 Hang Su1†Zhengyuan Han2†Yujie Fu2†Dong Zhao1*Fanhua Yu1Ali Asghar Heidari3Yu Zhang1Yeqi Shou2
Hang Su1†Zhengyuan Han2†Yujie Fu2†Dong Zhao1*Fanhua Yu1Ali Asghar Heidari3Yu Zhang1Yeqi Shou2 Peiliang Wu2
Peiliang Wu2 Huiling Chen4*Yanfan Chen2*
Huiling Chen4*Yanfan Chen2*- 1College of Computer Science and Technology, Changchun Normal University, Changchun, Jilin, China
- 2Department of Pulmonary and Critical Care Medicine, The First Affiliated Hospital of Wenzhou Medical University, Wenzhou, China
- 3School of Surveying and Geospatial Engineering, College of Engineering, University of Tehran, Tehran, Iran
- 4College of Computer Science and Artificial Intelligence, Wenzhou University, Wenzhou, Zhejiang, China
Introduction: Pulmonary embolism (PE) is a cardiopulmonary condition that can be fatal. PE can lead to sudden cardiovascular collapse and is potentially life-threatening, necessitating risk classification to modify therapy following the diagnosis of PE. We collected clinical characteristics, routine blood data, and arterial blood gas analysis data from all 139 patients.
Methods: Combining these data, this paper proposes a PE risk stratified prediction framework based on machine learning technology. An improved algorithm is proposed by adding sobol sequence and black hole mechanism to the cuckoo search algorithm (CS), called SBCS. Based on the coupling of the enhanced algorithm and the kernel extreme learning machine (KELM), a prediction framework is also proposed.
Results: To confirm the overall performance of SBCS, we run benchmark function experiments in this work. The results demonstrate that SBCS has great convergence accuracy and speed. Then, tests based on seven open data sets are carried out in this study to verify the performance of SBCS on the feature selection problem. To further demonstrate the usefulness and applicability of the SBCS-KELM framework, this paper conducts aided diagnosis experiments on PE data collected from the hospital.
Discussion: The experiment findings show that the indicators chosen, such as syncope, systolic blood pressure (SBP), oxygen saturation (SaO2%), white blood cell (WBC), neutrophil percentage (NEUT%), and others, are crucial for the feature selection approach presented in this study to assess the severity of PE. The classification results reveal that the prediction model’s accuracy is 99.26% and its sensitivity is 98.57%. It is expected to become a new and accurate method to distinguish the severity of PE.
Introduction
A potentially fatal cardiac condition known as pulmonary embolism (PE) occurs when one or more emboli clog the pulmonary artery, impairing breathing and pulmonary circulation (Goldhaber, 2004). Tumor, fat, amniotic fluid, or air can all cause PE. The most prevalent cause of pulmonary embolism, however, is deep vein thrombosis (DVT), a blood clot that most usually occurs in the deep veins of the lower legs. 53–162 DVT cases per 100,000 persons are reported annually, according to epidemiological studies. The yearly incidence of PE ranges from 39 to 115 per 100,000 people (Wendelboe and Raskob, 2016; Keller et al., 2020). In addition, PE claims about 300,000 lives annually in the US (Wendelboe and Raskob, 2016; Konstantinides et al., 2020).
The clinical symptoms of pulmonary embolism are non-specific. The typical clinical presentation of PE includes dyspnea, chest pain, hemoptysis, presyncope or syncope, collapse, hypotension, right heart failure, cardiogenic shock, and sudden cardiac death (Hirsh et al., 1986; Keller et al., 2016a,b). For young and previously healthy patients with excellent cardiac reserve, PE can also be asymptomatic (Goldhaber, 2004). The non-specific and variable clinical manifestations of PE, which challenge the diagnosis and treatment, are mainly related to the patient’s hemodynamic status and right ventricular load (Agnelli and Becattini, 2015).
Pulmonary embolism can take the form of small, asymptomatic blood clots or big, life-threatening emboli that block the pulmonary arteries and cause a rapid circulatory collapse. After diagnosing PE, risk stratification must be done in order to modify the course of treatment since PE poses a possible hazard to life (Konstantinides and Goldhaber, 2012). The optimum method for risk classification of patients with PE is currently that suggested by the European Cardiology Society (ESC) (Jen et al., 2018; Wang et al., 2019; Konstantinides et al., 2020). However, certain investigations continue to demonstrate that more than 50% of patients with acute PE remain hemodynamically stable according to clinical models, although there is a risk of mortality (Elias et al., 2016; Barrios et al., 2017). Another research investigated the 2014 ESC model’s capacity to forecast mortality 30 days after acute PE, demonstrating the need for additional development in the categorization of intermediate-risk patients (Becattini et al., 2016). Therefore, it is crucial to develop new techniques for more precise risk assessment of individuals with PE. In recent years, the use of machine learning techniques to aid physicians in resolving medical problems has increased.
By fusing the Chaotic Emperor Penguin Optimization (CEPO) algorithm with an Extreme Learning Machine, Baliarsingh and Vipsita (2020) proposed a cancer categorization prediction model with good accuracy and sensitivity. Ahmadi and Afshar (2016) introduced the traditional Particle Swarm Optimization algorithm into a Support Vector Machine (SVM) to achieve more accurate classification prediction of breast cancer. Mishra et al. (2021) used machine learning techniques to segment MRI brain images and improved the model’s accuracy using a whale optimization algorithm. For a brand-new ECG arrhythmia classification issue, Khazaee and Zadeh (2014) suggested a SVM classifier model based on particle swarm optimization (PSO). In order to forecast Parkinson’s illness, Cai et al. (2017) suggested an ideal SVM based on bacterial foraging optimization (BFO). They experimentally confirmed that the improved technique has a high classification accuracy. To control the nutritional cycle in hospitals, Ileri and Hacibeyoglu (2019) suggested a hybrid metaheuristic machine learning model that combines genetic algorithms, simulated annealing algorithms, and machine learning techniques. Zhou et al. (2014) used a Memetic algorithm to optimize chained weight vectors and combined it with an extreme learning machine for classifying metabolite features. Lambert and Perumal (2021) developed a new meta-heuristic classification model for the diagnosis and optimal feature selection of chronic kidney disease, and the proposed model achieved a high accuracy rate. Many medical diagnosis systems can assist doctors in making more intelligent and successful decisions (Li et al., 2022; Liu et al., 2022a,d). An increasing number of researchers can be seen to be using machine learning classification prediction techniques for medical diagnosis in recent years. Traditional feature selection methods are highly prone to data overlap when there are not enough features, which will lead to classifier failure in this case. In addition, when the dimensionality of features is too high, the distance of similar data in the space becomes sparse, which also decreases the efficiency and accuracy of the classifier. The feature selection model based on the swarm intelligence algorithm is based on global feature selection, which is less likely to overlap when the amount of data is small. On the other hand, the swarm intelligence algorithm can take advantage of its stochastic and collaborative nature when dealing with high-dimensional data and can produce high-quality solutions and high-precision classification results in a limited amount of time.
Most traditional optimizers need to deal with info related to the surface of the feature space, or they need an offline routine to deal with problems (Zhang M. et al., 2021). A fresh approach for resolving these issues is the swarm intelligence optimization algorithm, which is well-liked by academics due to its effectiveness and great precision. The swarm intelligence optimization technique is developed by abstractly modeling the cooperative behavior of animals, fish, insects, and other natural entities. For example, there are different evolution (DE) (Storn and Price, 1997), chaotic BA (CBA) (Adarsh et al., 2016), sine cosine algorithm (SCA) (Mirjalili, 2016), salp swarm algorithm (SSA) (Mirjalili et al., 2017), whale optimizer (WOA) (Mirjalili and Lewis, 2016), moth-flame optimization (MFO) (Mirjalili, 2015), hunger games search (HGS) (Yang et al., 2021), Harris hawks optimization (HHO) (Heidari et al., 2019), slime mold algorithm (SMA) (Li et al., 2020), moth-flame optimizer with sine cosine mechanisms (SMFO) (Chen et al., 2021), colony predation algorithm (CPA) (Tu et al., 2021), the weighted mean of vectors (INFO) (Ahmadianfar et al., 2022), Runge Kutta optimizer (RUN) (Ahmadianfar et al., 2021), particle swarm optimization (PSO) (Kennedy and Eberhart, 1995), fruit fly optimization algorithm (FOA) (Pan, 2012), improved ant colony optimizer (RCACO) (Zhao et al., 2020), improved WOA (EWOA) (Tu et al., 2020), chaotic SCA (Ji et al., 2020), and so on. They have also been used in many fields, such as image segmentation (Hussien et al., 2022; Yu et al., 2022), optimization of machine learning models (Chen et al., 2014), scheduling problems (Gao et al., 2020; Han et al., 2021; Wang G. G. et al., 2022), feature selection (Hu J. et al., 2022; Liu et al., 2022b), complex optimization problem (Deng et al., 2022b), bankruptcy prediction (Xu et al., 2019; Zhang Y. et al., 2021), resource allocation (Deng et al., 2022a), gate resource allocation (Deng et al., 2020a,b), airport taxiway planning (Deng et al., 2022c), robust optimization (He et al., 2019, 2020), solar cell parameter Identification (Ye et al., 2021), and medical diagnosis (Chen et al., 2016; Wang et al., 2017).
Yang and Suash (2009) proposed a novel and high-performance evolutionary algorithm called cuckoo search (CS) algorithm by simulating the parasitic collaborative behavior of cuckoos. It has been widely used by researchers in various fields of optimization problems due to its high exploration and exploitation capabilities. Jin et al. (2015) proposed a high search efficiency CS algorithm for designing PID controllers. Boushaki et al. (2018) introduced the quantum chaos mechanism into the CS algorithm to improve the convergence speed of the algorithm and used the improved algorithm in data clustering. Zhou et al. (2013) developed a CS algorithm combining three strategies for solving the planar graph coloring problem. Valian et al. (2013) improved the convergence accuracy and speed by adjusting the parameters of the CS algorithm and applying the algorithm to engineering optimization problems. Sheng et al. (2014) proposed an adaptive CS algorithm for optimizing the parameters of chaotic systems. Since no optimization algorithm can optimize all different types of problems, the original CS algorithm is no exception. The CS algorithm has low search breadth in the first iteration and it is easy to fall into local optimum in the process of optimal finding. The CS algorithm is prone to slow search speed and poor convergence accuracy when applied to optimize feature selection models.
As a result, a new and better version of the CS algorithm (SBCS) is proposed in this paper, which combines the sobol sequence and the black hole mechanism with the original algorithm to improve its optimization capability. This study performs benchmark experiments employing 30 CEC 2014 functions to validate the algorithm performance of SBCS. The SBCS algorithm is compared with four original algorithms and four improved algorithms. To further verify that the SBCS-KELM model is more competitive, a series of validation experiments are conducted for this model on real hospital datasets (PE), mainly including the comparison experiments of five classical machine learning classification algorithms based on SBCS, the comparison experiments of SBCS-KELM with other famous classifiers and the comparison experiments of 10 feature selection models based on group intelligence optimization algorithm and KELM. Furthermore, we successfully demonstrate the superior competitiveness of the proposed SBCS-KELM model by analyzing the results of the above three comparative experiments using the following four evaluation metrics: Accuracy, Sensitivity, F-measure, and MCC. Finally, we discuss the five key features obtained from the results of 10 time 10-fold cross-validation experiments based on a medical perspective to prove that the results align with the actual statistical significance in this paper.
The main contributions of this study can be summarized as: (1) An effective aid to the diagnosis of pulmonary embolism is proposed. (2) A KELM model is developed based on an improved swarm intelligence optimization algorithm. (3) The SBCS algorithm is proposed, while it is an improved strong performance swarm intelligence optimization algorithm.
The remainder of this paper is structured as follows. In section “Materials and methods,” this paper describes the materials used and the CS algorithm. In section “The proposed method,” the paper presents the improved SBCS algorithm and the SBCS-KELM model. In section “Experimental results and discussions,” the paper experimentally validates the core advantages of the SBCS algorithm and the SBCS-KELM model. In section “Discussions,” the paper combines practical medical knowledge and experimental results for a detailed discussion. Finally, in section “Conclusions and future works,” the paper is summarized and looks to the future.
Materials and methods
In this section, the source of the PE dataset and its acquisition criteria are first described. Then this section describes the original cuckoo (CS) algorithm, including its core idea, formulas, and pseudo-code.
Pulmonary embolism data collection
Data from pulmonary embolism patients hospitalized to the First Affiliated Hospital of Wenzhou Medical University between April 2014 and May 2020 were retrospectively gathered for this single-center study. The diagnosis of PE meets at least one of the following criteria: (1) confirmed by computed tomographic pulmonary angiography (CTPA). (2) Confirmed by pulmonary perfusion imaging. (3) Clinical diagnosis: need to meet the following conditions: (1) having typical clinical manifestations. (2) DVT confirmed by lower extremity vascular ultrasound. (3) D-Dimer > 0.5 mg/L. The 139 PE patients were divided into two groups: the intermediate-low-risk group (n = 70) and the high-risk group (n = 69). According to the definition of ESC guidelines and the American Heart Association (AHA) scientific statement, PE patients with a systolic blood pressure < 90 mmHg are classified as a high-risk group (Jaff et al., 2011; Konstantinides et al., 2020).
All 139 patients’ clinical details, blood test results, and information on arterial blood gas analysis were recorded. The blood samples were taken three days after the diagnosis of PE. Table 1 contains a list of the data. SPSS statistics 24.0 was used to conduct the statistical analysis. The chi-square test was used to assess categorical variables. Independent sample t-test was used to assess continuously varying variables. Statistics consider something significant if p < 0.05. The findings of the precise statistical analysis are displayed in Tables 2, 3.

Table 1. Numbered list of the characteristics utilized in this study and their meanings.
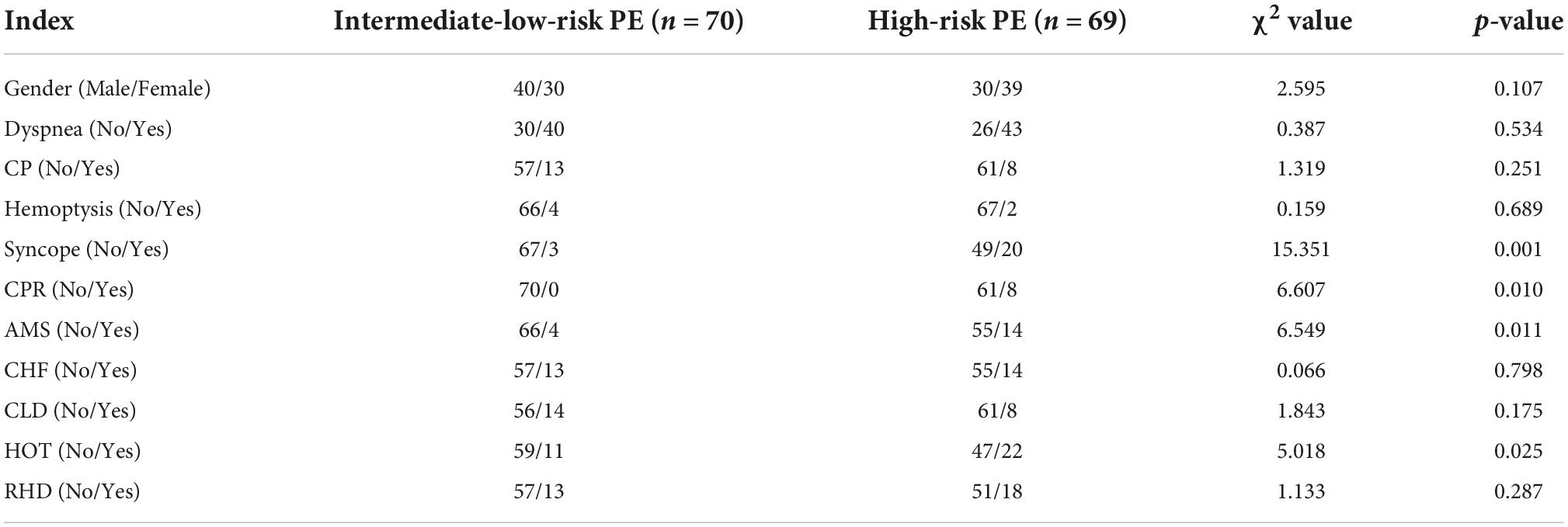
Table 2. Clinical characteristics in intermediate-low-risk PE patients and high-risk PE patients.
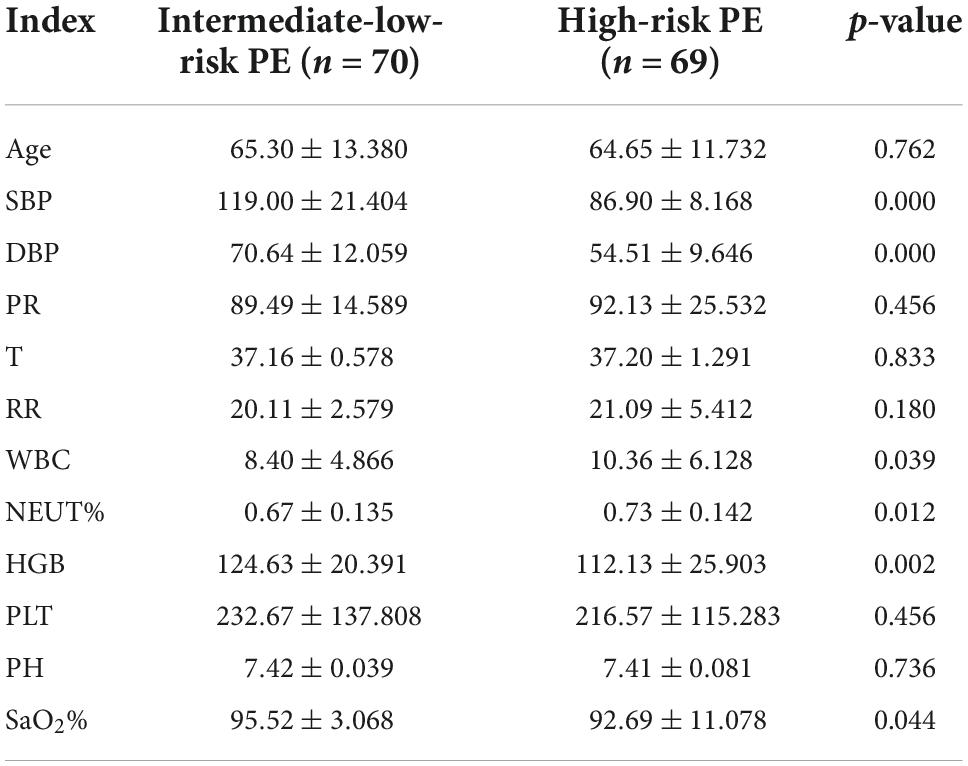
Table 3. Blood routine, arterial blood gas analysis and clinical parameters in intermediate-low-risk PE patients and high-risk PE patients.
