 Chaeun Lee
Chaeun Lee Kyungmi Noh1
Kyungmi Noh1 Tayfun Gokmen
Tayfun Gokmen Seyoung Kim
Seyoung Kim- 1Department of Materials Science and Engineering, Pohang University of Science and Technology, Pohang-si, South Korea
- 2IBM Research AI, Yorktown Heights, NY, United States
Recent progress in novel non-volatile memory-based synaptic device technologies and their feasibility for matrix-vector multiplication (MVM) has ignited active research on implementing analog neural network training accelerators with resistive crosspoint arrays. While significant performance boost as well as area- and power-efficiency is theoretically predicted, the realization of such analog accelerators is largely limited by non-ideal switching characteristics of crosspoint elements. One of the most performance-limiting non-idealities is the conductance update asymmetry which is known to distort the actual weight change values away from the calculation by error back-propagation and, therefore, significantly deteriorates the neural network training performance. To address this issue by an algorithmic remedy, Tiki-Taka algorithm was proposed and shown to be effective for neural network training with asymmetric devices. However, a systematic analysis to reveal the required asymmetry specification to guarantee the neural network performance has been unexplored. Here, we quantitatively analyze the impact of update asymmetry on the neural network training performance when trained with Tiki-Taka algorithm by exploring the space of asymmetry and hyper-parameters and measuring the classification accuracy. We discover that the update asymmetry level of the auxiliary array affects the way the optimizer takes the importance of previous gradients, whereas that of main array affects the frequency of accepting those gradients. We propose a novel calibration method to find the optimal operating point in terms of device and network parameters. By searching over the hyper-parameter space of Tiki-Taka algorithm using interpolation and Gaussian filtering, we find the optimal hyper-parameters efficiently and reveal the optimal range of asymmetry, namely the asymmetry specification. Finally, we show that the analysis and calibration method be applicable to spiking neural networks.
1. Introduction
Rapid advances in artificial neural network-based machine learning techniques enable significant performance boost in various artificial intelligence (AI) applications exemplified by image classification and natural language processing. As the larger and deeper neural networks trained with more data generally show higher performance in such cognitive tasks, there is an increasing demand for higher computing power and memory bandwidth to support the large number of operations and data processing required for neural network training and inference. Therefore, improving speed and energy-efficiency in AI computing hardware is one of the key challenges to realize more advanced AI applications and to extend the AI application space on low-power systems such as internet of things (IoT) and edge computing devices (Verhelst and Moons, 2017). To address the issue, various optimization techniques such as quantization (Guo, 2018) and compression (Han et al., 2015) are proposed to reduce the size and number of required computations. Along with such techniques for maximizing the efficiency of the existing hardware, there have been efforts to improve the digital hardware architecture (Chen et al., 2020) for energy-efficient AI computing (Zhou et al., 2019).
As an alternative to the existing digital approaches, analog crosspoint array-based neural network computation accelerators have been intensively studied due to the advances in resistive memory device technologies (Haensch et al., 2018; Tsai et al., 2018; Kim et al., 2019b) and their feasibility for various matrix-involved computations such as inversion, eigenvector solving, matrix pseudoinverse (Sun et al., 2019; Wang et al., 2020) and matrix-vector multiplication (MVM). Especially with MVM, by storing weight matrix in the crosspoint array of resistive memory devices and applying voltages corresponding to the input vector values, one can perform fully-parallel neural network computations in analog domain. As the time complexity of MVM with a resistive crosspoint array is approximately O(1) (Sun and Huang, 2021), such analog AI hardware is expected to have significant acceleration factor and higher energy efficiency, compared to those of digital counterparts (Agarwal et al., 2016; Gokmen and Vlasov, 2016). While the concept of the resistive crosspoint array-based neural network computation accelerator is promising, the actual implementation of such system has been difficult due to the non-ideal memory device characteristics. One of the major non-idealities which dramatically degrades the system performance is the conductance update asymmetry which indicates the nonidentical amount of up and down conductance changes at a given conductance level (Islam et al., 2019; Xiao et al., 2020). The update asymmetry causes an unexpected dynamic biasing during the training and prevents the weights from reaching the optimum values (Kim et al., 2019a). One obvious direction to resolve this issue is to build a memory device which features symmetric update property. However, the device with an ideal update symmetry is still under development (Lee et al., 2020). The other direction is to develop a special training algorithm which can train the neural network even with asymmetric devices. Tiki-Taka algorithm (Gokmen and Haensch, 2020) resolves the asymmetry issue by adopting an auxiliary array, which stores the information about the history of gradients, along with the main array to store weight values. It is shown that this algorithm minimizes the performance drop caused by update asymmetry and allows robust neural network training even when significant asymmetry presents. However, detailed quantitative study to reveal the relation between degree of update asymmetry and network performance has yet to be explored.
In this work, we dissect the impact of update asymmetry existing in main and auxiliary arrays on neural network performance when Tiki-Taka algorithm is used to train a neural network. We show that update asymmetry in the system is, indeed, a hyper-parameter of the neural network in the optimization point of view, affecting its convergence and performance. Our analysis shows that the auxiliary array is virtually a part of the optimizer to train a neural network; the degree of update asymmetry in the auxiliary array changes the configuration of the optimizer, similar to the case of momentum SGD where a decay factor determines the optimizer (Rumelhart et al., 1986). To further support this point, we compare the performance of different training algorithms on a convex problem and analyze the role of asymmetry in weight optimization process. On the other hand, if device characteristics such as update symmetry work as an hyper-parameter, it is important to fabricate devices with the hardware-side hyper-parameter in the range where the neural network performance is robust against other software-side hyper-parameters. We propose a method to identify the best asymmetry range by introducing a metric, robustness score, which provides a concrete rule for comparing the efficiency of training neural networks. By comparing robustness score among the different combinations of asymmetry levels in two arrays, it is possible to find the optimal asymmetry range for each array while maximizing the training efficiency and neural network performance. Optimized asymmetry range for each array can relieve the hardware constraints further hence hardware implementation of the algorithm can be accelerated. Finally, our approach can be applied to domains beyond deep neural networks (DNN), including spiking neural networks (SNN) which can be mapped into the resistive crosspoint arrays.
2. Preliminaries
2.1. Stochastic Gradient Descent With Resistive Crosspoint Array
Stochastic gradient descent (SGD) is a widely-used, first-order optimization method for training neural networks. During forward pass, a neural network infers output and estimates loss by comparing the output with expected values. Based on the loss, gradients of weights in a neural network are calculated during backward pass and later updated during the weight update phase by error back-propagation algorithm. The amount of weight update is proportional to the calculated gradient with the scaling factor called learning rate, η:
where wij indicates a weight from pre-synaptic neuron i to post-synaptic neuron j, L is the loss of a neural network, and ∇ij, kL indicates the derivative of L with respect to wij. xi is the input activation of pre-synaptic neuron i, and δj is the error of post-synaptic neuron j propagated from output neurons.
