 Qi Wang
Qi Wang Siwei Chen
Siwei Chen He Wang4
He Wang4 Yongan Sun
Yongan Sun Guiying Yan
Guiying Yan
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Comput. Neurosci., 21 May 2021
Volume 15 - 2021 | https://doi.org/10.3389/fncom.2021.659838
This article is part of the Research TopicTheories and Applications in Network ScienceView all 8 articles
Alzheimer's disease (AD) is a neurodegenerative disease that commonly affects the elderly; early diagnosis and timely treatment are very important to delay the course of the disease. In the past, most brain regions related to AD were identified based on imaging methods, and only some atrophic brain regions could be identified. In this work, the authors used mathematical models to identify the potential brain regions related to AD. In this study, 20 patients with AD and 13 healthy controls (non-AD) were recruited by the neurology outpatient department or the neurology ward of Peking University First Hospital from September 2017 to March 2019. First, diffusion tensor imaging (DTI) was used to construct the brain structural network. Next, the authors set a new local feature index 2hop-connectivity to measure the correlation between different regions. Compared with the traditional graph theory index, 2hop-connectivity exploits the higher-order information of the graph structure. And for this purpose, the authors proposed a novel algorithm called 2hopRWR to measure 2hop-connectivity. Then, a new index global feature score (GFS) based on a global feature was proposed by combing five local features, namely degree centrality, betweenness centrality, closeness centrality, the number of maximal cliques, and 2hop-connectivity, to judge which brain regions are related to AD. As a result, the top ten brain regions identified using the GFS scoring difference between the AD and the non-AD groups were associated to AD by literature verification. The results of the literature validation comparing GFS with the local features showed that GFS was superior to individual local features. Finally, the results of the canonical correlation analysis showed that the GFS was significantly correlated with the scores of the Mini-Mental State Examination (MMSE) scale and the Montreal Cognitive Assessment (MoCA) scale. Therefore, the authors believe the GFS can also be used as a new biomarker to assist in diagnosis and objective monitoring of disease progression. Besides, the method proposed in this paper can be used as a differential network analysis method for network analysis in other domains.
Alzheimer's disease (AD) is a neurodegenerative disease that commonly affects the elderly. It is a continuous process, from the pre-clinical stage to mild cognitive impairment (MCI) to dementia. Effective intervention in the pre-dementia or MCI stage can slow down or reverse the disease process. Therefore, early identification of patients with AD in the pre-dementia or MCI stage, as well as early and timely intervention, are of great importance to the prognosis of patients. With the development of imaging technology, the detection of AD is no longer limited to the phenomenon of abnormal protein deposition. Analysis of structural brain network information, such as brain connectome analysis, may be an effective method for early diagnosis and monitoring of disease progression (Fan et al., 2016).
Previous studies (Liu et al., 2017) have shown that changes in the topological features of the brain structural network are a hallmark of multiple neuropsychiatric disorders. Currently, there are several research efforts based on the graph theory of brain structural networks (Sanz-Arigita et al., 2010; John et al., 2017). The common method is to analyze some local features such as the degree centrality of nodes, clustering coefficient, and shortest path length of the brain structural network. Local features are difficult to be used to reveal the overall characteristics of the network. The global property by combining local properties can reveal the topological characteristics of the network more effectively, but it is never easy to choose which local indices are to be used. In this paper, the authors first defined a new local feature index, 2hop-connectivity, of the network to analyze the brain network more completely.
In this work, 20 patients with AD and 13 patients in the pre-dementia stages (non-AD) were recruited. The authors collected demographic data and clinical data and completed neuropsychological scale assessments and DTI scans. After preprocessing, the brain structural network was constructed based on the number of fibers between different brain regions. The data from the AD and the non-AD groups were analyzed to obtain the local topological features of the brain structural network. Meanwhile, the authors designed an algorithm called 2hopRWR to get the local feature index 2hop-connectivity, and then a new index global feature score (GFS) was proposed by combing four classical local features and 2hop-connectivity. As a result, the authors predicted and analyzed the top 10 brain regions based on the difference of the GFS scores between the AD and the non-AD groups. Then, the authors analyzed the correlation between the GFS and the cognitive scale scores by performing canonical correlation analysis (CCA). Finally, the strengths and limitations of the work presented in this paper and its prospects are discussed.
