 Zhaole Yu
Zhaole Yu Yu Liu
Yu Liu Xisheng Dai1*
Xisheng Dai1* Enming Cui
Enming Cui- 1School of Automation, Guangxi University of Science and Technology, Liuzhou, Guangxi, China
- 2Laboratory of Artificial Intelligence of Biomedicine, Guilin University of Aerospace Technology, Guilin, Guangxi, China
- 3Department of Radiology, Jiangmen Central Hospital, Jiangmen, Guangdong, China
Objectives: In patients with hepatocellular carcinoma (HCC), accurately predicting the preoperative microvascular invasion (MVI) status is crucial for improving survival rates. This study proposes a multi-modal domain-adaptive fusion model based on deep learning methods to predict the preoperative MVI status in HCC.
Materials and methods: From January 2008 to May 2022, we collected 163 cases of HCC from our institution and 42 cases from another medical facility, with each case including Computed Tomography (CT) images from the pre-contrast phase (PCP), arterial phase (AP), and portal venous phase (PVP). We divided our institution’s dataset (n=163) into training (n=119) and test sets (n=44) in an approximate 7:3 ratio. Additionally, we included cases from another institution (n=42) as an external validation set (test1 set). We constructed three single-modality models, a simple concatenated multi-modal model, two current state-of-the-art image fusion model and a multi-modal domain-adaptive fusion model (M-DAFM) based on deep learning methods. We evaluated and analyzed the performance of these constructed models in predicting preoperative MVI using the area under the receiver operating characteristic curve (AUC), decision curve analysis (DCA), and net reclassification improvement (NRI) methods.
Results: In comparison with all models, M-DAFM achieved the highest AUC values across the three datasets (0.8013 for the training set, 0.7839 for the test set, and 0.7454 for the test1 set). Notably, in the test set, M-DAFM’s Decision Curve Analysis (DCA) curves consistently demonstrated favorable or optimal net benefits within the 0-0.65 threshold probability range. Additionally, the Net Reclassification Improvement (NRI) values between M-DAFM and the three single-modal models, as well as the simple concatenation model, were all greater than 0 (all p < 0.05). Similarly, the NRI values between M-DAFM and the two current state-of-the-art image fusion models were also greater than 0. These findings collectively indicate that M-DAFM effectively integrates valuable information from multi-phase CT images, thereby enhancing the model’s preoperative predictive performance for MVI.
Conclusion: The M-DAFM proposed in this study presents an innovative approach to improve the preoperative predictive performance of MVI.
1 Introduction
Microvascular invasion (MVI) is one of the significant factors contributing to postoperative recurrence of hepatocellular carcinoma (HCC) (1–4), exerting a pronounced impact on disease recurrence and shortened survival in HCC patients (5–7). When MVI is positive in cases of HCC, the short-term recurrence rate of small liver cancers (8) (liver cell tumors <2cm) is higher, and patients with liver cell tumors ≥2cm exhibit lower long-term survival rates (9). Therefore, MVI is commonly regarded as a marker to assess the malignancy degree of HCC (10). However, in clinical practice, the presence of MVI can only be confirmed through histopathological examination of resected tumor tissue postoperatively (11, 12). Accurately predicting the preoperative MVI status in a noninvasive manner remains a challenge.
Prior research has demonstrated the feasibility of preoperative MVI prediction in HCC using Computed Tomography (CT) images (13), and many studies have extracted radiological features from CT images to construct radiological models for predicting the preoperative MVI status (2, 14, 15). Since the extraction of radiological features relies on the subjective expertise of radiologists, less experienced radiologists may overlook valuable features (16). Additionally, radiological features are often considered low to mid-level features, which may not fully capture the heterogeneity of HCC (17).
Deep learning based on Convolutional Neural Networks (CNN) has the capacity to automatically extract high-level features relevant to the target problem in CT images, surpassing explicitly designed low and mid-level features (18–21). Research has indicated that deep learning methods exhibit excellent performance in differentiating liver lesions and classifying fibrosis, offering diagnostic accuracy comparable to pathological gold standards (22, 23). In previous studies, deep learning methods have been applied to predict the preoperative status of MVI. For example, Liu et al. (24) used AP-phase CT images to construct a deep learning model and combined it with clinical factors for preoperative MVI prediction. Jiang et al. (25), on the other hand, built deep models using arterial phase (AP), portal venous phase (PVP), and delayed phase (DP) CT images separately and concatenated the deep features from these three phases to predict the preoperative MVI status. While these studies have achieved certain effectiveness in preoperative MVI prediction, they also exhibit certain limitations. For instance, Liu et al. used only a single-phase CT image, limiting their ability to comprehensively evaluate tumor characteristics. Jiang et al., although combining information from different phases of CT images, did not address the issue of feature distribution differences during the fusion process.
To address these issues, our study proposes a multimodal domain-adaptive fusion model based on deep learning. This model employs deep learning methods to extract information from CT images acquired at different phases, enabling a more comprehensive evaluation of HCC characteristics. Furthermore, it employs domain adaptation to align the feature distributions of various CT images, thereby enhancing the quality of the fused features. To the best of our knowledge, there is limited research considering the differences in data distribution between different modalities when utilizing multimodal image information. Our study aims to investigate the effectiveness of the domain-adaptive fusion method for preoperative MVI prediction in HCC, in comparison to single-modal and multimodal simple concatenation methods. Our research provides a novel approach to effectively integrate multimodal image information for predicting the preoperative MVI status.
2 Materials and methods
The ethics committee of our hospital has granted approval for this retrospective study. Since the data is sourced from an existing institution and imposes no additional burden on the patients, the requirement for informed consent has been waived. Figure 1 provides a schematic representation of the study’s design.
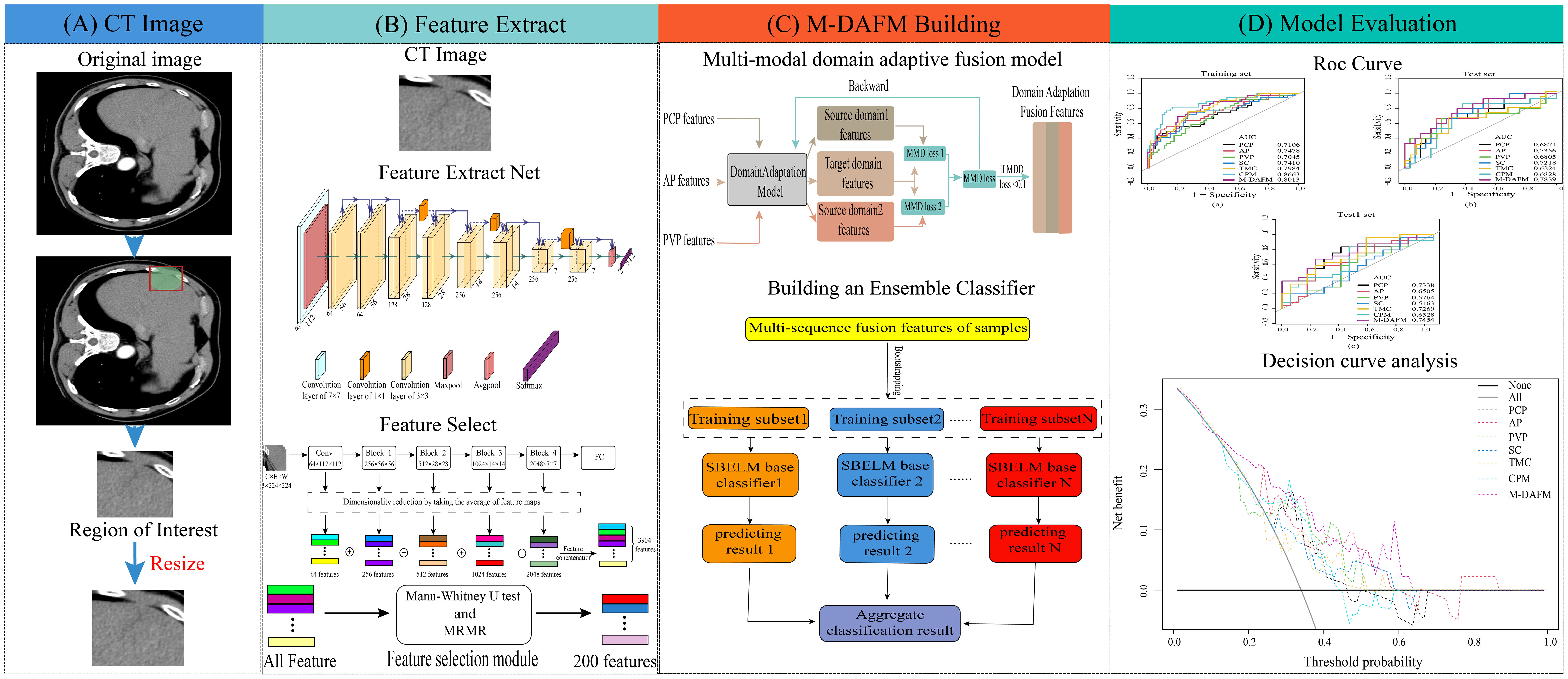
Figure 1 The overall design flowchart. (A) ROI extraction process; (B) DL feature extraction process; (C) M-DAFM building process; (D) Model evaluation.
