 Chuan Zhang1,2†Man Li3†
Chuan Zhang1,2†Man Li3† Zheng Luo2†Ruhui Xiao2†Bing Li2
Zheng Luo2†Ruhui Xiao2†Bing Li2 Jing Shi2Chen Zeng2BaiJinTao Sun2Xiaoxue Xu2
Jing Shi2Chen Zeng2BaiJinTao Sun2Xiaoxue Xu2 Hanfeng Yang1,2*
Hanfeng Yang1,2*- 1The First Affiliated Hospital, Jinan University, Guangzhou, China
- 2Department of Radiology, Affiliated Hospital of North Sichuan Medical College, Nanchong, China
- 3Shanghai United Imaging Intelligence, Co., Ltd., Shanghai, China
Purpose: Trigeminal neuralgia (TN) poses significant challenges in its diagnosis and treatment due to its extreme pain. Magnetic resonance imaging (MRI) plays a crucial role in diagnosing TN and understanding its pathogenesis. Manual delineation of the trigeminal nerve in volumetric images is time-consuming and subjective. This study introduces a Squeeze and Excitation with BottleNeck V-Net (SEVB-Net), a novel approach for the automatic segmentation of the trigeminal nerve in three-dimensional T2 MRI volumes.
Methods: We enrolled 88 patients with trigeminal neuralgia and 99 healthy volunteers, dividing them into training and testing groups. The SEVB-Net was designed for end-to-end training, taking three-dimensional T2 images as input and producing a segmentation volume of the same size. We assessed the performance of the basic V-Net, nnUNet, and SEVB-Net models by calculating the Dice similarity coefficient (DSC), sensitivity, precision, and network complexity. Additionally, we used the Mann–Whitney U test to compare the time required for manual segmentation and automatic segmentation with manual modification.
Results: In the testing group, the experimental results demonstrated that the proposed method achieved state-of-the-art performance. SEVB-Net combined with the ωDoubleLoss loss function achieved a DSC ranging from 0.6070 to 0.7923. SEVB-Net combined with the ωDoubleLoss method and nnUNet combined with the DoubleLoss method, achieved DSC, sensitivity, and precision values exceeding 0.7. However, SEVB-Net significantly reduced the number of parameters (2.20 M), memory consumption (11.41 MB), and model size (17.02 MB), resulting in improved computation and forward time compared with nnUNet. The difference in average time between manual segmentation and automatic segmentation with manual modification for both radiologists was statistically significant (p < 0.001).
Conclusion: The experimental results demonstrate that the proposed method can automatically segment the root and three main branches of the trigeminal nerve in three-dimensional T2 images. SEVB-Net, compared with the basic V-Net model, showed improved segmentation performance and achieved a level similar to nnUNet. The segmentation volumes of both SEVB-Net and nnUNet aligned with expert annotations but SEVB-Net displayed a more lightweight feature.
1. Introduction
Trigeminal neuralgia is a debilitating neuropathic pain condition that affects psychological, physical, and social needs, such as touching the face, talking, eating, and drinking (Bendtsen et al., 2020). This mental disorder is correlated with a poor quality of life and, in some cases, even a risk of suicide (Obermann, 2019). Clinical diagnosis of trigeminal neuralgia relies on three main criteria: pain localized to the territory of one or more divisions of the trigeminal nerve; paroxysms of intense and brief pain (<1 s to 2 min, but usually a few seconds) described as “shock” or “electric sensation”; and pain triggered by innocuous stimuli on the face or intraoral trigeminal territory (Bendtsen et al., 2019).
MR neurography (MRN), dedicated to imaging peripheral nerves, provides a detailed map of neuromuscular anatomy and offers a non-invasive view of intraneural architecture in multiple orthogonal planes (Kim et al., 2023). Furthermore, high-resolution MRI now provides exquisite anatomic detail, enabling radiologists to examine nearly the entire course of the trigeminal nerve, from its nuclei in the brainstem to the distal branches of its three main divisions: the ophthalmic, maxillary, and mandibular nerves (Seeburg et al., 2016). Our team has acquired expertise in utilizing MRI for comprehensive trigeminal nerve imaging, as illustrated in Figure 1. Given the complex course of the trigeminal nerve, reconstructing its peripheral branches is challenging and time-consuming. Therefore, achieving accurate manual delineation and reconstruction requires radiologists with advanced anatomical knowledge and proficient skills. Additionally, it is desirable to develop a trigeminal nerve segmentation model using deep learning methods to enhance clinical efficiency.
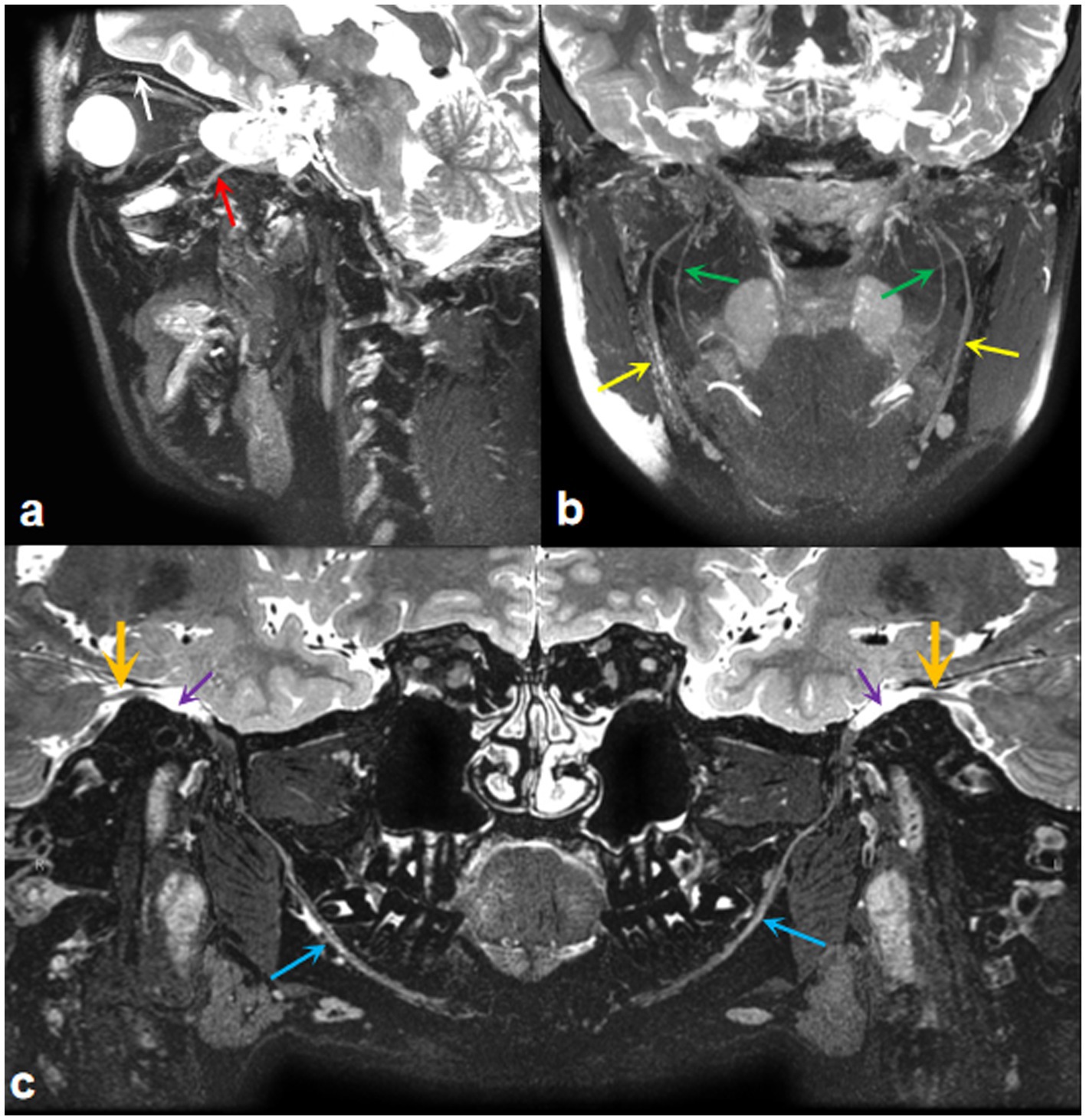
Figure 1. MRI imaging of the trigeminal nerve. (A) A three-dimensional T2WI-CUBE fs reconstruction image displays the ocular nerve (white arrow) and maxillary nerve (red arrow). (B) A three-dimensional T2WI-CUBE fs reconstruction image shows the branches of the mandibular nerve, inferior alveolar nerve (green arrows), and lingual nerve (yellow arrows). (C) A three-dimensional T2WI-CUBE fs reconstruction image provides a comprehensive view of the mandibular branch of the trigeminal nerve, including the trigeminal nerve itself (orange arrows), Meckel cavity (purple arrows), and mandibular nerve (blue arrows).
Since the introduction of artificial intelligence (AI), deep learning technology has consistently advanced (Aggarwal et al., 2021) demonstrating excellent performance in image analysis using convolutional neural networks (CNNs) (Alzubaidi et al., 2021a). This encompasses object detection, object classification, and object segmentation (Yang and Yu, 2021), all of which contribute to medical diagnosis by enhancing imaging analysis and evaluation (Hwang et al., 2019).
Previously, the statistical shape model (SSM) described by Abdolali et al. was used for automatic segmentation of the inferior alveolar nerve (Abdolali et al., 2016). Lim et al. reported the use of a customized three-dimensional nnU-Net for image segmentation, serving as a fast, accurate, and robust clinical tool for delineating the location of the inferior alveolar nerve (Lim et al., 2021). Lin et al. employed CS2Net to approximately segment the nerves and blood vessels in the trigeminal cistern segment and then refined the boundaries of nerves and blood vessels using three-dimensional UNet, resulting in successful segmentation (Lin et al., 2021). However, there are no existing reports on an artificial intelligence segmentation model for the three branches of the trigeminal nerve.
In this study, our aim was to develop a V-Net-based fully automated framework for the segmentation of the trigeminal nerve using MR imaging. The results show that, in comparison with the basic V-Net, our optimized deep learning algorithm, SEVB-Net, demonstrates good convergence, improved performance in terms of DSC and sensitivity, smoother results than manual segmentation, and superior segmentation performance.
2. Methods
2.1. Patient data collection
2.1.1. Inclusion and exclusion criteria
We analyzed data obtained from a consecutive series of 232 subjects who underwent MRN at the hospital between January 2020 and December 2022. We excluded 42 subjects due to poor image quality, making it difficult to identify the trigeminal nerve. These data did not clearly depict the nerve, and manual segmentation resulted in poor accuracy, rendering them unsuitable for clinical practice. Additionally, we excluded three subjects in whom manual segmentation did not correspond to the coordinates of the original image. As a result, images from 187 subjects were used in this study, and they were divided into the training (n = 152) and testing (n = 35) groups.
