 Chunyu Pan
Chunyu Pan Yuyan Zhu
Yuyan Zhu Meng Yu
Meng Yu Yongkang Zhao
Yongkang Zhao Changsheng Zhang1*
Changsheng Zhang1* Xizhe Zhang
Xizhe Zhang Yang Yao
Yang Yao- 1Northeastern University, Shenyang, China
- 2Joint Laboratory of Artificial Intelligence and Precision Medicine of China Medical University and Northeastern University, Shenyang, China
- 3Early Intervention Unit, Department of Psychiatry, Affiliated Nanjing Brain Hospital, Nanjing Medical University, Nanjing, China
- 4Department of Urology, The First Hospital of China Medical University, Shenyang, China
- 5Department of Reproductive Biology and Transgenic Animal, China Medical University, Shenyang, China
- 6National Institute of Health and Medical Big Data, China Medical University, Shenyang, China
- 7School of Biomedical Engineering and Informatics, Nanjing Medical University, Nanjing, China
- 8Department of Physiology, Shenyang Medical College, Shenyang, China
Background: MYCN is an oncogenic transcription factor of the MYC family and plays an important role in the formation of tissues and organs during development before birth. Due to the difficulty in drugging MYCN directly, revealing the molecules in MYCN regulatory networks will help to identify effective therapeutic targets.
Methods: We utilized network controllability theory, a recent developed powerful tool, to identify the potential drug target around MYCN based on Protein-Protein interaction network of MYCN. First, we constructed a Protein-Protein interaction network of MYCN based on public databases. Second, network control analysis was applied on network to identify driver genes and indispensable genes of the MYCN regulatory network. Finally, we developed a novel integrated approach to identify potential drug targets for regulating the function of the MYCN regulatory network.
Results: We constructed an MYCN regulatory network that has 79 genes and 129 interactions. Based on network controllability theory, we analyzed driver genes which capable to fully control the network. We found 10 indispensable genes whose alternation will significantly change the regulatory pathways of the MYCN network. We evaluated the stability and correlation analysis of these genes and found EGFR may be the potential drug target which closely associated with MYCN.
Conclusion: Together, our findings indicate that EGFR plays an important role in the regulatory network and pathways of MYCN and therefore may represent an attractive therapeutic target for cancer treatment.
Introduction
The MYC proto-oncogene family consists of three paralogs: c-MYC, MYCN, and MYCL (1, 2). Abnormal MYC regulation can lead to increased cell proliferation and growth, MYC family members are the dysregulation of MYC family is common in cancer (2). The MYCN cancer gene in the MYC family is a structurally and functionally similar fragment of MYC discovered by Schwab (3) in 1983. It acts to promote cell proliferation, and inhibit cell differentiation, apoptosis, or programmed cell death (4–6). Existing researches suggest that MYCN plays a key role in cell proliferation and cell growth during embryonic development (7) and it is associated with a number of childhood-onset tumors, including neuroblastoma, medulloblastoma, rhabdomyosarcoma, glioblastoma multiform, retinoblastoma, astrocytoma, hematologic malignancies, and small-cell lung cancer (8, 9), as well as some adult cancers such as prostate and lung cancer (10, 11). Despite the proven importance of MYCN, which has very promising therapeutic potential, how to directly target MYCN remains an open question. There is no better method to target MYCN directly in existing research (9), but we can still target MYCN indirectly by targeting molecules that interact directly with MYCN to control MYCN activity (9, 12–19). Thus, the problem of targeting MYCN can be translated into the study of the MYCN regulatory network of its interactions.
Recently, network controllability theory has made remarkable achievements in analyzing biological networks, such as Protein-Protein Interaction (PPI) network (20–24), brain network (25, 26) and disease-related networks (27, 28). Ryouji (20) applied network controllability theory on breast cancer gene expression networks, and designed a novel method to identify a set of critical control proteins that uniquely and structurally control the entire proteome. Wu (29) determined minimum dominating sets of proteins (MDSets) in human and yeast protein interaction networks and found that MDSet proteins were enriched with essential, cancer-related, and virus-targeted genes. Guo (30) developed an algorithm for identifying steering nodes to a gene regulatory network related to type 1 diabetes and they found that FASLG and CD80 are steering nodes for controlling the target nodes related to type 1 diabetes and supported by wet experiments.
In the view of control theory, drug targets in a biological network can be interpreted as a steering node. By applying an extra signal to this set of guide nodes, the network is expected to be steered to the desired state. In other words, for a biological system with an abnormal state, if some biomolecules affect other biomolecules by extra perturbations and steer the system towards a healthy state, these perturbed biomolecules can be considered potential drug targets. Thus, the problem of identifying drug targets can be mapped to the problem of finding a set of steering nodes in a network system. By applying a control signal to these nodes, the states of the network are expected to transition between the healthy state and the disease state.
Here, we utilized network controllability theory (31–36) to analyze the protein-protein interaction (PPI) network of MYCN. We identified possible potential drug targets of the MYCN regulatory network and evaluated the importance of these potential targets with several existing databases. The results showed that network controllability theory may provide new ideas to reveal the function of MYCN and target MCYN, which is of great importance and application prospect.
Methods
Network Controllability
Consider a linear time-invariant networked system, the dynamics of the process can be described as follows:
Where vector x(t) = (x1(t),…,xN(t))T represents the system state vector of N nodes at time t; matrix A is a state parameter describing the components of the system; matrix B of N*M(M≥ N) is the input matrix from which the controlled node is identified by the external controller. Vector u(t)=(u1(t),…,uM(t))T represents the input vector of M nodes at the time t and the controller uses the input vector u(t) to control the entire system and a single control signal ui(t) can typically drive multiple nodes.
According to the Kalman rank condition (31, 37):
The system is controllable if and only if the N*NM matrix C=(B,AB,A2B,…,AN–1B) is full rank, and the system can drive any initial state to any final state in a finite time. Based on this theory, Lin (33) proposed the theory of structural controllability, in which the state matrix A and the control matrix B can be regarded as a structured matrix, and if there are matrices A and B with non-zero weights that make the Kalman criterion hold, then for the way of combining different weights in matrices A and B, the system is almost always controllable except for the all-zero state and some special cases. On this basis, researchers in the field of network control (32, 34) have transformed the problem of least external input to a directed network into a problem of calculating the maximum matching for that network, as shown in Figure 1. For a directed network, a maximum matching is a set of maximal edges that do not share the starting and ending node, while nodes that do not have matching edges pointing to them are driver nodes. In contrast, the driver nodes computed by maximum matching is called minimum set of driver nodes (MDS). Since the maximum matching is often not unique for the same network, it is often possible to obtain multiple different MDS for the same network (38–41). In this case, we can analyze the nodes in different MDS and thus assess the importance of the nodes.
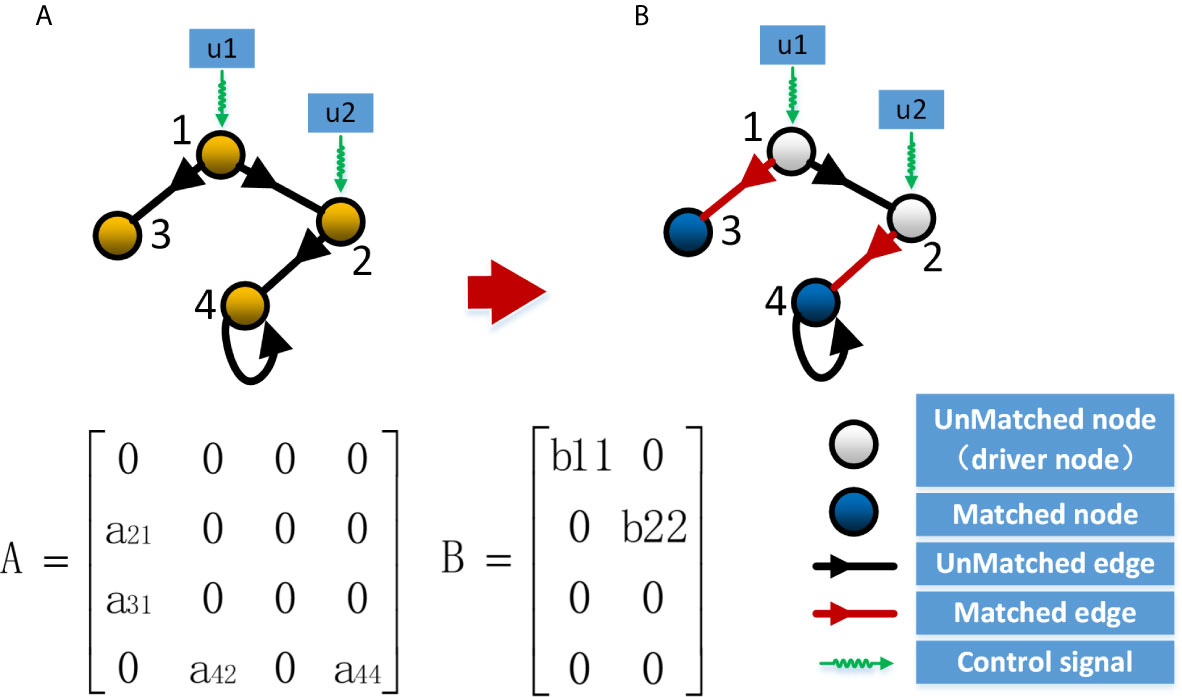
Figure 1 Control of the network system. (A) Controllability of a network through the controllability matrix; (B) Controllability of a network through the maximum matching.