2.1 Patients
We conducted a retrospective study by querying our medical institution’s pathology database from January 2008 to May 2022 to identify patients who underwent hepatic resection surgery for HCC. The patient data collected by our institution predominantly employs major resection as the types of resection. The inclusion criteria for our study were as follows: (a) patients who did not receive any other anti-tumor treatments before surgery (including liver resection, liver transplantation, chemotherapy, radiation therapy, radiofrequency ablation, immunosuppressive therapy); (b) liver nodules with comprehensive histopathological descriptions in the pathology reports; (c) a time interval of no more than 4 weeks between preoperative CT examination [including pre-contrast phase (PCP), arterial phase (AP), portal venous phase (PVP)] and surgery. We excluded HCC patients with pathological results obtained through puncture and patients with artifacts in imaging and incomplete clinical information. A total of 163 patients with CT images from our institution met the inclusion and exclusion criteria. Subsequently, we randomly divided this dataset into a training set (n=119) and a test set (n=44) in an approximate ratio of 7:3. Statistical analysis revealed that in the training set, the rate of MVI was found to be 32.8% (39/119). Furthermore, we gathered 42 cases from external medical institutions to constitute an external validation set (test1 set). These cases adhere to the inclusion and exclusion criteria of our institution, and undergo the same preprocessing procedures as our institution’s pathology. This was done to further assess the predictive performance of the model on previously unseen data. The inclusion and exclusion criteria of our medical institution are presented in Electronic Supplementary Material S1.
2.2 Medical history and laboratory parameters
Age, gender, hepatocirrhosis status, and the presence of hepatitis B surface antigen (HBsAg) were documented for every patient. A range of serum biochemical parameters related to liver function were assessed for each patient within two weeks before or after the CT examination. These parameters encompassed α-fetoprotein (AFP), Carbohydrate antigen 199 (CA199), total bilirubin (TBIL), direct bilirubin (DBIL), indirect bilirubin (IBIL), alanine aminotransferase (ALT), aspartate aminotransaminase (AST), albumin, total protein, alkaline phosphatase (ALP), and platelet count (PLT). The baseline characteristics of the included cohorts are summarized in the Table 1.
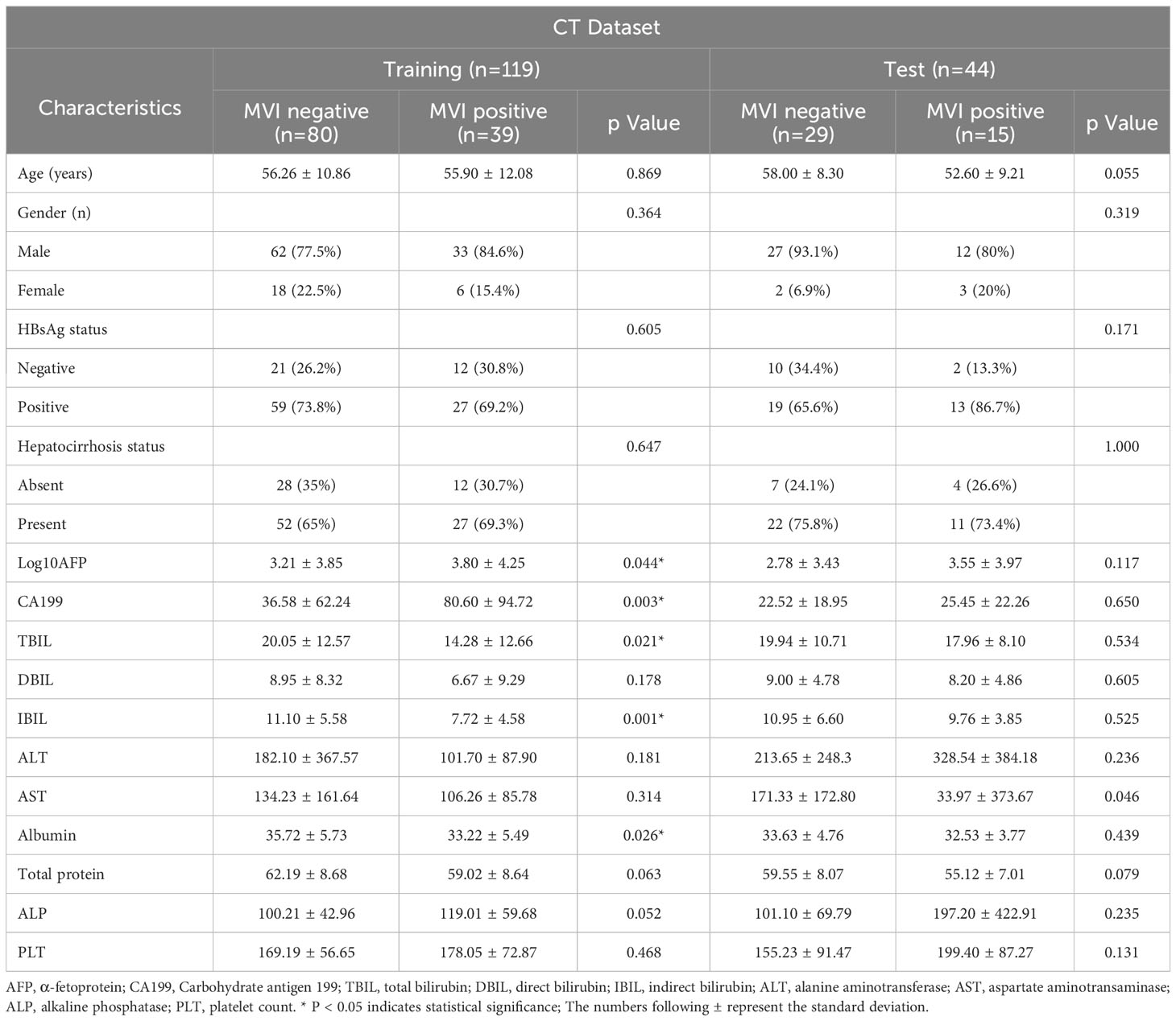
Table 1 Baseline characteristics of the CT training set and test set.
