 Imene Jemal
Imene Jemal Lina Abou-Abbas2,3
Lina Abou-Abbas2,3 Neila Mezghani
Neila Mezghani- 1Centre EMT, Institut National de la Recherche Scientifique, Montréal, QC, Canada
- 2Institute of Applied Artificial Intelligence (I2A), Université TÉLUQ, Montréal, QC, Canada
- 3Laboratoire de Recherche en Imagerie et Orthopédie, Centre de recherche du CHUM, Montréal, QC, Canada
The ability to predict the occurrence of an epileptic seizure is a safeguard against patient injury and health complications. However, a major challenge in seizure prediction arises from the significant variability observed in patient data. Common patient-specific approaches, which apply to each patient independently, often perform poorly for other patients due to the data variability. The aim of this study is to propose deep learning models which can handle this variability and generalize across various patients. This study addresses this challenge by introducing a novel cross-subject and multi-subject prediction models. Multiple-subject modeling broadens the scope of patient-specific modeling to account for the data from a dedicated ensemble of patients, thereby providing some useful, though relatively modest, level of generalization. The basic neural network architecture of this model is then adapted to cross-subject prediction, thereby providing a broader, more realistic, context of application. For accrued performance, and generalization ability, cross-subject modeling is enhanced by domain adaptation. Experimental evaluation using the publicly available CHB-MIT and SIENA data datasets shows that our multiple-subject model achieved better performance compared to existing works. However, the cross-subject faces challenges when applied to different patients. Finally, through investigating three domain adaptation methods, the model accuracy has been notably improved by 10.30% and 7.4% for the CHB-MIT and SIENA datasets, respectively.
1 Introduction
Epilepsy is a neurological disorder which causes recurrent seizures resulting from brain dysfunction. Symptoms of seizures vary greatly among patients and can range from brief disruptions in activity to loss of consciousness and severe convulsions. To diagnose epilepsy, physicians use electroencephalography (EEG), which records the electrical activity of the brain using electrodes placed on the skull. Studies have shown that there is a pre-ictal period, lasting several minutes before the onset of a seizure. During the pre-ictal EEG recordings display patterns that are different from those of the seizures and also from normal periods, called inter-ictal (Mormann et al., 2005). Thus, by distinguishing pre-ictal from inter-ictal states, it is possible to predict seizures.
Computer-aided models for seizure prediction can be grouped into three categories: (1) patient-specific modeling, which is tailored to each individual patient, (2) multiple-subject modeling, also called patient-independent modeling, which is applied to a dedicated set of patients, and (3) cross-patient modeling, a generalized model that uses data from multiple patients and can be applied to new, unseen patients.
1. Patient-specific modeling involves using a portion of a single patient's data for model training and the remaining data for performance evaluation. However, this type of model is not practical as it is limited by the amount of data available and the need to record a sufficient number of seizures for each individual patient.
2. Multiple-subject modeling, also called patient-independent modeling, is a complex task that predicts seizures for subjects in a dedicated ensemble of subjects. This modeling does not have the limitation of lack of data as it utilizes all patient data grouped into at least two sets to train and test the model. However, this approach faces the major challenge of adapting the prediction model to new data from unseen patients.
3. Cross-subject modeling, also known as generalized modeling, is the most complex type for seizure prediction. This approach allows generalization to other patients and does not require labeled data for new patients.
Research has mostly focused on multiple-subject modeling for seizure prediction (Khan et al., 2017; Tsiouris et al., 2017; Dissanayake et al., 2021a). As far as we know, cross-subject seizure prediction has not been investigated, although cross-subject modeling has been successfully applied to other tasks, such as seizure detection (Zhang et al., 2020), emotion recognition (Li et al., 2018), and mental load assessment (Albuquerque et al., 2019). Cross-subject modeling of seizure prediction is justified by the high variability between the data of different patients (Jemal et al., 2022). Indeed, data from a new patient may differ significantly from data of patients whose data served to train the cross-subject model. This is often referred to as a domain shift (Ben-David et al., 2010). It is common in real data applications, and can result in a significant drop in classification performance (Ponce et al., 2006). To address this issue, domain adaptation can be used. In this context, a domain refers theoretically to the probability distribution from which the problem data are drawn. The training dataset is called the source domain data and the test dataset is called the target domain data. Domain adaptation uses labeled source data and unlabeled target data to learn a model that performs well in both the target and source domains. This is generally achieved by re-weighting the source samples to minimize the distribution shift, so that the source samples closest to the target domain are given more importance (Huang et al., 2006; Sugiyama et al., 2007). Alternatively, one can use a pre-trained model from the source domain on the new target domain (Oquab et al., 2014). This approach, known as a parameter-based approach, can only be applied if some labeled data are available in the target domain. Another approach on which we focus in this study, called feature-based (Daumé III, 2009; Ganin et al., 2016; Long et al., 2018) uses the source and target data to learn features that display similar behavior in classification on both the source and the target domains data. The use of domain adaptation to classify EEG data has been successful in applications such as emotion recognition (Li et al., 2019; Ma et al., 2019; Zhang W. et al., 2019), motor imagery classification (Wu et al., 2019; Tang and Zhang, 2020), and evaluation of sleep quality (Zhang et al., 2017).
In this paper, we studied epileptic seizure prediction. We began by developing and investigating a new method of multiple-subject prediction by deep learning, and compared it to the state-of-the-art of such methods. Multiple-subject modeling broadens the scope of patient-specific modeling to account for the data from a fixed set of patients, thereby providing some useful level of generalization. To enhance seizure prediction and increase generalization across data from new patients, we have developed and investigated cross-subject model. We explored both model with and without domain adaptation, allowing us to assess the impact of data variability and underscore the significance of domain adaptation. Results show a significant improvement in accuracy, F1-score, and Area under the curve, on both CHB-MIT and SIENA datasets.
The remainder of this paper is organized as follows: Section 2 provides a summary of previous research on seizure prediction. Section 3 describes the EEG databases, the deep neural network architecture, as well as the domain adaptation methods used. Section 4 presents the experimental setup and results. Section 5 contains a conclusion and alludes to future directions of research.
2 Related work
Existing seizure prediction models fall into two major categories: the general multiple-subject modeling that applies to all patients, and the patient-specific modeling that addresses each patient individually. There has been little recent work on multiple-subject prediction modeling. The study (Tsiouris et al., 2017) compared different classification algorithms for seizure prediction, including the repeated incremental pruning to produce error reduction (RIPPER) algorithm, support vector machines (SVM), and neural networks (NN). The main objective was to distinguish between pre-ictal and inter-ictal EEG segments in data from multiple patients. Using a balanced number of selected pre-ictal and inter-ictal records from each patient in the CHB-MIT database, the SVM was found to have the best results with an accuracy of 68.5%. More recent studies, such as Khan et al. (2017), have demonstrated improved results using a convolutional neural network (CNN) on the wavelet transform of EEG signals, to achieve a sensitivity of 87.8% with a low false prediction rate of 0.142 FP/h. In Dissanayake et al. (2021a), a multi-task deep learning approach was used for both seizure classification and patient prediction using a Siamese network architecture. Using the CHB-MIT-EEG dataset, they reported an average accuracy of 91.54%. Another study, (Wu et al., 2022), utilized knowledge distillation to transfer information from a multiple-subject model trained on data from N − 1 patients to a patient-specific model trained on the remaining patient's data. This approach led to improved patient-specific prediction results compared to four other existing methods, with an average improvement of 3.37% in accuracy, 2.33% in sensitivity, and a reduction in false predictions by an average of 0.044/h when tested on 11 patients from the CHB-MIT dataset.
Recently, deep learning has gained attention for its application in seizure prediction. For instance, a study by Tsiouris et al. (2018) employed a deep Long Short-Term Memory (LSTM) network to predict seizures using EEG segments with a pre-ictal duration of 120 minutes. The study reported high sensitivity and specificity of 99.84% and 99.86%, respectively, using the CHB-MIT dataset. Other studies have applied CNNs, such as (Truong et al., 2018) which used spectrogram representations of EEG data, and Zhang Y. et al. (2019) which applied a common spatial algorithm model prior to the CNN. Another recent study (Zhao et al., 2020) proposed a one-dimensional CNN trained on raw EEG data trained with raw EEG data to predict seizure occurrence. The study reported an area under the curve, sensitivity, and false prediction rate of 0.915, 89.26%, 0.117/h and 0.970, 94.69%, 0.095/h on american epilepsy society (AES) and CHB-MIT data, respectively. An alternative study proposed adversarial training for data augmentation to account for the limited amount of pre-ictal data, which improved the performance and robustness of the model. Recently, there has been a focus on developing interpretable models for patient-specific seizure prediction, as seen in studies such as Jemal et al. (2022) and Pinto et al. (2021), which utilize a genetic algorithm and a deep learning classifier, respectively.
3 Materials and methods
3.1 Datasets and pre-processing
In this study, experiments were conducted using two open-access datasets, the SIENA EEG database and the CHB-MIT dataset. The datasets description is summarized in Table 1.
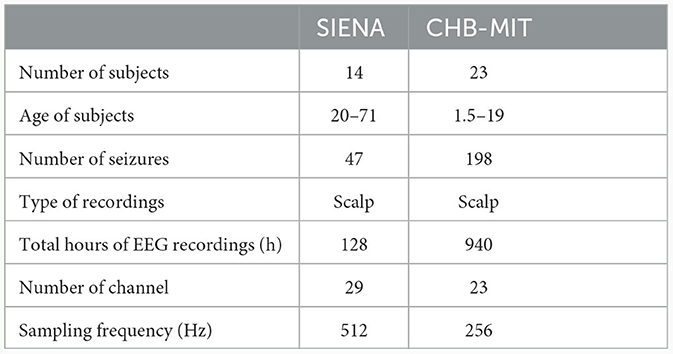
Table 1. Overview of SIENA and CHB-MIT datasets used in this study for seizure prediction.
