 Ashkan Faghiri1,2*
Ashkan Faghiri1,2* Eswar Damaraju1
Eswar Damaraju1 Aysenil Belger3
Aysenil Belger3 Judith M. Ford4,5
Judith M. Ford4,5 Daniel Mathalon4,5
Daniel Mathalon4,5 Sarah McEwen6
Sarah McEwen6 Bryon Mueller7
Bryon Mueller7 Godfrey Pearlson8Adrian Preda9
Godfrey Pearlson8Adrian Preda9 Jessica A. Turner10Jatin G. Vaidya11Theodorus Van Erp9
Jessica A. Turner10Jatin G. Vaidya11Theodorus Van Erp9 Vince D. Calhoun1,2,10
Vince D. Calhoun1,2,10- 1The Tri-Institutional Center for Translational Research in Neuroimaging and Data Science, Georgia Institute of Technology, Georgia State University, Emory University, Atlanta, GA, United States
- 2School of Electrical and Computer Engineering, Georgia Institute of Technology, Atlanta, GA, United States
- 3Department of Psychiatry, The University of North Carolina, Chapel Hill, Chapel Hill, NC, United States
- 4Department of Psychiatry, University of California, San Francisco, San Francisco, CA, United States
- 5San Francisco VA Medical Center, San Francisco, CA, United States
- 6Department of Psychiatry and Biobehavioral Sciences, University of California, Los Angeles, Los Angeles, CA, United States
- 7Department of Psychiatry, University of Minnesota, Minneapolis, MN, United States
- 8School of Medicine, Yale University, New Haven, CT, United States
- 9Department of Psychiatry and Human Behavior, University of California, Irvine, Irvine, CA, United States
- 10Department of Psychology, Georgia State University, Atlanta, GA, United States
- 11Department of Psychiatry, The University of Iowa, Iowa, IA, United States
Background: A number of studies in recent years have explored whole-brain dynamic connectivity using pairwise approaches. There has been less focus on trying to analyze brain dynamics in higher dimensions over time.
Methods: We introduce a new approach that analyzes time series trajectories to identify high traffic nodes in a high dimensional space. First, functional magnetic resonance imaging (fMRI) data are decomposed using spatial ICA to a set of maps and their associated time series. Next, density is calculated for each time point and high-density points are clustered to identify a small set of high traffic nodes. We validated our method using simulations and then implemented it on a real data set.
Results: We present a novel approach that captures dynamics within a high dimensional space and also does not use any windowing in contrast to many existing approaches. The approach enables one to characterize and study the time series in a potentially high dimensional space, rather than looking at each component pair separately. Our results show that schizophrenia patients have a lower dynamism compared to healthy controls. In addition, we find patients spend more time in nodes associated with the default mode network and less time in components strongly correlated with auditory and sensorimotor regions. Interestingly, we also found that subjects oscillate between state pairs that show opposite spatial maps, suggesting an oscillatory pattern.
Conclusion: Our proposed method provides a novel approach to analyze the data in its native high dimensional space and can possibly provide new information that is undetectable using other methods.
Introduction
Recent work in fMRI has focused on relaxing the assumption that the brain is static during an experimental session. There are many studies that have shown that the brain is time-varying (or dynamic) within a single scanning session (Chang and Glover, 2010; Sakoglu et al., 2010; Hutchison et al., 2013; Calhoun et al., 2014; Faghiri et al., 2018; Lurie et al., 2020). One common way to analyze the dynamic aspect of the brain is by estimating time varying connectivity using sliding window paired with a connectivity estimator such as Pearson correlation (Handwerker et al., 2012; Allen et al., 2014). This approach is useful and widely used due in part to its simplicity, but it has some limitations. Windowing the data results in smoothing the temporal information in fMRI, potentially missing important information. A more minor issue with this method is that one has to use a specific window length for this analysis and changing this window length can change the final results (Sakoglu et al., 2010; Shakil et al., 2016). To remedy the smoothing problem several methods have been proposed that are either more instantaneous (Shine et al., 2015; Omidvarnia et al., 2016; Faghiri et al., 2020) or use different filtering and time-frequency approaches to explore the full spectrum of connectivity (Chang and Glover, 2010; Yaesoubi et al., 2015; Faghiri et al., 2021). For more detailed reviews of time-varying connectivity please (see Bolton et al., 2020; Iraji et al., 2020a). Many of these proposed connectivity-based approaches do not directly leverage the dynamics of the data in its original high dimensional space (i.e., the data is used to calculate the sliding window correlation, which is calculated between each of the component pairs separately). This causes the data to be examined in many two-dimensional (2D) spaces independent of other 2D spaces (where each 2D space is specific to a component pair). Recently novel methods have been proposed that try to go from these 2D spaces to higher dimensions using different methods (Faskowitz et al., 2020; Iraji et al., 2020b).
Apart from connectivity-based approaches, there are others that aim to extract dynamism directly from activity domain information. For example, hidden Markov models have been used to estimate several hidden states from the activity data in fMRI (Karahanoğlu and Van De Ville, 2017; Vidaurre et al., 2018). Others have either including activity information in the pipeline directly (Fu et al., 2021) or have instead focused on a metric calculated based on activity like power (Chen et al., 2018). In addition, there are a family of methods based on co-activation between different part of the brain that directly include activity information in their analysis pipeline too (Liu and Duyn, 2013; Karahanoglu and Van De Ville, 2015).
Over the last decade, many studies have compared the brains of individuals with schizophrenia with those of healthy controls using both resting state (Damaraju et al., 2014; Guo et al., 2014; Faghiri et al., 2021) and task fMRI (Boksman et al., 2005; Ebisch et al., 2014). Recently more emphasize has been put on methods that explore the dynamic aspects of the brain (Damaraju et al., 2014; Kottaram et al., 2019; Gifford et al., 2020; Faghiri et al., 2021). Using dynamic methods, some studies have reported lower dynamism in individuals with schizophrenia (Miller et al., 2016; Kottaram et al., 2019; Gifford et al., 2020) or in individuals with high risk for schizophrenia (Mennigen et al., 2018a). In addition, Rashid et al. (2016) showed that using dynamic connectivity instead of static connectivity we can reach better classification of individuals with schizophrenia and bipolar disorder. For a detailed review on the matter (see Mwansisya et al., 2017; Mennigen et al., 2019).
In this study, we propose a novel approach to study brain dynamics in resting state fMRI. We consider the brain data at each time point as a location in a high dimensional space defined by multiple time series. Analyzing brain data within a high dimensional temporal space allows us to consider the fMRI data for each subject as a path along which each individual’s brain is moving within this high dimension space. In contrast to pairwise connectivity-based methods, we move beyond the bivariate/2D space (i.e., a focus on two time series without considering other time series) and work in a high dimensional space. Our proposed method does not use any temporal windowing unlike many sliding window methods (e.g., sliding window Pearson correlation) or filtering (e.g., amplitude of low-frequency fluctuation) therefore allowing us to use the information from the whole spectrum of data. In addition, unlike methods based on co-activation, our method is not sensitive to the absolute value of the time series and instead captures the density around each sample in a high dimensional space.
In the next section, we describe our proposed method in detail, show its utility via simulation data, and implement it on a real-world data set to compare the patients with schizophrenia (SZ) to healthy control (HC) participants.
Materials and Methods
Calculating Density
Let us assume our data for each subject includes C time series (each representing a separate component) with T time points. In our framework, this would mean that each subject occupies one location in a space with C dimension at each of the time points (i.e., the location of subject j at time t in this high dimension space is xj,t). This is a vector with a length of C.
Using these vectors, a scalar metric called density is defined (dj,t). This metric is higher if xj,t has several close points in our defined space. The formula for calculatingdj,t is:
Nj,tis a neighborhood around xj,t defined by a number of closest points to xj,t. So essentially, we calculate the distance between xj,t and all xj,t_0 for all values of t_0 and pick the ones that have the small distance value. We call this parameter the city size and it essentially determines the size of detectable high-density neighborhoods (hence the name city size). Note that we have one density time series with length T for each subject. i.e., density is defined using all components time series for each subject.
Next, we define a density threshold for each subject based on all of the density values for that specific subject:
Where max∀t(dj,t) is the maximum value of all dj,t for all t values for a specific subject (i.e., j). It is important to note that this threshold can be unique for each subject. An example value for cutoff can be 0.9. Next, this threshold was used to identify high-density time points for each subject (i.e., any time point with density greater than this value is defined as a high-density location (see Figure 1). Note that these high-density points are vectors with length C. Alternatively, we can calculate an average of the five highest percentile energies and use that value instead of max∀t(dj,t) to reduce the effect of outliers.
