 Hanna Dolhopiatenko
Hanna Dolhopiatenko Waldo Nogueira
Waldo Nogueira
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neurosci., 11 January 2023
Sec. Auditory Cognitive Neuroscience
Volume 16 - 2022 | https://doi.org/10.3389/fnins.2022.1057605
This article is part of the Research TopicListening with Two Ears – New Insights and Perspectives in Binaural ResearchView all 20 articles
The growing group of cochlear implant (CI) users includes subjects with preserved acoustic hearing on the opposite side to the CI. The use of both listening sides results in improved speech perception in comparison to listening with one side alone. However, large variability in the measured benefit is observed. It is possible that this variability is associated with the integration of speech across electric and acoustic stimulation modalities. However, there is a lack of established methods to assess speech integration between electric and acoustic stimulation and consequently to adequately program the devices. Moreover, existing methods do not provide information about the underlying physiological mechanisms of this integration or are based on simple stimuli that are difficult to relate to speech integration. Electroencephalography (EEG) to continuous speech is promising as an objective measure of speech perception, however, its application in CIs is challenging because it is influenced by the electrical artifact introduced by these devices. For this reason, the main goal of this work is to investigate a possible electrophysiological measure of speech integration between electric and acoustic stimulation in bimodal CI users. For this purpose, a selective attention decoding paradigm has been designed and validated in bimodal CI users. The current study included behavioral and electrophysiological measures. The behavioral measure consisted of a speech understanding test, where subjects repeated words to a target speaker in the presence of a competing voice listening with the CI side (CIS) only, with the acoustic side (AS) only or with both listening sides (CIS+AS). Electrophysiological measures included cortical auditory evoked potentials (CAEPs) and selective attention decoding through EEG. CAEPs were recorded to broadband stimuli to confirm the feasibility to record cortical responses with CIS only, AS only, and CIS+AS listening modes. In the selective attention decoding paradigm a co-located target and a competing speech stream were presented to the subjects using the three listening modes (CIS only, AS only, and CIS+AS). The main hypothesis of the current study is that selective attention can be decoded in CI users despite the presence of CI electrical artifact. If selective attention decoding improves combining electric and acoustic stimulation with respect to electric stimulation alone, the hypothesis can be confirmed. No significant difference in behavioral speech understanding performance when listening with CIS+AS and AS only was found, mainly due to the ceiling effect observed with these two listening modes. The main finding of the current study is the possibility to decode selective attention in CI users even if continuous artifact is present. Moreover, an amplitude reduction of the forward transfer response function (TRF) of selective attention decoding was observed when listening with CIS+AS compared to AS only. Further studies to validate selective attention decoding as an electrophysiological measure of electric acoustic speech integration are required.
The growing group of cochlear implant (CI) users includes subjects with preserved acoustic hearing on the opposite side to the CI. The combination of electric and contralateral acoustic stimulation, also referred to as bimodal stimulation, usually results in an improvement in sound localization (Ching et al., 2004; Potts et al., 2009; Arndt et al., 2011; Firszt et al., 2012; Prejban et al., 2018; Galvin et al., 2019), music perception (Kong et al., 2005; Ching et al., 2007), tinnitus suppression (Van de Heyning et al., 2008; Galvin et al., 2019) and quality of life (Galvin et al., 2019) compared to monaural listening. Moreover, subjects with bimodal stimulation can integrate electric and acoustic information to improve their speech understanding (Ching et al., 2004; Kong et al., 2005; Dorman et al., 2008; Potts et al., 2009; Vermeire and Van de Heyning, 2009; Yoon et al., 2015; Devocht et al., 2017). However, the observed benefits present high variability across subjects (Ching et al., 2007; Crew et al., 2015) and some subjects even experience worsened speech performance with bimodal stimulation (Litovsky et al., 2006; Mok et al., 2006; Galvin et al., 2019). This variability in speech outcomes with bimodal listening may be associated with the effectiveness of the speech integration between electric and acoustic stimulation. Some previous works suggested that this integration has a central origin (Yang and Zeng, 2013; Reiss et al., 2014; Fowler et al., 2016; Balkenhol et al., 2020). However, the integration mechanisms and its impact on bimodal benefit requires investigation.
Different mechanisms might contribute into electric acoustic integration of speech: the integration of complementary speech information conveyed through electric and acoustic stimulation, the integration of similar speech information conveyed electrically and acoustically or the combination of the two mechanisms. Reiss et al. (2014) showed that bimodal CI users obtain abnormal spectral integration, which might lead to speech perception interference between the electric and the acoustic stimulation sides. To solve this, they suggested to reduce overlap in frequency information transmitted through electric and acoustic stimulation (Reiss et al., 2012a,b). Fowler et al. (2016) also investigated the reduction of frequency overlap in bimodal CI users and observed that subjects with better residual hearing (< 60 dB HL at 250 and 500 Hz) might benefit when low frequency information is removed on the CI side. In contrast, Fu et al. (2017) showed that bimodal perception is not significantly impacted when changing the CI input low-cutoff frequency, claiming that bimodal CI users do not benefit from the mismatch correction. However, that study was conducted using a vocoder to simulate bimodal hearing in normal hearing subjects. The study of Kong and Braida (2011) assumed that bimodal listeners do not integrate available cues from both listening sides but rather rely on the cues processed by the dominant stimulation. However, Yoon et al. (2015) demonstrated that bimodal benefit does not depend on the performance of the dominant acoustic side alone but can be predicted by the difference between performances of the two stimulation modalities. Therefore, authors concluded that the bimodal benefit is a result of the integration between electric and acoustic stimulation.
The benefit of electric acoustic stimulation in bimodal CI users is usually measured behaviorally using clinical speech performance tests. These tests suffer from test-retest variability, cannot be applied to people with missing behavioral response and do not provide insights about the underlying physiological mechanisms related to electric acoustic integration. The understanding of these physiological mechanisms may provide novel approaches to program the CI and consequently improve speech perception in bimodal CI users. EEG is promising as an objective measure of speech integration for bimodal listening, however, its application is challenging because it is influenced by the CI electrical artifact.
Nowadays, there is a growing interest in the use of cortical auditory evoked potentials (CAEPs) as an objective measure of sound perception in NH listeners (Martin et al., 2007; Stapells, 2009; Papesh et al., 2015) and in CI users (Pelizzone et al., 1987; Ponton et al., 1996; Firszt et al., 2002; Maurer et al., 2002; Sharma et al., 2002). It has been shown that CAEPs provide information about binaural interaction at central level in NH listeners by analyzing the deviation of binaural responses from the sum of monaural responses (i.e. binaural interaction component (BIC) analysis) (McPherson and Starr, 1993; Jancke et al., 2002; Henkin et al., 2015). CAEPs were also measured in people with asymmetric hearing loss, revealing that the sound at cortical level is processed similarly for acoustic alone and electric alone stimulation (Sasaki et al., 2009; Balkenhol et al., 2020; Wedekind et al., 2020, 2021). However, the amount of studies investigating electric acoustic integration at cortical level in bimodal CI users is limited. The current study investigates the possibility to record CAEPs when listening with the CI side (CIS) alone, the acoustic side (AS) alone and both sides simultaneously (CIS+AS).
One of the main disadvantages of CAEPs is that they require the use of relatively short and simple stimuli. Therefore, the relation between CAEPs and speech understanding is not easy to establish. Another alternative EEG measure, which recently has gained significant interest as an objective measure is neural tracking of the envelope of an attended speech source (Ding and Simon, 2012; Giraud and Poeppel, 2012; Power et al., 2012; Mirkovic et al., 2015; OSullivan et al., 2015). The paradigm in which in addition to the attended speaker also an ignored speaker is introduced, is called selective attention decoding. Two linear approaches exist for selective attention decoding, the forward and the backward models. Both approaches are based on least mean square error minimization between audio features and neural signals. Most previous studies performed stimulus-response mapping in the forward direction, i.e. using forward models to investigate how the system generates or encodes information (Haufe et al., 2014). By applying the forward model, the temporal response function (TRF), which describes the relationship between speech and neural recordings, is obtained. The morphology of the TRF resembles the classical N1P2 complex of the late evoked potentials (Lalor et al., 2009; Crosse et al., 2016). Analysis of the N1P2 TRF complex might provide different information than the N1P2 complex of CAEPs due to the utilization of more ecological speech stimuli, as selective attention is decoded using continuous speech streams. In order to investigate how speech features are decoded from the neural representation, one can apply the backward model (Mesgarani et al., 2009; Ding and Simon, 2012; Pasley et al., 2012; Mirkovic et al., 2015; OSullivan et al., 2015; Crosse et al., 2016). By using the backward model, the speech stimulus is reconstructed from the neural activity recordings. The backward model explores the accuracy of decoding by analyzing speech features of reconstructed and original speech stimuli.