A case–control study design was adopted in this study. Patients with AD who were admitted to the neurology outpatient department or the neurology ward of Peking University First Hospital from September 2017 to March 2019 were recruited in the study. Normal controls were recruited at the same time. The inclusion criteria for the AD group were as follows: (1) Han nationality, over 18 years old, who were right-handed and agreed to participate in this study; (2) patients diagnosed as probable AD clinically according to the 2011 National Institute on Aging and the Alzheimer's Disease Society (NIA-AA) diagnostic criteria (McKhann et al., 2011); (3) no serious white matter lesions found by MRI examination, which meant that the Fazekas scale score was no more than 2. The inclusion criteria for the normal control group were as follows: (1) Han nationality, over 18 years old, who were right-handed and agreed to participate in this study, so as to match their ages with the ages of subjects of the AD group; (2) normal cognitive function and not meeting the diagnostic criteria of dementia; (3) no serious white matter lesions found on MRI examination, which meant that the Fazekas scale score was no more than 2. The exclusion criteria were as follows: (1) patients or their family members refusing to participate in the study; (2) unable to complete 3.0Tesla MRI examination due to various reasons; (3) with a history of cerebrovascular diseases, or cognitive impairment caused by toxication, metabolic disease, infection, autoimmune disease, or drug and with a history of demyelination of the central nervous system, white matter lesions, or other diseases that may affect the white matter structure of the brain; (4) with a history of serious mental illness, such as depression, mania, and schizophrenia; (5) having a long-term history of alcoholism or vegetarianism; (6) Patients with other types of dementia other than AD.
This study was approved by the Clinical Research Ethics Committee of Peking University First Hospital. All participants or their family members signed the informed consent.
In this research, 20 patients with AD and 13 healthy controls (non-AD) were recruited. Demographic information and the medical history of the participants were collected. Blood tests were conducted to exclude cognition impairment caused by other reasons. All the patients were assessed on a set of neuropsychological scales by the same trained neurologist to assess overall cognitive function including memory, executive function, language, and visuospatial and structural abilities of all the participants. The ability of daily living and mental and behavioral symptoms of the subjects were also evaluated (Supplementary Table 1).
Brain imaging examinations were performed by the Department of Imaging, Peking University First Hospital. The participants received imaging examination within 1 week before or after the completion of the scales. The images were collected by using a GE Discovery MR750 3.0Tesla MRI scanner. The acquisition sequence included the following: axial T1-weighted imaging, axial T2-weighted imaging, and high-resolution DTI sequences. Some of the sequence parameters were as follows:
Axial T1-weighted imaging: Repetition time (TR) = 2,500 ms. Echo time (TE) = 24.0 ms. Field of vision (FOV) = 24.0 cm × 24.0 cm. Layer thickness (ST) = 5 mm.
Axial T2-weighted imaging: TR = 8,400 ms. TE = 140.0 ms. FOV = 20.0 cm × 20.0 cm. ST = 3 mm.
DTI: TR = 4,600 ms. TE = 90.0 ms. FOV = 24.0 cm × 24.0 cm. ST = 4 mm. The dispersion sensitive gradient was applied in 25 directions, and 36 layers of images were scanned in each direction, b = 1,000 s/mm2. Besides, there was a group of images without dispersion weighting, b = 0.
In this study, PANDA (Pipeline for Analyzing braiN Diffusion imAges) (Cui et al., 2013), a toolkit based on MATLAB (R2009b; MathWorks) and FSL that integrates several processing steps, was used to process the data and construct the network. After preprocessing, which included the import of the DICOM format file, scalp and skull removing, brain tissue cutting, eddy current effect correction and head movement correction, multiple diffusion-weighted image acquisition, and processing could be finished.
The images of all individuals were placed in the standardized template and the eigenvalues of each dispersion were measured. The FA (fractional anisotropy) image of each individual was non-linearly loaded into the FA template (FMRIB58_FA_TEMPLATE) of the Montreal Neurological Institute (MNI) space. Through the results of transformation, the diffuse eigenvalues of each individual in the MNI space were resampled and the space was partitioned (the resolutions were 1 mm × 1 mm × 1 mm and 2 mm × 2 mm × 2 mm).
The deterministic fiber-tracking method, FACT [fiber assignment by continuous tracking [Mori and van Zijl, 2002]], was then used to construct the brain structural network. The FA threshold was set to be 0.2–1 and the angle threshold was set to be 45°, that is, when the FA was <0.2 or the tracking angle was >45°, the fiber tracking would end. The ICBM152 AAL−90 [Automated Anatomical Labeling, AAL [Tzourio-Mazoyer et al., 2002)] brain atlas was used to divide the brain of each subject into 45 left and right symmetrical brain regions, with 90 brain regions in total. Each node represented a brain region in the brain structural network. The fiber connection between any two brain regions was represented by an edge, and the edge weight represented the fiber number (FN). The FN matrix of 90 brain regions was obtained by using PANDA (Cui et al., 2013).
