 Taban Eslami
Taban Eslami Vahid Mirjalili
Vahid Mirjalili Alvis Fong
Alvis Fong Angela R. Laird
Angela R. Laird Fahad Saeed
Fahad Saeed
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neuroinform., 27 November 2019
Volume 13 - 2019 | https://doi.org/10.3389/fninf.2019.00070
This article is part of the Research TopicFrontiers in Neuroinformatics Editor’s Pick 2021View all 23 articles
Heterogeneous mental disorders such as Autism Spectrum Disorder (ASD) are notoriously difficult to diagnose, especially in children. The current psychiatric diagnostic process is based purely on the behavioral observation of symptomology (DSM-5/ICD-10) and may be prone to misdiagnosis. In order to move the field toward more quantitative diagnosis, we need advanced and scalable machine learning infrastructure that will allow us to identify reliable biomarkers of mental health disorders. In this paper, we propose a framework called ASD-DiagNet for classifying subjects with ASD from healthy subjects by using only fMRI data. We designed and implemented a joint learning procedure using an autoencoder and a single layer perceptron (SLP) which results in improved quality of extracted features and optimized parameters for the model. Further, we designed and implemented a data augmentation strategy, based on linear interpolation on available feature vectors, that allows us to produce synthetic datasets needed for training of machine learning models. The proposed approach is evaluated on a public dataset provided by Autism Brain Imaging Data Exchange including 1, 035 subjects coming from 17 different brain imaging centers. Our machine learning model outperforms other state of the art methods from 10 imaging centers with increase in classification accuracy up to 28% with maximum accuracy of 82%. The machine learning technique presented in this paper, in addition to yielding better quality, gives enormous advantages in terms of execution time (40 min vs. 7 h on other methods). The implemented code is available as GPL license on GitHub portal of our lab (https://github.com/pcdslab/ASD-DiagNet).
Mental disorders such as Autism Spectrum Disorder (ASD) are heterogeneous disorders that are notoriously difficult to diagnose, especially in children. The current psychiatric diagnostic process is based purely on behavioral observation of symptomology (DSM-5/ICD-10) and may be prone to misdiagnosis (Nickel and Huang-Storms, 2017). There is no quantitative test that can be prescribed to patients that may lead to definite diagnosis of a person. Such quantitative and definitive tests are a regular practice for other diseases such as diabetes, HIV, and hepatitis-C. It is widely known that defining and diagnosing mental health disorders is a difficult process due to overlapping nature of symptoms, and lack of a biological test that can serve as a definite and quantified gold standard (National Collaborating Centre for Mental Health (UK), 2018). ASD is a lifelong neuro-developmental brain disorder which causes social impairments like repetitive behavior and communication problems in children. More than 1% of children suffer from this disorder and detecting it at early ages can be beneficial. Studies show that some demographic attributes like gender and race vary among ASD and healthy individuals such that males are four times more prone to ASD than females (Baio et al., 2018). Diagnosing ASD has been explored from different aspects, like monitoring behavior, extracting discriminatory patterns from the demographic information and analyzing the brain data. Behavioral data such as eye movement and facial expression are studied in Liu et al. (2016), Jaiswal et al. (2017), Zunino et al. (2018). For instance, Zunino et al. classified ASD from healthy subjects by applying recurrent neural network to the video clips recorded from them (Zunino et al., 2018).
Quantitative analysis of brain imaging data can provide valuable biomarkers that result in more accurate diagnosis of brain diseases. Machine learning techniques using brain imaging data [e.g., Magnetic Resonance Imaging (MRI) and functional Magnetic Resonance Imaging (fMRI)] have been extensively used by researchers for diagnosing brain disorders like Alzheimer's, ADHD, MCI, and Autism (Colby et al., 2012; Peng et al., 2013; Yang et al., 2014; Deshpande et al., 2015; Hosseini-Asl et al., 2016; Khazaee et al., 2017; Eslami and Saeed, 2018b, 2019).
In this paper, we focus on classifying subjects suffering from ASD from healthy control subjects using fMRI data. We propose a method called ASD-DiagNet which consists of an autoencoder and a SLP. These networks are used for extracting lower dimensional features in a hybrid manner and the trained perceptron is used for the final round of classification. In order to enlarge the size of the training set, we designed a data augmentation technique which generates new data in feature space by using available data in the training set.
Detecting ASD using fMRI data has recently gained a lot of attention, thanks to Autism Brain Imaging Data Exchange (ABIDE) initiative for providing functional and structural brain imaging datasets collected from several brain imaging centers around the world (Craddock et al., 2013). Many studies and methods have been developed based on ABIDE data (Iidaka, 2015; Chen et al., 2016; Abraham et al., 2017; Heinsfeld et al., 2018; Itani and Thanou, 2019). Some studies included a subset of this dataset based on specific demographic information to analyze their proposed method. For example, Iidaka (2015) used probabilistic neural network for classifying resting state fMRI (rs-fMRI) data of subjects under 20 years old. In another work, Plitt et al. (2015) used two sets of rs-fMRI data, one containing 118 male individuals (59 ASD; 59 TD) and the other containing 178 age and IQ matched individuals (89 ASD; 89 TD) from ABIDE dataset and achieved 76.67% accuracy. Besides using fMRI data, some studies also included structural and demographic information of subjects for diagnosing ASD. For example, Parisot et al. (2018) proposed a framework based on Graph Convolutional Networks that achieved 70.4% accuracy. In their work, they represented the population as a graph in which nodes are defined based on imaging features and phenotypic information describe the edge weights. In another study, Sen et al. (2018) proposed a new algorithm which combines structural and functional features from MRI and fMRI data and got 64.3% accuracy by using 1111 total healthy and ASD subjects. Nielsen et al. (2013) obtained 60% accuracy on a group of 964 healthy and ASD subjects using the functional connectivity between 7266 regions and demographic information like age, gender, and handedness attributes. In another study, Parikh et al. (2019) tested the performance of different machine learning methods on demographic information provided by ABIDE dataset including age, gender, handedness, and three individual measures of IQ.
Machine learning techniques such as Support Vector Machines (SVM) and random forests are explored in multiple studies (Abraham et al., 2017; Subbaraju et al., 2017; Bi et al., 2018b; Fredo et al., 2018). For instance, Chen et al. (2016) investigated the effect of different frequency bands for constructing brain functional network, and obtained 79.17% accuracy using SVM technique applied to 112 ASD and 128 healthy control subjects.
Recently, using neural networks and deep learning methods such as autoencoders, Deep Neural Network (DNN), Long Short Term Memory (LSTM), and Convolutional Neural Network (CNN) have also become very popular for diagnosing ASD (Dvornek et al., 2017; Guo et al., 2017; Bi et al., 2018a; Brown et al., 2018; Khosla et al., 2018; Li et al., 2018). Brown et al. (2018) obtained 68.7% classification accuracy on 1, 013 subjects composed of 539 healthy control and 474 with ASD, by proposing an element-wise layer for DNNs which incorporated the data-driven structural priors.
