 Muhammad Sami Ullah1
Muhammad Sami Ullah1 Muhammad Attique Khan
Muhammad Attique Khan Anum Masood
Anum Masood Nazik Alturki
Nazik Alturki- 1Department of Computer Science, HITEC University, Taxila, Pakistan
- 2Department of Physics, Norwegian University of Science and Technology, Trondheim, Norway
- 3Department of Computer Science, College of Computer Engineering and Sciences, Prince Sattam bin Abdulaziz University, Al−Kharj, Saudi Arabia
- 4Department of Information Systems, College of Computer and Information Sciences, Princess Nourah Bint Abdulrahman University, Riyadh, Saudi Arabia
Brain tumor classification is one of the most difficult tasks for clinical diagnosis and treatment in medical image analysis. Any errors that occur throughout the brain tumor diagnosis process may result in a shorter human life span. Nevertheless, most currently used techniques ignore certain features that have particular significance and relevance to the classification problem in favor of extracting and choosing deep significance features. One important area of research is the deep learning-based categorization of brain tumors using brain magnetic resonance imaging (MRI). This paper proposes an automated deep learning model and an optimal information fusion framework for classifying brain tumor from MRI images. The dataset used in this work was imbalanced, a key challenge for training selected networks. This imbalance in the training dataset impacts the performance of deep learning models because it causes the classifier performance to become biased in favor of the majority class. We designed a sparse autoencoder network to generate new images that resolve the problem of imbalance. After that, two pretrained neural networks were modified and the hyperparameters were initialized using Bayesian optimization, which was later utilized for the training process. After that, deep features were extracted from the global average pooling layer. The extracted features contain few irrelevant information; therefore, we proposed an improved Quantum Theory-based Marine Predator Optimization algorithm (QTbMPA). The proposed QTbMPA selects both networks’ best features and finally fuses using a serial-based approach. The fused feature set is passed to neural network classifiers for the final classification. The proposed framework tested on an augmented Figshare dataset and an improved accuracy of 99.80%, a sensitivity rate of 99.83%, a false negative rate of 17%, and a precision rate of 99.83% is obtained. Comparison and ablation study show the improvement in the accuracy of this work.
1 Introduction
One of the deadliest brain disorders is a brain tumor, which develops from an abnormal development of tissue inside the skull. Primary and secondary forms can be distinguished among them. 70% of cases of primary brain tumors only spread within the brain (1). In contrast, secondary tumors start in an organ like the breast, kidney, or lung before metastasizing to the brain (2). The World Health Organization (WHO) divides malignant gliomas into two categories: grade IV/IV tumors, which include glioblastoma multiforme (GBM), and grade III/IV tumors, which include anaplastic astrocytoma, anaplastic oligodendroglioma, anaplastic oligoastrocytoma, and anaplastic ependymomas. With an incidence rate of 3.19 cases per 100,000 person a year and a median age of 64, GBM is the most prevalent malignant brain tumor. It makes up 80% of all primary malignant CNS tumors and 45.2% of all malignant CNS tumors. GBM is 1.5 times more common in men than in women, and it is twice as common in white people as it is in black people (3).
Meningioma is the most common primary tumor of the central nervous system, with 5/100,000 annual occurrence. Radiation therapy and hormone use are risk factors. According to the WHO’s 2016 histological criteria, the majority of meningiomas are grade I benign tumors; however, up to 15% can be atypical and 2% can be anaplastic (4). Pituitary adenomas usually are benign tumors that develop from unusual pituitary gland cell development. They appear either by producing too much hormone or by putting pressure on the surrounding structures, which causes less hormone to be secreted. Prolactinomas, non-functioning adenomas, adenomas that secrete growth hormone, and adenomas that secrete adrenocorticotrophic hormones are the four primary forms. Less frequent kinds include gonadotroph adenomas with clinically significant luteinizing hormone, follicle-stimulating hormone secretion, and thyroid-stimulating hormone-secreting adenomas. Pituitary incidentalomas are a subtype that was unintentionally found while undergoing brain MRI. They can be divided into macroadenomas (bigger, accounting for roughly 40% of occurrences) and microadenomas (less than 1 cm in diameter). Macroadenomas can strain essential structures and regions like the optic chiasm (5).
Gliomas and meningioma emerge from neuroglial and brain membranes, respectively; both are the most frequent primary brain cancers. Pituitary gland and nerve sheath tumors are also included in this group. High-grade gliomas are a common form of malignant tumor. Meningiomas are typically benign; however, they can occasionally turn cancerous (6). Gliomas are more common in men, whereas meningiomas are more common in women; other brain cancers affect both sexes equally (7). Pituitary tumors, whether benign or malignant, can have severe consequences due to their location. Malignant tumors spread quickly, whereas benign tumors develop slowly and are generally entirely eradicated through surgery (8).
Radiologists and clinicians have substantial difficulties in detecting brain tumors. Brain tumor images produced in medical settings might be challenging to analyze. As a result, there is a need for computer-aided procedures with increased early detection accuracy. Currently, there is a lot of interest in using multimodal images to classify brain tumors (9). Magnetic resonance imaging (MRI) is frequently used to diagnose brain malignancies. A tumor can be found via MRI, commonly used to identify brain tissues based on their size, shape, or location (10). Figshare is a publicly available MRI image-based brain tumor dataset containing 3,064 T1-weighted contrast-enhanced images. These are obtained from 233 patients. A total of 1,426 slices of glioma, 708 slices of meningioma, and 930 slices of pituitary tumors are included in said dataset (11, 12). A few sample images are shown in Figure 1.
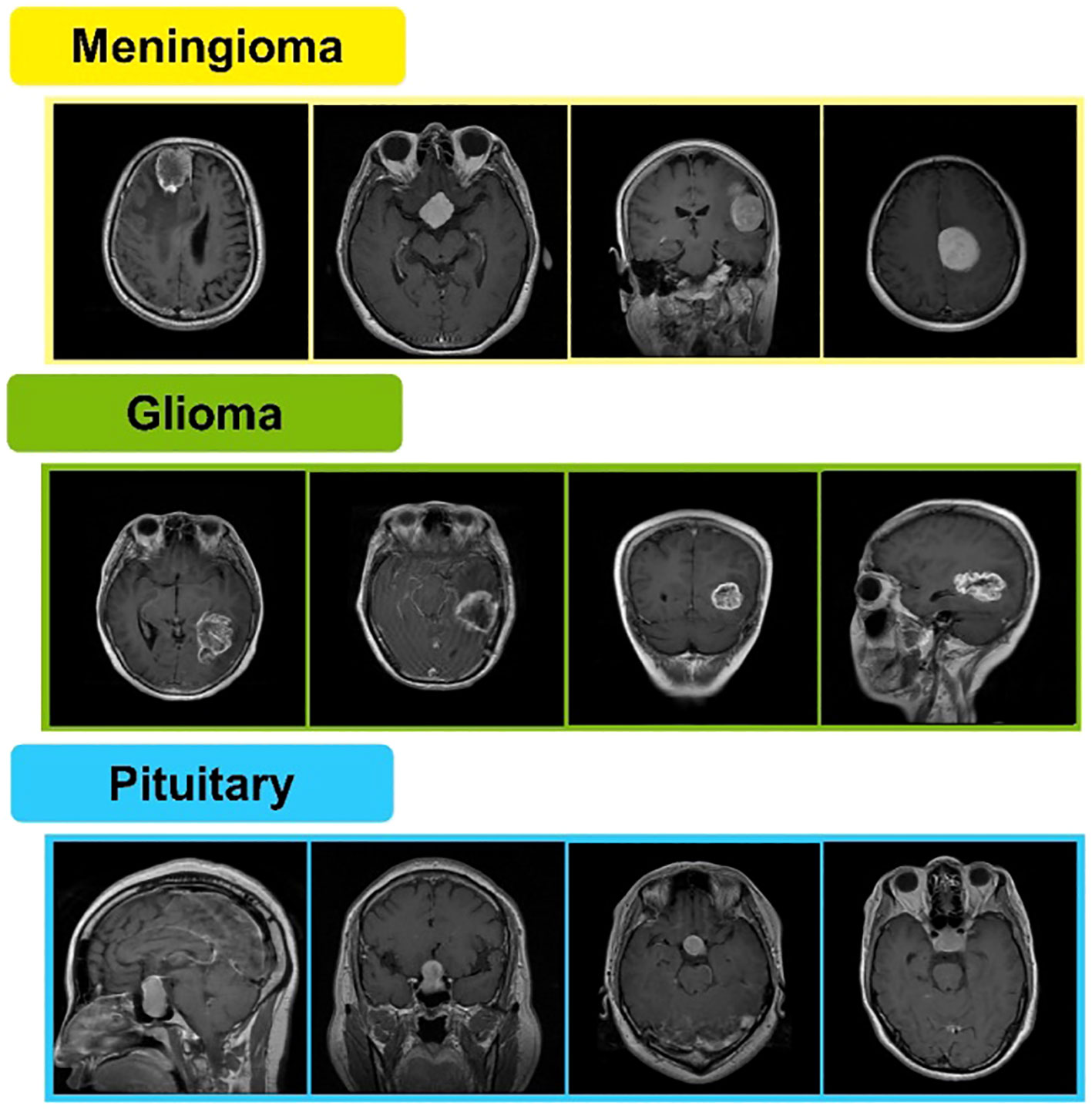
Figure 1 Sample MRI images of brain Meningioma, glioma, and pituitary tumors.
In recent years, interest in computer vision has grown across various fields of studies, from medical to industrial robotics. Computer science and advances in image processing techniques have greatly aided computer vision (13). Deep learning is a diverse set of techniques that includes neural networks, hierarchical probabilistic models, and a wide range of unsupervised and supervised feature learning algorithms. Deep learning approaches have recently gained popularity because of their ability to beat prior state-of-the-art techniques in various tasks and the amount of complex data from various sources (e.g., visual, auditory, medical, social, and sensor) (14). Deep learning has made significant advances in a wide range of computer vision tasks, including object recognition (15), motion tracking (16), and medical image classification and detection (17, 18). Classification of brain tumors for medical specialists is an important field where computer vision and deep learning techniques work together and bring prosperity to patients with non-invasive diagnosis of brain tumors using MRI.
1.1 Aims and objectives
Image acquisition from MRI has loss of information that leads to improper feature visibility. A technique is required to employ that can enhance the contrast of MRI images so that loss of information during the acquisition process can be minimized. Hence, feature visibility can be improved and classification problems can be addressed, which has a close relationship with feature visibility. In order to address classification problems for MRI images of brain tumors, there is an immense need to introduce a technique using state-of-the-art deep learning methods. In a quest to fulfill this need, a deep learning technique should acquire brain tumor MRI images from publically available benchmark datasets. The selected dataset explained in a related section of this manuscript has significant imbalance classes, so it is important to incorporate a data augmentation technique that can gracefully fill the gap of imbalanced dataset classes. After enhancement of contrast and data augmentation steps, lightweight pretrained deep leaning models need to be deployed and modified based on the low complexity for training of the balanced dataset. Optimization of hyperparameters to train deep learning models is required to select the optimal combination of values for model training on the selected dataset. Extracted features can be optimized using some optimization algorithms and then be fused together. Feature fusion greatly impacts the overall classification accuracy. The subsequent section presents the major challenges in order to develop an aimed technique and contribution to address these challenges in proposed work.
1.2 Major challenges and contributions
This imbalance in the training dataset impacts the performance of deep learning models because it causes the classifier performance to become biased in favor of the majority class. The authors tried to resolve this issue by using few traditional techniques such as flip image and rotate image, and few of the authors performed contrast enhancement. However, these techniques are not enough, and the images are highly duplicated. Therefore, it is essential to address this challenge by employing some of the latest techniques, such as GAN and encoders. Still, most currently used feature selection techniques ignore certain features that have particular significance and relevance to the classification problem in favor of extracting and choosing deep significance features. We proposed a hybrid deep learning framework with BO and QTbMPA feature selection algorithms to address these challenges. Our major contributions are listed below.
▪ Sparse Autoencoder architecture was proposed for the generation of new images based on the training data for the augmentation process.
▪ Two lightweight pretrained deep learning models were fine-tuned based on the additional layers and removal of pooling layers. The models were trained from scratch on an augmented dataset.
▪ A Bayesian optimization technique was implemented to initialize the hyperparameters of the fine-tuned deep models for improved learning.
▪ An efficient Quantum Theory-based Marine Predator Optimization algorithm was proposed for the selection of best features for the final classification.
▪ A detailed ablation study was performed on the proposed framework for the validation of the proposed framework.