Mathematically, the authors regarded 90 brain regions and their fiber connection as a weighted graph G(V, E, W), and V = {v1, v2, …, v90}, E = {evivj, vi ≠ vj}, W = {wvivj}, where vi denotes the i-th brain region, evivj is the edge if there were fiber connection between brain region vi and vj, and wvivj is the edge weight that is the fiber number between the brain region vi and vj. The average value of the FN matrix of AD was calculated by adding the FN matrix of each patient with AD and dividing it by the number of patients with AD. Similarly, the authors took the average value of the FN matrix of all normal controls to the FN matrix of the non-AD group.
Let d(vi) denote the degree of a node vi, which is the number of nodes associated with vi. And the degree centrality of a node vi is defined as follows:
Betweenness centrality cB of a node vi is the sum of the fraction of the shortest paths of all pairs that pass through vi:
where σ(vs, vt) is the number of the shortest paths between vs and vt, and σ(vs, vt|vi) is the number of the shortest paths passing through the node vi. If s = t, σ(vs, vt) = 1, and if i = s or i = t, σ(vs, vt|vi) = 0.
In short, if the shortest path between many nodes in the network passes through a point v, then v has a high degree of betweenness centrality. This node is on the shortcut between other node pairs.
Closeness centrality Cc of a node vi is the reciprocal of the sum of the shortest path distances from vi to all n − 1 other nodes. Since the sum of distances depends on the number of nodes in the graph, closeness is normalized by n − 1.
where d(vj, vi) is the shortest path distance between vj and vi, and n is the number of nodes in the graph.
Closeness centrality is the sum of the distance from a node to all other nodes. The smaller the sum, the shorter the path from this node to all other nodes is, and the closer the node is to all other nodes. It reflects the proximity between a node and other nodes.
In graph theory, the clique of graph G is a complete subgraph H of G. H is a maximal clique of graph G if it is not included by any other clique. The number of maximal cliques of a node can reflect the closeness between the node and other nodes. Only when multiple nodes are all connected can they be considered as maximal cliques. In this paper, the authors use NMC(vi) to represent the number of maximal cliques for node vi.
When examining the correlation between any two nodes in the network, most network analysis methods only consider whether there is an edge connection between two nodes, i.e., if there is an edge, the correlation is high, and if there is no connection, the correlation is weak. In this case, if the edges of the graph are missing due to the disturbance, the results may be highly biased. For example, for the general random walk (RW) algorithm, the state transition probability is determined by the adjacency matrix of the network. If the adjacency matrix is disturbed, its steady-state probability will change. Generally, when analyzing the correlation between network nodes, the correlation between unconnected nodes in the network will be very low, which makes it difficult to discover the potential characteristics of the network. For any two different nodes in the network, in order to describe the correlation more accurately, this work considers not only the first-order neighbors between the nodes but also the second-order neighbors between the nodes, and an algorithm called 2hopRWR is proposed. Finally, each node can get a novel local feature index 2hop-connectivity, whose numerical magnitude is represented by the local feature score S2−hop. The importance of a node can be judged based on S2−hop; the larger the S2−hop, the more important the node is.
The general random walk on the graph is a transition process that involves moving from a given node to a randomly selected neighboring node at each step. Therefore, the set of nodes {v1, v2, …, vn} is considered as a set of states {s1, s2, …, sn} in a finite Markov chain . The transition probability of is a conditional probability defined as P(vj, vi) = Prob(st+1 = vi | st = vj), which implies that the will be at vi at time t + 1 given that it was at vj at time t. is homogeneous because the transition probability from one state to another is independent of time t. Moreover, for any vj of V, there is = 1. Note that is memoryless, so the transition matrix P ∈ ℝ|V|×|V| of can be defined.
In general, the transition probability P(vj, vi) is defined as follows:
Denote DG = diag{d1, d2, …, dn} as the diagonal matrix, where . Thus, P can be rewritten in a matrix notation, given as follows:
Define as a vector in which the i-th element represents the probability of discovering the random walk at node vi at step t, so the probability rt+1 can be calculated iteratively by:
For the random walk with restart (RWR) algorithm (Tong et al., 2006–2006), there is an additional restart item compared to the above algorithm. The probability rt+1 can be calculated iteratively by using the following expression:
Define initial probability as a vector in which the i-th element is equal to 1, while other elements are 0s. And 1 − c is the restart probability (0 ≤ c ≤ 1).