Node Classification Based on Network Controllability
This method measures the nodes in different MDS and considers the importance of the nodes in the whole network. For a network, MDS can be obtained by using the maximum matching method (34) and the type of node can be determined by the size of MDS after this node removing from the network. A node is indispensable if the size of MDS decreases after removing the node from the network. A node is dispensable if the size of MDS increases after removing the node from the network. A node is neutral if the size of MDS do not change after removing the node from the network. The simple network (Figure 2A) has two different maximum matching (Figure 2B), and the size of original MDS is 2. The size of the MDS will change when the nodes in this network are removed and the size of MDS after different nodes removed are shown in Figures 2C–F.
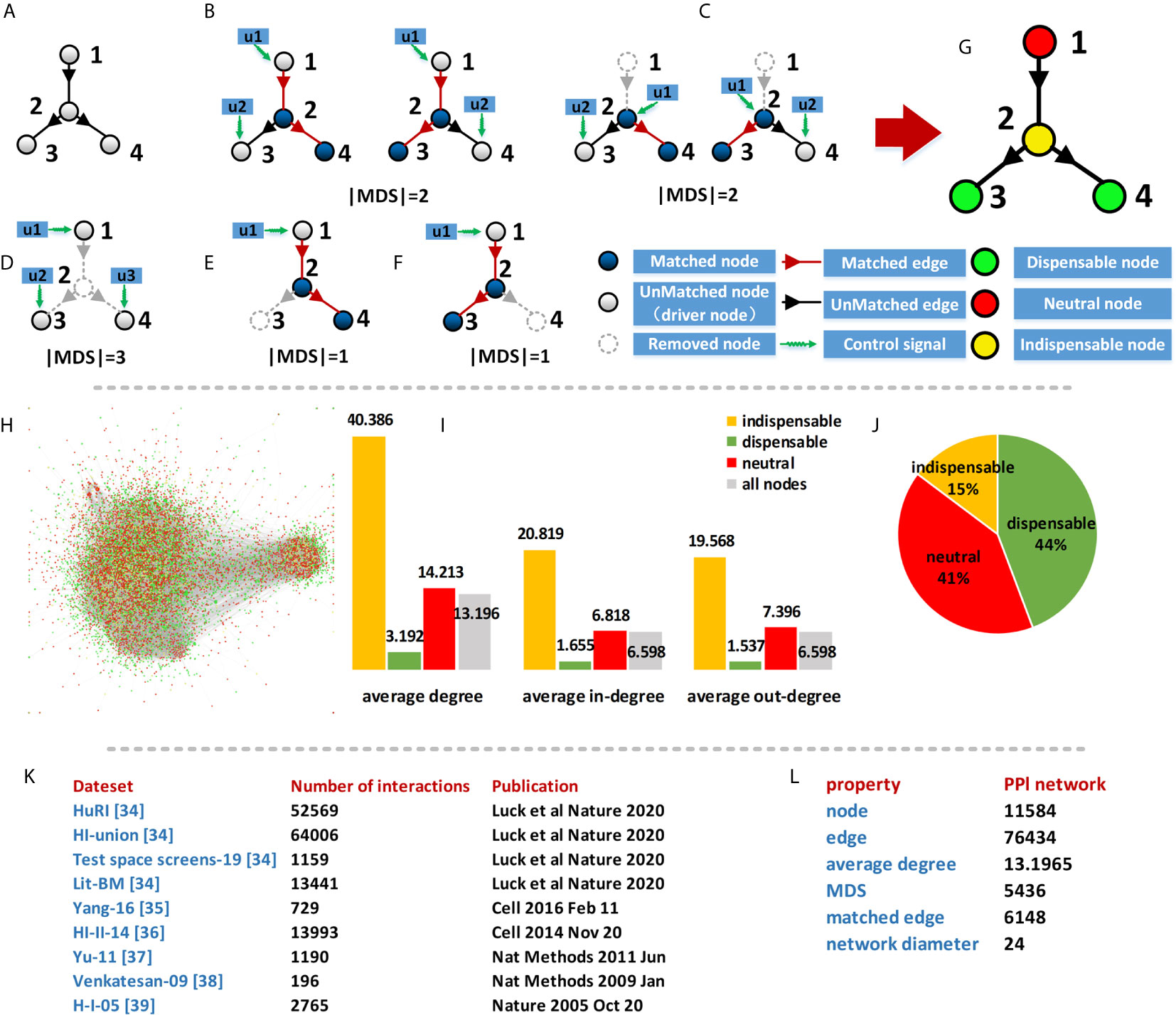
Figure 2 Characterizing of the PPI network. (A) A simple network; (B) Two different maximum matching of (A); (C–F) The size of MDS after different node removed; (G) Classification results of (A); (H) Classification results of PPI network; (I) Average degree of different type nodes in PPI network; (J) Percentages of different types in PPI network; (K) Data source of PPI network; (L) Basic property of PPI network.
In this simple network, the removal of node 1 does not change the MDS size of the network, as defined in the classification that node 1 is a neutral node. While the removal of node 2 increases the MDS size, and node 2 is an indispensable node. Similarly, node 3 and node 4 are dispensable nodes. The classification result of MYCN regulatory network is shown in Figure 3B.
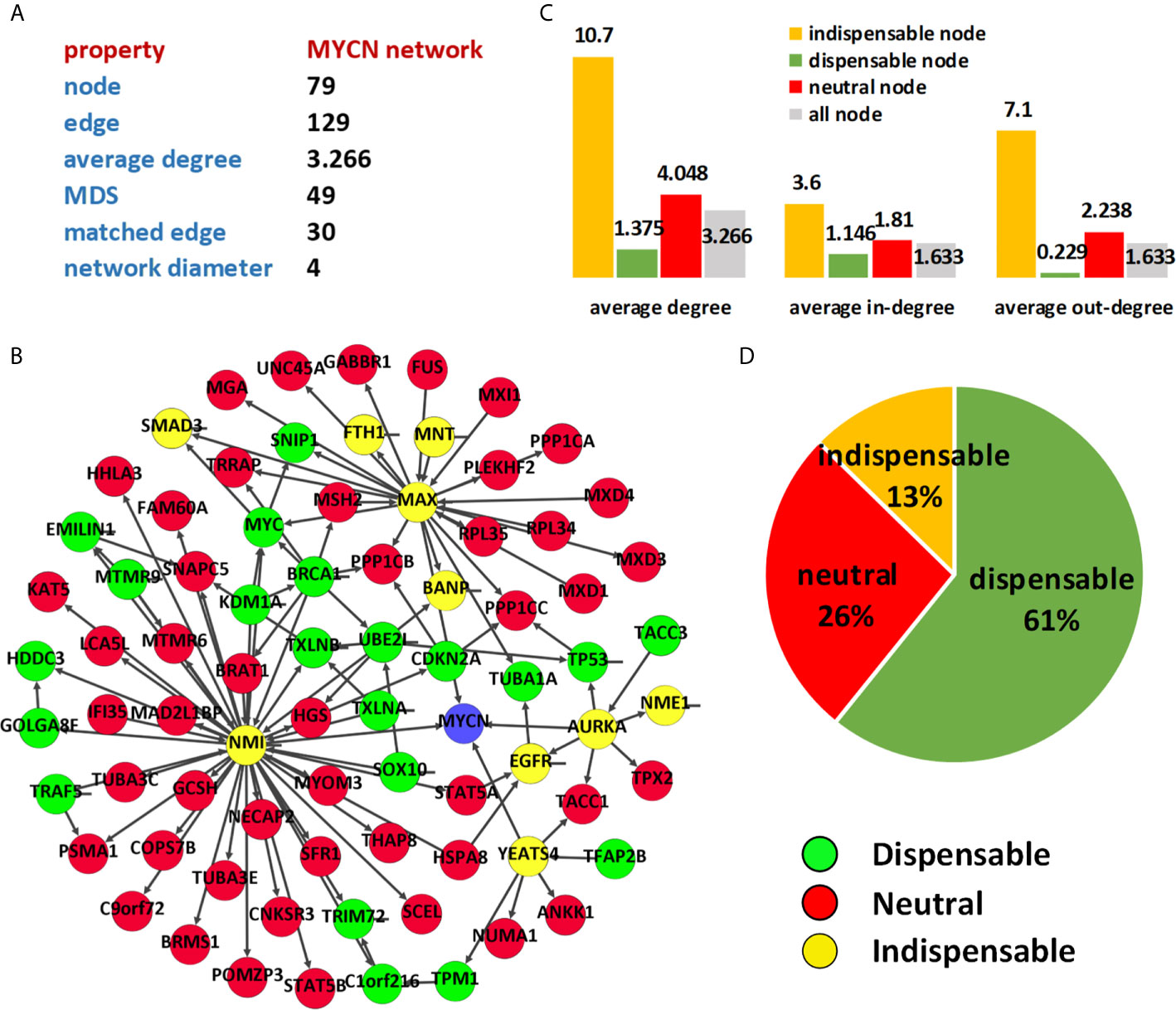
Figure 3 Characterizing of MYCN regulatory network. (A) Topological statistics of MYCN regulatory network; (B) Node classification of MYCN network; (C) Average degree of different type of nodes; (D) Percentages of different types in MYCN network.