2 Literature review
A wide range of classification approaches have been introduced for the Figshare dataset. Several techniques have been introduced in the literature for the classification of brain tumor from MRI images. Researchers used deep learning models for the feature extraction and later performed classification using Softmax and machine learning classifiers. A novel deep transfer learning-based model was identified by Alanazi et al. (19). It entails creating several convolutional neural network models and then utilizing transfer learning to repurpose a 22-layer model for subclass classification. The proposed model achieved 95.75% accuracy on three classes of the Figshare dataset. Moreover, the technique was also validated for an unseen dataset and achieved an accuracy of 96.89%. Another DeepTumorNet hybrid deep learning model was suggested by Raza et al. (20). The last five layers of GoogleNet were eliminated while creating the hybrid DeepTumorNet technique, and 15 new layers were added. They used the feature map’s leaky ReLU activation function to make the model more expressive. The suggested model was evaluated on the Figshare dataset and achieved 99.67% accuracy. Tummala et al. (21) used ensemble-oriented vision transformer-based pretrained models to classify the modalities of the Figshare dataset. An ensemble of B/16, B/32, L/16, and L/32 was used. The selected approach achieved an overall accuracy of 98.70%. Attention mechanism, patch-oriented input, and token embedding are techniques used in vision transformers, which make them more computationally expensive, and processing requires a tensor processing unit (TPU) environment.
Another work by Polat et al. (22) introduced a novel divergence-based feature extractor which is used for classification by decreasing weights for deep neural networks. The achieved accuracy was 99.18%. They have reduced the input image dimensions considerably , which can result in loss of spatial information. Loss of information at the input level can result in compromised accuracy. A technique that uses a multilevel attention network (MANet) (23) was suggested by Shaik et al. in which the model has an attention mechanism with several tiers of attention blocks and can concentrate on crucial spatial and category-specific properties. Prioritizing tumor details in the image is done by the first attention block, and the second attention layer is highlighted by the tumor-specific descriptors using ConvLSTM. MRI images are represented as input to the model using pretrained features from the XCeption network. The resultant accuracy of 96.51 for the Figshare dataset was obtained. In the presented technique, only those glioma images with tumor in it will be classified. A CNN-based approach was created by Haq et al. (24); they performed classification as well as segmentation. A classification accuracy of 98% was achieved. The proposed algorithm has a long running time and needs an improvement to reduce the running time. In another technique, Rahman et al. (25) implemented a Parallel Deep Convolutional Neural Network (PDCNN) technique. It operates in two concurrent stages to capture both global and local features. The model includes dropout regularization and batch normalization to alleviate the overfitting issue. The classification accuracy is 97.60%. The proportion of 80:20 training and testing data was respectively used. A major proportion of training data may lead to overfitting as it becomes specialized for known data but not for unseen or unknown data.
The authors Talukder et al. (22) presented a technique to classify brain tumors. They used different pretrained models and obtained an accuracy of 99.68% on ResNet50V2. The lack of sharp images is the main shortcoming of this study. In their work, Aloraini et al. (26) presented another technique in which the authors utilized a hybrid method combining a transformer with an attention mechanism to capture global features. Local features were extracted using a convolutional neural network (CNN). The approach attained an accuracy of 99.10% for the Figshare dataset. Few misclassifications were reported due to visual similarity between classes. In their work, authors Athisayamani et al. (27) introduced a new adaptive Canny Mayfly algorithm for edge identification. An algorithm that reduces the dimension of retrieved features, the enhanced chimpanzee optimization algorithm (EChOA), is utilized to choose features. The feature classification process is then done using the Softmax classifier and ResNet-152. The proposed technique achieved an accuracy of 98.85%. In their presented work, the authors Mishra et al. (28) provided a method for classifying brain tumors using a K-NN classifier, where the parameter is adjusted and the best feature set is selected using the binary version of the comprehensive learning elephant herding optimization (CLEHO) algorithm. The presented method obtained an accuracy of 98.97%, better than the recent techniques. A pretrained model-based approach was suggested by the authors Malla et al. (25), in which a transfer learning DCNN framework known as VGGNet was used. They employed transfer learning aspects such as fine-tuning the convolutional network and freezing layers for better performance. Features were extracted from the Global Average Pooling (GAP) layer. The technique resulted in an accuracy of 98.93% on the Figshare dataset. In the given approach, the feature dimensionality issue was not addressed, and that intended to address it in future research.
In another work, authors Cinar et al. (29) presented a Convolutional Neural Network (CNN) architecture for brain tumor classification. The model was compared with ResNet50, VGG19, DensetNet121, and InceptionV3 pretrained models. The presented model achieved an average classification accuracy of 98.32% on the prescribed dataset. The authors determined to enhance their technique using area and size-oriented metrics. In another technique, the authors Deepak et al. (30) coined an approach in which they trained CNN using three different methods: cross-entropy loss, class-weighted loss, and weighted local loss. They fused the features, and classification was performed with an accuracy of 95.40%. Another approach by authors by authors Zulfiqar et al. (31) suggested an approach in which five variations of the EfficientNets family’s pretrained models, EfficientNetB0 through EfficientNetB4, were fine-tuned. They also investigated how data augmentation affects the model’s accuracy. The best model’s attention maps are finally visualized using Grad-CAM, successfully highlighting the tumorous region of the brain cell. The achieved accuracy was 98.86%.
3 Methodology
The proposed methodology of brain tumor classification is illustrated in Figure 2. This section starts with the preprocessing phase in which the Figshare brain tumor dataset (32) is obtained. The contrast enhancement step is crucial to improving the quality of low-contrast images, and it was performed using a statistical technique presented in (33). Data augmentation is performed on contrast-enhanced images. This step is taken into account due to the high imbalance of classes in the original dataset. Augmentation of the data is performed using sparse autoencoders (34). The said technique augments the data by learning the most important features of the original data and leaving behind the least important features. Two pretrained models named InceptionResNetV2 (35) and EfficientNetB0 (36) are used and fine-tuned for the input of preprocessed data. Dynamic and optimized selection of hyperparameters of both models is carried out using Bayesian-based optimization (37). Features are extracted from each optimized resultant model. To further optimize the features, a nature-inspired algorithm named the Marine Predators Algorithm (MPA) (38) is used on the obtained features of each model. Feature fusion is carried out, final classification is performed.
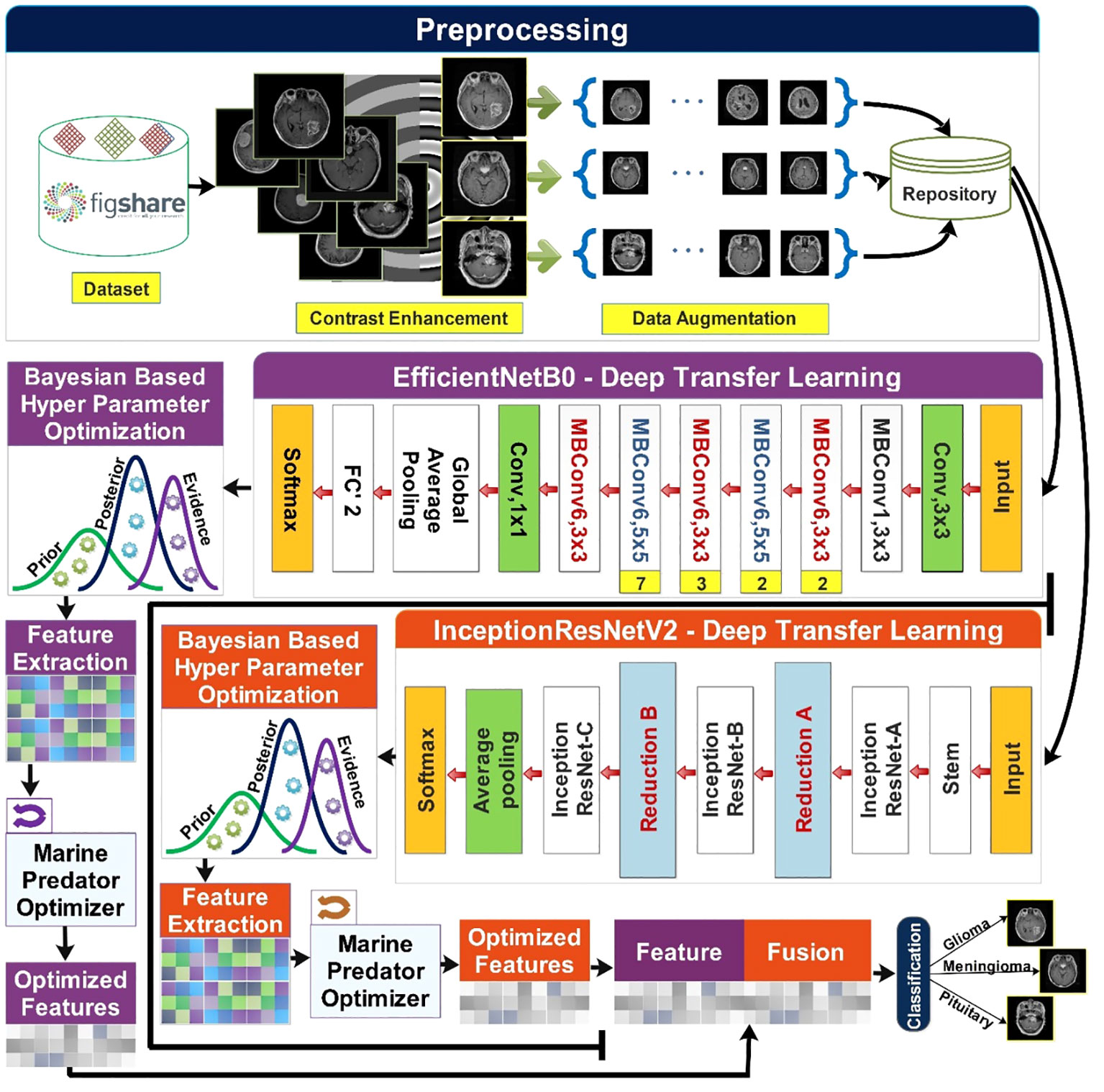
Figure 2 Proposed methodology of brain tumor classification using deep learning and optimization algorithm.
3.1 Dataset of this work
The Figshare dataset includes 3,064 T1 weighted contrast-enhanced MRI scans collected from 233 patients. There are three classes of these scans named meningioma, glioma, and pituitary, with 708, 1,426, and 930 MRI scans, respectively, in each class (32). Meningiomas are the most prevalent intracranial tumor, accounting for more than one-third of all primary central nervous system (CNS) tumors. They are typically benign tumors that can be observed or preferentially treated with extensive complete resection, which results in satisfactory outcomes. Meningioma with complex histology or in vulnerable areas has proven difficult to treat and predict prognostic outcomes (39).
Gliomas are divided into different categories based on the cells of their origin. They make up around 80% of all malignant primary brain tumors and are most frequent malignancies of the central nervous system (CNS). The most dangerous and common variety of glioma is called glioblastoma multiforme (GBM). More than 60% of adult brain tumors are caused by it. Despite the wide range of contemporary treatments available, GBM remains a fatal condition with a very bad prognosis. The median survival time for patients is typically 14 to 15 months after diagnosis of the deadly disease (40).
The anterior pituitary gland is the site of tumors called pituitary adenomas. They rank as the third most frequent adult cause of central nervous system malignancies (CNS). Most benign adenomas cause either a large-scale effect or an increase in hormone release. Depending on their size and hormone produced, pituitary adenomas appear differently in clinical evaluations (41). Samples of meningioma, glioma, and pituitary brain tumors from the Figshare dataset are presented in Figure 1.
3.2 Contrast enhancement
Analyzing medical images is challenging because of the inherent qualities present in medical images, such as poor contrast, speckle noise, signal dropouts, and complicated anatomical formation. Contrast enhancement is a vital component of subjective evaluation of image quality that aims to improve the overall excellence of medical imagery for feature visualization and clinical measurement (42). In fact, despite technological advancements in healthcare systems, they still produce images that demonstrate a deficiency in contrast due to improper locales and equipment limitations. To enhance the contrast of MRI images of the dataset discussed above, an existing technique for contrast enhancement (33) is employed. It uses basic statistics and some basic image processing methods. The approach adjusts the global and local contrast of a given image separately, then combines both results using logarithmic image processing (LIP), producing an output that is further analyzed by an adaptive linear stretching method to produce the improved version of the image. The overall process of contrast enhancement is defined as follows:
Letting a low-contrast image , at first, the local contrast is altered using contrast stretching transformation (CST). The CST process is defined in Equation 1.
In the above equation, is the output of the CST procedure where represents the dimensions of an image. The slope of the function is set by constant , and its value is set to 0.5 for this experiment. The mean value of the input image is represented by . A standard logic function is applied to the original image to change its global contrast. Mathematically, it is defined in Equation 2.
The resultant images with altered local and global contrast will be combined. The Logarithmic Image Processing (LIP) method devised in (43) is for this purpose and is mathematically defined as follows:
An exponent is used to control the enhancement, and the entire equation is raised to its power of it. The scalar parameter and its higher value lead to achieving a good level of contrast enhancement. Mathematically, it is defined in Equation 4.
Contrast enhancement of the image has been achieved after employing Equation 4, but the image does not correspond to the natural range of pixel values. A linear stretching method with adaptive form (40) brings a natural range of pixel values to the image. Mathematically, it is defined by Equation 5.
where is a resultant image, and and are the control variables for the stretching process. The value of these control variables is adjusted manually, but here, Equation 6 and Equation 7 are used to select the values of these variables automatically.
In the above equations, the variables and represent the upper and lower bounds of values for pixels of an image respectively. The pseudocode of the above mathematical description is given under Pseudo-code 1. A few visual images are also illustrated in Figure 3.
