
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Neuroinform. , 26 April 2022
Volume 16 - 2022 | https://doi.org/10.3389/fninf.2022.851188
 Weiyi Liu1†Junxia Pan1†Yuanxu Xu1†
Weiyi Liu1†Junxia Pan1†Yuanxu Xu1† Meng Wang2
Meng Wang2 Hongbo Jia3,4
Hongbo Jia3,4 Kuan Zhang1*
Kuan Zhang1* Xiaowei Chen1*Xingyi Li2*
Xiaowei Chen1*Xingyi Li2* Xiang Liao2*
Xiang Liao2*Two-photon Ca2+ imaging is a widely used technique for investigating brain functions across multiple spatial scales. However, the recording of neuronal activities is affected by movement of the brain during tasks in which the animal is behaving normally. Although post-hoc image registration is the commonly used approach, the recent developments of online neuroscience experiments require real-time image processing with efficient motion correction performance, posing new challenges in neuroinformatics. We propose a fast and accurate image density feature-based motion correction method to address the problem of imaging animal during behaviors. This method is implemented by first robustly estimating and clustering the density features from two-photon images. Then, it takes advantage of the temporal correlation in imaging data to update features of consecutive imaging frames with efficient calculations. Thus, motion artifacts can be quickly and accurately corrected by matching the features and obtaining the transformation parameters for the raw images. Based on this efficient motion correction strategy, our algorithm yields promising computational efficiency on imaging datasets with scales ranging from dendritic spines to neuronal populations. Furthermore, we show that the proposed motion correction method outperforms other methods by evaluating not only computational speed but also the quality of the correction performance. Specifically, we provide a powerful tool to perform motion correction for two-photon Ca2+ imaging data, which may facilitate online imaging experiments in the future.
Two-photon microscopy is widely used for investigating neural functions at diverse scales, from the size of a single spine to a neuronal population (Dombeck et al., 2007; Grienberger and Konnerth, 2012; Huber et al., 2012). Recent advances in optical imaging techniques have enabled the monitoring of neural activity with high temporal resolution. However, movement of the brain, which is generally induced by behaviors such as licking and limb movements, remains a serious limitation when recording animals that are awake (Greenberg and Kerr, 2009). Therefore, correction for brain movement enables the accurate analysis of morphology and activity for individual neurons in imaging data (Chen et al., 2013). In addition, when performing real-time processing during online functional imaging and photostimulation experiments (Griffiths et al., 2020), data processing must be performed with a high speed and robust performance. Therefore, a fast and accurate processing method for removing the movement artifacts from imaging data is a key requisite for online experiments (Mitani and Komiyama, 2018; Pnevmatikakis, 2019).
To reduce the image distortions caused by brain movements, frame-by-frame motion correction approaches have been developed based on image registration. An important set of image registration methods is based on image intensity. These algorithms are principally intuitive and provide good performance, but they are computationally expensive. As a representative intensity-based method, TurboReg (Thevenaz et al., 1998) has been integrated in ImageJ software and is widely used for correcting lateral motion artifacts. Moreover, to implement non-rigid transformation for the motion correction of Ca2+ imaging data, NoRMCorre (Pnevmatikakis and Giovannucci, 2017) was developed by splitting the imaging field into overlapping patches and estimating the transformation for each pixel via upsampling. The computational speed is slow for these motion correction methods, thus some efforts for improving the speed have been made. For instance, Moco (Dubbs et al., 2016) was programmed in Java and achieved faster motion correction than TurboReg by implementing a discrete Fourier transform and cache-aware upsampling. Similarly, fast Fourier transform was applied for processing motion correction in the Suite2p toolbox (Pachitariu et al., 2017).
An alternative type of image registration approach is based on feature detection. These approaches perform by extracting features through a global intensity gradient such as DoG (difference of Gaussians). In this way, the feature detection approaches to extracting features refer to representative structures. Thus, feature detection-based algorithms, such as SIFT (Lowe, 2004), ORB (Rublee et al., 2011), and AKAZE (Alcantarilla et al., 2013), have been used for image registration. However, these approaches are also relatively computationally expensive and perform unsatisfactorily in image registration applications.
Since the rise of deep learning methods, which have achieved state-of-the-art results in many research fields, deep learning-based image registration algorithms have been rapidly developed and used in many image registration applications (Haskins et al., 2020). However, these methods have also encountered the issue of high computational power demand (Thompson et al., 2020), which may limit their applications in online imaging experiments.
The current image registration-based motion correction methods are either computationally expensive or difficult to implement with a conventional computer, and some suffer from both disadvantages. In this work, we focus on rigid motion correction. As suggested in previous research (Mitani and Komiyama, 2018), rigid transformation is quite efficient when imaging with resonant scanners; the high sampling rate can only induce negligible within-frame motion distortion. With the goal of improving both computational speed and accuracy, we propose a fast image feature extraction and registration (FIFER) method for motion correction of two-photon Ca2+ imaging data. Our proposed method is based on an image density estimation and clustering approach (Hinneburg and Keim, 1998), which is fast and robust in the extraction of imaging data features. The efficacy of the proposed motion correction method was first assessed with raw two-photon Ca2+ imaging data at both the neuronal population and single-spine scales. The quantitative evaluation of motion-corrected imaging data demonstrates that our method provides superior performance in comparison to other motion correction approaches, and thus provides a powerful solution to facilitate online functional imaging and photostimulation experiments in neuroscience research.
Adult (8–12 weeks old) male C57BL/6J mice were obtained from the Laboratory Animal Center at the Third Military Medical University. All experimental procedures related to the use of animals were approved by the Third Military Medical University Animal Care and Use Committee and were conducted in accordance with institutional animal welfare guidelines.
For two-photon imaging in head-fixed awake mice (Li et al., 2018), we first glued a titanium head post to the skull for head fixation under isoflurane anesthesia. Three days after surgery, animals received 1 ml of water supply per day for 2–3 days and then underwent training and testing sessions with water deprivation in their home cages. For imaging experiments with Cal-520 AM (Tada et al., 2014), we exposed the right primary auditory cortex of the mouse (Chen et al., 2011). Cal-520 AM was dissolved in DMSO with 20% Pluronic F-127 to a final concentration of 567 μM with artificial cerebral spinal fluid (ACSF) for bolus loading. With a standard pipette solution, the solution was diluted 1/10 for cell loading. After that, we used a micropipette filling with the solution and inserted coaxially into the targeted cortex. Finally, the dye-containing solution was ejected in the cortical area by applying a pressure pulse to the pipette. Ca2+ imaging was performed approximately 2 hours after dye injection and lasted for up to 8 hours (Stosiek et al., 2003). The mice were trained to perform a sound-evoked licking task (Wang et al., 2020).
The imaging experiment was conducted with a custom-built two-photon microscope system constructed with a 12 kHz resonant scanner (model “LotosScan 1.0,” Suzhou Institute of Biomedical Engineering and Technology, Suzhou, China), in accordance with the set-up described previously (Jia et al., 2010, 2014). Two-photon excitation light was delivered by a mode-locked Ti:Sa laser (model “Mai-Tai DeepSee,” Spectra Physics, CA, United States), and a 40 × /0.8 NA water-immersion objective (Nikon, Minato, Japan) was used for imaging. For Ca2+ imaging experiments, the excitation wavelength was set to 920 nm. For neuronal population imaging, images of 600 × 600 pixels were acquired at a 40 Hz frame rate. The size of the field-of-view was approximately 200 × 200 μm. The average power delivered to the brain was 30–120 mW. For dendritic spine imaging, we used the LOTOS procedure (Chen et al., 2011, 2012). The images, consisting of 250 × 250 pixels, were acquired at a 160 Hz frame rate. The size of the field-of-view was therefore reduced to approximately 25 × 25 μm. The average power delivered to the brain was 15–30 mW.
Fast image feature extraction and registration (FIFER) operates in a rigid correction flow (Figure 1A). Initially, we generate features for an image with a density-based estimating and clustering algorithm (Figure 1B). This process begins a calculation with the template image (here we used the first frame of imaging data) and the first raw frame for correction (i.e., the second frame of imaging data). After obtaining features of the template and first raw frame, we then generated features for the rest of the raw frames by updating the features obtained from the first raw frame with a fast process (Figure 1C). After we obtained features for each frame, we matched the features between the template image and the raw frames according to the similarity metric (Figure 1D). Finally, we calculated the rigid transformation parameters and conducted the image registration. The computational details of each step are described in the following sections. In the figures, the brightness of the representative two-photon images was adjusted for better visualization.

Figure 1. Processing pipeline for two-photon Ca2+ imaging data. (A) Flowchart of the proposed motion correction method. The red marked modules are the key steps in the processing flowchart. (B) Illustration of the feature (red dots) extraction for the imaging data. (C) Illustration of the feature update for a raw frame. The features of the current frame and the next frame are marked as the red and blue dots, respectively. (D) Illustration of matching features between template image and raw frame. The anatomical direction: a, anterior; m, medial; p, posterior; l, lateral.
