
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Comput. Neurosci. , 14 October 2020
Volume 14 - 2020 | https://doi.org/10.3389/fncom.2020.00071
 Yuan Zhao1,2,3
Yuan Zhao1,2,3 Il Memming Park1,2,3*
Il Memming Park1,2,3*New technologies for recording the activity of large neural populations during complex behavior provide exciting opportunities for investigating the neural computations that underlie perception, cognition, and decision-making. Non-linear state space models provide an interpretable signal processing framework by combining an intuitive dynamical system with a probabilistic observation model, which can provide insights into neural dynamics, neural computation, and development of neural prosthetics and treatment through feedback control. This brings with it the challenge of learning both latent neural state and the underlying dynamical system because neither are known for neural systems a priori. We developed a flexible online learning framework for latent non-linear state dynamics and filtered latent states. Using the stochastic gradient variational Bayes approach, our method jointly optimizes the parameters of the non-linear dynamical system, the observation model, and the black-box recognition model. Unlike previous approaches, our framework can incorporate non-trivial distributions of observation noise and has constant time and space complexity. These features make our approach amenable to real-time applications and the potential to automate analysis and experimental design in ways that testably track and modify behavior using stimuli designed to influence learning.
Discovering interpretable structure from a streaming high-dimensional time series has many applications in science and engineering. Since the invention of the celebrated Kalman filter, state space models have been successful in providing a succinct (and thus a more interpretable) description of the underlying dynamics that explains the observed time series as trajectories in a low-dimensional state space. Taking a step further, state space models equipped with non-linear dynamics provide an opportunity to describe the latent “laws” of the system that is generating the seemingly entangled time series (Haykin and Principe, 1998; Ko and Fox, 2009; Mattos et al., 2016). Specifically, we are concerned with the problem of identifying a continuous non-linear dynamics in the state space x(t) ∈ ℝd that captures the spatiotemporal structure of a noisy observation y(t):
where F and G are continuous functions that may depend on parameter θ, u(t) is the control input, and P denotes a probability distribution that captures the noise in the observation, e.g., Gaussian distribution for field potentials or Poisson distribution for spike counts.
In practice, the continuous-time state dynamics is more conveniently formulated in discrete time as
where ϵt is intended to capture the unobserved (latent) perturbations of the state xt. Such (spatially) continuous state space models are natural in many applications where the changes are slow and the underlying system follows physical laws and constraints (e.g., object tracking) or where learning the laws are of great interest (e.g., in neuroscience and robotics) (Roweis and Ghahramani, 2001; Mante et al., 2013; Sussillo and Barak, 2013; Frigola et al., 2014; Zhao and Park, 2017). Specifically, in the context of neuroscience, the state vector xt represents the instantaneous state of the neural population, while f captures the time evolution of the population state. Further interpretation of f can provide understanding as to how neural computation is implemented (Mante et al., 2013; Zhao and Park, 2016; Russo et al., 2018).
If the non-linear state space model is fully specified, Bayesian inference methods can be employed to estimate the current state (Ho and Lee, 1964; Särkkä, 2013). Conventionally, the estimation of latent states using only the past observation is referred to as filtering—inference of the filtering distribution, p(xt∣y≤t). If both past and future observations are used, then the quantity of interest is usually the smoothing distribution, p(x≤t∣y≤t)). We are also interested in predicting the distribution over future states, p(xt:t+s∣y≤t), and observations, p(yt+1:t+s∣y≤t) for s > 0. In many applications, however, the challenge is in learning the parameters θ of the state space model (a.k.a. the system identification problem). We aim to provide a method for simultaneously learning both the latent trajectory xt and the latent (non-linear) dynamical and observational system θ, known as the joint estimation problem (Haykin, 2001).
Expectation maximization (EM) based methods have been widely used in practice (Ghahramani and Roweis, 1999; Valpola and Karhunen, 2002; Turner et al., 2010; Golub et al., 2013), and more recently variational autoencoder methods (Archer et al., 2015; Krishnan et al., 2015, 2016; Watter et al., 2015; Johnson et al., 2016; Karl et al., 2017) have been proposed, all of which are designed for offline analysis and are not appropriate for real-time applications. Recursive stochastic variational inference has been successful in streaming data assuming independent samples (Broderick et al., 2013), however, in the presence of temporal dependence, proposed variational algorithms (e.g., Frigola et al., 2014) remain theoretical and lack testing.
In this study, we are interested in real-time signal processing and state space control setting (Golub et al., 2013) where online algorithms are needed that can recursively solve the joint estimation problem on streaming observations. A popular solution to this problem exploits the fact that online state estimators for non-linear state space models such as extended Kalman filter (EKF) or unscented Kalman filter (UKF) can be used for non-linear regression formulated as a state space model. By augmenting the state space with the parameters, one can build an online dual estimator using non-linear Kalman filtering (Wan and Van Der Merwe, 2000; Wan and Nelson, 2001). They involve, however, coarse approximation of Bayesian filtering and many hyperparameters, do not take advantage of modern stochastic gradient optimization, and are not easily applicable to arbitrary observation likelihoods. There are also closely related online version of EM-type algorithms (Roweis and Ghahramani, 2001) that share similar concerns.
In hopes of lifting these concerns, we derive an online black-box variational inference framework, referred to as variational joint filtering (VJF), applicable to a wide range of non-linear state dynamics (dynamic models) and observation models, that is, the computational demand of the algorithm is constant per time step. Our approach is aimed as follows:
1. Online adaptive learning: Our target application scenarios are streaming data. This allows the inference during an experiment or as part of a neural prosthetics. If the system changes, the inference will catch up with the altered system parameters.
2. Joint estimation: The proposed method is supposed to simultaneously learn the latent states p(xt∣y≤t), state dynamics f(xt, ut) and the observation model G(x, u). No offline training is necessary to learn the system parameters.
3. Interpretability: Under the framework of state space modeling, rather than interpret the system via model parameters, we employ the language of dynamical systems and capture the characteristics of the system qualitatively via fixed point, limit cycle, strange attractor, bifurcation, and so on, which are key components of theories of neural dynamics and computation.
We focus on low-dimensional latent dynamics that often underlie many neuroscientific experiments and allow for producing interpretable visualizations of complex collective network dynamics in this study.
The crux of recursive Bayesian filtering is updating the posterior over the latent state one step at a time:
where the input ut and parameters θ are omitted for brevity. Unfortunately, the exact calculations of Equation (3) are not tractable in general, especially for non-linear dynamic models and/or non-conjugate distributions. We thus turn to approximate inference and develop a recursive variational Bayesian filter by deriving an evidence lower bound for the marginal likelihood as the objective function. Let q(xt) denote an arbitrary probability measure that will eventually approximate the filtering density p(xt∣y≤t). From Equation (3), we can rearrange the marginal log-likelihood as
where ℍ denotes Shannon's entropy and DKL denotes the Kullback-Leibler (KL) divergence (Cover and Thomas, 1991). Maximizing this lower bound would result in a variational posterior q(xt) ≈ p(xt∣y≤t) w.r.t. q(xt). Naturally we plug in the previous step's solution to the next time step, obtaining a loss function suitable for recursive estimation:
This also results in consistent q(xt) for all time steps as they are in the same family of distribution.
Meanwhile, as it is aimed to jointly estimate the observation model p(yt∣xt) and state dynamics p(xt∣xt−1), we achieve online inference by maximizing this objective w.r.t., their parameters (omitted for brevity), and the variational posterior distribution q(xt) simultaneously, provided that q(xt−1) takes some parameterized form and has been estimated from the previous time step. Maximizing the objective is equivalent to minimizing the two variational gaps: (1) the variational filtering posterior must be close to the true filtering posterior, and (2) the filtering posterior from the previous step needs to be close to p(xt−1∣xt, y<t). Note that the second gap is invariant to q(xt) if p(xt−1∣xt, y<t) = p(xt−1∣y<t), that is, the one-step backward smoothing distribution is identical to the filtering distribution.
On the flip side, intuitively, there are three components in that are jointly optimized: (1) reconstruction log-likelihood, which is maximized if q(xt) concentrates around the maximum likelihood estimate given only yt, (2) the dynamics log-likelihood, which is maximized if q(xt) concentrates at around the maximum of 𝔼q(xt−1)[log p(xt∣xt−1)], and (3) the entropy, which expands q(xt) and prevents it from collapsing to a point mass.