Description of cuckoo search algorithm
The mathematical model, pseudo-code and flowchart of the CS algorithm are described in detail in this subsection.
Mathematical model
The cuckoo search algorithm (CS) is an optimization algorithm that draws on the behavior of cuckoos in finding nest locations to find eggs to lay. The cuckoo does not make a nest nor does it brood. Before laying eggs, it pushes the eggs of the host bird out of the nest when the other bird (host bird) leaves the nest and lays its own eggs in the host’s nest, allowing the host bird to feed the cuckoo chicks. The juvenile cuckoos, which are raised by the host bird, also have the habit of pushing the host bird’s young out of the nest, and will mimic the behavior to reduce the probability of being detected by the host bird.
Assume that the cuckoo search algorithm satisfies the following three idealized conditions:
(1) Cuckoos randomly select a suitable nest to lay one egg at a time.
(2) The best nest from the group of nests chosen at random will be kept for the following generation.
(3) The number of nests that can be used is fixed, and the probability that the owner of a nest can find an alien egg, also known as Pa∈[0,1].
The algorithm location update formula is as follows:
where xi(t + 1) denotes the nest position of the ith nest at generation t; ⊗ is the inner product notation, which indicates the multiplication of vectors; α denotes the step control factor, and Levy(β) is the Levy random search path.
After updating the nest location, the adaptation values of the nests are calculated and compared, and the solution with better adaptation is selected. After that, an equal number of new solutions are generated by discarding some of the poor solutions according to the probability Pa and using a biased random walk.
where r,ε ∈ [0,1] are normally distributed random numbers; Heaviside(u) is the unit transitive function, which is the step function; xk(t),xj(t) are the different random solutions in the tth generation. The contemporary optimal solution and the associated fitness value are preserved after one population iteration is finished. The method above is then repeated until the maximum number of iterations is achieved, at which point the global optimal solution is produced.
The pseudo-code and flowchart
In this section, the pseudo-code and flowchart for CS is illustrated as shown in Algorithm 1 and Figure 1 respectively.
Algorithm 1. Pseudo-code of CS.
Initialize the fitness value function
f(x),x = (x1,x2,x3,⋯,xd)T
Initialize the number of
iterationst = 0, discovered parameters
Pa = 0.25
Initialize the individual solution of
the overall N solutions, (i = 1,2,…,N)
While l ≤ Maximum number of iterations
Using Lévy flight
Update all search agents in the
population
Evaluate the new solution xtnew,i for its
fitness value ftnew,i
If the new solution has a better
fitness value
Replace the old solution with the
updated solution xtnew,i
End If
Discard some poor-quality solutions
by probability Pa and replace them
with random ones
Increase in the number of iterations
t = t + 1
End While
Return the best solution
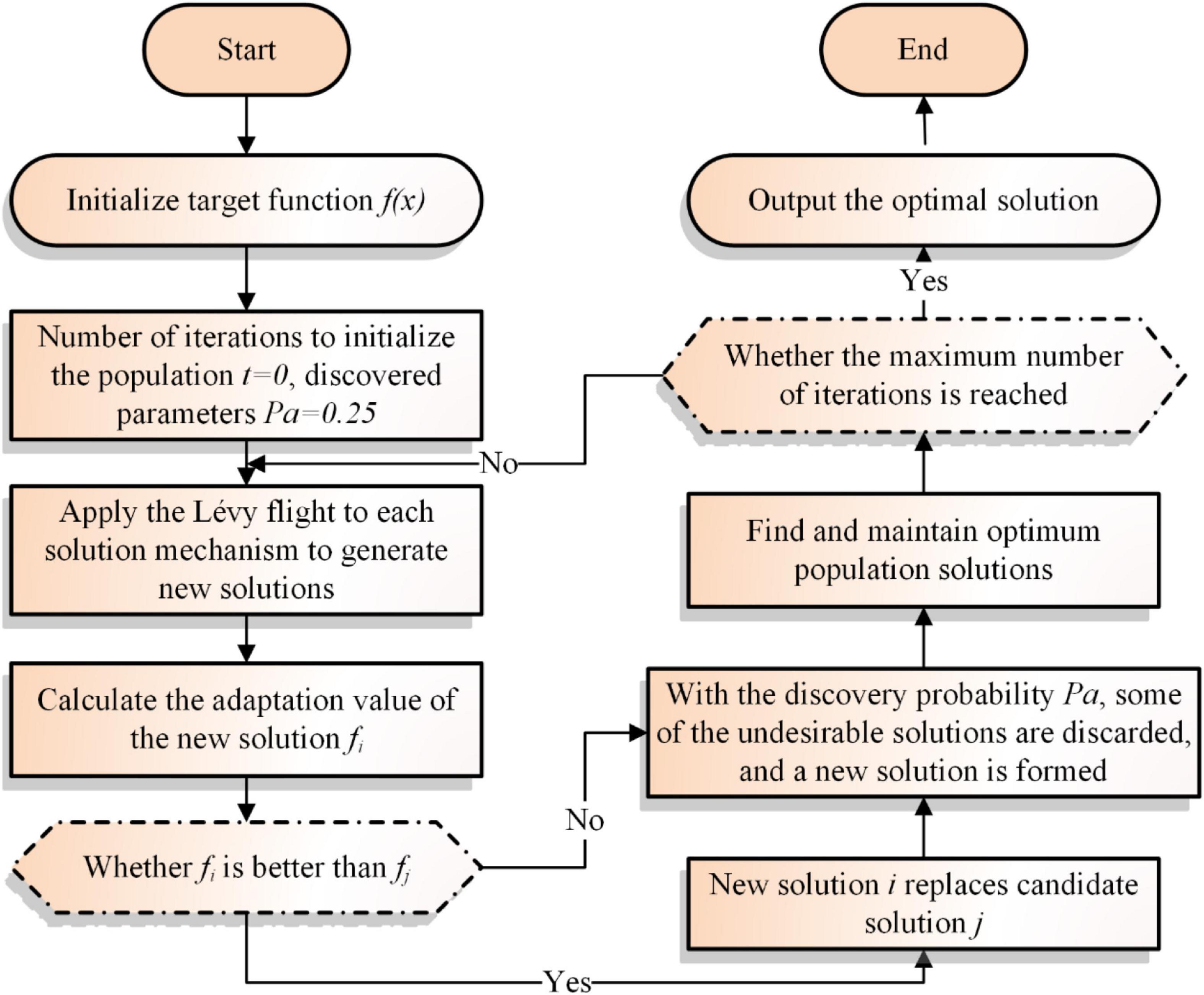
Figure 1. Flowchart of CS.
The proposed method
We first introduce the sobol sequence and the black hole mechanism and propose the SBCS algorithm by adding these two strategies to the CS algorithm. Further, this section introduces the discretization strategy and the KELM classifier and proposes the SBCS-KELM prediction model by combining the SBCS algorithm.
The proposed SBCS
Sobol sequence
The distribution of starting populations has a significant impact on the algorithm’s accuracy and speed of convergence in metaheuristic algorithms. To achieve high traversal and variety while solving issues with uncertain distributions, the starting population values should be dispersed over the search space as equally as feasible. The cuckoo search algorithm generates initialized populations in the search space using random numbers. This method has low traversal and unpredictable distribution of individuals.
Low discrepancy sequences, commonly known as the suggested Monte Carlo approach, employ deterministic low discrepancy sequences as opposed to pseudo-random sequences (QMC). QMC offers greater efficiency and uniformity in dealing with probabilistic problems by choosing reasonable sampling directions to fill the multidimensional hypercube cells with as many uniform points as possible. Among them, the Sobol sequence (Bratley and Fox, 2003) has a shorter computational cycle, faster sampling speed, and higher- efficiency in dealing with high-dimensional sequences. Therefore, this paper uses the Sobol sequence to map the initialized populations.
Setting the range of values of the optimal solution to [xmin,xmax], the Sobol sequence generates the random number Kn ∈ [0,1], then the initial position of the population can be defined as:
Black hole mechanism
The black hole mechanism is taken from the Multiverse Optimization algorithm (MVO). Each candidate solution in the iterative MVO method is a black hole, the ideal universe is a white hole according to the roulette principle, the black hole and the white hole exchange stuff (dimensional replacement), and some of the black holes can travel nearby through wormhole linkages (population optimal vicinity search). It is assumed that wormholes exist between each universe and the optimal universe so that local changes in each universe can increase the universe’s expansion rate through wormholes. The specific mechanism is expressed as follows.
Assume that wormholes exist between each universe and the optimal universe, allowing local variations in each universe to increase the universe’s expansion rate via the wormholes. The mechanism is denoted by Eq. (5)-Eq. (6), where WEP is the proportion of wormholes in the universe. TDR is the distance between the optimal universe and the object passing through the wormhole transformation.
when r2WEP,
when r2≥WEP,
where Xj is the current optimal universe, bu,j and bl,j are the boundary values of the jth variable, respectively; r2,r3,r4 are random numbers between 0 and 1; The values of WEP and TDR are shown in Eq. (7)- Eq. (8).
where WEPmax and WEPmin are the boundary values of WEP, WEPmin = 0.2 and WEPmax = 1; l is the current iteration number; L is the maximum number of iterations; p is a constant algorithm with a default value of 6.
Proposed SBCS
In order to improve the CS algorithm’s early-stage search capacity and late-stage convergence capability, the sobol initialization sequence and the black hole mechanism are added in this section. To begin with, the random starting technique of CS is replaced with the sobol low differentiation sequence in an effort to accelerate the early search phase of the algorithm and identify a high-quality solution more rapidly. Then, the optimal solution is found using the Lévy flight update strategy of the CS algorithm itself. Finally, the black hole mechanism is added at the late iteration stage to work with the CS update method to jointly identify the best solution and improve the algorithm’s convergence ability. SBCS pseudo-code and flowchart are also illustrated in Algorithm 2 and Figure 2.
Algorithm 2. Pseudo-code of SBCS.
Population and objective function
initialization using sobol sequences
f(x),x = (x1,x2,x3,⋯,xd)T
Initialize the number of
iterationst = 0, discovered parameters
Pa = 0.25
Initialize the solution of
the overall N solutions, (i = 1,2,…,N)
While t ≤ Maximum number of iterations(MaxNo)
If t > MaxNo/2
Update the current optimal solution
with the help of the black hole
mechanism
End If
Using Lévy flight
Update all search agents in the
population
Evaluate the new solution xtnew,i for its
fitness value ftnew,i
If the new solution has a better
fitness value
Replace the old solution with the
updated solution xtnew,i
End If
Discard some poor-quality solutions
by probability Pa and replace them
with random ones
Increase in the number of iterations
t = t + 1
End While
Return the best solution
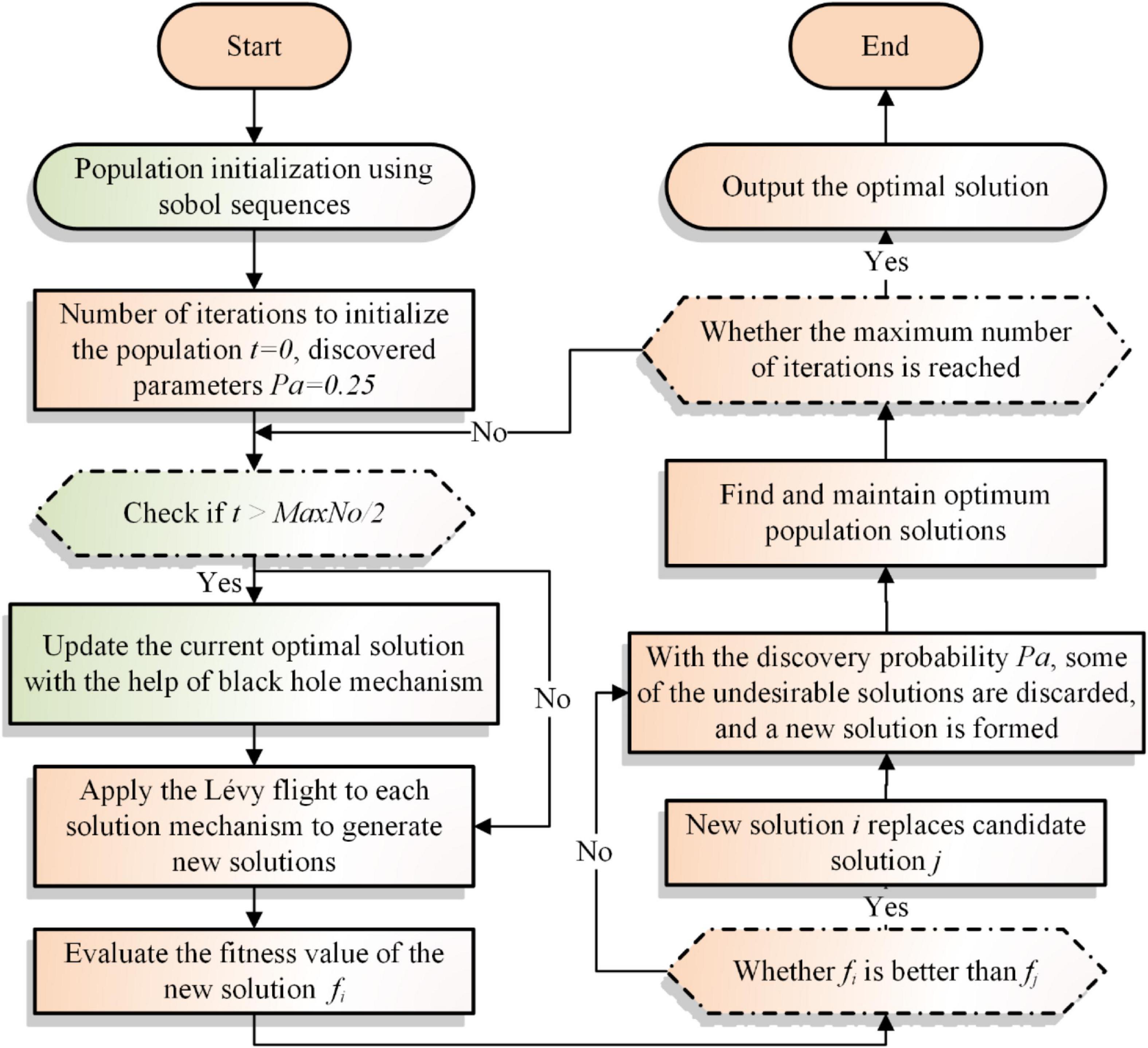
Figure 2. Flowchart of SBCS.
The introduced Sobol sequence, the roulette selection mechanism, the rapid sorting algorithm, and the determination of fitness values are the primary components of SBCS’ complexity. First, the Sobol sequence has a computational complexity of O(l*n*d + l*n2). Then, in two extreme circumstances, the computing complexity of the roulette selection mechanism is O(n)andO(logn). The rapid sorting algorithm has a best-case computational complexity of O(n*logn) and a worst-case computational complexity of O(n2), respectively. The fitness value calculation has a computational complexity of O(n*logn). Finally, the SBCS algorithm’s total complexity is O(SBCS) = O((d + n + d*logn)*l*n).
The proposed SBCS-KELM model
Discretization
The SBCS algorithm is made to solve continuous optimization issues with real numbers, whereas the feature selection approach is recognized to be a method utilized for binary optimization problems. Therefore, a discrete operation must be performed to transform real values to binary values before the SBCS algorithm can perform the feature selection task. This paper proposes a binary version of SBCS (bSBCS) based on continuous SBCS. First, bSBCS fixes the search range of the solution between [0, 1], i.e., the feature selection problem is regarded as a constrained optimization problem. Then, the searched solution is transformed into a real number of 0 or 1 by the S-type function transformation method, where a solution of 1 means this feature is selected by the model, and a solution of 0 means it is not selected. Eq. (9) displays the solution space’s binary representation.
where Xd(t + 1) is the solution after the t-th binary solution is being updated, and rand is a random integer in the range [0, 1]. The exact Sigmoid formula is shown in the following equation, Eq. (10), where x stands for the outcome of the SBCS iteration.
Kernel extreme learning machine
ELM has an input layer, a hidden layer, and an output layer, three independent layers, and a single implicit feed-forward neural network. For a given training set {(xi,ti)|xi ∈ Rn,ti ∈ Rn}, an activation function f(x), and a number of nodes in the hidden layer L, the ELM regression model, can be expressed as:
where ai,i = 1,…,L is the input weight, bi,i = 1,…,L is the bias, and k is the number of samples, the above equation can be rewritten as:
the neuron matrix Hk, which has the following expression:
The output layer matrix βk is represented by the notation:
The output layer matrix, Tk, may be written as follows:
The output weights can be obtained by solving Eq. (16).