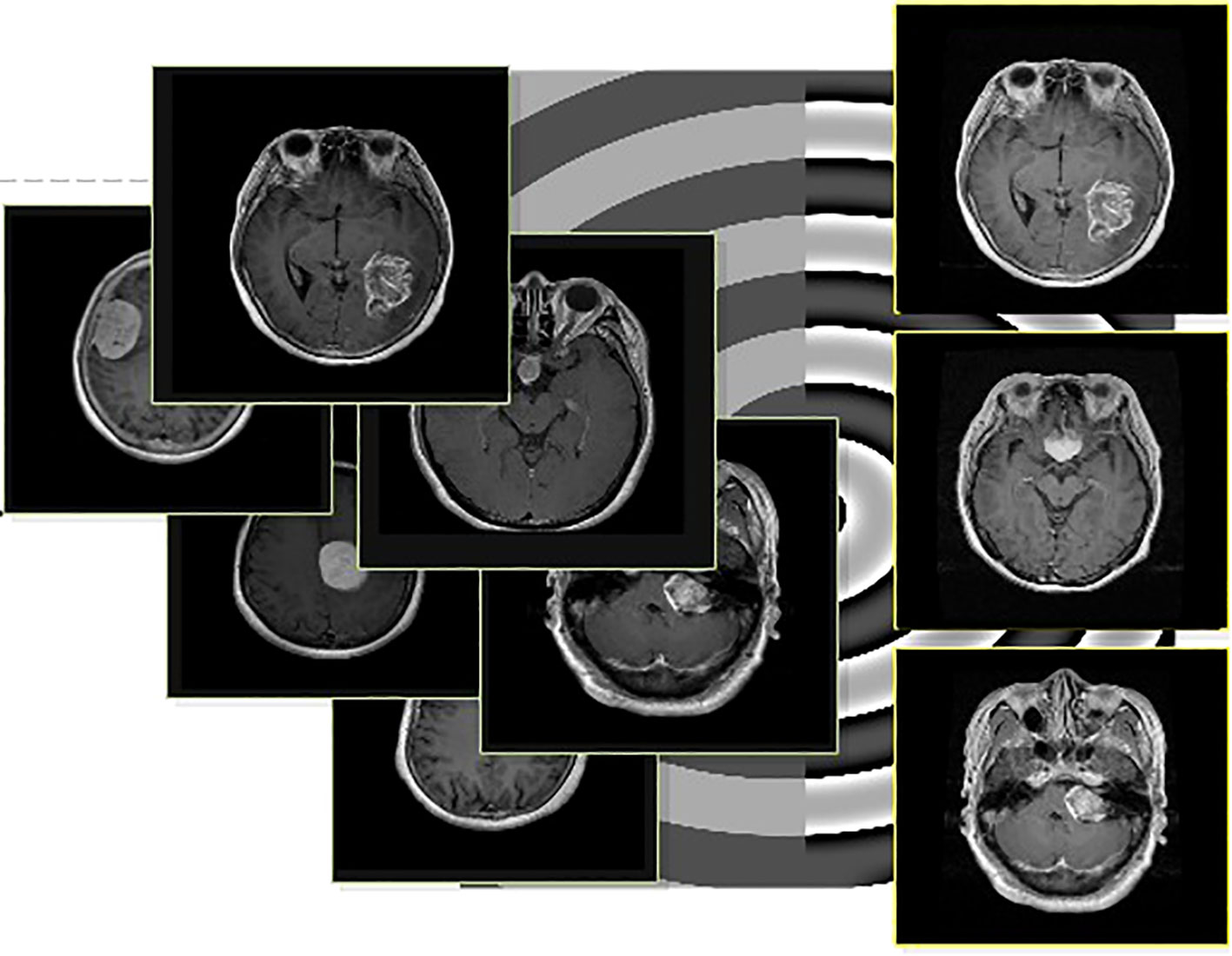
Figure 3 Visual illustration of the contrast enhancement process. The left images are original, and the right images are generated using contrast enhancement.

Pseudo Code 1. Proposed Contrast Enhancement Technique.
3.3 Data augmentation
Classification performance is negatively impacted by class imbalance. The impact of imbalance on classification performance gets more robust with increasing task size. The effect of imbalance depends on the distribution of observations (i.e., images) throughout the classes and cannot be solely attributed to a lower overall number of training cases (44). In Section 3.1, it is noted that our dataset has a high-class imbalance. Hence, creating a dataset bias may lead to an overfitting problem for some classes. To fill that gap, we employed a sparse autoencoder (45) to augment the dataset instead of traditional methods.
Sparse Autoencoders learn a compressed representation of the input data. The following hyperparameters are used to train a sparse autoencoder network:
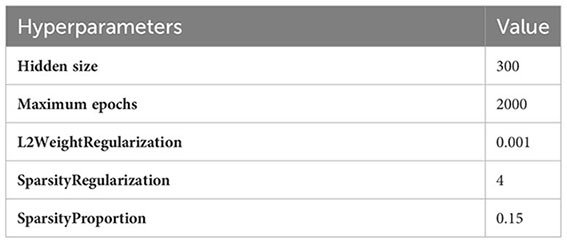
Hidden size parameter represents the number of neurons in layers. Few dozen neurons are enough for simpler tasks, but in order to use it with complex tasks, a few hundred neurons are used. A hidden size of 300 might be able to prevent overfitting while still having sufficient capacity to learn from the data, particularly in situations where bigger hidden sizes could cause overfitting.
One whole cycle through the whole training dataset is referred to as an epoch. The hyperparameter for maximum epochs indicates the maximum number of times the training dataset will be processed by the learning algorithm. In the proposed technique, the training dataset for augmentation took 2,000 epochs to converge at a suitable result for MRI images.
The intensity or weight of L2 regularization given to a neural network’s weights during training is commonly denoted by the hyperparameter L2WeightRegularization, which has a value of 0.001. The selection of 0.001 maintains a balance between letting the model learn from the data and regularizing it to avoid overfitting. It is also referred to as weight decay.
The sparsity regularization weight that is given to a neural network during training is indicated by the hyperparameter SparsityRegularization, and the chosen value for it is 4. By encouraging the model to have fewer active (non-zero) weights, the objective is to cause the weight matrices to become sparse, which means that during the training phase, a large number of the weights are driven to be zero or almost zero. Sparsity regularization helps to create a more effective and sparse representation for better feature selection.
The hyperparameter of “SparsityProportion” with a value of 0.15 commonly refers to a threshold sparsity level, which is used with sparsity regularization. The target of around 15% of the neural network’s weights becoming zero or almost zero is indicated by the value of 0.15. The sparsity regularization hyperparameter sets a threshold of 4, and weights that are below threshold are settled to zero. The value of 0.15 represents the proportion of weights that should actually fall below the specified threshold value during the training process.
The specified values for each hyperparameter are adjusted for augmentation of MRI images. The resultant images obtained from this step are used to augment the data.
The overall representation of sparse autoencoders is provided in Figure 4.
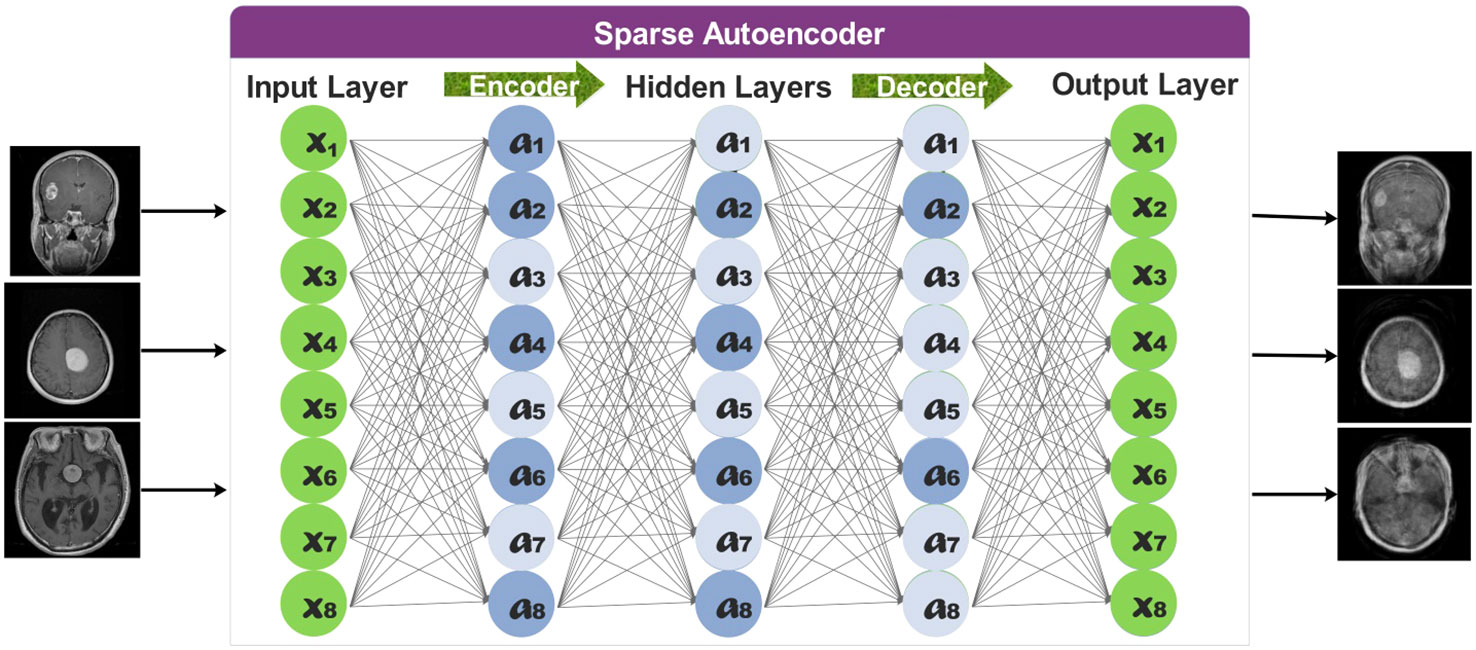
Figure 4 Representation of sparse autoencoder for data augmentation.
The total number of observations for each class increased to 2,000 after employing the proposed sparse encoder network. The newly generated images have been utilized to train selected deep learning models.
3.4 Hyperparameter selection for modified EfficientNetB0 and InceptionResNetV2
The augmented dataset is used to train fine-tuned deep-learning models. Three hyperparameters for both models are optimized using Bayesian optimization to train the models. These hyperparameters are named InitialLearnRate, Momentum, and L2Regularization. The dynamic tuning of hyperparameters is a crucial task for deep learning models. In this case, dynamically selected values for specific hyperparameters are used until a specific best-value threshold is achieved. The particular model is then trained, and features are extracted for classification tasks.
Bayesian optimization (BO) is an effective technique for hyperparameter tuning. Implementation (46) can be achieved by setting an optimization goal. The Equations 8 and 9 below describes the BO process.
In the equation, search space is for input . BO is based on the Bayes theorem that is mathematically defined as follows:
Given that an event or hypothesis has occurred, it is the likelihood that the event or hypothesis will also occur, where denotes the evidence data, denotes the model, and is the posterior probability that is proportional to the likelihood and is multiplied with a probability of . The foundation of BO is the combination of sample data (evidence) and the prior distribution of the function to produce the posterior of the function. Then, based on the criterion, the posterior information is used to determine the location where the function is maximized. The criterion is also called an acquisition function and is used to estimate the next sample point. Sampling points are searched using exploration and exploitation sampling methods while searching the sampling space. Exploration tends to search for sampling areas with high uncertainty. Exploitation searches for those samples that are of high value. These methods improve the performance, even with multiple local maxima solutions.
The prior distribution of the function , a crucial component in the statistical inference of the posterior distribution, is a requirement for Bayesian optimization in addition to sample information. The posterior distribution is updated using the Gaussian process to better align with the data, improving our forecasts’ accuracy and knowledge. Algorithm 1 describes the working of BO.

Algorithm 1. Bayesian optimization.
The algorithm consists of two parts: acquisition function maximization using step 2 and posterior distribution update using steps 3 and 4. Furthermore, the training dataset is denoted by with observations of function . Each processed observation updates the posterior distribution. The updated distribution helps to find the highest value of the acquisition function at some point, which is then added to the training dataset. This process continues until the maximum number of iterations is reached or the difference between the current and best values so far is less than a predetermined threshold. The following starting and stopping criteria are selected for experiments. Number of seed points = 4; Maximum Objective Evaluation = 30, and Maximum time = Infinite by default.
