 Toviah Moldwin
Toviah Moldwin Idan Segev
Idan Segev
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Comput. Neurosci., 24 April 2020
Volume 14 - 2020 | https://doi.org/10.3389/fncom.2020.00033
This article is part of the Research TopicFrom Neuronal Network to Artificial Neural Network: Structure, Function and IntelligenceView all 7 articles
The perceptron learning algorithm and its multiple-layer extension, the backpropagation algorithm, are the foundations of the present-day machine learning revolution. However, these algorithms utilize a highly simplified mathematical abstraction of a neuron; it is not clear to what extent real biophysical neurons with morphologically-extended non-linear dendritic trees and conductance-based synapses can realize perceptron-like learning. Here we implemented the perceptron learning algorithm in a realistic biophysical model of a layer 5 cortical pyramidal cell with a full complement of non-linear dendritic channels. We tested this biophysical perceptron (BP) on a classification task, where it needed to correctly binarily classify 100, 1,000, or 2,000 patterns, and a generalization task, where it was required to discriminate between two “noisy” patterns. We show that the BP performs these tasks with an accuracy comparable to that of the original perceptron, though the classification capacity of the apical tuft is somewhat limited. We concluded that cortical pyramidal neurons can act as powerful classification devices.
There has been a long-standing debate within the neuroscience community about the existence of “grandmother neurons”—individual cells that code for high-level concepts such as a person's grandmother. Recent experimental evidence, however, has indicated that there are units that are selective to specific high-level inputs. In particular (Quiroga et al., 2005) found cells in the human medial temporal lobe (MTL) that fire in response to images of a particular celebrity, such as Jennifer Aniston or Halle Berry. One remarkable aspect of this finding is that different images of the same celebrity would elicit a response in these neurons even if the subject of the image was facing a different direction, wearing different clothes, or under different lighting conditions. In other words, the specificity of these MTL cells is invariant to certain transformations of the sensory stimulus. Regardless of whether this finding is evidence for grandmother cells or merely for sparse coding (Quiroga et al., 2008), it is apparent that individual neurons can be highly selective for a particular pattern of sensory input and also possess a certain level of generalization ability, or “tolerance,” to differences in the input that do not change the essence of the sensory scene.
From a physiological standpoint, achieving a high degree of accuracy on a recognition task is a daunting challenge for a single neuron. To put this in concrete terms, a pyramidal neuron may receive around 30,000 excitatory synapses (Megías et al., 2001). As a first approximation, at any given moment, each of this neuron's presynaptic inputs can either be active or inactive, yielding 230,000 possible binary patterns. If the presynaptic inputs contain information about low-level sensory stimuli (such as pixels or orientation filters) and the postsynaptic neuron needs to respond only to images of Jennifer Aniston, for example, there must be some physiological decision procedure by which the neuron “chooses” which of those 230,000 patterns are sufficiently close to the binary representation of Jennifer Aniston to warrant firing a spike as output.
There are several ways that a neuron can selectively respond to different input patterns. The most well-known method is to adjust synaptic “weights” such that only input patterns which activate a sufficient number of highly-weighted synapses will cause the cell to fire. It is this principle which serves as the basis of the perceptron learning rule (Rosenblatt, 1958) which is, in turn, the foundation for the artificial neural networks (ANNs) that are commonly used today in machine learning and deep networks (Rumelhart et al., 1986; Krizhevsky et al., 2012).
The perceptron is a learning algorithm that utilizes a mathematical abstraction of a neuron which applies a threshold activation function to the weighted sum of its input (Figure 1A). This abstraction is known as the McCulloch and Pitts (M&P) neuron (McCulloch and Pitts, 1943). The non-linear output of the neuron plays the role of a classifier by producing a positive output (a spike, +1) in response to some input patterns and a negative output (no spike, −1) in response to other patterns. The perceptron is trained in a supervised manner wherein it receives training patterns which are labeled as belonging to either the positive or the negative category. The perceptron output is calculated for each pattern, and if the perceptron output for a particular pattern does not match the label, the perceptron's weights are updated such that its output will be closer to the correct output for that example in the future.