The regularized least squares solution of β is obtained, and a regularization factor C is added to improve generalization. Its expression is:
Thus, the extreme learning machine prediction model can be expressed as:
Kernel functions are used in an ELM algorithm’s implicit layer to replace the feature mapping in a technique known as KELM. The kernel function works by replacing the inner product operation in the new, high-dimensional space with the kernel function operation from the old space when the input training data is mapped into it.
The kernel matrix ΩELM in the KELM algorithm is as follows.
where xi and xj are the input vectors of the samples and K(xi,xj) is the kernel function, and the radial basis kernel function with strong localization and good generalization is selected in this paper.
where γ is the kernel parameter.
From the above equation, the output function of KELM can be expressed as
Proposed SBCS-KELM
The SBCS-KELM feature selection model, which attempts to filter the important characteristics to aid in medical diagnosis, is built in this part by combining the SBCS algorithm with the KELM. The main strategy for creating models is to use the binary SBCS (bSBCS) algorithm to obtain the best KELM solution. The optimum solutions provided by the bSBCS are then classified using the KELM to improve the model’s classification accuracy and efficiency. The goodness of the solution vector obtained by the bSBCS algorithm needs to be judged by Eq. (22). The bSBCS-KEML method’s main steps are shown in Figure 3.
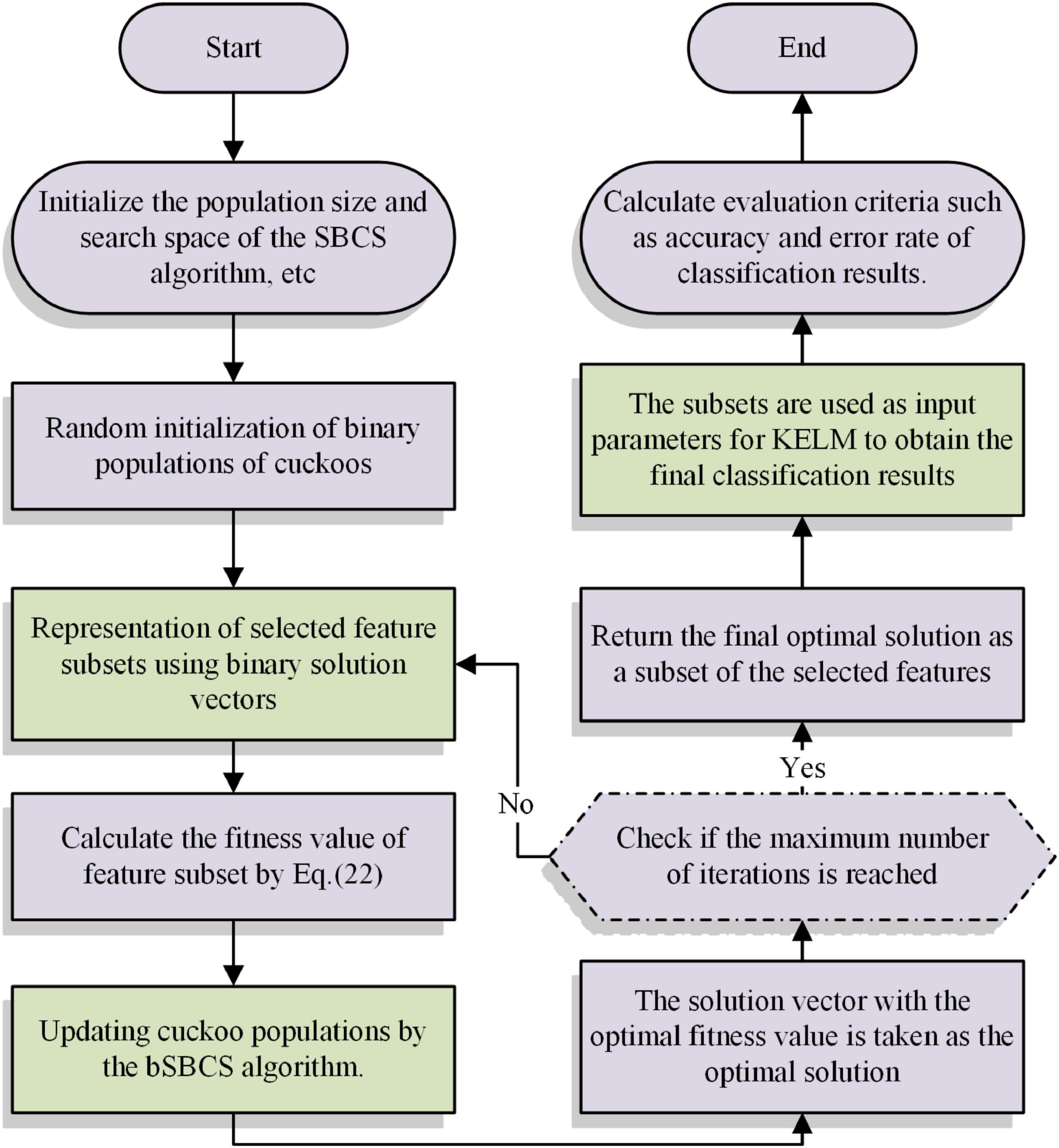
Figure 3. Flow chart of bSBCS-KEML model.
where |D| is the number of characteristic characteristics and |R| is the number of chosen attributes, and error is the error rate used to measure the classifier’s accuracy. β denotes the length of the chosen characteristics, and α denotes the weight of the mistake; The α = 0.99 and = β 0.01 in this work are the same as in many earlier publications.
Experimental results and discussion
We undertake benchmark function studies in this part to confirm the overall effectiveness of SBCS. Then, tests based on seven open data sets are carried out to confirm the performance of SBCS on the feature selection issue. This research performs assisted diagnostic studies using PE data gathered from hospitals in order to further certify the efficacy of the SBCS-KELM.
Benchmark functions comparison experiment
Benchmark test experiment setup
As the different algorithms rely on various features and trends, we need to benchmark algorithmic details in computer science to analyze the impact of computational components (Cao Z. et al., 2022; Liu et al., 2022c; Zhang Z. et al., 2022). For the experimental component of the benchmark functions, this work uses 30 benchmark functions from CEC2014 (Liang et al., 2013); Table 4 contains information about benchmark functions F1 through F30.

Table 4. The 30 benchmark functions in CEC2014.
The benchmark function comparison experiments in this study are being carried out in the same setting and with the same essential parameters, as stated in Table 5, to assure the fairness of the experimental findings. The mean, variance, Wilcoxon signed-rank test, and Freidman test are also employed to examine the final experimental findings in this experiment in order to confirm the validity and reliability of the data. To maintain a standard environment for all of the studies, a Windows Server 2008R2 operating system is used. The device’s main components are a Matlab2017b processor for code execution, an Intel(R) Xeon(R) CPUE5-2660v3 (2.60GHz), and 16 GB of RAM.

Table 5. Setting the baseline function experiment’s parameters.
Ablation experiments of SBCS
Section “The proposed method” introduces the sobol sequence and the black hole mechanism and both strategies are used to improve the CS algorithm. In this section, ablation experiments are designed to discuss the performance of one strategy alone for improving CS compared to SBCS. Where BCS is the improvement of CS using the black hole mechanism alone, and SCS denotes the improvement of CS using the sobol sequence alone. The algorithms for the comparison experiments include SBCS, BCS, SCS, MVO, and CS.
Table 6 shows the average optimal fitness results of the five compared algorithms and gives the Wilcoxon signed-rank of the compared experiments. The best results are bolded in each column. Where “+/-/ =” indicates that SBCS is better/worse/equal to the other algorithms; “Mean” denotes the average ranking of 30 independent experiments, and “rank” denotes the final ranking. It can be seen that the optimal solution of SBCS is the best among most of the tested functions, followed by BCS with only the black hole mechanism, then SCS with only the sobol sequence, and finally, the two original algorithms MVO and CS. This indicates that either the sobol sequence or the black hole mechanism has an improved effect on CS, and it works best when both are combined. The experiments prove that the improvement of the SBCS algorithm is reasonable and effective.
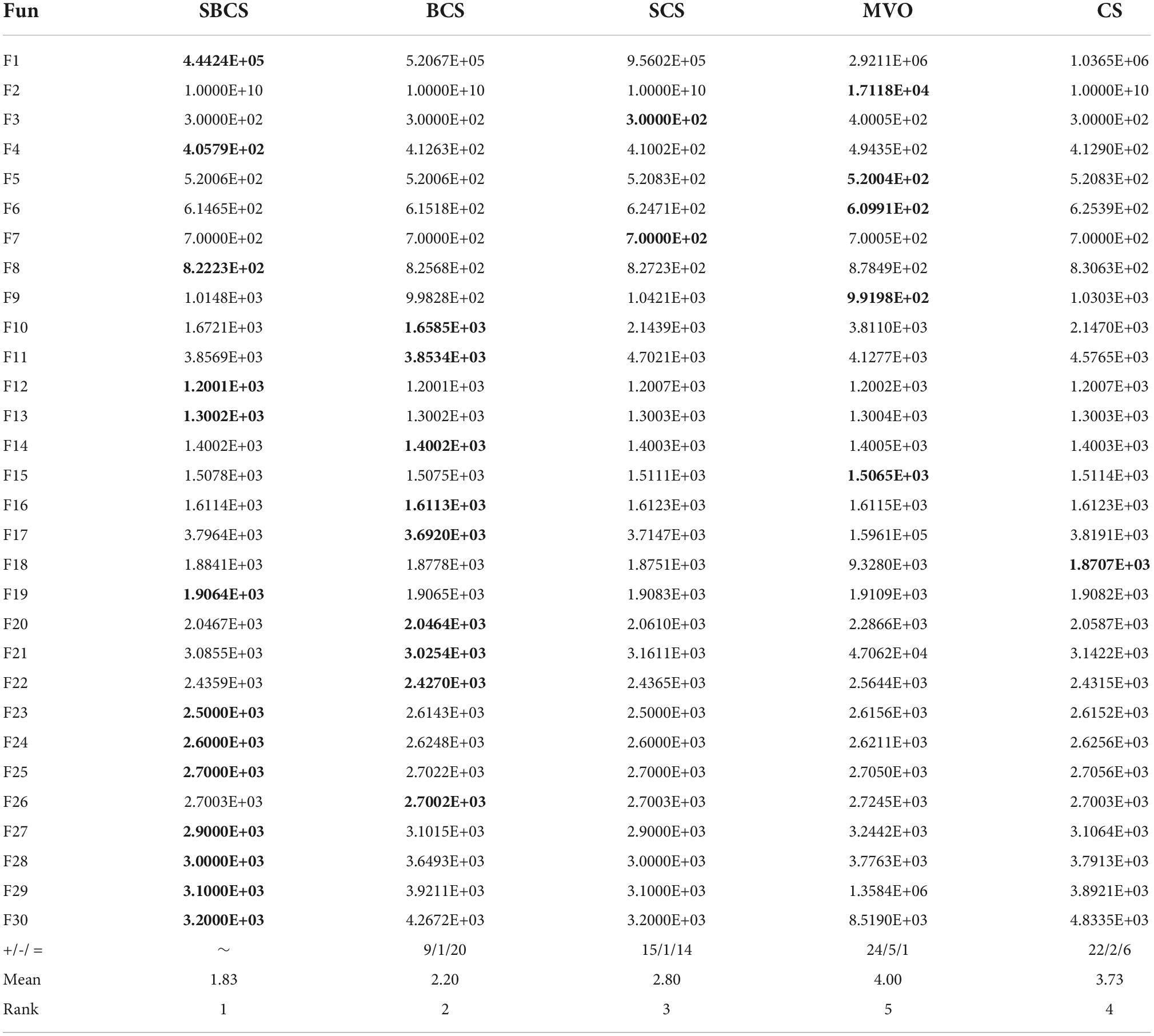
Table 6. Average fitness values of ablation experiments and Wilcoxon signed-rank.
Comparison of SBCS with well-known peer algorithms
In this section, based on the above-benchmarking functions, we compare SBCS with well-known similar algorithms to demonstrate the superiority of the algorithm performance. Eight algorithms are compared, four of which are the original algorithms SSA, DE, MFO, and WOA, and four of which are the improved algorithms RCACO, ASCA, SMFO, and EWOA. The benchmark experiment findings are shown in Table 7, where AVG and STD stand for the algorithms’ respective mean and variation after 30 separate runs. We can immediately tell by comparing and watching the mean values that SBCS has the least mean value for the majority of the benchmark functions. This demonstrates that when the benchmark functions are optimized using SBCS and related techniques, SBCS delivers considerably higher quality solutions. Additionally, the variation of the ideal solution is lower, demonstrating SBCS’s strong consistency in optimizing the benchmark functions. Additionally, SBCS outperforms hybrid and composition functions, demonstrating the upgraded algorithm’s greater ability to solve challenging situations.
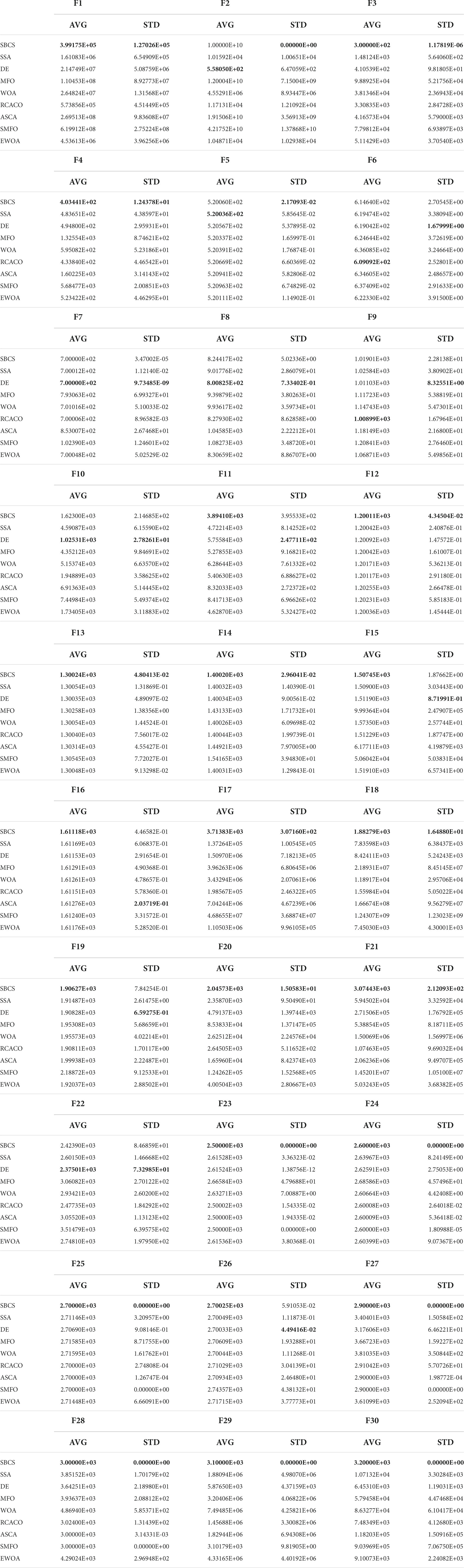
Table 7. Comparison of SBCS with well-known peer algorithms.
This study examines the experiment’s findings using the Wilcoxon signed-rank test and the Freidman test in order to confirm the statistical significance of the benchmark function experiment and the relative optimization performance of the SBCS algorithm. Based on the Wilcoxon signed-rank test, Table 8 compares the performance of the SBCS with that of other well-known algorithms. A value of “+” indicates that the SBCS outperforms other algorithms, a value of “=” indicates that it performs nearly as well as other algorithms, and a value of “–” indicates that it performs less well than other algorithms. On the 30 benchmark function trials, it is immediately obvious that SBCS is superior to at least 24 other functions and is rated first in this comparison. Figure 4 displays the results of the Freidman test. As can be observed, this technique test still clearly favors the SBCS algorithm. In conclusion, it is possible to infer that SBCS is a great improvement algorithm.
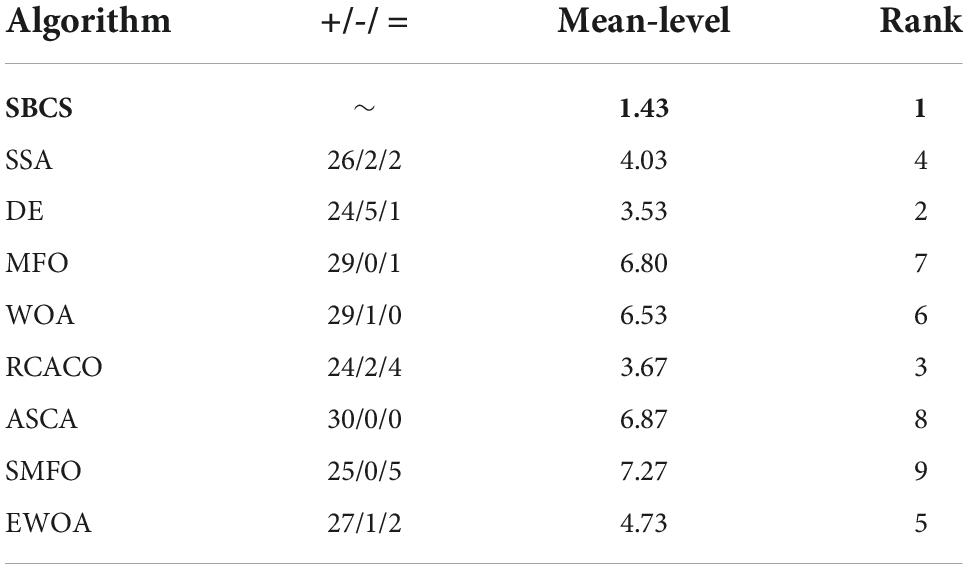
Table 8. Performance ranking of SBCS with other well-known algorithms.