However, the RW and RWR algorithms are based on the 1-hop neighbor relations, which means that the random walk is based on the existing edges of the graph. Figure 1 is the schematic diagram of 1-hop and 2-hop. If some edges of the graph are missing, the corresponding nodes cannot be directly transferred, which will lead to a large deviation in the steady-state probability. Therefore, the effectiveness of these algorithms is too dependent on the integrity of the graph structure. So in this work, in addition to the 1-hop neighbor relations, the 2-hop neighbors are also considered and a novel RW algorithm called 2hopRWR is proposed.
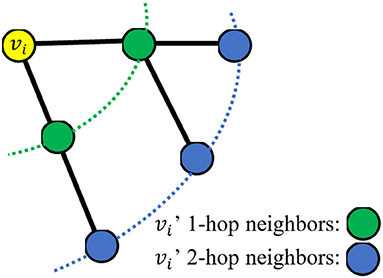
Figure 1. A schematic diagram of 1-hop and 2-hop neighbors.
The probability rt+1 can be calculated iteratively by:
where α1 and α2 are the percentages of choosing 1-hop and 2-hop neighbors, respectively. Specifically, for each point vi ∈ V, α1 is the ratio of the number of 1-hop neighbors to the total number of 1-hop and 2-hop neighbors, α2 is the ratio of the number of 2-hop neighbors to the total number of 1-hop and 2-hop neighbors. Therefore, α1 + α2 = 1.
At the beginning of the 2hopRWR, a starting node vi is chosen; then, it would have a probability of c to walk to other nodes and have a probability of 1 − c to stay in place. Specifically, when the process of walk reaches the node vj, it has a probability of α1c to walk based on existing edges to 1-hop neighbors and has a probability of α2c to walk to 2-hop neighbors, and it also has a probability of 1 − c to restart the walk, i.e., to go back to the node vi.
After some steps, the 2hopRWR will be stable, i.e., when t tends to infinity, rt+1 = rt. The proof is given in Section Proof of Convergence. When the 2hopRWR is stable, steady-state probability between node vi and node vj is defined as the j-th element of rt corresponding to the starting node is vi. Figure 2 is the flowchart of 2hopRWR algorithm.

Figure 2. 2hopRWR algorithm framework.
Here, the authors will prove that the RWR algorithm is convergent, i.e., for Equation (8) when t tends to infinity, rt+1 = rt.
Define:
Thus, using (9) and (10) we get:
Define,
Then,
By (13), when t = 0, we have B0 = (I − N)r0, thus:
Since , we have:
Hence,
which implies that the convergence of the algorithm is proved.
Considering higher-order structural properties of a network is not a new idea. Certain works in the literature (Salnikov et al., 2016; Benson et al., 2017) present the spacey random walk, a non-Markovian stochastic process whose stationary distribution is given by the tensor eigenvector. The higher-order structural properties of a network of Salnikov et al. (2016) and Benson et al. (2017) mean the transitions depend on the past few states, rather than just the last one. The process is called a higher-order Markov chain which is not a Markov chain. For example, for a directed graph network (Figure 3), the two definitions of higher-order information are compared.
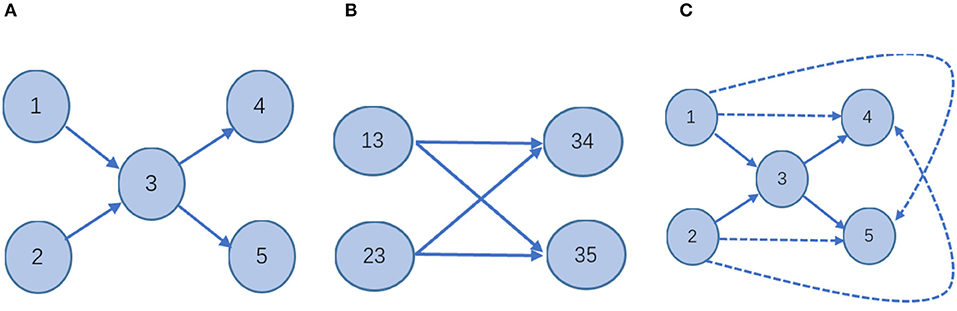
Figure 3. Schematic—different stochastic processes on the network. (A) In a first-order Markov model, the state space is isomorphic to the physical network: every node corresponds to one state; every link indicates a transition between those states. It is a Markov stochastic process. (B) In the second-order Markovian model, the state space is different from (A). In this case, the probability of moving from one node to another will appear non-Markovian. It is a non-Markovian stochastic process. (C) 2hopRWR is a first-order Markov model. A solid line indicates that the state is reachable in one step between states. The dashed lines indicate states that are reachable in one step to the second-order states with some probability. It is a Markov stochastic process.