Most recently, Heinsfeld et al. (2018) used a deep learning based approach and achieved 70% accuracy for classifying 1, 035 subjects (505 ASD and 530 controls). They claimed this approach improved the state of the art technique. In their technique, distinct pairwise Pearson's correlation coefficients were considered as features. Two stacked denoising autoencoders were first pre-trained in order to extract lower dimensional data. After training autoencoders, their weights were applied to a multi-layer perceptron classifier (fine-tuning process) which was used for the final classification. However, they also performed classification for each of the 17 sites included in ABIDE dataset separately, and the average accuracy is reported as 52%. The low performance on individual sites was justified to be due to the lack of enough training samples for intra-site training.
Generally, most related studies for ASD diagnosis using machine learning techniques have only considered a subset of ABIDE dataset, or they have incorporated other information besides fMRI data in their model. There are few studies such as Heinsfeld et al. (2018), which only used fMRI data without any assumption on demographic information and analyzed all the 1, 035 subjects in ABIDE dataset. To the best of our knowledge (Heinsfeld et al., 2018) is currently state of the art technique for ASD diagnosis on whole ABIDE dataset, which we use as the baseline for evaluating our proposed method.
Although employing other types of information like anatomical features and demographic attributes of subjects could provide more knowledge to the model and may increase its accuracy, the goal of our study is to merely design a quantitative model for ASD diagnosis based on the functional data of the brain. This model can be used in conjunction with other tools assisting clinicians to diagnose ASD with more precision. Another aspect that we targeted in this study is the running time of the model. Unfortunately, the running time required for training the model or analyzing the data is not discussed in most of research papers mentioned above. Achieving high diagnosis accuracy in a shorter amount of time would be more desirable in clinical studies. Deep learning models are time consuming techniques due to the huge number of parameters that should be optimized. Although utilizing GPUs has reduced the running time needed for training the models tremendously, it still depends on the architecture of the model and size of the data. We considered the running time of the model as a factor while designing the architecture of our model. Using our hybrid learning strategy the model needs fewer number of iterations for training, which reduces the running time of the model. We also decreased the number of features by keeping anti-correlated and highly correlated functional connections and removing the rest, which reduces the size of the network significantly.
The structure of this paper is as follows: First, in section 2 we provide a brief introduction to fMRI data, the dataset we used in this study and explain ASD-DiagNet method in detail. In section 3, we describe the experiment setting and discuss the results of ASD-DiagNet. Finally, in section 4, we conclude the paper and discuss the future direction.
Functional Magnetic Resonance Imaging (fMRI) is a brain imaging technique that is used for studying brain activities (Lindquist et al., 2008; Eslami and Saeed, 2018a). In fMRI data, the brain volume is represented by a group of small cubic elements called voxels. A time series is extracted from each voxel by keeping track of its activity over time. Scanning the brain using fMRI technology while the subject is resting is called resting state fMRI (rs-fMRI), which is widely used for analyzing brain disorders. In this study, we used preprocessed ABIDE-I dataset that is provided by the ABIDE initiative. This dataset consists of 1112 rs-fMRI data including ASD and healthy subjects collected from 17 different sites. We used fMRI data of the same group of subjects which was used in Heinsfeld et al. (2018). This set consists of 505 subjects with ASD and 530 healthy control from all the 17 sites. Table 1 shows the class membership information for each site. ABIDE-I provided the average time series extracted from seven sets of regions of interest (ROIs) based on seven different atlases which are preprocessed using four different pipelines. The data used in our experiments is preprocessed using C-PAC pipeline (Craddock et al., 2013) and is parcellated into 200 functionally homogeneous regions generated using spatially constrained spectral clustering algorithm (Craddock et al., 2012) (CC-200). The preprocessing steps include slice time correction, motion correction, nuisance signal removal, low frequency drifts, and voxel intensity normalization. It is worth mentioning that each site used different parameters and protocols for scanning the data. Parameters like repetition time (TR), echo time (TE), number of voxels, number of volumes, openness or closeness of the eyes while scanning are different among sites.

Table 1. Class membership information of ABIDE-I dataset for each individual site.
Functional connectivity between brain regions is an important concept in fMRI analysis and is shown to contain discriminatory patterns for fMRI classification. Among correlation measures, Pearson's correlation is mostly used for approximating the functional connectivity in fMRI data (Liang et al., 2012; Baggio et al., 2014; Zhang et al., 2017). It shows the linear relationship between the time series of two different regions. Given two times series, u and v, each of length T, the Pearson's correlation can be computed using the following equation:
where ū and are the mean of times series u and v, respectively. Computing all pairwise correlations results in a correlation matrix where m is the number of time series (or regions). Due to the symmetric property of Pearson's correlation, we only considered the strictly upper triangle part of the correlation matrix. Since we used CC-200 atlas in which the brain is parcellated into m = 200 regions, there are m × (m − 1)/2 = 19, 900 distinct pairwise Pearson's correlations. In this regard, we selected half of the correlations comprising 1/4 largest and 1/4 smallest values and eliminated the rest. To do so, we first compute the average of correlations among all subjects in training set and then pick the indices of the largest positive and negative values from averaged correlation array. We then pick the correlations at those indices from each sample as our feature vector. Keeping half of the correlations and eliminating the rest reduces the size of input features by a factor of 2. There is no limitation of the number of high- and anti-correlations that should be kept. Removing more features results in higher computational efficiency as well as reducing the chance of overfitting, however removing too many features can also cause losing important patterns.
In order to further reduce the size of features, we used an autoencoder to extract a lower dimensional feature representation. An autoencoder is a type of feed-forward neural network model, which first encodes its input x to a lower dimensional representation,
where τ is the hyperbolic tangent activation function (Tanh), and Wenc and benc represent the weight matrix and the bias for the encoder. Then, the decoder reconstructs the original input data
where Wdec and bdec are the weight matrix and bias for the decoder. In this work, we have designed an autoencoder with tied weights, which means . An autoencoder can be trained to minimize its reconstruction error, computed as the Mean Squared Error (MSE) between x and its reconstruction, x′. The choice of using autoencoder instead of other feature extraction techniques like PCA is its ability to reduce the dimensionality of features in a non-linear way. The structure of an autoencoder is shown in Figure 1.