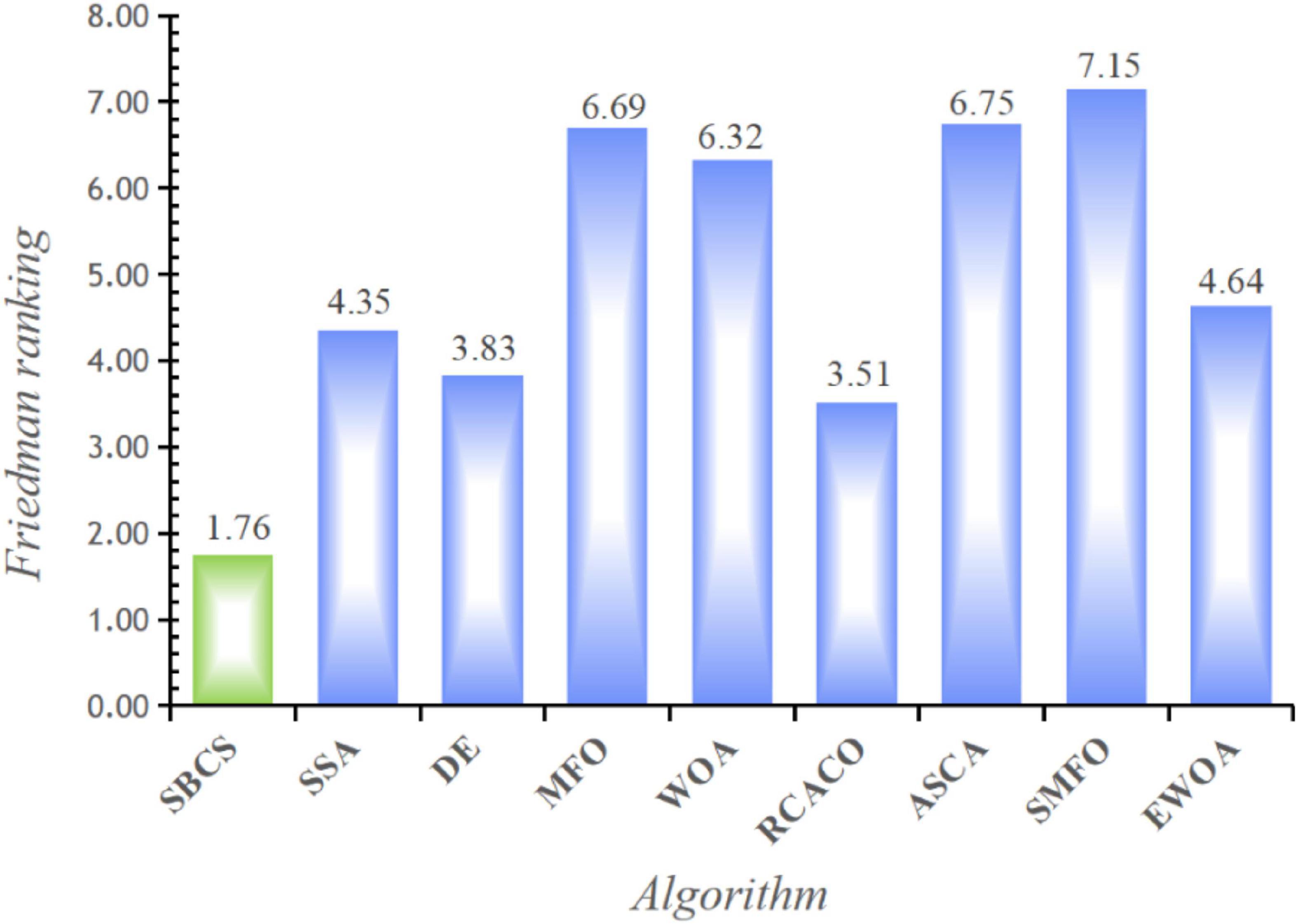
Figure 4. Comparison results of SBCS and other well-known algorithms.
This experiment shows the solutions produced throughout the iterations of the aforementioned SBCS and the other eight algorithms into curves to further highlight the benefits of SBCS. These four types are addressed in Figure 5 since the 30 benchmark test functions are split into four categories in total: simple multimodal functions, composition functions, hybrid functions, and unimodal functions. Where “FEs” is the quantity of evaluations and “Best Value” denotes the current optimum fitness value. It can be seen that SBCS is a little slower in the beginning of the function curve on functions F1, F3, and F16, but the final convergence is more accurate. What’s more, the convergence images of SBCS have obvious inflection points in the convergence process on functions F11 and F16, which indicates that the algorithm has escaped the trap of local optimum in the stage to achieves higher convergence accuracy. Finally, SBCS has better convergence accuracy than other algorithms for functions F17, F18, F21, F26, and F30, both in the early search phase and in the late convergence. To sum up, it can be concluded that SBCS is an excellent and enhanced algorithm by analyzing the experimental results of SBCS compared with other well-known algorithms.
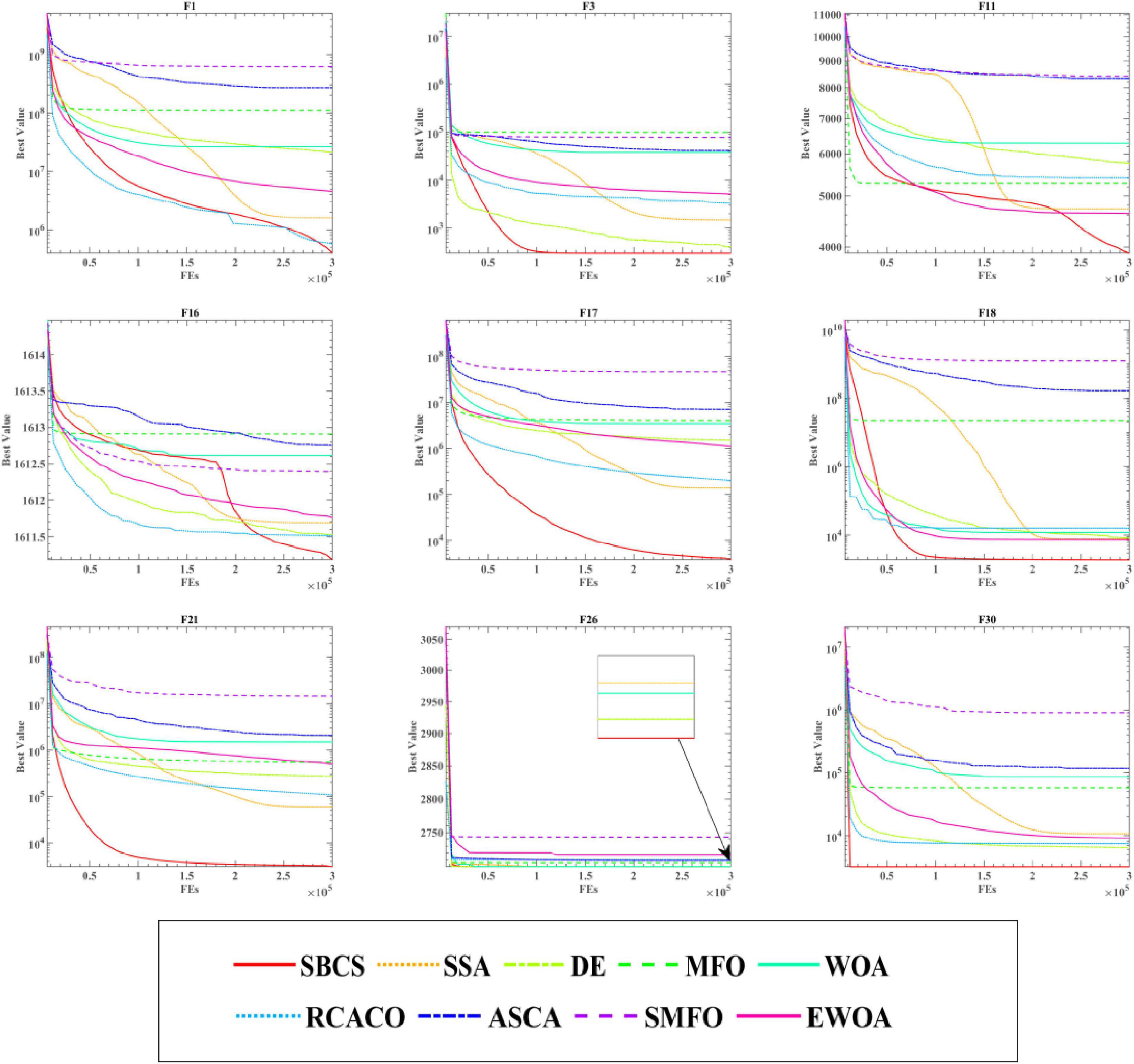
Figure 5. Convergence curves of SBCS and other well-known algorithms.
Feature selection experiments
The evaluation standards for the feature selection experiments are first described in this section. The effectiveness and generalizability of SBCS to handle feature selection issues are then demonstrated through feature selection experiments on open datasets. Finally, the five key features are chosen using SBCS in a real PE problem.
Feature selection experimental setup
We assess the SBCS-capacity KELM’s for classification in the feature selection experiments using the five conventional metrics of sensitivity, classification accuracy (ACC), precision, F-measure, and MCC. The evaluation metrics for classifier experiments are described in detail below.
The performance of binary classification models is typically assessed using 4 main criteria, which include the following:
(1) True Positive (TP): The sample is correctly identified by the classifier, and the sample is regarded as positive.
(2) False Positive (FP): The classifier incorrectly classifies the outcome and believes the sample to be positive when in fact the sample is negative.
(3) False Negative (FN): The classifier incorrectly identifies the outcome and interprets the sample as being negative when it is actually positive.
(4) True Negative (TN): The classifier correctly identified the sample and regarded it as a negative sample.
Accuracy indicates the proportion of the number of correctly classified samples.
The percentage of examples classified as positive cases that are actually positive cases is known as precision.
The effectiveness of the binary classification model in recognizing typical occurrences is evaluated using sensitivity.
A weighted average of Precision (P) and Recall (R) is called F-Measure. Recall is a measure of coverage, which counts the number of positive instances categorized as positive; precision is the percentage of positive examples that are really classified as positive.
A more balanced measure for evaluating dichotomies is MCC, another machine learning assessment technique. The measure continues to function effectively even when the difference between the two samples is quite significant since this technique incorporates all four classification situations, i.e., true positive, true negative, false positive, and false negative. A correlation coefficient known as the MCC illustrates the relationship between predicted and observed classifications. It accepts values in the range [–1,1], with 1 being the most accurate topic prediction and 0 indicating no prediction. A score of 1 demonstrates that the predicted and actual classifications agree exactly, a value of 0 shows that the prediction is only as accurate as a random guess, and a value of –1 shows that there is no agreement at all between the two.
Immediately following, the nine binary algorithms are used to comparison with the bSBCS in the experiments in this paper including bMFO, bGWO, BGSA, BPSO, bALO, BBA, BSSA, bWOA, and bCS. The parameter values shown in Table 9 for each algorithm are identical to the method’s initial parameter values. The population size of the algorithm is universally set to 20 and the dimension value is always the number of features in the dataset due to the nature of the feature selection approach. Among these 9 algorithms, BBA, BSSA, BWOA, bCS, and BMFO are optimization algorithms based on the original algorithm after discretization. Some other scholars articles mention the algorithms bGWO, BGSA, bALO, and BPSO.

Table 9. Setting the parameters for the optimization algorithms.
Public dataset experiments
Seven open datasets from the UCI Machine Learning Repository are used in this section to assess the overall performance of the bSBCS algorithm on the feature selection problem. These seven open datasets are listed in Table 10 along with additional information about them. These datasets will differ greatly in terms of classification type, number of features, and dataset size in order to simulate the feature selection problem in a wide range of scenarios. Different classification types such as BreastEW for dichotomous classification and segment for multiclassification; different number of features such as heart with 14 and semeion with 266; different dataset sizes such as hepatitis with 155 and CTG3 with 2310. The experimental findings’ mean and standard deviation are also contrasted. In order to further illustrate the experimental findings, each algorithm’s outcomes are statistically rated in this study.
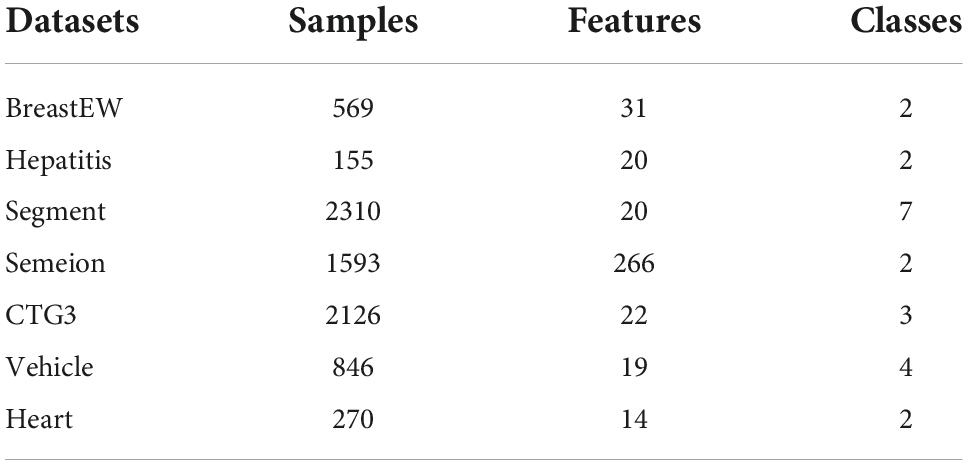
Table 10. Key messages from the seven public datasets.
The classification accuracy of the method suggested in this paper is contrasted with that of other feature selection methods in Table 11. bSBCS is first in the ranking, followed by BGSA, and BCS is last. The classification accuracy of bSBCS on the BreastEW, hepatitis, semeion, and heart datasets is all above 94%, according to specific classification results. Even though its classification accuracy on segment, CTG3, and vehicle did not reach 90%, bSBCS had the most significant classification accuracy of all of the feature selection techniques tested.
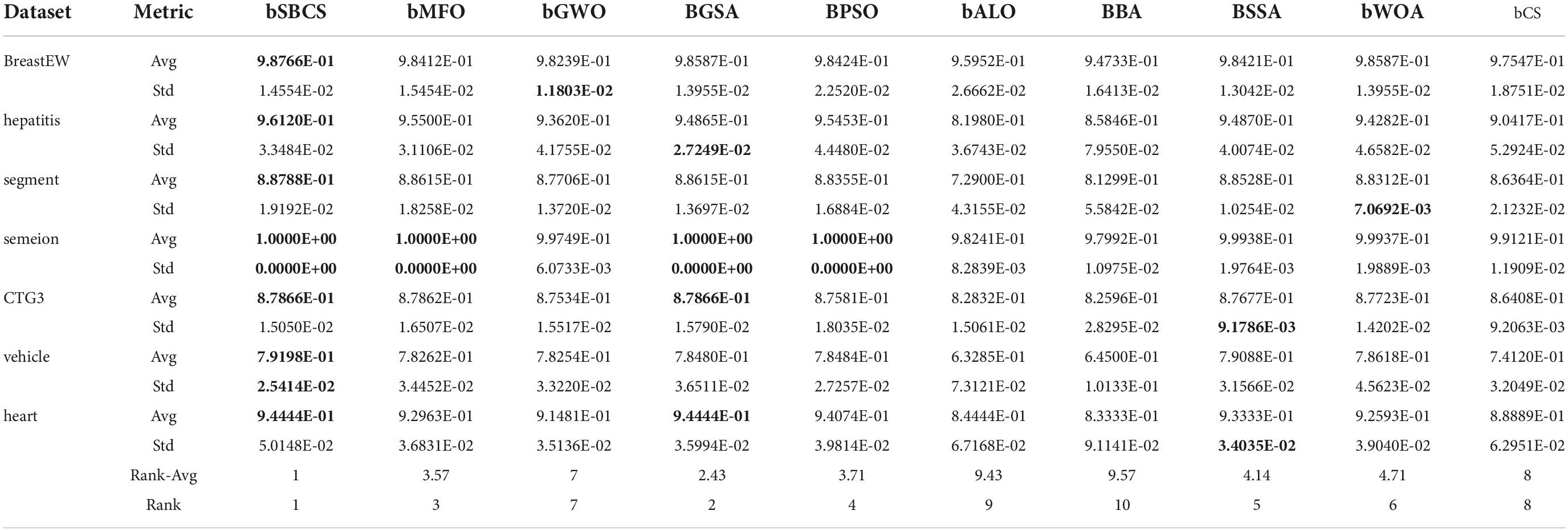
Table 11. Comparison results of SBCS and other peers with regard to accuracy.
Because using only accuracy as an evaluation criterion is insufficient, this study also looked at precision rate. The precision rate of the proposed method SBCS is contrasted with that of other feature selection methods in Table 12. The final two rows of the table display the Wilcoxon signed rank test ranking results; bSBCS is first, followed by BGSA, and lastly bCS. The final precision rate of all feature selection algorithms shows that bSBCS has the greatest accuracy rate, suggesting that its classification findings are the most accurate. SBCS has a lower value as well, as can be seen from Std. SBCS has high robustness, as evidenced by this.