Therefore, it is clear that the higher-order information on the network defined in the literature (Salnikov et al., 2016; Benson et al., 2017) is obtained by a random walk of the non-Markovian process, while the 2hopRWR is obtained by a random walk of the Markovian process. For the case of missing data, i.e., when the links between the nodes are missing, the second-order states [e.g., (13)] in Figure 3B constructed by the method of literature (Salnikov et al., 2016; Benson et al., 2017) will have a large error impact, while 2hopRWR can reduce this part of the impact because 2hopRWR attenuates the weight of the first-order connections.
Any two nodes can be ranked twice according to 2hopRWR. Define Π = {πij}|V|×|V| as the steady-state probability matrix, where πij indicates the steady-state probability between node vi and node vj, i.e., the probability of 2hopRWR starts from node vi and reaches node vj when the process is stable. In short, the value of πij is the j-th element of steady-state probability when the i-th element of r0 is 1. Therefore, the local feature score S2−hop for node vi is defined as follows:
The 2hop-connectivity exploits the higher-order information of the graph structure relative to the traditional graph theory metrics. Since there is a certain amount of noise in DTI data, a certain threshold is chosen for denoising when converting DTI data into brain networks, i.e., when the number of fibers between two brain regions is low (lower than the threshold), no fiber tracts (edges) are considered between two brain regions (nodes). However, since there are inherently fewer fiber tract connections between brain regions in patients with AD, the brain network constructed after denoising may differ significantly from the true situation. The 2hop-connectivity is insensitive to 1-hop order relations and more robust to changes in the network structure, so 2hop-connectivity is instead more effective for sparse networks (e.g., structural brain networks in patients with AD).
In this paper, the authors consider the integration of local features to obtain a new network index: global feature.
The authors normalized the component of different feature scores to [0, 1]. The normalized features are recorded as NCD, NCB, NCC, NNMC, and NS2−hop.
Then, define global feature score GFS for node vi as follows:
In general, let the weight αi = 1/5 (i = 1, 2, 3, 4, 5), and it also can be addressed by regression over AD-group's Mini Mental State Examination (MMSE) data. For example, using the MMSE scale or Montreal Cognitive Assessment (MoCA) scale data in Supplementary Table 1, the correlation between the five characteristic scores of the AD group with the MMSE or MoCA scale was analyzed. If the GFS of a node is relatively high, it means that the node plays a key role in the network. Figure 4 is the flowchart of our method.
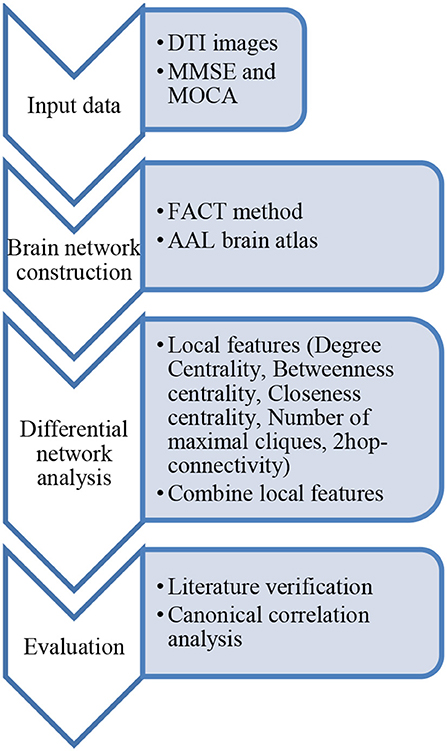
Figure 4. Workflow of the approach presented in this paper.
By comparing the GFS of the non-AD group with that of the AD group, the authors got the top ten brain regions in GFS scoring difference (i.e., GFSnon−AD (vi) − GFSAD (vi)). Then, literature verification was carried out to find out whether these brain regions were related to AD, and the results are shown in Table 1.