The SIENA dataset (Detti et al., 2020), acquired at the unit of neurology and neurophysiology of the university of SIENA, contains recordings from 14 epileptic subjects aged 20 to 71 years. The subjects were monitored using video EEG. A total of 29 EEG channels sampled at 512 Hz were recorded following the standard 10–20 system. During 128 hours of EEG recording, 47 epileptic seizures were recorded. The time of the onset of a seizure and its duration were identified by experts. The CHB-MIT dataset (Shoeb, 2009), collected at Boston children's hospital, contains 940 h of long-term continuous multichannel scalp EEG recordings from 23 epileptic subjects aged 1.5 to 19 years. A minimum of 19 EEG channels sampled at 256 Hz were recorded according to the international 10/20 standard. In total, these recordings included 198 seizures in which the onset and the end were precisely annotated by clinicians with expertise in neuroscience. In this study, we eliminated recordings with fewer than 23 electrodes.
The raw EEG channels from both datasets were filtered to focus on frequencies relevant to epilepsy analysis and to eliminate noise sources. This was done by using a notch filter with a cutoff frequency of 50Hz and a band-pass filter with a bandwidth of 0.5–70Hz. The pre-ictal period, which is the time before a seizure starts, was set to 1 hour based on published literature. Moreover, the post-ictal period, which is the time after the seizure ends, was eliminated to exclude any effects (Daoud and Bayoumi, 2019; Dissanayake et al., 2021a). Non-overlapping windows of 10 s were extracted from inter-ictal and pre-ictal recordings. To address the limited number of pre-ictal samples, under-sampling was used to randomly select examples from the majority class. The windows were then normalized so that the channels had zero mean and unit standard deviation. This resulted in a total of 77,529 inter-ictal samples and 89,783 pre-ictal samples from the CHB-MIT dataset and 197,805 inter-ictal samples and 80,845 pre-ictal samples from the SIENA dataset, which were split between training, validation, and testing data.
3.2 Deep learning architecture
The architecture used for the multiple-subject and cross-subject models in this study was previously proposed by our team for the prediction of patient-specific seizures, as outlined in Jemal et al. (2022). We used the same network architecture. However, in contrast to the work in Jemal et al. (2022), which focuses on patient-specific modeling, our study centers around both multiple-subject modeling and cross-subject modeling. Additionally, we integrated domain adaptation techniques to enhance overall performance. As shown in Figure 1 and Table 2, the network consists of a three-layer convolutional neural network designed to be interpretable. The first layer uses standard 2D convolutions to extract relevant frequency components of the signal. The second layer uses depth-wise filters, which is the application of convolution filters to each feature map (output from the previous layer) independently from the other maps. This step allows learn spatial filters from the previous outputs. The first and second steps are similar to the Filter Bank Common Spatial Pattern (FBCSP) algorithm commonly used for EEG data encoding. The third 2D convolutional layer is used for feature extraction. Finally, the output is passed through a fully connected layer with a Softmax activation function.
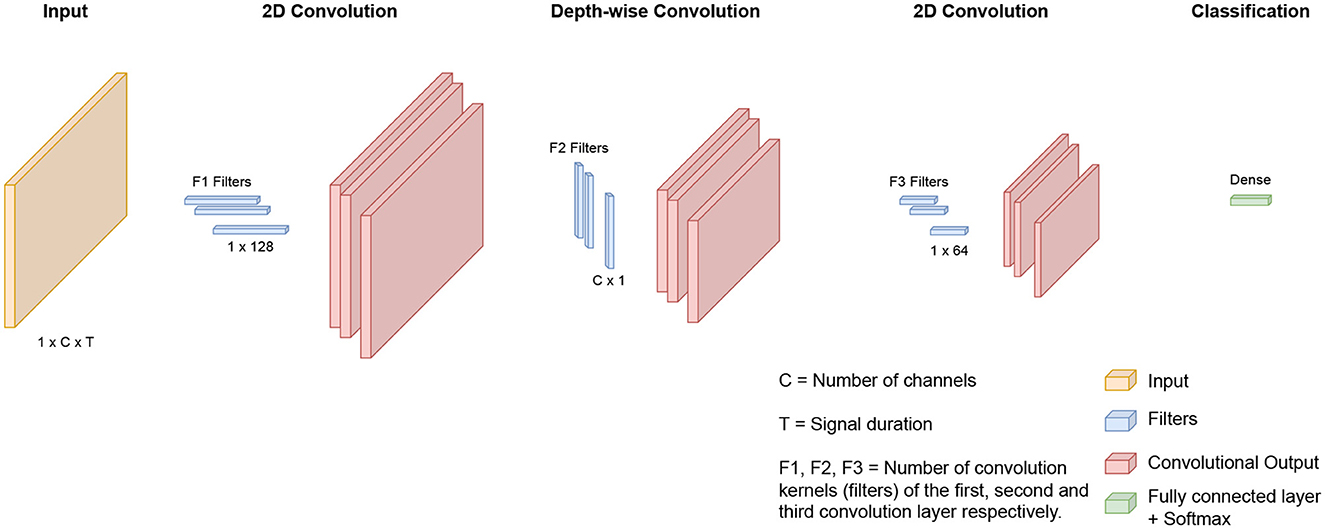
Figure 1. Illustration of the deep-learning architecture: The network processes EEG inputs with a standard 2D convolution to learn frequency filters. Next, depth-wise convolution is applied to learn spatial filters. Finally, features are extracted with a 2D convolution, and the outputs proceed through a fully connected layer with Softmax activation.
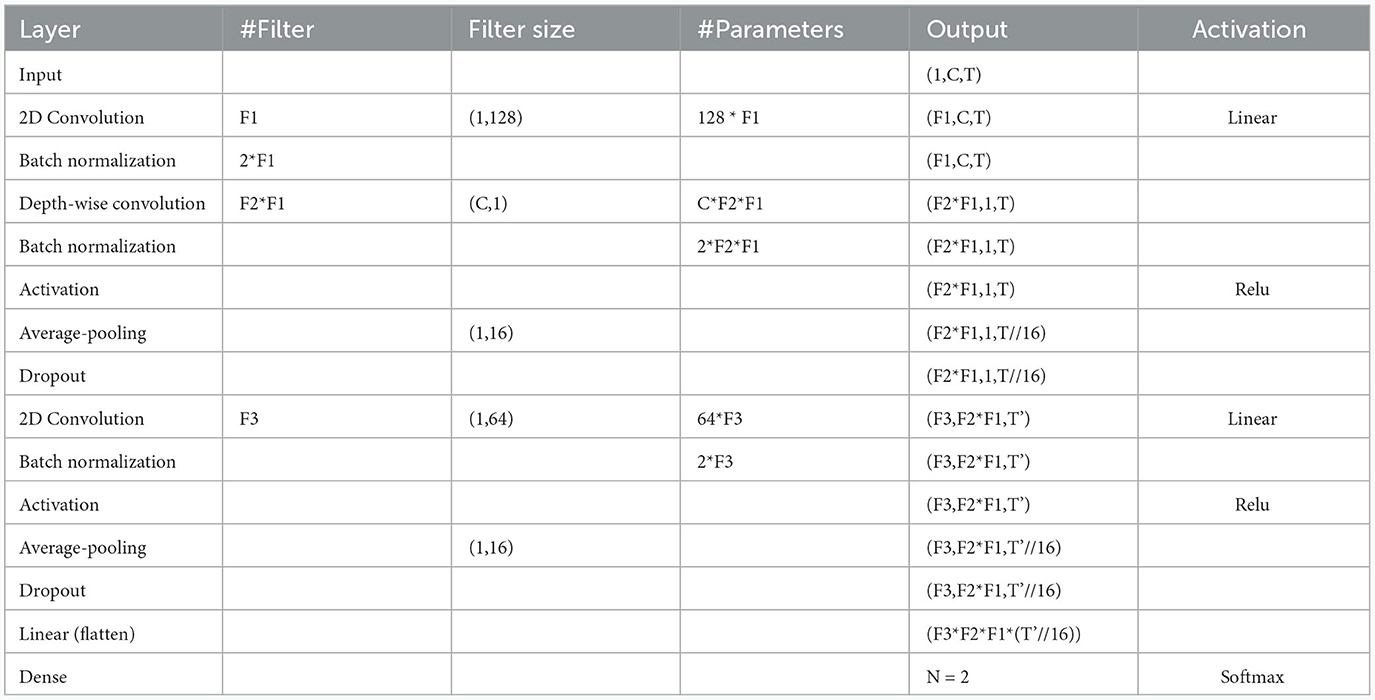
Table 2. The detailed architecture of the network, where C = number of channels, T = signal duration, F1 = number of convolution kernels filters to learn frequency filters, F2 = number of convolution kernels to learn spatial filters, F3 = number of convolution kernels for feature extraction, N = number of classes, respectively.
3.3 Multiple-subject vs. cross-patient modeling
The task of seizure prediction can be approached using several models as depicted in Figure 2. Patient-specific modeling involves using data from a single patient to train a unique model for that patient, as shown in Figure 2A. A more practical solution is multiple-subject modeling (Figure 2B), which uses data from multiple patients grouped into training and test sets to learn a single model that can be applied to all patients. However, this model may not generalize well to new patients. The focus of this work is cross-subject modeling (Figure 2C), which involves using labeled data from N − 1 patients for training and data from the remaining patient for testing.
