 Haoyu Cheng
Haoyu Cheng Ruijia Song2
Ruijia Song2 Biyu Zheng
Biyu Zheng- 1Unmanned System Research Institute, Northwestern Polytechnical University, Xi’an, China
- 2Xi’an Modern Control Technology Research Institute, Xi’an, China
- 3School of Astronautics, Northwestern Polytechnical University, Xi’an, China
In this study, a novel nonfragile deep reinforcement learning (DRL) method was proposed to realize the finite-time control of switched unmanned flight vehicles. Control accuracy, robustness, and intelligence were enhanced in the proposed control scheme by combining conventional robust control and DRL characteristics. In the proposed control strategy, the tracking controller consists of a dynamics-based controller and a learning-based controller. The conventional robust control approach for the nominal system was used for realizing a dynamics-based baseline tracking controller. The learning-based controller based on DRL was developed to compensate model uncertainties and enhance transient control accuracy. The multiple Lyapunov function approach and mode-dependent average dwell time approach were combined to analyze the finite-time stability of flight vehicles with asynchronous switching. The linear matrix inequalities technique was used to determine the solutions of dynamics-based controllers. Online optimization was formulated as a Markov decision process. The adaptive deep deterministic policy gradient algorithm was adopted to improve efficiency and convergence. In this algorithm, the actor–critic structure was used and adaptive hyperparameters were introduced. Unlike the conventional DRL algorithm, nonfragile control theory and adaptive reward function were used in the proposed algorithm to achieve excellent stability and training efficiency. We demonstrated the effectiveness of the presented algorithm through comparative simulations.
1 Introduction
Aerospace technology has developed rapidly since the 20th century (Wang et al., 2021; Giacomin and Hemerly, 2022; Wang and Xu, 2022). To satisfy the requirements of scientific exploration, military attack, transportation, industrial assistance, and other domains (Bao et al., 2021), flight vehicle systems are becoming increasingly complex (Wu et al., 2021; Lee and Kim, 2022). As an effective tool for the analysis of complex nonlinear systems, switched systems exhibit considerable potential for use in fast time-variation (Hu et al., 2019), full envelope, structural model mutation (Grigorie et al., 2022), re-modeling (Yue et al., 2019), among others (Chen et al., 2022; Yang et al., 2022).
Switched systems are a critical component of a series of discrete/continuous subsystems, and a switching signal controls the switching logic between these subsystems (Zhang et al., 2019). The switched system exhibits considerable potential for use in theoretical research and engineering applications (Sun and Lei, 2021), such as modeling (Huang et al., 2020), stability analysis (Yang et al., 2020; Zhang and Zhu, 2020), and control problems (Gong et al., 2020; Xiao et al., 2020). The stability analysis of the switched systems is typically used for controller design (Liu et al., 2020). The common Lyapunov function (CLF) method is widely used for stability analysis of arbitrary switching (Jiang et al., 2020). However, ensuring that a CLF is shared by all the subsystems remains challenging. This method is conservative to some degree, which leads to the research is required on the MLF and average dwell time (ADT) methods. Zhao et al. (2012) first studied the stability of the switched systems with ADT switching. In another study, the linear copositive function was extended to the MLF, and the multiple linear copositive Lyapunov function method was used to obtain a sufficient stability criterion for switched systems (Cheng et al., 2017). To obtain tight bounds on the dwell time, the mode-dependent average dwell time (MDADT) method was proposed to overcome the sharing problem of common parameters, and the worst cases were considered in the ADT method. The results were extended to a general case, and the properties of subsystems were considered. Generally, unstable modes may exist during the switching intervals. Therefore, a piecewise multi-Lyapunov function method was proposed in Zhao et al. (2017) for the stability analysis of unstable modes. To avoid dwelling for a long time in subsystems with poor performance and considering the MDADT methods, the slow switching is typically applied to stable modes, and fast switching is applied to unstable modes. Xu et al. (2019) proposed a time-dependent quadratic Lyapunov function method to solve the stability problem with all subsystems unstable. The bounded maximum ADT method is used to obtain the stability conditions of the linear switched system. However, these studies have only focused on infinite-time stability, whereas in finite time, the performance of the systems cannot be guaranteed. Unlike conventional Lyapunov stability, the FTS can achieve superior transient performance in finite time. Wei et al. (2020) proposed a novel MDADT switching signal. The dynamic decomposition technique was used to generate the switching signals, and sufficient conditions for FTS were detailed. For nonlinear switched systems with time delay, the Lyapunov-Razumikhin approach and Lyapunov-Krasovskii function method were used to investigate FTS problems (Wang et al., 2020). Furthermore, the tracking control is widely applied in flight vehicles (Liu et al., 2021). The finite-time tracking control problems in Wang et al. (2017) furthers research on finite-time robust tracking control of switched flight vehicles.
The tracking control problem for uncertain systems is investigated as follows (Liu et al., 2019; Chen et al., 2020; Lu et al., 2022): (1) constant parameter control, such as robust control, proportional integral derivative control, and optimal control, in which the worst case is considered for the bounded uncertainties and disturbances; (2) variable parameter control, such as adaptive and observer-based controls, in which the uncertainties and disturbances are compensated in real time; (3) learning-based control policy, such as reinforcement learning, which compensates uncertainties without prior knowledge and learns a control law through trial and error. In constant parameter control, the model uncertainties and external disturbances are assumed to be bounded with known boundaries, which result in performance degradation and conservative control laws. The variable parameter control method can be used to mitigate the problem of time-varying uncertainties with unknown boundaries. However, the model uncertainties are assumed to be linearly parameterized with predefined structure and unknown time-varying parameters. The learning-based control method can be used for addressing system uncertainties with unknown boundaries and unknown structures (Yuan et al., 2017). However, this method cannot ensure stability, and computational complexities increase. A novel model-reference adaptive law and a switching logic were developed for uncertain switched systems. Ban et al. (2018) designed an H∞ controller for polytopic uncertain switched systems. Introducing scalar parameters reduced the conservatism of the linear matrix inequality (LMI) conditions and simultaneously ensured robust H∞ performance of the system. The problems of nonfragile control for nonlinear switched systems considering actuator failures and parametric uncertainties were studied in Sakthivel et al. (2018). The Lyapunov-Krasovskii function method and ADT approach were used to design a nonfragile reliable sampled-data controller. These studies have focused on control in the ideal environment. However, in practice, because of the limitation of network bandwidth, a network delay and packet loss always exist, which cause inevitable asynchronous switching. Thus, the control switching lags behind state switching. This phenomenon results in performance degradation and instability. Li and Deng (2018) investigated the pth moment exponential input-to-state stability (ISS) of the switched systems with asynchronous switching. The indefinite differentiable Lyapunov function was combined with ADT to establish the ISS conditions of the switched systems with Lévy noise. The conclusion of these results (Zhang and Zhu, 2019) were generalized in Li and Deng (2018), and the ISS problems, stochastic-ISS, and integral-ISS for asynchronously switched systems with asynchronous switching were investigated. Fast ADT switching was introduced to mitigate the increase in the Lyapunov-Krasovskii function when active subsystems matches the controller. However, in most existing results on controller design for flight vehicles, although stability and robustness can be attained, achieving optimal control performance in real-time challenging.
With improvement in the calculating ability of computing devices, machine learning has been widely applied in many fields, including the control field (Cheng and Zhang, 2018; Guo et al., 2019; Gheisarnejad and Khooban, 2021). Xu et al. (2019) proposed a model-driven DDPG algorithm for robotic multi-peg-in-hole assembly to avoid the analysis of the contact model. A feedback strategy and a fuzzy reward function were proposed to improve data efficiency and learning efficiency. In Tailor and Izzo (2019), optimal trajectory for a quadcopter model in two dimensions was investigated. A near-optimal policy was proposed to construct trajectories that satisfy Pontryagin’s principle of optimality through supervised learning. With improved aircraft performance, the guidance and control system require rapidity, stability, and robustness. Therefore, deep learning and the exploration of reinforcement learning are an effective solution to this problem, which cannot be solved using conventional control. Cheng et al. (2019) and Gaudet et al. (2020) studied the fuel-optimal landing problems based on DRL. The optional control algorithms were designed considering the uncertainties of environment and system parameters by using deep neural networks and policy gradient methods to ensure the real-time performance and optimality of the landing mission. The design of the reward function is a critical factor for controller/filter design with DRL. In this method, the final performance of the training networks was determined but not treated satisfactorily. This study is motivated to solve this problem.
