 Nan Zheng
Nan Zheng Yurong Li
Yurong Li Wenxuan Zhang1,2
Wenxuan Zhang1,2- 1College of Electrical Engineering and Automation, Fuzhou University, Fuzhou, China
- 2Fujian Provincial Key Laboratory of Medical Instrument and Pharmaceutical Technology, Fuzhou, China
- 3Fujian Provincial Key Laboratory of Eco-Industrial Green Technology, Wuyishan University, Wuyishan, China
In a gesture recognition system based on surface electromyogram (sEMG) signals, the recognition model established by existing users cannot directly generalize to the across-user scenarios due to the individual variability of sEMG signals. In this article, we propose an adaptive learning method to handle the problem. The muscle synergy is chosen as the feature vector because it can well-characterize the neural origin of movement. The initial train set is composed of representative samples extracted from the synergy matrix of the existing user. When the new users use the system, the label is obtained by the adaptive K nearest neighbor algorithm (KNN). The recognition process does not require the pre-experiment for new users due to the introduction of adaptive learning strategy, namely, the qualified data and the label of new user data evaluated by a risk evaluator are used to update the train set and KNN weights, so as to adapt to the new users. We have tested the algorithm in DB1 and DB5 of Ninapro databases. The average recognition accuracy is 68.04, 73.35, and 83.05% for different types of gestures, respectively, achieving the effects of the user-dependent method. Our study can avoid the re-training steps and the recognition performance will improve with the increased frequency of uses, which will further facilitate the widespread implementation of sEMG control systems using pattern recognition techniques.
1. Introduction
Surface electromyogram (sEMG) signals contain information on muscular contractions, which is safe, non-invasive, and easy to be implemented. Hence, it has been widely utilized in human-computer interaction (HCI) based on gesture recognition (Ding et al., 2016a; Resnik et al., 2018; Ning et al., 2019). Compared with the image-based gesture recognition system, the sEMG-based gesture recognition system provides better portability and real-time performance. The HCI system based on sEMG signals consists of two main processes: first, a classification model is trained using a train set. Then, the classification model is used for gesture recognition and the result is used as the control input for HCI (Ding et al., 2016b). sEMG recognition method has been well studied during past decades, which can achieve more than 90% recognition accuracy for daily gestures (Tavakoli et al., 2018; Wahid et al., 2018; Jiang et al., 2020; Yang et al., 2021). However, due to the different muscle geometry, skin impedance, fat content, and maximal voluntary contraction of different users, sEMG signals can vary greatly when different users performed the same gestures (Jiang et al., 2012; Khushaba, 2014). Therefore, the sEMG model, trained with the sEMG data acquired from a specific user, can not perform well when applied directly to other users, which hinders the practical application of the HCI system based on the sEMG signals immensely.
Over the past few years, researchers have proposed two methods to deal with the aforementioned problems: the first method is to update the general model with a small amount of new user data. Khushaba (2014) applied canonical correlation analysis (CCA) in multi-user gesture recognition. Only a trial of the test user (for each movement) was used to map the train set and test set to a high correlation space. Xue et al. (2021) proposed a new framework CCA-OT that combined CCA and optimal transport (OT), which could further reduce the discrepancies in data distribution between the transformed feature matrix from the train set and the test set. Kim et al. (2020) introduced a user-independent gesture recognition method based on a muscle source activation model, which could only calibrate the model with a small subset of motions. In our previous study, a user-independent gesture recognition method, combined muscle synergy and the least square method (LSM) (Zheng et al., 2021), was proposed. The method combined a trial of the test data and LSM to obtain a transformation matrix, which would transform the train set. Although the above methods have an excellent performance in cross-user scenarios, the classifier still needs to be calibrated with some data from a new user, which will increase the use burden of new users. To improve the experience of a new user, some scholars shed the pre-experiment step and propose using deep learning models to mine user-independent features. Wei et al. (2019) proposed a multi-view convolutional neural network framework, by which an 82% recognition accuracy was achieved in NinaPro data sets. Chen et al. (2020) proposed a convolutional neural network based feature extraction approach (CNNFeat) and compared it with 25 traditional features. The results showed that CNNFeat outperforms all the tested traditional features in the inter-subject test. Recently, the idea of adaptive learning has been widely used in various fields (Luo et al., 2020; Chen et al., 2021; Wang et al., 2022). In gesture recognition, Li et al. (2019) applied incremental learning based on the Support Vector Machine (SVM) to solve the problem of individual variability and time variation of sEMG signals. The results showed that the incremental learning method could learn new knowledge from new users and significantly improve classification accuracy, however, the heavy training burden remains unsolved.
To sum up, the existing studies may have the following shortcomings:
i. The pre-experiment is required from new users, which will reduce the user experience. In practical application, balancing the relationship between the cost of pre-experiment acquisition and user experience is necessary.
ii. The large amounts of training data and complex computation are inevitable, which increase data acquisition costs and cause time-consuming.
iii. The time-varying nature of sEMG signals remains unsolved (Zhai et al., 2017), so the recognition accuracy will decrease with the onset of muscle fatigue.
In this study, a novel adaptive learning method is proposed to deal with multiple user problems. Inspired by incremental learning, we decide to update the train set with new user data evaluated by a risk evaluator. Considering that the KNN algorithm does not need a training process and can directly classify the query based on the information provided by the train set, the KNN algorithm is chosen as the basis of the classifier. First, the muscle synergy is extracted by Nonnegative Matrix Factorization (NMF) as a feature vector, and representative samples are extracted from the synergy matrix of the existing user using the k-means clustering algorithm. In this way, the amount of data can be reduced greatly. Then, the label of the test data is obtained by a designed KNN classifier that can adaptively adjust the K-values and weights. Finally, to overcome the individual differences of sEMG, the qualified data and their labels evaluated by the risk evaluator are used to update the weights and train set.
Different from related studies, the main innovations and contributions of this study lie in:
i. To avoid the pre-experiment process and to improve the experience of new users, qualified test data and the label are used to update the train set and KNN weight.
ii. To reduce the amount of data and the complexity of calculations, we extract muscle synergy as robust features and extract representative samples from the existing synergy matrix as the basis of classification.
iii. Updating the train set can learn the latest knowledge from new users, so it can adapt to the time-varying nature of sEMG signals, and the recognition accuracy will gradually increase with the frequency of uses, eventually achieving the level of the user-dependent model.
The remaining sections are arranged as follows. In Section 2, we describe the data set and processing procedures. In Section 3, we introduce the representative samples, adaptive KNN and risk evaluators, and describe how we apply the methods to our problem. Experimental results and discussions are demonstrated in Section 4. Finally, Section 5 concludes our study.
2. Data Set and Data Processing
2.1. Data Set
The Database1 (DB1) and Database5 (DB5) of the NinaPro project (Atzori et al., 2014b) is used in this study. The DB1 and DB5 are constructed to apply to the research and development of the HCI system based on sEMG signals. The acquisition setups are OttoBock MyoBock 13E200 and Myo armband, respectively, which are placed in the extensor and flexor muscles of the fingers below the forearm elbow. The placement of electrodes is shown in Figure 1 and the detailed information of the database is shown in Table 1.