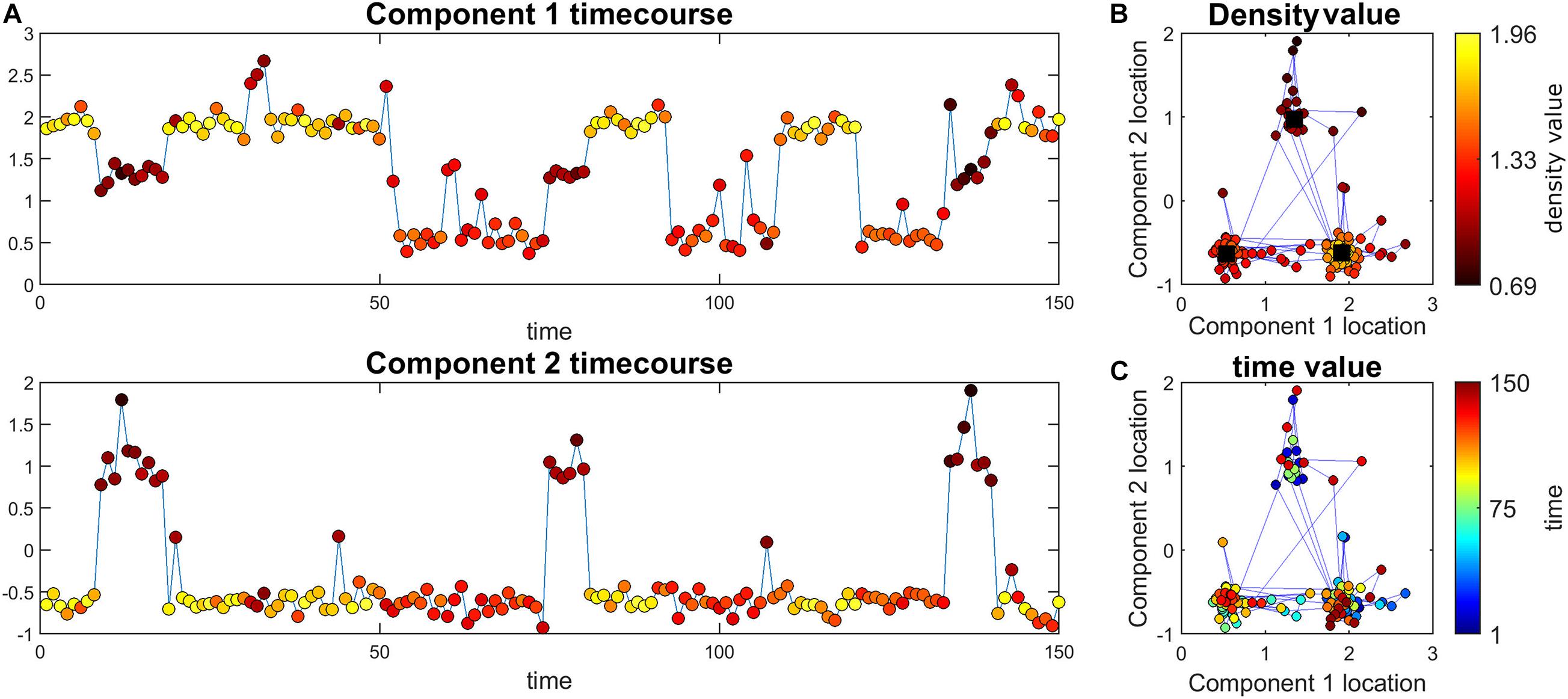
Figure 1. Illustration of the main ideas of the proposed method. (A) Simulated time course for the two components. The color of markers represents the density value of the data at each point. For each time point, density measures the closeness of that time point to all other time points. Note that this value is the same for the two components at each point (i.e., each point has an density value). (B) The black squares are the true high traffic nodes. The blue lines connect points that are adjacent in time. The color of points shows the density value. Here, the points close to high traffic nodes have higher density. (C) The same information as part b but the color of the points represent time.
The high-density locations for all subjects were then combined and clustered using k means. The number of clusters was calculated based on the elbow criteria (Thorndike, 1953). In the last step, we used the cluster centroids estimated via k means clustering on the high-density locations to initialize a clustering of all the data for each subject. A summary of the algorithm is explained in Table 1.

Table 1. Summary of all the steps in the clustering algorithm.
Simulation
To validate our proposed approach and explore the effect of different parameters of the method, we present different simulation scenarios here. All the simulations were constructed using two components for easy visualization (C = 2). For each simulation, we first randomly chose three locations in the 2D space to act as high-density nodes (Li;i1,2,3). A large portion of the data will be in the close neighborhood to these nodes. For each high-density node (i.e., cluster), a number is then chosen to act as that cluster size (CSi). Next, CSi samples are drawn from a 2D Gaussian with a mean equal to L_i and a standard deviation equal to a parameter we call path spread. This parameter defines how closely the cluster members are spread aroundLi. We believe this path spread can represent the noise impact on the data. For all simulations, a number of time points are simulated to act as noise (i.e., do not belong to any high-density clusters).
Next, these simulated time series are analyzed using steps discussed the in previous section. Below, we explain different simulation scenarios that we have designed. For each simulation, we give all the parameters of the simulation (CSi, and path spread) and the analysis (city size, and cutoff). Note that the first two scenarios are run only once and are designed to give the readers some intuition on the reasoning behind the design of the pipeline and parameters that can impact the results.
Scenario 1
In this scenario, our goal was to show the effect of path spread on the analysis. For this simulation, we have used 60 for all cluster sizes (CSi) while we have varied the path spread of the simulation between 0.1 and 0.3. For our analysis, we used 20 as the city size and 0.9 as the cutoff for the density.
Scenario 2
This scenario was designed to show the effect of using a different city size for analysis. This scenario has two simulations. In the first simulation, the cluster size is constant at 60 for all clusters. Path spread was chosen as 0.1. For the analysis, 0.9 was used as cutoff value. We used variable city size between 10 and 60 for analysis. In the second simulation, cluster sizes were varied (30, 50, and 80 were chosen). All other parameters were selected equal to the previous simulation.
Scenario 3
For this scenario, we show that our steps used for selecting high-density time points are improving the overall method. To do this for each simulated time series, we conducted the clustering step twice; one time using all time points as data to be clustered and another time using only high-density points (our proposed approach). For each path spread, we repeated the simulations 1,000 times and, for each method, the distance between estimated cluster centroids and the original cluster centroids (L_i) were calculated. City size and cutoff value were 50 and 0.9, respectively for this scenario.
Scenario 4
The last scenario is designed with the same aim as scenario 3. The difference here is that we first define a null hypothesis and then build the null space. Using this null space, we can define a p-value for results from our proposed method. The null hypothesis here is that our proposed method either perform as “good” or “worse” when compared to a method in which time points are chosen randomly and then clustered (in contrast to our method where density is defined for each point and high-density points are clustered). To do this for each simulation, first the number of high-density points is calculated, and then random points are drawn from the same simulation 10,000 times (number of random samples drawn is the same as the number of high-density points). Next, these random points are used in clustering and the sum of the distance of resulting centroids from the original high-density location (L_i) is calculated. This results in 10,000 distance values. We then compared the sum of the distance resulting from our proposed method to these 10,000 values. The p-value is defined as the ratio of times the distance resulting from null method was lower than the distance resulting from our proposed method. This approach resulted in one p-value for each simulation. For each of the path spread values, the simulation was repeated 1,000 times. City size and cutoff value were 50 and 0.9 respectively for this scenario.
Analysis of fMRI Data
The data used for this study has been published by our group previously (Damaraju et al., 2014). This data was acquired from 151 SZ patients and 163 HC participants. Resting state fMRI scans were acquired using 3T scanners at seven different sites. A gradient-echo planar imaging paradigm was used with the following parameters: FOV of 220 x 220, TR = 2 s, TE = 30 ms. 162 volumes were acquired during the scanning session. Table 2 shows some of the important parameters for both the data and the algorithm.

Table 2. Important parameters.
In summary, for preprocessing, motion correction, slice-timing correction, despiking, registering to MNI template and smoothing was done. Prior to conducting gICA, each voxel time course was variance normalized. Then gICA was used as implemented in the GIFT software (Calhoun et al., 2001; Calhoun and Adali, 2012). First, the subject-specific time dimension was reduced from 162 to 100 using principle component analysis (PCA) approach. Then, all subjects’ data were concatenated and group level dimension reduction (using PCA) was used to reduce the dimension to 100. Next, using gICA, the data was separated into maximally independent spatial maps and their associated time series (Calhoun et al., 2001; Erhardt et al., 2011). Subject-specific time series and spatial maps were calculated using back reconstruction methods. For a full explanation on gICA please (see Allen et al., 2014).
All spatial maps were visually inspected and 47 were used as components of interest based on the literature findings. For a more complete explanation of the analysis for this data set (see Damaraju et al., 2014).Here, we used the same 47 components used in that study. Consequently, for each subject we are working in a 47-dimension space. As mentioned in the first part of section “Materials and Methods,” density was calculated for each time point of each subject and high-density points for all subjects were concatenated and k means was used to cluster this matrix (we have 47 features for k means). This analysis thus represents an analysis in a high dimensional (D = 47) space. The cluster centroid that we calculated using k means was used to cluster all the time points for all subjects (k means only clustered the high-density time points). After doing this last clustering, each subject time point belongs to one of the clusters and we can calculate several metrics based on these results.
The first metric we calculated was mean dwell time. This metric is the average time each subject spends in one specific cluster (i.e., how long each individual stays in a given cluster). The next metric is called the transition number and is simply the number of times each subject changes states. For the last metric, we calculated a transition matrix that is the number of times each subject changed from one specific state to another state (if we have five clusters, this will be a 5 by 5 matrix). All these metrics were compared between HC and SZ groups.
Results
Simulation
Figure 1 depicts one of the simulations where cluster size is 50 and 3 clusters are simulated therefore we have 150 time points all in all. This data set was simulated to have three high traffic nodes (i.e., location in our defined space that has a lot of points that are in their close neighborhood) and a path spread of 0.2. As seen in this figure, points closer to high traffic nodes have higher density and therefore can pass density thresholds, while points further away from these clusters (e.g., more noisy points) have lower density.
For the first simulation scenario, we wanted to show the effect of path spread parameters on the simulation. Figure 2 shows the simulation results for different path spreads. Here filled markers show high-density points while empty markers are points with lower density values. The black squares are the high-density neighborhood. As seen here, increasing path spread causes clusters to have more overlap with each other.