2.3 Imaging scans
The CT scanning devices used in this study were the 16-detector CT (SOMATOM Sensation 16, Siemens Healthineers), the 64-detector CT (Aquilion 64, Canon Medical Systems), and the dual-source CT (SOMATOM Force, Siemens Healthineers). Patients maintained a supine position and held their breath during the procedure. The scanning sequences consisted of the pre-contrast phase (PCP), the arterial phase (AP, 30 seconds after contrast injection), and the portal venous phase (PVP, 60-70 seconds after contrast injection). The CT parameters included: tube voltage set at 120 kV, effective tube current-exposure time product ranging from 200 to 350 mAs, matrix size of 512×512, and a slice thickness of either 1.0 or 3.0 mm.
2.4 Radiologist assessment
The study utilized three different-phase CT images: PCP, AP, and PVP. Two radiologists, each possessing more than 5 and 11 years of expertise in abdominal imaging, independently conducted image assessments. These assessments were carried out in isolation from each other, with no knowledge of their respective ratings and no access to pathological findings. The degree of their confidence in detecting MVI was documented using a 5-point scale: 5, indicating a definite positive diagnosis; 4, signifying a probable positive finding; 3, expressing uncertainty; 2, suggesting a potential negative result; and 1, denoting a definite negative assessment (12). In cases of discordance, these two radiologists held discussions to reach a consensus score.
The summary of radiological features encompassed the following criteria: (1) tumor diameter (<5cm = 0; ≥5cm = 1); (2) the number of tumors (<2 = 0; ≥2 = 1); (3) the presence of a pseudocapsule (absent = 0; present = 1); (4) intratumoral necrosis (absent = 0; present = 1); (5) intratumoral hemorrhage (absent = 0; present = 1); (6) peritumoral enhancement during the arterial phase (AP) (absent = 0; present = 1); (7) AP hyperenhancement (absent = 0; present = 1); (8) wash-in and wash-out patterns (absent = 0; present = 1). Scores equal to or greater than 4 signified a heightened likelihood of MVI presence. Each image was individually examined and rated. In cases of multiple lesions, the option of surgical resection was considered.
2.5 Pathological diagnosis
The reference criteria for identifying MVI relied on the pathological examination of surgical specimens. MVI was specifically characterized as the presence of a tumor within a vascular space lined with endothelial cells, as visualized under microscopy (26). Moreover, to ensure precision, all our pathological findings underwent thorough review by a pathologist with twelve years of experience.
2.6 Tumor segmentation
After extracting patient images from our institutional picture archiving and communication system (PACS), we perform image de-identification and store them in the NIfTI format. Subsequently, these images are imported into 3D-Slicer (version 5.0.2). Next, we proceed with delineating the region of interest (ROI) on the CT images for each phase separately. The entire tumor is outlined at three distinct layers: the initial layer, the section with the maximum cross-sectional area, and the final layer. To ensure comprehensive coverage of the tumor, an additional 1-centimeter extension is applied at the margins. This delineation process is semi-automated to save the effort of radiologists and reduce the interference of subjective factors. The flowchart for image segmentation and preprocessing is presented in Electronic Supplementary Material S2.
2.7 Building the multi-modal domain adaptive fusion model
Multi-modal domain adaptive fusion model (M-DAFM) utilizesa convolutional neural network to extract feature information from the target task. It can predict the occurrence of MVI in HCC within a given ROI without the need for precise lesion segmentation. The training process of M-DAFM in this study consists of three stages: first, deep learning models are employed to extract features from single-phase CT images; then, domain adaptation techniques (27) are applied to align the distributions of features among the single-phase CT images and fuse these features; finally, an ensemble sparse Bayesian extreme learning machine (ESBELM) is used for preoperative prediction of MVI status in HCC. Detailed parameters for training the deep learning model can be found in Electronic Supplementary Material S3.
In the feature extraction stage, we employ a pre-trained ResNet18 model on ImageNet to extract features from multiple single-phase CT images, including PCP, AP, and PVP. Each single-phase image yields 3904 features. For a comprehensive understanding of the deep feature extraction process, please refer to Electronic Supplementary Material S4.
In the domain adaptation feature fusion stage, we perform feature selection using Mann-Whitney U test (28) and Maximum Relevance Minimum Redundancy (MRMR) algorithm (29) on the features extracted from individual single-phase images, selecting the top 200 features most relevant to the target task. Domain adaptation is a learning paradigm within transfer learning that primarily addresses distributional differences between the target domain and the source domain, enabling the adaptation of the source domain distribution to the target domain. In clinical practice, CT images from the PCP, AP, and PVP phases typically reflect relevant information about tumors from different perspectives. Consequently, there are often distributional differences among them. To alleviate these differences, we employ domain adaptation methods, treating the AP phase features as the target domain and the PCP and PVP phase features as the source domain, the Maximum Mean Discrepancy (MMD) (30) is utilized as the loss function to quantify the distributional differences between the source and target domains. This alignment aims to ensure that PCP, AP and PVP features exhibit similar distributions. The domain adaptation fusion algorithm proposed in this article can be divided into three steps: 1) We select the AP phase CT image features as the target domain and the PCP and PVP phase CT image features as two source domains. The purpose is to use the target domain as a standard to make the data distribution of the source domains closer to the target domain. 2) We use maximum mean discrepancy (MMD) as the model’s loss function to measure the distribution difference between the source domain (PCP and PVP features) and the target domain (AP features). By training the model to reduce these distribution differences, we make the distribution of the source domain tend to be consistent with the target domain. 3) We use a feature concatenation strategy to fuse the distribution-consistent PCP, AP, and PVP features, aiming to improve the model’s performance on unknown datasets. For a detailed description of the feature fusion process, please refer to Electronic Supplementary Material S5.
In the classification stage, we construct an ESBELM classifier. This classifier incorporates Bayesian linear regression algorithms into the framework of extreme learning machines (31) to reduce feature dimensions and mitigate model overfitting. Additionally, the classifier enhances model classification performance through the ensemble of multiple base classifiers. Detailed information about classifier construction can be found in Electronic Supplementary Material S6.
2.8 Statistical analysis
In this study, model performance was evaluated using metrics including accuracy, sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and area under the receiver operating characteristic curve (AUC). Comparing these metrics aids in assessing the model’s classification capability, accuracy, and reliability. The formulas for calculating classification performance metrics are provided in Electronic Supplementary Material S7.
Net reclassification improvement (NRI) is a metric used to evaluate the improvement of a predictive model, particularly for comparing the performance differences between two models in a classification task. The formula for calculating the metrics is provided in Electronic Supplementary Material S8.
Decision curve analysis (DCA) is a method for evaluating the performance of medical diagnostic or predictive models. The primary objective of DCA is to assess the impact of model classification results at different thresholds, assisting medical decision-makers in making more informed choices in various scenarios, thus enhancing overall patient benefit.
All statistical analyses were performed using Python 3.7 (https://www.python.org/), MATLAB R2020b (https://www.mathworks.com/products/matlab.html), and R 4.3.0 (http://www.rproject.org). The deep learning model was constructed using Python. Mann-Whitney U test and Maximum MRMR algorithm were computed and analyzed using Python. The ESBELM classifier was built using MATLAB for classification. The “pROC” package in RStudio was utilized to plot ROC curves, the NRI value was calculated used the “glm” package in RStudio.
