 Yuxing Fang
Yuxing Fang Quanjing Chen
Quanjing Chen Angelika Lingnau
Angelika Lingnau Zaizhu Han1
Zaizhu Han1 Yanchao Bi
Yanchao Bi
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Hum. Neurosci. , 08 March 2016
Sec. Speech and Language
Volume 10 - 2016 | https://doi.org/10.3389/fnhum.2016.00094
The observation of other people’s actions recruits a network of areas including the inferior frontal gyrus (IFG), the inferior parietal lobule (IPL), and posterior middle temporal gyrus (pMTG). These regions have been shown to be activated through both visual and auditory inputs. Intriguingly, previous studies found no engagement of IFG and IPL for deaf participants during non-linguistic action observation, leading to the proposal that auditory experience or sign language usage might shape the functionality of these areas. To understand which variables induce plastic changes in areas recruited during the processing of other people’s actions, we examined the effects of tasks (action understanding and passive viewing) and effectors (arm actions vs. leg actions), as well as sign language experience in a group of 12 congenitally deaf signers and 13 hearing participants. In Experiment 1, we found a stronger activation during an action recognition task in comparison to a low-level visual control task in IFG, IPL and pMTG in both deaf signers and hearing individuals, but no effect of auditory or sign language experience. In Experiment 2, we replicated the results of the first experiment using a passive viewing task. Together, our results provide robust evidence demonstrating that the response obtained in IFG, IPL, and pMTG during action recognition and passive viewing is not affected by auditory or sign language experience, adding further support for the supra-modal nature of these regions.
Action understanding supports the interpretation of others’ goals, intentions, and reasons (Brass et al., 2007). We can understand actions presented from both visual and auditory inputs, with potential interactions between the two modalities. Behaviorally, Thomas and Shiffrar (2010) found that detection sensitivity improved when point-light displays of human actions were paired with veridical auditory cues (footsteps) but not when paired with simple tones. On a neural level, the human mirror system (hMS), consisting of the posterior inferior frontal gyrus (IFG), and the inferior parietal lobule (IPL), and the superior temporal sulcus (STS) have been consistently suggested to play a crucial role in action understanding (Iacoboni et al., 1999; Rizzolatti et al., 2001; Carr et al., 2003; Buccino et al., 2004; Rizzolatti and Craighero, 2004; De Lange et al., 2008; Caspers et al., 2010; Caramazza et al., 2014). The macaque mirror neuron system shows multisensory properties: neurons in area F5 fire when an action is performed, heard, or seen (Kohler et al., 2002; Keysers et al., 2003). Likewise, the hMS has been reported to be activated not only when observing actions but also when listening to action-related sounds (Lewis et al., 2005; Gazzola et al., 2006; Lahav et al., 2007).
To understand the manners in which hMS activation reflects processes of modality-specific visual or auditory properties of actions, a set of elegant studies examined brain activation obtained during action observation in special populations that are deprived of visual or auditory experiences, i.e., blind or deaf individuals. A puzzling picture emerged, however. While hMS activation during action observation in congenitally blind participants was observed to be largely similar (Ricciardi et al., 2009) or partly similar (in IFG; Lewis et al., 2011) to hearing controls, two studies have reported that congenital deaf individuals do not engage the IPL and IFG, the regions they defined to be hMS, during action observation. Corina et al. (2007) used PET to study deaf signers and controls during passive observation of self-oriented actions, object-oriented actions, and actions used in American Sign Language (ASL). They found that the left frontal and posterior superior temporal language areas were activated during the observations of ASL actions, whereas the two non-linguistic action types elicited activation in middle occipital temporal-ventral regions, but not the hMS. By contrast, hearing individuals exhibited a robust activation in the hMS for all three types of action. Emmorey et al. (2007) reported that passive viewing of pantomime actions and action verbs used in ASL yielded little activation in the hMS in deaf signers. Despite the inconsistent results regarding the ASL condition, both studies suggested that deprivation of auditory experience and/or gaining of ASL experience modulates the activation of the hMS, at least the IFG and IPL regions.
These findings pose an intriguing question to the mechanisms underlying the activation of the hMS. Why does visual experience, presumably the dominant modality through which action is perceived and understood, not appear to affect the recruitment of the hMS during action observation, whereas auditory experience seems to have an effect? The interpretation being proposed (Emmorey et al., 2010) was that besides the deprivation of auditory experience, the deaf population also differs from the controls in having a different modality of linguistic experience, i.e., sign language, which heavily relies on action observation and understanding. The possibility that language experience may modulate the activation of the hMS was raised by previous studies where deaf signers exhibited no hMS activation during action observation. It was suggested that the extensive training with comprehending sign language, which is expressed by sophisticated hand/upper body actions, deaf signers might be more efficient and automatic than controls, at least when the action tasks do not explicitly require action understanding (e.g., passive viewing). It is thus empirically open whether these regions would be recruited to support action understanding (rather than passive viewing) in congenitally deaf signers similarly to hearing controls without sign language experience.
To examine whether deaf signers’ neural activity in processing actions is different to hearing controls only during passive action observation tasks, we employed tasks where explicit responses based on action understanding are required. We further tested the manner in which the tentative plasticity in deaf was attributable to sign language experience by examining whether the hMS responses in the deaf are modulated by the nature of the actions (sharing similar effectors with sign language or not) and sign language experience. If the functionality of hMS in hearing controls is only altered in deaf signers when action understanding is required, we would predict similar hMS activation for deaf and hearing participants (Experiment 1). Furthermore, if the tentative plasticity is driven by sign language usage, we expect greater plastic changes for arm actions (common effector with sign language actions) relative to leg actions, and for deaf individuals with longer sign language experience.
Specifically, in Experiment 1 the level of processing required for action processing (goal/effector vs. low level perception) and the type of effector (arm, leg) were manipulated. Point light animations, which were used to encourage action understanding with minimal properties of non-motion aspects, depicted either arm- or leg-related actions. Participants had to either detect whether one of the dots briefly turned red (Red Dot Task), judge whether the action consisted of a movement of the arm or leg (Effector Task) or judge the goal of the action (Goal Task; Lingnau and Petris, 2013). The Red Dot Task was specifically designed to control for the “low level” stimuli properties, allowing to more specifically tap into the process engaged during understanding an action. A group of deaf participants with varying degrees of sign language experience were enrolled.
In addition to Experiment 1, we carried out Experiment 2 to replicate findings of previous passive viewing studies of deaf signers (Corina et al., 2007), using human action videos similar to those used by Corina et al. (2007). The two experiments were carried out in one scanning session, but differed with respect to the underlying designs and rationales, and are thus reported separately below.
Thirteen congenitally deaf individuals (two males) and 13 hearing individuals (two males) participated in Experiment 1. One deaf individual was discarded during data analysis due to excessive head motion. One run of a hearing participant was discarded due to an unexpected pause of the scanner. All participants were undergraduate students, with deaf participant recruited from a department specialized for disable students in a local community colledge and the hearing control group from Beijing Normal University, with normal or corrected-to-normal vision, with no history of any neurological disorders, were right-handed (Edinburgh Handedness Questionnaire) except for one deaf subject who was ambidextrous. All deaf individuals (mean age = 20.4 years; SD = 1.45; range: 17–22 years) reported a profound hearing loss (≥95 dB), were using Chinese Sign Language (CSL, mean acquired age = 6.5 years; SD = 3.2; range: 2–12), and had poor articulation intelligibility. To test the ability of the articulation intelligibility, 11 deaf subjects were asked to read aloud 30 words. Two naive raters judged the speech intelligibility on a 5-point scale (0 – 4, 4 being most clear), with high inter-rater reliability (Spearman’s ρ = 0.94). The mean rating was 0.8 (range: 0.1–2.8, SD: 0.73). More information about the written and phonological ability of this deaf participants could be found in Wang et al. (2015). The hearing participants (mean age = 20.5 years; SD = 1.13; range: 19–23 years) reported normal hearing and no knowledge of CSL. The participants completed a written informed consent approved by the institutional review board of the Beijing Normal University Imaging Center for Brain Research. The consent form, safety instruction, and experimental procedures were shown in written Chinese language. A sign language interpreter helped us explain these materials and communicate with deaf signers for any questions. The characteristics of the participants are presented in Table 1.