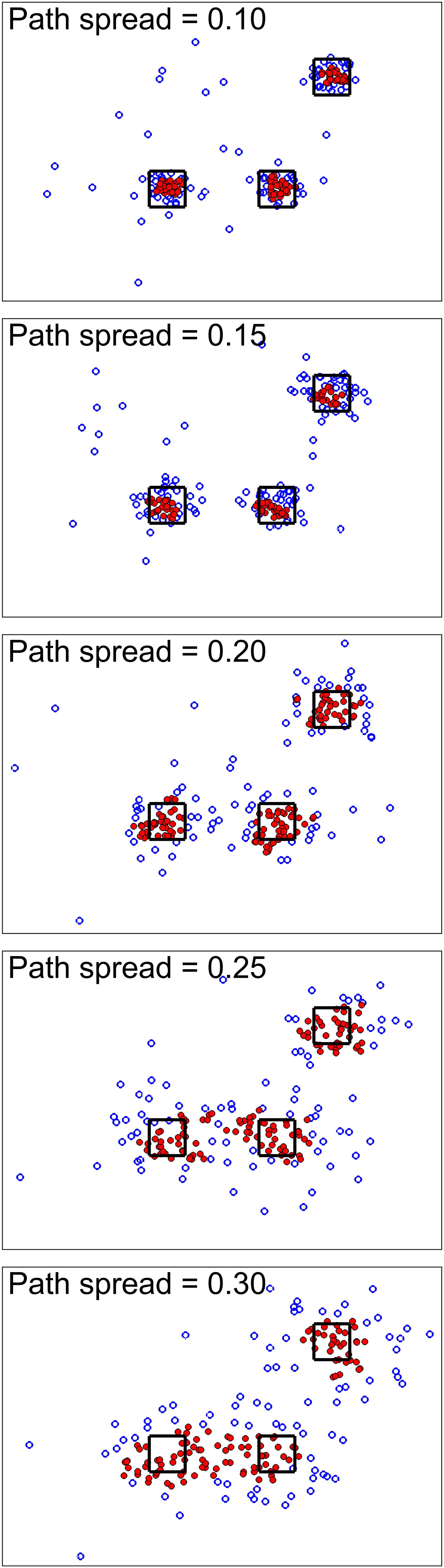
Figure 2. Simulation scenario 1. For this scenario, different simulations were done using different path spread values. Circle markers show points in our defined 2D space. The filled ones are high-density points while the empty ones are points with lower density values. The black squares are centered around the high traffic node (their size is for better visualization only). Higher path spread causes the clusters to have more overlap as was expected.
For the next scenario, our goal was to show the effect of city size (one of the analysis parameters). Figures 3, 4 show two cases for this scenario. For the first cases, the data set was simulated to have clusters with equal member numbers (60), while for the second case each cluster had a different number of members. Figure 3 shows the first case where clusters are balanced. As seen here, the points closer to the center of the squares are mostly high-density points. For all city sizes, we have an almost equal number of members from each cluster as high-density points. This is different for the second case (Figure 4). The clusters with a higher number of members (80) have more high-density points for all city size values. Please note that the smaller cluster (with 30 members) does not have any high-density points for city sizes 40 and 60 (which are larger values compared to 30). This is the reason we have added city size to our proposed approach. In contrast, if we would calculate the density of one point using all of the other points in the data, the larger clusters would dominate the results. Therefore, this city size parameter defines the cluster size detectable by the algorithm.
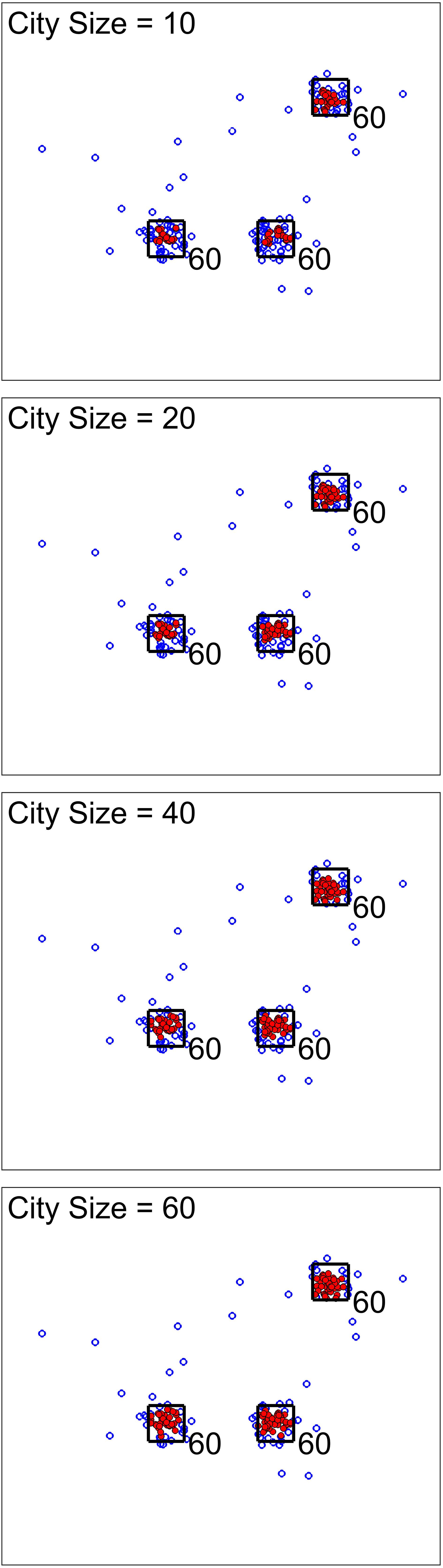
Figure 3. Scenario 2 results. This analysis shows one simulated data set with balanced clusters using different city size values. The black squares indicate the high traffic nodes used for simulation (the size is for visualization). Each marker shows one point of the simulated data in the 2D space. The filled markers are high-density points while the empty markers are low density ones. As expected, the city size parameters do not seem to significantly impact the results.
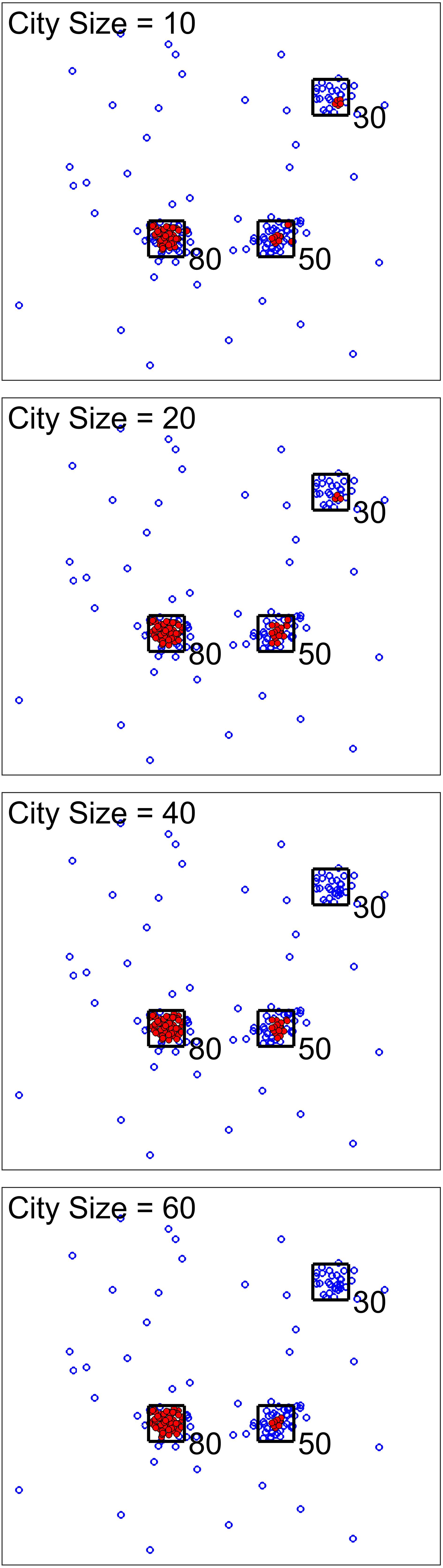
Figure 4. Scenario 2 results. We analysed one simulated data set with unbalanced clusters using different city size values. The black squares show the high traffic nodes used for simulation (the size is for visualization). Each marker shows one point of the simulated data in the 2D space. Filled markers are high-density points while the empty markers are low density ones. As seen here, larger clusters have more high-density points. In addition, using larger city sizes, we were unable to generate any high-density points for clustering with the 30 original members.
For scenario 3, we compared our proposed method to a method which uses all time points for clustering (In contrast to our approach which only uses high-density points). For different path spread values 1000 simulations were ran and the sum of distances from estimated clusters to the original clusters were calculated for each simulation. Figure 5 show the results for this scenario. It is obvious that our method has resulted in lower distances for all path spread values. This is more apparent for smaller path spreads. For this scenario around 50% of points passed the density threshold for each cluster. This value was not different between different path spread which means that no matter how much points spread around the cluster centroids around 50% of them are high density points. On the contrary, the number of high-density points for noisy points (points not in any given cluster) are below 5% of those points which is a positive finding as it shows that those points are not included in clustering part.
