 Jipeng Yan
Jipeng Yan Zhuo Hu
Zhuo Hu Zong-Wei Li
Zong-Wei Li Shiren Sun
Shiren Sun Wei-Feng Guo
Wei-Feng Guo- 1Department of Nephrology, Xijing Hospital, The Fourth Military Medical University, Xi’an, China
- 2School of Electrical Engineering, Zhengzhou University, Zhengzhou, China
- 3State Key Laboratory of Oncology in South China, Collaborative Innovation Center for Cancer Medicine, Sun Yat-sen University Cancer Center, Guangzhou, China
Due to rapid development of high-throughput sequencing and biotechnology, it has brought new opportunities and challenges in developing efficient computational methods for exploring personalized genomics data of cancer patients. Because of the high-dimension and small sample size characteristics of these personalized genomics data, it is difficult for excavating effective information by using traditional statistical methods. In the past few years, network control methods have been proposed to solve networked system with high-dimension and small sample size. Researchers have made progress in the design and optimization of network control principles. However, there are few studies comprehensively surveying network control methods to analyze the biomolecular network data of individual patients. To address this problem, here we comprehensively surveyed complex network control methods on personalized omics data for understanding tumor heterogeneity in precision medicine of individual patients with cancer.
Introduction
Increasing studies on cancer genomics data have revealed that individual heterogeneity of cancer patients is one of the main reasons for no substantive breakthrough in cancer treatment methods. With the recent development in high-throughput omics technology, data resources have become available for cancer research, such as genomic and transcriptomic data (1, 2). Personalized omics data of individual patients should be analyzed for understanding the tumor heterogeneity of cancer diseases. The key challenges are how to integrate multi-level omics data, such as genomic and transcriptomic data, for understanding the regulatory mechanism in individual patients, and how to identify cancer-related drug targets (3). Therefore, it is of great theoretical significance and clinical application value for designing computational methods through integration of the omics data of individual patients and screening for drug targets related to phenotype transitions of these patients.
Modern medical studies have shown that cancer is generally an outcome of the dysfunction of related dynamic systems. From the system biology perspective, cancer can be driven by the state transition of key driver genes, which can lead to the dysfunction of molecular networks (e.g., gene regulation networks or signal transduction networks) that regulate molecular pathways and cellular processes. Moreover, the state of biomolecules (e.g., gene expression value) with complex dynamic characteristics in individual patients changes with time and environmental conditions (Figure 1). To understand the dynamics of individual patients, the regulatory mechanism of molecular networks needs to be understood from the perspective of network control theory. This theory considers the state variables of a high-dimensional dynamic system as a complex network and studies how to effectively control the state of driving variables through control signals in the system with optimal control objectives (such as minimum number of controllers or minimum energy), thus changing the network state to the desired stable state (4).
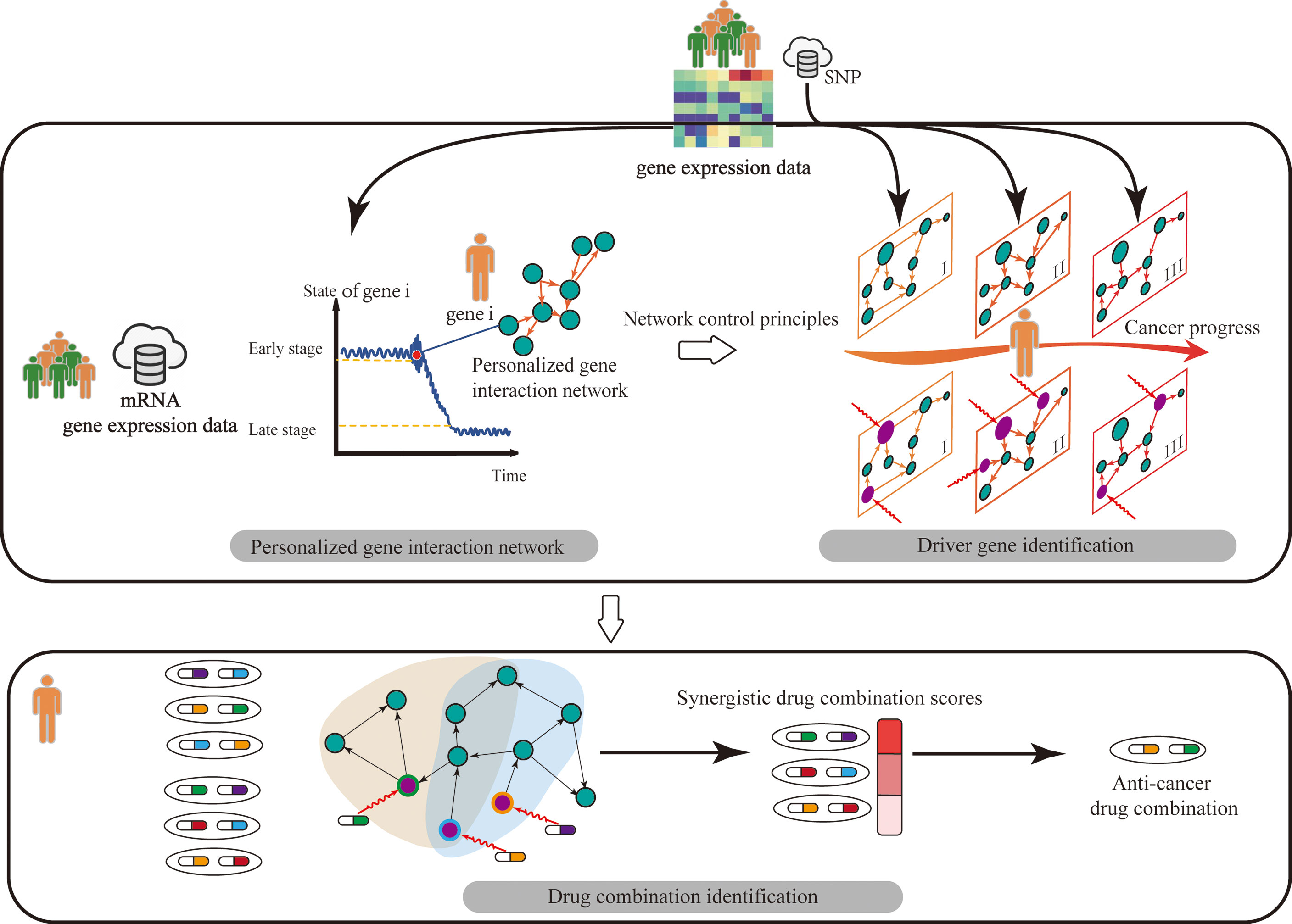
Figure 1 Overview of our review. The contents of our review consist of three parts. Firstly, we summarized the works to construct personalized gene interaction network from genomics of individual patients. Then on the personalized gene interaction networks, we pointed out how to identify personalized driver gene by using network control tools. Finally, we described how to discover synergistic drug combinations by targeting personalized driver genes.
Although traditional control theory (5) has been studied extensively, it is not suitable for a biological network system with numerous nodes (e.g., genes). Network control methods provide the technology for analyzing biomolecule networks with complex dynamic characteristics and quantifying their ability to intervene the biomolecule system of individual patients through proper control signals (6, 7). Moreover, researchers have made progress about network control principles. However, few studies comprehensively surveyed network control methods to analyze the biomolecular network data of individual patients. Considering these facts, this study provided a comprehensive survey for complex network control methods on the multi-omics data of individual patients including methods for personalized gene interaction network construction, network control principles, driver gene prediction, and drug combination identification (Figure 1), which aims to reveal the molecular mechanism and regulation law of personalized biomolecular systems for the diagnosis, prevention, and treatment of individual patients.
