 Hanan Al-Hadeethi1
Hanan Al-Hadeethi1 Mohammed Diykh
Mohammed Diykh
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neuroinform., 03 February 2022
Volume 15 - 2021 | https://doi.org/10.3389/fninf.2021.808339
This article is part of the Research TopicAdvanced EEG Analysis Techniques for Neurological DisordersView all 8 articles
Identification of alcoholism is clinically important because of the way it affects the operation of the brain. Alcoholics are more vulnerable to health issues, such as immune disorders, high blood pressure, brain anomalies, and heart problems. These health issues are also a significant cost to national health systems. To help health professionals to diagnose the disease with a high rate of accuracy, there is an urgent need to create accurate and automated diagnosis systems capable of classifying human bio-signals. In this study, an automatic system, denoted as (CT-BS- Cov-Eig based FOA-F-SVM), has been proposed to detect the prevalence and health effects of alcoholism from multichannel electroencephalogram (EEG) signals. The EEG signals are segmented into small intervals, with each segment passed to a clustering technique-based bootstrap (CT-BS) for the selection of modeling samples. A covariance matrix method with its eigenvalues (Cov-Eig) is integrated with the CT-BS system and applied for useful feature extraction related to alcoholism. To select the most relevant features, a nonparametric approach is adopted, and to classify the extracted features, a radius-margin-based support vector machine (F-SVM) with a fruit fly optimization algorithm (FOA), (i.e., FOA-F-SVM) is utilized. To assess the performance of the proposed CT-BS model, different types of evaluation methods are employed, and the proposed model is compared with the state-of-the-art models to benchmark the overall effectiveness of the newly designed system for EEG signals. The results in this study show that the proposed CT-BS model is more effective than the other commonly used methods and yields a high accuracy rate of 99%. In comparison with the state-of-the-art algorithms tested on identical databases describing the capability of the newly proposed FOA-F-SVM method, the study ascertains the proposed model as a promising medical diagnostic tool with potential implementation in automated alcoholism detection systems used by clinicians and other health practitioners. The proposed model, adopted as an expert system where EEG data could be classified through advanced pattern recognition techniques, can assist neurologists and other health professionals in the accurate and reliable diagnosis and treatment decisions related to alcoholism.
The human brain, as an integral part of the central nervous system (CNS), operates normally by receiving signals from the body’s organs and providing information to the muscles (Pelvig et al., 2008). The effects of alcohol on the CNS can lead to long- and short-term issues such as impaired vision, impaired hearing, dementia, and depression (Deiner and Silverstein, 2009). Alcoholism is a common neurological disorder caused by excessive and repetitive drinking of alcoholic beverages; the harmful effects of alcoholic beverages could be physical and mental as well as social, legal, and economic (Lieber, 1995; Volkow et al., 2017). The heavy consumption of alcohol disturbs the functioning of the entire nervous system, especially the brain. It not only weakens the brain neurons but also leads to cognitive and mobility weakness (Knight and Longmore, 1994; Oscar-Berman et al., 1997). Based on the latest reports issued by the WHO https://www.who.int/health-topics/alcohol#tab=tab_1, three million deaths every year are caused by the harmful use of alcohol. In addition, more than 200 disease- and injury-related conditions are caused by the excessive use of alcohol. An effective method of recognizing alcoholics from nonalcoholics could decrease unnecessary economic losses and social problems as well as expedite diagnosis in clinical settings.
Electroencephalogram (EEG) technology is becoming increasingly important in the identification, diagnosis, and treatment of mental and neurodegenerative diseases and abnormalities (Isaksson et al., 1981). The function of the EEG assists physicians in establishing an accurate diagnosis. Thus, it can be utilized as a diagnostic tool to discern alcoholics from nonalcoholic subjects based on the variation in the signals.
Much effort has been expended in deducing the preferred classification method in analyzing EEG signals for alcoholism. For instance, Faust et al. (2008) analyzed normal, epileptic, and alcoholic EEG signals utilizing fast Fourier transform (FFT) and autoregressive (AR) model and their techniques. Their results showed that the power spectral density (PSD) of these signals was varied. Patidar et al. (2017) applied tunable Q-wavelet transform (TQWT) to decompose EEG rhythms into different bands. The principal component analysis (PCA) was utilized for feature extraction and then fed to a least squares-support-vector machine (LS-SVM). Cao et al. (2017) utilized a synchronization likelihood to measure synchronization variations among 28 alcoholics and 28 control subjects. The study showed that the synchronization for the control group reflected the complexity levels of the cognitive tasks, while the alcoholics only displayed erratic changes. Lin et al. (2009) analyzed the clinical alcoholic and normal control FP1 EEG signals based on a Hilbert-Huang Transformation. The PCA and WT were also applied to analyze EEG data by Sun et al. (2006), and other studies have used the power spectrum of Haar mother wavelet, approximate entropy, sample entropy, and empirical mode decomposition. Kousarrizi et al. (2009) applied the power spectrum of the Haar mother wavelet to extract the features with PCA. The extracted features were fed to a support vector machine (SVM) and neural networks. The simulation results showed that their method achieved a higher rate of classification accuracy than other methods. Shooshtari and Setarehdan (2010) proposed a reduction method to select an optimum subset of EEG channels based on spectral analysis and correlation matrices: their technique was successful in selecting an optimal number of channels. Kumar et al. (2012) employed an approximate entropy and sample entropy to extract entropy features from EEG time series: they illustrated that the average value of ApEn and SampEn for an epileptic time series was less than that of a nonepileptic time series. The study of Priya et al. (2018) has used mode decomposition (EMD) for features extraction.
Time-frequency (T–F) image information, high-pass infinite impulse response (IIR) filter with zero phase distortion, Separability and Correlation analysis (SEPCOR), computer-aided diagnosis, and EEG rhythms-based features were utilized in many studies that follow. Bajaj et al. (2017) proposed a new hybrid method to classify automatically an alcoholic and a control EEG signal based on T–F image information and found it useful in conveying key characteristics in EEG signals. The results of this study were promising. Fattah et al. (2015) proposed a new method based on a high-pass IIR filter with zero phase distortion, which aimed to preserve the Gamma band and all higher frequencies with K-nearest neighbor (KNN) classifier and leave-one-out cross-validation technique. Their proposed scheme also classified alcoholic and nonalcoholic subjects with a higher rate of accuracy than did existing methods. To select an optimal feature subset automatically and to obtain a minimum correlation between selected channels and maximum class separation, a statistical feature selection technique based on SEPCOR was proposed by Shri and Sriraam (2016); a significant improvement in the classification accuracy based on the SEPCOR method was noted in that study compared with feature selection methods used in previous studies. The study of Acharya et al. (2014) presented a review of the known features of EEGs gained from people with alcoholism. EEG-rhythms-based features for automatic identification of alcohol EEG signals were also proposed by the study of Taran and Bajaj (2017); in that study, an extreme learning machine (ELM) and a least squares SVM classifiers were used to detect nonalcoholic and alcoholic EEG signals, with the investigators’ techniques showing an accuracy of 97.92%.
Recently, there is a trend of using deep learning models for BP estimation; for example, Gao et al. (2021) designed an approach that combined recurrence plots and convolutional neural network to recognize fatigue driving. They showed that that complex network based on a deep learning model gave a high recognition rate. Tao et al. (2020) developed an attention-based convolutional recurrent neural network mode to classify emotion EEG signals. In that study, the convolutional recurrent neural network was used to extract spatial characteristics of EEG signals. Singhal et al. (2021) integrated FFT, a convolution neural network, and long short-term memory to classify EEG recordings into an alcoholic or control. Buriro et al. (2021) utilized wavelet scattering transform with a convolutional neural network and SVM to classify alcoholism from EEG signals. They found that wavelet scattering transform-based features with a conventional neural network had a high potential to detect alcoholic subjects.
As demonstrated in previous studies, finding new techniques for the detection of alcoholism can help in further clinical applications and research. The present study provides a new mechanism for the classification of alcoholism from multichannel EEG signals. This study has developed a new machine learning model for the reduction of data prior to the classification process by integrating the clustering and bootstrapping clustering technique-based bootstrap (CT-BS) technique in one phase of model design. To detect and further analyze the abnormalities in the EEG signal, the eigenvalues of the covariance matrix, determined from EEG signals, are investigated using a statistical method by extracting ten statistical features from the eigenvalues of the covariance matrix. These features are represented by the mean, median, maximum, minimum, mode, range, SD, variation, skewness, and kurtosis commonly used in EEG classification problems. To improve the automated detection system, a combination-based approach using the F-SVM and fruit fly optimization algorithm (FOA), i.e., FOA-F-SVM, has been proposed to correctly classify alcoholism from multichannel EEG signals. Based on an extensive literature search, the CT-BS- covariance matrix method with its eigenvalues (Cov-Eig)-based FOA-F-SVM model is proposed in this study for the first time to analyze and detect alcoholism from EEG signals. In respect to the results, compared with the other algorithms, the proposed model, CT-BS-Cov-Eig-based FOA-F-SVM, has promising performance, and can, therefore, be adopted as a classification technique for alcoholism-detection in EEG signals.
This research article is divided into several sections: Section 2 presents the methodology; Section 3 contains a description and explanation of the datasets, segmentation, sampling, feature extraction, and feature selection; Section 4 contains performance evaluation methods; Section 5 includes radius-margin-based SVM (F-SVM), fruit fly optimization algorithm (FOR), and the proposed classification model FOR-F-SVM; Section 6 includes experimental results, evaluation of the performance of the proposed FOA-F-SVM model, channels selection based on classification accuracy, comparison of classification accuracy of the proposed model FOA-F-SVM with KNN, k-means, and SVM, and comparison the proposed model, FOA-F-SVM, with previous studies and discussion; and Section 7 presents the conclusions.
In the work described in this study, we have utilized a public database known as the machine learning repository (UCI) Knowledge Discovery in Databases (KDD) Archive www.kdd.ics.usi.edu from Irvine, CA: the University of California, Department of Information and Computer Science (Hettich and Bay, 1999). Data were collected from 122 participants; for each participant, there were 120 trials with three kinds of stimuli (Zhang et al., 1997). The EEG signals were recorded from 64 channels, two electrooculography (EOG) channels, and one reference electrode. The duration of each trial was one second and the sampling rate of all channel data was 256 Hz. UCI KDD contains three types of datasets, which are SMNI CMI TEST, SMNI CMI TRAIN, and FULL, respectively. FULL datasets contain a few all-zero recordings (Zhu et al., 2011); therefore, the first two databases were utilized. There are 600 recorded files in SMNI CMI TEST and the same number in the SMNI CMI TRAIN, which equals 1,200 recorded files, and for each recording, there are signals from 64 electrode caps.
This article describes the design of a new technique trained to classify alcoholism from multichannel EEG signals. A hybrid method called (CT-BS) by integrating clustering technique (CT) and bootstrapping (BS) has been developed to reduce the dimensions of the EEG data. Then, the covariance matrix with its eigenvalues, coupled with the FOA-F-SVM, is proposed to predict alcoholism in patients’ recordings. KDD recorded at the University of California, Department of Information and Computer Science (Gao et al., 2021) is used for the evaluation of the proposed model. Figure 1 demonstrates the proposed model. The EEG signals are divided into four segments; after that, each segment is sent into the CT-BS method for the sampling phase. To extract EEG features, the covariance matrix with its eigenvalues is applied. Following this, to detect and analyze abnormalities in the EEG signal, the eigenvalues of the covariance matrix are investigated and ten statistical features were extracted from eigenvalues of each covariance matrix. These features are mean, median, maximum, minimum, mode, range, SD, variation, skewness, and kurtosis. In this study, we used a nonparametric method, named the Kolmogorov–Smirnov test (KST), for selecting the most relevant features. The selected features are fed to the FOA-F-SVM to classify EEG signals. To estimate the performance of the proposed model, different types of assessment metrics, such as accuracy, sensitivity, and specificity, are used in the performance evaluation.