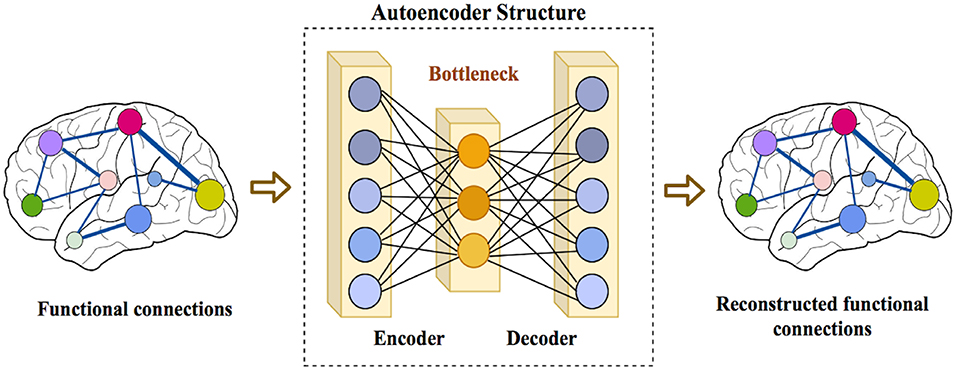
Figure 1. Structure of an autoencoder consisting of an encoder that receives the input data and encodes it into a lower dimensional representation at the bottleneck layer, and a decoder that reconstructs the original input from the bottleneck layer.
The lower dimensional data generated during the encoding process contains useful patterns from the original input data with smaller size, and can be used as new features for classification. For the classification task, we used a single layer perceptron (SLP) which uses the bottleneck layer of the autoencoder, henc, as input, and computes the probability of a sample belonging to the ASD patient class using a sigmoid activation function, σ,
where Wslp and bslp are the weight matrix and the bias for the SLP network. The SLP network can be trained by minimizing the Binary Cross Entropy loss, , using the ground-truth class label, y, and the estimated ASD probability for each sample, f(x):
Finally, the predicted class label is determined by thresholding the estimated probability
Typically, an autoencoder is fully trained such that its reconstruction error is minimized, then, the features from bottleneck layer, henc, are used as input for training the SLP classifier, separately. In contrast, here, we train the autoencoder and the SLP classifier simultaneously. This can potentially result in obtaining low dimensional features that have two properties
1. Useful for reconstructing the original data,
2. Contain discriminatory information for the classification task.
This is accomplished by adding the two loss functions, i.e., MSE loss for reconstruction, and Binary Cross Entropy for the classification task, and training both networks jointly. After the joint training process is completed, we further fine-tune the SLP network for a few additional epochs.
Machine learning and especially deep learning techniques can be advantageous if they are provided with enough training data. Insufficient data causes overfitting and non-generalizability of the model (Raschka and Mirjalili, 2017). Large training sets are not always available and collecting new data might be costly like in medical imaging field. In these situations, data augmentation techniques can be used for generating synthetic data using the available training set (Karpathy et al., 2014; Eitel et al., 2015; Wong et al., 2016; Xu et al., 2016; Perez and Wang, 2017). There are a few data augmentation methods proposed for different applications, such as random translation/rotation/cropping (for image data), adding random noise to the features (for general type of data), extracting overlapping windows from the original time series (for time series data), as well as more sophisticated methods such as Generative Adversarial Networks. However, these methods are not either applicable to our data due to the structure of our features, not interpretable, or they may be computationally more intensive than our proposed method.
The data augmentation technique that we propose in this study is inspired by Synthetic Minority Over-sampling Technique (SMOTE) (Chawla et al., 2002). SMOTE is an effective model which is used for oversampling the data in minority class of imbalanced datasets. SMOTE generates synthetic data in feature space by using the nearest neighbors of a sample. After k-nearest neighbors of sample p are found ({q1, q2, ..., qk}), a random neighbor is selected (qr) and the synthetic feature vector is computed using the following equation:
In this equation, α is a random number selected uniformly in the range [0, 1]. Finding the nearest neighbors of a sample is based on a distance or similarity metric. In our work, the samples have feature vectors of size 9, 950 (half of the correlations). One idea for computing nearest neighbors is to use Euclidean distance, however, computing the pairwise Euclidean distances with 9, 950 features is not efficient. In order to compute the similarity between samples and finding the nearest neighbors, we used a measure called Extended Frobenius Norm (EROS). This measure computes the similarity between two multivariate time series (MTS) (Yang and Shahabi, 2004). fMRI data consists of several regions each having a time series so we can consider it as a multivariate time series. Our previous study on ADHD disorder has shown that EROS is an effective similarity measure for fMRI data and using it along with k-Nearest-Neighbor achieves high classification accuracy (Eslami and Saeed, 2018b). This motivated us to utilize it as part of the data augmentation process. EROS computes the similarity between two MTS items A and B based on eigenvalues and eigenvectors of their covariance matrices using the following equation:
where, θi is the cosine of the angle between ith corresponding eigenvectors of covariance matrices of multivariate time series A and B. Furthermore, w is the weight vector which is computed based on eigenvalues of all MTS items using Algorithm 1. This algorithm computes the weight vector w by normalizing eigenvalues of each MTS item followed by applying an aggregate function f (here, we used mean) to all eigenvalues over the entire training dataset and finally normalizing them so that .
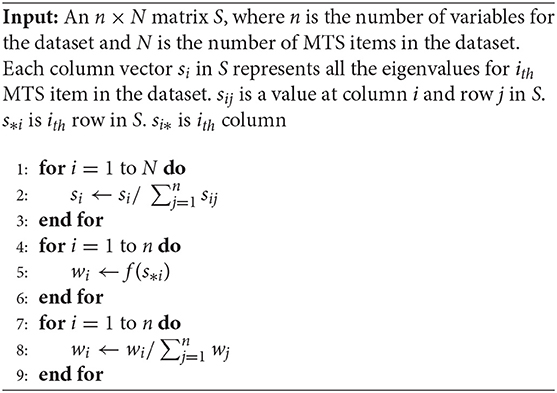
Algorithm 1: Computing weight vector for EROS (Yang and Shahabi, 2004)

Algorithm 2: Data augmentation using EROS similarity measure
The dimension of each sample's covariance matrix is m × m, where m is the number of brain regions. The covariance matrix of each subject is pre-computed in the beginning and is re-used when the sample is selected as a candidate. In order to further reduce the time needed for computing the pairwise similarities, we considered using the first two eigenvectors of each sample. Our experiments showed that this simplification does not affect the results while reducing the running time significantly compared to using all eigenvectors and eigenvalues.
Now, using EROS as the similarity measure, our data augmentation process is shown in Algorithm 2. After finding k = 5 nearest neighbors of each sample i in the training set, one of them is randomly selected, a new sample is generated using linear interpolation between the selected neighbor and sample i. Choosing k = 5 was based on the original implementation of SMOTE algorithm (Chawla et al., 2002). Our experiments did not show a significant change in the results when using different values of k. Using this approach, one synthetic sample is created for each training point which results in doubling the size of the training set. Figure 2 shows the data augmentation process and Figure 3 shows the overall process of ASD-DiagNet method.