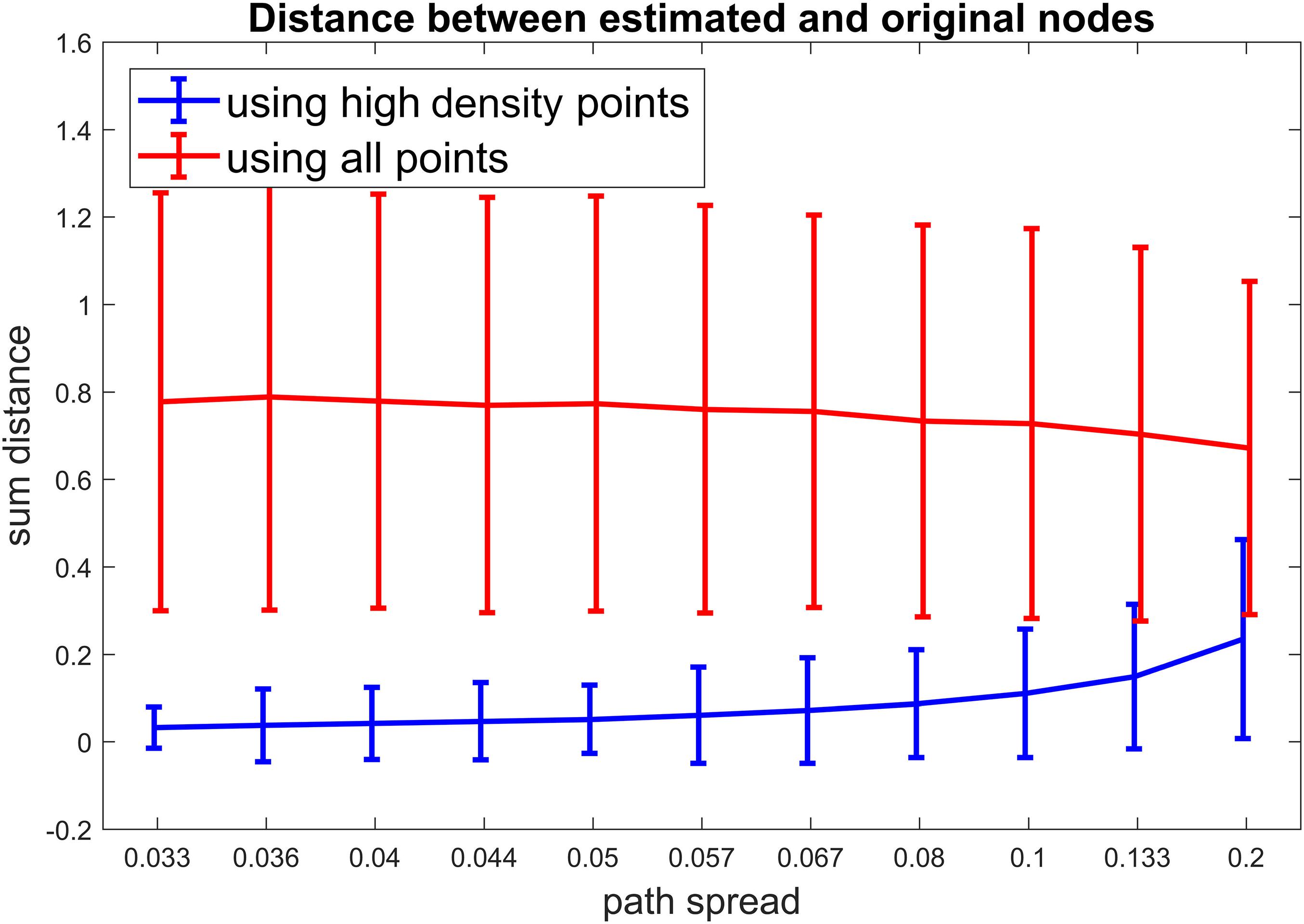
Figure 5. Scenario 3 results. For this simulation, we aimed to examine if our calculated metric improves the clustering accuracy. For each simulated time series, First all the points were included in the clustering (the red line). Next, only the high-density points were included in the clustering (the blue line). To access the accuracy of clustering, the distance between estimated cluster centroids and the true cluster centroids were calculated and summed for our three clusters. As visible in this figure, our proposed metric improves the accuracy of clustering by a noticable margin (especially for lower path spread values).
As explained in the previous section, we built a null hypothesis for the last scenario to check if the proposed feature selection step works better than a completely random method. Figure 6 shows the p values calculated using this approach. The p value for all path spread values are low and also pass a 0.01 threshold (the average p value for the largest path spread is less than 0.5e-3). These results provide evidence that our feature selection step (finding points with high density) is informative and improves the results considerably.
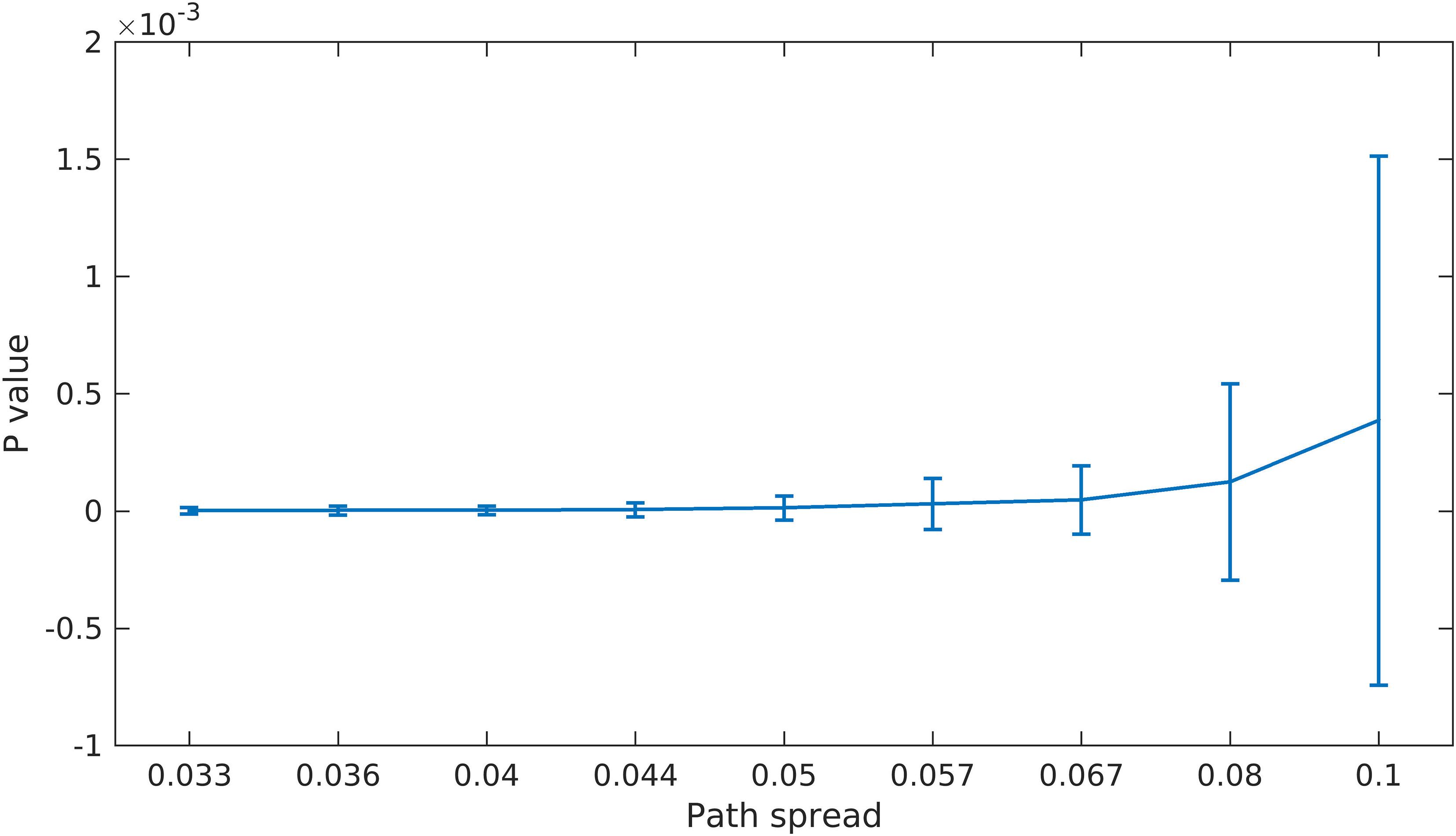
Figure 6. Scenario 4 Results. For this scenario, we first built a null space by using random points in clustering. We then calculate the p value by finding the portion of times the randomly selected points resulted in better clustering accuracy (defined as the sum of distances between estimated centroids and the true ones). As can be seen here, even for the largest path spread values the p value is small (compare to significant p value of 1 × 10–2).
Real Data
Figure 7 illustrates the selected 47 components grouped into seven connectivity domains following our earlier work (Damaraju et al., 2014).