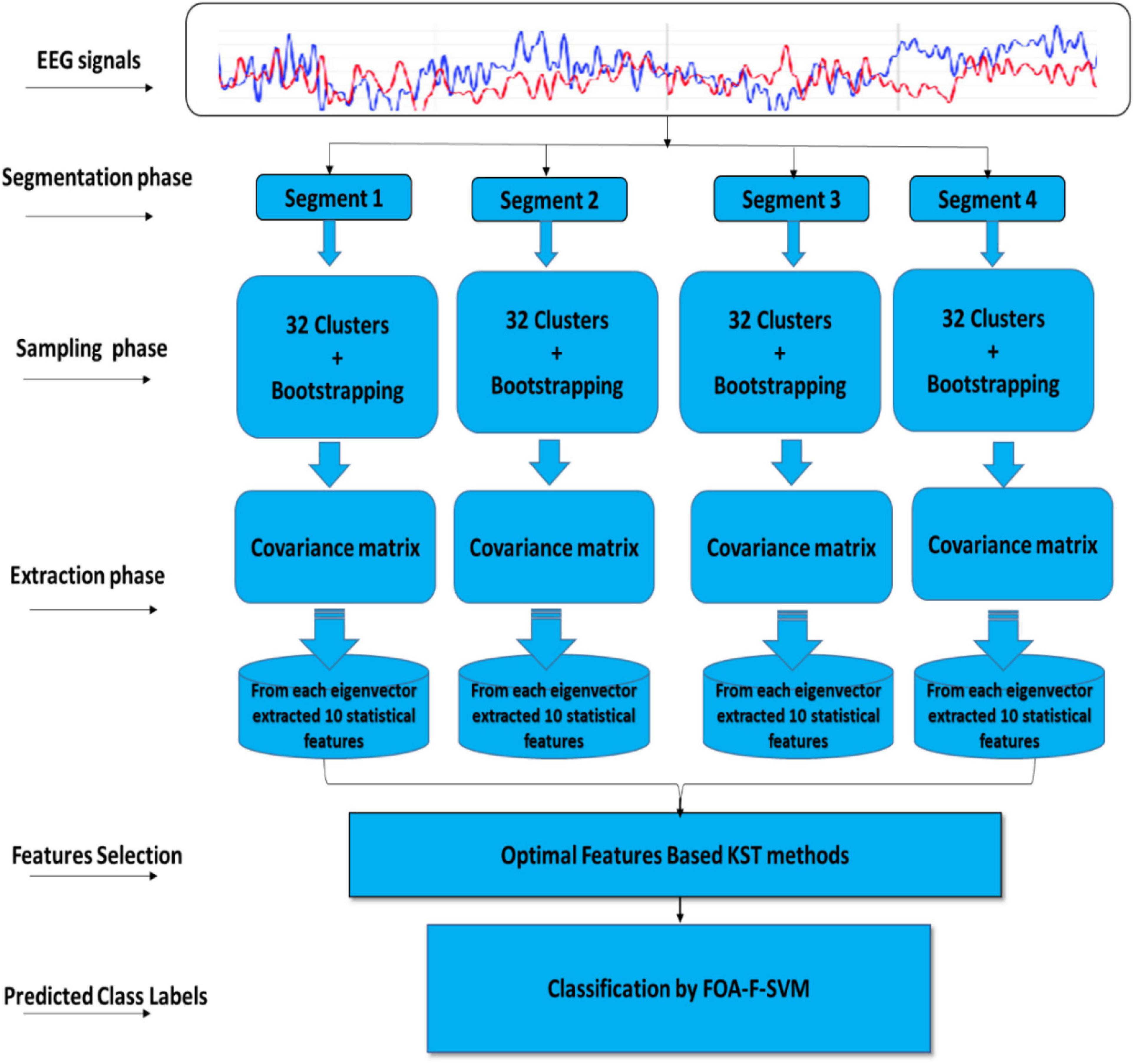
Figure 1. A flow diagram representation of the algorithm developed for detection and classification of alcoholism-based EEG signals.
Based on our previous work (Diykh et al., 2018, 2019a,2019b,2020, 2021), this project has applied the sliding window technique to split the EEG signals into their respective periods. It was found that the proposed method generated highly satisfactory classification accuracy. Mathematically, let an EEG signal be denoted as: X = x1,x2,…..,xn with n being the data points. In this study, the EEG signal X was segmented into m segments, with each segment containing k datapoints (Diykh et al., 2020, 2021). Figure 2 shows an example of an EEG signal being partitioned into segments.
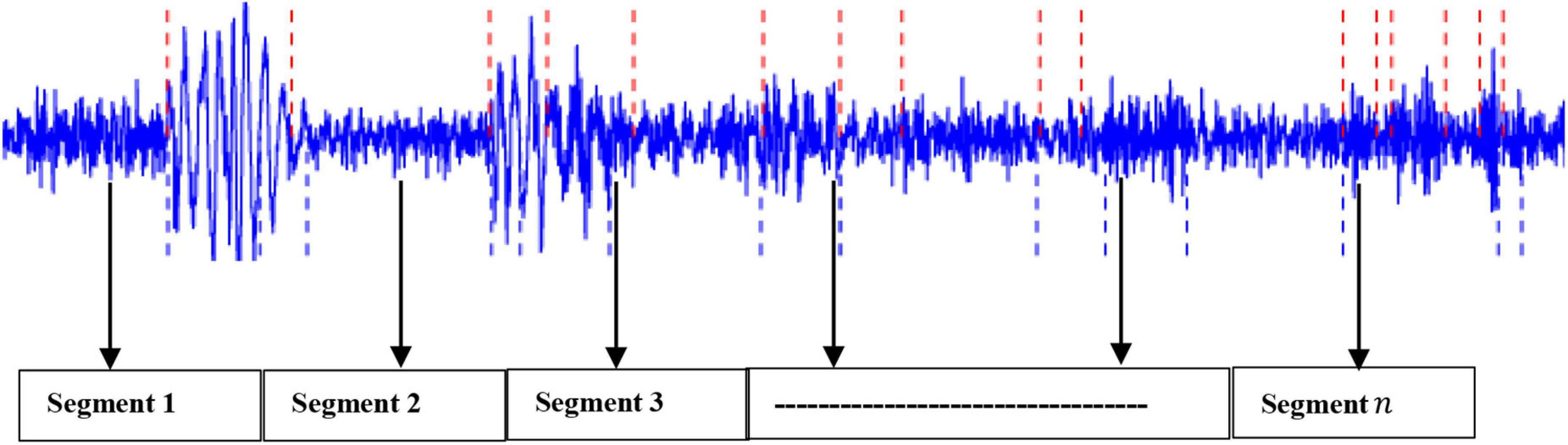
Figure 2. An example of EEG being partitioned into segments.
To design a powerful sampling technique, a hybrid method that integrates the CT and BS, (CT-BS), is proposed in this study for reducing the dimensionality of EEG signals. This also prevents problems such as bias and variation that may occur when applying a CT. Not only is BS a method that depends on random sampling with replacement, but it also estimates the properties of an estimator. Adapting standard errors for clustering can be a very important part of any statistical analysis (Hennig, 2007); further, in terms of statistical modeling, validation is extremely important in cluster analysis because CTs resort to generate clustering even for completely homogeneous data groups. Most CTs suppose a certain paradigm for clusters, and this could be adequate for some portions of data, but not for others. The issue of stability in cluster analysis is complex, but it is considered an important part of cluster validity (Alonso et al., 2007). We propose to use the bootstrap method to reduce the error rate, which leads to reducing the bias and variation. The main concept behind utilizing the nonparametric bootstrap for the estimation of cluster constancy or stability is the following:
Suppose that there is a mixture distribution where i = 1, 2, 3, …, z, are the distributions generating z “true” clusters, and εi is the probability that a point from K_i is drawn (Hira and Gillies, 2015). For a given dataset with n points, the “true” clustering would then be composed of z clusters, each of which includes precisely the points generated by Ki, i = 1, 2, 3,…, z. The dataset, when generated from K, is clustered; the generated clusters vary from the “true”’ clusters because the clustering approach introduces an assured bias and variation.
The concept of bias and variation can be expressed via the maximum Jaccard coefficient. It is a measure of similarity for the two sets of data, with a range from 0 to 100%. A high percentage refers that two populations are similar among all the points created via Ki and the two sets belong to an identical cluster. The bootstrap is habitually utilized to grant an idea of bias and variation caused via a certain statistical approach because no true clustering is known and there is no true underlying distribution. To simulate K, the empirical distribution of the observed dataset is taken. The originally found clusters can be treated as the “true” ones, and the points can be drawn from the dataset. The mean maximal Jaccard coefficient can be explained as denoting the stability of the authentic clusters. Given a number b of bootstrap replications and a cluster C from the original clustering En(y), the schema works as below:
Reiterate for i = 1, 2, 3, …, b:
• For n points, draw a bootstrap sample with replacement from the original dataset y_n.
• Calculate the clustering .
• Suppose be the points of the original dataset that are also in the bootstrap sample. Suppose , .
• If , calculate the maximum Jaccard similarity between the induced cluster and the induced new clustering △ on : (i.e., D is the maximizer of ; else ).
where Jaccard coefficient (Jaccard, 1901): .
This generates a sequence τ(C,i), i = 1, 2, 3, …,b. Based on (Cameron et al., 2008; Diykh et al., 2019b) they suggested the mean: as stability measure (b* being the number of bootstrap replications for which and is utilised here because in all other cases τ(C,i) = 0).
In machine learning, with huge dimensions of data, the necessity to provide a reliable analysis grows exponentially (Alonso et al., 2007; Hira and Gillies, 2015). There are diverse types of mental and neurological conditions where the EEG data size is huge and requires observation by the clinician over an extended period. Alcoholism EEG signals may contain valuable and useful information about the different states of the brain. Since the biological signal is highly random in both the time and frequency domain, computerized analysis is indispensable. Due to the signals being nonstationary, appropriate analysis is fundamental for EEG to differentiate the alcoholic/control EEG signals. A covariance matrix method that was used in previous work (Al-Hadeethi et al., 2020) is proposed to reduce the EEG signal (and data) dimensionality while extracting the most important features for better classification accuracy.
The time series (EEG signals) can be defined as a vector of length X = {x1,x2,…..,xn}. Feature nominees can be integrated into a feature vector for a point in time series. Let Pi the number of features. The feature vector for the Nth point of the subsequence can be manifested as (Ergezer and Leblebicioǧlu, 2016, 2018):
After combining the feature vectors for all points, this study gets a feature matrix H,
It can be calculated as the covariance of the feature matrix as follows:
where μ is the mean vector of feature vectors {h1,h2,…,hW}.
Based on separating the time series into L overlapping subsequences with each having a length W, the general representation was adapted for the time series classification problem. In this study, to decrease the dimensionality of data which leads to enhance detection of possible abnormalities in the prescribed EEG signal, the eigenvalues of the covariance matrix are investigated by extracting 10 features from each eigenvector.
In this research, the data were derived from multichannel EEG signals, where each channel consists of a matrix (256 × 30), where 256 represents the number of rows and 30 represents the number of columns. For more clarification, we will explain using the following example: an experiment of 61channels that consists of a matrix (15,616 × 30) was used in this article. The time series was divided into four segments (n = 4), each segment containing (3,904 × 30) data points. Then, each segment of 3,904 datapoints was divided into 32 clusters with each cluster containing 120 data points. Based on our previous work (Zhu et al., 2011), it was found that dividing each EEG segment into 32 clusters gave satisfactory results. As a result, each segment was represented by a matrix of 120 × 32. To reduce the dimensionality of each segment, the sampling technique was applied to reduce the number of clusters. The number of clusters was reduced from 32 to 30. Consequently, each segment was represented by 120 × 30 instead of 120 × 32. To remove any redundant information and extract features from each cluster, each cluster was divided into 4 sub-clusters, and a covariance matrix was applied to each subcluster, from each its eigenvector, 10 statistical features were selected to form a vector of 40 statistical features. As a result, each segment was represented by a matrix of 40 × 30, where 40 refers to the number of features and 30 indicates the number of clusters.