To perform image density-based feature estimating and clustering, we first initialized the generation of features with the density estimate. To minimize the computational cost, we acquired the coordinates around the high-intensity area, instead of randomly inputting coordinates, to decrease the cost for the following hill climbing procedure. In this work, we assume that the features from accelerated segment test (FAST) (Rosten et al., 2008) detector is a suitable algorithm to detect corners with high speed. Figure 2A demonstrates that the corners detected by the FAST algorithm are mostly distributed in high-intensity areas. To reduce the number of repeated FAST features, we down-sampled these coordinates by merging those near each other (Figure 2B). Based on the initial FAST-detected features, we described the distribution of the empirical density field in an image. Inspired by Denclue (Hinneburg and Keim, 1998), we propose a weighted kernel density estimation (W-KDE) algorithm, with which we mapped each image pixel to a Gaussian kernel function weighted by this pixel’s image value as its estimated density:
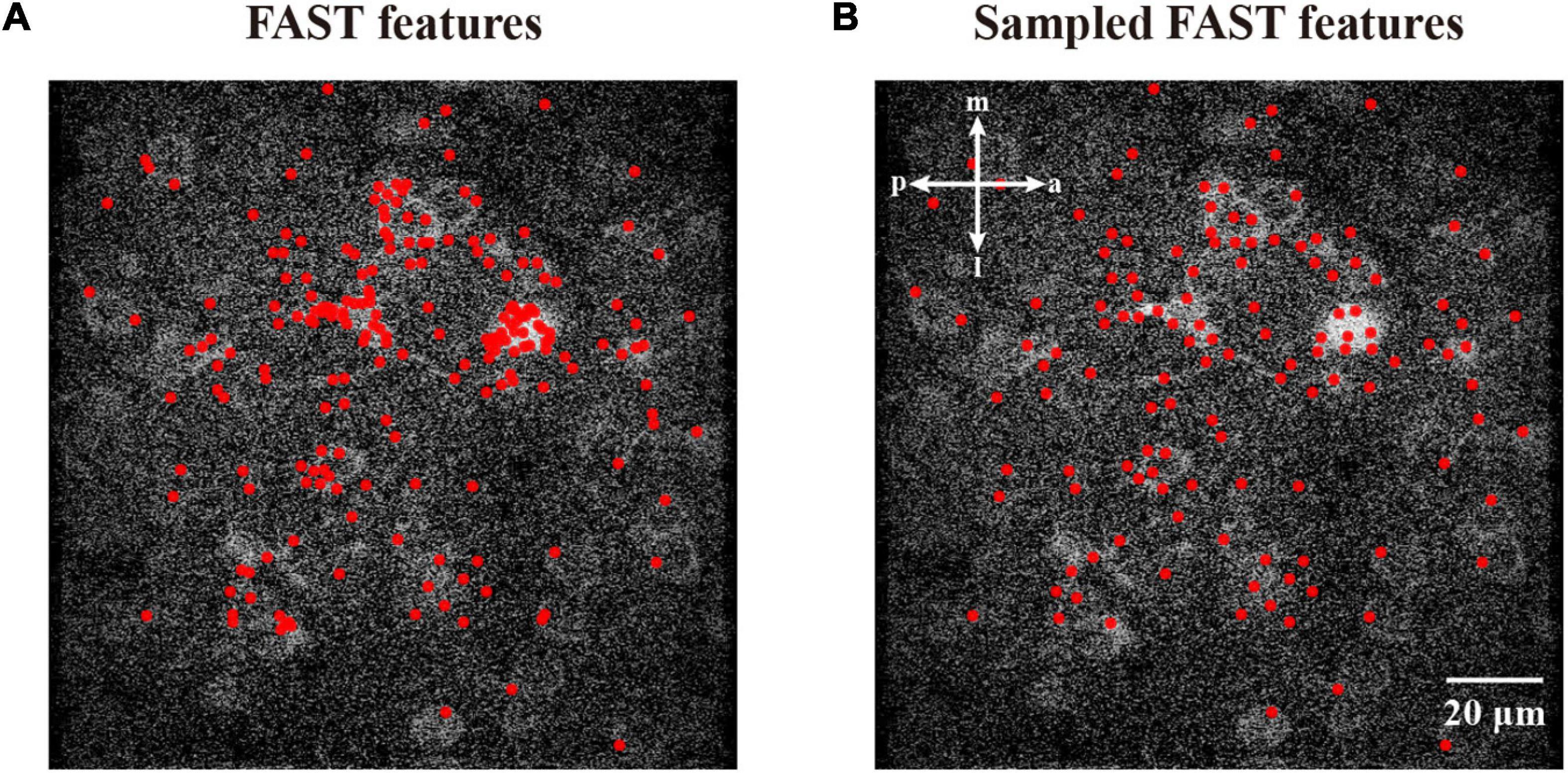
Figure 2. Features from accelerated segment test feature detection and sampled FAST features. (A) The corner features detected by FAST algorithm. (B) The sampled FAST features are uniformly distributed for reducing the computational cost. The features are represented as red dots.
where is an arbitrary coordinate in a partitioned ROI (region of interest) of an image, is one coordinate in the ROI, is the pixel value in this position , n is the number of pixels sampled from the ROI, h is a bandwidth to smooth the density distribution, and is a Gaussian kernel function which maps a two-dimensional vector onto a constant. Considering the distance between a given coordinate and pixel intensity, we describe the influence from one pixel with a pixel value of to an arbitrary coordinate of the image as , which is quantified by a weighted Gaussian kernel function. Thus, we could estimate the density of an arbitrary coordinate in a partitioned ROI by calculating the sampled ROI’s pixel component density and normalizing the sum of these components, which ensures that the whole distribution is a normalized density distribution. In brief, is the weighted mixture density of position within the total influence of the ROI. To demonstrate that, we selected a fully sized ROI around an image and calculated each pixel’s density given the ROI (Figure 3A) through W-KDE and revealed the density field (Figure 3B) to visualize the density distribution.
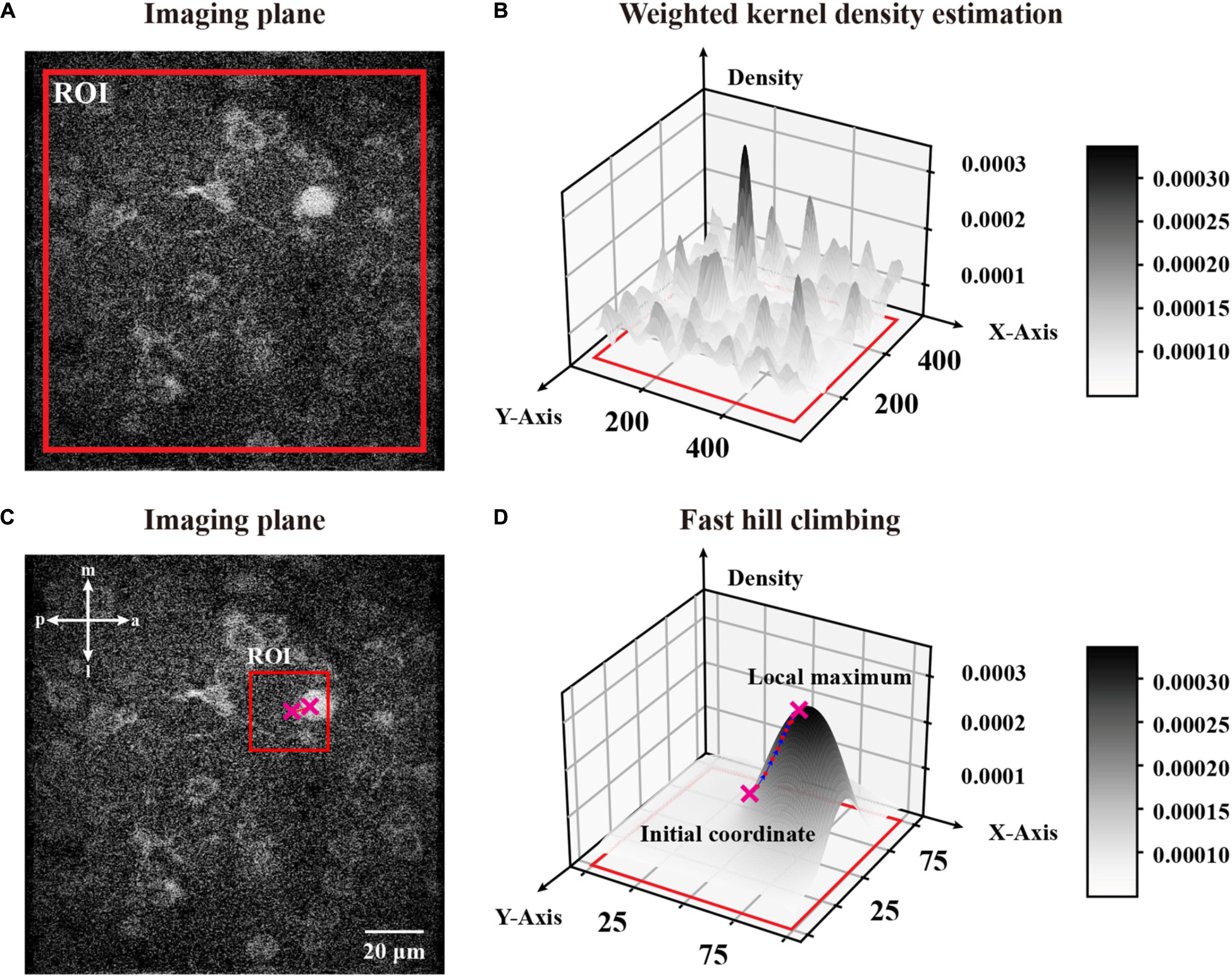
Figure 3. A global W-KDE for a two-photon image and a visual demonstration of fast hill climbing to update initial coordinates. (A) A representative two-photon image within a global range ROI marked in red. (B) A topography of global W-KDE. The density map indicated with the grayscale bar painted on the right. (C) An initial coordinate obtained from sampled FAST features with a 101 pixels-sized ROI centered by it. We mark the ROI in red and plot the initial coordinate and the local maximum with crosses that are also plotted in panel (D). (D) A W-KDE of this ROI is to reveal the topography and process of fast hill climbing. The density map is indicated with the grayscale bar painted on the right. Each iteration of this feature is marked on the topography by pink dots.
Since we estimated a ROI’s density distribution, we analyzed its ridge topography for feature extraction. Here, we obtained the coordinates of high intensity regions and hence determined the local maximums as cluster centers (Hinneburg and Keim, 1998). The eq. (2) shows the derivation of W-KDE function with the hill climbing algorithm:
where is the gradient of an arbitrary coordinate in the ROI, and δ is the step stride in hill climbing. Other variables are the same as W-KDE equation. However, a fixed-step hill climbing algorithm is generally poor in efficiency. Therefore, we adapted a fast automatically step-adapted hill climbing approach in our algorithm, which was based on previous work (Hinneburg and Gabriel, 2007), as eq. (3) shows.
where ε is a given restriction to end hill climbing that also represents the precision of the local maximum. Therefore, we optimized the hill climbing to a faster algorithm by reducing the iteration numbers based on the increase in rate of density. Alternatively, we can simply stop the iteration when a coordinate update distance is smaller than a threshold η.
Hence we can start with any coordinate in the ROI and cluster it to a local maximum, which is the top of a ridge topography and probably represents a neuronal object. To update the initial coordinates to a local maximum, we used a ROI centered by the feature with an appropriate size of 101 pixels (Figure 3C). After repeating the fast hill climbing procedure (Figure 3D) to the coordinates of sampled FAST features with a rough termination, where we calculate step distance of each feature during iterations and simply terminate the fast hill climbing when the step distance is smaller than a rough constant η in eq. (4), and we obtained rough features with noise (Figure 4A). Then, we sorted all of the rough features by their estimated densities and treated the upper quartile features as filtered results (Figure 4B). Finally, we repeated the fast hill climbing procedure on rough features with a precise termination, where we finally terminate the hill climbing when the density change rate of each feature is smaller than a critical value as described in eq. (3), and merged the coincident features (Figure 4C). After conducting these processes on the template image and the first raw frame individually, we obtained the initial pair of image features.