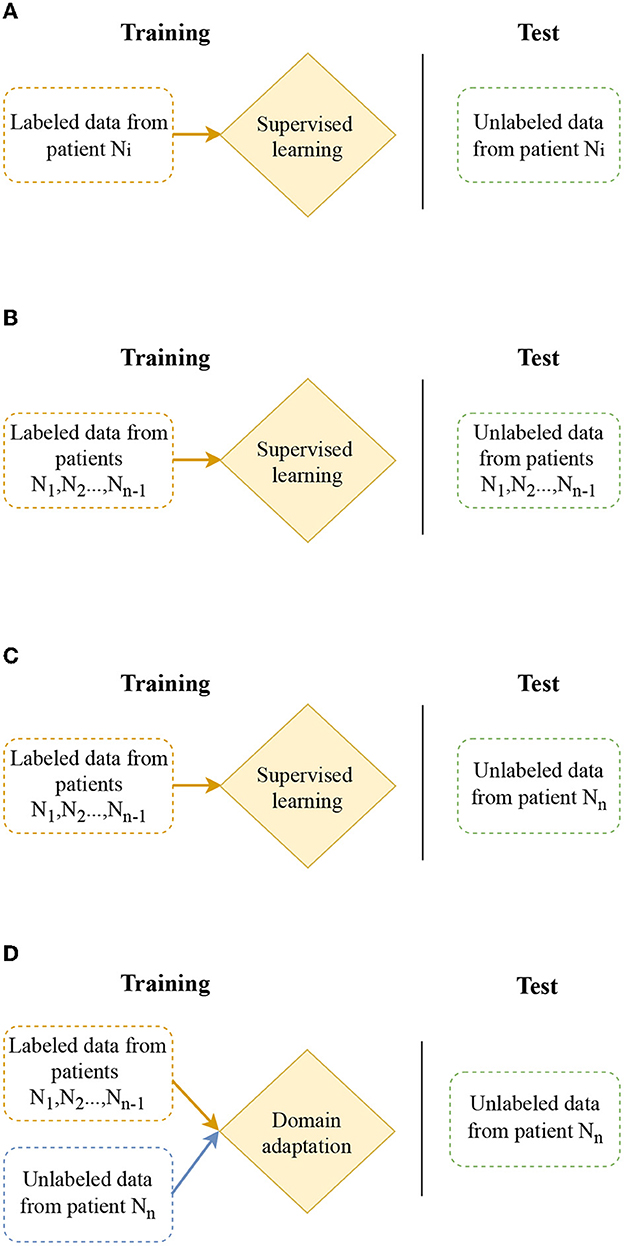
Figure 2. Different modeling for seizure prediction: patient-specific modeling, multiple-subject modeling, cross-patient modeling, and cross-patient modeling with domain adaptation. (A) Patient-specific modeling: design model which focus on individual patient. (B) Multiple-subject modeling: design model considering data from different patients. (C) Cross-patient modeling: design model which generalize to a new patient. (D) Cross-patient modeling with domain adaptation: improve model to work effectively across different patients through domain adaptation.
This study investigates domain adaptation methods to improve cross-subject modeling (Figure 2C). Domain adaptation involves using labeled data from N − 1 patients (source domain) and unlabeled data from a new patient (target domain) to transfer the model. With this method, the model is able to perform well on both the N − 1 patients used for training and the new patient. To accomplish this, we adopt a feature-based approach, which aims at learning features allowing good classification in both the source domain and the target domain. We investigate our architecture with three different domain adaptation algorithms: Discriminative Adversarial Neural Network (DANN), Domain Adversarial Conditional Adaptation (CDAN), and the Entropic conditioning variant of CDAN (CDAN+E). The selection of Domain-Adversarial Neural Network (DANN), Conditional Domain Adversarial Network (CDAN), and Conditional Domain Adversarial Network with Entropy minimization (CDAN+E) is motivated by their effectiveness in addressing domain shift challenges in previous studies (Du et al., 2020; Tang and Zhang, 2020; Li et al., 2022). DANN is chosen for its capacity to learn domain-invariant features, while CDAN incorporates conditional information for complex relationships between source and target domains. CDAN+E further enhances CDAN by integrating entropy minimization to boost model confidence in predictions.
3.4 Domain adaptation and cross-subject generalization
3.4.1 Supervised learning
Let X be the input space, the set of all possible examples or data points and Y be its corresponding label space. For example, Y would be {0, 1} for a binary classification case. A domain D is defined as a distribution over X.
Moreover, let F:X→Y be a deterministic mapping function such as a neural network. In general, the quality of the predictor F(x) can be measured using loss function l(F(x), y). Supervised learning (Duda et al., 1973) can be defined as searching the optimal predictor F* using the optimization problem of the following form
The training data are used to find the optimal predictor F*, and the test data for the evaluation. Generally, the training and test data are assumed drawn from the same distribution. However, this assumption often does not hold in practice, thus justifying domain adaptation.
3.4.2 Domain adaptation
Let XS be the source domain data (training data) drawn from the distribution PS(XS) and the target domain data (test data) denoted as XT are drawn from the distribution PT(XT).
In the training stage, we assume in the training stage of sufficient labeled source domain data and unlabeled target domain data, . The input spaces and label spaces between domains are assumed the same: if xS = xT, then yS = yT. However, due to the data shift, PS(XS) ≠ PT(XT) and PS(YS/XS) ≠ Pt(YS/XT).
The objective of domain adaptation is to adjust a model trained on a source domain to perform effectively on a new target domain. The feature-based approach aims to learn features that minimize the difference between the source and target distributions (Ganin and Lempitsky, 2015). Mathematically, this is expressed as:
where represents the task-specific loss on the labeled source domain data, is a domain discrepancy measure, and λ is a balancing parameter.
We will discuss three different methods for achieving this: the Discriminative Adversarial Neural Network (DANN), the Domain Adversarial Conditional Adaptation (CDAN), and the Entropic conditioning variant of CDAN (CDAN+E).
3.4.3 Discriminative adversarial neural network
The DANN method, as described by Ganin et al. (2016), aims at learning a feature representation that is discriminative for the classification task on the source domain and not so regarding the shift between domains. It is based on the assumption that unlabeled target domain data is available. As shown in Figure 3, it consists of three main components: a feature extractor ϕ, a label predictor F and a domain discriminator D. The feature extractor ϕ also referred to as the generator, is a neural network that is trained using data from both the source and target domains to learn a feature representation that is not specific to any particular domain. The label predictor F is trained to minimize the classification error on the source domain data, while the domain discriminator D is trained to differentiate between the source domain and the target domain. The label predictor and the domain discriminator work adversarially, encouraging the feature extractor to learn domain-invariant representations. The parameters of all three components are optimized according to the following objective function:
where λ is a trade-off parameter.
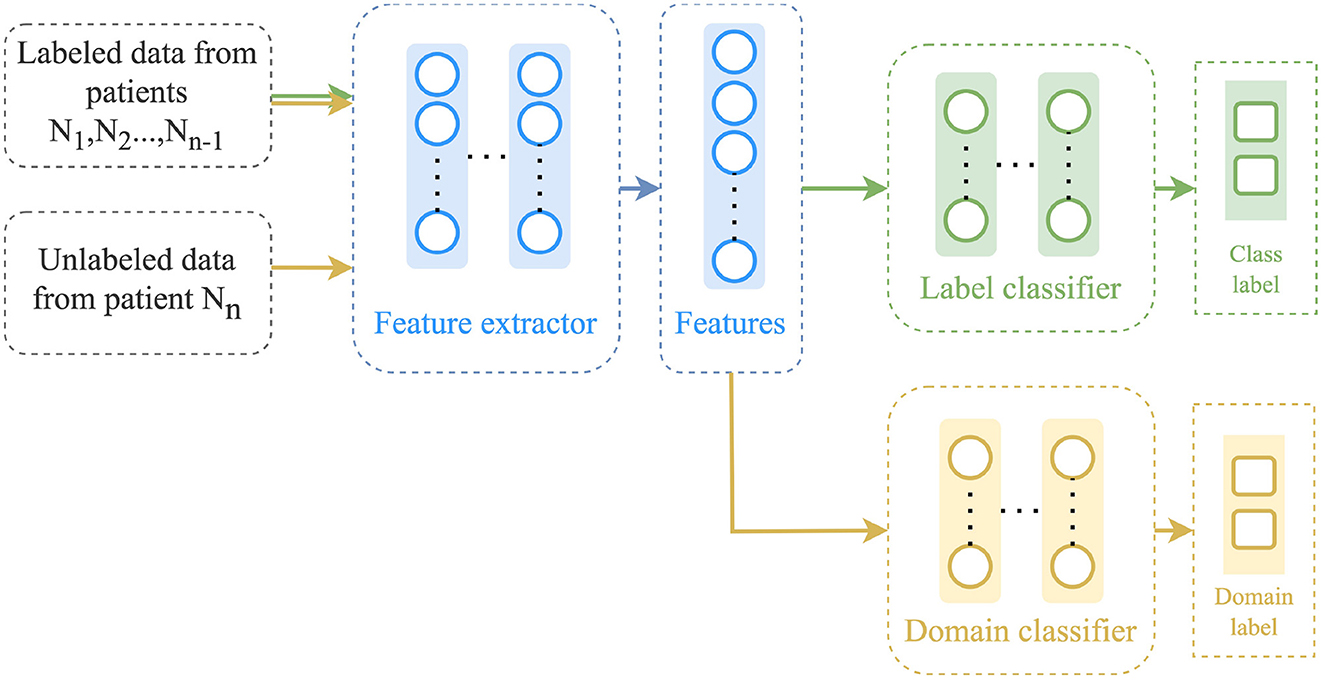
Figure 3. Architecture of the discriminative adversarial neural network (DANN).