2.1.2. Image acquisition
To obtain MR neurograms, we utilized magnetic resonance imaging (MRI) scanners, specifically the uMR 790 3.0 T, GE Discovery 750 3.0 T, Magnetom Aera 1.5 T, and Magnetom Skyra 3.0 T, for data acquisition. The scanning sequences for capturing images of the trigeminal nerve are detailed in Table 1. The images of 187 subjects used in this study were sourced from these four scanners: 58 from the uMR 790 3.0 T, 71 from the GE Discovery 750 3.0 T, 32 from the Magnetom Aera 1.5 T, and 26 from the Magnetom Skyra 3.0 T.

Table 1. MR scanner and MR neurography protocol.
To ensure an even distribution of scanning protocols in both the training and testing datasets, we randomly divided the data from each scanner according to an 80:20 ratio. In the final dataset, the data quantities for the four scanning protocols were as follows: 47, 58, 26, and 21 in the training set (n = 152) and 11,13,6, and 5 in the testing set (n = 35).
2.2. Manual segmentation
Manual segmentation served as the ground truth in this study, and all manual segmentations were conducted by two radiologists, C and D, each possessing more than 10 years of experience in neuroimaging diagnosis. The 3D Slicer software was employed for pre-processing and manual segmentation, extracting a schematic diagram of the trigeminal nerve from the brainstem to the periphery for each subject. The procedure was as follows:
First, we imported and loaded the 3D-MX STIR images from the Picture Archiving and Communication System (PACS) into 3D Slicer. Then, the images were reformatted and adjusted to display the nerve as clearly as possible. The editor tool in 3D Slicer was used to segment the intracranial and extracranial segments of the trigeminal nerve and its branches (ophthalmic, maxillary, and mandibular nerves) in axial and coronal positions, respectively.
The segmentation accuracy for the trigeminal nerve was subjectively evaluated by two medical experts, Prof. A and Prof. B, each with more than 20 years of experience in neuroimaging diagnosis. The evaluation criteria adopted three levels of scoring: 0, poor (unusable in clinical practice, not included in the study, as mentioned earlier); 1, acceptable (minor revisions needed, subjects included in the study after revision); and 2, good (nearly no revisions needed, subjects directly included in the study).
2.3. Data pre-processing
In this study, two types of data pre-processing were employed. The first type was conducted before training and included bias field correction and region of interest (ROI) division based on connected domains.
2.3.1. Bias field correction
Various factors such as different scanners, scanning schemes, and acquisition artifacts can result in an uneven display intensity of MR images during visualization, causing variations in the intensity values of the same tissue across the entire MR image (Ullah et al., 2021). This variation in intensity is referred to as the bias field (Bernal et al., 2019), which can affect the quality of the acquired MR images. To address this bias field distortion, we applied the N4ITK bias field correction algorithm, a commonly used strategy in the literature, proposed by Tustison et al. (2010), and evaluated the publicly available datasets BraTS-2013, BraTS-2015, and BraTS-2018 (Ullah et al., 2021). The N4ITK bias field correction algorithm was applied to all images to mitigate image artifacts and enhance grayscale distribution. Sample images before and after bias field correction are shown in Figures 2A,B.
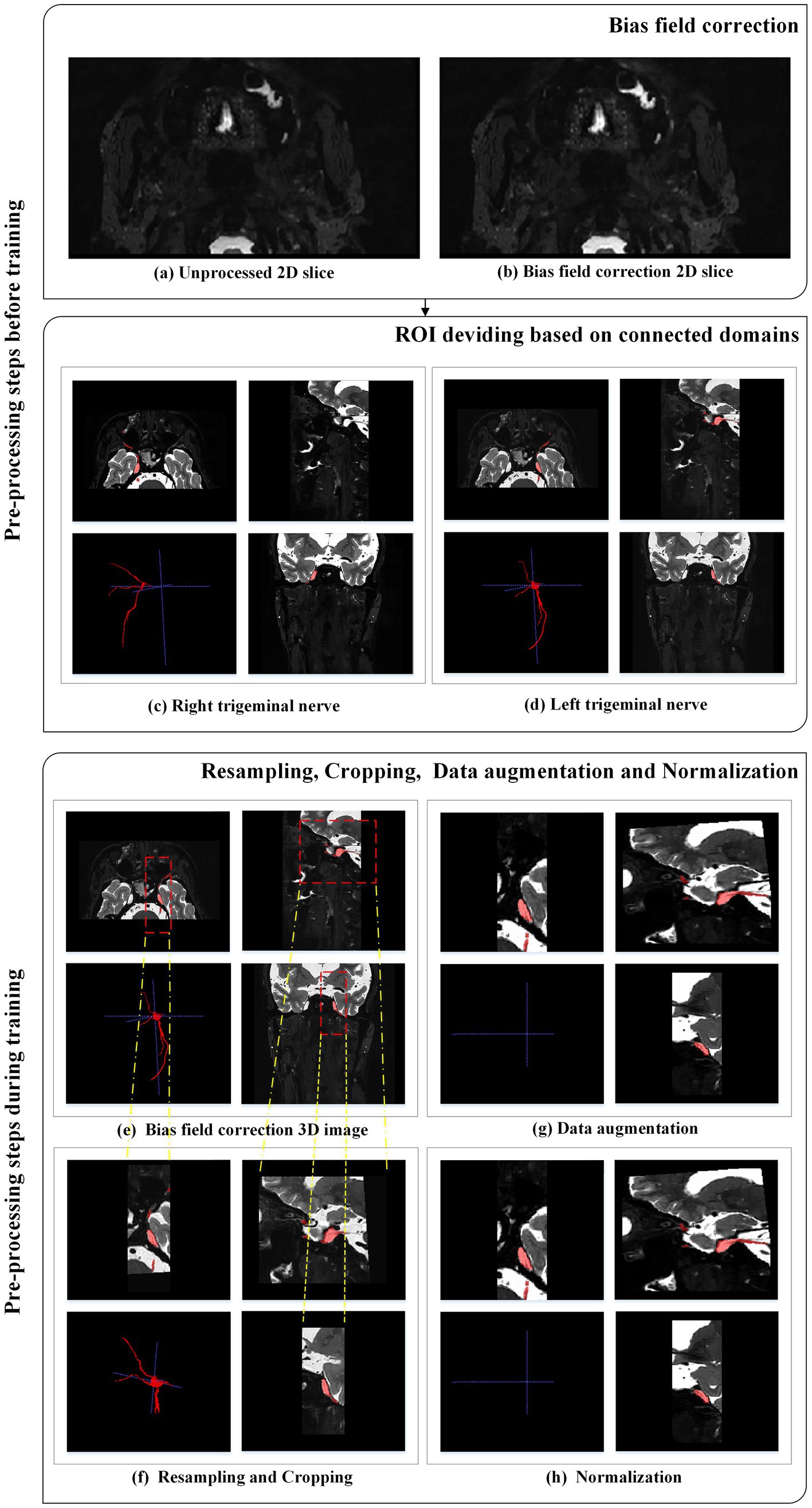
Figure 2. Pre-processing steps applied to each MRI case.
2.3.2. Region of interest dividing based on connected domain
After radiologists manually segmented the trigeminal nerve regions, these regions were then divided based on connected domains. The original bilateral trigeminal nerves were divided into left and right trigeminal nerves (as shown in Figures 2C,D). This division not only doubled the amount of training data but also reduced GPU memory consumption during training.
The second type of data pre-processing occurred during training.
2.3.3. Resampling and cropping
Medical images often have inconsistent resolutions. To enable the network to accurately learn spatial semantics, all patients were resampled to the median voxel spacing of the dataset (Isensee et al., 2021). We used nearest-neighbor interpolation for both the original image data and the corresponding segmentation mask. During training, we randomly sampled cropped patches of the same size from the image and used them as network input to reduce GPU memory consumption, as shown in Figures 2E,F.
2.3.4. Data augmentation
Data augmentation was applied to the original images (as shown in Figures 2F,G). Data augmentation is crucial in deep learning as it helps generate additional equivalent data to expand the dataset (Chlap et al., 2021). In this study, we employed various data augmentation techniques, including common geometric transformations (such as rotation, scaling, translation, mirror image, and elastic deformation) and color transformations (such as brightness transformation, gamma correction, cover, filling, Gaussian noise transformation, and Gaussian blurring transformation). Increasing the training data is beneficial for improving the model’s generalization ability, and incorporating appropriate noise data can enhance the model’s robustness.
2.3.5. Intensity normalization
The images were adaptively normalized to the range of [−1, 1], as illustrated in Figure 2H. All intensity values within the ROI of the image were collected and scaled to occupy [0.01, 0.99] of these intensity values, and z-score normalization was performed based on the minimum and maximum intensity values. Figure 2 illustrates the pre-processing steps applied to each MRI case.
2.4. Overall framework for trigeminal nerve segmentation
This research employed an end-to-end network model for semantic segmentation, independently developed by a dedicated data processing team, utilizing a three-dimensional segmentation scheme. Expanding upon the V-Net network as the baseline, we introduced the BottleNeck and SE-Net components to optimize the V-Net network structure (Milletari et al., 2016). We named the architecture as SEVB-Net, where “SE” stands for SE-Net and “B” stands for bottleneck. As depicted in Figure 3, the bottleneck structure comprises three convolutional layers and replaces the original 3 × 3 × 3 kernel layers (He et al., 2016). Two 1 × 1 × 1 kernel layers are utilized to reduce and increase (recover) the number of channels, respectively, while the central 3 × 3 × 3 kernel layer is employed for feature map processing. This design offers several advantages: (1) It significantly reduces the number of parameters, leading to reduced computational complexity and a smaller model size; (2) after dimension reduction, it enables more effective and intuitive data training and feature extraction. The features following dimension increase are tailored specifically to the current task; and (3) compared with the traditional convolutional structure, it incorporates a shortcut branch that facilitates the transmission of low-level information, thereby enhancing deep and efficient training.