Recently, the possibility to predict speech intelligibility from selective attention decoding has been shown in NH listeners (Keitel et al., 2018; Vanthornhout et al., 2018; Dimitrijevic et al., 2019; Etard and Reichenbach, 2019; Lesenfants et al., 2019), in hearing impaired listeners with hearing aids (Petersen et al., 2017) and in bilateral (Paul et al., 2020) and monaural CI users (Nogueira and Dolhopiatenko, 2022). However, the application of such objective measures in CI users is still challenging because of the CI electrical artifact leaking into the EEG recordings (Hofmann and Wouters, 2010; Somers et al., 2010; Deprez et al., 2017). Artifact rejection techniques such as independent component analysis (ICA) can suppress artifacts in EEG, however, the full removal of the CI electrical artifact can not be ensured. Nevertheless, some previous works showed that it is still feasible to decode selective attention in CI users (Nogueira et al., 2019a,b; Aldag et al., 2022). In this regard, these previous works showed that the maximum differentiation between the attended and the ignored speaker occurs at 200–400 ms after stimulus onset showing a minimization effect of the CI electrical artifact at this time interval. However, as selective attention is recorded to the continuous speech, the impact of the CI electrical artifact cannot be fully discarded and more evidences that selective attention decoding is possible in CI users are necessary. Therefore, the main goal of the current study is to confirm the feasibility to decode selective attention in bimodal CI users, which will provide further evidence on the use of continuous EEG recordings to speech stimuli in this population, despite the presence of the CI electrical artifact. This work investigates selective attention decoding in bimodal CI users when listening with CIS only, AS only and both sides together (CIS+AS). It is hypothesized that combined electric and acoustic stimulation results in improved selective attention decoding with respect to listening with CIS alone. If this hypothesis is confirmed, it can be concluded that it is possible to decode selective attention in CI users, as the additional neural activity provided by the acoustic stimulation is used to improve the decoding, even if CI artifact is present. Moreover, the confirmation of the main hypothesis might open the possibility to further investigate selective attention decoding as a measure of speech integration between electric and acoustic stimulation in bimodal CI users using continuous speech which is a natural and ecologically valid signal.
To find a descriptive link between speech understanding and selective attention decoding, the current study also included a behavioral measure. The behavioral measure consisted of a speech understanding performance test to a target speaker in the presence of a competing talker. Speech material was presented using the three listening modes (CIS only, AS only, and CIS+AS). The second part of the study included recording of EEG. The possibility to record cortical responses to short stimuli with all three listening modes was demonstrated through CAEPs. Afterwards, selective attention decoding, which is a novel approach when applied to bimodal CI users, was measured. In the selective attention paradigm, a target and a competing talker were presented to the subjects using the three listening modes (CIS only, AS only, CIS+AS). The main goal of this study is to investigate the feasibility to decode selective attention in CI users despite the presence of CI electrical artifact. Furthermore, first attempts to investigate the potential of selective attention decoding as a speech integration measure between electric and acoustic stimulation in bimodal CI users were conducted.
Ten subjects participated in the study (mean age: 57.7). All participants were implanted with an Oticon Medical CI and had a device experience of 6–48 months. Demographics of the participants are shown in Table 1. Prior to the experiment, all participants provided written informed consent and the study was carried out in accordance with the Declaration of Helsinki principles, approved by the Ethics Committee of the Hannover Medical School.
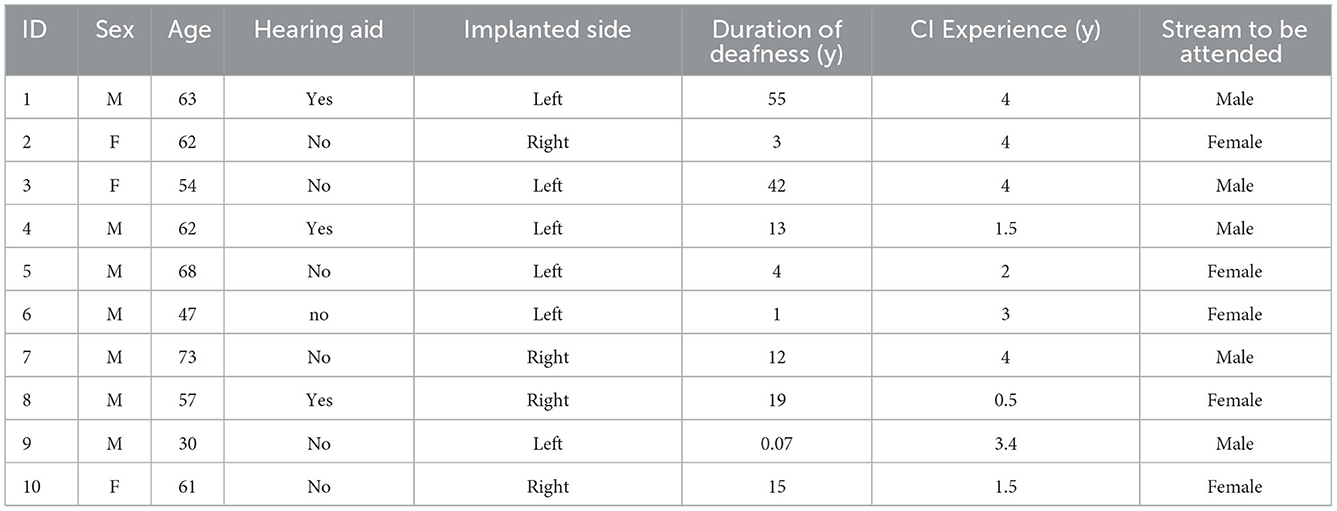
Table 1. Demographics of participants.
A pure tone audiogram on the non-implanted ear in unaided condition was measured via a calibrated audiometry system (CAS AD2117, Audio-DATA, Duvensee, Germany). The audiograms for the study participants are presented in Figure 1.
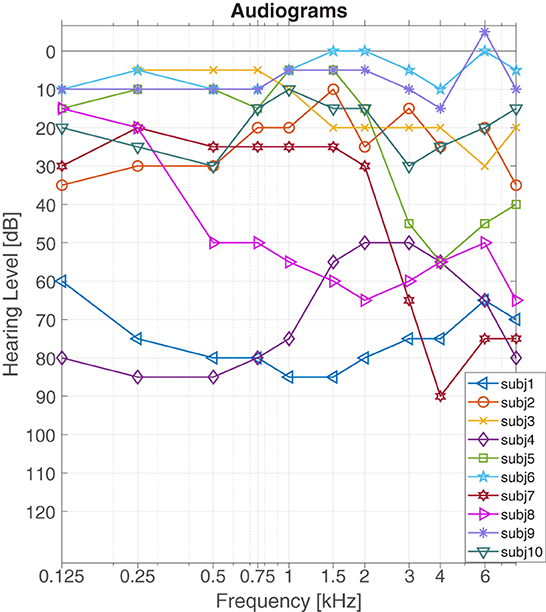
Figure 1. Audiograms of study participants.
The German Hochmair-Schulz-Moser sentence test (HSM test) (Hochmair-Desoyer et al., 1997) was used to assess speech understanding behaviorally. Each list consists of 20 semantically structured sentences, uttered by a male or by a female talker. Two sentence lists were presented to the acoustic side only (AS only), to the CI side only (CIS only) and to both sides simultaneously (CIS+AS). Target and interference speech streams were co-located and presented at 0 dB signal-to-interference ratio (SIR) between the target (male/female) and the interference (female/male) speech stream. Subjects were instructed to attend to the target talker and to repeat all words after each sentence. The speech stream to be attended was randomized within subjects and is indicated in Table 1. The attended speech stream was kept the same through the whole experiment. The speech understanding performance score was calculated in percentage of correct recalled words per listening mode. Speech material was presented to the CI side via the Oticon Bluetooth Streamer and to the acoustic side via inner-ear phones (E-A-RTONE Gold 3A, 3M, St. Paul, Minneapolis). For subjects wearing a hearing aid on the contralateral side to the CI, speech material presented to the AS was preprocessed using a digital hearing aid implemented in a PC. The hearing aid was based on the half-gain rule amplification according to the measured audiogram (Lybarger, 1963). This hearing aid implementation has been successfully used in previous studies in our group (Krüger et al., 2022). Stimulus presentation was controlled by the Presentation Software (Neurobehavioral Systems, Inc., Berkeley, CA, United States; version 20.1). The presentation level for the CIS and AS was set to a most comfortable level, using a seven point loudness rating-scale (from 1 to 7: from extremely soft to extremely loud; 4 - most comfortable level).
The electrophysiological part of the experiment consisted of EEG recordings. The recording was conducted in an electromagnetically and acoustically shielded booth. High-density continuous EEG was recorded using a SynAmps RT System with 64 electrodes mounted in a customized, infracerebral electrode cap (Compumedics Neuroscan, Australia). The reference electrode was placed on the nose tip; two additional electrodes were placed on the mastoids. Impedances were controlled and maintained below 15 kΩ. Electrodes with high impedance were excluded from further analysis. Each subject was instructed to sit relaxed, avoid any movements, and to keep their eyes open in order to minimize physiological artifacts. All material was presented via Bluetooth Streaming to the CIS and via inner-ear phones to the AS. For AS in CI users with a hearing aid on the contralateral side, all presented material was processed with the same digital hearing aid and adjusted in loudness to their MCL exactly in the same manner as in the behavioral paradigm described in Section 2.2.