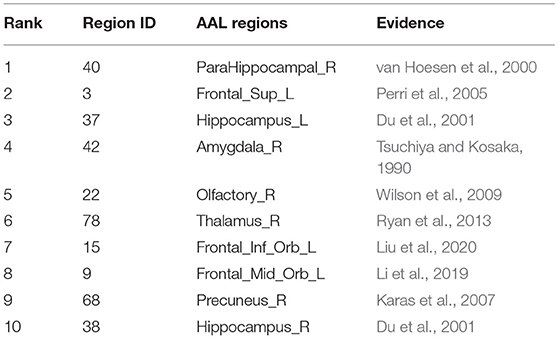
Table 1. Top 10 brain regions in GFS scoring difference between AD and non-AD groups.
For the brain structure network of the AD and non-AD groups, visualization results (Manning et al., 2014) showed a relative concentration of the top ten brain regions, as shown in Figures 5, 6.
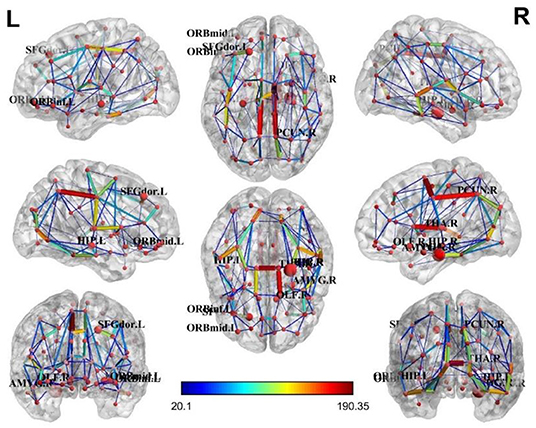
Figure 5. Brain structural network of the AD group.
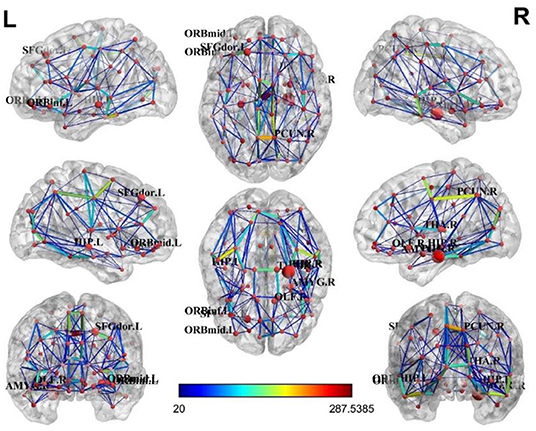
Figure 6. Brain structural network of the non-AD group.
More importantly, the authors compared the respective predictive effects of all local features. As can be learned from Table 2, whether it is the top 10, 20, 30, or 40% brain regions with the largest differences, the predictive effect (Table 2) of GFS is always better than the other local features from the results validated in the literature, as detailed in the Supplementary Data Sheet 1.

Table 2. Comparison of the proportion of verified AD-related brain regions for top 10, 20, 30, and 40% ranked by different measures.
In this section, the authors analyze whether GFS in the top ten brain regions correlates with the results of MMSE and MoCA. It allows for the analysis of whether there is a correlation between two sets of variables. Since some people were illiterate, so they could not complete the MoCA test; the authors took all the people who completed two scales, which were 29 in total (19 AD and 10 non-AD). At this point, canonical correlation analysis can be used. The basic principle is that to grasp the correlation between the two groups of variables as a whole, two composite variables U and V (linear combination of the two groups of variables) are extracted from the two groups of variables, respectively, and the correlation between the two composite variables is used to reflect the overall correlation between the two groups of variables.
The results of the canonical correlation analysis showed that the correlation coefficient between the typical variable pair 1 is 0.7136, which means that there is a very strong correlation between GFS and MMSE/MoCA scale information.
In this paper, a new local feature index 2hop-connectivity was set up to measure the correlation between different regions. 2hop-connectivity is a node importance metric, just like graph-theoretic metrics such as degree centrality. Since most biological networks are relatively sparse, 2hop-connectivity may work better for node importance metrics of sparse networks. And for this purpose, a novel random walk algorithm 2hopRWR is proposed, which can calculate the local feature index 2hop-connectivity. Also, the proof of convergence is given. Next, the idea of combining five local features to obtain the GFS was used in this paper, which is more convincing than using a single network parameter to describe the importance of network nodes. Then, the results of literature verification and canonical correlation analysis also verify the rationality and the validity of the proposed method. Thus, GFS can be used to distinguish DTI images of the AD and the non-AD groups. Finally, the top 10 brain regions in the GFS scoring difference predicted in this paper have been validated in the literature. Literature validation results comparing GFS with local features showed that GFS outperforms individual local features. However, the brain network constructed in this paper is a structural network, and the structure and function should be combined in the future. For example, more results may be obtained upon combining the available fMRI data and analyzing the differences of different brain regions in different tasks. For the importance evaluation of network nodes, there is no perfect standard measurement at present, and it is difficult to evaluate the advantages and disadvantages of the node importance algorithm. Another important problem is the need to design evaluation indicators to measure the importance of nodes.