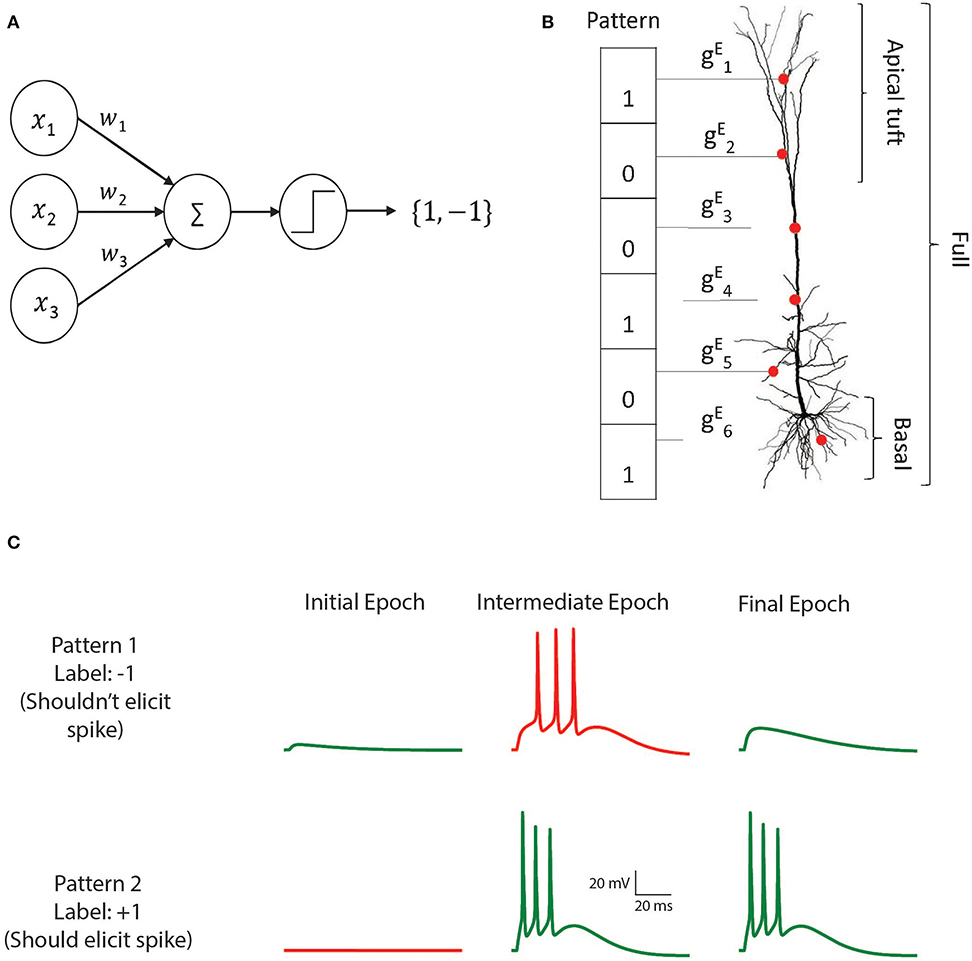
Figure 1. The M&P and biophysical perceptron. (A) The M and P perceptron. In any given input pattern, the presynaptic neurons are represented by their firing rates, x1, x2, x3, …xi, each of which is multiplied by the respective synaptic weight w1, w2, w3, …wi and then summed together with the other inputs. The perceptron produces an output of +1 if the weighted sum of all inputs is greater than a threshold and −1 otherwise. The task of the perceptron is to learn the appropriate synaptic weights, such that it will produce an output of +1 for a predefined subset of patterns, and −1 for the remaining subset of input patterns. (B) Schematic of the biophysical perceptron. A layer 5 pyramidal cell model with excitatory synapses (red dots) receiving an exemplar presynaptic input pattern. The synaptic weights are the excitatory conductance, , for the respective synapse, i. In this model, a presynaptic input pattern consists of a particular set of synaptic inputs that are either active “1” or inactive “0”. (C) An example of the learning process in the biophysical perceptron. Two input patterns, each with 1,000 synapses, were presented to the model neuron. For pattern 1 the model cell should not generate any spike, whereas for pattern 2 it should. In the initial epoch neither pattern elicits a spike (left column). The output for the pattern 1 is thus correct (green trace, top) but incorrect (red trace, bottom) for pattern 2. In an intermediate epoch of the learning algorithm (middle column), some of the synaptic conductances were sufficiently increased so that pattern 2 does elicit spikes, however pattern 1 also (incorrectly) produces spikes. By the final epoch (right column), the weights are adjusted such that the neuron correctly classifies the two patterns.
While the remarkable efficacy of networks of M&P neurons has demonstrated for various learning tasks, few attempts have been made to replicate the perceptron learning algorithm in a detailed biophysical neuron model with a full morphology and active dendrites with conductance-based synapses. It thus remains to be determined whether real cells in the brain, with all their biological complexity, can integrate and classify their inputs in a perceptron-like manner.
In this study, we used the perceptron learning algorithm to teach a detailed realistic biophysical model of a layer 5 pyramidal cell with a wide variety of active dendritic channels (Hay et al., 2011) to solve two kinds of classification problems: a classification task, where the neuron must correctly classify (by either spiking or not) a predefined set of “positive” and “negative” input patterns, and a generalization task, in which the neuron has to discriminate between two patterns that are corrupted by noise in the form of bit flips (i.e., where active synaptic inputs are switched to inactive and vice versa). We explored the ability of real neurons with extended non-linear dendritic trees and conductance-based excitatory synapses to perform classification tasks of the sort commonly solved by artificial neurons (see section Discussion for a treatment of why only excitatory synapses were used). We found that the performance of the biophysical perceptron (BP) is close to that of its artificial M&P counterpart.
To implement the perceptron learning algorithm in a modeled layer 5 thick tufted pyramidal cell (L5PC) we distributed excitatory conductance-based AMPA and NMDA synapses on the detailed model developed by Hay et al. (2011). We created input patterns consisting of 1,000 excitatory synapses, 200 of which were active in any given pattern. We varied the total number of patterns (P) presented to the modeled neuron in order to determine its classification capacity (Figure 1B). We tested conditions of P = 100, P = 1,000, and P = 2,000. These binary patterns were evenly divided into a “positive” (+1) group (for which the modeled neuron should produce at least one spike) and a “negative” (−1) group (for which the modeled neuron should not produce a spike). To achieve perfect accuracy, the neuron would have to correctly fire in response to all the patterns in the positive group and not fire in response to all the patterns in the negative group. Note that, initially, there is no reason for the neuron to perform at better than chance level, because all the patterns contain the same number of active synapses.