However, the methods proposed in Tailor and Izzo (2019) and Gaudet et al. (2020) could not ensure the robustness and stability of the given system. Considering the advantages and limitations of the model-based and model-free methods, we proposed a novel nonfragile DRL for achieving asynchronously finite-time robust tracking control of switched flight vehicles. In this method, the best compromise was realized between system stability, robustness, and rapidity. The intelligent controller based on nonfragile H∞ control and DRL was proposed to compensate model uncertainties and realize superior control performance. The FTS and finite-time robustness were realized by nonfragile H∞ control, and the transient performance was optimized by using the adaptive deep deterministic policy gradient (ADDPG) algorithm. Because of the significance of reward function design in the training process, adaptive hyperparameters were introduced to construct a generalized reward function to improve the performance and achieve robustness. Therefore, the contributions of the paper can be summarized as follows:
1. A novel control structure consisting of dynamics-based and learning-based controllers was proposed for the finite-time tracking control of switched flight vehicles. The robust control is focused on the worst case of uncertainties. However, transient performance is not ensured. The learning-based method, such as DRL, can address uncertainties with unknown boundaries and structures. However, stability is not guaranteed. Compared with the conventional method, in such a design structure, the advantages of both conventional robust control method and pure DRL are combined. The DRL is used to enhance control performance without exploiting their structures or boundaries, and the robustness is guaranteed by using model-based robust control. Thus, an optimal compromise between robustness and dynamic performance was achieved.
2. The stability and robustness of closed-loop system were guaranteed by using non-fragile control theory. The restricted DRL algorithm was proposed, in which the boundaries of scheduling intervals were predefined. The scheduling of parameters can be viewed as the perturbation of parameters within a given interval. Compared with pure DRL, the proposed method improved training efficiency and ensured stability of the closed-loop system.
3. The adaptive reward functions were proposed to realize rapid training convergence. The reward functions were crucial for the DRL algorithm. The conventional method of reward functions typically depends on the designing experience of the researchers, which degrade training efficiency and result in trial and error. Therefore, in the proposed method, adaptive factors for reward functions were used to improve training efficiency.
The rest of the paper is organized as follows. In Section 2, the structure of intelligent switched controllers is presented. In Section 3, the finite-time robust tracking control algorithm using DRL and H∞ control was proposed. A numerical example is provided in Section 4. Finally, Section 5 presents the summary and directions for future studies.
2 Problem statement
The HiMAT vehicle was studied, which is an unmanned flight vehicle. Its nonlinear model can be described in Eq. (1).
where mf and v denote the mass and velocity of the flight vehicle, respectively. Here, , , , and q are the attack angle, flight path angle, pitch angle, and pitch rate, respectively. Furthermore, Myy and Iy are the pitch moment and the moment of inertia about the pitch axis, respectively. Furthermore, g denotes the gravitational constant. The notations of , , and represent the thrust, drag force, and lift force, which can be expressed as follows:
where , , , , in which and are the air density and throttle setting.
Based on Jacobian linearization, the nonlinear model of HiMAT vehicle can be converted into the linear model to bridge the connection between complex nonlinear and linear models. Therefore, the longitudinal short-period model of the HiMAT vehicle can be modeled as switched systems as follows:
where is the state vector, represents the external disturbance that belongs to , with , , and representing the elevator, elevon, and canard deflection, and denoting the control and output signals. Here, is the switching function, which is a piecewise continuous constant function. Furthermore, is the number of subsystems. The characteristic of subsystems is assumed to depend on the switching signal, which are known previously. Here, , , , and are system matrices with appropriate dimensions.
In the network environment, because of the limit source of network bandwidth, the packet dropouts should be considered. The packet dropouts are considered in the channel of sensors–controllers to satisfy the Bernoulli distribution (Cheng et al., 2018). Therefore, the measured output is described as follows:
where is the measured output, represents a stochastic variable satisfying the Bernoulli distribution and takes value of , and is the probability of packet dropouts.
The control structure of switched flight vehicles to ensure stability and improve transient performance is displayed in Figure 1.
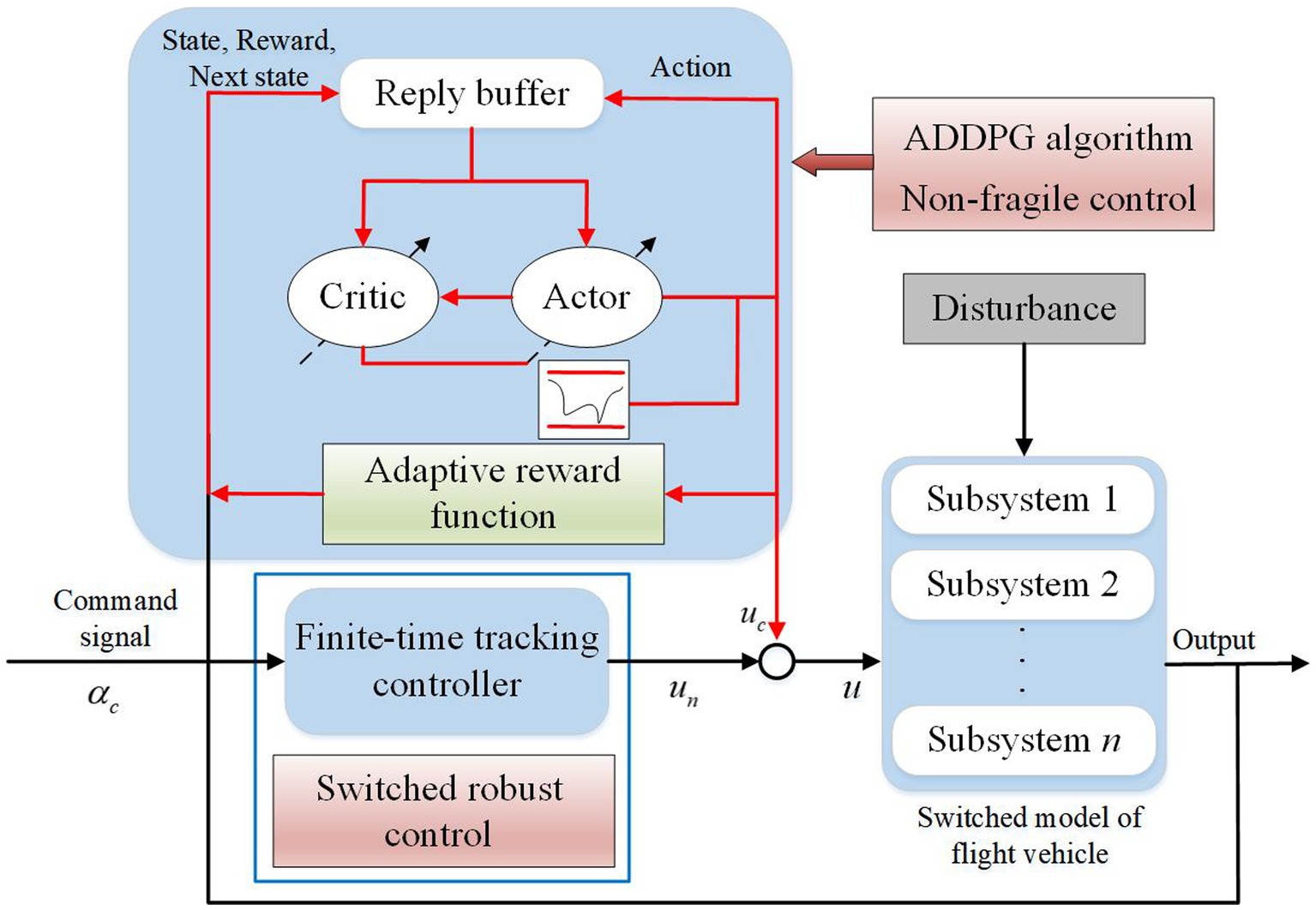
Figure 1. Structure of the controller.
The controller diagram reveals that the controller is composed of two parts:
where is the dynamics-based controller, and u c is the learning-based controller, which are developed based on finite-time control and DRL. The FTS and prescribed attenuation index are ensured by , whose parameters can be obtained by the LMI technique. The transient performance is improved by , whose parameters are scheduled by the ADDPG algorithm.
The tracking error of the output is defined as , and the objective of tracking control is as follows:
where denotes the command signal.
We set the integral of tracking error as follows:
The feedback controller is proposed as follows:
where , and are the gain matrices to be determined.
Nominal controller parameters and can be designed by the control, the variation internal of learning-based controller in subsystem can be perceived as the additional bounded uncertainties of the dynamics-based controller. Thus, the parameters vary in the interval and the stability of learning-based controller can be analyzed by using nonfragile control theory. Here, is defined as the additional compensation to obtain the actual gain matrices as follows:
where and denote the lower and upper bounds of ; set , and are known parameters with appropriate dimensions, and are uncertain matrices satisfying the following equation:
Remark 1: The model of flight vehicle can be given based on switched systems. The variation of states in the envelope can be viewed as the switching between subsystems. The tracking controller is composed of two parts, namely dynamics-based controller , which is developed based on finite-time control to ensure stability and prescribed attenuation index; the learning-based controller , which is based on ADDPG algorithm to achieve superior performance in real time. The output of varies in the neighbor interval of with given bounds. Therefore, the nonfragile control can be used to ensure the stability of . As mentioned, ensuring stability, robustness, and optimal performance simultaneously remains difficult. To improve training efficiency, adaptive factors for reward functions were applied in DDPG algorithm. With inspiration from the achievements in the DDPG algorithm and robust control, the advantages of model-based method ( control) and model-free method (DRL) were considered the problem.
Remark 2: The compensation of learning-based controller is considered as an additional gain value on the controller parameters with known bounds, which can be predefined and can presented by and . The optimal control policy can be realized in the scheduling interval by using the ADDPG algorithm.