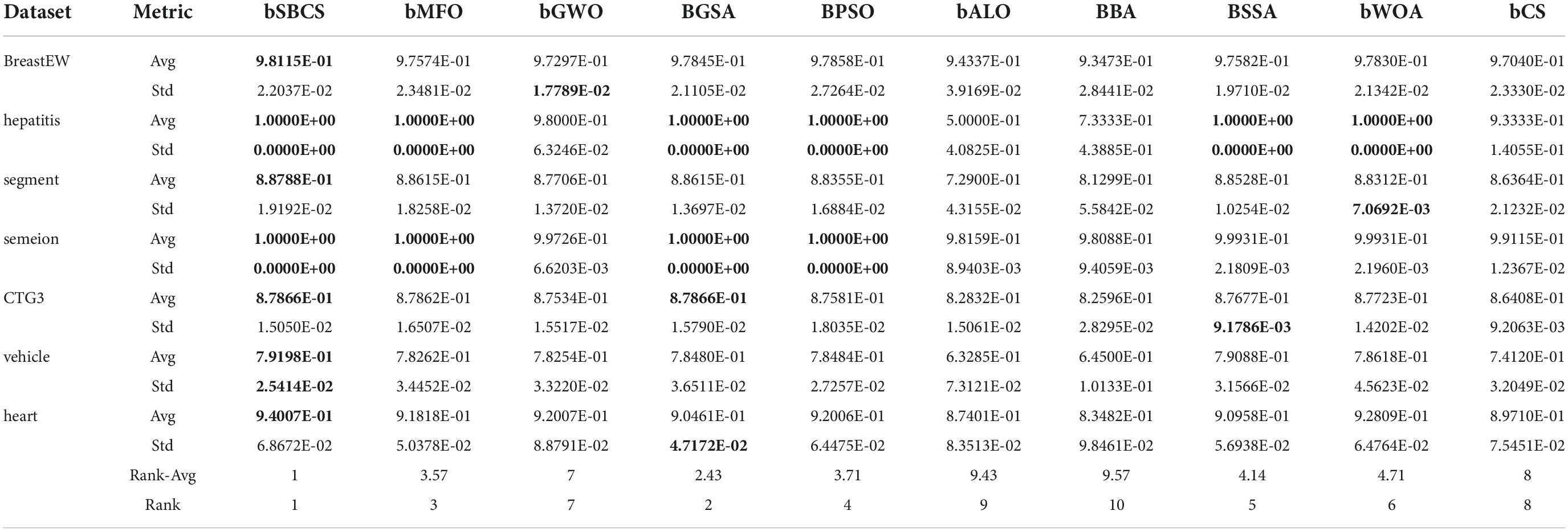
Table 12. Comparison results of SBCS and other peers with regard to precision rate.
Pulmonary embolism dataset experiment
In this part, the obtained PE dataset is utilized for feature selection tests to demonstrate the bSBCS-KELM model’s real predictive performance and efficacy for practical medical assistance diagnosis. Furthermore, to demonstrate the performance of the bSBCS-KELM, four traditional evaluation techniques are utilized to fully analyze the model’s classification ability: classification sensitivity, ACC, F-measure, and MCC, in that order. This section compares bSBCS with other classical machine learning classification algorithms in combination, primarily fuzzy k-nearest neighbor (FKNN), k-nearest neighbor (KNN), multilayer perceptron (MLP), and SVM, to demonstrate that the combination of bSBCS and KELM is excellent. This section also examines the performance differences between the proposed model and conventional classification techniques, such as BP, CART, and others. The codes for these classical classifiers and machine learning algorithms, in particular, are embedded in MATLAB, and the number of neurons for the BP and ELM algorithms is 10 and 20, respectively, with the remainder set to default settings. Furthermore, this part compares bSBCS with well-known algorithms like as bMFO and bGWO to indicate that bSBCS is also suited for KELM among swarm intelligence optimization techniques. To create fair and objective results, the classification performance is analyzed using 10-fold cross-validation (CV) analysis, according to machine learning literature.
Because various approaches give varied experimental results, a comparative experiment with other classifiers is performed to illustrate the advantages of combining bSBCS with the KELM classifier. Figure 6 depicts the box plots of classifier comparison trials, which reveal that classification performance varies dramatically for various classifiers paired with bSBCS. bSBCS MLP has the lowest accuracy, sensitivity, F-measure, and MCC. bSBCS KNN and bSBCS KELM perform equally in these four categories. A deeper look at the figure represents that bSBCS KELM outperforms all four criteria. As a result, it is possible to speculate that bSBCS KELM is the best classifier among the five.
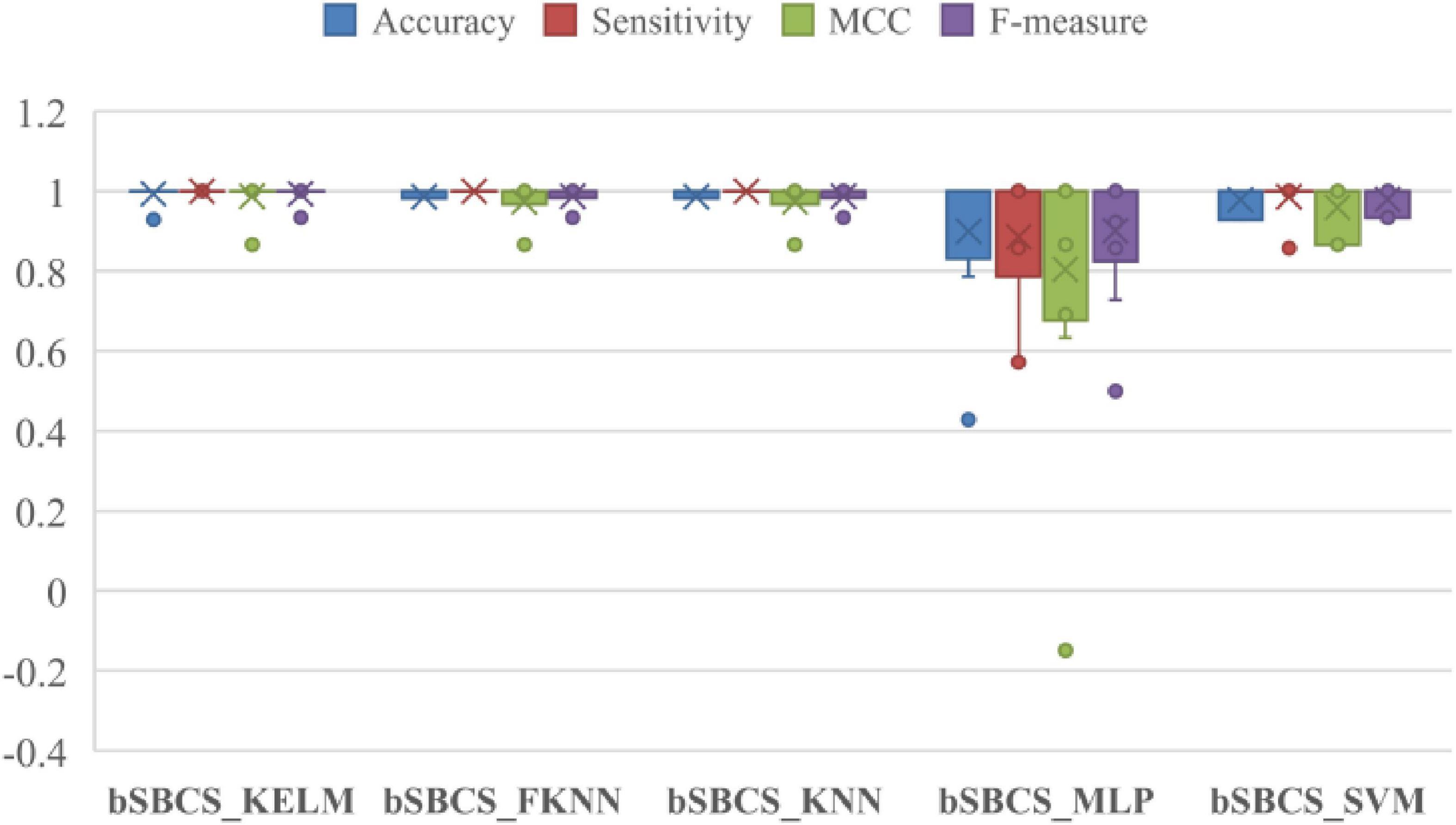
Figure 6. Comparison results of SBCS on five classifiers.
The influence and effectiveness of feature selection are examined by contrasting the given bSBCS algorithm to those that did not. Figure 7 displays the comparison outcomes of the six classifiers. As shown in the figure, the recommended bSBCS method with feature selection performs better than the original classification strategy without the swarm intelligence algorithm. The bSBCS approach is the best feature selection model for the PE dataset in terms of accuracy, sensitivity, F-measure, and MCC.
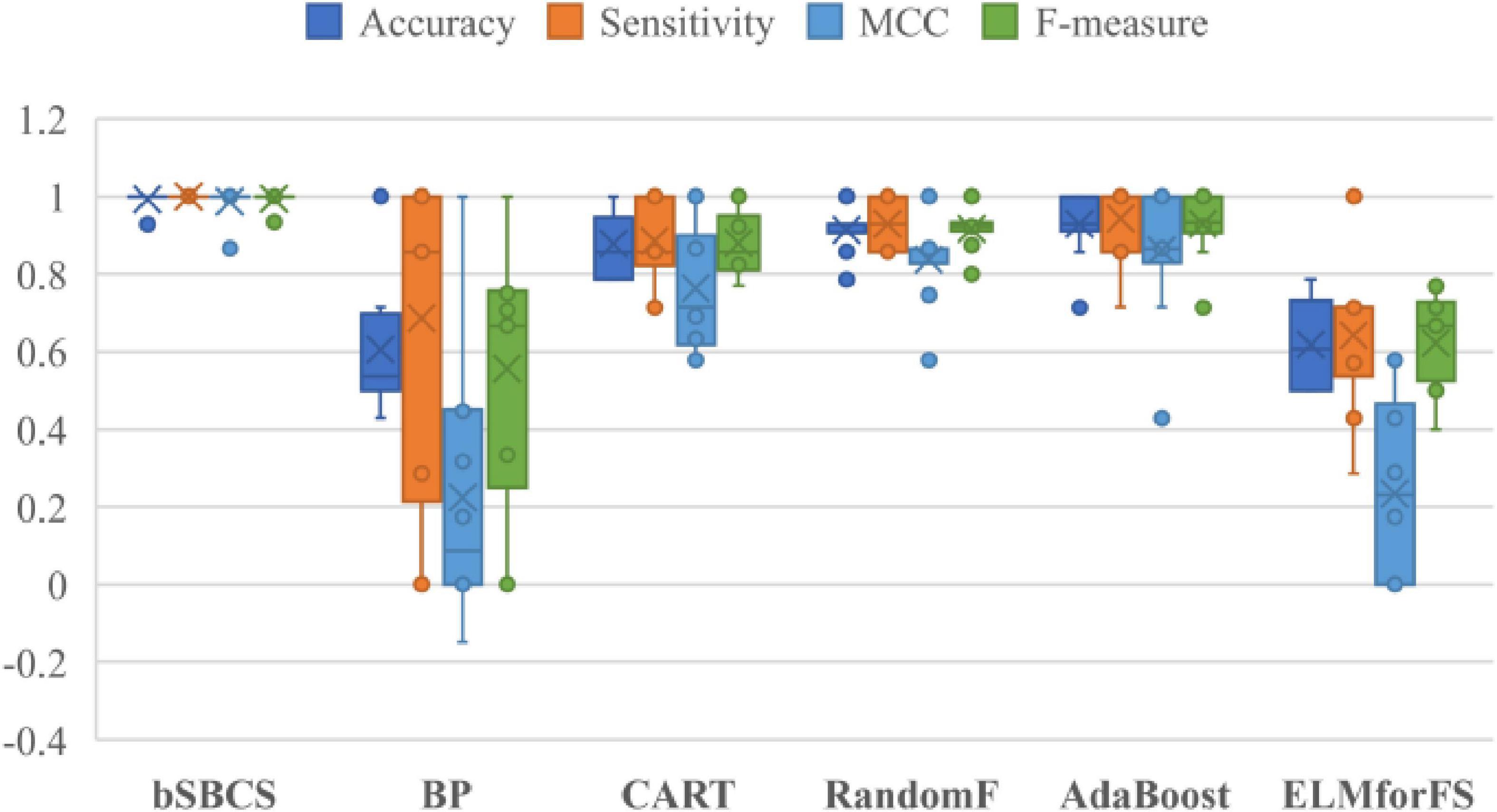
Figure 7. Comparison of bSBCS and other well-known machine learning algorithms.
We compared the proposed bSBCS method to other generally used feature selection algorithms such as BMFO, BGWO, BGSA, BPSO, BALO, BBA, BSSA, and BWOA to assess its performance on PE datasets. The algorithms’ performance was then evaluated in four areas: classification accuracy, sensitivity, F-measure, and MCC in terms of feature selection.
A box plot of the statistical findings of 10 independent 10-fold cross-validation runs on the dataset is given in Figure 8. SBCS performs well on all six evaluation criteria, according to the results. SBCS has the highest classification accuracy, with sensitivity and F-measure, which represent classification correctness, of 0.98 or higher. Furthermore, the classification accuracy box plots are very concentrated, indicating that the bias of the ten experimental results is small. MCC is also the variable used to indicate the connection between actual and anticipated classes. SBCS’s box plot is the most similar to 1, showing that SBCS can better categorize the PE dataset effectively. Finally, we did the Freidman test on the experimental findings to further demonstrate the outcomes of the comparison between SBCS and other approaches, and the particular ranking results are as follows. In five of the six assessment indicators listed above, bSBCS ranks top, according to the data in Table 13. bSBCS takes longer than other feature selection algorithms since it adds a new mechanism to the original method. bSBCS takes longer than the other algorithms, but it is still within reasonable boundaries. Finally, bSBCS outperforms all other algorithms on the PE dataset.
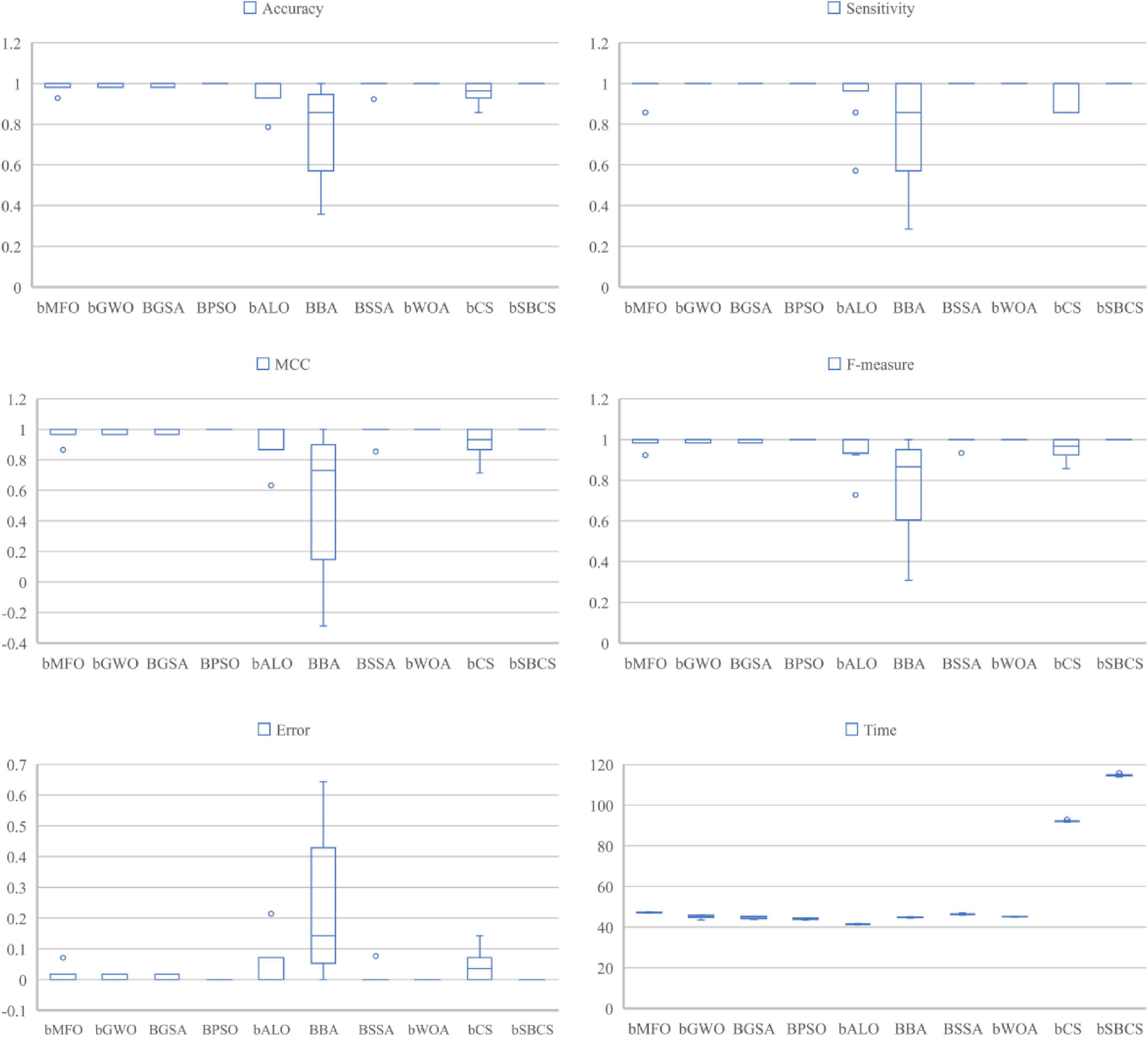
Figure 8. Comparison results of SBCS and other swarm intelligence optimization algorithms.