Analog computation with a resistive cross-point array resembles fixed point or quantized number system unlike the digital computation done with floating point number system. For the forward pass, the input activation, xi is converted to a corresponding discrete voltage, , through analog-to-digital converter (ADC). Then, xi is encoded into a pulse, , by pulse width modulation (PWM). As the pulse trains are applied to the rows, currents flowing through the devices are summed at each column line, and one can obtain the weighted sum, zj:
where operation “*" includes the integration of currents through the time domain and gij is conductance value of ith column and jth row device. Then, analog-valued zj is again quantized into by ADC, and propagates to the next layer as inputs. For the backward pass, the error of pre-synaptic neuron i, ei, is calculated in a similar fashion to the errors of post-synaptic neurons, :
In the update phase, is converted to a pulse train, , by stochastic pulse generator (SPG) for stochastic update of a resistive memory device. In compliance with the rules in Equation (1), the update of gij is determined by xi and δj.
where SPG function is defined by pulse bit length (BL) and parameters for pulse probability, satisfying η = ηxηδ. ηx and ηδ can be modulated, such that two SPGs will have similar pulse generating probability (Gokmen and Vlasov, 2016; Gokmen et al., 2017). Δgij(gij) is the amount of conductance change of gij as a function of gij, which is dependent on the update characteristics of the specific memory device. Here, we assume a linear model for Δgij(gij) which is described in section 2.2.
When mapping a neural network into resistive cross-point arrays for analog operations, we note that each weight can be expressed with a single or multiple memory cells depending on the architecture or weight mapping scheme (Xiao et al., 2020). As an example, a pair of memory cells, gij and gij, ref, can be read differentially to represent a single weight: wij = K(gij−gij, ref), where K is a factor that scales the weight into the conductance (Gokmen and Haensch, 2020).
2.2. Asymmetric Conductance Update in Resistive Memory Devices
Practical resistive memory devices feature various types of non-ideal characteristics such as asymmetric conductance response (or update asymmetry), short retention time, device-to-device variation and limited number of states. Among them, update asymmetry is known to hamper the convergence (Huang et al., 2020) of SGD-based neural network training and causes a significant performance drop. As shown in Equation (4), it is the Δgij(gij) term which distorts the actual update from the ideal update behavior defined in Equation (1). That is, gij will represent a weight value distorted form ideal software calculation after several cycles of weight update unless Δgij(gij) is unity. For most variants of resistive memory devices, as illustrated in Figure 1A, Δgij(gij) scales up or down the amounts of updates, which results in inconsistent updates of the conductance of devices (or weights). This type of behavior not only misguides the direction of updates, but also reduces the effective number of states in resistive memory devices.

Figure 1. (A) Normalized conductance of three resistive memory devices with different AF values as a function of pulse number when 4,000 positive pulses (+V) and 4,000 negative pulses (−V) are applied. The conductance change (Δg) with respect to the normalized conductance (g) is shown below. (see Supplementary Materials section 3.1 for the details of experimental environments.) (B) Comparison of conductance update process between SGD and Tiki-Taka algorithm. In case of SGD, an array, W, is updated with two parameters, x and δ in the update phase. In Tiki-Taka algorithm, there are two steps: (1) update and (2) occasional transfer. In the update phase, like SGD, the auxiliary array, WA, is updated. In the following transfer phase, its state is occasionally transferred and updates WC.
Figure 1A illustrates the conductance(g) and the conductance change behavior (Δg) which can be described by the following equations, Equation (5):
gmin, ij and gmax, ij is the minimum and maximum conductance state of resistive device and is the amount of Δgij when gij of the device is at g0, ij = (gmax, ij+gmin, ij)/2. sij, namely slope, is defined as for nonlinear device, which represents the reciprocal of approximate number of states of the device. For ideal device, i.e., perfectly symmetric and linear device, slope is defined zero. dij,k is number of pulse needed to achieve desired amount of wij,k (see Supplementary Materials section 1.1 for the details).
To embody the update asymmetry of a device, we introduce a parameter called asymmetry factor, AF(>0), which is associated with existing parameters: , where is a unit amount of Δg0, ij. Thus, Equation (6) can be rewritten into Equation (7):
Equation (7) shows that symmetry of device is solely defined with , if gmin, ij, gmax, ij and is fixed. Therefore, we can compare the asymmetry of device within the same range by modulating AF. In the case of ideal device, slope equals zero and Δg0, ij is constant regardless of AFij. However, to make the notation consistent, we denote this case as AFij = 0. For instance, there are three different cases in Figure 1A, namely, AFij = 0;AFij = 2.0;andAFij = 6.0. All three cases have the same gmin, ij, gmax, ij and . We note that many devices show non-zero AF behavior (Brivio et al., 2018; van De Burgt et al., 2018; Islam et al., 2019; Kim et al., 2019b).
2.3. Tiki-Taka Algorithm
Tiki-Taka algorithm (Gokmen and Haensch, 2020) is proposed to resolve the performance degradation issue in neural network training caused by the update asymmetry in the crosspoint elements. We showed that the asymmetric update prevents devices from being accurately updated by the amount of calculated gradients. Figure 1B illustrates the key difference between SGD and Tiki-Taka algorithm in the weight update phase. In the case of SGD, an array, W, stores the weight vectors of a neural network. In the update phase, a weight, wij, is updated with the gradient ∇ijL(= xiδj). On the other hand, Tiki-Taka algorithm requires one additional array, namely A, and it stores ΔW by accumulating gradient vectors, ∇L. The weight vectors stored in the array A are denoted as WA and the array, C, stores the weight vectors denoted as WC. When compared to SGD, Tiki-Taka algorithm accumulates the gradient, ∇ijL, in . Then, the accumulated gradient is transferred to update the weight, at every ns steps. Tiki-Taka algorithm supports sparse update by adopting cell-selection vector, uπ, where uπ(i) is the ith element of a sparse vector, u, such as a one-hot vector and π is a permutation, π:{1, ⋯ , n} → {1, ⋯ , n}. Finally, Tiki-Taka algorithm allows the array A to participate in the forward pass by introducing a parameter, γ∈[0, 1]: . Therefore, the effective weight wij depends on γ: if γ = 1, replace the effective weight vector. Otherwise, if γ = 0, then the effective weight is . In summary, Tiki-Taka algorithm can be formulated as follows:
where indicates the derivative of the L with respect to . η and λ indicates SGD learning rate and transfer learning rate, respectively.