In the work described in this study, one of the primary objectives of conducting many experiments was to find the optimal features that improved results. The features briefly summarize the most important information in the data, thus, this is used in cases where there is a large number of dimensions (Abdulla et al., 2019). Selecting the optimal features could lead to a high rate of classification accuracy. Therefore, six experiments were conducted on EEG channels to determine the features set using KST. More details are given in the results section.
Given the training set q = (x1,y1),(xn,yn), the fundamental SVM paradigm is displayed below. The paradigm only deems the maximization of margin. However, an accurate description can explain that the generalization error bounds of SVM are the function of radius and margin (Hedges et al., 1999).
Given the radius, a group of researchers, (Ergezer and Leblebicioǧlu, 2016) have proposed a novel formula Let the matrix K = ATA where A is denoted as transform matrix, the slack variables δi(i = 1, 2, 3,n). The paradigm of linear F-SVM is represented in (2):
Wu et al. (2018) solved the nonlinear classification problems by incorporating kernel PCA into linear F-SVM. The proportion of cumulative eigenvalues to the sum of all eigenvalues is set as 0.9 in the dimension selection of kernel PCA. The paradigm can be formulated as follows:
where is indicated tothe eigenvectors corresponding to the first G eigenvalues. The mapping function of kernel F-SVM that is always utilized is radial-basis-function (RBF), i.e., (xi,xj) = exp(−γ||xi−xj||2), where γ is the specified parameter to limit the width of the RBF (Chen et al., 2014). Between the minimization of training error and maximization of the classification margin in the paradigm, factor Z controls the trade-off (Tharwat and Hassanien, 2018). The classification accuracy differs between these two parameters. Therefore, defining the values of the parameters is essential to the performance of the SVM classifier.
The fruit fly optimization algorithm is based on the foraging behavior of the insect after which it is named (Pan, 2012). The main concept of the algorithm is that the insect primarily flies toward food via utilizing its olfactory sensory neurons: one of the groups of neurons will emit a pheromone when it is near to food. Thereafter, the fruit fly will change its direction and fly to meet its peers. Through continually updating its status and flying direction, the fruit fly will finally get nearer to the food, the position of which is the optimum solution. The algorithm will be completed if the iteration reaches maximization or the outcome is to archive the permissible accuracy. The algorithm can be split into a number of steps:
1) The position of the fruit fly is random initialization (InitX, InitY).
2) For each fruit fly, given a random direction and distance to hunt for food via its olfactory sensory neurons:
3) Due to the unknown exact location of food, the distance will be computed from the location of the fly to the origin; thereafter, the mutual distance is computed. As a result, the value will be defined as a smell concentration judgment value (d):
4) to detect a better smell concentration, set the above smell concentricity judgment value into smell concentricity judgment function:
5) discover individuals with the raised concentricity in the population:
6) preserve the most appropriate concentricity and an assortment of the fruit fly, and other fruit flies to that coordinates utilizing vision:
7) In Steps 2-5, the iterative optimization was performed. Thereafter, judge whether the concentricity is higher than that of the former level. If so, perform Step 6.
This section introduces the main idea used in developing the newly proposed FOA-F-SVM system. In order to improve and further develop the performance accuracy of the traditional SVM model, the F-SVM for joint learning of the feature transformation and SVM classifier integrated with FOA were proposed for the analysis of alcoholism through multichannel EEG signals. As shown in Figure 3, the proposed model consists of different stages. The first five steps represent internal parameter optimization and the next five steps display the external evaluation of the classification performance. The path of the proposed model is this: tune parameters depend on the FOA, after that gain an optimum classifier. Eventually, by testing the dataset through external assessment, the performance of the classifier was measured.
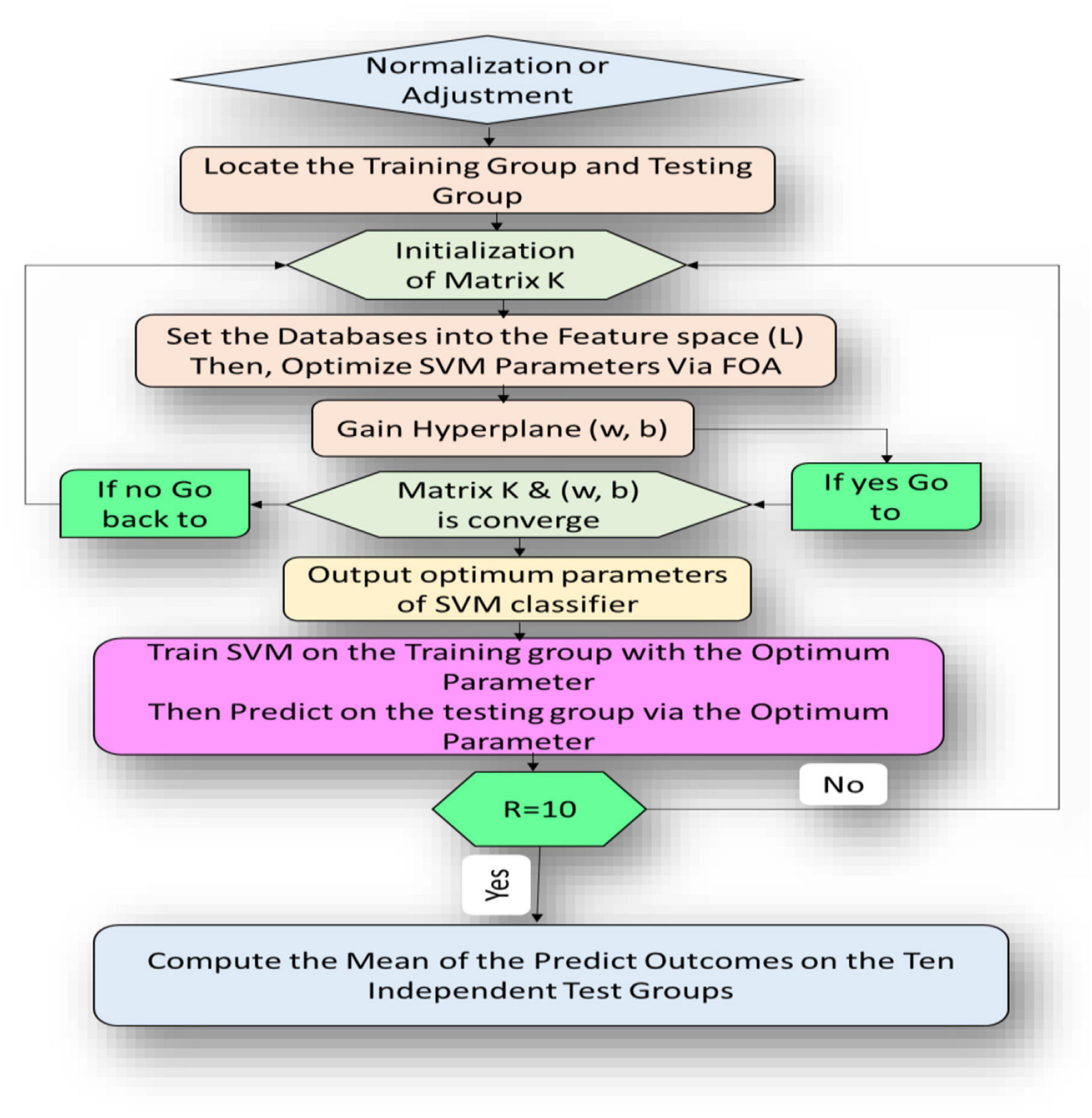
Figure 3. Flow diagram representation algorithm of the proposed FOA-F-SVM model.
The fruit fly optimization algorithm was utilized to set the parameters in the section of parameter optimization. Depending on the RBF kernel of the SVM classifier, the fruit fly’s solution was used to represent the classifier parameters Z and γ. To direct the updating of the fruit fly location, the rate of classification accuracy of the structure SVM classifier was used. The optimum solution was gained via the iterative optimization procedure, depending on the location. The SVM classifier was built up with the optimum parameters gained above in the external assessment section; thereafter, the eventual classification outcomes were gained on the test set via this classifier.
In the FOA-F-SVM model, there are many unknown variables, such as in the formula (11). To solve obscure variables (matrix K and hyperplane (w,b)) of the FOA-F-SVM model, there are three main steps:
(i) Initiating K
Suppose the weighted covariance Nq performs eigenvalues decomposition, i.e., Nq = D⋀DT, where ⋀ = Diag{λ1,2…, λn} and λ is arranged in order from highest to lowest. After algebraic computation, matrix K0 can be denoted as K0 = D∧−(1/2)DT. Due to K = ATA, the transformation matrix A can be written as A0 = ∧−(1/4)DT. Therefore, the samples are transformed into z = dataset * A0.
(ii) Resolve hyperplane (w, b)
This step consists of an explanation of how the FOA model is adopted to gain an optimum SVM classifier. The particular operation is that: the range of each parameter is given; thereafter, various values are randomly allocated within this range for every fruit fly. In the meantime, the fruit fly is represented in every group solution. Subsequently, find the preferable of these solutions. The finding operation includes two portions: via a smell search procedure, every fruit fly adjusts its position; based on the preferable fruit fly through the vision-based search procedure, the worst fruit fly in the population will be encouraged. This will then lead to obtaining a solution of the parameters via the iteration. Eventually, the test samples from z and gained optimum parameters are fed to the F-SVM prediction model.
(iii) Resolve matrix K
Now, having gained the SVM classifier, formula (11) can be formulated again as follows:
The function is cambered and is able to be differentiated for K, thus, to solve K, the gradient-projection method was chosen. The derived function for this term is given below. Thereafter, update K via Kh1 = PN(Kh−t1∇f(Kh)) until K converges.
(iv) From all the illustrations and explanations above, it is clear that the matrix K is a significant parameter in the FOA-F-SVM. Only via initializing K, it can transform the dataset into a new feature space. Thereafter, an SVM classifier is gained via optimizing parameters through FOA. Eventually, an optimal classifier is gained by constantly updating K.
It is important to evaluate the performance of any classification or detection system. A set of methods was used to assess the performance of the alcoholism classification and detection system based on the proposed FOA-F-SVM technique, as described below:
(a) Accuracy (Acc.) is a degree of proximity of a measured or calculated quantity to its actual (true) value. The term accuracy is utilized to assess the performance of the SVM method depending on the formula as given below:
(b) Sensitivity (Sen.) is a statistical measure of the performance of a binary classification test used to measure the rate of the real positive prediction. This is defined as follows:
(c) Specificity (Spe.) is utilized to measure the proportion of the real negative predication and is defined as follows:
(d) Predictive positive value (PPV) is defined as the rate of positives that correspond to the presence of the condition described via the formula as below:
(e) Predictive negative value (PNV) is the ratio of negatives that correspond to the absence of the condition and is defined as follows:
To conduct the simulation effectively, the same number of iterations and the same population size were set for particle swarm optimization (PSO), genetic algorithm (GA), and FOA. According to our preliminary experiment, when the number of maximum iteration and population size are, respectively, set as 100 and 20, the methods involved result in satisfactory classification performance. Furthermore, in the experiment, parameter Z is in range Z ∈ {2−10,1,20}, parameter g is set asg ∈ {220,1,10}. The parameters of each model are as follows: for FOA-F-SVM, the x and y are denoted to initialize the location of fruit fly and the search direction ax,bx,ay,andby are set as 10, 20, 20, and 10, respectively, in the distance function. For PSO-SVM, the maximum velocity is 0.5 times the maximum parameter Z. The learning factors Z1,Z2 were set as 1.6, 1.5, and the intermediate variable w was set as 1 in the updating velocity function and updating location function. All experiments were carried out on a desktop computer with a CPU (2.30 GHz) and 8.00 GB RAM under the MATLAB 2020 programming environment.