The switching of controller always lags the switching of system mode because of packet dropouts. The th subsystem is assumed to be activated at , and the controller of th subsystem is activated at , where denotes the length of unmatched periods. The condition in which unmatched and matched periods exist simultaneously is called asynchronous switching. The Lyapunov-like function decreases in matched periods and increases in unmatched periods with bounded rates, where are introduced to represent the decreasing rate in matched periods, and represent the increasing rate in unmatched periods. The increasing coefficients of the Lyapunov-like function at switching instants are set to be .
For proof, the following assumptions are introduced.
Assumption 1 (Cheng et al., 2017): For given positive constant , the time-varying exogenous disturbance satisfies the following equation:
where is the upper bound of external disturbance.
Assumption 2 (Cheng et al., 2017): The maximum number of consecutive data missing is set to be N1, and the maximum probability of data missing is set to be .
According to the aforementioned statement, the closed-loop switched systems can be described as follows:
where .
Furthermore, the definitions of finite-time stable, finite-time boundedness, and finite-time H∞ performance for switched systems are expressed as follows:
Definition 1 (Wei et al., 2020): For given appropriate constant positive matrix , positive constants , , and with , respectively. The switched systems in Eq. (12) with and are finite-time stable with respect to if Eq. (13) holds.
Definition 2 (Wei et al., 2020): For given appropriate constant positive matrix , constants , , , and with , respectively. The switched system in Eq. (12) is finite-time bounded (FTB) with respect to such that the following expression holds:
where the external disturbance satisfies Assumption 1.
Definition 3 (Wei et al., 2020): For a given appropriate constant positive matrix , constants , for and with . The system in Eq. (12) exhibits finite-time performance if the system is FTB and satisfies the following expression:
Thus, the main purposes of controller design is to ensure that the switched system is FTS with prescribed performance with respect to , which is equivalent to design the robust controller, such that the following condition is satisfied:
1. The switched systems in Eq. (12) is FTB.
2. For given constant , the system in Eq. (12) satisfies Eq. (15) under zero-initial situation for all external disturbance satisfies Eq. (11).
Based on the structure of control diagram, the design process is categorized into two steps:
Step 1: The scheduling interval of control parameters can be assumed to be the uncertain compensation of dynamics-based controller. Considering the controller uncertainties and asynchronous switching caused by packet dropouts, the finite-time controllers are derived as dynamics-based controller according to nonfragile control theory and finite-time robust control theory in terms of LMI.
Step 2: The variations of controller parameters are assumed to be the action, and the dynamic model of flight vehicles is assumed to be the environment. The DRL algorithm was introduced to derive the learning-based controller to realize optimal control policy, in which the ADDPG algorithm was proposed as the model-free method in the actor–critic framework.
3 Main results
A dynamics-based controller was proposed to ensure stability and a prescribed performance index. The ADDPG algorithm was developed to realize performance and ensure controllers can adaptively schedule parameters.
3.1 Dynamics-based controller design
Definition 4 (Zhao et al., 2017): Given switching signal and any , let be the activated number of th subsystem over the time interval . Here, denotes the total running time of th subsystem during the time interval , . If positive numbers and , exist such that
then is called the MDADT and is called the mode-dependent chatter bounds.
Lemma 1 (Cheng et al., 2017): For given symmetric matric , matrices , , and , if a scalar exists such that
then we can obtain the following:
where satisfies .
Lemma 2 (Aristidou et al., 2014): For given matrix Q , which satisfies
where , and Q 11 and Q 22 are invertible matrices. Then we can conclude that the following three conditions are equivalent, which is called Schur Complement.
Theorem 1: Given system Eq. (12) and constant scalars , , , , if matrices , , , and , , then the following expression is obtained:
then the switched system in Eq. (12) is FTB with respect to if the MDADT satisfies the following equations:
where .
Proof: For positive constant , we define and as the switching instants over the interval , suppose the following Lyapunov functions exist:
Class functions exist as follows:
where are Lyapunov matrices.
Define and combining with Eqs. (12) and (27), we can obtain the following expression:
where
Setting and performing a congruence transformation to Eqs. (29), (30) by matrices and , we can obtain the following expression:
The inequality implies the following:
We can conclude that Eq. (31) is equivalent to Eq. (21) and Eq. (32) is equivalent to Eq. (22), such that the following expression holds true:
Combining Eqs. (25), (26), (28), (34), we can obtain the following equations by iteration operation:
With the definitions of and , we have the following expression:
Moreover, using , we can obtain the following expression:
Based on Definition 2, we have , which can be expressed as follows:
If Eqs. (23), (24) hold, then we can conclude that the following expression is true:
which is equivalent to . Thus, the switched system in Eq. (12) is FTB, which completes the proof.
The sufficient guarantees of FTS are given in Theorem 1, and the prescribed attenuation performance are discussed in Theorem 2.
Theorem 2: Given system Eq. (12) and constant scalars , , , , if matrices , , , and , , such that the following expression holds:
then the system with MDADT satisfying the following expression is FTS with performance with respect to .
where . Proof: The Lyapunov functions are determined in Eq. (25). We can obtain the following equations under the zero-initial condition.
where
The system in Eq. (12) is stable with predefined performance such that
Setting and performing congruence transformation to the aforementioned inequalities through and , we can obtain the following expression:
Similar to the transformation in Eq. (33), we can obtain the following expression:
With Eqs.(40), (41), we have and , which implies that the following expression:
The following equation can be obtained by setting as . Moreover, the system in Eq. (12) is FTB with respect to by setting and .
According to and zero-initial condition, we have the following expression:
Multiplying both sides of Eq. (53) by , we obtain the following equation:
Based on the definition of MDADT and Eq. (42), we have the following:
Combining with Eqs. (43), (45), we infer the following:
Thus, we have the following equation:
Next, we have the following expression:
Setting , we can obtain the following:
Therefore, the system Eq. (12) is FTB with given attenuation index , which completes the proof.
Based on Theorems 1 and 2, the parameters of finite-time tracking controller of switched systems is derived in Theorem 3.
Theorem 3: Given system Eq. (12) and constant scalars , , , , if positive matrices , and , , exist such that the following holds true:
System Eq. (12) with MDADT satisfying Eqs. (42), (43) is finite-time stable with predefined attenuation index with respect to , and the parameters of robust controller can be expressed as follows:
where
Proof: According to Schur Complement (Aristidou et al., 2014) and Lemma 1, we can calculate the following equation:
Let , , , , Eq. (60) is equivalent to Eq. (40), and Eq. (61) is equivalent to Eq. (41). Therefore, the parameters of controller can be given according to Eqs. (59)–(61) by solving linear matrix inequalities Eqs. (62), (63).
3.2 Online scheduling based on the ADDPG algorithm
Based on the finite-time H∞ control, the sufficient conditions to ensure the FTS and prescribed performance are presented. The process of online scheduling can be formulated as the Markov decision process (MDP). Because the control process is a series of continuous decision process, the ADDPG algorithm was proposed based on the actor–critic framework to realize superior control performance of switched flight vehicles.
The DRL is composed of an agent and the interacting environment. At each time, the agent obtains a state , selects an action , and can receive reward and by interacting with the environment, in which is used to evaluate the performance of state-action pair at the time instant. In this study, the switched tracking controller can be viewed as the agent, whose purpose is maximizing the sum of the expected discounted reward function over a series of future steps:
where denotes the discount factor. Here, denotes the terminal step of reinforcement learning. The value of reward depends on the action undertaken and the current state. The action and state are defined as follows:
The ADDPG algorithm is provided based on the DDPG algorithm, in which the advantages of both deep Q learning and actor–critic framework are used to realize the optimal action, which is updated in continuous action spaces based on policy gradient theory. The ADDPG algorithm is realized in the following two sections: the action-value in each step is approximated by the critic network with weights , the current control policy is obtained by the actor network with weights . The weights of the critic network are updated by minimizing the loss function, which can be described as follows:
where
The weights of actor network are updated according to the policy gradient in the following equations:
where is the learning rate of .
To overcome the divergence of Q learning, two separated networks were adopted: the actor target network and the critic target network , the mentioned two networks can update their weights as follows:
where and are the learning rates.
Moreover, an exploration noise is added to the actor to realize exploration and actual control policy, which is generated by actor and can be rewritten as follows:
Unlike the conventional DDPG algorithm, the adaptive parameters were introduced to achieve superior convergence and robustness, respectively. By introducing robustness as a continuous parameter, the reward function enables the convenient exploration to realize adaptive training. The control policy is used to reduce the tracking error with lower control input and unsaturated actuator, therefore, the reward function depends on the tracking error, amplitude of control signal, and the saturation of actuator, which can be expressed as follows:
where represents the reward of tracking error, denotes the reward of control input, and is the reward of saturation, respectively. Here, , , and denote the weights of , , and in the reward function. Furthermore, , are the adaptive shape parameters, which determine the robustness of the reward function. and are the parameters that controls the size of the quadratic bowl near the origin, respectively. Here, is predefined constant and denotes the upper bound of the actuator. Next, the final reward function and with adaptive parameters can be rewritten as follows:
The adaptive updating law of hyper parameters are defined as follows to improve transient performance and robustness of the algorithm:
where and denote the maximum and minimum values of . Similarly, we can obtain the definitions of , , , and . The length of each segment is determined by training episodes.
