 Rabindev Bishal1
Rabindev Bishal1 Nandini Chatterjee Singh
Nandini Chatterjee Singh Neelima Gupte
Neelima Gupte
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Netw. Physiol., 23 August 2022
Sec. Networks in the Brain System
Volume 2 - 2022 | https://doi.org/10.3389/fnetp.2022.924446
This article is part of the Research TopicWomen in Networks in the Brain System: 2021View all 4 articles
The topological analysis of fMRI time series data has recently been used to characterize the identification of patterns of brain activity seen during specific tasks carried out under experimentally controlled conditions. This study uses the methods of algebraic topology to characterize time series networks constructed from fMRI data measured for adult and children populations carrying out differentiated reading tasks. Our pilot study shows that our methods turn out to be capable of identifying distinct differences between the activity of adult and children populations carrying out identical reading tasks. We also see differences between activity patterns seen when subjects recognize word and nonword patterns. The results generalize across different populations, different languages and different active and inactive brain regions.
Functional magnetic resonance imaging (fMRI) measurements provide patterns of brain activity during specific tasks with respect to control conditions. To distinguish if patterns of brain activity might characterize specific brain states, recent research has sought to use simplicial analysis to identify metric spaces that optimally distinguish brain states across experimentally defined conditions (Bashan et al., 2012; Bartsch et al., 2015; Simas et al., 2015; Bianconi, 2021; Jacob et al., 2021).
The purpose of the present study is to explore the identification of metric spaces to characterize reading populations. The fMRI data obtained from children and adults reading words and nonwords, matched in performance, showed common regions of activation across both populations. The time series obtained from common regions of activation from both populations was used to construct a complex network (a time series network (Zhang and Small, 2006)), further subjected to simplicial analysis using methods of algebraic topology (Jonsson, 2008). This analysis can provide insights into the short term correlations in the time series in different regions of imaging in the brain, as well as different segments of the reading task and distinct reading populations. We hypothesize that a comparison of the topology of reading networks (Cherodath and Singh, 2015) might provide novel insights into reading patterns in adult and child populations.
We analyze fMRI data obtained from subjects carrying out reading tasks in two languages, English and Hindi. The fMRI paradigms employed involved reading tasks in Hindi and English in a simple and identical block design. The task comprised of alternating word and nonwords reading blocks separated by rest blocks with a visual baseline. Participants were instructed to read aloud words and nonwords that appeared during the task blocks, and to fixate on the symbol strings displayed during rest blocks without any oral response. In each task block either 10 words or nonwords were presented, each item appearing for a duration of 2 s at the center of the screen. During the length of the task in each language, 60 words and 60 nonwords were presented, with each item randomly selected from a word or nonword list respectively. During every rest block, one false font string from a list of four false font stimuli was randomly selected and presented for 20 s. The participants performed two runs of the fMRI task in each language, where each run consisted of 3 word blocks, 3 nonword blocks and 6 rest blocks. The total duration of the reading task was 16 min. The details of the stimuli used are presented in Ref. (Cherodath and Singh, 2015). The fMRI task performance accuracies of adult and children groups, calculated from in-scanner vocal responses during various tasks conditions were compared. Although adults showed trends of higher accuracies than children, the group differences were not statistically significant in any condition. Therefore, the two groups were matched on task performance, ruling out performance effects on activation patterns.The neuroimaging results were subjected to the following statistical analysis. Two sample t tests were performed to explore group differences in neural activity in the combined contrast of all reading conditions versus baseline (FDR p < 0.05, k > 10). Results revealed higher levels of activity in the right hippocampus in children. On the other hand, adults showed higher activity in a network of regions - bilateral articulatory motor regions, putamen and thalamus, right superior temporal region, supramarginal gyrus, inferior frontal region and the left fusiform gyrus.
