimen optimization conducted using the most suitable ML and popPK models are shown in Supplementary Table S6 and Supplementary Table S7. Most dose regimens suggested by the two models were reasonable, except for patients #192, #201, #812, and #909, whose concentrations were below the target ranges. Although the doses suggested by the ML model and popPK model were higher than the actual dosage. They were inconsistent with each other. The doses suggested by the ML model were higher than those suggested by the popPK model. However, for patient #169, whose concentrations were in the target ranges, a lower dose proposal was suggested by the ML model than by the popPK model and the actual dosage.
A comparison of the actual CsA dose, which was used based on the personal experiences of physicians, and optimal daily doses of CsA recommended by the most suitable ML and popPK models is shown in part in Figure 4, and the complete comparison for all patients is presented in Supplementary Figure S1.
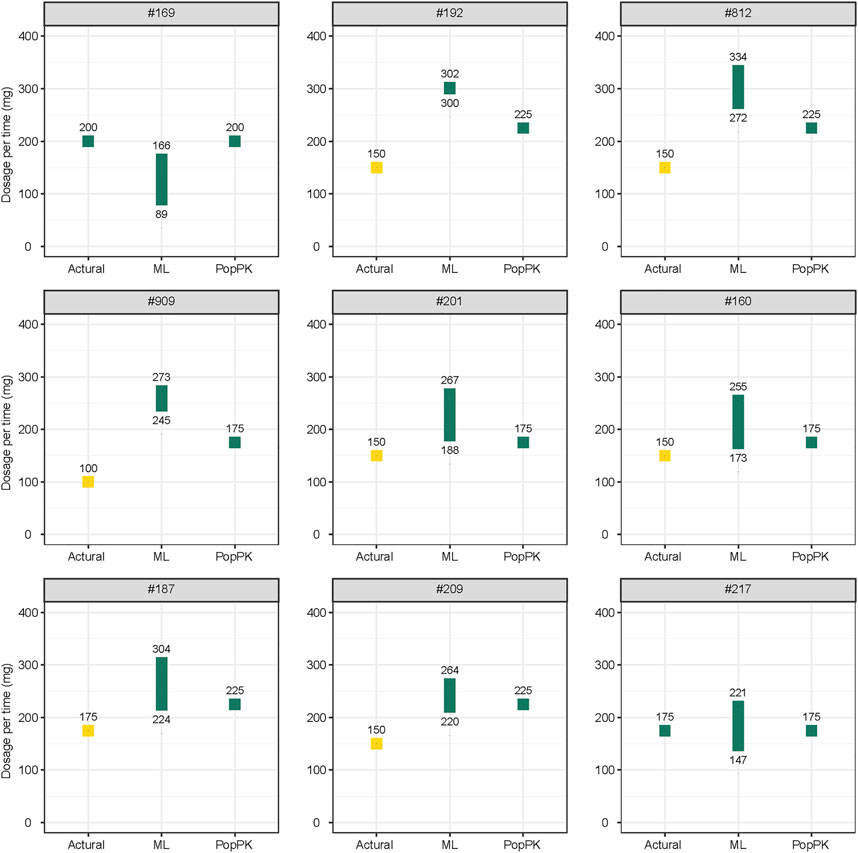
FIGURE 4. Comparison of the actual and optimal daily doses of cyclosporine recommended by the most suitable ML model and popPK models. Yellow plot indicates the concentration below the therapeutic windows; green plot indicates the concentration in the therapeutic windows. All doses are recommended twice daily. ML, machine learning; popPK, population pharmacokinetic model.
4 Discussion
In this study, we systematically established seven ML models to predict blood trough and peak concentrations from CsA daily dose and other important variables selected using the LASSO algorithm. Thirteen out of 16 covariates compared to those of the previously built popPK model were newly identified.
LASSO is usually employed to get a quick idea of which covariates are important for predicting the outcome variable. It is unsuitable when the number of variables is greater than the number of observations and when many variables are correlated (Laura Freijeiro-González, 2022). The dataset we collected had a large number of observations, with mostly independent variables and a few collinear variables, which generally eliminates the limitation of LASSO. One advantage of LASSO is that it quickly incorporates a reduced set of variables, which are interpretable and reduce the complexity for the next step of model building.