The experimental EEG data used to assist the proposed model were obtained from the University of California, Irvine Knowledge Discovery in Databases Archive UCI KDD. The EEG signals were collected from 122 participants, and each subject performed 120 trials with three types of stimuli (Tao et al., 2020). The recordings were obtained from 61 channel EEG signals, two EOG channels, and one reference electrode. There are three datasets, named SMNI_CMI_- TRAIN, SMNI_CMI_TEST, and FULL, respectively. In this study, only the first two databases were utilized because the full datasets contain a few all-zero recordings. There were 600 recorded files in SMNI_CMI_TRAIN, with each recording containing the signals from 64 electrodes caps. The 64 electrodes are FC4, FC3, C6, C5, F2, F1, TP8, TP7, AFZ, CP3, CP4, P5, P6, C1, C2, PO7, FP1, FP2, F7, F8, AF1, AF2, FZ, F4, F3, FC6, FC5, FC2, FC1, T8, T7, CZ, C3, C4, CP5, CP6, CP1, CP2, P3, P4, PZ, P8, P7, PO2, PO1, O2, O1, X, AF7, AF8, F5, F6, FT7, FT8, FPZ, PO8, FCZ, POZ, OZ, P2, P1, CPZ, nd, and Y. The electrodes X and Y are EOG signals, and nd is reference electrode. The EOG and nd were removed in our analysis. However, the features were extracted from 61 channels.
In this section, six experiments were conducted to select the most powerful features to classify EEG signals.
In the first experiment, 11 channels were tested (AF1, AF2, AF7, AF8, AFZ, C1, C2, C3, C4, C5, and C6) to determine whether these channels were adequate to analyze the alcoholism signals. Table 1 reports the results of feature selection using KST. Based on statistical analysis, the results showed that using these channels could explain 60% of the data.
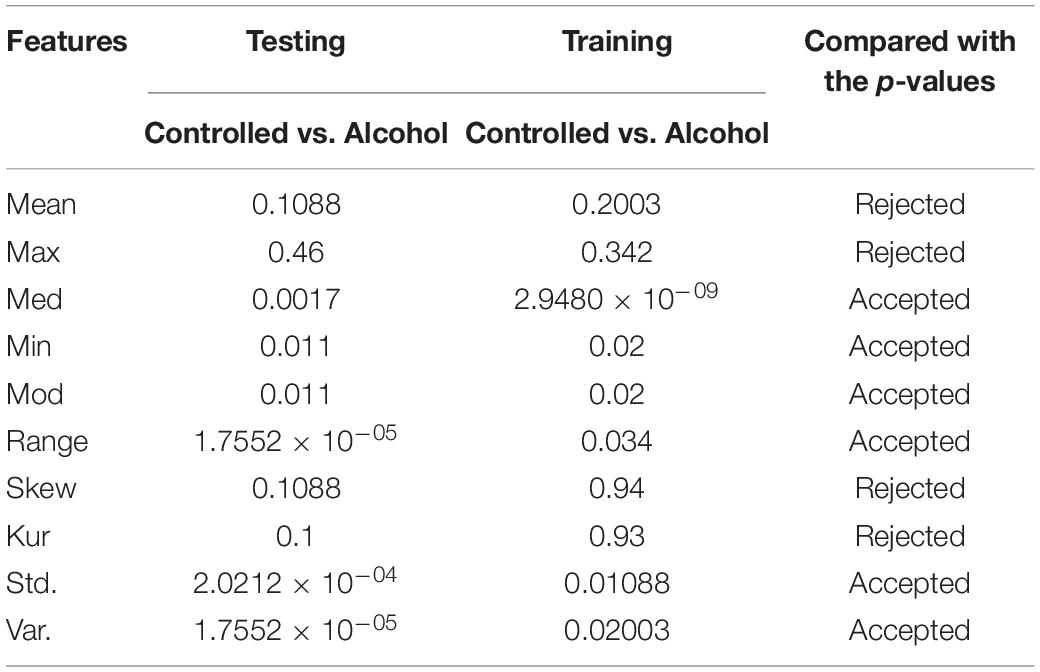
Table 1. Feature set outcome of Experiment No. 1.
In the second experiment, the channels AF8, C1, C2, C3, C4, CP1, CP5, CP6, FC5, FT7, P8, PO8, and P were utilized in the second experiment below. The outcomes indicate that the acceptance rate was high, reaching 90%, which means that the signal in these channels was suitable for detecting the EEG signals. Table 2 reports the obtained results.
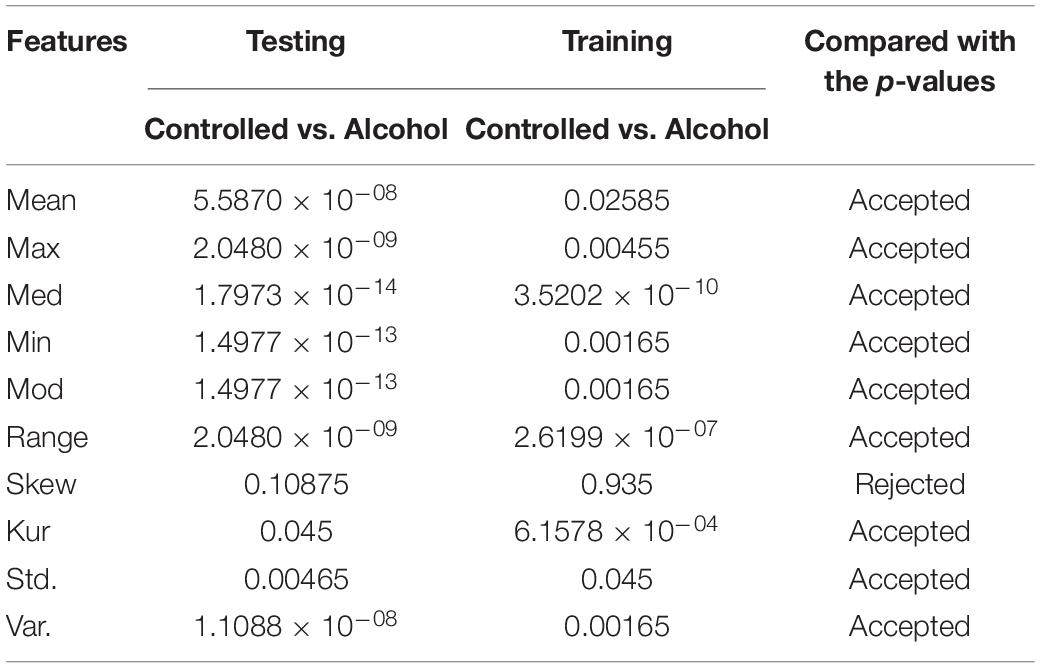
Table 2. Feature set outcome of Experiment No. 2.
In the third experiment, the number of channels tested was 23. The success rate was 70%. The channels were CP1, CP2, CP3, CP4, CP5, CP6, CPZ, CZ, F1, F2, F3, F4, F5, F6, F7, F8, FC1, FC2, FC3, FC4, FC5, FC6, and FCZ. Table 3 reports the results of experiment 3.
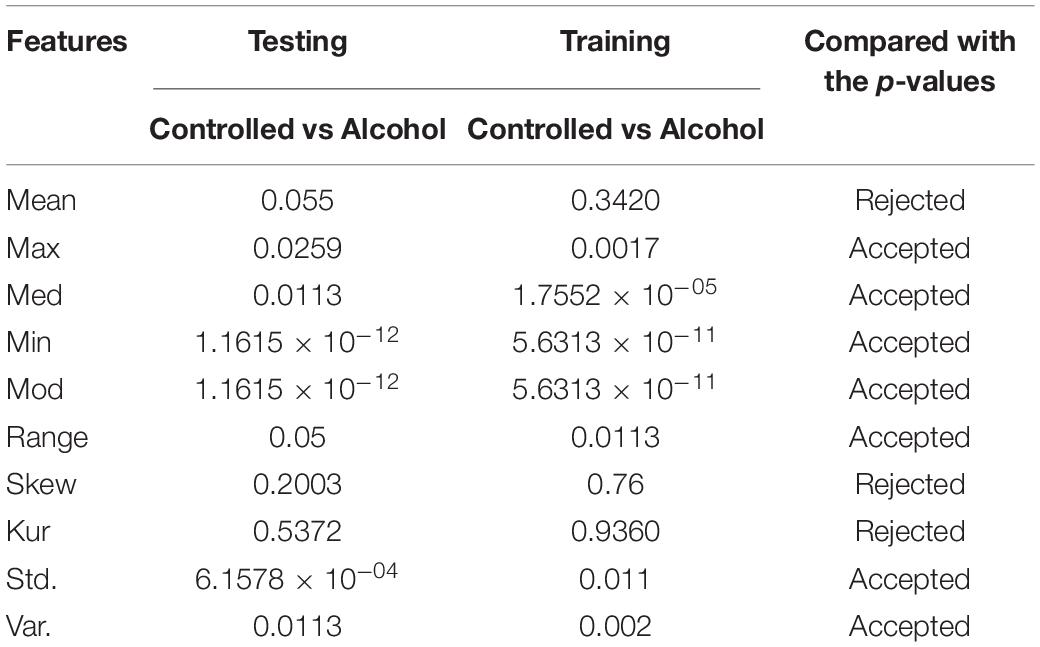
Table 3. Feature set outcome of Experiment No. 3.
In the fourth experiment, the acceptance rate was 50%. A total of twenty-eight channels passed the test in this experiment. The channels used in this experiment were FP1, FP2, FPZ, FT7, FT8, FZ, O1, O2, OZ, P1, P2, P3, P4, P5, P6, P7, P8, PO1, PO2, PO7, PO8, POZ, PZ, S1, T7, T8, TP7, and TP8 (Table 4).
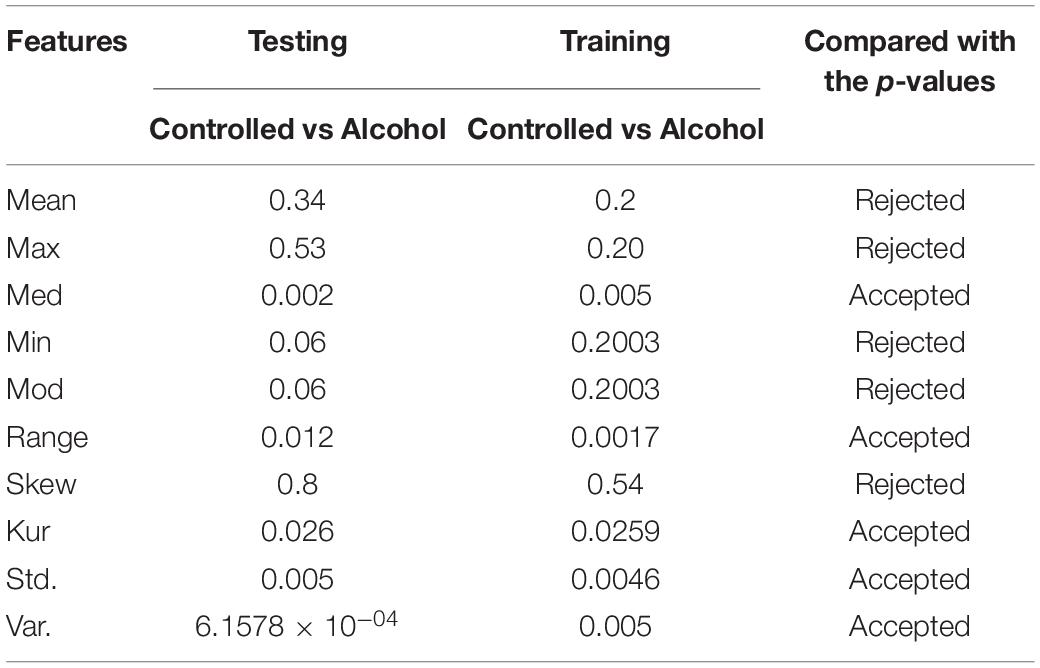
Table 4. Feature set outcome of Experiment No. 4.