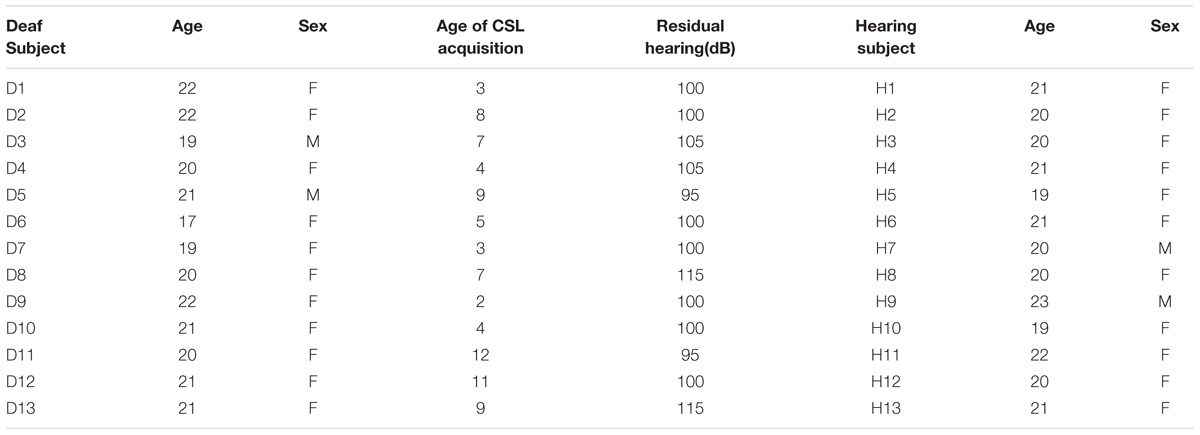
TABLE 1. Background information of the 13 deaf subjects and 13 hearing subjects.
The experimental materials and the procedure were adapted from Lingnau and Petris (2013), as presented in Figure 1. Briefly, point-light displays were based on digitized movements of human actors. Thirteen reflective markers were attached to the head, shoulders, elbows, hands, hips, knees, and feet. Each point-light display depicted one action lasting 1.5 s. There were four different types of human actions that involved either the hand or leg: throwing a ball, kicking a ball, punching someone and kicking someone. To manipulate task difficulty, original trajectories of six randomly selected markers were randomly rotated by 90°, 180°, or 270°, resulting in two difficulty levels (easy/original trajectories; difficult/rotated markers).
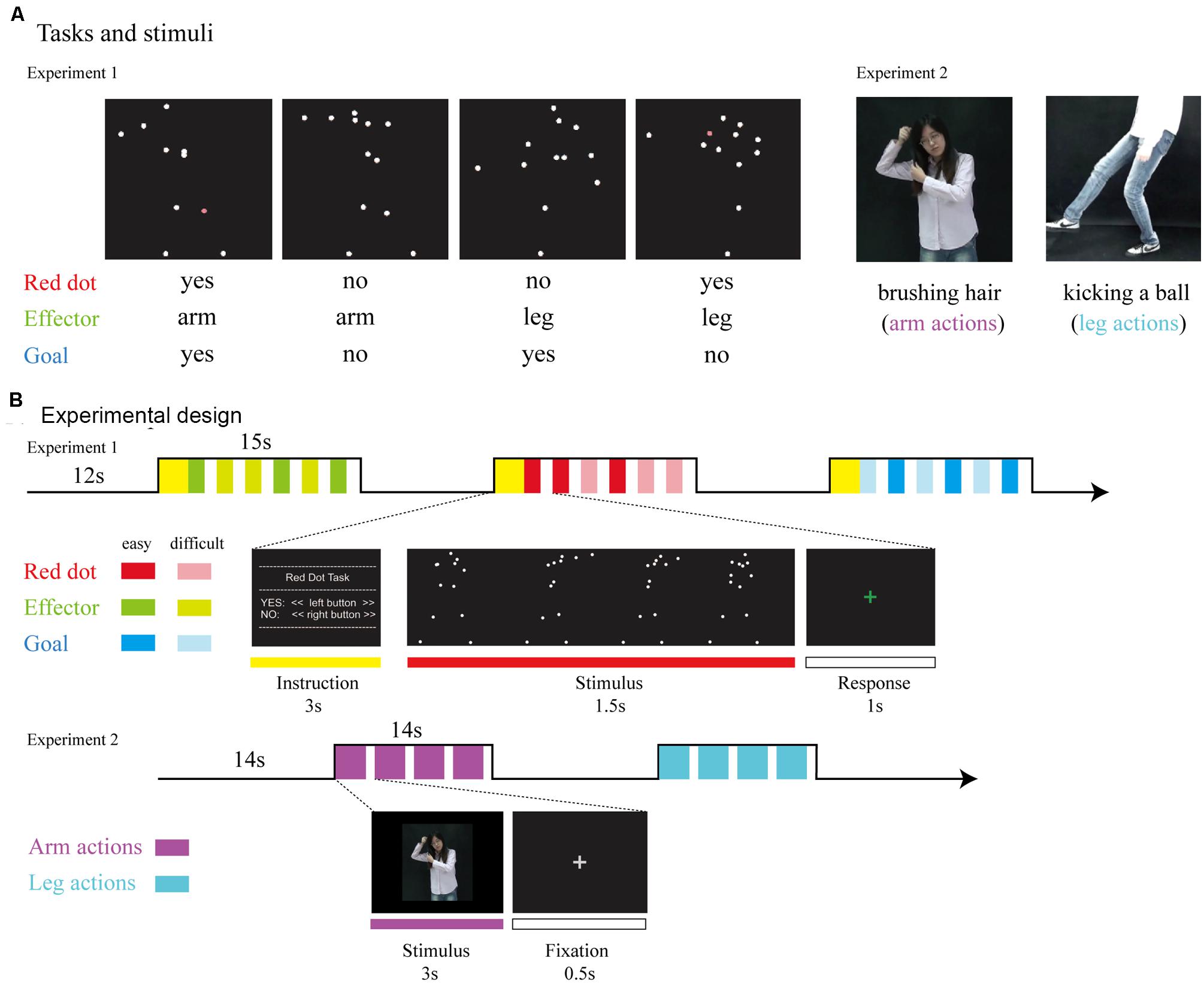
FIGURE 1. (A) Tasks and stimuli. For Experiment 1, stimuli consisted of point-light displays depicting four different actions (throwing a ball, punching someone, kicking a ball, and kicking someone). During the Red Dot Task, participants had to indicate whether or not 1 of the 13 markers had briefly turned red. During the Effector Task, participants had to indicate whether the relevant effector was the arm (as in throwing a ball) or the leg (as in kicking a ball). During the Goal Task, participants had to indicate whether the point-light display depicted an action involving a ball (as in throwing a ball) or not (as in punching someone). For Experiment 2, stimuli consisted of video clips which were recoded by a hearing female with no knowledge of CSL performing arm and leg actions. (B) Experimental design. For Experiment 1, we used a mixed design, with task blocked (15 s task, followed by 12 s rest). Within each block, the noise level was varied from trial to trial, with each noise level occurring three times per block, leading to six trials per block. The type of action was assigned randomly. For Experiment 2, stimuli were presented in 14-s blocks consisting of four video clips of either arm or leg actions.
Participants responded by pressing buttons with their right index and middle fingers. For the Red Dot Task, they indicated whether any one of the 13 markers had briefly turned red. For the Effector Task, participants indicated whether the display depicted the action of the arm (throwing a ball/punching someone) or the action of the leg (kicking a ball/kicking someone). For the Goal Task, participants were required to judge whether the action involved a ball (throwing/kicking a ball) or not (punching/kicking someone). Both the Effector and Goal task required a certain degree of action understanding and was combined in our analyses as the action judgment tasks.
The experiment used a mixed design (for details, see Lingnau and Petris, 2013). Task was blocked, whereas the type of effector (arm, leg) and goal (action involving a ball or no ball) were assigned randomly within blocks. Blocks lasted 15 s and consisted of six trials. Each trial lasted 1.5 s, with a 1-s inter-trial-interval during which participants were asked to respond. There was a 3-s written instruction to inform the participants of the next task before each block and a 12-s rest afterward. Participants performed six runs. Each run lasted for 6 min 15 s and contained 12 blocks, with four blocks for each task (Red Dot, Effector, Goal) and 36 trials for each effector (arm, leg). Prior to scanning, participants were given written instructions and performed several practice blocks to ensure that they understood the requirements correctly.
Participants viewed the stimuli through a mirror attached to the head coil adjusted to allow foveal viewing of a back-projected monitor (refresh rate: 60 Hz; spatial resolution: 1024 × 768). The width and height of the point-light stimuli were approximately 14.7° × 11.1° on the screen. The size of each single dot was approximately 0.24°. ASF (Schwarzbach, 2011) based on MATLAB (MathWorks, Inc., Natick, MA, USA) and Psychtoolbox-3 (Brainard, 1997) was used to present the stimuli.
Structural and functional MRI data were collected with a 3-T Siemens Trio Tim scanner at the Beijing Normal University MRI center. A high-resolution 3D structural data set was acquired with a 3D-MPRAGE sequence in the sagittal plane (TR: 2530 ms, TE: 3.39 ms, flip angle: 7°, matrix size: 256 × 256, 144 slices, voxel size: 1.33 × 1 × 1.33 mm, acquisition time: 8.07 min). Functional data were measured with an EPI sequence (TR: 2000 ms, TE: 30 ms, flip angle: 90, matrix size: 64 × 64, voxel size: 3.125 × 3.125 × 4 mm, inter-slice distance: 4.6 mm, number of slices: 33; slice orientation: axial).