A Gaussian process prior with additional Gaussian noise in the observations serves as the fundamental probabilistic model for the objective function . Therefore, the Gaussian process with mean and covariance kernel function represent the prior distribution on Here, represents the initial value, denotes the updated value, and is a parameter containing a kernel vector vector. Therefore, looking into more detail, we show a set of points with associated objective function and the prior joint probability distribution of the function value where and initially . Moreover, Gaussian noise is added, which is denoted by so the prior distribution has covariance and therefore, the final Gaussian process regression is depicted by the following Equation 11.
where is length scale prediction and , is the signal standard deviation, , and is a Kernel function that significantly affects the quality of Gaussian process regression. In Bayesian optimization, the ARD Matern 5/2 kernel is optimized by default and is given in the following Equation 12.
where . BO employs the acquisition function to derive the highest value of the function after collecting the posterior distribution of the objective function. Typically, we believe the large value of the objective function matches the high value of the acquisition function. Therefore, the increasing the acquisition function is the same as increasing the function , as presented in Equation 13:
The acquisition function named expected improvement per second plus is employed for hyperparameter optimization. The family of acquisition functions known as “expected improvement” assesses the expected rate of improvement in the objective function while ignoring values that increase the objective. The equation for expected improvement is defined in Equation 14:
where is the location of the lowest posterior mean and is the lowest value of the posterior mean. The anticipated improvement per second used by the acquisition function during the objective function assessment is formulated in Equation 15:
where is the posterior mean of the timing Gaussian process model. Finally, the maximization process was performed and returned the best hyperparameter value. The initial learn rate (InitialLearnRate) range is 0.01–0.9, the momentum value is selected between 0.8 and 0.98, and the L2Regularization range is . To find the values of the hyperparameters, the search space needs to be transformed logarithmically. A logarithmic transformation is used to improve the search process order-of-magnitude balance. Results for optimizing the hyperparameters for EfficientNetB0 are provided in Figure 5A. While optimizing the hyperparameters, the best objective function value is achieved during iteration number 5.
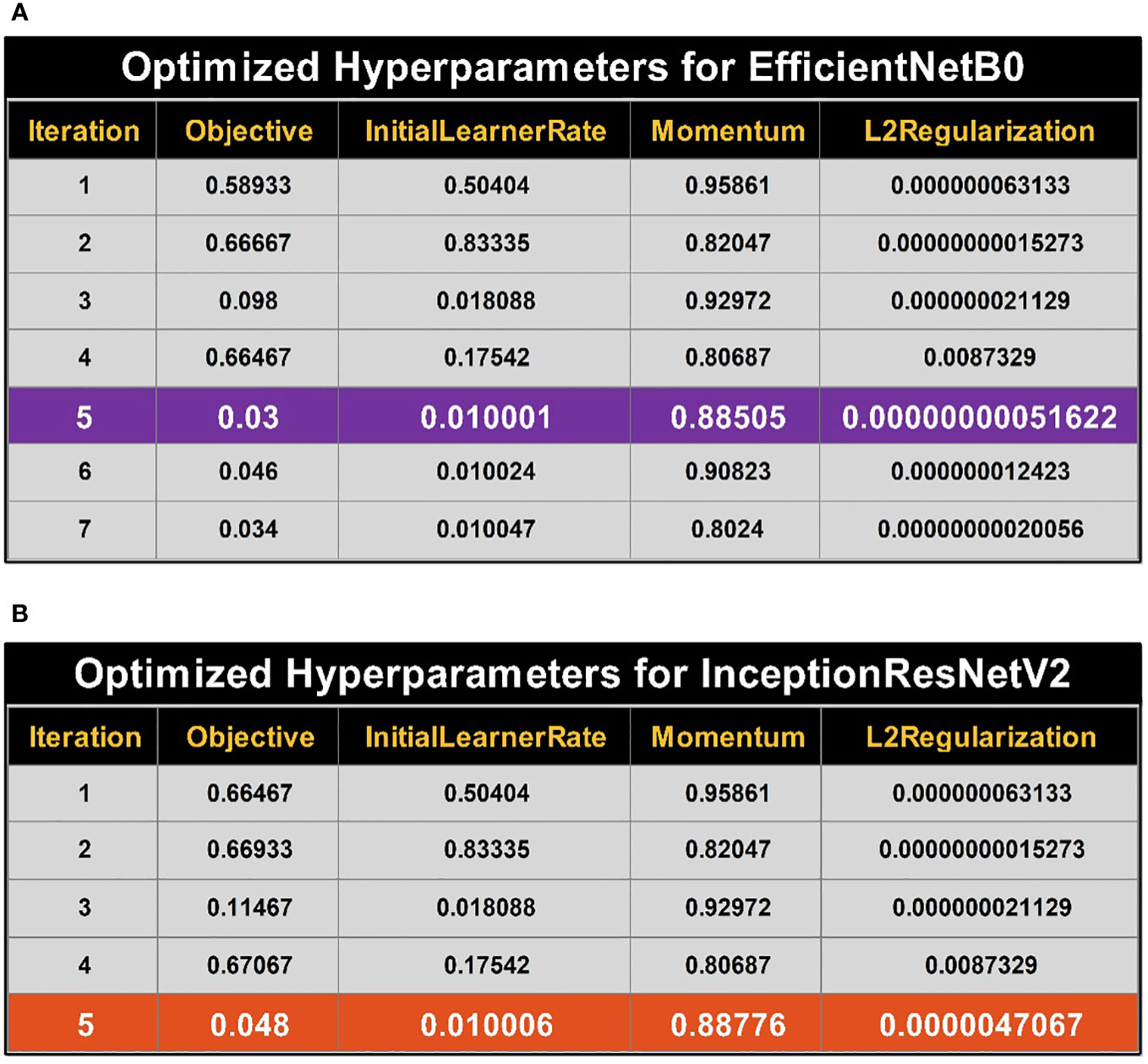
Figure 5 Summary of best selected hyperparameter values using BO. (A) Bayesian optimized (BO) hyperparameters for training of EfficientNetB0. (B) Bayesian optimized (BO) hyperparameters for training of InceptionResNetV2.
Optimizing results for hyperparameters of the InceptionResNetV2 model are provided in Figure 5B. The best object value (i.e., optimized hyperparameters) is achieved at iteration number 5, the best and last iteration per already defined termination criteria.
3.5 Training and feature extraction
Both fine-tuned models have been trained on the augmented dataset, and deep features are extracted from the global average pooling layer. The sigmoid activation function has been employed in the feature extraction process and obtained a feature vector of and from fine-tuned EfficientNetb0 and fine-tuned InceptionResNetV2, respectively. The complex patterns are captured from the deeper layers of the above models, and higher spatial dimensions are achieved. The Global Average Pooling layer reduces the higher dimensions to a fixed-size vector; however, optimizing the features’ size for accurate classification is necessary.
3.6 Improved MPA optimization
In this work, we proposed an improved Quantum Theory-based Marine Predator Algorithm to select the best features. The MPA is a metaheuristics algorithm. Random walk describes the behavior of particles or objects in various physical and biological domains. These are effective methods for studying the movement of organisms such as bacteria or animals looking for food. The random character of each step in these circumstances allows for a realistic picture of how these organisms explore and navigate their surroundings. Lévy and Brown’s movements are random walks. Different velocity ratios are extracted and used in the three phases of MPA. These are strategies behind MPA (38). MPA is based on population as many other metaheuristic algorithms. The initial solution is homogeneously disseminated over the entire search space through the first sample see, Equation 16.
Upper and lower bounds of variables are represented with and respectively, whereas uniform random vector is denoted by whose range is between and .
According to the notion of survival of the fittest, top natural predators are better foragers. As a result, the top predator, also known as elite, in the matrix is chosen as the fittest solution. The chosen matrix is constructed, and arrays of the matrix provide a detail of searching and finding the prey based on the position of the prey. The matrix is given in Equation 17:
In the above matrix, is a vector representing the top predator, and it is repeated times to create the matrix. Dimensions are represented by whereas search agents are denoted by . Predators and prey are considered search agents because predators look for its prey and the prey is looking for its food. The matrix is updated once a better predator replaces the existing top predator.
Another matrix with the same dimensions is constructed depending on the position of the prey. Predator updates the position based on the prey’s position matrix. The matrix is named and is given in Equation 18:
In matrix the represents the dimension, and represents the prey. These two matrices are the backbone for optimization.
There are three phases of MPA. These are based on the predator and prey’s life cycle and velocity criteria. These three phases are discussed separately as follows: In the first phase, the predator is considered moving faster than the prey, which is also called as the high-velocity ratio phase. The ideal predator strategy is to remain still. The mathematical model for this phase is defined in Equation 19:
This scenario occurs in the first third of iterations. represents the current iteration, whereas represents maximum iterations. is a vector containing random values from the normal distribution exhibiting Brownian movement. Entry-wise multiplications are denoted by . Movement of prey is simulated by the multiplication of . Here, is a constant, and its value is . denotes a vector of uniform random numbers between and .
The second phase occurs in unit velocity ratio or when the prey and predator move at the same speed. It means that the predator is actively looking for prey, and the prey is actively looking for its food. This optimization stage is where the transition from exploration to exploitation occurs. The prey does exploitation, whereas exploration is the predator’s primary goal. Half of the population is designated for exploitation and the other half for exploration. If the velocity ratio (), then the prey moves in Lévy and the predator follows the Brownian motion. A mathematical model for this is given below:
The first half of the population can be modeled by Equation 20:
In the above equation, represents the Lévy movement of the first half of the population. The multiplication of describes the Lévy movement of the prey, and adding the step size of the prey position determines its movement. The second half of the population can be modeled in the given below Equation 21:
where is regarded as an adaptive parameter to regulate the predator’s movement’s step size. The multiplication of determines the step size in the Brownian movement of the predator, whereas the prey modifies its position in relation with the predator’s movement. The third phase starts with a low velocity ratio or when a predator has a faster pace than the prey. It is the last phase of optimization. High exploitation capability is demonstrated in this phase. In such a low-velocity ratio of the predator adopts the Lévy strategy. The mathematical model is provided in Equation 22:
In the Lévy method, multiplying simulates the predator’s movement, whereas adding the step size to the Elite position assists in updating the position of the prey. Fish aggregating devices (FADs), considered local optima in their search space, are where sharks spend most of their time (i.e., more than 80% of the time). They make longer jumps in diverse directions during the remaining 20% of their time, probably to locate different prey distributions. To ensure a more dynamic search during the simulation, these lengthier hops help prevent them from being stuck in local optima. The FAD effect’s mathematical elaboration can be represented as the following Equation 23:
The likelihood that FADs may affect the optimization process is represented by the probability, given as . A binary vector is made up of zeros and ones. It is created by a random vector with values between [0,1], with a zero set for values below 0.2 and one for values above 0.2. Additionally, stands for a random number uniformly distributed between [0,1]. and denote lower and upper bounds of dimensions. matrix’s random indexes are denoted by subscripts and .
Novelty in this method
The problem of the MPA algorithm is finding an optimal global position; therefore, we added a concept of Quantum Theory that improves populations’ motion behavior. The initial population in the modified version is defined as follows:
where denotes the iteration value, is a random value between (0,1), is a current iteration, and and denote the upper and lower limits, respectively. The fitness value is computed to find the best solution in the next step. The following Equations 24–27 is utilized for this purpose:
The notation denotes the best position in the ith iteration for the predator, and is the best position for all predators at each iteration. The average best predator is denoted by , and is the distribution of a chaotic number on (0,1). The denotes the contraction expression phase, and it is used to control the convergence rate. Mathematically, is defined by Equation 28:
Hence, the final equation is formulated as the following Equation 29:
Every solution in the current iteration is compared with its equivalent in the prior iteration for fitness. If the current solution is found to be a superior match, the previous one is superseded. This iterative procedure improves solution quality with time and imitates the behavior of predators that return to locations with abundant prey after successful foraging attempts. After completion of optimization, a feature vector of dimension and a feature vector of , respectively, are obtained.
3.7 Feature fusion and classification
The selected features are finally fused and later classified using machine learning classifiers. The fusion process improves an object’s information that directly relates to better accuracy. In this work, a simple serial-based fusion has been chosen to combine the selected feature vectors in a single vector.
Using the following equation, we can determine the dimension of the serial-based fusion vector if we have two feature vectors, and , with dimensions of and , respectively, where denotes the total number of observations as defined by Equation 30.