The fMRI data from the Lputamen and RSTG (Right Superior Temporal Gyrus) which are activated in both children and adults are subjected to simplicial analysis. A comparison of the characteristics observed for both cases is carried out. Our pilot study reveals differences between the networks for adults and children, across differentiated reading tasks, and across different languages. The differences are seen more strongly in active regions. We also carry out a comparison of activity in highly active and less active regions during the task, as well as in the recognition of words and nonwords. The terms “active” and “less active” have been quantified in terms of the BOLD (blood oxygen level-dependent) signal seen in the fMRI images in Ref (Cherodath and Singh, 2015). This is a measure associated with blood flow and blood oxygenation levels in the regions in the brain which is known to be correlated with neuronal activity.” Further information on the BOLD signal can be found at https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6859204.
The time series described here are the time series from fMRI data obtained in the case of sets of 5 adults and 5 children carrying out a reading task, and are averaged over all the members of each set. The time series consists of 240 data points sampled at an interval of 3 s. The highly active regions picked up here for analysis were the Lputamen and RSTG and two less active regions viz. L1 (Lingual Gyrus) and S1 (a prefrontal region). We present here the results of the analysis of the Lputamen and L1 regions. The results for the RSTG and S1 are similar, and hence are not shown here. The graphs can be downloaded from the site https://github.com/tsardb/f_vector_results. The time series network is constructed here using the visibility algorithm (Lacasa et al., 2008) which is outlined in Figure 1. The visibility algorithm is implemented by connecting two points (yi, ti) and (yj, tj) by a straight line, provided no other intermediate point, (yr, tr) lies above the line, i.e. (yi, ti) and (yj, tj) should be “visible” to each other, with no other intermediate point obstructing the line of visibility in between (Figure 1A). For this, all intermediate points should satisfy the condition
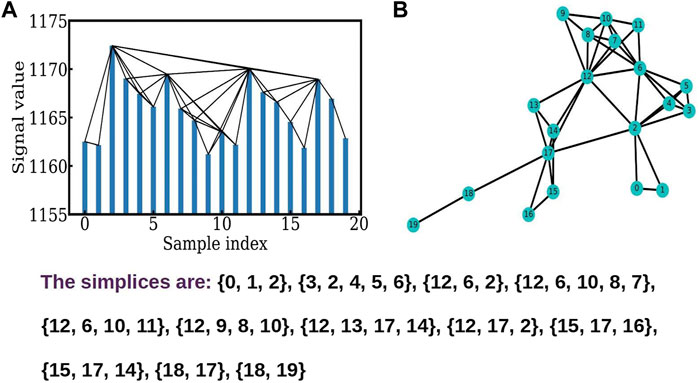
FIGURE 1. (A) shows the connections between the nodes obtained using the visibility algorithm. (B) The corresponding constructed network showing different simplices.
Figure 1A shows the visibility algorithm (Lacasa et al., 2008) for the time series of the fMRI data used here. The time series is sampled at intervals of, up to the first points, and the neighbors of each node, i.e. the points which are visible to each other, are seen in the graph. The network graph, and its connectivity matrix is constructed by setting up a link between all pairs i and j which are visible to each other using the algorithm above. The network graph so constructed is shown in Figure 1B. The simplicial structures are identified using the Bron-Kerbosch algorithm (Bron and Kerbosch, 1973). The graph shows simplicial structures (Bron and Kerbosch, 1973; Johnston, 1976) of dimension ranging from 1 to 4.
The network graphs so generated are then analyzed using recently constructed topological characterisers or simplicial characterisers. Such characterisers have been known to yield useful information in the analysis of neural data (Sizemore et al., 2019) as well as chaotic systems (Chutani et al., 2020), traffic on networks (Andjelković et al., 2015a), social networks (Andjelković et al., 2015b) etc. The specific characteriser used here is the quantity called the f − vector which has proved to be of utility earlier in the analysis of neural data (Giusti et al., 2016). We define this quantity in the next subsection.
