
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Oncol., 14 April 2022
Sec. Breast Cancer
Volume 12 - 2022 | https://doi.org/10.3389/fonc.2022.858453
This article is part of the Research TopicQuantitative Imaging and Artificial Intelligence in Breast Tumor DiagnosisView all 27 articles
 Hong Liu1*
Hong Liu1* Wen-Dong Xu1,2
Wen-Dong Xu1,2 Zi-Hao Shang1,2
Zi-Hao Shang1,2 Xiang-Dong Wang1Hai-Yan Zhou3Ke-Wen Ma3Huan Zhou3Jia-Lin Qi3Jia-Rui Jiang3Li-Lan Tan3Hui-Min Zeng3Hui-Juan Cai3
Xiang-Dong Wang1Hai-Yan Zhou3Ke-Wen Ma3Huan Zhou3Jia-Lin Qi3Jia-Rui Jiang3Li-Lan Tan3Hui-Min Zeng3Hui-Juan Cai3 Kuan-Song Wang3,4*Yue-Liang Qian1
Kuan-Song Wang3,4*Yue-Liang Qian1Molecular subtypes of breast cancer are important references to personalized clinical treatment. For cost and labor savings, only one of the patient’s paraffin blocks is usually selected for subsequent immunohistochemistry (IHC) to obtain molecular subtypes. Inevitable block sampling error is risky due to the tumor heterogeneity and could result in a delay in treatment. Molecular subtype prediction from conventional H&E pathological whole slide images (WSI) using the AI method is useful and critical to assist pathologists to pre-screen proper paraffin block for IHC. It is a challenging task since only WSI-level labels of molecular subtypes from IHC can be obtained without detailed local region information. Gigapixel WSIs are divided into a huge amount of patches to be computationally feasible for deep learning, while with coarse slide-level labels, patch-based methods may suffer from abundant noise patches, such as folds, overstained regions, or non-tumor tissues. A weakly supervised learning framework based on discriminative patch selection and multi-instance learning was proposed for breast cancer molecular subtype prediction from H&E WSIs. Firstly, co-teaching strategy using two networks was adopted to learn molecular subtype representations and filter out some noise patches. Then, a balanced sampling strategy was used to handle the imbalance in subtypes in the dataset. In addition, a noise patch filtering algorithm that used local outlier factor based on cluster centers was proposed to further select discriminative patches. Finally, a loss function integrating local patch with global slide constraint information was used to fine-tune MIL framework on obtained discriminative patches and further improve the prediction performance of molecular subtyping. The experimental results confirmed the effectiveness of the proposed AI method and our models outperformed even senior pathologists, which has the potential to assist pathologists to pre-screen paraffin blocks for IHC in clinic.
Breast cancer is intrinsically heterogeneous and has been commonly categorized into molecular subtypes since the late 1990s (1). According to various molecular expressions of certain genes, breast cancer can be classified into four molecular subtypes, namely, Luminal A, Luminal B, Her-2, and Basal-like (2). Molecular subtypes directly reveal the biological behavior of breast cancer and represent changes in gene expression, which can be used to determine tailored treatment approaches and predict prognosis (3).
In clinic, molecular subtype diagnosis usually comes from immunohistochemistry (IHC) (4). IHC uses the high specificity between antigen and antibody, as well as histochemical procedures to mark antigen and antibody positions. IHC staining is used to identify aberrant cells such as those found in cancerous tumors. Certain biological activities, such as growth or cell death, are associated with certain molecular markers (5). Four biomarkers, including estrogen receptor (ER), progesterone receptor (PR), human epidermal growth factor receptor 2 (HER2), and Ki67, are commonly utilized to immunostain the slides to determine molecular subtypes of breast cancer. Diagnosed subtypes basically determine corresponding treatment strategies, such as targeted drugs for HER2-positive and hormone therapy for Luminal-A. Due to tumor heterogeneity, gene expression of ER, PR, and HER2 often varies in different paraffin blocks and thus may lead to inaccurate subtype diagnosis. For cost and labor savings, pathologists usually examine only one of the paraffin blocks in a case to determine the molecular subtype of breast cancer. Since molecular subtypes determine treatment strategies, inevitable sampling error is risky due to the tumor heterogeneity and could result in a delay in medical treatment. Molecular subtype prediction from conventional H&E pathological whole slide images (WSI) using the AI method is useful and critical to assist pathologists to pre-screen proper paraffin block for subsequent IHC in clinic.
Changes in gene expression will cause variations in texture in pathological images. Some pathologists have attempted to investigate the statistical relationship between specific gene expression with hematoxylin and eosin (H&E)-stained pathological images (6). Directly predicting molecular subtypes of breast cancer using H&E pathological images based on AI is a prospective study, which may also help improve diagnosis reliability of molecular subtypes.
Molecular subtyping on H&E-stained pathological images is a challenging task since we can only obtain the slide-level label for each molecular subtype without detailed local region information. Even experienced pathologists have difficulty annotating corresponding molecular subtype regions in H&E pathological images (7). Due to the extremely high resolution of whole slide images (WSIs), WSIs are computationally infeasible to be directly fed into a network for training and testing; therefore, they are usually divided into small patches. The lack of patch-level labels makes it a weak label problem for machine learning.
Deep learning is becoming increasingly widely used in computer vision tasks. Most deep learning tasks require a large amount of fine-labeled data for supervised learning, which is time-consuming, especially in medical fields. Weakly supervised learning, for example, has been a hotspot for research on reducing the dependence on labeling data. Benenson et al. (8) adopted an interactive method, in which human annotations and the model collaborate to complete the segmentation task. Berthelot et al. (9) augmented labeled data with unlabeled data for classification. To reduce the influence of noisy data, Cheng et al. (10) presented a weakly supervised learning method using a side information network, which largely alleviates the negative impact of noisy image labels. Qu et al. (11) addressed noisy label problem by enforcing prominent feature extraction by matching feature distribution between clean and noisy data.
In recent years, multi-instance learning (MIL) (12) methods are generally adopted for weakly supervised learning. For WSI classification based on MIL, all patches extracted from a pathological image form a bag, and patches are instances of this bag. With only the bag-level labels in the training stage, the goal of MIL is to train a classifier to predict bag-level labels and even instance-level labels. Some previous work extended and enhanced MIL framework using multiple techniques. Wu et al. (13) proposed DE-MIMG that allows each bag to contain pairs of instances and graphs and results in optimal representation. Discriminative bag mapping (14) was adopted to build a discriminative instance pool that can properly separate bags in the mapping space. As attention mechanism gained its popularity in deep neural networks, Ilse et al. (15) and Shi et al. (16) introduced attention mechanism to MIL, where attention weights can represent how much instances contribute to the bag label. Instead of assuming instances in each bag are independent and identically distributed (i.i.d.), Zhang et al. (17) proposed MIVAE that explicitly models the dependencies among instances within each bag for both instance-level and bag-level prediction. Li et al. (18) proposed to use contrast learning to extract multiscale WSI features and a novel MIL aggregator that models the relations of the instances. Shao et al. (19) devised transformer-based correlated MIL that explored both morphological and spatial information. However, most attention-based and correlated MIL methods require large-scale training datasets and significant computational resources. In addition, feature clustering methods have also drawn some attention in MIL. Wang et al. (20) modeled each WSI as k groups of tiles with similar features to ensure learning both diverse and discriminative features. Similarly, Sharma et al. (21) performed K-means clustering on patches within each WSI and randomly sampled a certain amount of patches from each cluster to accommodate for computational limit without much information loss. However, besides the variability of patches within a WSI, the variability of WSIs from the same category is also considerable, where clustering techniques can be used to refine class-level learned features for more accurate subtyping.