3 Results
3.1 Performance analysis of different classifiers
In this experiment, we conducted a comparative analysis among ESBELM, Ensemble Random Forest (ERF), and Extreme Learning Machine (ELM) to validate the superiority of ESBELM. The experimental results can be found in Tables 2, 3. On the test set, ESBELM achieved AUC values of 0.7011, 0.7011, and 0.6805 when using single-phase features PCP, AP, and PVP as inputs, respectively. Additionally, M-DAFM achieved an AUC value of 0.7839, all of which outperformed the predictive performance of ERF and ELM.
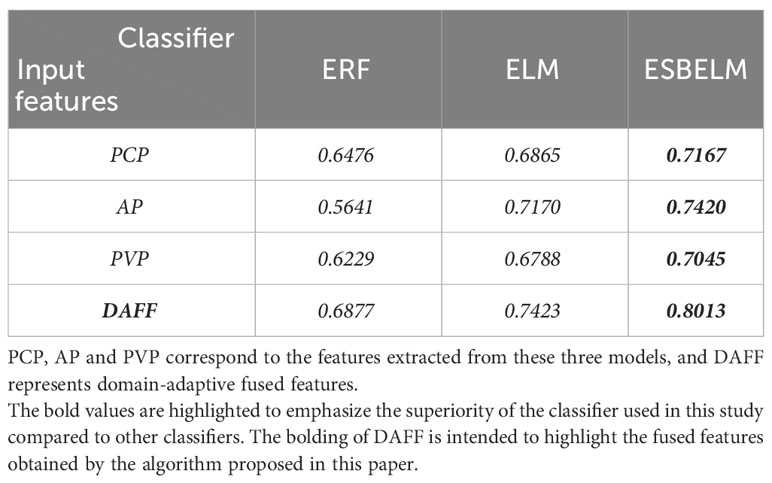
Table 2 AUC values of different classifiers on the training set.
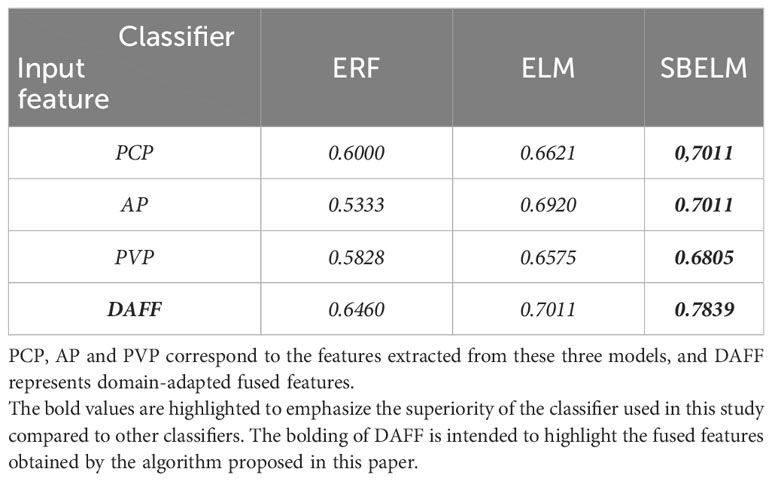
Table 3 AUC values of different classifiers on the test set.
3.2 Analyzing the predictive performance of different models
We will compare the proposed M-DAFM model with the following models: (1) Single-modal model: Construct a deep learning model using only one phase of CT images (PCP, AP, or PVP) from patients for preoperative prediction of MVI; (2) Simple concatenation model (SC): Employ deep learning methods to extract deep features from PCP, AP, and PVP phase CT images of patients separately, followed by straightforward concatenation for preoperative prediction of MVI.; (3) State-of-the-Art models, where we selected two state-of-the-art image fusion models: TMC (Trusted Multi-View Classification model) (32), which dynamically acquires the credibility of different modalities and integrates information from each modality based on its credibility, thereby effectively improving the predictive performance of the model; CPM (Cross Partial Multi-View Networks) (33), which integrates information from different modalities by constructing a non-parametric classification loss function, allowing the model to learn the consistency and complementary information of different modalities for the target task, thereby enhancing model performance.
Table 4 presents the diagnostic performance of each model for preoperative prediction of MVI; Figure 2 shows the ROC (receiver operating characteristic) curves of each model on the training set, test set, and test1 set; Table 5 demonstrates the improvement performance of M-DAFM compared to other models; Figure 3 displays the DCA curves of each model on the test set.
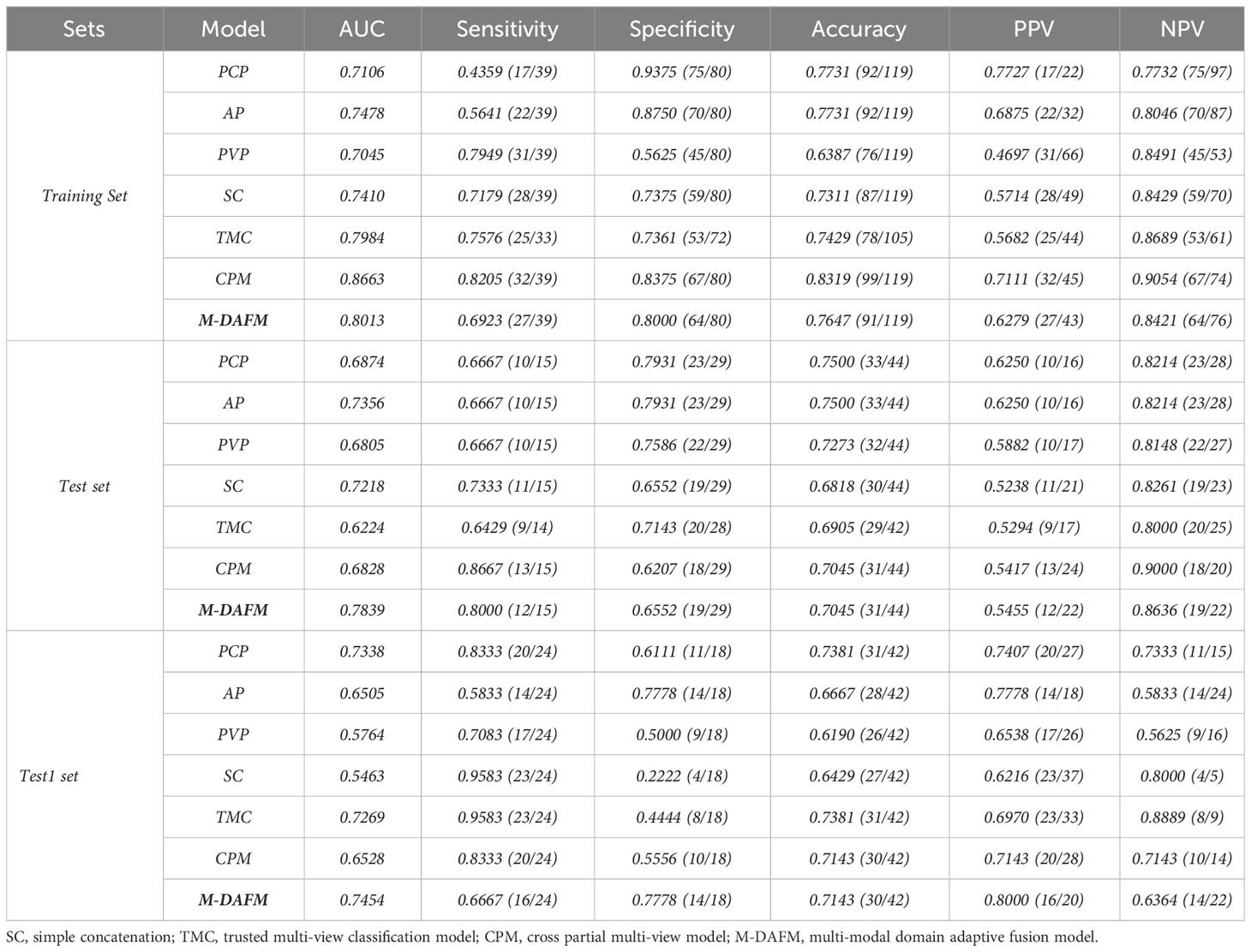
Table 4 Comparison of classification performance between M-DAFM and PCP, AP, PVP, TMC, CPM and SC models.