The f − vector analysis for a time series network, is a useful handle on the short term correlations in the system. The TS network is constructed using the visibility algorithm (Lacasa et al., 2008) and is analyzed by identifying the cliques (Bron and Kerbosch, 1973; Johnston, 1976) and simplicial complexes. Here, cliques are complete sub-graphs, and simplices are sets of connected nodes, with isolated nodes, two nodes connected by a link, and three nodes connected by links being examples of 0, 1, and 2 dimensional simplices (Andjelković et al., 2015a; Andjelković et al., 2015b; Chutani et al., 2020). It is clear from the Figure 1B that the simplicial structure reflects the short term correlations in the system. Figure 1B shows the triangles and tetrahedra present in this part of the data. The number of q − dimensional simplices, forms the q − th component of the f − vector, where the
The f − vectors of the system contain information about the short term correlations of the system, and reflect the correlations of the system in terms of the number of simplices of each type, and the complexity of the structures. The nature of the time series and the regions of imaging have been described above. We note that many pairwise comparisons are possible, e.g. between words, nonwords and rests, between different languages (here, English and Hindi), between active and inactive regions, and many other combinations. We looked for combinations where the differences were clear, and were also robust to changes in the details. Within our observations, the clearest differences were as follows:
We show below the f − vector comparison between English words and nonwords in English for an active region, in this case the Lputamen. We consider adults and children separately.
The f − vector distributions seen in Figure 2 for English words and English nonwords, both clearly indicate that the simplices seen in the case of children are higher dimensional as compared to adults. For e.g. Figure 2A shows that in the case of words, the highest dimensional simplex seen for adults is 5 dimensional, whereas the highest dimension seen in the case of children is 10. Similarly for English nonwords (Figure 2B), the highest dimension seen is 5 for adults and 9 for children. We suggest that this indicate that adults are able to resolve the words and nonwords within 5 − point correlations, and hence within shorter time scales, as explained above. On the other hand, the time series for children show higher order structures, which reflects higher correlations. Thus children need to correlate more data, and need more time, to resolve the same word and nonword information than the adults. Hence we suggest that the adults process the information more efficiently. We also note that this behavior was seen for both English and Hindi, and also for another active sampling region (viz. LSG).
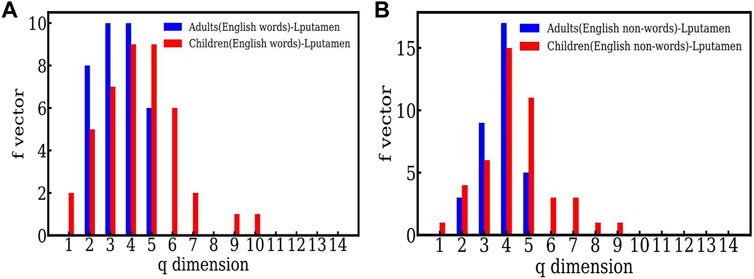
FIGURE 2. (A) The comparison between the f-vector of an active (Lputamen) region for adults and children in the task of reading English words. (B) The comparison between the f-vector of an active (Lputamen) region for adults and children in the task of reading English nonwords.
Figure 3 plots the same data for the Lputamen in another way, namely the two populations, adults and children for words (Figure 3A) and nonwords (Figure 3B). Here, the number of simplices for words is about the same for both groups. However, in the case of nonwords, the number of simplices of dimension 5 is much larger in children. This suggests that the efficiency of the networks in children is similar to that in adults when reading English words, but not English nonwords. The higher order correlations seen in children for English nonword reading may be indicative of their lower efficiency owing to the relatively high difficulty of reading nonwords as compared to words. Overall, the findings suggest adult-like efficiency in reading English words, but not the more difficult stimuli—English nonwords.