To maximize responses, a broadband noise of 50 ms duration was used as a stimulus. To ensure time synchronization between both listening sides, the delay between electric and acoustic stimulation needs to be considered. The technical CI delay was measured using an oscilloscope and a research implant unit. The stimulus was presented through the Bluetooth Streamer to the CI processor, and the delay between audio start and the start of electrical stimulation resulted in 30 ms. On the acoustic side however, the delay between stimulus onset and the auditory nerve response is frequency dependent and variable across subjects (Elberling et al., 2007). It was estimated from the literature that the average delay for a stimulus to travel from the outer ear to the auditory nerve is 7 ms (Elberling et al., 2007), therefore, the stimulus for AS started 23 ms after the onset of the stimulus on the CIS. Note that delay compensation was conducted at group level and not adjusted individually for each subject. The stimuli were presented with an inter-stimulus interval of 1 s. In total, 100 trials were recorded. The EEG data was recorded with a sampling rate of 20 kHz.
Recorded EEG data was processed through the EEGLAB MATLAB toolbox (Delorme and Makeig, 2004). ICA based on second-order blind identification (SOBI) was applied to the recorded data to remove physiological and CI electrical artifacts (Kaur and Singh, 2015). Data recorded with CIS only and with CIS+AS listening mode was concatenated prior to SOBI in order to ensure equal portion of the removed CI electrical artifact in both listening modes. The topology and the signal in the time and spectral domain were visually analyzed for each component. On average 1.8 (std:±0.64) components for each subject were removed from the data. EEG with the suppressed artifacts was afterwards epoched in the time interval ranging from –200 to 1,000 ms. The CAEPs were obtained from the vertex electrode (Cz). The signal was filtered between 1 and 15 Hz and re-referenced to the mean of the two mastoid electrodes.
For the selective attention paradigm HSM sentence lists with a male and a female talker at 0 dB SIR were used. The speech stream to be attended was kept the same as in the behavioral part of the experiment (Table 1). For each listening condition (CIS only, AS only, and CIS+AS) 8 lists were presented, resulting in approximately 6 min of stimulation per listening mode. To extend the training dataset for the decoder, additional speech material consisting of two audio story books were used. The story books included two German narrations (“A drama in the air” by Jules Verne, narrated by a male speaker and “Two brothers” by the Grimm brothers, narrated by a female speaker) at 0 dB SIR. In total, 36 min of story (12 min per listening mode) were presented. To ensure the continuous engagement of the CI user when listening to the corresponding speaker, questions to the context of the presented speech material were asked every 2 min. The presented speech material was randomized across listening conditions to avoid the influence of the material. EEG data was recorded with a sampling rate of 1,000 Hz.
EEG data was processed offline in MATLAB (MATLAB, 2018) and the EEGLAB toolbox (Delorme and Makeig, 2004). SOBI artifact rejection was applied to the EEG data to suppress physiological and CI electrical artifact. The location of the CI and the signal in the time and spectral domain of each component were analyzed. On average, 3.5 (std: ±1.08) components were removed from the data. Afterwards, the EEG data was split into the trials corresponding with the duration of each sentence list and 1 min segments of the story. Next, the digital signal was band-pass filtered for frequencies 2–8 Hz and downsampled to 64 Hz. The envelopes of the original attended and unattended speech streams were extracted through the Hilbert transform. The envelopes were filtered with a low-pass filter having cut-off frequency of 8 Hz and downsampled to 64 Hz. Selective attention was analyzed using the forward and the backward model approaches (Crosse et al., 2016). By applying the forward model, the TRF was obtained. By using the backward model the speech stimulus was reconstructed from the neural activity recordings. The correlation coefficient between the original envelope of the attended audio and the reconstructed envelope (attended correlation coefficient ρA) as well as the correlation coefficient between the original envelope of the unattended audio and the reconstructed envelope (unattended correlation coefficient ρU) were calculated. Selective attention decoding was analyzed in terms of ρA and the difference between ρA and ρU (ρDiff). Both, forward and backward models were applied across time lag. The time lag performs a time shift of the EEG signal that reproduces the physiological delay between the audio presentation and its processing up to the cortex (OSullivan et al., 2015). In total 38 lags spanning the interval from 16 to 608 ms were used. The lag window, over which reconstruction was conducted, was set to △ = 16 ms. The regularization parameter λ was set to 100 to maximize the peak amplitudes of the TRF for the forward model and to 0.01 to maximize the difference between the attended and unattended correlation coefficients for the backward model. Further details on the analysis of TRFs and correlation coefficients across λ can be found in the Supplementary material. For more details on the reconstruction procedure see Nogueira et al. (2019a,b). A classical leave-one-out cross-validation approach was used to train and test the decoder. HSM lists and the story were used to train the decoder. Only HSM sentences were used for testing, resulting in 8 folds for cross-validation (corresponding to the amount of lists) with each listening mode.
Statistical analysis was carried out with the SPSS software (version 26, IBM). The effect of listening mode on the investigated parameters was explored through a repeated measures analysis of variance (ANOVA). Pairwise comparisons between listening modes were conducted with post-hoc analysis based on the t-test for each pair of observations. To avoid type I error for multiple comparisons, Bonferroni correction was applied. For non-normally distributed data, the non-parametric Friedman test followed by a post-hoc Wilcoxon signed-rank test for pairwise comparisons was applied to the data.
Figure 2 shows the individual speech understanding performance for each listening mode.
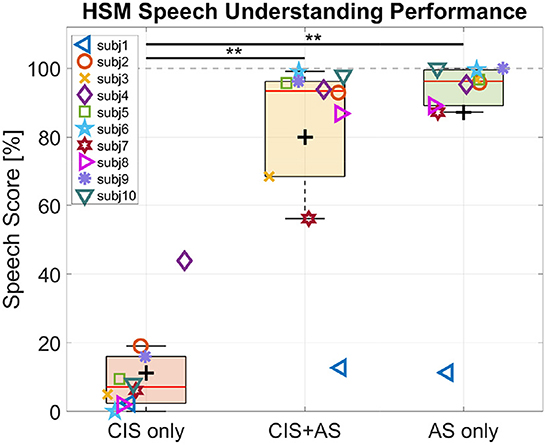
Figure 2. Behavioral speech understanding performance for three listening modes: CIS only, CIS+AS, and AS only. Asterisk indicates significant difference between a pair of conditions revealed through the Wilcoxon signed-rank test.
On average, the highest score was observed with AS only listening mode (87.18%), followed by CIS+AS listening mode (80.01%). The lowest score was obtained with CIS only (11.21%) and can be explained by the high difficulty of the task for the participants when listening with CIS alone. A Friedman test revealed a significant effect of listening mode on speech performance scores . Post-hoc analysis with the Wilcoxon signed-rank test with a Bonferroni correction resulted in a significant effect for the pairs CIS+AS—CIS only (p = 0.005) and AS only—CIS only (p = 0.005). No significant difference between CIS+AS and AS only was observed.
Figure 3 presents the averaged CAEPs across subjects after SOBI artifact rejection for the three listening modes (CIS only, AS only, and CIS+AS). Subject 1 was excluded from the analysis due to the low quality of the recorded signal.
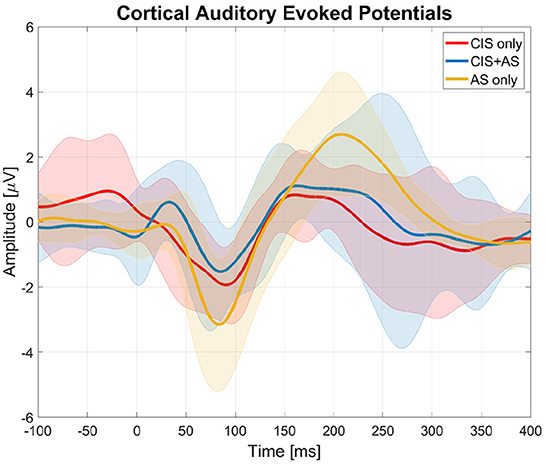
Figure 3. Cortical auditory evoked potentials (CAEPs) obtained from the central electrode (Cz) with three listening modes (CIS only, AS only, and CIS+AS) averaged across subjects. The thick lines represent the mean values across subjects and the shaded areas represent the standard deviation across subjects.
In general, it was possible to distinguish the cortical response with all three listening modes. The peak-to-peak amplitude of the N1P2 was estimated for each subject individually. An ANOVA analysis revealed a significant effect of listening mode on the N1P2 amplitude [F(2, 16) = 6.544;p = 0.008]. A post-hoc t-test with Bonferroni correction revealed a significantly higher N1P2 amplitude with AS only than with CIS only listening mode (p = 0.014). No significant differences between CAEPs recorded with CIS only and CIS+AS listening modes were found.