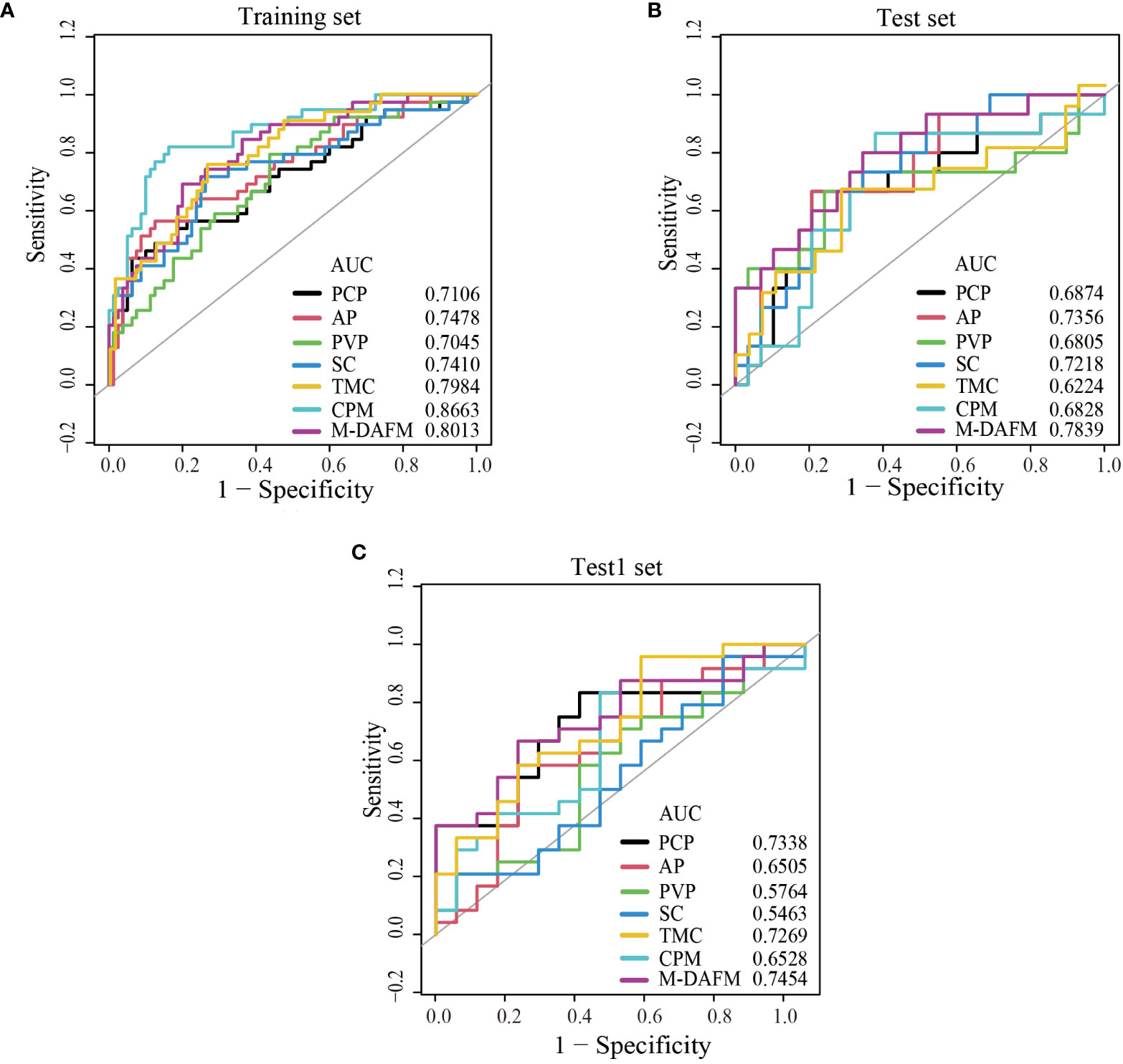
Figure 2 ROC curves of PCP, AP, PVP, SC, TMC, CPM models, and M-DAFM on the training (A), test (B) and test1 (C) sets. SC, simple concatenation; TMC, trusted multi-view classification model; CPM, cross partial multi-view model. M-DAFM, multi-modal domain adaptive fusion model.
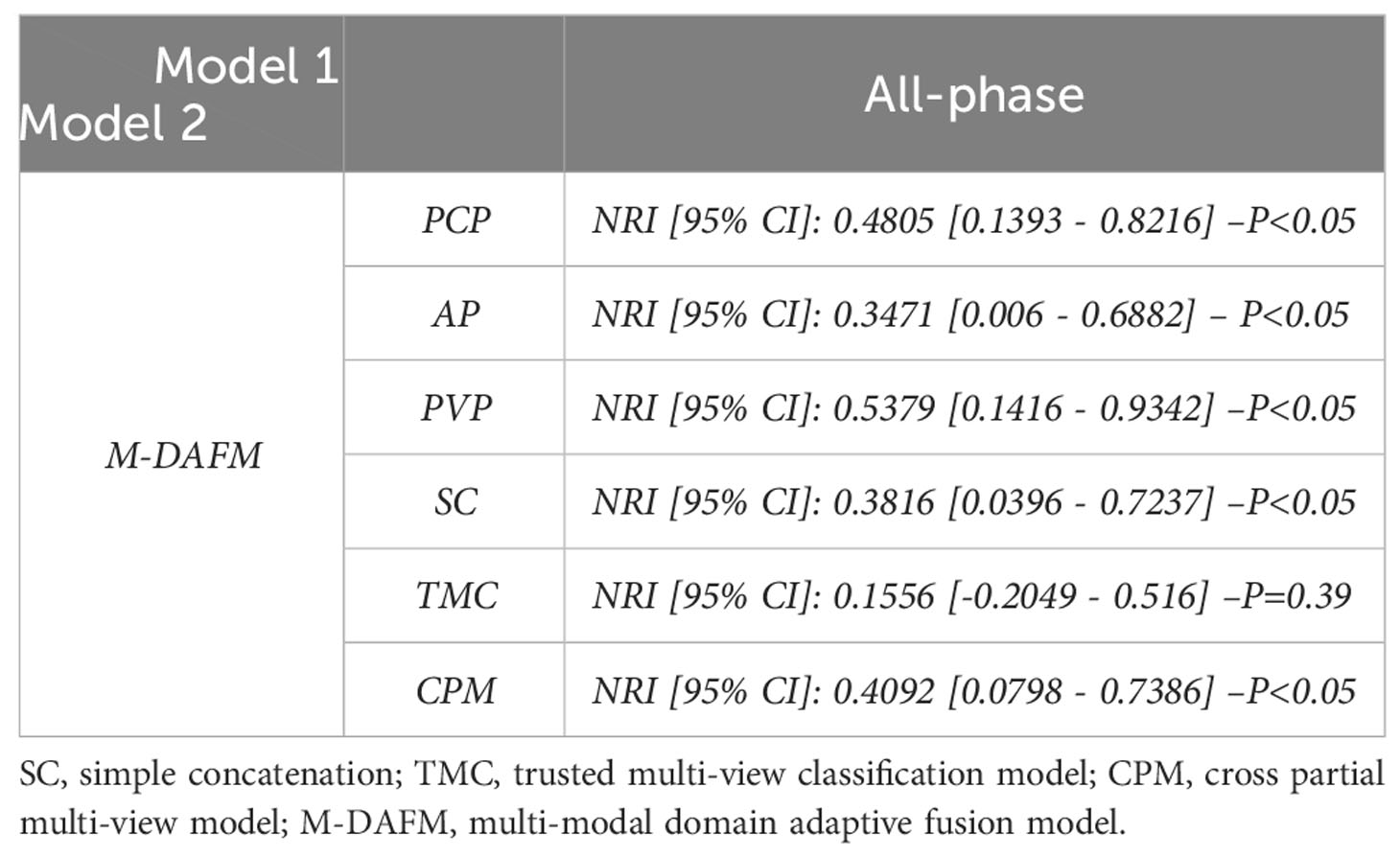
Table 5 NRI comparison of M-DAFM with AP, PCP, PVP, TMC, CPM and SC models in the test set.