3.4.4 Conditional domain adaptation network and Entropic conditioning variant of CDAN (CDAN+E)
The CDAN approach, proposed by Long et al. (2018), is similar to the DANN approach and also contains three main components: a feature extractor ϕ, a label predictor F, and a domain discriminator D as illustrated in Figure 4. However, in CDAN, a conditional discriminator D is used through the joint variable H = (ϕ, F) in order to improve discriminability by capturing the cross-covariance between feature representations and classifier predictions. The method uses a multilinear conditioning strategy to combine the feature vector with the predicted label. The label predictor and domain discriminator are trained alternatively to minimize the label classification and domain classification losses, respectively. The optimization formulation for CDAN is as follows:
where λ is a trade-off parameter, and, ϕ(XS)⊗F(XS) is the multilinear map between the encoded sources and the task predictions.
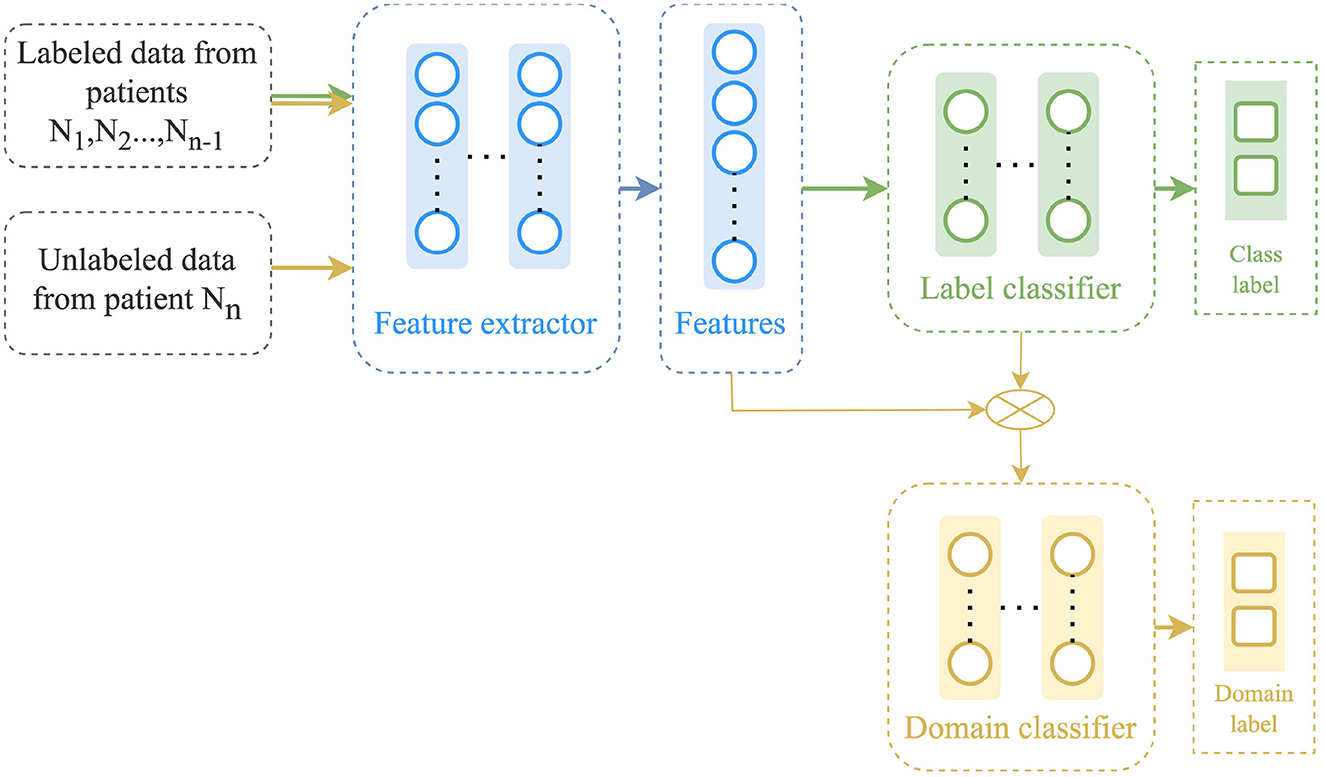
Figure 4. Architecture of the conditional domain adaptation network (CDAN).
In addition, an extension of the CDAN algorithm, known as CDAN+E, was also proposed by Long et al. (2018), in which an entropy conditioning strategy was introduced to improve transferability. This approach involves using a score that quantifies the uncertainty of the classifier predictions. The score is based on an entropy criterion, and it is used to re-weight each example used by the conditional domain discriminator. This helps obtain better transferability.
4 Results
Performance evaluation of this study multiple-subject and cross-patient models for EEG based seizure prediction was conducted on CHB-MIT and SIENA datasets. Pytorch (Paszke et al., 2017) was used to implement the proposed architecture. Data pre-processing was done using the MNE-Python package (Gramfort et al., 2013). Across all models, we employed the gradient-based ADAM optimizer with coefficients β1 and β2 set to 0.9 and 0.999 respectively for its efficiency and reliability in reaching a global minimum. The learning rate was set to 0.005. To prevent over-fitting, we used a holdout validation method to divide the data into a validation set and a training set, and the training. The training stopped after 500 epochs or when the validation loss remained constant for at least 20 epochs. To evaluate the models, we used various metrics including accuracy, precision, recall, F1-score, as well as the receiver operating characteristic (ROC) and the area under the curve (AUC).
4.1 Multiple-subject modeling
The multiple-subject model was evaluated using data from all patients in the SIENA dataset, which was divided into training, validation, and test sets. The model achieved a high accuracy of 96.01%, sensitivity of 97.24%, and specificity of 94.57%. The model also produced a high AUC value of 0.96. The training and validation loss curves indicate that the model does not suffer from over-fitting, as shown in Figure 5. The confusion matrix in Figure 6 demonstrates the model's classification performance. Comparison with current state-of-the-art seizure prediction models, as shown in Table 3, indicates that the model has comparable performance.
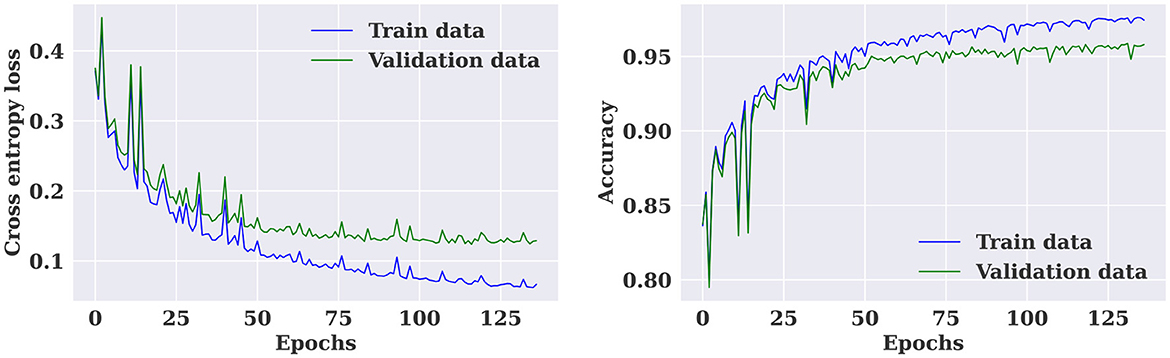
Figure 5. Training and validation loss and accuracy curves for the multiple-subject seizure prediction model trained using SIENA dataset.
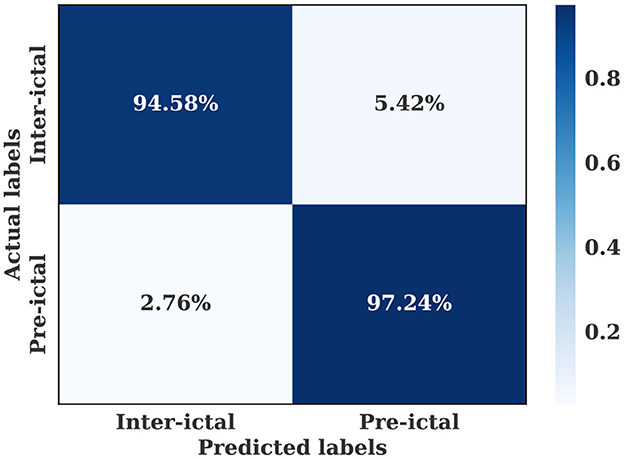
Figure 6. Confusion matrix for the multiple-subject seizure prediction model trained using SIENA dataset.

Table 3. Comparisons of state-of-the-art seizure prediction methods applied on SIENA dataset using a multiple-subject modeling.
The multiple-subject model showed also high performance when evaluated using the CHB-MIT dataset, with an accuracy of 97.36%, a sensitivity of 98.31%, and a specificity of 96.97%. As shown in Figure 7, the training and validation loss decreased to a stable point, with a small gap between the training and validation curves, indicating that the model is well-fitting. The confusion level is relatively low, as indicated by the percentages of confusion between inter-ictal and pre-ictal instances (3.03% and 1.69%, respectively) as shown in Figure 8. According to Table 4, the model outperforms current state-of-the-art models evaluated on the same dataset.