In the fifth experiment, the channels AF1, AF2, AF7, AF8, AFZ, FP1, FP2, FPZ, FT7, FT8, P1, P2, P3, P4, P5, P6, P6, P7, P8, PO1, PO2, PO7, PO8, POZ, F1, F2, F3, F4, F5, F6, F7, F8, T7, T8, TP7, and TP8 were used in this experiment. The acceptance rate was very low, that is, 40%. This indicates that the channels used were not valid for classification (Table 5).
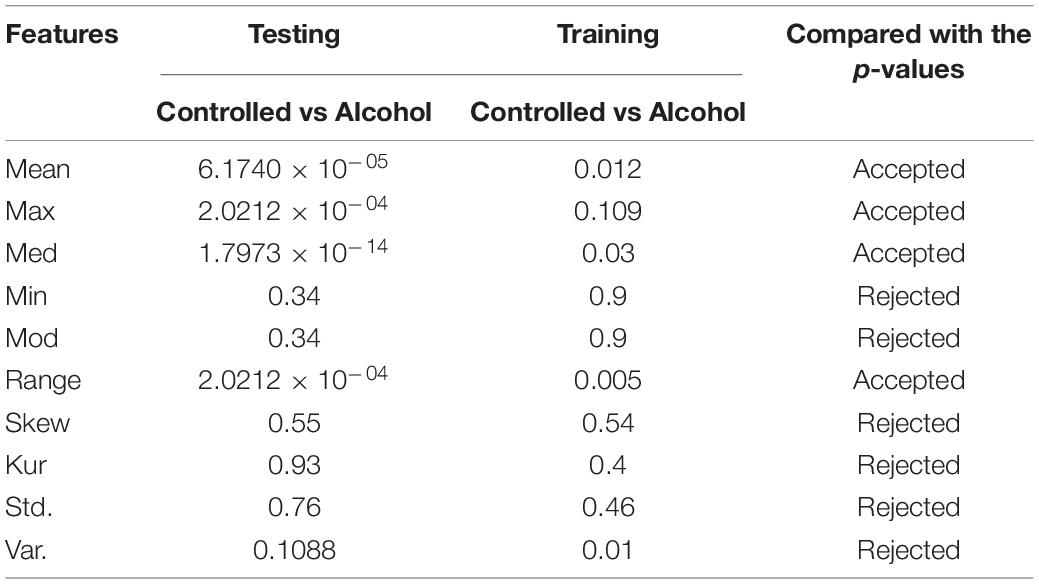
Table 5. Feature set outcome of Experiment No. 5.
In the sixth experiment, the results obtained from Experiment No. 6 indicate that the use of 61 channels was efficient in the analysis. They could, thus, be used to classify EEG signals. The 61 channels were as follows: FC4, FC3, C6, C5, F2, F1, TP8, TP7, AFZ, CP3, CP4, P5, P6, C1, C2, PO7, FP1, FP2, F7, F8, AF1, AF2, FZ, F4, F3, FC6, FC5, FC2, FC1, T8, T7, CZ, C3, C4, CP5, CP6, CP1, CP2, P3, P4, PZ, P8, P7, PO2, PO1, O2, O1, AF7, AF8, F5, F6, FT7, FT8, FPZ, PO8, FCZ, POZ, OZ, P2, P1, CPZ (Table 6).
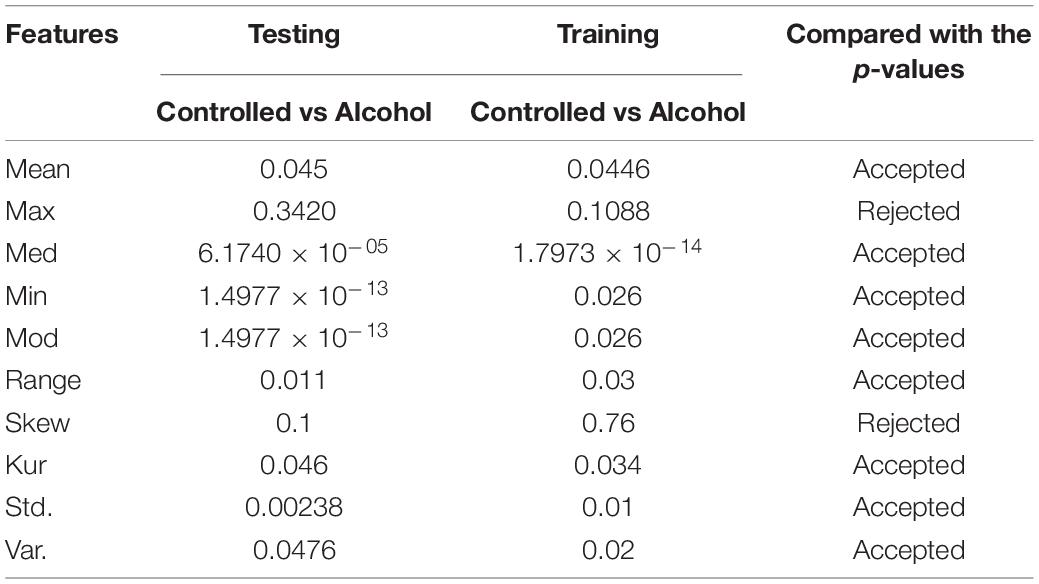
Table 6. Feature set outcome of Experiment No. 6.
As a result, with the highest acceptance rates, the second and sixth experiments performed the best. The last group of features utilized to identify each pair of EEG groups (Controlled vs. Alcoholic) were [Mean, Median, Minimum, Mode, Range, Kurtosis, SD, and Variance]. Therefore, by conducting a number of experiments, we were able to thoroughly investigate the feature selection in order to select the most effective feature set to recognize EEG groups.
To evaluate the performance of the FOA-F-SVM in alcoholic EEG signals, a comparison was made with SVM, PSO-SVM, GA-SVM, and F-SVM. Table 7 shows the average results of the comparison among the FOA-F-SVM, PSO-SVM, GA-SVM, F-SVM, and SVM. Based on the results, the performance of the FOA-F-SVM attains higher classification accuracy than other approaches. However, the PSO-SVM and GA-SVM scored the second highest results, and they outperformed the basic SVM. These research findings indicate that tuning parameters were important in improving classification accuracy of EEG signals. In addition, the classification accuracy obtained by the F-SVM is higher than the basic SVM.
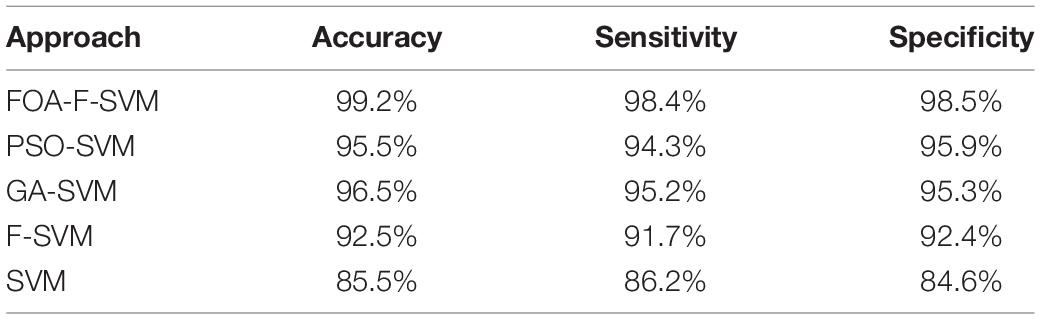
Table 7. Classification accuracy of the comparison among FOA-F-SV, PSO-SVM, GA-SVM, F-SVM, and SVM.
Figure 4 shows the detailed classification accuracy of 10 runs, as well the results of FOA-F-SVM, which are up to 98%, while the results of PSO-SVM and GA-SVM are distributed in the range from 90 to 94%. While the F-SVM and SVM gained a rate of accuracy from 86 to 93%. As a result, it can be observed that the FOA-F-SVM obtained the highest accuracy on each run and the best value is 100%. However, because of the robustness of the proposed method, the average result is the highest with 99.2%.
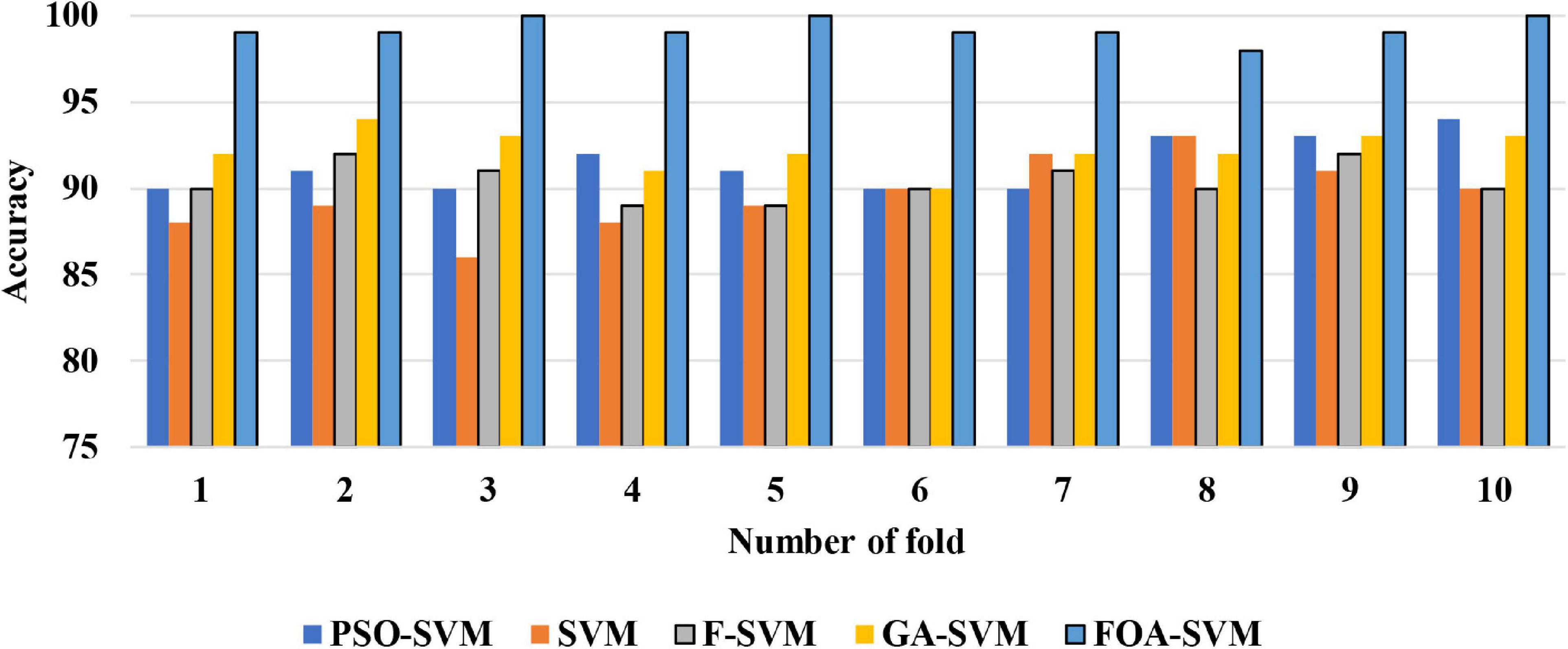
Figure 4. The detailed classification accuracy of 10 folds.
