 Jing-Shan Huang
Jing-Shan Huang Yang Li1
Yang Li1 Bin-Qiang Chen
Bin-Qiang Chen Chuang Lin
Chuang Lin
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
BRIEF RESEARCH REPORT article
Front. Neurosci. , 30 September 2020
Sec. Neuroprosthetics
Volume 14 - 2020 | https://doi.org/10.3389/fnins.2020.00808
This article is part of the Research Topic Advanced Deep-Transfer-Leveraged Studies on Brain-Computer Interfacing View all 23 articles
The classification of electroencephalogram (EEG) signals is of significant importance in brain–computer interface (BCI) systems. Aiming to achieve intelligent classification of EEG types with high accuracy, a classification methodology using sparse representation (SR) and fast compression residual convolutional neural networks (FCRes-CNNs) is proposed. In the proposed methodology, EEG waveforms of classes 1 and 2 are segmented into subsignals, and 140 experimental samples were achieved for each type of EEG signal. The common spatial patterns algorithm is used to obtain the features of the EEG signal. Subsequently, the redundant dictionary with sparse representation is constructed based on these features. Finally, the samples of the EEG types were imported into the FCRes-CNN model having fast down-sampling module and residual block structural units to be identified and classified. The datasets from BCI Competition 2005 (dataset IVa) and BCI Competition 2003 (dataset III) were used to test the performance of the proposed deep learning classifier. The classification experiments show that the recognition averaged accuracy of the proposed method is 98.82%. The experimental results show that the classification method provides better classification performance compared with sparse representation classification (SRC) method. The method can be applied successfully to BCI systems where the amount of data is large due to daily recording.
Brain–computer interface (BCI) is one of the research hotspots in the fields of biomedicine and signal processing in recent years. Brain–computer interface technology is a human–computer interaction method based on brain signals. It provides a communication channel for non-neuromuscular control. Brain–computer interface is a communication system that enables the human brain to interact with the external environment without relying on the peripheral nervous system and muscles.
In the BCI system, electroencephalography (EEG) signal is the manifestation of brain nerve electrical signals. It is also the basis of signal processing in the system. Electroencephalography signals comprehensively reflect the physical and chemical activities of the nervous system and are powerful tools for analyzing neural activity and brain conditions (Wu et al., 2008). Any changes in brain function and structure caused by neurological brain diseases can lead to abnormal brain electrical signals. In clinical medicine, the information processing of EEG signals not only provides an objective basis for the diagnosis of certain brain diseases, but also provides effective treatment for some brain diseases (Thornton, 2002). For a long time, doctors need to manually detect and analyze the waveform characteristics of EEG, with intensive labor and strong subjectivity. Therefore, the classification of EEG signals is of great significance to the identification, morbid prediction, and prevention of brain diseases.
In the BCI, the EEG signal is the main medium for human–computer interaction. An important part of the BCI system is processing the collected EEG signals to determine the type of commands issued by the brain. Motor imaging (MI) signal is a type of EEG signals. It refers to brain signals generated by imagining limb movement without actual limb movement. By analyzing the MI signal, it is possible to judge the imaginary’s movement intention and operate the external device. At present, the motion imaging control has great potential application value in various fields such as sports function rehabilitation, motor function assistance, and so on. Therefore, the MI signal becomes the most commonly used signal in the BCI. It is also the EEG signal studied in this article. Because of the non-stationarity of the EEG signal and the influence of a large number of background waveforms and artifacts, EEG classification is a challenging problem. At present, researchers have done a lot of work in various fields to study the feature extraction and classification of EEG signals.
Common spatial patterns (CSPs) is a popular method of extracting features in EEG studies. The CSP method has been applied successfully in many EEG classification studies (Ramoser et al., 2000; Grossewentrup and Buss, 2008; Mousavi et al., 2011; Keng et al., 2012). Other well-known feature extraction and dimension reduction methods such as principal component analysis and independent component analysis are also used frequently to improve the EEG classification accuracy (Ince et al., 2006; Guo et al., 2008; Talukdar et al., 2014). Autoregressive model and power spectral density estimation are also common feature extraction algorithms for EEG classification (Argunsah and Cetin, 2010; Seth et al., 2017). In the classification part, the frequently used classification methods include linear discriminant analysis (Rajaguru and Prabhakar, 2017), Bayesian method (Bashashati et al., 2016), BP neural network (Gao et al., 2012), support vector machine (SVM) (Liu et al., 2012), and so on (Wang et al., 2006; Yang et al., 2012; Roeva and Atanassova, 2016). The characteristics of EEG signals mainly include the following aspects: randomness, weakness, catastrophe, non-stationarity, low frequency, and non-linearity. Therefore, it is difficult to determine the representation and appropriate description (Gao et al., 2018).