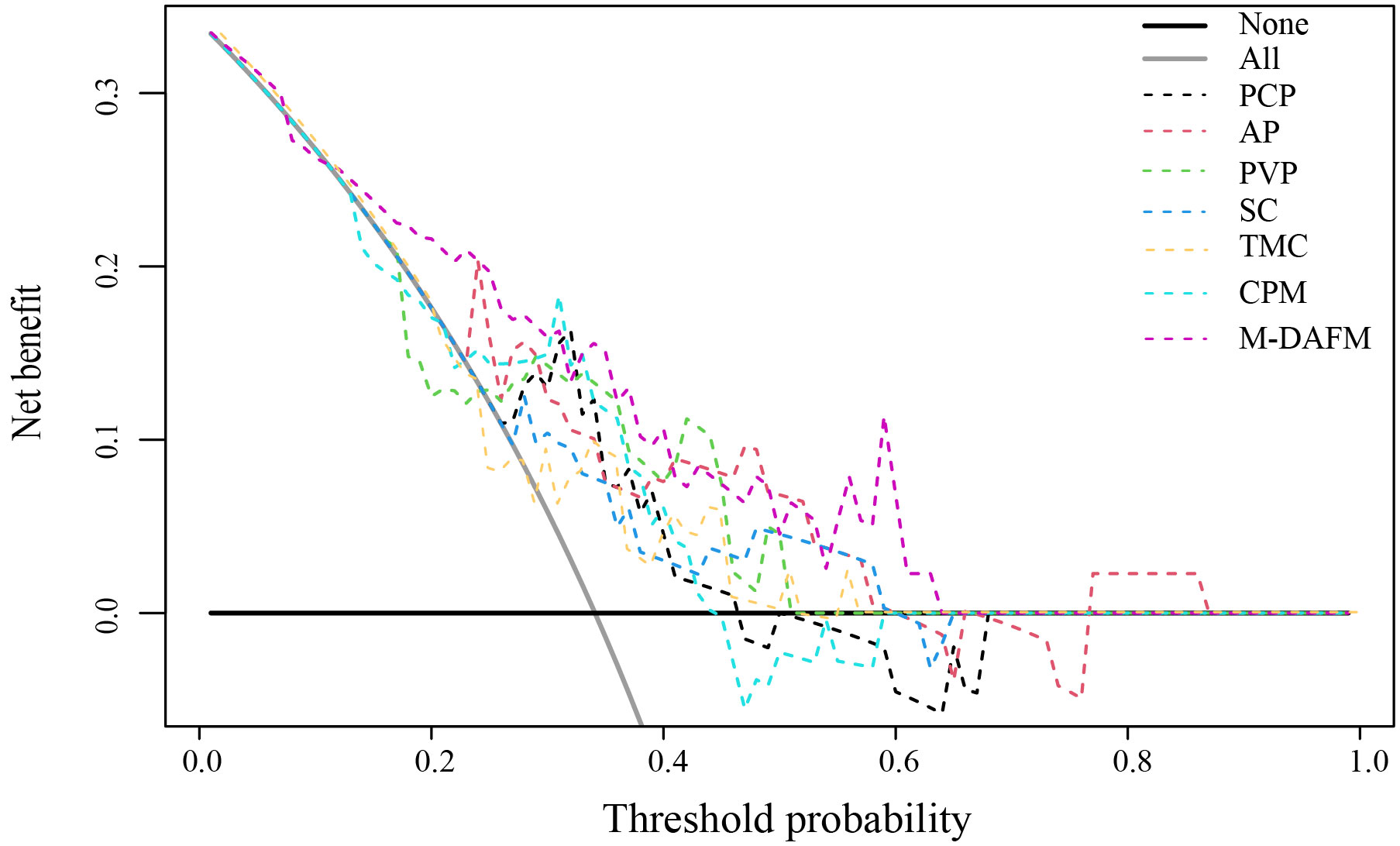
Figure 3 Decision curve analysis (DCA) of PCP, AP, PVP, SC, TMC, CPM models, and M-DAFM on the test set. SC, simple concatenation; TMC, trusted multi-view classification model; CPM, cross partial multi-view model. M-DAFM, multi-modal domain adaptive fusion model.
As evident from Table 4 and Figure 2, M-DAFM achieved AUC values in the test set close to those in the training set (<5%). This indicates that M-DAFM successfully learned relevant and effective information highly correlated with the target task in the training set. Moreover, M-DAFM exhibited good predictive performance on the test1 set with an AUC of 0.7454, indicating strong generalization capabilities. In other words, the model performed well on datasets with substantial differences from the training set. In comparison, the AUC values of single-modal models (PCP, AP, PVP) and the SC were consistently lower than M-DAFM across all three datasets. The AUC values of TMC and CPM in the test set are significantly lower than those in the training set, indicating a certain degree of overfitting. This implies that both TMC and CPM models have overly adapted to the noise or specific characteristics of the training set during the training process, leading to suboptimal performance on unseen data. Therefore M-DAFM exhibits superior predictive and generalization performance compared to other models, while TMC and CPM require further optimization to enhance their generalization performance on unknown data.
According to Table 5, the NRI values of M-DAFM compared to the single-modal models (PCP, AP, PVP) and the SC are 0.4805 (p < 0.05), 0.3471 (p < 0.05), 0.5379 (p < 0.05), and 0.3816 (p < 0.05), respectively. This indicates that M-DAFM exhibits a significantly improved predictive performance compared to these models. Furthermore, the NRI values of M-DAFM compared to the current state-of-the-art models, TMC and CPM, are 0.1556 (p = 0.39) and 0.4092 (p < 0.05), respectively, suggesting that M-DAFM still demonstrates some improvement in predictive performance compared to the current state-of-the-art models.
According to Figure 3, we visually represented the DCA curves for all models in the test set. It can be observed that, within the 0-0.65 threshold range, M-DAFM consistently achieves better or the best net benefit compared to other models.
In summary, through quantitative visual comparisons and analyses from various perspectives, including AUC, NRI, and DCA, we found that M-DAFM demonstrates excellent performance in preoperative prediction of MVI. Based on these analytical results, it can be concluded that M-DAFM not only excels in predictive performance but also holds significant potential for clinical applications.
4 Discussion
The diagnosis of MVI can only be confirmed through postoperative pathological examination, while the preoperative diagnosis of MVI relies on liver biopsy (34). However, due to factors such as tumor heterogeneity and challenges in sample acquisition, preoperative liver biopsy faces several limitations (35). If it were possible to predict the status of MVI preoperatively, doctors could tailor personalized treatment plans for patients at an earlier stage, thereby improving patient survival rates.
