 Lei Chen1
Lei Chen1 Haiting Xu2Jianqing He3Chunlei Zhang3
Haiting Xu2Jianqing He3Chunlei Zhang3 Andrew I. R. Maas4Daan Nieboer4,5Rahul Raj6Hong Sun4
Andrew I. R. Maas4Daan Nieboer4,5Rahul Raj6Hong Sun4 Yuhai Wang1,3*
Yuhai Wang1,3*- 1Department of Neurosurgery, Wuxi Clinical Hospital, Anhui Medical University (The 904th Hospital of PLA), Wuxi, China
- 2Department of Emergency, Joint Logistics Support Unit No. 904 Hospital, Wuxi, China
- 3Department of Neurosurgery, Neurotrauma Centre of PLA, Joint Logistics Support Unit No. 904 Hospital, Wuxi, China
- 4Department of Neurosurgery, Antwerp University Hospital and University of Antwerp, Edegem, Belgium
- 5Department of Public Health, Erasmus MC, Rotterdam, Netherlands
- 6Department of Neurosurgery, Helsinki University Hospital, Helsinki, Finland
Background and aim: Prediction models for patients with traumatic brain injury (TBI) require generalizability and should apply to different settings. We aimed to validate the IMPACT and Helsinki prognostic models in patients with TBI who underwent cranial surgery in a Chinese center.
Methods: This validation study included 607 surgical patients with moderate to severe TBI (Glasgow Coma Scale [GCS] score ≤12) who were consecutively admitted to the Neurotrauma Center of People's Liberation Army (PLANC), China, between 2009 and 2021. The IMPACT models (core, extended and lab) and the Helsinki CT clinical model were used to estimate 6-month mortality and unfavorable outcomes. To assess performance, we studied discrimination and calibration.
Results: In the PLANC database, the observed 6-month mortality rate was 28%, and the 6-month unfavorable outcome was 52%. Significant differences in case mix existed between the PLANC cohort and the development populations for the IMPACT and, to a lesser extent, for the Helsinki models. Discrimination of the IMPACT and Helsinki models was excellent, with most AUC values ≥0.80. The highest values were found for the IMPACT lab model (AUC 0.87) and the Helsinki CT clinical model (AUC 0.86) for the prediction of unfavorable outcomes. Overestimation was found for all models, but the degree of miscalibration was lower in the Helsinki CT clinical model.
Conclusion: In our population of surgical TBI patients, the IMPACT and Helsinki CT clinical models demonstrated good performance, with excellent discrimination but suboptimal calibration. The good discrimination confirms the validity of the predictors, but the poorer calibration suggests a need to recalibrate the models to specific settings.
Introduction
Traumatic brain injury (TBI) is a leading cause of mortality and disability in China, affecting up to 2% of the population per year (1, 2). A recent population-based study, extrapolating from data from China's disease surveillance points system, reported an age-adjusted mortality rate of ~13 per 100,000 population over 2013. The patient volume is very high in most Chinese centers, and a great need is felt for prognostic models for predicting outcome that apply to the setting in China. If applicable, these models could serve as a tool to evaluate healthcare levels of different healthcare institutions as a new plan for brain injury. Uncertainty, however, exists if models developed in other settings apply to the situation in China, where decompressive craniectomy is frequently performed in patients with more severe TBI (3). A relatively large number of prognostic models have been developed for TBI, but only two have been developed on large patient numbers and validated externally: the CRASH (Corticosteroid Randomization After Significant Head injury) (4) and IMPACT (5) (International Mission for Prognosis and Analysis of Clinical Trials in TBI) prognostic models. More recently, the Helsinki CT (computerized tomography) clinical model was proposed based on the Helsinki CT score and clinical parameters (6). Good performance was reported, but external validation in a new setting has not yet been performed. External validation is important to assess generalizability and to support the use of the models for a wide range of applications, since differences in treatment and health care organization between populations exist and may affect the performance of models (6, 7). In our setting, which serves as a regional referral center for neurotrauma, a large number of patients admitted for TBI are treated surgically either for evacuation of a mass lesion or for treatment of raised intracranial pressure (ICP) by decompressive craniectomy. For this validation study, we focused on the IMPACT prognostic models as they have been previously extensively validated and on the Helsinki CT clinical model, as the development population for this model is more recent and shows better comparability to our patient cohort than that of the IMPACT models.
This study aimed to explore the applicability of the IMPACT and Helsinki CT clinical models for the prediction of 6-month mortality and unfavorable outcomes in a cohort of TBI patients in China who underwent surgical treatment.
Methods
Study population
The study was conducted at the Neurotrauma Center of the People's Liberation Army (PLANC) in Wuxi, China, which provides emergency neurosurgical care for a regional population of approximately 6,500,000 people. The standard medical management of raised intracranial pressure (ICP) was based on the 2007 Brain Trauma Foundation guidelines (8). Data on patients with TBI are prospectively included in the ongoing PLANC database. Data collected included patient demographics (age, sex, and ethnicity), mechanism of injury (falls, road traffic incidents, assault and others), severity of injury (Glasgow Coma Scale [GCS] score, pupillary response, and presence of extracranial injuries), second insults (hypoxia, hypotension, and hypo/hyperthermia), lab tests (hemoglobin and glucose levels), brain CT characteristics, surgical therapy and 6-month outcome. Data on admission characteristics were collected before any hospital intervention. Outcome was assessed according to the Glasgow Outcome Scale (GOS) by a staff neurosurgeon during the follow-up visit (Appendix 1). The cohort consisted of 607 consecutive patients who had undergone cranial surgery for TBI between 2009 and 2021. The following inclusion criteria were applied: patients older than 14 years, with an admission GCS score ≤12, admitted within 8 h after injury. Additional radiological information, necessary to calculate the IMPACT models and the Helsinki CT score, was retrospectively obtained on central review by one of the authors (C.L.Z.) blinded to the outcome.