Sparse representation is a fast developing field by constructing sparse linear models. It represents a given input signal as a linear superposition of base signals selected from a predetermined dictionary (Chen, 2016). It can find a suitable dictionary for ordinary densely expressed signal samples, and convert the samples into a suitable sparse expression form. Sparse representation can simplify learning tasks and reduce model complexity. Sparse representation has a large number of applications in the fields of signal acquisition, denoising, and image restoration (Elad and Aharon, 2006; Yang and Li, 2009; Li et al., 2013). The classification of EEG signals based on sparse representation is also developing gradually. Shin et al. (2015) proposed simple adaptive sparse representation-based classification (SRC) schemes for EEG classification, and the proposed adaptive schemes show relatively improved classification accuracy as compared to conventional methods without requiring additional computation. Zhou et al. (2012) proposed a method to learn a new dictionary with smaller size and more discriminative ability for the classification, and the experimental results of the EEG classification show that the proposed method outperforms the SRC method. Sreeja and Samanta (2020) proposed a weighted SRC (WSRC) for classifying MI signals to further boost the proficiency of SRC technique, and the experimental results substantiate that WSRC is more efficient and accurate than SRC.However, there is a contradiction between dictionary size and algorithm recognition accuracy.
Deep learning methodologies show outstanding performances in pattern recognition problems (Huang et al., 2019). Although the traditional pattern recognition method has been widely adopted, there is still a problem of relying on experience and prior knowledge in the process of manually selecting EEG signal features. In addition, feature extraction algorithms and feature classification algorithms use different objective functions so as to affect the pattern recognition accuracy. The deep learning neural network can extract more distinguishable and interpretable features of EEG signals. Meanwhile, the classification method based on deep learning neural network includes feature extraction and feature classification in a frame so as to avoid the loss of signal information caused by separating the two steps. Therefore, EEG classification based on deep learning related techniques has become a research hotspot. A deep belief network model (An et al., 2014)was applied for two class motor imagery (MI) classification, and the proposed model was shown more successful than the SVM method. Tsinalis et al. (2016) used convolutional neural networks (CNNs) to learn a single-channel EEG-based classification task filter for the automatic scoring of the sleep stage.Yang et al. (2015) used CNN to classify MI EEG signals. Chambon et al. (2018) proposed an end-to-end deep learning method to extract information from the EEG channel, which can finally correctly classify 91% of sleep stages from EEG signal. A recurrent CNN architecture was proposed by Bashivan et al. (2015) to model cognitive events from EEG data. A deep learning network with principal component–based covariate shift adaptation was proposed by Jirayucharoensak et al. (2014) for automatic emotion recognition.
Because the EEG signal contains a lot of noise and redundant information, it is not effective to obtain classification information directly from it. The sparse representation method can effectively remove the redundant information and retain the feature information that is beneficial to classification to best express the signal feature information. Meanwhile, the deep learning neural network has a wide range of applications in pattern recognition. Therefore, we combine the advantages of these two methods. We innovatively use the sparse features of the EEG signal as the input terminal of the deep neural network model and train the deep neural network model parameters to realize the automatic classification of the EEG signal.
In this article, we propose an intelligent EEG classification method based on sparse representation and enhanced deep learning networks. The features of the EEG signal are obtained through the CSP algorithm, and then the redundant dictionary with sparse representation is constructed based on these features. Subsequently, the sparse features were utilized as input of the fast compression deep learning networks to achieve the classification of EEG signals. The dataset downloaded from the website of BCI Competition 2005 (dataset IVa) and BCI Competition 2003 (dataset III) was used as the training and testing data. The classification results using the proposed method can reach an averaged accuracy of 98.82%.
The rest of this article is organized as follows. In Methods, we explain the methodology used for the EEG classification, including methodology overview, database and segmentation, and data preprocessing. We also explain the sparse representation classification model and the proposed fast compression deep learning networks. In Results, numerical evaluation and experimental results of EEG classification are shown, including evaluation metrics and the experimental classification results. Finally, we give the discussion and conclusion in Discussion.
The overall procedures of the proposed EEG classification method based on sparse representation and fast compression deep learning networks are shown in Figure 1. The original EEG signals were shared by the BCI Competition database (Blankertz et al., 2006). First, EEG waveforms are segmented into subsignals. Then the EEG signal features are obtained through the CSP algorithm, and the redundant dictionary with sparse representation is constructed based on these EEG signal features. Subsequently, the sparse features were utilized as input of the fast compression deep learning networks to complete the classification of EEG signals. Finally, EEG types are classified by the fast compression residual CNNs (FCRes-CNNs) classifier intelligently.

Figure 1. Overall procedures in EEG classification based on the proposed method.
The experimental data in this article comes from the databases in BCI Competition 2005 (dataset IVa) and BCI Competition 2003 (dataset III). The databases contain datasets recorded by five different healthy subjects (aa, al, av, aw, ay). All five subjects underwent BCI experiments with three MI exercises of left hand, right hand, and right foot. In this experiment, only two types of right hand (R) and right foot (F) were used for data analysis, and they are named class 1 and class 2. Each EEG signal has 118channels. The common goal of BCI Competitions was to classify these MI tasks by using EEG signals recorded at C3, Cz, and C4 channels.First, the EEG signal is filtered by a bandpass filter of 0.05 to 200 Hz. Then, the EEG signal is digitized at a frequency of 1,000 Hz. Finally, the EEG signal is down-sampled to 100 Hz, and it is analyzed offline by the Berlin research team.
During the experiment, the subjects were seated in a comfortable chair, with their arms resting naturally on the armrests. At the beginning of the experiment, a visual cue in the form of a shoulder appeared in the center of the screen, informing the subjects of the MI task to be performed. The subject’s imagination time was 3.5 s. After the end of the MI, the subjects had a short time to rest and the rest time varied randomly from 1.75 to 2.25 s.