The resultant feature vector is obtained of dimension . The fused feature vector is finally classified using traditional machine learning classifiers named as Cubic SVM and Weighted KNN and neural network-based classifiers such as narrow, wide, tri-layered, bi-layered, and medium. The hyperparameters used to train these classifiers are provided in Table 1 as follows:
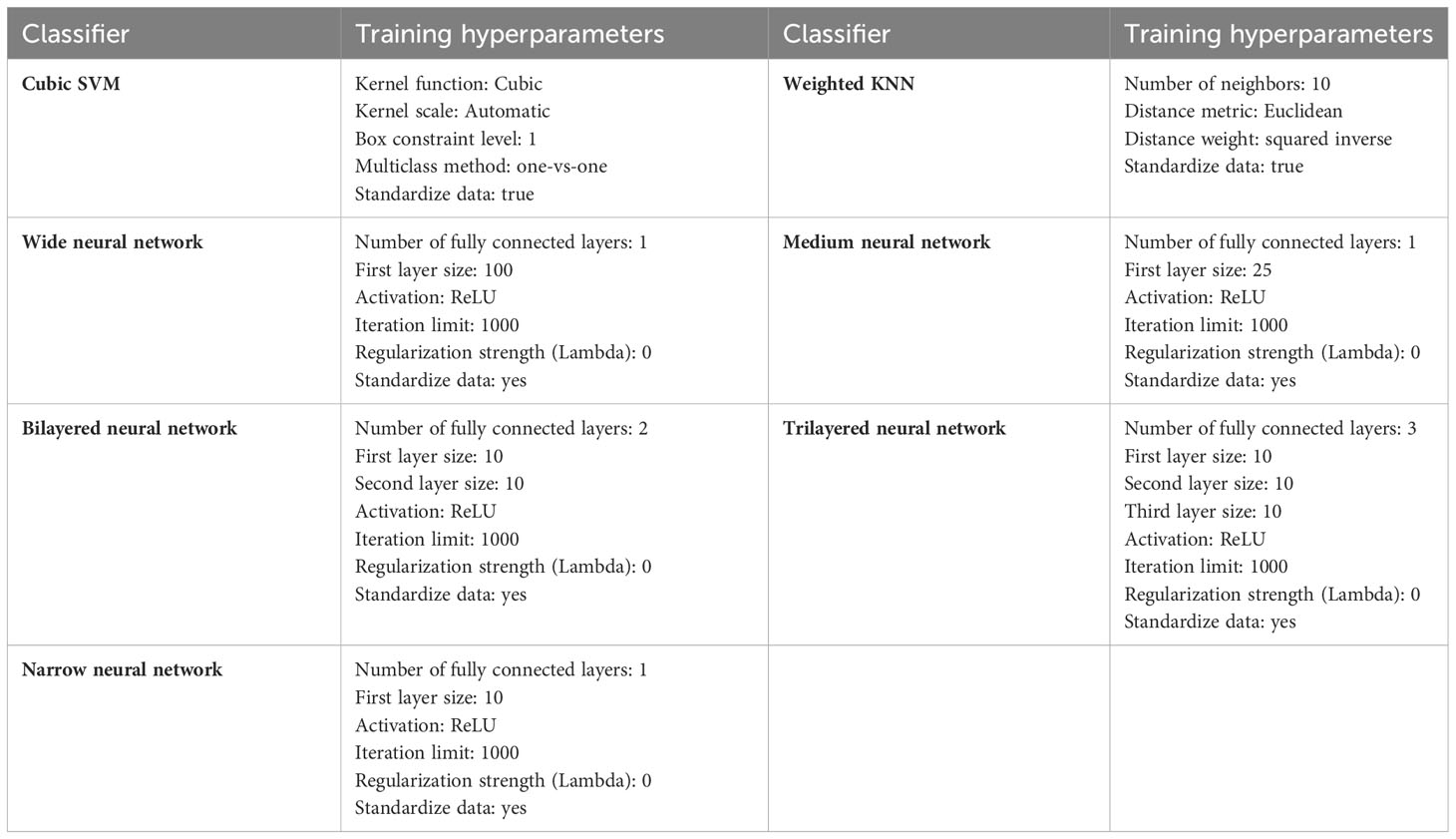
Table 1 Classifiers and training hyperparameters of each classifier.
3.8 Dataset and performance evaluation
The augmented Figshare dataset is used for our experiments and is contributed by (11). The dataset is publicly available for research purposes. A model or algorithm’s ability to predict outcomes based on the available data is measured using performance metrics in machine learning. The calculated measures contain each classifier’s sensitivity rate, false negative rate (FNR), precision rate, and area under the curve (AUC). Time and accuracy measures are also used to interpret the performance of each classifier. Table 2 provides more details on these performance metrics.

Table 2 Performance measures used to validate the proposed methodology.
TP is for true positive, TN is for true negative, FP is for false positive, and FN is for false negative.
The reason to choose each measure provided in Table 1 is given below:
• Accuracy is the ratio of accurately predicted occurrences to total instances. This gives a general idea of how well a model is predicting in every class. Accuracy by itself, though, could not be enough if the classes are unbalanced. In our proposed technique, classes are balanced. Balance among classes is achieved by data augmentation process.
• Time required to finish a specific task is given in seconds.
• Sensitivity quantifies the percentage of actual positive instances that the model accurately predicted. In order to reduce false negatives, it is very crucial. For example, in the medical domain, high sensitivity indicates that the model is effective in identifying positive cases.
• False negative rate refers to the percentage of true positive cases that were mistakenly forecast as negative. It stands for the probability of overlooking favorable examples. When the cost of missing positive occurrences is large, it is essential to reduce false negative rate.
• Precision gauges how well the model predicts positive occurrences. If you wish to reduce false positives, accuracy is crucial. For instance, high precision in medical diagnosis indicates that the model is likely to be accurate when it predicts a positive case.
• The area under the receiver operating characteristic (ROC) curve is known as the area under the curve (AUC). The trade-off between true positive rate (sensitivity) and false positive rate is represented graphically by the ROC curve. AUC offers a single scalar value that sums up the model’s overall performance. Perfect categorization is indicated by an AUC of 1.0; random chance is suggested by an AUC of 0.5.
4 Results and discussion
4.1 Experimental setup
In this section, detailed experimental setup is discussed. The data augmentation is performed using a sparse auto-encoder. A single hidden layer with 300 neurons is selected while the training parameters like a maximum epochs are 2,000, L2WeightRegularization is set equal to 0.001, SparsityRegularization is equal to 4, and finally, SparsityProportion is set to 0.15. Hyperparameter optimization is performed to optimize the parameters of fine-tuned deep models such as EfficientNetB0 and InceptionResNetV2. The original dataset is split into a ratio of 50:50 in training and test proportions. After that, the training and testing images are separately augmented and trained models. The gradient vectors are accelerated via stochastic gradient descent (SGDM) for quicker convergence at the convolutional layers. During the algorithm learning phase for both models, a mini-batch size 128 is chosen. Additionally, the experiments are carried out using MATLAB R2023a on a machine equipped with 128 GB of RAM and CPU Intel(R) Core(TM) i7-6700 @ 3.40 GHz and 12 GB RTX3000.
4.2 Proposed framework results (fine-tuned models)
In this section, results of the first step of the proposed framework are presented. The hyperparameter optimization using the Bayesian method is performed separately for EfficientNetB0 and InceptionResNetV2 models and numerical results are computed.
4.2.1 Fine-tuned Bayesian optimization-based EfficientNetB0
Table 3 describes the classification performance of fine-tuned EfficientNetB0 deep architecture with an accuracy value of 99.10%, achieved by the Cubic SVM classifier. The wide neural network obtained the second best accuracy of 98.90%. The rest of the classifiers obtained accuracies of 98.80%, 98.70%, 98.60%, and 98.50%. The sensitivity and precision rates of each classifier are also noted, and the maximum value of Cubic SVM is 99.10%. In addition, the performance of Cubic SVM can be confirmed by a confusion matrix, given in Figure 6A. The diagonal numbers in the figure represent the number of true observations and the true positive rate for glioma, meningioma, and pituitary classes. The computational time of each classifier is also noted during the classification process, and it is observed that the minimum noted time is 12.512 (seconds) for Medium Neural Network.
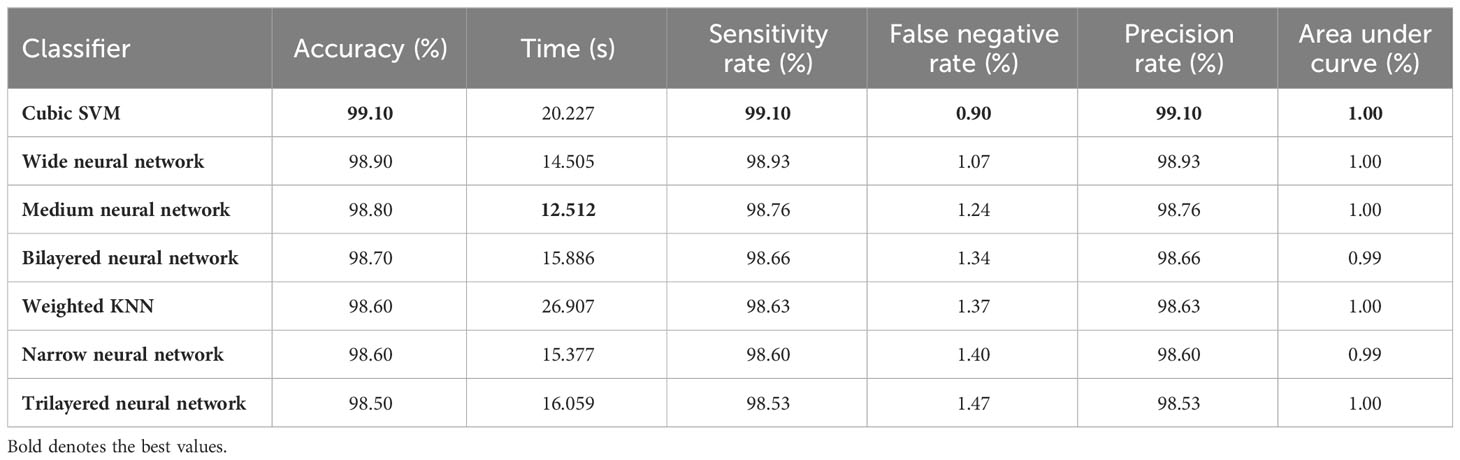
Table 3 Classification results using the BO-based EfficientNetB0 model.
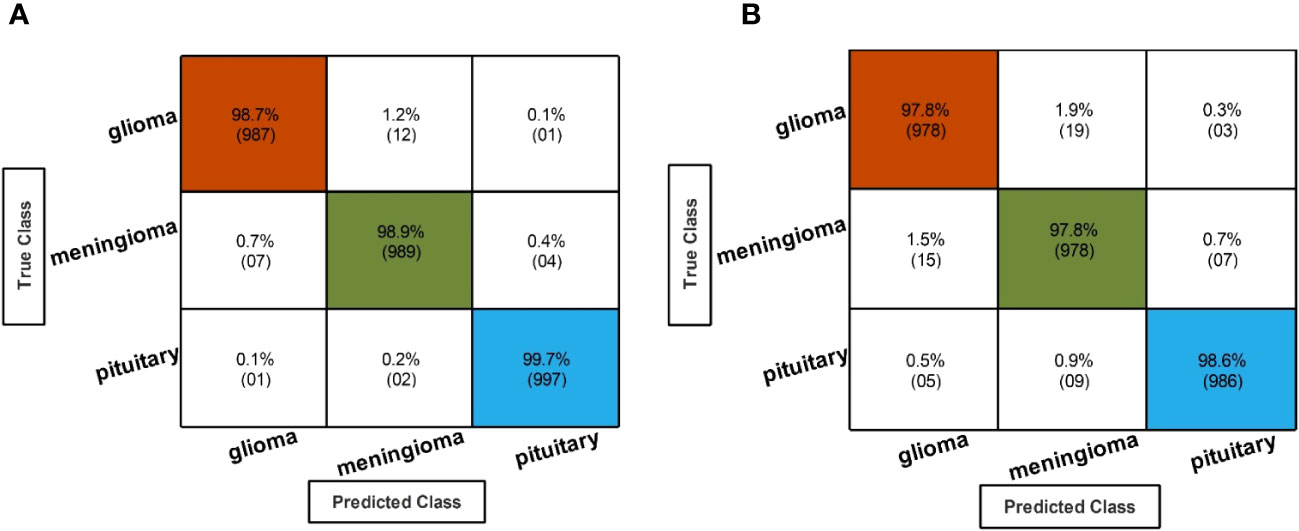
Figure 6 Confusion matrix of EffficientNetB0 and InceptionResNetV2 hyperparameter optimization using BO. (A) Confusion matrix of fine-tuned EffficientNetB0 hyperparameter optimization using BO. (B) Confusion matrix of fine-tuned InceptionResNetV2 hyperparameter optimization using BO.
4.2.2 Fine-tuned Bayesian optimization-based InceptionResNetV2
In the second step, the classification results are computed using fine-tuned InceptionResNetV2 with the initialization of BO-based hyperparameters. The results of this step are given in Table 4, which shows the maximum accuracy of 98.10 for the Cubic SVM classifier. The minimum computational time of this step is 20.543 (second) for the Narrow Neural Network classifier. In addition, the performance of the Cubic SVM classifier can be confirmed by a confusion matrix, illustrated in Figure 6B. Compared with the performance of this step with step 1, it is observed that the accuracy of this step is degraded by approximately 1%. Moreover, the increase in time shows the drawbacks of this step. In order to reduce the drawbacks of this step, a feature selection method is employed, which selects only important features for classification.