Figure 1. Acquisition setups and the placement: (A) DB1 OttoBock MyoBock 13E200, (B) DB5 Double Myo armband (Pizzolato et al., 2017).
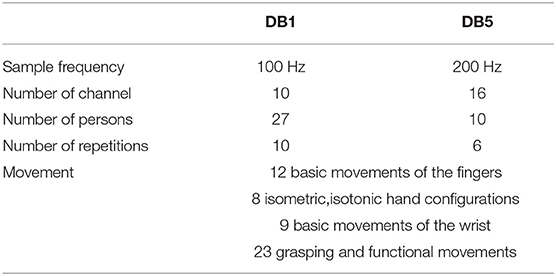
Table 1. Database information.
From the 52 movements in the NinaPro database, we choose 22 daily gestures and divide them into three groups. Figure 2 graphically shows the selected gestures.
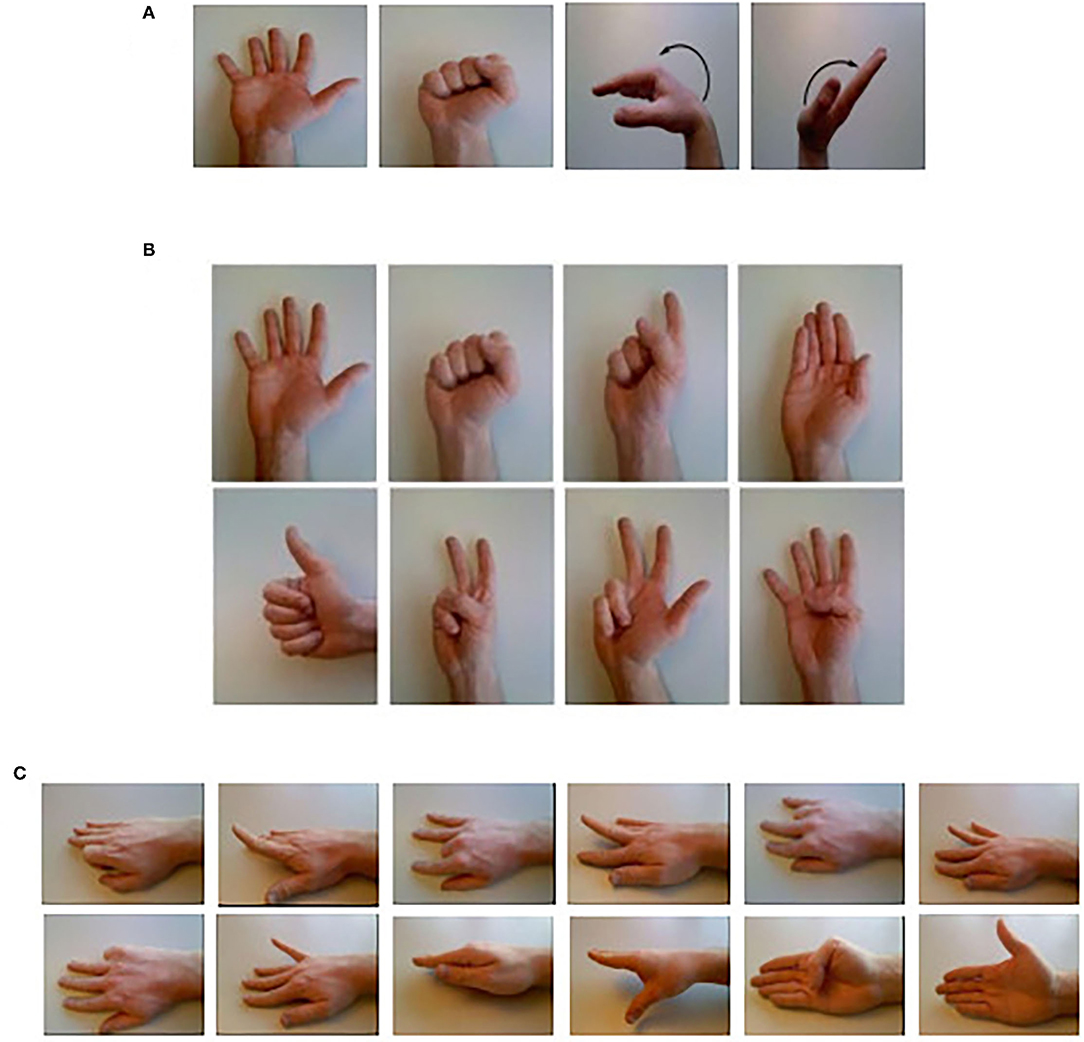
Figure 2. Twenty-two daily gesture: (A) four basic movements of the wrist and hand (Group one), (B) eight isometric, isotonic hand configurations (Group two), and (C) 12 basic movements of the fingers (Group three) (Atzori et al., 2014b).
To compare with existing research using the same database, the experiments of group one are conducted with the DB5, while group two and group three are conducted with the DB1.
2.2. Data Preprocessing
The data preprocessing includes full-wave rectification, a three-order Butterworth low-pass filter with a cut-off frequency of 1 Hz, and active segment extraction. The envelope obtained by low-pass filtering is used to acquire active segment data. Taking DB5 as an example, a sliding window with a size of 200 ms (40 samples) was selected for the next steps, denoted as E(t). The threshold value is 0.015 times the peak value in the sliding window. When 35 samples in E(t) are all greater than the threshold value, the window is determined as an active window; otherwise, it is a resting window. Multiple active windows between two resting windows constitute an active segment. To improve the reliability of data, the active segments with apparent differences in repeated movements are discarded.
2.3. Muscle Synergy
Muscle synergy theory explains well how the nervous system recruit muscles to produce action. Combined with the analysis of muscle synergy in the previous study (Zheng et al., 2021), muscle synergy is selected as the feature of the sEMG signal.
To ensure the real-time performance of online recognition, a sliding window with a size of 200 ms overlapped by 50 ms is chosen for online recognition (Jaramillo-Yánez et al., 2020). For each sliding window, the sEMG signal can be decomposed into two matrices by NMF (Teng et al., 2021):
Where V is the m×n initial envelope signal matrix (m is the number of muscles, n is the length of the muscle activation pattern), W is the m×r synergy matrix (r is the number of synergies), and H is the r×n coefficient matrix.
W and H can be solved by (2) and (3):
Where i = 1, 2, 3⋯m, o = 1, 2, 3⋯r, and j = 1, 2, 3⋯n. According to the references (Zheng et al., 2021), the optimal number of muscle synergies is 1, so r = 1.
Finally, to unify the dimensions of the features, all sEMG features are normalized as shown in Formula (4):
Where Xnorm represents the normalized sEMG features, X denotes the sEMG features, Xmax and Xmin, respectively, are the maximum value and minimum value of X.
3. Methods
3.1. The Proposed Adaptive Method for Gesture Recognition
The overall framework of adapting learning for gesture recognition is shown in Figure 3.