The local IRB of the People's Liberation Army (PLANC) Hospital in Wuxi approved the study and waived the need for obtaining informed consent, as the study is purely observational.
Indications for surgical management
Surgical management of intracranial mass lesions conformed to published guidelines (9, 10). Within the hospital, a relatively liberal indication exists for performing a decompressive craniectomy. This was performed in the following situations: (1) After evacuation of a mass lesion (a large bony decompression usually performed within the confines of patient positioning), if the brain is swollen or ICP remains consistently above 20 mmHg after the bone flap is replaced. (2) as treatment of raised ICP, refractory to medical therapy.
Unilateral decompression was performed when the cerebral swelling was predominantly in one hemisphere; bifrontal decompression was performed when the cerebral swelling was distributed over both hemispheres.
Prognostic models
The IMPACT prognostic models have been developed on large patient samples from multiple countries with state-of-the-art methodology and have been extensively validated externally (7, 11–15). The IMPACT models were developed on prospectively collected data from adult patients (age ≥14 years) with a GCS score of ≤12 who had been included in eight randomized controlled trials (RCTs) and three observational series (total n = 8,509) between 1984 and 1997 (5, 16). The IMPACT core model is based on three basic predictors: age, the GCS motor scale component and pupillary reactivity. The IMPACT extended model further includes the presence of second insults (hypoxia and hypotension), the Marshall CT classification, presence of an epidural hematoma (EDH) and presence of traumatic subarachnoid hemorrhage (tSAH) as additional predictors (5). The IMPACT lab model further adds admission glucose and hemoglobin concentrations. The more complex IMPACT models have been shown to have better discrimination.
The Helsinki CT clinical model was developed on patient data from an open-cohort retrospective study including 869 adults with traumatic brain injury aged 14 years or over (6). The Helsinki CT clinical model consists of the Helsinki CT score and three clinical variables (age, GCS motor scale component and pupillary reactivity) (http://links.lww.com/NEU/A676). The Helsinki CT score is based on four key variables: bleeding type and size, intraventricular hemorrhage, and status of suprasellar cisterns. In the development population, the Helsinki CT score showed good discrimination with an area under the receiver operating characteristic curve (AUC) of 0.74–0.75 for mortality and unfavorable outcomes. Combining the Helsinki CT score with clinical variables (i.e., Helsinki CT clinical model) increased the discriminative ability for mortality (non-significant) and significantly for unfavorable outcomes (6).
Statistical analyses and outcome assessment
Missing values of baseline characteristics were statistically imputed by applying a multiple imputation procedure following the Hmisc function in R software (AregImpute function in the R Hmisc package). The highest percentage of missing values was for the variable glucose (5%; Supplementary Table S1). Imputation of baseline variables is considered preferable to complete case analysis (17). Patient characteristics were summarized descriptively, reporting the median (and interquartile range) for continuous variables and frequency (percentage) for categorical variables. Differences in characteristics between data sets were analyzed by the chi-square test and Student's t-test. The prognostic effects of parameters in the PLANC study were assessed in a multivariable logistic regression model, and their strength was expressed by the odds ratio (OR). The odds ratios obtained were compared to those previously reported in the analysis of IMPACT data (5).
We evaluated the performance of the models in terms of discrimination and calibration. Discrimination informs how well the models distinguish between the outcomes of interest. The discriminative ability of the models was evaluated by the AUC. An AUC equal to 0.5 indicates that the discriminative ability of the model is no better than a coin toss, and an AUC of 1 indicates perfect discrimination. An AUC≥ 0.8 is considered to represent adequate discriminative ability of the model. Differences in discriminatory performance between the IMPACT and Helsinki models were analyzed with the DeLong test (18). Calibration refers to the agreement between predicted and observed outcomes. Calibration was quantified using calibration-in-the-large and the calibration slope and was assessed visually using calibration plots. Calibration-in-the-large measures whether predicted risks are systematically too high or too low and ideally should be equal to zero (19). The calibration slope measures whether predictor effects are on average too strong or too weak and should ideally be equal to one. Furthermore, we calculated Nagelkerke R2 values as a measure of overall model performance. All statistical analyses were performed in R version 2.10 (R Foundation, Vienna, Austria).
Results
Data were collected on 607 surgical patients with moderate to severe TBI admitted to our neurotrauma intensive care unit between 2009 and 2021 in Wuxi, China. Decompressive craniectomy was performed in 531 cases (87%). Of these, 449 patients (85%) underwent unilateral decompressive craniectomy, and 82 patients (15%) underwent bilateral decompressive craniectomy. Details on the surgical and CT characteristics of the PLANC cohort are described in Table 1.