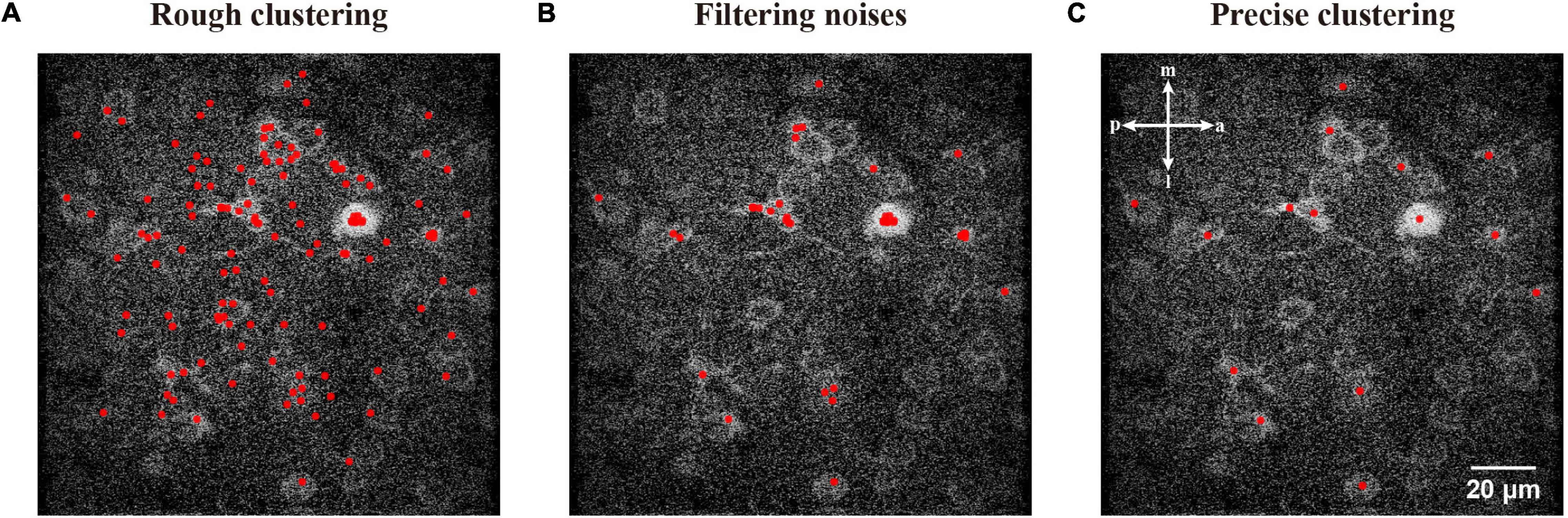
Figure 4. Demonstration of the processing used to generate precise high-density features. (A) The sampled FAST features were processed by rough clustering. (B) A filtering of features to reduce noises. (C) Clustering with a precise termination and merging the coincident features.
Starting the calculation for the features of the first raw frame, we updated the features of the current frame to those of the next frame through the following procedure (Figure 5). First, we used a fixed-size ROI centered on every coordinate of the feature in the current frame under the hypothesis that the features between two consecutive frames are adjacent. Then, we applied the fast hill climbing algorithm to achieve local maxima in the same way as before. This procedure is ultrafast and efficient for updating features from consecutive imaging frames due to: (1) Only a small number of features, which were extracted from the first raw frame, were updated in this process; (2) features between two consecutive frames were normally adjacent, so the hill climbing iteration was stopped quickly; and (3) the fast hill climbing algorithm could automatically adapt the step of hill climbing depending on the distance to the local maximum. Therefore, our approach has an advantage in computational efficiency by updating features from consecutive imaging frames.
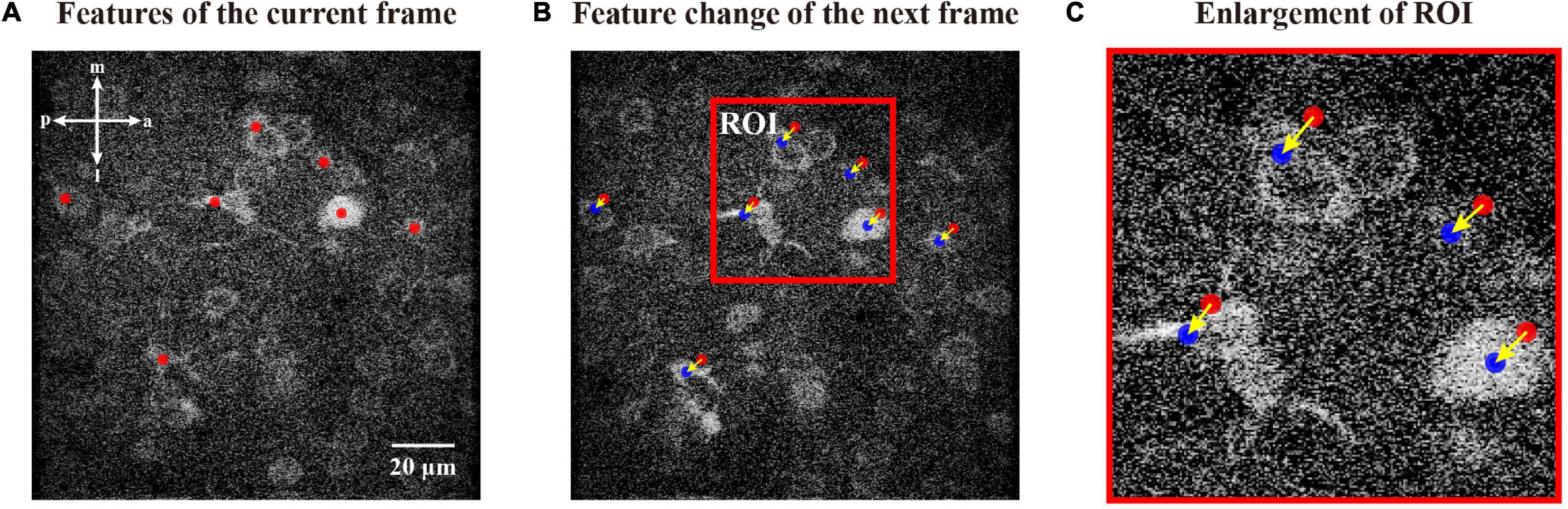
Figure 5. Updating features in a consecutive mode. (A) Features of current frame marked by red dots. (B) Features of the next frame updated from features of the current frame. We indicate features of the next frame with blue dots and those of the current frame with red dots. (C) Enlargement of the respective ROI in panel (B), i.e., the change flow of coordinates during this iteration. The arrows indicate the movement directions.
When we obtained features of the template image (Figure 6A) and one raw frame in the imaging sequence (Figure 6B), we matched those features to obtain transformation parameters for image registration. We then constructed the feature vector in three dimensions: the x- and y-axis positions and the normalized density (Figures 6C,D). In addition, we assumed that the template image and the raw frame have similar image structure in terms of position and density. Based on this hypothesis, we deduced that the coupled features in the template image and raw frame have the same relative position and estimated density. Thus, we propose to create a descriptor for each feature by reserving the differences between this feature and the rest (Figures 6E,F).

Figure 6. A visualization of the process to generate the descriptor. (A) The features for the template image obtained by FIFER features are marked by red dots. (B) A raw frame to be corrected with its corresponding features. (C) The density distribution of the template image with corresponding features. (D) The density distribution of the raw frame with corresponding features. The density maps in panels (C) and (D) are indicated with the grayscale bar painted on the right. (E) The descriptor of a feature selected from the template image. (F) The descriptor of a feature from the raw frame. This descriptor represents a collection of the differences between itself and all the other features in panels (E,F).
where the descriptors or are in their groups of point sets. After obtaining the descriptor of each feature, we matched the features by comparing the similarity of their descriptors. To match two feature descriptors, the corresponding elements between two descriptors were calculated for the Jaccard similarity coefficient with a parameter ζ1 set as the tolerable limit. If the calculated Jaccard similarity coefficient was larger than a given threshold ζ2, their corresponding two features were successfully matched. Eq. (6) describes this matching process.
where τsame represents the counts of multi-matching features. We demonstrate matching the features of a template image (Figure 7A) with a raw frame (Figure 7B). The matched relations of those features are shown in Figure 7C.
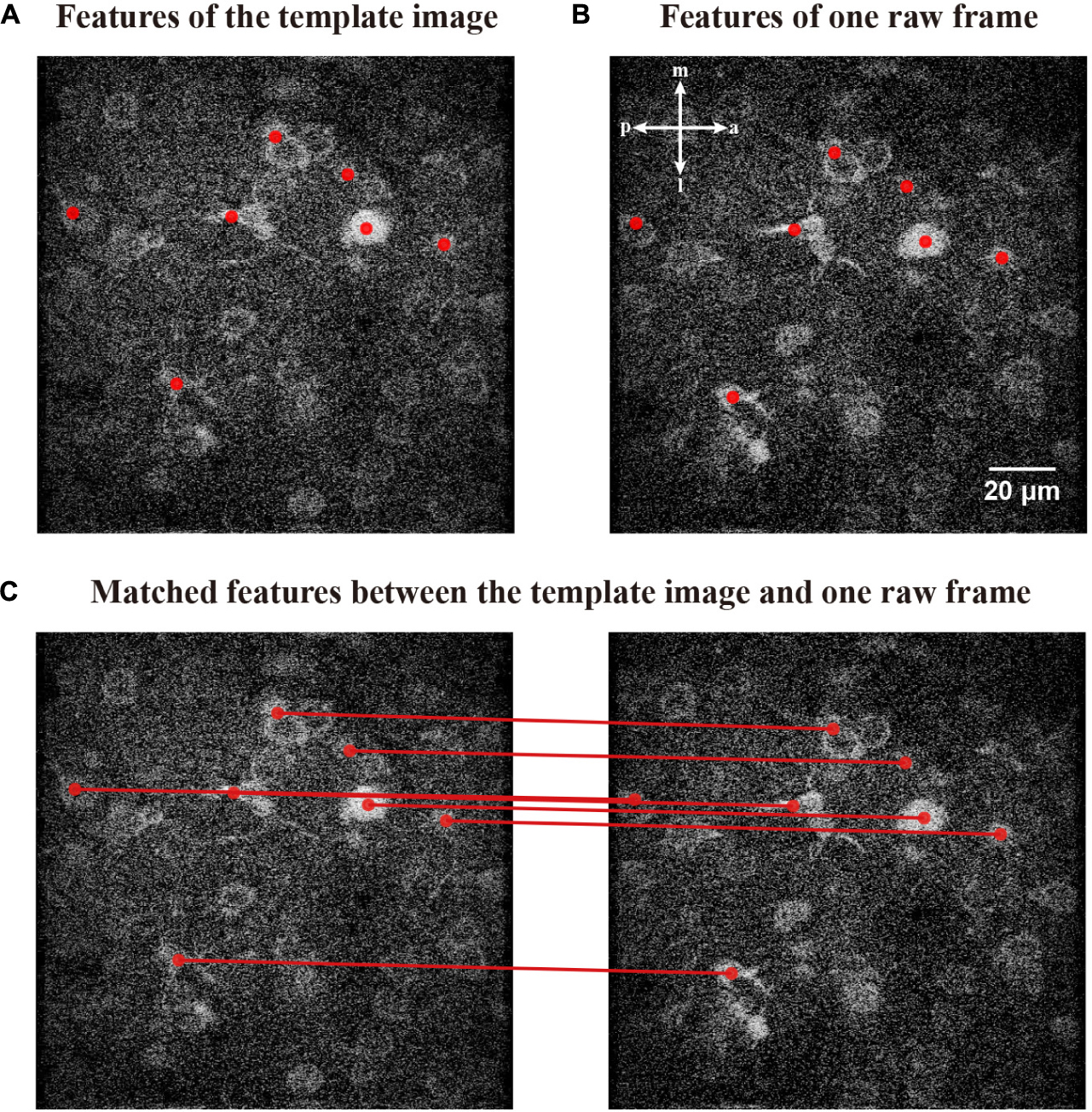
Figure 7. Matching relationships between the features of template image and raw frame. (A) The features obtained by FIFER of the template image; features are marked by red dots. (B) A raw frame to be corrected with its corresponding features. (C) The corresponding coupling of the features; the matched relationships are indicated by red lines.