3. Tiki-Taka Algorithm and Update Asymmetry
3.1. Mismatch Factor and Weight Update Formulation
Here, we formulate the impact of asymmetry by adopting even-odd function decomposition, with which any function can be represented (Gokmen and Haensch, 2020), and integrate the model into the SGD update rule in Equation (1) (see Supplementary Materials section 1.2 for the details):
where the function Sym represents symmetry of the devices and the function Asym corresponds to asymmetry. The weight, wij, is scaled with a factor K from the conductance, gij: wij = K·(gij−gref, ij) and . wmax, ij is a correspond weight to the maximum amount of conductance, gmax, ij. To analyze it in the aspect of optimization, Equation (10) is reformulated as follows:
Definition 3.1 (Mismatch factor (MF)). Mismatch factor (MF) is an additional factor appeared in the original SGD weight update rule, originated from the update asymmetry of the weight storage device:
MF is multiplied to the gradient of a weight, ∇ijL, and affects the weight optimization process. As observed in the Definition 3.1, MFij scales with AF, and is dependent on the sign of gradient and the current weight state, wij, of a device. The dependence on the sign of gradient can create fluctuation of MFij if sgn(∇ijL) changes the sign, and AFij magnifies the fluctuation of MFij. Therefore, there can be abrupt change in MFij affecting the neural network training.
3.2. Impact of Asymmetry: Case Studies
Figure 2 displays the classification error in MNIST handwritten digit recognition problem as a function of training epoch for various scenarios of training algorithm and AF values. We perform the experimental simulation using the open-source toolkit aihwkit (Rasch et al., 2021) and further details about the experimental environment can be found in Supplementary Materials section 3.3. First, performing SGD with asymmetric devices results in severe accuracy drop both for the train and test datasets when compared with the software baseline. Since the update asymmetry leads to non-unity MF and consequent unfavorable behavior in weight update process, a sharp drop in performance is found during the training. On the other hand, the cases with Tiki-Taka algorithm and finite asymmetry show robust performance reaching to the floating point baseline (Gokmen and Haensch, 2020). As shown in Figure 2, when AFA = AFC = 1.0, the train and test error gradually decrease and can reach to the baseline. However, the remaining question is how much asymmetry Tiki-Taka algorithm can tolerate. Other cases shown in Figure 2 with various pairs of AFA and AFC answer the question. The train error does not gradually decrease, which indicates that the weight vectors of neural networks are stuck at bad local optima. Interestingly, the case with AFA = AFC = 0 shows higher train and test error than those of SGD with asymmetric non-linear devices. This result indicates that there exist optimal pairs of AF, and a reliable method to determine the optimal pair of AFA and AFC is necessary. To find the method, it is necessary to quantify and understand how MF affects the optimizer, Tiki-Taka algorithm, during the neural network training.
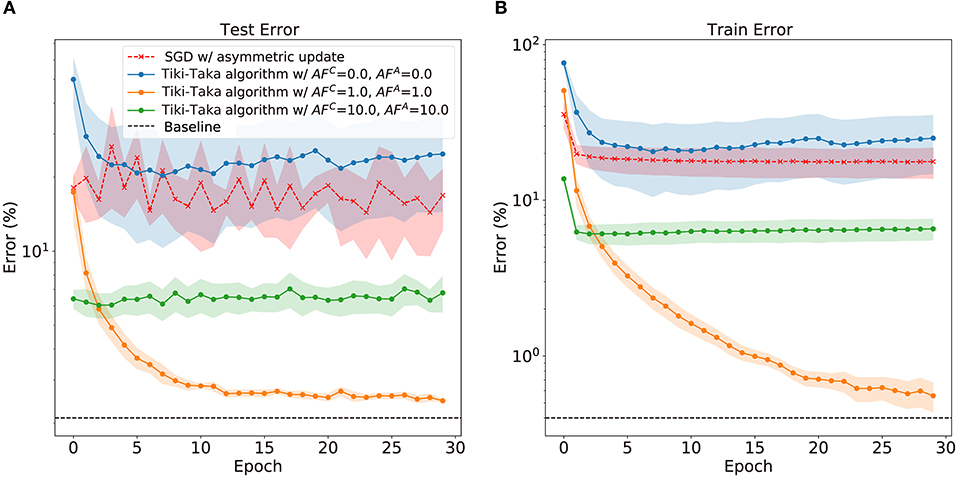
Figure 2. The train error (A) and test error (B) on handwritten digits images (MNIST) dataset with MLP. The baseline indicates the averaged error of the last 3 epochs with symmetric linear device, and the neural network is trained with SGD. In the case of SGD with asymmetric non-linear device, the error is averaged over various AF > 0. In the case of Tiki-Taka algorithm, the error is averaged over various pair of SGD and transfer learning rates. The shaded area indicates standard deviation.
4. Optimization based on History of Gradients
4.1. General Formulation for Gradient History-Based SGD Variants
Recent variants of SGD introduce the concept of history-dependent update and utilize gradient information at each step, including momentum and adaptive gradient, to overcome the issues of vanilla SGD (Kandel et al., 2020). In such methods, the weight update is determined not only by the current gradient calculation, but also by the history of previous gradients and their importance at the current step. For instance, if the current weight update includes only the first-order gradient, then the history dependent update is composed of first-order gradient vectors and their respective importance for each step.
Definition 4.1 (Gradient Scheduler). History-dependent optimization algorithm is generalized by the governing rules including nth order gradients:
t = t(k) (k = 1, ⋯ , T) is a gradient scheduler or scheduler, which contains information on the importance of the kth gradients, .
Therefore, the scheduler, t(k), defines how the gradients of previous steps for k < T affect the update of current step at k = T, since t(k) contains information on weighting of the gradients dependent on the step, k.
4.2. Gradient Scheduler in Tiki-Taka Algorithm
From the Definition 4.1, we can find the t(k) for Tiki-Taka algorithm as follows (see Supplementary Materials section 2.2 for the detailed derivation):
where 1T≡ns0 is an indicator function which returns 1 every ns steps, t(k) is controlled by three hyper-parameters (Gokmen and Haensch, 2020): γ, ns, and uπ. These parameters cause the weight matrix W to be updated sparsely and asynchronously.
Figure 3 compares the gradient schedulers in three algorithms: vanilla SGD, momentum-based optimizer, and Tiki-Taka algorithm. The parameters of Tiki-Taka used are ns = 1, u = 1, and γ = 0, and the ideal, symmetric and linear, switching characteristics are assumed for the devices in both arrays (i.e., ). With ideal devices, Tiki-Taka algorithm memorizes all the previous gradients with equal importance. Therefore, it resembles the momentum-based optimizer if β → 1. However, it should not be confused with the momentum-based optimizer, because the scheduler of Tiki-Taka algorithm with asymmetric devices depends not only on the step, but also on the history of gradients and slopes of devices unlike the momentum-based optimizer.