With the application of deep learning in the medical field, there have been studies that use deep learning methods to construct deep models for the preoperative prediction of MVI (22–24). In clinical practice, CT images at different phases can reveal the tumor’s vascular characteristics and its surrounding relationships at different time points. PCP images primarily display the basic anatomical features of the liver; AP images significantly enhance the detection of hepatic arterial blood flow, and PVP images can detect the blood flow and vascular distribution in the portal vein of the liver. Therefore, finding an objective and efficient way to integrate multi-phase image information, complementing the characteristics of each phase, may prove effective for diagnosis. This study innovatively predicts MVI by constructing the M-DAFM, which combines effective information from PCP, AP, and PVP modalities. Experimental validation demonstrates the superiority of multi-modal image fusion.
Comparative experiments with different classifiers reveal, as shown in Tables 2, 3, that ESBELM performs the best in classifying MVI. This is possibly because CT image data often contain complex features and non-linear relationships, such as tumor morphology, texture, and vascular distribution. In contrast, ERF is insensitive to complex non-linear relationships, ELM is prone to overfitting when dealing with complex data, while ESBELM, by introducing ensemble strategies and Bayesian optimization algorithms, enhances its ability to handle high-dimensional and non-linear relationships while mitigating model overfitting.
Comparative experiments between single-modal models and multi-modal fusion models: As shown in Figure 2 and Table 4, M-DAFM demonstrates superior performance in preoperative MVI prediction (The AUC values for the training set, test set, and Test1 set are 0.8013, 0.7839, and 0.7454, respectively). This could be attributed to the successful reduction of inter-modal differences by M-DAFM, allowing the model to better leverage complementary information from each modality for preoperative MVI prediction. In contrast, the performance of single-modal models (PCP, AP, PVP) in this aspect is significantly lower than that of M-DAFM, possibly due to the limited effective information provided by a single CT modality image, restricting the performance of single-modal models in preoperative MVI prediction tasks.On the other hand, the performance of SC in preoperative MVI prediction is relatively average, and even its predictive performance in the test set and Test1 set is inferior to some single-modal models. This may be because each modality typically predicts MVI from different perspectives, and SC does not consider the correlation between modalities, leading to negative interactions between modalities and affecting the predictive performance of SC.Regarding TMC and CPM, although they also integrate information from multiple modalities, the strategies adopted by these models may struggle to effectively distinguish between valuable information and noise within CT images, which often contain rich and complex microscopic information, encompassing multi-level structures of tumor lesions. This difficulty in effective discrimination may result in suboptimal predictive performance for these models.
The method proposed in this paper for preoperative prediction of MVI has three advantages in clinical practice:1) In terms of tumor segmentation, we employ a semi-automatic segmentation algorithm that only requires radiologists to perform rough segmentation of the tumor area. This significantly reduces the workload for radiologists in tumor segmentation, while reducing subjective interventions during the segmentation process. Consequently, it enhances the consistency and repeatability of the final results.2) Regarding feature extraction, we utilize a convolutional neural network for automatic, accurate, and objective extraction of specific features from the tumor region.3) In clinical practice, doctors often employ various methods for disease diagnosis. Inspired by this, our study considers the PCP, AP, and PVP of CT images as three distinct modalities. Using a domain adaptation approach, we design a multimodal fusion network to build a more robust and accurate preoperative prediction model, which holds practical significance.
This retrospective study has certain limitations. Firstly, the extensive time span of data collection may introduce variations in data quality. However, our experimental results demonstrate the effectiveness of the proposed method, highlighting the robustness of M-DAFM. Further improvements in data quality may enhance the model’s performance. Secondly, this study lacks multi-center CT image data for further validation of the model’s universality. Lastly, this study only explores the diagnostic performance of deep learning models, which enhances practical portability but may compromise accuracy. As for analyzing clinical models as a single modality within the multi-modal fusion model, we will continue to investigate in our future research.
5 Conclusions
This study introduces a novel approach for preoperative MVI prediction by effectively integrating information from multi-phase CT images through mitigating the distribution differences between different modalities.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material. Further inquiries can be directed to ZY, MTAyMzQ5NDg0MkBxcS5jb20=.
Ethics statement
The studies involving humans were approved by the institutional review board of Jiangmen Central Hospital, which waived the requirement for written informed consent for participation. The studies were conducted in accordance with the local legislation and institutional requirements.
Author contributions
ZY: Conceptualization, Methodology, Writing – original draft. YL: Conceptualization, Methodology, Writing – review & editing. XD: Conceptualization, Supervision, Writing – review & editing. EC: Conceptualization, Data curation, Writing – review & editing. JC: Data curation, Investigation, Writing – review & editing. CM: Conceptualization, Data curation, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the National Natural Science Foundation of China (81960324, 12261027) and Guangdong Basic and Applied Basic Research Foundation [2021A1515220080].
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fonc.2024.1332188/full#supplementary-material
Glossary
References
1. Lee S, Kim SH, Lee JE, Sinn DH, Park CK. Preoperative gadoxetic acid–enhanced MRI for predicting microvascular invasion in patients with single hepatocellular carcinoma. J Hepatol (2017) 67(3):526–34. doi: 10.1016/j.jhep.2017.04.024
2. Xu X, Zhang HL, Liu QP, Sun SW, Zhang J, Zhu FP, et al. Radiomic analysis of contrast-enhanced CT predicts microvascular invasion and outcome in hepatocellular carcinoma. J Hepatol (2019) 70(6):1133–44. doi: 10.1016/j.jhep.2019.02.023
3. Gao F, Qiao K, Yan B, Wu M, Wang L, Chen J, et al. Hybrid network with difference degree and attention mechanism combined with radiomics (H-DARnet) for MVI prediction in HCC. Magnetic Resonance Imaging (2021) 83:27–40. doi: 10.1016/j.mri.2021.06.018
4. Hong SB, Choi SH, Kim SY, Shim JH, Lee SS, Byun JH, et al. MRI features for predicting microvascular invasion of hepatocellular carcinoma: a systematic review and meta-analysis. Liver Cancer (2021) 10(2):94–106. doi: 10.1159/000513704
5. Benson AB, D’Angelica MI, Abbott DE, Anaya DA, Anders R, Are C, et al. Hepatobiliary cancers, version 2.2021, NCCN clinical practice guidelines in oncology. J Natl Compr Cancer Network (2021) 19(5):541–65. doi: 10.6004/jnccn.2021.0022