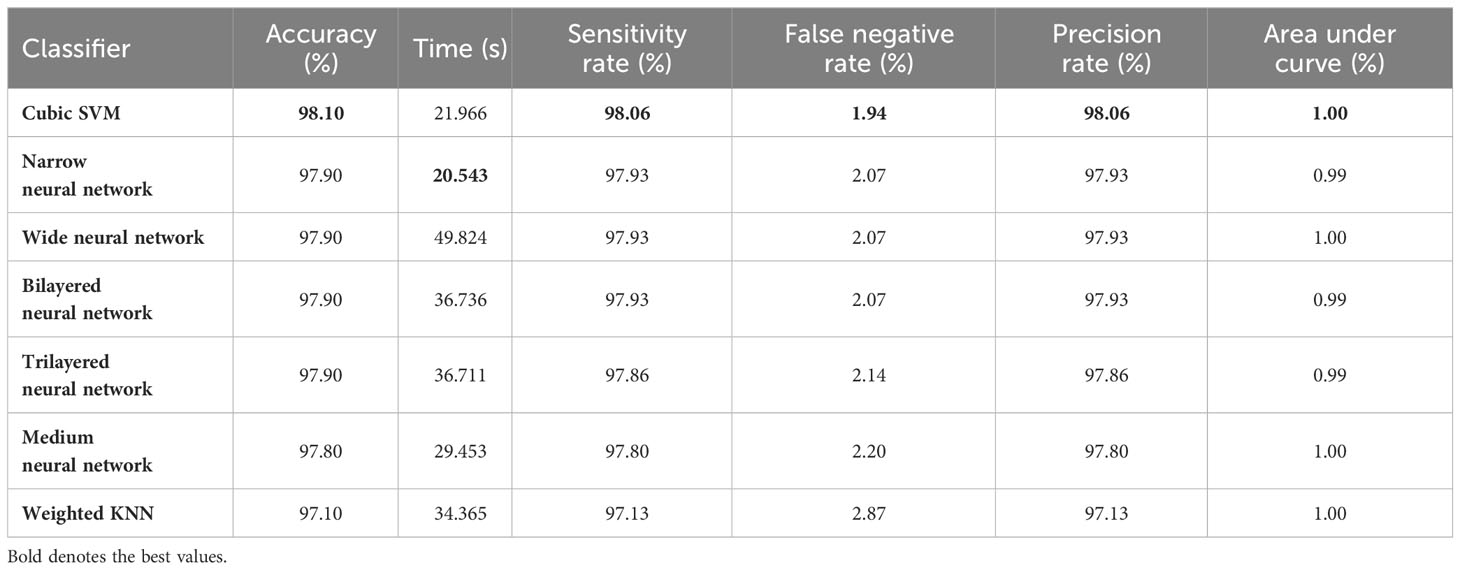
Table 4 Classification results of using BO-based InceptionResNetV2.
4.3 Feature selection using proposed QTbMPA feature selection
The third and fourth steps correspond to the best feature selection.
4.3.1 QTbMPA feature selection on fine-tuned EfficientNetB0
In the third step, the proposed feature selection method is applied to deep extracted features; in return, the best optimal features are obtained. The results of the feature selection method on fine-tuned EfficientNetB0 are presented in Table 5. In this table, the maximum accuracy of 99.00% by the Cubic SVM classifier is shown. The sensitivity and precision rate of this classifier are also 99% that the confusion matrix in Figure 7A can confirm. Wide neural network obtained the second best accuracy of 98.80%. Each classifier’s computational time is noted, and its minimum reported time is 3.8078 (sec). In step 1, the minimum time was 12.52 (s), which is now reduced by almost 300%. Moreover, the accuracy of this step is consistent, which can be a strength of the proposed feature selection method.
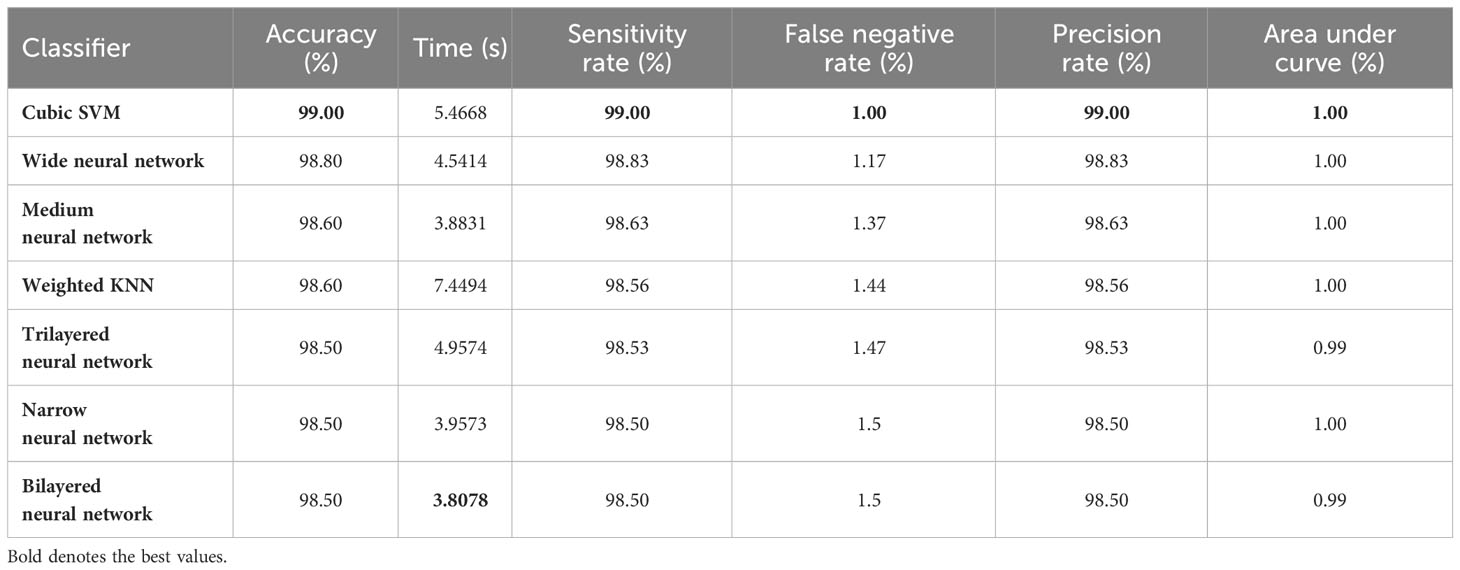
Table 5 Proposed classification results after employing the QTbMPA selection method on features returned from the Bayesian-based EfficientNetB0 model.
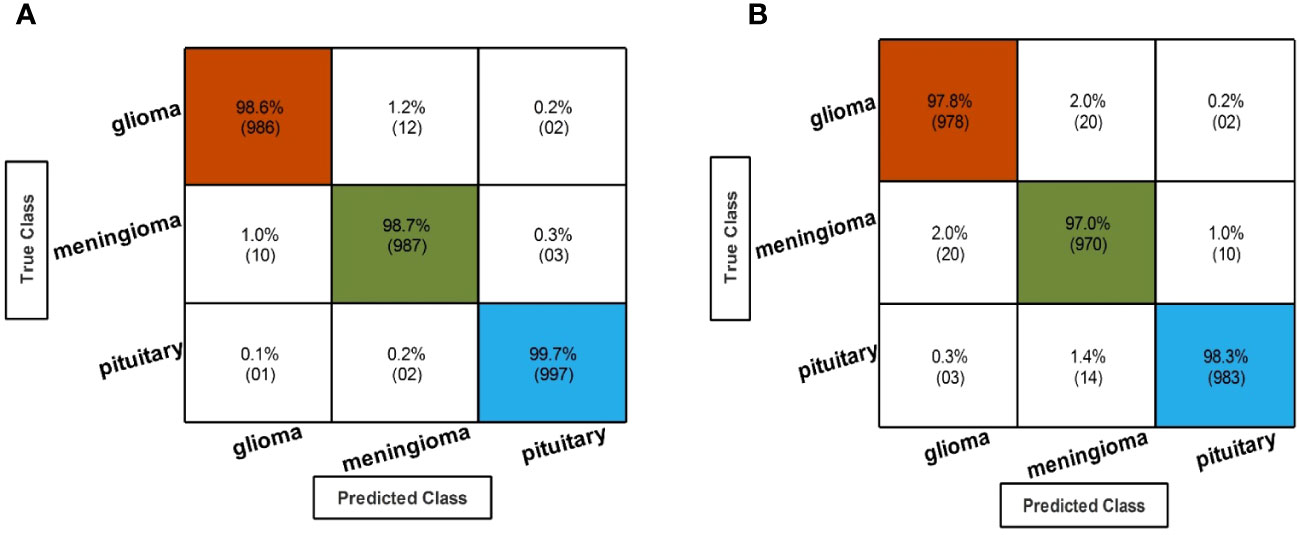
Figure 7 Confusion matrix of the QTbMPA selection technique for EffficientNetB0 and InceptionResNetV2. (A) Confusion matrix of QTbMPA based best selected EfficentNetB0 deep features. (B) Confusion matrix of QTbMPA based best selected InceptionResNetV2 deep features.
4.3.2 QTbMPA feature selection on fine-tuned InceptionResNetV2
In the fourth step, features of the fine-tuned InceptionResNetV2 model are selected using the proposed QTbMPA method and classification is performed. Table 6 describes the results of this step, showing an maximum accuracy of 97.70% by Cubic SVM. The sensitivity and precision rate of this classifier is also 97.70%. The confusion matrix in Figure 7B can further confirm these values. The computational time of each classifier is also given in this table, and the minimum reported time is 6.1486 (s) for Cubic SVM. Compared with the computational time of this step with the second step, the time is reduced almost 300%.
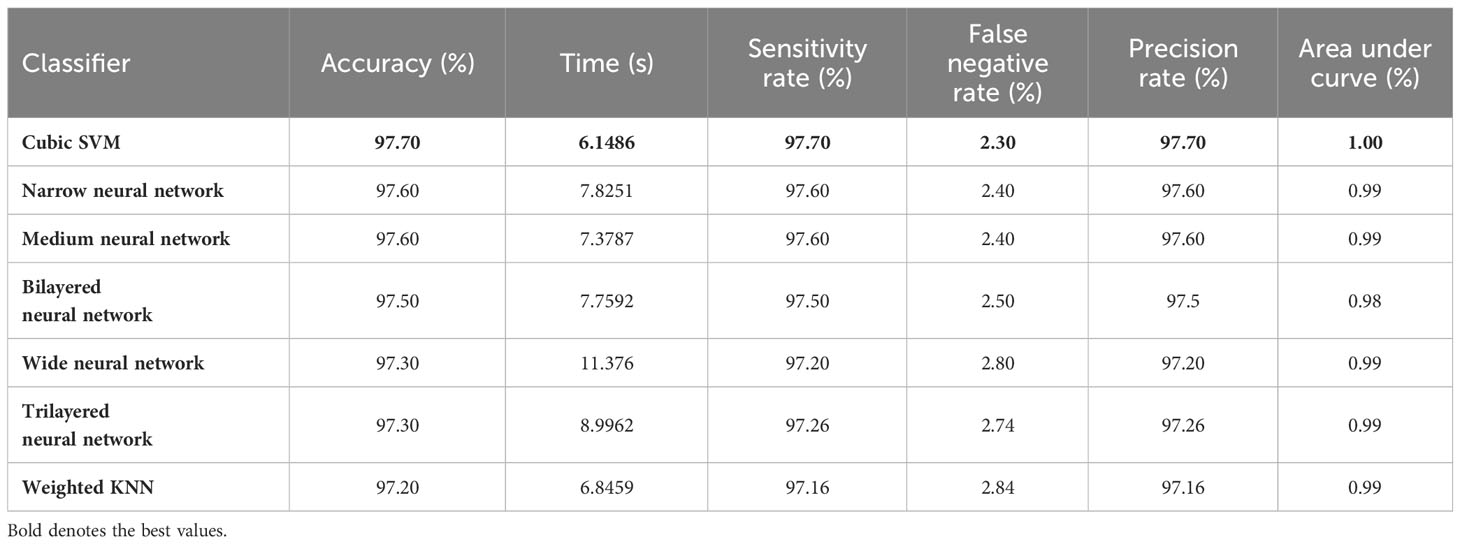
Table 6 Proposed classification results after employing the QTbMPA selection method on features returned from the Bayesian-based InceptionResNetV2 model.
4.3.3 Fusion of best selected features
Finally, the best-selected features of both models, in the third and fourth steps, are fused using a serial approach. The cubic SVM classifier obtained the maximum accuracy of 99.80% and the sensitivity and precision rates of 99.83% (can be seen in Table 7). The confusion matrix in Figure 8 can further confirm these values. A minor increase in computational time is observed after the fusion process; however, the accuracy is significantly improved for all classifiers. In comparison, with all previous steps, noted accuracy has significantly improved and is the highest among all early noted accuracies. Moreover, Table 8 shows a detailed comparison of the proposed method with state-of-the-art techniques and shows significant improvement.