We then used the perceptron learning algorithm (see section Materials and Methods) to modify the synaptic weights such that the cell could correctly classify all the patterns (Figure 1C). This procedure was repeated in conditions in which synapses were placed over the whole dendritic tree, only on the apical tuft, only on the basal tree, or only on the soma in order to determine how the location of the synapses affects the cell's ability to classify patterns using the perceptron learning rule (see section Discussion for the biological significance of input patterns on different parts of the dendritic tree). We also tested the algorithm with current-based synapses rather than of conductance-based synapses, to examine whether conductance-based synapses have any advantages or disadvantages with respect to the cell's performance as a classifier.
Figure 2 shows the learning curves (Figure 2A) and classification accuracy (Figure 2B) for each of the above conditions. In all cases the cell is able to improve its performance relative to chance, indicating that the complexity of biophysical cells does not preclude perceptron learning despite the fact that the learning algorithm was devised for a much simpler abstraction of a cell.
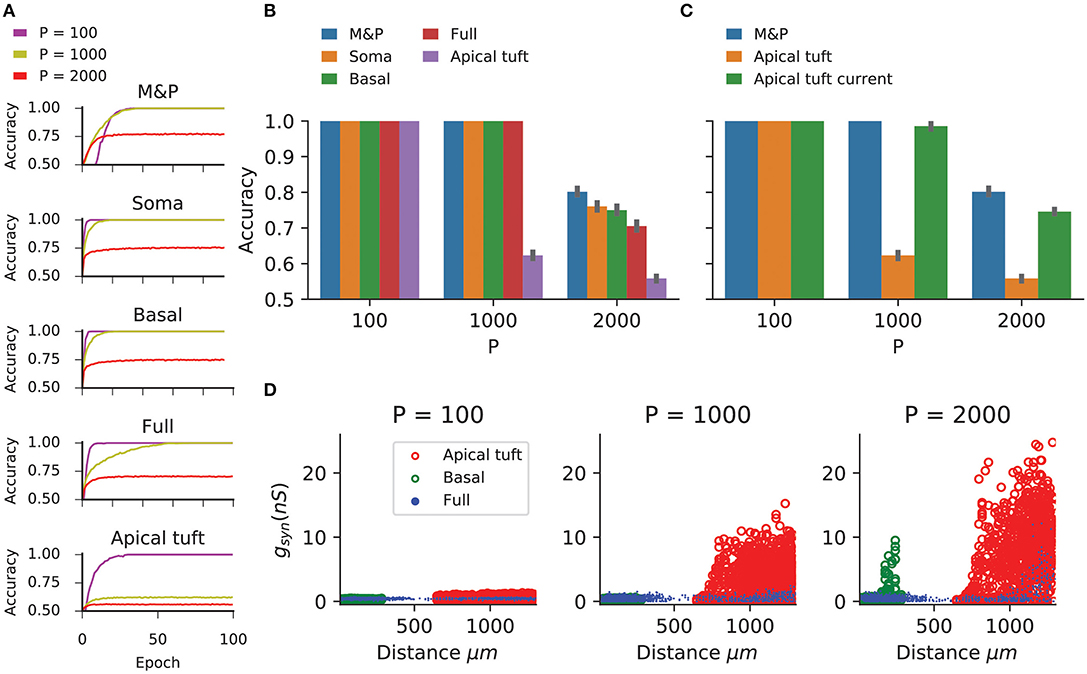
Figure 2. Learning the classification task with the biophysical perceptron. (A) Learning curves for the classification task, in which a neuron with 1,000 excitatory synapses had to classify patterns (half of which should produce a spike, half should not). The results for tasks involving 100, 1,000, and 2,000 patterns are shown (P, colored traces). The learning curves of a M and P perceptron is depicted at the top and the four different conditions of synaptic placement in the L5PC model shown in Figure 1 are shown subsequently. Soma: all synapses are placed only at the modeled soma; Full: all synapses are distributed on the whole dendritic tree; Basal: all synapses are distributed on the basal tree (see Figure 1B); Apical tuft: all synapses are distributed on the apical tuft (see Figure 1B). (B) Accuracy in the classification task for different synaptic placement conditions. Mean accuracy after 100 epochs is shown (error bars: standard deviation) for different numbers of patterns (P). The blue bar within each grouping shows the performance of a M&P neuron. Note the poor performance in the apical tuft placement condition. (C) Effect of conductance synapses vs. current synapses on classification capacity in the apical tuft. As in (B), blue bar is the performance of an M&P neuron for comparison. Note that classification capacity of the apical tuft is restored to near that of the M&P perceptron when switching from conductance synapses to current synapses. Error bars as in (B). (D) Value of synaptic conductances obtained after the completion of the learning algorithm as a function of distance of the synapses from the soma for learning tasks with different numbers of patterns. The cases of synapses placed only on the apical tuft (red), basal tree (green) and full (blue) placement conditions are shown for a single exemplar run. Note the large synaptic conductances obtained during the learning task for the case where the synapses are placed at the apical tuft for P = 1,000 and 2,000.
We compared the classification accuracy for each condition in the biophysical model to an equivalent M&P perceptron with excitatory weights (see section Materials and Methods). When all synapses are placed on the soma or the proximal basal tree of the biophysical perceptron, the classification accuracy of the biophysical perceptron is near to that of the M&P perceptron.
As expected from the theoretical literature (Chapeton et al., 2012), the accuracy in each condition decreases with the number of patterns that the neuron must learn. This can be seen in Figure 2B, where the classification accuracy degrades in each condition as we move from P = 100 to P = 1,000 and from P = 1,000 to P = 2000.