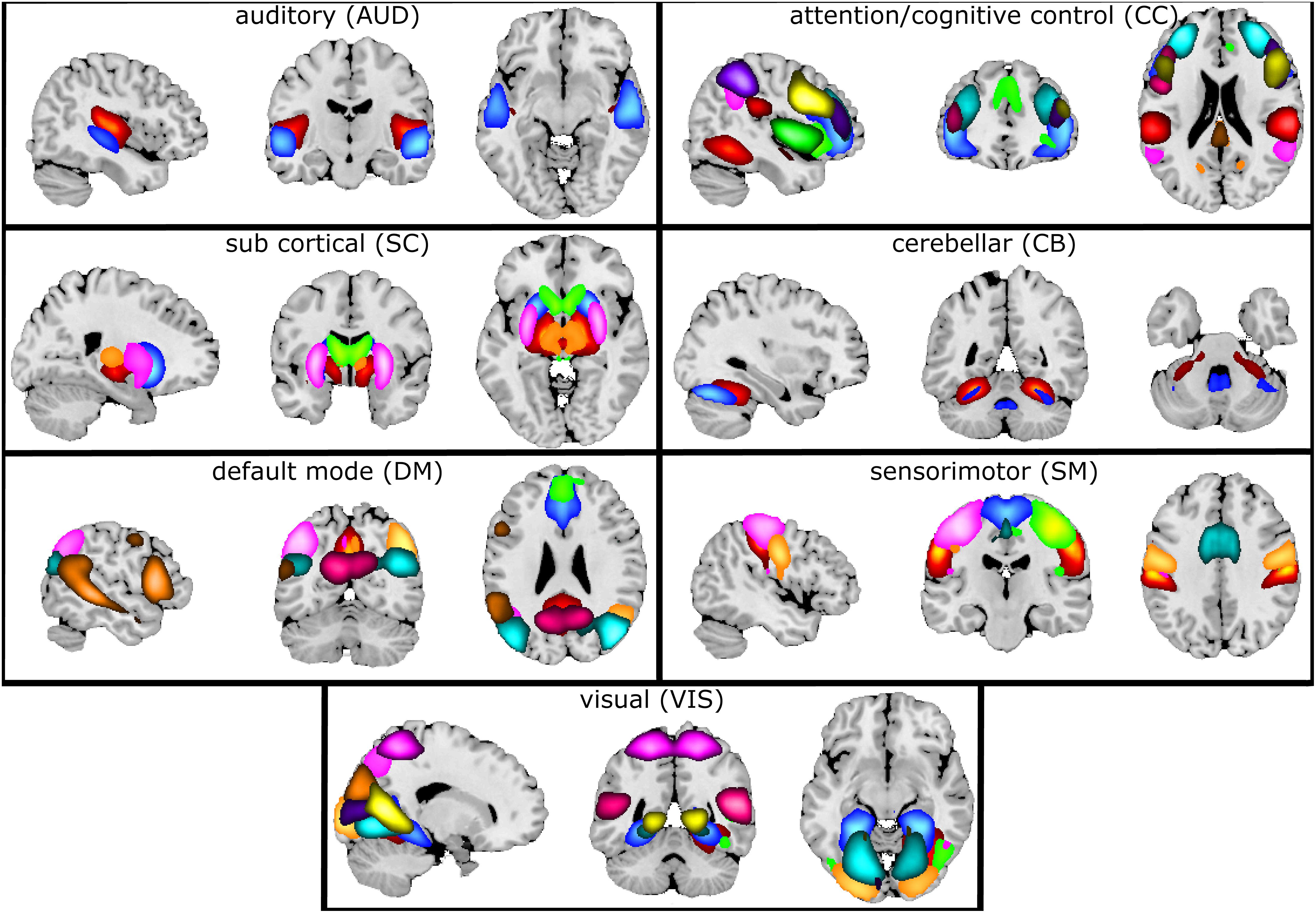
Figure 7. Composite maps of the seven connectivity domains. After gICA, 47 components were chosen and grouped into seven different connectivity domains. Each color in each domain represents a separate component.
The elbow criterion was used to determine a cluster number of 5. We used 0.9 as the cutoff for calculating density threshold based on the simulation results. City size was equal to 16 (10% of number of time points). Figure 8 shows the calculated centroids for the five clusters. The centroids (each representing one cluster) are visibly different between clusters. Cluster 1 shows negative activations for cognitive control (CC) and some components of default mode (DM). Clusters 2 and 3 show strong activations in auditory (AUD), visual (VIS), and sensorimotor (SM) domains with cluster 2 being mostly positive while cluster 3 is mostly negative. Clusters 4 and 5 show somewhat strong activations in CC and DM domains. One very interesting observation here is that cluster pairs 2–3 and 4–5 show opposite effects.
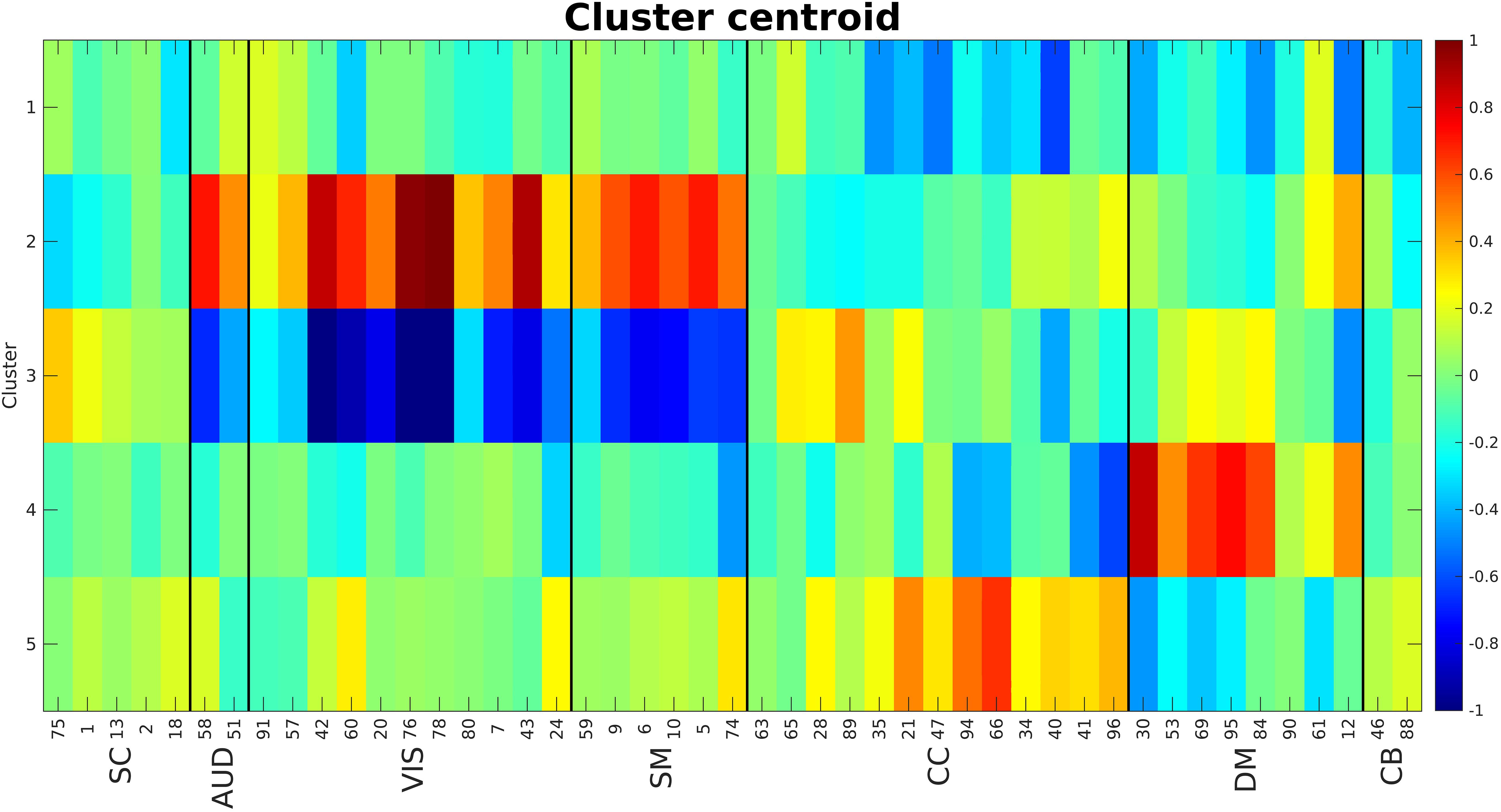
Figure 8. Cluster centroids. Cluster 1 shows a strong negative activation in CC and DM. Clusters 2 and 3 show strong (positive and negative respectively) activations in AUD, VIS and SM domains. Clusters 4 and 5 show strong activations in CC and DM. The main point here is these cluster centroids are different from each other while pairs 2–3 and 4–5 show very opposite patterns. The numbers at the bottom of the image are the component numbers.
Next, the cluster centroids were used to cluster all the original data. The first metric calculated based on these final clustering results, was the mean dwell time. Figure 9 show the mean dwell time for all 5 clusters. The p-values are corrected using FDR method. As seen, dwell time for all clusters are significantly different between HC and SZ subjects. SZ subjects tend to stay more in states 1, 4, and 5 (which show similar patterns where clusters 4 and 5 show opposite patterns). HC subjects tend to stay more in clusters 2 and 3. Figure 10 shows that the transition number between clusters is significantly higher in HC subjects compared to SZ (P < 0.05).
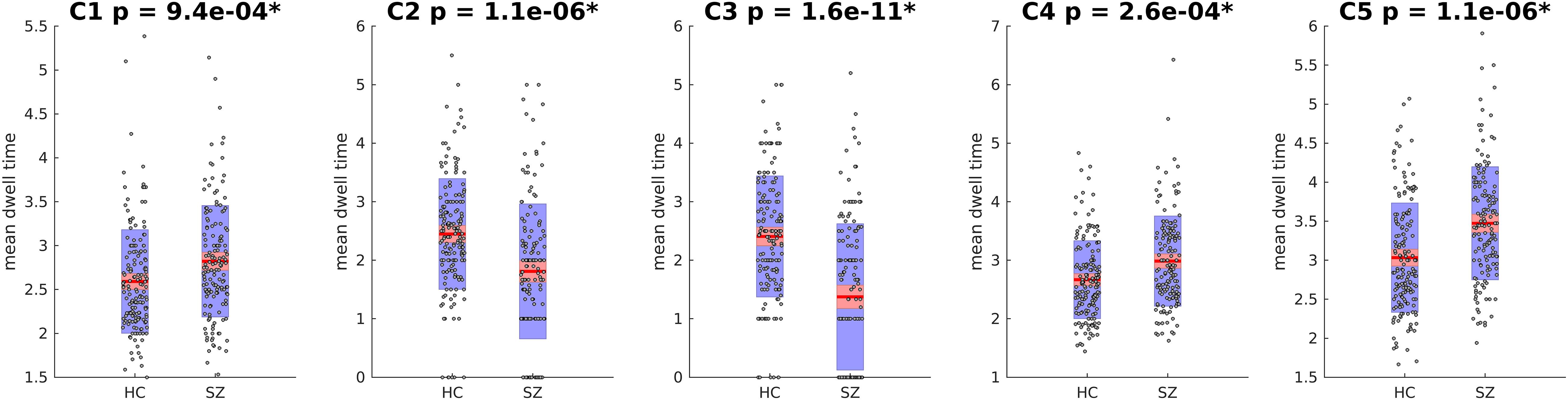
Figure 9. Mean Dwell Time for each Cluster. Mean dwell time is significantly different between HC and SZ for all clusters. SZ patients stay more in clusters 1, 4, and 5 that show strong activation in DM and CC (both positive and negative). HC subjects stay more in cluster 2 and 3 that have strong activations in AUD, VIS, and SM. Asterisk indicates p < 0.01 (p-values are corrected using FDR method).