Among these important covariates, the MDR1 haplotype CGC is the only genetic factor. Allelic variations in exons 12 (1236C>T), 21 (2677G>T/A), and 26 (3435C>T) of the MDR1 gene are associated with altered P-glycoprotein (P-gp) function (Kim, 2002), which contributes to the bioavailability of P-gp substrates, such as CsA (Zhang et al., 2008; Mao et al., 2021). Therefore, the MDR1 haplotype was thought to be associated with CsA blood concentration. Based on our previous study, the CL/F of non-CGC haplotype carriers is 14.4% lower than that of CGC haplotype carriers 3 months after renal transplantation (Mao et al., 2021).
We identified other important variables in addition to CGC. The daily dose of CsA was positively associated with concentration, consistent with a previous study finding (Mao et al., 2020). In population analysis, the function of daily dose may primarily reflect the non-linearity of clearance, as seen in CsA concentration (Cai et al., 2020; Huang et al., 2020; Mao et al., 2020). In addition, the incorporation of the daily dose can significantly improve the model predictability. However, the depth of the relationship between CsA daily dose and concentration cannot be explored in the ML model.
Several biomedical indices, including WBC, HCT, PLT, TBIL, rGT, UN, CR, and CLCR, were also selected as important covariates of CsA blood concentration. Specifically, we reported that WBC, HCT, and PLT were positively correlated with CsA blood concentration. The relationship between the WBC count and CsA concentration has rarely been reported. For renal transplant patients, an elevated WBC count indicates potential infection or immune rejection. A higher dosage may increase CsA blood concentration, resulting in over-immunosuppression and subsequently infection.
Unlike WBC, the relationship between HCT and CsA concentration is commonly observed. In our previous study, the CL/F of CsA decreased significantly (52.6%) as HCT increased from 10.5% to 60.5% (Mao et al., 2021). Similarly, HCT was also selected as significant covariate inversely associated with tacrolimus CL/F (Woillard et al., 2011). A low HCT level may reduce the binding of CsA to red blood cells, increasing the proportion of CsA in plasma. Specifically, plasma CsA is easily metabolized, leading to a lower CsA blood concentration.
Meanwhile, Suehiro et al. (2002) found that both CsA and tacrolimus enhance platelet aggregation via the serotonin pathway. According to another study, CsA potentiates a collagen-evoked platelet procoagulant response (Tomasiak et al., 2007). Therefore, the level of PLT may indicate the level of CsA blood concentration. Additionally, TBIL and rGT levels, which reflect liver function, were positively associated with CsA blood concentration. Caban et al. observed that CsA could increase the levels of aspartate aminotransferase, alanine transaminase, and bilirubin by changing oxidative stress parameters and lipid peroxidation products in liver supernatants (Korolczuk et al., 2016). Changes in oxidative stress markers in parallel with mitochondrial damage suggest that the mechanisms play a crucial role in CsA-induced hepatotoxicity (Korolczuk et al., 2016). Poor liver function affects CsA metabolism, leading to a higher concentration of CsA.
Height was rarely identified as an influencing factor for CsA pharmacokinetics. However, it showed an inverse correlation with the CsA concentration. Sam et al. identified height as a significant influencing factor for the apparent volume of distribution in Asian liver transplant patients taking tacrolimus (Sam et al., 2006). They found that every meter of increase in height is associated with an 82.5% increase in Vd/F. Based on other ML study on tacrolimus, height is also an important factor in the prediction model (Zheng et al., 2021).
POD after renal transplantation was also an influencing factor in CsA pharmacokinetics. Using the LASSO algorithm, in this study, we found that POD was negatively associated with CsA concentration. Likewise, Okada et al. and Mao et al. found that an increase in CL/F, along with POD, decreases the concentration of CsA (Okada et al., 2017; Mao et al., 2021).
As an immunosuppressive agent, CsA decreases the incidence of acute rejection and increases long-term survival after renal transplantation (Rodicio, 2000). Unfortunately, long-term CsA treatment can lead to several serious side effects, including systemic hypertension, permanent renal damage, cardiovascular disease, and numerous metabolic abnormalities. Calcium channel blockers (CCBs) are considered the best treatment for CsA-induced hypertension (Bernard et al., 2014). Certain CCBs, such as amlodipine, diltiazem, felodipine nicardipine, nifedipine, and verapamil, are relatively potent cytochrome P450 3A4 enzyme (CYP3A4) inhibitors at clinically relevant doses (Wang et al., 2016); these are metabolized by CYP3A4. In turn, these inhibit CYP3A4, which plays a key role in CsA metabolism (Bernard et al., 2014). As such, the co-administration of CCBs and CsA may increase CsA blood concentration. In our study, amlodipine, the first oral CCB used, was positively associated with CsA concentration. Bernard et al. (2014) found that blood trough concentrations of dose-normalized CsA increase significantly in patients treated with amlodipine, consistent with the results of our study . The co-prescription of acyclovir and CsA was also selected as a variable for increased CsA blood concentration.