In brief, GFS is expected to be an important and useful index for identifying the difference between network nodes and detecting the changes in information transmission between brain regions in patients with AD. Moreover, it may provide useful insights into the underlying mechanisms of AD. Many elder test subjects are illiterate and are not able to perform the MMSE and MoCA scales properly, so the GFS can be used as a diagnostic aid to infer whether a subject may be a patient with AD from DTI imaging data alone, which can greatly reduce the workload of medical practitioners. Finally, GFS can be used as a differential network analysis method (Lichtblau et al., 2017) in other areas of network analysis. The authors also expect the application of the 2hopRWR algorithm in traditional network analysis tasks, such as node classification, link prediction, and graph classification.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
QW designed the work, developed the computing method, wrote the code, analyzed the result, and wrote the manuscript. SC collected clinical data, analyzed the statistics, and polished the manuscript. HW and LC contributed to the imaging work and the statistical analysis. YS designed the work, collected clinical data, and contributed with theoretical support. GY designed the work, analyzed the result, and revised the manuscript. All authors contributed to the article and approved the submitted version.
This work was supported by the National Natural Science Foundation of China under Grant No.11631014.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
We thank Prof. Ang Li, Institute of Biophysics, Chinese Academy of Sciences, for his suggestions for the results section. We would also like to thank the two reviewers for their comments on improving this manuscript.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fncom.2021.659838/full#supplementary-material
Supplementary Table 1. MMSE & MoCA data.
Supplementary Table 2. DTI data overview.
Supplementary Data Sheet 1. Results of literature validation for GFS and local features.
Benson, A. R., Gleich, D. F., and Lim, L.-H. (2017). The spacey random walk: a stochastic process for higher-order data. SIAM Rev. 59, 321–345. doi: 10.1137/16M1074023
Cui, Z., Zhong, S., Xu, P., He, Y., and Gong, G. (2013). PANDA: a pipeline toolbox for analyzing brain diffusion images. Front. Hum. Neurosci. 7:42. doi: 10.3389/fnhum.2013.00042
Du, A. T., Schuff, N., Amend, D., Laakso, M. P., Hsu, Y. Y., Jagust, W. J., et al. (2001). Magnetic resonance imaging of the entorhinal cortex and hippocampus in mild cognitive impairment and Alzheimer's disease. J. Neurol. Neurosurg. Psychiatry 71, 441–447. doi: 10.1136/jnnp.71.4.441
Fan, L., Li, H., Zhuo, J., Zhang, Y., Wang, J., and Chen, L. (2016). The human brainnetome atlas: a new brain atlas based on connectional architecture. Cereb. Cortex 26, 3508–3526. doi: 10.1093/cercor/bhw157
John, M., Ikuta, T., and Fe Rbinteanu, J. (2017). Graph analysis of structural brain networks in Alzheimer's disease: beyond small world properties[J]. Brain Struct. & Funct., 222:923–942.