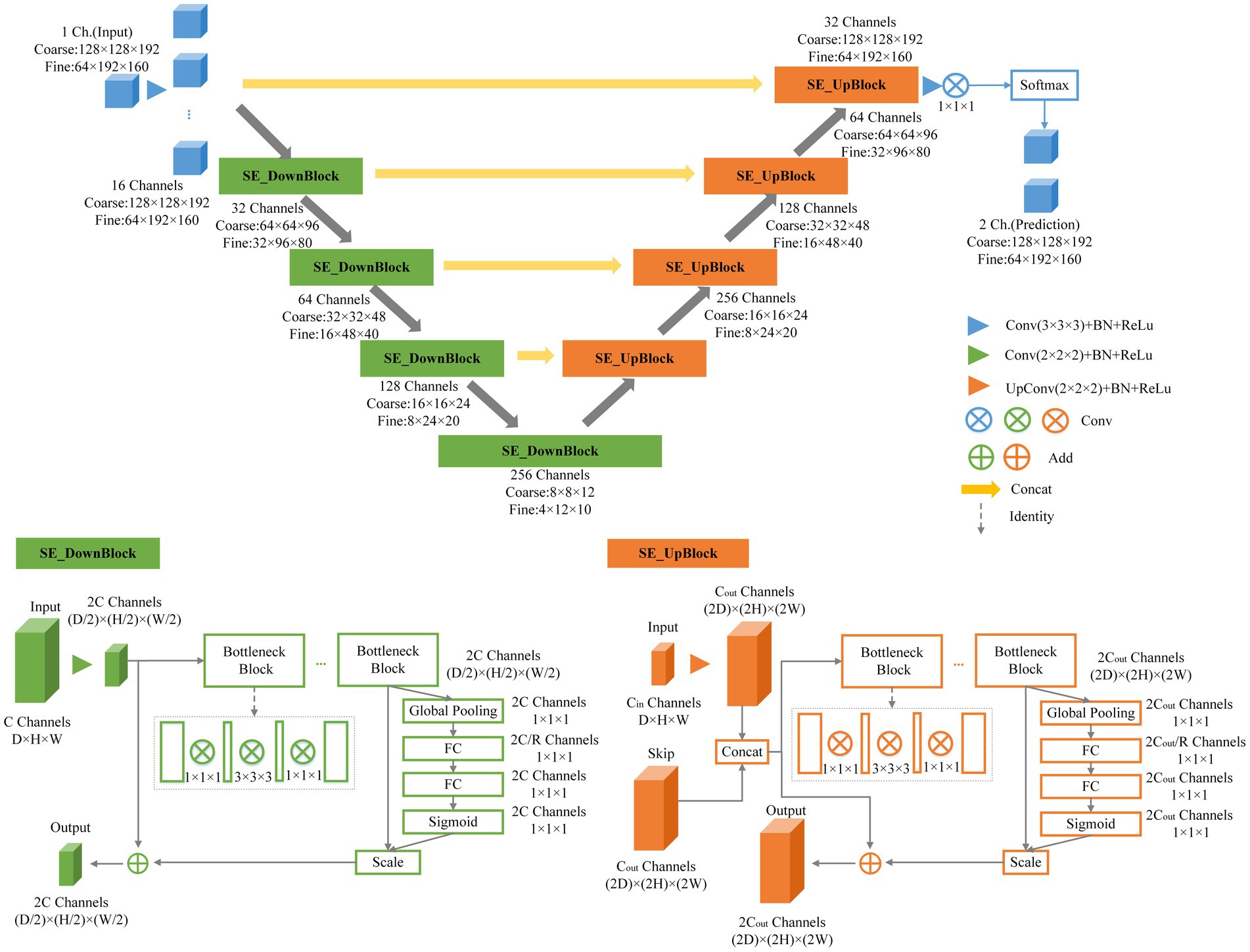
Figure 3. Schematic representation of our network architecture.
SE-Net adopts a channel-centric perspective and introduces the “Squeeze and Excitation (SE)” module, which enhances accuracy by modeling the correlation between feature channels and strengthening critical features (Hu et al., 2020). The squeeze operation compresses features along the spatial dimension, resulting in a one-dimensional feature matching the number of feature channels. This feature represents the global distribution of responses across the feature channels. The excitation operation models correlations between feature channels through two fully connected layers and assigns weight to each feature channel. These weights signify the importance of each feature channel after feature selection. Finally, the channels are applied to the previous features, completing the recalibration of the original features along the channel dimension. Through this mechanism, the network leverages global information to selectively emphasize informative features while suppressing less useful ones.
2.5. Training procedure
There were 152 MR T2 scans with the trigeminal nerve for training and 35 for testing. Images in the training set had a spatial resolution of 0.5 × 0.5 × 0.5 mm. Owing to the large size of three-dimensional medical images, to reduce memory usage, we adopted a multi-resolution strategy to train two SEVB-Nets on different image resolutions (Mu et al., 2019). As illustrated in Figure 4, at the coarse resolution, we trained an SEVB-Net to approximately localize the entire trigeminal nerve region. This was achieved by resampling images to an isotropic spacing of 1 mm and using a fixed input patch size of 128 × 128 × 192, randomly sampled from the entire image domain for training.
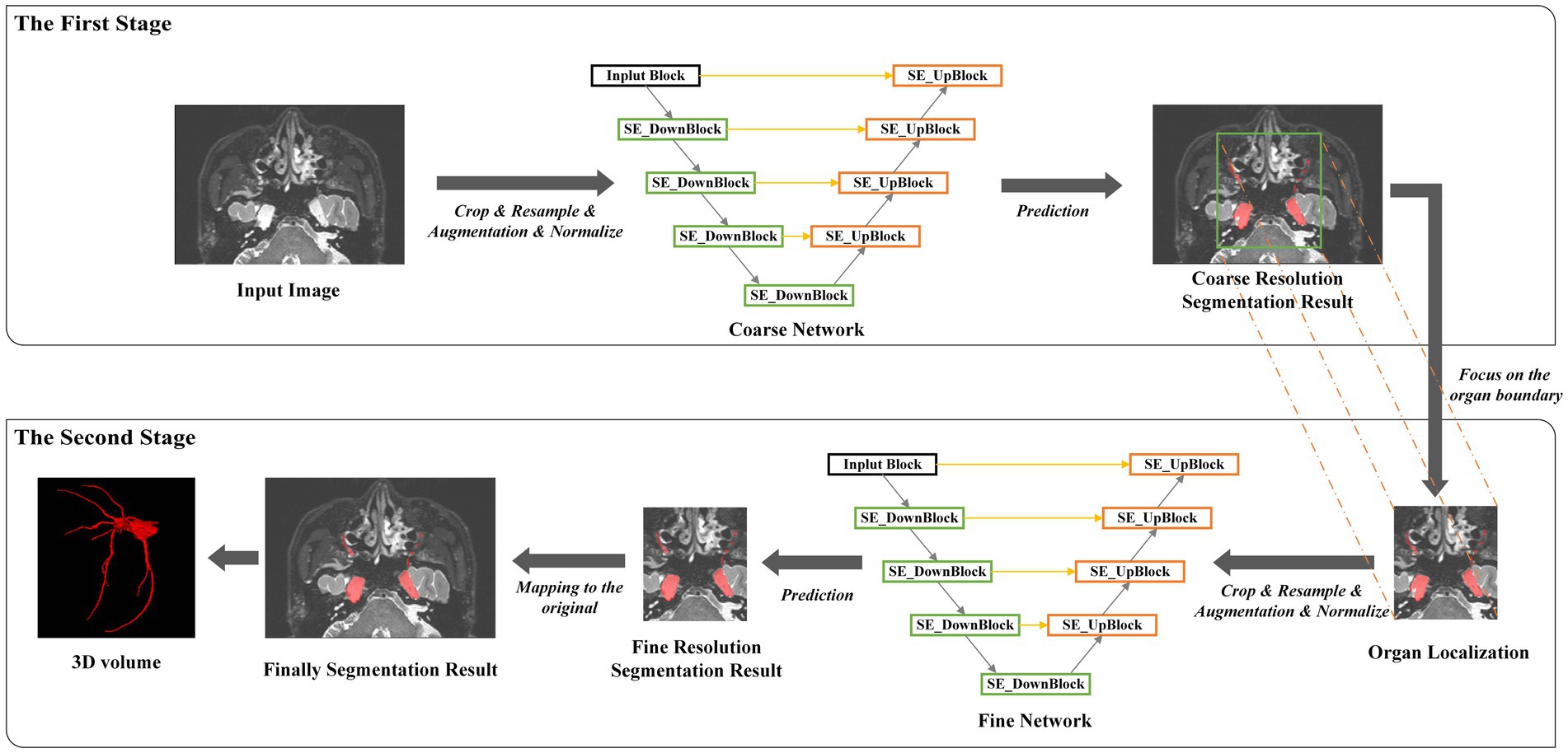
Figure 4. An overview of the multi-resolution network.
Following the localization of the trigeminal nerve region, we trained a fine-resolution SEVB-Net for detailed segmentation. As the trigeminal nerve had already been segmented at the coarse resolution, the fine segmentation model was only trained by resampling images to an isotropic spacing of 0.5 mm and randomly sampling image patches 64 × 192 × 160 in size from the unilateral trigeminal nerve region indicated by the split manual segmentation (as shown in Figures 2C,D) of input images.
During the inference stage, the entire image volume was divided into overlapping subvolumes using a sliding window, and the overlapping parts were combined using Gaussian weighted averaging. This approach allowed SEVB-Net to accurately segment the trigeminal nerve boundaries.
2.6. Loss function
Image segmentation based on supervised learning requires a loss function to quantify the error between the predicted segmentation and the manual segmentation during the learning process. This helps in continuously optimizing the segmentation performance. In this study, we employed a multi-loss mixture function to measure the predicted segmentation of the network. Specifically, we used the dice coefficient loss (Ldice) and the focal loss (Lfocal) as the loss functions LDoubleLoss for network training. The LDoubleLoss is defined as:
where ω is a weight balance parameter between Ldice (Milletari et al., 2016) and Lfocal (Lin et al., 2020), which is empirically set as ω = 0.5.
The dice loss reduces the model’s sensitivity to unbalanced classes by considering the entire situation and focusing primarily on the foreground voxels. The focal loss, on the other hand, addresses pixel-level issues from a micro perspective and complements the dice loss. It guides the dice loss and provides the network with a gradient descent direction when the dice coefficient is zero during training. The dice loss function is defined as:
where the inner summation runs over the N voxels in the image domain, C represents the number of class labels, pc(i) is the probability of class c at voxel i predicted by the network, and gc(i) is the binary label indicating whether the label of voxel i is class c.
Additionally, the Lfocal is defined as:
Here, pt is the predicted probability, α is the class weighting parameter, and γ is the modulating factor that shifts the model’s focus toward learning hard negatives during training by down-weighting the easy examples. We define pt as (Lin et al., 2020):
In the case of the trigeminal nerve in this study, the segmentation difficulty lay in the fact that, within the same sample, the trigeminal nerve root and ganglion were relatively easy to segment, whereas the trigeminal nerve branches, including the ophthalmic nerve, maxillary nerve, and mandibular nerve, were prone to under-segmentation. To address this limitation, morphological processing was used to approximately separate easily segmented areas from challenging ones. As shown in Figure 5, the trigeminal nerve branches and peripheral trigeminal nerve roots and ganglia were distinguished from the core trigeminal nerve roots and ganglia. Subsequently, we defined the original manual segmentation as Ω, with inside Ω (as shown in Figures 4B,E) and outside Ω (as shown in Figures 4C,F) denoting the above two areas, respectively (Lv et al., 2019). The weighted focal loss was defined as:
where λ1 and λ2 are two balancing parameters used to modulate the influence of the inside Ω error and outside Ω error.