Datasets
With the development of cancer genomics technology, many data resources are available for understanding the cancer mechanism. In the past decade, a large amount of cancer genome data from large-scale cancer genomics projects facilitated the development of computational methods for mining personalized omics data of individual patients and understanding tumor heterogeneity in cancer precision medicine. Among these cancer genomics projects, The Cancer Genome Atlas, an important database for mining cancer omics data (2), has created a genomic panorama of different cancers. It currently contains 33 cancer types and more than 20,000 samples. The Cancer Cell Line Encyclopedia is a compilation of gene expression, chromosomal copy number, and massively parallel sequencing data from 1457 cell lines. It provides the pharmacological activities of 24 anticancer drugs in 504 cell lines (8, 9). Gene Expression Omnibus (GEO) is a public repository of functional genomics data currently storing approximately 23,002 public series submitted directly by 168,607 laboratories. This series comprises 4,851,647 samples derived from more than 1600 organisms (10).
BioGPS (11) is an online gene annotation database integrating 150 resources. It can query gene name information, chromosome location, gene function, transcript information, encoded protein information, and related protein names. However, this database cannot provide a detailed gene annotation list, and therefore, users find it difficult to annotate the genes for a large number of samples. The cancer gene census (CGC) data (12) offers a detailed list of driver genes that have been experimentally verified as cancer driver genes (13–15). The Network of Cancer Genes (NCG) (16) is a database that collects and annotates cancer genes from a large amount of cancer sequencing data. This database contains 2372 genes, including experimentally verified cancer driver genes.
Construction of Personalized Gene Interaction Network
A biological system is a complex dynamic multi-scale system involving different time, space, and functions. Cells contain genes that store information, proteins, and metabolites and perform biological functions for forming basic functional modules. A complex biological system is composed of multiple functional modules. In system biology, the key to constitute a biological system is not its components (e.g., genes, proteins, and small biological molecules), but their interactions with components having different properties. These interactions constitute the regulatory network controlling different biological functions.
The rich information can be obtained from the high-dimensional data of samples of individual patients. However, the individual genomics data of these patients are often limited and incomplete. Therefore, methods to ensure complete use of personalized genomics data for designing effective gene interaction network construction algorithms of individual patients must be developed. The personalized gene interaction network represents which gene pairs are involved in the disease development for each patient. Because the principles of the personalized network dynamics are hidden, it is important to reconstruct the personalized state transition networks with the personalized genetic data (e.g., expression profiles). It is a key challenge to unravel the dynamic nature of gene regulation during a biological process in systems biology.
Current gene interaction network construction methods, such as Gene Network Reconstruction tool (GNR) (17), dynamic cascaded method (DCM) (18), and Hotnet2 (19), use gene expression data of population cancer patients. Although these gene regulation networks can reflect the gene interaction mechanism of the disease, they cannot describe the gene interaction relationship of individual patients. Numerous single-sample gene interaction network construction methods have recently been proposed. Several common techniques including Single Sample Network construction method (SSN) (20), Paired Single Sample Network construction method (Paired-SSN) (21), Single Pearson Correlation Coefficient calculation method (SPCC) (22, 23), and Cell Specific Network construction method (CSN) (24), and Linear Interpolation to Obtain Network Estimates for Single Samples (LIONESS) (25) were introduced as follows. In Table S1 of Supplementary Tables, we gave a summary of these methods including brief descriptions and input data for constructing personalized gene interaction network.
1) SSN
SSN is a statistical method to construct an individual-specific network based on statistical perturbation analysis of a single sample against a group of given control samples (20). For the SSN method, the co-expression network of the tumor sample network or normal sample network for each patient is constructed based on statistical perturbation analysis of one sample against a group of given reference samples (e.g., choosing the normal sample data of all of the patients as the reference data).
2) Paired-SSN
For the paired-SSN method (21), the co-expression network of the tumor sample network and normal sample network for each patient is firstly constructed in the same way as for the SSN method. Then, the personalized differential co-expression network between the normal sample network and tumor sample network can be constructed in which the edge will exist if the P-value of the gene pair is less than (greater than) 0.05 in the tumor network but greater than (less than) 0.05 in the normal network for their corresponding patient.
3) SPCC method
To overcome the difficulty in obtaining correlations or edges from one sample, the SPCC approach (22, 23) was developed by decomposing each PCC measurement into multiple additive elements that form a new vector embedding correlation-like information of two variables for one sample.
4) LIONESS
LIONESS does not rely upon differential analysis between the tumor sample and a group of normal samples, and it reconstructs the individual specific network in a population of tumor samples as the personalized gene state transition network for each tumor sample (25). LIONESS constructs the state transition network by calculating the edge statistical significance between all the tumor samples and the tumor samples without a given single sample.
5) CSN
The CSN method is derived from a theoretical model based on statistical dependency (24), which can be viewed as data transformation from the “unstable” gene expression data to the “stable” gene association data. CSN designs a statistic for gene pairs and can obtain the P-value corresponding to the edge between genes by the statistic.
We should note that conditional or partial sample-specific correlation network can be generally used to eliminate the indirect co-expressions between genes (26, 27). Furthermore, the reference reliable gene/protein interaction network are generally used to take overlapped edges from the original gene co-expression edges, forming the final personalized gene interaction networks for the above methods. However, the current single-sample gene regulation network construction methods ignore temporal data of individual patients (28), and their accuracy and stability need improvement.
Network Control Principles
A core concept in network science is to control and intervene on network dynamics (4). Network control methods have recently received extensive attention (29–36). Therefore, network control methods are better than the traditional control concept in revealing the dynamic characteristics of biological networks with a lot of noise in edge weight. In particular, considering the gene expression profiles in normal and tumor samples as the respective state of a given patient, network control tools aim to detect a small number of driver nodes by the input signals related with the state transition of individual patient depending on adequate knowledge of the network structure. The input signals may be oncogene activation signals such as gene mutation or metabolites changes in specific tissue. The “controllers” in network control problem for molecular networks mean the genetic or environment factors which produce the oncogene activation signals. As per our best understanding, current methods can be classified as directed and undirected network control methods.
i) For the control methods of directed networks, Liu et al. (37) studied the structural control of directed networks and proposed Maximum Matching Sets-based controllability methods by referring to the structural controllability theory of linear systems, which has greatly inspired the promotion of research of network control methods and applications. Although these network control tools have been applied to biomolecular systems, some interesting properties of biological systems have also been discovered. For example, driving mutant genes (38) and drug targets (39) were found in cancer datasets, and driving metabolites were detected in human liver metabolic networks (40). However, these tools only describe the linear dynamic behavior of the network and are not sufficient for completely characterizing the complex nonlinear dynamic system. Recently, a Feedback Vertex Set (FVS)-based control method based on the framework of feedback vertex set control theory (FC) that can be used to study network systems with nonlinear dynamics was proposed. However, for the FVS-based control method, not only the network structure needs to be known but also the functional form of the governing equation must satisfy certain properties (41, 42). Zanudo et al. applied FVS-based control to directed networks (43). By comparing FVS predictions with those of MMS-based controllability methods, they identified topological features underlying different observed phenomena.
ii) For the control methods of undirected networks, Yuan et al. proposed an accurate control method (44) that can identify the minimum set of driver nodes in the undirected networks. Because the precise control method only describes the linear dynamic behavior of biological networks, it cannot be used to accurately describe their nonlinear dynamic behavior. To overcome the aforementioned problems, some researchers proposed minimum dominating set (MDS)-based control methods (45). These methods, however, have a strong assumption on control signals, that is, these signals can independently control their neighborhood nodes. However, most controllers cannot satisfy the strong conditions; therefore, FVS-based methods of undirected networks (namely NCUA) based on the framework of feedback vertex set control theory (FC) have been proposed (46). Since most current methods are designed based on the time-invariant network system, temporal networks can accurately describe the characteristics of cancer omics data. Thus, more accurate network control methods need to be further developed to accurately understand the dynamic characteristics of the network.