First, EEG waveforms need to be segmented to the 3-s time samples, and140 experimental samples can be achieved for each type of EEG signal. To reduce the interference from other sources such as electrooculogramsand electromyograms, 8- to 15-Hz bandpass filters were applied in this article (Gao et al., 2018). The CSP method is an effective method in the feature extraction problem of motion imaging signals. It is suitable for two classes (conditions) of multichannel EEG-baBCIs, so this article adopts the CSP method to filter the EEG signals and extract energy features. When the number of CSP filters is set as 32, after filtering operation, training and testing EEG samples can be converted to 32 CSP eigenvalues, which can be used for data classification.
Sparse representation represents a given input signal as a linear superposition of a small set of base signals selected from a predetermined dictionary. It can be said that the problem of sparse representation is a problem of representing a given input signal as simply as possible. For the EEG signals, a feature vector can be obtained by CSP (Legendre and Fortin, 1989):
where m is the sample dimension. If all the characteristic vector signals from different types of EEG signals are put in A, the matrix A can be written as the following form:
Rajaguru and Prabhakar (2017) declared that if the training data from the ith category are enough, the test sample y from the same category can be shown as a linear combination of the training set associated with subject :
where ∝ is the coefficient vector, and its elements are not all zero. By concatenating Ai, the dictionary matrix A for all k classes can be acquired as i = 1,2,…….k. The dictionary can be given as follows:
If the EEG feature signal y is the tested signal, y can be written as a linear combination of.
allnk training data.
where x = [v1,1,v2,2,…,vk,n]T ∈ Rnk are the coefficients vectors. In the ideal case,
x = [0,0…….,vi,1,vi,2,…,0,0…….,0] is a vector, which is mostly zero value except for those elements corresponding to the class of ith; thus, the corresponding class of EEG feature signals can be classified. The two types of sparse presentation classification operations are shown in Figure 2.
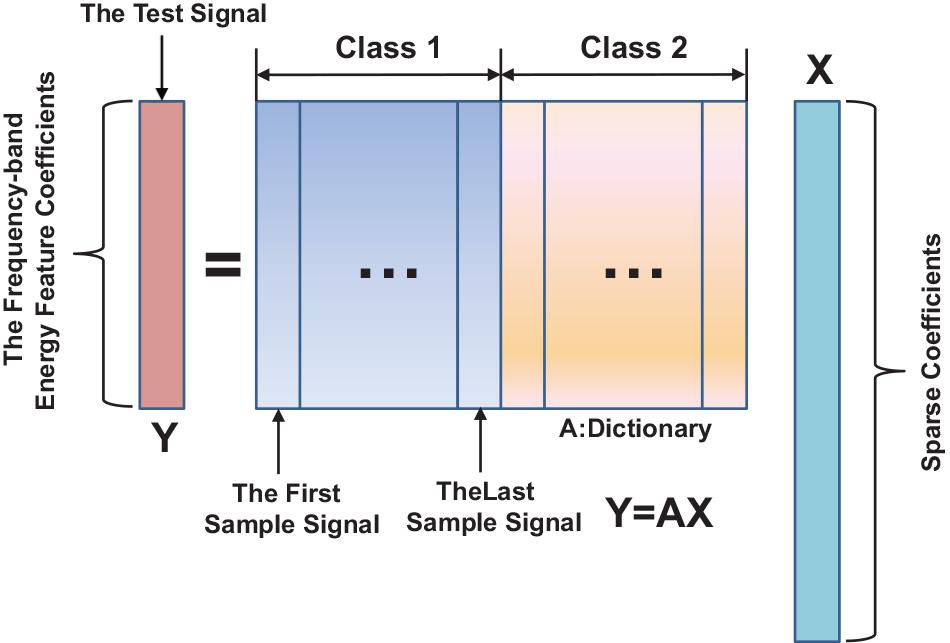
Figure 2. Sparse representation classification model.
The test sample feature vector can be expressed as a linear combination of feature vectors of the training sample. The sparse coefficients x are used to encode the identity information of the test sample. The sparse coefficients are obtained by solving the linear equation of (5). Because the number of CSP filters is smaller than the number of training samples, the solution of x is not unique so that Eq.5 is underdetermined. New theories of sparse representation and compressed sensing have pointed out that L1 norm optimization can be used to solve underdetermined linear equations as long as x is sufficiently sparse. Based on the vector x and the test signal y, L1-norm minimization equation can be listed as follows:
In the ideal case, when we obtained the estimate, it should have non-zero element corresponding to y. Through analyzing the indices of the non-zero elements in , the class of y can be determined. However, because of the modeling limitations and noise, is not exactly zero but is close to zero. To resolve this problem, the following equation will be calculated generally as follows:
The test samples are classified according to the approximation residuals. The smaller the approximation residual, the closer the test sample is to this category. Therefore, the test sample is discriminated as the smallest category that approximates the residual. For each class i,δi(x) is obtained by nulling all the elements corresponding to the other class, then class i can be classified by analyzing the residuals, that is:
Convolutional neural network is a special deep feedforward neural network designed by the inspiration of the concept of “receptive field” in the field of biological neuroscience (Liu, 2018). For traditional CNNs, the learning ability of the network will increase as the depth of the network increases. Meanwhile, the convergence speed of the network will slow down, and the time required for training will also become longer (Huang et al., 2020). The aim of residual networks is to address the degradation problem, which is defined as the decrease in accuracy as depth becomes greater than a certain threshold (He et al., 2016). Convolutional neural networks composed of residual block local deep neural networks units can address the degradation problem by facilitating the learning of identity mappings and solve difficulty in tuning of deep networks.