Figure 4A presents the mean TRF across subjects, where the TRF represents the decoder weights of the forward model approach. The TRF were analyzed comparing the first negative (N1) and second positive (P2) peaks for each listening mode and listener. The analysis revealed highest N1P2 peak-to-peak amplitude for the AS only, followed by the CIS+AS and the lowest amplitude for the CIS only listening mode. Moreover, weights of the TRF at the N1 and P2 peaks were estimated for each subject and presented in the form of topographical maps per each listening mode (Figure 4B). The weight distribution is similar across all listening modes, however, the activation power with the CIS only listening mode is visibly weaker.
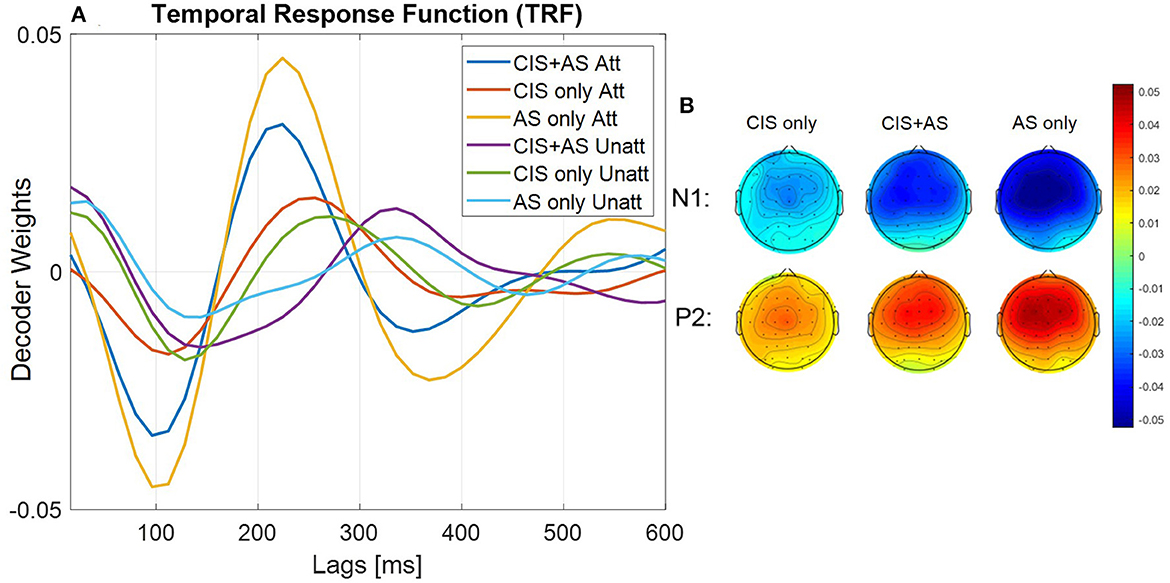
Figure 4. (A) Forward transfer response function (TRF) averaged across subjects. Attended TRF and unattended TRF are estimated using attended and unattended decoder respectively; (B) Topographical maps show TRF weights across subjects at first and second peaks of attended curve for each listening mode.
From Figure 4A, it can be observed that the latencies of the TRF peaks for the CIS+AS and the AS only listening modes are similar, while the latency for CIS only is delayed. Moreover, the amplitude of the N1P2 peak of the TRF was compared to the amplitude of the N1P2 peaks obtained from CAEPs presented in Section 3.2. A significant correlation between the N1P2 peak-to-peak amplitude from TRFs and CAEPs was observed for CIS only and AS only listening modes (CIS only: r = 0.715, p = 0.031; AS only: r = 0.793, p = 0.011) (Figure 5). For the CIS+AS listening mode, no significant correlation between the N1P2 amplitude derived from CAEPs and TRFs was found. This may be explained by the temporal delay correction between electric and acoustic stimulation implemented in CAEP measurements, which was not applied during the selective attention decoding experiment.
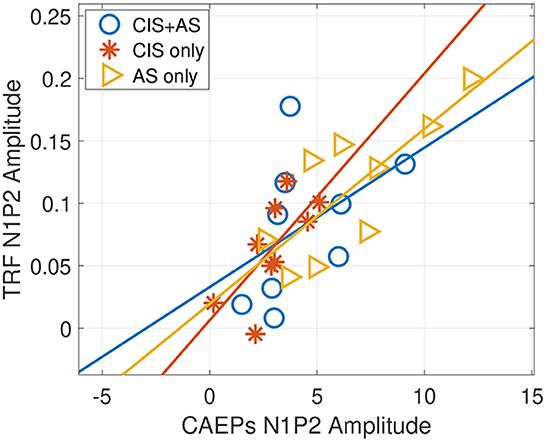
Figure 5. Pearson correlation between N1P2 peak amplitudes of the temporal response function (TRF) and N1P2 peak amplitudes of cortical auditory evoked potentials (CAEPs) with three listening modes: CIS only, CIS+AS, and AS only.
Figure 6 presents the ρA and ρU coefficients across lags obtained from selective attention decoding using the backward model after SOBI artifact rejection. Note, that lag △ is used to time shift the EEG, modeling the physiological delay required for a sound to travel along the auditory pathway up to the cortex.
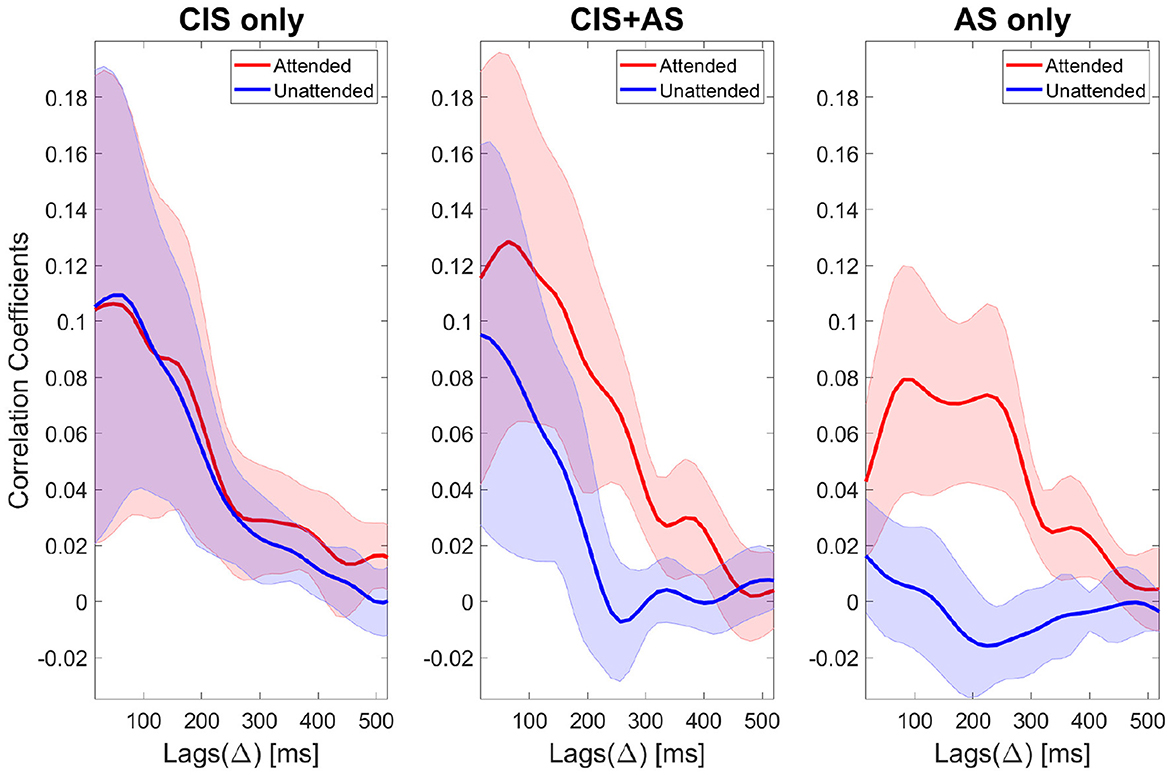
Figure 6. Attended correlation coefficients (red color) and unattended correlation coefficients (blue color) of selective attention decoding for three listening modes: CIS only (left), CIS+AS (center), and AS only (right). Correlation coefficients are denoted as corr coeff and calculated across lags (△). The thick lines represent the mean values and the shaded areas represent the standard deviation across subjects.
The correlation coefficients across lags for the AS only condition present a morphology consistent with the morphology reported in NH listeners (Nogueira et al., 2019a). In NH listeners, the typical morphology of the ρA curve presents two peaks at around 100 and 250 ms associated with different stages of neural processing. The correlation coefficients obtained with the CIS only and CIS+AS listening modes at early lags were higher than with AS only indicating a contribution of the CI electrical artifact. SOBI artifact rejection suppressed part of this artifact, however, full removal could not be achieved. In order to minimize the effect of the CI artifact, a later lag interval was chosen for further analysis. Based on previous works (Nogueira et al., 2019a,b), the chosen lag interval spanned the time between 208 and 304 ms, which also corresponds to the second peak of the ρA curve for the AS only condition (Figure 6). At that chosen lag interval, a t-test comparing the ρA and the ρU coefficients for each listening mode revealed a significant difference for the CIS+AS (p < 0.001) and for the AS only (p < 0.001) listening modes, but not for the CIS only mode (p = 0.405) due to the small differences between the ρA and the ρU. This result confirms the possibility to decode selective attention in CI users despite the presence of CI electrical artifact.