Nevertheless, breast cancer molecular subtyping specifically on H&E images has been insufficiently studied. Shamai et al. (22) used logistic regression to explore correlations between histomorphology and biomarker expression and a deep neural network to predict biomarker expression in examined tissue. Rawat et al. (23) introduced “tissue fingerprints” that can learn H&E features to distinguish patients, which are further used to predict ER, PR, and HER2 status. In these studies, machine learning technique is adopted to predict biomarker expression level from H&E histomorphology; direct molecular subtype prediction, however, has not been achieved. Jaber et al. (24) proposed an intrinsic molecular subtype (IMS) classifier from H&E images and analyzed heterogeneity within patches from the same WSI. Although using Inception-v3 to extract features, they adopted traditional PCA and SVM for classification, leading to limited performance.
Since the patches cut from each WSI may come from various regions including lesion, benign, or background of the WSI, some research (25, 26) regard the non-lesion areas in the patches of the pathological images as noisy labels. Differing from pathological classification tasks, such as ductal carcinoma in situ and invasive ductal carcinoma for breast cancer, where pathologists can label tumor regions with different pathological classes, it is impossible to distinguish tumor regions representing different molecular subtypes even for senior pathologists. Although tumor region annotations are useful information for deep networks to learn molecular subtypes, these manual annotations are time-consuming for pathologists. This paper focuses on molecular subtyping with only slide-level labeling instead of detailed tumor region labeling information. The crucial challenge is to eliminate the influence of noise patches and learn expressive features for classifying molecular subtypes.
In this paper, we modeled the patch-based molecular subtype prediction task of pathological slides as a noisy labeling problem in weakly supervised learning. A multi-instance learning framework DPMIL for pathological image molecular subtyping prediction based on discriminative patch filtering was proposed. First, in order to distinguish noise patches, a pre-classification strategy for molecular classification of pathological slides based on co-teaching was presented. This method adopted co-teaching strategy to train two backbone networks and used co-teaching loss function to filter out noise patches to update model parameters. Then, a local outlier factor algorithm was used to reveal the outliers in the feature space for each molecular subtype, and the patches with features close to the cluster center were retained as discriminative patches. Finally, based on the filtered discriminative patches, the pathological slide-level global loss and patch-level local loss were integrated to fine-tune the prediction model for better feature representation of molecular subtypes. The experimental results confirmed the effectiveness of our proposed framework on the molecular subtyping dataset; breast cancer pathological images were provided by Xiangya Hospital. Our AI models outperformed even senior pathologists, which has the potential to assist in pre-screening proper paraffin block of patients for subsequent IHC molecular subtyping in clinic.
This paper used breast cancer H&E pathology dataset BCMT (Breast Cancer with Molecular Typing) provided by Xiangya Hospital. All the pathology WSIs used a pyramid storage structure.
As Table 1 shows, the BCMT dataset contains 1,254 pathological WSIs from 1,254 patients or cases with slide-level molecular subtype annotations between 2017 and 2019. The dataset contains 313 slides for Luminal A, 382 slides for Luminal B, 316 slides for Her-2 overexpression subtype, and 243 slides for the Basal-like subtype. We randomly divided the slides into training set and validation set with a ratio of 8:2 for each type. This paper uses accuracy, precision, recall, and F1 score to measure the performance of four molecular subtypes.

Table 1 Distribution of each molecular subtyping in the BCMT dataset.
We use 4 GeForce GTX 2080 Tis with 11 GB memory to train the network and Python with Pytorch to implement our algorithm. The initial learning rate is 0.1 and the poly learning rate policy with the power of 0.9 is employed. The minibatch size is set as 32.
This paper proposes a breast cancer molecular subtype prediction framework based on multi-instance learning and discriminative patch filtering. The pipeline of our framework is illustrated in Figure 1.
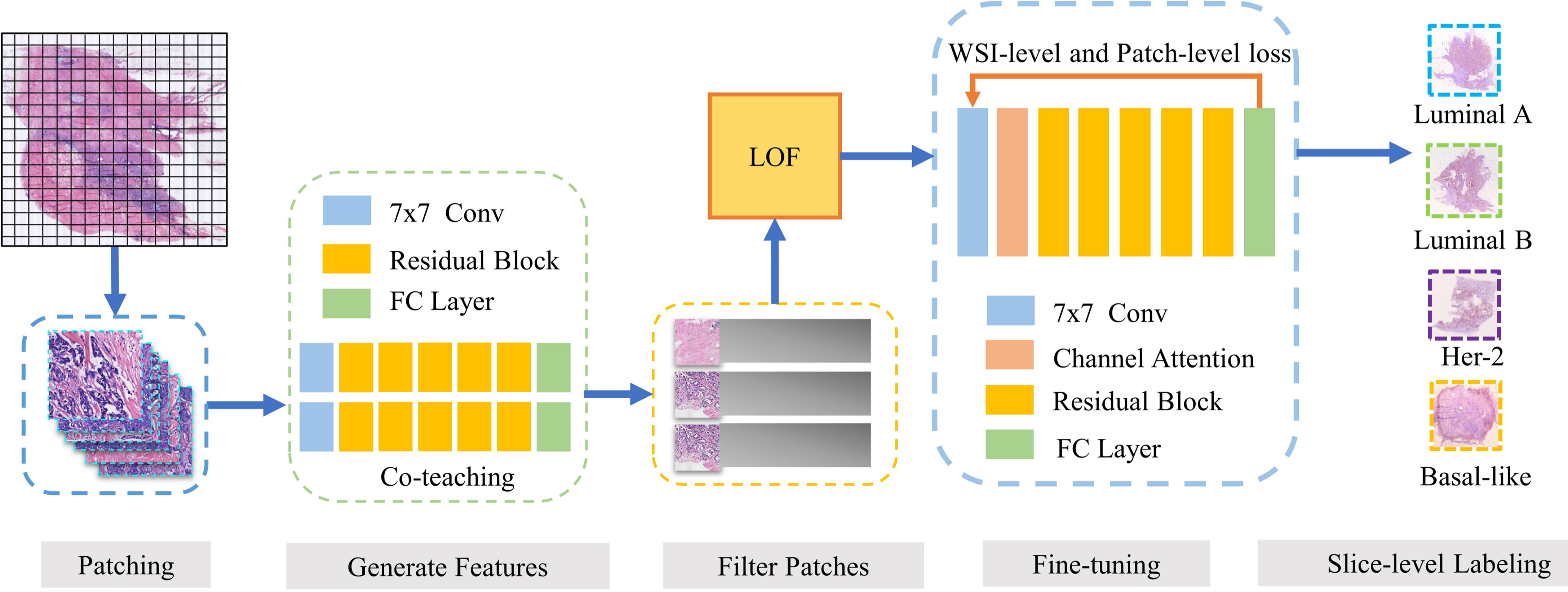
Figure 1 Our framework DPMIL for molecular subtype prediction. The pipeline of out framework contains 5 stages. (1) WSIs are divided into patches. (2) ResNet trained with Co-teaching generate feature for each patch. (3) LOF is adopted to select discriminative patches based on features. (4) Discriminative patches are used to finetune ResNet with WSI and patch loss. (5) Finetuned model predict final molecular subtypes for patches and WSIs.
Firstly, patches from H&E WSIs are extracted to train a molecular subtype classifier. Co-teaching (27) between two networks is used to obtain the patch-level classification and select candidate discriminative patches. Then, local outlier factor (LOF) (28) based on cluster centers of subtypes is adopted to further filter out noise patches and obtain discriminative patches. Based on these discriminative patches, we fine-tuned a new molecular subtyping model initialized by the model performed better in co-teaching stage. Finally, the local loss function and global loss function are combined as constraint information in multi-instance learning framework to improve feature representation of molecular subtypes. The fine-tuned model is used to obtain the final patch-level and slide-level molecular subtyping results.