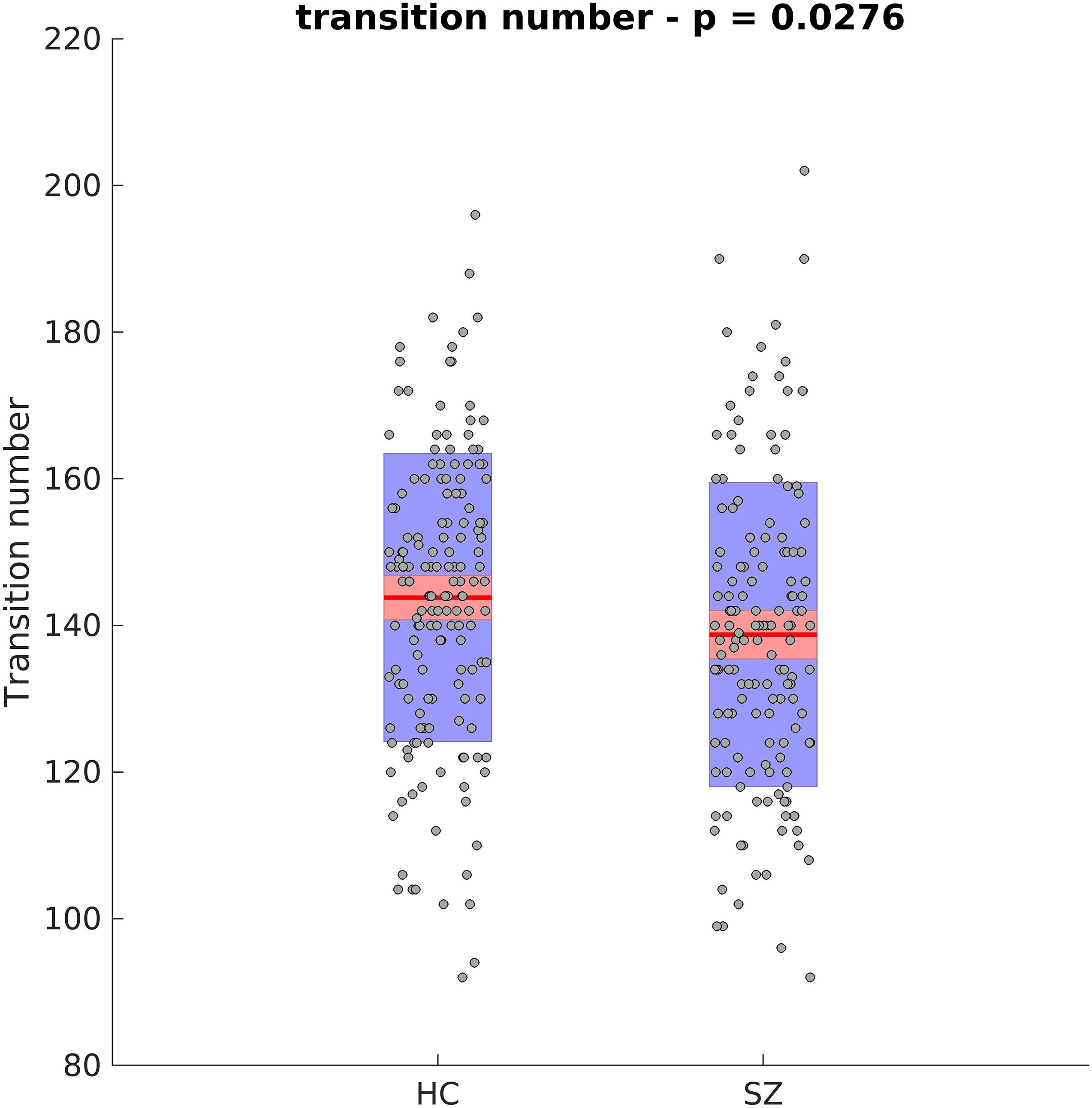
Figure 10. Transition Number Between Different Clusters. HC subjects move between different clusters more. Asterisk indicates p < 0.01.
We also calculated state transition matrices for 1 lag. FDR was used to correct for multiple comparison (p < 0.01; Figure 11). Only significant entries for the matrix are shown. The values of the matrix are the mean state transition for SZ subtracted by the mean state transition for HC.
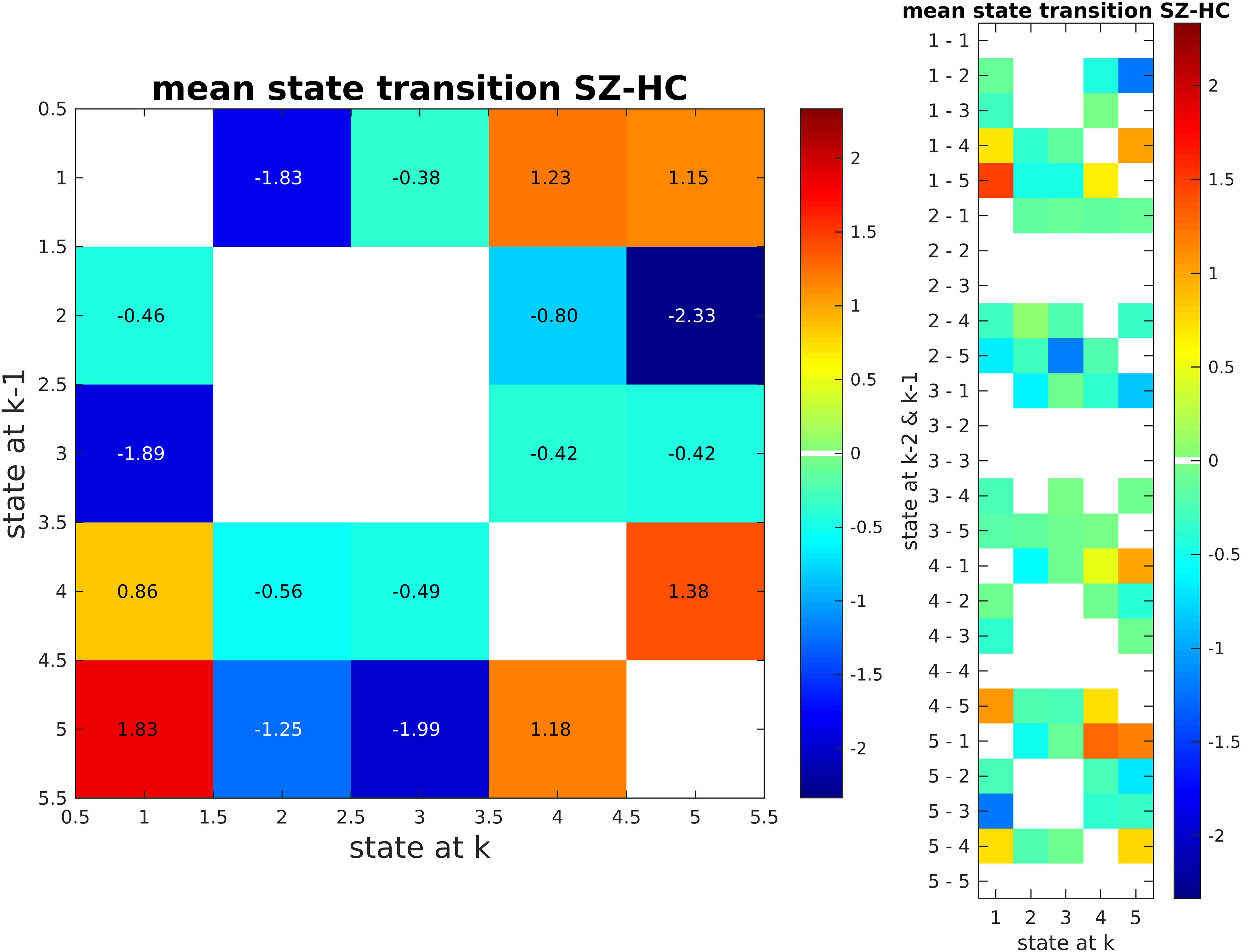
Figure 11. State Transition Matrix for Two Lag Values (SZ - HC). SZ subjects tend to transition between clusters 4 and 5. These are the clusters that SZ subjects tend to stay in more as compared to HC subjects. In contrast, HC subjects go from states 2 and 3 to states 4 and 5.
Results from different analysis parameter are show in Supplementary Figures 1–6.
Discussion
In this article, a new approach is used to study the dynamic aspects of brain functional activity. This approach allows us to identify specific activation patterns exhibiting similar behavior by analyzing the trajectory of the dynamics directly, hence avoiding the need for windowing. First, we used a simulation to validate our approach. Then, using an actual dataset including SZ patients and HCs, we have demonstrated the utility of our approach.