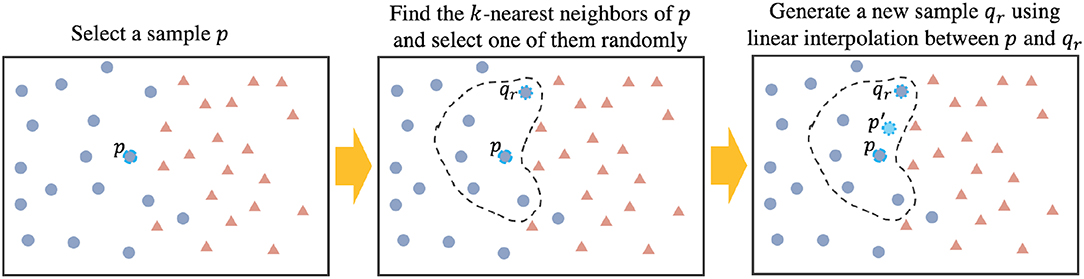
Figure 2. Generating new artificial data: Step (1) Selecting a sample (p). Step (2) Find k-nearest neighbors of p from the same class, and pick one random neighbor (qr). Step (3) Generate new sample p′ using p and qr by linear interpolation.
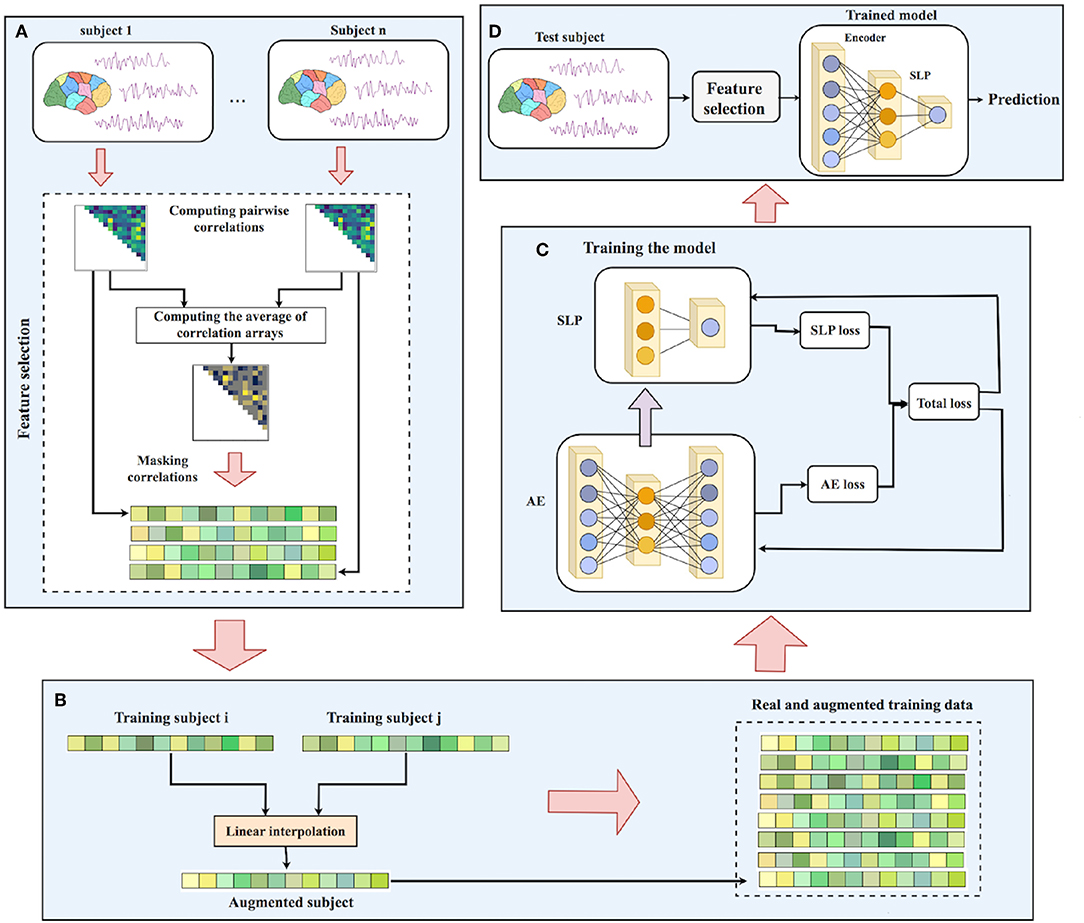
Figure 3. Workflow of ASD-DiagNet: (A) Pairwise Pearson's correlations for each subject in the training set is computed. The average of all correlation arrays is computed and the position of 1/4 largest and 1/4 smallest values in the average array is considered as a mask. Masked correlation array of each sample is considered as its feature vectors. (B) A set of artificial samples is generated using the feature vectors of training samples. (C) Autoencoder and SLP are jointly trained by adding up their training loss in each iteration. (D) For a test subject, the features are extracted using the mask generated in part A, followed by passing the features through the encoder part of the autoencoder, and finally predicting its label using the trained SLP.
For all the experiments reported in this section, we used a Linux server running Ubuntu Operating System. The server contains two Intel Xeon E5-2620 Processors at 2.40 GHz with a total 48 GBs of RAM. The system contains an NVIDIA Tesla K-40c GPU with 2, 880 CUDA cores and 12 GBs of RAM. CUDA version 8 and PyTorch library were used for conducting the experiments.
We evaluated ASD-DiagNet model in two phases by performing k-fold cross validation. In the first phase, the model was evaluated using the whole 1, 035 subjects from all sites and in the second phase, the model was evaluated for each site separately. As stated earlier, data centers may have used different experimental parameters for scanning fMRI images, so considering all of them in the same pool determines how our model generalizes to data with heterogeneous scanning parameters. On the other hand, by considering each data center separately, fewer subjects are available for training the model and the results indicate how it performs on small datasets. In each of these experiments, the effect of data augmentation is evaluated.
The value of k in k-fold cross validation must be chosen such that train/test partitions are representative of the whole dataset. Since the whole dataset contains a lot more samples than each individual site, using a large value of k like 10 in k-fold cross validation provides more samples in the training process. This helps the model to capture more information from the data while leaving enough test samples to measure the ability of the model in classifying unseen data. On the other hand, we are dealing with a small number of samples in some of the sites, for example, CMU which only contains 27 samples. Hence performing k-fold cross validation with large values of k like 10 results in only 2–3 samples in test set and increases the variance of cross-validation estimation, so we chose k = 5 when analyzing each site separately. Other studies such as Heinsfeld et al. (2018) used the same values of k for performing k-fold cross validation.
We report accuracy, sensitivity, and specificity of different methods for evaluating their classification performance. Accuracy measures the proportion of correctly classified subjects (actual ASD classified as ASD and actual healthy classified as healthy). Sensitivity represents the proportion of actual ASD subjects which are correctly classified as ASD and specificity measures the proportion of actual healthy subjects which are classified as healthy. We also compared the performance of each model's diagnostic test by their Receiver Operating Characteristic (ROC) curves. The area under ROC curves (AUC) shows the capability of the model for distinguishing between ASD and healthy subjects based on different thresholds. The higher AUC value indicates that the model is better in distinguishing between ASD and healthy subjects. We compared the performance of ASD-DiagNet with three other baselines: SVM, random forest and the method proposed by Heinsfeld et al. (2018). Hyperparameter tuning for SVM and random forest classifiers are performed by grid search technique. Hyperparameters such as kernel type, regularization constant (C), kernel coefficient (γ) for SVM, and the number of trees as well as the function to measure the quality of a split for random forest are tuned using grid search. SVM and random forest were trained using 19, 900 pairwise Pearson's correlations for each subject. The implementations of the grid search, SVM, and random forest are carried out using the built-in functions provided by scikit-learn library. In order to speed up the grid search, it is parallelized on 10 cores.