In all synaptic placement conditions, the M&P perceptron and the BP performed with perfect accuracy on the “easy” task with P = 100. In conditions where the synapses were placed only on the soma or only on the basal tree, the performance of the BP is comparable to that of the M&P neuron for P = 1,000 (M&P: 100%, basal: 100%, soma: 100%) and for P = 2,000 (M&P: 77%, basal: 75%, soma: 76%). In the condition where synapses were placed uniformly over the full tree, the discrepancies were somewhat larger for P = 2,000 (M&P: 77%, full: 70.5%).
However, when the synapses are all placed on the apical tuft of the biophysical cell, the classification accuracy of the biophysical perceptron decreases dramatically, even in the presence of supra-linear boosting mechanisms such as NMDA receptors and active Ca2+ membrane ion channels. For P = 1,000, the M&P neuron achieves 100% classification accuracy, whereas if the synapses are all placed on the apical tuft, the neuron only achieves 62% accuracy. In the condition with P = 2,000, the M&P neuron achieves 77% classification accuracy whereas the BP achieves only 55.8% classification accuracy, barely better than chance level. However, by switching from conductance-based synapses to current-based synapses in the apical tuft condition, it was possible to regain almost all of the “loss” in the classification accuracy (In the P = 1,000 condition, from 62% with conductance synapses to 98.5% with current synapses, in the P = 2,000 condition, from 55.8% with conductance synapses to 74.5% with current synapses) (Figure 2C).
We argue that the reason for the discrepancy in classification accuracy for the biophysical perceptron between the conditions wherein synapses are placed on the apical tuft, as opposed to the soma or basal dendrites, is due to the passive filtering properties of the neuronal cable and the saturation effect of conductance synapses. Specifically, the attenuation of voltage along the length of cable from apical tuft dendrites to the spike initiation zone means that the effective weight of that synapse—namely the magnitude of the resultant somatic EPSP—is greatly reduced. This phenomenon has been observed previously (Rall, 1967; Stuart and Spruston, 1998), but it has been argued (Häusser, 2001; Rumsey and Abbott, 2006) that the cell might be able to overcome this drop in voltage by simply increasing the strength (i.e., conductance) of distal synapses. We demonstrated, however, that this is not the case. We show (Figure 2D) that the perceptron learning algorithm will, on its own, increase the weights of apical tuft synapses far beyond the biologically plausible range of 0.2–1.3 nS (Sarid et al., 2007; Eyal et al., 2018) in attempting to correctly classify all the patterns. Still, the classification accuracy of the apical tuft biophysical perceptron remains quite poor [see, however Gidon and Segev (2009) who show that the opposite phenomena will occur with a standard STDP rule, resulting in smaller synaptic conductances for distal synapses].
We claim that “democratization” via disproportionally increasing distal synaptic conductances does not solve the classification accuracy problem for synapses located on the apical tuft because effective synaptic weights are bounded by the synaptic reversal potential in the distal dendrites, even if one were to increase synaptic conductances to arbitrarily high values. As such, the maximal effective synaptic weight (MESW)—defined as the peak somatic EPSP voltage when a given dendritic location approaches the synaptic reversal potential (Figure 3A)—is equivalent to the synaptic driving force multiplied by the attenuation factor from that dendritic location to the soma. (Note: This is true in the passive case, dendritic non-linearities can affect the MESW values. Our calculations of MESWs in this study are based on simulations of the model with all non-linearities present, as shown Figure 3A). The MESWs for distal synapses are thus smaller than those for proximal synapses (Figure 3B).
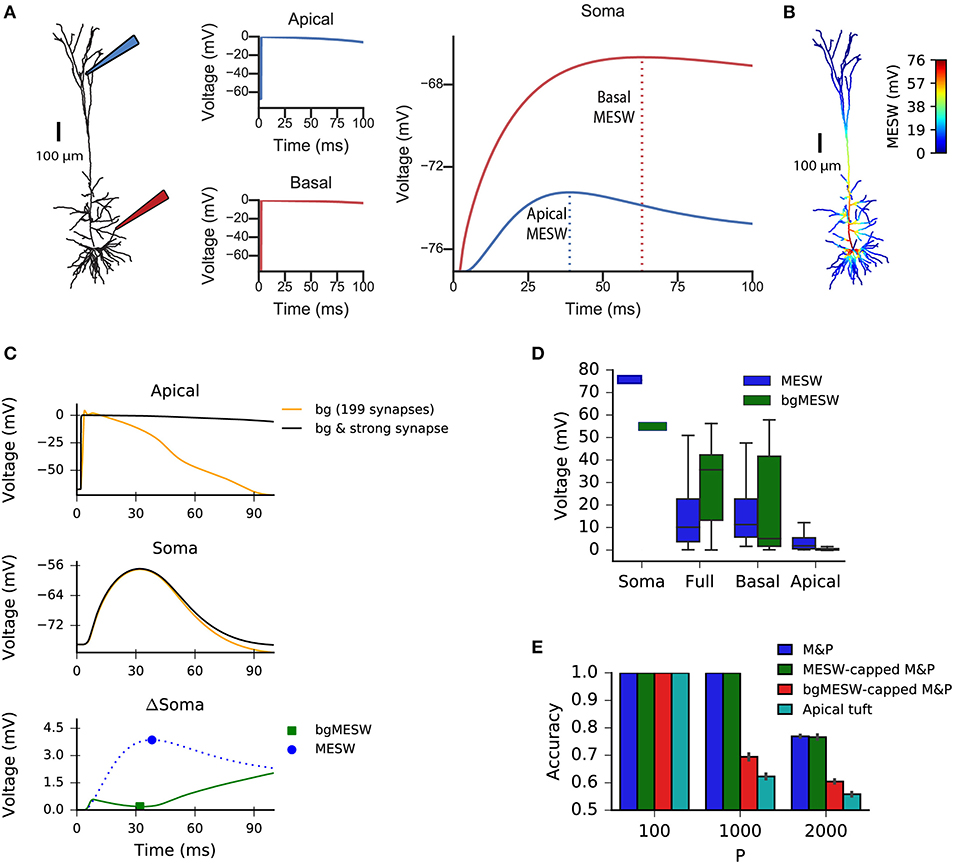
Figure 3. Effect of location of dendritic synapses on the maximum effective synaptic weight (MESW). (A) The simulated L5 pyramidal neuron with red (proximal basal) and blue (distal apical) electrodes. To calculate the MESW for each location, we activated a strong synapse with a conductance of 500 nS, bringing the local dendritic voltage near 0 mV, the reversal potential for AMPA/NMDA synapses, for 20 ms (middle column) and record the resultant somatic voltage (right column). The MESW for two dendritic loci (dashed lines) is defined as the voltage difference between the somatic resting potential and the peak voltage observed at the soma during the recording period. Note that the decline of the somatic depolarization after the peak is due to non-linear dendritic ion channels. (B) A simulated L5PC with the MESW values superimposed for each dendritic segment. Note the steep voltage attenuation from distal dendritic branches to the soma (blue regions). While