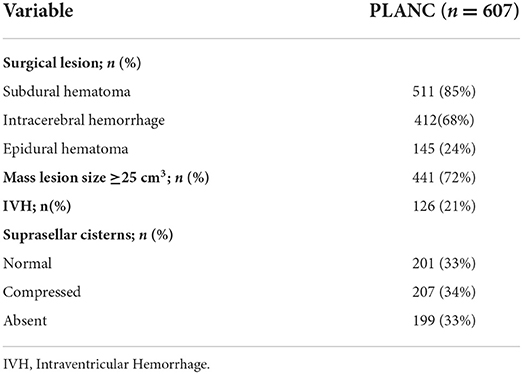
Table 1. Surgical and computerized tomography characteristics of the PLANC cohortsa.
Comparison of cohorts
Table 2 presents the baseline characteristics of the PLANC cohort and compares these to the patient characteristics of the cohorts used to develop the IMPACT and the Helsinki CT clinical models. Compared to the IMPACT cohort, patients in the PLANC cohort were significantly older (median of 48 vs. 30 years), had a higher proportion of one non-reactive pupil (26 vs. 12%), higher proportions of hypoxia, hypotension, tSAH, EDH and more patients with a GCS motor score of 5 or 6 (50 vs. 30%). No patients in PLANC had a CT classification of I (no visible damage) or II (abnormalities present, but no mass lesion or signs of raised intracranial pressure) vs. 42% in IMPACT. The percentage of patients in CT Class V/VI (mass lesion) was nearly twice as high in PLANC compared to IMPACT (70 vs. 38%). The frequency of the 6-month vegetative state was higher in the PLANC cohort than in the IMPACT cohort (12 vs. 4%, p < 0.05), as was the proportion of unfavorable outcomes (52 vs. 48%).
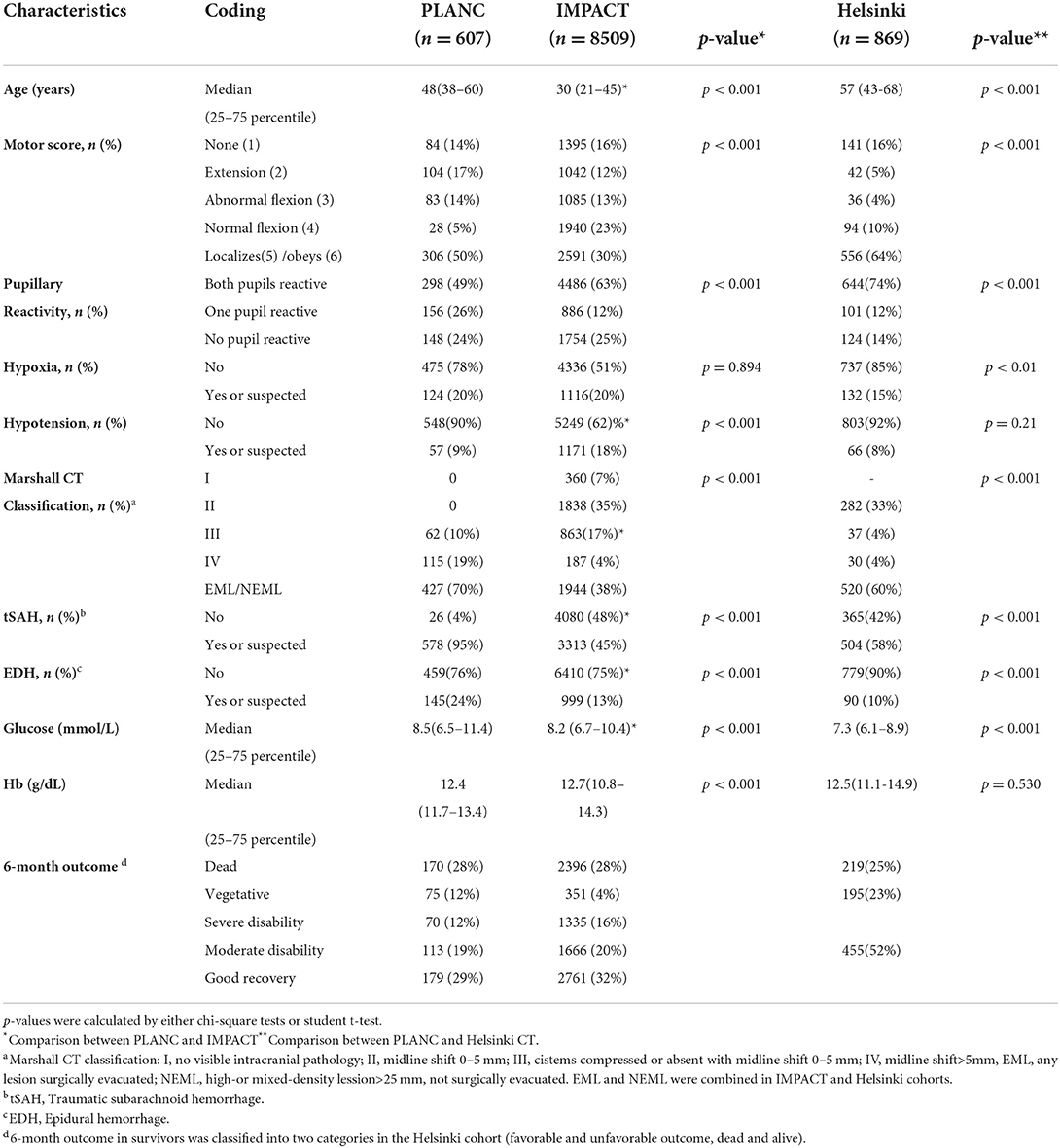
Table 2. Characteristics of patients in IMPACT study (no imputation of missing values), Helsinki and PLANC cohorts.