In addition, we calculated the rotation transformation parameters for the image feature descriptors. Inspired by SIFT (Lowe, 2004), we used a histogram of oriented gradients (HoG) to set a constructive main direction to transform each feature for matching images (Figures 8A,B). Initially, we created several bins to calculate the distributions of the summed magnitude of vectors within 36 directions for each descriptor. Then, we decomposed each element of a descriptor of magnitudes into the upper and lower boundaries and counted the total magnitude in those 36 directions (Figures 8C,D). After that, we determined the main direction whose bin had the largest total magnitude. To obtain continuous directions, we used parabola interpolation to estimate a relative precise direction. Since we obtained the individual direction of a descriptor, we transformed the descriptor for matching features (Figures 8E,F). Then, we estimated a rotation angle by applying singular value decomposition (SVD) to multiple couples of the matched features (Besl and McKay, 1992). Hence we calculated the covariance matrix among two groups of features and applied SVD to obtain a transformation matrix and perform the registration of the image.
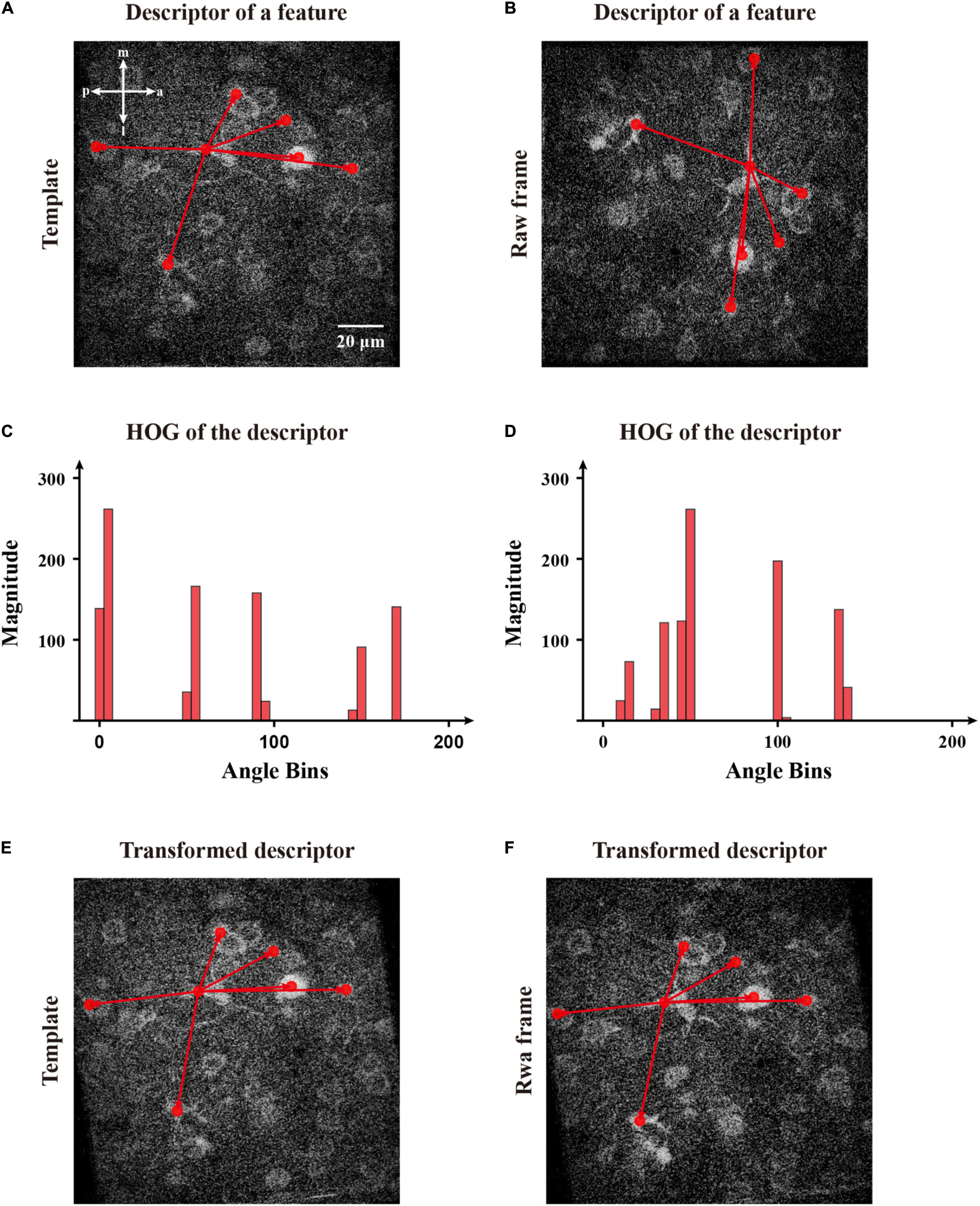
Figure 8. The calculation of direction of the selected features and transformation of corresponding descriptors for matching. (A) The features obtained by FIFER; features are marked by red dots. (B) A raw frame with a rotation deviation and its corresponding features. The red arrows represent a two-dimensional descriptor of the selected feature in panels (A,B). (C) The histogram of magnitude in directions bins of the template feature’s descriptor. (D) The histogram of magnitude in directions bins of the raw frame feature’s descriptor. (E) The descriptor of the selected template feature within its main direction. (F) The transformed descriptor of the selected frame feature within its main direction.
For the acquired two-photon imaging datasets, the similarities between the template image and corrected imaging data frames were calculated to evaluate motion correction performance. Here, four popular image quality metrics, including the normalized root mean square error (NRMSE), the peak signal-to-noise ratio (PSNR), the structural similarity (SSIM) index, and the normalized mutual information (NMI), were adopted in our evaluation tests. A smaller NRMSE value and a larger PSNR/SSIM/NMI value indicate better image correction quality (Luo et al., 2021). The calculation time was measured for processing each raw two-photon image of 600 × 600, 512 × 512 (neuronal population imaging) or 250 × 250 pixels (dendritic spine imaging) using an AMD Ryzen 7 5800X 3.8 GHz CPU, with 32 GB RAM.
To first perform an experimental validation of the proposed method, we evaluated the motion correction results on simulated imaging data. Here we used the NAOMi simulation toolbox (Song et al., 2021) to simulate two-photon imaging data. We set the numerical aperture (NA) of the objective lens as 0.8, the NA of the illumination light as 0.6 and the laser power as 40 mW. The generated data video had a size of 500 × 500 pixels and 100 frames. Figure 9A shows a representative example of simulated clean two-photon image. Then the synthetic noisy imaging data were generated with random spatial shifts and added Gaussian noise as the previous work (Pnevmatikakis and Giovannucci, 2017). Gaussian noise with zero mean and standard deviation sampled from [0, 0.25] were added to the clean two-photon images to generate testing images. Figures 9B,C show two noisy shifted images (noise levels: σ = 0.10 and σ = 0.25). As we can see (Figure 9D), the FIFER algorithm can estimate the shifts remarkably well. We evaluated the performance of motion correction for the simulated data with different noise levels, and the estimate errors do not change much with the noise level increases. Therefore, our proposed method achieved good performance on the simulation data test.
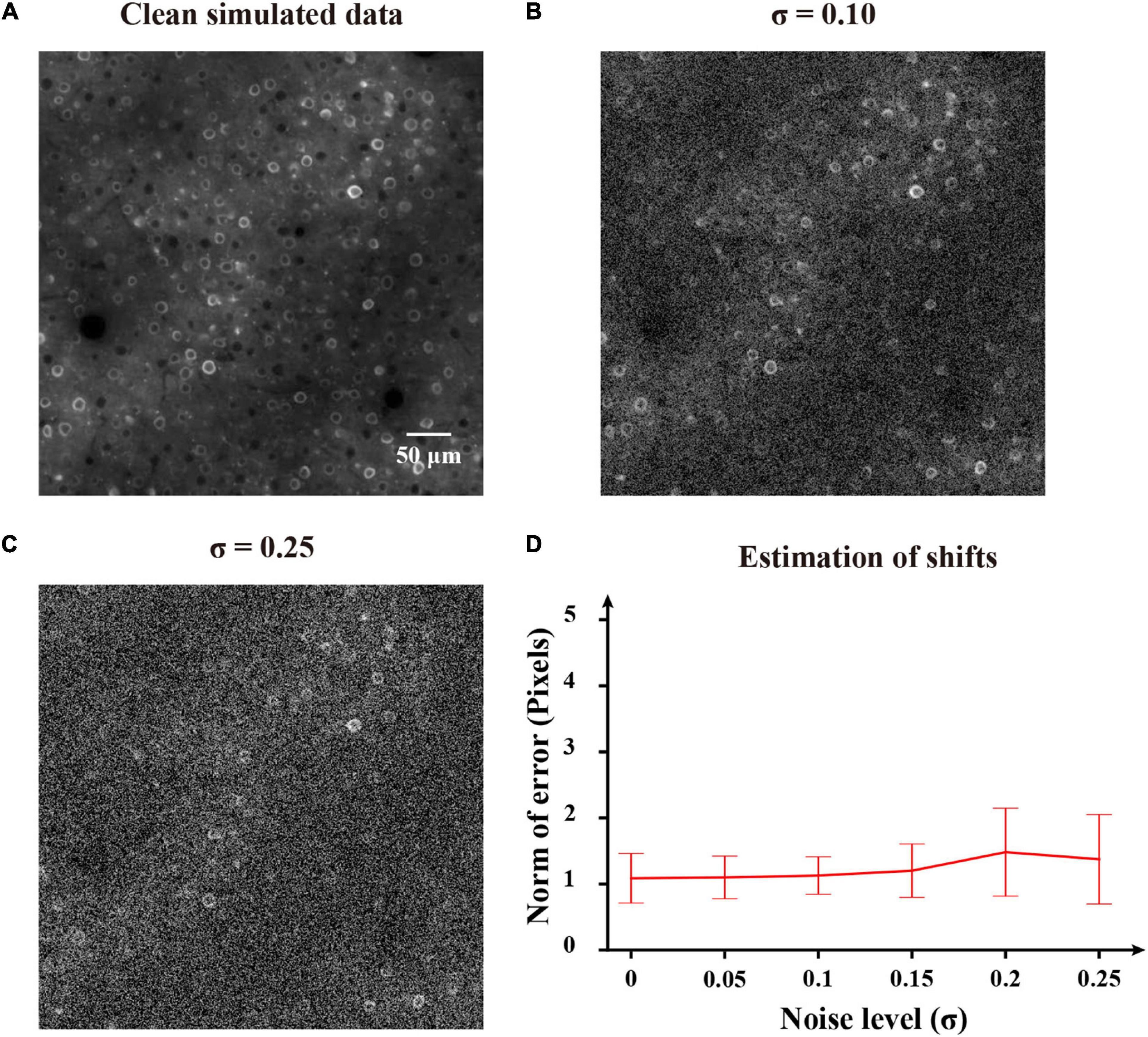
Figure 9. Application of FIFER to simulated data. (A) Template image (the first frame) of the clean simulated data. (B) Template image (the first frame) of the simulated data added with Gaussian noise of a standard deviation σ = 0.10. (C) Template image (the first frame) of the simulated data combined with Gaussian noise of a standard deviation σ = 0.25. (D) Estimation of shifts for the simulated data of different noise levels. FIFER’s error is calculated as the 2d-norm between the estimated offsets by FIFER and ground truth offsets (artificially introduced).