there are regions of the basal tree that also have steep attenuation to the soma, the average attenuation from the apical tuft is greater, as shown in (D). (C) Effect of background synaptic activity (bg) on the marginal contribution of the apical synapse at the location shown in (A). Top: local dendritic voltage at the apical location when only the background activity is activated (orange trace) or when the background activity is activated in addition to a strong synapse at that location (black trace). Note that the background activity is sufficient to bring the dendrite near the local excitatory reversal potential. Middle: voltage contribution of the background activity alone (orange trace) and together with the strong synapse (black) to the somatic EPSP. Bottom: Difference in somatic EPSP in the presence of background activity when the strong apical synapse is present vs. absent—i.e., subtraction of the orange trace from the black trace in the middle plot (green trace). The bgMESW is defined as the value of this difference at the time when the somatic EPSP (black trace in middle plot) is maximal. The contribution of the strong synapse in the absence of background activity is shown for reference (blue dashed trace, as in A, right panel). (D) Box-and-whiskers plot of MESW and bgMESW distributions for the full dendritic tree, basal tree, apical tuft, and soma (see section Materials and Methods). Notches represent the median values for all synaptic locations within that region, box edges and error bars, respectively, represent the first and second quartiles of the data. Note that the effect of the background on the marginal synaptic effect on the soma can be either superlinear or sublinear. (E) Effect of constraining the synaptic weights in the M&P model according to the distribution of MESWs and bgMESWs observed for the apical tuft. Note that the classification capacity of the bgMESW-constrained M&P perceptron is substantially reduced and becomes closer to the capacity of the biophysical perceptron.
Importantly, the marginal effect of each synapse in the presence of background dendritic activity (as in our case, where we activated 200 synapses simultaneously) differs from the MESW (measured when the synapse acts in isolation). For example, a single synapse brought to its reversal potential can interact supralinearly with other synapses via activating NMDA-conductance, strengthening the effect of the other synapses (Polsky et al., 2004). Alternatively, if there is a substantial amount of background activity in the dendrite, the voltage in the dendrite near the location of a given synapse may already be close to the synaptic reversal potential. In this case, the marginal effect of activating that synapse, even with an arbitrarily large conductance, can be substantially below its MESW (Figure 3C). Indeed, when the apical tuft is sufficiently active to bring the soma near the spike threshold, this sublinear interaction between synapses dominates, and the background-adjusted maximum effective weight of each synapse (bgMESW) tends to be below the MESW of that synapse activated in isolation (Figure 3D, see section Materials and Methods).
From the standpoint of learning theory, the “cap” on the effective weights of distal apical synapses restricts the parameter space of the biophysical perceptron, reducing its capacity. When a perceptron learns to classify between two sets of patterns, it creates a linear separation boundary—i.e., a hyperplane—which separates the patterns in an N-dimensional space, where N is the number of synaptic inputs in each pattern. The separation boundary learned by the perceptron is defined by the hyperplane orthogonal to the vector comprising the perceptron's weights. When the weights of the perceptron are unconstrained, the perceptron can implement any possible hyperplane in the N-dimensional space. However, when the weights are constrained—for example by the MESWs of the apical tuft of L5PCs—the perceptron can no longer learn every conceivable linear separation boundary, reducing the ability of the perceptron to discriminate between large numbers of patterns [Note: because we use only excitatory synapses, the weight space in all synaptic placement conditions is already substantially constrained to positive values even before imposing MESWs, see Chapeton et al. (2012) for a full treatment]. To demonstrate this effect, we calculated the MESW for each synapse in the apical tuft and then imposed this distribution of MESWs onto an M&P perceptron (see section Materials and Methods). Interestingly, the MESW caps on the synaptic weights of the M&P neuron did not hamper its classification performance on our task. However, when we used caps based on the marginal effect of each synapse in the presence of the other synaptic activity in the patterns—the bgMESWs—the weight-capped M&P perceptron produced a reduced classification capacity in a manner similar to the biophysical perceptron when synapses were restricted to the apical tuft (Figure 3E).