Source of Data Sets
The Cancer Genome atlas (TCGA, https://tcga-data.nci.nih.gov/tcga), a project initiated jointly by the National Cancer Institute (NCI) and the National Genome Research Institute (NHGRI). Utilize large scale sequencing based genomic analysis techniques to finalize a complete set of mapping associated with all cancer genomic alterations. To date, TCGA has been tested in over 10,000 human samples with whole cancers. We selected PanCancer Atlas Studies as our data set from TCGA for validating the results of the method, which included 32 different cancers with 10,967 samples. Survival analysis is provided by Cbioportal (www.cbioportal.org), it supports the use of custom data and provides researchers with an interactive interface to discover associations between genetic alterations and the clinic, and the data source for Cbioportal is TCGA. Co-expression and pathway analysis is also provided by Cbioportal, whose pathway data are provided by TCGA research and the TCGA PanCanAtlas project (42–50). These pathways have been rigorously extrapolated and validated and are published, which is of great biological significance and very important for the analysis of disease or gene interaction mechanisms.
Data sets of drug targets provided by Behan et al.’s work (51), they used genome-scale CRISPR–Cas9 screens in 324 human cancer cell lines from 30 cancer types and developed a data-driven framework to prioritize candidates for cancer therapeutics.
Results
Control Analysis of Human Protein-Protein Interaction Network
Consider a Protein-Protein interactions (PPI) network, a node of the network represents a protein and the interactions between proteins are the edges of the network. We used human binary protein interactions (HuRI) (52), a Protein interaction database which is the largest human protein interactome data to date. The protein-protein interaction in the network is of paramount importance both for understanding the underlying biological processes and for understanding disease occurrence. In addition, we have combined the protein-protein interactions provided by other databases (53–57) to form a more comprehensive network. The specific data sources are shown in Figure 2A.
The result of the PPI network consists of 11,584 proteins and 76,434 interactions. The average degree of the network is 13.2 and the diameter of the network is 24. To analyze the control properties of the PPI network, we used the maximum matching method to compute the Minimum Driver nodes Set (MDS) in the network. Although the MDSs are not unique for the PPI network, but the size of all MDSs is same and determined by the network topology. In the PPI network, there are 5436 (46.93%) driver proteins which composed of the MDS of the PPI network. It means that to fully control the PPI network, we need to control nearly half of the proteins in the network. Therefore, the MDS did not provide much information for identifying potential drug target of the network.
Furthermore, We used a control classification method (21) to divide the proteins into three types: indispensable, dispensable, and neutral proteins. This node classification is based on the size changes of MDS after removing the node from the network. A node is indispensable if the size of MDS decreases after removing the node from the network. A node is dispensable if the size of MDS increases after removing the node from the network. A node is neutral if the size of MDS do not change after removing the node from the network. An example network is shown in Figure 2. For the PPI network, a total of 1710 (15%) proteins are indispensable, 5218 (44%) proteins are dispensable nodes and 4749 (41%) proteins are neutral. We found the average degree of the indispensable nodes is much higher than the other class nodes, which means the selected indispensable proteins have more interactions and are more closely related to other molecules than the other proteins in the network.
Control Analysis of MYCN Sub-Network
To find potential drug target of MYCN, we extracted the second-order egocentric network of MYCN from the PPI network. The MYCN-egocentric network includes the neighbor nodes that interact directly with MYCN and the neighbor nodes that interact with the neighbors of MYCN. We used the second-order egocentric network to analyze the MYCN network because the goal of our analysis is to find molecules that can be targeted among the direct or indirect interactions of MYCN, and the nodes we selected should not be too far away from MYCN. Figure 3 shows the result of control analysis of MYCN network. The network consists of 79 nodes and 129 edges and the size of MDS of MYCN network is 49 (62.03%). The number of matching edges is 30 (23.26%) and the network diameter is 4.
By using the node classification method (21) based on controllability analysis, we computed the control types of the proteins in the MYCN network. As the same as the PPI network, the average degree of the indispensable nodes is much higher than the other type nodes in MYCN regulation network (Figure 3C). However, the value of average degree is not involved in the processing of the classification and the phenomenon is not accidental or biased. For all the nodes in the MYCN regulatory network, we found 10 (13%) nodes are indispensable, 21 (26%) nodes are neutral nodes and 48 (61%) nodes are dispensable. Table 1 showed the indispensable proteins and their topological properties and associated diseases. Meanwhile, among these 10 indispensable nodes, MAX, AURKA, YEATS4, and NMI are the nodes directly associated with MYCN, these proteins are present in the first-order egocentric network of MYCN and have close interactions with MYCN.
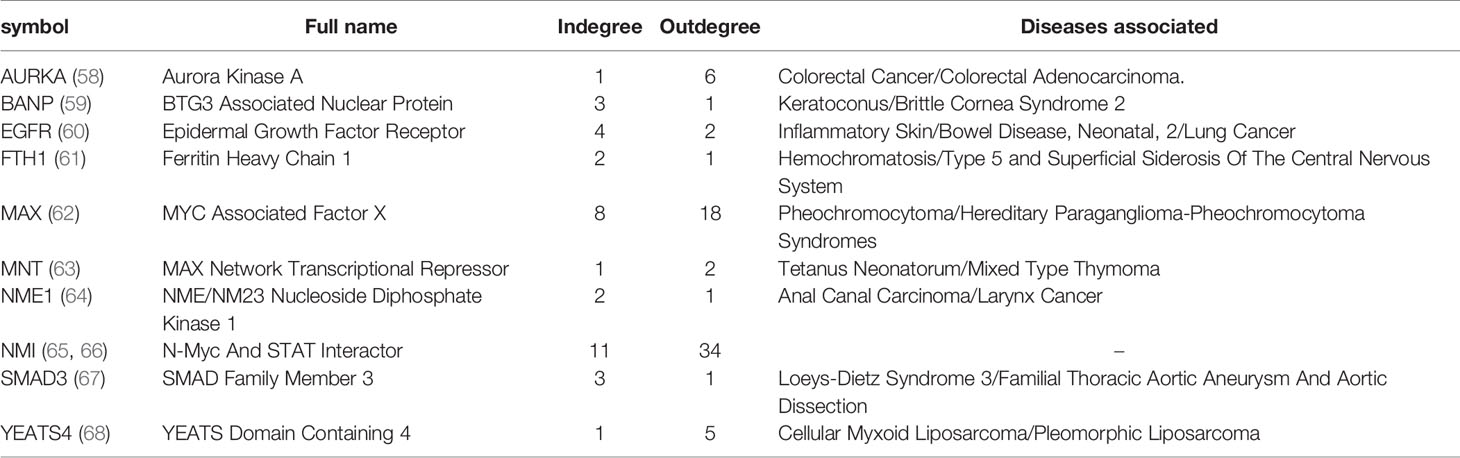
Table 1 Indispensable genes in MYCN regulatory network.