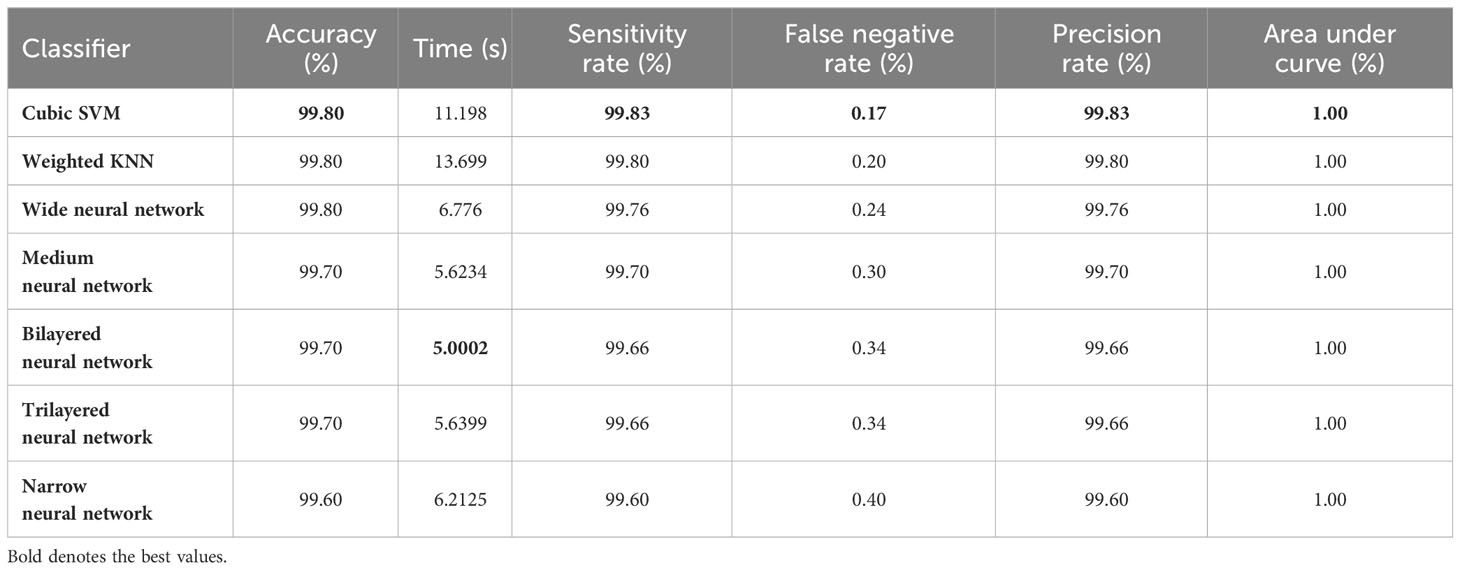
Table 7 Classification results after fusing of the best selected features of both models.
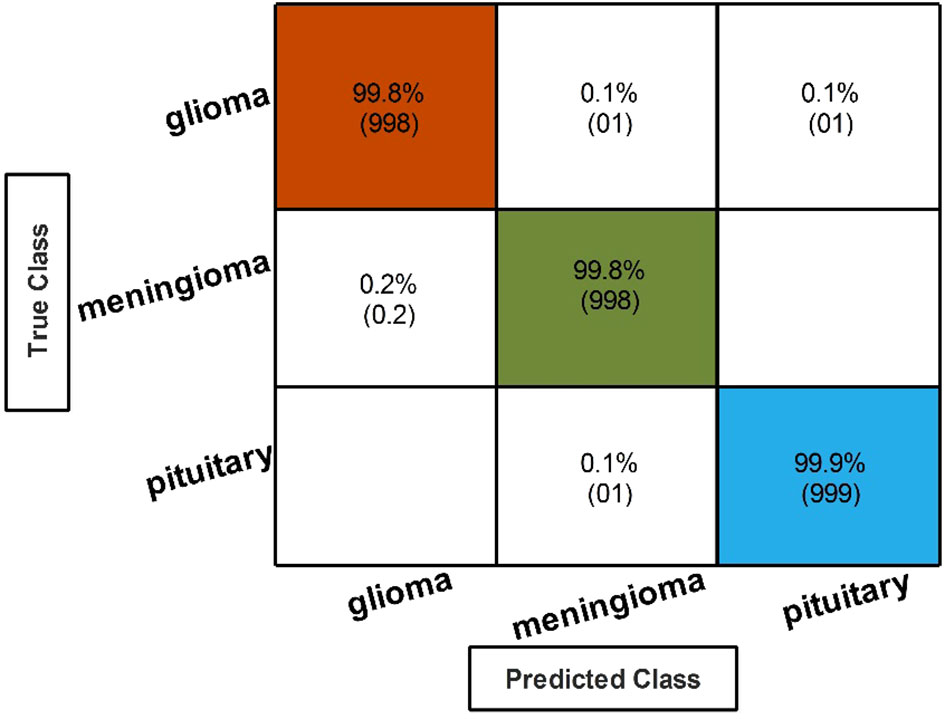
Figure 8 Classification results after the fusion of selected feature features.

Table 8 Summary of recent state-of-the-art (SOTA) techniques for brain tumor classification using Figshare dataset.
4.4 Discussion
A t-test is a statistical technique used to compare the mean values of two groups. It is frequently used in hypothesis testing to see whether a particular process or treatment has a noticeable effect on the target population or whether there is a significant difference between the two groups. In order to test the significant difference between the classifiers, t-test is applied.
In the proposed technique, t-test is conducted to check any considerable gap between accuracies at different stages of our proposed model. The gap is resulted when we have unbalanced classes of dataset (54). The augmented step balanced the classes of dataset; however, to validate our augmentation step, t-test is applied on all phases of the proposed technique. The test starts by setting a null hypothesis as below:
Additionally, two best-performing classifiers at all phases of the proposed technique are chosen. The accuracy achieved by respective classifier at each phase is selected to conduct experiments.
A detailed overview of test is given below:

The mean of the differences for all experiments are calculated using the following Equations 31–34:
where is the number of experiments and the noted mean value after this step is . After calculating the , the is calculated by using the following equation:
The resultant standard deviation value is later used in the formula.
The value was obtained after calculation using the above formula. The obtained value will be considered as a decisive point to conduct the . Moreover, the is calculated using the formula: ; the resultant value is four and selected (55). After looking at the corresponding output value in the t-test chart, the value is . The decisive value is ; based on the given below formulation in equation 35, it is established that is rejected, and there is no noteworthy difference between the atp10ccuracy of the selected classifiers.
Hypothesis test establishes that throughout the phases of the proposed technique, there is a consistency in accuracy of each phase; it means that the class imbalance problem is accurately addressed. Inconsistent accuracies are the result of imbalance classes of dataset, which lead to loss of accuracies. The proposed data augmentation step helps to properly address class imbalance problem.
Heat map-based analysis: Heat map-based techniques are employed to express the decisive features of classification for each class. Grad-CAM, LIME, and Occlusion Sensitivity are three methods commonly used to represent decision features for classification of an image. Grad-CAM uses gradients to determine the classification score about the final convolutional feature map. It draws attention to that part of input image that has the biggest influence on this score. The method uses a global average pooling layer to extract features. Equation 36 serves as the basis for this procedure, which is illustrated below:
where represents class scores of features from the Global Average Pooling layer, represents total pixels in a feature map, depicts the class score, and is the considered output. The whole expression represents the convolution map. In the expression, and represent two dimensions and represents gradients. Features with negative weight can be possible using the above equation; therefore, the Relu activation function is used to convert the negative weights to positive and is represented using the given below Equation 37:
Mathematical details of LIME and Occlusion Sensitivity can be seen from (56) and (57), respectively. Figure 9 represents the visualization of important features of each class using the explained methods of the heat map.
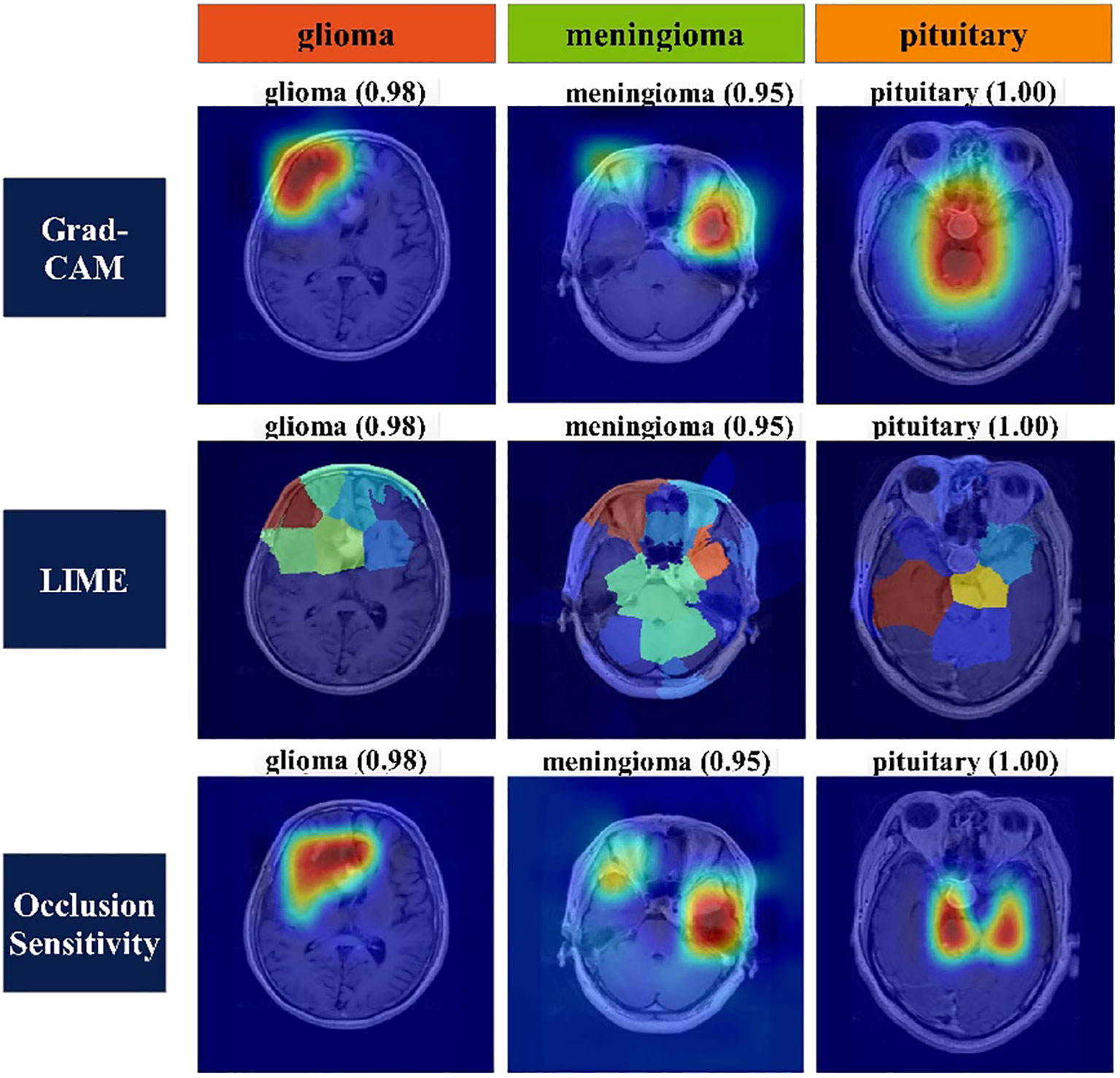
Figure 9 Heat map of classes using Grad-CAM, LIME, and occlusion sensitivity.
5 Conclusion
This article presents a novel deep learning framework with an efficient QTbMPA feature selection technique for the classification of brain tumor types such as meningioma, glioma, and pituitary from MRI images. Instead of manual data augmentation, a sparse autoencoder architecture was proposed and generated new images based on the training set. Two lightweight deep learning architectures were modified and trained with the help of BO hyperparameter initialization. The deeper layer (global average pool) was employed for feature extraction and performed classification. The classification process shows that there exist few irrelevant features, which are impacted on the classification computational time. Therefore, we proposed an efficient QTbMPA feature selection algorithm that almost 300% reduced the computational time and maintained the classification accuracy. The selected features were finally fused and classified using ML and neural network classifiers. On the augmented dataset, the proposed framework obtained an improved accuracy of 99.80% than the SOTA technique.
The goal of the proposed research is to create a deep learning (DL) model for brain tumor classification, utilizing DL’s capabilities to classify various forms of brain tumors more accurately. This finding could have a significant clinical impact in neuro-oncology and have a wide variety of potential applications. The proposed research can assist doctors and radiologists in making accurate diagnoses when using medical imaging data, such as MRI scans, to identify brain tumors. It offers dependable and consistent tumor categorization results, lowering the misdiagnosis risk and enabling early brain tumor discovery. Furthermore, the accurate classification of brain tumors might help in developing customized treatment plans for patients. The model assists physicians in developing customized treatment regimens that lead to more accurate and successful treatment outcomes by aiding in the identification of the exact type of tumor.
5.1 Limitations and future work
Although we obtained the maximum accuracy, there are few limitations that make the proposed architecture more consistent. The limitations of this work are selection of pretrained models and best feature selection. The pretrained models have been selected based on the Top-5 accuracy on ImageNet dataset and total number of parameters. In addition, the selection process reduces the overfitting, but still there are few irrelevant features selected for the classification. The proposed architecture has been evaluated on brain tumor MRIs of the Figshare dataset; however, in future, it will be tested on BRATS datasets. Moreover, a new self-attention and vision transformer model will be proposed for the improved accuracy and efficiency.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: https://www.kaggle.com/datasets/masoudnickparvar/brain-tumor-mri-dataset.
Author contributions
MU: Data curation, Methodology, Conceptualization, Investigation, Project administration, Software, Writing – original draft. MK: Conceptualization, Investigation, Methodology, Software, Supervision, Writing – original draft. AM: Conceptualization, Formal analysis, Methodology, Software, Writing – original draft. OM: Data curation, Formal analysis, Project administration, Visualization, Writing – review & editing. OS: Conceptualization, Data curation, Formal analysis, Funding acquisition, Project administration, Visualization, Writing – review & editing. NA: Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This research was funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R333), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. This study is supported via funding from Prince Sattam bin Abdulaziz University project number (PSAU/2023/R/1445).