The fact that switching the apical synapses from conductance-based to current-based substantially improves classification accuracy supports the notion that voltage saturation due to synaptic reversal potential is responsible for the reduced performance of the apical tuft synapses (Figure 2C). It should be emphasized that the limited capacity of the apical tuft is not because apical synapses cannot induce the neuron to fire, as the neuron with only apical synapses performs with perfect accuracy when it only needs to classify 100 patterns, indicating that 200 active synapses on the apical tuft are fully capable of generating a somatic spike. It is thus evident that the reduced classification capacity of the apical patterns is due to the restriction of the weight space needed to properly discriminate between positive and negative patterns, not because the apical tuft input is insufficiently strong to create a somatic spike.
To explore whether the apical tuft is always at a disadvantage when it comes to pattern classification, we also tested the biophysical perceptron on a generalization task. Instead of classifying a large set of fixed patterns, in the generalization task the neuron was presented with “noisy” patterns drawn from one of two underlying fixed patterns. In this task, noise was added to the underlying pattern by performing “bit flips,” i.e., flipping an active synapse to an inactive synapse or vice versa (Figure 4A). We tested both the biophysical perceptron (with different synaptic placement conditions, as in the classification task) and the positive-weighted M&P neuron on their ability to classify these noisy patterns in conditions with varying levels of difficulty, as determined by the number of bit flips. The goal of the task was that the neuron should fire in response to noisy patterns generated by the first underlying pattern, but not fire in response to noisy patterns generated by the second underlying pattern (Figure 4B).

Figure 4. Generalization task with the biophysical perceptron. (A) Left column: Two binary patterns, represented by two faces, each consisting of 200 black pixels and 800 white pixels. The black pixels represent active synapses and the white pixels represent inactive synapses. These patterns can be corrupted by flipping active synapses to inactive synapses or vice versa, creating a new “noisy” pattern (middle and right columns). As we increase the number of flipped synapses, the noisy patterns become more difficult to identify with the original pattern. The faces are for illustration of the sparsity and noise level only, actual input patterns were not created with a facial structure. (B) Task schematic. A noisy pattern (lower face), drawn from one of two original patterns (top faces) is presented to the modeled neuron. The neuron must decide from which of the two original patterns the noisy pattern came, by either firing (for the first pattern) or not firing (for the second pattern).
In this task, we observe that in all conditions the BP performs similarly to the M&P perceptron. We do not observe any substantial diminution in classification performance between the apical tuft and the soma, as we do in the classification task (Figures 5A,B). In the condition with 100 bit flips, the difference in accuracy between the apical tree and the soma were small (M&P: 85% soma: 85%, apical tuft: 81.8%). The same is true for the more difficult task with 200 bit flips (M&P: 72%, soma: 71.8%, apical tuft: 67.4%). Changing the conductance synapses to current synapses did not substantially affect these results (Figure 5C). Moreover, capping the weights of the M&P neuron with the bgMESWs from the apical tuft, as we did in the classification task, did not considerably worsen the M&P perceptron's performance (Figure 5D). We also note that, while the some of the synaptic weights of the apical tuft did increase beyond the biological range during learning in the biophysical perceptron (Figure 5E), the effect is much smaller in the classification task (Figure 2D).
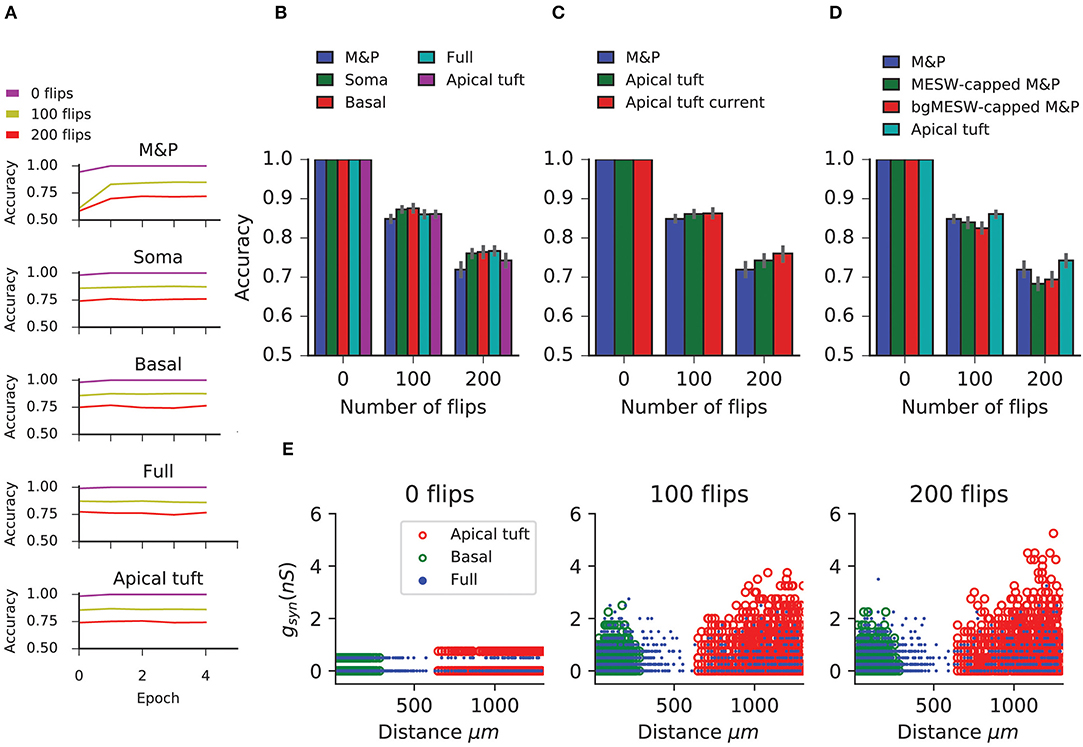
Figure 5. Learning the generalization task with the biophysical perceptron. (A) Learning curves for the generalization task, in which a neuron with 1,000 synapses had to classify noisy patterns (see Figure 4) drawn from one of two underlying original patterns (see Figure 4). The neuron was presented with 100 different noisy patterns each epoch, 50 from each original pattern. The results for tasks involving different amounts of noise are shown (bit flips, colored traces). The learning traces of an M&P perceptron is depicted at the top and the four different conditions of synaptic placement in the L5PC model are shown subsequently. Synaptic placement as in Figure 2A. (B) Accuracy in the generalization task for different synaptic placement conditions. Mean accuracy after 100 epochs is shown (error bars: standard deviation) for different amounts of noise (bit flips). The blue bar within each grouping shows the performance of a M&P neuron. (C) Effect of conductance synapses vs. current synapses on classification capacity in the apical tuft. As in (B), blue bar is the performance of an M and P neuron for comparison. Error bars as in (B). (D) Effect of constraining the synaptic weights in the M&P model according to the distribution of MESWs and bgMESWs observed for the apical tuft. (E) Value of synaptic conductances obtained after the completion of the learning algorithm as a function of distance of the synapses from the soma for learning tasks with different levels of noise. The cases of synapses placed only on the apical tuft (red), basal tree (green), and full (blue) placement conditions are shown for a single exemplar run.