Based on the statement, the pseudocode for the ADDPG algorithm proposed in this paper is presented in Algorithm 1.

Remark 3: Although the conventional DDPG algorithm can realize parameter optimization (Xu et al., 2019; Gaudet et al., 2020; Gheisarnejad and Khooban, 2021), guaranteeing data efficiency and system stability because it attempts to explore the optimal control policy for all possible action in the action space is difficult. Moreover, the proposed adaptive hyper parameters can increase robustness and achieve generalized case because the reward function determines training performance.
4 Numerical examples
In this study, the HiMAT vehicle is given to validate the proposed method. The three-view drawing and trim condition for operation points can be obtained from the study performed by Wang et al. (2015). The flight condition and the model of longitudinal motion dynamics are given as Wang et al. (2015).
Based on the trim condition within the flight envelope, the longitudinal motion dynamics can be described by switched systems. We set the sampling time and obtain the system matrices and , which can be described as follows:
The switching of subsystems in the flight envelope is supposed to be 19-18-12-9-8-4-2-1, which is described in Figure 2.
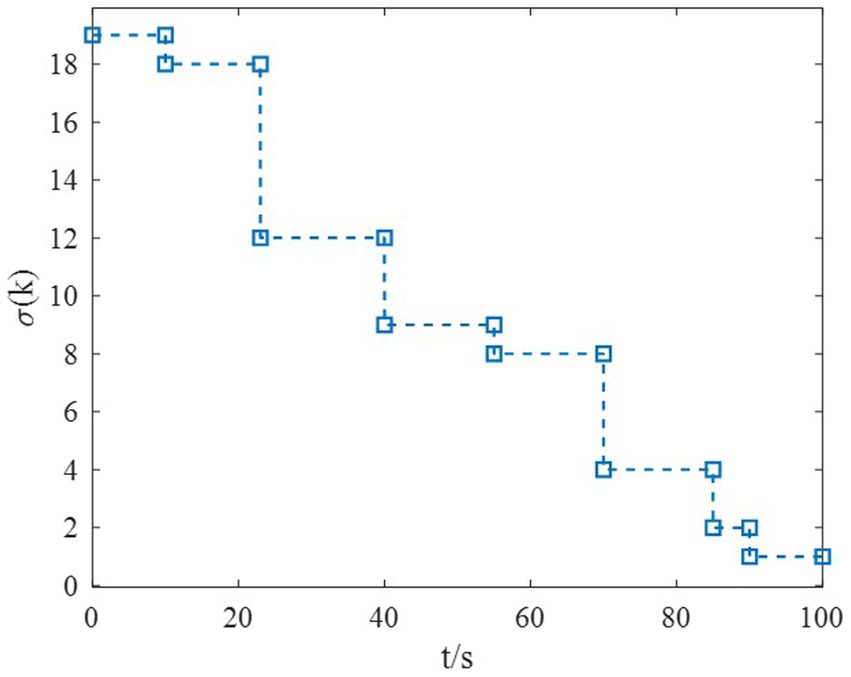
Figure 2. Switching logic of HiMAT in the flight envelope.
The harmonics wind gust is considered in the paper, which is described in Eq. (83).
where represents the state of external disturbance with initial value of .Furthermore, a command filter was provided to improve the performance of the intelligent tracking controller, which can be generated as follows:
where denotes the state vector; represents the output of the filter; and are the damping ratio and band width; and denote the transfer functions of the amplitude limiting and the rate limiting filters.
The parameters of the switched systems are given as , , , , and . Compared with the conventional ADT method, tighter bounds on FTS analysis can be obtained. The ADT method can be considered to be a special case of the MDADT method, and we can obtain that , which is illustrated in Table 1. Therefore, the proposed method can realize limited conservative results than the ADT method. We set the probability of data missing as , the maximum number of consecutive data missing N1 is set to be 5. Moreover, the matrices , , , and can be solved by Eqs. (62), (63) in Theorem 3. The dynamics-based controller was constructed, and its parameter matrices and structure are given as follows:

Table 1. Dwell time of various switching logics.
Moreover, to overcome the problem of operation points with static instability, an angular rate compensator was introduced as follows:
where denotes the transfer function of angular rate compensator, and are the parameters of compensator.
Next, we presented two examples to validate the proposed method.
Example 1: The tighter bounds on the dwell time can be obtained by the proposed method according to the data in Table 1. Moreover, because the characteristic of each subsystem is considered, the transient performance can be achieved by using the MDADT method. The switching of subsystems is displayed in Figure 2. Notably, the parameters of flight vehicles switch at the switching instants. First, to compare the difference between the two switching logic mechanisms, the simulation results under ADT switching logic and MDADT switching logic are displayed in Figures 3, 4, in which the labels are defined as ADT and MDADT, respectively. Figures 3, 4 reveal that the curves of the attack angle highlight the tracking performance in the flight envelope of switched controllers under ADT switching logic and MDADT switching logic. Thus, the tracking error can converge within the given time interval, and the transient performance of MDADT method is superior. Moreover, in Figures 3, 4, we provide the detailed enlargement of simulation curves near the switching time and steady process. Switched controllers with MDADT logic can achieve better transient performance than the those of controllers with ADT logic. Furthermore, the MDADT method corresponds to smoother response. The switched controllers with MDADT logic can obtain excellent transient performance with tighter bounds on the dwell time, which is less conservative than the ADT logic.
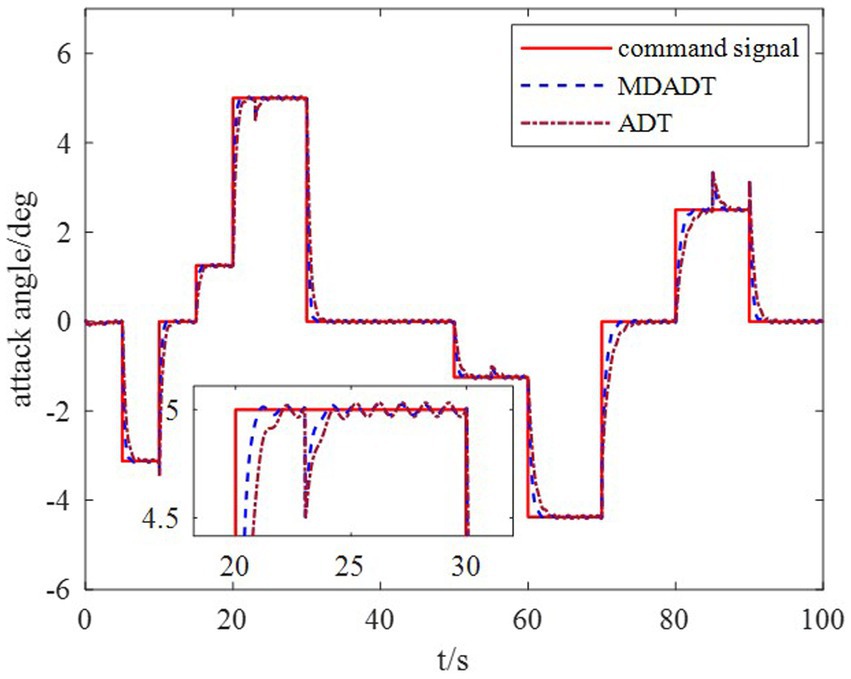
Figure 3. Response of the attack angle.

Figure 4. Tracking error.
Example 2. In this section, the feasibility of the ADDPG algorithm for flight aircraft is validated. The weights of actor network and critic network are updated such that the learning-based controller adaptively compensates the model uncertainties and external disturbance in the environment. The action of supplementary control is added to the dynamics-based controller, which constitutes the real-time finite-time adaptive tracking control for the flight vehicles. The design parameters of the ADDPG algorithm are defined in Table 2.