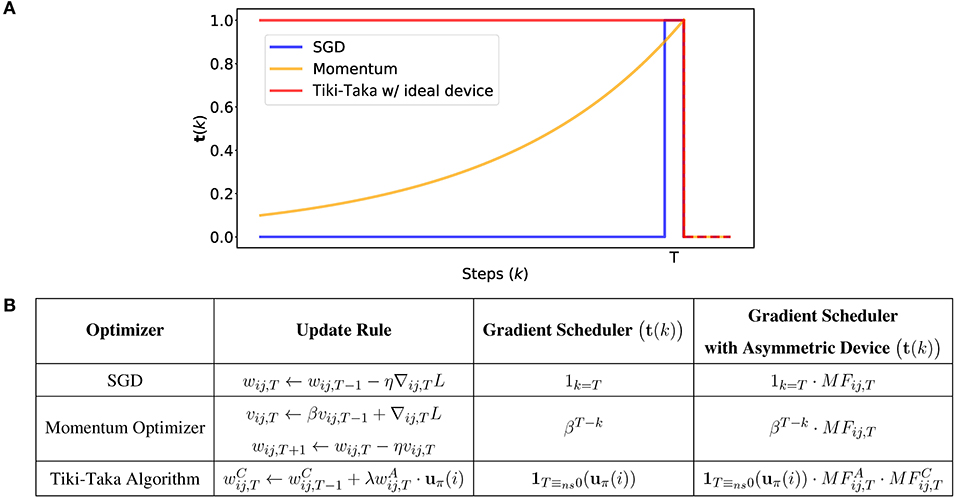
Figure 3. (A) Comparison of gradient scheduler, t(k), of SGD, momentum-based optimizer, and Tiki-Taka algorithm with respect to steps, k. t(k) is normalized by the value of t(T). (B) Summarized table of gradient scheduler of optimizers from (A).
By including the update asymmetry, we can reformulate the scheduler of Tiki-Taka algorithm, Equation (14), as follows (see Supplementary Materials section 2.2) for the detailed derivation):
Equation (15) indicates that both MFA and MFC play an critical role in weight optimization. MFA kicks in every step of k, and MFC provides a factor until the last step of T in the scheduler of Tiki-Taka algorithm. Therefore, the optimizer of Tiki-Taka algorithm is uniquely determined by two MF's. Considering that is determined by the history of gradients, , the scheduler of Tiki-Taka algorithm is parameterized by the step and the history of the first-order gradients. MFC affects the optimization process for different T, T+1, ⋯ steps in common by scaling all the ideal t(k). Therefore, MFC is one of key components in building the optimizer, and MFA determines the optimizer of Tiki-Taka algorithm.
5. Linear Regression Analysis
To analyze the impact of update asymmetry in neural network training, we perform a series of linear regression experiments with different algorithms and display the results in Figure 4. With the presence of update asymmetry, the weight vectors of a neural network are stuck at sub-optima (Kim et al., 2019a) as shown in Figure 4B, and the linear regression is unable to approach the global optimum in this convex problem. Since the expected change of a weight around the sub-optima region over the given distribution of data D, EX~D[Δwij], is 0 on average, there is no room for the weight to progress further (Gokmen and Haensch, 2020). If the asymmetry factor of a crosspoint element, AF, is large, then the weight vector will converge to the region further away from the global optimum. This is because larger AF values cause larger variations in MF and equilibrium region to be formed away from the global optimum.
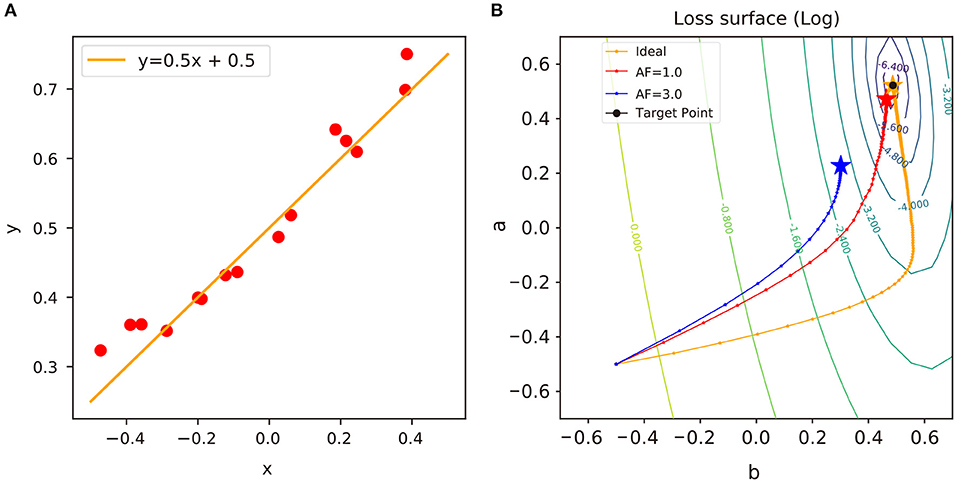
Figure 4. (A) An example of linear regression model and sampled data: y = ax + b + ϵ, where a ∈ R and ϵ~N(0, σ 2). In this example, a = 0.5, b = 0.5, and σ = 0.05. (B) Trajectories of weights in the log-scaled loss surface. A “target” point indicates a closed-form solution of linear regression model. i.e., (a b)T= (XTX)−1XTy, where X is the N × 2 input matrix and y is the N × 1 output vector. The “ideal” trajectory indicates a trajectory of a neural network optimized by vanilla SGD using ideal device. We denote it as “ideal” only in reference to the problem of convex optimization (see Supplementary Materials section 3.2 for the details of experimental environments).
In Figure 5, we repeat the linear regression experiments with Tiki-Taka algorithm and different combinations of AF values and observe the impact of update asymmetry on the linear regression results. Unlike the previous results with vanilla SGD, neural networks trained by Tiki-Taka algorithm with certain combinations of AFA and AFC are able to converge to the global optimum, even with the update asymmetry. Since Tiki-Taka algorithm can accumulate gradients of previous steps in the auxilary array and utilize the information for optimization, the weight vector can escape from the sub-optima dug by MF and converge to the global optimum.
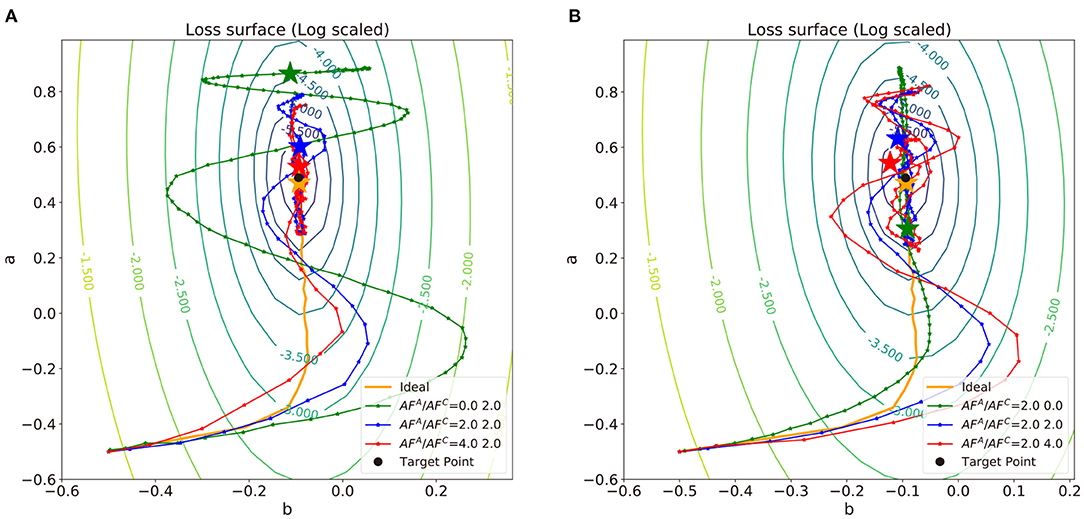
Figure 5. Trajectories of weights in the log-scaled loss surface for convex problem where the data is sampled from the same distribution as described in Figure 4A and the normalized schedulers, t(k), of a variable b described in Figure 4A. (A) AFC is fixed with 2.0 and (B) AFA is fixed with 2.0. The points of each trajectory are marked for every epoch.