To further evaluate the performance of motion correction, we used two different two-photon imaging scales of datasets, i.e., the scale of a neuronal population (Figure 10, top) and the scale of a dendritic spine (Figure 10, bottom). Figures 10A,B shows the examples of the template images and the raw imaging frames (mixed with template images) to be corrected, respectively. After we applied our motion correction method for processing the raw imaging frames, the two representative frames were aligned to their corresponding templates (Figure 10C). This figure demonstrates that the raw frames were correctly transformed (here, a translation) to be matched with the template images.
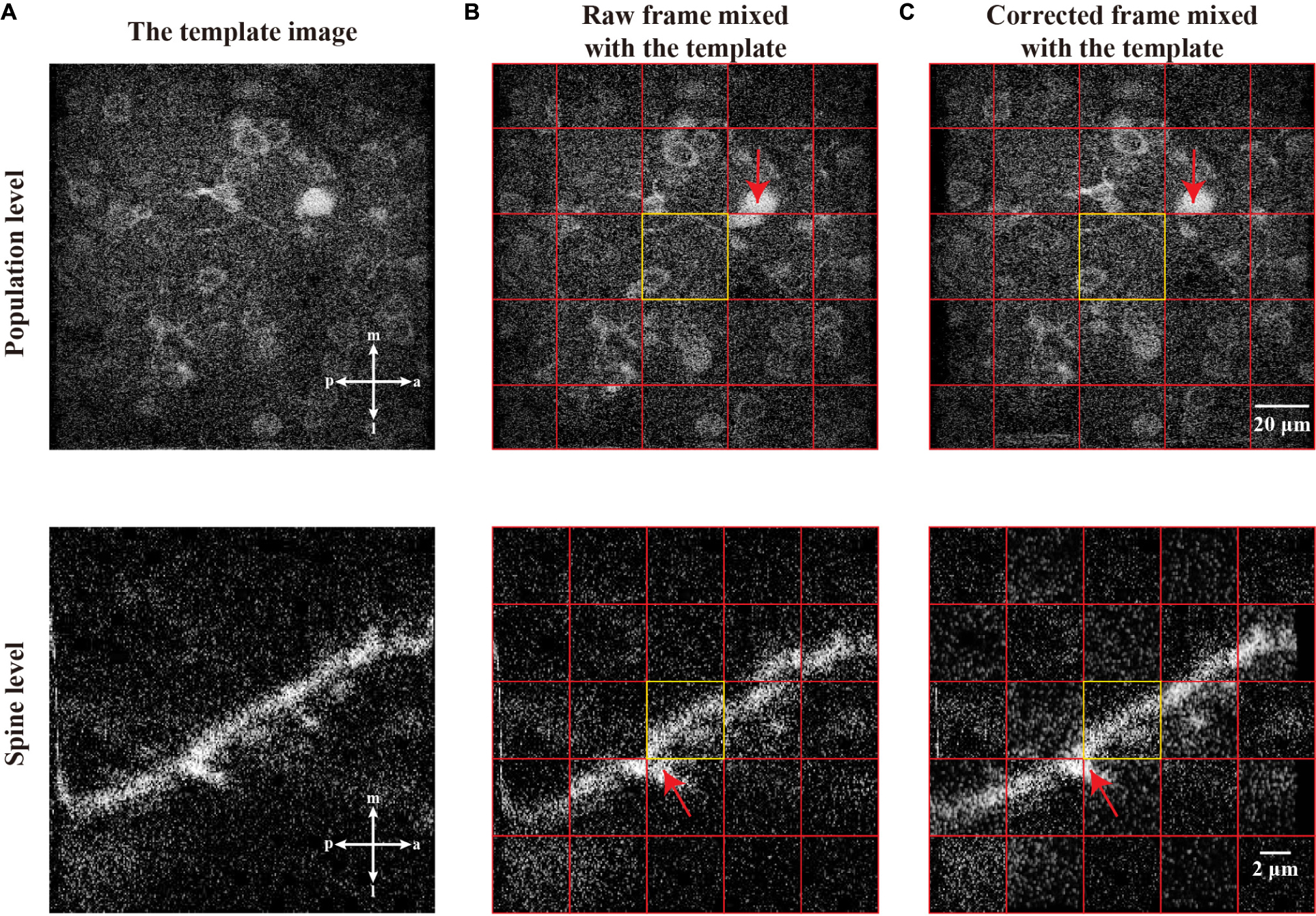
Figure 10. The motion correction effect in single raw frame of two-photon imaging data. (A) The template images of the population level and spine level. (B) Raw frames from population level and spine level with motion artifacts which are mixed with corresponding template image. (C) The correction of the raw frames, which are mixed with corresponding template image. In a mixed image, the image patches from the template and single frame are equally distributed and marked by red grid lines. The equally distribution means any two adjacent patches are from the template image and single frame, respectively. Each center of the mixed image is a patch from corresponding template image, which is marked by yellow rectangle. The red arrows indicate the performance of registration.
In Figure 11, we demonstrate the motion correction effects by showing the average image of the imaging data before and after motion correction. As the motion artifacts distort some of the imaging frame sequences, the average of a functional imaging data might suffer from inconsistency. As can be seen from the averaged raw image of the two imaging datasets (Figure 11A), both the neuronal population and dendritic spine imaging data show a blur effect due to motion artifacts during recording. By contrast, after we performed our motion correction method with the raw imaging data, the average of corrected images shows greatly improved quality, and the cells and spines are clearly visible without obvious blurred effect (Figure 11B). Thus, the imaging data were successfully restored.
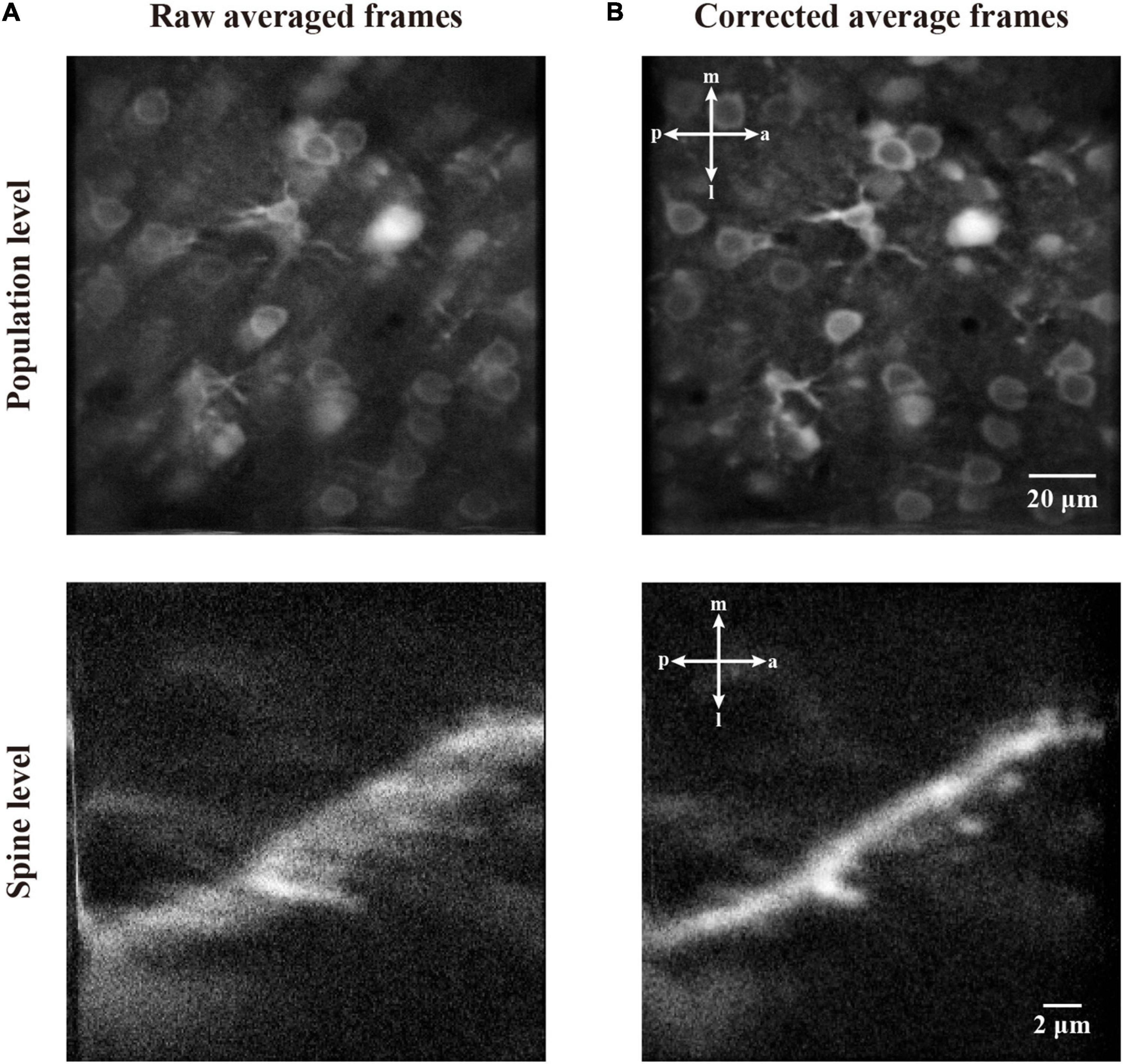
Figure 11. The correction effect in average frame of two-photon imaging data. (A) The average of raw frames at population level and spine level. (B) The average of motion corrected frames at population level and spine level.