In order for this recursive estimation to be real-time, we choose q(xt) to be a multivariate normal with diagonal covariance where μt is the mean vector and st is the diagonal of the covariance matrix in this study. Moreover, to amortize the computational cost of optimization to obtain the best q(xt) on each time step, we employ the variational autoencoder architecture (Hinton et al., 1995) to parameterize q(xt) with a recognition model. Intuitively, the recognition model embodies the optimization process of finding q(xt), that is, it performs an approximate Bayesian filtering computation (in constant time) of Equation (3) according to the objective function . We use a recursive recognition model that maps q(xt−1) and yt to q(xt). In particular, the recognition model takes a deterministic recursive form:
Specifically h takes a simple the form of the multi-layer perceptron (MLP) (Hastie et al., 2009) in this study, and we refer to its parameters as the recognition model parameters. Note that the recursive architecture of the recognition model reflects the Markovian structure of the assumed dynamics (c.f., smoothing networks often use bidirectional recurrent neural network (RNN) (Sussillo et al., 2016) or graphical models (Archer et al., 2015; Johnson et al., 2016)).
The expectations appearing in the reconstruction log-likelihood and dynamics log-likelihood are not always tractable in general. For those intractable cases, one can use the reparameterization trick and stochastic variational Bayes (Kingma and Welling, 2014; Rezende et al., 2014): rewriting the expectations over q as expectation over a standard normal random variable, i.e., , and using a single sample for each time step. Hence, in practice, we optimize the following objective function (the other variables and parameters are omitted for brevity),
where and represent random samples from q(xt) and q(xt−1) respectively. Note that the remaining expectation over q(xt) has a closed form solution under our Gaussian state noise, ϵt, assumption. Our method can thus handle arbitrary observation and dynamic models, unlike dual form non-linear Kalman filtering methods, which usually suffer difficulties in sampling, e.g., transforming Gaussian random numbers into point process observations.
The schematics of the proposed inference algorithm is summarized by two passes in Figure 1. In the forward pass, the previous latent state generates the new state through the dynamic model, and the new state transforms into the observation through the observation model. In the backward pass, the recognition model recovers the current latent state from the observation, and the observation model, recognition model, and dynamic model are updated by backpropagation.
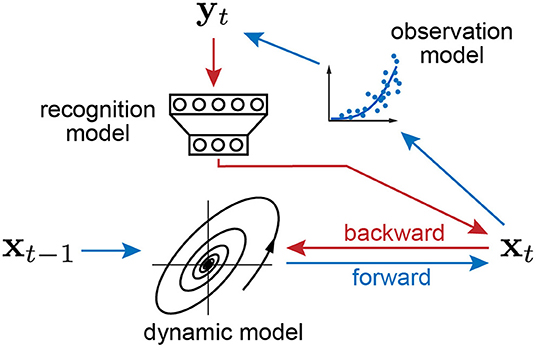
Figure 1. Schematics of variational joint filtering. Blue arrows indicates forward pass in which the previous latent state generates the new state through the state dynamics, and the new state transforms into the observation through the observation model. Red arrows indicate backward pass in which the recognition model recovers the current latent state from the observation. The three components, observation model, recognition model, and dynamical system, are updated by backpropagation.
Algorithm 1 is an overview of the recursive estimation algorithm. Denoting the set of all parameters by Θ of the observation model, recognition model and dynamic models, the objective function in Equation (6) is differentiable w.r.t. Θ, and we thus employ empirical Bayes and optimize it through stochastic gradient ascent (using Adam, Kingma and Ba, 2014). We outline the algorithm for a single vector time series, but we can filter multiple time series with a common state space model simultaneously, in which case the gradients are averaged across the instantiations. Note that this algorithm has constant time and space complexity per time step.
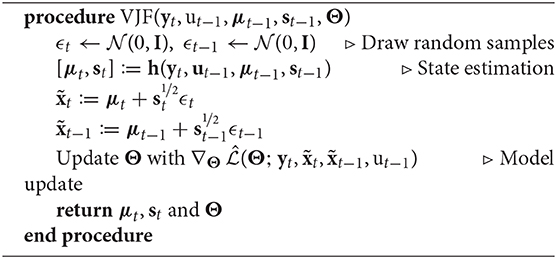
Algorithm 1. Variational Joint Filtering (single step).
In practice, the measurements yt and input ut are sampled at a regular interval. Algorithm 1 is called after every such observation event, which will return the state estimate along with the parameters and the dynamical system. One can visualize these for real-time for monitoring, and/or have it streamed to another system for further automated processing (e.g., detect anomalies and raise an alarm or deliver feedback controls).
Our primary applied aim is real-time neural interfaces where a population of neurons are recorded while a low-dimensional stimulation is delivered (Newman et al., 2015; El Hady, 2016; Hocker and Park, 2019). State-space modeling of such neural time series have been successful in describing population dynamics (Macke et al., 2011; Zhao and Park, 2017). Moreover, models of neural computation are often described as dynamical systems (Hopfield, 1982; Dayan and Abbott, 2001; Barak et al., 2013). For example, attractor dynamics where the convergence to one of the attractors represents the result of computation (Wang, 2002; Nassar et al., 2019). Here, we propose a parameterization and tools for visualization of the model suitable for studying neural dynamics and building neural interfaces (Zhao and Park, 2016). In this section, we provide methodological details for the results presented in the next section.
Having in mind high-temporal resolution neural spike trains where each time bin has at most one action potential per channel, we describe the case for point process observation. Our method, however, generalizes to arbitrary observation likelihoods that are appropriate for other modalities, including calcium imaging or local field potentials. The observed point process time series yt is a stream of sparse binary vectors. All experiments of point process observation were binned finely so that the time bins contain one event each at most in this study.
Our observation model, Equation (7), assumes that the observation vector yt is sampled from a probability distribution P determined by the latent state xt though a linear-non-linear map possibly together with extra parameters at each time t,
where g:ℝ → ℝ is a point-wise map. We use the canonical link g(·) = exp(·) for Poisson likelihood and identity for Gaussian likelihood in this study. Note that this observation model is not identifiable since where R is an arbitrary invertible matrix. We normalize the loading matrix C in each iteration. It is straightforward to include more additive exogenous variables, a history filter for refractory period, coupling between processes, and stimulation artifacts (Truccolo et al., 2005; Pillow et al., 2008).
For state dynamic model, we propose using a specific additive parameterization with state transition function and input interaction as a special case of Equation (2),
where ϕ(·) is a vector of r continuous basis functions, i.e., , W is the weight matrix of the radial basis functions, and Bt is the interaction with the input ut. The interaction Bt can be globally linear, parameterized as a matrix independent from xt, or locally linear, parameterized as a matrix-valued function of xt using also RBF networks. i.e., vec(B(xt)) = WBϕ(xt) where WB is the respective weight matrix. In this study, we used squared exponential radial basis functions (Roweis and Ghahramani, 2001; Sussillo and Barak, 2013; Frigola et al., 2014; Zhao and Park, 2016),
with centers ci and corresponding inverse squared kernel width γi. Though the dynamics can be modeled by other universal approximators such as perception and RNN, we chose the radial basis function network for the reasons of non-wild extrapolation (zero velocity when the state is far away from data) and fast computation.
The time complexity of our algorithm is , where n, m, p, q, r denote the dimensions of observation, latent space, input, the numbers of hidden units, and radial basis functions for this specific parameterization. Practically to achieve realistic computation time for real-time applications in neuroscience, the number of radial basis functions and hidden units are constrained by the requirement. Note that the time complexity does not grow with time that enable efficient online inference. If we compare this to an efficient offline algorithm such as PLDS (Macke et al., 2011) run repeatedly for every new observation (“online mode”), its time complexity is per time step at time t, which increases as time passes, making it impractical for real-time application.
Phase portrait displays key qualitative features of dynamics, and, with a little bit of training, it provides a visual means to interpreting dynamical systems. The law that governs neural population dynamics captured in the inferred function f(x) directly represents the velocity field of an underlying smooth dynamics (1a) in the absence of input (Roweis and Ghahramani, 2001; Zhao and Park, 2016). In the next section, we visualize the estimated dynamics as phase portrait which consists of the vector field, example trajectories, and estimated dynamical features (namely fixed points) (Strogatz, 2000). We can numerically identify candidate fixed points x* that satisfy f(x*) ≈ 0. For the synthetic experiments, we performed an affine transformation to orient the phase portrait to match the canonical equations in the main text when the simulation is done through the proposed observation model if the observation model is unknown and estimated.