Furthermore, we focus our analysis only on the difference between the attended and the unattended correlation coefficients (ρDiff), which reduces the impact of the CI artifact (Nogueira and Dolhopiatenko, 2022). Figure 7 shows the ρDiff at the lag interval 208–304 ms for each listening mode. The ANOVA test revealed a significant effect of listening mode on the ρDiff F(2, 18) = 23.640;p < 0.001. The post-hoc pairwise t-test comparison showed a significant difference for the pairs CIS+AS—CIS only (p = 0.003) and AS only—CIS only (p = 0.011). Note that the behavioral speech understanding scores were also significantly different for the same pairs of comparisons.
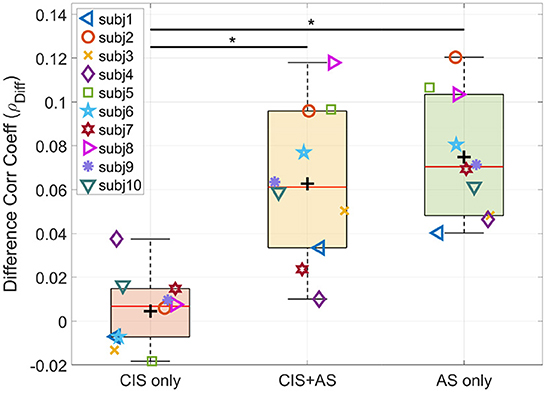
Figure 7. Difference between attended and unattended correlation coefficients (ρDiff) of selective attention decoding at the 208–304 ms lag interval. Asterisk indicates significance between pair of observations revealed by the t-test.
Pearson correlation between the behavioral speech score and the ρDiff revealed a significant correlation only between ρDiff and the speech score obtained with the CIS only listening mode (r = 0.712, p = 0.021) (Figure 8). A lack of significance in correlation between speech understanding performance and the selective attention correlation coefficients for AS only and CI+AS listening modes can be explained by the ceiling effect observed in the behavioral speech understanding performance.
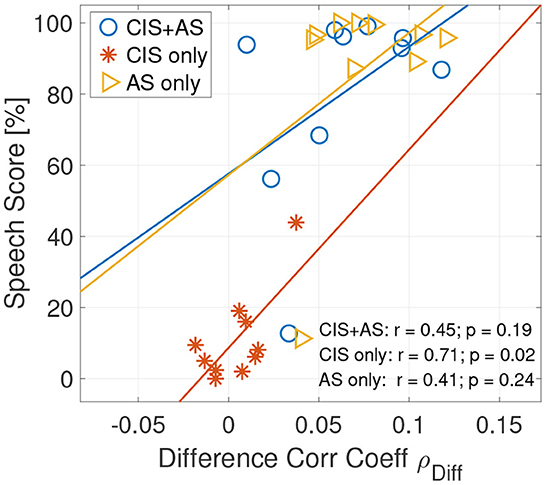
Figure 8. Correlation plot between the speech understanding scores and the attended correlation coefficients ρA (left) and between the speech understanding scores and the difference between the attended and the unattended correlation coefficients ρDiff (right) of selective attention decoding at the 208–304 ms lag interval.
The main goal of this work was to investigate a possible electrophysiological measure of speech integration between electric and acoustic stimulation in bimodal CI users. An electrophysiological paradigm based on CAEPs to short stimuli showed the feasibility to record cortical responses with CIS only, AS only and CIS+AS listening modes. As an electrophysiological measure of speech integration, decoding of selective attention was proposed and validated in bimodal CI users. The results of the study confirmed that it is possible to decode selective attention in CI users despite the presence of CI electrical artifact in the EEG. Moreover, this work investigated how selective attention decoding is related to behavioral speech understanding performance. No bimodal benefit in speech understanding with respect to listening with the better ear was found, mainly due to the ceiling effects observed when listening with the CIS+AS and the AS only listening modes.
Based on previous studies (e.g., Ching et al., 2004; Kong et al., 2005; Dorman et al., 2008; Potts et al., 2009; Vermeire and Van de Heyning, 2009; Yoon et al., 2015; Devocht et al., 2017), this work assumed a benefit in speech understanding for bimodal CI users when listening with CIS+AS listening mode in comparison to listening with the CIS only or with the AS only mode. Nevertheless, the interpretation of the reported results in the literature about the benefit of electric acoustic stimulation in bimodal CI users depends on the reference listening mode used to report the bimodal benefit and the inclusion criteria of the subjects participating in these studies. For instance, in agreement with the results of the current study, some previous studies have shown a benefit of bimodal listening compared to CIS only listening mode, but not compared to AS only listening mode (Mok et al., 2006; Devocht et al., 2017). In contrast, the study of Potts et al. (2009) observed a bimodal benefit compared to CIS only and to AS only, however, the authors of the study recruited candidates for bilateral CI implantation, i.e. with poor residual hearing.
Nevertheless, because of a ceiling effect observed in the speech scores with the CIS+AS and AS only listening modes, it was not possible to demonstrate a possible bimodal benefit compared to the best performing ear for some of the study participants. Despite this, two subjects obtained lower speech scores with the CIS+AS than with the AS only listening mode. Demographical data for these two subjects (Table 1) was analyzed and revealed long duration of deafness for subject 3, which can explain the reduction in speech understanding when listening with both sides compared to the better ear (Cohen and Svirsky, 2019). Moreover, a significant negative correlation between duration of deafness and speech scores with the CIS+AS listening mode was observed across all subjects (r = −0.846, p = 0.004). Subject 7 presented shorter duration deafness but reported not using the CI frequently in daily life, which probably explains the reduction in performance observed with the CIS+AS listening mode for this subject. To confirm the benefit of using the CI in daily life, subjects were additionally asked to answer questions regarding their listening experience in different acoustic situations. Results of the questionnaire are presented in the Supplementary material. Interestingly, all participants reported a benefit of using the CI in daily life. A number of previous studies showed benefit of bimodal hearing for CI users through improved quality of life (Galvin et al., 2019), drop in self-reported listening effort (Devocht et al., 2017) or even tinnitus suppression (Van de Heyning et al., 2008). Therefore, bimodal hearing provides benefits to CI users but these could not be measured through the speech understanding task proposed in this study.
Another possible explanation for the interference effect observed in two bimodal subjects when listening with CIS+AS is the reduced integration between electric and acoustic stimulation in our group of subjects. According to Yoon et al. (2015), bimodal benefit is greater in subjects that obtain similar performance with the CIS alone and the AS alone. Subjects recruited in the current study had normal or close to normal hearing with the AS only and relatively poor performance with the CIS only, due to the long duration of deafness prior to implantation. Therefore, this might have led to reduced integration between electric and acoustic stimulation. Moreover, Reiss et al. (2014) and Fowler et al. (2016) suggested that bimodal CI users can better integrate mismatched rather than matched spectral information across listening sides. The participants of the current study had a good residual hearing causing broad frequency range overlap across ears. As a result, this abnormal broad spectral integration may have lead to speech perception interference when listening with the CIS+AS compared to AS alone.
On the other hand, the interpretation of the results about bimodal benefit reported in the literature depends on the utilized materials and tests. The present work investigated the benefit of electric acoustic stimulation on speech understanding with a co-located target and interferer presented at the same level. The same speech material was presented in both ears, which does not allow to measure some binaural effects such as spatial release from masking or binaural squelch. Moreover, the interferer consisted of a speech signal which reduces speech understanding in CI users compared to the utilization of non-intelligible maskers, such as stationary or babble noise (Dieudonné and Francart, 2020). Studies using a similar paradigm as the one used in the current study observed no speech understanding improvement in bimodal CI users compared to the better ear performance (Vermeire and Van de Heyning, 2009; Galvin et al., 2019; Dieudonné and Francart, 2020). In the current study, we decided to use the same material for the behavioral and for the selective attention decoding paradigm such that the results of both experiments could be compared to each other. The selective attention paradigm, which has been extensively validated in our previous works in CI users, is based on a target and an interferer speech streams presented at the same level to reduce the effect of the CI artifact.
It was possible to measure CAEPs and to distinguish the N1P2 complex with all three listening modes for 9 out of 10 participants. Subject 1 was excluded from the analysis due to the low quality of the EEG signal caused by high impedances of the EEG electrodes. The peak-to-peak N1P2 latencies and amplitudes were in the range of 85–130 ms and 3–7 μV, respectively. These results are in agreement with the results reported in NH listeners (Martin et al., 2007; Stapells, 2009; Papesh et al., 2015) and CI users (Pelizzone et al., 1987; Ponton et al., 1996; Maurer et al., 2002; Sharma et al., 2002).