The accuracy of the proposed model based on 61-channel EEG signals is shown in Figure 5. In this experiment, the features were extracted from each channel and forwarded to the proposed model. The results show that not all channels yielded high classification accuracy. As a result, 13 optimal channels, including AF8, C1, C2, C3, C4, CP1, CP5, CP6, FC5, FT7, P8, PO8, PZ, were selected and used to classify EEG signals as shown in Figure 5.
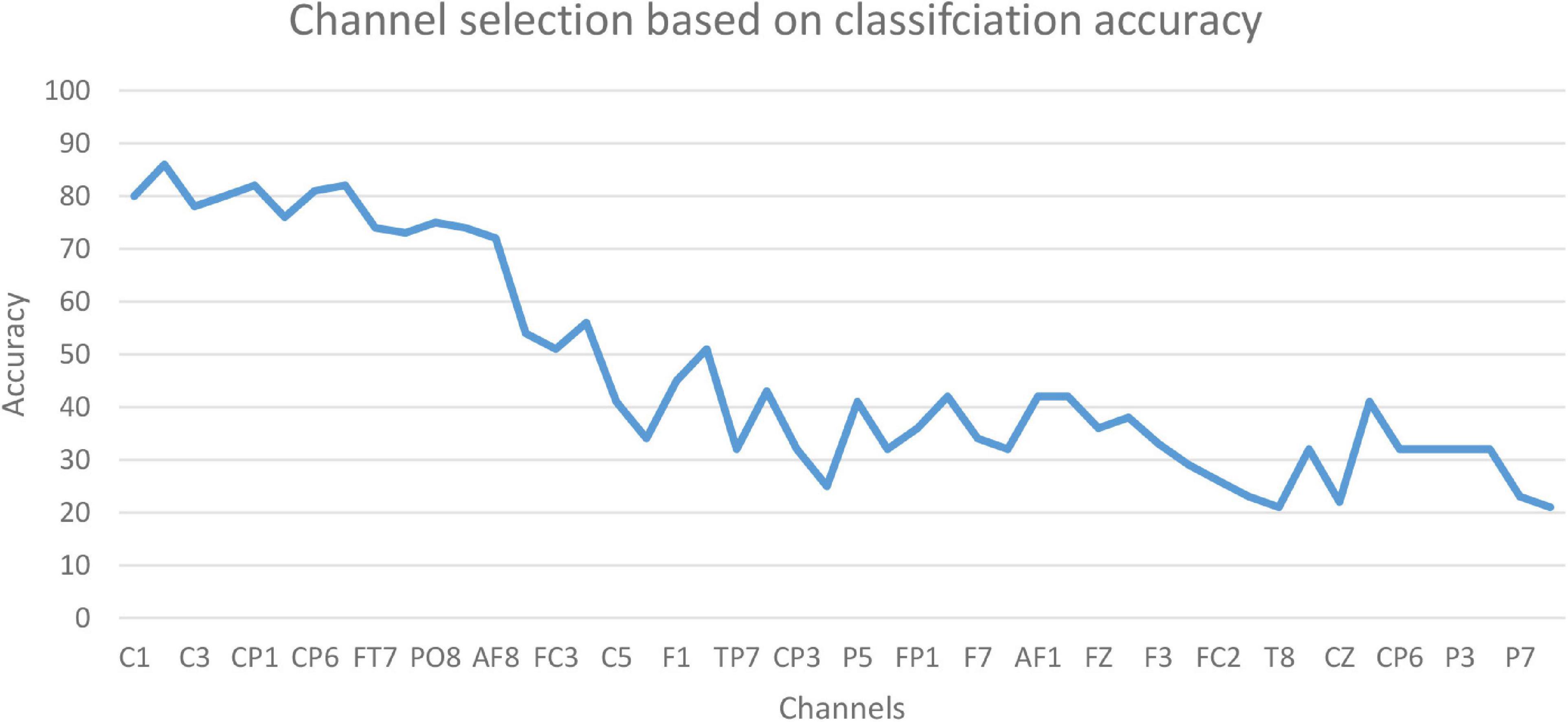
Figure 5. The accuracy based on EEG channels.
The results in Figure 5 are compatible with the results obtained by statistical metrics in the feature selection and enhanced the results (not all channels gave high classification accuracy). The present study thus demonstrates the ability of the proposed model to assess alcoholic EEG signals from multichannel EEG signals. The extracted features from electrodes C1, C3, and FC5 were found to be significantly effective in classifying EEG signals: an accuracy of 87.6 % was achieved. In addition, it was found that when the 13 channels were used to extract the features, the classification accuracy was close to the whole 61-channel performance. Table 8 presents the classification accuracy based on the number of channels.
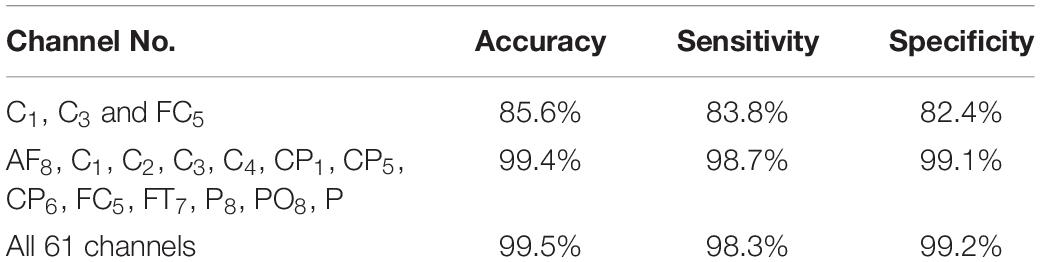
Table 8. Classification accuracy based on the number channels.
This study carried out an analysis of EEG signals to detect the prevalence and health effects of alcoholism from multichannel EEG signals. We integrated the CT with BS, CT-BS, to reduce the dimensionality of EEG signals. Then, the covariance matrix with its eigenvalues was applied to investigate the EEG signals, and to extract the important features. Arithmetic operators based on the KST technique were utilized to remove the noisy features from the obtained features set. The FOA-F-SVM was proposed to classify the EEG signals. The proposed FOA-F-SVM classification mode was compared with different methods such as SVM, PSO-SVM, GA-SVM, and F-SVM. In this section, we summarized the following main findings:
(1) The novelty of this article lies in the utilization of CT and BS (CT-BS) coupled with the covariance matrix for feature extraction. It has been shown that the low dimensionality of EEG signals achieved by CT-BS can efficiently improve the classification rate. In comparison to other dimension-reduction techniques such as linear discriminate analysis (LDA) and PCA, the experimental results indicate that CT-BS performs better than PCA and LDA, and the classification rate of the FOA-F-SVM was increased with CT-BS by more than 9%. Table 9 reports the classification rate based on dimension reduction techniques.
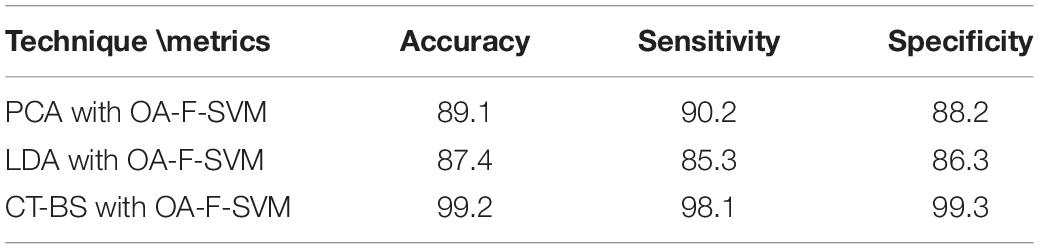
Table 9. Classification rate based on different features reduction algorithms.
(2) The proposed approach is a simple classification method for the identification of normal versus alcoholic EEG signals. The complexity of the proposed method was tested using a different number of samples. The results of the simulation showed that the proposed method achieved a better performance among traditional classification algorithms with acceptable time consumption. Therefore, this method could be a practical and feasible model for a real-time brain–computer interface (BCI) system. Figure 6 reports the run time of the proposed classification model compared with LS-SVM, k-nearest, f-SVM, and GA-SVM. It can be noticed that the proposed model is faster than LS-SVM, k-nearest, f-SVM, and GA-SVM.
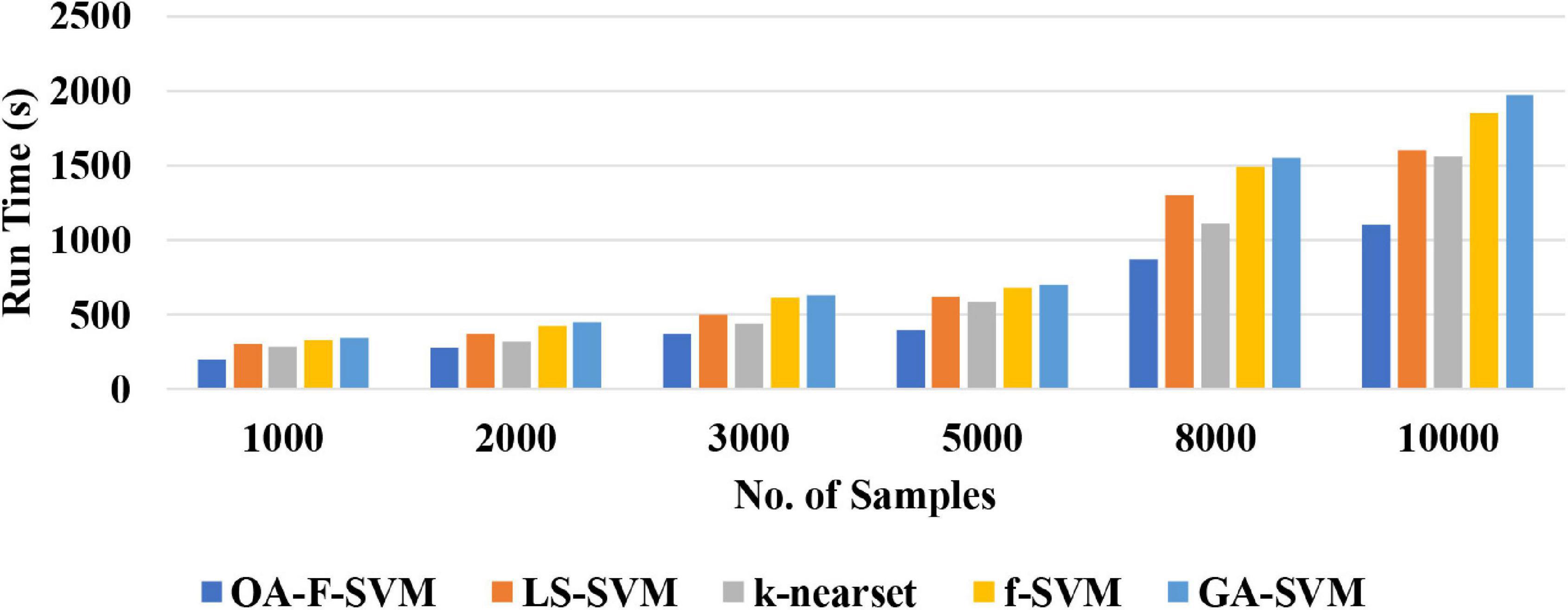
Figure 6. A Comparison of run time among the proposed model with other.
(3) The proposed model is still at the experimental stage. Larger datasets are required to make further validation of this model before it could be utilized as a tool in real-time applications.