To analyze the impact of update asymmetry in the array A and C independently, we modulate AFA (Figure 5A) and AFC (Figure 5B) in an alternating fashion and compare the neural network training performance. The corresponding t(K) and WA value as a function of training step for each case are visualized in Figure 6. Figure 5A shows the trajectories of weight vectors in three cases where AFA values are 0.0, 2.0 and 4.0, respectively, and AFC is fixed at 2.0. First, if AFA = 0, then at all steps k, which indicates that . In this case, the large oscillation and deviation from the path by SGD are observed in the weight trajectory since the optimizer memorizes all the history of gradients with equal importance in the array A and the previous gradients can only be changed slowly. On the other hand, when AFA is 2.0 or 4.0, t(k) abruptly changes curvature near the 150th step point as illustrated in Figure 6. If ∇ijL < 0 for T−1 steps, then decreases as increases as discussed in Definition 3.1. After the T steps, abruptly increases as sgn(∇ijL) is inverted. The implication of the “abruptness" is that the optimizer is likely to forget the gradients of previous steps right before sgn(∇ijL) is inverted, and accept newly updated gradients. The “abruptness" amplifies with devices with larger AFA. In other words, the optimizer has an “easy come, easy go" memory that stores the history of gradients, and t(k) determines the speed of accumulating and forgetting the gradients. This behavior resembles that of the first order momentum optimizer. However, Tiki-Taka algorithm decides to decay the gradients by accumulating the successive gradients of same sgn(∇ijL) while the first order momentum optimizer merely decays the gradients far from the current step. In Figure 5, the trajectories with large AFA are less inclined to oscillate and deviate as the optimizer forgets the information right before sgn(∇ijL) is inverted. It helps the weight vector to converge to the global optimum. However, it also fades out the regularization effect. Thus, there exists optimal range of AFA that guarantees convergence and regularization.
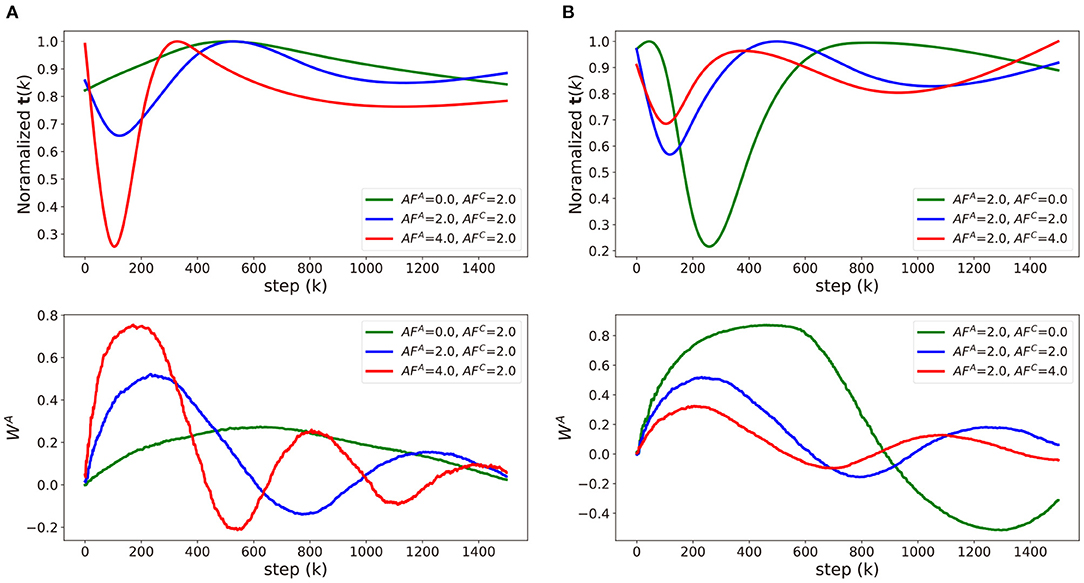
Figure 6. Comparisons of approximated t(k) and WA of three cases in (A) Figure 5A and (B) Figure 5B. Raw data of t(k) and WA was averaged using exponential moving average and approximated with natural smoothing spline method.
Modulating AFC impacts differently on the weight vector trajectories as shown in Figure 5B, where the trajectories of weight vectors with AFC = 0.0, 2.0, and 4.0 are displayed while AFA is fixed at 2.0. As AFC increases, the weight update becomes less frequent with larger update steps, and, consequently, the frequency and magnitude of the oscillation in the weight vector becomes larger. This observation is expected from the fact that and . With large AFC, the array A value fluctuates by frequently changing signs as shown in Figure 6 and cannot drive WC in a consistent manner, which leads to a large oscillation in WC. In that sense, array A can capture the gradient history better when AFC is smaller. However, with larger AFC, gradually decreases as a function of step k, if the signs of are the same. This observation shows the similar effects of the adaptive gradient (Duchi, 2011; Zeiler, 2012; Kingma and Ba, 2014), which can help the weight vector to converge by decreasing the amount of updates around the global optimum when AFC is set within the proper range. Therefore, the impact of AFA and AFC becomes highly entangled during optimization process, and it is a challenging task to find the optimal AF value for each array. A systematic method to find the optimal values of AFA and AFC, which are highly dependent on the specific dataset and neural network architecture, is required for the convergence and performance of the neural network training.
6. Impact of Update Asymmetries on Neural Network Performance
6.1. Experimental Results
As we discussed in the previous sections, the update asymmetry in array A and C plays an important role in neural network training with Tiki-Taka algorithm as an optimizer. To experimentally explore the impact of AFA and AFC on training neural networks, we perform a series of experiments by varying AFA and AFC values and training a multi-layer perceptron (MLP) with MNIST dataset. For this experiment, we set (wmin, wmax) = (–1,1) and for all devices in the array as mentioned in section 2.2, which illustrates the device reaching wmax = 1 from initial weight value of wmin = −1 within 600 updates if (, ) = (1, –1) is given during update phase (see Supplementary Materials section 3.2 for the details of experimental environments).