We further addressed the effects of motion corrected neuronal activity as a time series of fluorescence changes. We identified the individual neurons and extracted their Ca2+ signals from the imaging frames to assess the change dynamics of Ca2+ transients both before (Figure 12A) and after (Figure 12B) motion correction. The raw imaging data exhibit that the motion resulted in spike-like changes (Figure 12C, left) or even larger distortions (Figure 12D, left) in the time series, which are indicated by the black arrows in Figures 12C,D. After we processed the raw imaging data with our method, the motion artifact-induced changes were successfully reduced and the neuronal signals were clearly restored (Figures 12C,D, right). Hence, the quality of individual Ca2+ transients processed by motion correction algorithm was clearly higher than that of the raw signals, which can facilitate downstream analyses, e.g., the detection of soma (Guan et al., 2018) and neuronal Ca2+ transients.

Figure 12. The motion correction effect of the neuronal signals. (A) Two representative neurons in the raw averaged frames, the neurons are indicated by dashed circles in yellow. (B) Two representative neurons in the corrected averaged frames. (C) The raw and corrected Ca2+ signals of neuron #1. (D) The raw and corrected Ca2+ signals of neuron #2. The black arrows indicate the distorted period due to motion artifacts.
To further assess the motion correction performance of our proposed method, we compared FIFER with other popular image registration methods. We tested them with three two-photon imaging datasets, including neuronal population (n = 200 and n = 1825) and dendritic spine (n = 1500) imaging frames to evaluate the motion correction performance of the methods. The image registration methods used for comparison consisted of two groups: feature-based methods and intensity-based methods. For the classic feature-based methods, the SIFT (Lowe, 2004), ORB (Rublee et al., 2011), and AKAZE (Alcantarilla et al., 2013) methods were used for comparison. For the widely used intensity-based methods, TurboReg (Thevenaz et al., 1998), Moco (Dubbs et al., 2016), NoRMCorre (Pnevmatikakis and Giovannucci, 2017), the real-time processing method (Mitani and Komiyama, 2018), and Suite2p (Pachitariu et al., 2017) were used for testing.
First, we tested FIFER and the abovementioned methods with our dataset of neuronal population imaging. As the testing results showing in Table 1, our FIFER method exhibits superior motion correction performance compared to existing image registration approaches in terms of NRMSE (0.9131 ± 0.0416), PSNR (19.7529 ± 0.3930), SSIM (0.1972 ± 0.0105), and NMI (0.0281 ± 0.0027). In addition, the calculation time of our proposed method is just 2.92 ms for processing each image. For the feature-based methods, SIFT shows better relative motion correction performance than ORB and AKAZE with a longer computational time, and ORB is relatively fast but has poor correction ability. For the intensity-based methods, we tested TurboReg with two working modes: Accurate and Fast. The Accurate mode of TurboReg achieved a better correction performance than that of Fast mode, while also requiring a longer calculation time. As the previous work reported, Moco achieved a fast processing of the data, using 26.92 ms for processing each frame. However, the motion correction performance of Moco is just comparable to the Fast mode of TurboReg. Moreover, we also tested NoRMCorre with its two modes, Rigid and Non-rigid. The Non-rigid mode of NoRMCorre performed well and was the closest to matching the motion correction performance achieved by FIFER, ranking second in our comparative analysis. However, the calculation time for the Non-rigid mode was the longest among the tested methods. In comparison, the Rigid mode of NoRMCorre also achieved good results with a much shorter time for processing. For the real-time processing method, it was very fast when processing the raw frames, requiring 3.85 ms for each frame, and its correction performance was as the same level as that of Moco and the Fast mode of TurboReg. For correcting the images with Suite2p, it used 11.91 ms for processing each frame and revealed similar performance as that of Moco. Hence Suite2p achieved a moderate motion correction accuracy and speed. Taken together, our proposed method not only provides superior motion correction results (P < 0.05, paired t-test), but also uses minimum processing time compared to the other tested methods.
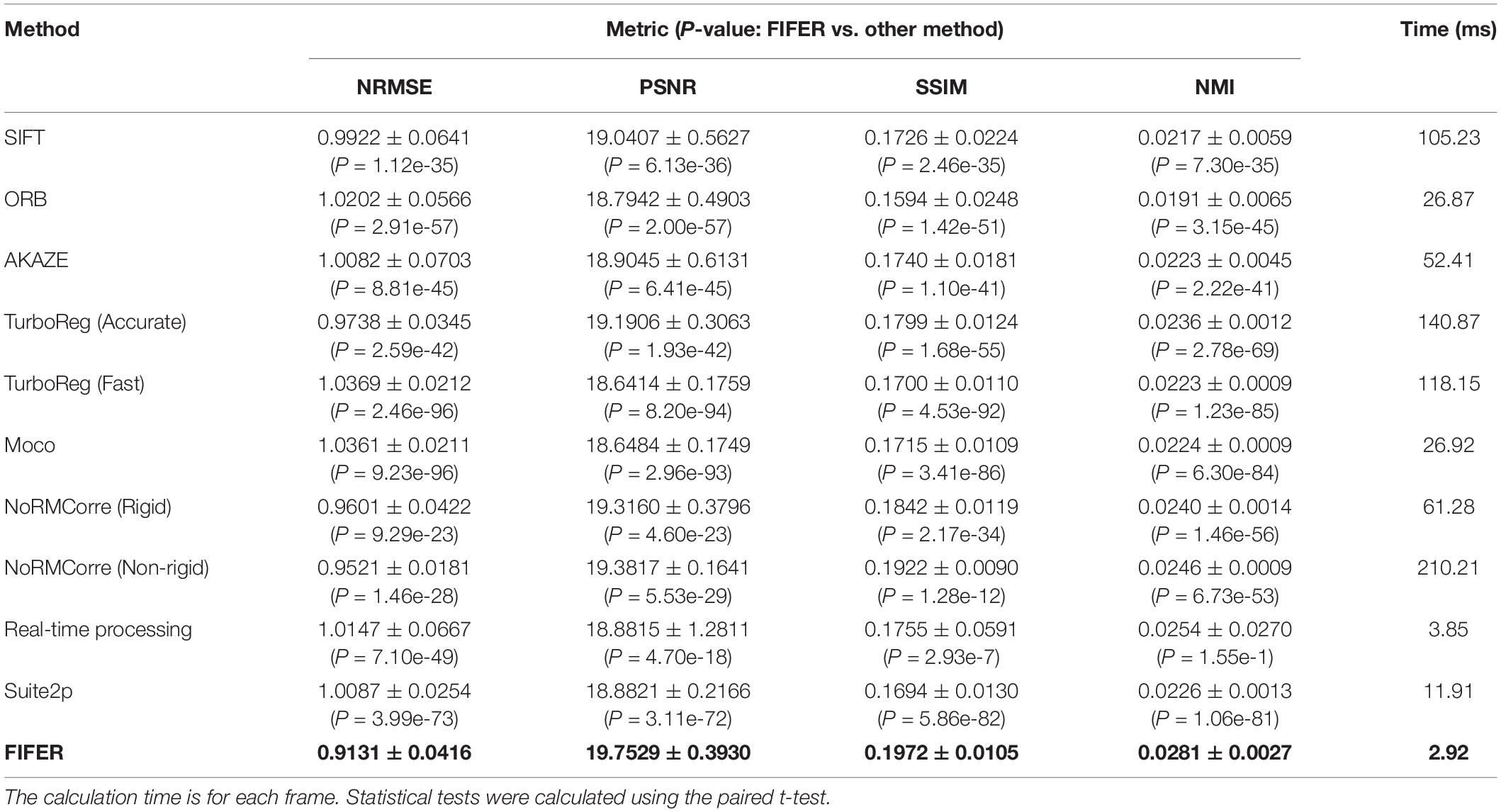
Table 1. Comparison of fast image feature extraction and registration (FIFER) with other methods (Mean ± SD) for neuronal population imaging dataset (n = 200 frames, 600 × 600 pixels for each frame).
We next compared FIFER with those methods for another dendritic spine imaging dataset, because this is also a popular imaging scale. As the results (Table 2) demonstrate, our proposed method also provided the best correction results (P < 0.05, paired t-test) in terms of NRMSE (0.8490 ± 0.0508), PSNR (18.5548 ± 0.5045), SSIM (0.1791 ± 0.0149), NMI (0.0733 ± 0.0043), and the fastest processing speed (0.59 ms for processing each frame). Among the other tested methods, the Accurate mode of TurboReg achieved the second-best correction result, and the real-time processing method achieved the second fastest processing speed (0.76 ms for processing each frame).