Karas, G., Scheltens, P., Rombouts, S., van Schijndel, R., Klein, M., Jones, B., et al. (2007). Precuneus atrophy in early-onset Alzheimer's disease: a morphometric structural MRI study. Neuroradiology 49, 967–976. doi: 10.1007/s00234-007-0269-2
Li, J., Jin, D., Li, A., Liu, B., Song, C., Wang, P., et al. (2019). ASAF: altered spontaneous activity fingerprinting in Alzheimer's disease based on multisite fMRI. Sci. Bull. 64, 998–1010. doi: 10.1016/j.scib.2019.04.034
Lichtblau, Y., Zimmermann, K., Haldemann, B., Lenze, D., Hummel, M., and Leser, U. (2017). Comparative assessment of differential network analysis methods. Brief. Bioinform. 18, 837–850. doi: 10.1093/bib/bbw061
Liu, J., Li, M., Pan, Y., Lan, W., Zheng, R., Wu, F.-X., et al. (2017). Complex brain network analysis and its applications to brain disorders: a survey. Complexity 2017, 1–27. doi: 10.1155/2017/3014163
Liu, Y., Chen, Y., Liang, X., Li, D., Zheng, Y., Zhang, H., et al. (2020). Altered resting-state functional connectivity of multiple networks and disrupted correlation with executive function in major depressive disorder. Front. Neurol. 11:272. doi: 10.3389/fneur.2020.00272
Manning, J. R., Ranganath, R., Norman, K. A., and Blei, D. M. (2014). Topographic factor analysis: a Bayesian model for inferring brain networks from neural data. PLoS ONE 9:e94914. doi: 10.1371/journal.pone.0094914
McKhann, G. M., Knopman, D. S., Chertkow, H., Hyman, B. T., Jack, C. R., Kawas, C. H., et al. (2011). The diagnosis of dementia due to Alzheimer's disease: recommendations from the National Institute on Aging-Alzheimer's Association workgroups on diagnostic guidelines for Alzheimer's disease. Alzheimer's Dem. 7, 263–269. doi: 10.1016/j.jalz.2011.03.005
Mori, S., and van Zijl, P. C. M. (2002). Fiber tracking: principles and strategies - a technical review. NMR Biomed. 15, 468–480. doi: 10.1002/nbm.781
Perri, R., Koch, G., Carlesimo, G. A., Serra, L., Fadda, L., Pasqualetti, P., et al. (2005). Alzheimer's disease and frontal variant of frontotemporal dementia– a very brief battery for cognitive and behavioural distinction. In Journal of neurology 252, 1238–1244. doi: 10.1007/s00415-005-0849-1
Ryan, N. S., Keihaninejad, S., Shakespeare, T. J., Lehmann, M., Crutch, S. J., Malone, I. B., et al. (2013). Magnetic resonance imaging evidence for presymptomatic change in thalamus and caudate in familial Alzheimer's disease. Brain J. Neurol. 136, 1399–11414. doi: 10.1093/brain/awt065
Salnikov, V., Schaub, M. T., and Lambiotte, R. (2016). Using higher-order Markov models to reveal flow-based communities in networks. Scient. Rep. 6:23194. doi: 10.1038/srep23194
Sanz-Arigita, E. J., Schoonheim, M. M., Damoiseaux, J. S., Rombouts, S. A. R. B., Maris, E., Barkhof, F., et al. (2010). Loss of ‘small-world' networks in Alzheimer's disease: graph analysis of fMRI resting-state functional connectivity. PLoS ONE 5:e13788. doi: 10.1371/journal.pone.0013788
Tong, H., Faloutsos, C., and Pan, J.-Y. (2006–2006). Fast random walk with restart and its applications. In: Sixth International Conference on Data Mining (ICDM'06). Sixth International Conference on Data Mining (ICDM'06) (Hong Kong: IEEE), 613–622. doi: 10.1109/ICDM.2006.70
Tsuchiya, K., and Kosaka, K. (1990). Neuropathological study of the amygdala in presenile Alzheimer's disease. J. Neurol. Sci. 100, 165–173. doi: 10.1016/0022-510X(90)90029-M
Tzourio-Mazoyer, N., Landeau, B., Papathanassiou, D., Crivello, F., Etard, O., Delcroix, N., et al. (2002). Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. NeuroImage 15, 273–289. doi: 10.1006/nimg.2001.0978
van Hoesen, G. W., Augustinack, J. C., Dierking, J., Redman, S. J., and Thangavel, R. (2000). The parahippocampal gyrus in Alzheimer's disease. Clinical and preclinical neuroanatomical correlates. Ann. N. Y. Acad. Sci. 911, 254–274. doi: 10.1111/j.1749-6632.2000.tb06731.x
Keywords: Alzheimer's disease, diffusion tensor imaging, brain structural network, 2hop-connectivity, global featurescore, differential network analysis
Citation: Wang Q, Chen S, Wang H, Chen L, Sun Y and Yan G (2021) Predicting Brain Regions Related to Alzheimer's Disease Based on Global Feature. Front. Comput. Neurosci. 15:659838. doi: 10.3389/fncom.2021.659838
Received: 28 January 2021; Accepted: 22 April 2021;
Published: 21 May 2021.
Edited by:
Feng Shi, Amazon, United StatesReviewed by:
Jingyun Chen, New York University, United StatesCopyright © 2021 Wang, Chen, Wang, Chen, Sun and Yan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yongan Sun, c3lhNzVAMTYzLmNvbQ==; Guiying Yan, eWFuZ3lAYW1zcy5hYy5jbg==
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.