6. Sumie S, Nakashima O, Okuda K, Kuromatsu R, Kawaguchi A, Nakano M, et al. The significance of classifying microvascular invasion in patients with hepatocellular carcinoma. Ann Surg Oncol (2014) 21:1002–9. doi: 10.1245/s10434-013-3376-9
7. Yang L, Gu D, Wei J, Yang C, Rao S, Wang W, et al. A radiomics nomogram for preoperative prediction of microvascular invasion in hepatocellular carcinoma. Liver Cancer (2018) 8(5):373–86. doi: 10.1159/000494099
8. Yamashita YI, Tsuijita E, Takeishi K, Fujiwara M, Kira S, Mori M, et al. Predictors for microinvasion of small hepatocellular carcinoma≤ 2 cm. Ann Surg Oncol (2012) 19:2027–34. doi: 10.1245/s10434-011-2195-0
9. Shindoh J, Andreou A, Aloia TA, Zimmitti G, Lauwers GY, Laurent A, et al. Microvascular invasion does not predict long-term survival in hepatocellular carcinoma up to 2 cm: reappraisal of the staging system for solitary tumors. Ann Surg Oncol (2013) 20:1223–9. doi: 10.1245/s10434-012-2739-y
10. Erstad DJ, Tanabe KK. Prognostic and therapeutic implications of microvascular invasion in hepatocellular carcinoma. Ann Surg Oncol (2019) 26:1474–93. doi: 10.1245/s10434-019-07227-9
11. Zhang X, Li J, Shen F, Lau WY. Significance of presence of microvascular invasion in specimens obtained after surgical treatment of hepatocellular carcinoma. J Gastroenterol Hepatol (2018) 33(2):347–54. doi: 10.1111/jgh.13843
12. Min JH, Lee MW, Park HS, Lee DH, Park HJ, Lim S. Interobserver variability and diagnostic performance of gadoxetic acid–enhanced MRI for predicting microvascular invasion in hepatocellular carcinoma. Radiology (2020) 297(3):573–81. doi: 10.1148/radiol.2020201940
13. Lewin M, Laurent-Bellue A, Desterke C, Radu A, Feghali JA, Farah J, et al. Evaluation of perfusion CT and dual-energy CT for predicting microvascular invasion of hepatocellular carcinoma. Abdominal Radiol (2022) 47(6):2115–27. doi: 10.1007/s00261-022-03511-7
14. He M, Zhang P, Ma X, He B, Fang C, Jia F. Radiomic feature-based predictive model for microvascular invasion in patients with hepatocellular carcinoma. Front Oncol (2020) 10:574228. doi: 10.3389/fonc.2020.574228
15. Gao L, Xiong M, Chen X, Han Z, Yan C, Ye R, et al. Multi-region radiomic analysis based on multi-sequence MRI can preoperatively predict microvascular invasion in hepatocellular carcinoma. Front Oncol (2022) 12:818681. doi: 10.3389/fonc.2022.818681
16. Ni M, Zhou X, Lv Q, Li Z, Gao Y, Tan Y, et al. Radiomics models for diagnosing microvascular invasion in hepatocellular carcinoma: which model is the best model? Cancer Imaging (2019) 19:1–10. doi: 10.1186/s40644-019-0249-x
17. Wang W, Chen Q, Iwamoto Y, Aonpong P, Lin L, Hu H, et al. Deep fusion models of multi-phase CT and selected clinical data for preoperative prediction of early recurrence in hepatocellular carcinoma. IEEE Access (2020) 8:139212–20. doi: 10.1109/access.2020.3011145
18. Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. Communications of the ACM (2017) 60(6):84–90. doi: 10.1145/3065386
19. Liu Z, Mao H, Wu CY, Feichtenhofer C, Darrell T, Xie S. (2022). A convnet for the 2020s, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. New Orleans, LA, USA: Institute of Electrical and Electronics Engineers (IEEE), pp. 11976–86. doi: 10.1109/CVPR52688.2022.01167
20. He K, Zhang X, Ren S, Sun J. (2016). Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition. Las Vegas, NV, USA: Institute of Electrical and Electronics Engineers (IEEE), pp. 770–8. doi: 10.1109/cvpr.2016.90
21. He K, Chen X, Xie S, Li Y, Dollár P, Girshick R. (2022). Masked autoencoders are scalable vision learners, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. New Orleans, LA, USA: Institute of Electrical and Electronics Engineers (IEEE), pp. 15979–88. doi: 10.1109/CVPR52688.2022.01553
22. Yasaka K, Akai H, Abe O, Kiryu S. Deep learning with convolutional neural network for differentiation of liver masses at dynamic contrast-enhanced CT: a preliminary study. Radiology (2018) 286(3):887–96. doi: 10.1148/radiol.2017170706
23. Wang K, Lu X, Zhou H, Gao Y, Zheng J, Tong M, et al. Deep learning Radiomics of shear wave elastography significantly improved diagnostic performance for assessing liver fibrosis in chronic hepatitis B: a prospective multicentre study. Gut (2019) 68(4):729–41. doi: 10.1136/gutjnl-2018-316204
24. Liu SC, Lai J, Huang JY, Cho CF, Lee PH, Lu MH, et al. Predicting microvascular invasion in hepatocellular carcinoma: a deep learning model validated across hospitals. Cancer Imaging (2021) 21:1–16. doi: 10.1186/s40644-021-00425-3
25. Jiang YQ, Cao SE, Cao S, Chen JN, Wang GY, Shi WQ, et al. Preoperative identification of microvascular invasion in hepatocellular carcinoma by XGBoost and deep learning. J Cancer Res Clin Oncol (2021) 147:821–33. doi: 10.1007/s00432-020-03366-9
26. Rodriguez-Peralvarez M, Luong TV, Andreana L, Meyer T, Dhillon AP, Burroughs AK. A systematic review of microvascular invasion in hepatocellular carcinoma: diagnostic and prognostic variability. Ann Surg Oncol (2013) 20:325–39. doi: 10.1245/s10434-012-2513-1
27. Herath S, Harandi M, Porikli F. (2017). Learning an invariant hilbert space for domain adaptation, in: Proceedings of the IEEE conference on computer vision and pattern recognition. Honolulu, HI, USA: Institute of Electrical and Electronics Engineers (IEEE), pp. 3845–54. doi: 10.1109/cvpr.2017.421
28. Dührkop K, Nothias LF, Fleischauer M, Reher R, Ludwig M, Hoffmann MA, et al. Systematic classification of unknown metabolites using high-resolution fragmentation mass spectra. Nat Biotechnol (2021) 39(4):462–71. doi: 10.1101/2020.04.17.046672
29. Peng H, Long F, Ding C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans Pattern Anal Mach Intell (2005) 27(8):1226–38. doi: 10.1109/tpami.2005.159
30. Gretton A, Borgwardt KM, Rasch MJ, Schölkopf B, Smola A. A kernel two-sample test. J Mach Learn Res (2012) 13(1):723–73. doi: 10.5555/2503308.2188410
31. Huang GB, Zhu QY, Siew CK. Extreme learning machine: theory and applications. Neurocomputing (2006) 70(1-3):489–501. doi: 10.1016/j.neucom.2005.12.126
32. Han Z, Zhang C, Fu H, Zhou JT. Trusted multi-view classification with dynamic evidential fusion. IEEE Trans Pattern Anal Mach Intell (2022) 45(2):2551–66. doi: 10.1109/TPAMI.2022.3171983
33. Zhang C, Han Z, Fu H, Zhou JT, Hu Q. CPM-Nets: Cross partial multi-view networks. Adv Neural Inf Process Syst (2019) 32:559–69. doi: 10.5555/3454287.3454338
34. Sheng H, Mao M, Huang K, Zheng H, Liu W, Liang Y. A clinical tool to predict the microvascular invasion risk in patients with hepatocellular carcinoma. Technol Cancer Res Treat (2023) 22:15330338231182526. doi: 10.1177/15330338231182526
Keywords: hepatocellular carcinoma, microvascular invasion, multi-modal, domain adaptation, feature fusion
Citation: Yu Z, Liu Y, Dai X, Cui E, Cui J and Ma C (2024) Enhancing preoperative diagnosis of microvascular invasion in hepatocellular carcinoma: domain-adaptation fusion of multi-phase CT images. Front. Oncol. 14:1332188. doi: 10.3389/fonc.2024.1332188
Received: 03 November 2023; Accepted: 09 January 2024;
Published: 25 January 2024.
Edited by:
Francisco Tustumi, University of São Paulo, BrazilReviewed by:
Jianguo Xu, Sichuan University, ChinaXiaopeng Yao, Southwest Medical University, China
Daniel Szor, University of São Paulo, Brazil
Copyright © 2024 Yu, Liu, Dai, Cui, Cui and Ma. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xisheng Dai, bWF0aGR4c0AxNjMuY29t; Enming Cui, Y2VtMjAwOEAxNjMuY29t
†These authors share first authorship