Compared to the Helsinki cohort, patients in PLANC were younger (median 48 vs. 57 years), less often had a GCS motor score of 5 and 6 (50 vs. 64%), but more often had one or two non-reactive pupils (26, 24 vs. 12, 14%, respectively; p < 0.001). The percentage of patients with hypoxia, tSAH, and EDH was higher in the PLANC cohort. A difference existed in the percentage of patients in CT Class V/VI (mass lesion) between PLANC and Helsinki (70 vs. 60%), but this was less pronounced than for IMPACT (38%).
Predictor effects
A detailed overview of the associations between baseline characteristics and 6-month GOS is presented in Supplementary Table S2. Compared to IMPACT, PLANC patients with a GCS motor scale of 1–3, with absent pupillary activity, hypoxia, and hypotension had a poorer outcome. Compared to Helsinki, those with an absent motor response, hypoxia, hypotension or an EDH had poorer outcomes in PLANC. A detailed comparison of predictor effects between the IMPACT and PLANC cohorts is shown in Table 3. The effects of absent motor score, EDH, hypotension and glucose were all stronger in PLANC, whereas that of age was weaker in PLANC. The predictor effects of hemoglobin were in the opposite direction to those described for IMPACT.
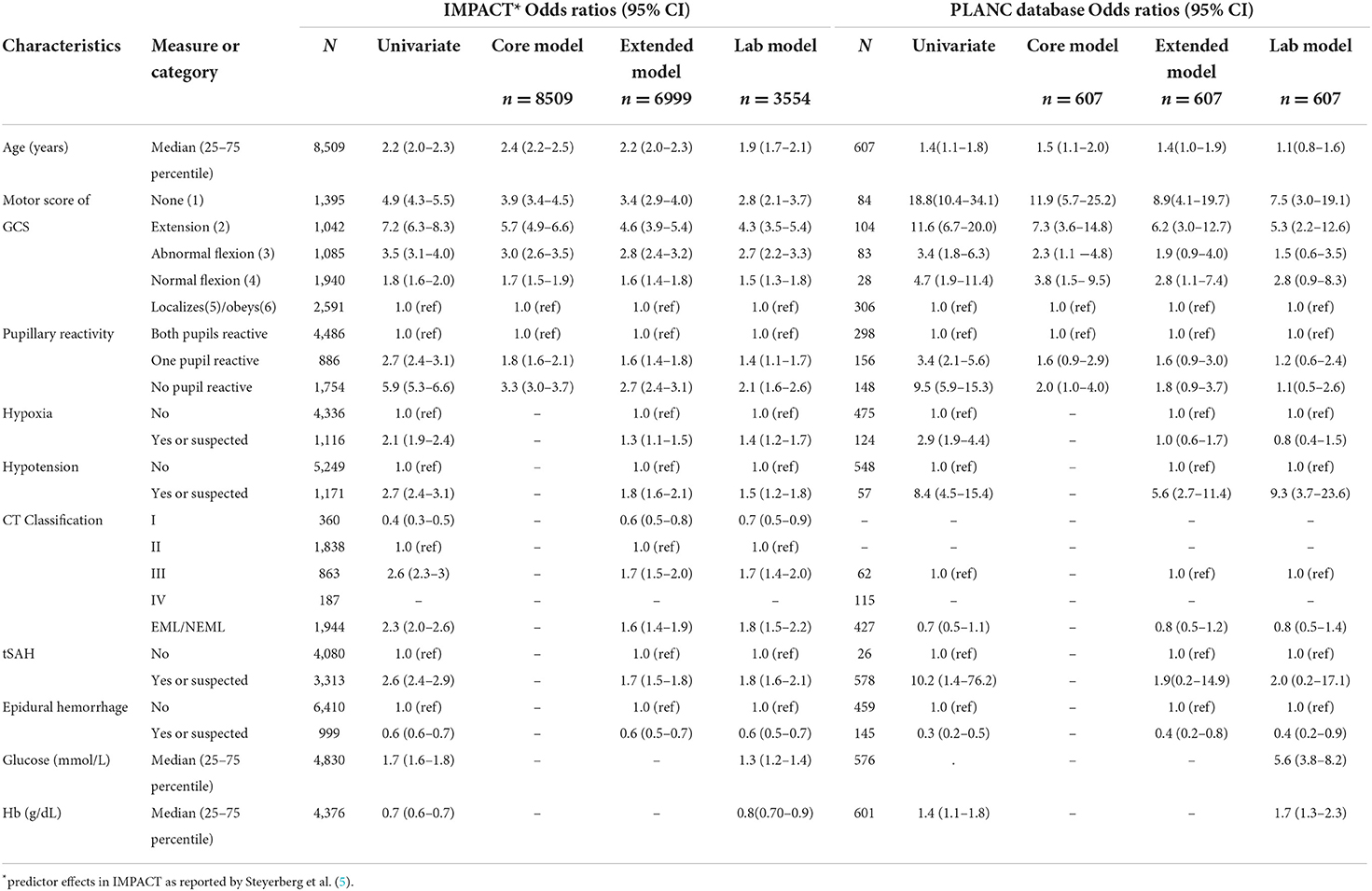
Table 3. Predictor effects in IMPACT (n = 8,509) and PLANC cohorts (n = 607) (missing values were imputed).