The following subsections explain each experiment in more details.
In this phase, we performed 10-fold cross-validation on the whole 1, 035 subjects using CC-200 atlas. Table 2 compares accuracy, sensitivity, and specificity of our approach with Heinsfeld et al. (2018), random forest, and SVM. As the results show, ASD-DiagNet achieves 70.3% which outperforms other methods.1
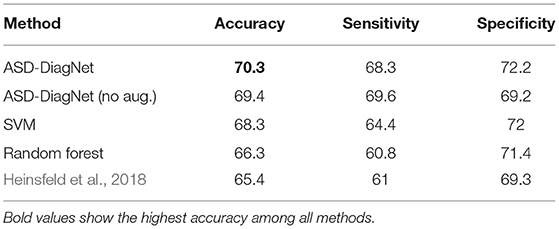
Table 2. Classification performance using 10-fold cross-validation on the whole dataset; Note that our proposed approach, ASD-DiagNet (with data augmentation) achieves the highest accuracy among other methods.
The proposed data augmentation helps to improve the results by around 1%. Based on Figure 4, ASD-DiagNet (with and without data augmentation) achieved higher area under comparing to other methods.
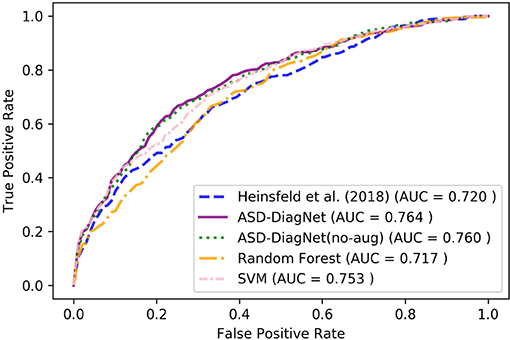
Figure 4. ROC curves of different methods for classification of whole dataset using CC-200 parcellation.
In this phase, we performed 5-fold cross-validation on each site separately using CC-200 atlas. The accuracy of each method is provided in Table 3. Based on these results, our method achieves the highest accuracy in most cases (10 out of 17 sites) and outperforms other methods on average. In addition, note that the proposed data augmentation helps improving the result around 3% overall. Especially, for OHSU, the data augmentation improves the accuracy significantly (10% increase). However, in a couple of datasets no improvement is observed (e.g., MaxMun). These datasets have shown low prediction accuracy by other methods as well. In these cases, the artificial data generated by data augmentation does not improve the results since the functional connectivity of the original data does not carry enough discriminatory information that can be used by the classifiers.
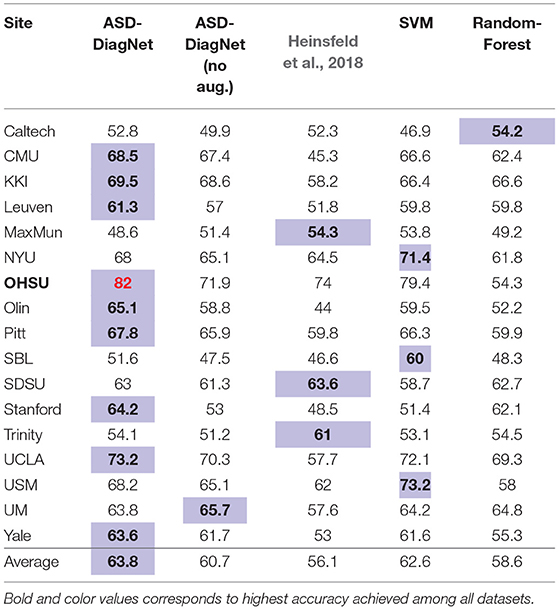
Table 3. Classification accuracy using 5-fold cross-validation on individual data centers using our proposed method, ASD-DiagNet (with and without data augmentation), compared with other methods.
We measured the running time of performing 10-fold cross validation by different approaches. The training and evaluation for all methods are performed on the same Linux system (described in section 3). The running time needed by each method is as follows: 41 min by ASD-DiagNet, 20 min by ASD-DiagNet (no aug.), 7 h and 48 min by SVM, 17 min by random forest and 6 h by Heinsfeld et al. (2018). As can be observed, ASD-DiagNet performs significantly faster than SVM and Heinsfeld et al. (2018). The data augmentation doubles the size of the training set by generating one artificial sample per subject in the training set. As a result, the data augmentation increases the computation time by a factor of 2.
We tested ASD-DiagNet on two other ROI atlases besides CC-200: Automated Anatomical Labeling (AAL) and Talaraich and Tournoux (TT) which parcellate the brain into 116 and 97 regions respectively. The data for these parcellations is provided by ABIDE-I consortium. Similar to CC-200 atlas, for each parcellation, half of the correlations (keeping the 1/4 largest and 1/4 smallest values, and removing the rest intermediate values) are selected as input features to the model. The resulting average accuracy, sensitivity, and specificity of performing 10-fold cross-validation on the whole dataset using different approaches for AAL and TT are shown in Tables 4, 5.
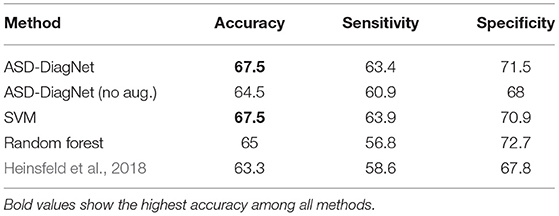
Table 4. Classification accuracy using 10-fold cross-validation on the whole dataset based on AAL atlas.
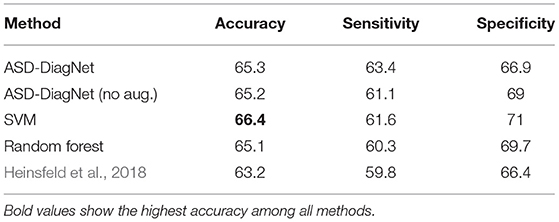
Table 5. Classification accuracy using 10-fold cross-validation on the whole dataset based on TT atlas.
For AAL parcellation, ASD-DiagNet and SVM outperform other techniques with the classification accuracy of 67.5% and achieve competitive result for TT atlas. Note that the classification accuracy obtained using these parcellations are below the accuracy obtained using CC-200 atlas, which implies that the pairwise correlations among CC-200 regions contain more discriminatory patterns than AAL and TT atlases. Based on Figures 5, 6, SVM and ASD-DiagNet achieved higher AUC than other methods.