The residual neural network draws on the ideas of Highway networks (Srivastava et al., 2015). When the number of network layers reaches a certain threshold, the learning rate will decrease, and there is a risk of accuracy rate decline. The input of each layer in the general conventional CNN is derived from the output of the previous layer (Qin, 2019). It will be easily paralyzed if a network with many layers is performed with gradient calculations. The network structure of the residual network is similar to a “short circuit” structure. The output of the previous layers in the residual network does not go through the middle multiple network layers but directly serves as the input part of the network layer behind (Ji, 2019). Therefore, the residual structure has transformed the learning objectives. It no longer learns a complete mapping relationship from input to output, but the difference between the optimal solution H(x) and the input congruent mapping x (Huang et al., 2020). The residual calculation formula is as follows:
The residual network can be regarded as a type of architecture consisting of a stack of residual blocks. The input data in the residual network come from different combinations of the previous network structure. This method introduces sufficient reference information to extract the effective features of the input EEG signal data (Liu, 2018). Because the paths in the network are relatively independent of each other, the regularity of the deep learning network structure is improved greatly.
In this section, we propose the FCRes-CNNs. As shown in Figure 3, the FCRes-CNN is mainly composed of a fast down-sampling module, three residual convolution modules, and a classification module. In the proposed FCRes-CNN model, the learning rate is set as 0.001, and the batch size parameter is set as 2,500.
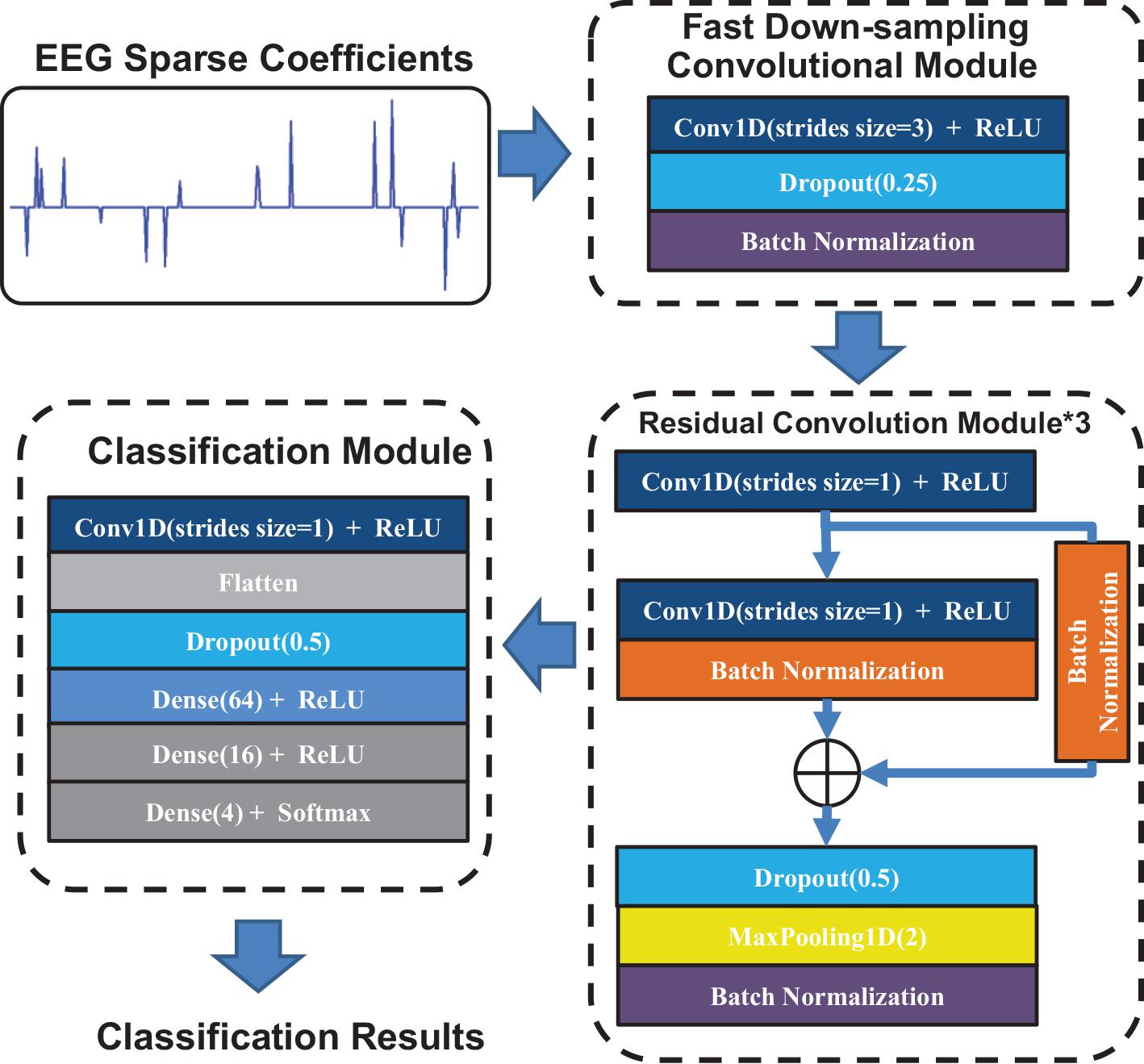
Figure 3. The architecture of the proposed FCRes-CNN.