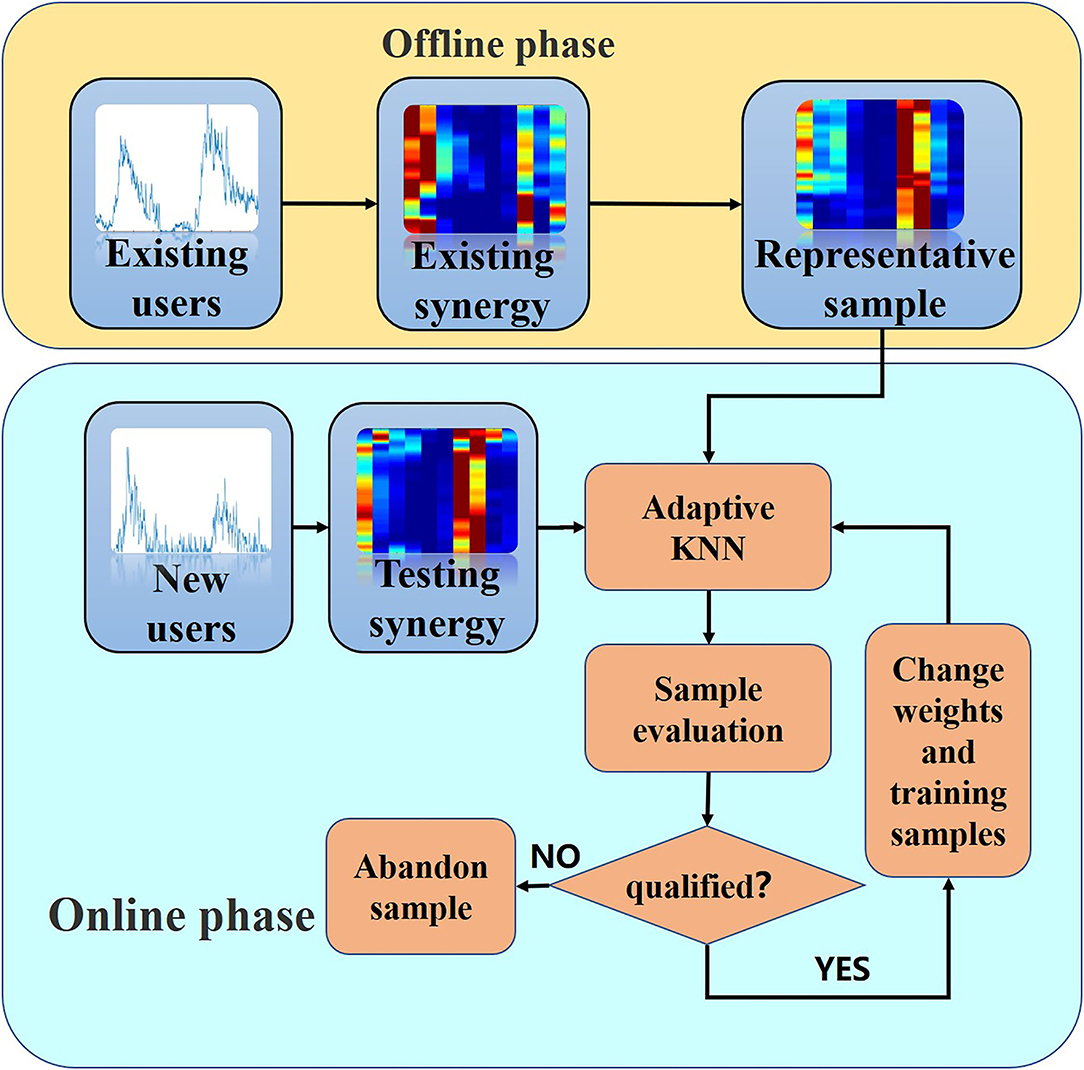
Figure 3. The framework for user-independent gesture recognition.
It can be seen from Figure 3, our proposed framework consists of two parts: offline processing and online recognition. In the offline phase, we first extract muscle synergy (denoted as existing synergy) from existing user data by NMF algorithm. The existing user data is removed by noise signal by data processing in advance. Then, the clustering center of each action is extracted using the clustering method, and the nearest sample of the existing synergy to the clustering center is extracted as the representative sample, which is the basis of the next steps.
In the online stage, the test data, after the same data processing as in the offline phase, obtain the labels by the KNN classifier. Then, the test data is evaluated by a risk evaluator, and the qualified one and its labels are used to update the weights and replace the remote samples of the train set, whereas those samples that do not meet the requirements are discarded.
3.2. The Method of Extracting Representative Sample Based on K-Means Algorithm
K-means algorithm is an unsupervised clustering method (Yu et al., 2020), which classifies the class by the distance between sample and centroid. In this study, the K-means algorithm is used to extract the template of each gesture, and then the representative samples of each gesture can be obtained. Assuming that the test data is x, the cluster is Ci ( i = 1, 2, 3⋯N, N is the number of gesture categories), and the centroid of the cluster Ci is μi, the optimization objective is to minimize the error E:
To solve the Formula (5), the vector mean of each gesture is chosen as the initial centroid. We set the upper limit of iterating as 100, and the procedure terminates when several iterations are reached or the difference between the centroid of the last generation and the centroid of the previous generation is <0.02. In the process of iterations, the centroid of each generation was recorded.
The final centroid of each gesture is chosen as the template, and we select the 30 samples closest to the template as a representative sample for each gesture of each user. Taking DB5 as an example, the dimension of the initial train set is 12,312 ×16, and the dimension of the representative sample is 1,080 × 16, which greatly reduces the amount of the train set.
3.3. Adaptive KNN Algorithm
Traditional incremental learning methods discard samples after learning some characteristics of samples, which will result in information loss. To make full use of the new user data, this article proposes to update the train set directly by using the new user data. As a typical case-based algorithm, the KNN algorithm only needs to compare the distance between the test set and the train set to get the label during classification. Therefore, there is no need to train the model again after updating the train set, which significantly improves the efficiency of the algorithm.
The traditional KNN algorithm searches for the points closest to the test sample in the train set and counts the categories of the nearest points. The category with the most significant number is the category of the test sample. The method is simple and effective but it also has some disadvantages: First, the K-value of the traditional KNN algorithm is fixed, which is not suitable for samples with uneven distribution (Mullick et al., 2018; Pan et al., 2020). Second, the KNN algorithm has the same weight on each neighbor point without considering the contribution of different samples to the classification (Gou et al., 2014).
To address the problems of the traditional KNN algorithm, this article proposes an improved method that automatically selects the appropriate K-values according to the distribution of samples and adjusts the weights according to the contribution of samples to the classification.
The process of the adaptive K-value is shown in Figure 4. It mainly has three stages. First, the distances between the test sample x and the train set Y = [y1, y2, ...yn] are calculated and sorted in ascending order:
where i = 1, 2, 3⋯q , q is the number of samples in the train set.