To easier understand these network control methods, we gave the concept comparisons including the network types and targeted states and input and network dynamics between different network control method including MMS, MDS and DFVS and NCUA (Table S2 of Supplementary Tables). In Figure 2, we intuitively explained these methods. We summarized some key points of different structure network control methods as follow:
i) The MMS control methods investigate the controllability of directed structural networks with linear or local nonlinear dynamics through a minimum set of input nodes and they only give an incomplete view of the network control properties for a system with nonlinear dynamics.
ii) MDS control method studies the controllability of undirected networks by assuming that each driver node in the MDS model can control its associated edges independently in the undirected networks. Since MDS works with the strong assumption that the controllers can control its outgoing links independently, it requires higher costs in many kinds of networks which may underestimate the structural control analysis of undirected networks;
iii) NCUA and DFVS study the structural network control of undirected and direct networks respectively based on the framework of FC (42). Therefore NCUA and DFVS methods ultimately depict the structure-based network control of the large-scale system with nonlinear dynamics. Since FC assumes that the functional form of the governing equations must satisfy some continuous, dissipative, and decaying properties, DFVS and NCUA may be only suitable some specialized nonlinear systems.
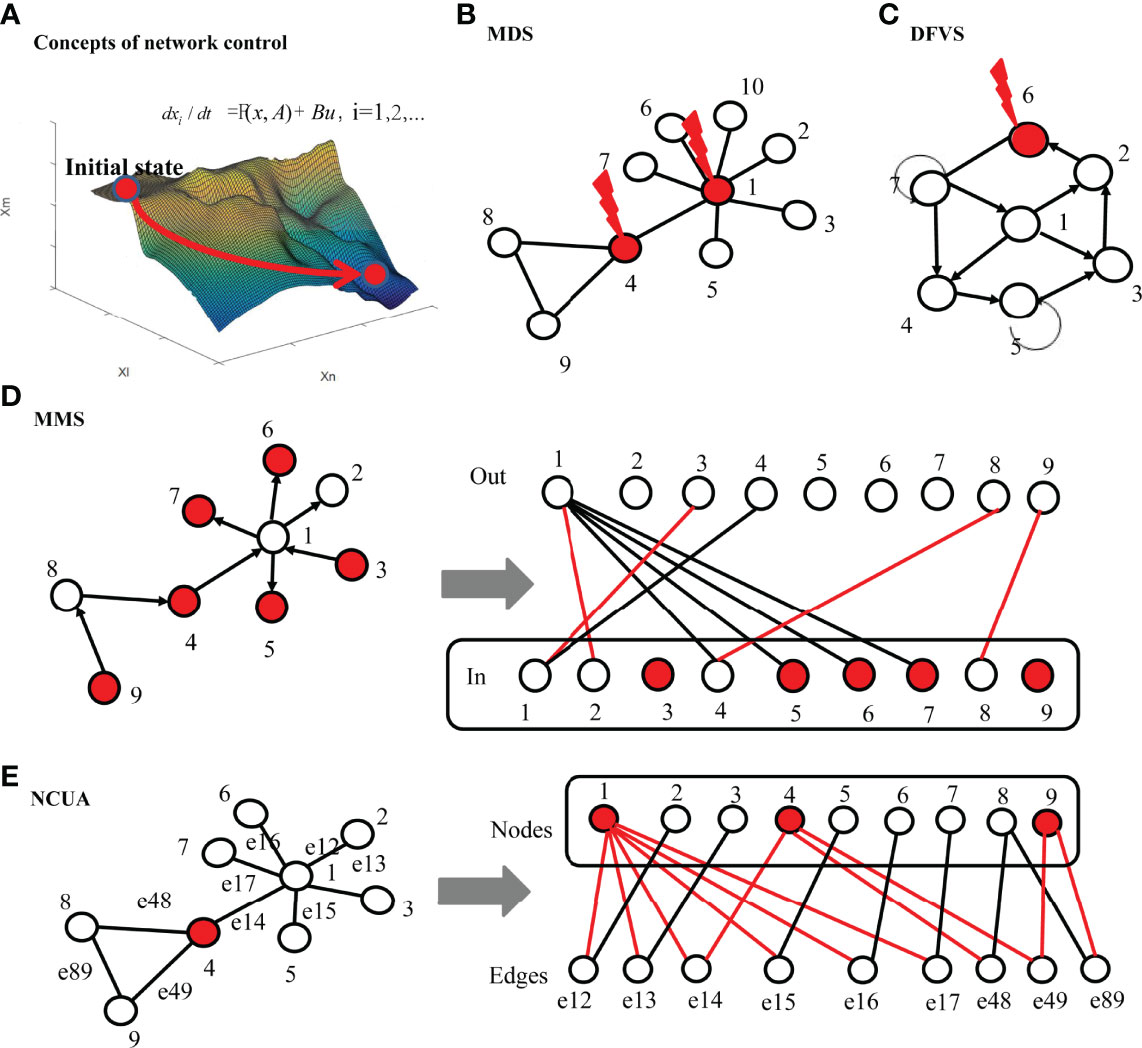
Figure 2 The principles of different network control methods. (A) Concept demonstration of network control methods. Network control tools aim to detect a small number of driver nodes which form the input matrix and are injected by the input signals for driving the state transition of high dimension networked system depending on adequate knowledge of the network structure. (B) MDS based control methods. If the connected edges of MDS are removed, there will be no edges in the network. By assuming that the driving node can independently control all neighbor nodes, the minimum dominating set (MDS) in the undirected network is taken as the set of driver nodes, and the red node represents the minimum driving node. (C) DFVS based control methods. The red nodes represent the minimum set of feedback nodes (FVS), that is, if the connected edges of FVS are removed, there will be no loops in the network. For FVS based control methods, by controlling the nodes in FVS, the whole system can be transformed from one stable attractor to another attractor. (D) MMS based control methods. The directed network is transformed into a bipartite graph. For the bipartite graph, the upper side represents the out degree of the original network, while the bottom side represent the in degree of the original network nodes. If there is an edge from one node to another node in the original network, an edge connecting these two nodes is added to the bipartite graph. According to the maximum matching of bipartite graph, the maximum matching (i.e., red edges) can be obtained, and 6 unmatched nodes (i.e., red nodes) can be found in the bottom side of bipartite graph. By controlling these 6 nodes, the system structure can be completely controllable for MMS based control methods. (E) NCUA based control methods. Firstly, the original undirected network is transformed into a bipartite graph, in which the upper side represents the nodes of the original network and the bottom side represent the edges of the original network respectively. Then, the nodes covering the nodes on the bottom side (i.e., red nodes) are obtained in the bipartite graph and are considered as driver nodes for the NCUA method. The red edges represent the links between the driver nodes and the nodes of bottom side in the bipartite graph.