Functional imaging data were analyzed using the Statistical Parametric Mapping package (SPM 12, Wellcome Department of Cognitive Neurology, London, UK). The first nine volumes were discarded. Preprocessing of functional data included head motion correction with respect to the first (remaining) volume of the run scanned closest to the 3D structural data, slice timing correction (ascending interleaved order), and spatial smoothing (Gaussian filter, 8-mm Full Width Half Maximum). For each participant, functional data were registered to her/his high-resolution structural data. Finally, both functional and structural data were normalized into Montreal Neurological Institute (MNI) space, and functional data were resampled to 3 mm × 3 mm × 3 mm resolution.
To carry out whole brain group data analysis, we used the general linear modelling (GLM), including six motion parameters as regressors of no interest. We combined the Effector and Goal tasks to a common regressor labeled ‘Action Judgment Task.’ All incorrect trials were excluded. To identify brain areas recruited while participants are engaged in the judgment of an action, we computed the contrast between the beta estimates obtained during the Action Judgment Task and the Red Dot Task. We conducted a within-group analysis and then performed a group comparison to examine the differences between deaf and hearing participants. Correction for multiple comparisons was performed using false discovery rate (FDR) correction (q < 0.05).
Regions of interests were defined using the data from all of the participants (deaf and hearing individuals combined), using the contrast Action Judgment Tasks > Red Dot Task (FWE corrected, P < 0.05), to identify regions recruited by action understanding without biasing toward either subject groups or either action understanding tasks. We used FWE correction here because using the FDR correction threshold very large continuous clusters were obtained covering different frontal, parietal, and temporal regions. Thus the higher threshold was used to separate the continuous clusters into different clusters with different activation peaks. Beta estimates of all voxels falling within a 6 mm radius sphere centered on the peak voxel within each ROI for each factor (effector or task) of each subject group were then extracted and analyzed.
Within these ROIs, we performed three different types of repeated measures ANOVAs. (1) To examine the effect of effectors (arm, leg) on the neural activity of brain regions involved during the judgment of an action (in comparison to a low level visual control task), we carried out a repeated ANOVA on the beta estimates for the contrast ‘Action Judgment Task > Red Dot Task’ (2) To examine group differences specifically for the goal task (rather than collapsing across the effector and the goal task), we carried out a repeated measures ANOVA with the factors effector (arm, leg) and group (deaf, hearing) on the beta estimates for the contrast ‘Goal task > Red Dot Task.’ (3) To examine the effect of the two action understanding tasks (Goal Task. Effector Task), we carried out a repeated measures ANOVA with the factor task the beta estimates for the contrast ‘Goal Task > Red Dot Task’ and ‘Effector Task > Red Dot Task.’
Behavioral data were collected inside the MR scanner. The result of accuracy and RT are shown on Table 2. Accuracy and RT were analyzed using a 3 × 2 × 2 ANOVA including Task (Red Dot, Effector, Goal) and Effector (arm, leg) as within-subject factors and Group (deaf, hearing) as the between-subject factor.
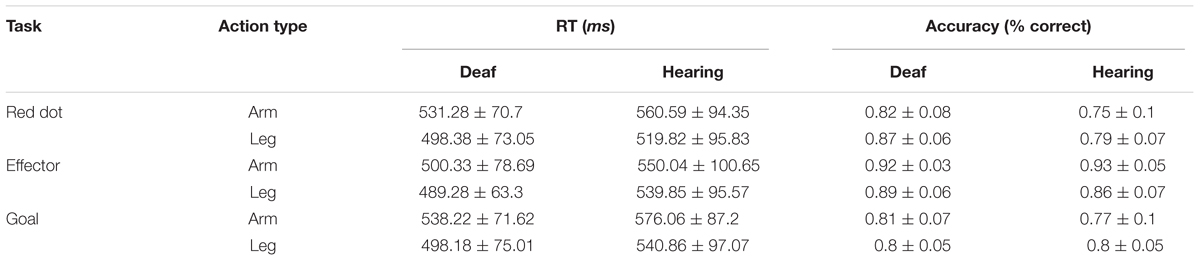
TABLE 2. RT and accuracy (Experiment 1).
The analysis of accuracy revealed significant main effects of Task [F(2,48) = 39.74, P < 0.001] and Group [F(1,24) = 4.25, p = 0.05] and no effect of Effector [F(1,24) = 0.15, p = 0.70]. We also found a significant interaction between Task and Group [F(2,48) = 3.38, P < 0.05] and a significant interaction between Task and Effector [F(2,48) = 11.90, P < 0.001]. During the Red Dot Task, deaf participants performed better than the hearing participants [t(25) = 2.63, P < 0.05]. No group difference was found for the other two tasks. The interaction between Effector and Group [F(1,24) < 0.001, P > 0.99] and the interaction among these three factors were not significant [F(2,48) = 2.37, p = 0.10].
For RT, there was no difference between participant groups [F(1,24) = 1.46, p = 0.24]. We found significant main effects of task [F(2,48) = 6.68, P < 0.01] and effector [F(1,24) = 54.93, P < 0.001], and a significant interaction between task and effector [F(2,48) = 5.74, P < 0.01]. RT for the Goal Task was longer than that of the Red Dot Task [t(25) = 2.15, P < 0.05], whereas the other comparisons revealed no significant difference (all Ps > 0.05). Longer RTs were associated for the arm than the leg in the Red Dot Task [t(25) = 6.29, P < 0.001] and Goal task [t(25) = 5.78, P < 0.001].
Taken together, there was a tendency for deaf individuals to perform better than hearing control participants in low level visual detection (Red Dot Task), but there was little evidence for behavioral differences between the two groups in the two action understanding tasks. Next we tested whether activation in the ROI was modulated by behavioral differences. To this aim we correlated behavoiral performance (RT, accuracy) with the mean beta estimate obtained from the contrast (action judgment > red dot; see below) in each ROI across participants. We found no significant correlation in any ROI for either accuracy or RT (Bonferroni corrected Ps > 0.05).
We conducted a whole-brain group comparison using the contrast Action Judgment Task > Red Dot Task (FDR q < 0.05). In the deaf individuals, this contrast revealed the following areas: bilateral triangular parts of IFG, the left superior parietal gyrus (SPL), the left anterior inferior parietal gyrus (aIPL), the left MOG, the pMTG, the right inferior temporal gyrus (ITG), the right superior temporal sulcus (STS), and bilateral cerebellum (Figure 2A, first row). In the hearing individuals, a similar pattern was obtained: bilateral triangular parts of IFG, the left pMTG, the left supplementary motor area (SMA), the right middle occipital gyrus MOG, the right IPL, the right precuneus and the bilateral cerebellum (Figure 2A, second row). Detailed information about the activation peak coordinates and cluster sizes is given in Table 3. Critically, there was no group difference between hearing and deaf individuals (FDR q < 0.05).

FIGURE 2. (A) Areas engaged in action understanding by the contrast Action Judgment Task > Red Dot Task in Experiment 1 separately for the two groups (top two rows) and comparison between groups (bottom row). There is no significant cluster revealed by the contrast Hearing > Deaf or Deaf > Hearing (FDR q < 0.05). (B) Areas revealed by the contrast Action Judgment Task > Rest (fixation baseline) in Experiment 1 separately for the two groups (top two rows) and comparison between groups (bottom row). The large cluster in the bottom row was one contiguous cluster in volume space but not when displayed on the surface. There is no significant cluster revealed by the contrast Hearing > Deaf (FDR q < 0.05). (C) Areas revealed by the contrast Action Observation > Rest (fixation baseline) in Experiment 2 separately for the two groups (top two rows) and comparison between groups (bottom row). There is no significant cluster revealed by the contrast Hearing > Deaf (FDR q < 0.05).