In the proposed convolutional networks, convolutional layer with a stride of three is applied in the fast down-sampling module. Although a pooling layer also has effect of data compression, reducing overfitting, it will lose most of the original signal information while increasing network depth and spatial information loss due to the averaging nature of the pooling layer. Compared with the pooling layer, the convolutional layer with a large stride can adaptively learn the convolution kernel while compressing the input data (Huang et al., 2020). Therefore, we applied a convolutional layer with a large stride instead of a pooling layer in the fast down-sampling module.
The fast down-sampling module consists of a convolutional layer, a random dropout layer, and a batch-normalization layer. The convolutional layer with a stride of 3 is the main part of the fast down-sampling module. A random dropout layer and a batch-normalization layer follow the convolutional layer to enhance the generalization of the networks model. The fast down-sampling module can effectivelysimplify the calculation of deep network models, reduce data redundancy, and promote model learning (Huang et al., 2020).
Convolutional layers in series are applied in the residual convolution module, which are followed by residual short circuit. Then, a random dropout layer is added after the convolutional layer, and the max-pooling layer is applied to down-sample the EEG signal feature vectors.
In the classification module, a convolution layer is first used to reduce the dimension of the feature vectors. Then, a flattened layer follows the convolution layer. After the flattened layer, a random dropout layer is applied to prevent overfitting.
The accuracy and loss were used as the evaluation criteria in the pattern recognition field.Therefore, we used the two evaluation criteria for the classification performance of EEG types. The accuracy and loss were calculated through Eqs10 and 11.
where TP stands for true positive, meaning the correct classification as class 1 of EEG; TN stands for true negative, meaning correct classification as class 2 of EEG; FP stands for false positive, meaning incorrect classification as class 1 of EEG; and FN represents false negative, meaning incorrect classification as class 2of EEG (Yin et al., 2016).
As for the metric of loss, it is defined as the difference between the predicted value of the EEG classification model and the true value for aspecific EEG sample (Huang et al., 2020). In this study, the mathematical expressionof categorical cross entropy loss is shown as Eq.11.
where n represents the number of EEGsamples; m represents the number of EEG types; represents the predictive output value; and y represents the actual value.
In classification for the EEG signals of classes 1 and 2, each class can get 140 groups of 32 eigenvalues after the above data processing. Based on the training samples, the redundant dictionaries of sparse classification algorithm were constructed by using the CSP eigenvalues obtained by classes 1 and 2. Then, we scrambled all the EEG training sample data randomly and then selected the last 100 samples as the testing set. This approach ensures that the distribution of the training set and testing set is random and uncertain, and it can better reflect the classification effect of the proposed classifier.
The classification of EEG signals was completed based on the classification algorithm described insection “Methods.” The raw EEG waveforms are segmented into subsignals. The features of the EEG signal are obtained through the CSP algorithm. Then the redundant dictionary with sparse representation is constructed based on these features. Finally, the sparse features were utilized as input of the fast compression deep learning networks to complete the classification of EEG signals. The experiment runs on a PC with 16GB of memory and 16GB of GPU memory.
Figure 4 represents the accuracy and loss curves of the sparse representation algorithm (SRC) and the proposed classification method (SRC +FCRes-CNN). From Figure 4, we can find that the accuracy value curve convergence rate of the proposed model is faster than that of SRC model, and the final accuracy convergence value of the proposed model is also much higher than that of SRC model. The loss value curve convergence rate of the proposed model is faster than that of SRC model, and the final loss convergence value of the proposed model is also much lower than that of SRC model. From these results, we can conclude that the proposed model achieves a higher average accuracy with lower loss than the SRC model based on the classification results of EEG signals. The proposed model outperforms the SRC model in the EEG classification application.