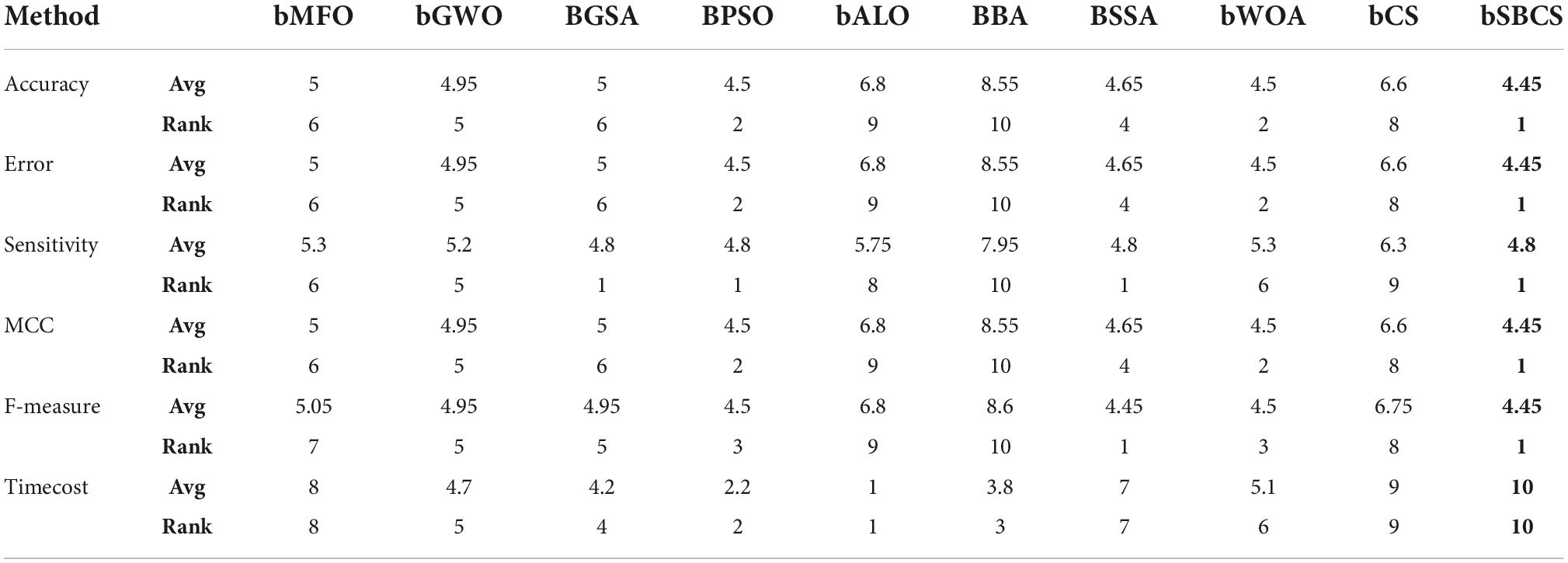
Table 13. Freidman test results.
Table 14 displays the outcomes of the bSBCS algorithm’s feature selection. The first column displays the number of 10-fold cross-validation folds, while the second displays the number of features that remain after feature selection. Classification accuracy, sensitivity, MCC, and F-measure are the final four columns, in that sequence. The chart indicates that the proposed hybrid approach can effectively choose characteristics from a limited collection while retaining good classification accuracy. The results show that the Accuracy value is 99.29%, the Sensitivity value is 98.57%, the MCC value is 0.9866, and the F-measure value is 0.9933.
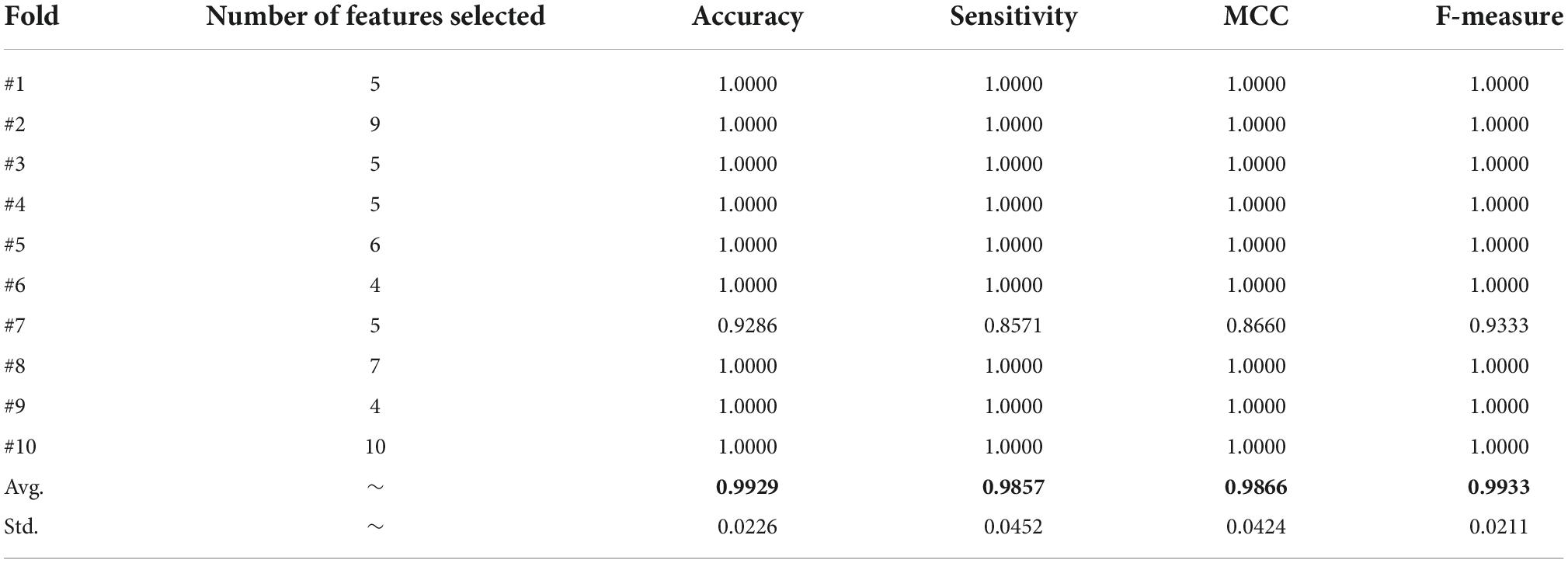
Table 14. The detailed results obtained by bSBCS.
The precise experimental outcomes of bSBCS on the PE dataset for 10 times 10-fold cross-validation are shown in Figure 9. The PE dataset’s numerous attributes are shown on the figure’s horizontal axis, and the vertical axis shows how often each feature was chosen. As indicated in the diagram, attribute 6, attribute 12, attribute 17, attribute 18, and attribute 22 are mostly selected more than 52 times, while the other attributes are being selected fewer than 47 times. Syncope, SBP, WBC, NEUT%, and SaO2 are the five features. The following section provides a detailed explanation of the experiment findings and how they relate to actual medical applications.
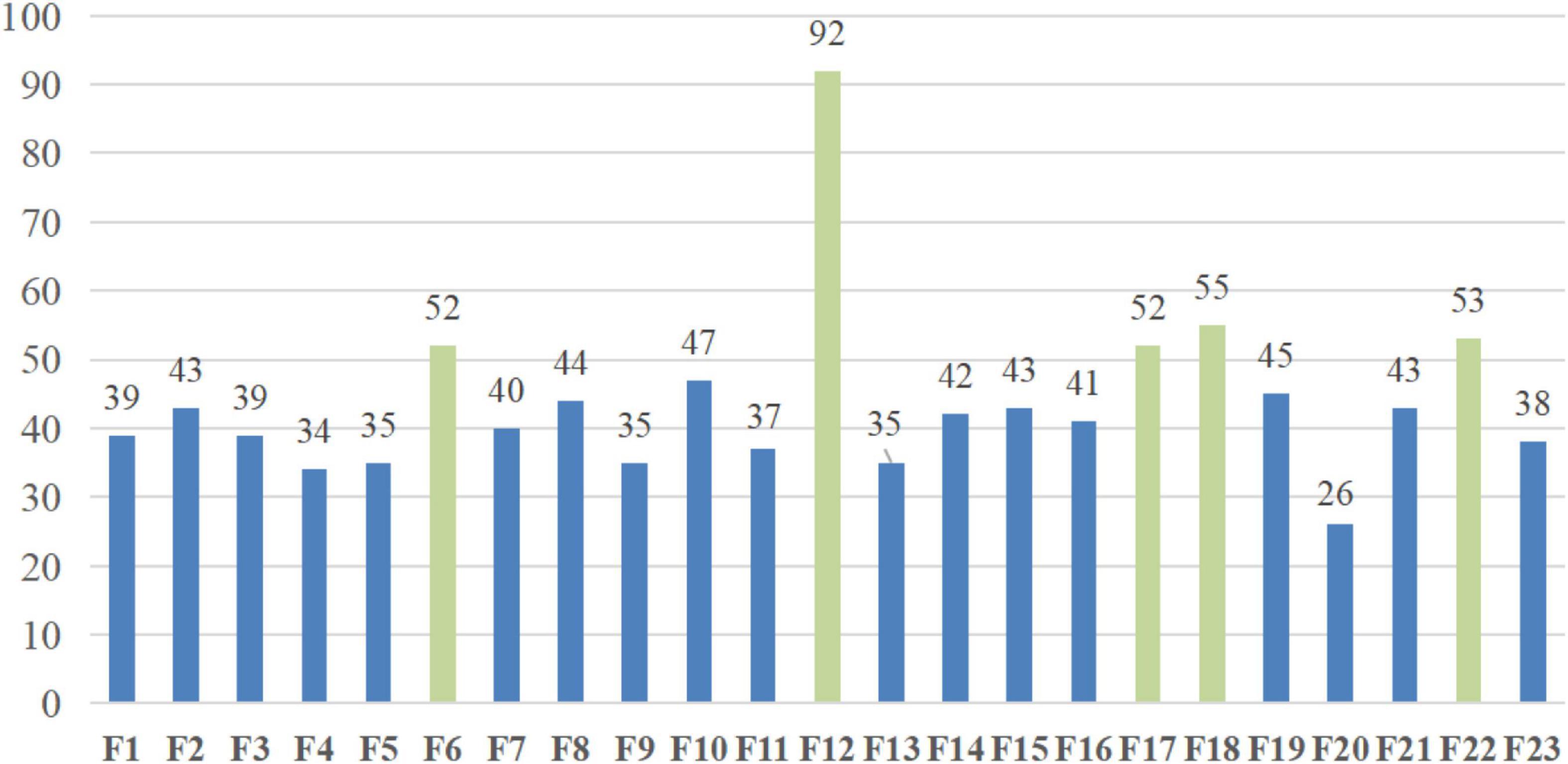
Figure 9. Selected features of the bSBCS method in the 10 times 10-fold CV process.
Discussion
Syncope is linked to a poor prognosis for acute PE, according to earlier research (Goldhaber et al., 1999; Lobo et al., 2006; Lankeit et al., 2013; Keller et al., 2016a; Prandoni et al., 2016; de Winter et al., 2020). According to the ESC, syncope is characterized by transient global cerebral hypoperfusion, which results in transient loss of consciousness (T-LOC). It has a quick onset, a brief course, and a full, natural recovery (Brignole et al., 2018). Uncertainty surrounds the pathogenesis of syncope during PE. According to the available data, a significant pulmonary embolism with pulmonary vascular tree occlusion, right heart dysfunction, decreased cardiac output, hypotension, decreased cerebral blood flow, and ultimately caused syncope is the primary mechanism (Castelli et al., 2003; Theilade et al., 2010; Jenab et al., 2015). A blood clot may also result in arrhythmia if it exits the venous system and remains in the pulmonary circulation. PE syncope may also result from this (Akinboboye et al., 1993; Keller et al., 2015b). The Bezold–Jarisch reflex, as well as a sudden drop in cardiac output, vasodilation, and cardiogenic syncope, may also result from occlusion of the pulmonary artery bed (Mark, 1983; Simpson et al., 1983; Castelli et al., 2003). In general, people who experience cardiac syncope are more likely to pass away from cardiovascular causes (Soteriades et al., 2002). de Winter et al. (2020) discovered through mete analysis that syncope is linked to 4% high short-term mortality and 12% high hemodynamic instability in patients with acute PE. Hemodynamic instability can be used to explain the higher short-term mortality. Additionally, the current risk stratification for pulmonary embolism is based on hemodynamic status (Jaff et al., 2011; Konstantinides et al., 2020). Thus, syncope can be a potent indicator of the severity of a pulmonary embolism because it may reflect hemodynamic instability brought on by right ventricular dysfunction and decreased left ventricular filling.
Systolic blood pressure (SBP) is an important factor in the early risk classification of PE patients, according to current recommendations. While both the ESC recommendations and the AHA statement advocate SBP 90 mmHg as a crucial sign of early mortality from acute PE (Jaff et al., 2011; Konstantinides et al., 2020), the important PE prognosis score, PESI, indicates hypotension with SBP 100 mmHg as an essential predictor of poor prognosis (Wicki et al., 2000; Aujesky et al., 2005). Hemodynamics have a major role in the outcome of an acute PE event, and Keller et al. noted in research with SBP120 mmHg would suggest an elevated risk of mortality in patients with pulmonary embolism (Keller et al., 2015a). Hemodynamics, which may be seen when 30% of the pulmonary artery bed is obstructed by thrombus material, are the major outcome of an acute PE episode. The substantial obstruction of the blood flow to the lung lobes or multiple lungs by PE thrombotic material may result in right heart failure, inadequate blood pressure control (hypotension), and a high risk of short-term death (Grifoni et al., 2000). In conclusion, SBP is a potent predictor of the likelihood of pulmonary embolism.
Acute PE may affect the patient’s heart, lungs, gas exchange, and circulation, which might result in hypoxia. Hypoxia may have physiological effects such tachycardia, dyspnea, dilated blood vessels in the extremities, and increased cardiac output. Additionally, hypoxia-mediated vasoconstriction is one of the causes of acute pulmonary hypertension and a key contributor to acute right heart failure in PE patients (Wang et al., 2019; Labaki and Rosenberg, 2020). Pulse oximetry (SpO2) or arterial blood sample (SaO2) may both be used to assess SO2, which is the ratio of the volume of HbO2 bound to oxygen in the blood to the total volume of bound hemoglobin (Collins et al., 2015). One of the PESI and simplified PESI indicators is SO2. Patients who had an oxygen saturation level of 90% or above did not get a score (Aujesky et al., 2005). In order to guarantee that the real oxygen level stays over 90% for the majority of the time, the British Thoracic Society recommendations advise that the target SO2 for patients with hypoxemia (including PE patients) be greater than 94% (O’Driscoll et al., 2008). The bottom limit of pulse oximetry at sea level, according to Kline et al. (2003), is 94.5%, which may successfully separate PE patients into high-risk and low-risk groups. However, according to Kristen et al., the lowest limit for SO2 should be set at 92.5% (Nordenholz et al., 2011). The investigation by Erol et al. (2018) yielded the best target saturation of 91.5%. So, SO2 has been shown to be a reliable predictor of PE prognosis risk.
White blood cell (WBC) count and neutrophil percentage (NEUT%) are powerful predictors in this model. Several biological explanations exist for the link between increased WBC counts and increased PE mortality. More and more studies have shown that acute PE combined with moderate or severe pulmonary hypertension can lead to the lysis of right ventricular myocytes and the infiltration of inflammatory cells such as neutrophils in humans and rats (Iwadate et al., 2001; Begieneman et al., 2008; Watts et al., 2008). This inflammation can independently magnify the damage (Watts et al., 2010). Therefore, elevated WBC and NEUT% may indicate PE-related right heart dysfunction (Venetz et al., 2013). Some evidence also suggests that WBC counts are correlated with fibrinogen, factor VII, and factor VIII levels (Bovill et al., 1996). Consequently, elevated WBC may be a sign of hypercoagulability, leading to a poor prognosis of PE. The study of Venetz et al. (2013) showed that WBC is an independent risk factor predicting the prognosis of acute PE (Venetz et al., 2013). The study of Jo et al. (2013) also reached a similar conclusion. In addition, the study of Wang et al. (2018) also showed the importance of neutrophils in the prognostic evaluation of PE.
However, this study also has some limitations. First of all, our data set is single-center; we need to conduct a multi-center study to verify this model externally. Secondly, we plan to add more indicators to improve the model’s predictive ability in future research. Finally, we will discuss ways to improve the model performance in many domains, such as information retrieval services (Wu et al., 2020a,2021b), recommender systems (Li et al., 2014, 2017), human activity recognition (Qiu et al., 2022), location-based services (Wu et al., 2020b,2021a), named entity recognition (Yang et al., 2022), clustering of cancer attributed networks (Gao et al., 2021; Wu and Ma, 2022), disease identification and diagnosis (Su et al., 2019; Tian et al., 2020), image denoising (Zhang et al., 2020), tensor completion (Wang W. et al., 2022), structured sparsity optimization (Zhang X. et al., 2022), power flow optimization (Cao X. et al., 2022), colorectal polyp region extraction (Hu K. et al., 2022), and smart contract vulnerability detection (Zhang L. et al., 2022).
Conclusion and future works
In this paper, we propose a stronger meta-heuristic algorithm SBCS and a KELM model based on SBCS to achieve feature selection for real PE datasets. SBCS is a CS-based algorithm that has been enhanced. The sobol sequence and the black hole mechanism are combined with CS in this work to improve SBCS’s search skills and its capacity to break out of local optimal solutions, enabling SBCS to get higher-quality solutions. First, we do comparative testing on 30 benchmark functions. The findings of the aforementioned compared experiments show that SBCS outperforms CS in terms of search effectiveness and ability to locate high-quality answers. Additionally, a comparison between SBCS and related algorithms shows that SBCS has a stronger overall ability to avoid the local optimum trap and provide better solutions than comparable algorithms. As a result, SBCS is a well-validated and outstanding SIOA. Later, we construct the SBCS-KELM prediction model by discretizing the SBCS algorithm and applying it to the KELM classifier. The model verifies the accuracy and stability of the SBCS-KELM prediction model through the same type classifier experiment, the same type swarm intelligence algorithm experiment, and the same type data set to experiment and taking the sensitivity of classification results, ACC, F-measure, and MCC as experimental indicators. The experimental results show that the five most important characteristics of PE are syncope, SBP, WBC, NEUT%, and SaO2. Finally, the detailed discussion of the model shows that the five characteristics are statistically significant, further illustrating its validity and significance for medical diagnosis. The proposed model also has some limitations, as the introduction of sobol sequence and black hole mechanism makes SBCS more complex and time-consuming than the original algorithm. However, this issue will soon be resolved due to the quick development of parallel computing and high-performance computing technology.