For state space models, we can predict both future latent trajectory and future observations. The s-step ahead prediction can be sampled from the predictive distributions:
given estimated parameters by current time t without seeing the data yt+1:t+s during these steps. In the figures of experiments, we plot the mean of the predictive distribution as trajectories.
We demonstrate our method on a range of non-linear dynamical systems relevant to neuroscience. Many theoretical models have been proposed in neuroscience to represent different schemes of computation. For the purpose of interpretable visualization, we choose to simulate from two- or three-dimensional dynamical systems. We apply the proposed method to four such low-dimensional models: a ring attractor model as a model of internal head direction representation, a non-linear oscillator as a model of rhythmic population-wide activity, a biophysically realistic cortical network model for a visual discrimination experiment, and a chaotic attractor.
In the synthetic experiments, we first simulated state trajectories by respective differential equations, and we then generated either Gaussian or point process observations (to mimic spikes) via Equation (7) with corresponding distributions. The parameters C and b were randomly drawn, and they were constrained to keep firing rate < 60 Hz on average for realistic spiking behavior. All observations are spatially 200-dimensional unless otherwise mentioned. We refer to their conventional formulations under different coordinate systems, but our simulations and inferences are all done in Cartesian coordinates. Note that we focus on online learning in this study and always train our model with streaming data, even while comparing with offline methods.
The approximate posterior distribution is defined recursively in Equation (5) as diagonal Gaussian with mean and variance determined by corresponding observation, input, and previous step via a recurrent neural network. We used a one-hidden-layer MLP in this study. Typically, the state noise variance σ2 is unknown and has to be estimated from data. To be consistent with Equation (8c), we set the starting value of σ2 to be 1, and hence μ0 = 0, s0 = I. We initialize the loading matrix C by factor analysis, and column-wisely normalize it by ℓ2 norm every iteration to keep the system identifiable.
Continuous attractors are often used as models for neural representation of continuous variables (Mante et al., 2013; Sussillo and Barak, 2013). For example, a bump attractor network with ring topology is proposed as the dynamics underlying the persistently active set of neurons that are tuned for the angle of the animal's head direction (Peyrache et al., 2015). Here we use the following two-variable reduction of the ring attractor system. First, we study the following two-variable ring attractor system:
where φ represents the direction driven by input I, and r is the radial component representing an internal circular variable, such as head direction. We simulated 100 trajectories (1,000 steps) with step size Δt = 0.1, r0 = 1, τr = 1, and τφ = 1 with Gaussian state noise (std = 0.005) added each step. Though the ring attractor is defined in polar coordinate system, we transformed it into Cartesian system for simulation and training. In simulation we used strong input (tangent drift) to keep the trajectories flowing around the ring clockwise or counterclockwise. The point process observations were generated by passing the states through a linear-non-linear map (Equation 7) and sampling from a Poisson distribution. We streamed the observations into the proposed algorithm that consists of point process likelihood, a dynamic model with 20 radial basis functions and locally linear input interaction in Equation (2), and a recognition MLP with 100 hidden units.
Figure 2A illustrates one latent trajectory (black) and its variational posterior mean (blue). These two trajectories start at green circle and diamond respectively and end at the red markers. The inference starts near the center (origin) that is relatively far from the true location because the initial posterior mean is set at zero. The final states are very close, which implies that the recognition model works well. Figure 2B shows the reconstructed velocity field by the model. We visualized the velocity as colored directional streamlines. We can see the velocity toward the ring attractor and the speed is smaller closer to the ring. The model also identifies a number of fixed points arranged around the ring attractor via numerical roots finding. Figure 2C shows the distribution of posterior means of all data points in the state space. We have more confidence of the inferred dynamical system in the denser area.
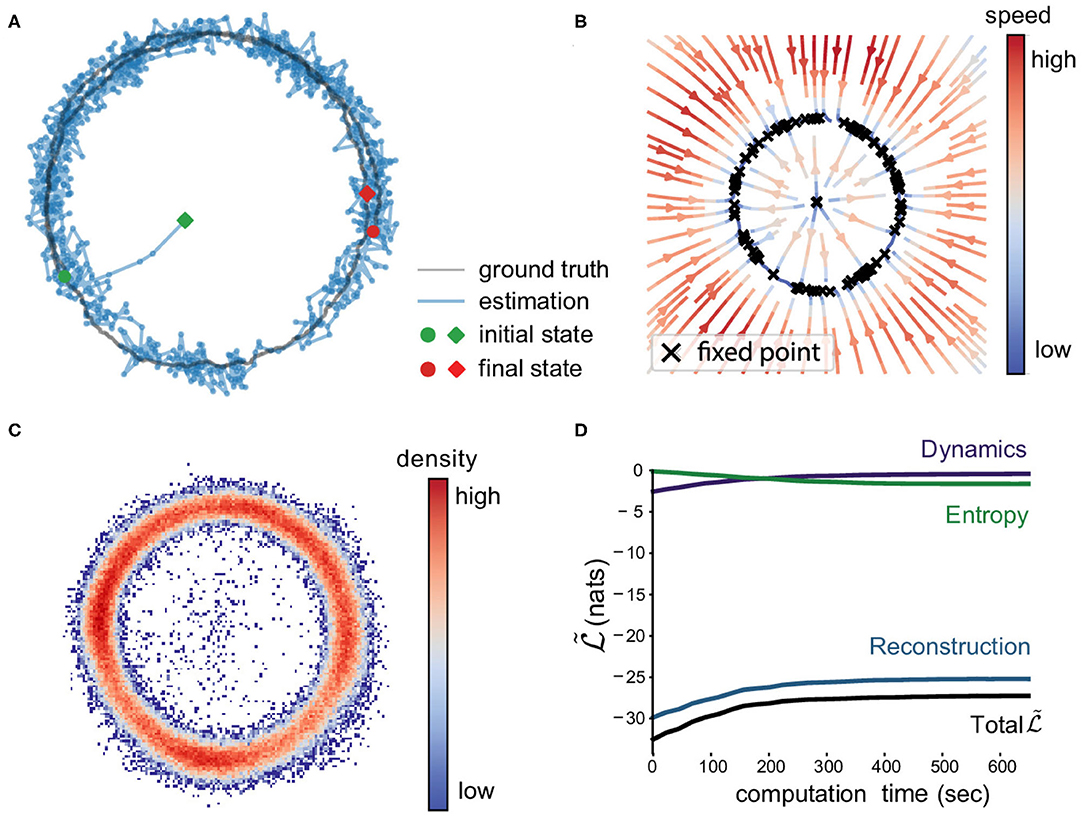
Figure 2. Ring attractor model. (A) One latent trajectory (black) in the training set and the corresponding filtered mean μt (blue). (B) Velocity field reconstructed from the trained proposed model. The colored streamlines indicate the speed and the directions. The black crosses are candidate fixed points obtained from inferred dynamics. Note the collection of fixed points around the ring shape. The central fixed point is unstable. (C) Density of the posterior means. The density of inferred means of all trajectories in the training set. The higher it is, the more confidence we have on the inferred dynamics where we have more data. (D) Convergence on the ring attractor. We display the three components of the objective lower bound: reconstruction log-likelihood, dynamics log-likelihood, entropy, and the lower bound itself from Equation (4). The average computation time per step is 1.1 ms (more than 900 data points per sec).
Figure 2D shows the three components of Equation (4) and the objective lower bound clearly, demonstrating the convergence of the algorithm. We can see each component reaches a plateau within 400 s. As the reconstruction and dynamics log-likelihoods increase, the recognition model and dynamical model are getting more accurate while the decreasing entropy indicates the increasing confidence (inverse posterior variance) on the inferred latent states. The average computation time of a joint estimation step is 1.1 ms (hardware specification: Intel Xeon E5-2680 2.50G Hz, 128GB RAM, no GPU).