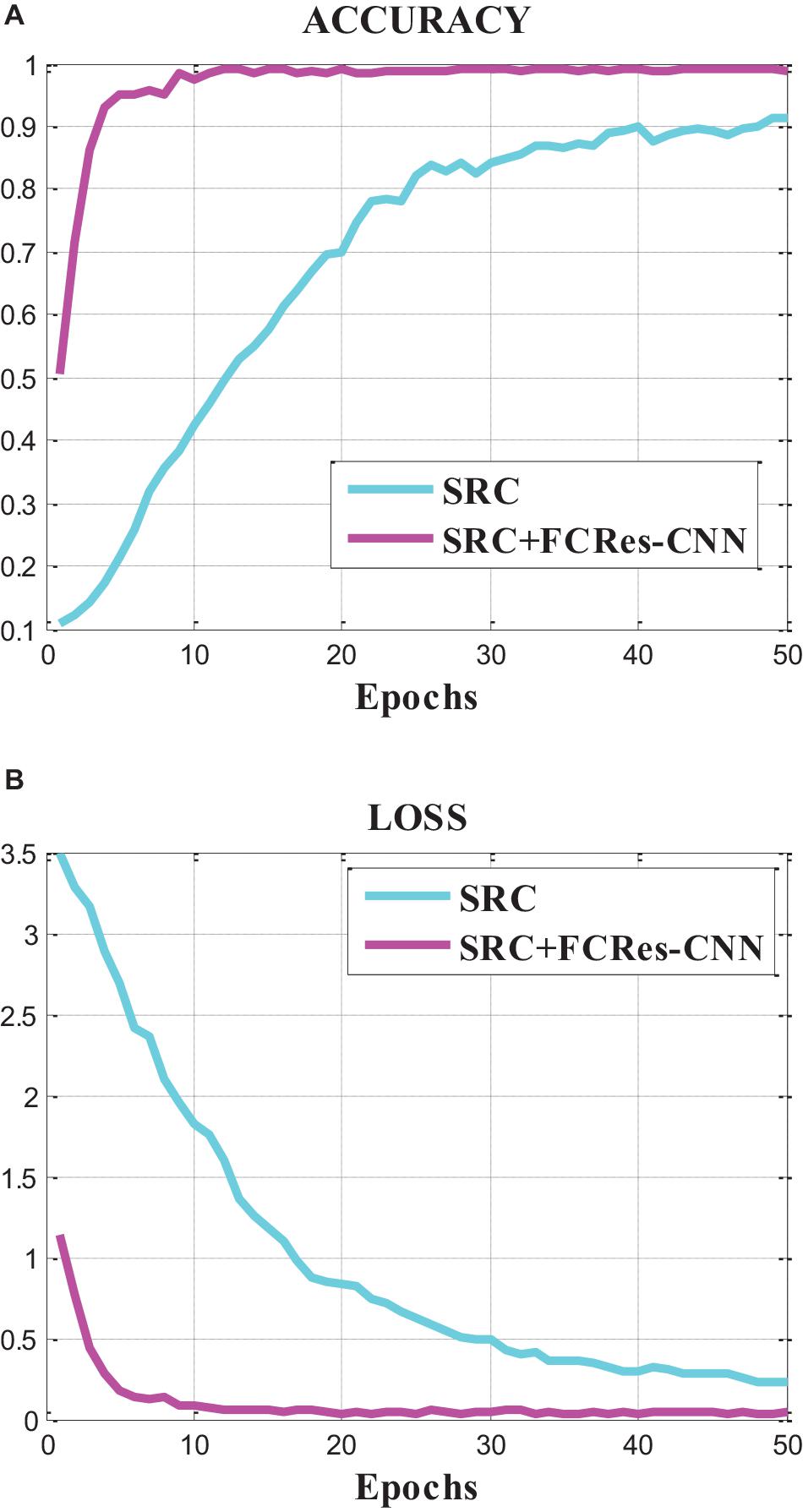
Figure 4. Accuracy and loss curves of the SRC and the proposed method.
In the contrast experiment, the SRC model achieved an average accuracy of 88.79% and an average loss of 18.10%. In contrast, the proposed SRC +FCRes-CNN model achieved an average accuracy of 98.82% and an average loss of 4.74%. In this article, the total number of EEG training trials is 280. For the training process of deep learning, the number of samples is still insufficient. If the number of training samples is sufficient, the accuracy of classification will be further improved.
In this article, we proposed an EEG classification method based on sparse representation enhanced deep learning networks.
The original EEG signals were shared by the BCI Competition database. In the procedure of the proposed method, EEG waveforms of classes 1 and 2 are segmented into subsignals. The 3-s time samples after the prompt to conduct the classification experiment was applied, and 140 experimental samples can be achieved for each type of EEG signal. The CSP algorithm is used to obtain the features of the EEG signal. Then the redundant dictionary with sparse representation is constructed based on these features. Finally, the sparse features were utilized as input of the fast compression deep learning networks to complete the classification of EEG signal. The EEG classification is performed in the FCRes-CNN classifier automatically and intelligently.
The accuracy result of the proposed method on BCI Competition dataset Iva and dataset III is 98.82%, which is higher than the sparse representation classification method. The proposed method performs higher classification accuracy than other methods in literature by a training even using only a few samples, which is 280 trials in this article. We believe that the proposed method is of great significance for BCI applications that require real-time EEG classification of daily life use.
Publicly available datasets were analyzed in this study. This data can be found here: http://www.bbci.de/competition/iii/, http://www.bbci.de/competition/ii/#datasets.
J-SH, B-QC, and BY conceived and designed the classification method. CL and YL performed the experiment. J-SH preprocess and analyzed the data and wrote the manuscript. BY and B-QC reviewed and edited the manuscript. All authors read and approved the manuscript.