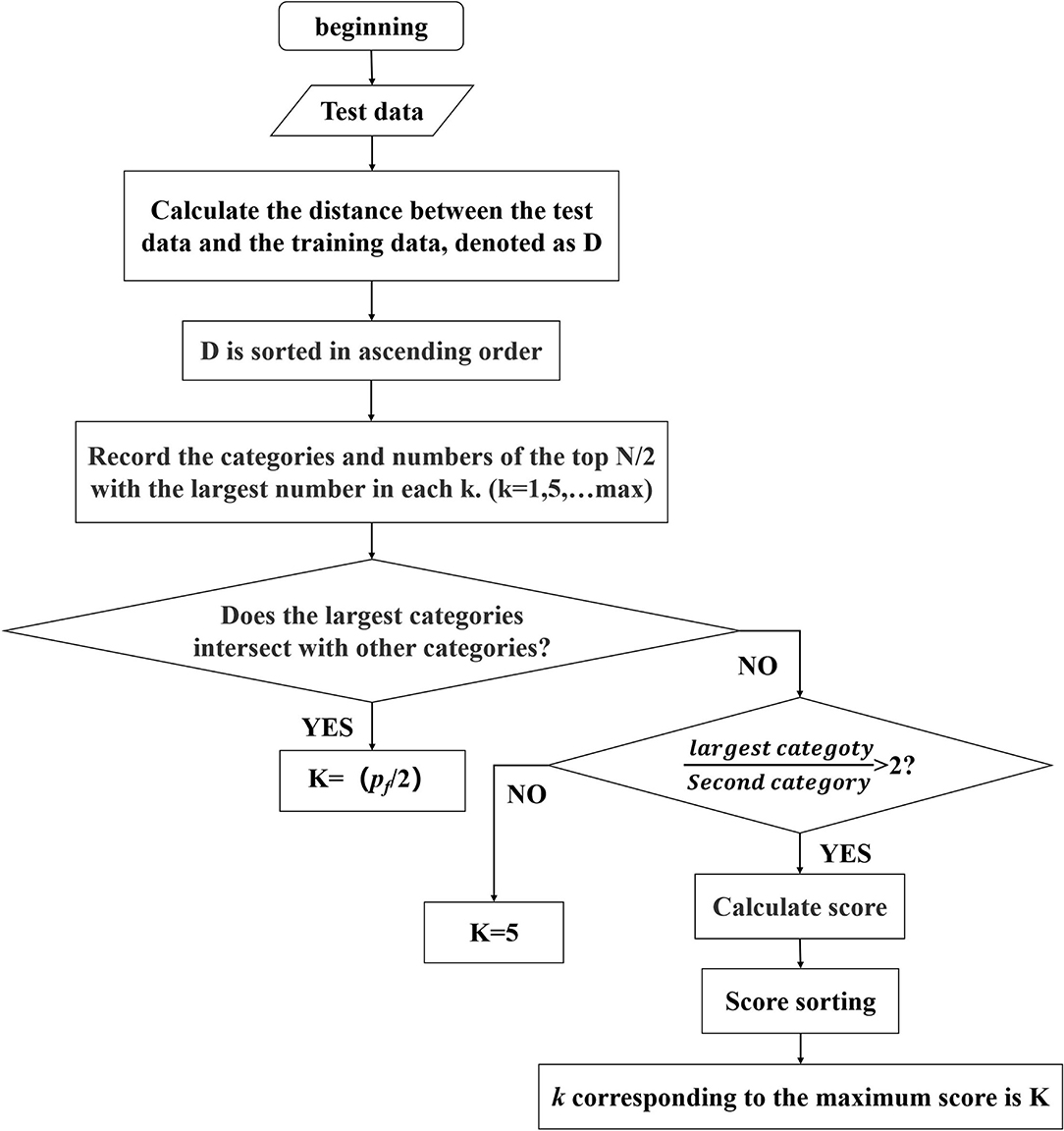
Figure 4. The process of adapting K-value.
Then, the k value of each time is a multiple of 5, and the top N/2 categories with the largest number in k are recorded each time. N is the number of gesture categories.
Finally, we judge whether the largest category has remained the same. If not, it means that the distribution of different gestures overlaps together. In this condition, a larger K-value indicates that more weights have to be updated, which will bring great risks. The first intersection between the largest category and other categories is recorded, denoted as pf. So, K can be obtained as follow:
If there are no intersections between the largest category and other categories, the ratio of the maximum number of categories to the second category is calculated. If the ratio is <2, we set K = 5; If it is >2, we calculate the score of each k according to Formula (9) and sort the score, and k corresponding to the maximum score is K.
where s is the number of the largest category and d is the longest distance in the largest category sample.
In Formula (10), v denotes purity, and den denotes density. It is normalized to avoid an order of magnitude too large for one of the parameters.
The approach to adaptive weights can be introduced through three steps. First, the initial weight of 1 is assigned to each sample. Then, the label of the test samples is obtained by the adaptive K-value KNN algorithm. Finally, the label of the qualified samples (refer to Section 3.4) is used to update the weight.
The weight of the sample will increase if it is chosen by the classification steps and its label is the same as the label of qualified samples. To avoid the weight of one sample being too large to cover other samples, it is considered to add amplitude limiting. The increased weight is as follows:
On the contrary,we reduce the weight of our sample if these samples are selected by the classification steps but its label is different from that of qualified ones. The weight should not be negative, so the weight is reduced proportionally.
In the case of K = 10, the diagram of updating the weight is shown in Figure 5. As can be seen from the graph, the number of Category 1 is greater than the number of Category 2, so the test sample is classified as Category 1. In the circle of K = 10, the weight of Category 1 is updated by qnew1, and the weight of Category 2 is updated by qnew2.
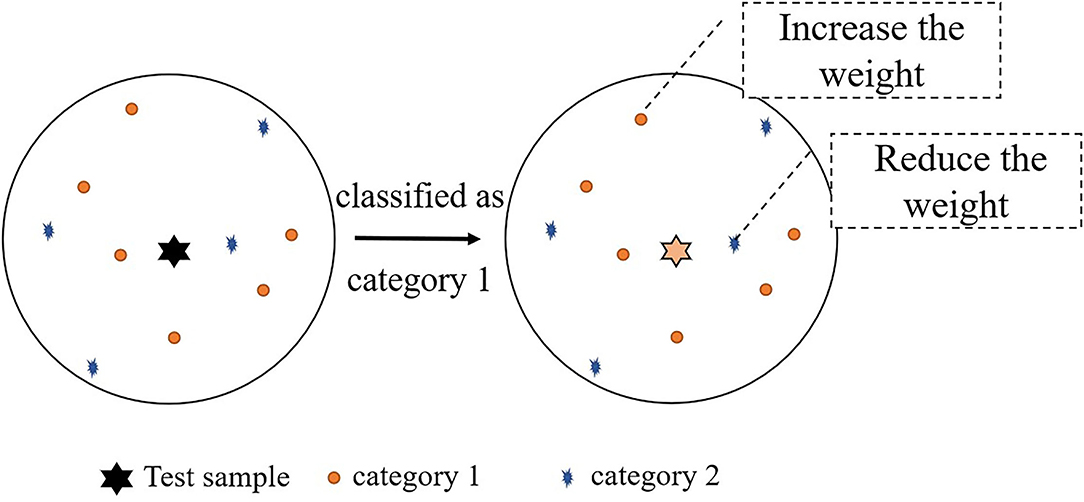
Figure 5. Schematic diagrams of updating the weight.