Functional Analysis of Indispensable Proteins
To further investigate the biological significance of indispensable genes in the MYCN network, we perform survival analysis of indispensable genes base on the clinical data of The Cancer Genome Atlas (TCGA) (69) included 32 different cancers with 10,967 samples. Here we used overall survival without disease-specific for a gene, it can eliminate the survival differences in certain diseases. By plotting the relationship between survival months and surviving percentage, can obtain the differences in survival for altered group and unaltered group. Figure 4 showed the clinical survival of 10 indispensable genes. Among the ten indispensable genes, EGFR and YEATS4 had a significant difference between the altered group and the unaltered group, which suggested that the mutation of these two genes will significantly change the survival of patients. Clinical samples and median survival Months are shown in Table 2. Considering the differences in disease grade and treatment strategy, we also divided the sample into multiple groups for statistical analysis (Supplement 2).
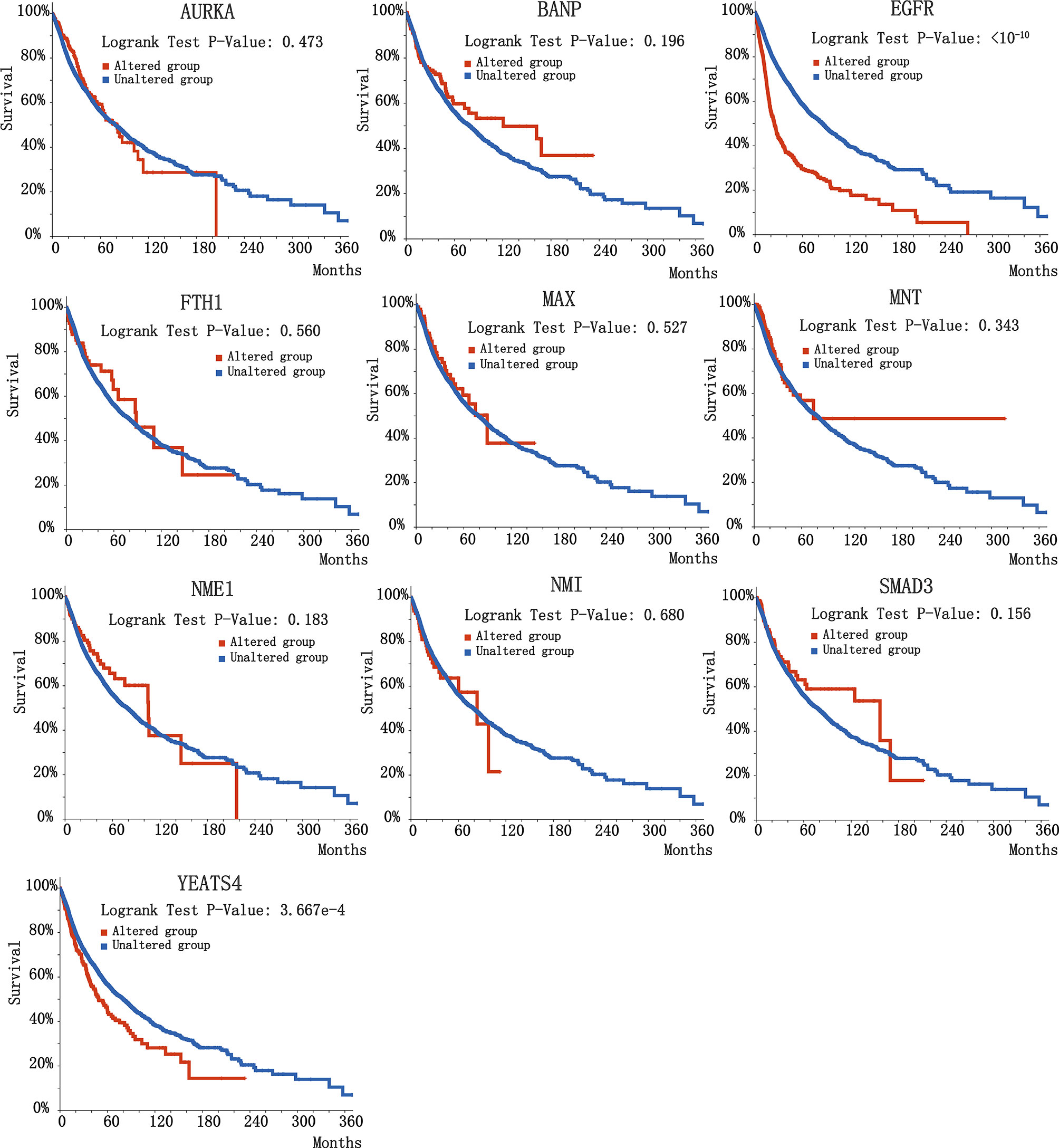
Figure 4 Survival curve of 10 indispensable genes. 10 plots correspond to different indispensable genes, here we chose overall survival data rather than disease-specific survival data.
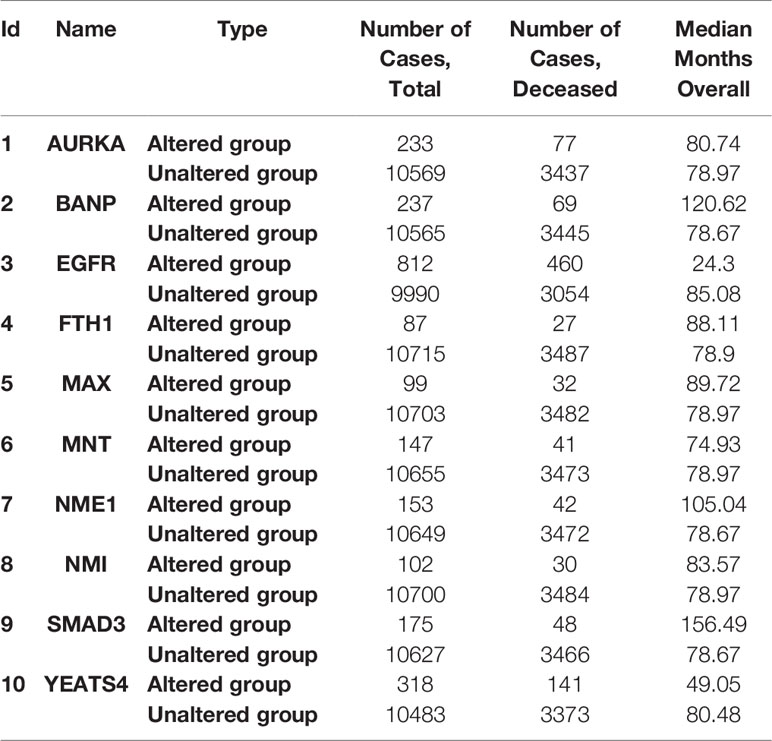
Table 2 Clinical samples of indispensable genes.
Furthermore, we performed pathway analysis for the indispensable genes (42–50) based on Cbioportal (70). We found that EGFR, MAX, MNT and SMAD3 are associations with MYCN or MYC family in several pathways, as shown in Figure 5. EGFR was indirectly associated with MYC activity in ESAD-2017-RTK-RAS-PI(3)K-pathway and HNSC-2015-RTK-RAS-PI(3)K-pathway by PIK3CA. MAX and MNT are correlated with MYCN in the MYC-pathway, where MAX and MYCN form the MYC/MAX complex, and MNT associated with the MAX/MGA complex. The pathway analysis shows that the indispensable genes computed by the network controllability theory are precise and are directly or indirectly associated with MYCN in different pathways.