Dynamical systems have been a successful application in the biophysical models of single neuron in neuroscience. We used a relaxation oscillator, the FitzHugh-Nagumo (FHN) model (Izhikevich, 2007), which is a two-dimensional reduction of the Hodgkin-Huxley model with the following non-linear state dynamics
where v is the membrane potential, w is a recovery variable, and I is the magnitude of stimulus current in modeling single neuron biophysics. This model was also used to model global brain state that fluctuates between two levels of excitability in anesthetized cortex (Curto et al., 2009). We use the following parameter values a = −0.1, b = 0.01, c = 0.02, and I = 0.1 to simulate 100 trajectories of 1,000 steps with step size 0.5 and Gaussian noise (std=0.002). At this regime, unlike the ring attractor, the spontaneous dynamics is a periodic oscillation, and the trajectory follows a limit cycle. The point process observations were also sampled via the observation model of the same parametric form as that of the ring attractor example. We used 20 radial basis functions for dynamic model and 100 hidden units for recognition model. While training the model, the input was clamped to zero, and the model was expected to learn the spontaneous oscillator.
We compare the state estimation with the standard particles filtering (PF), which are powerful online methods theoretically capable of producing arbitrarily accurate filtering distribution. We run two variants of the particle filter with different proposal distributions. One used diffusion as the proposal, i.e., xt = xt−1 + ϵt where x is the vector of state variables v and w, and the other, a.k.a. bootstrap particle filter (Gordon et al., 1993), used the true dynamics in Equation (12). We provided the true parameters for the observation model and noise term to PF, which gives them an advantage. Both particle filters and VJF were run on 50 realizations of 5,000-step long observation series. Figure 3 shows the root mean squared deviations (RMSE) (mean and standard error over 50 realizations). It is expected that the bootstrap particle filter outperformed the diffusion particle filter since the former utilized the true dynamics. One can see the state estimation by VJF improved as learning carrying on and eventually outperformed both particle filters. Note that VJF had to learn the parameters of likelihood, dynamic model and recognition model during the run. We varied the number of RBFs (20 and 30), but the results are not substantially different.
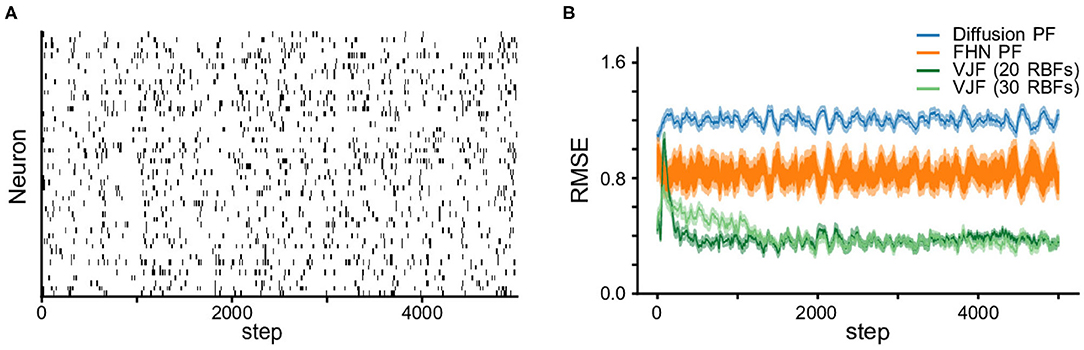
Figure 3. Non-linear oscillator (FitzHugh-Nagumo) observation and state estimation. (A) The synthetic spike train. (B) RMSEs (the shades are s.e.m.) of state estimation on the observation in (A). We report the RMSE of estimated states among the proposed method VJF and two particle filters, one with diffusion dynamics and the other with the true FHN dynamics. Varying the number of RBFs did not substantially change the quality of the results.
We also reconstructed the phase portrait (Figure 4B) comparing to the truth (Figure 4C). The two dashed lines are the theoretical nullclines of the true model on which the velocity of corresponding dimension is zero. The reconstructed field shows a low speed valley overlapping with the nullcline especially on the right half of the figure. There is an unstable fixed point at the intersection of the two nullclines. We can see the identified fixed point is close to the intersection. As most of the trajectories lie on the oscillation path (limit cycle) with merely few data points elsewhere, the inferred system shows the oscillation dynamics similar to the true system around the data region. The difference mostly happens in the region far from the trajectories because of the lack of data.
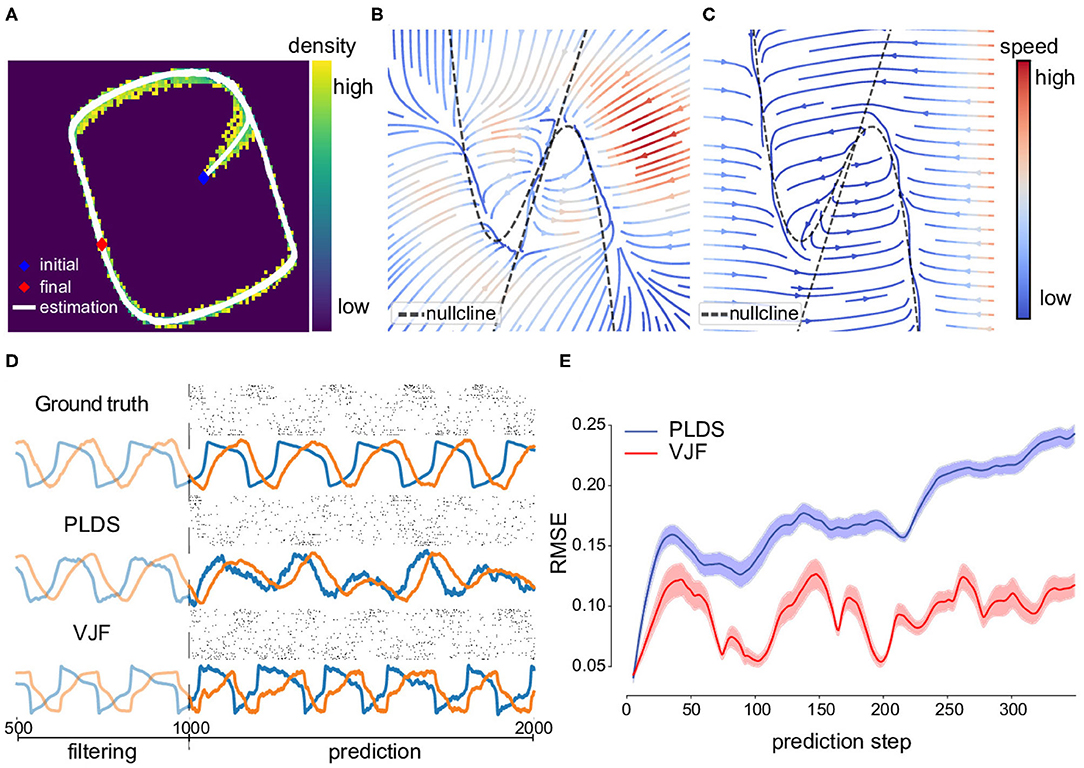
Figure 4. Non-linear oscillator (FitzHugh-Nagumo) dynamical system and prediction. (A) One inferred latent trajectory and the density of posterior means of all trajectories. Most of the inferred trajectory lies on the oscillation path. (B) Velocity field reconstructed by the inferred dynamical system. (C) Velocity field of the true dynamical system. The dashed lines are two nullclines of the true model on which the gradients are zero so as the velocity. (D) 1,000-step prediction continuing the trajectory and sampled spike trains compared to ground truth from (A). (E) Mean (solid line) and standard error (shade) of root mean square error of prediction of 2,000 trials. The prediction started at the same states for the true system and models. Note that PLDS fails to predict long term due to its linear dynamics assumption. A linear dynamical system without noise can only produce damped oscillations.
We ran a long-term prediction using VJF without seeing the future data yt+1:T during these steps (T = 1,000 steps = 1 s) beginning at the final state of training data. The truth and prediction can be seen in Figure 4D. The upper row is the true latent trajectory and corresponding observations. The lower row is the filtered trajectory and prediction by the proposed method. The light-colored parts are the 500 steps of inference before prediction and the solid-colored parts are 1,000-step truth and prediction. We also show the sample observations from the trained observation model during the prediction period.
One of the popular latent process modeling tools for point process observation that can make prediction is the Poisson Linear Dynamical System (PLDS) (Macke et al., 2011) which assumes latent linear dynamics. We compared PLDS fit with EM on its long-term prediction on both the states and spike trains (Figure 4). This demonstrates the non-linear dynamical model outperforming the linear model even in the unfair online setting.