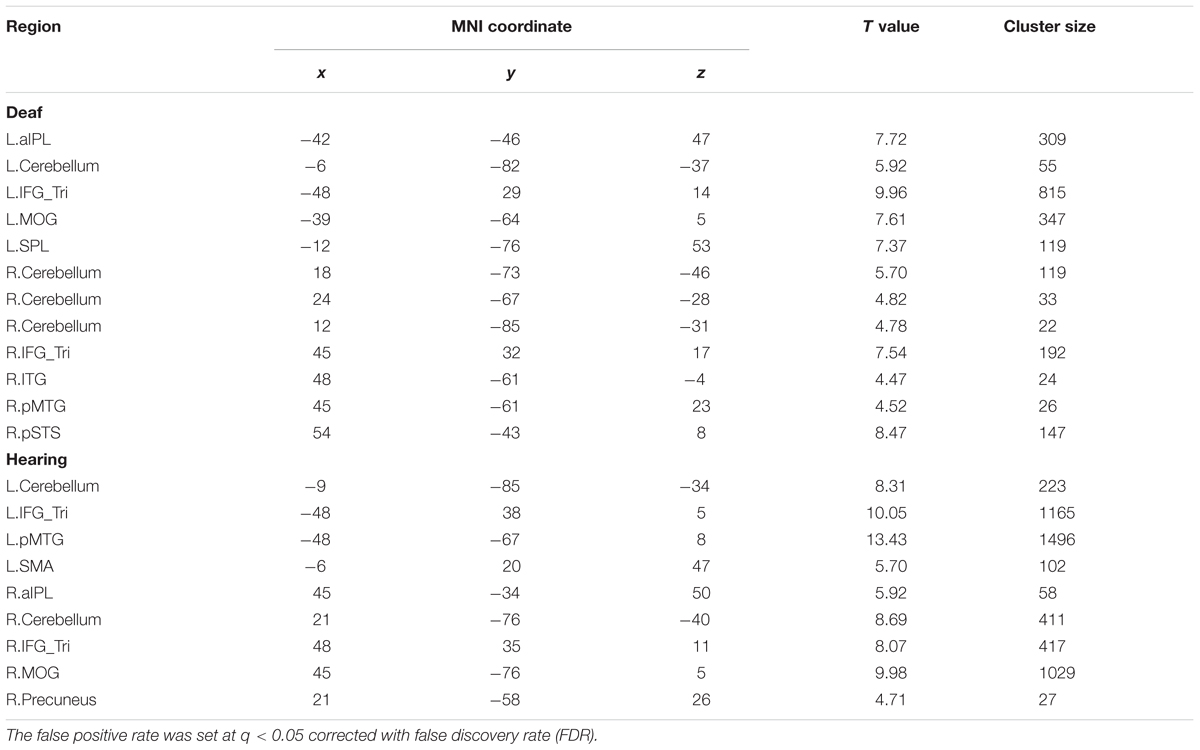
TABLE 3. Montreal Neurological Institute (MNI) coordinates of the regions revealed by the contrast Action Judgment Task > Red Dot Task for the separate group in Experiment 1.
We further carried out another contrast using a less specific contrast: Action Judgment Task > Rest (Fixation) corrected at FDR q < 0.05. This contrast results in cognitive components of action understanding, as well as low level visual processes. When comparing hearing and deaf individuals, we found stronger activation in deaf in comparison to hearing individuals in very large clusters around the bilateral auditory cortex: the left cluster encompassed almost the entire STG, which extended to the pMTG [peak, -60, -22, 2; size, 373 voxels]; the right cluster included the right STG, extending to pMTG and orbital IFG [peak, 60, -1, -7, size, 659 voxels]; see Figure 2B, bottom row, in which the large clusters was one contiguous cluster in volume space but not when displayed on the surface.
To investigate whether the effects of group (deaf vs. hearing) on activation during action understanding is modulated by effector (arm, leg), task (Effector Task, Goal Task), or sign language experience, we conducted a series of ROI analysis in areas recruited during the action judgment tasks. Following Lingnau and Petris (2013), we defined ROIs by the GLM contrast Action Judgment Task (Goal + Effector Task) > Red Dot Task (FWE corrected, P < 0.05). We collapsed across the two groups and the two tasks in order to avoid biased ROI selection (Kriegeskorte et al., 2009). This contrast revealed 13 ROIs: bilateral ITG, bilateral triangular and opercular parts of IFG, bilateral posterior MTG, left anterior and posterior IPL, left middle frontal gyrus (MFG), left precuneus and right posterior STS (Figure 3). The ROIs opercular part of IFG, the IPL, and the pSTS were within the traditional hMS regions. Beta estimates revealed by this contrast are shown in Figure 3, separately for each ROI.
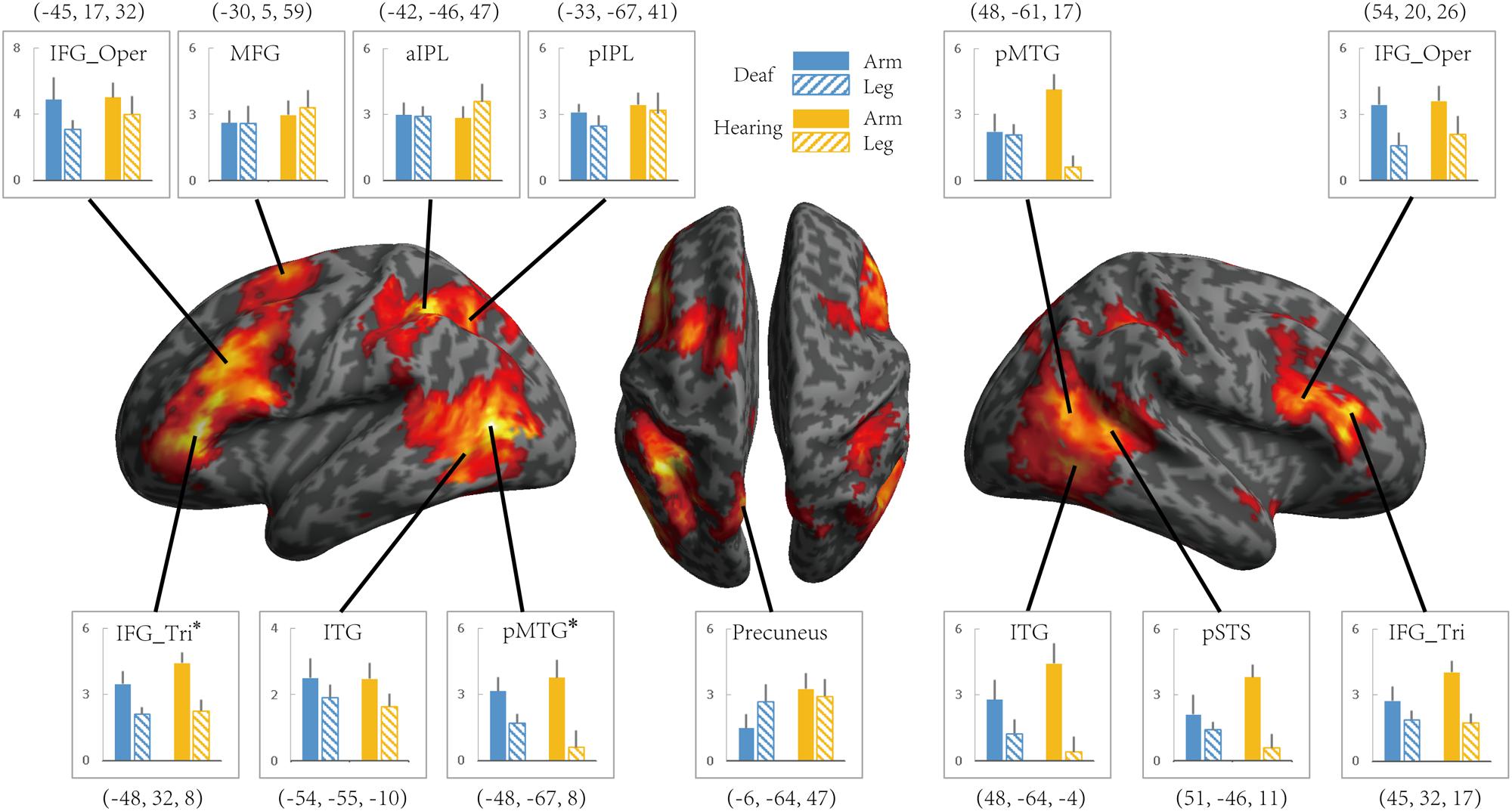
FIGURE 3. Areas recruited in action understanding (contrast Action Judgment Task > Red Dot Task) in Experiment 1 for all participants (FDR q < 0.05). ROIs were defined using the same contrast but at a stricter threshold (FWE P < 0.05). The blue and yellow bars depict beta estimates in the hearing and deaf group, respectively. Solid and slash bars represent the arm and leg actions, respectively. Asterisk indicates significant main effect between arm and leg condition. (P < 0.004, significant at Bonferroni corrected 0.05 for multiple comparison across 13 ROIs).
Whether the potential difference between deaf and hearing groups is modulated by action effector type was examined by the repeated-measures ANOVA with the factors Group and Effector, the results of which are presented in Table 4 for each ROI. For the left triangular part of IFG and the pMTG, the main effect of Effector was significant (P < 0.004, Bonferroni corrected P < 0.05), with both regions showing a higher BOLD response for arm actions than leg actions in all of the ROIs. Importantly, no regions showed a main effect of Group or an interaction between Effector and Group.