3.4. Risk Assessors
In this study, we decide to update the train set with new user data, so the new user data should be evaluated by the risk evaluator. Only qualified samples can be used to update the train set. The process of evaluating is as follows: First, the partial train set corresponding to the label of the test sample is extracted, and the farthest point between the partial train set and the template is calculated and denoted as ps.
Then, let test sample x and ps be A and calculate the risk using the following Formula (13).
where μ1 represents the templates of the categories corresponding to the labels, μj(j = 2, 3⋯N) represents the templates of the other categories. Additionally, the number of muscles m is the characteristic length.
In the above formula, the first term of the denominator represents the degree of similarity intra the class, and the second term represents the degree of difference inter the classes.
In the case that the risk value of the test sample is less than the farthest point, we think that the test sample has better inter class distance and intra class distance. Therefore, the farthest point is replaced by the test sample to update the train set, making the train set constantly learn new user features. Meanwhile, the weight of the qualified sample is initialized.
3.5. Evaluation
The classification performance of the algorithm in DB1 and DB5 is evaluated by the classification accuracy, i.e., the number of correctly classified samples divided by the total number of samples.
The data processing and classification using MATLAB R2018A, and a one-way Analysis of Variance (ANOVA) are used to analyze the experimental results. The p < 0.05 shows a significant difference.
3.6. Cross-Validation
To verify whether the recognition accuracy will improve with the increased frequency of uses, each time a group of repetitive actions of new users is randomly selected for testing until all the groups of repetitions are tested, which is recorded as a cycle. To make the results more objective, 10 cycles are conducted, and the average of 10 cycles is the final recognition rate of the new user.
To avoid the influence of random selection on the objectivity of the results, we use M-fold cross-validation, M is the number of users. Each time M-1 user is selected as an existing user, and the remaining user is considered as a new user. This process is repeated M times until each user is treated as a new user. Finally, the average value of the result is the accuracy of gesture recognition.
4. Results and Discussion
4.1. The Results of Extracting the Envelope and Active Segment
Taking the hand closed motion of DB5 as an example, according to the method in Section 2, the result of signal preprocessing is shown in Figure 6. It can be seen that the algorithm can extract the active segment well and make the signal more smoother, which is conducive to subsequent classification.
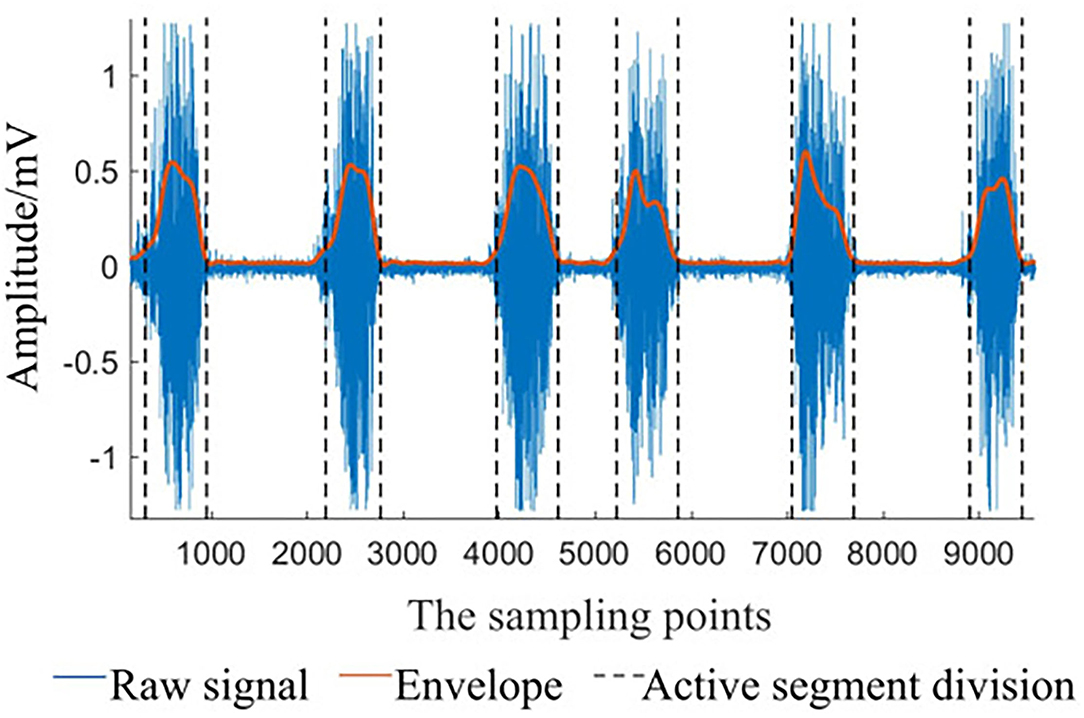
Figure 6. Envelope and activity segment.
4.2. The Relationship Between Frequency of Use and Recognition Accuracy
The adaptive learning proposed in this article is mainly reflected in replacing poor samples with qualified samples in the train set and updating weights. Since the classifier learns the characteristics of new users, the recognition performance should increase with the frequency of use. The average recognition accuracy of 10 users (DB5) and 27 users (DB1) improves with the increased frequency of use, as shown in Figure 7.