Driver Gene Prediction
Using new methods, researchers have recently made some progress in predicting cancer driver genes of population cohorts. These methods are based on mutation frequency, machine learning, and complex network. (1) In gene mutation frequency-based methods, the mutation frequency of driver genes is usually assumed to be significantly higher than that of other genes (13, 47–51). However, due to the tumor heterogeneity, it is difficult to build a reliable background mutation model. In addition, these methods cannot be used to detect the low-mutated frequency and non-mutated cancer driver genes, because a part of driver genes is mutated at high frequencies (>20%), while most of cancer mutations occur at intermediate frequencies (2–20%) or even lower (52), and even many genes that play important roles in tumorigenesis are not altered on the DNA sequences, and these genes are dysregulated through various cellular mechanisms (53). (2) Machine learning-based methods (49, 51, 54–56) usually train the classifier (e.g., random forest, support vector machine) by extracting various kinds of features from different types of cancer data to predict new cancer driver genes. Although machine learning-based methods can effectively predict some cancer driver genes, because of the incomplete database, some key driver genes may be ignored, thus generating false-positive results. (3) Complex network-based methods usually assume that driver genes have obvious structural characteristics at the biological network level (19, 57, 58). Although these methods have been successfully used for detecting cancer driver genes, they are still limited to incomplete and unreliable interactions in biological network (59).
The aforementioned algorithms focus on how to identify driver genes in population cohorts but cannot be directly applied to the data of individual patients because of the following reasons. On the one hand, TCGA provides 33 cancer types with more than 10,000 samples and 3,000,000 mutation data, while the sample size for individual patients is typically very small. On the other hand, the functional characteristics of cancer mutations in population cohorts are different from those observed in individual cancer patient data with complex and unclear dynamics. Therefore, considering that network techniques such as random walk with restart (RWR) (60), network diffusion (19, 61), subnetwork enrichment analysis (62), matrix completion (63) and network structure control (6, 64–66) to predict cancer driver genes at the biological network level by incorporating the knowledge of pathways, protein-protein interactions, can deal with high-dimensional data having a small sample size, researchers proposed some network algorithms for predicting personalized driver genes of individual patients (14, 15, 67). Although these algorithms can predict personalized driver genes with important biological functions, they do not consider dynamic changes in the structure of the personalized gene interaction network, thereby leading to false-positive results and affecting the accuracy of driver gene identification. Therefore, dynamic changes in the structure of the personalized gene interaction network must be considered for inferring the evolution trajectory of driver genes and accurately understanding the cancer development mechanism.
Drug Combination Identification
Computational methods for predicting combination drugs have recently attracted extensive attention (68). These methods can predict a large number of combination drugs with enhanced efficacy and reduced adverse effects (69), which are beneficial for providing efficient clinical treatments (70). At present, drug combination prediction methods mainly include complex network- and machine learning-based methods. (1) The complex network-based methods generally use some network optimization algorithms to predict drug combinations (71–73). However, their predictive performance relies on prior knowledge of drug targets and disease-related networks and is generally only suitable for a few specific diseases. (2) The machine learning-based methods use drug attribute information and cell line experimental data to predict combination drugs (74). The drug characteristics include chemical structure (75, 76), physical and chemical properties of the substructure and toxic modules (77), drug targets (78), and single drug dose response (79, 80). The cell line data include gene expression profile (81), transcriptome (76), pathway network (82), gene interaction network (83), microRNA expression and protein abundance (84), gene variation information, and copy number variation (78). The machine learning algorithms for drug combination prediction mainly include logistic regression (76), Bayesian network (85), random forest (86), multi-decision assemble (87), deep neural network (77), and deep residual neural network (88).
The existing methods ignore the heterogeneity of combination drugs among individual patients, and thus cannot predict effective drug combinations for individual patients. Therefore, an appropriate and effective drug combination prediction method needs to be designed by considering the information of individual patients. However, because personalized genomics data are generated from a small sample size and have a high dimension, these drug combination methods based on large samples cannot be used to accurately identify individual drug combinations from such data. Several studies have attempted to provide such recommendations through predictive models that can predict the efficacy of a drug for an input genomic profile. For instance, Sheng et al. (89) proposed an algorithm on a cell line (or a patient profile) based on similarity of the input drug and cell line to those in Genomics of Drug Sensitivity in Cancer (GDSC) and Cancer Cell Line Encyclopedia (CCLE). Recently, Drug Recommendations by Integrating Multiple Biomedical Databases (DruID) (90) utilized a Prescriptive Analytics framework based on Integer Programming on multiple public well known databases (91) for personalized drug recommendations. These methods require genomics data from cell lines and a list of genes with mutations, from a single patient, as input which ignore the personalized gene interaction for identifying personalized drug combinations. In our previous work, we used the network control theory to design a personalized drug combination prediction model, aiming to identify personalized synergistic drug combinations by targeting personalized driver genes of individual patients (6, 7). In fact, the model neglected the individual dynamic characteristics of drug activity and toxic concentration in drug combination therapy, and thus could not provide precise personalized drug combination. Therefore, a more effective personalized drug combination prediction model needs to be designed considering more information of individual patients’ omics data.
Future Directions
Due to the complex dynamics of cancer data, some of the future directions for designing network control methods are as follows:
i)Designing Boolean network control methods. Although network control methods can analyze the dynamics of a biomolecular network, the positive and negative sign characteristics of interactions are currently ignored. For example, in a gene interaction network, the activation or inhibition regulatory relationship between genes is indicated as a connection with positive and negative signs (92). These signs of the gene interaction network become important when the network is controlled in a particular manner, whereas most current network control methods for personalized genome omics data only assume that their state of interactions are non-zero and do not make any assumptions about the sign of interactions. Therefore, designing Boolean network control methods considering the positive and negative sign characteristics of network interactions is an important future direction.
ii) Designing temporal network control methods. Driver genes influence the cell state through a combination of molecular interactions that may change dynamically during cancer progression (93, 94). At present, most network control methods are designed based on the static time-invariant network structure. However, the network structures of cancer patients differ at different cancer stages, which needs to be considered (95). Therefore, how to design reasonable temporal network control methods for inferring the evolutionary trajectory of driver genes in cancer patients needs to be determined.
iii) Predicting biomarker for individual patients based on network observability. Individual early diagnosis has become essential in precision medicine, which has thus made biomarker prediction increasingly important in drug development (96–102). Therefore, more effective methods are required to describe transitions in cancer status and to identify more biologically significant biomarkers. Network observability is dual with network controllability for network with linear dynamics (103, 104). It focuses on how to select key sensor nodes in the network to reconstruct the state of the entire network. Therefore, developing effective biomarker prediction algorithms for individual patients based on network observability is another crucial future direction.
iv) Designing network control methods on personalized single-cell data. With the development of biological sequencing technology, single-cell data provides a powerful resource for revealing the gene interaction of a single cell and understanding the tumor heterogeneity of individual patients with cancer (105). Therefore, how to design effective network control methods on the single-cell data of individual patients to predict biomarkers, driver genes, and drug targets for such patients is another important research direction.
v) Designing deep learning techniques for network controllability. Over the past decade, deep learning has become a focal topic in artificial intelligence and machine learning (106, 107).In fact, deep learning techniques have been developed for predicting the controllability robustness according to the input network-adjacency matrices (108). However, there are no related works to apply deep learning techniques especially graph based deep learning techniques (107) for studying controllability of personalized gene interaction network. Therefore, how to utilize deep learning methods to analyze controllability of personalized gene network is another interesting and important topic in the future.