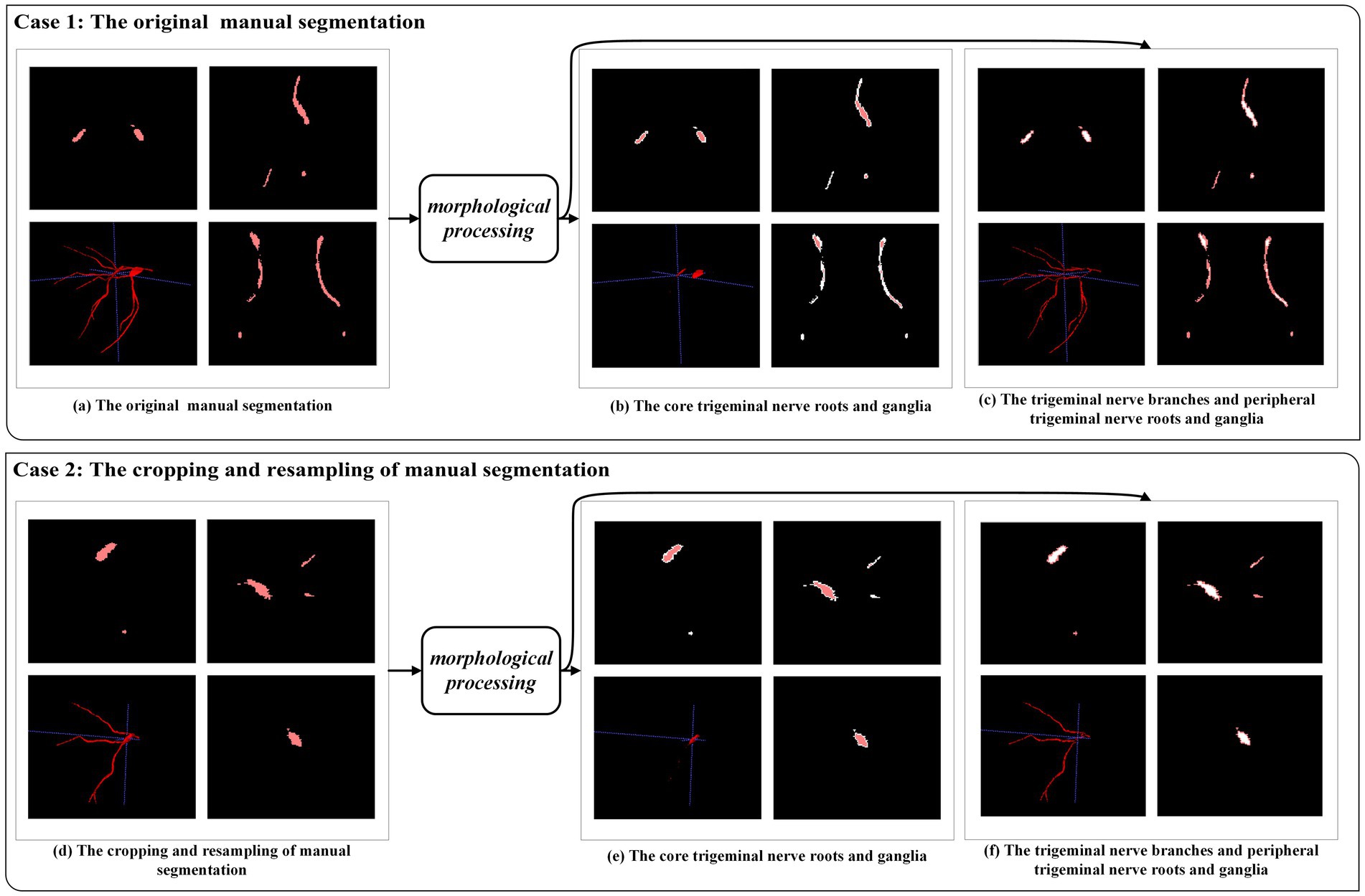
Figure 5. An example of morphological processing. Case 1: morphological processing of the original manual segmentation. Case 2: morphological processing after cropping and resampling of manual segmentation.
Based on these considerations, we used the dice coefficient loss (Ldice) and the weighted focal loss (Lωfocal) as the final loss function LωDoubleLoss for network training, defined as:
where ω is a weight balance parameter between Ldice and Lωfocal and λ1 and λ2 are two balancing parameters used to modulate the influence of inside Ω error and outside Ω error.
2.7. Comparison of segmentation time between manual and automatic segmentation with manual modification
To evaluate the segmentation efficiency of the deep learning model, we first calculated the time required for manually segmenting 35 test data points and then determined the time required for automatic segmentation with manual modification of the same 35 test data points. The process of manual modification was carried out by two experienced radiologists (C and D), each specializing in segmentation. The scores for manual segmentation and automatic segmentation with manual modification, evaluated by Prof. A and Prof. B, should be up to 3. We used the Mann–Whitney U test to compare the difference in average time needed between manual segmentation and automatic segmentation with manual modification.
3. Material and evaluation metrics
3.1. Data set characteristics
The characteristics of the subjects in the training and testing groups are summarized in Table 2. Continuous features such as age were compared using ANOVA. Categorical features such as gender and clinical features were compared using the Chi-square method. There were no significant differences among the three groups concerning age, gender, and clinical features.
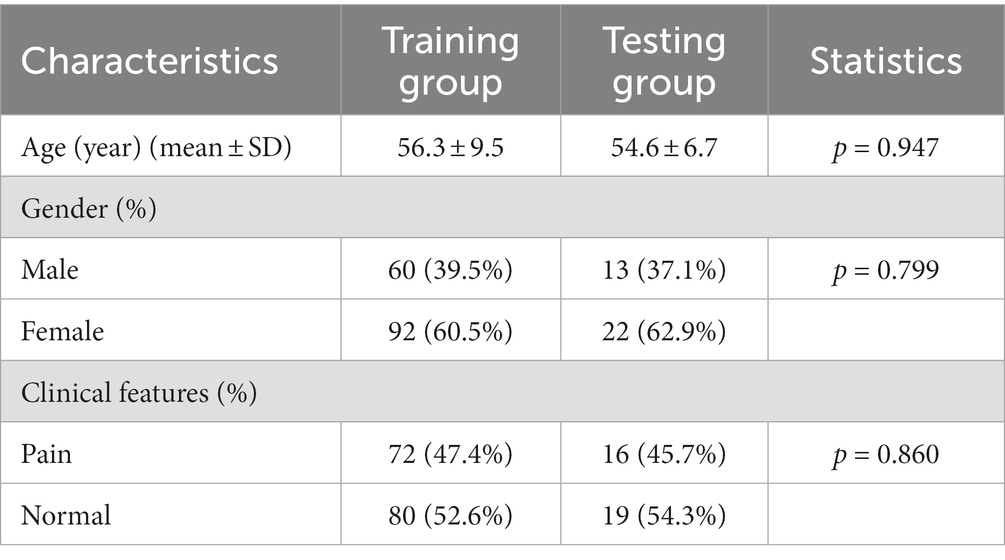
Table 2. Demographic and clinical characteristics of subjects in the training (n = 152) and test groups (n = 35).
3.2. Evaluation metrics
To quantitatively measure the performance of the proposed method, we used the Dice similarity coefficient (also known as F1 score) (Jaffari et al., 2021) to assess the similarity between the segmentation volume and manual segmentation. The evaluation measure is within the range of 0 to 1, with higher coefficient values indicating better segmentation performance. The definition is as follows:
Additionally, the quality of the segmentation volume is typically evaluated using accuracy, precision, sensitivity (also known as recall), and specificity (Cruz-Aceves et al., 2018; Gao et al., 2022). However, there is a significant class imbalance in the samples, as the trigeminal nerve and background pixels are denoted as positive and negative classes, respectively. Accuracy and specificity primarily assess the performance of background pixel segmentation. Therefore, our main focus is on precision and sensitivity (also known as recall), which are two parameters used to evaluate the performance of foreground pixel segmentation. These evaluation parameters are defined as follows:
where trigeminal nerve and background pixels are denoted as positive and negative classes. TP, TN, FP, and FN represent the pixel counts of true positives, true negatives, false positives, and false negatives, respectively.
4. Experimental results
We compared the most popular models for medical image segmentation, V-Net, and nnUNet, with SEVB-Net. Simultaneously, we compared the proposed loss function DoubleLoss and its variant ωDoubleLoss to demonstrate the segmentation performance of the proposed method. The training process adopted a multi-resolution strategy, with the learning rate set to 1e−4, the decay rate set to 0.1 every 1,000 epochs, and a maximum of 6,000 epochs. Within these 6,000 epochs, the model with the best performance was selected for evaluation. The training loss of SEVB-Net combined with the ωDoubleLoss method is displayed in Figure 6, showing good convergence (Man et al., 2019).
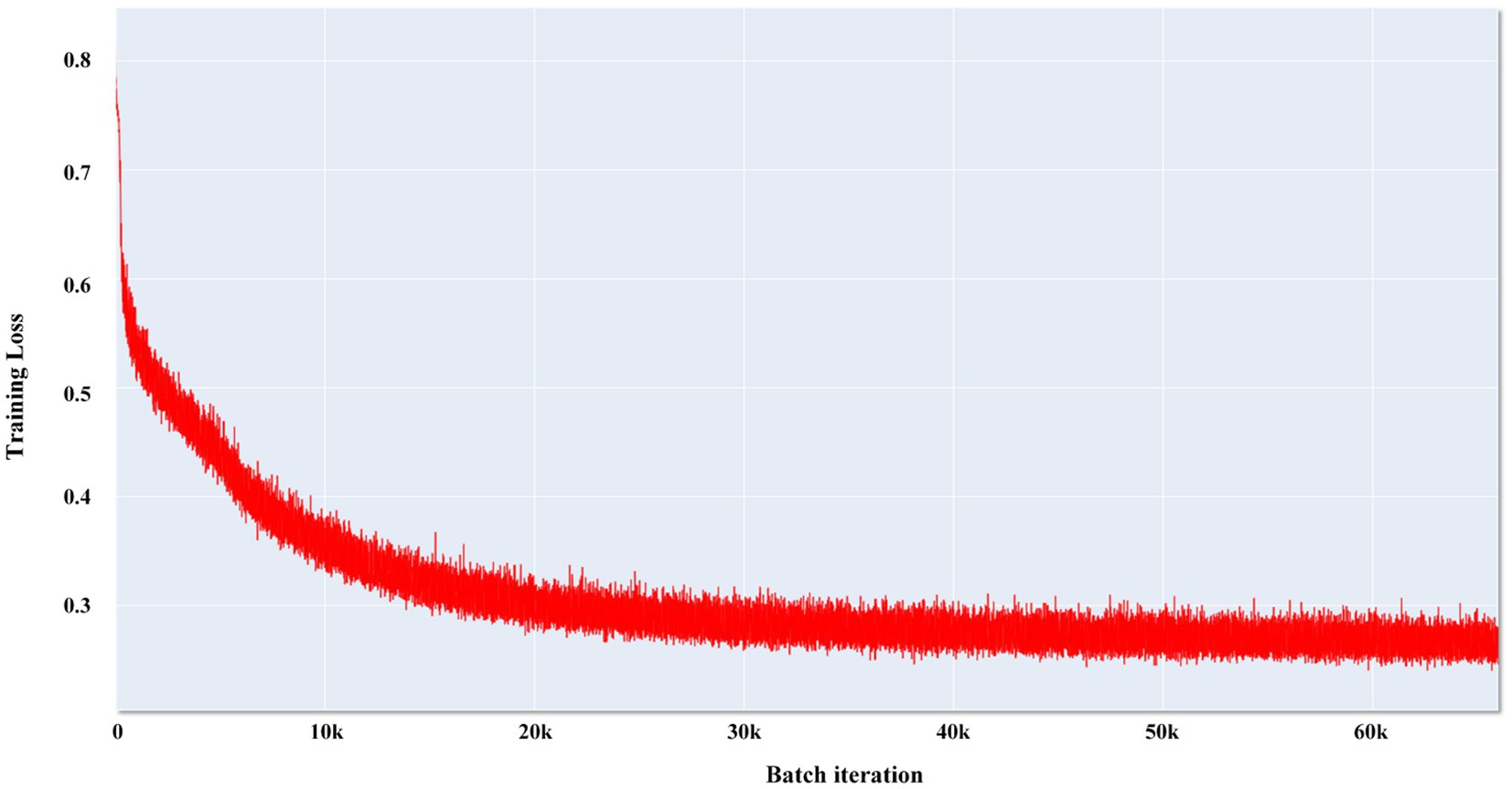
Figure 6. Convergence curve of SEVB-Net combined with the ωDoubleLoss method.