In multi-instance learning framework, each patch is usually assigned the same label as WSI it belongs to (29–31), while for molecular subtyping, patches from WSI may contain benign or other tissues, which will make slide-level prediction difficult. To reduce these noise patches, this paper adopts co-teaching strategy (27), which usually trains two neural networks and enables them to learn from each other. This strategy assumes that the two models simultaneously consider the samples with the lowest loss as non-noisy samples. These selected instances are considered more representative of the category of the bag than other instances. Each network treats samples with minimal loss in each batch as knowledge and feeds these samples to the other network. Co-teaching strategy is inherently suitable for classification with noisy labels.
This paper uses ResNet-50 (32) as the backbone for co-teaching. The parameters of the two models are randomly initialized and the selection strategy of K follows (27). During co-teaching process, the ResNet-50 network is used to obtain representative features and confidence for each patch. Patches with higher confidence are selected as candidate discrimination patches for subsequent process.
Although the above co-teaching strategy used co-teaching loss to filter out some noise patches, many noise patches from benign or other tissue regions remain. For selected high confidence patches, we can obtain the feature of each patch before the classification layer. Patches belonging to the same molecular subtype tend to gather into the same cluster in feature space.
This paper further proposed a noise filtering method based on local outlier factors (LOF), which is a classic density-based algorithm (28). The main idea is to calculate a numerical score to represent the abnormality degree of a sample to the cluster center with average density. In feature space, the density of a certain point is compared with the average density of points around it. If the former score is lower, the point may be abnormal and vice versa.
Figure 2 shows an example of point set (blue point) in feature space for certain molecular subtyping. We query whether these four points are outliers of the point set. The green point is not an outlier with a lower LOF score, and the red points are outliers with high ones. The size of the red point is the value of the LOF scores and represents the abnormality degree of a certain point.

Figure 2 Local outlier factor example.
We perform LOF for each subtype of molecular features and regard patches that do not belong to a specific cluster of molecular subtype as noise patches.
The above selected discriminative patches are further used to improve feature representation of molecular subtypes based on multi-instance learning framework (MIL). MIL regards the WSI as a bag containing a number of patches. These patches are considered as instances, and their predictions are aggregated to obtain a bag-level prediction. ResNet-50 is also adopted as a backbone to train the MIL classification model. We initialize the MIL model with the model that performs better in co-teaching and use discriminative patches for fine-tuning.
We introduce the slide-level loss function to impose global information constraints to guide the MIL training. The slide-level loss function LWSI is defined as Formula 1, where LWSI represents the slide-level loss function of the ith pathological image defined as the cross-entropy function (32). NWSI represents the total number of pathological slides in the training set, and α is the weight of slide-level loss.
is defined as Formula 2, where M is the molecular type number, and Yo,c is the indicator function. When the output prediction result in o is the same as the true label c of the pathological slide, it is set to 1; otherwise, it is 0.
Pc is defined in Formula 3, representing the confidence level of slide-level molecular subtyping. Np s the total number of patches of the pathological image, and Pi,c represents the confidence value when the ith patch of WSI is classified as type c. As shown in Formula 3, the average confidence value of all patches from the same WSI are obtained and used as the slide-level molecular subtyping confidence.
The two-stage training diagram is shown in Figure 3. We use the patches by LOF-Denoising as input. In each epoch, the training process is divided into two stages. The first stage uses all patches to calculate the patch-level loss to train the model, and we use cross-entropy as the loss function, which is defined in Formula 4.
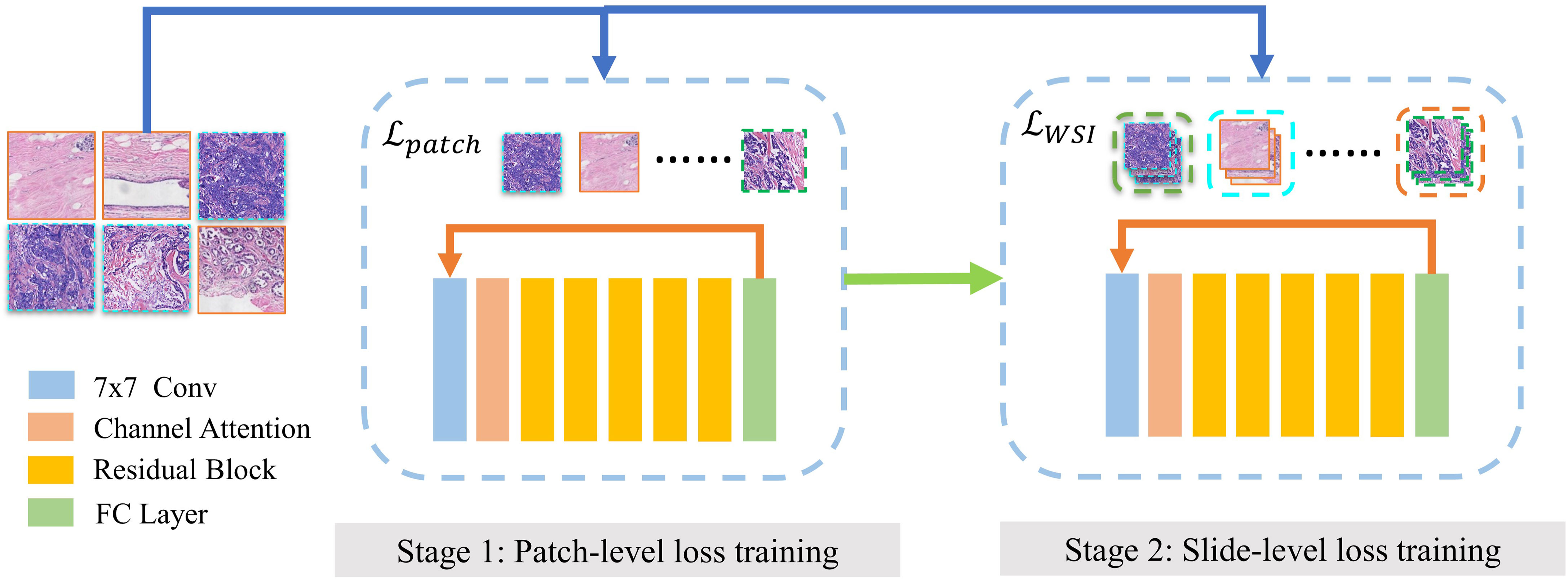
Figure 3 Two-stage training of MIL model. Finetuning of MOL model contains two stages. (1) Model is trained on discriminative patches using patch-level loss. (2) Model is trained for slide-level subtyping using slice-level loss.
M represents the total number of molecular types and Yc is the indicator function, which is equal to 1 when prediction c equals the ground truth of the slide. pc denotes the confidence level and the current patch is classified as type c. The second stage is trained for slide-level subtyping using slide-level loss function as global constraint information.
This section introduces several experiments to evaluate the performance of our proposed framework DPMIL, including the patch resampling strategy, co-teaching, LOF, and MIL training successively. The performance of model is evaluated using average accuracy, recall, precision, and macro F1 for four subtypes.
The total number of different types of patches at different resolutions is shown in Figure 4, which shows the imbalance of number of patches for each molecular subtype and each resolution. To deal with the imbalance of dataset, we use a patch resampling strategy to ensure category equalization. For each epoch, the number of training data for each molecular subtype is set as a constant value. The common part is randomly sampled from all patches, and the number of sampled patches is different according to their resolution: 180,000 patches at 5×, 700,000 patches at 10× and, 5,000,000 patches at 20×. The rare part of the data is generated by data augmentation such as randomly flip, horizontal, and vertical symmetry.