Conclusions
The genomic profiles of cancer patients are diverse and heterogeneous. These profiles are believed to be responsible for heterogeneity of drug response in cancer patients. The current main challenge in cancer precision medicine is to develop effective computational methods for finding personalized biomarkers, driver genes, and drug targets for individual patients. These personalized biomarkers, driver genes, and drug targets would help improve the outcome of cancer patients, especially those with drug resistance. As the number of samples of an individual patient is usually limited, the accuracy and reliability of statistical methods based on a large sample size (109, 110) will greatly be reduced for mining personalized omics data of individual patients. Therefore, considering the multi-omics data of individual patients, this study discusses cancer datasets, construction of gene regulation network, network structure control method, driver gene prediction, and drug combination prediction for individual patients in order to understand tumor heterogeneity in precision medicine.
Author Contributions
W-FG developed the methodology and designed research. JY and W-FG wrote the original manuscript. JY, ZH, Z-WL, SS and W-FG revised the manuscript. SS and W-FG supervised the work, made critical revisions of the paper, and approved the submission of the manuscript. All authors contributed to the article and approved the submitted version.
Funding
This paper was supported by the National Natural Science Foundation of China [62002329 (W-FG)], and Key scientific and technological projects of Henan Province [2102310083(W-FG)], and China postdoctoral foundation [2021M692915(W-FG)], and Henan postdoctoral foundation [202002021(W-FG)], Research start-up funds for top doctors in Zhengzhou University [32211739 (W-FG)], and open Funds of State Key Laboratory of Oncology in South China [HN2021-01 (W-FG)]. The funders had no role in study design, data collection, and analysis, decision to publish, or preparation of the manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We thank BMCSCI (www.bmcscience.com) for its linguistic assistance during the preparation of this manuscript.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fonc.2022.891676/full#supplementary-material
References
1. Levine DA, C.G.A.R. Network. Integrated Genomic Characterization of Endometrial Carcinoma. Nature (2013) 497:67. doi: 10.1038/nature12113
2. Zhu Y, Qiu P, Ji Y. TCGA-Assembler: Open-Source Software for Retrieving and Processing TCGA Data. Nat Methods (2014) 11:599. doi: 10.1038/nmeth.2956
3. Caravagna G, Graudenzi A, Ramazzotti D, Sanz-Pamplona R, De Sano L, Mauri G, et al. Algorithmic Methods to Infer the Evolutionary Trajectories in Cancer Progression. Proc Natl Acad Sci (2016) 113:E4025–34. doi: 10.1073/pnas.1520213113
4. Liu Y-Y, Barabási A-L. Control Principles of Complex Systems. Rev Mod Phys (2016) 88:035006. doi: 10.1103/RevModPhys.88.035006
5. Kalman RE. Mathematical Description of Linear Dynamical Systems. J Soc Ind Appl Math Ser A: Control (1963) 1:152–92. doi: 10.1137/0301010
6. Guo WF, Zhang SW, Feng YH, Liang J, Zeng T, Chen L. Network Controllability-Based Algorithm to Target Personalized Driver Genes for Discovering Combinatorial Drugs of Individual Patients. Nucleic Acids Res (2021) 49:e37. doi: 10.1093/nar/gkaa1272
7. Guo W-F, Yu X, Shi Q-Q, Liang J, Zhang S-W, Zeng T. Performance Assessment of Sample-Specific Network Control Methods for Bulk and Single-Cell Biological Data Analysis. PloS Comput Biol (2021) 17:e1008962. doi: 10.1371/journal.pcbi.1008962
8. Cancer Cell Line Encyclopedia Consortium, Genomics of Drug Sensitivity in Cancer Consortium. Pharmacogenomic Agreement between Two Cancer Cell Line Data Sets. Nature (2015) 528:84. doi: 10.1038/nature15736
9. Barretina J, Caponigro G, Stransky N, Venkatesan K, Margolin AA, Kim S, et al. The Cancer Cell Line Encyclopedia Enables Predictive Modelling of Anticancer Drug Sensitivity. Nature (2012) 483:603. doi: 10.1038/nature11003
10. Edgar R, Domrachev M, Lash AE. Gene Expression Omnibus: NCBI Gene Expression and Hybridization Array Data Repository. Nucleic Acids Res (2002) 30:207–10. doi: 10.1093/nar/30.1.207
11. Wu C, Orozco C, Boyer J, Leglise M, Goodale J, Batalov S, et al. BioGPS: An Extensible and Customizable Portal for Querying and Organizing Gene Annotation Resources. Genome Biol (2009) 10:R130. doi: 10.1186/gb-2009-10-11-r130
12. Futreal PA, Coin L, Marshall M, Down T, Hubbard T, Wooster R, et al. A Census of Human Cancer Genes. Nat Rev Cancer (2004) 4:177. doi: 10.1038/nrc1299
13. Jia P, Zhao Z. VarWalker: Personalized Mutation Network Analysis of Putative Cancer Genes From Next-Generation Sequencing Data. PloS Comput Biol (2014) 10:e1003460. doi: 10.1371/journal.pcbi.1003460
14. Bertrand D, Chng KR, Sherbaf FG, Kiesel A, Chia BK, Sia YY, et al. Patient-Specific Driver Gene Prediction and Risk Assessment Through Integrated Network Analysis of Cancer Omics Profiles. Nucleic Acids Res (2015) 43:e44–4. doi: 10.1093/nar/gku1393
15. Hou JP, Ma J. DawnRank: Discovering Personalized Driver Genes in Cancer. Genome Med (2014) 6:56. doi: 10.1186/s13073-014-0056-8
16. Repana D, Nulsen J, Dressler L, Bortolomeazzi M, Venkata SK, Tourna A, et al. The Network of Cancer Genes (NCG): A Comprehensive Catalogue of Known and Candidate Cancer Genes From Cancer Sequencing Screens. Genome Biol (2019) 20:1. doi: 10.1186/s13059-018-1612-0
17. Wang Y, Joshi T, Zhang X-S, Xu D, Chen L. Inferring Gene Regulatory Networks From Multiple Microarray Datasets. Bioinformatics (2006) 22:2413–20. doi: 10.1093/bioinformatics/btl396
18. Zhu H, Rao RSP, Zeng T, Chen L. Reconstructing Dynamic Gene Regulatory Networks From Sample-Based Transcriptional Data. Nucleic Acids Res (2012) 40:10657–67. doi: 10.1093/nar/gks860
19. Leiserson MD, Vandin F, Wu H-T, Dobson JR, Eldridge JV, Thomas JL, et al. Pan-Cancer Network Analysis Identifies Combinations of Rare Somatic Mutations Across Pathways and Protein Complexes. Nat Genet (2015) 47:106–14. doi: 10.1038/ng.3168