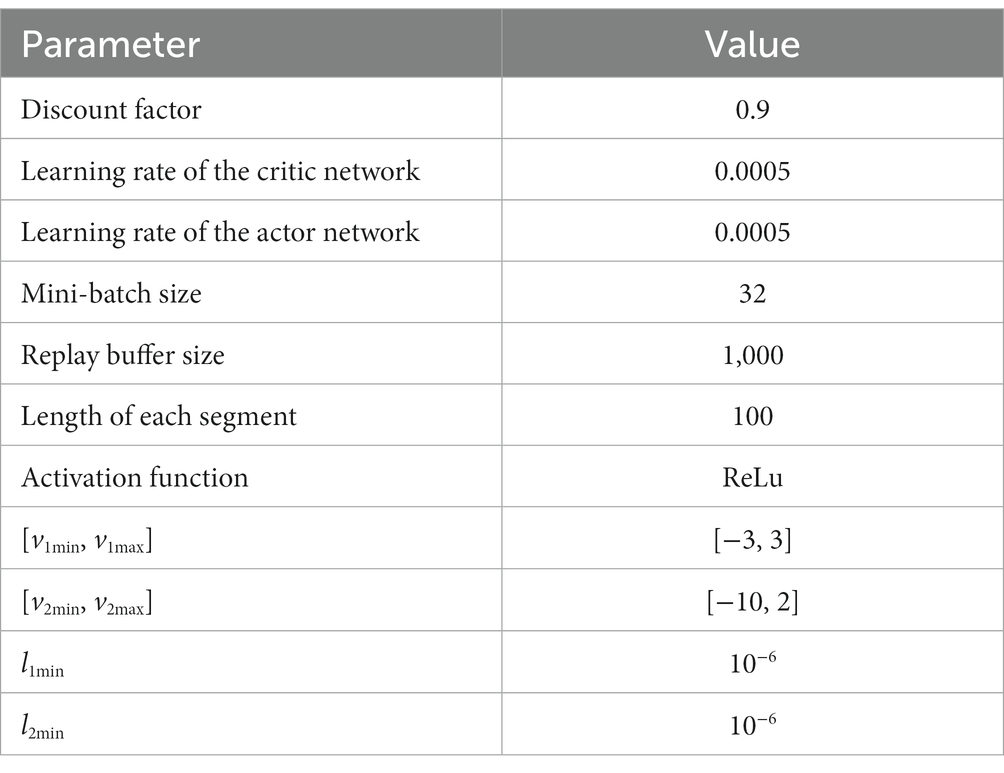
Table 2. Parameters setting of the ADDPG.
The input is divided into two paths for critic networks, corresponding to the observation and action. The number of neurons in the input layer of the observation path is the dimension of the observed states, which is represented by obs. The number of neurons in the input layer of the action path corresponding to the controller parameters. The critic networks are updated based on the adaptive moment estimation (Adam) algorithm. The regularization factor is set to be .
We define the input of actor network is the observed states and the output is the compensated controller parameters. The activation function of fully connected layers is set to be ReLu and the activation function of output layer is tanh. The weights of actor network are updated based on the Adam algorithm. The variance of noise is set to be 0.1 and the variance decay rate is . Because the stability and robustness of the closed-loop system are guaranteed by the switched control theory and robust control theory, we consider wind gust in the training environment, the perturbations of aerodynamic parameters and wind gust are introduced in the testing environment. Then the algorithms can be implemented on a desktop with Intel Core i7-10700K @3.80GHz RAM 16.00 GB and operation system of Windows 10.
The DDPG algorithm was simulated to verify the advantages of the proposed method in terms of control performance and convergence for algorithms. The robust controller proposed by the MDADT method was designed as the dynamics-based controller. Both the ADDPG and DDPG algorithms are given in the simulation as the learning-based controller to compensate the unexpected uncertainties in the flight environment. The simulation results are displayed in Figures 5–9, in which the MDADT method, MDADT with DDPG method, and MDADT with ADDPG method are labeled as MDADT, DDPG, and ADDPG, respectively. As displayed in Figures 5, 6, the ADDPG algorithm outperformed the episodes reward convergence of DDPG algorithm, which required fewer episodes to converge in the neighbor of the origin. Therefore, the ADDPG algorithm outperformed the conventional DDPG algorithm in terms of the control performance and steady error. The responses of attack angle are displayed in Figure 7. Both DDPG and ADDPG algorithms could achieve convergence and efficient performance. However, the transient convergence of the ADDPG algorithm was superior to that of the DDPG algorithm. The tracking errors are displayed in Figure 8. The controller compensated with the DDPG and ADDPG algorithms can exhibit improved performance of steady-state response. However, the steady-state error of the ADDPG algorithm was less than that of the DDPG algorithm. The reward function of an episode is displayed in Figure 9. The ADDPG algorithm can achieve superior final performance.
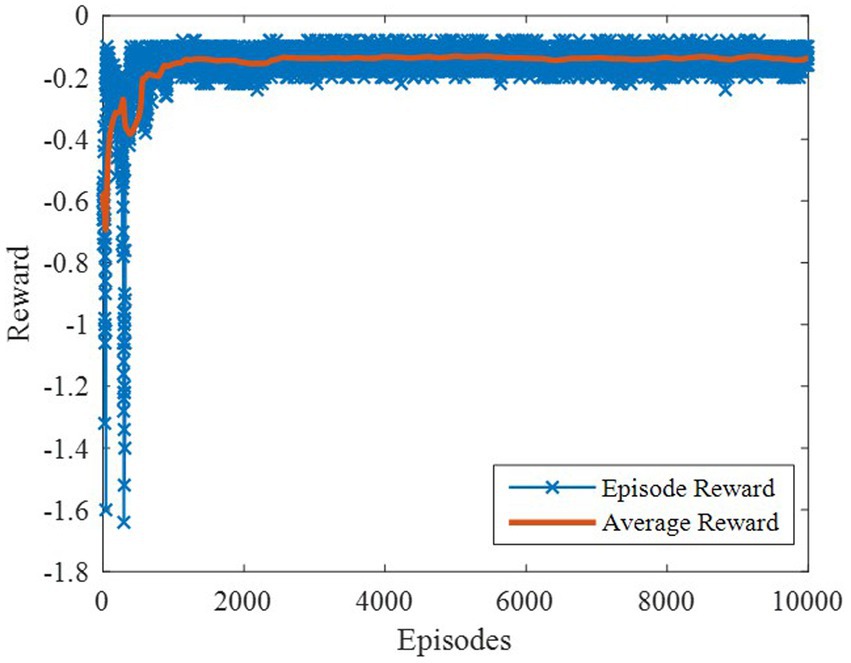
Figure 5. Episodes reward of the ADDPG.
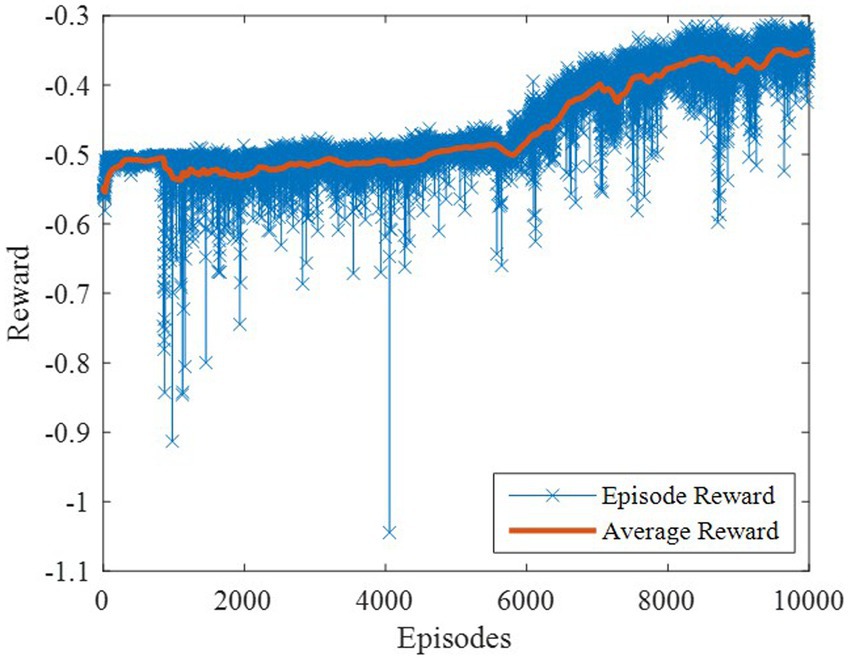
Figure 6. Episodes reward of the DDPG.
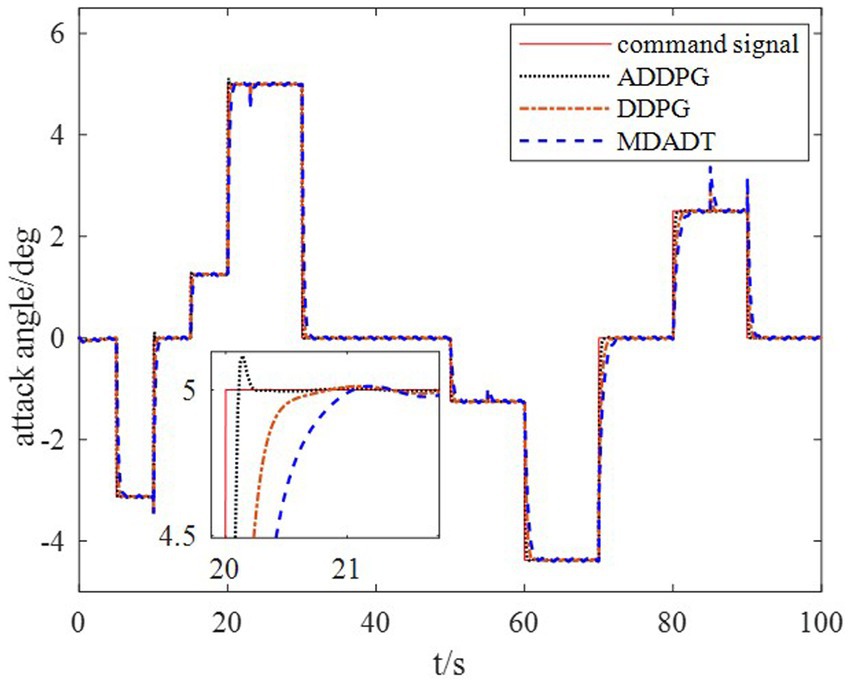
Figure 7. Response of the attack angle.