Acknowledgments
This research was funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R333), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. This study is supported via funding from Prince Sattam bin Abdulaziz University project number (PSAU/2023/R/1445).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Ohgaki H. Epidemiology of brain tumors. In: Verma M, editor. Cancer Epidemiology: Modifiable Factors. Totowa, NJ: Humana Press (2009). p. 323–42.
2. Kibriya H, Amin R, Alshehri AH, Masood M, Alshamrani SS, Alshehri A. A novel and effective brain tumor classification model using deep feature fusion and famous machine learning classifiers. Comput Intell Neurosci (2022) 2022. doi: 10.1155/2022/7897669
3. Bush NAO, Chang SM, Berger MS. Current and future strategies for treatment of glioma. Neurosurgical Rev (2017) 40(1):1–14. doi: 10.1007/s10143-016-0709-8
4. Apra C, Peyre M, Kalamarides M. Current treatment options for meningioma. Expert Rev Neurother (2018) 18(3):241–9. doi: 10.1080/14737175.2018.1429920
5. Daly AF, Beckers A. The epidemiology of pituitary adenomas. Endocrinol Metab Clinics (2020) 49(3):347–55. doi: 10.1016/j.ecl.2020.04.002
6. Baba AI, Câtoi C. Comparative oncology. Netherland: Publishing House of the Romanian Academy Bucharest (2007).
7. Carrano A, Juarez JJ, Incontri D, Ibarra A, Cazares HG. Sex-specific differences in glioblastoma. Cells (2021) 10(7):1783. doi: 10.3390/cells10071783
8. Yildirim M, Cengil E, Eroglu Y, Cinar A. Detection and classification of glioma, meningioma, pituitary tumor, and normal in brain magnetic resonance imaging using deep learning-based hybrid model. Iran J Comput Sci (2023) 6(4):455–64. doi: 10.1007/s42044-023-00139-8
9. Naseer A, Yasir T, Azhar A, Shakeel T, Zafar K. Computer-aided brain tumor diagnosis: performance evaluation of deep learner CNN using augmented brain MRI. Int J BioMed Imaging (2021) 2021:5513500. doi: 10.1155/2021/5513500
10. Gull S, Akbar S. Artificial intelligence in brain tumor detection through MRI scans: advancements and challenges. Artif Intell Internet Things (2021) 10:241–76.
11. Cheng J, Huang W, Cao S, Yang R, Yang W, Yun Z, et al. Enhanced performance of brain tumor classification via tumor region augmentation and partition. PloS One (2015) 10(10):e0140381. doi: 10.1371/journal.pone.0140381
12. Cheng J, Yang W, Huang M, Huang W, Jiang J, Zhou Y, et al. Retrieval of brain tumors by adaptive spatial pooling and fisher vector representation. PloS One (2016) 11(6):e0157112. doi: 10.1371/journal.pone.0157112
13. Xu S, Wang J, Shou W, Ngo T, Sadick A-M, Wang X. Computer vision techniques in construction: A critical review. Arch Comput Methods Eng (2021) 28(5):3383–97. doi: 10.1007/s11831-020-09504-3
14. Voulodimos A, Doulamis N, Doulamis A, Protopapadakis E. Deep learning for computer vision: A brief review. Comput Intell Neurosci (2018) 2018. doi: 10.1155/2018/7068349
15. Balamurugan D, Aravinth S, Reddy PCS, Rupani A, Manikandan A. Multiview objects recognition using deep learning-based wrap-CNN with voting scheme. Neural Process Lett (2022) 54(3):1495–521. doi: 10.1007/s11063-021-10679-4
16. Bjerge K, Mann HM, Høye TT. Real-time insect tracking and monitoring with computer vision and deep learning. Remote Sens Ecol Conserv (2022) 8(3):315–27. doi: 10.1002/rse2.245
17. Kim HE, Cosa-Linan A, Santhanam N, Jannesari M, Maros ME, Ganslandt T. Transfer learning for medical image classification: a literature review. BMC Med Imaging (2022) 22(1):69. doi: 10.1186/s12880-022-00793-7
18. Zhang J, Rao VM, Tian Y, Yang Y, Acosta N, Wan Z, et al. Detecting schizophrenia with 3d structural brain mri using deep learning. Sci Rep (2023) 13(1):14433. doi: 10.1038/s41598-023-41359-z
19. Alanazi MF, Ali MU, Hussain SJ, Zafar A, Mohatram M, Irfan M, et al. Brain tumor/mass classification framework using magnetic-resonance-imaging-based isolated and developed transfer deep-learning model. Sensors (2022) 22(1):372. doi: 10.3390/s22010372
20. Raza A, Ayub H, Khan JA, Ahmad I, Salama AS, Daradkeh YI, et al. A hybrid deep learning-based approach for brain tumor classification. Electronics (2022) 11(7):1146. doi: 10.3390/electronics11071146
21. Tummala S, Kadry S, Bukhari SAC, Rauf HT. Classification of brain tumor from magnetic resonance imaging using vision transformers ensembling. Curr Oncol (2022) 29(10):7498–511. doi: 10.3390/curroncol29100590
22. Polat Ö, Dokur Z, Ölmez T. Brain tumor classification by using a novel convolutional neural network structure. Int J Imaging Syst Technol (2022) 32(5):1646–60. doi: 10.1002/ima.22763
23. Shaik NS, Cherukuri TK. Multi-level attention network: application to brain tumor classification. Signal Image Video Process (2022) 16(3):817–24. doi: 10.1007/s11760-021-02022-0
24. Haq EU, Jianjun H, Huarong X, Li K, Weng L. A hybrid approach based on deep cnn and machine learning classifiers for the tumor segmentation and classification in brain MRI. Comput Math Methods Med (2022) 2022. doi: 10.1155/2022/6446680
25. Rahman T, Islam MS. MRI brain tumor detection and classification using parallel deep convolutional neural networks. Measurement: Sensors (2023) 26:100694.
26. Aloraini M, Khan A, Aladhadh S, Habib S, Alsharekh MF, Islam M. Combining the transformer and convolution for effective brain tumor classification using MRI images. Appl Sci (2023) 13(6):3680. doi: 10.3390/app13063680
27. Athisayamani S, Antonyswamy RS, Sarveshwaran V, Almeshari M, Alzamil Y, Ravi V. Feature extraction using a residual deep convolutional neural network (ResNet-152) and optimized feature dimension reduction for MRI brain tumor classification. Diagnostics (2023) 13(4):668. doi: 10.3390/diagnostics13040668
28. Mishra HK, Kaur M. Classification of brain tumour based on texture and deep features of magnetic resonance images. Expert Syst (2023) 21:e13294. doi: 10.1111/exsy.13294
29. Cinar N, Kaya M, Kaya B. A novel convolutional neural network-based approach for brain tumor classification using magnetic resonance images. Int J Imaging Syst Technol (2023) 33(3):895–908. doi: 10.1002/ima.22839
30. Deepak S, Ameer PM. Brain tumor categorization from imbalanced MRI dataset using weighted loss and deep feature fusion. Neurocomputing (2023) 520:94–102. doi: 10.1016/j.neucom.2022.11.039
31. Zulfiqar F, Ijaz Bajwa U, Mehmood Y. Multi-class classification of brain tumor types from MR images using EfficientNets. Biomed Signal Process Control (2023) 84:104777. doi: 10.1016/j.bspc.2023.104777
33. Al-Ameen Z. (2020). Contrast enhancement of medical images using statistical methods with image processing concepts, in: 2020 6th International Engineering Conference “Sustainable Technology and Development"(IEC), , IEEE.
34. Vincent P, Larochelle H, Bengio Y, Manzagol P-A. Extracting and Composing Robust Features with Denoising Autoencoders. Springer (2021).
35. Szegedy C, Ioffe S, Vanhoucke V, Alemi A. (2017). Inception-v4, inception-resnet and the impact of residual connections on learning, in: Proceedings of the AAAI conference on artificial intelligence.
36. Tan M, Le Q. (2019). Efficientnet: Rethinking model scaling for convolutional neural networks, in: International conference on machine learning, , PMLR.
37. Hutter F, Hoos HH, Leyton-Brown K. (2011). Sequential model-based optimization for general algorithm configuration, in: Learning and Intelligent Optimization: 5th International Conference, LION 5, Rome, Italy, January 17-21, 2011, Selected Papers 5Springer.
38. Faramarzi A, et al. Marine Predators Algorithm: A nature-inspired metaheuristic. Expert Syst Appl (2020) 152:113377. doi: 10.1016/j.eswa.2020.113377
39. Ogasawara C, Philbrick BD, Adamson DC. Meningioma: a review of epidemiology, pathology, diagnosis, treatment, and future directions. Biomedicines (2021) 9(3):319. doi: 10.3390/biomedicines9030319
40. Hanif F, et al. Glioblastoma multiforme: a review of its epidemiology and pathogenesis through clinical presentation and treatment. Asian Pacific J Cancer prevention: APJCP (2017) 18(1):3.
41. Banskota S, Adamson DC. Pituitary adenomas: from diagnosis to therapeutics. Biomedicines (2021) 9(5):494. doi: 10.3390/biomedicines9050494
42. Dawood FA, Abood ZM. The importance of contrast enhancement in medical images analysis and diagnosis. Int J Eng Res Technol (IJERT) (2018) 7(12). doi: 10.17577/IJERTV7IS120006
43. Florea C, Florea L. Parametric logarithmic type image processing for contrast based auto-focus in extreme lighting conditions. Int J Appl Mathematics Comput Sci (2013) 23(3). doi: 10.2478/amcs-2013-0048
44. Buda M, Maki A, Mazurowski MA. A systematic study of the class imbalance problem in convolutional neural networks. Neural Networks (2018) 106:249–59. doi: 10.1016/j.neunet.2018.07.011
46. Wu J, et al. Hyperparameter optimization for machine learning models based on Bayesian optimization. J Electronic Sci Technol (2019) 17(1):26–40.
47. Talukder MA, Islam MM, Uddin MA, Akhter A, Pramanik MAJ, Aryal S, et al. An efficient deep learning model to categorize brain tumor using reconstruction and fine-tuning. Expert Syst Appl (2023) 120534. doi: 10.1016/j.eswa.2023.120534
48. Agrawal T, Choudhary P, Shankar A, Singh P, Diwakar M. MultiFeNet: Multi-scale feature scaling in deep neural network for the brain tumour classification in MRI images. Int J Imaging Syst Technol (2019).
49. Malla PP, Sahu S, Alutaibi AI. Classification of tumor in brain MR images using deep convolutional neural network and global average pooling. Processes (2023) 11(3):679. doi: 10.3390/pr11030679
50. Asif S, Zhao M, Chen X, Zhu Y. BMRI-NET: A deep stacked ensemble model for multi-class brain tumor classification from MRI images. Interdiscip Sciences: Comput Life Sci (2023) 17:1–16. doi: 10.1007/s12539-023-00571-1
51. Shyamala B, Brahmananda SH Dr. Brain tumor Classification using Optimized and Relief-based Feature Reduction and Regression Neural Network. Biomed Signal Process Control (2023) 86:105279. doi: 10.1016/j.bspc.2023.105279
52. Yapici M, Karakiş R, Gürkahraman K. Improving brain tumor classification with deep learning using synthetic data. Computers Materials Continua (2023) 74(3). doi: 10.32604/cmc.2023.035584
53. Kumar Sahoo A, Parida P, Muralibabu K, Dash S. Efficient simultaneous segmentation and classification of brain tumors from MRI scans using deep learning. Biocybernetics Biomed Eng (2023) 43(3):616–33. doi: 10.1016/j.bbe.2023.08.003
54. Wang L, et al. Review of classification methods on unbalanced data sets. IEEE Access (2021) 9:64606–28. doi: 10.1109/ACCESS.2021.3074243
55. Di Leo G, Sardanelli F. Statistical significance: p value, 0.05 threshold, and applications to radiomics—reasons for a conservative approach. Eur Radiol Exp (2020) 4(1):1–8.
56. Ribeiro MT, Singh S, Guestrin C. (2016). "Why should I trust you?": explaining the predictions of any classifier, in: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Association for Computing Machinery: San Francisco, California, USA. pp. 1135–44.
Keywords: brain tumor, MRI, contrast enhancement, deep learning, hyperparameters optimization, feature selection
Citation: Ullah MS, Khan MA, Masood A, Mzoughi O, Saidani O and Alturki N (2024) Brain tumor classification from MRI scans: a framework of hybrid deep learning model with Bayesian optimization and quantum theory-based marine predator algorithm. Front. Oncol. 14:1335740. doi: 10.3389/fonc.2024.1335740
Received: 09 November 2023; Accepted: 12 January 2024;
Published: 08 February 2024.
Edited by:
Poonam Yadav, Northwestern University, United StatesReviewed by:
Summrina Kanwal, Independent Researcher, Helsinborg, SwedenL. J. Muhammad, Bayero University Kano, Nigeria
Copyright © 2024 Ullah, Khan, Masood, Mzoughi, Saidani and Alturki. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Anum Masood, YW51bS5tYXNvb2RAbnRudS5ubw==