20. Liu X, Wang Y, Ji H, Aihara K, Chen L. Personalized Characterization of Diseases Using Sample-Specific Networks. Nucleic Acids Res (2016) 44:e164–4. doi: 10.1093/nar/gkw772
21. Guo W-F, Zhang S-W, Wei ZG, Zeng T, Chen L. Constrained Target Controllability of Complex Networks. J Stat Mech Theory Exp (2017) 2017(6):063402. doi: 10.1088/1742-5468/aa6de6
22. Yu X, Zeng T, Wang X, Li G, Chen L. Unravelling Personalized Dysfunctional Gene Network of Complex Diseases Based on Differential Network Model. J Transl Med (2015) 13:189–9. doi: 10.1186/s12967-015-0546-5
23. Zhang W, Zeng T, Liu X, Chen L. Diagnosing Phenotypes of Single-Sample Individuals by Edge Biomarkers. J Mol Cell Biol (2015) 7:231–41. doi: 10.1093/jmcb/mjv025
24. Dai H, Li L, Zeng T, Chen L. Cell-Specific Network Constructed by Single-Cell RNA Sequencing Data. Nucleic Acids Res (2019) 47:e62–2. doi: 10.1093/nar/gkz172
25. Kuijjer ML, Tung MG, Yuan G, Quackenbush J, Glass K. Estimating Sample-Specific Regulatory Networks. iScience (2019) 14:226–40. doi: 10.1016/j.isci.2019.03.021
26. Huang Y, Chang X, Zhang Y, Chen L, Liu X. Disease Characterization Using a Partial Correlation-Based Sample-Specific Network. Brief Bioinform (2020) 22:6. doi: 10.1093/bib/bbaa062
27. Li L, Dai H, Fang Z, Chen L. C-CSN: Single-cell Rna Sequencing Data Analysis by Conditional Cell-Specific Network. Genomics Proteomics Bioinformatics (2021) 19(2):319–29. doi: 10.1101/2020.01.25.919829
28. van der Wijst MG, de Vries DH, Brugge H, Westra H-J, Franke L. An Integrative Approach for Building Personalized Gene Regulatory Networks for Precision Medicine. Genome Med (2018) 10:96. doi: 10.1186/s13073-018-0608-4
30. Lombardi A, Hörnquist M. Controllability Analysis of Networks. Phys Rev E (2007) 75:056110. doi: 10.1103/PhysRevE.75.056110
31. Gao J, Liu Y-Y, D'souza RM, Barabási A-L. Target Control of Complex Networks. Nat Commun (2014) 5:5415. doi: 10.1038/ncomms6415
32. Cornelius SP, Kath WL, Motter AE. Realistic Control of Network Dynamics. Nat Commun (2013) 4:1942. doi: 10.1038/ncomms2939
33. Wu F-X, Wu L, Wang J, Liu J, Chen L. Transittability of Complex Networks and its Applications to Regulatory Biomolecular Networks. Sci Rep (2014) 4:4819. doi: 10.1038/srep04819
34. Nacher JC, Akutsu T. Minimum Dominating Set-Based Methods for Analyzing Biological Networks. Methods (2016) 102:57–63. doi: 10.1016/j.ymeth.2015.12.017
35. Delpini D, Battiston S, Riccaboni M, Gabbi G, Pammolli F, Caldarelli G. Evolution of Controllability in Interbank Networks. Sci Rep (2013) 3:1626. doi: 10.1038/srep01626
36. Lin C-T. Structural Controllability. IEEE Trans Automat Control (1974) 19:201–8. doi: 10.1109/TAC.1974.1100557
37. Liu Y-Y, Slotine J-J, Barabási A-L. Controllability of Complex Networks. Nature (2011) 473:167. doi: 10.1038/nature10011
38. Dinstag G, Shamir R. PRODIGY: Personalized Prioritization of Driver Genes. Bioinformatics (2019) 36:6. doi: 10.1093/bioinformatics/btz815
39. Asgari Y, Salehzadeh-Yazdi A, Schreiber F, Masoudi-Nejad A. Controllability in Cancer Metabolic Networks According to Drug Targets as Driver Nodes. PloS One (2013) 8:e79397. doi: 10.1371/journal.pone.0079397
40. Liu X, Pan L. Detection of Driver Metabolites in the Human Liver Metabolic Network Using Structural Controllability Analysis. BMC Syst Biol (2014) 8:51. doi: 10.1186/1752-0509-8-51
41. Fiedler B, Mochizuki A, Kurosawa G, Saito D. Dynamics and Control at Feedback Vertex Sets. I: Informative and Determining Nodes in Regulatory Networks. J Dyn Differ Equ (2013) 25:563–604. doi: 10.1007/s10884-013-9312-7
42. Mochizuki A, Fiedler B, Kurosawa G, Saito D. Dynamics and Control at Feedback Vertex Sets. II: A Faithful Monitor to Determine the Diversity of Molecular Activities in Regulatory Networks. J Theor Biol (2013) 335:130–46. doi: 10.1016/j.jtbi.2013.06.009
43. Zañudo JGT, Yang G, Albert R. Structure-Based Control of Complex Networks with Nonlinear Dynamics. Proc Natl Acad Sci (2017) 114:7234–9. doi: 10.1073/pnas.1617387114
44. Yuan Z, Zhao C, Di Z, Wang W-X, Lai Y-C. Exact Controllability of Complex Networks. Nat Commun (2013) 4:2447. doi: 10.1038/ncomms3447
45. Nacher JC, Akutsu T. Dominating Scale-Free Networks with Variable Scaling Exponent: Heterogeneous Networks are Not Difficult to Control. New J Phys (2012) 14:073005. doi: 10.1088/1367-2630/14/7/073005
46. Guo WF, Zhang SW, Zeng T, Li Y, Gao JX, Chen LN. A Novel Network Control Model for Identifying Personalized Driver Genes in Cancer. PloS Comput Biol (2019) 15:27. doi: 10.1371/journal.pcbi.1007520
47. Dees ND, Zhang Q, Kandoth C, Wendl MC, Schierding W, Koboldt DC, et al. MuSiC: Identifying Mutational Significance in Cancer Genomes. Genome Res (2012) 22:1589–98. doi: 10.1101/gr.134635.111
48. Lawrence MS, Petar S, Paz P, Kryukov GV, Kristian C, Andrey S, et al. Mutational Heterogeneity in Cancer and the Search for New Cancer-Associated Genes. Nature (2013) 499:214–8. doi: 10.1038/nature12213
49. Wong WC, Kim D, Carter H, Diekhans M, Ryan MC, Karchin R. CHASM and SNVBox: Toolkit for Detecting Biologically Important Single Nucleotide Mutations in Cancer. Bioinformatics (2011) 27:2147–8. doi: 10.1093/bioinformatics/btr357
50. Mao Y, Chen H, Liang H, Meric-Bernstam F, Mills GB, Chen K. CanDrA: Cancer-Specific Driver Missense Mutation Annotation with Optimized Features. PloS One (2013) 8:e77945. doi: 10.1371/journal.pone.0077945
51. Luo P, Ding Y, Lei X, Wu F-X. Deepdriver: Predicting Cancer Driver Genes Based on Somatic Mutations Using Deep Convolutional Neural Networks. Front Genet (2019) 10:13. doi: 10.3389/fgene.2019.00013
52. Lawrence MS, Stojanov P, Mermel CH, Robinson JT, Garraway LA, Golub TR, et al. Discovery and Saturation Analysis of Cancer Genes Across 21 Tumour Types. Nature (2014) 505:495–501. doi: 10.1038/nature12912
53. Vogelstein B, Papadopoulos N, Velculescu VE, Zhou S, Diaz LA Jr., Kinzler KW. Cancer Genome Landscapes. Science (2013) 339:1546–58. doi: 10.1126/science.1235122
54. Tokheim CJ, Papadopoulos N, Kinzler KW, Vogelstein B, Karchin R. Evaluating the Evaluation of Cancer Driver Genes. Proc Natl Acad Sci USA (2016) 113:14330–5. doi: 10.1073/pnas.1616440113