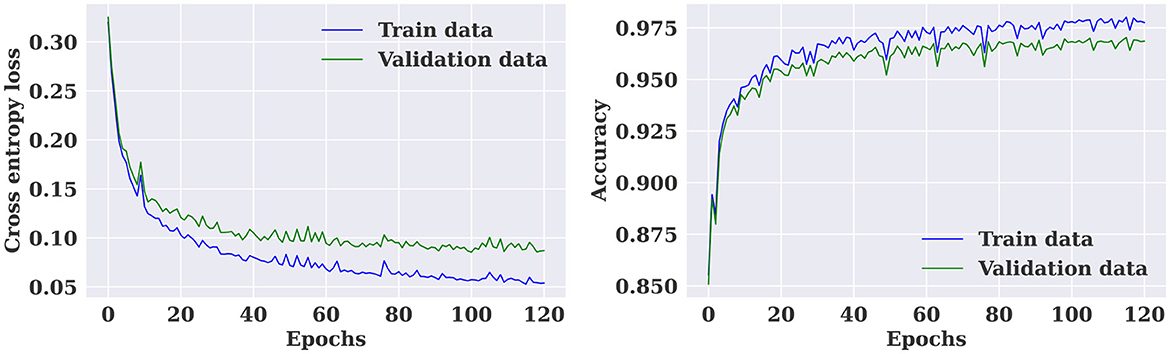
Figure 7. Training and validation loss and accuracy curves for the multiple-subject seizure prediction model trained using CHB-MIT dataset.
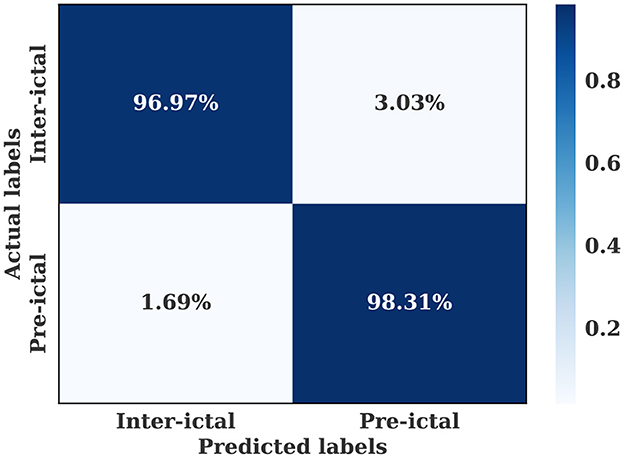
Figure 8. Confusion matrix for the multiple-subject seizure prediction model trained using the CHB-MIT dataset.
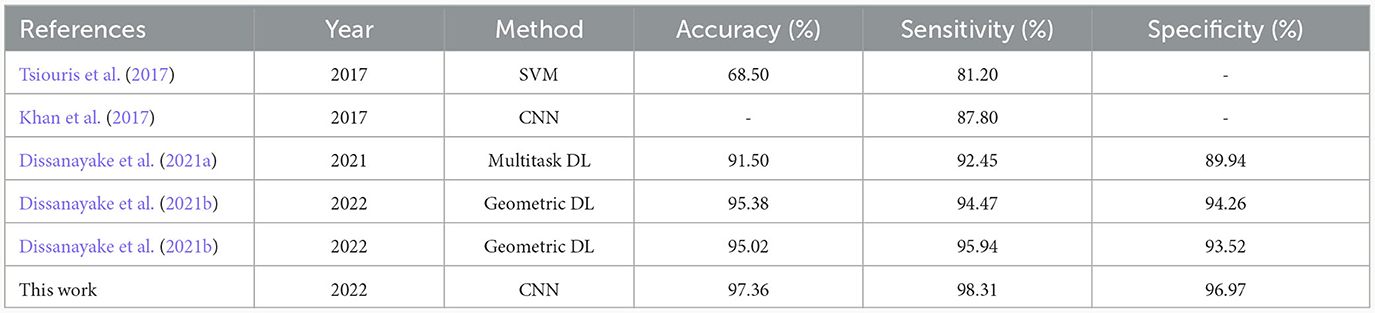
Table 4. Comparison of the state-of-the-art seizure prediction methods applied on the CHB-MIT dataset using a multiple-subject modeling.
4.2 Cross-subject modeling
In contrast to the multiple-subject modeling approach, the cross-subject modeling employs a validation strategy called leave-one-patient-out. This strategy involves using data from each patient in the dataset, one at a time, for testing while training the classifier with data from the remaining N − 1 patients. This method is commonly used to assess the ability of the classifier to generalize to new patients.
We evaluated the proposed cross-subject method using both data sets by measuring performance in terms of F1-score, accuracy, and AUC. The results, presented in Tables 5, 6, show the evaluation results for each patient in the SIENA and CHB-MIT datasets respectively. The overall averages across all patients in the SIENA dataset were 39.81% for F1-score, 48.69% for accuracy, and 0.48 for AUC. Results were slightly better with the CHB-MIT dataset which uses more patients, with averaged F1-score, accuracy, and AUC, equal to, respectively, 55.34%, 63.5%, and 0.69. The performance degradation can be attributed to the mismatch between the distribution of the new patient data and the training distribution. This issue is particularly pronounced in seizure prediction, as most studies in this field focus on patient-specific models. Additionally, our previous research (Jemal et al., 2021) on the complexity of EEG features in predicting epileptic seizures, highlighted the significant variability in EEG data between patients. To mitigate the potential data shift, we explored three domain adaptation methods: DANN, CDAN, and CDAN+E.
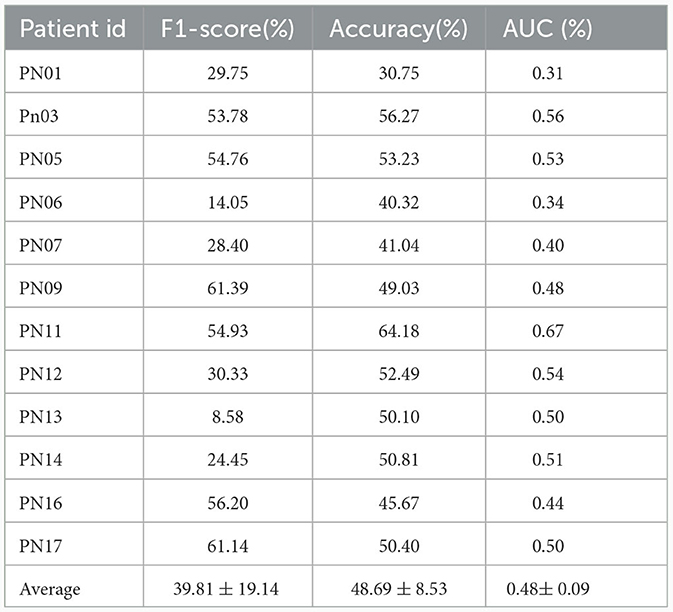
Table 5. Evaluation of cross-subject modeling using the leave-one-patient out strategy (SIENA dataset).
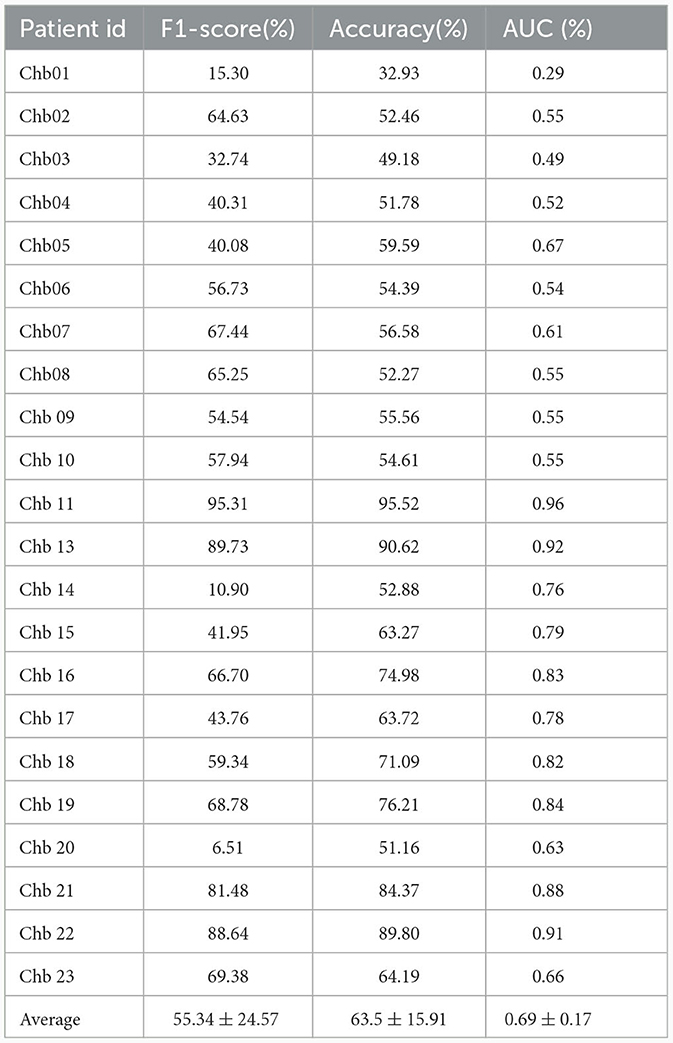
Table 6. Evaluation of cross-subject modeling using leave-one-patient out strategy (CHB-MIT dataset).