This research was supported financially by the National Natural Science Foundation of China (Grant No. 51605403), the Fundamental Research Funds for the Central Universities under Grant No. 20720190009, International Science and Technology Cooperation Project of Fujian Province of China under Grant No. 2019I0003, the Shenzhen Basic Research Grant No. JCYJ20170413152804728, and the Shenzhen Basic Research Grant No. JCYJ20180507182508857.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
An, X., Kuang, D., Guo, X., Zhao, Y., and He, L. (2014). “A deep learning method for classification of EEG data based on motor imagery,” in Proceedings of the 10th International Conference on Intelligent Computing, ICIC 2014, Taiyuan, 203–210. doi: 10.1007/978-3-319-09330-7_25
Argunsah, A. O., and Cetin, M. (2010). “AR-PCA-HMM approach for sensorimotor task classification in EEG-based brain-computer interfaces,” in Proceedings of the 20th International Conference on Pattern Recognition, (Istanbul:IEEE), 113–116.
Bashashati, H., Ward, R. K., and Bashashati, A. (2016). “Bayesian optimization of bci parameters,” in Proceedings of the IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), (Vancouver, BC: IEEE), 1–5.
Bashivan, P., Rish, I., Yeasin, M., and Codella, N. (2015). Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv[Preprint].
Blankertz, B., Muller, K. R., Krusienski, D. J., Schalk, G., Wolpaw, J. R., Schlögl, A., et al. (2006). The BCI competition III: validating alternative approaches to actual BCI problems. IEEE Trans. Neural Syst. Rehabil. Eng. 14, 153–159. doi: 10.1109/tnsre.2006.875642
Chambon, S., Galtier, M. N., Arnal, P. J., Wainrib, G., and Gramfort, A. (2018). A deep learning architecture for temporal sleep stage classification using multivariate and multimodal time series. IEEE Trans. Neural Syst. Rehabil. Eng. 26:758. doi: 10.1109/tnsre.2018.2813138
Chen, S. (2016). Research on Epilepsy EEG Classification and Recognition Method Based on Sparse Representation and Feature Extraction. Ph.D. thesis, Jinan University, Guangzhou.
Elad, M., and Aharon, M. (2006). “Image denoising via learned dictionaries and sparse representation,”. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), (New York, NY: IEEE), Vol. 1, 895–900.
Gao, G., Shang, L., Xiong, K., Fang, J., Zhang, C., and Gu, X. (2018). EEG classification based on sparse representation and deep learning. NeuroQuantology 16, 789–795.
Gao, X. Z., Wang, J., Tanskanen, J. M. A., Bie, R., and Guo, P. (2012). “BP neural networks with harmony search method-based training for epileptic EEG signal classification,” in Proceedings of the 8th International Conference on Computational Intelligence and Security, (Guangzhou:IEEE), 252–257.
Grossewentrup, M., and Buss, M. (2008). Multiclass common spatial patterns and information theoretic feature extraction. IEEE Trans. Biomed. Eng. 55, 1991–2000. doi: 10.1109/tbme.2008.921154
Guo, X., Wang, L., Wu, X., and Zhang, D. (2008). “Dynamic analysis of motor imagery EEG using kurtosis based independent component analysis,” in Advances in Cognitive Neurodynamics ICCN 2007, eds R. Wang, E. Shen, and F. Gu (Dordrecht: Springer), 381–385. doi: 10.1007/978-1-4020-8387-7_65
He, K., Zhang, X., Ren, S., and Sun, J. (2016). “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (Las Vegas, NV: IEEE), 770–778.
Huang, J., Chen, B., Yao, B., and He, W. (2019). ECG arrhythmia classification using STFT-based spectrogram and convolutional neural network. IEEE Access 7, 92871–92880. doi: 10.1109/access.2019.2928017
Huang, J., Chen, B., Zeng, N., Cao, X.-C., and Li, Y. (2020). Accurate classification of ECG arrhythmia using MOWPT enhanced fast compression deep learning networks. J. Amb. Intell. Hum. Comput.
Ince, N. F., Arica, S., and Tewfik, A. (2006). Classification of single trial motor imagery EEG recordings with subject adapted non-dyadic arbitrary time–frequency tilings. J. Neural Eng. 3:235. doi: 10.1088/1741-2560/3/3/006
Ji, T. (2019). Research on Remote Sensing Image Scene Classification Based on Convolutional Neural Network. Ph.D. thesis, Henan University, Kaifeng.
Jirayucharoensak, S., Panngum, S., and Israsena, P. (2014). EEG-based emotion recognition using deep learning network with principal component based covariate shift adaptation. Sci. World J. 2014:627892.
Keng, A. K., Yang, C. Z., Chuanchu, W., Guan, C., and Zhang, H. (2012). Filter bank common spatial pattern algorithm on BCI competition IV datasets 2a and 2b. Front. Neurosci. 6:39. doi: 10.3389/fnins.2012.00039
Legendre, P., and Fortin, M. J. (1989). Spatial pattern and ecological analysis. Vegetatio 80, 107–138.
Li, S., Xu, L. D., and Wang, X. (2013). A continuous biomedical signal acquisition system based on compressed sensing in body sensor networks. IEEE Trans. Indust. Inform. 9, 1764–1771. doi: 10.1109/tii.2013.2245334
Liu, C. (2018). Research and Design of Handwritten Digit Recognition Based on Convolutional Neural Network. Ph.D. thesis, Chengdu University of Technology, Chengdu.