Prognostic model performance
Discrimination
The IMPACT models and Helsinki CT clinical model showed good ability to discriminate between survival and death and between favorable and unfavorable outcomes (Table 4, Figure 1), with AUC values mostly over 0.8. Higher values were achieved for the prediction of unfavorable outcomes than for mortality in nearly all cases. The IMPACT core model and the IMPACT extended model had AUCs of 0.80 (95% CI, 0.77–0.84) and 0.79 (95% CI, 0.75–0.83), respectively, for predicting mortality and 0.83 (95% CI, 0.80–0.86) and 0.84 (95% CI, 0.81–0.88), respectively, for predicting unfavorable outcomes for the 607 patients in the PLANC cohort. When applying the IMPACT lab model, the discrimination improved with an AUC of 0.87 for both mortality (95% CI, 0.84–0.91) and unfavorable outcomes (95% CI, 0.84–0.92). The Helsinki CT clinical model showed very similar discriminative ability for mortality (AUC 0.80, 95% CI 0.76–0.83) and unfavorable outcome (AUC 0.86, 95% CI 0.83–0.89). The Helsinki CT clinical model showed comparable discrimination with the IMPACT core and extended model for predicting 6-month mortality. The IMPACT lab model had a significantly higher AUC than the Helsinki CT clinical model for predicting 6-month mortality (AUC 0.87 vs. AUC 0.80, p < 0.001). Conversely, the Helsinki CT clinical model had significantly higher AUC values for predicting 6-month unfavorable outcomes than the IMPACT core and extended models (AUC 0.86 vs. AUC 0.83–0.84, p < 0.05 for both). However, the AUC values for the Helsinki CT clinical model and the IMPACT lab model were comparable for predicting unfavorable outcomes (AUC 0.86 vs. AUC 0.87, p > 0.05).
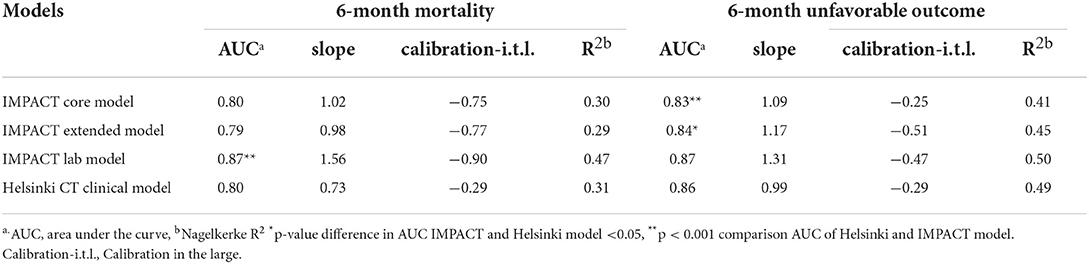
Table 4. Validation of IMPACT models and Helsinki CT clinical model for prediction of 6-month mortality and unfavorable outcome in PLANC cohort.
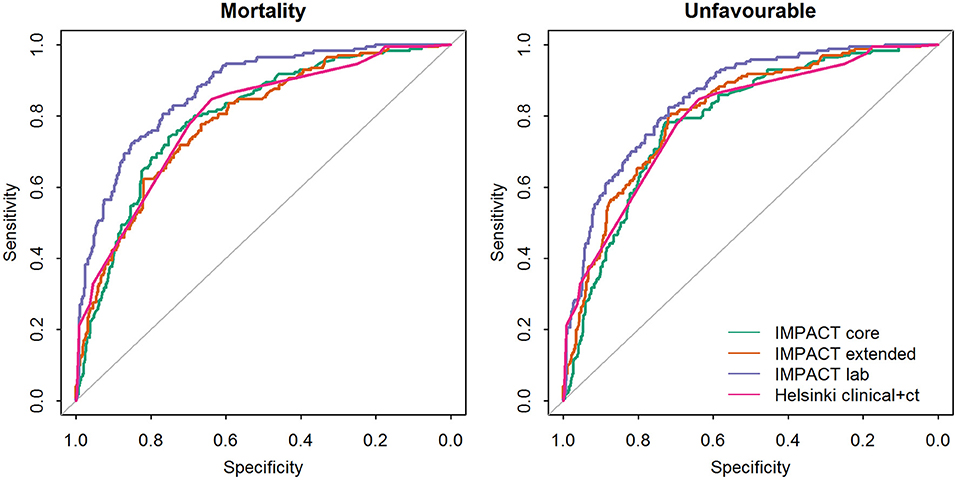
Figure 1. Comparison of the areas under the receiver operating characteristic curve (AUC's) between the prognostic models validated on the PLANC cohort.
Calibration
The calibration plots showed a reasonable agreement between observed and predicted outcomes for all models, which was generally better for the prediction of unfavorable outcomes (Figure 2). Overestimation was, however, substantial for the IMPACT models. The observed frequencies of unfavorable outcomes and death were lower than those predicted in all cases for the IMPACT models (calibration-in-the-large < 0). The calibration slopes of the IMPACT core and extended model were close to one, while the predictor effects of the IMPACT lab model were on average too weak. The calibration slope of the Helsinki CT clinical model was well-below one, indicative of predictive risks that were too high. The calibration slope of the Helsinki CT clinical model predicting an unfavorable outcome was close to one.