Table 3 summarizes the average Dice similarity coefficient (DSC), sensitivity, and precision of the network direct output results of the four experiments (experiment 1, V-Net combined with the DoubleLoss method; experiment 2, SEVB-Net combined with the DoubleLoss method; experiment 3, nnUNet combined with the DoubleLoss method; and experiment 4, SEVB-Net combined with the ωDoubleLoss method) on the testing set (n = 35). First, ANOVA was used to determine whether there was a difference between the means of the four experiments. From the results of the first row of each indicator in Table 4, it could be concluded that there was no significant difference in the DSC (p = 0.17, p > 0.1) between the four experiments, the sensitivity tended to be significantly different (p = 0.0794, p < 0.1), and there was a significant difference in the precision (p = 0.0291, p < 0.05). After that, Tukey’s test in multiple comparisons was used to further determine which two means differed from each other, and which did not. Additionally, a post-hoc Benjamini–Hochberg (BH) adjustment was applied to balance the likelihood of false positive and false negative findings. Finally, the effect sizes for individual t-tests obtained by Cohen’s d were reported. As shown in Table 4, the difference in precision between experiment 2 (SEVB-Net combined with the DoubleLoss method) and experiment 3 (nnUNet combined with DoubleLoss method) tended to be significantly different (adjusted value of p = 0.0972, p < 0.1; d = 0.7335, d > 0.5). A commonly used interpretation is to refer to effect sizes as small (d = 0.2), medium (d = 0.5), and large (d = 0.8) based on benchmarks suggested by Cohen. The individual pairwise comparisons were analyzed in the following subsections.

Table 3. Quantitative performance of different algorithms.
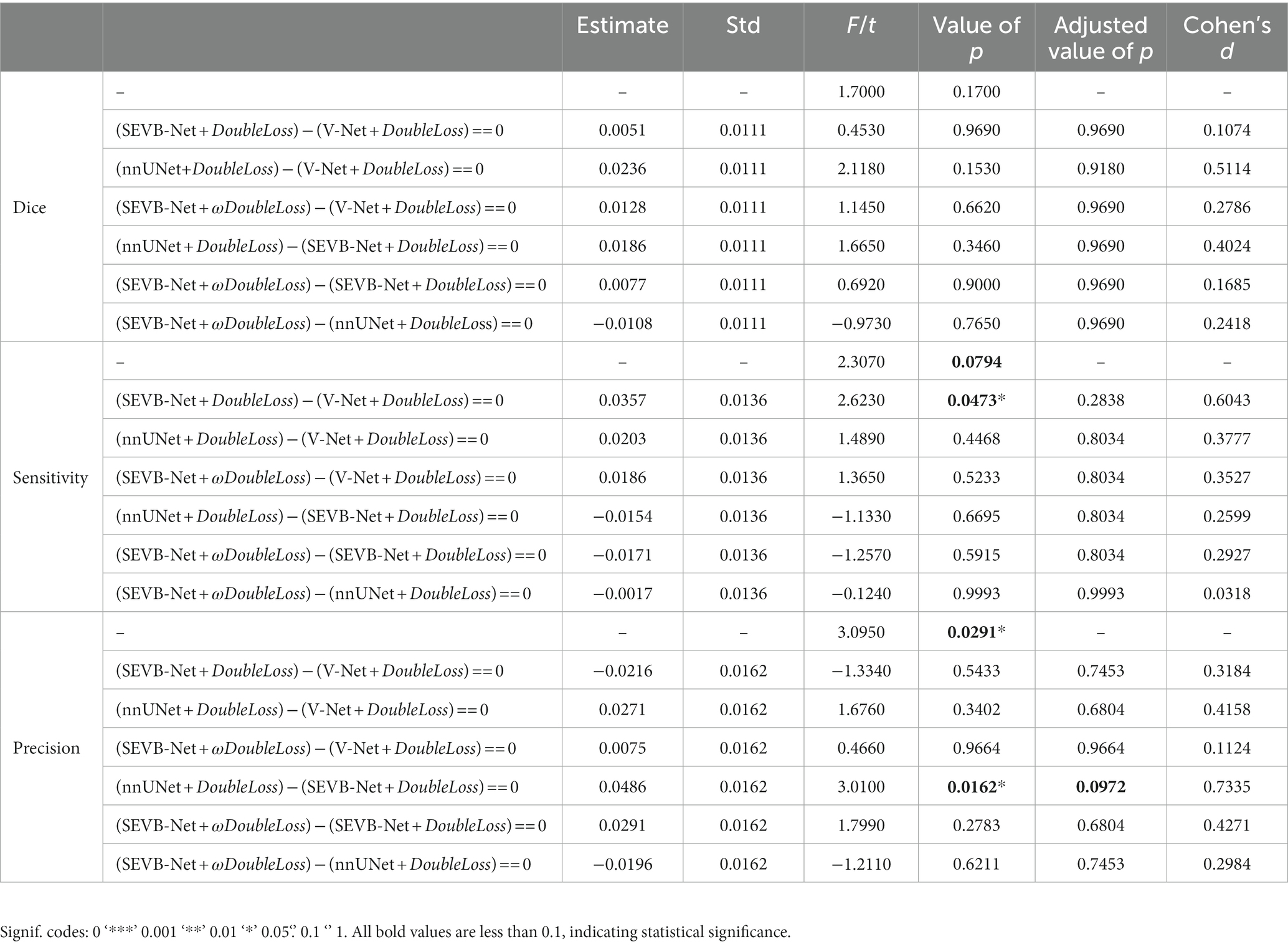
Table 4. Significance test of quantitative performance of different algorithms.
4.1. Comparison of the quantitative performances of different network structures
When comparing experiment 1 (V-Net combined with the DoubleLoss method) to experiment 2 (SEVB-Net combined with the DoubleLoss method), the performance of SEVB-Net improved in both the DSC and sensitivity but there were no significant differences. Compared with experiment 1 (V-Net combined with the DoubleLoss method), experiment 3 (nnUNet combined with the DoubleLoss method) showed an improved performance in terms of the DSC, sensitivity, and precision but there were also no significant differences. The difference in precision between experiment 2 (SEVB-Net combined with the DoubleLoss method) and experiment 3 (nnUNet combined with the DoubleLoss method) tended to be significantly different (adjusted value of p = 0.0972, p < 0.1; d = 0.7335, d > 0.5), and the output results of SEVB-Net were not as good as those of nnUNet in terms of precision but there were no significant differences in the DSC and sensitivity.
4.2. Comparison of quantitative performance of different loss functions
After using ωDoubleLoss instead of DoubleLoss, the performance of experiment 4 (SEVB-Net combined with the ωDoubleLoss method) was improved compared with experiment 1 (V-Net combined with the DoubleLoss method) in terms of the DSC, sensitivity, and precision, but there were no significant differences. When comparing experiment 2 (SEVB-Net combined with the DoubleLoss method) with experiment 4 (SEVB-Net combined with the ωDoubleLoss method), the network outputs of the ωDoubleLoss method compared with the DoubleLoss method had an advantage in terms of DSC and precision, but there were no significant differences. There was no significant difference between experiment 3 (nnUNet combined with the DoubleLoss method) and experiment 4 (SEVB-Net combined with the ωDoubleLoss method), indicating that the trend of significant difference in precision between SEVB-Net and nnUNet was brought closer after using ωDoubleLoss instead of DoubleLoss.
4.3. Overall quantitative performance comparison
The rows in Figure 7 represent the three performance metrics of the DSC, sensitivity, and precision, respectively. Each column displays each metric using a scatter plot, box plot, and area plot, further confirming the results of Tables 3, 4. First, regarding the DSC, the highest DSC values for the four experiments were 0.7789, 0.7850, 0.8084, and 0.7923, and the lowest DSC values were 0.5919, 0.6054, 0.6307, and 0.6070, respectively. The highest and lowest DSCs of SEVB-Net combined with the ωDoubleLoss method were lower than the nnUNet method but higher than the other two methods. Additionally, SEVB-Net combined with the DoubleLoss method had an advantage in sensitivity and nnUNet performed best in precision. Finally, the nnUNet method and SEVB-Net combined with the ωDoubleLoss method achieved a DSC, sensitivity, and precision above 0.7, indicating that the segmentation volumes were in agreement with expert annotations.
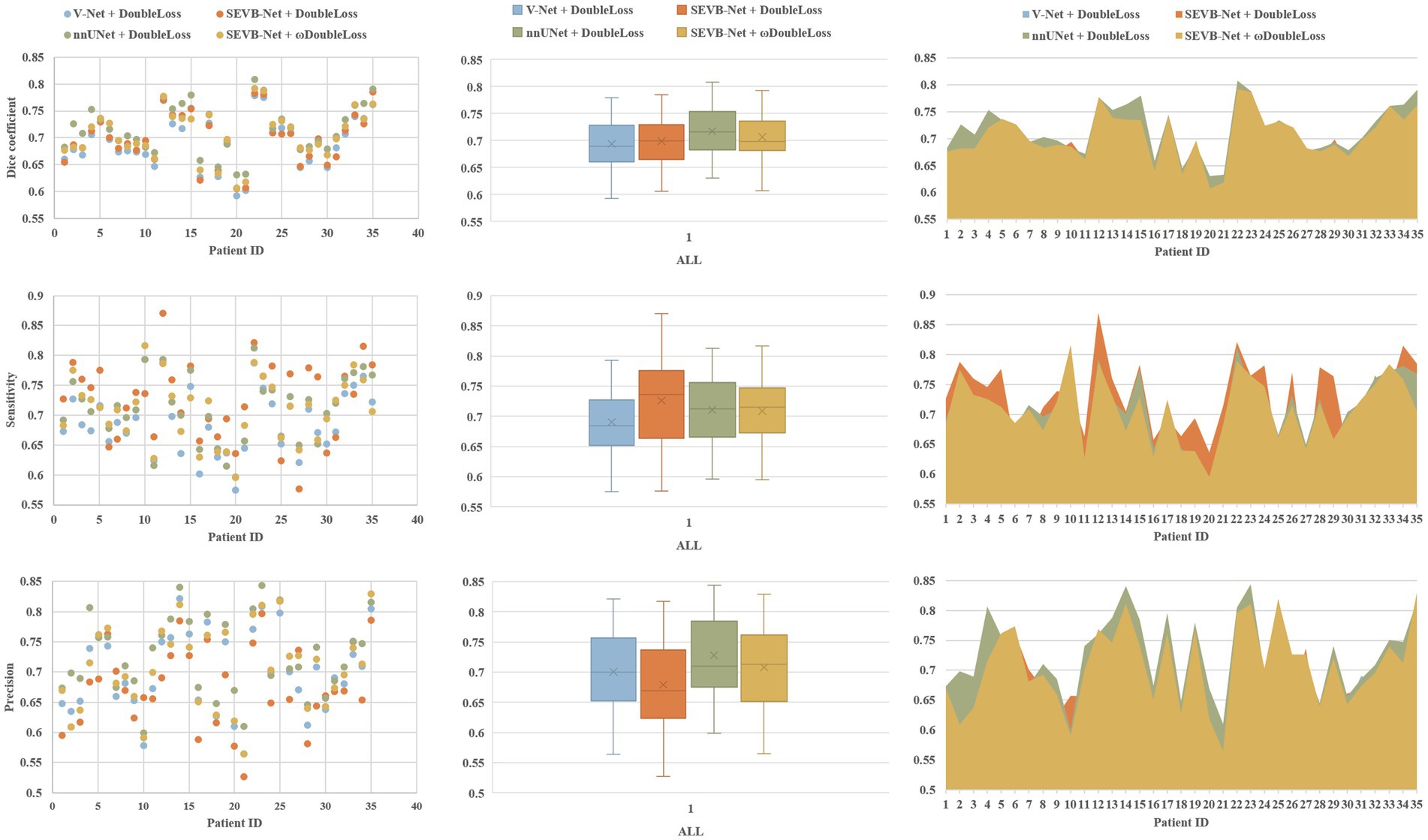
Figure 7. Comparative analysis of the Dice similarity coefficient (DSC), sensitivity, and precision of the three experiments on the testing set.