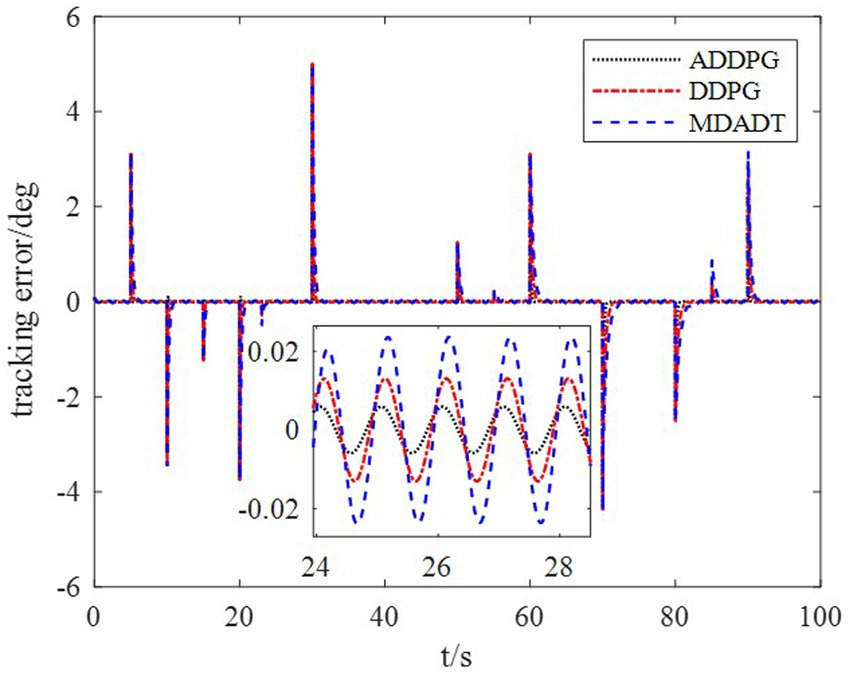
Figure 8. Tracking error.
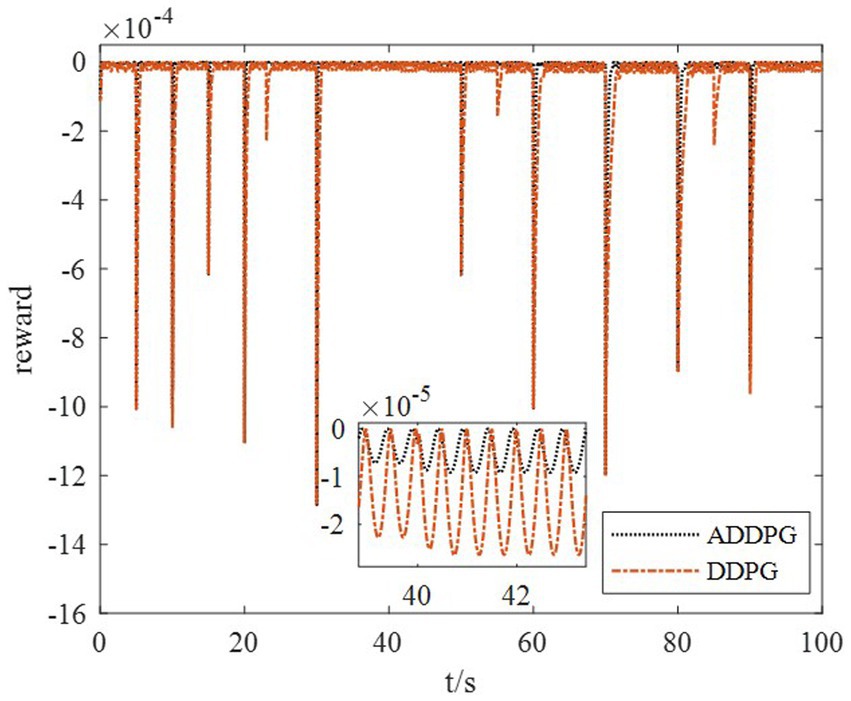
Figure 9. Response of reward function.
The average tracking errors of methods are presented in Table 3. The online scheduling through DDPG and ADDPG can efficiently reduce the average tracking error; the adaptive reward function can improve the tracking performance. The proposed method can overcome the undesirable response caused by asynchronous switching and uncertainties in the flight environment.
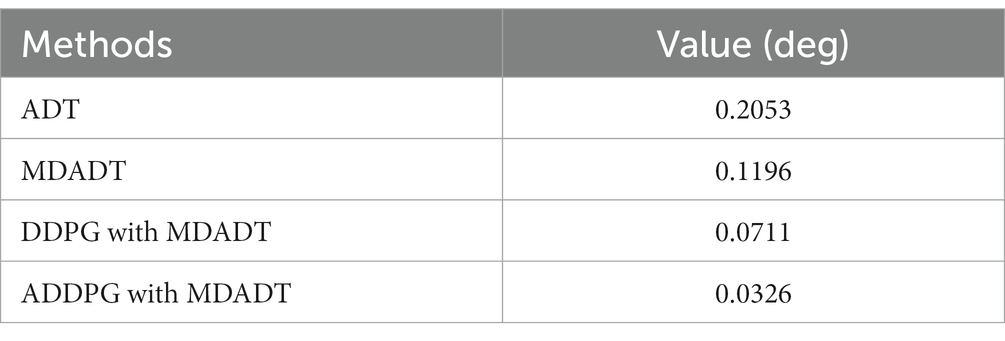
Table 3. Average tracking errors.
Moreover, to show the effectiveness to deal with system uncertainties and disturbance, we give the simulation results of HiMAT vehicle with disturbances and uncertainties of aerodynamic parameters, which can also illustrate the potential application prospects for practical environment. The results are described in Figures 10, 11, in which we consider the cases where the aerodynamic parameter perturbations are 10, 15, and 20%. The responses of attack angle are given in Figure 10 and the tracking errors are given in Figure 11. The average tracking errors in the presence of aerodynamic perturbations are also provided in Table 4. We can see that the stability and tracking performance can be guaranteed with uncertainties and disturbances by using the proposed method, which illustrates that the proposed method can ensure the control accuracy, stability, and robustness simultaneously.
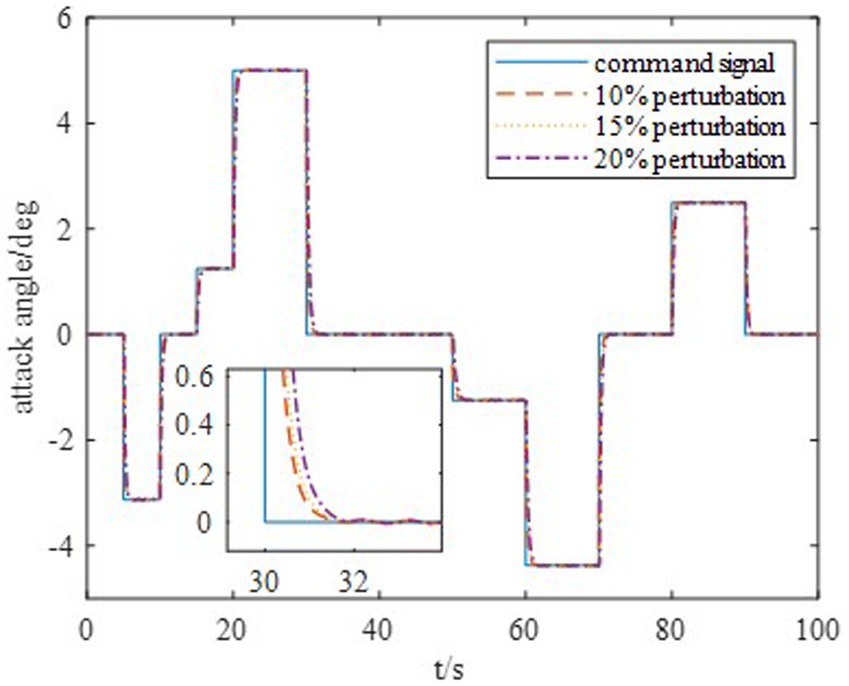
Figure 10. Response of the attack angle.