The discrepancy between the apical tuft and soma may be smaller in the generalization task than in the classification task because the difficulty in the classification task is fundamentally about finding the correct hyperplane that will separate between the two classes of patterns. As we increase the number of patterns in each of the classes, we require more flexibility in the weight space of the neuron to ensure that all the positive and negative patterns end up on opposite sides of the separating hyperplane. This flexibility is impeded by the bgMESWs of the apical tuft. By contrast, the generalization problem only contains two canonical “patterns.” The difficulty in learning the generalization task with a large amount of noise (in terms of bit flips) does not stem from the challenge of precisely defining a separation boundary. Rather, solving the generalization task is hard because, even if we had an optimal separation boundary, the noise in the input entails that some of the noisy patterns would still necessarily be misclassified.
We utilized a detailed biophysical model of a cortical layer 5b thick-tufted rat pyramidal cell written in NEURON with a Python wrapper (Carnevale and Hines, 1997; Hines et al., 2009). The parameters of the model, which includes numerous active mechanisms, are described in Hay et al. (2011). The mechanisms used in this model were: Im, Ca_LVAst, Ca_HVA, CaDynamics_E2, SKv3_1, SK_E2, K_Tst, K_Pst, Nap_Et2, NaTa_t, NaTs2_t. The model had 108 apical compartments and 83 basal compartments.
Excitatory synapses were AMPA/NMDA-based synapses as in Muller and Reimann (2011) with a dual-exponential conductance profile with a voltage-dependent magnesium gate (Jahr and Stevens, 1990; Rhodes, 2006) with a gate constant of 0.08. The AMPA conductance had a rise time (τ) of 0.2 ms and a decay time of 1.7 ms while the NMDA conductance had a rise time of 0.29 ms and a decay time of 43 ms. The synaptic depression and facilitation parameters set to 0. The NMDA: AMPA conductance ratio was set to 1.6:1. In both the classification and generalization experiments, we placed all 1,000 synapses in each pattern either on the soma, basal tree, or apical tuft according to a uniform spatial distribution.
For the classification task, each of the P patterns was generated by randomly choosing 200 out of the 1,000 synapses to be activated. The patterns were then randomly assigned to either the positive or negative class. Patterns were presented to the cell by simultaneously stimulating the 200 active synapses with a single presynaptic spike at the beginning of the simulation. Simulations of the neuron were run with a Δt of 0.1 ms for a total of 100 ms. Patterns were considered to have been classified as “positive” if they produced at least one spike within the 100 ms time window and as “negative” if no spikes occurred.
The choice of 200 active synapses was to simulate a regime of high cortical activity. The maximal firing rate for excitatory cortical neurons is estimated to be around 20 Hz (Heimel et al., 2005; Hengen et al., 2013). Assuming the maximum firing rate per excitatory synapse, a pyramidal cell with 10,000 excitatory synapses would receive 200,000 synaptic inputs/sec or 200 inputs/ms.
We utilized an “online” version of the perceptron learning algorithm, applying the plasticity rule every time a pattern was presented to the neuron. Also, because we limited our analysis to excitatory synapses, we use the modified algorithm proposed in Amit et al. (1999) for sign-constrained synapses, which ensures that synaptic weights never become negative.
The algorithm works as follows: A presynaptic input pattern x is presented to the neuron, where x is a vector consisting of 1,000 binary inputs, each of which is labeled xi and associated with a particular synapse on the dendritic tree with synaptic weight wi (for conductance synapses, this is the excitatory conductance of the synapse, ). Each pattern has a target value, y0 ∈ {1, − 1} associated with it, where 1 means “should spike” and −1 means “shouldn't spike.” When the pattern is presented to the neuron via simultaneous activation of all the synapses in the pattern, the soma of the neuron will produce a voltage response. If that voltage response contains at least one spike within 100 ms, we set the output variable y = 1. If the voltage response does not contain any spikes, we set y = −1. For each presynaptic input pattern, the plasticity rule for synapse i to update its weight wi at time is defined as:
where dwi is defined as:
and η is the learning rate.