SBCS might be used not only for medical diagnosis but also for engineering and artificial neural network optimization in the future. In addition, we will discuss ways to improve SBCS’ performance in many domains.
Data availability statement
The original contributions presented in this study are included in the article/supplementary material, further inquiries can be directed to the corresponding authors.
Ethics statement
This study complied with the Helsinki declaration and was approved by the Ethics Committees of The First Affiliated Hospital of Wenzhou Medical University (Wenzhou, China) (Ethical approval code: KY2021-R097).
Author contributions
HS, ZH, DZ, FY, AH, YF, and YZ: writing—original draft, writing—review and editing, software, visualization, and investigation. YS, PW, HC, and YC: conceptualization, methodology, formal analysis, investigation, writing—review and editing, funding acquisition, and supervision. All authors contributed to the article and approved the submitted version.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Adarsh, B. R., Raghunathan, T., Jayabarathi, T., and Yang, X.-S. (2016). Economic dispatch using chaotic bat algorithm. Energy 96, 666–675. doi: 10.1016/j.energy.2015.12.096
Agnelli, G., and Becattini, C. (2015). Anticoagulant treatment for acute pulmonary embolism: A pathophysiology-based clinical approach. Eur. Respir. J. 45, 1142–1149. doi: 10.1183/09031936.00164714
Ahmadi, A., and Afshar, P. (2016). Intelligent breast cancer recognition using particle swarm optimization and support vector machines. J. Exp. Theor. Artif. Intell. 28, 1021–1034. doi: 10.1080/0952813X.2015.1055828
Ahmadianfar, I., Asghar Heidari, A., Gandomi, A. H., Chu, X., and Chen, H. (2021). RUN beyond the metaphor: An efficient optimization algorithm based on runge kutta method. Expert Syst. Appl. 181:115079. doi: 10.1016/j.eswa.2021.115079
Ahmadianfar, I., Asghar Heidari, A., Noshadian, S., Chen, H., and Gandomi, A. H. (2022). INFO: An efficient optimization algorithm based on weighted mean of vectors. Expert Syst. Appl. 195:116516. doi: 10.1016/j.eswa.2022.116516
Akinboboye, O. O., Brown, E. Jr., Queirroz, R., Cusi, V., Horowitz, L., Jonas, E., et al. (1993). Recurrent pulmonary embolism with second-degree atrioventricular block and near syncope. Am. Heart J. 126, Pt 1, 731–732. doi: 10.1016/0002-8703(93)90433-A
Aujesky, D., Obrosky, D. S., Stone, R. A., Auble, T. E., Perrier, A., Cornuz, J., et al. (2005). Derivation and validation of a prognostic model for pulmonary embolism. Am. J. Respir. Crit. Care Med. 172, 1041–1046. doi: 10.1164/rccm.200506-862OC
Baliarsingh, S. K., and Vipsita, S. (2020). Chaotic emperor penguin optimised extreme learning machine for microarray cancer classification. IET Syst. Biol. 14, 85–95. doi: 10.1049/iet-syb.2019.0028
Barrios, D., Yusen, R. D., and Jiménez, D. (2017). Risk stratification for proven acute pulmonary embolism: What information is needed? Semin Respir. Crit. Care Med. 38, 11–17. doi: 10.1055/s-0036-1597556
Becattini, C., Agnelli, G., Lankeit, M., Masotti, L., Pruszczyk, P., Casazza, F., et al. (2016). Acute pulmonary embolism: Mortality prediction by the 2014 European society of cardiology risk stratification model. Eur. Respir. J. 48, 780–786. doi: 10.1183/13993003.00024-2016
Begieneman, M. P., Goot, F. R., Bilt, I. A., Noordegraaf, A. V., Spreeuwenberg, M. D., Paulus, W. J., et al. (2008). Pulmonary embolism causes endomyocarditis in the human heart. Heart 94, 450–456. doi: 10.1136/hrt.2007.118638
Boushaki, S. I., Kamel, N., and Bendjeghaba, O. (2018). A new quantum chaotic cuckoo search algorithm for data clustering. Expert Syst. Appl. 96, 358–372. doi: 10.1016/j.eswa.2017.12.001
Bovill, E. G., Bild, D. E., Heiss, G., Kuller, L. H., Lee, M. H., Rock, R., et al. (1996). White blood cell counts in persons aged 65 years or more from the cardiovascular health study. Correlations with baseline clinical and demographic characteristics. Am. J. Epidemiol. 143, 1107–1115. doi: 10.1093/oxfordjournals.aje.a008687
Bratley, P., and Fox, B. (2003). Implementing sobols quasirandom sequence generator (algorithm 659). ACM Trans. Math. Softw. 29, 49–57. doi: 10.1145/641876.641879
Brignole, M., Moya, A., de Lange, F., Deharo, J., Elliott, P., Fanciulli, A., et al. (2018). 2018 ESC guidelines for the diagnosis and management of syncope. Eur. Heart J. 39, 1883–1948. doi: 10.1093/eurheartj/ehy037
Cai, Z., Gu, J., and Chen, H.-L. (2017). A new hybrid intelligent framework for predicting Parkinson’s disease. IEEE Access 5, 17188–17200. doi: 10.1109/ACCESS.2017.2741521
Cao, X., Wang, J., and Zeng, B. (2022). A Study on the strong duality of second-order conic relaxation of AC optimal power flow in radial networks. IEEE Trans. Power Syst. 37, 443–455. doi: 10.1109/TPWRS.2021.3087639
Cao, Z., Wang, Y., Zheng, W., Yin, L., Tang, Y., Miao, W., et al. (2022). The algorithm of stereo vision and shape from shading based on endoscope imaging. Biomed. Signal Process. Control 76:103658. doi: 10.1016/j.bspc.2022.103658
Castelli, R., Tarsia, P., Tantardini, C., Pantaleo, G., Guariglia, A., and Porro, F. (2003). Syncope in patients with pulmonary embolism: Comparison between patients with syncope as the presenting symptom of pulmonary embolism and patients with pulmonary embolism without syncope. Vasc. Med. 8, 257–261. doi: 10.1191/1358863x03vm510oa
Chen, C., Wang, X., Yu, H., Wang, M., and Chen, H. (2021). Dealing with multi-modality using synthesis of Moth-flame optimizer with sine cosine mechanisms. Math. Comput. Simul. 188, 291–318. doi: 10.1016/j.matcom.2021.04.006
Chen, H. l, Yang, B., Wang, S. j, Wang, G., Li, H. z, and Liu, W. b (2014). Towards an optimal support vector machine classifier using a parallel particle swarm optimization strategy. Appl. Math. Comput. 239, 180–197. doi: 10.1016/j.amc.2014.04.039
Chen, H.-L., Wang, G., Ma, C., Cai, Z.-N., Liu, W.-B., and Wang, S.-J. (2016). An efficient hybrid kernel extreme learning machine approach for early diagnosis of Parkinson’s disease. Neurocomputing 184, 131–144. doi: 10.1016/j.neucom.2015.07.138
Collins, J. A., Rudenski, A., Gibson, J., Howard, L., and O’Driscoll, R. (2015). Relating oxygen partial pressure, saturation and content: The haemoglobin-oxygen dissociation curve. Breathe (Sheff) 11, 194–201. doi: 10.1183/20734735.001415
de Winter, M. A., van Bergen, E. D. P., Welsing, P. M. J., Kraaijeveld, A. O., Kaasjager, K., and Nijkeuter, M. (2020). The prognostic value of syncope on mortality in patients with pulmonary embolism: A systematic review and meta-analysis. Ann. Emerg. Med. 76, 527–541. doi: 10.1016/j.annemergmed.2020.03.026
Deng, W., Ni, H., Liu, Y., Chen, H., and Zhao, H. (2022a). An adaptive differential evolution algorithm based on belief space and generalized opposition-based learning for resource allocation. Appl. Soft Comput. 127:109419. doi: 10.1016/j.asoc.2022.109419
Deng, W., Xu, J., Gao, X. Z., and Zhao, H. (2022b). An enhanced MSIQDE algorithm with novel multiple strategies for global optimization problems. IEEE Trans. Syst. Man Cybern. Syst. 52, 1578–1587. doi: 10.1109/TSMC.2020.3030792
Deng, W., Xu, J., Song, Y., and Zhao, H. (2020a). An effective improved co-evolution ant colony optimization algorithm with multi-strategies and its application. Int. J. Bio Inspir. Comput. 16, 158–170. doi: 10.1504/IJBIC.2020.10033314
Deng, W., Xu, J., Zhao, H., and Song, Y. (2020b). A novel gate resource allocation method using improved PSO-Based QEA. IEEE Trans. Intell. Transp. Syst.
Deng, W., Zhang, L., Zhou, X., Zhou, Y., Sun, Y., Zhu, W., et al. (2022c). Multi-strategy particle swarm and ant colony hybrid optimization for airport taxiway planning problem. Inf. Sci. 612, 576–593. doi: 10.1016/j.ins.2022.08.115
Elias, A., Mallett, S., Daoud-Elias, M., Poggi, J. N., and Clarke, M. (2016). Prognostic models in acute pulmonary embolism: A systematic review and meta-analysis. BMJ Open 6:e010324. doi: 10.1136/bmjopen-2015-010324
Erol, S., Gürün Kaya, A., Arslan Ciftçi, F., Çiledağ, A., Şen, E., Kaya, A., et al. (2018). Is oxygen saturation variable of simplified pulmonary embolism severity index reliable for identification of patients, suitable for outpatient treatment. Clin. Respir. J. 12, 762–766. doi: 10.1111/crj.12591
Gao, D., Wang, G.-G., and Pedrycz, W. (2020). Solving fuzzy job-shop scheduling problem using DE algorithm improved by a selection mechanism. IEEE Trans. Fuzzy Syst. 28, 3265–3275. doi: 10.1109/TFUZZ.2020.3003506
Gao, X., Ma, X., Zhang, W., Huang, J., Li, H., Li, Y., et al. (2021). “Multi-view clustering with self-representation and structural constraint,” in IEEE transactions on big data, (Piscataway, NJ: IEEE). doi: 10.1109/TBDATA.2021.3128906
Goldhaber, S. Z. (2004). Pulmonary embolism. Lancet 363, 1295–1305. doi: 10.1016/S0140-6736(04)16004-2
Goldhaber, S. Z., Visani, L., and De Rosa, M. (1999). Acute pulmonary embolism: Clinical outcomes in the international cooperative pulmonary embolism registry (ICOPER). Lancet 353, 1386–1389. doi: 10.1016/S0140-6736(98)07534-5
Grifoni, S., Olivotto, I., Cecchini, P., Pieralli, F., Camaiti, A., Santoro, G., et al. (2000). Short-term clinical outcome of patients with acute pulmonary embolism, normal blood pressure, and echocardiographic right ventricular dysfunction. Circulation 101, 2817–2822. doi: 10.1161/01.CIR.101.24.2817
Han, X., Han, Y., Chen, Q., Li, J., Sang, H., Liu, Y., et al. (2021). “Distributed flow shop scheduling with sequence-dependent setup times using an improved iterated greedy algorithm,” in Complex system modeling and simulation, Vol. 1, (Manila: TUP), 198–217. doi: 10.23919/CSMS.2021.0018
He, Z., Yen, G. G., and Ding, J. (2020). Knee-based decision making and visualization in many-objective optimization. IEEE Trans. Evol. Comput. 25, 292–306. doi: 10.1109/TEVC.2020.3027620
He, Z., Yen, G. G., and Lv, J. (2019). Evolutionary multiobjective optimization with robustness enhancement. IEEE Trans. Evol. Comput. 24, 494–507. doi: 10.1109/TEVC.2019.2933444
Heidari, A. A., Mirjalili, S., Faris, H. I, Aljarah, M., Mafarja, M., and Chen, H. (2019). Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 97, 849–872. doi: 10.1016/j.future.2019.02.028
Hirsh, J., Hull, R. D., and Raskob, G. E. (1986). Diagnosis of pulmonary embolism. J. Am. Coll. Cardiol. 8, Suppl B, 128b–136b. doi: 10.1016/S0735-1097(86)80014-6
Hu, J., Gui, W., Heidari, A. A., Cai, Z., Liang, G., Chen, H., et al. (2022). Dispersed foraging slime mould algorithm: Continuous and binary variants for global optimization and wrapper-based feature selection. Knowl. Based Syst. 237:107761. doi: 10.1016/j.knosys.2021.107761
Hu, K., Zhao, L., Feng, S., Zhang, S., Zhou, Q., Gao, X., et al. (2022). Colorectal polyp region extraction using saliency detection network with neutrosophic enhancement. Comput. Biol. Med. 147:105760. doi: 10.1016/j.compbiomed.2022.105760
Hussien, A. G., Heidari, A. A., Ye, X., Liang, G., Chen, H., and Pan, Z. (2022). Boosting whale optimization with evolution strategy and Gaussian random walks: An image segmentation method. Eng. Comput. 1–45 doi: 10.1007/s00366-021-01542-0
Ileri, Y. Y., and Hacibeyoglu, M. (2019). Advancing competitive position in healthcare: A hybrid metaheuristic nutrition decision support system. Int. J. Mach. Learn. Cybern. 10, 1385–1398. doi: 10.1007/s13042-018-0820-y
Iwadate, K., Tanno, K., Doi, M., Takatori, T., and Ito, Y. (2001). Two cases of right ventricular ischemic injury due to massive pulmonary embolism. Forensic. Sci. Int. 116, 189–195. doi: 10.1016/S0379-0738(00)00367-4
Jaff, M. R., McMurtry, M. S., Archer, S. L., Cushman, M., Goldenberg, N., Goldhaber, S. Z., et al. (2011). Management of massive and submassive pulmonary embolism, iliofemoral deep vein thrombosis, and chronic thromboembolic pulmonary hypertension: A scientific statement from the american heart association. Circulation 123, 1788–1830. doi: 10.1161/CIR.0b013e318214914f
Jen, W. Y., Jeon, Y., Kojodjojo, P., Lee, E., Lee, Y., Ren, Y., et al. (2018). A new model for risk stratification of patients with acute pulmonary embolism. Clin. Appl. Thromb. Hemost. 24, 277s–284s. doi: 10.1177/1076029618808922
Jenab, Y., Lotfi-Tokaldany, M., Alemzadeh-Ansari, M., Seyyedi, S., Shirani, S., Soudaee, M., et al. (2015). Correlates of syncope in patients with acute pulmonary thromboembolism. Clin. Appl. Thromb. Hemost. 21, 772–776. doi: 10.1177/1076029614540037
Ji, Y., Zhou, H., Gui, W., Liang, G., Chen, H., et al. (2020). An adaptive chaotic sine cosine algorithm for constrained and unconstrained optimization. Complexity doi: 10.1155/2020/6084917
Jin, Q., Qi, L., Jiang, B., and Wang, Q. (2015). Novel improved cuckoo search for PID controller design. Trans. Inst. Meas. Control 37, 721–731. doi: 10.1177/0142331214544211
Jo, J. Y., Lee, M. Y., Lee, J. W., Rho, B. H., and Choi, W. I. (2013). Leukocytes and systemic inflammatory response syndrome as prognostic factors in pulmonary embolism patients. BMC Pulm. Med. 13:74. doi: 10.1186/1471-2466-13-74
Keller, K., Beule, J., Balzer, J. O., and Dippold, W. (2015a). Blood pressure for outcome prediction and risk stratification in acute pulmonary embolism. Am. J. Emerg. Med. 33, 1617–1621. doi: 10.1016/j.ajem.2015.07.009
Keller, K., Beule, J., Balzer, J. O., and Dippold, W. (2016a). Syncope and collapse in acute pulmonary embolism. Am. J. Emerg. Med. 34, 1251–1257. doi: 10.1016/j.ajem.2016.03.061
Keller, K., Beule, J., Balzer, J. O., and Dippold, W. (2016b). Typical symptoms for prediction of outcome and risk stratification in acute pulmonary embolism. Int. Angiol. 35, 184–191. doi: 10.1016/j.artres.2016.05.002
Keller, K., Hobohm, L., Ebner, M., Kresoja, K., Münzel, T., Konstantinides, S. V., et al. (2020). Trends in thrombolytic treatment and outcomes of acute pulmonary embolism in Germany. Eur. Heart J. 41, 522–529. doi: 10.1093/eurheartj/ehz236
Keller, K., Prochaska, J., Coldewey, M., Gobel, S., Ullmann, A., Jünger, C., et al. (2015b). History of deep vein thrombosis is a discriminator for concomitant atrial fibrillation in pulmonary embolism. Thromb. Res. 136, 899–906. doi: 10.1016/j.thromres.2015.08.024
Kennedy, J., and Eberhart, R. (1995). “Particle swarm optimization, in proceedings of ICNN’95,” in Proceesings of the International conference on neural networks, Vol. 4, (Perth, WA: IEEE), 1942–1948.