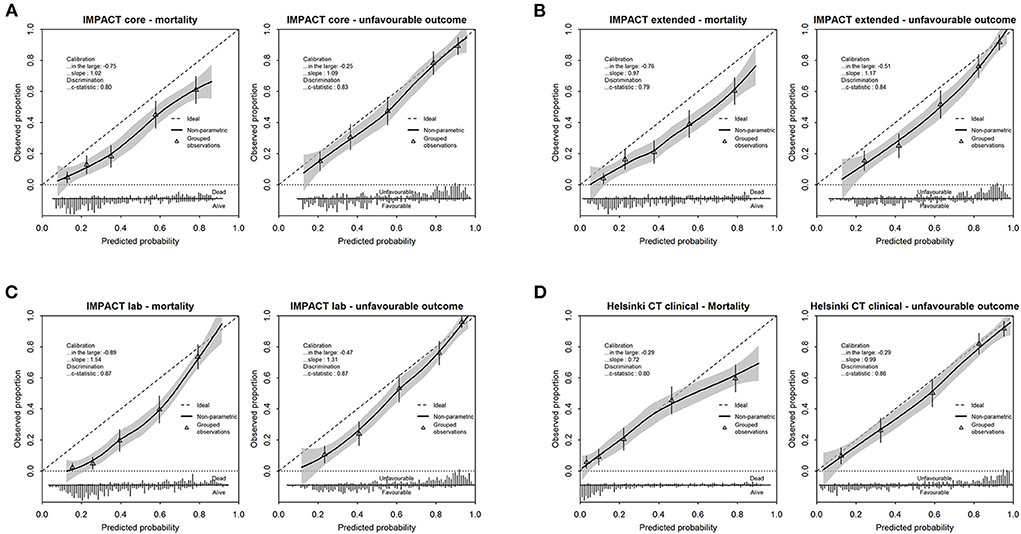
Figure 2. Calibration plots depicting observed vs. predicted outcome for mortality and unfavorable outcome for the IMPACT models [core model (A), extended model (B), lab model (C)] and Helsinki CT clinical model (D). Performance parameters (calibration in the large, slope and c-statistic) are displayed in each calibration plot. The frequencies of predicted probabilities, differentiated for the observed outcome of interest, is presented in the lower bar graph.
When predicting 6-month mortality, the IMPACT lab model showed the highest Nagelkerke R2 (0.47). The R2 values of the other IMPACT models and the Helsinki model were comparable, with values of ~0.30. The R2 values when predicting an unfavorable outcome were highest for the IMPACT lab model and Helsinki model (0.50 and 0.49) and lower for the IMPACT core and IMPACT extended model (0.41 and 0.45, respectively).
Discussion
Prognostication is important, especially when considering a potentially life-saving but not necessarily restorative surgical intervention (20, 21). Uncertainty, however, exists if prediction models developed in broad populations and other settings may apply to the specific population of surgical patients with TBI, of whom a large number underwent decompressive craniectomy. This external validation study demonstrated that both the IMPACT and the Helsinki CT clinical model provided adequate to good prediction of 6-month mortality and outcome in surgical patients with TBI, consistent with other validation studies (7, 11–15). Notably, significant differences did exist between model iterations in predictive performance. The more complex IMPACT models and the Helsinki CT clinical model consistently provided greater predictive power than the IMPACT core model. The use of CT predictor variables can explain the superiority. We found that all the models suffered from an overestimation of 6-month outcome risk (i.e., the models' predicted risk of poor outcome was higher than the observed frequency of poor outcome). We considered several potential causes contributing to the observed differences in model performance: case mix and treatment, predictor effects and geographical setting.
Case-mix and therapy
The population we focused on was very different from that on which the IMPACT models were developed but more comparable to the Helsinki population. In particular, mass lesions were more frequent in PLANC than in IMPACT (70 vs. 38%). In the Helsinki cohort, a mass lesion was recorded in 60% of cases. This difference may largely explain the poor calibration intercept of the IMPACT models compared to the Helsinki CT clinical model. The second major difference relates to the rate of surgery. In the PLANC cohort, all patients underwent surgical therapy. In the IMPACT studies, the rate of surgery was substantially lower and varied, being 37 to 39% in the observational studies underpinning IMPACT and 11–38% with a median of 27% in the randomized clinical trials. In the Helsinki cohort, the rate of surgery was 35%. More than 85% of our patients underwent a decompressive craniectomy following the development of intractable intracranial hypertension or evacuation of an intracranial hematoma (Table 5). Miscalibration of the CRASH model in patients undergoing a decompressive craniectomy has previously been reported by Honeybull et al. (22). In a cohort of 270 patients undergoing decompressive craniectomy, they – like us – found excellent discriminatory ability but poor calibration. An interaction between the effectiveness of decompressive craniectomy and the severity of TBI should perhaps be considered and may explain the higher rate of unfavorable outcomes (74%) in patients who had undergone bilateral decompression (n = 82) compared to those with unilateral decompression (53%; n = 449). The poor outcome in patients with bilateral decompression (diffuse injury) is consistent with the results of the DECRA study (23).
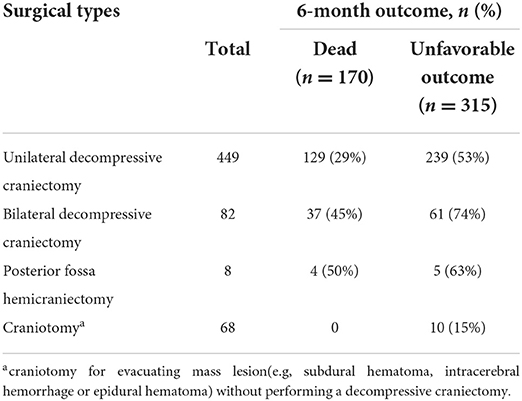
Table 5. Differences in surgical types were examined as a potential explanation for outcome in PLANC cohort.