(4) In this article, a small EEG dataset was used to evaluate the proposed model. The next work will focus on the use of a large EEG dataset such as EEG sleep stages, aesthetic EEG data, to analyze the performance of the proposed model under a huge dataset. This can guide us to improve the effectiveness of the proposed model.
(5) Although the CT-BS technique improved the performance of the classification model, it took more time than the PCA and LDA. In the future, we will work on how to reduce the complexity time of the CT-BS model.
(6) Comparison of classification accuracy of the proposed model FOA-F-SVM with KNN, k-means, and SVM: In this experiment, on the performance of the proposed model, FOA-F-SVM based on 13 EEG channels was reported. For further verification and to reach the highest level of reliability, the results were compared with KNN, k-means, and SVM. To the best of our knowledge after extensive research, this is the first time the FOA-F-SVM model has been proposed and applied to the analysis and detection of alcoholism EEG signals. The results showed that compared to other algorithms, the proposed model FOA-F-SVM has promising performance that can be adopted as a classification technique of alcoholism EEG signals. The database SMNI_CMI_TRAIN was used for the training, and the database SMNI_CMI_TEST was utilized for the testing set. To show clearly the classification results based on the 13 selected channels, Figure 7 depicts the accuracy of the proposed model FOA-F-SVM with KNN, k-means, and SVM. The proposed model outperformed KNN, k-means, and SVM over all the 13 channels. In addition, the proposed model achieves 99% when all channels are used for the classification of EEG signals.
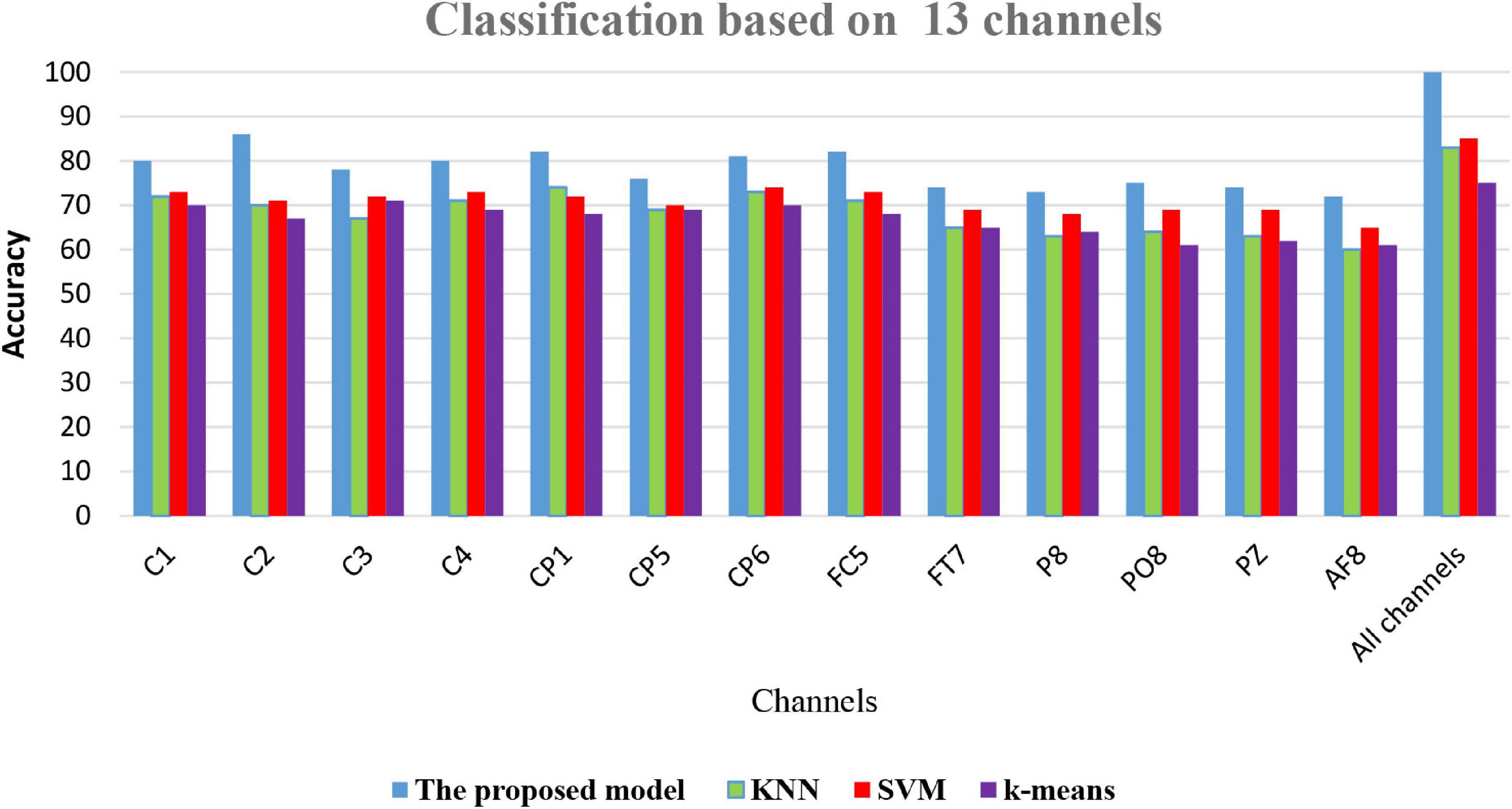
Figure 7. A Comparison among the proposed model with SVM, k-means, and KNN.
(7) Many studies were focused on finding a system that could be utilized for the automated detection of alcoholism EEG signals to estimate the effect of treatment and help significantly with clinical diagnosis. In this point, we shall review some of the previous studies that used the same data as this work did; for each, we shall provide a comparison of results. The identification of nonlinear features such as SAMENT, APPENT, largest Lyapunov exponent (LLE), and higher-order spectra (HOS) with LS-SVM classifier was used by Acharya et al. (2012), who obtained an average classification accuracy of 91.7%. However, the classification accuracy that is achieved by the proposed model is significantly higher than that of Acharya et al. (2012). Another group of researchers (Faust et al., 2013b) has improved an automated system utilizing wavelet packet-based energy measures with the KNN classifier; this method achieved a classification accuracy of 95.8%, which is less than the rate obtained by the proposed model.
A study by Patidar et al. (2017) suggested an automated system for the diagnosis of alcoholism. The study utilised TQWT to decompose EEG signals into various bands (SBS). Compared to the results obtained by the proposed method, the model of Patidar et al. (2017) obtained a classification accuracy of 97.02%, which is, again, less than our classification accuracy of 99%. For the detection of alcoholic-related changes in EEG signals, (Pan, 2012) have proposed the use of HOS cumulants-based features. Based on the fuzzy Sugeno classifier (FSC), the investigators achieved a classification accuracy of 92.4%, which is considerably less than the 99% obtained in the present work. Finally, the largest Lyapunov exponent (LLE), entropies, correlation dimension (CD), and Hurst exponent (H) were proposed by (Kannathal et al., 2005) to obtain the features for detecting alcoholism from EEG signals: the rate of accuracy was 90%, which is considerably less than the classification accuracy achieved by the model proposed in this study. Anuragi et al. (Anuragi and Sisodia, 2020) proposed an adaptive filtering model to extract time–frequency-domain characteristics from Hilbert–Huang transform. LS-SVM and KNN were used to classify the extracted features into alcoholic and normal signals. Bavkar et al., 2021) also applied empirical mode decomposition to classify alcoholic EEG signals. The extracted features using empirical mode decomposing were sent to the KNN classifier.
The results in Table 10 show that the method proposed was superior to other studies and obtained a higher level of accuracy. After conducting many experiments and various types of comparisons, it has become clear that the proposed CT-BS-OFA-F-SVM model has a promising future in analyzing and classifying EEG signals with a high rate of accuracy. It was also noted that most of the previous studies were working on developing one part of the analysis, whereas, in this study, the focus was on most of the analysis steps.

Table 10. Comparison with existing methods using the same database.
Accurate detection algorithms can be used effectively to help clinical research as a fast, reliable, and easy-to-use tool in the diagnosis and monitoring of neurological disorders and in alcoholism. We developed an effective method that was designed for sampling by integrating CT and BS (CT-BS) in one phase. To detect and analyze abnormalities in the EEG signal, the eigenvalues of the covariance matrix were investigated utilizing a statistical method that extracted ten statistical features from the eigenvalues of the covariance matrix. To classify EEG signals, the FOA-F-SVM was proposed to detect and analyze multichannel EEG signals. The proposed model was compared to previous studies, and the results showed that the proposed model was superior, with a high accuracy rate of 99%.
The acquired results clearly illustrate the superior performance of the proposed CT-BS model coupled with FOA-F-SVM to the existing state-of-the-art methods. The proposed model can be used to assist neurologists and other medical specialists in the precise diagnosis of alcoholism EEG signals. Future studies may investigate the improvement of the performance of the proposed model by decreasing the number of features used in this initial study. Also, because there is a great similarity between the results of feature selection and the results of channel selection, the possibility of proposing and implementing feature selection methods will be studied to find the optimal channels. Furthermore, with regard to the few numbers of studies focused on designing feature extraction as well as a detection model for the reliable diagnosis of alcoholism EEG signals, there is a need for further research in this area.
The original contributions presented in the study are publicly available. This data can be found here: https://kdd.ics.uci.edu/databases/eeg/eeg.html.
SA: conceptualization, methodology, software, validation, data curation, formal analysis, and writing – review and editing. MD: methodology, resources, software, and validation. RD: investigation, methodology, resources, software, validation, visualization, and writing - review and editing. JG: writing - review and editing and investigation. All authors contributed to the article and approved the submitted version.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The authors acknowledge the EEG data from the University of California, Department of Information and Computer Science. The authors also thank all reviewers and the journal Editor-in-Chief for considering this article and facilitating the review process.