Khazaee, A., and Zadeh, A. E. (2014). ECG beat classification using particle swarm optimization and support vector machine. Front. Comput. Sci. 8:217–231. doi: 10.1007/s11704-014-2398-1
Kline, J. A., Hernandez-Nino, J., Newgard, C. D., Cowles, D. N., Jackson, R. E., and Courtney, D. M. (2003). Use of pulse oximetry to predict in-hospital complications in normotensive patients with pulmonary embolism. Am. J. Med. 115, 203–208. doi: 10.1016/S0002-9343(03)00328-0
Konstantinides, S. V., Meyer, G., Becattini, C., Bueno, H., Geersing, G., Harjola, V., et al. (2020). 2019 ESC Guidelines for the diagnosis and management of acute pulmonary embolism developed in collaboration with the European Respiratory Society (ERS). Eur. Heart J. 41, 543–603. doi: 10.1093/eurheartj/ehz405
Konstantinides, S., and Goldhaber, S. Z. (2012). Pulmonary embolism: Risk assessment and management. Eur. Heart J. 33, 3014–3022. doi: 10.1093/eurheartj/ehs258
Labaki, W. W., and Rosenberg, S. R. (2020). Chronic obstructive pulmonary disease. Ann. Intern. Med. 173, Itc17–Itc32. doi: 10.7326/AITC202008040
Lambert, J. R., and Perumal, E. (2021). Oppositional firefly optimization based optimal feature selection in chronic kidney disease classification using deep neural network. J. Ambient Intell. Humaniz. Comput. 13, 1799–1810. doi: 10.1007/s12652-021-03477-2
Lankeit, M., Friesen, D., Schäfer, K., Hasenfuß, G., Konstantinides, S., and Dellas, C. (2013). A simple score for rapid risk assessment of non-high-risk pulmonary embolism. Clin. Res. Cardiol. 102, 73–80. doi: 10.1007/s00392-012-0498-1
Li, C., Dong, M., Li, J., Xu, G., Liu, W., Ota, K., et al. (2022). “Efficient medical big data management with keyword-searchable encryption,” in Proceesings of the healthChain, IEEE systems journal, (Piscataway, NJ: IEEE). doi: 10.1109/JSYST.2022.3173538
Li, J., Chen, C., Chen, H., and Tong, C. (2017). Towards context-aware social recommendation via individual trust. Knowl. Based Syst. 127, 58–66. doi: 10.1016/j.knosys.2017.02.032
Li, J., Zheng, X.-L., Chen, S.-T., Song, W.-W., and Chen, D.-r. (2014). An efficient and reliable approach for quality-of-service-aware service composition. Inf. Sci. 269, 238–254. doi: 10.1016/j.ins.2013.12.015
Li, S., Chen, H., Wang, M., Heidari, A. A., and Mirjalili, S. (2020). Slime mould algorithm: A new method for stochastic optimization. Future 111, 300–323. doi: 10.1016/j.future.2020.03.055
Liang, J. J., Qu, B. Y., and Suganthan, P. N. (2013). Problem definitions and evaluation criteria for the CEC 2014 special session and competition on single objective real-parameter numerical optimization, Computational Intelligence Laboratory, Vol. 635. Zhengzhou: Zhengzhou University, 490.
Liu, S., Yang, B., Wang, Y., Tian, J., Yin, L., and Zheng, W. (2022a). 2D/3D multimode medical image registration based on normalized cross-correlation. Appl. Sci. 12:2828. doi: 10.3390/app12062828
Liu, Y., Heidari, A. A., Liang, G., Chen, H., Pan, Z., et al. (2022b). Simulated annealing-based dynamic step shuffled frog leaping algorithm: Optimal performance design and feature selection. Neurocomputing 503, 325–362. doi: 10.1016/j.neucom.2022.06.075
Liu, Y., Tian, J., Hu, R., Yang, B., Liu, S., Yin, L., et al. (2022c). Improved feature point pair purification algorithm based on SIFT during endoscope image stitching. Front. Neurorobot. 16:840594. doi: 10.3389/fnbot.2022.840594
Liu, Z., Su, W., Ao, J., Wang, M., Jiang, Q., He, J., et al. (2022d). Instant diagnosis of gastroscopic biopsy via deep-learned single-shot femtosecond stimulated Raman histology. Nat. Commun. 13:4050. doi: 10.1038/s41467-022-31339-8
Lobo, J. L., Zorrilla, V., Aizpuru, F., Uresandi, F., Garcia-Bragado, F., Conget, F., et al. (2006). Clinical syndromes and clinical outcome in patients with pulmonary embolism: Findings from the RIETE registry. Chest 130, 1817–1822. doi: 10.1378/chest.130.6.1817
Mark, A. L. (1983). The Bezold-Jarisch reflex revisited: Clinical implications of inhibitory reflexes originating in the heart. J. Am. Coll. Cardiol. 1, 90–102. doi: 10.1016/S0735-1097(83)80014-X
Mirjalili, S. (2015). Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 89, 228–249. doi: 10.1016/j.knosys.2015.07.006
Mirjalili, S. (2016). SCA: A sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 96, 120–133. doi: 10.1016/j.knosys.2015.12.022
Mirjalili, S., and Lewis, A. (2016). The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67. doi: 10.1016/j.advengsoft.2016.01.008
Mirjalili, S., Gandomi, A. H., Mirjalili, S. Z., Saremi, S., Faris, H., and Mirjalili, S. M. (2017). Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 114, 163–191. doi: 10.1016/j.advengsoft.2017.07.002
Mishra, P. K., Satapathy, S. C., and Rout, M. (2021). Optimized shannon and fuzzy entropy based machine learning model for brain MRI image segmentation. J. Sci. Ind. Res. 80, 543–549. doi: 10.56042/jsir.v80i6.45579
Nordenholz, K., Ryan, J., Atwood, B., and Heard, K. (2011). Pulmonary embolism risk stratification: Pulse oximetry and pulmonary embolism severity index. J. Emerg. Med. 40, 95–102. doi: 10.1016/j.jemermed.2009.06.004
O’Driscoll, B. R., Howard, L. S., and Davison, A. G. (2008). BTS guideline for emergency oxygen use in adult patients. Thorax 63 Suppl 6, vi1–vi68. doi: 10.1136/thx.2008.102947
Pan, W. T. (2012). A new fruit fly optimization algorithm: Taking the financial distress model as an example. Knowl. Based Syst. 26, 69–74. doi: 10.1016/j.knosys.2011.07.001
Prandoni, P., Lensing, A. W., Prins, M. H., Ciammaichella, M., Perlati, M., Mumoli, N., et al. (2016). Prevalence of pulmonary embolism among patients hospitalized for syncope. N. Engl. J. Med. 375, 1524–1531. doi: 10.1056/NEJMoa1602172
Qiu, S., Zhao, H., Jiang, N., Wang, Z., Liu, L., An, Y., et al. (2022). Multi-sensor information fusion based on machine learning for real applications in human activity recognition: State-of-the-art and research challenges. Inf. Fusion 80, 241–265. doi: 10.1016/j.inffus.2021.11.006
Sheng, Z., Wang, J., Zhou, S., and Zhou, B. (2014). Parameter estimation for chaotic systems using a hybrid adaptive cuckoo search with simulated annealing algorithm. Chaos 24:013133. doi: 10.1063/1.4867989
Simpson, R. J. Jr., Podolak, R., Mangano, C. A. Jr., Foster, J. R., and Dalldorf, F. G. (1983). Vagal syncope during recurrent pulmonary embolism. JAMA 249, 390–393. doi: 10.1001/jama.1983.03330270054034
Soteriades, E. S., Evans, J. C., Larson, M. G., Chen, M. H., Chen, L., Benjamin, E. J., et al. (2002). Incidence and prognosis of syncope. N. Engl. J. Med. 347, 878–885. doi: 10.1056/NEJMoa012407
Storn, R., and Price, K. (1997). Differential evolution – a simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 11, 341–359. doi: 10.1023/A:1008202821328
Su, Y., Li, S., Zheng, C., and Zhang, X. (2019). A heuristic algorithm for identifying molecular signatures in cancer. IEEE Trans. NanoBiosci. 19, 132–141. doi: 10.1109/TNB.2019.2930647
Theilade, J., Winkel, B. G., Holst, A. G., Tfelt-Hansen, J., Svendsen, J. H., and Haunsø, S. (2010). A nationwide, retrospective analysis of symptoms, comorbidities, medical care and autopsy findings in cases of fatal pulmonary embolism in younger patients. J. Thromb. Haemost. 8, 1723–1729. doi: 10.1111/j.1538-7836.2010.03922.x
Tian, Y., Su, X., Su, Y., and Zhang, X. (2020). EMODMI: A multi-objective optimization based method to identify disease modules. IEEE Trans. Emerg. Top. Comput. Intell. 5, 570–582. doi: 10.1109/TETCI.2020.3014923
Tu, J., Chen, H., Liu, J., Heidari, A. A., and Pham, Q. V. (2020). Evolutionary biogeography-based Whale optimization methods with communication structure: Towards measuring the balance. Knowl. Based Syst. 212:106642. doi: 10.1016/j.knosys.2020.106642
Tu, J., Chen, H., Wang, M., and Gandomi, A. H. (2021). The colony predation algorithm. J. Bionic Eng. 18, 674–710. doi: 10.1007/s42235-021-0050-y
Valian, E., Tavakoli, S., Mohanna, S., and Haghi, A. (2013)., Improved cuckoo search for reliability optimization problems. Comput. Ind. Eng. 64, 459–468. doi: 10.1016/j.cie.2012.07.011
Venetz, C., Labarère, J., Jiménez, D., and Aujesky, D. (2013). White blood cell count and mortality in patients with acute pulmonary embolism. Am. J. Hematol. 88, 677–681. doi: 10.1002/ajh.23484
Wang, G.-G., Gao, D., and Pedrycz, W. (2022). “Solving multi-objective fuzzy job-shop scheduling problem by a hybrid adaptive differential evolution algorithm,” in Proceesings of the IEEE transactions on industrial informatics, (Piscataway, NJ: IEEE). doi: 10.1109/TII.2022.3165636
Wang, M., Chen, H., Yang, B., Zhao, X., Hu, L., Cai, Z., et al. (2017). Toward an optimal kernel extreme learning machine using a chaotic moth-flame optimization strategy with applications in medical diagnoses. Neurocomputing 267, 69–84. doi: 10.1016/j.neucom.2017.04.060
Wang, Q., Ma, J., Jiang, Z., and Ming, L. (2018). Prognostic value of neutrophil-to-lymphocyte ratio and platelet-to-lymphocyte ratio in acute pulmonary embolism: A systematic review and meta-analysis. Int. Angiol. 37, 4–11. doi: 10.23736/S0392-9590.17.03848-2
Wang, W., Zheng, J., Zhao, L., Chen, H., and Zhang, X. (2022). A non-local tensor completion algorithm based on weighted tensor nuclear norm. Electronics 11:3250. doi: 10.3390/electronics11193250
Wang, Y., Yang, H., Qiao, L., Tan, Z., Jin, J., Yang, J., et al. (2019). The predictive value of PaO(2)/FIO(2) and additional parameters for in-hospital mortality in patients with acute pulmonary embolism: An 8-year prospective observational single-center cohort study. BMC Pulm. Med. 19:242. doi: 10.1186/s12890-019-1005-5
Watts, J. A., Gellar, M. A., Obraztsova, M., Kline, J. A., and Zagorski, J. (2008). Role of inflammation in right ventricular damage and repair following experimental pulmonary embolism in rats. Int. J. Exp. Pathol. 89, 389–399. doi: 10.1111/j.1365-2613.2008.00610.x
Watts, J. A., Marchick, M. R., and Kline, J. A. (2010). Right ventricular heart failure from pulmonary embolism: Key distinctions from chronic pulmonary hypertension. J. Card. Fail. 16, 250–259. doi: 10.1016/j.cardfail.2009.11.008
Wendelboe, A. M., and Raskob, G. E. (2016). Global burden of thrombosis: Epidemiologic aspects. Circ. Res. 118, 1340–1347. doi: 10.1161/CIRCRESAHA.115.306841
Wicki, J., Perrier, A., Perneger, T. V., Bounameaux, H., and Junod, A. F. (2000). Predicting adverse outcome in patients with acute pulmonary embolism: A risk score. Thromb. Haemost. 84, 548–552. doi: 10.1055/s-0037-1614065
Wu, W., and Ma, X. (2022). “Network-based structural learning nonnegative matrix factorization algorithm for clustering of scRNA-seq data,” in IEEE/ACM transactions on computational biology and bioinformatics, (Piscataway, NJ: IEEE). doi: 10.1109/TCBB.2022.3161131
Wu, Z., Li, G., Shen, S., Cui, Z., Lian, X., and Xu, G. (2021a). Constructing dummy query sequences to protect location privacy and query privacy in location-based services. World Wide Web 24, 25–49. doi: 10.1007/s11280-020-00830-x
Wu, Z., Li, R., Xie, J., Zhou, Z., Guo, J., and Xu, X. (2020a). A user sensitive subject protection approach for book search service. J. Assoc. Inf. Sci. Technol. 71, 183–195. doi: 10.1002/asi.24227
Wu, Z., Shen, S., Zhou, H., Li, H., Lu, C., and Zou, D. (2021b). An effective approach for the protection of user commodity viewing privacy in e-commerce website. Knowl. Based Syst. 220, 106952. doi: 10.1016/j.knosys.2021.106952
Wu, Z., Wang, R., Li, Q., Lian, X., and Xu, G. (2020b). “A location privacy-preserving system based on query range cover-up for location-based services,” in IEEE transactions on vehicular technology, Vol. 69, (Piscataway, NJ: IEEE). doi: 10.1109/TVT.2020.2981633
Xu, Y., Chen, H., Heidari, A., Luo, J., Zhang, Q., Zhao, X., et al. (2019). an efficient chaotic mutative moth-flame-inspired optimizer for global optimization tasks. Expert Syst. Appl. 129, 135–155. doi: 10.1016/j.eswa.2019.03.043
Yang, X., and Suash, D. (2009). “Cuckoo search via lévy flights,” in Proccedings of the 2009 World congress on nature & biologically inspired computing (NaBIC), Coimbatore, 210–214. doi: 10.1109/NABIC.2009.5393690
Yang, Y., Chen, H., Heidari, A. A., and Gandomi, A. H. (2021). Hunger games search: Visions, conception, implementation, deep analysis, perspectives, and towards performance shifts. Expert Syst. Appl. 177:114864. doi: 10.1016/j.eswa.2021.114864
Yang, Z., Chen, H., Zhang, J., and Chang, Y. (2022). “Context-aware attentive multi-level feature fusion for named entity recognition,” in IEEE transactions on neural networks and learning systems, (Piscataway, NJ: IEEE). doi: 10.1109/TNNLS.2022.3178522
Ye, X., Li, H., Wang, M., Chi, C., Liang, G., Chen, H., et al. (2021). Modified whale optimization algorithm for solar cell and PV module parameter identification. Complexity 2021:8878686. doi: 10.1155/2021/8878686
Yu, H., Song, J., Chen, C., Heidari, A. A., Liu, J., Yu, H., et al. (2022). Image segmentation of leaf spot diseases on maize using multi-stage cauchy-enabled grey wolf algorithm. Eng. Appl. Artif. Intell. 109:104653. doi: 10.1016/j.engappai.2021.104653
Zhang, L., Wang, J., Wang, W., Jin, Z., Su, Y., and Chen, H. (2022). Smart contract vulnerability detection combined with multi-objective detection. Comput. Netw. 217:109289. doi: 10.1109/JIOT.2021.3051060
Zhang, M., Chen, Y., and Lin, J. (2021). A privacy-preserving optimization of neighborhood-based recommendation for medical-aided diagnosis and treatment. IEEE Internet Things J. 8, 10830–10842. doi: 10.1109/TCSVT.2019.2927603
Zhang, X., Zheng, J., Wang, D., and Zhao, L. (2020). Exemplar-based denoising: A unified low-rank recovery framework. IEEE Trans. Circuits Syst. Video Technol. 30, 2538–2549. doi: 10.1109/TPAMI.2022.3213716
Zhang, X., Zheng, J., Wang, D., Tang, G., Zhou, Z., and Lin, Z. (2022). “Structured sparsity optimization with non-convex surrogates of l2,0-norm: A unified algorithmic framework,” in Proceedings of the IEEE transactions on pattern analysis and machine intelligence, (Piscataway, NJ: IEEE). doi: 10.1016/j.neucom.2020.10.038
Zhang, Y., Liu, R., Heidari, A., Wang, X., Chen, Y., Wang, M., et al. (2021). Towards augmented kernel extreme learning models for bankruptcy prediction: Algorithmic behavior and comprehensive analysis. Neurocomputing 430, 185–212. doi: 10.1016/j.bspc.2021.103261
Zhang, Z., Wang, L., Zheng, W., Yin, L., Hu, R., and Yang, B. (2022). Endoscope image mosaic based on pyramid ORB. Biomed. Signal Process. Control 71:103261. doi: 10.1016/j.knosys.2020.106510
Zhao, D., Liu, L., Yu, F., Heidari, A. A., and Chen, H. (2020). Chaotic random spare ant colony optimization for multi-threshold image segmentation of 2D kapur entropy. Knowl. Based Syst. 216:106510.
Zhou, J., Zhu, Z., and Ji, Z. (2014). A memetic algorithm based feature weighting for metabolomics data classification. Chin. J. Electron. 23, 706–711.
Keywords: pulmonary embolism, feature selection, extreme learning machine, disease diagnosis, machine learning, meta-heuristic, swarm-intelligence
Citation: Su H, Han Z, Fu Y, Zhao D, Yu F, Heidari AA, Zhang Y, Shou Y, Wu P, Chen H and Chen Y (2022) Detection of pulmonary embolism severity using clinical characteristics, hematological indices, and machine learning techniques. Front. Neuroinform. 16:1029690. doi: 10.3389/fninf.2022.1029690
Received: 27 August 2022; Accepted: 24 November 2022;
Published: 16 December 2022.
Edited by:
Ardalan Aarabi, University of Picardie Jules Verne, FranceReviewed by:
Robert W. Newcomb, University of Maryland, College Park, United StatesEssam Halim Houssein, Minia University, Egypt
Wu Deng, Civil Aviation University of China, China
Copyright © 2022 Su, Han, Fu, Zhao, Yu, Heidari, Zhang, Shou, Wu, Chen and Chen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dong Zhao, emQtaHlAMTYzLmNvbQ==; Huiling Chen, Y2hlbmh1aWxpbmcuamx1QGdtYWlsLmNvbQ==; Yanfan Chen, Y2hlbnlmMjYwNUAxNjMuY29t
†These authors have contributed equally to this work