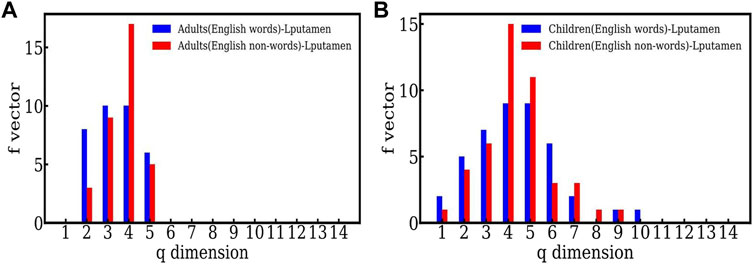
FIGURE 3. (A) The f − vector of the simplicial complex of the active (Lputamen) region for adults carrying out a reading task involving English words and nonwords. (B) The f − vector of the simplicial complex of the active (Lputamen) region for the reading task with English words and nonwords in the case of children.
We note that the largest number of simplices have dimension 4 here, for both words and nonwords. This appears at the dimension 3 in the case of Hindi. We speculate that this may be some indicator of the language structure. Further studies are required to make a statement on this.
It is interesting to see if the language chosen for the reading task affects structure of the f − vector distribution. To see this, we study the f − vector distributions for Hindi words and nonwords, and compare them with the behavior seen for English words and nonwords (see Figure 4). Here, again the structures are skewed towards to lower q − levels, indicating more efficient separation between words and nonwords in the case of adults. In the case of children, the word-nonword distinction is less efficient in Hindi as well. Thus both conclusions are in agreement with those seen in the case of English, indicating that the adults process the distinction between word-nonword information more efficiently. We note that the structures seen in the case of children have lower dimensions than those seen for English, both for words and nonwords.
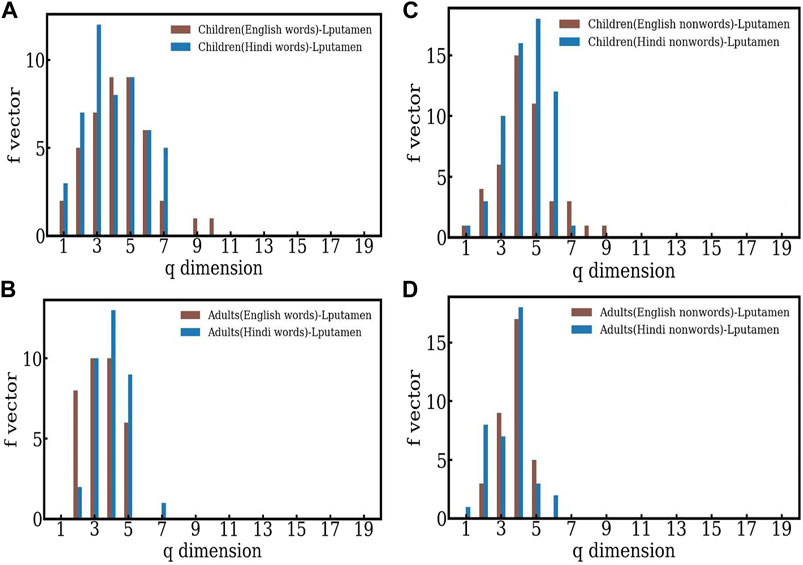
FIGURE 4. (A)–(B) The comparison of the f-vectors computed for children and adults in the case of English and Hindi words respectively. (C)–(D) The comparison of the f-vectors computed for children and adults in the case of English and Hindi nonwords respectively.
We now carry out a comparison of a region of high (Lputamen) and low (L1) activity, as indicated by the highlights in the fMRI in Ref. (Cherodath and Singh, 2015). The high and low activity is as measured in terms of the BOLD signal described above. We have considered the English reading task, which consists of 240 data points. There are three cycles in the reading tasks. Each cycle contains 80 points which follow the sequence words, rest, nonwords, rest, respectively; each section contains twenty points. Thus the time series samples all the elements of the reading task over the two regions.
Figure 5A, shows the f − vector of the TS network constructed from time-series data of the high activity region (Lputamen) and low activity region (L1) in the case of the English reading task by adults. The highly active region has more simplices of lower dimensions than the region of less activity, indicating the dominant short range structure of the correlations. Figure 5B shows the comparison between the highly active and less active regions for children for the English reading task. Here again, higher dimensional structures are seen for both the highly active and less active regions, but the distinction between the two regions is less sharp than that seen for the adults. We note that the behavior seen in other choices of highly active and less active regions,viz. RSTG and S1 is similar. As mentioned above, the plots and further details can be found at https://github.com/tsardb/f_vector_results.