To compare to the methods with non-linear dynamical models, we also run latent factor analysis via dynamical systems (LFADS) (Pandarinath et al., 2018) offline using the same data. LFADS implements its dynamical model with the gated recurrent unit (GRU) (Cho et al., 2014) that requires high dimensions. For this two-dimensional system, we tried different GRU dimensionalities. We made minimal changes to its recommended setting, including only the generator dimensionality, batch, and no controller. The result shows that LFADS requires much higher dimension than the true system to capture the oscillation (Figure S1). (The figure of its inferred trajectories is shown in the supplement.) We report the fitted log-likelihood per time bin as −0.1274, −0.1272, and −0.1193 for 2D, 20D, and 50D GRU, respectively. In comparison, the log-likelihood of the proposed approach is −0.1142 with a two-dimensional dynamical model (higher the better).
Perceptual decision-making paradigm is a well-established cognitive task where typically a low-dimensional decision variable needs to be integrated over time, and subjects are close to optimal in their performance. To understand how the brain implements such neural computation, many competing theories have been proposed (Wang, 2002; Wong and Wang, 2006; Ganguli et al., 2008; Barak et al., 2013; Mante et al., 2013). We test our method on a simulated biophysically realistic cortical network model for a visual discrimination experiment (Wang, 2002). In the model, there are two excitatory subpopulations that are wired with slow recurrent excitation and feedback inhibition to produce attractor dynamics with two stable fixed points (Figure 5A). Each fixed point represents the final perceptual decision, and the network dynamics amplify the difference between conflicting inputs and eventually generates a binary choice.
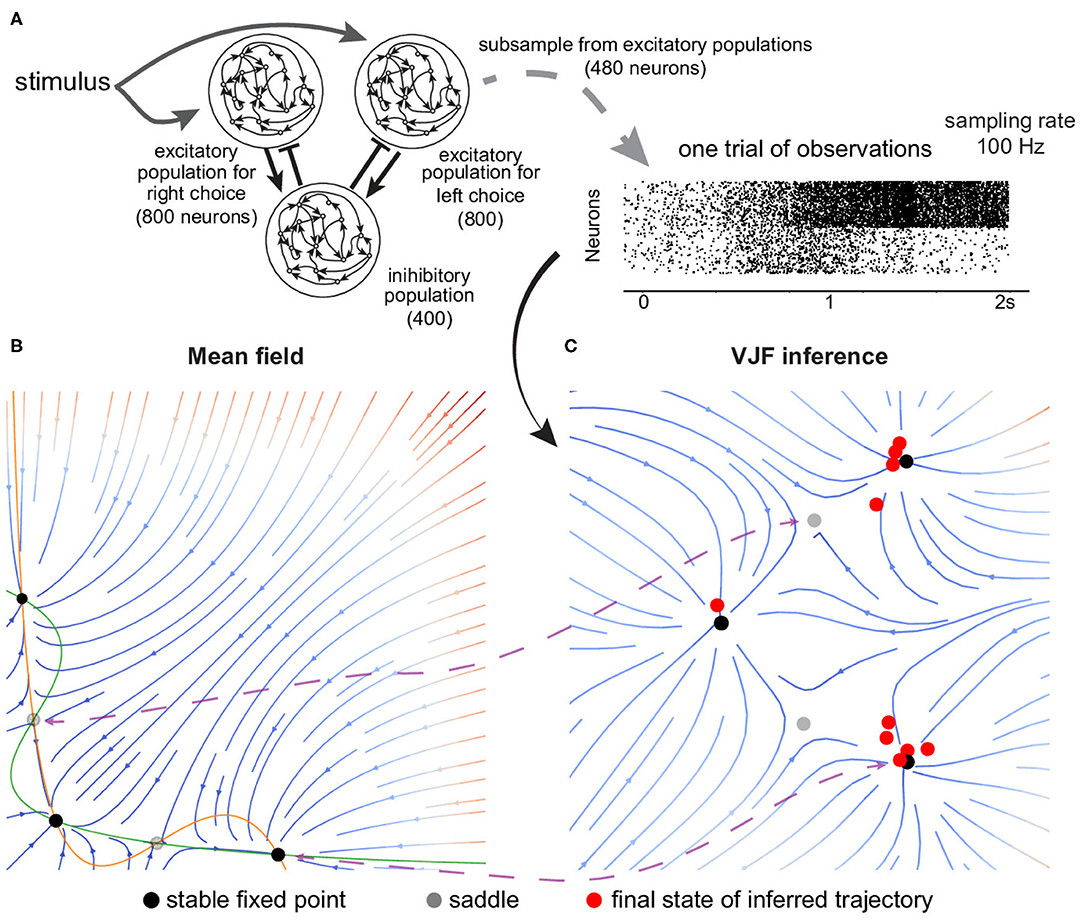
Figure 5. Fixed point attractor for decision-making. (A) Schematics of the neural network. There are two excitatory populations that are wired with slow recurrent excitation and feedback inhibition to produce attractor dynamics. The simulation was organized into decision-making trials. Each trial begins with a 0.5 s period of spontaneous activity, and the input is then given to the two excitatory populations for 1.5 s. We subsampled 480 selective neurons out of 1,600 excitatory neurons from the simulation to be observed by our algorithm. (B) Mean field reduction of the network. Theoretical work has shown that the collective population dynamics can be reduced to two dimensions (Wong and Wang, 2006). (C) VJF inferred dynamical model. The red dots are the inferred final states of zero-coherent trials. The black dots are fixed points (the solid are stable and the gray are unstable). Although the absolute arrangement is dissimilar, the topology and relation of the five identified fixed points show correspondence (indicated by purple lines).
Unlike former examples that use a linear-non-linear map of latent states, the point process observations (spikes) of this experiment were directly sampled from the spiking neural network1(1 ms binwidth) that was governed by its own high-dimensional intrinsic dynamics. It is filling the gap between fully specified state space models and real neuron populations.
We subsampled 480 selective neurons out of 1,600 excitatory neurons from the simulation to be observed by our algorithm. The simulated data is organized into decision-making trials where each trial lasts for 2 s and with different strength of visual evidence, controlled by “coherence.” Our method with 20 radial basis functions learned the dynamics from 140 training trials (20 per coherence level c, c = −1, −0.2, −0.1, 0, 0.1, 0.2, and1).
Figure 5C shows the velocity field at zero coherence stimulus as colored streamlines. Note that our approach did not have prior knowledge of the network dynamics as the mean-field reduction (Wong and Wang, 2006) in Figure 5B. Although the absolute arrangement is dissimilar, the topology and relation of the five identified fixed points show correspondence with the mean-field reduction. The inference was completely data-driven (partial observation of spike trains), while the mean-field method required knowing the true dynamical model of the network and careful approximation by Wong and Wang (2006). We showed that our method can provide a qualitatively similar result to the theoretical work, which reduces the dimensionality and complexity of the original network.
Chaotic dynamics (or edge-of-chaos) have been postulated to support asynchronous states in the cortex and neural computation over time by generating rich temporal patterns (Maass et al., 2002; Laje and Buonomano, 2013). We consider the three-dimensional standard Lorenz attractor as an example chaotic system to demonstrate the flexibility of our method. We simulated 216 latent trajectories from:
The each coordinate of the initial states are on the uniform grid of 6 values in [−50, 50] inclusively, of which the combination results in 216 unique states. We discarded the first 500 transient steps of each trajectory and then use the following 1,000 steps. We generated 200-dimensional Gaussian observations driven by the trajectories. Figure 6A shows estimated latent trajectory and the ground truth. One can see that the estimation lies in a similar manifold. In addition, we predicted 500 steps of future latent states without knowing the respective observations. Figure 6B shows four predicted trajectories starting from different initial states. One can see that the inferred system could generate qualitatively similar trajectory at most initial states but not perfectly for the true system is chaotic.