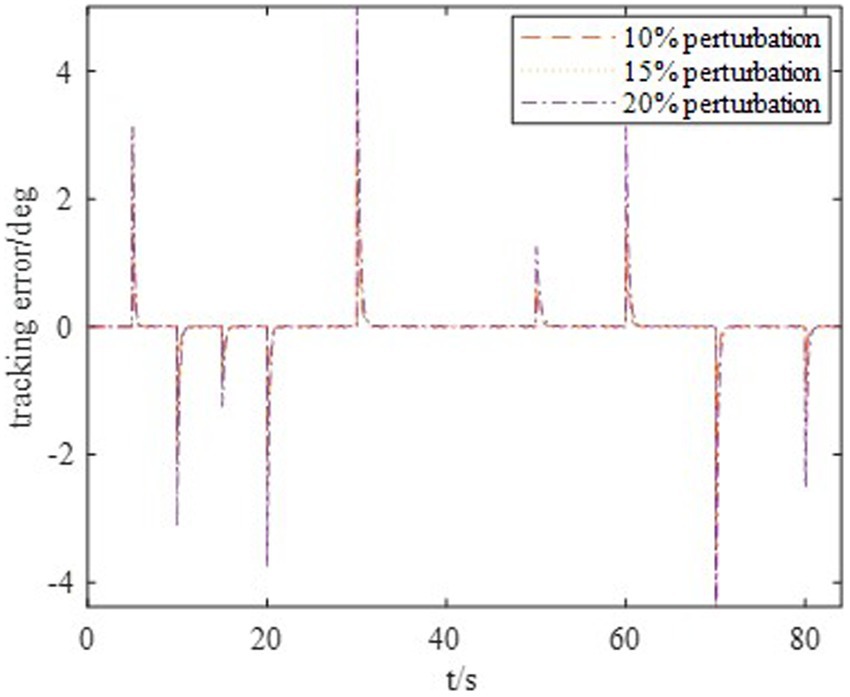
Figure 11. Tracking error.
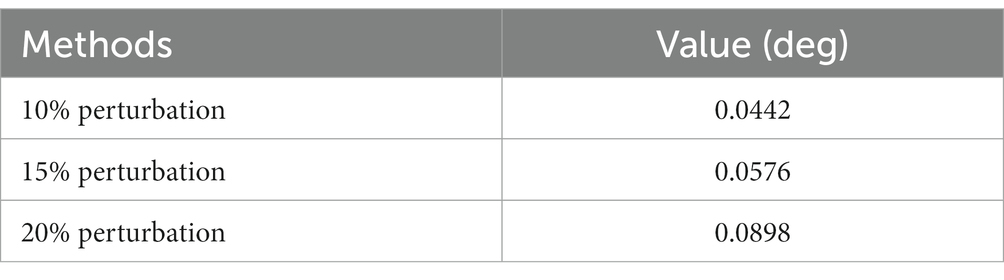
Table 4. Average tracking errors in the presence of aerodynamic perturbations.
Remark 4: We draw inspiration from the traditional method of dealing with the sim-to-real transfer issue. Firstly, the nonlinear model is converted to a linear model by employing Jacobian linearization. Then we can design the nominal controller on the reference points. In most engineering applications, the stability margin is introduced and analyzed to ensure the robustness. Similarly, in this paper, we developed finite-time robust control theory to ensure the stability and attenuation performance. The uncertainties and disturbances in practical environment can be overcome. However, we noticed that it is difficult to realize optimal compromise between robustness and transient performance. The ADDPG algorithm is given to improve the control accuracy. Moreover, the non-fragile control theory is introduced, which ensures the stability and prescribed attenuation performance on the scheduling intervals.
Remark 5: The problem of finite-time tracking control for switched flight vehicles was investigated. According to the numerical examples, the advantages of the suggested control method to address the flight vehicle considering disturbances and uncertainties over the existing control methods are demonstrated, which can be described as follows: (1) Unlike the conventional model-based control methods, the proposed method was developed by using DRL, which can improve control performance and overcome the undesirable response caused by uncertainties. (2) In the proposed method, the advantages of model-based and model-free method are combined. The dynamics-based controller was developed to ensure stability and robustness, and the learning-based controller was proposed to compensate the uncertainties in the flight environment. (3) The established adaptive generalized reward function can improve convergence and robustness.
5 Conclusion
The finite-time control of switched flight vehicles with asynchronous switching was realized using a novel nonfragile DRL method. The flight vehicles were modeled as the switched system, and the asynchronous switching caused by packet dropouts was considered. The MDADT and MLF methods were used to ensure FTS and weighted prescribed attenuation index. LMIs were used to determine the solutions of the finite-time tracking controller. To compensate the external disturbance and improve tracking performance, the ADDPG algorithm based on the actor–critic framework was provided to optimize the parameters of tracking controllers. To improve optimization efficiency and decrease computational complexity, parameter optimization was assumed to be limited in the given range. The compensation of control policy in a given range is considered as the uncertainties of the controller parameters, and the FTS is ensured by nonfragile control theory. Compared with the conventional DDPG algorithm, the adaptive hyper parameters of reward function were introduced to achieve superior control performance and realize a general case. The FTS, robustness, and transient performance were ensured simultaneously by the proposed method. In the future, the following four points should be studied: (1) The event-triggered control structure should be considered to reduce the load and improve the robustness of information transformation. (2) The parallel optimization methods should be presented to improve training efficiency. (3) The fitting ability and generalization ability of neural networks should be studied to improve the robustness in the complex environment. (4) The semi physical simulations and flight tests of mini drones should be developed to further demonstrate the engineering feasibility of the proposed method.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
HC: Writing – original draft, Writing – review & editing. RS: Writing – original draft, Writing – review & editing. HL: Writing – review & editing, Writing – original draft. WW: Writing – review & editing, Writing – original draft. BZ: Writing – review & editing, Writing – original draft. YF: Writing – original draft, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This study was co-supported by National Natural Science Foundation of China (No. 62303380,62176214, 62003268, 62101590), and the Aero-nautical Science Foundation of China (No. 201907053001).
Acknowledgments
The authors would like to thank all the reviewers who participated in the review.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Aristidou, P., Fabozzi, D., and Cutsem, V. T. (2014). Dynamic simulation of large-scale power systems using a parallel Schur-complement-based decomposition method. IEEE Trans. Para. and Dis. Sys. 25, 2561–2570. doi: 10.1109/TPDS.2013.252
Ban, J., Kwon, W., Won, S., and Kim, S. (2018). Robust H∞ finite-time control for discrete-time polytopic uncertain switched linear systems. Nonlinear Anal-Hybri 29, 348–362. doi: 10.1016/j.nahs.2018.03.005
Bao, C. Y., Wang, P., and Tang, G. J. (2021). Integrated method of guidance, control and morphing for hypersonic morphing vehicle in glide phase. Chin. J. Aeronaut. 34, 535–553. doi: 10.1016/j.cja.2020.11.009
Chen, L. H., Fu, S. S., Zhao, Y. X., Liu, M., and Qiu, J. B. (2020). State and fault observer design for switched systems via an adaptive fuzzy approach. IEEE Trans. Fuzzy Syst. 28, 2107–2118. doi: 10.1109/TFUZZ.2019.2930485
Chen, S. Z., Ning, C. Y., Liu, Q., and Liu, Q. P. (2022). Improved multiple Lyapunov functions of input–output-to-state stability for nonlinear switched systems. Inf. Sci. 608, 47–62. doi: 10.1016/j.ins.2022.06.025
Cheng, H. Y., Dong, C. Y., Jiang, W. L., Wang, Q., and Hou, Y. Z. (2017). Non-fragile switched H∞ control for morphing aircraft with asynchronous switching. Chin. J. Aeronaut. 30, 1127–1139. doi: 10.1016/j.cja.2017.01.008
Cheng, H. Y., Fu, W. X., Dong, C. Y., Wang, Q., and Hou, Y. Z. (2018). Asynchronously finite-time H∞ control for morphing aircraft. Trans. Inst. Meas. Control. 40, 4330–4344. doi: 10.1177/0142331217746737
Cheng, L., Wang, Z. B., and Jiang, F. H. (2019). Real-time control for fuel-optimal moon landing based on an interactive deep reinforcement learning algorithm. Astrodynamics 3, 375–386. doi: 10.1007/s42064-018-0052-2
Cheng, Y., and Zhang, W. D. (2018). Concise deep reinforcement learning obstacle avoidance for underactuated unmanned marine vessels. Neurocomputing 272, 63–73. doi: 10.1016/j.neucom.2017.06.066
Gaudet, B., Linares, R., and Furfaro, R. (2020). Deep reinforcement learning for six degree-of-freedom planetary landing. Adv. Space Res. 65, 1723–1741. doi: 10.1016/j.asr.2019.12.030
Gheisarnejad, M., and Khooban, H. M. (2021). An intelligent non-integer PID controller-based deep reinforcement learning: implementation and experimental results. IEEE Trans. Ind. Electron. 68, 3609–3618. doi: 10.1109/TIE.2020.2979561
Giacomin, P. A. S., and Hemerly, E. M. (2022). A distributed, real-time and easy-to-extend strategy for missions of autonomous aircraft squadrons. Inf. Sci. 608, 222–250. doi: 10.1016/j.ins.2022.06.043
Gong, L. G., Wang, Q., Hu, C. H., and Liu, C. (2020). Switching control of morphing aircraft based on Q-learning. Chin. J. Aeronaut. 33, 672–687. doi: 10.1016/j.cja.2019.10.005
Grigorie, L. T., Khan, S., Botez, M. R., Mamou, M., and Mébarki, Y. (2022). Design and experimental testing of a control system for a morphing wing model actuated with miniature BLDC motors. Chin. J. Aeronaut. 33, 1272–1287. doi: 10.1016/j.cja.2019.08.007