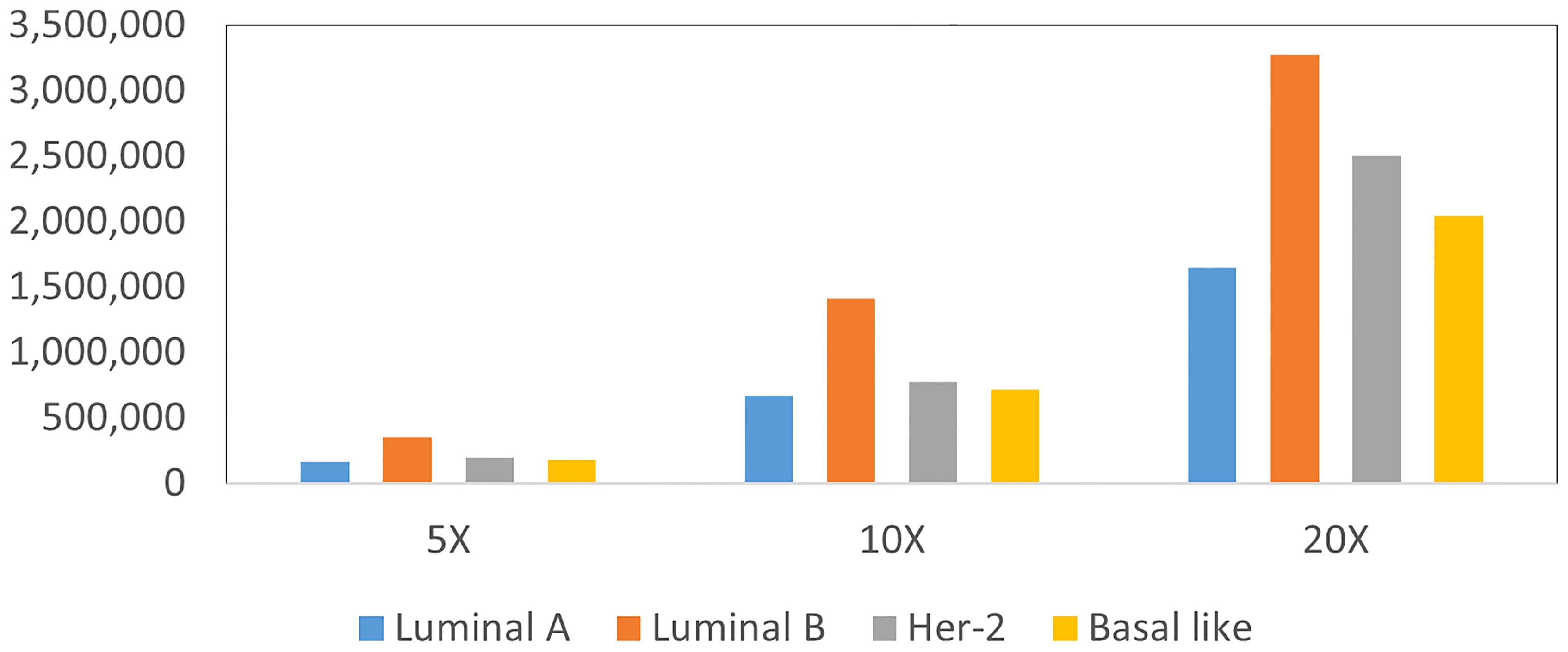
Figure 4 Statistics patches of different molecular subtypes at each resolution.
We use ResNet-50 as the classifier to evaluate the performance of the sampling strategy. Figure 5 shows the results of molecular subtyping with patches resampling at different resolutions. The accuracy of models with resampling strategy are all higher than those without resampling at three resolutions.
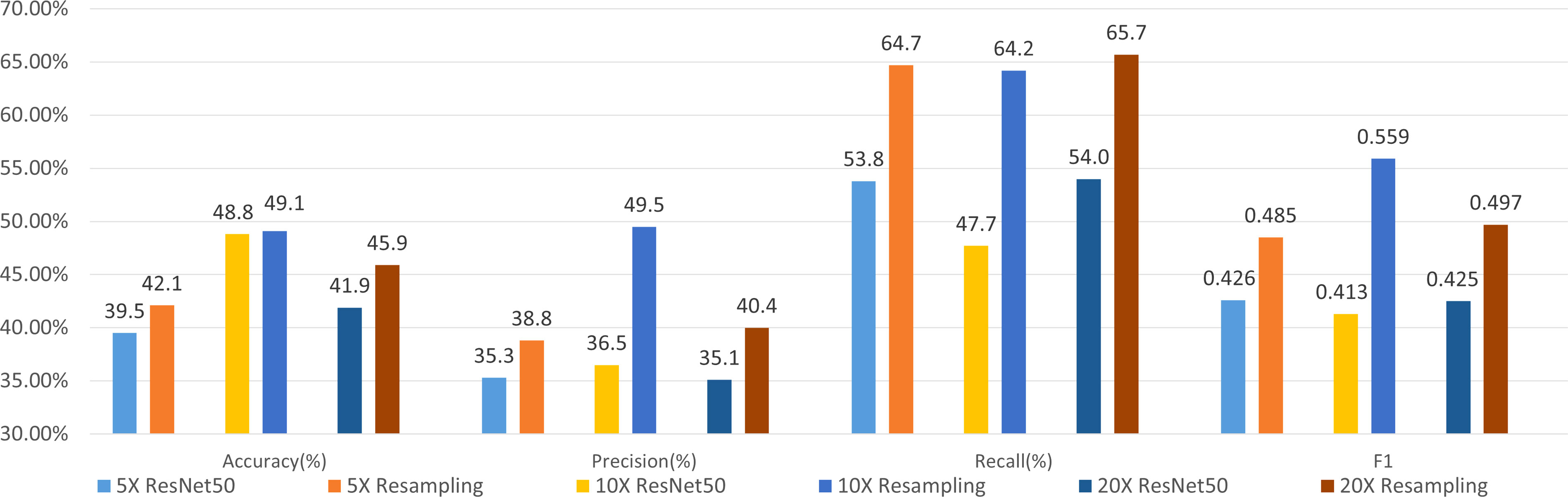
Figure 5 Results of 4-class molecular subtype classification with patch resampling at different resolutions.
F1 values improve about 6% with patch resampling methods for all the resolutions. In addition, the highest accuracy and F1 value are all achieved at 10×, which indicates that patch size and tissue texture make a good compromise at 10×.
This section describes experiments to verify the effectiveness of the co-teaching strategy. ResNet-50 was selected as two backbones for co-teaching. The model is trained for 20 epochs with a minibatch of 32. The initial value of the learning rate is 0.01, and the polynomial learning rate decay method (33) is used to adjust the learning rate.
Figure 6 shows the results of molecular subtype classification with and without co-teaching at different resolutions. The accuracy improves 4% to 6% and F1 score improves 4% to 11% with co-teaching. The co-teaching framework trains two neural networks and enable them to learn from each other, which can reduce the influence of noise patches. The F1 value of 10×-Co-teaching reaches 0.604 and improves 4.5% compared with 10×-resampling.