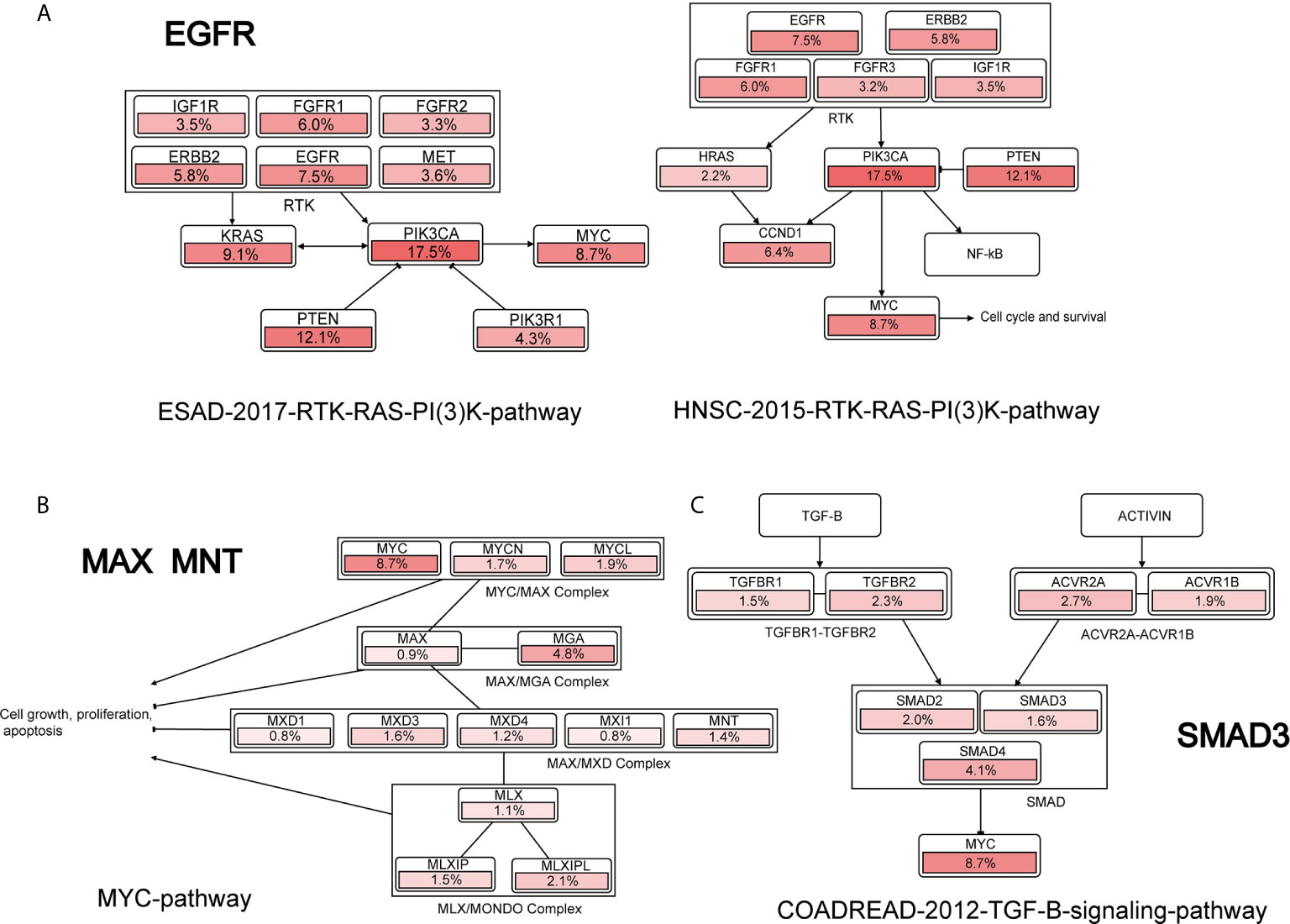
Figure 5 Cancer pathway of indispensable genes. (A–C) are the pathways that EGFR, MAX, MNT, SMAD3 associated with MYCN or MYC, respectively.
Finally, we analyzed the indispensable node that are targeted by the drugs. Based on the database of drug targets in 324 human cancer cell lines from 30 cancer types (51), we found that EGFR is an anti-cancer target in Squamous Cell Lung Carcinoma, Lung Adenocarcinoma, Oral Cavity Carcinoma, Ovarian Carcinoma, Head and Neck Carcinoma and Esophagus. It has a high priority and has a class B biomarker, making it a more desirable target. EGFR has at least one drug that has been developed for the cancer type in which the target was identified as a priority. In relation to our research of the MYCN regulatory network, EGFR may be the potential drug target which closely associated with MYCN.
Overall, based on the survival analysis, cancer pathway and drug targets analysis of indispensable genes, it is clear that the indispensable genes have a significant role in the MYCN regulatory network. The indispensable genes are directly associated with cancers, especially EGFR, MAX, MNT, SMAD3. EGFR is also a drug target that has already been developed and is considered to be the most promising potential target in the MYCN regulatory network.
Indispensable Proteins in Brain Lower Grade Glioma
To further validate the biological significance of indispensable genes, in this section, we verified the effectiveness of our results with the specific-diseases. For the choice of specific-diseases, we should select a disease that is associated with MYCN, to analyze the survival of indispensable genes and the co-expression relationship with MYCN. Due to MYCN plays a key role in cell proliferation and cell growth during embryonic development (7) and it is often associated with a number of childhood-onset tumors, here we combined Brain Lower Grade Glioma to show the results of analysis. The survival curves for indispensable genes for Brain Lower Grade Glioma are shown in Figure 6. And the co-expression correlation between indispensable genes and MYCN of Brain Lower Grade Glioma are shown in Table 3. We found that BANP, NME1, YEATS4, and EGFR, have relatively significant Spearman’s Correlation with MYCN. Among them, YEATS4 has been shown in existing studies to have a direct interaction with MYCN (53–57). Although there are no direct association between three other genes and MYCN in existing studies, from the co-expression of Brain Lower Grade Glioma, it is possible that had correlation between them.
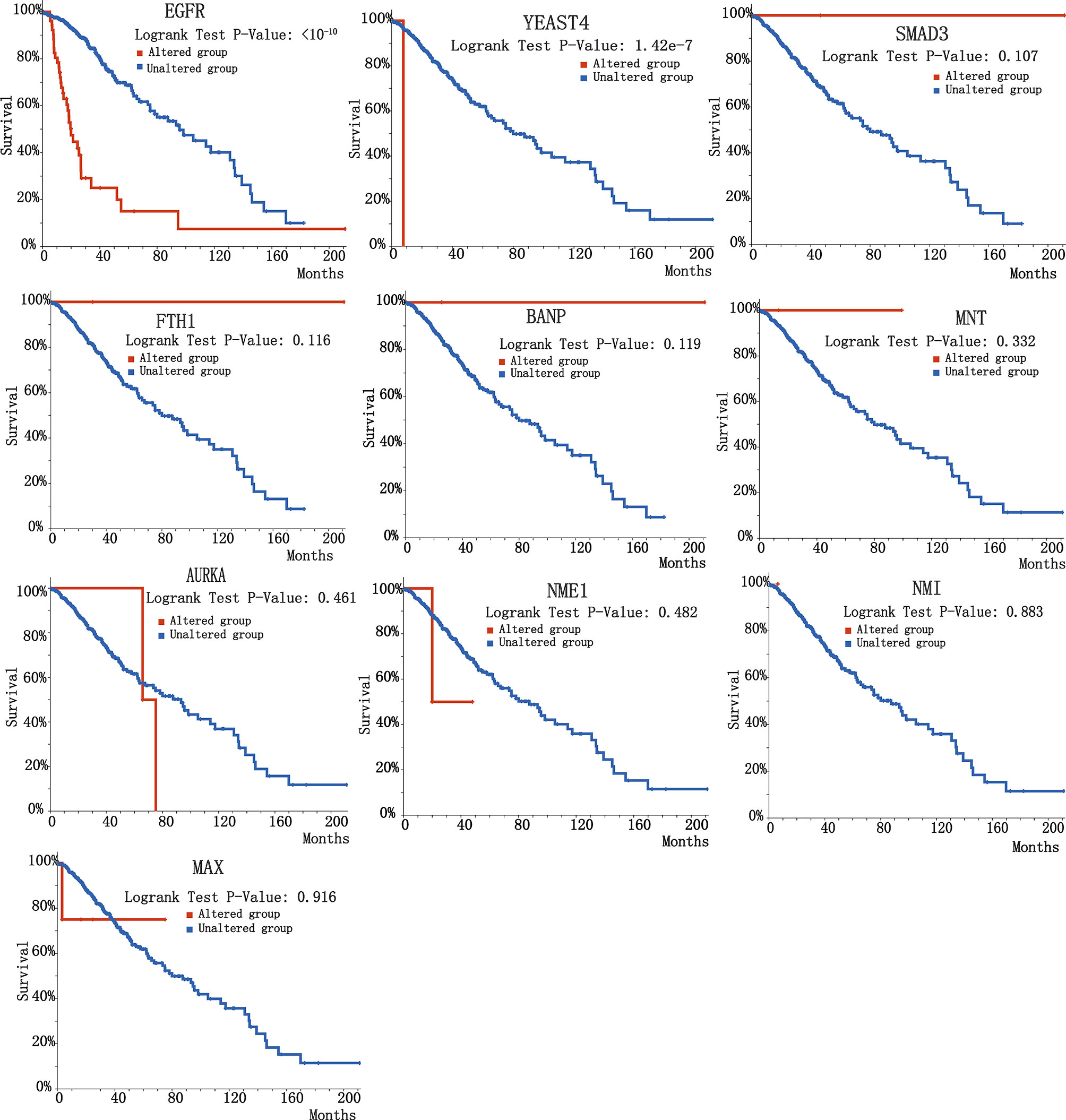
Figure 6 Survival curve of 10 indispensable genes of Brain Lower Grade Glioma. 10 plots are the survival curves of different indispensable genes and Brain Lower Grade Glioma respectively.