Guo, Q., Zhang, Y., Celler, G. B., and Su, W. S. (2019). Neural adaptive backstepping control of a robotic manipulator with prescribed performance constraint. IEEE Trans. Neural Netw. Learn. Syst. 30, 3572–3583. doi: 10.1109/TNNLS.2018.2854699
Hu, Q. L., Xiao, L., and Wang, C. L. (2019). Adaptive fault-tolerant attitude tracking control for spacecraft with time-varying inertia uncertainties. Chin. J. Aeronaut. 32, 674–687. doi: 10.1016/j.cja.2018.12.015
Huang, L. T., Li, Y. M., and Tong, S. C. (2020). Fuzzy adaptive output feedback control for MIMO switched nontriangular structure nonlinear systems with unknown control directions. IEEE Trans. Syst. Man. Cybern. Syst. 50, 550–564. doi: 10.1109/TSMC.2017.2778099
Jiang, W. L., Wu, K. S., Wang, Z. L., and Wang, Y. N. (2020). Gain-scheduled control for morphing aircraft via switching polytopic linear parameter-varying systems. Aerosp. Sci. Technol. 107:106242. doi: 10.1016/j.ast.2020.106242
Lee, S., and Kim, D. (2022). Deep learning based recommender system using cross convolutional filters. Inf. Sci. 592, 112–122. doi: 10.1016/j.ins.2022.01.033
Li, M. L., and Deng, F. Q. (2018). Moment exponential input-to-state stability of non-linear switched stochastic systems with Lévy noise. IET Contr. Theory Appl. 12, 1208–1215. doi: 10.1049/iet-cta.2017.1229
Liu, Y., Dong, C. Y., Zhang, W. Q., and Wang, Q. (2021). Phase plane design based fast altitude tracking control for hypersonic flight vehicle with angle of attack constraint. Chin. J. Aeronaut. 34, 490–503. doi: 10.1016/j.cja.2020.04.026
Liu, T. J., Du, X., Sun, X. M., Richter, H., and Zhu, F. (2019). Robust tracking control of aero-engine rotor speed based on switched LPV model. Aerosp. Sci. Technol. 91, 382–390. doi: 10.1016/j.ast.2019.05.031
Liu, L. J., Zhao, X. D., Sun, X. M., and Zong, G. D. (2020). Stability and l2-gain analysis of discrete-time switched systems with mode-dependent average dwell time. IEEE Trans. Syst. Man. Cybern. Syst. 50, 2305–2314. doi: 10.1109/TSMC.2018.2794738
Lu, Y., Jia, Z., Liu, X., and Lu, K. F. (2022). Output feedback fault-tolerant control for hypersonic flight vehicles with non-affine actuator faults. Acta Astronaut. 193, 324–337. doi: 10.1016/j.actaastro.2022.01.023
Sakthivel, R., Wang, C., Santra, S., and Kaviarasan, B. (2018). Non-fragile reliable sampled-data controller for nonlinear switched time-varying systems. Nonlinear Anal-Hybri 27, 62–76. doi: 10.1016/j.nahs.2017.08.005
Sun, Y. M., and Lei, Z. (2021). Fixed-time adaptive fuzzy control for uncertain strict feedback switched systems. Inf. Sci. 546, 742–752. doi: 10.1016/j.ins.2020.08.059
Tailor, D., and Izzo, D. (2019). Learning the optimal state-feedback via supervised imitation learning. Astrodynamics 3, 361–374. doi: 10.1007/s42064-019-0054-0
Wang, J. H., Ha, L., Dong, X. W., Li, Q. D., and Ren, Z. (2021). Distributed sliding mode control for time-varying formation tracking of multi-UAV system with a dynamic leader. Aerosp. Sci. Technol. 111:106549. doi: 10.1016/j.ast.2021.106549
Wang, Z. C., Sun, J., Chen, J., and Bai, Y. Q. (2020). Finite-time stability of switched nonlinear time-delay systems. Int. J. Robust Nonlinear Control. 30, 2906–2919. doi: 10.1002/rnc.4928
Wang, Z. L., Wang, Q., Dong, C. Y., and Gong, L. G. (2015). Closed-loop fault detection for full-envelope flight vehicle with measurement delays. Chin. J. Aeronaut. 28, 832–844. doi: 10.1016/j.cja.2015.04.009
Wang, H., and Xu, R. (2022). Heuristic decomposition planning for fast spacecraft reorientation under multiaxis constraints. Acta Astronaut. 198, 286–294. doi: 10.1016/j.actaastro.2022.06.012
Wang, F., Zhang, X. Y., Chen, B., Chong, L., Li, X. H., and Zhang, J. (2017). Adaptive finite-time tracking control of switched nonlinear systems. Inf. Sci. 421, 126–135. doi: 10.1016/j.ins.2017.08.095
Wei, J. M., Zhang, X. X., Zhi, H. M., and Zhu, X. L. (2020). New finite-time stability conditions of linear discrete switched singular systems with finite-time unstable subsystems. J. Frankl. Inst. 357, 279–293. doi: 10.1016/j.jfranklin.2019.03.045
Wu, C. H., Yan, J. G., Lin, H., Wu, X. W., and Xiao, B. (2021). Fixed-time disturbance observer-based chattering-free sliding mode attitude tracking control of aircraft with sensor noises. Aerosp. Sci. Technol. 111:106565. doi: 10.1016/j.ast.2021.106565
Xiao, X. Q., Park, H. J., Zhou, L., and Lu, G. P. (2020). Event-triggered control of discrete-time switched linear systems with network transmission delays. Automatica 111:108585. doi: 10.1016/j.automatica.2019.108585
Xu, J., Hou, Z. M., Wang, W., Xu, B. H., Zhang, K. G., and Chen, K. (2019). Feedback deep deterministic policy gradient with fuzzy reward for robotic multiple peg-in-hole assembly tasks. IEEE Trans. Ind. Inform. 15, 1658–1667. doi: 10.1109/TII.2018.2868859
Xu, X. Z., Mao, X., Li, Y., and Zhang, H. B. (2019). New result on robust stability of switched systems with all subsystems unstable. IET Contr. Theory Appl. 13, 2138–2145. doi: 10.1049/iet-cta.2019.0018
Yang, D., Li, X. D., and Song, S. J. (2020). Design of state-dependent switching laws for stability of switched stochastic neural networks with time-delays. IEEE Trans. Neural Netw. Learn. Syst. 31, 1808–1819. doi: 10.1109/TNNLS.2019.2927161
Yang, D., Zong, G. D., Liu, Y. J., and Ahn, C. K. (2022). Adaptive neural network output tracking control of uncertain switched nonlinear systems: an improved multiple Lyapunov function method. Inf. Sci. 606, 380–396. doi: 10.1016/j.ins.2022.05.071
Yuan, S., Schutter, D. B., and Baldi, S. (2017). Adaptive asymptotic tracking control of uncertain time-driven switched linear systems. IEEE Trans. Autom. Control 62, 5802–5807. doi: 10.1109/TAC.2016.2639479
Yue, T., Xu, Z. J., Wang, L. X., and Wang, T. (2019). Sliding mode control design for oblique wing aircraft in wing skewing process. Chin. J. Aeronaut. 32, 263–271. doi: 10.1016/j.cja.2018.11.002
Zhang, L. X., Nie, L., Cai, B., Yuan, S., and Wang, D. Z. (2019). Switched linear parameter-varying modeling and tracking control for flexible hypersonic vehicle. Aerosp. Sci. Technol. 95:105445. doi: 10.1016/j.ast.2019.105445
Zhang, M., and Zhu, Q. X. (2019). Input-to-state stability for non-linear switched stochastic delayed systems with asynchronous switching. IET Contr. Theory Appl. 13, 351–359. doi: 10.1049/iet-cta.2018.5956
Zhang, M., and Zhu, Q. X. (2020). Stability analysis for switched stochastic delayed systems under asynchronous switching: a relaxed switching signal. Int. J. Robust Nonlinear Control 30, 8278–8298. doi: 10.1002/rnc.5240
Zhao, X. D., Shi, P., Yin, Y. F., and Nguang, S. K. (2017). New results on stability of slowly switched systems: a multiple discontinuous Lyapunov function approach. IEEE Trans. Autom. Control 62, 3502–3509. doi: 10.1109/TAC.2016.2614911
Keywords: switched systems, asynchronous switching, deep reinforcement learning, nonfragile control, finite H∞ control
Citation: Cheng H, Song R, Li H, Wei W, Zheng B and Fang Y (2023) Realizing asynchronous finite-time robust tracking control of switched flight vehicles by using nonfragile deep reinforcement learning. Front. Neurosci. 17:1329576. doi: 10.3389/fnins.2023.1329576
Edited by:
Ziming Zhang, Worcester Polytechnic Institute, United StatesCopyright © 2023 Cheng, Song, Li, Wei, Zheng and Fang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Haoyu Cheng, Y2hlbmdoYW95dUBud3B1LmVkdS5jbg==