Figure 7 shows the heat map of train (Figure 7A) and test accuracies of MLP as a function of AFA and AFC values and with two different set of SGD and transfer learning rates (Figures 7B,C). The results show the consistent observations as analyzed in section 5. First, when AFC is fixed, the train and test accuracies peak at AFA = 1.78 and decrease as it becomes larger or smaller. Smaller AFA causes the optimizer to accumulate the history of gradient with equal importance, which hampers the convergence of the weight vectors due to oscillation. However, this effect is reduced with larger AFC thanks to the adaptive gradient impact. In contrary, larger AFA values disallow accumulation of the full history of gradients, which results in reduction of the regularization effect. This tendency is more significant for larger AFC values, where the variance and expectation of updates for the array C is large enough not to store the entire history of gradients. Considering that larger AFA causes memorization of short-term gradients, the regularization effect becomes weakened.
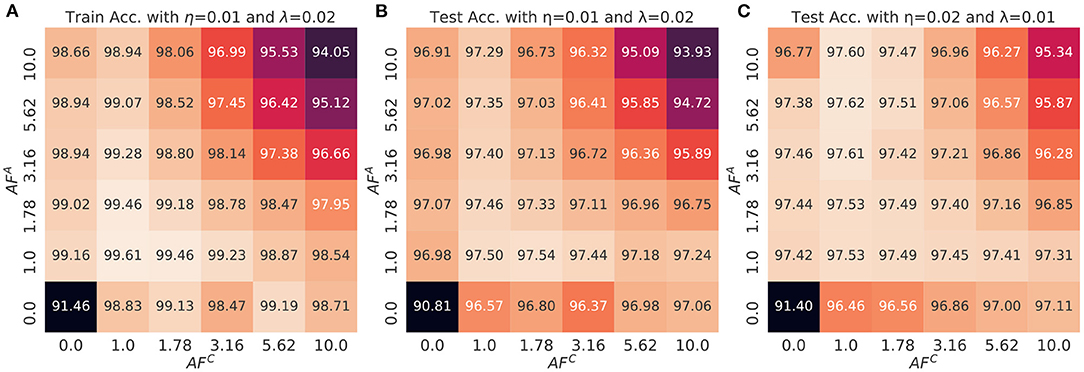
Figure 7. The (A) train and (B,C) test accuracy of a multi-layer perceptron as a function of AFA and AFC. The displayed values are averaged over the last three epochs of the training and also three different initialization conditions. The mini-batch size is 1. The transfer learning rate and SGD learning rate is (0.01 and 0.02) for (B) and (0.02 and 0.01) for (C).
6.2. Impact of Learning Rates and Robustness Score
The optimal combination of AF values, which provide the best accuracy, can be changed when the combination of learning rates vary. For example, in Figure 7B, the test accuracy peaks at the combinations, (AFA, AFC) ∈ {(1.0, 1.0), (1.78, 1.0), (1.0, 1.78)} when the transfer learning rate and SGD learning rate is (0.01, 0.02). However, as shown in Figure 7C, the combination of AF is optimal when (AFA, AFC)∈{(3.16, 1.0), (5.62, 1.0), (10.0, 1.0)} if the neural network is trained with different pair of learning rates, (0.02, 0.01). Considering that AF of each device is typically pre-determined at the moment of device fabrication, it is crucial to find the robust AFA and AFC values over the learning rate space which do not degrade the accuracy. From this perspective, finding the robust region of AF without searching the best pair of learning rates can be guaranteed by introducing the thresholds of certain measurements such as test accuracy. The following robustness score provides the hard-bound threshold for finding the optimal combination of AF over the space of learning rates.
Definition 6.1 (Robustness score). Suppose that m is a neural network model, and Meas(·) is a measurement such as accuracy or loss of the model m after training for a given dataset D. is a hyper-parmeter space for software training, , where η = SGD learning rate andλ = transfer learning rate}. A Robustness score, RS(m), for the given threshold, th, is defined as follows:
Figure 8 illustrates the robustness score, RS(m), over a learning rate space, , where η∈{0.01, 0.02, 0.04} and λ∈{0.01, 0.02, 0.04}. As discussed in section 3.2, AF of each array affects the test accuracy of the network using Tiki-Taka algorithm. Test accuracies do not reach sufficient value when AF of each array is too small (AFA, C = 0) or large (AFA, C = 10). Therefore, optimal AF value pairs which maximize the robustness score exist near AFA, C = 1 as shown in Figure 8. The score map has two implications. First of all, if the minimum requirement of test accuracy (threshold) is determined, the region whose robustness scores are over a certain criteria could be used to define the minimum specifications of update asymmetry. Therefore, one can obtain the range of AF value for each array which gurantees the minimum test accuracy. Second, by scanning over various pairs of learning rates, one can identify the region which provides the AF values which are most independent on the learing rates. To find such region, the score is post-processed with interpolation and gaussian filtering. The robustness score is approximated by piece-wise linear interpolation in the domain of AFA and AFC. The interpolated data is smoothed by gaussian filtering (g(AFA, AFC))) to obtain the robust region in the domain: g(AFA, AFC) = (2πσ2)−1/2·exp(−(((AFA)2+(AFC)2)/(2σ2)), where we define the degree of “robustness" of the score map by modulating σ of a gaussian filter. Finding the robust region with a gaussian filter is consistent with the definition of variations in AF of devices. In Figure 8C, the robust region is around AFA = 1.2 and AFC = 1.0 with the score greater than 8.95. As we experiment with a total of 9 scenarios of learning rates, the region with the score greater than 8.95 displays the required test accuracy within the given range of learning rate pairs. When compared to the region with RS(m) = 4.5, the region with RS(m)≥8.95 shows almost doubled efficiency during on-device training. In other words, it requires half of the resources to find the optimal pair of learning rates. This calibration method to find the best combination of AF is applicable to other types of hyper-parameters if the hyper-parameters space can be expanded to include them.
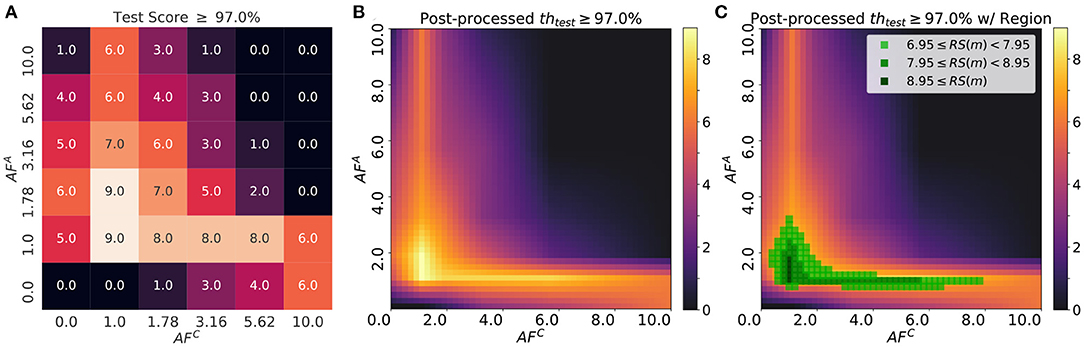
Figure 8. (A) The robustness score based on the test accuracy with a given threshold, 97.0%, where the number indicates how many cases with the test accuracy over the threshold. dwmin is set at 0.001. (B) The post-processed robustness score, where the step size of each domain in AF is 0.2 and σ = 0.2. (C) The regions with high robustness score are highlighted to visualize the area where the test accuracy is universally high as the learning rates change.