The highest N1P2 amplitude of 6.7 μV was obtained for the AS only condition. No significant difference between the N1P2 measured with the CIS+AS and the CIS only listening modes was observed. Previous studies have shown greater N1P2 responses with bilateral stimulation compared to monaural stimulation in NH listeners. The mentioned study claimed that the greater response evoked by the bilateral stimulus compared to the monaural stimulus can be explained by binaural integration or fusion of stimuli across both ears (Butler et al., 1969). In the current study higher N1P2 amplitudes for the CIS+AS listening mode compared to the CIS only or AS only listening modes were expected due to possible synergetic integration of electric and acoustic stimulation (Ching et al., 2001; Kong et al., 2005; Kong and Carlyon, 2007). However, the responses for the CIS+AS and the CIS only listening modes were not significantly different.
One possible explanation for the reduced bimodal response is the time processing difference or the lack of synchronization between the two listening sides. The time delay for the CIS is caused by the CI sound processor and the implant. The delay for an acoustic stimulus to reach the auditory nerve comprises ear canal, middle ear and the basilar membrane traveling wave delays. In this work, the processing delay for the CIS was measured through an oscilloscope and the delay for the AS was estimated from the literature. While the delay for the CIS is device dependent and has negligible variability across CI users with Oticon Medical CI, the time delay on the AS is less obvious, it depends on the individual anatomy and physiology of the ear, and it is frequency dependent due to the tonotopic organization of the cochlea. If to compare the estimated traveling wave delays provided by different authors utilizing different measurement techniques, a high variability across studies can be observed (Elberling et al., 2007). In this work, the delay between the two listening sides was not individually compensated, which may have caused reduced electric acoustic integration and consequently reduced bimodal CAEP responses. One possible solution for an individual delay compensation in bimodal CI users, is to correct the delay based on the wave V of the auditory brainstem response (ABR) as proposed by Zirn et al. (2015). However, the implementation of this procedure in the current work would have dramatically increased the time required to conduct the experiment. Nevertheless, the individual temporal synchronization between the two listening sides using ABRs has to be considered for future work.
The topographical analysis of the decoder weight distribution for the forward model approach revealed weaker activation when listening with the CIS only than with the CIS+AS or the AS only listening modes. This weaker activation may be related to the difficulties experienced by the bimodal CI users to concentrate on the desired speech stream using the CIS only listening mode. The TRF morphology across lags for all three listening modes is consistent with previous reported results in NH listeners (Crosse et al., 2016) and CI users (Paul et al., 2020). For TRFs the highest N1P2 peak-to-peak amplitude was obtained when listening with the AS only, followed by the CIS+AS and the CIS only listening modes. The amplitude reduction of the TRF curve for CIS+AS listening mode may be explained by reduced integration between electric and acoustic stimulation or interference caused by the CI when listening with CIS+AS. Such an interference effect was observed at least in two subjects in the speech understanding performance test. Unfortunately, it was not possible to establish a relation between TRF amplitude and behavioral speech understanding performance in the current study due to ceiling effects observed in the speech understanding test with the AS only and CIS+AS listening modes. Moreover, a delay between TRF peaks for the AS only and the CIS only listening modes was observed. Therefore, the reduction of the TRF amplitude for the CIS+AS listening mode compared to the AS only listening mode can be also explained by the lack of the temporal synchronization between electric and acoustic stimulation.
As the TRF curve resembles the N1P2 complex of CAEPs, the individual N1P2 amplitudes from TRFs were compared to the N1P2 amplitudes of the CAEP responses.A significant correlation between both measures was observed for CIS only and AS only listening modes. For the CIS+AS listening mode no significant correlation was observed, possibly because a delay compensation between both sides was applied in the CAEP measurements but not in the selective attention paradigm. In the future, the impact of interaural delay on selective attention decoding should be further investigated.
The correlation coefficients of backward selective attention decoding with the CIS+AS and the CIS only listening modes obtained high values for the first lags, probably because of the contribution of residual CI artifact. As the target and interference were presented at 0 dB SIR, the contribution of the CI artifact is almost equal for both the attended and the unattended speech envelopes. Therefore, in absence of neural activity, the correlation coefficients to the attended and unattended envelopes should be almost identical, as demonstrated by an artifact model in our previous study (Nogueira et al., 2019a). In the current study, only a small difference between the attended and unattended correlation coefficients in the CIS only condition was observed. This is not surprising, taking into account the poor behavioral speech understanding performance obtained by the study participants when listening with the CIS only mode. Meanwhile, when listening with the CIS+AS mode, a significant difference between the attended and unattended correlation coefficients was observed. This result confirms the possibility to decode selective attention in CI users despite the presence of residual CI electrical artifact leaking into the EEG. Two peaks were observed at 100 and 220 ms. Coming back to the CI artifact model mentioned before, high correlation coefficients at early lags up to 80 ms followed by a decay ending at around 150 ms have been observed in our previous study (Nogueira et al., 2019a). Therefore, the first peak might be contaminated by the CI artifact, but the second peak might be less contaminated by the artifact. For this reason, this second peak could potentially be a valid parameter to compare selective attention decoding between different listening modes. The time occurrence of the second peak also corresponds to the late locus of attention reported by Power et al. (2012). Therefore, the lag interval of 208–304 ms was chosen for further analysis. Moreover, we focus our analysis on the difference between the attended and the unattended correlation coefficients, which further reduces the effect of the CI artifact as shown in previous studies (Paul et al., 2020; Nogueira and Dolhopiatenko, 2022). Besides that, the analysis of the difference between attended and unattended correlation coefficients might reduce the impact of some individual factors, such as artifact, skin thickness or electrode impedance. The comparison of the difference correlation coefficient revealed higher values for the CIS+AS and AS only listening modes compared to the CIS only listening mode, which is consistent with the speech understanding behavioral results. The correlation between selective attention decoding coefficients and behavioral data was significant only for the CIS only listening mode. A lack of significance for the CIS+AS and AS only modes can be explained by the ceiling effect in the speech understanding scores observed in these conditions. For this reason, the results of the current study cannot conclude whether selective attention decoding can be used as an electric acoustic speech integration measure. An extension of the dataset including bimodal CI users with less residual hearing or the use of different speech understanding performance tests to avoid ceiling or floor effects need to be considered for future work.
This work demonstrates that it is possible to decode selective attention in bimodal CI users. This result provides more evidence on the use of continuous EEG recordings to speech stimuli in CI users despite the presence of continuous electric artifact. The analysis of CAEPs and TRFs from selective attention decoding demonstrated an amplitude reduction when listening with CIS+AS relative to listening with AS only. The outcomes of this study may pave the way toward novel speech integration measures for bimodal CI users using EEG to continuous stimuli. However, further validation of these measurements are required.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by Ethics Committee of the Hannover Medical School. The patients/participants provided their written informed consent to participate in this study.
HD implemented the algorithm and conducted the data collection and analysis. HD and WN contributed to the experimental setup and wrote the manuscript. WN conceived the study and contributed to data analysis and interpretation. All authors contributed to the article and approved the submitted version.
This work is a part of the project BiMoFuse: Binaural Fusion between Electric and Acoustic Stimulation in Bimodal CI Subjects (ID: 20-1588, PI: WN) funded by William Demant Foundation. This work was also supported by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) cluster of excellence EXC 2177/1. Part of these results is part of the project that received funding from the European Research Council (ERC) under the European Union's Horizon-ERC programme (Grant agreement READIHEAR No. 101044753. PI: WN).