55. Rogers MF, Gaunt TR, Campbell C. Prediction of Driver Variants in the Cancer Genome Via Machine Learning Methodologies. Brief Bioinform (2021) 22:bbaa250. doi: 10.1093/bib/bbaa250
56. Liu C, Dai Y, Yu K, Zhang ZK. Enhancing Cancer Driver Gene Prediction by Protein-Protein Interaction Network. IEEE/ACM Trans Comput Biol Bioinform (2021) 99:1–1. doi: 10.1109/TCBB.2021.3063532
57. Ciriello G, Cerami E, Sander C, Schultz N. Mutual Exclusivity Analysis Identifies Oncogenic Network Modules. Genome Res (2012) 22:398–406. doi: 10.1101/gr.125567.111
58. Zhang S-Y, Zhang S-W, Liu L, Meng J, Huang Y. M6a-Driver: Identifying Context-Specific mRNA m6A Methylation-Driven Gene Interaction Networks. PloS Comput Biol (2016) 12:e1005287. doi: 10.1371/journal.pcbi.1005287
59. Cheng FX, Zhao JF, Zhao ZM. Advances in Computational Approaches for Prioritizing Driver Mutations and Significantly Mutated Genes in Cancer Genomes. Brief Bioinform (2016) 17:642–56. doi: 10.1093/bib/bbv068
60. Zhou Y, Wang S, Yan H, Pang B, Zhang X, Pang L, et al. Identifying Key Somatic Copy Number Alterations Driving Dysregulation of Cancer Hallmarks in Lower-Grade Glioma. Front Genet (2021) 12:654736. doi: 10.3389/fgene.2021.654736
61. Cowen L, Ideker T, Raphael BJ, Sharan R. Network Propagation: A Universal Amplifier of Genetic Associations. Nat Rev Genet (2017) 18:551–62. doi: 10.1038/nrg.2017.38
62. Zhang D, Bin YN. Driversubnet: A Novel Algorithm for Identifying Cancer Driver Genes by Subnetwork Enrichment Analysis. Front Genet (2021) 11:10. doi: 10.3389/fgene.2020.607798
63. Zhang T, Zhang S-W, Li Y. Identifying Driver Genes for Individual Patients through Inductive Matrix Completion. Bioinformatics (2021) 37, 23:4477–84. doi: 10.1093/bioinformatics/btab477
64. Guo WF, Zhang SW, Liu LL, Liu F, Shi QQ, Zhang L, et al. Discovering Personalized Driver Mutation Profiles of Single Samples in Cancer by Network Control Strategy. Bioinformatics (2018) 34:1893–903. doi: 10.1093/bioinformatics/bty006
65. Guo WF, Zhang SW, Shi QQ, Zhang CM, Zeng T, Chen L. A Novel Algorithm for Finding Optimal Driver Nodes to Target Control Complex Networks and its Applications for Drug Targets Identification. BMC Genomics (2018) 19(S1):924. doi: 10.1186/s12864-017-4332-z
66. Guo WF, Zhang SW, Zeng T, Akutsu T, Chen LN. Network Control Principles for Identifying Personalized Driver Genes in Cancer. Brief Bioinform (2020) 21:1641–62. doi: 10.1093/bib/bbz089
67. Page L, Brin S, Motwani R, Winograd T. The PageRank Citation Ranking: Bringing Order to the Web. Stanford University, Stanford: Stanford Digital Libraries Working Paper (1998).
68. Huang L, Jiang Y, Chen Y. Predicting Drug Combination Index and Simulating the Network-Regulation Dynamics by Mathematical Modeling of Drug-Targeted EGFR-ERK Signaling Pathway. Sci Rep (2017) 7:40752. doi: 10.1038/srep40752
69. Chen D, Liu X, Yang Y, Yang H, Lu P. Systematic Synergy Modeling: Understanding Drug Synergy From a Systems Biology Perspective. BMC Syst Biol (2015) 9:56. doi: 10.1186/s12918-015-0202-y
70. Madani Tonekaboni SA, Soltan GL, Manem VS, Haibe-Kains B. Predictive Approaches for Drug Combination Discovery in Cancer. Brief Bioinform (2016) 19:2. doi: 10.1093/bib/bbw104
71. Kaifang P, Ying-Wooi W, Choi WT, Donehower LA, Jingchun S, Dhruv P, et al. Combinatorial Therapy Discovery Using Mixed Integer Linear Programming. Bioinformatics (2014) 30:1456. doi: 10.1093/bioinformatics/btu046
72. Lei H, Fuhai L, Jianting S, Xiaofeng X, Jinwen M, Ming Z, et al. DrugComboRanker: Drug Combination Discovery Based on Target Network Analysis. Bioinformatics (2014) 30:i228. doi: 10.1093/bioinformatics/btu278
73. Yadav B, Wennerberg K, Aittokallio T, Tang J. Searching for Drug Synergy in Complex Dose–Response Landscapes Using an Interaction Potency Model. Comput Struct Biotechnol J (2015) 13:504–13. doi: 10.1016/j.csbj.2015.09.001
74. Ding P, Luo J, Liang C, Xiao Q, Cao B, Li G. Discovering Synergistic Drug Combination From a Computational Perspective. Curr Top Med Chem (2018) 18:965–74. doi: 10.2174/1568026618666180330141804
75. Chen X, Ren B, Chen M, Wang Q, Zhang L, Yan G. Nllss: Predicting Synergistic Drug Combinations Based on Semi-supervised Learning. PloS Comput Biol (2016) 12:e1004975. doi: 10.1371/journal.pcbi.1004975
76. Liu Y, Zhao H. Predicting Synergistic Effects Between Compounds Through Their Structural Similarity and Effects on Transcriptomes. Bioinformatics (2016) 32:3782. doi: 10.1093/bioinformatics/btw509
77. Preuer K, Rpi L, Hochreiter S, Bender A, Bulusu KC, Klambauer G. Deepsynergy: Predicting Anti-Cancer Drug Synergy With Deep Learning. Bioinformatics (2018) 34:9. doi: 10.1093/bioinformatics/btx806
78. Jeon M, Kim S, Park S, Lee H, Kang J. In Silico Drug Combination Discovery for Personalized Cancer Therapy. BMC Syst Biol (2018) 12:16. doi: 10.1186/s12918-018-0546-1
79. Gayvert KM, Aly O, Platt J, Bosenberg MW, Stern DF, Elemento O. A Computational Approach for Identifying Synergistic Drug Combinations. PloS Comput Biol (2017) 13:e1005308. doi: 10.1371/journal.pcbi.1005308
80. Zhang M, Lee S, Yao B, Xiao G, Xu L, Xie Y. DIGREM: An Integrated Web-Based Platform for Detecting Effective Multi-Drug Combinations. Bioinformatics (2018) 35(10):1792–4. doi: 10.1093/bioinformatics/bty860
81. Hsu YC, Chiu YC, Chen Y, Hsiao TH, Chuang EY. A Simple Gene Set-Based Method Accurately Predicts the Synergy of Drug Pairs. BMC Syst Biol (2016) 10:66. doi: 10.1186/s12918-016-0310-3
82. Chen D, Zhang H, Lu P, Liu X, Cao H. Synergy Evaluation by a Pathway-Pathway Interaction Network: A New Way to Predict Drug Combination. Mol Biosyst (2015) 12:614–23. doi: 10.1039/C5MB00599J
83. Rabadan R, Kribelbauer J, Wang J. Network Propagation Reveals Novel Features Predicting Drug Response of Cancer Cell Lines. Curr Bioinfrm (2016) 11:2. doi: 10.2174/1574893611666160125222144
84. Angermueller C, Pärnamaa T, Parts L, Stegle O. Deep Learning for Computational Biology. Mol Syst Biol (2016) 12:878. doi: 10.15252/msb.20156651