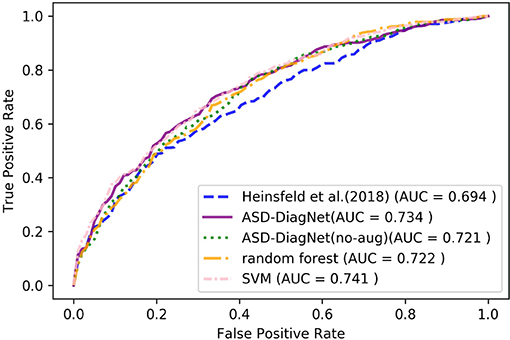
Figure 5. ROC curves of different methods for classification of whole dataset using AAL parcellation.
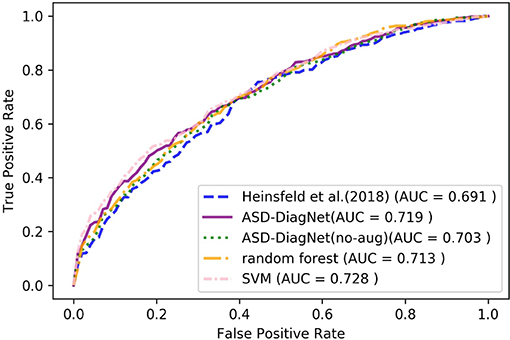
Figure 6. ROC curves of different methods for classification of whole dataset using TT parcellation.
Diagnosing ASD at early ages and starting medical treatment can have a positive effect on the patient's life. In this experiment, we evaluated our proposed method as well as other baselines on subjects below the age of 15 (550 subjects in ABIDE dataset containing 448 males and 102 females) using CC-200 atlas. Considering this subset of subjects, the classification performance, as well as ROC curves of performing 10-fold cross-validation of different methods are provided in Table 6 and Figure 7.
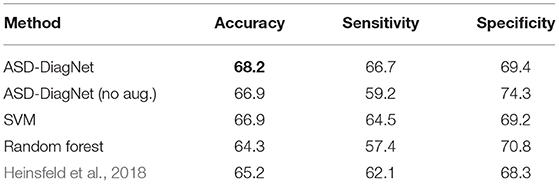
Table 6. Classification accuracy using 10-fold cross-validation on the subjects below the age of 15.
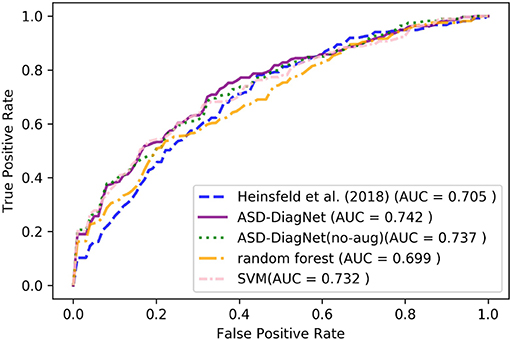
Figure 7. ROC curves of different methods for classification of subjects below the age of 15 using CC-200 parcellation.
As can be observed from the results, ASD-DiagNet achieves higher accuracy as well as higher AUC value compared to other methods. The overall accuracy is around 2% below the accuracy achieved for classification of the whole dataset, which we believe is due to the smaller training set.
In this paper, we targeted the problem of classifying subjects with ASD disorder from healthy subjects. We used fMRI data provided by ABIDE consortium, which has been collected from different brain imaging centers. Our approach, called ASD-DiagNet, is based on using the most correlated and anti-correlated connections of the brain as feature vectors and using an autoencoder to extract lower dimensional patterns from them. The autoencoder and a SLP are trained in a joint approach for performing feature selection and classification. We also proposed a data augmentation method in order to increase the number of samples using the available training set. We tested this method by performing 10-fold cross-validation on the whole dataset and achieved 70.3% accuracy in 40 min. The running time of our approach is significantly shorter than 6 h needed by the state of the art method while achieving higher classification accuracy. In another experiment, we evaluated our method by performing 5-fold cross-validation on each data center, separately. The average result shows significant improvement in accuracy compared to the state of the art method. In this case, data augmentation helps to improve the accuracy by around 3%. A different range of accuracies can be observed among sites, from low accuracies in sites such as Caltech and MaxMun to higher accuracies for OHSU and UCLA. The variable accuracy among different sites can also be observed in other studies (Nielsen et al., 2013; Heinsfeld et al., 2018). It should be noted that the protocols and parameters used for scanning the subjects are heterogeneous among sites, which can cause variability in the functional patterns among different subjects. Also, the difference in demographic information among the datasets, such as age, IQ, and gender, makes the data distribution different among them. These differences could be the reason for variable accuracies. We will consider this issue in our future works by involving the demographic information of the samples in data augmentation and the learning process. This will help the classifier to learn associations between functional connectivity patterns and demographic features which decreases the disparity among accuracies of different sites. We will also analyze other parcellations such as Power-264 by Power et al. (2011). The functional network constructed using this parcellation has shown promising results in diagnosing brain disorders (Greene et al., 2016; Khazaee et al., 2016).
Overall, experiments on different parcellations as well as subjects below the age of 15 show higher accuracy and AUC value for ASD-DiagNet comparing to other methods. These results demonstrate that our approach can be used for both intra-site brain imaging data, which are usually small sets generated in research centers, and bigger multi-site datasets like ABIDE in a reasonable amount of time.
While our model has shown promising results for diagnosing ASD disorder, there is still room for improvement by fusing structural and phenotypic information of the subjects to the functional patterns and creating hybrid features. Combination of discriminatory information provided by these three sources could increase the prediction accuracy of ASD. We consider this feature fusion as one of the future directions of our study. Another direction that we will pursue is improving the data augmentation strategy. Overall, the proposed data augmentation has improved the accuracy by generating synthetic data, but in a couple of cases low or no improvement is observed. Optimizing the current data augmentation method and considering the structural and phenotypic data for generating new samples could potentially improve the data augmentation process, and as a result, may lead to increase the diagnosis accuracy.
The datasets analyzed for this study can be found in the ABIDE-I repository (Craddock et al., 2013).
TE, VM, and FS conceived the study. TE pursued the implementation of the method, conducted the experiments and generated the results. TE and FS wrote the manuscript. AL and AF provided critical feedback and suggestions for performing the experiments. FS, AF, and VM provided valuable suggestions in writing the manuscript.
This research was supported by National Institute of General Medical Sciences (NIGMS), NIH Award Number R15GM120820, and National Science Foundations (NSF) under Award Numbers NSF OAC 1925960. The content is solely the responsibility of the authors and does not necessarily represent the official views of governmental agencies.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
This manuscript has been released as a Pre-Print at Eslami et al. (2019).