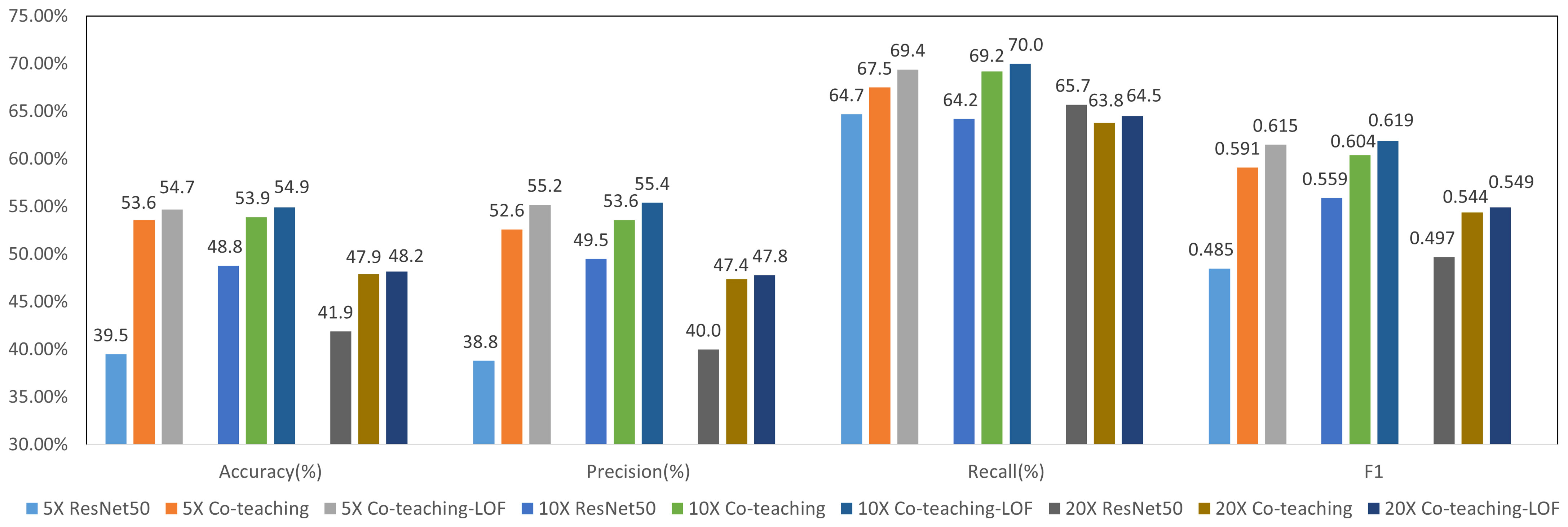
Figure 6 Results of 4-class molecular subtype classification with co-teaching and LOF at different resolutions.
We selected the model from Co-teaching with the higher F1 value at each resolution. Features before classification layer were input into LOF-Denoising for patch filtering for all molecular types. We supposed Si is the number of normal patches of the ith molecular type and there were features in total. These features in co-teaching were used for statistical classification of output logits, the number of which is limited to 2,000. The experimental results are shown in Figure 6, which shows that LOF after co-teaching can further improve the metrics since more noise patches are filtered out. We select 10× resolution in the following experiments.
Based on the above discriminative patch selection, we further verify the multi-instance learning framework with slide-level loss. We used a four-class classification model for molecular subtyping and compared the results with different weights in Formula 1. In the second training stage of the model with global constraint, the influence of the weight K in loss function of formula 1 was examined.
When 0 ≤ α ≤ 1, the influence of the second stage on the model parameters is weakened. When α = 0, the second stage of training does not affect the model. When α > 1, the influence of the second stage is enhanced. We set the value to 0.5, 1.0, and 2.0, respectively, to evaluate the effectiveness of global loss constraint in the second stage of training.
Figure 7 shows the results of MIL for molecular subtyping, proving that using slide-level loss function can improve the performance of the model. The reason may be that there are still some noise patches in the selected patches after noise filtering. We used a slide-level loss to add global constraint information, which can further reduce the influence of noise patches.
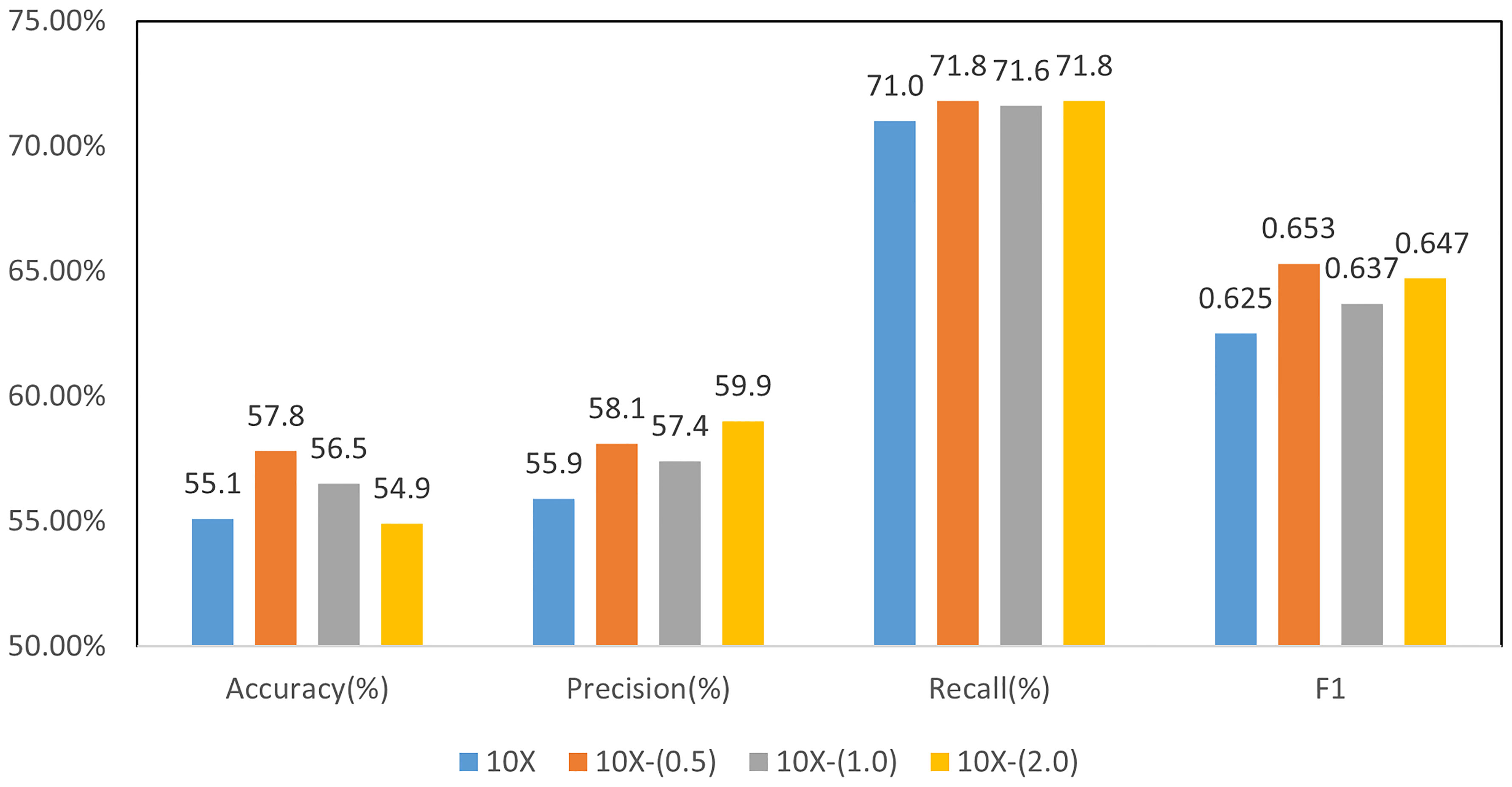
Figure 7 Results of 4-class molecular subtype classification with MIL finetuning at different resolutions.
Apart from the four-class classification model, to further improve the performance of molecular subtype classification, we also tried binary classification models for each molecular subtype. Finally, a weighted fusion method is adopted to accomplish the final four-type classification.