85. Peng L, Chao H, Yingxue F, Jinan W, Ziyin W, Jinlong R, et al. Large-Scale Exploration and Analysis of Drug Combinations. Bioinformatics (2015) 31:2007. doi: 10.1093/bioinformatics/btv080
86. Li X, Xu Y, Cui H, Huang T, Wang D, Lian B, et al. Prediction of Synergistic Anti-Cancer Drug Combinations Based on Drug Target Network and Drug Induced Gene Expression Profiles. Artif Intell Med (2017) 83:35–43. doi: 10.1016/j.artmed.2017.05.008
87. Shi JY, Li JX, Gao K, Lei P, Yiu SM. Predicting Combinative Drug Pairs Towards Realistic Screening Via Integrating Heterogeneous Features. BMC Bioinform (2017) 18:409. doi: 10.1186/s12859-017-1818-2
88. Xia F, Shukla M, Brettin T, Garcia-Cardona C, Cohn J, Allen JE, et al. Predicting Tumor Cell Line Response to Drug Pairs With Deep Learning. BMC Bioinform (2018) 19:486. doi: 10.1186/s12859-018-2509-3
89. Sheng J, Li F, Wong STC. Optimal Drug Prediction from Personal Genomics Profiles. J BioMed Health Inform (2017) 19:1264–70. doi: 10.1109/JBHI.2015.2412522
90. Liany H, Jeyasekharan A, Rajan V. DruID: Personalized Drug Recommendations by Integrating Multiple Biomedical Databases for Cancer. bioRxiv (2021). 2021.04.11.439315. doi: 10.1101/2021.04.11.439315
91. Piñeiro-Yáñez E, Reboiro-Jato M, Gómez-López G, Perales-Patón J, Troulé K, Rodríguez JM, et al. PanDrugs: A Novel Method to Prioritize Anticancer Drug Treatments According to Individual Genomic Data. Genome Med (2018) 10:41. doi: 10.1186/s13073-018-0546-1
92. Choo SM, Ban B, Joo JI, Cho KH. The Phenotype Control Kernel of a Biomolecular Regulatory Network. BMC Syst Biol (2018) 12:49. doi: 10.1186/s12918-018-0576-8
93. Caravagna G, Graudenzi A, Ramazzotti D, Sanz-Pamplona R, De SL, Mauri G, et al. Algorithmic Methods to Infer the Evolutionary Trajectories in Cancer Progression. Proc Natl Acad Sci USA (2015) 113:e4025. doi: 10.1101/027359
94. Nussinov R, Jang H, Tsai C-J, Cheng F. Precision Medicine Review: Rare Driver Mutations and Their Biophysical Classification. Biophys Rev (2019) 11:5–19. doi: 10.1007/s12551-018-0496-2
95. Patil A, Kumagai Y, Liang K-c, Suzuki Y, Nakai K. Linking Transcriptional Changes Over Time in Stimulated Dendritic Cells to Identify Gene Networks Activated During the Innate Immune Response. PloS Comput Biol (2013) 9:e1003323. doi: 10.1371/journal.pcbi.1003323
96. Chen L, Liu R, Liu ZP, Li M, Aihara K. Detecting Early-Warning Signals for Sudden Deterioration of Complex Diseases by Dynamical Network Biomarkers. Sci Rep (2012) 2:342. doi: 10.1038/srep00342
97. Kazuyuki A, Liu R, Koizumi K, Liu X, Chen L. Dynamical Network Biomarkers: Theory and Applications. Gene (2021) 808:145997. doi: 10.1016/j.gene.2021.145997
98. Honda K, Ono M, Shitashige M, Masuda M, Kamita M, Miura N, et al. Proteomic Approaches to the Discovery of Cancer Biomarkers for Early Detection and Personalized Medicine. Jpn J Clin Oncol (2012) 43:103–9. doi: 10.1093/jjco/hys200
99. Li M, Zeng T, Liu R, Chen L. Detecting Tissue-Specific Early Warning Signals for Complex Diseases Based on Dynamical Network Biomarkers: Study of Type 2 Diabetes by Cross-Tissue Analysis. Brief Bioinform (2013) 15:229–43. doi: 10.1093/bib/bbt027
100. Xu J, Wu M, Zhu S, Lei J, Gao J. Detecting the Stable Point of Therapeutic Effect of Chronic Myeloid Leukemia Based on Dynamic Network Biomarkers. BMC Bioinform (2019) 20:202. doi: 10.1186/s12859-019-2738-0
101. Sun Y, Zhao H, Wu M, Xu J, Zhu S, Gao J. Identifying Critical States of Hepatocellular Carcinoma Based on Landscape Dynamic Network Biomarkers. Comput Biol Chem (2020) 85:107202. doi: 10.1016/j.compbiolchem.2020.107202
102. Zhang X, Xie R, Liu Z, Pan Y, Liu R, Chen P. Identifying Pre-Outbreak Signals of Hand, Foot and Mouth Disease Based on Landscape Dynamic Network Marker. BMC Infect Dis (2021) 21:6. doi: 10.1186/s12879-020-05709-w
103. Liu YY, Slotine JJ, Barabási AL. Observability of Complex Systems. Proc Natl Acad Sci U S A (2013) 110:2460–5. doi: 10.1073/pnas.1215508110
104. Montanari AN, Duan C, Aguirre LA, Motter AE. Functional Observability and Target State Estimation in Large-Scale Networks. Proc Natl Acad Sci (2022) 119:e2113750119. doi: 10.1073/pnas.2113750119
105. Ulirsch JC, Lareau CA, Bao EL, Ludwig LS, Guo MH, Benner C, et al. Interrogation of Human Hematopoiesis at Single-Cell and Single-Variant Resolution. Nat Genet (2019) 51:683–93. doi: 10.1038/s41588-019-0362-6
106. Ching T, Himmelstein DS, Beaulieu-Jones BK, Kalinin AA, Do BT, Way GP, et al. Opportunities and Obstacles for Deep Learning in Biology and Medicine. J R Soc Interface (2018) 15:20170387. doi: 10.1098/rsif.2017.0387
107. Greener JG, Kandathil SM, Moffat L, Jones DT. A Guide to Machine Learning for Biologists. J Nat Rev Mol Cell Biol (2021) 23:40–55. doi: 10.1038/s41580-021-00407-0
108. Lou Y, He Y, Wang L, Chen G. Predicting Network Controllability Robustness: A Convolutional Neural Network Approach. IEEE Trans Cybern (2020) 1–12. doi: 10.1109/TCYB.2020.3013251
109. Harley JB, Alarcón-Riquelme ME, Criswell LA, Jacob CO, Kimberly RP, Moser KL, et al. Genetics, Genome-Wide Association Scan in Women With Systemic Lupus Erythematosus Identifies Susceptibility Variants in ITGAM, PXK, KIAA1542 and Other Loci. Nat Genet (2008) 40:204. doi: 10.1038/ng.81
Keywords: personalized omics, network control principles, tumor heterogeneity, precision medicine, cancer individual patients
Citation: Yan J, Hu Z, Li Z-W, Sun S and Guo W-F (2022) Network Control Models With Personalized Genomics Data for Understanding Tumor Heterogeneity in Cancer. Front. Oncol. 12:891676. doi: 10.3389/fonc.2022.891676
Received: 08 March 2022; Accepted: 12 April 2022;
Published: 31 May 2022.
Edited by:
George Bebis, University of Nevada, Reno, United StatesReviewed by:
Avantika Lal, National Centre for Biological Sciences, IndiaFei Liu, Baoji University of Arts and Sciences, China
Zhi-Ping Liu, Shandong University, China
Copyright © 2022 Yan, Hu, Li, Sun and Guo. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wei-Feng Guo, Z3Vvd2ZAenp1LmVkdS5jbg==; Shiren Sun, c3Vuc2hpcmVuQG1lZG1haWwuY29tLmNu