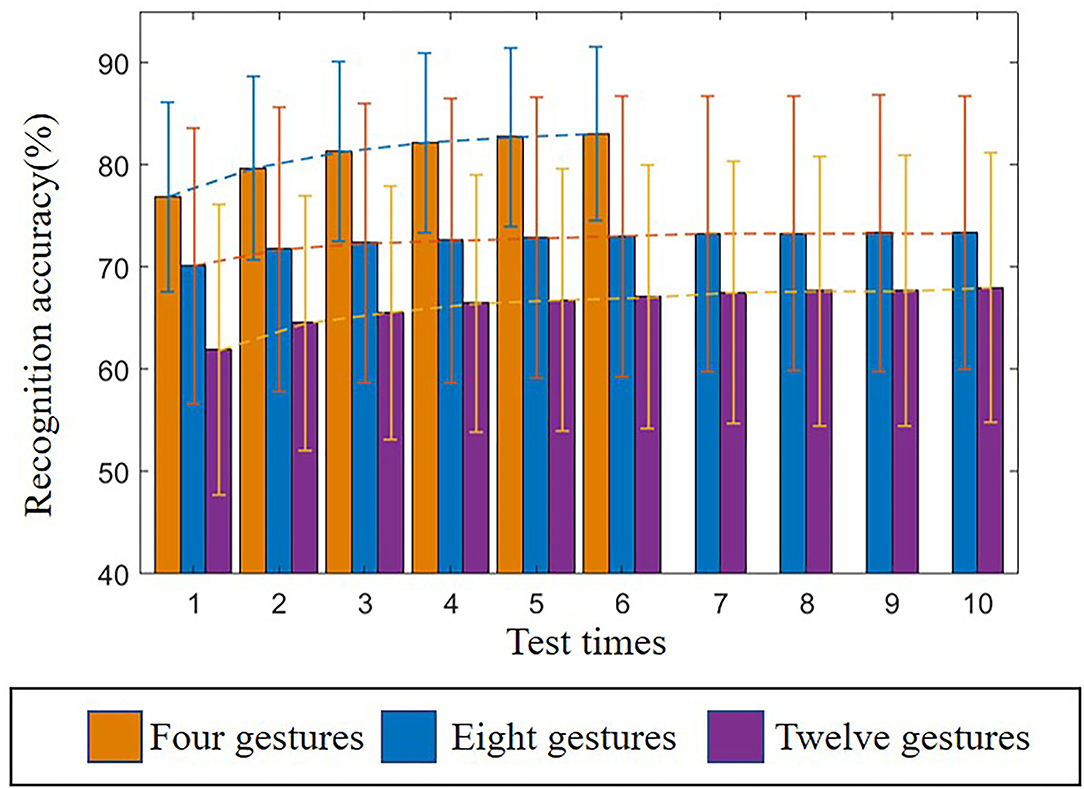
Figure 7. Relationship between average recognition accuracy and test times.
According to this histogram, with the increase of the number of tests, the average recognition accuracy of the three group's gestures increase steadily, which proves that the method of replacing the bad samples with the qualified samples can effectively improve the recognition accuracy, and it can adapt to the time-varying characteristics of sEMG during exercise. However, Figure 7 also reflects the slow growth rate of the accuracy. The possible reason is that the classifier has learned enough new user features, and the recognition accuracy is close to the user-dependent model. Therefore, the increase of data is of limited help to improve the recognition accuracy.
4.3. Changes of Channel Weights at Different Stages
If the user-independent gesture recognition method wants to reach a good recognition accuracy, the distribution of the train set must be similar to the test set. In this article, we use the weights of the channels to measure the similarity of the dataset with the new user data at different stages. The changes in weight are shown in Figure 8.

Figure 8. Changes in channel weights at different stages of (A) the existing samples, (B) the initial train set, (C) the updated train set, and (D) test samples.
Figure 8 shows that different hand gestures will activate different channels. In Figure 8D, for test data, hand closed movement mainly activates channel 9, hand open movement mainly activates channels 8 and 10, wrist flexion movement mainly activates channels 1, 5, and 9, and wrist extension movement mainly activates channels 1 and 9. For the existing data without processing, as shown in Figure 8A, the activated channels are significantly different from the test sample. It can be seen from Figure 8B, the representative sample (denoted initial train set) discards remote samples from the existing synergy matrix, so the channel weights are more similar to the test set, but the initial train set does not learn the distribution of the test sample, so it still fails to meet the requirements. Test samples that pass the risk evaluator evaluation can be used to replace remote samples in the initial train set, so the updated train set begins to resemble the distribution of the test set. As can be seen from Figure 8C, hand closed movement mainly activates channel 9, hand closed movement mainly activates channels 8 and 10, wrist flexion movement mainly activates channels 1, 5, and 9, and wrist extension movement mainly activates 1, 2, and 9. Although there are differences in the degree of activation, the differences are at an acceptable level.
4.4. Gesture Recognition Results
4.4.1. Comparison With Benchmark Algorithm
To verify the effectiveness, advantages, and performance of the proposed algorithm, three benchmark comparison schemes, including two user-independent schemes and one user-dependent scheme, are set up as follows:
Scheme A (user-independent): one user is selected at a time as a new user, and the remaining user is an existing user. Muscle synergy is extracted as the feature, and muscle synergy of all existing users is used to train the model, while muscle synergy of new users is used to test the model.
Scheme B (user-independent): one user is selected as the new user, and the remaining user is the existing user. Muscle synergy is taken as a feature. Representative samples of existing user data are extracted according to Section 3.2. The representative samples are used to train the model, and muscle synergy of new users is used to test the model.
Scheme C (user-dependent): for each user, muscle synergy is extracted as a feature, 70% of all synergy is used to train the model, and the remaining 30% is used to test the model.
Scheme D is the algorithm presented in this article.
The above schemes are applied to three groups of gesture recognition experiments, and the result is shown in Figure 9.
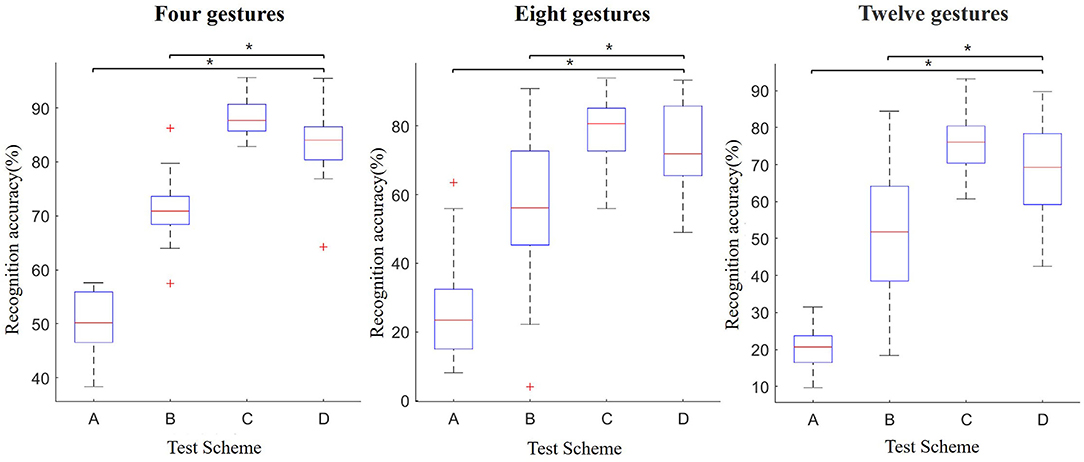
Figure 9. Comparison of significance among different schemes (*p < 0.05).
According to Figure 9, in the three groups of gesture experiments, the recognition accuracy of the proposed method (scheme D) is 35% higher than scheme A. Meanwhile, there is a significant difference between scheme A and scheme D (p = 1.17e-08, p = 3.35e-17, p = 5.69e-23). The result indicates that the proposed method can significantly improve the user-independent recognition performance.
The averaged classification rates in three groups of gesture experiments are 61.31 and 74.67%, corresponding to scheme B and scheme D. Our method achieves significantly better results as validated by an ANOVA test with the achieved p < 0.05 against scheme B (p = 0.005, p = 0.001, and p = 0.0004). The comparison results show that based on representative samples in this article, updating the train set and weight can effectively improve the recognition accuracy.