Binary classification models were trained similar to four-class classification model, including co-teaching, LOF, and slide-level loss of MIL. Parameter α is set to 0.5 for all the experiments. The prediction results of each molecular type of binary classification model are shown in Figure 8, where F1 reached over 0.72 for all subtypes. Notably, Basal-like molecular type obtained the highest F1 value of 0.774.
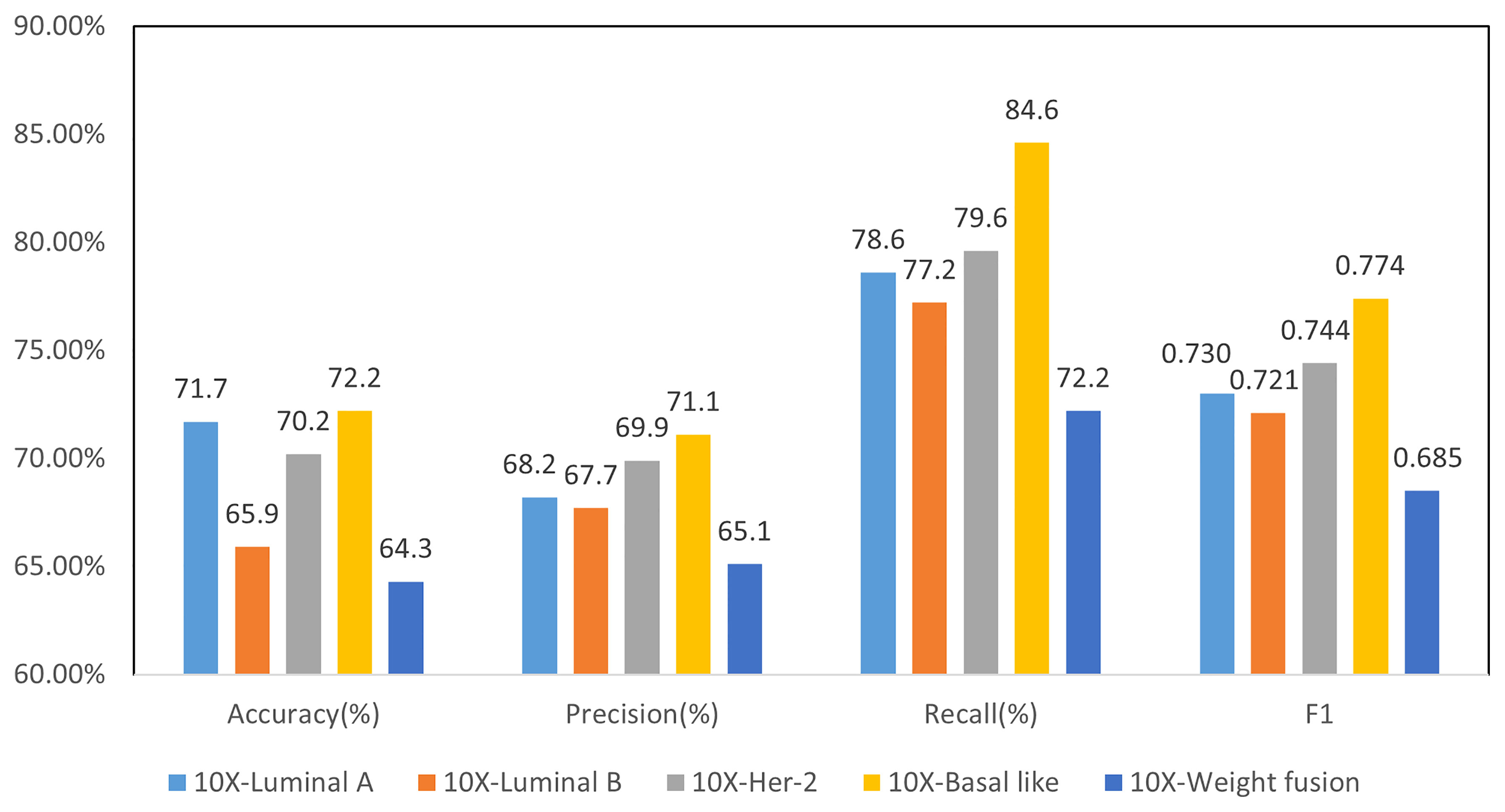
Figure 8 Results of 2-class molecular subtype classification and 4-class weighted fusion at 10× resolution.
For four-class classification, we averaged the confidence level of all patches from a WSI, and then use it as the confidence of the molecular subtype of the WSI. We used grid search (34) for the best weight setting of the four-class prediction model and finally take 0.6, 0.9, 0.5, and 0.7 as weights of four subtypes. The final weighted four-class classification results are shown in Figure 8. Compared with the direct four-class molecular type prediction from model 10×- (0.5) in Figure 7, four-classifier weighted fusion in Figure 8 can increase the accuracy by 6.7% and the F1 score by 3.2%.
To compare our method with pathology doctors in molecular-type classification, nine pathologists were invited to diagnose molecular subtypes of a total of 99 randomly selected WSIs from test dataset. In clinic, pathologists usually can classify molecular subtypes on IHC images but not on H&E-stained images. Therefore, pathologists can only conduct subtyping totally based on image pattern and their clinical experience. Table 2 shows the average accuracy, precision, recall, and macro F1 scores according to the labels of pathologists (D1: 5 years’ experience, D2: 10 years’ experience, and D3: 15 years’ experience) assigned to each H&E WSI. Specifically, we provide the means and ranges of 4 metrics from seven 5-year pathologists (D1s). As shown in Table 2, 5-year experienced doctors can hardly make better predictions than random guess, which indicates the unusual difficulty in breast cancer subtyping on H&E images. To be optimistic, more experienced doctors can provide a more accurate diagnosis on molecular subtypes. Our four-class classification model (10×-0.5) and fused binary classification model (10×-Weight fusion) show obvious superiority over doctors in all metrics, surpassing predictions of the most experienced doctor (D3) by 15.4% and 21.5% in accuracy and F1, respectively.

Table 2 Comparison of molecular subtyping results among doctors and our best models.
Molecular subtyping is becoming more and more important in the therapy of malignant disease. However, accurate molecular subtyping on H&E images is challenging due to tumor heterogeneity. Pathologists should examine every paraffin block of the tumor in order to confirm subtype theoretically, but it is so costly that most pathologists usually examine only one block in a case. In this situation, the sampling error is inevitable and a predictive AI model for molecular subtyping on H&E images can significantly improve the present clinical procedure. Pathologists can quickly make preliminary subtype predictions of a tumor and select the most representative block based on our AI model. Then, the representative block is examined to further confirm the molecular subtyping prediction with IHC in clinic. In addition, the inference time and computing resources our model requires are negligible compared to the expensive IHC. Therefore, pathologists could avoid the sampling error with the help of the AI model at almost no additional cost and provide a more reliable result for oncologists to improve curative effect.
Since WSI-level labels lack detailed region annotation information, most of the existing methods use patch-based methods for WSI recognition. How to eliminate the influence of noise patches and learn the corresponding features for molecular subtyping through training process is the key problem. Our work aims to predict slide-level labels of H&E pathological slides using only weakly annotated information at the slide level. This paper proposes a framework by selecting these discriminant patches to reduce the impact of noise patches and combined MIL for molecular subtype classification. The experimental results show the effectiveness of our proposed framework on the partner hospital’s breast cancer H&E pathological image dataset.
MIL has been applied in diverse diseases and image modalities including classification of cancer in histopathology images, dementia in brain MR, tuberculosis in x-ray images, and others. MIL classifiers can benefit from information about cooccurrence and structure of instances when classifying bags (35). For example, Melendez et al. (36) trained a MIL classifier only with x-ray images labeled as healthy or abnormal, yet outperforming its supervised version trained on outlines of tuberculosis lesions.