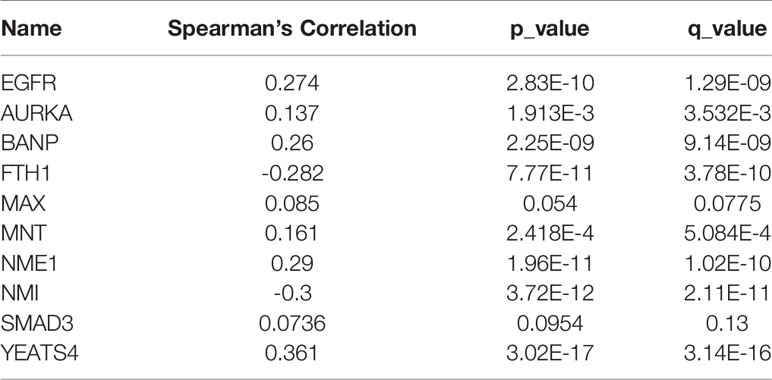
Table 3 Co-expression correlation between indispensable genes and MYCN of Brain Lower Grade Glioma.
Discussion
MYCN plays an important role in many diseases and cancers (2, 7–11), in-depth understanding of the role of MYCN has a great significance and application prospect. However, MYCN is difficult to directly target and design therapeutic strategies in existing research (9). Therefore, we hope to find potential targets around the MYCN regulatory network and regulate MYCN indirectly by controlling the potential targets. By using network controllability method (21), we found ten indispensable genes in the MYCN regulatory network. Through the pathway, survival, drug target analysis, we found that the indispensable genes, especially EGFR, play an important role in MYCN regulatory networks.
To validate the biological significance of indispensable genes, especially EGFR, we calculated the correlation between the 10 indispensable genes and MYCN using the TCGA dataset (Supplement 1). For the 33 cancers proposed by TCGA, we analyzed spearman’s correlation, p-value (2-sided t-test), and q-value (Benjamini-Hochberg FDR correction) of MYCN with indispensable genes in expression in different diseases sequentially. Our core target EGFR had significant positive correlation results in Thymoma, Kidney Chromophobe, Diffuse Large B-Cell Lymphoma, Brain Lower Grade Glioma, and Skin Cutaneous Melanoma. All other indispensable genes also had a significant co-expression results with MYCN in specific diseases, this is concur with the results of existing studies. For the ten potential targets we obtained, MAX, AURKA, YEATS4 and NMI are directly associated with MYCN. MAX and AURKA in particular have been rigorously argued to be tightly associated with MYCN activity (71). For the other 6 potential targets, they are indirectly connected to MYCN. Although current research of these genes hasn’t a direct interaction with MYCN, in the theory of network control when this type of node changes, it can alter the features of network and affect the state of MYCN result in indirectly target MYCN. Among them, EGFR, MNT, and SMAD3 are all directly or indirectly associated with the MYCN or MYC families in different pathway. EGFR, in particular, is not only significantly different between the altered and unaltered groups in clinical survival data, but also a molecule that can already be drug-targeted (51).
As the driving gene of many kinds of tumors, EGFR plays an important role in promoting the malignant progression of tumors (60). Its role in non-small cell lung cancer, glioblastoma and basal-like breast cancers has spurred many research and drug development efforts. Tyrosine kinase inhibitors have shown efficacy in EGFR amplified tumors, most notably gefitinib and erlotinib. But the mutations in EGFR have been shown to confer resistance to these drugs, particularly the variant T790M, which has been functionally characterized as a resistance marker for both of these drugs. The later generation TKI’s have seen some success in treating these resistant cases, and targeted sequencing of the EGFR locus has become a common practice in treatment of non-small cell lung cancer (72–74). Therefore, we consider EGFR to be the most promising potential target among these indispensable genes (Supplement 2).
Meanwhile, referring to the biological properties of MYCN (7, 75) (Supplement 2), we selected Brain Lower Grade Glioma to validating indispensable genes. Among them, BANP, NME1, YEATS4, and EGFR, have relatively significant Spearman’s Correlation with MYCN. It is worth noting that NMI has a high negative correlation with MYCN. Due to the algorithm views the biological network as an abstract network structure in isolation from the specific biological constraints, this algorithm without specific biological constraints is able to filter out genes with high correlation (positive and negative), not just positive correlation. And NMI as an interactor of MYCN, has a high absolute value of correlation with MYCN in the network, which is consistent with the algorithm results. For EGFR, which we considered the most potentially target, there were more significant results in Brain Lower Grade Glioma, both in the co-expression and survival.
Each cancer is extremely complex and different networks will come with different results. In this study, we chose pan-cancer data to construct a more comprehensive network to predict potential targets for MYCN in terms of overall relationships, and finally verified the effect of indispensable genes combined with specific-diseases. The theory of network controllability bring a new view and theoretical framework to the analysis of regulatory networks. However, the composition of nodes and edges will impact the accuracy of the results. Therefore, it is still a challenge to accurate construction of the initial network and find the exact target network from a large amount of data and specific-diseases. This is a new methodological trying to identify potential targets, and after the network control framework analysis, how to design wet experiments to further verify the analysis results is also one of our subsequent concerns.
Overall, the method of network controllability in this paper is able to screen potential targets against MYCN and our findings indicate that EGFR plays an important role in the MYCN regulatory network. In the future, experimental evidence to support the above regulatory relationship will be further provided through in vitro and in vivo experimental systems, so as to promote the identification and discovery of potential new regulatory targets.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material. Further inquiries can be directed to the corresponding authors.
Ethics Statement
The studies involving human participants were reviewed and approved by TCGA Ethics & Policies and were originally published by the National Cancer Institute. The patients/participants provided their written informed consent to participate in this study. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
Author Contributions
XZZ is the lead author. XZZ, YYZ, YKZ and YY conceived the study and revised the manuscript. CYP and CSZ performed data analysis and interpretation and drafted the manuscript. MY searched the databases and acquired the data. All authors contributed substantially to the preparation of the manuscript.
Funding
This work was supported by the Fundamental Research Funds for the Central Universities (N2017013, N2017014), National Natural Science Foundation of China (U1908212, 81672523, 81472404, 81472403, 81272834 and 31000572), 2018 Support Plan for innovative talents in Colleges and Universities of Liaoning Province, 2018 “million talents Project” funded Project of Liaoning Province, 2019 Key R & D Projects of Shenyang.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors thank the members of participants for taking part in the study.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fonc.2021.633579/full#supplementary-material
References
1. Mathsyaraja H, Eisenman R. Parsing Myc Paralogs in Oncogenesis. Cancer Cell (2016) 29(1):1–2. doi: 10.1016/j.ccell.2015.12.009
2. Wilde B, Ayer D. Interactions between Myc and MondoA transcription factors in metabolism and tumourigenesis. Br J Cancer (2015) 113(11):1529–33. doi: 10.1038/bjc.2015.360
3. Schwab M, Alitalo K, Klempnauer K-H, Varmus HE, Bishop JM, Gilbert F, et al. Amplified DNA with limited homology to myc cellular oncogene is shared by human neuroblastoma cell lines and a neuroblastoma tumour. Nature (1983) 305(5931):245–8. doi: 10.1038/305245a0
4. Chen L, Iraci N, Gherardi S, Gamble L, Wood K, Perini G, et al. p53 is a direct transcriptional target of MYCN in neuroblastoma. Cancer Res (2010) 70(4):1377–88. doi: 10.1158/0008-5472.CAN-09-2598
5. Ly JD, Grubb DR, Lawen A. The mitochondrial membrane potential (Δψm) in apoptosis; an update. Apoptosis (2003) 8:115–28:2. doi: 10.1023/A:1022945107762
6. Czabotar P, Lessene G, Strasser A, Adams J. Control of apoptosis by the BCL-2 protein family: Implications for physiology and therapy. Nat Rev Mol Cell Biol (2013) 15:49–63. doi: 10.1038/nrm3722
7. Eilers M, Eisenman RN. Myc’s broad reach. Genes Dev (2008) 22(20):2755–66. doi: 10.1101/gad.1712408
8. Molenaar JJ, Koster J, Ebus ME, van Sluis P, Westerhout EM, de Preter K, et al. Copy number defects of G1-Cell cycle genes in neuroblastoma are frequent and correlate with high expression of E2F target genes and a poor prognosis. Genes Chrom Cancer (2011) 51(1):10–9. doi: 10.1002/gcc.20926
9. Rickman DS, Schulte JH, Eilers M. The expanding world of N-MYC-driven tumors. Cancer Dis (2018) 2159–8290. CD-2117-0273v2151.