Among the ML models, the ANN model exhibited the best predictive performance. Without prior observations, the predictive performance of the most suitable ML model was superior to that of the popPK model. The replacement of the popPK model with the ML model may depend on the model application scenario. ML algorithms could learn the hidden patterns from data themselves and do not require any prior knowledge. Therefore, for patients with unstable status or during initial dose optimization, the ML model is preferred (Woillard et al., 2021c). In addition, as ML models are data-driven, increasing the input participant data can continually optimize the parameters to improve accuracy and practicality. Therefore, the ML model is suitable for big-data analysis (observations >1000 and dimensions >50) without mechanistic assumptions (Graaf, 2014; McComb et al., 2021). However, the ML model works as a “black box,” and user-friendly interfaces should be developed to facilitate clinical application.
Moreover, the goals and possibilities of the ML and popPK models are different. No simulations were possible for the ML model, whereas the popPK model can simulate a time-concentration profile and estimate the probability of target achievement. Besides, popPK model is more flexible in regard to deviations in the sampling time. Specifically, the goal of the ML model is accuracy-centered, using the necessary variables. In contrast, the goal of the popPK model is to describe physiological phenomena and variability during the PK process. In addition, the mathematics underlying each method is different. To increase model predictability and interpretability, a combination of ML and pharmacometrics models may be necessary (Koch et al., 2020; Tang et al., 2021).
Among all patients recruited in this study, the percentages of follow-up concentrations within the target CsA C0 and C2 were 46.2% and 39.0%, respectively. This result highlighted the need to perform model-informed precision dosing in clinical practice (Kluwe et al., 2020). According to our results, the predictability and suggested dose regimens of the ML and popPK models were comparable. However, there is also some discrepancy between these two methods. The final prescription should be determined by the combination of the predicted dosage and clinical information.
This study had limitations. First, we used a retrospective, observational design. Therefore, the adherence of patients to their prescribed dose regimens cannot be confirmed. Second, the TDM data used were collected from one center. Therefore, multicenter validation is necessary to confirm the model predictability. Third, we applied covariates selection using a linear association-based method, and then used those covariates for nonlinear model construction. This procedure might remove features that could have been of interest. Fourth, the distribution of CsA concentrations was not equivalent. Approximately only 15% of cases had a CsA concentration above 1200 ng/ml, and ML algorithms have difficulty extracting useful information from limited samples with high CsA concentrations. The ML model should be used with caution to predict concentrations higher than 1200 ng/ml. Finally, the relationship between the dependent and independent variables was extremely complicated in all statistical algorithms, and the existence of gene-gene and gene-environment interactions introduces more challenges for researchers (Hunter, 2005).
5 Conclusion
The predictability of the ML and popPK models was comparable, except for linear regression, indicating that considering the nonlinear relationship of patient covariates may help to improve the model predictability. These results could facilitate the application of ML models in clinic, especially for patients with unstable status or during initial dose optimization.
Data availability statement
The raw data supporting the conclusion of this article will bemade available by the authors, without undue reservation.
Ethics statement
The studies involving human participants were reviewed and approved by Huashan Hospital. The patients/participants provided their written informed consent to participate in this study.
Author contributions
JM, YC, and WQ participated in the study design; JM, YC, LX, WC, BC, ZF, WQ, and MZ implemented and conducted the study; JM, YC, WC and WQ performed the study and analyzed the data. JM and YC drafted the manuscript, which was revised and approved by all the authors.
Funding
This work was partially funded by the Shanghai Municipal Health and Family Planning Commission through grants from the 2019 Key Clinical Program of Clinical Pharmacy, grant number shslczdzk06502, and the Weak Discipline Construction Project, grant number 2016ZB0301-01. This work was also partially funded by the Shanghai Municipal Science and Technology Commission through grants from the 2021 Pujiang Talent Program, grant number 21PJ1423100.
Acknowledgments
We would like to thank Editage (www.editage.cn) for the English language editing.