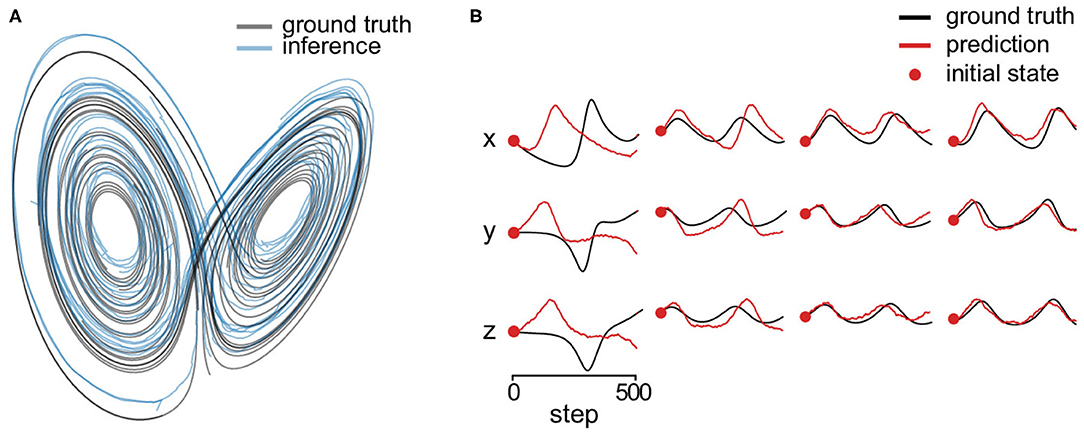
Figure 6. Lorenz attractor. (A) Estimated state trajectory (blue) and the ground truth (black) in three dimensions. (B) We predict 500 steps of future latent states (without knowing the respective observations) starting from four different initial states (red dots) using the inferred dynamical system. The red lines are the prediction and the black lines are the corresponding ground truth state.
Another feature of our method is that its state dynamics estimate never stops. As a result, the algorithm is adaptive, and can potentially track slowly varying (non-stationary) latent dynamics. To test this feature, we compared a dual EKF and the proposed approach on non-stationary linear dynamical system. A spiral-in linear system was suddenly changed from clockwise to counterclockwise at the 2000th step, and the latent state was perturbed (Figure 7). To adapt EKF, we used Gaussian observations that were generated through linear map from a two-dimensional state to 200-dimensional observation with additive noise (). To focus on the dynamics, we fixed all the parameters except the transition matrix for both methods, while our approach still must learn the recognition model in addition. Figure 7 shows that our approach achieved better online performance as dual EKF in this experiment.
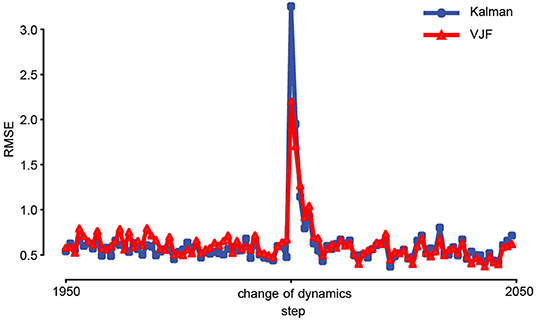
Figure 7. Prediction of non-stationary dynamical system. The colored curves (blue: EKF, red: VJF) are the mean RMSEs of one-step-ahead prediction of non-stationary system during online learning (50 trials). The linear system was changed, and the state was perturbed at the 2000th step (center). The lines are average RMSEs. Both online algorithms quickly learned the change after a few steps.
We applied the proposed method to a large-scale recording to validate that it picks up meaningful dynamics. The dataset (Graf et al., 2011) consists of 148 simultaneously recorded single units from the primary cortex (V1) while directional drifting gratings were presented to an anesthetized monkey for around 1.3s per trial (Figure 8A). We used the spike trains from 63 well-tuned units. The spike times were binned with a 1ms window (max 1 spike per bin). There is one continuous circular variable in the stimuli space: temporal phase of oscillation induced by the drifting gratings.
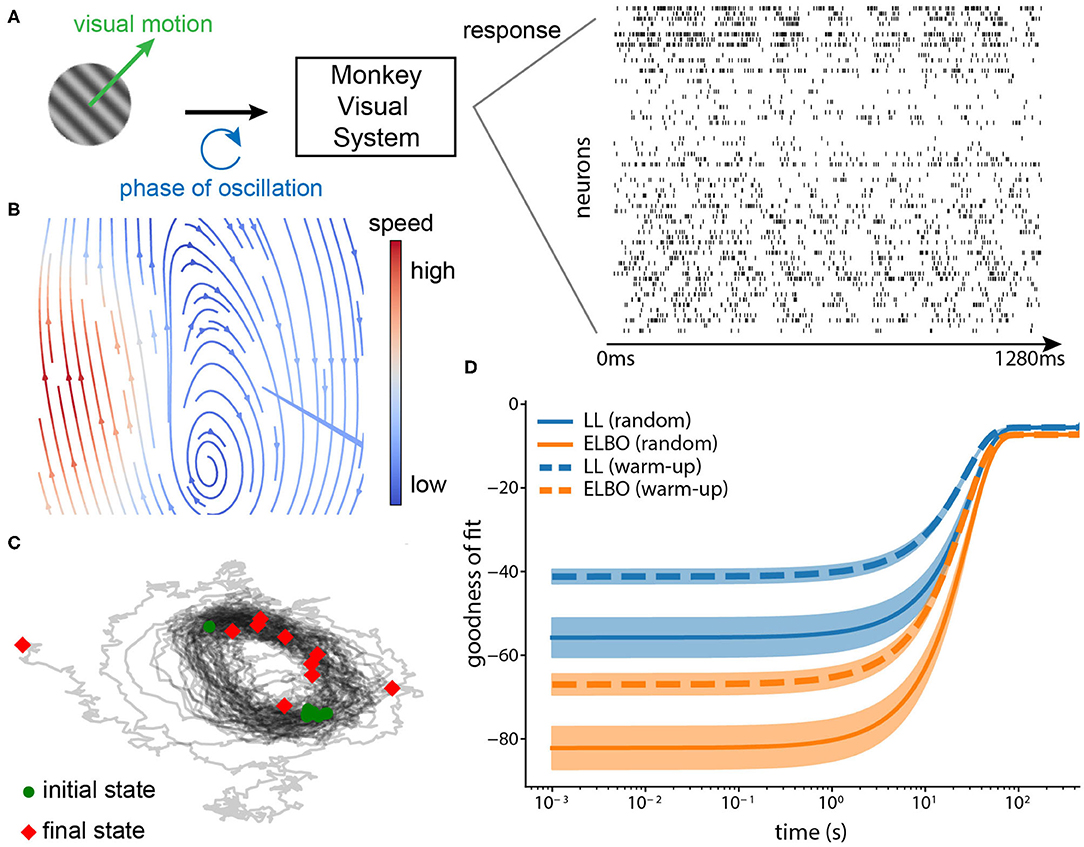
Figure 8. (A) Neurophysiological experiment. Drifting gratings were shown to the monkey (on the left). The neural spike trains (63 neurons, 1,280 ms) from area V1 during the motion onset were recorded (on the right). Each row is one neuron and the binwidth is 1 ms. The phase of the oscillation forms a circular variable. (B) Phase portrait of the inferred dynamical system (arrows: direction, blue: low speed, and red: high speed). The flow shows that the inferred system forms an oscillator. (C) Trajectories simulated from the inferred dynamical system. We simulated 10 state trajectories using the inferred system with random initial states (1,000 steps each, black lines: trajectories, green circles: initial states, red diamonds: final states). The trajectories also confirm that the inferred system captured the oscillation underlying the data. (D) Convergence of the online method in terms of its goodness-of-fit. We calculated two goodness-of-fit measures (mean ± standard deviation, 10 repetitions), log-likelihood (LL) and ELBO for two strategies of initializing the observation model, warm-up and random initialization. Warm-up indicates that we initialized the observation model using dimensionality reduction methods before VJF; Random initialization indicates that the parameters of observation model were randomly drawn and learned completely by VJF.