The authors would like to thank Manuel Segovia-Martinez, Aswin Wijetillake, and colleagues from Oticon Medical for their contribution in this work. The authors would also like to thank all subjects who participated in the study.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnins.2022.1057605/full#supplementary-material
Aldag, N., Büchner,1, A., Lenarz, T., and Nogueira, W. (2022). Towards decoding selective attention through cochlear implant electrodes as sensors in subjects with contralateral acoustic hearing. J. Neural Eng. 19, 2772–2785. doi: 10.1088/1741-2552/ac4de6
Arndt, S., Aschendorff, A., Laszig, R., Beck, R., Schild, C., Kroeger, S., et al. (2011). Comparison of pseudobinaural hearing to real binaural hearing rehabilitation after cochlear implantation in patients with unilateral deafness and tinnitus. Otol. Neurotol. 32, 39–47. doi: 10.1097/MAO.0b013e3181fcf271
Balkenhol, T., Wallhäusser-Franke, E., Rotter, N., and Servais, J. (2020). Cochlear implant and hearing aid: objective measures of binaural benefit. Front. Neurosci. 14, 586119. doi: 10.3389/fnins.2020.586119
Butler, R. A., Keidel, W. D., and Spreng, M. (1969). An investigation of the human cortical evoked potential under conditions of monaural and binaural stimulation. Acta Otolaryngol. 68, 317–326. doi: 10.3109/00016486909121570
Ching, T., Incerti, P., and Hill, M. (2004). Binaural benefits for adults who use hearing aids and cochlear implants in opposite ears. Ear. Hear. 25, 9–21. doi: 10.1097/01.AUD.0000111261.84611.C8
Ching, T., van Wanrooy, E., and Dillon, H. (2007). Binauralbimodal fitting or bilateral implantation for managing severe to profound deafness: a review. Trends Amplif. 11, 161–192. doi: 10.1177/1084713807304357
Ching, T. Y. C., Psarros, C., Hill, M., Dillon, H., and Incerti, P. (2001). Should children who use cochlear implants wear hearing aids in the opposite ear? Ear. Hear. 22, 365–380. doi: 10.1097/00003446-200110000-00002
Cohen, S., and Svirsky, M. (2019). Duration of unilateral auditory deprivation is associated with reduced speech perception after cochlear implantation: a single-sided deafness study. Cochlear Implants Int. 20, 51–56. doi: 10.1080/14670100.2018.1550469
Crew, J., Galvin, J. r., Landsberger, D., and Fu, Q. (2015). Contributions of electric and acoustic hearing to bimodal speech and music perception. PLoS ONE 10, 0120279. doi: 10.1371/journal.pone.0120279
Crosse, M. J., Di Liberto, G. M., Bednar, A., and Lalor, E. C. (2016). The multivariate temporal response function (mtrf) toolbox: a matlab toolbox for relating neural signals to continuous stimuli. Front. Hum. Neurosci. 10, 604. doi: 10.3389/fnhum.2016.00604
Delorme, A., and Makeig, S. (2004). Eeglab: an open-source toolbox for analysis of single-trial eeg dynamics. J. Neurosci. Methods 134, 9–21. doi: 10.1016/j.jneumeth.2003.10.009
Deprez, H., Gransier, R., Hofmann, M., Wieringen, A., Wouters, J., and Moonen, M. (2017). Characterization of cochlear implant artifacts in electrically evoked auditory steady-state responses. Biomed. Signal Process. Control 31, 127–138. doi: 10.1016/j.bspc.2016.07.013
Devocht, E., Janssen, A., Chalupper, J., Stokroos, R., and George, E. (2017). The benefits of bimodal aiding on extended dimensions of speech perception: intelligibility, listening effort, and sound quality. Trends Hear. 21, 1–20. doi: 10.1177/2331216517727900
Dieudonn,é, B., and Francart, T. (2020). Speech understanding with bimodal stimulation is determined by monaural signal to noise ratios: No binaural cue processing involved. Ear. Hear. 41, 1158–1171. doi: 10.1097/AUD.0000000000000834
Dimitrijevic, A., Smith, M., Kadis, D., et al. (2019). Neural indices of listening effort in noisy environments. Sci. Rep. 9, 11278. doi: 10.1038/s41598-019-47643-1
Ding, N., and Simon, J. Z. (2012). Emergence of neural encoding of auditory objects while listening to competing speakers. Proc. Natl. Acad. Sci. U.S.A. 109, 11854–11859. doi: 10.1073/pnas.1205381109
Dorman, M., Gifford, R., Spahr, A., and McKarns, S. (2008). The benefits of combining acoustic and electric stimulation for the recognition of speech, voice and melodies. Audiol. Neurootol. 13, 105–112. doi: 10.1159/000111782
Elberling, C., Don, M., Cebulla, M., and Stürzebecher, E. (2007). Auditory steady-state responses to chirp stimuli based on cochlear traveling wave delay. J. Acoust. Soc. Am. 122, 2772–2785. doi: 10.1121/1.2783985
Etard, O., and Reichenbach, T. (2019). Neural speech tracking in the theta and in the delta frequency band differentially encode clarity and comprehension of speech in noise. J. Neurosci. 39, 1828–1818. doi: 10.1523/JNEUROSCI.1828-18.2019
Firszt, J., Chambers, R., Kraus, N., and Reeder, R. (2002). Neurophysiology of cochlear implant users i: effects of stimulus current level and electrode site on the electrical abr, mlr, and n1-p2 response. Ear. Hear. 23, 502–515. doi: 10.1097/00003446-200212000-00002
Firszt, J., Holden, L., Reeder, R., Cowdrey, L., and King, S. (2012). Cochlear implantation in adults with asymmetric hearing loss. Ear. Hear. 32, 521–533. doi: 10.1097/AUD.0b013e31824b9dfc
Fowler, J. R., Eggleston, J. L., Reavis, K. M., McMillan, G. P., and Reiss, L. A. (2016). Effects of removing low-frequency electric information on speech perception with bimodal hearing. J. Speech Lang. Hear. Res. 59, 99–109. doi: 10.1044/2015_JSLHR-H-15-0247
Fu, Q., Galvin, J., and Wang, X. (2017). Integration of acoustic and electric hearing is better in the same ear than across ears. Sci. Rep. 7, 2500. doi: 10.1038/s41598-017-12298-3
Galvin, J. J., Fu, Q.-J., Wilkinson, E., Mills, D., Hagan, S., Lupo, J. E., et al. (2019). Benefits of cochlear implantation for single-sided deafness: data from the house clinic-university of southern california-university of california,. Ear. Hear. 40, 766–781. doi: 10.1097/AUD.0000000000000671
Giraud, A.-L., and Poeppel, D. (2012). Cortical oscillations and speech processing: emerging computational principles and operations. Nat. Neurosci. 15, 511–517. doi: 10.1038/nn.3063
Haufe, S., Meinecke, F., Görgen, K., Dähne, S., Haynes, J.-D., Blankertz, B., et al. (2014). On the interpretation of weight vectors of linear models in multivariate neuroimaging. Neuroimage 87, 96–110. doi: 10.1016/j.neuroimage.2013.10.067
Henkin, Y., Yaar-Soffer, Y., Givon, L., and Hildesheimer, M. (2015). Hearing with two ears: evidence for cortical binaural interaction during auditory processing. J. Am. Acad Audiol. 26, 384–392. doi: 10.3766/jaaa.26.4.6
Hochmair-Desoyer, I., Schulz, E., Moser, L., and Schmidt, M. (1997). The hsm sentence test as a tool for evaluating the speech understanding in noise of cochlear implant users. Am. J. Otol. 18, 83.
Hofmann, M., and Wouters, J. (2010). Electrically evoked auditory steady state responses in cochlear implant users. J. Assoc. Res. Otolaryngol. 11, 267–282. doi: 10.1007/s10162-009-0201-z
Jancke, L., Wiistenberg, T., Schulze, K., and Heinze, H. (2002). Asymmetric hemodynamic responses of the human auditory cortex to monaural and binaural stimulation. Hear. Res. 170, 166–178. doi: 10.1016/S0378-5955(02)00488-4
Kaur, C., and Singh, P. (2015). “EEG artifact suppression based on SOBI based ICA using wavelet thresholding,” in IEEE 2015 2nd International Conference on Recent Advances in Engineering Computational Sciences (Chandigarh: IEEE), 1–4. doi: 10.1109/RAECS.2015.7453319
Keitel, A., Gross, J., and Kayser, C. (2018). Perceptually relevant speech tracking inauditory and motor cortex reflects distinct linguistic features. PLos Biol. 16, e2004473. doi: 10.1371/journal.pbio.2004473
Kong, Y., and Braida, L. (2011). Cross-frequency integration for consonant and vowel identification in bimodal hearing. J. Rehabil. Res. Dev. 54, 959–980. doi: 10.1044/1092-4388(2010/10-0197)
Kong, Y., and Carlyon, R. (2007). Improved speech recognition in noise in simulated binaurally combined acoustic and electric stimulation. J. Acoust. Soc. Am. 121, 3717–3727. doi: 10.1121/1.2717408
Kong, Y., Stickney, G., and Zeng, F.-G. (2005). Speech and melody recognition in binaurally combined acoustic and electric hearing. J. Acoust. Soc. Am. 3, 1351–1361. doi: 10.1121/1.1857526
Krüger, B., Büchner, A., and Nogueira, W. (2022). Phantom stimulation for cochlear implant users with residual low-frequency hearing. Ear. Hear. 43, 631–645. doi: 10.1097/AUD.0000000000001121
Lalor, E. C., Power, A. J., Reilly, R. B., and Foxe, J. J. (2009). Resolving precise temporal processing properties of the auditory system using continuous stimuli. Neurophysiol 102, 349–359. doi: 10.1152/jn.90896.2008
Lesenfants, D., Vanthornhout, J., Verschueren, E., Decruy, L., and Francart, T. (2019). Predicting individual speech intelligibility from the neural tracking of acoustic- and phonetic-level speech representations. Hear. Res. 380, 1–9. doi: 10.1016/j.heares.2019.05.006
Litovsky, R., Johnstone, P., and Godar, S. (2006). Benefits of bilateral cochlear implants and/or hearing aids in children. Int. J. Audiol. 45, 78–91. doi: 10.1080/14992020600782956
Martin, B., Tremblay, K., and Stapells, S. (2007). “Principles and applications of cortical auditory evoked potentials,” in Auditory Evoked Potentials. Basic Principles and Clinical Application (Philadelphia, PA: Lippincott Williams and Wilkins), 482–507.