1. ^We like to mention that Heinsfeld et al. (2018) reported 70% accuracy in their paper, however, the accuracy we reported here is the result of running their method on our system using their default parameters and the code they provided online. The different results observed here could be due to some missing details in the implementation.
Abraham, A., Milham, M. P., Di Martino, A., Craddock, R. C., Samaras, D., Thirion, B., et al. (2017). Deriving reproducible biomarkers from multi-site resting-state data: An autism-based example. Neuroimage 147, 736–745. doi: 10.1016/j.neuroimage.2016.10.045
Baggio, H.-C., Sala-Llonch, R., Segura, B., Marti, M.-J., Valldeoriola, F., Compta, Y., et al. (2014). Functional brain networks and cognitive deficits in parkinson's disease. Human Brain Mapp. 35, 4620–4634. doi: 10.1002/hbm.22499
Baio, J., Wiggins, L., Christensen, D. L., Maenner, M. J., Daniels, J., Warren, Z., et al. (2018). Prevalence of autism spectrum disorder among children aged 8 years—autism and developmental disabilities monitoring network, 11 sites, united states, 2014. MMWR Surveill. Summar. 67:1. doi: 10.15585/mmwr.ss6706a1
Bi, X.-A., Liu, Y., Jiang, Q., Shu, Q., Sun, Q., and Dai, J. (2018a). The diagnosis of autism spectrum disorder based on the random neural network cluster. Front. Human Neurosci. 12:257. doi: 10.3389/fnhum.2018.00257
Bi, X.-A., Wang, Y., Shu, Q., Sun, Q., and Xu, Q. (2018b). Classification of autism spectrum disorder using random support vector machine cluster. Front. Genet. 9:18. doi: 10.3389/fgene.2018.00018
Brown, C. J., Kawahara, J., and Hamarneh, G. (2018). “Connectome priors in deep neural networks to predict autism,” in 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018) (Washington, DC: IEEE), 110–113. doi: 10.1109/ISBI.2018.8363534
Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer, W. P. (2002). SMOTE: synthetic minority over-sampling technique. J. Artif. Intell. Research 16, 321–357. doi: 10.1613/jair.953
Chen, H., Duan, X., Liu, F., Lu, F., Ma, X., Zhang, Y., et al. (2016). Multivariate classification of autism spectrum disorder using frequency-specific resting-state functional connectivity—a multi-center study. Prog. Neuro Psychopharmacol. Biol. Psychiatry 64, 1–9. doi: 10.1016/j.pnpbp.2015.06.014
Colby, J. B., Rudie, J. D., Brown, J. A., Douglas, P. K., Cohen, M. S., and Shehzad, Z. (2012). Insights into multimodal imaging classification of ADHD. Front. Syst. Neurosci. 6:59. doi: 10.3389/fnsys.2012.00059
Craddock, C., Benhajali, Y., Chu, C., Chouinard, F., Evans, A., Jakab, A., et al. (2013). The neuro bureau preprocessing initiative: open sharing of preprocessed neuroimaging data and derivatives. Neuroinformatics. doi: 10.3389/conf.fninf.2013.09.00041
Craddock, R. C., James, G. A., Holtzheimer, P. E. III., Hu, X. P., and Mayberg, H. S. (2012). A whole brain fMRI atlas generated via spatially constrained spectral clustering. Human Brain Mapp. 33, 1914–1928. doi: 10.1002/hbm.21333
Deshpande, G., Wang, P., Rangaprakash, D., and Wilamowski, B. (2015). Fully connected cascade artificial neural network architecture for attention deficit hyperactivity disorder classification from functional magnetic resonance imaging data. IEEE Trans. Cybernet. 45, 2668–2679. doi: 10.1109/TCYB.2014.2379621
Dvornek, N. C., Ventola, P., Pelphrey, K. A., and Duncan, J. S. (2017). “Identifying autism from resting-state fMRI using long short-term memory networks,” in International Workshop on Machine Learning in Medical Imaging (Quebec, QC: Springer), 362–370. doi: 10.1007/978-3-319-67389-9_42
Eitel, A., Springenberg, J. T., Spinello, L., Riedmiller, M., and Burgard, W. (2015). “Multimodal deep learning for robust RGB-D object recognition,” in 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Hamburg: IEEE), 681–687. doi: 10.1109/IROS.2015.7353446
Eslami, T., Mirjalili, V., Fong, A., Laird, A., and Saeed, F. (2019). ASD-diagnet: a hybrid learning approach for detection of autism spectrum disorder using fMRI data. arXiv [preprint]. arXiv:1904.07577.
Eslami, T., and Saeed, F. (2018a). Fast-GPU-PCC: a GPU-based technique to compute pairwise pearson's correlation coefficients for time series data–fMRI study. High Throughput 7:11. doi: 10.3390/ht7020011
Eslami, T., and Saeed, F. (2018b). “Similarity based classification of ADHD using singular value decomposition,” in Proceedings of the ACM International Conference on Computing Frontiers 2018 (ACM), 19–25.
Eslami, T., and Saeed, F. (2019). “Auto-ASD-network: a technique based on deep learning and support vector machines for diagnosing autism spectrum disorder using fMRI data,” in Proceedings of ACM Conference on Bioinformatics, Computational Biology, and Health Informatics (Niagara Falls, NY: ACM).
Fredo, A. J., Jahedi, A., Reiter, M., and Müller, R.-A. (2018). Diagnostic classification of autism using resting-state fMRI data and conditional random forest. Age 12, 6–41.
Greene, D. J., Church, J. A., Dosenbach, N. U., Nielsen, A. N., Adeyemo, B., Nardos, B., et al. (2016). Multivariate pattern classification of pediatric tourette syndrome using functional connectivity MRI. Dev. Sci. 19, 581–598. doi: 10.1111/desc.12407
Guo, X., Dominick, K. C., Minai, A. A., Li, H., Erickson, C. A., and Lu, L. J. (2017). Diagnosing autism spectrum disorder from brain resting-state functional connectivity patterns using a deep neural network with a novel feature selection method. Front. Neurosci. 11:460. doi: 10.3389/fnins.2017.00460
Heinsfeld, A. S., Franco, A. R., Craddock, R. C., Buchweitz, A., and Meneguzzi, F. (2018). Identification of autism spectrum disorder using deep learning and the abide dataset. Neuroimage Clin. 17, 16–23. doi: 10.1016/j.nicl.2017.08.017
Hosseini-Asl, E., Gimel'farb, G., and El-Baz, A. (2016). Alzheimer's disease diagnostics by a deeply supervised adaptable 3D convolutional network. arXiv [preprint]. arXiv:1607.00556.
Iidaka, T. (2015). Resting state functional magnetic resonance imaging and neural network classified autism and control. Cortex 63, 55–67. doi: 10.1016/j.cortex.2014.08.011
Itani, S., and Thanou, D. (2019). Combining anatomical and functional networks for neuropathology identification: a case study on autism spectrum disorder. arXiv [preprint]. arXiv:1904.11296.