Although the recognition accuracy is lower than scheme C, there is no significant difference between scheme C and scheme D (p = 0.09, p = 0.07, and p = 0.05). This shows that the performance of the proposed method can achieve the level of the user-dependent model, which also confirms the conjecture that we proposed in the analysis of Figure 7. From a methodological point of view, although using qualified samples to replace remote samples directly can improve the recognition accuracy, some samples will inevitably be updated with the wrong labels. This part of the sample results in the accuracy being lower than the user-dependent model.
4.4.2. Comparison of Results With Other Research
The research results of user-independent gesture recognition using the same database as in this article are shown in Table 2.
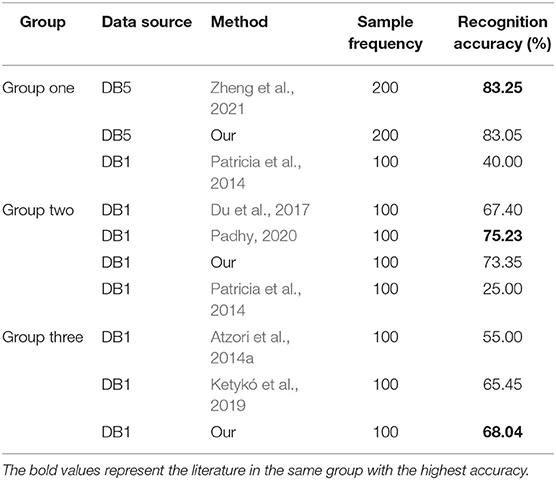
Table 2. Comparison of results with other searches.
Table 2 shows that the recognition accuracy of the proposed method is slightly lower than the references Padhy (2020) and Zheng et al. (2021) in Group one and Group two, but it is higher than the existing literature in Group three. Padhy (2020) proposed a tensor-based approach using multilinear singular value decomposition (MLSVD) for hand gesture recognition. This method achieved good recognition accuracy in user-independent gesture recognition, but it required larger computational resources because of the complex transformation relationship. Meanwhile, the sliding window length was 150 ms, and the average processing time of each channel was 199 ms. It demonstrated that the recognition time of a single gesture was over 300 ms, which did not meet the requirements of real-time for gesture recognition. Zheng et al. (2021) was preliminary work of our team. The combination of a trial (for each movement) for new users and LSM was adopted to update the train set. This method had great recognition accuracy and computation advantages compared with other studies. In this article, we extract representative samples to reduce the amount of data further. At the same time, we use adaptive learning to adapt to the feature distribution of new users, which can avoid the pre-experiment step for new users. We optimize preliminary work in two aspects, and the final recognition accuracy is only slightly lower than the preliminary work. Therefore, the optimization strategy proposed in this article is effective, and the biggest advantage of this method is that it completely avoids the pre-experiment process required in other studies.
5. Conclusion
In this article, an adaptive learning gesture recognition method is proposed to solve the user-independent problem. To simplify the calculation and eliminate abnormal samples, K-means clustering is first used to extract representative samples from existing synergy. Then, the label of the test data can be obtained by the adaptive KNN classifier. Finally, we evaluate the test sample by risk evaluator, and the qualified samples and their labels are used to update the weight and train set. Our method is analyzed by three comparisons in different directions, such as before-and-after processing comparison, comparison of various schemes, and comparison of different algorithms. All the results prove the effectiveness of the proposed method. The method proposed in this article not only improves the classification accuracy but also adapts to the time variability of the sEMG signal. In the practical application, the pre-experiment does not request new users, which is conducive to the promotion of sEMG signal-based HCI systems. Inspired by the literature (Zeng et al., 2020, 2021), the optimization of the risk evaluator, the template, and the neighborhood will be our next investigation to further enhance the user-independent sEMG classification results.
Data Availability Statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
Author Contributions
NZ and WZ wrote this manuscript. NZ, YL, and WZ conduced the conception of the study. YL and MD revised the manuscript critically for important intellectual content. All authors reviewed, revised, and finalized the manuscript. All authors contributed to the article and approved the submitted version.
Funding
This study was supported in part by the Fujian Province Nature Science Foundation of China under Grant 2019J01544 and in part by the National Nature Science Foundation of China under Grant 61773124.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Atzori, M., Gijsberts, A., Castellini, C., Caputo, B., Hager, A.-G. M., Elsig, S., et al. (2014a). Electromyography data for non-invasive naturally-controlled robotic hand prostheses. Sci. Data 1, 1–13. doi: 10.1038/sdata.2014.53
Atzori, M., Gijsberts, A., Kuzborskij, I., Elsig, S., Mittaz Hager, A.-G., Deriaz, O., et al. (2014b). Characterization of a benchmark database for myoelectric movement classification. IEEE Trans. Neural Syst. Rehabil. Eng. 23, 73–83. doi: 10.1109/TNSRE.2014.2328495
Chen, H., Zhang, Y., Li, G., Fang, Y., and Liu, H. (2020). Surface electromyography feature extraction via convolutional neural network. Int. J. Mach. Learn. Cybernet. 11, 185–196. doi: 10.1007/s13042-019-00966-x
Chen, L., Zhu, Y., and Ahn, C. K. (2021). Adaptive neural network-based observer design for switched systems with quantized measurements. IEEE Trans. Neural Netw. Learn. Syst. 1–14. doi: 10.1109/TNNLS.2021.3131412
Ding, Q., Han, J., and Zhao, X. (2016a). Continuous estimation of human multi-joint angles from sEMG using a state-space model. IEEE Trans. Neural Syst. Rehabil. Eng. 25, 1518–1528. doi: 10.1109/TNSRE.2016.2639527
Ding, Q., Han, J., and Zhao, X. (2016b). A review on researches and application of sEMG-based motion intent recognition methods. Acta Autom. Sin. 42, 13–25. doi: 10.16383/j.aas.2016.c140563
Du, Y., Jin, W., Wei, W., Hu, Y., and Geng, W. (2017). Surface emg-based inter-session gesture recognition enhanced by deep domain adaptation. Sensors 17:458. doi: 10.3390/s17030458
Gou, J., Xiong, T., and Kuang, Y. (2014). A novel weighted voting for k-nearest neighbor rule. J.Comput. 6, 833–840. doi: 10.4304/jcp.6.5.833-840
Jaramillo-Yánez, A., Benalcázar, M. E., and Mena-Maldonado, E. (2020). Real-time hand gesture recognition using surface electromyography and machine learning: a systematic literature review. Sensors 20, 2467. doi: 10.3390/s20092467
Jiang, N., Dosen, S., Muller, K., and Farina, D. (2012). Myoelectric control of artificial limbsis there a need to change focus? IEEE Signal Process. Mag. 29, 152–150. doi: 10.1109/MSP.2012.2203480
Jiang, S., Gao, Q., Liu, H., and Shull, P. B. (2020). A novel, co-located EMG-FMG-sensing wearable armband for hand gesture recognition. Sensors Actuat. A 301:111738. doi: 10.1016/j.sna.2019.111738
Ketykó, I., Kovács, F., and Varga, K. Z. (2019). “Domain adaptation for sEMG-based gesture recognition with recurrent neural networks,” in 2019 International Joint Conference on Neural Networks (IJCNN) (Stockholm), 1–7. doi: 10.1109/IJCNN.2019.8852018
Khushaba, R. N.. (2014). Correlation analysis of electromyogram signals for multiuser myoelectric interfaces. IEEE Trans. Neural Syst. Eng. Rehabil. 22, 745–755. doi: 10.1109/TNSRE.2014.2304470
Kim, M., Chung, W. K., and Kim, K. (2020). Subject-independent sEMG pattern recognition by using a muscle source activation model. IEEE Robot. Autom. Lett. 5, 5175–5180. doi: 10.1109/LRA.2020.3006824
Li, Y., Chai, G., Lu, C., and Tang, Z. (2019). On-line sEMG hand gesture recognition based on incremental adaptive learning. Comput. Sci. 46, 274–279.