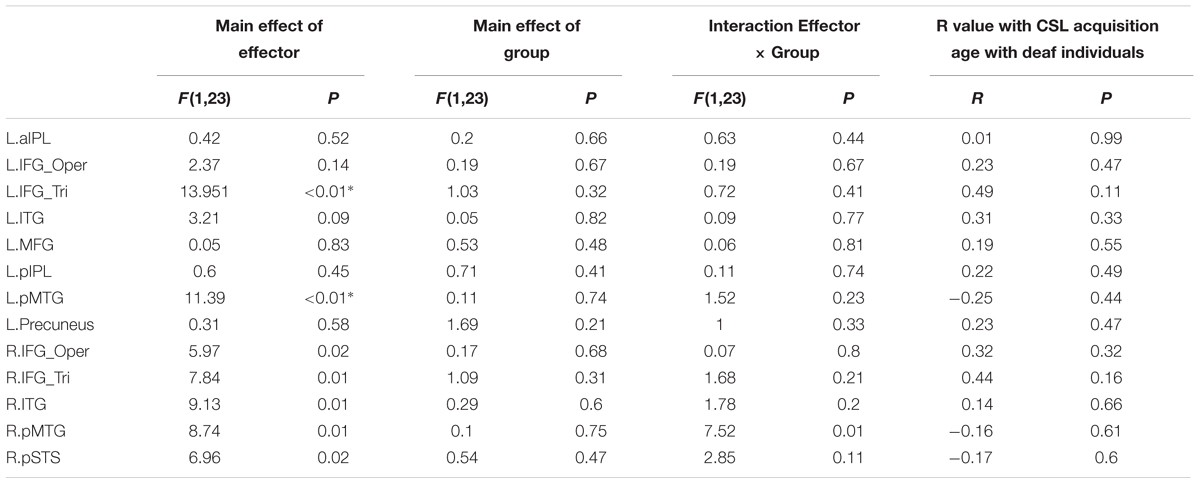
TABLE 4. Statistical details for main effect of Effector, Group, Interaction Effector × Group and R value with CSL acquisition age with Deaf individuals by the contrast Action Judgment Task > Red Dot Task in Experiment 1 (∗P < 0.004, significant at Bonferroni corrected 0.05 for multiple comparisons across 13 ROIs).
It might be possible to perform the Effector Task without understanding the actions. We thus examined if there are any group differences when focusing on the contrast ‘Goal task > Red Dot Task’ (see Table 5). For the left pMTG, right ITG and pSTS, the main effect of Effector was significant (P < 0.004, Bonferroni corrected at P < 0.05), with both regions showing a higher BOLD response for leg actions in comparison to arm actions. No regions showed a main effect of Group or an interaction between Effector and Group.
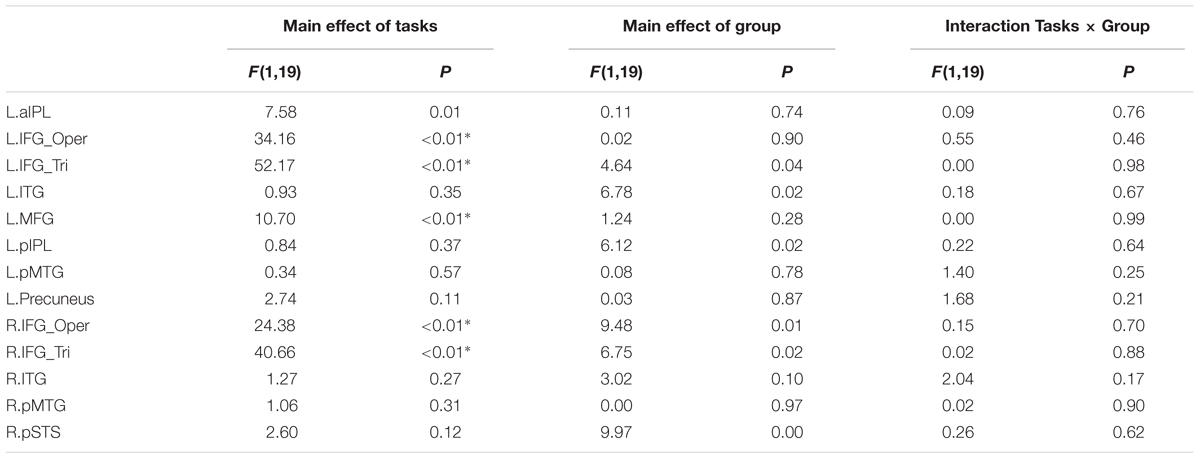
TABLE 5. Statistical details for main effect of Tasks (Goal task/Effector task), Group, Interaction Tasks × Group and R value in Experiment 1 (∗P < 0.004, significant at Bonferroni corrected 0.05 for multiple comparisons across 13 ROIs).
We further tested whether the group difference is affected by the type of task using a repeated measures ANOVA with the factors Group (deaf vs. hearing) and Task (Goal vs. Effector Task; see Table 5). For the left triangular part and opercular part of IFG and the MFG, right triangular part and opercular part of IFG, the main effect of Task was significant (P < 0.004, Bonferroni corrected P < 0.05), with a higher BOLD amplitude for the Goal Task in comparison to the Effector Task. Importantly, however, no region showed a main effect of Group or an interaction between Task and Group.
To test whether activation in ROIs identified by the contrast Action Judgment Task > Red Dot Task is modulated by sign language experience, we computed the correlation between the beta value of each ROI and the age of CSL acquisition, a common measure of language experience, across deaf subjects. We obtained no significant correlation in any ROI (Ps > 0.1, Table 4).
We further divided the deaf subjects into two groups according to the age of CSL acquisition (>6 years, N = 6 vs. <6 years, N = 6, results presented in Table 6). Two sample t-test was used to test whether the two groups differed in each ROI. No significant differences were obtained in any ROI (Bonferroni corrected Ps > 0.05).
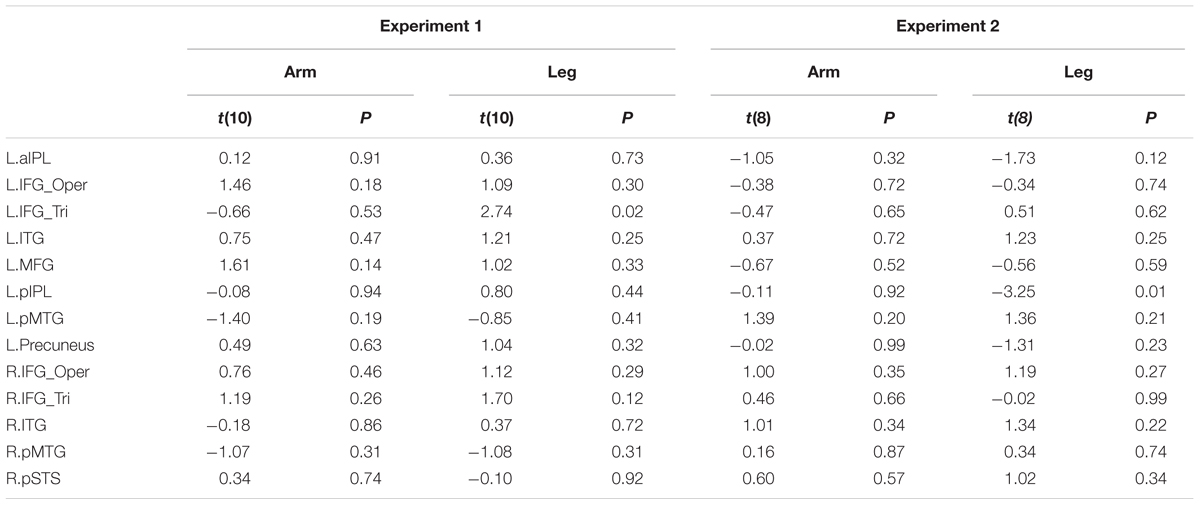
TABLE 6. Statistical details for comparing two sub-groups of deaf individuals (the age of acquisition CSL > 6 years vs. < 6 years) in Experiments 1 and 2 (P > 0.004, no significant result at Bonferroni corrected.05 for multiple comparisons across 13 ROIs).
Ten deaf and 11 hearing individuals from Experiment 1 took part in Experiment 2.
To be as close as possible to previous studies on action observation in deaf participants (Corina et al., 2007; Emmorey et al., 2010), we used action videos instead of point light displays in Experiment 2 (see Figure 1). A hearing female with no knowledge of CSL performed arm and leg actions that were recorded with a video camera and edited into video clips. The arms actions consisted of the hand manipulating a variety of common objects (objects not presented) or acting upon a part of the body, such as brushing hair, knocking at the door and washing hands. Leg actions were performed by the leg and foot, such as walking, running and kicking a ball. In total there were 48 arms action video clips and 48 arm action clips, created from 28 different arm actions and 24 leg actions (see the full list of materials in Appendix A) by repeating each action twice or occasionally once.
In the scanner, stimuli were presented in 14-s blocks consisting of four video clips of either arm or leg actions. There were two runs, each consisted of 12 blocks, with six blocks for each type of effector, and lasted for 5 min 50 s. Within each run, the order of blocks was randomized and each action appeared once. Within a block, each video clip lasted for 3 s, followed by a 500-ms fixation cross. Between blocks, as well as before the first and after the last block, a baseline condition, consisting of a fixation cross, was presented for 14 s. The width and height of the video clips were approximately 16.8° × 12.6° on the screen. Psychtoolbox-3 was used for controlling stimulus presentation.
Participants performed a passive viewing task. Following Emmorey et al. (2010), participants were instructed to pay attention to all videos without explicitly trying to memorize them.
After scanning, participants received a short recognition test to examine whether they observed the stimuli in the scanner. Twenty-five video clips were presented, of which five clips were novel, and 20 clips were shown in the scanner. The participants were asked to judge whether they had seen them during the experiment. The mean accuracy was 78% for the deaf group and 70% for the hearing group, with no significant difference between groups [t(19) = 0.96, P > 0.05].