Some studies combine traditional machine learning algorithms with weakly supervised learning and apply them to pathological slide classification tasks. Hou et al. (37) combined the EM method based on multi-instance learning with a convolutional neural network and used it to predict patch-level results. Campanella et al. (38) used a recurrent neural network model to extract feature representations between different patch examples to obtain a slide-level classification for basal cell carcinoma and breast cancer axillary lymph node metastasis. Raju et al. (39) proposed a graph attention clustering multi-instance learning algorithm based on texture features to predict the TNM staging of rectal cancer tumor metastasis and improved the accuracy of pathological slide staging. Wang et al. (40) proposed a classification framework for pathological slides for gastric cancer diagnosis, which used localization networks to extract patch features and critical filtered patches to replace the general clustering module. After local network extraction and screening of key patch feature maps, concatenation is performed to obtain an overall feature map describing pathological slides.
Recent studies rely largely on the powerful feature extraction capability of deep learning. Yang et al. (41) trained a six-type classifier for identification of lung lesions from WSIs based on EfficientNet (42). To obtain slide-level diagnosis, a threshold-based tumor-first aggregation method that fused majority voting and probability threshold was proposed. Wang et al. (43) developed a second-order multiple instances learning method with an adaptive aggregator stacked by attention mechanism and RNN for histopathological image classification, attempting to explore second-order statistics of deep features for histopathological images. MIL framework can also be applied to similar tasks like survival prediction. Yao et al. (12) proposed Deep Attention Multiple Instance Learning by introducing Siamese MI-FCN that learns features from phenotype clusters, and attention-based MIL pooling that performs trainable weighted aggregation. While our paper focuses on the selection of discriminative patches and combined local and global constraint information in a MIL framework.
The retrospective study design would have resulted in inevitable bias and all the data were collected from a single center, thereby limiting the sample size of the study. In future work, we will combine multi-center and multi-resolution information of pathological images to improve the accuracy and to evaluate on larger datasets.
Molecular subtype prediction from H&E pathological slides is a challenging task. Based on slide-level weak labels, this paper proposes a multi-instance learning framework for molecular subtype classification with discriminative patches selection. Firstly, we use co-teaching strategy to train the molecular subtype prediction model with noise patches. Then, the noise patches are filtered out according to features obtained from the model through local outlier factor algorithm. Finally, based on the filtered discriminative patches, a multi-instance learning based molecular subtyping model using both slide-level and patch-level loss is fine-tuned. The experimental results show the effectiveness of the proposed framework on the breast cancer H&E pathological image dataset from Xiangya hospital. Although its performance is not sufficient to replace pathologists’ clinical diagnosis directly, it is reasonable to employ our framework to preliminary screening for more convenient and reliable molecular subtyping.
The datasets presented in this article are not readily available because no interviewees consented to their data being retained or shared due to the ethically sensitive nature of the research. Requests to access the datasets should be directed to HL, aGxpdUBpY3QuYWMuY24=.
HL and WDX proposed methods, analyzed results, and wrote and modified the manuscript. Z-HS and X-DW analyzed results and modified the manuscript. H-YZ, K-WM, HZ, J-LQ, J-RJ, L-LT, H-MZ, H-JC, and K-SW collected original data, labeled data, and reviewed the manuscript. Y-LQ gave suggestions on methods. All authors contributed to the article and approved the submitted version.
This work was supported by the Beijing Natural Science Foundation (Z190020), the National Natural Science Foundation of China (81972490) and Natural Science Foundation of Hunan Province (2019JJ50781).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. Golub TR, Slonim DK, Tamayo P, Huard C, Gaasenbeek M, Mesirov JP, et al. Molecular Classification of Cancer: Class Discovery and Class Prediction by Gene Expression Monitoring. Science (1999) 286(5439):531–7. doi: 10.1126/science.286.5439.531
2. Pusztai L, Mazouni C, Anderson K, Wu Y, Symmans WF. Molecular Classification of Breast Cancer: Limitations and Potential. Oncol (2006) 11(8):868–77. doi: 10.1634/theoncologist.11-8-868
3. Yersal O, Barutca S. Biological Subtypes of Breast Cancer: Prognostic and Therapeutic Implications. World J Clin Oncol (2014) 5(3):412. doi: 10.5306/wjco.v5.i3.412
4. Sengal AT, Haj-Mukhtar NS, Elhaj AM, Bedri S, Kantelhardt EJ, Mohamedani AA. Immunohistochemistry Defined Subtypes of Breast Cancer in 678 Sudanese and Eritrean Women; Hospitals Based Case Series. BMC Cancer (2017) 17(1):1–9. doi: 10.1186/s12885-017-3805-4
5. Whiteside G, Munglani R. TUNEL, Hoechst and Immunohistochemistry Triple-Labelling: An Improved Method for Detection of Apoptosis in Tissue Sections—an Update. Brain Res Protoc (1998) 3(1):52–3. doi: 10.1016/S1385-299X(98)00020-8
6. Zhu X, Yao J, Zhu F, Huang J. (2017). Wsisa: Making Survival Prediction From Whole Slide Histopathological Images, in: 2017 Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7234–42.
7. Chen JM, Li Y, Xu J, Gong L, Wang LW, Liu WL, et al. Computer-Aided Prognosis on Breast Cancer With Hematoxylin and Eosin Histopathology Images: A Review. Tumor Biol (2017) 39(3):1010428317694550. doi: 10.1177/1010428317694550
8. Benenson R, Popov S, Ferrari V. (2019). Large-Scale Interactive Object Segmentation With Human Annotators, in: 2019 Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11700–9.
9. Berthelot D, Carlini N, Goodfellow I, Papernot N, Oliver A, Raffel CA. Mixmatch: A Holistic Approach to Semi-Supervised Learning. Adv Neural Inf Process Syst (2019) 32:5049–59. doi: 10.5555/3454287.3454741
10. Cheng L, Zhou X, Zhao L, Li D, Shang H. Weakly Supervised Learning With Side Information for Noisy Labeled Images. In: European Conference on Computer Vision. Springer: Cham (2020). p. 306–21.
11. Qu Y, Mo S, Niu J. (2021). DAT: Training Deep Networks Robust To Label-Noise by Matching the Feature Distributions, in: 2021 Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6821–9.
12. Yao J, Zhu X, Jonnagaddala J, Hawkins N, Huang J. Whole Slide Images Based Cancer Survival Prediction Using Attention Guided Deep Multiple Instance Learning Networks. Med Image Anal (2020) 65:101789. doi: 10.1016/j.media.2020.101789
13. Wu J, Zhu X, Zhang C, Cai Z. (2013). Multi-Instance Multi-Graph Dual Embedding Learning, in: 2013 IEEE 13th International Conference on Data Mining, pp. 827–36. IEEE.
14. Wu J, Pan S, Zhu X, Zhang C, Wu X. Multi-Instance Learning With Discriminative Bag Mapping. IEEE Trans Knowl Data Eng (2018) 30(6):1065–80. doi: 10.1109/TKDE.2017.2788430
15. Ilse M, Tomczak J, Welling M. (2018). Attention-Based Deep Multiple Instance Learning, in: International conference on machine learning, pp. 2127–36. PMLR.
16. Shi X, Xing F, Xie Y, Zhang Z, Cui L, Yang L. Loss-Based Attention for Deep Multiple Instance Learning. Proc AAAI Conf Artif Intell (2020) 34(04):5742–9. doi: 10.1609/aaai.v34i04.6030
17. Zhang W. Non-IID Multi-Instance Learning for Predicting Instance and Bag Labels Using Variational Auto-Encoder. (2021). doi: 10.24963/ijcai.2021/465
18. Li B, Li Y, Eliceiri KW. (2021). Dual-Stream Multiple Instance Learning Network for Whole Slide Image Classification With Self-Supervised Contrastive Learning, in: 2021 Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 14318–28.