6.3. Inspection on Optimal Range of Slope for Different Thresholds
In practical applications, the target performance of the network, such as the test accuracy of the MNIST classification task using MLP, is one of the most significant design choices as some tasks require the maximum accuracy while others do not. Considering that the robustness score, RS(m), varies as target accuracy changes, studying the relationship between RS(m) and the target threshold value can provide insights on the choice of AF for each array. Figure 9 illustrates the robustness score maps with two different threshold values, 97.0 and 97.5%. When the threshold is set to 97.0%, the score is robust against the change in AFC value and the efficiency of searching over the hyper-parameter space, with AFA is not degraded in the proper region. However, in the case of the threshold being 97.5%, the best choice is to fix AFC around 1.0. Then the asymmetry requirement for the array A is lifted. Although the robustness scores of the case with the threshold being 97.5% are relatively lower than those of 97.0%, selecting AFA and AFC of the region has comparative advantages over the other regions.
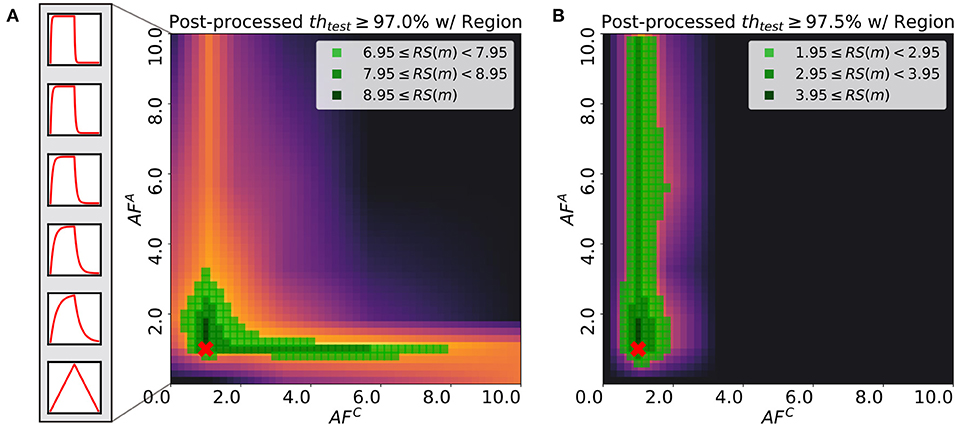
Figure 9. Post-processed test robustness score on various thresholds: (A) 97.0% and (B) 97.5%. The green-colored regions are highlighted with different light and shade. Red cross point indicates the pair of asymmetric factors for baseline model used in original Tiki-Taka algorithm (Gokmen and Haensch,2020). Boxes on the left side of (A) show the asymmetry of device response in accordance with each asymmetric factor.
Consistent with the analysis in sections 5 and 6.1, Figure 9A describes that the neural networks are able to find the optimum with a wide range of AFC values over if AFA is in the proper region. This observation is due to the adaptive gradient effect that AFC brings, which helps the convergence around the nearest local optimum. In this case, the neural network converges to the local optimum instead of further exploring the loss surface. This results in the high robustness score region along the wide range of AFC, though it does not guarantee higher accuracy. In Figure 9B, on the other hand, the region satisfying over 97.5% accuracy is spread along the axis of AFA, which indicates that the specification for AFC value is strict. If AFC value is within the specification, then the robustness score depends on the choice of AFA. With smaller AFA values, the optimizer allows the weights of neural networks to explore over loss surface, which enables to find better optimum.
6.4. Application to SNN
Recent research on SNN and its implementations using resistive memory devices have shown that the devices are designed explicitly to be embedded with the learning algorithm for SNN such as Spike-timing-dependent plasticity (STDP) and equilibrium propagation (Scellier and Bengio, 2017). Accordingly, the update asymmetry of devices is more likely to affect the process of training neural networks (Kwon et al., 2020). Inspired by this motivation, they demonstrated that asymmetric non-linear devices are more powerful than symmetric linear devices (Brivio et al., 2018, 2021; Kim et al., 2021). Our analytical tools and calibration method can be applied to illustrate the relationship between the update asymmetry of devices and its impact on training in detail. Therefore, it is worthwhile to pursue further studies on the relationship in more extensive range of cases of learning algorithms.
7. Conclusion and Discussion
In this work, the impact of update asymmetry in array A and C and learning rates on network performance when training neural networks with Tiki-Taka algorithm is quantitatively analyzed. We introduced the concept of gradient scheduler, which defines the weights of previous gradient values, to explain how the update asymmetry impacts on solving a convex problem. With update asymmetry, we derived that asymmetry factor involved in gradient scheduler that the training of neural networks is affected. As we inspected on the gradient schedulers, larger asymmetry factor of A accelerates accumulating and forgetting the history of gradients while that of C brings adaptive gradient effects. We showed that the update asymmetry levels in the main and auxiliary arrays impact differently on training neural networks, indicating that requirements for asymmetry on each array are different. We also proposed a novel calibration metric, Robustness Score, to quantify and visualize the performance of the network as a function of device asymmetry and network parameters with respect to the target accuracy threshold. By searching over the hyper-parameter space of Tiki-Taka algorithm, we quantified the specification of device asymmetry for A and C arrays depending on the target accuracy value of choice. Our analysis shed light on further relaxing device specifications for the realization of analog neural network accelerators in hardware and provide a guideline to realize the resistive switching devices with robust training performance over the space of hyper parameters.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author Contributions
SK conceived the original idea. CL formulated the theory. CL, KN, and WJ developed methodology and conducted experiments. CL, TG, and SK analyzed and interpreted results. All authors drafted and revised the manuscript.
Funding
This work was supported by Samsung Science & Technology Foundation (grant no. SRFC-IT2001-06).
Conflict of Interest
CL is employed by NAVER Clova, South Korea. TG is employed by IBM Research, USA.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We thank Malte J. Rasch and Diego Moreda for many useful discussions and technical supports.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnins.2021.767953/full#supplementary-material
References
Agarwal, S., Quach, T.-T., Parekh, O., Hsia, A. H., DeBenedictis, E. P., James, C. D., et al. (2016). Energy scaling advantages of resistive memory crossbar based computation and its application to sparse coding. Front. Neurosci. 9:484. doi: 10.3389/fnins.2015.00484
Brivio, S., Conti, D., Nair, M. V., Frascaroli, J., Covi, E., Ricciardi, C., et al. (2018). Extended memory lifetime in spiking neural networks employing memristive synapses with nonlinear conductance dynamics. Nanotechnology 30, 015102. doi: 10.1088/1361-6528/aae81c
Brivio, S., Ly, D. R., Vianello, E., and Spiga, S. (2021). Nonlinear memristive synaptic dynamics for efficient unsupervised learning in spiking neural networks. Front. Neurosci. 15:27. doi: 10.3389/fnins.2021.580909
Chen, Y., Xie, Y., Song, L., Chen, F., and Tang, T. (2020). A survey of accelerator architectures for deep neural networks. Engineering 6, 264–274. doi: 10.1016/j.eng.2020.01.007
Duchi, J., Hazan, E., and Singer, Y. (2011). Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 12, 2121–2159.