In the null simulation, we show that our method works well for finding the high traffic locations. It is important to note that this simulation was done in 2D, while the data occupy a high dimension and should benefit even more from our proposed approach for selecting high-density time points.
In our simulation, we found that our approach does not work as well for medium noise amplitudes. To explain this, note that if the noise amplitude is relatively high, the affected points will have a higher distance from the original high-density node; therefore, their corresponding density will be lower. This can prevent those points from passing the high-density threshold, which results in their exclusion from clustering. This is an interesting aspect of our proposed method and might point to possible noise reduction applications that require further exploration.
Using a previously analyzed dataset, we demonstrated the use of our proposed method. Results show that the state transition number is significantly higher in HC subjects. More specifically, HC subjects tend to transition between activation states more frequently than the patients. In agreement with this finding, some studies have reported diminished connectivity dynamism in SZ compared to HC using different approaches (Miller et al., 2016; Mennigen et al., 2018b).
One of the state that SZ subjects tend to occupy more (i.e., state 1) shows an overall sparse activation. This is to some degree in line with the previous study that has used the same data set (Damaraju et al., 2014). In that study, the authors reported that SZ subjects stay in states that show weak connectivities in general. This sparse connectivity has been reported in other studies as well (Garrity et al., 2007; Whitfield-Gabrieli et al., 2009; Liu et al., 2012).
In the previous study (Damaraju et al., 2014), it was reported that HC subjects stay more in states that have strong connectivity in AUD, VIS, and SM. In our study, HC subjects have a significantly higher dwell time for states 2 and 3, which shows a strong connectivity in the same three domains. In addition, this observation can be viewed as more evidence for disconnectivity in SZ that has been previously reported. For a review of the matter (see Pettersson-Yeo et al., 2011).
Beyond this, our approach shows that SZ subjects transition more between states 4 and 5 when compared to HCs, while HC subjects tend to transit between states 2 and 3 to states 4 and 5 (Figure 11). That is, SZ subjects tend to stay in states that are similar to each other (strong connectivity in DMN and CC), while HC subjects switch between states that are quite different (i.e., transit between states 2, 3 to 4, 5). A restriction in dynamic range like what we found here has been reported in another study (Miller et al., 2016).
As can be seen from Figure 8, cluster pairs of 2 and 3 have an almost opposite spatial map. This can point to an oscillatory organization of brain networks. In a similar fashion, Gutierrez-Barragan et al. (2018) reported several functional states with opposing spatial maps. We have found this phenomena in our other work using the same dataset (Faghiri et al., 2021). In our future work, we want to explore if there is any difference between SZ and HC in their ability to oscillate between the opposite state pairs.
There are some limitations to our approach. First in our proposed formulas, we have one major parameter that we have to define (city size). As we showed using our simulations, City size determines the size of detectable states (in our defined high dimensional space). This parameter is quite similar to window size in sliding window approaches, where using large window sizes results in undetected information while using short window sizes increase the standard error of the estimator. For our approach, we performed our whole pipeline on fBIRN data set using different city size values and found no notable difference between the results. As a rule of thumb we suggest using 10 percent of time courses length as the city size.
Another limitation of the proposed method is that it does not directly consider the connectivity aspect of fMRI as in other studies (e.g., calculating a windowed Pearson correlation and then clustering). However, because of the nature of gICA, the concept of connectivity is indirectly present in our results. Each component resulting from gICA can be viewed as a small connectivity between smaller regions. In addition, this method uses all component information for the analysis; therefore, we are not able to use results to study a subset of the whole components. This could be done by rerunning analysis on the subsets of the components. This is a topic for future work. Finally, although the number of subjects in this study is relatively large for a clinical study, the impact of study size cannot be overlooked. Future studies are needed for both examining the replicability of the results and the impact of study size on this specific algorithm.
Conclusion
Our method provides a new and useful approach for studying brain dynamics that analyzes the data in a high dimensional temporal space without requiring any windowing. Using this approach, we found several interesting new results related to schizophrenia. Importantly, we believe our approach provides a novel way to study brain dynamics by computing metrics directly from the high-dimensional space (in contrast to the sliding window Pearson correlation approach that looks at each of the component pairs separately). In addition, our proposed method can also be used to visualize fMRI data in low dimensions (2 or 3) while preserving interesting information.
Data Availability Statement
The data analyzed in this study is subject to the following licenses/restrictions. Due to limitations imposed by the IRB we are unable to share the raw data, but it is possible to share the derived results. In addition, all the code used in this study will be shared upon direct request. Requests to access these datasets should be directed to AF, YXNoa2FuZmEuc2hpcmF6dUBnbWFpbC5jb20=.
Ethics Statement
The participants provided their written informed consent to the institutional IRBs to participate in the study.
Author Contributions
AF: conceptualization, methodology, software, visualization, and writing – original draft. ED: data curation, writing, reviewing, and editing. AB, JF, DM, SM, BM, GP, AP, JT, JV, and TV: investigation, writing, reviewing, and editing. VC: supervision, conceptualization, writing, reviewing, editing, and funding acquisition. All authors contributed to the article and approved the submitted version.
Funding
Data collection was supported by the National Institutes of Health (NIH) grant numbers: 1U24RR021992 and NIH1U24RR025736. Data analysis was supported by the following NIH grants (R01EB020407, R01MH118695, RF1AG063153, and R01 MH-58262) and VA (I01 CX0004971, and Senior Research Career Scientist).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnins.2021.621716/full#supplementary-material
References
Allen, E. A., Damaraju, E., Plis, S. M., Erhardt, E. B., Eichele, T., and Calhoun, V. D. (2014). Tracking whole-brain connectivity dynamics in the resting state. Cereb. Cortex 24, 663–676. doi: 10.1093/cercor/bhs352
Boksman, K., Theberge, J., Williamson, P., Drost, D. J., Malla, A., Densmore, M., et al. (2005). A 4.0-T fMRI study of brain connectivity during word fluency in first-episode schizophrenia. Schizophr. Res. 75, 247–263. doi: 10.1016/j.schres.2004.09.025
Bolton, T. A. W., Morgenroth, E., Preti, M. G., and Van De Ville, D. (2020). Tapping into multi-faceted human behavior and psychopathology using fMRI brain dynamics. Trends Neurosci. 43, 667–680. doi: 10.1016/j.tins.2020.06.005
Calhoun, V. D., and Adali, T. (2012). Multisubject independent component analysis of fMRI: a decade of intrinsic networks, default mode, and neurodiagnostic discovery. IEEE Rev. Biomed. Eng. 5, 60–73. doi: 10.1109/RBME.2012.2211076
Calhoun, V. D., Adali, T., Pearlson, G. D., and Pekar, J. J. (2001). A method for making group inferences from functional MRI data using independent component analysis. Hum. Brain Mapp. 14, 140–151.
Calhoun, V. D., Miller, R., Pearlson, G., and Adali, T. (2014). The chronnectome: time-varying connectivity networks as the next frontier in fMRI data discovery. Neuron 84, 262–274. doi: 10.1016/j.neuron.2014.10.015
Chang, C., and Glover, G. H. (2010). Time-frequency dynamics of resting-state brain connectivity measured with fMRI. Neuroimage 50, 81–98. doi: 10.1016/j.neuroimage.2009.12.011
Chen, J., Sun, D., Shi, Y., Jin, W., Wang, Y., Xi, Q., et al. (2018). Dynamic alterations in spontaneous neural activity in multiple brain networks in subacute stroke patients: a resting-state fMRI study. Front. Neurosci. 12:994. doi: 10.3389/fnins.2018.00994
Damaraju, E., Allen, E. A., Belger, A., Ford, J. M., McEwen, S., Mathalon, D. H., et al. (2014). Dynamic functional connectivity analysis reveals transient states of dysconnectivity in schizophrenia. Neuroimage Clin. 5, 298–308. doi: 10.1016/j.nicl.2014.07.003
Ebisch, S. J., Mantini, D., Northoff, G., Salone, A., De Berardis, D., Ferri, F., et al. (2014). Altered brain long-range functional interactions underlying the link between aberrant self-experience and self-other relationship in first-episode schizophrenia. Schizophr. Bull. 40, 1072–1082.
Erhardt, E. B., Rachakonda, S., Bedrick, E. J., Allen, E. A., Adali, T., and Calhoun, V. D. (2011). Comparison of multi-subject ICA methods for analysis of fMRI data. Hum. Brain Mapp. 32, 2075–2095. doi: 10.1002/hbm.21170
Faghiri, A., Iraji, A., Damaraju, E., Belger, A., Ford, J., Mathalon, D., et al. (2020). Weighted average of shared trajectory: a new estimator for dynamic functional connectivity efficiently estimates both rapid and slow changes over time. J. Neurosci. Methods 334:108600. doi: 10.1016/j.jneumeth.2020.108600
Faghiri, A., Iraji, A., Damaraju, E., Turner, J., and Calhoun, V. D. (2021). A unified approach for characterizing static/dynamic connectivity frequency profiles using filter banks. Netw. Neurosci. 5, 56–82. doi: 10.1162/netn_a_00155
Faghiri, A., Stephen, J. M., Wang, Y. P., Wilson, T. W., and Calhoun, V. D. (2018). Changing brain connectivity dynamics: from early childhood to adulthood. Hum. Brain Mapp. 39, 1108–1117. doi: 10.1002/hbm.23896
Faskowitz, J., Esfahlani, F. Z., Jo, Y., Sporns, O., and Betzel, R. F. (2020). Edge-centric functional network representations of human cerebral cortex reveal overlapping system-level architecture. Nat. Neurosci. 23, 1644–1654. doi: 10.1038/s41593-020-00719-y
Fu, Z., Iraji, A., Turner, J. A., Sui, J., Miller, R., Pearlson, G. D., et al. (2021). Dynamic state with covarying brain activity-connectivity: on the pathophysiology of schizophrenia. Neuroimage 224:117385. doi: 10.1016/j.neuroimage.2020.117385
Garrity, A. G., Pearlson, G. D., McKiernan, K., Lloyd, D., Kiehl, K. A., and Calhoun, V. D. (2007). Aberrant “default mode” functional connectivity in schizophrenia. Am. J. Psychiatry 164, 450–457. doi: 10.1176/ajp.2007.164.3.450
Gifford, G., Crossley, N., Kempton, M. J., Morgan, S., Dazzan, P., Young, J., et al. (2020). Resting state fMRI based multilayer network configuration in patients with schizophrenia. Neuroimage Clin. 25:102169. doi: 10.1016/j.nicl.2020.102169
Guo, W., Yao, D., Jiang, J., Su, Q., Zhang, Z., Zhang, J., et al. (2014). Abnormal default-mode network homogeneity in first-episode, drug-naive schizophrenia at rest. Prog. Neuro Psychopharmacol. Biol. Psychiatry 49, 16–20.