A partial warm-up helps with the training. We chose a good initialization for the observation model, specifically the loading matrix and bias. There are 72 motion directions in total, each repeated 50 trials. We used the trials corresponding to 0 deg direction to initialize the observation model with dimensionality reduction methods, such as variational latent Gaussian processes Zhao and Park (2017), and then trained VJF with a two-dimensional dynamic model fully online on the trials corresponding to 180 deg direction that it had not seen before. Since we do not have long enough continuously-recorded trials, we concatenated the trials (equivalent to 500 s) as if they were continuously recorded to mimic an online setting. As expected, Figures 8B,C shows the inferred dynamical system is able to implement the oscillation. The two goodness of fit measures (log-likelihood and ELBO) in Figure 8D shows that our method benefits from but does not necessarily require such a warm-up. The model with warm-up initialization had better starting goodness of fit than the random initialized model, but the random initialized model eventually achieved similar goodness of fit with adequate amount of data.
Neurotechnologies for recording the activity of large neural populations during meaningful behavior provide exciting opportunities for investigating the neural computations that underlie perception, cognition, and decision-making. However, the datasets provided by these technologies currently require sophisticated offline analyses that slow down the scientific cycle of experiment, data analysis, hypothesis generation, and further experiment. Moreover, in closed-loop neurophysiological setting, real-time adaptive algorithms are extremely valuable (Jordan and Park, 2020).
To fulfill this demand, we proposed an online algorithm for recursive variational Bayesian inference that simultaneously performs system identification and state filtering under the framework of state space modeling, in hope that it can greatly impact neuroscience research and biomedical engineering. There is no other method capable of all features, hence we compared several methods in different measures, often giving them the advantage. We showed that our proposed method consistently outperforms the state-of-the-art methods.
Using the language of dynamical systems, we interpret the target system not via model parameters but via dynamical features: fixed points, limit cycles, strange attractors, bifurcations, and so on. In our current approach, this interpretation heavily relies on visual inspection of the qualitative non-linear dynamical system features. In contrast, most popular state space models assume linear dynamics (Ho and Lee, 1964; Katayama, 2005; Macke et al., 2011), which is appropriate for smoothing latent states is but not expressive enough to recover the underlying vector field. Recently the Koopman theory that allows representation of general non-linear dynamics as linear operators in infinite dimensional spaces (Koopman, 1931) has gained renewed interest in modeling non-linear dynamics. Although elegant in theory, in practice, however, the Koopman operators need to be truncated to a finite dimensional space with linear dynamics (Brunton et al., 2016). We note that the resulting linear models do not allow for topological features such as multiple isolated fixed points, non-linear continuous attractors, stable limit cycles—features critical for non-trivial neural computation.
Our algorithm is highly flexible and general, allowing for a wide range of observation models (likelihoods) and dynamic models, is computationally tractable, and produces interpretable visualizations of complex collective network dynamics. Our key assumption is that the dynamics consists of a continuous and slow flow, which enable us to parameterize the velocity field directly. This assumption reduces the complexity of the non-linear function approximation; it is therefore easy to identify the fixed/slow points. We specifically chose the radial basis function network to model the dynamics for our experiments, which regularizes and encourages the dynamics to occupy a finite phase volume around the origin.
Our method has several hyperparameters. In the experiments, the differentiable hyperparameters were learnt via gradient descent while the selection of the other hyperparameters were made simple. In general, our method was robust; Perturbing the number of RBFs did not produce qualitatively different results (Figure 3). Liu et al. (2009) discussed growing radial basis function network adaptively, which could be incorporated into our method to enable online tuning of the number of RBFs. The depth and width of neural networks were chosen empirically to improve the interpretability of resulting dynamical systems, but tuning did not result in large changes in the results.
This work opens many avenues for future work. One direction is to apply this model to large-scale neural recording from a behaving animal. We hope that further development would enable on-the-fly analysis of high-dimensional neural spike train during electrophysiological experiments. Clinically, a non-linear state space model provides a basis for non-linear feedback control as a potential treatment for neurological diseases that arise from diseased dynamical states.
The datasets generated for this study are available on request to the corresponding author.
All authors developed the methods. All authors conducted all simulations and analyses and created all figures in the manuscript. All authors wrote the manuscript.
This work was supported by National Science Foundation (IIS-1734910) and National Institutes of Health (NIH/NIBIB EB026946).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fncom.2020.00071/full#supplementary-material
1. ^The detail of the spiking neural network can be found in Wang (2002), and the code can be found at https://github.com/xjwanglab/book/tree/master/wang2002.
Archer, E., Park, I. M., Buesing, L., Cunningham, J., and Paninski, L. (2015). Black box variational inference for state space models. arXiv preprints arXiv:1511.07367.
Barak, O., Sussillo, D., Romo, R., Tsodyks, M., and Abbott, L. F. (2013). From fixed points to chaos: three models of delayed discrimination. Prog. Neurobiol. 103, 214–222. doi: 10.1016/j.pneurobio.2013.02.002
Broderick, T., Boyd, N., Wibisono, A., Wilson, A. C., and Jordan, M. I. (2013). “Streaming variational bayes,” in Advances in Neural Information Processing Systems 26, eds C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger (Lake Tahoe, CA: Curran Associates, Inc), 1727–1735.
Brunton, B. W., Johnson, L. A., Ojemann, J. G., and Kutz, J. N. (2016). Extracting spatial-temporal coherent patterns in large-scale neural recordings using dynamic mode decomposition. J. Neurosci. Methods 258, 1–15. doi: 10.1016/j.jneumeth.2015.10.010
Cho, K., van Merrienboer, B., Bahdanau, D., and Bengio, Y. (2014). On the properties of neural machine translation: encoder-decoder approaches. arXiv preprints arXiv:1409.1259.
Cover, T. M., and Thomas, J. A. (1991). Elements of Information Theory. New York, NY: Wiley-Interscience.
Curto, C., Sakata, S., Marguet, S., Itskov, V., and Harris, K. D. (2009). A simple model of cortical dynamics explains variability and state dependence of sensory responses in Urethane-Anesthetized auditory cortex. J. Neurosci. 29, 10600–10612. doi: 10.1523/jneurosci.2053-09.2009
Dayan, P., and Abbott, L. F. (2001). Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems. Cambridge, MA: Massachusetts Institute of Technology Press.
Frigola, R., Chen, Y., and Rasmussen, C. E. (2014). “Variational gaussian process state-space models,” in Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2 (Montreal, QC), 3680–3688.
Ganguli, S., Bisley, J. W., Roitman, J. D., Shadlen, M. N., Goldberg, M. E., and Miller, K. D. (2008). One-dimensional dynamics of attention and decision making in LIP. Neuron 58, 15–25. doi: 10.1016/j.neuron.2008.01.038
Ghahramani, Z., and Roweis, S. T. (1999). “Learning nonlinear dynamical systems using an EM algorithm,” in Advances in Neural Information Processing Systems 11, eds M. J. Kearns, S. A. Solla, and D. A. Cohn (Denver, CO: MIT Press), 431–437.
Golub, M. D., Chase, S. M., and Yu, B. M. (2013). “Learning an internal dynamics model from control demonstration,” in JMLR Workshop and Conference Proceedings (Atlanta, GA), 606–614.
Gordon, N. J., Salmond, D. J., and Smith, A. F. M. (1993). Novel approach to nonlinear/non-gaussian bayesian state estimation. IEE Proc. Radar Signal Process. 140:107.
Graf, A. B. A., Kohn, A., Jazayeri, M., and Movshon, J. A. (2011). Decoding the activity of neuronal populations in macaque primary visual cortex. Nat. Neurosci. 14, 239–245. doi: 10.1038/nn.2733
Hastie, T., Tibshirani, R., and Friedman, J. (2009). The Elements of Statistical Learning. New York, NY: Springer-Verlag GmbH.
Haykin, S. and Principe, J. (1998). Making sense of a complex world [chaotic events modeling]. IEEE Signal Process. Magaz. 15, 66–81. doi: 10.1109/79.671132
Hinton, G., Dayan, P., Frey, B., and Neal, R. (1995). The "wake-sleep" algorithm for unsupervised neural networks. Science 268, 1158–1161.
Ho, Y., and Lee, R. (1964). A Bayesian approach to problems in stochastic estimation and control. IEEE Trans. Autom. Control 9, 333–339.
Hocker, D., and Park, I. M. (2019). Myopic control of neural dynamics. PLoS Comput. Biol. 15:e1006854. doi: 10.1371/journal.pcbi.1006854
Hopfield, J. J. (1982). Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. U.S.A. 79, 2554–2558.
Izhikevich, E. M. (2007). Dynamical Systems in Neuroscience : The Geometry of Excitability and Bursting. Computational Neuroscience. Cambridge, MA: MIT Press.