An identical procedure to Experiment 1 was used for data collection, preprocessing, and whole brain analysis of the fMRI data. The only exceptions were that the first 14 s (7 volumes) in each functional run were discarded and that we did not apply slice timing correction. The critical contrast was the comparison between the action observation condition and the fixation baseline. In parallel to Experiment 1, we carried out whole brain analysis and ROI analysis to test whether the deaf and hearing groups differed in terms of brain activation patterns when viewing actions.
Areas recruited during passive action observation were identified by the contrast Action Observation Task > Fixation (FDR q < 0.05), revealing widely distributed regions in the inferior frontal, parietal, posterior temporal and occipital cortex in both deaf and hearing individuals (Figures 2 and 4, first two rows).
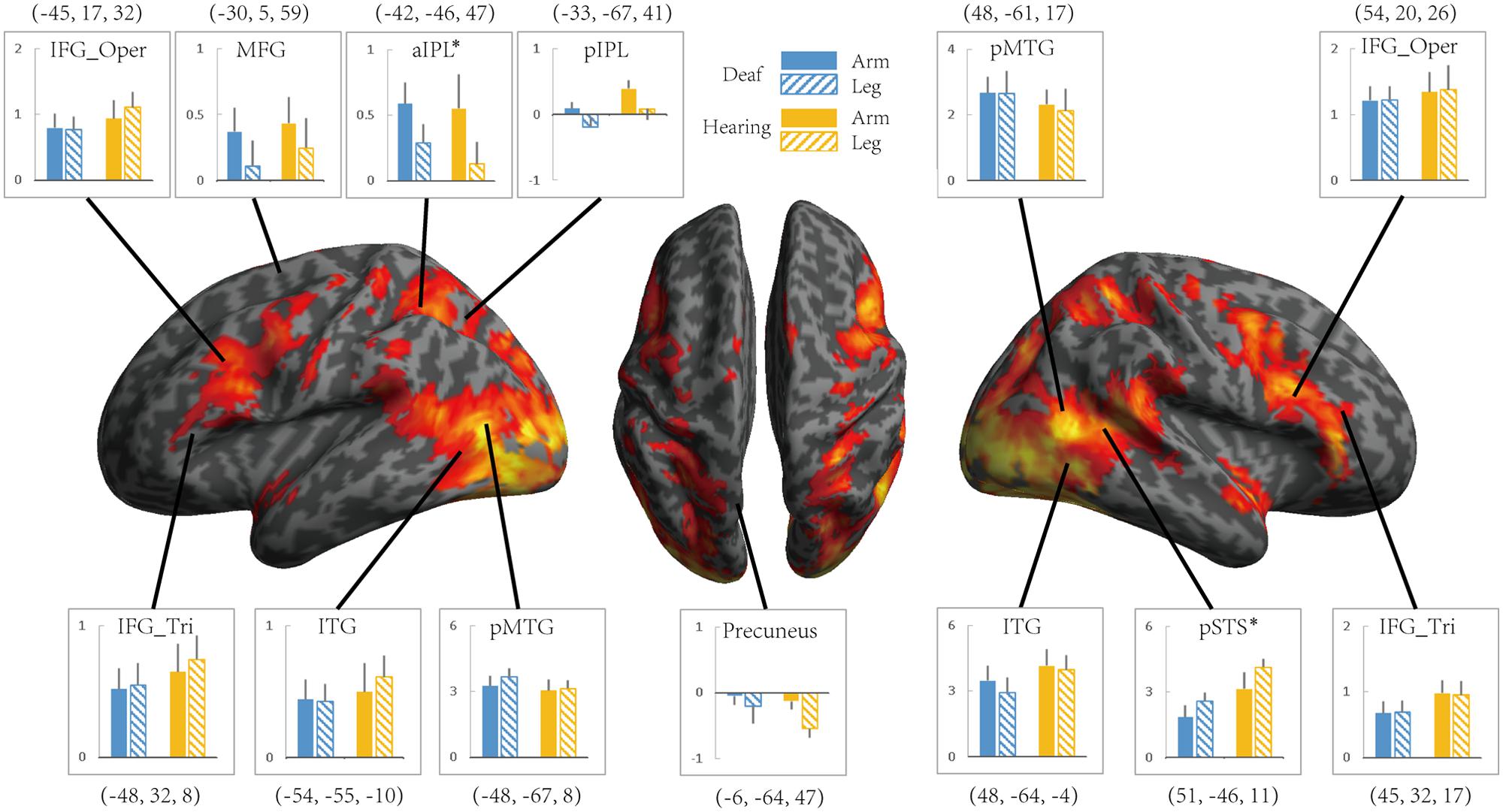
FIGURE 4. The effect of the Effector for Action Observation in Experiment 2. Areas recruited during action observation (contrast Action Observation > Fixation baseline) in Experiment 2 for all participants (FDR q < 0.05). ROIs were defined in Experiment 1 by the contrast Action Judgment Task > Red Dot (FWE P < 0.05). Colors and symbols are the same as in Figure 3.
The whole-brain group comparison between the two groups yielded no region that was more active for the hearing compared to deaf individuals (FDR q < 0.05). Regions in the bilateral superior and middle temporal gyrus showed significantly stronger activation in deaf individuals than in hearing controls [for left, peak, -63, -10, -1, size, 295 voxels; for right, peak, 63, -10, 2, size, 344 voxels] (Figure 2, bottom row).
We further tested the effects of Group and Effector in the ROIs identified in Experiment 1 (see Figure 3 for the ROIs) by carrying out ANOVA of 2 (deaf vs. hearing) × 2 (arm vs. leg) for each of the ROIs, with the dependent variable being the beta estimate of the contrast (action passive viewing vs. fixation). The result is shown in Figure 4 and Table 7. We found a main effect of Effector in two regions: left aIPL [F(1,19) = 12.97, P < 0.005] and right pSTS [F(1,19) = 26.13, P < 0.001]. Arm actions evoked a greater activation than leg actions in left aIPL, whereas we found the opposite pattern in the right pSTS. No region showed the main effector of Group or an interaction between Effector and Group.
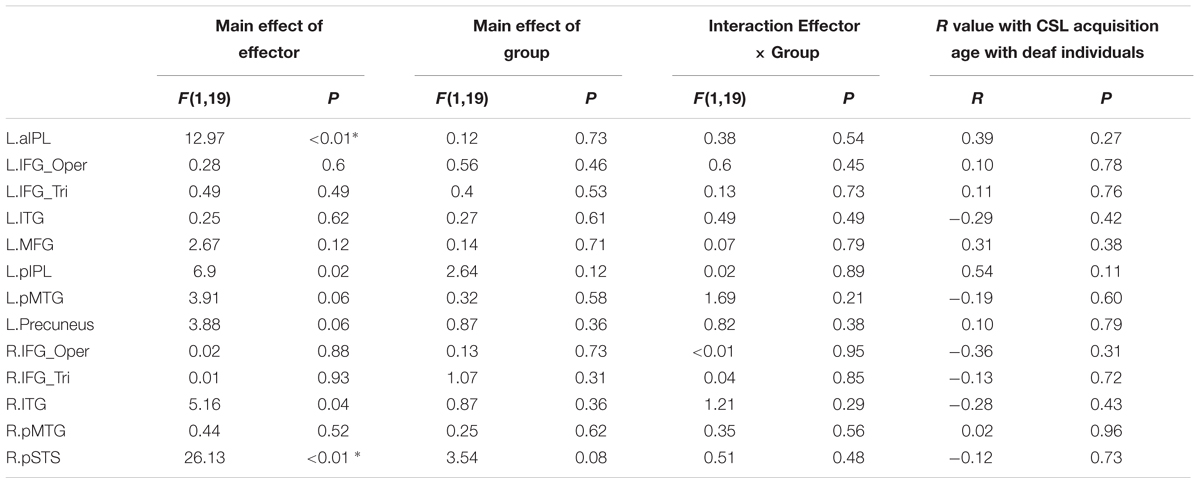
TABLE 7. Statistical details for main effect of Effector, Group, Interaction Effector × Group and R value with CSL acquisition age with deaf individuals during action observation in Experiment 2 (asterisk indicates P < 0.004, significant at Bonferroni corrected 0.05 for multiple comparisons across 13 ROIs).
For the ROIs described above, no region exhibited a significant association between the strength of the BOLD signal and the age of CSL acquisition across deaf participants (Ps > 0.1, Table 7). When the deaf individuals were divided into groups with early or late CSL acquisition (see Experiment 1, Table 6), no difference was observed between the two groups in any ROI (Bonferroni corrected P < 0.05).
In this study, we used both an action judgment task and a passive action observation task to investigate whether the processing of arm- and leg-related actions is affected by auditory experience deprivation and/or sign language experience. We found highly similar activation in the action observation network in congenitally deaf and hearing individuals in both action judgment and passive action observation tasks. Whole brain analyses showed that both groups recruited a comparable network of parieto-frontal regions, including IFG, IPL, and pMTG. Both the whole brain analyses and the ROI analyses showed that the activation amplitude between the two groups were comparable. Likewise, the potential effects of effector type (arm, leg) or task (Effector task, Goal task) did not differ across groups, and that the activation in the action observation network within the deaf group did not seem to be influenced by sign language experience. Taken together, we observed that the action-understanding-related areas were similarly recruited when congenitally deaf participants or hearing controls processed action stimuli, in both action understanding tasks and a passive viewing task.