4.4. Comparison of network complexity
We compared the parameters, memory consumption, FLOPS, forward time (averaged over 100 trials on an NVIDIA TITAN RTX), number of convolutional layers, and the coarsest stride of the different network. The number of parameters (2.20 M), memory consumption (11.41 MB), and model size (17.02 MB) of SEVB-Net were significantly reduced, and the computation and forward time were substantially improved compared with nnUNet (the details are listed in Table 5).
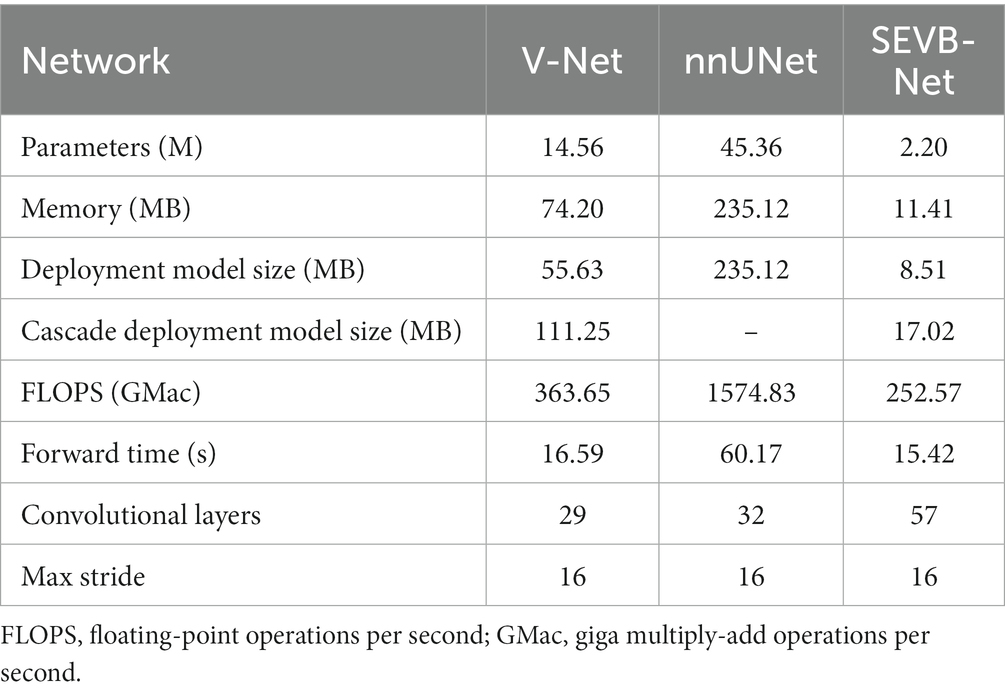
Table 5. Comparison of parameters, memory consumption, FLOPS, forward time (averaged over 100 trials on an NVIDIA TITAN RTX), number of convolutional layers, and the coarsest stride of different networks.
In addition, we performed three-dimensional rendering on the segmentation volumes of the four experiments. Figure 8 displays the rendering results of two test samples. For each case, the first row represents a two-dimensional slice, the second row depicts the three-dimensional rendering of the segmentation volume, and the third row illustrates partial three-dimensional rendering. Upon observation, it was evident that in the current training scale, the segmentation results all exhibited under-segmentation across the four experiments. However, V-Net was more prone to under-segmentation and incorrect segmentation, which SEVB-Net improved to a certain extent. Subsequently, after replacing DoubleLoss with ωDoubleLoss, the segmentation result became more continuous and accurate, comparable with the nnUNet segmentation, as indicated by the trigeminal nerve highlighted by the yellow arrow in Figure 8. In Figure 9, the segmentation boundaries were compared between manual segmentation and the four deep learning methods, revealing that deep learning boundaries were often smoother than manual segmentation. For each case, the first row represents a two-dimensional slice, the second row represents the three-dimensional rendering of the segmentation volume, and the third row represents the partial three-dimensional rendering.
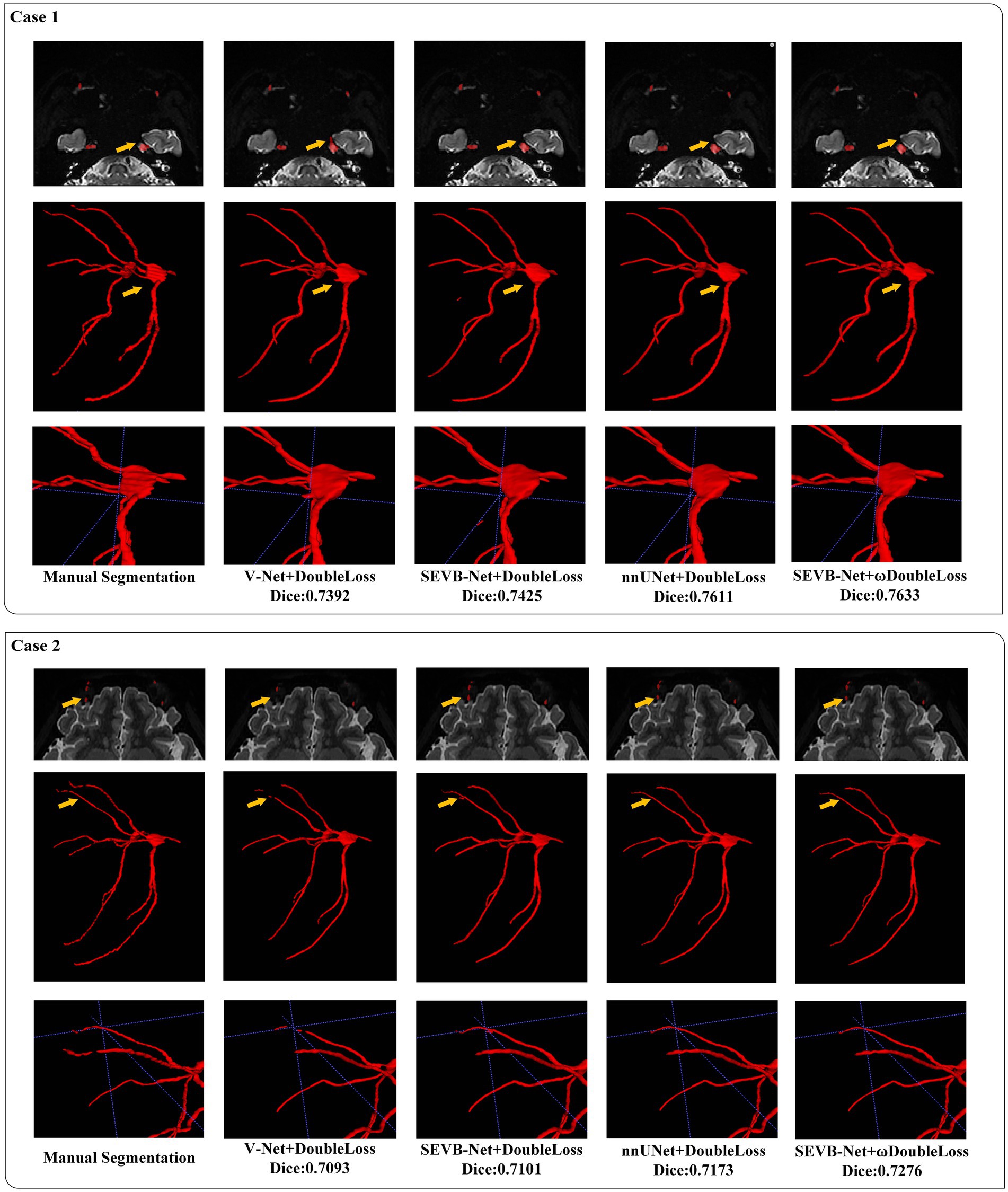
Figure 8. Visualization of the segmentation results.
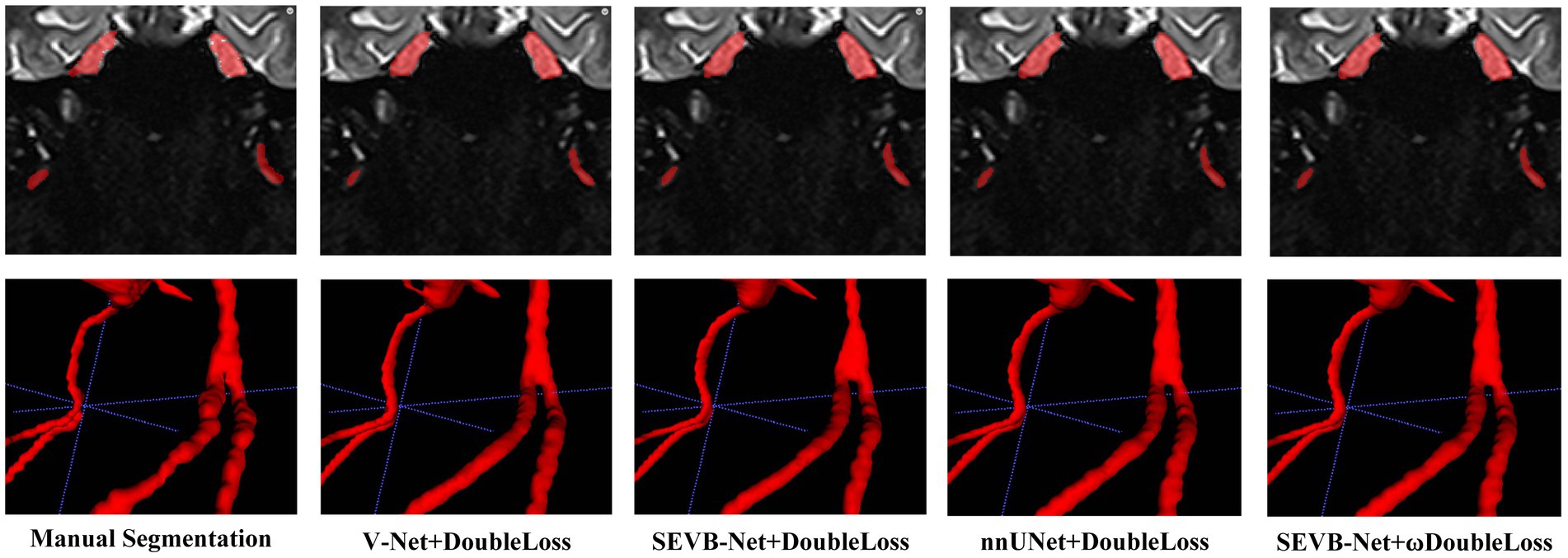
Figure 9. Comparison of the boundaries of segmentation results.