10. Wenzel A, Cziepluch C, Hamann U, Schürmann J, Schwab M. The N-Myc oncoprotein is associated in vivo with the phosphoprotein Max(p20/22) in human neuroblastoma cells. EMBO J (1991) 10(12):3703–12. doi: 10.1002/j.1460-2075.1991.tb04938.x
11. Ruiz-Pérez M, Henley A, Arsenian-Henriksson M. The MYCN Protein in Health and Disease. Genes (Basel) (2017) 8(4). doi: 10.3390/genes8040113
12. Barone G, Anderson J, Pearson A, Petrie K, Chesler L. New strategies in neuroblastoma: Therapeutic targeting of MYCN and ALK. Clin Cancer Res (2013) 19(21):5814–21. doi: 10.1158/1078-0432.CCR-13-0680
13. Cole KA, Huggins J, Laquaglia M, Hulderman CE, Russell MR, Bosse K, et al. RNAi screen of the protein kinome identifies checkpoint kinase 1 (CHK1) as a therapeutic target in neuroblastoma. Proc Natl Acad Sci USA (2011) 108(8):3336–41. doi: 10.1073/pnas.1012351108
14. Dominguez-Sola D, Ying C, Grandori C, Ruggiero L, Chen B, Li M, et al. Non-transcriptional control of DNA replication by c-Myc. Nature (2007) 448(7152):445–51. doi: 10.1038/nature05953
15. Stracker T, Petrini JJ. The MRE11 complex: starting from the ends. Nat Rev Mol Cell Biol (2011) 12(2):90–103. doi: 10.1038/nrm3047
16. Petroni M, Giannini G. A MYCN-MRN complex axis controls replication stress for the safe expansion of neuroprogenitor cells. Mol Cell Oncol (2016) 3:(2):e1079673. doi: 10.1080/23723556.2015.1079673
17. Walton M, Eve P, Hayes A, Valenti M, De Haven Brandon A, Box G, et al. CCT244747 is a novel potent and selective CHK1 inhibitor with oral efficacy alone and in combination with genotoxic anticancer drugs. Clin Cancer Res (2012) 18(20):5650–61. doi: 10.1158/1078-0432.CCR-12-1322
18. Zirath H, Frenzel A, Oliynyk G, Segerström L, Westermark U, Larsson K, et al. MYC inhibition induces metabolic changes leading to accumulation of lipid droplets in tumor cells. Proc Natl Acad Sci U S A (2013) 110(25):10258–63. doi: 10.1073/pnas.1222404110
19. Bashash D, Sayyadi M, Safaroghli-Azar A, Sheikh-Zeineddini N, Riyahi N, et al. Small molecule inhibitor of c-Myc 10058-F4 inhibits proliferation and induces apoptosis in acute leukemia cells, irrespective of PTEN status. Intl J Biochem Cell Biol (2019) 108:7–16. doi: 10.1016/j.biocel.2019.01.005
20. Ryouji W, Masayuki I, Toshihiko K, Tomoshiro O, Nacher JC, Petter H. Identification of genes and critical control proteins associated with inflammatory breast cancer using network controllability. PLoS ONE (2017) 12(11):e0186353. doi: 10.1371/journal.pone.0186353
21. Vinayagam A, Gibson TE, Lee HJ, Yilmazel B, Roesel C, Hu YH, et al. Controllability analysis of the directed human protein interaction network identifies disease genes and drug targets. Proc Natl Acad Sci U S A (2016) 113(18):4976–81.
22. Wu L, Tang L, Li M, Wang J, Wu F. Biomolecular Network Controllability With Drug Binding Information. IEEE Trans Nanobioscience (2017) 16(5):326–32.
23. Wuchty S. Controllability in protein interaction networks. Proc Natl Acad Sci U S A (2014) 111(19):7156–60. doi: 10.1073/pnas.1311231111
24. Zhang X. Altering indispensable proteins in controlling directed human protein interaction network. IEEE-Acm Trans Comput Biol Bioinform (2018) 15(6):2074–8.
25. Gu S, Pasqualetti F, Cieslak M, Telesford QK, Yu AB, Kahn AE, et al. Controllability of structural brain networks. Nat Commun (2015) 6:8414. doi: 10.1038/ncomms9414
26. Muldoon SF, Pasqualetti F, Gu S, Cieslak M, Grafton ST, Vettel JM, et al. Stimulation-Based Control of Dynamic Brain Networks. PloS Comput Biol (2016) 12(9):e1005076. doi: 10.1371/journal.pcbi.1005076
27. AL B, Gulbahce N, Loscalzo J. Network medicine: a network-based approach to human disease. Nat Rev Gen (2011) 12(1):56–68. doi: 10.1038/nrg2918
28. Wu L, Li M, Wang J-X, Wu F-X. Controllability and Its Applications to Biological Networks. J Comput Sci Technol (2019) 34(1):16–34. doi: 10.1007/s11390-019-1896-x
29. Wu L, Li M, Wang J, Wu F. Minimum steering node set of complex networks and its applications to biomolecular networks. IET Syst Biol (2016) 10(3):116–23. doi: 10.1049/iet-syb.2015.0077
30. Guo W-F, Zhang S-W, Wei Z-G, Zeng T, Liu F, Zhang J, et al. Constrained target controllability of complex networks. J Stat Mech: Theory Exp (2017) 6:063402. doi: 10.1088/1742-5468/aa6de6
31. Kalman R,E. A. Mathematical Description of Linear Dynamical Systems. J Soc Ind Appl Math Series A Control (1963) 1(2):152–92. doi: 10.1137/0301010
32. Liu Y-Y, Slotine J-J, Barabási A-L. Controllability of complex networks. Nature (2011) 473(7346):167–73. doi: 10.1038/nature10011
33. Lin CT. Structural controllability. IEEE Trans Autom Contr (1974) 19(3):201–8. doi: 10.1109/TAC.1974.1100557
34. Murota K. Matrices and matroids for systems analysis. Algorithms Combin (2008) 20(1):6–10. doi: 10.1007/978-3-642-03994-2_1
35. Zhang X, Zhu Y, Zhao Y. Altering control modes of complex networks by reversing edges. Physica A Stat Mech Appl (2021) 561(C):125249. doi: 10.1016/j.physa.2020.125249
36. Zhang X, Li Q. Altering control modes of complex networks based on edge removal. Physica a-Statistical Mechanics and Its Applications (2019) 516:185–93. doi: 10.1016/j.physa.2018.09.146
37. Luenberger DG. Introduction to dynamic systems: Theory, models and applications. John Wiley & Sons (1979).
38. Zhang X, Lv T, Pu YJR. Input graph: the hidden geometry in controlling complex networks. Rep (2016) 6(1):38209. doi: 10.1038/srep38209
39. Jia T, Liu YY, Csóka E, Pósfai M, Slotine JJ, Barabási AL. Emergence of bimodality in controlling complex networks. Nat Commun (2013) 4:2002. doi: 10.1038/ncomms3002
40. Zhang XZ, Wang HZ, Lv TY. Efficient target control of complex networks based on preferential matching. PloS One (2017) 12(4):10. doi: 10.1371/journal.pone.0175375
41. Zhang X, Han J, Zhang W. An efficient algorithm for finding all possible input nodes for controlling complex networks. Sci Rep (2017) 7(1):10677. doi: 10.1038/s41598-017-10744-w
42. Cancer Genome Atlas Research, N. Comprehensive genomic characterization defines human glioblastoma genes and core pathways. Nature (2008) 455(7216):1061–8. doi: 10.1038/nature07385
43. Cancer Genome Atlas Research, N. Integrated genomic analyses of ovarian carcinoma. Nature (2011) 474(7353):609–15. doi: 10.1038/nature10166
44. Muzny DM, Bainbridge MN, Chang K, Dinh HH, Drummond JA, Drummond JA, et al. Comprehensive molecular characterization of human colon and rectal cancer. Nature (2012) 487(7407):330–7. doi: 10.1038/nature11252
45. Hammerman PS, Lawrence MS, Voet D, Jing R, Cibulskis K, Sivachenko A, et al. Comprehensive genomic characterization of squamous cell lung cancers. Nature (2012) 489(7417):519–25. doi: 10.1038/nature11404
46. Levine DA, Getz G, Gabriel SB, Cibulskis K, Lander E, Sivachenko A, et al. Integrated genomic characterization of endometrial carcinoma. Nature (2013) 497(7447):67–73. doi: 10.1038/nature12113
47. Collisson EA, Campbell JD, Brooks AN, Berger AH, Lee W, Chmielecki J, et al. Comprehensive molecular profiling of lung adenocarcinoma. Nature (2014) 511(7511):543–50. doi: 10.1038/nature13385
48. Cancer Genome Atlas Research N. Integrated genomic characterization of papillary thyroid carcinoma. Cell (2014) 159(3):676–90.