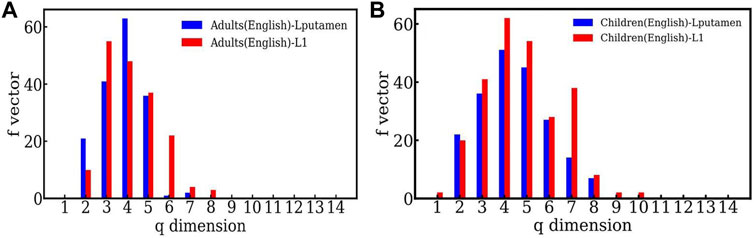
FIGURE 5. (A) The f-vector of the simplicial complex of one active (Lputamen) and one inactive (L1) region in the case of the English language reading task respectively. Both the cases are for the adults. (B) The f − vector of the high activity (Lputamen) region and the low activity (L1) region for the English reading task, in the case of children.
We have carried out a comparison between various pairs of data here using usual network characterisers. It is also interesting to see if the usual network characterisers show any signatures of the behavior seen here. The usual characterisers seen here are listed in Table 1.
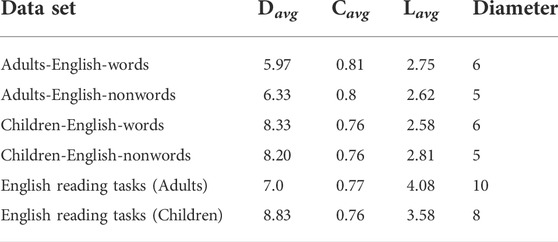
TABLE 1. The 2nd—5th columns of the table correspond to the average degree (Davg), average clustering coefficient (Cavg) average path length and diameter (Lavg) of the TS network constructed for the time series for different tasks (English words and nonwords) in the Lputamen regions respectively.
The quantities studied here are the average degree, the average clustering co-efficient and the average shortest path length of the network. The average degrees (Davg) are smaller for adults than for children. The same effect is seen for the clustering coefficients and Lavg, although the changes are small. For the full time series (last two lines), the results are unclear. Thus the usual clustering coefficients show no clear signature of the population, and the simplicial characterisers do a much better distinction.
We use the methods of algebraic topology to characterize the TS networks obtained from fMRI data via the visibility algorithm for adult and child populations carrying out reading tasks. Our methods look at the f − vector, which counts the number of simplices of each type, and thus is a measure of the complexity of short term correlations in the series. The adult populations consistently show lower dimensional simplicial structure than the child population across different segments of the reading task. This indicates the dominance of short term correlations in the adult populations, as compared to the child population, and can be indicative of the fact that the children take longer to process the reading information. Thus the adults demonstrate more efficient analysis, presumably due to their longer experience in such tasks. There is also a differentiation between the f − vector distributions seen for the word and nonword segments of the reading tasks, which indicates higher efficiency for the adults for both cases. Within each population, the word and nonword distributions show distinct behavior, for two different languages. However, the reading circuits in the brain for adults and children are different, so further analysis is required here. Finally, we note that similar effects are seen in the less active regions as well, indicating some response to the stimuli. However, the effects are more marked in the case of the highly active region.
To conclude, the simplicial characterization of TS networks constructed from brain data, can provide valuable information about the structure, function and hidden geometry of cognitive networks. This characterization can complement and support conclusions drawn from older methods of analysis. We note that other simplicial characterisers are also available which can further this analysis. We hope this pilot study will provoke further and more extensive studies in the field.
The original contributions presented in the study are included in the article/Supplementary Materials, further inquiries can be directed to the corresponding author.
The studies involving human participants were reviewed and approved by Human ethics committee of the National Center for Brain Research. Written informed consent to participate in this study was provided by the participants’ legal guardian/next of kin.