Gutierrez-Barragan, D., Basson, M. A., Panzeri, S., and Gozzi, A. (2018). Oscillatory brain states govern spontaneous fMRI network dynamics. bioRxiv [Preprint] doi: 10.1101/393389
Handwerker, D. A., Roopchansingh, V., Gonzalez-Castillo, J., and Bandettini, P. A. (2012). Periodic changes in fMRI connectivity. Neuroimage 63, 1712–1719. doi: 10.1016/j.neuroimage.2012.06.078
Hutchison, R. M., Womelsdorf, T., Allen, E. A., Bandettini, P. A., Calhoun, V. D., Corbetta, M., et al. (2013). Dynamic functional connectivity: promise, issues, and interpretations. Neuroimage 80, 360–378. doi: 10.1016/j.neuroimage.2013.05.079
Iraji, A., Faghiri, A., Lewis, N., Fu, Z., Rachakonda, S., and Calhoun, V. D. (2020a). Tools of the trade: estimating time-varying connectivity patterns from fMRI data. Soc. Cogn. Affect. Neurosci. doi: 10.1093/scan/nsaa114 [Epub ahead of print],
Iraji, A., Lewis, N., Faghiri, A., Fu, Z., DeRamus, T., Abrol, A., et al. (2020b). “Functional multi-connectivity: a novel approach to assess multi-way entanglement between networks and voxels,” in Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI) (Iowa City, IA), 1698–1701.
Karahanoglu, F. I., and Van De Ville, D. (2015). Transient brain activity disentangles fMRI resting-state dynamics in terms of spatially and temporally overlapping networks. Nat. Commun. 6:7751. doi: 10.1038/ncomms8751
Karahanoğlu, F. I., and Van De Ville, D. (2017). Dynamics of large-scale fMRI networks: deconstruct brain activity to build better models of brain function. Curr. Opin. Biomed. Eng. 3, 28–36. doi: 10.1016/j.cobme.2017.09.008
Kottaram, A., Johnston, L. A., Cocchi, L., Ganella, E. P., Everall, I., Pantelis, C., et al. (2019). Brain network dynamics in schizophrenia: reduced dynamism of the default mode network. Hum. Brain Mapp. 40, 2212–2228. doi: 10.1002/hbm.24519
Liu, H., Kaneko, Y., Ouyang, X., Li, L., Hao, Y., Chen, E. Y., et al. (2012). Schizophrenic patients and their unaffected siblings share increased resting-state connectivity in the task-negative network but not its anticorrelated task-positive network. Schizophr. Bull. 38, 285–294. doi: 10.1093/schbul/sbq074
Liu, X., and Duyn, J. H. (2013). Time-varying functional network information extracted from brief instances of spontaneous brain activity. Proc. Natl. Acad. Sci. U.S.A. 110, 4392–4397. doi: 10.1073/pnas.1216856110
Lurie, D. J., Kessler, D., Bassett, D. S., Betzel, R. F., Breakspear, M., Kheilholz, S., et al. (2020). Questions and controversies in the study of time-varying functional connectivity in resting fMRI. Netw. Neurosci. 4, 30–69. doi: 10.1162/netn_a_00116
Mennigen, E., Miller, R. L., Rashid, B., Fryer, S. L., Loewy, R. L., Stuart, B. K., et al. (2018a). Reduced higher-dimensional resting state fMRI dynamism in clinical high-risk individuals for schizophrenia identified by meta-state analysis. Schizophr. Res. 201, 217–223.
Mennigen, E., Miller, R. L., Rashid, B., Fryer, S. L., Loewy, R. L., Stuart, B. K., et al. (2018b). Reduced higher-dimensional resting state fMRI dynamism in clinical high-risk individuals for schizophrenia identified by meta-state analysis. Schizophr. Res. 201, 217–223. doi: 10.1016/j.schres.2018.06.007
Mennigen, E., Rashid, B., and Calhoun, V. D. (2019). “Connectivity and dysconnectivity: a brief history of functional connectivity research in schizophrenia and future directions,” in Connectomics, eds B. C. Munsell, G. Wu, L. Bonilha, and P. J. Laurienti (Amsterdam: Elsevier), 123–154.
Miller, R. L., Yaesoubi, M., Turner, J. A., Mathalon, D., Preda, A., Pearlson, G., et al. (2016). Higher dimensional meta-state analysis reveals reduced resting fMRI connectivity dynamism in schizophrenia patients. PLoS One 11:e0149849. doi: 10.1371/journal.pone.0149849
Mwansisya, T. E., Hu, A., Li, Y., Chen, X., Wu, G., Huang, X., et al. (2017). Task and resting-state fMRI studies in first-episode schizophrenia: a systematic review. Schizophr. Res. 189, 9–18. doi: 10.1016/j.schres.2017.02.026
Omidvarnia, A., Pedersen, M., Walz, J. M., Vaughan, D. N., Abbott, D. F., and Jackson, G. D. (2016). Dynamic regional phase synchrony (DRePS): an instantaneous measure of local fMRI connectivity within spatially clustered brain areas. Hum. Brain Mapp. 37, 1970–1985. doi: 10.1002/hbm.23151
Pettersson-Yeo, W., Allen, P., Benetti, S., McGuire, P., and Mechelli, A. (2011). Dysconnectivity in schizophrenia: where are we now? Neurosci. Biobehav. Rev. 35, 1110–1124. doi: 10.1016/j.neubiorev.2010.11.004
Rashid, B., Arbabshirani, M. R., Damaraju, E., Cetin, M. S., Miller, R., Pearlson, G. D., et al. (2016). Classification of schizophrenia and bipolar patients using static and dynamic resting-state fMRI brain connectivity. Neuroimage 134, 645–657. doi: 10.1016/j.neuroimage.2016.04.051
Sakoglu, U., Pearlson, G. D., Kiehl, K. A., Wang, Y. M., Michael, A. M., and Calhoun, V. D. (2010). A method for evaluating dynamic functional network connectivity and task-modulation: application to schizophrenia. MAGMA 23, 351–366. doi: 10.1007/s10334-010-0197-8
Shakil, S., Lee, C. H., and Keilholz, S. D. (2016). Evaluation of sliding window correlation performance for characterizing dynamic functional connectivity and brain states. Neuroimage 133, 111–128. doi: 10.1016/j.neuroimage.2016.02.074
Shine, J. M., Koyejo, O., Bell, P. T., Gorgolewski, K. J., Gilat, M., and Poldrack, R. A. (2015). Estimation of dynamic functional connectivity using Multiplication of Temporal Derivatives. Neuroimage 122, 399–407. doi: 10.1016/j.neuroimage.2015.07.064
Thorndike, R. L. (1953). Who belongs in the family? Psychometrika 18, 267–276. doi: 10.1007/bf02289263
Vidaurre, D., Abeysuriya, R., Becker, R., Quinn, A. J., Alfaro-Almagro, F., Smith, S. M., et al. (2018). Discovering dynamic brain networks from big data in rest and task. Neuroimage 180(Pt B), 646–656. doi: 10.1016/j.neuroimage.2017.06.077
Whitfield-Gabrieli, S., Thermenos, H. W., Milanovic, S., Tsuang, M. T., Faraone, S. V., McCarley, R. W., et al. (2009). Hyperactivity and hyperconnectivity of the default network in schizophrenia and in first-degree relatives of persons with schizophrenia. Proc. Natl. Acad. Sci. U.S.A. 106, 1279–1284. doi: 10.1073/pnas.0809141106
Keywords: functional magnetic resonance imaging, brain dynamics, independent component analyses, resting state– fMRI, density clustering
Citation: Faghiri A, Damaraju E, Belger A, Ford JM, Mathalon D, McEwen S, Mueller B, Pearlson G, Preda A, Turner JA, Vaidya JG, Van Erp T and Calhoun VD (2021) Brain Density Clustering Analysis: A New Approach to Brain Functional Dynamics. Front. Neurosci. 15:621716. doi: 10.3389/fnins.2021.621716
Received: 26 October 2020; Accepted: 18 March 2021;
Published: 13 April 2021.
Edited by:
Kamran Avanaki, University of Illinois at Chicago, United StatesCopyright © 2021 Faghiri, Damaraju, Belger, Ford, Mathalon, McEwen, Mueller, Pearlson, Preda, Turner, Vaidya, Van Erp and Calhoun. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ashkan Faghiri, YXNoa2FuZmEuc2hpcmF6dUBnbWFpbC5jb20=