Jaiswal, S., Valstar, M. F., Gillott, A., and Daley, D. (2017). “Automatic detection of ADHD and ASD from expressive behaviour in RGBD data,” in 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017) (Washington, DC: IEEE), 762–769.
Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., and Fei-Fei, L. (2014). “Large-scale video classification with convolutional neural networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Columbus, OH), 1725–1732.
Khazaee, A., Ebrahimzadeh, A., and Babajani-Feremi, A. (2016). Application of advanced machine learning methods on resting-state fMRI network for identification of mild cognitive impairment and alzheimer's disease. Brain Imaging Behav. 10, 799–817. doi: 10.1007/s11682-015-9448-7
Khazaee, A., Ebrahimzadeh, A., Babajani-Feremi, A., Initiative, A. D. N., et al. (2017). Classification of patients with MCI and AD from healthy controls using directed graph measures of resting-state fMRI. Behav. Brain Res. 322, 339–350. doi: 10.1016/j.bbr.2016.06.043
Khosla, M., Jamison, K., Kuceyeski, A., and Sabuncu, M. (2018). “3D convolutional neural networks for classification of functional connectomes,” in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support (Granada: Springer), 137–145. doi: 10.1007/978-3-030-00889-5_16
Li, H., Parikh, N. A., and He, L. (2018). A novel transfer learning approach to enhance deep neural network classification of brain functional connectomes. Front. Neurosci. 12:491. doi: 10.3389/fnins.2018.00491
Liang, X., Wang, J., Yan, C., Shu, N., Xu, K., Gong, G., and He, Y. (2012). Effects of different correlation metrics and preprocessing factors on small-world brain functional networks: a resting-state functional MRI study. PLoS ONE 7:e32766. doi: 10.1371/journal.pone.0032766
Lindquist, M. A. (2008). The statistical analysis of fMRI data. Stat. Sci. 23, 439–464. doi: 10.1214/09-STS282
Liu, W., Li, M., and Yi, L. (2016). Identifying children with autism spectrum disorder based on their face processing abnormality: a machine learning framework. Autism Res. 9, 888–898. doi: 10.1002/aur.1615
National Collaborating Centre for Mental Health (UK) (2018). Attention Deficit Hyperactivity Disorder: Diagnosis and Management of ADHD in Children, Young People and Adults. Leicester: British Psychological Society.
Nickel, R. E., and Huang-Storms, L. (2017). Early identification of young children with autism spectrum disorder. Indian J. Pediatr. 84, 53–60. doi: 10.1007/s12098-015-1894-0
Nielsen, J. A., Zielinski, B. A., Fletcher, P. T., Alexander, A. L., Lange, N., Bigler, E. D., et al. (2013). Multisite functional connectivity MRI classification of autism: Abide results. Front. Human Neurosci. 7:599. doi: 10.3389/fnhum.2013.00599
Parikh, M. N., Li, H., and He, L. (2019). Enhancing diagnosis of autism with optimized machine learning models and personal characteristic data. Front. Comput. Neurosci. 13:9. doi: 10.3389/fncom.2019.00009
Parisot, S., Ktena, S. I., Ferrante, E., Lee, M., Guerrero, R., Glocker, B., and Rueckert, D. (2018). Disease prediction using graph convolutional networks: application to autism spectrum disorder and Alzheimer's disease. Med. Image Anal. 48, 117–130. doi: 10.1016/j.media.2018.06.001
Peng, X., Lin, P., Zhang, T., and Wang, J. (2013). Extreme learning machine-based classification of ADHD using brain structural MRI data. PLoS ONE 8:e79476. doi: 10.1371/journal.pone.0079476
Perez, L., and Wang, J. (2017). The effectiveness of data augmentation in image classification using deep learning. arXiv [preprint]. arXiv:1712.04621.
Plitt, M., Barnes, K. A., and Martin, A. (2015). Functional connectivity classification of autism identifies highly predictive brain features but falls short of biomarker standards. Neuroimage Clin. 7, 359–366. doi: 10.1016/j.nicl.2014.12.013
Power, J. D., Cohen, A. L., Nelson, S. M., Wig, G. S., Barnes, K. A., Church, J. A., et al. (2011). Functional network organization of the human brain. Neuron 72, 665–678. doi: 10.1016/j.neuron.2011.09.006
Sen, B., Borle, N. C., Greiner, R., and Brown, M. R. (2018). A general prediction model for the detection of ADHD and autism using structural and functional MRI. PLoS ONE 13:e0194856. doi: 10.1371/journal.pone.0194856
Subbaraju, V., Suresh, M. B., Sundaram, S., and Narasimhan, S. (2017). Identifying differences in brain activities and an accurate detection of autism spectrum disorder using resting state functional-magnetic resonance imaging: a spatial filtering approach. Med. Image Anal. 35, 375–389. doi: 10.1016/j.media.2016.08.003
Wong, S. C., Gatt, A., Stamatescu, V., and McDonnell, M. D. (2016). “Understanding data augmentation for classification: when to warp?” in 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA) (Gold Coast, QLD: IEEE), 1–6. doi: 10.1109/DICTA.2016.7797091
Xu, Y., Jia, R., Mou, L., Li, G., Chen, Y., Lu, Y., et al. (2016). “Improved relation classification by deep recurrent neural networks with data augmentation,” in Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers (Osaka: The COLING 2016 Organizing Committee), 1461–1470.
Yang, K., and Shahabi, C. (2004). “A PCA-based similarity measure for multivariate time series,” in Proceedings of the 2nd ACM International Workshop on Multimedia Databases (Washington, DC: ACM), 65–74.
Yang, Z., Zhong, S., Carass, A., Ying, S. H., and Prince, J. L. (2014). “Deep learning for cerebellar ataxia classification and functional score regression,” in International Workshop on Machine Learning in Medical Imaging (Springer), 68–76.
Zhang, Y., Zhang, H., Chen, X., Lee, S.-W., and Shen, D. (2017). Hybrid high-order functional connectivity networks using resting-state functional MRI for mild cognitive impairment diagnosis. Sci. Rep. 7:6530. doi: 10.1038/s41598-017-06509-0
Keywords: fMRI, ASD, SLP, autoencoder, ABIDE, classification, data augmentation
Citation: Eslami T, Mirjalili V, Fong A, Laird AR and Saeed F (2019) ASD-DiagNet: A Hybrid Learning Approach for Detection of Autism Spectrum Disorder Using fMRI Data. Front. Neuroinform. 13:70. doi: 10.3389/fninf.2019.00070
Received: 31 July 2019; Accepted: 12 November 2019;
Published: 27 November 2019.
Edited by:
Pierre Bellec, Université de Montréal, CanadaReviewed by:
Nianming Zuo, Institute of Automation (CAS), ChinaCopyright © 2019 Eslami, Mirjalili, Fong, Laird and Saeed. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fahad Saeed, ZnNhZWVkQGZpdS5lZHU=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.