4.3 Domain adaptation for cross-subject seizure prediction
Individual differences in physiological states, neural activity patterns, and EEG signal characteristics among patients can indeed introduce noise and confusion when combining data for model training. To address the problem, we use domain adaptation. Specifically, we use unlabeled data from new patients in learning of domain-invariant features. With domain adaptation, our model learns to discern and adapt to the inherent variations among individual patients, effectively mitigating the impact of noise introduced by inter-subject differences. This approach enables the model to generalize more robustly across patient populations, thereby enhancing its reliability and performance in the presence of accrued physiological and neural characteristics variability. We assessed the effectiveness of three different domain adaptation methods against a baseline cross-subject modeling method using leave-one-patient-out. The results displayed in Tables 7, 8, indicate that all three methods (DANN, CDAN, and CDAN+E) enhanced performance on both SIENA and CHB-MIT datasets. Notably, the CDAN method performed exceptionally well with 60.27% accuracy, 59.77% F1 score, and 0.61 AUC on the SIENA dataset. Significant improvement in performance was also observed on the CHB-MIT dataset with 70.90% accuracy, 66.45% F1-score, and 0.75 AUC for CDAN+E adaptation.
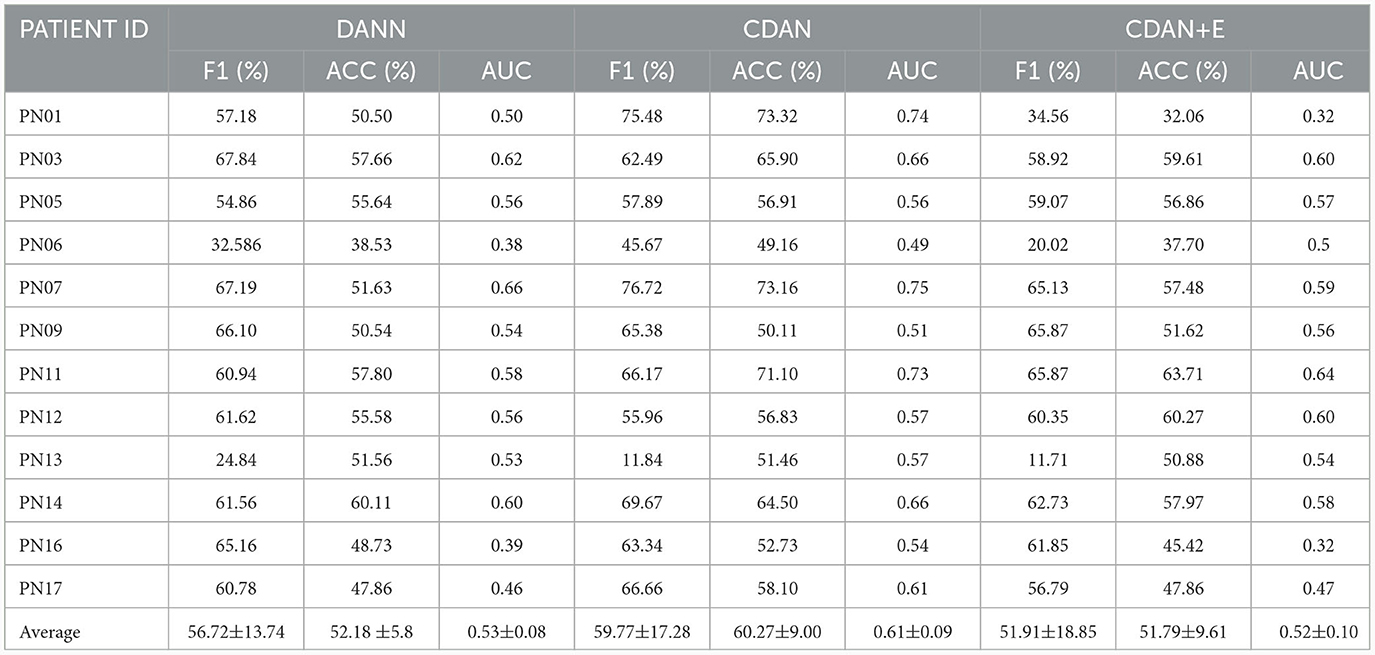
Table 7. Domain adaptation for cross-subject modeling: results obtained using DANN, CDAN, and CDAN+E adaptation methods using the leave-one-patient-out strategy on the SIENA dataset.
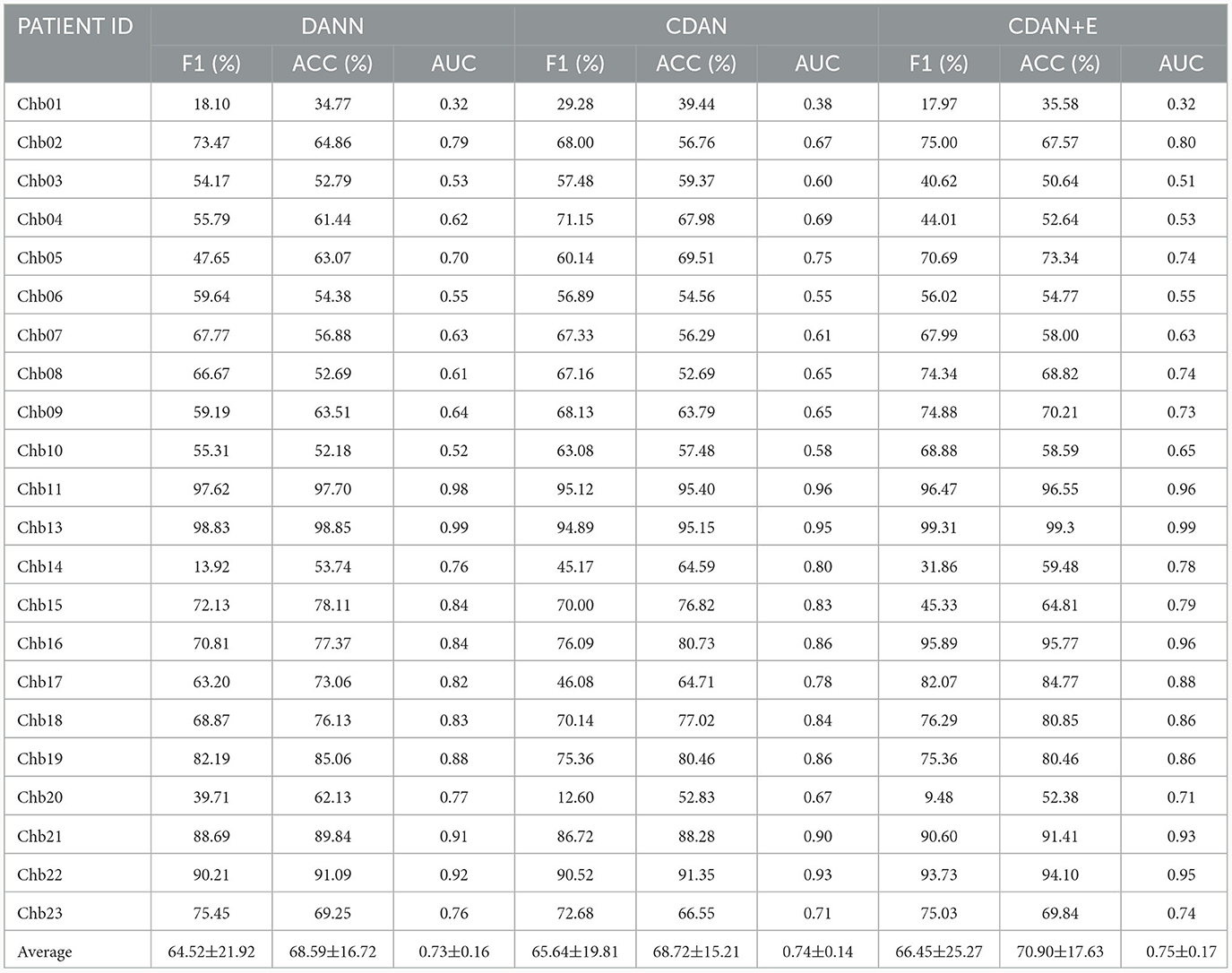
Table 8. Domain adaptation for cross-subject modeling: Results obtained using DANN, CDAN, and CDAN+E adaptation methods using the leave-one-patient-out strategy on the CHB-MIT dataset.
The comparisons shown in Figure 9 reveal the importance of incorporating domain adaptation in cross-subject modeling compared to a traditional leave-one-patient-out approach. The CDAN method was found to significantly enhance the accuracy, F1-score, and AUC by 11.58%, 19.59%, and 0.13, respectively. The results were even better when evaluated on the CHB-MIT dataset (Figure 10), with an average improvement in accuracy, F1-score, and AUC of +7.40%, +11.11%, and +0.06%, respectively, using the CDAN+E method. Additionally, it was noted that the model's performance improved as the number of patients in the dataset increased.