Predictor effects
Predictor effects were different in the validation data. Compared to the IMPACT cohort, specifically the prognostic strength of a low GCS motor score (no response or extension) and non-reactive pupillary responses were much stronger, while EDH and tSAH were smaller in the PLANC cohort (Table 3). The substantially stronger effect of an absent motor score is likely explained by the fact that in our region, only a few patients are sedated and intubated at the scene of the accident. As a consequence, an absent motor score accurately reflects a poor neurological condition without being influenced by the effects of sedation. A false low GCS score has been reported in 13% of patients with severe TBI (24). Miscalibration might also occur because of differences in the scoring of GOS between settings; these changes may influence both the outcome distribution and predictor effects and lead to miscalibration (7).
Geographic setting
The different geographic settings of PLANC recruitment with enrollment of exclusively Asian patients may also be a relevant factor. In Asian patients, poorer outcomes were found, but the numbers were too small to permit definitive conclusions. To date, it is uncertain whether these differences may be related to genetic constitution or possibly result from disparities in treatment. Differences in outcomes related to geographic location have previously been identified in the CRASH trial (4).
Perspective
We consider that differences in case-mix and in predictor effects have mainly contributed to the poor calibration of the models. It would appear unlikely that geographic setting or race were of major influence, as we found a better than predicted outcome, which would be opposite to the effects attributed to race. Despite substantial differences in baseline characteristics between the PLANC and Helsinki cohorts, the proportion of patients with a mass lesion was much more comparable between these cohorts than between PLANC and IMPACT. This better comparability may explain the better calibration of the Helsinki CT clinical model. The high discriminative performance of both models confirms the validity of the predictors. Nevertheless, the presence of miscalibration suggests the need to recalibrate models when used in very different settings than the development population. As the standards of care advance and the treatment results improve, it is only to be expected that the calibration of existing models will change. Recalibration or updating over time is advocated.
Strengths and limitations
Several limitations of our study should be acknowledged. First, the validation population concerns a selected population with a different case mix compared to the development populations. Second, it was performed in different settings. These limitations may, however, be considered strengths, as they address generalizability. Third, CT assessments were performed by a single expert, and intraobserver agreement was not determined. Fourth, it is a single center setting, which makes inadequate calibration impossible to distinguish from center level effects. This may have induced some bias in scorings, but if present these would be consistent.
Conclusions
The IMPACT and Helsinki clinical models for predicting outcome in patients with moderate to severe TBI showed excellent discrimination upon external validation on a large cohort of surgically treated patients, of whom 87% underwent a decompressive craniectomy. On calibration, all models showed some overestimation with a better than predicted outcome. These findings confirm the validity of predictors but suggest a need to recalibrate models to specific settings.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The study protocol was approved by the Renmin Hospital of Wuhan University and Anhui Medical University Affiliated Wuxi Clinical College Clinical Research Ethics Committee (YXLL-2022019). Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
Author contributions
LC, YW, and HX were involved in the conception and design of the study. JH and CZ were involved in the data analysis. AM, HS, and DN were involved in the acquisition of data. RR and AM contributed substantially to drafting the manuscript and figures. All authors read and approved the final manuscript.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fneur.2022.1031865/full#supplementary-material
References
1. Wu X, Hu J, Zhuo L, Fu C, Hui G, Wang Y, et al. Epidemiology of traumatic brain injury in eastern China, 2004: a prospective large case study. J Trauma. (2008) 64:1313–9. doi: 10.1097/TA.0b013e318165c803
2. Cheng P, Yin P, Ning P, Wang L, Cheng X, Liu Y, et al. Trends in traumatic brain injury mortality in China, 2006-2013: a population-based longitudinal study. PLoS Med. (2017) 14:e1002332. doi: 10.1371/journal.pmed.1002332
3. Li J, Jiang JY. Chinese Head Trauma Data Bank: effect of hyperthermia on the outcome of acute head trauma patients. J Neurotrauma. (2012) 29:96–100. doi: 10.1089/neu.2011.1753
4. Perel P, Arango M, Clayton T, Edwards P, Komolafe E, Poccock S, et al. Predicting outcome after traumatic brain injury: practical prognostic models based on large cohort of international patients. Bmj. (2008) 336:425–9. doi: 10.1136/bmj.39461.643438.25