Conflict of interest
YC, WC, BC, and ZF were employed by the WuXi Diagnostics Co. Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphar.2022.1016399/full#supplementary-material
References
Alhamzawi, R., and Ali, H. T. M. (2018). The Bayesian adaptive lasso regression. Math. Biosci. 303, 75–82. doi:10.1016/j.mbs.2018.06.004
Asberg, A., Falck, P., Undset, L. H., Dorje, C., Holdaas, H., Hartmann, A., et al. (2010). Computer-assisted cyclosporine dosing performs better than traditional dosing in renal transplant recipients: Results of a pilot study. Ther. Drug Monit. 32(2), 152–158. doi: Doi doi:10.1097/Ftd.0b013e3181d3f822
Badillo, S., Banfai, B., Birzele, F., Davydov, , Hutchinson, L., Kam-Thong, T., et al. (2020). An introduction to machine learning. Clin. Pharmacol. Ther. 107 (4), 871–885. doi:10.1002/cpt.1796
Bernard, E., Goutelle, S., Bertrand, Y., and Bleyzac, N. (2014). Pharmacokinetic drug-drug interaction of calcium channel blockers with cyclosporine in hematopoietic stem cell transplant children. Ann. Pharmacother. 48 (12), 1580–1584. doi:10.1177/1060028014550644
Cai, X., Song, H., Jiao, Z., Yang, H., Zhu, M., Wang, C., et al. (2020). Population pharmacokinetics and dosing regimen optimization of tacrolimus in Chinese lung transplant recipients. Eur. J. Pharm. Sci. 152, 105448. doi:10.1016/j.ejps.2020.105448
Fahr, A. (1993). Cyclosporin clinical pharmacokinetics. Clin. Pharmacokinet. 24 (6), 472–495. doi:10.2165/00003088-199324060-00004
Friedman, J., Hastie, T., Tibshirani, R., Narasimhan, B., Tay, K., Simon, N., et al. (2022). glmnet: Lasso and elastic-net regularized generalized linear models. https://CRAN.R-project.org/package=glmnet.
Gautier, T., Ziegler, L. B., Gerber, M. S., Campos-Nanez, E., and Patek, S. D. (2021). Artificial intelligence and diabetes technology: A review. Metabolism. 124, 154872. doi:10.1016/j.metabol.2021.154872
Graaf, P. H. (2014). Introduction to population pharmacokinetic/pharmacodynamic analysis with nonlinear mixed effects models. CPT. Pharmacometrics Syst. Pharmacol. 3, e153. doi:10.1038/psp.2014.51
Huang, L., Liu, Y., Jiao, Z., Wang, J., Fang, L., and Mao, J. (2020). Population pharmacokinetic study of tacrolimus in pediatric patients with primary nephrotic syndrome: A comparison of linear and nonlinear michaelis-menten pharmacokinetic model. Eur. J. Pharm. Sci. 143, 105199. doi:10.1016/j.ejps.2019.105199
Hunter, D. J. (2005). Gene-environment interactions in human diseases. Nat. Rev. Genet. 6 (4), 287–298. doi:10.1038/nrg1578
Kim, R. B. (2002). MDR1 single nucleotide polymorphisms: Multiplicity of haplotypes and functional consequences. Pharmacogenetics 12 (6), 425–427. doi:10.1097/00008571-200208000-00002
Kluwe, F., Michelet, R., Mueller-Schoell, A., Maier, C., Klopp-Schulze, L., van Dyk, M., et al. (2020). Perspectives on model-informed precision dosing in the digital Health era: Challenges, opportunities, and recommendations. Clin. Pharmacol. Ther. 109, 29–36. doi:10.1002/cpt.2049
Koch, G., Pfister, M., Daunhawer, I., Wilbaux, M., Wellmann, S., and Vogt, J. E. (2020). Pharmacometrics and machine learning partner to advance clinical data analysis. Clin. Pharmacol. Ther. 107 (4), 926–933. doi:10.1002/cpt.1774
Korolczuk, A., Caban, K., Amarowicz, M., Czechowska, G., and Irla-Miduch, J. (2016). Oxidative stress and liver morphology in experimental cyclosporine A-induced hepatotoxicity. Biomed. Res. Int. 2016, 5823271. doi:10.1155/2016/5823271