The average time required for the automatic segmentation with manual modification (performed by radiologists C and D) of 35 test data points was 40.43 ± 7.19 and 35.49 ± 7.28 min, respectively. The average time required for the manual segmentation (performed by radiologists C and D) of 35 test data points was 95.28 ± 7.31 and 95.12 ± 7.33 min, respectively (Table 6). The difference in the average required time between manual segmentation and automatic segmentation with manual modification for both radiologists was statistically significant (p < 0.001).
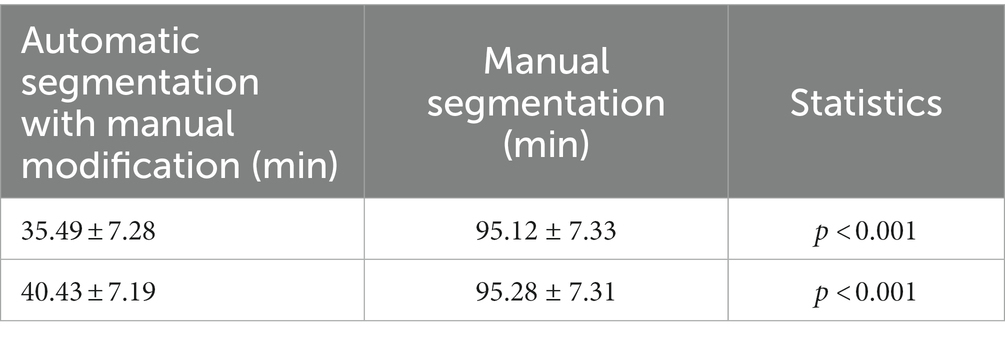
Table 6. Comparison of needed time between the manual segmentation and automatic segmentation with manual modification.
5. Discussion
Trigeminal neuralgia, often referred to as the “king of pain,” poses a significant threat to the physical and mental health of patients (DeSouza et al., 2014). Currently, for trigeminal neuralgia diagnosis, most clinicians primarily focus on the relationship between the nerve and blood vessels in the cistern segment of the trigeminal nerve (Maarbjerg et al., 2014). Nevertheless, some studies have highlighted that abnormalities in the peripheral branches of the trigeminal nerve can also lead to trigeminal neuralgia (Cassetta et al., 2014). With the advancements in magnetic resonance neuroimaging, it has become possible to comprehensively image the trigeminal nerve (Zhang et al., 2021). However, owing to the complex anatomy of the extracranial segment of the trigeminal nerve, the reconstruction process is time-consuming and prone to human error.
The rise of artificial intelligence has led to the application of various deep learning methods in medical image processing. Since AlexNet’s victory in the ImageNet image classification competition in 2012, convolutional neural networks have gained considerable attention due to their superior feature extraction capabilities. This has resulted in the rapid development of three-dimensional medical image processing based on deep learning (Alzubaidi et al., 2021b). Zeng used a three-dimensional U-net network to segment the trigeminal nerve on a three-dimensional FIESTA sequence and segment blood vessels in MRA. By combining the two segmentation results, the relationship between nerve and blood vessel can be automatically recognized (Zeng et al., 2013). Xia et al. proposed a convolutional neural network (Re-NET) based on a reverse edge attention mechanism to achieve three-dimensional cerebral vascular segmentation and surface reconstruction (Xia et al., 2022). Lin et al. used CS2Net to approximately segment the trigeminal nerve and blood vessel, refining their boundaries with three-dimensional UNet to obtain good segmentation results (Lin et al., 2021). Currently, numerous studies focus on deep learning for the trigeminal cistern segment, but applying them clinically remains challenging due to the limited sample size. Deep learning research on peripheral segment branches primarily focuses on the inferior alveolar nerve. For instance, XI et al. employed U-net to segment the inferior alveolar nerve and the third molar on the dental panoramic X-ray films, enabling preoperative evaluation of molar extraction (Vinayahalingam et al., 2019). Lim et al. used a three-dimensional nnU-Net to automatically segment the inferior alveolar nerve on cone-beam CT, achieving a Dice similarity coefficient of (0.58 ± 0.08), indicating relatively general segmentation results (Lim et al., 2021). By contrast, our study is the only one reporting complete automatic segmentation of all three branches of the trigeminal nerve. Compared with previous studies, our study focuses on the entire trigeminal nerve. The SEVB-Net model used in this study demonstrated excellent segmentation performance.
In our study, we explored four approaches: V-Net combined with the DoubleLoss method, SEVB-Net combined with the DoubleLoss method, nnUNet combined with the DoubleLoss method, and SEVB-Net combined with the ωDoubleLoss method. Table 3 summarizes the performance of these four models on the testing set. Compared with V-Net and nnUNet, SEVB-Net, which incorporates the bottleneck structure (He et al., 2016), significantly reduced the model’s parameters, resulting in smaller model size, reduced memory usage, and faster forward time. This makes it more suitable for the deployment of network models in cloud or mobile applications in the future. Our results show that, compared with V-Net, nnUNet and SEVB-Net exhibited improved performance in terms of the Dice similarity coefficient (DSC) and sensitivity. Additionally, there was a trend of significant difference in precision between SEVB-Net combined with the DoubleLoss method and nnUNet combined with the DoubleLoss method (adjusted value of p = 0.0972, p < 0.1; d = 0.7335, d > 0.5). Although SEVB-Net did not perform as well as nnUNet in precision, there were no differences in Dice and sensitivity. After replacing DoubleLoss with ωDoubleLoss, SEVB-Net also outperformed V-Net in precision. Furthermore, there was no significant difference between nnUNet combined with the DoubleLoss method and SEVB-Net combined with the ωDoubleLoss method, indicating that the trend of a significant precision gap between SEVB-Net and nnUNet was reduced after using ωDoubleLoss. Both nnUNet combined with the DoubleLoss method and SEVB-Net combined with the ωDoubleLoss method achieved a DSC, sensitivity, and precision above 0.7, indicating that the segmentation volumes were in agreement with expert annotations. These results can be attributed to the improved network structure and changes in the loss function. The addition of the bottleneck structure, which includes an extra shortcut branch compared with traditional convolutional structures, allows for deeper network training and mitigates the problem of deep neural network degradation. Furthermore, the SE-Net structure models the correlation between feature channels and strengthens important features to improve accuracy (Hu et al., 2020). Finally, nnUNet exhibits unique advantages in precision, as demonstrated by Ding et al. (2023), Isensee et al. (2021), indicating its potential for complex and fine anatomical structure segmentation. The anatomical complexity of the entire trigeminal nerve poses segmentation challenges. Thicker segments, such as the trigeminal nerve root and ganglion, are easy to segment, whereas the branches of the trigeminal nerve, such as the ophthalmic, maxillary, and mandibular nerves, are prone to under-segmentation due to their thinness. When using the loss function DoubleLoss, the network loss is already relatively low when segmenting the thicker trigeminal root, ganglion, and proximal trigeminal branches. The remaining distal trigeminal branches, which are not segmented, have a limited impact on the overall loss, resulting in under-segmentation of the distal trigeminal nerve once the model converges. This limitation can be improved with a larger training dataset, but in cases with limited training data, changing the loss function can improve it to a certain extent. The ωDoubleLoss method approximately separates the thicker easily segmented trigeminal nerve root and ganglion from the thinner difficult-to-segment trigeminal nerve branches based on morphological structure. This division results in two regions: the difficult-to-segment region and the easy-to-segment region. By assigning a larger weight to the difficult-to-segment region and a smaller weight to the easy-to-segment region, the loss of the easy-to-segment region is significantly reduced. As the loss in the difficult-to-segment region is relatively high, the model prioritizes optimizing the loss in the difficult-to-segment region.
Owing to the complex anatomy of the whole trigeminal nerve, manual segmentation is a time-consuming process. In this study, both manual segmentation and model-assisted segmentation with manual modification achieved excellent segmentation results but the segmentation process was significantly shorter with the assistance of the deep learning model. Vinayahalingam et al. developed a deep learning method to segment the inferior alveolar nerve and found that model-assisted segmentation with manual modification was 40 s faster than manual segmentation (Vinayahalingam et al., 2019).
In comparison with previous studies, our dataset includes a diverse dataset comprising patients with trigeminal neuralgia and healthy volunteers scanned by four different magnetic resonance scanners with varying field strengths. This diversity in data sources improves the model’s generalization ability. It is well known that learning from a single type of source data can lead to biased outputs tailored to that type of data source. Although the trained model may perform well on that specific data, it may struggle when presented with data from other sources (Hampel et al., 1986). The inclusion of images scanned from multiple devices and the incorporation of data from patients and healthy individuals significantly increases the diversity of input data sources, thereby enhancing generalization ability and model robustness. However, this study also has limitations, primarily stemming from the size of our training dataset, which is relatively small. The minimum dataset size required for effective deep learning varies and is based on multiple factors, including the problem complexity, data diversity, and data quality. In this study, it is recommended that the training sample size should not be less than 100 to achieve desirable segmentation results. According to the power law of deep learning, performance tends to increase with larger datasets (Lei et al., 2019). Data quality and quantity are crucial in deep learning tasks and expanding the training dataset will be essential for further enhancing the model’s performance.
6. Conclusion
In conclusion, our results demonstrate that the SEVB-Net model can accurately segment the trigeminal nerve on magnetic resonance three-dimensional volume T2 imaging in patients with trigeminal neuralgia and healthy volunteers. Compared with the basic V-Net model, SEVB-Net enhances segmentation performance, matching nnUNet. It maintains accuracy while offering a more lightweight solution, making it a promising tool for automated trigeminal nerve segmentation, and eliminating manual delineation’s time-consuming obstacle.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by Medical Ethics Committee of Affiliated Hospital of North Sichuan Medical College (2023ER178-1). The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
CZh: Writing – review & editing, Formal analysis, Funding acquisition, Investigation, Writing – original draft, Methodology, Project administration, Resources. ML: Data curation, Software, Writing – original draft. ZL: Formal analysis, Methodology, Data curation, Writing – original draft. RX: Investigation, Writing – review & editing, Data curation, Methodology. BL: Writing – review & editing. JS: Methodology, Writing – original draft. CZe: Conceptualization, Visualization, Writing – review & editing, Methodology. BS: Investigation, Writing – review & editing. XX: Project administration, Writing – review & editing. HY: Funding acquisition, Project administration, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. China Ministry of Education Industry University Cooperative Education Project (22097112074016), Sichuan Medical Research Project (S22003), Nanchong City School Cooperation Project (22SXQT0029).