Luo, X., Yuan, Y., Chen, S., Zeng, N., and Wang, Z. (2020). Position-transitional particle swarm optimization-incorporated latent factor analysis. IEEE Trans. Knowl. Data Eng. doi: 10.1109/TKDE.2020.3033324
Mullick, S. S., Datta, S., and Das, S. (2018). Adaptive learning-based k-nearest neighbor classifiers with resilience to class imbalance. IEEE Trans. Neural Netw. Learn. Syst. 29, 5713–5725. doi: 10.1109/TNNLS.2018.2812279
Ning, Y., Dias, N., Li, X., Jie, J., Li, J., and Zhang, Y. (2019). Improve computational efficiency and estimation accuracy of multi-channel surface EMG decomposition via dimensionality reduction. Comput. Biol. Med. 112, 103372. doi: 10.1016/j.compbiomed.2019.103372
Padhy, S.. (2020). A tensor-based approach using multilinear SVD for hand gesture recognition from sEMG signals. IEEE Sensors J. 21, 6634–6642. doi: 10.1109/JSEN.2020.3042540
Pan, Z., Wang, Y., and Y, P. (2020). A new locally adaptive k-nearest neighbor algorithm based on discrimination class. Knowl. Based Syst. 204, 106185. doi: 10.1016/j.knosys.2020.106185
Patricia, N., Tommasi, T., and Caputo, B. (2014). “Multi-source adaptive learning for fast control of prosthetics hand,” in 2014 22nd International Conference on Pattern Recognition (Budapest), 2769–2774. doi: 10.1109/ICPR.2014.477
Pizzolato, S., Tagliapietra, L. J., Cognolato, M., Reggiani, M., Müller, H., and Atzori, M. (2017). Comparison of six electromyography acquisition setups on hand movement classification tasks. PLoS ONE 12, e0186132. doi: 10.1371/journal.pone.0186132
Resnik, L. J., Huang, H., Winslow, A. T., Crouch, D. L., Zhang, F., and Wolk, N. (2018). Evaluation of emg pattern recognition for upper limb prosthesis control: a case study in comparison with direct myoelectric control. J. NeuroEng. Rehabil. 15, 1–13. doi: 10.1186/s12984-018-0361-3
Tavakoli, M., Benussi, C., Lopes, P. A., Osorio, L. B., and Almeida, A. T. d. (2018). Robust hand gesture recognition with a double channel surface EMG wearable armband and SVM classifier. Biomed. Signal Process. Control 46, 121–130. doi: 10.1016/j.bspc.2018.07.010
Teng, Z., Xu, G., Liang, R., Li, M., and Zhang, S. (2021). Evaluation of synergy-based hand gesture recognition method against force variation for robust myoelectric control. IEEE Trans. Neural Syst. Rehabil. Eng. 29, 2345–2354. doi: 10.1109/TNSRE.2021.3124744
Wahid, M. F., Tafreshi, R., Al-Sowaidi, M., and Langari, R. (2018). Subject-independent hand gesture recognition using normalization and machine learning algorithms. J. Comput. Sci. 27, 69–76. doi: 10.1016/j.jocs.2018.04.019
Wang, Z., Zhu, Y., Xue, H., and Liang, H. (2022). Neural networks-based adaptive event-triggered consensus control for a class of multi-agent systems with communication faults. Neurocomputing 470, 99–108. doi: 10.1016/j.neucom.2021.10.059
Wei, W., Dai, Q., Wong, Y., Hu, Y., Kankanhalli, M., and Geng, W. (2019). Surface-electromyography-based gesture recognition by multi-view deep learning. IEEE Trans. Biomed. Eng. 66, 2964–2973. doi: 10.1109/TBME.2019.2899222
Xue, B., Wu, L., Wang, K., Zhang, X., Cheng, J., Chen, X., et al. (2021). Multiuser gesture recognition using sEMG signals via canonical correlation analysis and optimal transport. Comput. Biol. Med. 130, 104188. doi: 10.1016/j.compbiomed.2020.104188
Yang, K., Xu, M., Yang, X., Yang, R., and Chen, Y. (2021). A novel EMG-based hand gesture recognition framework based on multivariate variational mode decomposition. Sensors 21, 7002. doi: 10.3390/s21217002
Yu, H., Wen, G., Gan, J., Zheng, W., and Lei, C. (2020). Self-paced learning for k-means clustering algorithm. Pattern Recogn. Lett. 132, 69–75. doi: 10.1016/j.patrec.2018.08.028
Zeng, N., Song, D., Li, H., You, Y., Liu, Y., and Alsaadi, F. E. (2021). A competitive mechanism integrated multi-objective whale optimization algorithm with differential devolution. Neurocomputing 432, 170–182. doi: 10.1016/j.neucom.2020.12.065
Zeng, N., Wang, Z., Liu, W., Zhang, H., Hone, K., and Liu, X. (2020). A dynamic neighborhood-based switching particle swarm optimization algorithm. IEEE Trans. Cybern. 1–12. doi: 10.1109/TCYB.2020.3029748
Zhai, X., Jelfs, B., Chan, R. H. M., and Tin, C. (2017). Self-recalibrating surface EMG pattern recognition for neuroprosthesis control based on convolutional neural network. Front. Neurosci. 11, 379. doi: 10.3389/fnins.2017.00379
Keywords: muscle synergy, user-independent, adaptive learning, surface electromyogram, pattern recognition
Citation: Zheng N, Li Y, Zhang W and Du M (2022) User-Independent EMG Gesture Recognition Method Based on Adaptive Learning. Front. Neurosci. 16:847180. doi: 10.3389/fnins.2022.847180
Received: 01 January 2022; Accepted: 13 January 2022;
Published: 31 March 2022.
Edited by:
Nianyin Zeng, Xiamen University, ChinaReviewed by:
Yanzheng Zhu, Huaqiao University, ChinaWeibo Liu, Brunel University London, United Kingdom
Copyright © 2022 Zheng, Li, Zhang and Du. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yurong Li, bGl5dXJvbmdAZnp1LmVkdS5jbg==