Laura Freijeiro-González, M. F.-B., González-Manteiga, W., and Gonzalez‐Manteiga, W. (2022). A critical review of LASSO and its derivatives for variable selection UnderDependence among covariates. Int. Stat. Rev. 90 (1), 118–145. doi:10.1111/insr.12469
Mahabub, A. (2019). A robust voting approach for diabetes prediction using traditional machine learning techniques. SN Appl. Sci. 1 (1667), 1667. doi:10.1007/s42452-019-1759-7
Mao, J., Jiao, Z., Qiu, X., Zhang, M., and Zhong, M. (2020). Incorporating nonlinear kinetics to improve predictive performance of population pharmacokinetic models for ciclosporin in adult renal transplant recipients: A comparison of modelling strategies. Eur. J. Pharm. Sci. 153, 105471. doi:10.1016/j.ejps.2020.105471
Mao, J. J., Jiao, Z., Yun, H. Y., Zhao, C. Y., Chen, H. C., Qiu, X. Y., et al. (2018). External evaluation of population pharmacokinetic models for ciclosporin in adult renal transplant recipients. Br. J. Clin. Pharmacol. 84 (1), 153–171. doi:10.1111/bcp.13431
Mao, J., Qiu, X., Qin, W., Xu, L., Zhang, M., and Zhong, M. (2021). Factors affecting time-varying clearance of cyclosporine in adult renal transplant recipients: A population pharmacokinetic perspective. Pharm. Res. 38 (11), 1873–1887. doi:10.1007/s11095-021-03114-9
McComb, M., Bies, R., and Ramanathan, M. (2021). Machine learning in pharmacometrics: Opportunities and challenges. Br. J. Clin. Pharmacol. 88, 1482–1499. doi:10.1111/bcp.14801
Meier-Kriesche, H. U., Li, S., Gruessner, R. W., Fung, J. J., Bustami, R. T., Barr, M. L., et al. (2006). Immunosuppression: Evolution in practice and trends, 1994-2004. Am. J. Transpl. 6 (2), 1111–1131. doi:10.1111/j.1600-6143.2006.01270.x
Mizuno, T., Dong, M., Taylor, Z. L., Ramsey, L. B., and Vinks, A. A. (2020). Clinical implementation of pharmacogenetics and model-informed precision dosing to improve patient care. Br. J. Clin. Pharmacol. 88, 1418–1426. doi:10.1111/bcp.14426
Okada, A., Ushigome, H., Kanamori, M., Morikochi, A., Kasai, H., Kosaka, T., et al. (2017). Population pharmacokinetics of cyclosporine A in Japanese renal transplant patients: Comprehensive analysis in a single center. Eur. J. Clin. Pharmacol. 73 (9), 1111–1119. doi:10.1007/s00228-017-2279-2
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-learn: Machine learning in Python. J. Mach. Learn Res. 12, 2825–2830. doi:10.5555/1953048.2078195
Popescu, M. C. B., Valentina Perescu, P. L., and Mastorakis, N. (2009). Multilayer perceptron and neural networks. WSEAS Trans. Circuits Syst. 8 (7), 579–588. doi:10.5555/1639537.1639542
Rodicio, J. L. (2000). Calcium antagonists and renal protection from cyclosporine nephrotoxicity: Long-term trial in renal transplantation patients. J. Cardiovasc. Pharmacol. 35 (1), S7–S11. doi:10.1097/00005344-200000001-00002
Sam, W. J., Tham, L. S., Holmes, M. J., Aw, M., Quak, S. H., Lee, K. H., et al. (2006). Population pharmacokinetics of tacrolimus in whole blood and plasma in Asian liver transplant patients. Clin. Pharmacokinet. 45 (1), 59–75. doi:10.2165/00003088-200645010-00004
Shaw, L. M., Bowers, L., and Demers, L. (1987). Critical issues in cyclosporine monitoring: Report of the task force on cyclosporine monitoring. Clin. Chem. 33 (7), 1269–1288.