19. Shao Z, Bian H, Chen Y, Wang Y, Zhang J, Ji X, et al. Transmil: Transformer Based Correlated Multiple Instance Learning for Whole Slide Image Classification. Adv Neural Inf Process Syst (2021) 34. doi: 10.48550/arXiv.2106.00908
20. Wang X, Chen H, Gan C, Lin H, Dou Q. Weakly Supervised Deep Learning for Whole Slide Lung Cancer Image Analysis. IEEE Trans Cybern (2019) 50(9):3950–62. doi: 10.1109/TCYB.2019.2935141
21. Sharma Y, Shrivastava A, Ehsan L, Moskaluk CA, Syed S, Brown D. Cluster-To-Conquer: A Framework for End-To-End Multi-Instance Learning for Whole Slide Image Classification. Med Imaging Deep Learn (2021), 682–98. doi: 10.48550/arXiv.2103.10626
22. Shamai G, Binenbaum Y, Slossberg R, Duek I, Gil Z, Kimmel R. Artificial Intelligence Algorithms to Assess Hormonal Status From Tissue Microarrays in Patients With Breast Cancer. JAMA Netw Open (2019) 2(7):e197700. doi: 10.1001/jamanetworkopen.2019.7700
23. Rawat R, Ortega I, Roy P, Sha F, Shibata D, Ruderman D, et al. Deep Learned Tissue “Fingerprints” Classify Breast Cancers by ER/PR/Her2 Status From H&E Images. Sci Rep (2020) 10(1):1–13. doi: 10.1038/s41598-020-64156-4
24. Jaber MI, Song B, Taylor C, Vaske CJ, Benz SC, Rabizadeh S, et al. A Deep Learning Image-Based Intrinsic Molecular Subtype Classifier of Breast Tumors Reveals Tumor Heterogeneity That may Affect Survival. Breast Cancer Res (2020) 22(1):1–10. doi: 10.1186/s13058-020-1248-3
25. Karimi D, Dou H, Warfield SK, Gholipour A. Deep Learning With Noisy Labels: Exploring Techniques and Remedies in Medical Image Analysis. Med Image Anal (2020) 65:101759. doi: 10.1016/j.media.2020.101759
26. Xue C, Dou Q, Shi X, Chen H, Heng PA. (2019). Robust Learning at Noisy Labeled Medical Images: Applied to Skin Lesion Classification, in: 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), pp. 1280–3. IEEE.
27. Han B, Yao Q, Yu X, Niu G, Xu M, Hu W, et al. Co-Teaching: Robust Training of Deep Neural Networks With Extremely Noisy Labels. Adv Neural Inf Process Syst (2018) 31:8536–46. doi: 10.5555/3327757.3327944
28. Breunig M, Kriegel HP, Ng RT, Sander J. (2000). LOF: Identifying Density-Based Local Outliers, in: Proceedings of the 2000 ACM SIGMOD international conference on Management of data. New York, NY, USA: Association for Computing Machinery. pp. 93–104.
29. Chikontwe P, Kim M, Nam SJ, Go H, Park SH. Multiple Instance Learning With Center Embeddings for Histopathology Classification. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer (2020). p. 519–28.
30. Hashimoto N, Fukushima D, Koga R, Takagi Y, Ko K, Kohno K, et al. (2020). Multi-Scale Domain-Adversarial Multiple-Instance CNN for Cancer Subtype Classification With Unannotated Histopathological Images, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 3852–61.
31. Srinidhi CL, Ciga O, Martel AL. Deep Neural Network Models for Computational Histopathology: A Survey. Med Image Anal (2020) 67:101813. doi: 10.1016/j.media.2020.101813
32. He K, Zhang X, Ren S, Sun J. (2016). Deep Residual Learning for Image Recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–8.
33. He T, Zhang Z, Zhang H, Zhang Z, Xie J, Li M, et al. (2019). Bag of Tricks for Image Classification With Convolutional Neural Networks, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 558–67.
34. Chicco D. Ten Quick Tips for Machine Learning in Computational Biology. BioData Min (2017) 10(1):1–17. doi: 10.1186/s13040-017-0155-3
35. Carbonneau MA, Cheplygina V, Granger E, Gagnon G. Multiple Instance Learning: A Survey of Problem Characteristics and Applications. Pattern Recogn (2018) 77:329–53. doi: 10.1016/j.patcog.2017.10.009
36. Melendez J, van Ginneken B, Maduskar P, Philipsen RH, Reither K, Breuninger M, et al. A Novel Multiple-Instance Learning-Based Approach to Computer-Aided Detection of Tuberculosis on Chest X-Rays. IEEE Trans Med Imaging (2014) 34(1):179–92. doi: 10.1109/TMI.2014.2350539
37. Hou L, Samaras D, Kurc TM, Gao Y, Davis JE, Saltz JH, et al. (2016). Patch-Based Convolutional Neural Network for Whole Slide Tissue Image Classification, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2424–33.
38. Campanella G, Hanna MG, Geneslaw L, Miraflor A, Werneck Krauss Silva V, Busam KJ, et al. Clinical-Grade Computational Pathology Using Weakly Supervised Deep Learning on Whole Slide Images. Nat Med (2019) 25(8):1301–9. doi: 10.1038/s41591-019-0508-1
39. Raju A, Yao J, Haq MH, Jonnagaddala J, Huang J. Graph Attention Multi-Instance Learning for Accurate Colorectal Cancer Staging. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer (2020). p. 529–39.
40. Wang S, Zhu Y, Yu L, Chen H, Lin H, Wan X, et al. RMDL: Recalibrated Multi-Instance Deep Learning for Whole Slide Gastric Image Classification. Med image Anal (2019) 58:101549. doi: 10.1016/j.media.2019.101549
41. Yang H, Chen L, Cheng Z, Yang M, Wang J, Lin C, et al. Deep Learning-Based Six-Type Classifier for Lung Cancer and Mimics From Histopathological Whole Slide Images: A Retrospective Study. BMC Med (2021) 19(1):1–14. doi: 10.1186/s12916-021-01953-2
42. Tan M, Le Q. (2019). Efficientnet: Rethinking Model Scaling for Convolutional Neural Networks, in: International Conference on Machine Learning, . pp. 6105–14. PMLR.
Keywords: pathological image, weakly supervised learning, molecular subtype, breast cancer, H&E
Citation: Liu H, Xu W-D, Shang Z-H, Wang X-D, Zhou H-Y, Ma K-W, Zhou H, Qi J-L, Jiang J-R, Tan L-L, Zeng H-M, Cai H-J, Wang K-S and Qian Y-L (2022) Breast Cancer Molecular Subtype Prediction on Pathological Images with Discriminative Patch Selection and Multi-Instance Learning. Front. Oncol. 12:858453. doi: 10.3389/fonc.2022.858453
Received: 20 January 2022; Accepted: 14 March 2022;
Published: 14 April 2022.
Edited by:
Yanhui Guo, University of Illinois at Springfield, United StatesReviewed by:
Jia Wu, Macquarie University, AustraliaCopyright © 2022 Liu, Xu, Shang, Wang, Zhou, Ma, Zhou, Qi, Jiang, Tan, Zeng, Cai, Wang and Qian. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hong Liu, aGxpdUBpY3QuYWMuY24=; Kuan-Song Wang, d2FuZ2tzMDAxQGNzdS5lZHUuY24=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.