Conflict of interest
ML was employed by Shanghai United Imaging Intelligence, Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abdolali, F., Zoroofi, R. J., Abdolali, M., Yokota, F., and Sato, Y. (2016). Automatic segmentation of mandibular canal in cone beam CT images using conditional statistical shape model and fast marching. Int. J. Comput. Assist. Radiol. Surg. 12, 581–593. doi: 10.1007/s11548-016-1484-2
Aggarwal, R., Sounderajah, V., Martin, G., Ting, D., Karthikesalingam, A., King, D., et al. (2021). Diagnostic accuracy of deep learning in medical imaging: a systematic review and meta-analysis. npj Digital Med. 4:65. doi: 10.1038/s41746-021-00438-z
Alzubaidi, L., Duan, Y., Al-Dujaili, A., Ibraheem, I. K., Alkenani, A. H., Jose Santamaría, J., et al. (2021a). Deepening into the suitability of using pre-trained models of image net against a lightweight convolutional neural network in medical imaging: an experimental study. Peer J. Comput. Science. 7:e715. doi: 10.7717/peerj-cs.715
Alzubaidi, L., Zhang, J., Humaidi, A. J., Al-Dujaili, A., Duan, Y., Al-Shammaet, O., et al. (2021b). Review of deep learning: concepts, CNN architectures, challenges, applications, future directions. J. Big Data. 8:53. doi: 10.1186/s40537-021-00444-8
Bendtsen, L., Zakrzewska, J. M., Abbott, J., Braschinsky, M., Stefano, G. D., Donnet, A., et al. (2019). European academy of neurology guideline on trigeminal neuralgia. Eur. J. Neurol. 26, 831–849. doi: 10.1111/ene.13950
Bendtsen, L., Zakrzewska, J. M., Heinskou, B. K., Hodaie, M., Leal, P. R. L., Nurmikko, T., et al. (2020). Advances in diagnosis, classification, pathophysiology, and management of trigeminal neuralgia. Lancet Neurol. 19, 784–796. doi: 10.1016/s1474-4422(20)30233-7
Bernal, J., Kushibar, K., Asfaw, D. S., Valverde, S., Oliver, A., Martí, R., et al. (2019). Deep convolutional neural networks for brain image analysis on magnetic resonance imaging: a review. Artif. Intell. Med. 95, 64–81. doi: 10.1016/j.artmed.2018.08.008
Cassetta, M., Pranno, N., Pompa, V., Barchetti, F., and Pompa, G. (2014). High resolution 3-T MR imaging in the evaluation of the trigeminal nerve course. Eur. Rev. Med. Pharmacol. Sci. 18, 257–264.
Chlap, P., Min, H., Vandenberg, N., Dowling, J., Holloway, L., Haworth, A., et al. (2021). A review of medical image data augmentation techniques for deep learning applications. J. Med. Imaging Radiat. Oncol. 65, 545–563. doi: 10.1111/1754-9485.13261
Cruz-Aceves, I., Cervantes-Sanchez, F., and Avila-Garcia, M. S. (2018). A novel multiscale Gaussian-matched filter using neural networks for the segmentation of X-ray coronary angiograms. Journal of healthcare. Engineering 2018, 1–11. doi: 10.1155/2018/5812059
DeSouza, D. D., Hodaie, M., and Davis, K. D. (2014). Diffusion imaging in trigeminal neuralgia reveals abnormal trigeminal nerve and brain white matter. Pain 155, 1905–1906. doi: 10.1016/j.pain.2014.05.026
Ding, A. S., Lu, A., Li, Z., Sahu, M., Galaiya, D., Siewerdsen, J. H., et al. (2023). A self-configuring deep learning network for segmentation of temporal bone anatomy in cone-beam CT imaging. Otolaryngol. Head Neck Surg. 169:988. doi: 10.1002/ohn.317
Gao, Z., Wang, L., Soroushmehr, R., Wood, A., Gryak, J., Nallamothu, B., et al. (2022). Vessel segmentation for X-ray coronary angiography using ensemble methods with deep learning and filter-based features. BMC Med. Imaging 22:10. doi: 10.1186/s12880-022-00734-4
Hampel, F. R., Ronchetti, E. M., Rousseeuw, P. J, and Stahel, W. A. (1986). Robust statistics: The approach based on influence functions. Wiley, New York
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep residual learning for image recognition. IEEE Conf. Comput. Vision Pattern Recogn. 2016:90. doi: 10.1109/cvpr.2016.90
Hu, J., Shen, L., Albanie, S., Sun, G., Wu, E., et al. (2020). Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 42, 2011–2023. doi: 10.1109/tpami.2019.2913372
Hwang, J. J., Jung, Y. H., Cho, B. H., and Heo, M. S. (2019). An overview of deep learning in the field of dentistry. Imag. Sci. Dentist. 49:1. doi: 10.5624/isd.2019.49.1.1
Isensee, F., Jaeger, P. F., Kohl, S. A. A., Petersen, J., and Maier-Hein, K. H. (2021). Nn U-net: a self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 18, 203–211. doi: 10.1038/s41592-020-01008-z
Jaffari, R., Hashmani, M. A., and Reyes-Aldasoro, C. C. (2021). A novel focal phi loss for power line segmentation with auxiliary classifier U-net. Sensors 21:2803. doi: 10.3390/s21082803
Kim, H. J., Kim, Y. K., and Seong, M. (2023). Magnetic resonance imaging evaluation of trigeminal neuralgia. Trigeminal Neural. 6, 31–44. doi: 10.1007/978-981-19-9171-4_6
Lei, S., Zhang, H., Wang, K., and Su, Z. (2019). How training data affect the accuracy and robustness of neural networks for image classification. ICLR Conference
Lim, H. K., Jung, S. K., Kim, S. H., Cho, Y., and Song, I. S. (2021). Deep semi-supervised learning for automatic segmentation of inferior alveolar nerve using a convolutional neural network. BMC Oral Health 21:630. doi: 10.1186/s12903-021-01983-5
Lin, T. Y., Goyal, P., Girshick, R., He, K., and Dollar, P. (2020). Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 42, 318–327. doi: 10.1109/tpami.2018.2858826
Lin, J., Mou, L., Yan, Q., Ma, S., Yue, X., Zhou, S., et al. (2021). Automated segmentation of trigeminal nerve and cerebrovasculature in MR-angiography images by deep learning. Front. Neurosci. 15:744967. doi: 10.3389/fnins.2021.744967
Lv, T. L., Yang, G., Zhang, Y. D., Yang, J., Chen, Y., Shu, H., et al. (2019). Vessel segmentation using centerline constrained level-set method. Multimed. Tools Appl. 78, 17051–17075. doi: 10.1007/s11042-018-7087-x
Maarbjerg, S., Wolfram, F., Gozalov, A., Olesen, J., and Bendtsen, L. (2014). Significance of neurovascular contact in classical trigeminal neuralgia. Brain 138, 311–319. doi: 10.1093/brain/awu349
Man, Y., Huang, Y. S., Feng, J. Y., Li, X., and Wu, F. (2019). Deep Q learning driven CT pancreas segmentation with geometry-aware U-net. IEEE Trans. Med. Imaging 38, 1971–1980. doi: 10.1109/tmi.2019.2911588
Milletari, F., Navab, N., and Ahmadi, S. A. (2016). V-net: fully convolutional neural networks for volumetric medical image segmentation. Fourth International Conference on 3D Vision (3DV)
Mu, G., Lin, Z. Y., Han, M. F., and Yao, G. (2019). Segmentation of kidney tumor by multi-resolution VB-nets. Kidney Tumor Segmentation Challenge: KiTS19. doi: 10.24926/548719.003
Obermann, M. (2019). Recent advances in understanding/managing trigeminal neuralgia. F1000Research 8:505. doi: 10.12688/f1000research.16092.1
Seeburg, D. P., Northcutt, B., Aygun, N., and Blitz, A. M. (2016). The role of imaging for trigeminal neuralgia. Neurosurg. Clin. N. Am. 27, 315–326. doi: 10.1016/j.nec.2016.02.004
Tustison, N. J., Avants, B. B., Cook, P. A., Zheng, Y. J., Egan, A., Yushkevich, P. A., et al. (2010). N4ITK: improved N3 bias correction. IEEE Trans. Med. Imaging 29, 1310–1320. doi: 10.1109/TMI.2010.2046908
Ullah, F., Ansari, S. U., Hanif, M., Ayari, M. A., Chowdhury, M. E. H., and Khandakar, A. A. (2021). Brain MR image enhancement for tumor segmentation using 3D U-net. Sensors 21:7528. doi: 10.3390/s21227528
Vinayahalingam, S., Xi, T., Bergé, S., Maal, T., and Jong, G. D. (2019). Automated detection of third molars and mandibular nerve by deep learning. Sci. Rep. 9:9007. doi: 10.1038/s41598-019-45487-3
Xia, L., Zhang, H., Wu, Y., Song, R., Ma, Y., Mou, L., et al. (2022). 3D vessel-like structure segmentation in medical images by an edge-reinforced network. Med. Image Anal. 82:102581. doi: 10.1016/j.media.2022.102581
Yang, R., and Yu, Y. (2021). Artificial convolutional neural network in object detection and semantic segmentation for medical imaging analysis. Front. Oncol. 11:638182. doi: 10.3389/fonc.2021.638182
Zeng, Q., Zhou, Q., Liu, Z., Li, C., Ni, S., and Xue, F. (2013). Preoperative detection of the neurovascular relationship in trigeminal neuralgia using three-dimensional fast imaging employing steady-state acquisition (Fiesta) and magnetic resonance angiography (MRA). J. Clin. Neurosci. 20, 107–111. doi: 10.1016/j.jocn.2012.01.046
Keywords: trigeminal neuralgia, trigeminal nerve, deep learning, automatic segmentation, magnetic resonance imaging
Citation: Zhang C, Li M, Luo Z, Xiao R, Li B, Shi J, Zeng C, Sun B, Xu X and Yang H (2023) Deep learning-driven MRI trigeminal nerve segmentation with SEVB-net. Front. Neurosci. 17:1265032. doi: 10.3389/fnins.2023.1265032
Edited by:
Xiaosu Hu, University of Michigan, United StatesReviewed by:
Soroush Arabshahi, Columbia University, United StatesJixin Liu, Xidian University, China
Sreenivasan Meyyappan, University of California, Davis, United States
Copyright © 2023 Zhang, Li, Luo, Xiao, Li, Shi, Zeng, Sun, Xu and Yang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hanfeng Yang, eWhmY3RqckB5YWhvby5jb20=
†These authors have contributed equally to this work and share first authorship