Sheiner, L. B., and Beal, S. L. (1980). Evaluation of methods for estimating population pharmacokinetics parameters. I. Michaelis-menten model: Routine clinical pharmacokinetic data. J. Pharmacokinet. Biopharm. 8 (6), 553–571. doi:10.1007/BF01060053
Sheiner, L. B., and Beal, S. L. (1981). Some suggestions for measuring predictive performance. J. Pharmacokinet. Biopharm. 9(4), 503–512. doi: Doi doi:10.1007/Bf01060893
Sheiner, L. B., Rosenberg, B., and Marathe, V. V. (1977). Estimation of population characteristics of pharmacokinetic parameters from routine clinical data. J. Pharmacokinet. Biopharm. 5 (5), 445–479. doi:10.1007/bf01061728
Shi, B. Y., and Yuan, M. (2016). Guidelines for immunosuppressive therapy in Chinese renal transplant recipients. Organ Transplant. 7, 327–331. doi:10.3969/j.issn.1674-7445.2016.05.001
Suehiro, A., Sawada, A., Hasegawa, Y., Takatsuka, H., Higasa, S., and Kakishita, E. (2002). Enhancement by cyclosporine A and tacrolimus of serotonin-induced formation of small platelet aggregation. Bone Marrow Transpl. 29 (2), 107–111. doi:10.1038/sj.bmt.1703335
Tang, B., Guan, Z., Allegaert, K., Wu, Y., Manolis, E., Leroux, S., et al. (2021). Drug clearance in neonates: A combination of population pharmacokinetic modelling and machine learning approaches to improve individual prediction. Clin. Pharmacokinet. 60, 1435–1448. doi:10.1007/s40262-021-01033-x
Tomasiak, M., Rusak, T., Gacko, M., and Stelmach, H. (2007). Cyclosporine enhances platelet procoagulant activity. Nephrol. Dial. Transpl. 22 (6), 1750–1756. doi:10.1093/ndt/gfl836
Wang, Y. C., Hsieh, T. C., Chou, C. L., Wu, J. L., and Fang, T. C. (2016). Risks of adverse events following coprescription of statins and calcium channel blockers: A nationwide population-based study. Med. Baltim. 95 (2), e2487. doi:10.1097/MD.0000000000002487
Woillard, J. B., Labriffe, M., Debord, J., and Marquet, P. (2021a). Mycophenolic acid exposure prediction using machine learning. Clin. Pharmacol. Ther. 110 (2), 370–379. doi:10.1002/cpt.2216
Woillard, J. B., Labriffe, M., Debord, J., and Marquet, P. (2021b). Tacrolimus exposure prediction using machine learning. Clin. Pharmacol. Ther. 110 (2), 361–369. doi:10.1002/cpt.2123
Woillard, J. B., Salmon Gandonniere, C., Destere, A., Ehrmann, S., Merdji, H., Mathonnet, A., et al. (2021c). A machine learning approach to estimate the glomerular filtration rate in intensive care unit patients based on plasma iohexol concentrations and covariates. Clin. Pharmacokinet. 60 (2), 223–233. doi:10.1007/s40262-020-00927-6
Woillard, J., de Winter, B., Kamar, N., Marquet, P., Rostaing, L., and Rousseau, A. (2011). Population pharmacokinetic model and Bayesian estimator for two tacrolimus formulations--twice daily Prograf and once daily Advagraf. Br. J. Clin. Pharmacol. 71 (3), 391–402. doi:10.1111/j.1365-2125.2010.03837.x
Zhang, Y. T., Yang, L. P., Shao, H., Li, K. X., Sun, C. H., and Shi, L. W. (2008). ABCB1 polymorphisms may have a minor effect on ciclosporin blood concentrations in myasthenia gravis patients. Br. J. Clin. Pharmacol. 66 (2), 240–246. doi:10.1111/j.1365-2125.2008.03180.x
Keywords: cyclosporine, renal transplantation, machine learning, population pharmacokinetic model, artificial neural network, predictive performance
Citation: Mao J, Chen Y, Xu L, Chen W, Chen B, Fang Z, Qin W and Zhong M (2022) Applying machine learning to the pharmacokinetic modeling of cyclosporine in adult renal transplant recipients: a multi-method comparison. Front. Pharmacol. 13:1016399. doi: 10.3389/fphar.2022.1016399
Received: 10 August 2022; Accepted: 10 October 2022;
Published: 24 October 2022.
Edited by:
Pascal Le Corre, University of Rennes 1, FranceReviewed by:
Jean-Baptiste Woillard, University of Limoges, FranceSojeong Yi, United States Food and Drug Administration, United States
Copyright © 2022 Mao, Chen, Xu, Chen, Chen, Fang, Qin and Zhong. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Weiwei Qin, d3dxaW5AZnVkYW4uZWR1LmNu; Zhuo Fang, ZmFuZ196aHVvQHd1eGlkaWFnbm9zdGljcy5jb20=
†These authors have contributed equally to this work and share first authorship