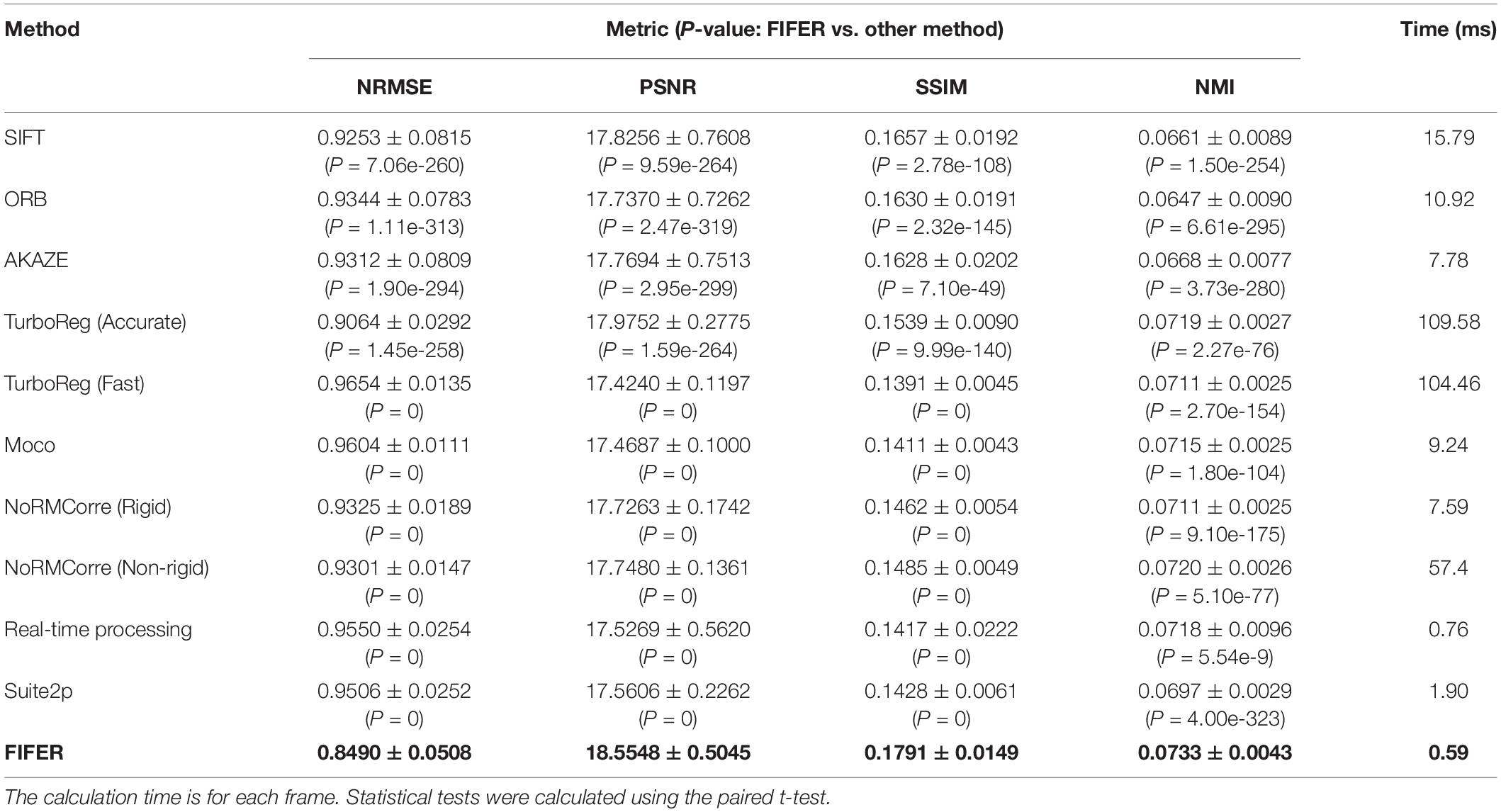
Table 2. Comparison of FIFER with other methods (mean ± SD) for dendritic spine imaging dataset (n = 1500 frames, 250 × 250 pixels for each frame).
To supplement the validation datasets, we further tested FIFER and those methods with a publicly available dataset provided by the CaImAn project (Giovannucci et al., 2019). The testing results (Table 3) show that, FIFER (1.77 ms for processing each frame) was clearly faster than all other algorithms, meanwhile it also achieved the best (P < 0.05, paired t-test) correction performance in terms of NRMSE (0.7930 ± 0.1346), PSNR (27.0004 ± 1.3278), SSIM (0.4632 ± 0.0382), and NMI (0.0434 ± 0.0033). These validation results indicate a high generalization ability of FIFER, as it performed consistently fast and accurate for processing multiple datasets acquired from different labs.
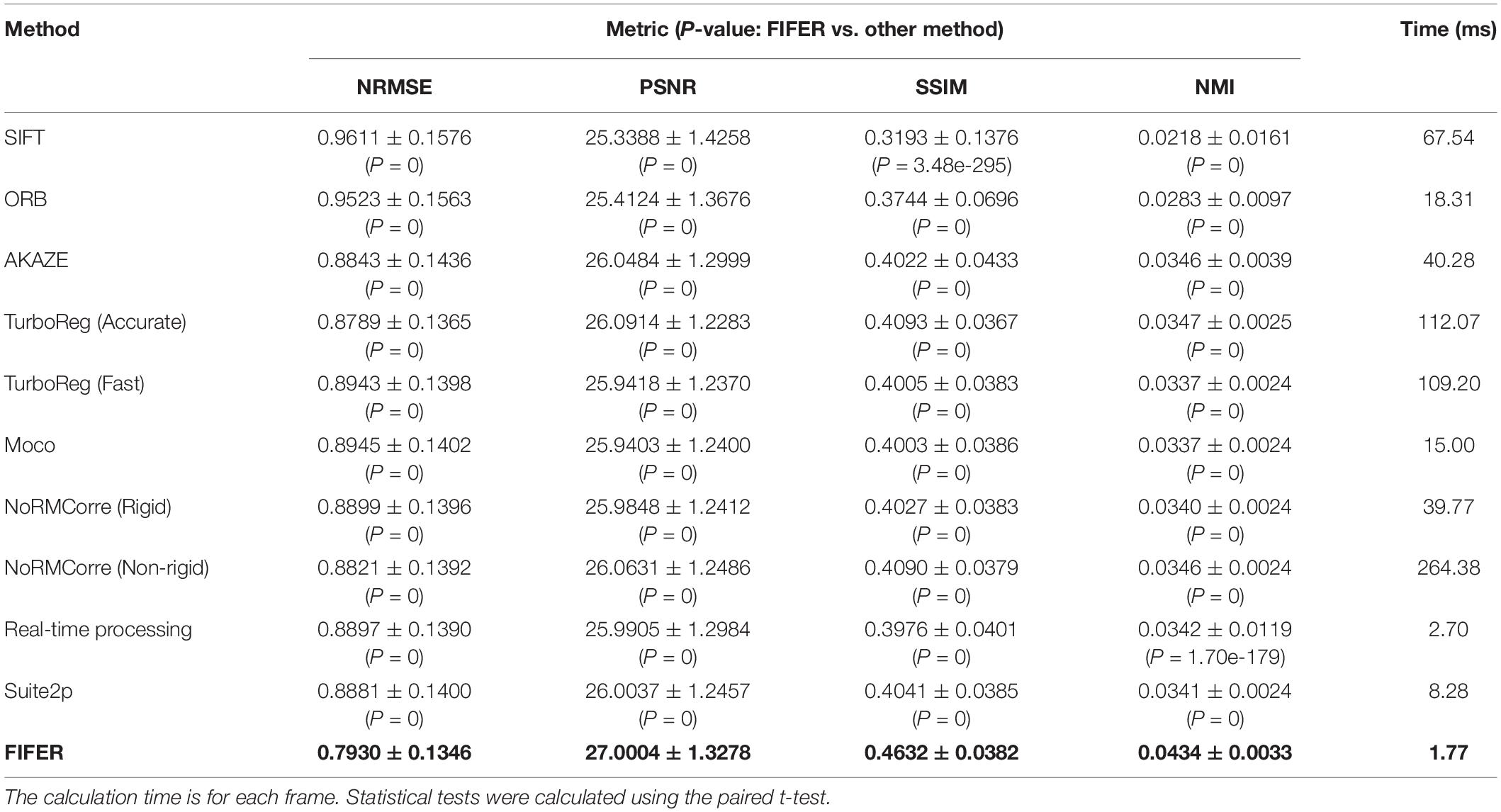
Table 3. Comparison of FIFER with other methods (Mean ± SD) for neuronal population imaging dataset (the CaImAn dataset file images_N.01.01, n = 1825 frames, 512 × 512 pixels for each frame).
In this work, we proposed the FIFER method to perform motion correction for two-photon Ca2+ imaging data by extracting features via image density-based estimation and raw image registration. Using a regular personal computer, the proposed method showed promising performance in both computational speed and motion correction precision. The testing results showed that our method achieved strong results for not only simulated imaging data (Figure 9) but also both neuronal population and dendritic spine imaging datasets (Figures 10, 11). In addition, we demonstrated that the individual neuronal signal quality was clearly improved using our approach (Figure 12). The comparative analyses of FIFER against previously reported image registration approaches for motion correction in three imaging datasets (Tables 1–3) highlight the superior ability of our proposed method, as it is faster than other approaches while also achieving the best image correction accuracy. Hence, adopting our image correction method for online two-photon imaging experiments will benefit both functional imaging and closed loop photostimulation. The code implementing FIFER is published on the project’s GitHub page.
To extract features for matching images, we proposed a new algorithm, namely, W-KDE and density-based clustering, to extract the density features from a single frame of two-photon imaging data. Our proposed method outperformed the other feature-based and intensity-based methods for motion correction because it operates in a robust way to extract features, and then finds the optimal template matching solution. As our proposed method registered a pair of images by extracting local features, it reduced the differential contents from the global image. By contrast, the other feature-based methods, including SIFT, ORB, and AKAZE, did not show good performance. The reason for this might be that their feature extraction suffered from the signal-to-noise ratio issues with the imaging data. The insufficient common neuronal morphology or uneven background might cause classical feature-based motion correction methods to fail. Specially, the features extracted by our approach mostly represent some certain cellular structures: the feature marks the strongest Ca2+ signals of the soma or the dendritic spine, hence the extracted features by our approach are more accurate than the traditional feature extraction approaches for two-photon images. In addition, the intensity-based methods, including TurboReg, Moco, NoRMCorre, Suite2p and the real-time processing method, also perform image registration based on global image information. Hence, they might also encounter the issue that the intensity difference between the non-common areas (e.g., the noisy background) from the image pair may have a negative impact on the image registration and result in a sub-optimal image registration solution (Li et al., 2020). Furthermore, the sparse features extracted from foreground cellular structures by our approach hardly suffer from the background noise and might lead to an optimal solution. For instance, the dendritic spine imaging data only presented small common areas, so FIFER using local features achieved better results than other methods (Table 2). Therefore, the testing results show that our feature extraction and matching method provides robust results for correcting motion artifacts at different two-photon imaging scales.
Moreover, the testing results show that our method is ultrafast to find an optimal matching solution for an image pair. Only the real-time processing method achieved comparable calculation speed, and the other methods are much slower (Tables 1–3). With our algorithm, once features were extracted for the first raw frame, we could conduct an ultrafast update of features with nearby ROI gradients within several iterations. Across the whole imaging frame sequence, this kind of feature extraction strategy needs only once global image search to cluster features for the first raw frame and template image. Following this initial search, the features of the remaining raw frames can be quickly generated based on the previous information. By contrast, the other methods used global image content (Mitani and Komiyama, 2018); as a result, their computational costs were relatively larger than that of our method.
It is also worth to note that, the features in the raw two-photon images are non-stationary, hence one of the best approaches for feature detection might be performing spatio-temporal feature extraction to tackle temporal inconsistencies. Although computational complexity increases with spatio-temporal information extracted from consecutive frames of imaging data, the processing can preserve both the morphology features and temporal neural dynamics (Luo et al., 2021). As another consequence of non-stationarity, it also poses a challenge for evaluating motion correction, because single metric is hardly able to quantify the performance well. Therefore, a series of complementary metrics in both spatial and temporal dimensions can be combined as the most appropriate solution for measuring the performance quantification, which still needs further investigations.