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Andjelković, M., Gupte, N., and Tadić, B. (2015a). Hidden geometry of traffic jamming. Phys. Rev. E Stat. Nonlin. Soft Matter Phys. 91, 052817. doi:10.1103/PhysRevE.91.052817
Andjelković, M., Tadić, B., Maletić, S., and Rajković, M. (2015b). Hierarchical sequencing of online social graphs. Phys. A Stat. Mech. its Appl. 436, 582–595. doi:10.1016/j.physa.2015.05.075
Bartsch, R. P., KangLiu, K. L., Bashan, A., and PlamenIvanov, C. (2015). Network physiology: How organ systems dynamically interact. PloS one 10 (11), e0142143. doi:10.1371/journal.pone.0142143
Bashan, Amir, Bartsch, Ronny P., Kantelhardt, Jan. W., Havlin, Shlomo, and Plamen, Ch (2012). Network physiology reveals relations between network topology and physiological function. Nat. Commun. 3 (1), 702. doi:10.1038/ncomms1705
Bron, C., and Kerbosch, J. (1973). Algorithm 457: Finding all cliques of an undirected graph. Commun. ACM 16 (9), 575–577. doi:10.1145/362342.362367
Cherodath, S., and Singh, N. C. (2015). The influence of orthographic depth on reading networks in simultaneous biliterate children. Brain Lang. 143, 42–51. doi:10.1016/j.bandl.2015.02.001
Chutani, M., Rao, N., Thyagu, N., and Gupte, N. (2020). Characterizing the complexity of time series networks of dynamical systems: A simplicial approach. Chaos 30 (1), 013109. doi:10.1063/1.5100362
Giusti, C., Ghrist, R., and Bassett, S. (2016). Two's company, three (or more) is a simplex : Algebraic-topological tools for understanding higher-order structure in neural data. J. Comput. Neurosci. 41 (1), 1–14. doi:10.1007/s10827-016-0608-6
Jacob, B., Saggar, M., Hlinka, J., Keilholz, S., and Petri, G. (2021). Simplicial and topological descriptions of human brain dynamics. Netw. Neurosci. 5 (2), 549–568. doi:10.1162/netn_a_00190
Johnston, H. C. (1976). Cliques of a graph-variations on the bron-kerbosch algorithm. Int. J. Comput. Inf. Sci. 5 (3), 209–238. doi:10.1007/bf00991836
Lacasa, L., Luque, B., Ballesteros, F., and Luque, J. (2008). From time series to complex networks: The visibility graph. Proc. Natl. Acad. Sci. U. S. A. 105 (13), 4972–4975. doi:10.1073/pnas.0709247105
Simas, T., Chavez, M., Rodriguez, P., and Diaz-Guilera, A. (2015). An algebraic topological method for multimodal brain networks comparisons. Front. Psychol. 6, 904. doi:10.3389/fpsyg.2015.00904
Sizemore, A. E., Phillips-Cremins, J. E., Ghrist, R., and Bassett, D. S. (2019). The importance of the whole: Topological data analysis for the network neuroscientist. Netw. Neurosci. 3 (3), 656–673. doi:10.1162/netn_a_00073
Keywords: fMRI, brain networks, simpicial characterisers, time series, reading tasks
Citation: Bishal R, Cherodath S, Singh NC and Gupte N (2022) A simplicial analysis of the fMRI data from human brain dynamics under functional cognitive tasks. Front. Netw. Physiol. 2:924446. doi: 10.3389/fnetp.2022.924446
Received: 20 April 2022; Accepted: 25 July 2022;
Published: 23 August 2022.
Edited by:
Marianna La Rocca, Università degli Studi di Bari “A. Moro”, ItalyReviewed by:
Loredana Bellantuono, University of Bari Aldo Moro, ItalyCopyright © 2022 Bishal, Cherodath, Singh and Gupte. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Neelima Gupte, Z3VwdGVAcGh5c2ljcy5paXRtLmFjLmlu
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.