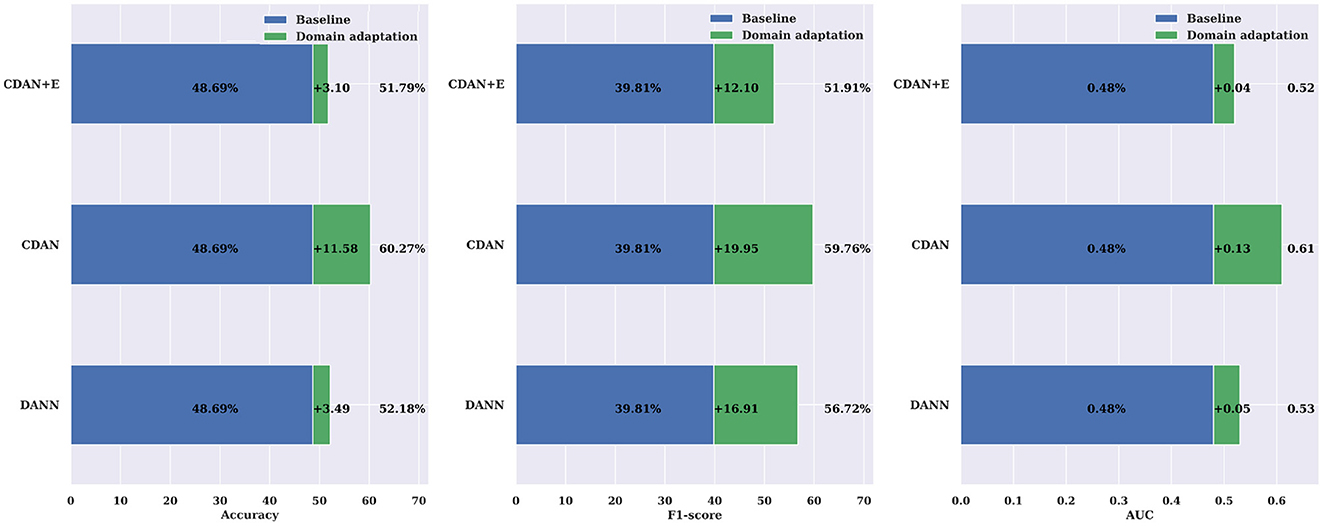
Figure 9. Domain adaptation for cross-subject modeling: a comparison between DANN, CDAN, and CDAN+E adaptation neural networks against the baseline cross-subject modeling using the leave-one-patient-out strategy on the SIENA dataset. Noticeable improvements over the baseline are consistently significant in terms of accuracy, F1-score, and AUC.
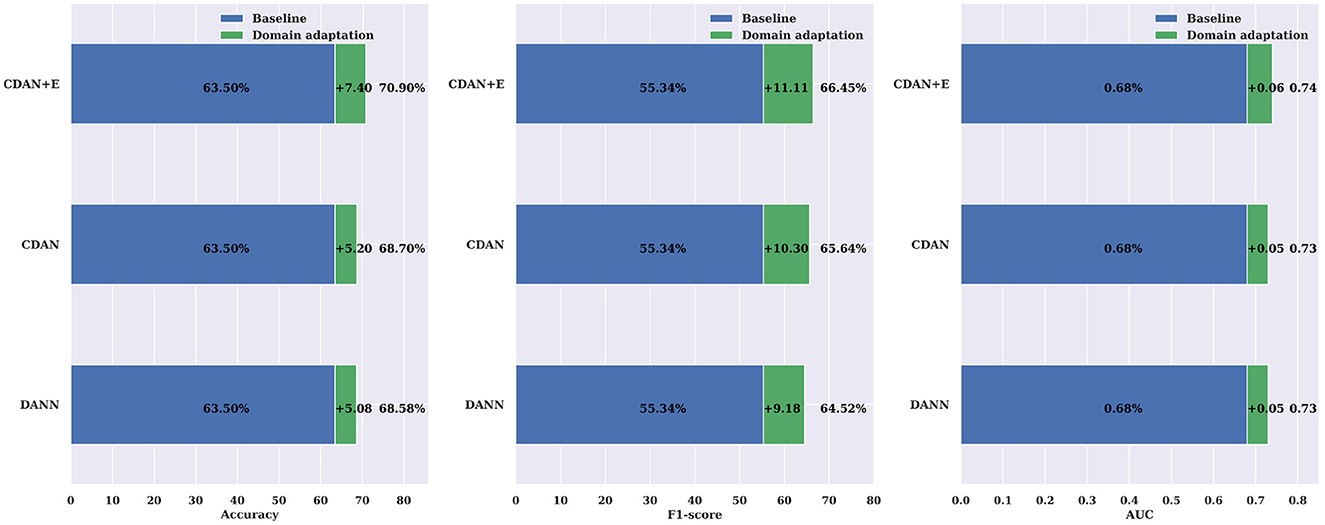
Figure 10. Domain adaptation for cross-subject modeling: a comparison between DANN, CDAN, and CDAN+E adaptation neural networks against the baseline cross-subject modeling using the leave-one-patient-out strategy on the CHB-MIT dataset. Noticeable improvements over the baseline are consistently significant in terms of accuracy, F1-score, and AUC.
A pertinent issue to consider is data under sampling to obtain a balanced dataset for improved learned model and reduced computational burden. Our examination of the SIENA dataset, with nearly balanced samples, demonstrated minimal impact from under-sampling. However, with the larger CHB-MIT dataset, potential implications become more evident. A key concern is the reduction of the majority class size, potentially impeding the model ability to capture diverse non-seizure patterns. This downsized dataset may result in decreased model performance, heightened sensitivity to noise, and biased representations of the majority class. Furthermore, under-sampling presents challenges in generalizing to new data and accurately identifying minority class instances like seizure events. A comparative analysis of results using the SIENA dataset, with limited data under sampling, and the extensively under sampled CHB-MIT dataset, suggests that under sampling does not significantly impact model performance or induce severe negative effects. Further investigations would be worthy of research, such as data augmentation, or neural networks of more representative objective functions. This line of investigation is crucial for ensuring the reliability and robustness of seizure prediction models in a scientific context.
Although accounting for patient sensitivity and specificity in model generalization ability is a problem worthy of consideration and research, it was not intended in the scope of this study. We acknowledge this as a limitation of the current study and mention it as a vein for future research that may significantly improve the method. Moreover, this study is subject to limitations inherent in the CHB-MIT and SIENA datasets, notably concerning gender, age, and ethnicity disparities. The datasets may not be representative of diverse populations, potentially introducing biases that affect the external validity of the findings. Gender imbalances may impact the generalizability of results, as conditions or responses to interventions may vary between genders. Additionally, uneven age distribution within the datasets may restrict the study's applicability to specific age groups, and ethnicity disparities may limit the generalizability of conclusions across different ethnic backgrounds. These inherent biases should be considered when interpreting the study's outcomes, emphasizing the need for cautious extrapolation to broader and more diverse populations.
In conclusion, the results of predicting seizures using cross-subject models show promising outcomes. Implementing seizure prediction models in clinical settings holds promise for early intervention and personalized treatment strategies. However, challenges include the necessity for high-quality, unbiased training data, and ensuring interpretability for healthcare professionals. Seamless integration into existing clinical workflows, ethical considerations regarding patient privacy, and legal compliance are crucial. The model's ability to generalize across diverse patient populations and adapt to external factors needs careful consideration. Navigating these challenges is essential to harness the potential of seizure prediction models while ensuring ethical and practical implementation.
5 Conclusion
In this study, our goal was to assess the generalization capability of a seizure prediction model to new patients. Therefore, we used a deep-learning architecture previously developed for patient-specific modeling in both multiple-subject and cross-subject scenarios. Our deep-learning architecture for multiple-subject seizure prediction was compared to existing state-of-the-art models and demonstrated superior performance. Despite the impressive accuracy of the model, its ability to generalize to new patients not in the dataset was uncertain. Thus, to better assess the model's performance and its ability to generalize to new patients, we employed a cross-subject modeling approach. This resulted in a noticeable decrease in performance when tested on open-access data. To overcome this issue, we investigated various domain adaptation methods to enhance the performance of cross-subject modeling. The results showed that all three methods (DANN, CDAN, and CDAN+E) significantly improved performance on both SIENA and CHB-MIT datasets.
Although this study realized significant progress in epileptic seizure prediction, there are currently limitations that could be addressed in future research. One limitation is the use of data under-sampling to deal with data imbalance, which not only impacts the computational cost of the training method but could also remove potentially valuable data relevant to seizure prediction. Another limitation is related to the size of the datasets used in the study. While the current amount of data allowed for a fair investigation of the problem, incorporating more data from additional EEG databases would offer further support to the findings and enhance the overall validity of the study. Moreover, it's crucial to acknowledge that the study refrained from using extensive statistical analyses, presenting an avenue for future investigations to delve deeper into the quantitative aspects of the predictive model.
In future research, we aim to address this limitations. This involves exploring alternative methods, beyond under-sampling, to balance our dataset. Techniques like over-sampling, employing synthetic data, or leveraging advanced neural networks designed for imbalanced datasets will be considered. Additionally, we intend to combine patient data from various datasets to address the challenge of limited data. This expanded dataset will be evaluated to better understand how well the model performs in different datasets.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: The CHB-MIT Scalp EEG Database is available at https://physionet.org/content/chbmit/1.0.0/. The SIENNA Database is available at https://physionet.org/content/siena-scalp-eeg/1.0.0/.
Ethics statement
The studies involving humans were approved by the dataset are publicly available. The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required from the participants or the participants' legal guardians/next of kin in accordance with the national legislation and institutional requirements.