We aimed at evaluating the origins of the absence of hMS activation during action observation previously reported in congenitally deaf individuals by assessing the effects of task, effector type, and sign language experience. In contrast to previous studies (Corina et al., 2007; Emmorey et al., 2010), we observed robust activation in IFG and IPL in both hearing and deaf individuals. In addition, both groups showed robust activation in STS and pMTG, highly consistent with more recent studies on the neural basis of action understanding (Oosterhof et al., 2012; Lingnau and Petris, 2013; Lingnau and Downing, 2015; Tarhan et al., 2015; Wurm and Lingnau, 2015; Wurm et al., 2015). That is, both the hMS (IFG, IPL, STS) and pMTG are resilient to the auditory experience deprivation and to the adoption of a new action system, i.e., sign language. While both hemispheres were activated, there was a tendency of left lateralization, with larger regions in the left hemispheric (left MFG and left IPL) being recruited during action understanding in both groups, in line with the literature on hearing populations (Rocca et al., 2008; Lingnau and Petris, 2013).
Note that ideally adding a hearing sign user group and/or a deaf group without sign language experience would help tease apart the roles of auditory experience and sign language experience. Also note that we here tested the effects of sign language experience rather than sign language fluency. It would be interesting to further examine whether there is subtle modulation effect of hMS activation associated with fluency. However, given that we observed comparable-to-hearing hMS activation in congenital deaf groups who use CSL as the primary language, it is safe to conclude that hMS activation is robust to the presence of both auditory deprivation and sign language usage. Below we discuss possible reasons for the discrepancy between our results and the two previous studies showing no hMS activation in deaf (Corina et al., 2007; Emmorey et al., 2010), in the context of implications of these results in the functional properties of areas involved during action understanding.
Several aspects differing between our current study and the previous studies are worth considering, including tasks, stimulus properties, and subject characteristics. In Experiment 1 we used point-light animations and tasks that require understanding, as opposed to the passive viewing task used in the previous two studies where understanding was not necessary. In Experiment 2, we administered a passive viewing task similar to that used by Corina et al. (2007) and Emmorey et al. (2007), but found similar results as in Experiment 1. That is, the mismatch between our results and those observed by Corina et al. (2007) and Emmorey et al. (2010) cannot readily be explained by task variables.
The difference in subject sampling might be more relevant. Deaf individuals in the previous two studies were all native signers who were exposed to ASL from birth, whereas in our cohort only three individuals were native signers. Emmorey et al. (2010) contended that sign language experience improved the neural efficiency within the hMS, leading to reduced activation. However, not only that this proposal does not explain the absence of activation, it was further challenged by several additional observations. First, we did not obtain any correlation between sign language experience and activation strength in the hMS in either experiment. Second, given that CSL primarily involves hand and arm action, if CSL experience modulates hMS activation, one would predict that hand/arm and leg actions are processed differently in CSL users and non-users. However, while observing main effects of the effector in the hMS and other action related regions, we observed no interaction with the subject group. That is, arm actions were not treated differently by signers and by hearings subjects. Finally, we carried out individual analyses with the three native signers in our deaf group and observed robust activation of the hMS (IFG, IPL) and pMTG in each of these individuals.
Another intriguing difference lies in the properties of the stimuli. We specifically focused on avoiding actions that resembled sign language symbols in Experiment 2, which aimed to understand the general processing mechanism of actions when deaf participants viewed passive action video clips following previous studies. To assess whether the video stimuli contain the CNL symbols, we asked two native CNL deaf signers and a hearing sign language interpreter to judge whether the video stimuli were CNL symbols. All video stimuli were judged as “not CNL symbols.” While in both Corina et al. (2007) and Emmorey et al. (2007) ASL conditions were included to compare the activation in the hMS with and without linguistic processing. It is possible that processing sign language entails linguistic properties such as lexical, semantic, “phonological” or syntactic processing that are also processed by (subregions of) the hMS, resulting in the different hMS activations. Although most stimuli in Emmorey et al. (2010) were judged not to be linguistic, it is conceivable that the inclusion of even a small proportion of linguistically meaningful actions may encourage linguistic interpretation of the non-linguistic actions and thus affect the hMS activation. Note, however, that Corina et al. (2007) and Emmorey et al. (2007) did not obtain consistent results regarding sign language processing: while Corina et al. (2007) found a marked difference between the brain regions subserving linguistic and non-linguistic human actions in deaf signers, in the study of Emmorey et al. (2007), no region was significantly more engaged in processing ASL verbs compared to pantomimes. Emmorey et al. (2007) suggested that the pantomimes they used contained sentence-level concepts with both an agent and a patient, which evoked more extensive semantic processing than the ASL condition. The roles of the hMS and other action-related regions in sign language action processing warrant further clarifications (Neville et al., 1998; Alaerts et al., 2011; Rogalsky et al., 2013).
A few other findings outside the hMS are worth further discussion. First, when contrasting with fixation, regions outside of the action understanding network were observed, mostly in the primary visual cortex, likely reflecting responses to the presence of (low level) visual stimulation. More interestingly, using this contrast the deaf individuals showed stronger auditory cortex activation to visual stimuli (in comparison to the fixation baseline) than hearing controls. This is well in line with the classical literature of plastic changes in the auditory cortex in the case of auditory deprivation (Finney et al., 2001, 2003; Pekkola et al., 2005). Another finding is more puzzling. The regions showing significant effector effects differed across the two experiments, with left IFG and pMTG showing stronger responses to arm actions than leg actions in the action judgment task, and the left IPL and right pSTS showing stronger responses to arm and leg actions respectively in the passive viewing experiment. This difference might be related to the different arm and action stimuli used in the two experiments: Experiment 1 used simple throwing and kicking action point light displays with minimal object implications, while Experiment 2 used action videos containing highly rich contents implying various specific objects such as peeling a banana, playing a piano, or dancing a waltz. Such implied information associated with the specific actions may further modulate the hMS regions in complex manners. The important point in the current context, however, is that in neither experiment the effector effect interacted with groups, indicating that whatever variables caused the differences of effectors, they were not modulated by auditory experience.
Our results, that the action observation network is similarly recruited in individuals without hearing experience and with rich sign language experiences, corroborate previous studies demonstrating the recruitment of IFG, IPL, and pMTG during the recognition of sounds depicting actions in congenitally blind individuals (Ricciardi et al., 2009; Lewis et al., 2011). These results together suggest that some of the areas recruited during action understanding are not modulated by specific visual or auditory inputs. Such areas might represent or process “supra-modal” (Ricciardi et al., 2014) action knowledge that is not specific to individual modalities.
YB, ZH, and QC designed research; YF and QC performed research; YF and QC analyzed data; YF, QC, AL, and YB wrote the paper. AL provided the experimental materials.
This work was supported by the National Basic Research Program of China (2013CB837300 and 2014CB846103 to YB), National Natural Science Foundation of China (31221003 to YB and 31271115 to ZH) New Century Excellent Talents (12-0055 to YB and 12-0065 to ZH), and the Provincia Autonoma di Trento and the Fondazione Cassa di Risparmio di Trento e Rovereto (AL).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
We thank Qixiang Lin for help with data preprocessing, and Hongyu Li for data collection.