Maurer, J., Collet, L., Pelster, H., Truy, E., and Gallégo, S. (2002). Auditory late cortical response and speech recognition in digisonic cochlear implant users. Laryngoscope 112, 2220–2224. doi: 10.1097/00005537-200212000-00017
McPherson, D., and Starr, A. (1993). Binaural interaction in auditory evoked potentials: brainstem, middle- and long-latency components. Hear. Res. 66, 91–98. doi: 10.1016/0378-5955(93)90263-Z
Mesgarani, N., David, S. V., Fritz, J. B., and Shamma, S. A. (2009). Influence of context and behavior on stimulus reconstruction from neural activity in primary auditory cortex. Neurophysiol 102, 3329–3339. doi: 10.1152/jn.91128.2008
Mirkovic, B., Debener, S., Jaeger, M., and De Vos, M. (2015). Decoding the attended speech stream with multi-channel EEG: implications for online, daily-life applications. J. Neural Eng. 12, 046007. doi: 10.1088/1741-2560/12/4/046007
Mok, M., Grayden, D., Dowell, R., and Lawrence, D. (2006). Speech perception for adults who use hearing aids in conjunction with cochlear implants in opposite ears. J. Rehabil. Res. Dev. 49, 338–351. doi: 10.1044/1092-4388(2006/027)
Nogueira, W., Cosatti, G., Schierholz, I., Egger, M., Mirkovic, B., and Buchner, A. (2019a). Towards decoding selective attention from single-trial eeg data in cochlear implant users. IEEE Trans. Biomed. Eng. 67, 38–49. doi: 10.1109/ICASSP40776.2020.9054021
Nogueira, W., and Dolhopiatenko, H. (2022). Predicting speech intelligibility from a selective attention decoding paradigm in cochlear implant users. J. Neural Eng. 19, 5991. doi: 10.1088/1741-2552/ac599f
Nogueira, W., Dolhopiatenko, H., Schierholz, I., Büchner, A., Mirkovic, B., Bleichner, M. G., et al. (2019b). Decoding selective attention in normal hearing listeners and bilateral cochlear implant users with concealed ear eeg. Front. Neurosci. 13, 720. doi: 10.3389/fnins.2019.00720
OSullivan, J. A., Power, A. J., Mesgarani, N., Rajaram, S., Foxe, J. J., Shinn-Cunningham, B. G., et al. (2015). Attentional selection in a cocktail party environment can be decoded from single-trial eeg. Cereb. Cortex 25, 1697–1706. doi: 10.1093/cercor/bht355
Papesh, M., Billings, C., and Baltzell, L. (2015). Background noise can enhance cortical auditory evoked potentials under certain conditions. Clin. Neurophysiol. 126, 31319–31330. doi: 10.1016/j.clinph.2014.10.017
Pasley, B. N., David, S. V., Mesgarani, N., Flinker, A., Shamma, S. A., Crone, N. E., et al. (2012). Reconstructing speech from human auditory cortex. PLoS Bio.l 10, e1001251. doi: 10.1371/journal.pbio.1001251
Paul, B., Uzelac, M., and Chan, E. (2020). Poor early cortical differentiation of speech predicts perceptual difficulties of severely hearing impaired listeners in multitalker environments. Sci. Rep. 10, 6141. doi: 10.1038/s41598-020-63103-7
Pelizzone, M., Hari, R., Mäkel,ä, J., Kaukoranta, E., and Montandon, P. (1987). Cortical activity evoked by a multichannel cochlear prosthesis. Acta Otolaryngol. 103, 632–636.
Petersen, E. B., Wöstmann, M., Obleser, J., and Lunner, T. (2017). Neural tracking of attended versus ignored speech is differentially affected by hearing loss. J. Neurophysiol. 117, 18–27. doi: 10.1152/jn.00527.2016
Ponton, C., Don, M., Eggermont, J., Waring, M., and Masuda, A. (1996). Maturation of human cortical auditory function: differences between normal-hearing children and children with cochlear implants. Ear. Hear. 17, 430–437. doi: 10.1097/00003446-199610000-00009
Potts, L., Skinner, M., Litovsky, R., Strube, M., and Kuk, F. (2009). Recognition and localization of speech by adult cochlear implant recipients wearing a digital hearing aid in the nonimplanted ear (bimodal hearing). J. Am. Acad. Audiol. 20, 353–373. doi: 10.3766/jaaa.20.6.4
Power, A. J., Foxe, J. J., Forde, E.-J., Reilly, R. B., and Lalor, E. C. (2012). At what time is the cocktail party? a late locus of selective attention to natural speech. Eur. J. Neurosci. 35, 1497–1503. doi: 10.1111/j.1460-9568.2012.08060.x
Prejban, D., Hamzavi, J., Arnoldner, C., Liepins, R., Honeder, C., Kaider, A., et al. (2018). Single sided deaf cochlear implant users in the difficult listening situation: speech perception and subjective benefit. Otol. Neurotol. 39, e803-e809. doi: 10.1097/MAO.0000000000001963
Reiss, L., Ito, R., Eggleston, J., and Wozny, D. (2014). Abnormal binaural spectral integration in cochlear implant users. J. Assoc. Res. Otolaryngol. 15, 235–248. doi: 10.1007/s10162-013-0434-8
Reiss, L., Perreau, A., and CW, T. (2012a). Effects of lower frequency-to-electrode allocations on speech and pitch perception with the hybrid short-electrode cochlear implant. Audiol. Neurotol. 17, 357–372. doi: 10.1159/000341165
Reiss, L., Turner, C., Karsten, S., Ito, R., Perreau, A., McMenomey, S., et al. (2012b). Electrode Pitch Patterns in Hybrid and Long-Electrode Cochlear Implant Users: Changes Over Time and Long-Term Data. San Diego, CA: Midwinter Research Meeting of the Association for Research in Otolaryngology.
Sasaki, T., Yamamoto, K., Iwaki, T., and Kubo, T. (2009). Assessing binaural/bimodal advantages using auditory event-related potentials in subjects with cochlear implants. Auris Nasus Larynx 36, 541–546. doi: 10.1016/j.anl.2008.12.001
Sharma, A., Dorman, M., and Spahr, A. (2002). A sensitive period for the development of the central auditory system in children with cochlear implants: implications for age of implantation. Ear. Hear. 23, 532–539. doi: 10.1097/00003446-200212000-00004
Somers, B., Francart, T., and Bertrand, A. (2010). A generic EEG artifact removal algorithm based on the multi-channel wiener filter. J. Neural Eng. 15, 36007. doi: 10.1088/1741-2552/aaac92
Stapells, D. R. (2009). “Cortical event-related potentials to auditory stimuli,” in Handbook of Clinical Audiology Edition (Baltimore, MD: Lippingcott; Williams Wilkins).
Van de Heyning, P., Vermeire, K., Diebl, M., Nopp, P., Anderson, I., and De Ridder, D. (2008). Incapacitating unilateral tinnitus in single-sided deafness treated by cochlear implantation. An. Otorhinolaryngol. 117, 645–652. doi: 10.1177/000348940811700903
Vanthornhout, J., Decruy, L., Wouters, J., Simon, J. Z., and Francart, T. (2018). Speech intelligibility predicted from neural entrainment of the speech envelope. J. Assoc. Res. Otolaryngol. 19, 181–191. doi: 10.1007/s10162-018-0654-z
Vermeire, K., and Van de Heyning, P. (2009). Binaural hearing after cochlear implantation in subjects with unilateral sensorineural deafness and tinnitus. Audiol. Neurootol. 14, 163–171. doi: 10.1159/000171478
Wedekind, A., Rajan, G., Van Dun, B., and Távora-Vieira, D. (2020). Restoration of cortical symmetry and binaural function: cortical auditory evoked responses in adult cochlear implant users with single sided deafness. PLoS ONE 15, e0227371. doi: 10.1371/journal.pone.0227371
Wedekind, A., Távora-Vieira, D., Nguyen, A. T., Marinovic, W., and Rajan, G. P. (2021). Cochlear implants in single-sided deaf recipients: near normal higher-order processing. Clin. Neurophysiol. 132, 449–456. doi: 10.1016/j.clinph.2020.11.038
Yang, H., and Zeng, F. (2013). Reduced acoustic and electric integration in concurrent-vowel recognition. Sci. Rep. 3, 1419. doi: 10.1038/srep01419
Yoon, Y., Shin, Y., Gho, J., and Fu, Q. (2015). Bimodal benefit depends on the performance difference between a cochlear implant and a hearing aid. Cochlear Implants Int. 16, 159–167. doi: 10.1179/1754762814Y.0000000101
Keywords: cochlear implant, selective attention, electric acoustic stimulation, electrophysiological measures, central integration, bimodal hearing, bimodal stimulation, electroencephalography
Citation: Dolhopiatenko H and Nogueira W (2023) Selective attention decoding in bimodal cochlear implant users. Front. Neurosci. 16:1057605. doi: 10.3389/fnins.2022.1057605
Received: 29 September 2022; Accepted: 20 December 2022;
Published: 11 January 2023.
Edited by:
Lina Reiss, Oregon Health and Science University, United StatesReviewed by:
Inyong Choi, The University of Iowa, United StatesCopyright © 2023 Dolhopiatenko and Nogueira. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Waldo Nogueira,  bm9ndWVpcmF2YXpxdWV6LndhbGRvQG1oLWhhbm5vdmVyLmRl
bm9ndWVpcmF2YXpxdWV6LndhbGRvQG1oLWhhbm5vdmVyLmRl
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.