Liu, Y., Zhou, W., Yuan, Q., and Chen, S. (2012). Automatic seizure detection using wavelet transform and SVM in long-term intracranial EEG. IEEE Trans. Neural Syst. Rehabil. Eng. 20, 749–755. doi: 10.1109/tnsre.2012.2206054
Mousavi, E. A., Maller, J. J., Fitzgerald, P. B., and Lithgow, B. J. (2011). Wavelet common spatial pattern in asynchronous offline brain computer interfaces. Biomed. Signal Process. Control 6, 121–128. doi: 10.1016/j.bspc.2010.08.003
Qin, S. (2019). Research on Handwritten Digit Recognition Based on Deep Residual Network. Ph.D. thesis, Xidian University of Electronic Science and Technology, Chengdu.
Rajaguru, H., and Prabhakar, S. K. (2017). “Epilepsy classification using fuzzy optimization and Kernel Fisher discriminant analysis,” in Proceedings of the 2nd International Conference on Communication and Electronics Systems (ICCES), (Coimbatore: IEEE), 183–186.
Ramoser, H., Mullergerking, J., and Pfurtscheller, G. (2000). Optimal spatial filtering of single trial EEG during imagined hand movement. IEEE Trans. Rehabil. Eng. 8, 441–446. doi: 10.1109/86.895946
Roeva, O., and Atanassova, V. (2016). Cuckoo search algorithm for model parameter identification. Algorithms 1:26.
Seth, D., Chakraborty, D., Ghosal, P., and Sanyal, S. K. (2017). “Brain computer interfacing: a spectrum estimation based neurophysiological signal interpretation,” in Proceedings 4th International Conference on Signal Processing and Integrated Networks (SPIN), (Noida: IEEE), 534–539.
Shin, Y., Lee, S., Ahn, M., Cho, H., Jun, S. C., and Lee, H.-N. (2015). Simple adaptive sparse representation based classification schemes for EEG based brain–computer interface applications. Comput. Biol. Med. 66, 29–38. doi: 10.1016/j.compbiomed.2015.08.017
Sreeja, S. R., and Samanta, D. (2020). Distance-based weighted sparse representation to classify motor imagery EEG signals for BCI applications. Multimed. Tools Appl. 79, 13775–13793. doi: 10.1007/s11042-019-08602-0
Talukdar, M. T. F., Sakib, S. K., Pathan, N. S., and Fattah, S. A. (2014). “Motor imagery EEG signal classification scheme based on autoregressive reflection coefficients” in Proceedings of the International Conference on Informatics, Electronics & Vision (ICIEV), (Dhaka: IEEE), 1–4.
Thornton, K. E. (2002). Electrophysiological(QEEG) correlates of effective reading: towards a generator/activation theory of the mind. J. Neurother. 6, 37–66. doi: 10.1300/j184v06n03_04
Tsinalis, O., Matthews, P. M., Guo, Y., and Zafeiriou, S. (2016). Automatic sleep stage scoring with single-channel EEG using convolutional neural networks. arXiv[Preprint].
Wang, Y., Gao, S., and Gao, X. (2006). “Common spatial pattern method for channel selelction in motor imagery based brain-computer interface,” in Proceedings of the 27th Annual Conference IEEE Engineering in Medicine and Biology, (Shanghai:IEEE), 5392–5395.
Wu, M., Wei, Z., Tang, L., Su, Y., and Liu, T. (2008). An EEG signal analysis method based on sparse representation model. Chin. J. Tissue Eng. Res. Clin. Rehabil. 4, 81–84.
Yang, B., and Li, S. (2009). Multifocus image fusion and restoration with sparse representation. IEEE Trans. Instrument. Meas. 59, 884–892. doi: 10.1109/tim.2009.2026612
Yang, H., Sakhavi, S., Ang, K. K., and Guan, C. (2015). On the use of convolutional neural networks and augmented CSP features for multi-class motor imagery of EEG signals classification. Conf. Proc. IEEE Eng. Med. Biol. Soc. 2015:2620–2623.
Yang, Y., Yu, Z. L., Gu, Z., and Zhou, W. (2012). “A new method for motor imagery classification based on Hidden Markov Model,” in Proceedings of the 7th IEEE Conference on Industrial Electronics and Applications (ICIEA), (Singapore: IEEE), 1588–1591.
Yin, W., Yang, X., Zhang, L., and Oki, E. (2016). ECG monitoring system integrated with 42IR-UWB radar based on CNN. IEEE Access 4, 6344–6351.
Keywords: electroencephalogram, common spatial patterns, sparserepresentation, residual convolutional neural networks, fast compression
Citation: Huang J-S, Li Y, Chen B-Q, Lin C and Yao B (2020) An Intelligent EEG Classification Methodology Based on Sparse Representation Enhanced Deep Learning Networks. Front. Neurosci. 14:808. doi: 10.3389/fnins.2020.00808
Received: 29 May 2020; Accepted: 10 July 2020;
Published: 30 September 2020.
Edited by:
Yizhang Jiang, Jiangnan University, ChinaReviewed by:
Zhe Yang, Dongguan University of Technology, ChinaCopyright © 2020 Huang, Li, Chen, Lin and Yao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Bin-Qiang Chen, Y2JxQHhtdS5lZHUuY24=; Chuang Lin, Y2h1YW5nLmxpbkBzaWF0LmFjLmNu
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.