Gokmen, T., and Haensch, W. (2020). Algorithm for training neural networks on resistive device arrays. Front. Neurosci. 14:103. doi: 10.3389/fnins.2020.00103
Gokmen, T., Onen, M., and Haensch, W. (2017). Training deep convolutional neural networks with resistive cross-point devices. Front. Neurosci. 11:538. doi: 10.3389/fnins.2017.00538
Gokmen, T., and Vlasov, Y. (2016). Acceleration of deep neural network training with resistive cross-point devices: design considerations. Front. Neurosci. 10:333. doi: 10.3389/fnins.2016.00333
Guo, Y.. (2018). A survey on methods and theories of quantized neural networks. arXiv preprint arXiv:1808.04752.
Haensch, W., Gokmen, T., and Puri, R. (2018). The next generation of deep learning hardware: analog computing. Proc. IEEE 107, 108–122. doi: 10.1109/JPROC.2018.2871057
Han, S., Mao, H., and Dally, W. J. (2015). Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149.
Huang, S., Sun, X., Peng, X., Jiang, H., and Yu, S. (2020). “Overcoming challenges for achieving high in-situ training accuracy with emerging memories,” in 2020 Design, Automation &Test in Europe Conference &Exhibition (DATE) (Grenoble: IEEE), 1025–1030.
Islam, R., Li, H., Chen, P.-Y., Wan, W., Chen, H.-Y., Gao, B., et al. (2019). Device and materials requirements for neuromorphic computing. J. Phys. D Appl. Phys. 52, 113001. doi: 10.1088/1361-6463/aaf784
Kandel, I., Castelli, M., and Popovič, A. (2020). Comparative study of first order optimizers for image classification using convolutional neural networks on histopathology images. J. Imaging 6, 92. doi: 10.3390/jimaging6090092
Kim, H., Rasch, M., Gokmen, T., Ando, T., Miyazoe, H., Kim, J.-J., et al. (2019a). Zero-shifting technique for deep neural network training on resistive cross-point arrays. arXiv preprint arXiv:1907.10228.
Kim, S., Todorov, T., Onen, M., Gokmen, T., Bishop, D., Solomon, P., et al. (2019b). “Metal-oxide based, cmos-compatible ecram for deep learning accelerator,” in 2019 IEEE International Electron Devices Meeting (IEDM) (San Francisco, CA: IEEE), 35–7.
Kim, T., Hu, S., Kim, J., Kwak, J. Y., Park, J., Lee, S., et al. (2021). Spiking neural network (snn) with memristor synapses having non-linear weight update. Front. Comput. Neurosci. 15:22. doi: 10.3389/fncom.2021.646125
Kingma, D. P., and Ba, J. (2014). Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Kwon, D., Lim, S., Bae, J.-H., Lee, S.-T., Kim, H., Seo, Y.-T., et al. (2020). On-chip training spiking neural networks using approximated backpropagation with analog synaptic devices. Front. Neurosci. 14:423. doi: 10.3389/fnins.2020.00423
Lee, C., Rajput, K. G., Choi, W., Kwak, M., Nikam, R. D., Kim, S., et al. (2020). Pr 0.7 ca 0.3 mno 3-based three-terminal synapse for neuromorphic computing. IEEE Electr. Device Lett. 41, 1500–1503. doi: 10.1109/LED.2020.3019938
Rasch, M. J., Moreda, D., Gokmen, T., Gallo, M. L., Carta, F., Goldberg, C., et al. (2021). A flexible and fast pytorch toolkit for simulating training and inference on analog crossbar arrays. arXiv preprint arXiv:2104.02184. doi: 10.1109/AICAS51828.2021.9458494
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1986). Learning representations by back-propagating errors. Nature 323, 533–536. doi: 10.1038/323533a0
Scellier, B., and Bengio, Y. (2017). Equilibrium propagation: bridging the gap between energy-based models and backpropagation. Front. Comput. Neurosci. 11:24. doi: 10.3389/fncom.2017.00024
Sun, Z., and Huang, R. (2021). Time complexity of in memory matrix vector multiplication. IEEE Trans. Circ. Syst. II Express Briefs 68, 2785–2789. doi: 10.1109/TCSII.2021.3068764
Sun, Z., Pedretti, G., Ambrosi, E., Bricalli, A., Wang, W., and Ielmini, D. (2019). Solving matrix equations in one step with cross-point resistive arrays. Proc. Natl. Acad. Sci. U.S.A. 116, 4123–4128. doi: 10.1073/pnas.1815682116
Tsai, H., Ambrogio, S., Narayanan, P., Shelby, R. M., and Burr, G. W. (2018). Recent progress in analog memory-based accelerators for deep learning. J. Phys. D Appl. Phys. 51, 283001. doi: 10.1088/1361-6463/aac8a5
van De Burgt, Y., Melianas, A., Keene, S. T., Malliaras, G., and Salleo, A. (2018). Organic electronics for neuromorphic computing. Nat. Electron. 1, 386–397. doi: 10.1038/s41928-018-0103-3
Verhelst, M., and Moons, B. (2017). Embedded deep neural network processing: algorithmic and processor techniques bring deep learning to iot and edge devices. IEEE Solid State Circ. Mag. 9, 55–65. doi: 10.1109/MSSC.2017.2745818
Wang, Z., Wu, H., Burr, G. W., Hwang, C. S., Wang, K. L., Xia, Q., et al. (2020). Resistive switching materials for information processing. Nat. Rev. Mater. 5, 173–195. doi: 10.1038/s41578-019-0159-3
Xiao, T. P., Bennett, C. H., Feinberg, B., Agarwal, S., and Marinella, M. J. (2020). Analog architectures for neural network acceleration based on non-volatile memory. Appl. Phys. Rev. 7, 031301. doi: 10.1063/1.5143815
Keywords: resistive memory, update asymmetry, Tiki-Taka algorithm, neural network, deep learning accelerator, analog AI hardware
Citation: Lee C, Noh K, Ji W, Gokmen T and Kim S (2022) Impact of Asymmetric Weight Update on Neural Network Training With Tiki-Taka Algorithm. Front. Neurosci. 15:767953. doi: 10.3389/fnins.2021.767953
Received: 31 August 2021; Accepted: 26 October 2021;
Published: 06 January 2022.
Edited by:
Yimao Cai, Peking University, ChinaReviewed by:
Hongwu Jiang, Georgia Institute of Technology, United StatesZhong Sun, Peking University, China
Copyright © 2022 Lee, Noh, Ji, Gokmen and Kim. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Seyoung Kim, a2ltc2V5b3VuZ0Bwb3N0ZWNoLmFjLmty
†Present address: Chaeun Lee, NAVER Clova, Seongnam-si, South Korea