49. Cancer Genome Atlas N. Comprehensive genomic characterization of head and neck squamous cell carcinomas. Nature (2015) 517(7536):576–82. doi: 10.1038/nature14129
50. Kim J, Bowlby R, Mungall A, Robertson G, Odze R, Cherniack AD, et al. Integrated genomic characterization of oesophageal carcinoma. Nature (2017) 541(7636):169–75. doi: 10.1038/nature20805
51. Behan F, Iorio F, Picco G, Gonçalves E, Beaver C, Migliardi G, et al. Prioritization of cancer therapeutic targets using CRISPR-Cas9 screens. Nature (2019) 568(7753):511–6. doi: 10.1038/s41586-019-1103-9
52. Luck K, Kim D, Lambourne L, Spirohn K, Begg B, Bian W, et al. A reference map of the human binary protein interactome. Nature (2020) 580(7803):402–8.
53. Yang X, Coulombe-Huntington J, Kang S, Sheynkman GM, Hao T, Richardson A, et al. Widespread Expansion of Protein Interaction Capabilities by Alternative Splicing. Cell (2016) 164(4):805–17. doi: 10.1016/j.cell.2016.01.029
54. Rolland T, Taşan M, Charloteaux B, Pevzner SJ, Zhong Q, Sahni N, et al. A proteome-scale map of the human interactome network. Cell (2014) 159(5):1212–26. doi: 10.1016/j.cell.2014.10.050
55. Yu H, Tardivo L, Tam S, Weiner E, Gebreab F, Fan C, et al. Next-generation sequencing to generate interactome datasets. Nat Methods (2011) 8(6):478–80. doi: 10.1038/nmeth.1597
56. Venkatesan K, Rual JF, Vazquez A, Stelzl U, Lemmens I, Hirozane-Kishikawa T, et al. An empirical framework for binary interactome mapping. Nat Methods (2009) 6(1):83–90. doi: 10.1038/nmeth.1280
57. Rual JF, Venkatesan K, Hao T, Hirozane-Kishikawa T, Dricot A, Li N, et al. Towards a proteome-scale map of the human protein-protein interaction network. Nature (2005) 437(7062):1173–8. doi: 10.1038/nature04209
58. Furukawa T, Kanai N, Shiwaku H, Soga N, Uehara A, Horii A. AURKA is one of the downstream targets of MAPK1/ERK2 in pancreatic cancer. Oncogene (2006) 25(35):4831–9. doi: 10.1038/sj.onc.1209494
59. Jalota-Badhwar A, Kaul-Ghanekar R, Mogare D, Boppana R, Paknikar K, Chattopadhyay S, et al. SMAR1-derived P44 peptide retains its tumor suppressor function through modulation of p53. J Biol Chem (2007) 282(13):9902–13. doi: 10.1074/jbc.M608434200
60. Rodríguez P, Rodríguez G, González G, Lage A. Clinical development and perspectives of CIMAvax EGF, Cuban vaccine for non-small-cell lung cancer therapy. MEDICC Rev (2010) 12(1):17–23. doi: 10.37757/MR2010.V12.N1.4
61. Singh A, Severance S, Kaur N, Wiltsie W, Kosman DJ. Assembly, activation, and trafficking of the Fet3p.Ftr1p high affinity iron permease complex in Saccharomyces cerevisiae. J Biol Chem (2006) 281(19):13355–64. doi: 10.1074/jbc.M512042200
62. Ayer D, Lawrence Q, Eisenman R. Mad-Max transcriptional repression is mediated by ternary complex formation with mammalian homologs of yeast repressor Sin3. Cell (1995) 80(5):767–76. doi: 10.1016/0092-8674(95)90355-0
63. Hofer B, Ruge M, Dreiseikelmann B. The superinfection exclusion gene (sieA) of bacteriophage P22: identification and overexpression of the gene and localization of the gene product. J Bacteriol (1995) 177(11):3080–6. doi: 10.1128/JB.177.11.3080-3086.1995
64. Okabe-Kado J, Kasukabe T, Honma Y, Hanada R, Nakagawara A, Kaneko Y. Clinical significance of serum NM23-H1 protein in neuroblastoma. Cancer Sci (2005) 96(10):653–60. doi: 10.1111/j.1349-7006.2005.00091.x
65. Shannon JG, Howe DH, et al. Virulent Coxiella burnetii does not activate human dendritic cells: Role of lipopolysaccharide as a shielding molecule. Proc Natl Acad Sci U S A (2005) 102(24):8722–7. doi: 10.1073/pnas.0501863102
66. Philimonenko V, Zhao J, Iben S, Dingová H, Kyselá K, Kahle M, et al. Nuclear actin and myosin I are required for RNA polymerase I transcription. Nat Cell Biol (2004) 6(12):1165–72. doi: 10.1038/ncb1190
67. Ross K, Corey D, Dunn J, Kelley TJ. SMAD3 expression is regulated by mitogen-activated protein kinase kinase-1 in epithelial and smooth muscle cells. Cell Signal (2007) 19:(5):923–31. doi: 10.1016/j.cellsig.2006.11.008
68. Park JH, Roeder RG. GAS41 is required for repression of the p53 tumor suppressor pathway during normal cellular proliferation. Mol Cell Biol (2006) 26(11):4006–16. doi: 10.1128/MCB.02185-05
69. Hoadley K, Yau C, Hinoue T, Wolf D, Lazar A, Drill E, et al. Cell-of-Origin Patterns Dominate the Molecular Classification of 10,000 Tumors from 33 Types of Cancer. Cell (2018) 173(2):291–304.e296.
70. Bahceci I, Dogrusoz U, La KC, Babur Ö., Gao J, Schultz N. PathwayMapper: a collaborative visual web editor for cancer pathways and genomic data. Bioinformatics (2017) 33(14):2238–40. doi: 10.1093/bioinformatics/btx149
71. Chen H, Liu H, Qing G. Targeting oncogenic Myc as a strategy for cancer treatment. Signal Transduct Target Ther (2018) 3:5. doi: 10.1038/s41392-018-0008-7
72. Yewale C, Baradia D, Vhora I, Patil S, Misra A. Epidermal growth factor receptor targeting in cancer: a review of trends and strategies. Biomaterials (2013) 34(34):8690–707. doi: 10.1016/j.biomaterials.2013.07.100
73. Charpidou A, Blatza D, Anagnostou V, Syrigos KN. Review. EGFR mutations in non-small cell lung cancer–clinical implications. In Vivo (Athens Greece) (2008) 22(4):529–36.
74. Arteaga CL, Engelman JA. ERBB receptors: from oncogene discovery to basic science to mechanism-based cancer therapeutics. Cancer Cell (2014) 25(3):282–303. doi: 10.1016/j.ccr.2014.02.025
Keywords: PPI network, MYCN, potential targets, network controllability, EGFR
Citation: Pan C, Zhu Y, Yu M, Zhao Y, Zhang C, Zhang X and Yao Y (2021) Control Analysis of Protein-Protein Interaction Network Reveals Potential Regulatory Targets for MYCN. Front. Oncol. 11:633579. doi: 10.3389/fonc.2021.633579
Received: 25 November 2020; Accepted: 04 March 2021;
Published: 21 April 2021.
Edited by:
Shilpa S. Dhar, University of Texas MD Anderson Cancer Center, United StatesReviewed by:
Amriti Rajender Lulla, University of Texas MD Anderson Cancer Center, United StatesGoutham Narla, University of Michigan, United States
Copyright © 2021 Pan, Zhu, Yu, Zhao, Zhang, Zhang and Yao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yang Yao, eWFveWFuZzE5NzJAZ21haWwuY29t; Xizhe Zhang, Wmhhbmd4aXpoZUBuam11LmVkdS5jbg==; Changsheng Zhang, emhhbmdjaGFuZ3NoZW5nQG1haWwubmV1LmVkdS5jbg==
†These authors contributed equally to this article