The Supplementary Material for this article can be found online at: http://journal.frontiersin.org/article/10.3389/fnhum.2016.00094
Alaerts, K., Swinnen, S. P., and Wenderoth, N. (2011). Action perception in individuals with congenital blindness or deafness: how does the loss of a sensory modality from birth affect perception-induced motor facilitation? J. Cogn. Neurosci. 23, 1080–1087. doi: 10.1162/jocn.2010.21517
Brainard, D. H. (1997). The psychophysics toolbox. Spat. Vis. 10, 433–436. doi: 10.1163/156856897X00357
Brass, M., Schmitt, R. M., Spengler, S., and Gergely, G. (2007). Investigating action understanding: inferential processes versus action simulation. Curr. Biol. 17, 2117–2121. doi: 10.1016/j.cub.2007.11.057
Buccino, G., Vogt, S., Ritzl, A., Fink, G. R., Zilles, K., Freund, H.-J., et al. (2004). Neural circuits underlying imitation learning of hand actions: an event-related fMRI study. Neuron 42, 323–334. doi: 10.1016/S0896-6273(04)00181-3
Caramazza, A., Anzellotti, S., Strnad, L., and Lingnau, A. (2014). Embodied cognition and mirror neurons: a critical assessment. Annu. Rev. Neurosci. 37, 1–15. doi: 10.1146/annurev-neuro-071013-013950
Carr, L., Iacoboni, M., Dubeau, M.-C., Mazziotta, J. C., and Lenzi, G. L. (2003). Neural mechanisms of empathy in humans: a relay from neural systems for imitation to limbic areas. Proc. Natl. Acad. Sci. U.S.A. 100, 5497–5502. doi: 10.1073/pnas.0935845100
Caspers, S., Zilles, K., Laird, A. R., and Eickhoff, S. B. (2010). ALE meta-analysis of action observation and imitation in the human brain. Neuroimage 50, 1148–1167. doi: 10.1016/j.neuroimage.2009.12.112
Corina, D., Chiu, Y. S., Knapp, H., Greenwald, R., San Jose-Robertson, L., and Braun, A. (2007). Neural correlates of human action observation in hearing and deaf subjects. Brain Res. 1152, 111–129. doi: 10.1016/j.brainres.2007.03.054
De Lange, F. P., Spronk, M., Willems, R. M., Toni, I., and Bekkering, H. (2008). Complementary systems for understanding action intentions. Curr. Biol. 18, 454–457. doi: 10.1016/j.cub.2008.02.057
Emmorey, K., Mehta, S., and Grabowski, T. J. (2007). The neural correlates of sign versus word production. Neuroimage 36, 202–208. doi: 10.1016/j.neuroimage.2007.02.040
Emmorey, K., Xu, J., Gannon, P., Goldin-Meadow, S., and Braun, A. (2010). CNS activation and regional connectivity during pantomime observation: no engagement of the mirror neuron system for deaf signers. Neurouimage 49, 994–1005. doi: 10.1016/j.neuroimage.2009.08.001
Finney, E. M., Clementz, B. A., Hickok, G., and Dobkins, K. R. (2003). Visual stimuli activate auditory cortex in deaf subjects: evidence from MEG. Neuroreport 14, 1425–1427. doi: 10.1097/00001756-200308060-00004
Finney, E. M., Fine, I., and Dobkins, K. R. (2001). Visual stimuli activate auditory cortex in the deaf. Nat. Neurosci. 4, 1171–1173. doi: 10.1038/nn763
Gazzola, V., Aziz-Zadeh, L., and Keysers, C. (2006). Empathy and the somatotopic auditory mirror system in humans. Curr. Biol. 16, 1824–1829. doi: 10.1016/j.cub.2006.07.072
Iacoboni, M., Woods, R. P., Brass, M., Bekkering, H., Mazziotta, J. C., and Rizzolatti, G. (1999). Cortical mechanisms of human imitation. Science 286, 2526–2528. doi: 10.1126/science.286.5449.2526
Keysers, C., Kohler, E., Umiltà, M. A., Nanetti, L., Fogassi, L., and Gallese, V. (2003). Audiovisual mirror neurons and action recognition. Exp. Brain Res. 153, 628–636. doi: 10.1007/s00221-003-1603-5
Kohler, E., Keysers, C., Umilta, M. A., Fogassi, L., Gallese, V., and Rizzolatti, G. (2002). Hearing sounds, understanding actions: action representation in mirror neurons. Science 297, 846–848. doi: 10.1126/science.1070311
Kriegeskorte, N., Simmons, W. K., Bellgowan, P. S., and Baker, C. I. (2009). Circular analysis in systems neuroscience: the dangers of double dipping. Nat. Neurosci. 12, 535–540. doi: 10.1038/nn.2303
Lahav, A., Saltzman, E., and Schlaug, G. (2007). Action representation of sound: audiomotor recognition network while listening to newly acquired actions. J. Neurosci. 27, 308–314. doi: 10.1523/JNEUROSCI.4822-06.2007
Lewis, J. W., Brefczynski, J. A., Phinney, R. E., Janik, J. J., and Deyoe, E. A. (2005). Distinct cortical pathways for processing tool versus animal sounds. J. Neurosci. 25, 5148–5158. doi: 10.1523/JNEUROSCI.0419-05.2005
Lewis, J. W., Frum, C., Brefczynski-Lewis, J. A., Talkington, W. J., Walker, N. A., Rapuano, K. M., et al. (2011). Cortical network differences in the sighted versus early blind for recognition of human-produced action sounds. Hum. Brain Mapp. 32, 2241–2255. doi: 10.1002/hbm.21185
Lingnau, A., and Downing, P. E. (2015). The lateral occipitotemporal cortex in action. Trends Cogn. Sci. 19, 268–277. doi: 10.1016/j.tics.2015.03.006
Lingnau, A., and Petris, S. (2013). Action understanding within and outside the motor system: the role of task difficulty. Cereb. Cortex 23, 1342–1350. doi: 10.1093/cercor/bhs112
Neville, H. J., Bavelier, D., Corina, D., Rauschecker, J., Karni, A., Lalwani, A., et al. (1998). Cerebral organization for language in deaf and hearing subjects: biological constraints and effects of experience. Proc. Natl. Acad. Sci. U.S.A. 95, 922–929. doi: 10.1073/pnas.95.3.922
Oosterhof, N. N., Tipper, S. P., and Downing, P. E. (2012). Viewpoint (in) dependence of action representations: an MVPA study. J. Cogn. Neurosci. 24, 975–989. doi: 10.1162/jocn_a_00195
Pekkola, J., Ojanen, V., Autti, T., Jääskeläinen, I. P., Möttönen, R., Tarkiainen, A., et al. (2005). Primary auditory cortex activation by visual speech: an fMRI study at 3 T. Neuroreport 16, 125–128. doi: 10.1097/00001756-200502080-00010
Ricciardi, E., Bonino, D., Pellegrini, S., and Pietrini, P. (2014). Mind the blind brain to understand the sighted one! Is there a supramodal cortical functional architecture? Neurosci. Biobehav. Rev. 41, 64–77. doi: 10.1016/j.neubiorev.2013.10.006
Ricciardi, E., Bonino, D., Sani, L., Vecchi, T., Guazzelli, M., Haxby, J. V., et al. (2009). Do we really need vision? How blind people “see” the actions of others. J. Neurosci. 29, 9719–9724. doi: 10.1523/JNEUROSCI.0274-09.2009
Rizzolatti, G., and Craighero, L. (2004). The mirror-neuron system. Annu. Rev. Neurosci. 27, 169–192. doi: 10.1146/annurev.neuro.27.070203.144230
Rizzolatti, G., Fogassi, L., and Gallese, V. (2001). Neurophysiological mechanisms underlying the understanding and imitation of action. Nat. Rev. Neurosci. 2, 661–670. doi: 10.1038/35090060
Rocca, M. A., Falini, A., Comi, G., Scotti, G., and Filippi, M. (2008). The mirror-neuron system and handedness: a “right” world? Hum. Brain Mapp. 29, 1243–1254. doi: 10.1002/hbm.20462
Rogalsky, C., Raphel, K., Tomkovicz, V., O’grady, L., Damasio, H., Bellugi, U., et al. (2013). Neural basis of action understanding: evidence from sign language aphasia. Aphasiology 27, 1147–1158. doi: 10.1080/02687038.2013.812779
Schwarzbach, J. (2011). A simple framework (ASF) for behavioral and neuroimaging experiments based on the psychophysics toolbox for MATLAB. Behav. Res. Methods 43, 1194–1201. doi: 10.3758/s13428-011-0106-8
Tarhan, L. Y., Watson, C. E., and Buxbaum, L. J. (2015). Shared and distinct neuroanatomic regions critical for tool-related action production and recognition: evidence from 131 left-hemisphere stroke patients. J. Cogn. Neurosci. 27, 2491–2511. doi: 10.1162/jocn_a_00876
Thomas, J. P., and Shiffrar, M. (2010). I can see you better if I can hear you coming: action-consistent sounds facilitate the visual detection of human gait. J. Vis. 10:14. doi: 10.1167/10.12.14
Wang, X., Caramazza, A., Peelen, M. V., Han, Z., and Bi, Y. (2015). Reading without speech sounds: VWFA and its connectivity in the congenitally deaf. Cereb. Cortex 25, 2416–2426. doi: 10.1093/cercor/bhu044
Wurm, M. F., Ariani, G., Greenlee, M. W., and Lingnau, A. (2015). Decoding concrete and abstract action representations during explicit and implicit conceptual processing. Cereb. Cortex doi: 10.1093/cercor/bhv169 [Epub ahead of print].
Keywords: action recognition, mirror neuron, deaf, auditory experience, sign language
Citation: Fang Y, Chen Q, Lingnau A, Han Z and Bi Y (2016) Areas Recruited during Action Understanding Are Not Modulated by Auditory or Sign Language Experience. Front. Hum. Neurosci. 10:94. doi: 10.3389/fnhum.2016.00094
Received: 14 October 2015; Accepted: 22 February 2016;
Published: 08 March 2016.
Edited by:
Nathalie Tzourio-Mazoyer, Centre National de la Recherche Scientifique, Commissariat à l’Energie Atomique – Université de Bordeaux, FranceReviewed by:
Monica Baciu, Université Pierre-Mendès-France, FranceCopyright © 2016 Fang, Chen, Lingnau, Han and Bi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yanchao Bi, eWJpQGJudS5lZHUuY24=
†These authors have contributed equally to this work.
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.