In this study, we demonstrate that FIFER performed well for motion correction task and required only a conventional computer, such success indicates that it would be desirable to implement FIFER as online processing software and use it for neurobiology experiments requiring online observation and stimulation. However, it warrants to mention that FIFER is designed as a frame-by-frame 2D motion correction method, hence it has the limitation for dealing with the distortions induced by 3D brain movements, which requires 3D motion correction method, e.g., (Griffiths et al., 2020). In addition, although our method demonstrated promising motion correction performance and a fast processing speed in a rigid mode, it would be worthwhile to extend our method to treat affine (Li et al., 2020) or non-rigid distortions (Pnevmatikakis and Giovannucci, 2017) in complex imaging experiments, such as in chronic two-photon imaging to study learning-induced neuronal activity changes.
The imaging data supporting the conclusions of this article are available from the corresponding author upon reasonable request. The code is provided at https://github.com/Weiyi-Liu-Unique/FIFER. We used a public dataset (the CaImAn dataset file images_N.01.01.zip from https://zenodo.org/record/1659149) to evaluate the performance of FIFER and other methods. For a detailed description of the dataset (see Giovannucci et al., 2019).
This study was approved by the Institutional Animal Care and Use Committee of Third Military Medical University. All experimental procedures were conducted in accordance with animal ethical guidelines of the Third Military Medical University Animal Care and Use Committee.
KZ, XC, XnL, and XaL contributed to the design of the study and wrote the manuscript with help from other authors. JP and MW performed the imaging experiments and acquired the data. WL, YX, XnL, and XaL designed the method. WL, JP, YX, HJ, KZ, and XC processed the data sets. All authors contributed to the article and approved the submitted version.
This work was supported by grants from the National Natural Science Foundation of China (No. 32171096) to XaL and the National Natural Science Foundation of China (Nos. 31925018, 31861143038, and 32127801) to XC. XC was a junior fellow of the CAS Center for Excellence in Brain Science and Intelligence Technology.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
We thank Jia Lou for technical assistance.
Alcantarilla, P. F., Nuevo, J., and Bartoli, A. (2013). “Fast explicit diffusion for accelerated features in nonlinear scale spaces,” in Proceedings of the British Machine Vision Conference (BMVC), Bristol, 1–11. doi: 10.5244/C.27.13
Besl, P. J., and McKay, N. D. (1992). A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. 14, 239–256. doi: 10.1109/34.121791
Chen, J. L., Pfäffli, O. A., Voigt, F. F., Margolis, D. J., and Helmchen, F. (2013). Online correction of licking-induced brain motion during two-photon imaging with a tunable lens. J. Physiol. 591, 4689–4698. doi: 10.1113/jphysiol.2013.259804
Chen, X., Leischner, U., Rochefort, N. L., Nelken, I., and Konnerth, A. (2011). Functional mapping of single spines in cortical neurons in vivo. Nature 475, 501–505. doi: 10.1038/nature10193
Chen, X., Leischner, U., Varga, Z., Jia, H., Deca, D., Rochefort, N. L., et al. (2012). LOTOS-based two-photon calcium imaging of dendritic spines in vivo. Nat. Protoc. 7, 1818–1829. doi: 10.1038/nprot.2012.106
Dombeck, D. A., Khabbaz, A. N., Collman, F., Adelman, T. L., and Tank, D. W. (2007). Imaging large-scale neural activity with cellular resolution in awake, mobile mice. Neuron 56, 43–57. doi: 10.1016/j.neuron.2007.08.003
Dubbs, A., Guevara, J., and Rafael, Y. (2016). Moco: fast motion correction for calcium imaging. Front. Neuroinform. 10:6. doi: 10.3389/fninf.2016.00006
Giovannucci, A., Friedrich, J., Gunn, P., Kalfon, J., Brown, B. L., Koay, S. A., et al. (2019). CaImAn an open source tool for scalable calcium imaging data analysis. elife 8:e38173. doi: 10.7554/eLife.38173
Greenberg, D. S., and Kerr, J. N. (2009). Automated correction of fast motion artifacts for two-photon imaging of awake animals. J. Neurosci. Meth. 176, 1–15. doi: 10.1016/j.jneumeth.2008.08.020
Grienberger, C., and Konnerth, A. (2012). Imaging calcium in neurons. Neuron 73, 862–885. doi: 10.1016/j.neuron.2012.02.011
Griffiths, V. A., Valera, A. M., Lau, J. Y., Roš, H., Younts, T. J., Marin, B., et al. (2020). Real-time 3D movement correction for two-photon imaging in behaving animals. Nat. Methods 17, 741–748. doi: 10.1038/s41592-020-0851-7
Guan, J., Li, J., Liang, S., Li, R., Li, X., Shi, X., et al. (2018). NeuroSeg: automated cell detection and segmentation for in vivo two-photon Ca2+ imaging data. Brain Struct. Funct. 223, 519–533. doi: 10.1007/s00429-017-1545-5
Haskins, G., Kruger, U., and Yan, P. (2020). Deep learning in medical image registration: a survey. Mach. Vision Appl. 31: 8. doi: 10.1007/s00138-020-01060-x
Hinneburg, A., and Gabriel, H.-H. (2007). “Denclue 2.0: fast clustering based on kernel density estimation,” in Advances in Intelligent Data Analysis VII. IDA 2007. Lecture Notes in Computer Science, Vol. 4723, eds R. M. Berthold, J. Shawe-Taylor, and N. Lavraè (Berlin: Springer), 70–80. doi: 10.1007/978-3-540-74825-0_7
Hinneburg, A., and Keim, D. A. (1998). An efficient approach to clustering in large multimedia databases with noise. Proc. KDD 98, 58–65. doi: 10.1155/2018/9391635
Huber, D., Gutnisky, D. A., Peron, S., O’connor, D. H., Wiegert, J. S., Tian, L., et al. (2012). Multiple dynamic representations in the motor cortex during sensorimotor learning. Nature 484, 473–478. doi: 10.1038/nature11039
Jia, H., Rochefort, N. L., Chen, X., and Konnerth, A. (2010). Dendritic organization of sensory input to cortical neurons in vivo. Nature 464, 1307–1312. doi: 10.1038/nature08947
Jia, H., Varga, Z., Sakmann, B., and Konnerth, A. (2014). Linear integration of spine Ca2+ signals in layer 4 cortical neurons in vivo. Proc. Natl. Acad. Sci. U.S.A. 111, 9277–9282. doi: 10.1073/pnas.1408525111
Li, C., Yang, X., Ke, Y., and Yung, W. H. (2020). Fully affine invariant methods for cross-session registration of calcium imaging data. eNeuro 7:ENEURO.0054-0020.202020. doi: 10.1523/eneuro.0054-20.2020
Li, R., Wang, M., Yao, J., Liang, S., Liao, X., Yang, M., et al. (2018). Two-photon functional imaging of the auditory cortex in behaving mice: from neural networks to single spines. Front. Neural Circuits 12:33. doi: 10.3389/fncir.2018.00033
Lowe, D. G. (2004). Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vision 60, 91–110. doi: 10.1023/B:VISI.0000029664.99615.94
Luo, L., Xu, Y., Pan, J., Wang, M., Guan, J., Liang, S., et al. (2021). Restoration of two-photon Ca2+ imaging data through model blind spatiotemporal filtering. Front. Neurosci. 15:630250. doi: 10.3389/fnins.2021.630250
Mitani, A., and Komiyama, T. (2018). Real-time processing of two-photon calcium imaging data including lateral motion artifact correction. Front. Neuroinform. 12:98. doi: 10.3389/fninf.2018.00098
Pachitariu, M., Stringer, C., Dipoppa, M., Schröder, S., Rossi, L. F., Dalgleish, H., et al. (2017). Suite2p: beyond 10,000 neurons with standard two-photon microscopy. bioRxiv [Preprint]. doi: 10.1101/061507
Pnevmatikakis, E. A. (2019). Analysis pipelines for calcium imaging data. Curr. Opin. Neurobiol. 55, 15–21. doi: 10.1016/j.conb.2018.11.004
Pnevmatikakis, E. A., and Giovannucci, A. (2017). NoRMCorre: an online algorithm for piecewise rigid motion correction of calcium imaging data. J. Neurosci. Methods 291, 83–94. doi: 10.1016/j.jneumeth.2017.07.031
Rosten, E., Porter, R., and Drummond, T. (2008). Faster and better: a machine learning approach to corner detection. IEEE Trans. Pattern Anal. 32, 105–119. doi: 10.1109/TPAMI.2008.275
Rublee, E., Rabaud, V., Konolige, K., and Bradski, G. (2011). “ORB: an efficient alternative to SIFT or SURF,” in Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, 2564–2571. doi: 10.1109/ICCV.2011.6126544
Song, A., Gauthier, J. L., Pillow, J. W., Tank, D. W., and Charles, A. S. (2021). Neural anatomy and optical microscopy (NAOMi) simulation for evaluating calcium imaging methods. J. Neurosci. Methods 358:109173. doi: 10.1016/j.jneumeth.2021.109173
Stosiek, C., Garaschuk, O., Holthoff, K., and Konnerth, A. (2003). In vivo two-photon calcium imaging of neuronal networks. Proc. Natl. Acad. Sci. U.S.A. 100, 7319–7324. doi: 10.1073/pnas.1232232100
Tada, M., Takeuchi, A., Hashizume, M., Kitamura, K., and Kano, M. (2014). A highly sensitive fluorescent indicator dye for calcium imaging of neural activity in vitro and in vivo. Eur. J. Neurosci. 39, 1720–1728. doi: 10.1111/ejn.12476
Thevenaz, P., Ruttimann, U. E., and Unser, M. (1998). A pyramid approach to subpixel registration based on intensity. IEEE Trans. Image Process. 7, 27–41. doi: 10.1109/83.650848
Thompson, N. C., Greenewald, K., Lee, K., and Manso, G. F. (2020). The computational limits of deep learning. arXiv [Preprint]. arXiv: 2007.05558,Google Scholar
Keywords: two-photon Ca2+ imaging, motion correction, behaving mice, image density feature, image registration, online experiment
Citation: Liu W, Pan J, Xu Y, Wang M, Jia H, Zhang K, Chen X, Li X and Liao X (2022) Fast and Accurate Motion Correction for Two-Photon Ca2+ Imaging in Behaving Mice. Front. Neuroinform. 16:851188. doi: 10.3389/fninf.2022.851188
Received: 09 January 2022; Accepted: 07 March 2022;
Published: 26 April 2022.
Edited by:
Valentin Nägerl, UMR 5297 Institut Interdisciplinaire de Neurosciences, FranceReviewed by:
Vassiliy Tsytsarev, University of Maryland, College Park, United StatesCopyright © 2022 Liu, Pan, Xu, Wang, Jia, Zhang, Chen, Li and Liao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Kuan Zhang, emhhbmdrdWFuQHRtbXUuZWR1LmNu; Xiaowei Chen, eGlhb3dlaV9jaGVuQHRtbXUuZWR1LmNu; Xingyi Li, eGluZ3lpX2xpQGNxdS5lZHUuY24=; Xiang Liao, eGlhbmcubGlhb0BjcXUuZWR1LmNu
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.