5. Steyerberg EW, Mushkudiani N, Perel P, Butcher I, Lu J, McHugh GS, et al. Predicting outcome after traumatic brain injury: development and international validation of prognostic scores based on admission characteristics. PLoS Med. (2008) 5, e165. discussion e165. doi: 10.1371/journal.pmed.0050165
6. Raj R, Siironen J, B. Skrifvars M, Hernesniemi J, Kivisaari R. Predicting outcome in traumatic brain injury: development of a novel computerized tomography classification system (Helsinki computerized tomography score). Neurosurgery. (2014) 75:632–46. doi: 10.1227/NEU.0000000000000533
7. Roozenbeek B, Lingsma HF, Lecky FE, Lu J, Weir J, Butcher I, et al. Prediction of outcome after moderate and severe traumatic brain injury: external validation of the international mission on prognosis and analysis of clinical trials (IMPACT) and corticoid randomisation after significant head injury (CRASH) prognostic models. Crit Care Med. (2012) 40:1609–17. doi: 10.1097/CCM.0b013e31824519ce
8. Carney N, Totten AM, O'Reilly C, Ullman JS, Hawryluk GW, Bell MJ, et al. Guidelines for the management of severe traumatic brain injury. XIII. Antiseizure prophylaxis. J Neurotrauma. (2007) 24(Suppl 1):S83–6. doi: 10.1089/neu.2007.9983
9. Bullock MR, Chesnut R, Ghajar J, Gordon D, Hartl R, Newell DW, et al. Surgical management of traumatic parenchymal lesions. Neurosurgery. (2006) 58:S25–46. doi: 10.1227/01.NEU.0000210365.36914.E3
10. Bullock MR, Chesnut R, Ghajar J, Gordon D, Hartl R, Newell DW, et al. Surgical management of acute subdural hematomas. Neurosurgery. (2006) 58:S16–24. doi: 10.1227/01.NEU.0000210364.29290.C9
11. Panczykowski DM, Puccio AM, Scruggs BJ, Bauer JS, Hricik AJ, Beers SR, et al. Prospective independent validation of IMPACT modeling as a prognostic tool in severe traumatic brain injury. J Neurotrauma. (2012) 29:47–52. doi: 10.1089/neu.2010.1482
12. Lingsma H, Andriessen TM, Haitsema I, Horn J, Van Der Naalt J, Franschman G, et al. Prognosis in moderate and severe traumatic brain injury: external validation of the IMPACT models and the role of extracranial injuries. J Trauma Acute Care Surg. (2013) 74:639–46. doi: 10.1097/TA.0b013e31827d602e
13. Raj R, Siironen J, Kivisaari R, Hernesniemi J, Tanskanen P, Handolin L, et al. External validation of the international mission for prognosis and analysis of clinical trials model and the role of markers of coagulation. Neurosurgery. (2013) 73:305–11. doi: 10.1227/01.neu.0000430326.40763.ec
14. Harrison DA, Griggs KA, Prabhu G, Gomes M, Lecky FE, Hutchinson PJ, et al. External validation and recalibration of risk prediction models for acute traumatic brain injury among critically ill adult patients in the United Kingdom. J Neurotrauma. (2015) 32:1522–37. doi: 10.1089/neu.2014.3628
15. Castaño-Leon AM, Lora D, Munarriz PM, Cepeda S, Paredes I, de la Cruz J, et al. Predicting outcomes after severe and moderate traumatic brain injury: an external validation of impact and crash prognostic models in a large Spanish cohort. J Neurotrauma. (2016) 33:1598–606. doi: 10.1089/neu.2015.4182
16. Maas AI, Marmarou A, Murray GD, Teasdale SG, Steyerberg EW. Prognosis and clinical trial design in traumatic brain injury: the IMPACT study. J Neurotrauma. (2007) 24:232–8. doi: 10.1089/neu.2006.0024
17. Steyerberg EW. Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating. New York: NY: Springer (2009).
18. Delong ER, Delong DM, Clarke-Pearson DL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics. (1988) 44:837–45. doi: 10.2307/2531595
19. Steyerberg EW, Vickers AJ, Cook NR, Gerds T, Gonen M, Obuchowski N, et al. Assessing the performance of prediction models: a framework for traditional and novel measures. Epidemiology. (2010) 21:128–38. doi: 10.1097/EDE.0b013e3181c30fb2
20. Puetz V, Campos CR, Eliasziw M, Hill MD, Demchuk AM. Assessing the benefits of hemicraniectomy: what is a favourable outcome? Lancet Neurol. (2007) 6:580:580–581. doi: 10.1016/S1474-4422(07)70160-6
21. Honeybul S, Gillett G, Ho K, Lind C. Ethical considerations for performing decompressive craniectomy as a life-saving intervention for severe traumatic brain injury. J Med Ethics. (2012) 38:657–61. doi: 10.1136/medethics-2012-100672
22. Honeybul S, Ho KM, Lind CR, Gillett GR. Validation of the CRASH model in the prediction of 18-month mortality and unfavorable outcome in severe traumatic brain injury requiring decompressive craniectomy. J Neurosurg. (2014) 120:1131–7. doi: 10.3171/2014.1.JNS131559
23. Cooper DJ, Rosenfeld JV, Murray L, Arabi YM, Davies AR, D'Urso P, et al. Decompressive craniectomy in diffuse traumatic brain injury. N Engl J Med. (2011) 364:1493–502. doi: 10.1056/NEJMoa1102077
Keywords: external validation, outcome, prognostic model, Helsinki CT, traumatic brain injury
Citation: Chen L, Xu H, He J, Zhang C, Maas AIR, Nieboer D, Raj R, Sun H and Wang Y (2022) Performance of the IMPACT and Helsinki models for predicting 6-month outcomes in a cohort of patients with traumatic brain injury undergoing cranial surgery. Front. Neurol. 13:1031865. doi: 10.3389/fneur.2022.1031865
Received: 30 August 2022; Accepted: 17 October 2022;
Published: 31 October 2022.
Edited by:
Guoyi Gao, Shanghai General Hospital, ChinaReviewed by:
Stephen Honeybul, Sir Charles Gairdner Hospital, AustraliaHE Hinson, Oregon Health and Science University, United States
Javier De La Cruz, University Hospital October 12, Spain
Copyright © 2022 Chen, Xu, He, Zhang, Maas, Nieboer, Raj, Sun and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yuhai Wang, d2FuZ3l1aGFpNjdAMTI2LmNvbQ==