Author contributions
IJ: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Software, Supervision, Visualization, Writing – original draft, Writing – review & editing. LA-A: Investigation, Validation, Writing – review & editing. KH: Validation, Writing – review & editing. AM: Project administration, Resources, Validation, Writing – review & editing. NM: Funding acquisition, Resources, Validation, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This research was supported by the Canada Research Chair on Biomedical Data Mining (950-231214).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Albuquerque, I., Monteiro, J., Rosanne, O., Tiwari, A., Gagnon, J.-F., and Falk, T. H. (2019). “Cross-subject statistical shift estimation for generalized electroencephalography-based mental workload assessment,” in 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), 3647–3653. IEEE. doi: 10.1109/SMC.2019.8914469
Ben-David, S., Blitzer, J., Crammer, K., Kulesza, A., Pereira, F., and Vaughan, J. W. (2010). A theory of learning from different domains. Mach. Learn. 79, 151–175. doi: 10.1007/s10994-009-5152-4
Daoud, H., and Bayoumi, M. A. (2019). Efficient epileptic seizure prediction based on deep learning. IEEE Trans. Biomed. Circ. Syst. 13, 804–813. doi: 10.1109/TBCAS.2019.2929053
Detti, P., Vatti, G., and Zabalo Manrique de Lara, G. (2020). Eeg synchronization analysis for seizure prediction: a study on data of noninvasive recordings. Processes 8, 846. doi: 10.3390/pr8070846
Dissanayake, T., Fernando, T., Denman, S., Sridharan, S., and Fookes, C. (2021a). Deep learning for patient-independent epileptic seizure prediction using scalp eeg signals. IEEE Sensors J. 21, 9377–9388. doi: 10.1109/JSEN.2021.3057076
Dissanayake, T., Fernando, T., Denman, S., Sridharan, S., and Fookes, C. (2021b). Geometric deep learning for subject-independent epileptic seizure prediction using scalp EEG signals. IEEE J. Biomed. Health Inform. 26, 527–538. doi: 10.1109/JBHI.2021.3100297
Du, X., Ma, C., Zhang, G., Li, J., Lai, Y.-K., Zhao, G., et al. (2020). An efficient LSTM network for emotion recognition from multichannel EEG signals. IEEE Trans. Affect. Comput. 13, 1528–1540. doi: 10.1109/TAFFC.2020.3013711
Duda, R. O.Hart, P. E., et al. (1973). Pattern Classification and Scene Analysis, volume 3. New York: Wiley.
Ganin, Y., and Lempitsky, V. (2015). “Unsupervised domain adaptation by backpropagation,” in International Conference on Machine Learning (PMLR), 1180–1189.
Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., et al. (2016). Domain-adversarial training of neural networks. J. Mach. Learn. Res. 17, 2096–2030.
Gramfort, A., Luessi, M., Larson, E., Engemann, D. A., Strohmeier, D., Brodbeck, C., et al. (2013). Meg and eeg data analysis with mne-python. Front. Neurosci. 7:267. doi: 10.3389/fnins.2013.00267
Huang, J., Gretton, A., Borgwardt, K., Schölkopf, B., and Smola, A. (2006). “Correcting sample selection bias by unlabeled data,” in Advances in Neural Information Processing Systems 19. doi: 10.7551/mitpress/7503.003.0080
Jemal, I., Mezghani, N., Abou-Abbas, L., and Mitiche, A. (2022). An interpretable deep learning classifier for epileptic seizure prediction using EEG data. IEEE Access. 10, 60141–60150. doi: 10.1109/ACCESS.2022.3176367
Jemal, I., Mitiche, A., and Mezghani, N. (2021). A study of eeg feature complexity in epileptic seizure prediction. Appl. Sci. 11:1579. doi: 10.3390/app11041579
Khan, H., Marcuse, L., Fields, M., Swann, K., and Yener, B. (2017). Focal onset seizure prediction using convolutional networks. IEEE Trans. Biomed. Eng. 65, 2109–2118. doi: 10.1109/TBME.2017.2785401
Li, J., Qiu, S., Du, C., Wang, Y., and He, H. (2019). Domain adaptation for eeg emotion recognition based on latent representation similarity. IEEE Trans. Cogn. Dev. Syst. 12, 344–353. doi: 10.1109/TCDS.2019.2949306
Li, R., Wang, L., and Sourina, O. (2022). Subject matching for cross-subject eeg-based recognition of driver states related to situation awareness. Methods 202, 136–143. doi: 10.1016/j.ymeth.2021.04.009
Li, X., Song, D., Zhang, P., Zhang, Y., Hou, Y., and Hu, B. (2018). Exploring eeg features in cross-subject emotion recognition. Front. Neurosci. 12:162. doi: 10.3389/fnins.2018.00162
Long, M., Cao, Z., Wang, J., and Jordan, M. I. (2018). “Conditional adversarial domain adaptation,” in Advances in Neural Information Processing Systems 31.
Ma, B.-Q., Li, H., Zheng, W.-L., and Lu, B.-L. (2019). “Reducing the subject variability of EEG signals with adversarial domain generalization,” in International Conference on Neural Information Processing (Springer), 30–42. doi: 10.1007/978-3-030-36708-4_3
Mormann, F., Kreuz, T., Rieke, C., Andrzejak, R., Kraskov, A., David, P., et al. (2005). On the predictability of epileptic seizures. Clin. Neurophysiol. 116, 569–587. doi: 10.1016/j.clinph.2004.08.025
Oquab, M., Bottou, L., Laptev, I., and Sivic, J. (2014). “Learning and transferring mid-level image representations using convolutional neural networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 1717–1724. doi: 10.1109/CVPR.2014.222
Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., et al. (2017). “Automatic differentiation in pytorch,” in 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
Pinto, M., Leal, A., Lopes, F., Dourado, A., Martins, P., Teixeira, C. A., et al. (2021). A personalized and evolutionary algorithm for interpretable EEG epilepsy seizure prediction. Sci. Rep. 11, 1–12. doi: 10.1038/s41598-021-82828-7
Ponce, J., Berg, T. L., Everingham, M., Forsyth, D. A., Hebert, M., Lazebnik, S., et al. (2006). “Dataset issues in object recognition,” in Toward Category-Level Object Recognition (Springer), 29–48. doi: 10.1007/11957959_2
Shoeb, A. H. (2009). Application of machine learning to epileptic seizure onset detection and treatment. PhD thesis, Massachusetts Institute of Technology.
Sugiyama, M., Nakajima, S., Kashima, H., Buenau, P., and Kawanabe, M. (2007). “Direct importance estimation with model selection and its application to covariate shift adaptation,” in Advances in Neural Information Processing Systems 20.
Tang, X., and Zhang, X. (2020). Conditional adversarial domain adaptation neural network for motor imagery EEG decoding. Entropy 22:96. doi: 10.3390/e22010096
Truong, N. D., Nguyen, A. D., Kuhlmann, L., Bonyadi, M. R., Yang, J., Ippolito, S., et al. (2018). Convolutional neural networks for seizure prediction using intracranial and scalp electroencephalogram. Neural Netw. 105, 104–111. doi: 10.1016/j.neunet.2018.04.018
Tsiouris, K. M., Pezoulas, V. C., Koutsouris, D. D., Zervakis, M., and Fotiadis, D. I. (2017). “Discrimination of preictal and interictal brain states from long-term EEG data,” in 2017 IEEE 30th International Symposium on Computer-Based Medical Systems (CBMS) (IEEE), 318–323. doi: 10.1109/CBMS.2017.33
Tsiouris, K. M., Pezoulas, V. C., Zervakis, M., Konitsiotis, S., Koutsouris, D. D., and Fotiadis, D. I. (2018). A long short-term memory deep learning network for the prediction of epileptic seizures using EEG signals. Comput. Biol. Med. 99, 24–37. doi: 10.1016/j.compbiomed.2018.05.019
Wu, D., Yang, J., and Sawan, M. (2022). Bridging the gap between patient-specific and patient-independent seizure prediction via knowledge distillation. arXiv preprint arXiv:2202.12598. doi: 10.1088/1741-2552/ac73b3
Wu, H., Niu, Y., Li, F., Li, Y., Fu, B., Shi, G., et al. (2019). A parallel multiscale filter bank convolutional neural networks for motor imagery EEG classification. Front. Neurosci. 13:1275. doi: 10.3389/fnins.2019.01275
Zhang, B., Wang, W., Xiao, Y., Xiao, S., Chen, S., Chen, S., et al. (2020). Cross-subject seizure detection in eegs using deep transfer learning. Comput. Mathem. Methods Med. 2020:7902072. doi: 10.1155/2020/7902072
Zhang, W., Wang, F., Jiang, Y., Xu, Z., Wu, S., and Zhang, Y. (2019). “Cross-subject EEG-based emotion recognition with deep domain confusion,” in International Conference on Intelligent Robotics and Applications (Springer), 558–570. doi: 10.1007/978-3-030-27526-6_49
Zhang, X.-Z., Zheng, W.-L., and Lu, B.-L. (2017). “EEG-based sleep quality evaluation with deep transfer learning,” in International Conference on Neural Information Processing (Springer), 543–552. doi: 10.1007/978-3-319-70093-9_57
Zhang, Y., Guo, Y., Yang, P., Chen, W., and Lo, B. (2019). Epilepsy seizure prediction on EEG using common spatial pattern and convolutional neural network. IEEE J. Biomed. Health Inform. 24, 465–474. doi: 10.1109/JBHI.2019.2933046
Keywords: epileptic seizure prediction, deep learning, domain adaptation, EEG, cross-subject modeling
Citation: Jemal I, Abou-Abbas L, Henni K, Mitiche A and Mezghani N (2024) Domain adaptation for EEG-based, cross-subject epileptic seizure prediction. Front. Neuroinform. 18:1303380. doi: 10.3389/fninf.2024.1303380
Received: 27 September 2023; Accepted: 09 January 2024;
Published: 02 February 2024.
Edited by:
Rachel Sparks, King's College London, United KingdomReviewed by:
Mario Versaci, Mediterranea University of Reggio Calabria, ItalyIlya Pyatnitskiy, The University of Texas at Austin, United States
Xiaoling Peng, United International College, China
Copyright © 2024 Jemal, Abou-Abbas, Henni, Mitiche and Mezghani. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Imene Jemal, aW1lbmUuamVtYWxAaW5ycy5jYQ==