Abdulla, S., Diykh, M., Laft, R. L., Saleh, K., and Deo, R. C. (2019). Sleep EEG signal analysis based on correlation graph similarity coupled with an ensemble extreme machine learning algorithm. Expert Syst. Appl. 138:112790. doi: 10.1016/j.eswa.2019.07.007
Acharya, U. R., Bhat, S., Adeli, H., and Adeli, A. (2014). Computer-aided diagnosis of alcoholism-related EEG signals. Epilepsy Behav. 41, 257–263. doi: 10.1016/j.yebeh.2014.10.001
Acharya, U. R., Sree, S. V., Chattopadhyay, S., and Suri, J. S. (2012). Automated diagnosis of normal and alcoholic EEG signals. Int. J. Neural Syst. 22:1250011. doi: 10.1142/S0129065712500116
Al-Hadeethi, H., Abdulla, S., Diykh, M., Deo, R. C., and Green, J. H. (2020). Adaptive boost LS-SVM classification approach for time-series signal classification in epileptic seizure diagnosis applications. Expert Syst. Appl. 161:113676. doi: 10.1016/j.eswa.2020.113676
Alonso, I. P., Llorca, D. F., Sotelo, M. Á., Bergasa, L. M., de Toro, P. R., Nuevo, J., et al. (2007). Combination of feature extraction methods for SVM pedestrian detection. IEEE Trans. Intell. Transp. Syst. 8, 292–307. doi: 10.1109/TITS.2007.894194
Anuragi, A., and Sisodia, D. S. (2020). Empirical wavelet transform based automated alcoholism detecting using EEG signal features. Biomed. Signal Process. Control 57:101777. doi: 10.1016/j.bspc.2019.101777
Bajaj, V., Guo, Y., Sengur, A., Siuly, S., and Alcin, O. F. (2017). A hybrid method based on time–frequency images for classification of alcohol and control EEG signals. Neural Comput. Appl. 28, 3717–3723. doi: 10.1007/s00521-016-2276-x
Bavkar, S., Iyer, B., and Deosarkar, S. (2021). Optimal EEG channels selection for alcoholism screening using EMD domain statistical features and harmony search algorithm. Biocybernetics 41, 83–96. doi: 10.1016/j.bbe.2020.11.001
Buriro, A. B., Ahmed, B., Baloch, G., Ahmed, J., Shoorangiz, R., Weddell, S. J., et al. (2021). Classification of alcoholic EEG signals using wavelet scattering transform-based features. Comput. Biol. Med. 139:104969. doi: 10.1016/j.compbiomed.2021.104969
Cameron, A. C., Gelbach, J. B., and Miller, D. L. (2008). Bootstrap-based improvements for inference with clustered errors. Rev. Econ. Stat. 90, 414–427. doi: 10.1162/rest.90.3.414
Cao, R., Deng, H., Wu, Z., Liu, G., Guo, H., and Xiang, J. (2017). Decreased synchronization in alcoholics using EEG. IRBM 38, 63–70. doi: 10.1016/j.irbm.2017.02.002
Chen, H. L., Yang, B., Wang, S. J., Wang, G., Liu, D. Y., Li, H. Z., et al. (2014). Towards an optimal support vector machine classifier using a parallel particle swarm optimization strategy. Appl. Mathemat. Comput. 239, 180–197. doi: 10.1016/j.amc.2014.04.039
Deiner, S., and Silverstein, J. (2009). Postoperative delirium and cognitive dysfunction. Br. J. Anaesth. 103(Suppl._1), i41–i46. doi: 10.1093/bja/aep291
Diykh, M., Abdulla, S., Saleh, K., and Deo, R. C. (2019a). Fractal dimension undirected correlation graph-based support vector machine model for identification of focal and non-focal electroencephalography signals. Biomed. Signal Process. Control 54:101611. doi: 10.1016/j.bspc.2019.101611
Diykh, M., Abdulla, S., Siuly, S., Green, J. H., and Deo, R. C. (2021). A new framework for classification of multi-category hand grasps using EMG signals. Artif. Intell. Med. 112:102005. doi: 10.1016/j.artmed.2020.102005
Diykh, M., Li, Y., and Abdulla, S. (2020). EEG sleep stages identification based on weighted undirected complex networks. Comput. Methods Programs Biomed. 184:105116. doi: 10.1016/j.cmpb.2019.105116
Diykh, M., Li, Y., Wen, P., and Li, T. (2018). Complex networks approach for depth of anesthesia assessment. Measurement 119, 178–189. doi: 10.1016/j.measurement.2018.01.024
Diykh, M., Miften, F. S., Abdulla, S., Saleh, K., and Green, J. H. (2019b). Robust approach to depth of anaesthesia assessment based on hybrid transform and statistical features. IET Sci. Meas. Technol. 14, 128–136. doi: 10.1049/iet-smt.2018.5393
Ergezer, H., and Leblebicioǧlu, K. (2016). Anomaly detection and activity perception using covariance descriptor for trajectories. Paper Presented at the European Conference on Computer Vision, Amsterdam. doi: 10.1007/978-3-319-48881-3_51
Ergezer, H., and Leblebicioǧlu, K. (2018). Time series classification with feature covariance matrices. Knowl. Inf. Syst. 55, 695–718. doi: 10.1007/s10115-017-1098-1
Fattah, S., Fatima, K., and Shahnaz, C. (2015). An approach for classifying alcoholic and non-alcoholic persons based on time domain features extracted from EEG signals. Paper Presented at the 2015 IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE), Dhaka. doi: 10.1109/WIECON-ECE.2015.7443972
Faust, O., Acharya, R., Allen, A. R., and Lin, C. (2008). Analysis of EEG signals during epileptic and alcoholic states using AR modeling techniques. IRBM 29, 44–52. doi: 10.1016/j.rbmret.2007.11.003
Faust, O., Yanti, R., and Yu, W. (2013a). Automated detection of alcohol related changes in electroencephalograph signals. J. Med. Imaging Health Inform. 3, 333–339. doi: 10.1166/jmihi.2013.1170
Faust, O., Yu, W., and Kadri, N. A. (2013b). Computer-based identification of normal and alcoholic EEG signals using wavelet packets and energy measures. J. Mech. Med. Biol. 13:1350033. doi: 10.1142/S0219519413500334
Gao, Z., Dang, W., Wang, X., Hong, X., Hou, L., Ma, K., et al. (2021). Complex networks and deep learning for EEG signal analysis. Cogn. Neurodyn. 15, 369–388. doi: 10.1007/s11571-020-09626-1
Hedges, L. V., Gurevitch, J., and Curtis, P. S. (1999). The meta-analysis of response ratios in experimental ecology. Ecology 80, 1150–1156. doi: 10.1890/0012-9658(1999)080[1150:TMAORR]2.0.CO;2
Hennig, C. (2007). Cluster-wise assessment of cluster stability. Comput. Stat. Data Anal. 52, 258–271. doi: 10.1016/j.csda.2006.11.025
Hira, Z. M., and Gillies, D. F. (2015). A review of feature selection and feature extraction methods applied on microarray data. Adv. Bioinformatics 2015:198363. doi: 10.1155/2015/198363
Isaksson, A., Wennberg, A., and Zetterberg, L. H. (1981). Computer analysis of EEG signals with parametric models. Proc. IEEE 69, 451–461. doi: 10.1109/PROC.1981.11988
Jaccard, P. (1901). Étude Comparative de la distribuition florale dans une portion des Alpes et des Jura. Bull. Soc. Vaudoise Sci. Nat. 7, 547–579.
Kannathal, N., Acharya, U. R., Lim, C. M., and Sadasivan, P. (2005). Characterization of EEG—a comparative study. Comput. Methods Programs Biomed. 80, 17–23. doi: 10.1016/j.cmpb.2005.06.005
Knight, R. G., and Longmore, B. E. (1994). Clinical Neuropsychology of Alcoholism. Mahwah, NJ: Lawrence Erlbaum Associates.
Kousarrizi, M. R. N., Ghanbari, A. A., Gharaviri, A., Teshnehlab, M., and Aliyari, M. (2009). “Classification of alcoholics and non-alcoholics via EEG using SVM and neural networks,” in Proceedings of the 2009 3rd International Conference on Bioinformatics and Biomedical Engineering, Beijing.
Kumar, Y., Dewal, M., and Anand, R. (2012). “Features extraction of EEG signals using approximate and sample entropy,” in Proceedings of the 2012 IEEE Students’ Conference on Electrical, Electronics and Computer Science, Bhopal. doi: 10.1109/SCEECS.2012.6184830
Lieber, C. S. (1995). Medical disorders of alcoholism. N. Engl. J. Med. 333, 1058–1065. doi: 10.1056/NEJM199510193331607
Lin, C.-F., Yeh, S.-W., Chien, Y.-Y., Peng, T.-I., Wang, J.-H., and Chang, S.-H. (2009). A HHT-based time frequency analysis scheme for clinical alcoholic EEG signals. WSEAS Trans. Biol. Biomed. 5, 249–260.
Oscar-Berman, M., Shagrin, B., Evert, D. L., and Epstein, C. (1997). Impairments of brain and behavior: the neurological effects of alcohol. Alcohol Health Res. World 21, 65–75.
Pan, W.-T. (2012). A new fruit fly optimization algorithm: taking the financial distress model as an example. Knowl. Based Syst. 26, 69–74. doi: 10.1016/j.knosys.2011.07.001
Patidar, S., Pachori, R. B., Upadhyay, A., and Acharya, U. R. (2017). An integrated alcoholic index using tunable-Q wavelet transform based features extracted from EEG signals for diagnosis of alcoholism. Appl. Soft Comput. 50, 71–78. doi: 10.1016/j.asoc.2016.11.002
Pelvig, D. P., Pakkenberg, H., Stark, A. K., and Pakkenberg, B. (2008). Neocortical glial cell numbers in human brains. Neurobiol. Aging 29, 1754–1762. doi: 10.1016/j.neurobiolaging.2007.04.013
Priya, A., Yadav, P., Jain, S., and Bajaj, V. (2018). Efficient method for classification of alcoholic and normal EEG signals using EMD. J. Eng. 2018, 166–172. doi: 10.1049/joe.2017.0878
Shooshtari, M. A., and Setarehdan, S. K. (2010). “Selection of optimal EEG channels for classification of signals correlated with alcohol abusers,” in Proceedings of the 2010 IEEE 10th International Conference on Signal, Beijing. doi: 10.1109/ICOSP.2010.5656482
Shri, T. P., and Sriraam, N. (2016). Spectral entropy feature subset selection using SEPCOR to detect alcoholic impact on gamma sub band visual event related potentials of multichannel electroencephalograms (EEG). Appl. Soft Comput. 46, 441–451. doi: 10.1016/j.asoc.2016.04.041
Singhal, V., Mathew, J., and Behera, R. K. (2021). Detection of alcoholism using EEG signals and a CNN-LSTM-ATTN network. Comput. Biol. Med. 138:104940. doi: 10.1016/j.compbiomed.2021.104940
Sun, Y., Ye, N., and Xu, X. (2006). “EEG analysis of alcoholics and controls based on feature extraction,” in Proceedings of the 2006 8th International Conference on Signal Processing, Guilin. doi: 10.1109/ICOSP.2006.344501
Tao, W., Li, C., Song, R., Cheng, J., Liu, Y., Wan, F., et al. (2020). “EEG-based emotion recognition via channel-wise attention and self attention,” in Proceedings of the 2020 IEEE Transactions on Affective Computing, Beijing. doi: 10.1109/TAFFC.2020.3025777
Taran, S., and Bajaj, V. (2017). Rhythm-based identification of alcohol EEG signals. IET Sci. Meas. Technol. 12, 343–349. doi: 10.1049/iet-smt.2017.0232
Tharwat, A., and Hassanien, A. E. (2018). Chaotic antlion algorithm for parameter optimization of support vector machine. Appl. Intell. 48, 670–686. doi: 10.1007/s10489-017-0994-0
Volkow, N. D., Wiers, C. E., Shokri-Kojori, E., Tomasi, D., Wang, G.-J., and Baler, R. (2017). Neurochemical and metabolic effects of acute and chronic alcohol in the human brain: studies with positron emission tomography. Neuropharmacology 122, 175–188. doi: 10.1016/j.neuropharm.2017.01.012
Wu, X., Zuo, W., Lin, L., Jia, W., and Zhang, D. (2018). F-SVM: combination of feature transformation and SVM learning via convex relaxation. IEEE Trans. Neural Netw. Learn. Syst. 29, 5185–5199. doi: 10.1109/TNNLS.2018.2791507
Zhang, X. L., Begleiter, H., Porjesz, B., and Litke, A. (1997). Electrophysiological evidence of memory impairment in alcoholic patients. Biol. Psychiatry 42, 1157–1171. doi: 10.1016/S0006-3223(96)00552-5
Keywords: alcoholism, electroencephalogram, covariance matrix, support vector machine (SVM), eigenvalues and fruit fly optimization
Citation: Al-Hadeethi H, Abdulla S, Diykh M, Deo RC and Green JH (2022) An Eigenvalues-Based Covariance Matrix Bootstrap Model Integrated With Support Vector Machines for Multichannel EEG Signals Analysis. Front. Neuroinform. 15:808339. doi: 10.3389/fninf.2021.808339
Received: 03 November 2021; Accepted: 20 December 2021;
Published: 03 February 2022.
Edited by:
Rajesh Kumar Tripathy, Birla Institute of Technology and Science, IndiaReviewed by:
Ram Bilas Pachori, Indian Institute of Technology Indore, IndiaCopyright © 2022 Al-Hadeethi, Abdulla, Diykh, Deo and Green. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mohammed Diykh, bW9oYW1tZWQuZGl5a2hAdXNxLmVkdS5hdQ==; bW9oYW1tZWQuZGl5a2hAdXRxLmVkdS5hdQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.