Johnson, M., Duvenaud, D. K., Wiltschko, A., Adams, R. P., and Datta, S. R. (2016). “Composing graphical models with neural networks for structured representations and fast inference,” in Advances in Neural Information Processing Systems 29, eds D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, and R. Garnett (Barcelona: Curran Associates, Inc), 2946–2954.
Jordan, I. D., and Park, I. M. (2020). Birhythmic analog circuit maze: a nonlinear neurostimulation testbed. Entropy 22:537. doi: 10.3390/e22050537
Karl, M., Soelch, M., Bayer, J., and van der Smagt, P. (2017). “Deep variational Bayes filters: unsupervised learning of state space models from raw data,” in 5th International Conference on Learning Representations (Toulon).
Kingma, D. P., and Welling, M. (2014). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114. arXiv: 1312.6114.
Ko, J., and Fox, D. (2009). GP-BayesFilters: Bayesian filtering using gaussian process prediction and observation models. Auton. Robots 27, 75–90. doi: 10.1007/s10514-009-9119-x
Koopman, B. O. (1931). Hamiltonian systems and transformation in hilbert space. Proc. Natl. Acad. Sci. U.S.A. 17, 315–318.
Krishnan, R. G., Shalit, U., and Sontag, D. (2016). Structured inference networks for nonlinear state space models. arXiv, abs/1511.05121.
Laje, R., and Buonomano, D. V. (2013). Robust timing and motor patterns by taming chaos in recurrent neural networks. Nat. Neurosci. 16, 925–933. doi: 10.1038/nn.3405
Liu, W., Park, I., and Principe, J. C. (2009). An information theoretic approach of designing sparse kernel adaptive filters. IEEE Trans. Neural Netw. 20, 1950–1961. doi: 10.1109/tnn.2009.2033676
Maass, W., Natschläger, T., and Markram, H. (2002). Real-time computing without stable states: a new framework for neural computation based on perturbations. Neural Comput. 14, 2531–2560. doi: 10.1162/089976602760407955
Macke, J. H., Buesing, L., Cunningham, J. P., Yu, B. M., Shenoy, K. V., and Sahani, M. (2011). “Empirical models of spiking in neural populations,” in Advances in Neural Information Processing Systems 24, eds J. Shawe-Taylor, R. S. Zemel, P. L. Bartlett, F. Pereira, and K. Q. Weinberger (Granada: Curran Associates, Inc), 1350–1358.
Mante, V., Sussillo, D., Shenoy, K. V., and Newsome, W. T. (2013). Context-dependent computation by recurrent dynamics in prefrontal cortex. Nature 503, 78–84. doi: 10.1038/nature12742
Mattos, C. L. C., Dai, Z., Damianou, A., Forth, J., Barreto, G. A., and Lawrence, N. D. (2016). “Recurrent gaussian processes,” in International Conference on Learning Representations (ICLR) (San Juan, Puerto Rico).
Nassar, J., Linderman, S. W., Bugallo, M., and Park, I. M. (2019). “Tree-structured recurrent switching linear dynamical systems for multi-scale modeling,” in International Conference on Learning Representations (ICLR) (New Orleans, LA).
Newman, J. P., Fong, M.-F., Millard, D. C., Whitmire, C. J., Stanley, G. B., and Potter, S. M. (2015). Optogenetic feedback control of neural activity. eLife 4:e07192. doi: 10.7554/eLife.07192
Pandarinath, C., O'Shea, D. J., Collins, J., Jozefowicz, R., Stavisky, S. D., Kao, J. C., et al. (2018). Inferring single-trial neural population dynamics using sequential auto-encoders. Nat. Methods 15, 805–815. doi: 10.1038/s41592-018-0109-9
Peyrache, A., Lacroix, M. M., Petersen, P. C., and Buzsaki, G. (2015). Internally organized mechanisms of the head direction sense. Nat. Neurosci. 18, 569–575. doi: 10.1038/nn.3968
Pillow, J. W., Shlens, J., Paninski, L., Sher, A., Litke, A. M., Chichilnisky, E. J., et al. (2008). Spatio-temporal correlations and visual signalling in a complete neuronal population. Nature 454, 995–999. doi: 10.1038/nature07140
Rezende, D. J., Mohamed, S., and Wierstra, D. (2014). “Stochastic backpropagation and approximate inference in deep generative models,” in International Conference on Machine Learning (Bejing).
Roweis, S., and Ghahramani, Z. (2001). Learning Nonlinear Dynamical Systems Using the Expectation-Maximization Algorithm. New York, NY: John Wiley & Sons, Inc, 175–220.
Russo, A. A., Bittner, S. R., Perkins, S. M., Seely, J. S., London, B. M., Lara, A. H., et al. (2018). Motor cortex embeds muscle-like commands in an untangled population response. Neuron 97, 953–966. doi: 10.1016/j.neuron.2018.01.004
Strogatz, S. H. (2000). Nonlinear Dynamics and Chaos. Studies in nonlinearity. Boulder, CO: The Perseus Books Group.
Sussillo, D., and Barak, O. (2013). Opening the black box: low-dimensional dynamics in high-dimensional recurrent neural networks. Neural Comput. 25, 626–649. doi: 10.1162/necoa00409
Sussillo, D., Jozefowicz, R., Abbott, L. F., and Pandarinath, C. (2016). LFADS - latent factor analysis via dynamical systems. arXiv, abs/1608.06315.
Truccolo, W., Eden, U. T., Fellows, M. R., Donoghue, J. P., and Brown, E. N. (2005). A point process framework for relating neural spiking activity to spiking history, neural ensemble, and extrinsic covariate effects. J. Neurophysiol. 93, 1074–1089. doi: 10.1152/jn.00697.2004
Turner, R., Deisenroth, M., and Rasmussen, C. (2010). “State-space inference and learning with gaussian processes,” in Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, volume 9 of Proceedings of Machine Learning Research, eds Y. W. Teh and M. Titterington (Sardinia: PMLR), 868–875.
Valpola, H., and Karhunen, J. (2002). An unsupervised ensemble learning method for nonlinear dynamic State-Space models. Neural Comput. 14, 2647–2692. doi: 10.1162/089976602760408017
Wan, E. A., and Nelson, A. T. (2001). Dual Extended Kalman Filter Methods. New York, NY: John Wiley & Sons, Inc, 123–173.
Wan, E. A., and Van Der Merwe, R. (2000). “The unscented Kalman filter for nonlinear estimation,” in Proceedings of the IEEE 2000 Adaptive Systems for Signal Processing, Communications, and Control 529 Symposium (Cat. No.00EX373) (Lake Louise, AB: IEEE), 153–158. doi: 10.1109/asspcc.2000.882463
Wang, X.-J. (2002). Probabilistic decision making by slow reverberation in cortical circuits. Neuron 36, 955–968. doi: 10.1016/s0896-6273(02)01092-9
Watter, M., Springenberg, J., Boedecker, J., and Riedmiller, M. (2015). “Embed to control: a locally linear latent dynamics model for control from raw images,” in Advances in Neural Information Processing Systems 28, eds C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett (Montréal, QC: Curran Associates, Inc), 2746–2754.
Wong, K.-F., and Wang, X.-J. (2006). A recurrent network mechanism of time integration in perceptual decisions. J Neurosci. 26, 1314–1328. doi: 10.1523/jneurosci.3733-05.2006
Zhao, Y., and Park, I. M. (2016). “Interpretable nonlinear dynamic modeling of neural trajectories,” in Advances in Neural Information Processing Systems (NIPS) (Barcelona).
Keywords: state space models, online learning, variational Bayes, filtering, system identification
Citation: Zhao Y and Park IM (2020) Variational Online Learning of Neural Dynamics. Front. Comput. Neurosci. 14:71. doi: 10.3389/fncom.2020.00071
Received: 16 March 2020; Accepted: 25 June 2020;
Published: 14 October 2020.
Edited by:
Petia D. Koprinkova-Hristova, Institute of Information and Communication Technologies (BAS), BulgariaReviewed by:
Philippe Dreesen, Vrije University Brussel, BelgiumCopyright © 2020 Zhao and Park. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Il Memming Park, bWVtbWluZy5wYXJrQHN0b255YnJvb2suZWR1
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.