In other words, if the target output is the same as the actual output of the neuron, we do nothing. If the target is “should spike” and the neuron does not spike, we increase the weight of all synaptic inputs that were active in the pattern. If the target is “shouldn't spike” and the neuron does spike, we decrease the synaptic weights of all synaptic inputs that were active in the pattern, unless that would decrease the synaptic weight below 0, in which case we reduced the weight of that synapse to 0.
The accuracy of the neuron's output was calculated after each epoch, which consisted of a full pass of presenting each pattern (in random order) to the neuron. To ensure that accuracy improved on every epoch and reached a reasonable asymptote for all conditions, we set the learning rate η to 0.002 for the condition with AMPA/NMDA conductance synapses and an active tree, and a rate of 0.19 for the condition with current synapses. We also used the “momentum” technique (Rumelhart et al., 1986) to improve learning speed. The average simulation time for a complete run of the learning algorithm for the classification task (i.e., 100 epochs) was several hours to 2–3 days depending on the task (more patterns required more simulation time). Results shown in Figures 2A–D, 3D are averaged over 10 runs of the classification task.
To compare the BP to an equivalent M&P perceptron (Figures 2A,B, 5A,B) we used a M&P perceptron with only excitatory weights as described in Amit et al. (1999) (See Equations (1) and (2) above). A M&P neuron with no inputs would have a “bias” input value of −77.13 to mimic the resting potential of the BP and a “spiking threshold” of −53.1 to mimic the voltage spiking threshold of the biophysical neuron. The learning algorithm used a learning rate η of 0.0008 which was dynamically modified in the learning algorithm via the momentum technique (Rumelhart et al., 1986). Initial learning rates were hand-tuned according to the criteria that the learning curves should monotonically increase and reach an asymptote (verified by visual inspection). We also tested smaller learning rates than the ones listed in the M&P model to see if accuracy could be improved via smaller learning steps; however the improvement in classification obtained by doing so was negligible and thus was deemed not worth the additional computational time in the biophysical model.
To calculate the MESWs for the L5PC model, we added a very strong synapse (500 nS) to each dendritic segment in the neuron model bringing the segment within 2.5 mV of the synaptic reversal potential of 0 mV. The MESW for a dendritic segment is defined as the difference between the somatic resting potential and the peak depolarization obtained at the soma within 100 ms after synaptic activation (Figure 3A).
To create an MESW-constrained M&P model for the apical tuft, we calculated the distribution of MESWs per unit length of the dendritic membrane in the apical tuft. The median and quartile values of the MESWs for all synaptic placement conditions are shown in the box-and-whisker plot in Figure 3D. We then created an M&P neuron where each weight was individually given a “cap” drawn randomly from the apical tuft MESW probability distribution which would prevent the weight of that input from increasing above a certain value. In other words, if the plasticity algorithm (Equation 1) would bring wi to be greater than cap, ci, we would “freeze” the weight at ci. Formally, this means that the plasticity rule in the case of an error for the MESW-capped neuron is
where η and dwi are as defined above in Equation (2).
To calculate the bgMESWs for the L5PC model, we distributed 199 “background” synapses on the neuron according to a uniform distribution per unit length of the dendritic membrane. All background synapses had the same conductance. To find the synaptic conductance required to bring the neuron near its spiking threshold, we gradually increased the synaptic conductances of all synapses by 0.05 ns steps until the neuron produced at least one spike. The largest conductance that didn't cause the neuron to spike was used as the conductance for the near-threshold background activity. The conductances for each distribution condition were: Soma: 0.3 nS, Basal: 0.3 nS, Apical tuft: 0.52 nS, Full: 0.48 nS (values are averaged over 10 trials of this procedure to account for the randomness in the placement of the background synapses). In the presence of this background activity, we added a strong synapse to each dendritic location, as detailed in the section for the MESW calculation. To find the marginal contribution of a single strong input at each location, we subtracted the somatic EPSP obtained via the background activity from the somatic EPSP obtained when both the background activity and the strong synapse at that location are active, creating a difference curve (Figure 3C). The bgMESW is defined as the value of this difference curve at the time when the somatic EPSP is maximal in the condition when both the strong synapse and background activity are active.
In the second task (generalization), we created two underlying patterns of 1,000 synapses each, where 200 synapses were active, as in the classification task. These patterns were then corrupted by flipping a given number synapses (0, 100, or 200, depending on the condition) and presented to the neuron. To maintain the sparsity of the patterns, half of the flipped synapses were switched from active to inactive and the other half switched from inactive to active. For example, in the condition with 100 flipped bits, 50 out of the 200 previously active synaptic inputs were flipped to inactive, and 50 out of the 800 previously inactive synaptic inputs were switched to active.
In every epoch of the learning task, we presented the neuron with 50 noisy patterns generated by the first underlying pattern and 50 noisy patterns generated by the second underlying pattern for a total of 100 patterns per epoch (the order of the presentation of patterns from the two underlying patterns was also randomized). We set the learning rate η to 0.25 for the condition with AMPA/NMDA conductance synapses and an active tree, and a rate of 10 for the condition with current synapses. Learning rates were hand-tuned as described above. Similar to the classification task, we used the online perceptron learning rule with the momentum modifier. In this task we only ran the algorithm for 5 epochs, as this was enough for the learning to achieve a plateau. Results shown in Figures 5A–D are averaged over 20 repetitions of the generalization task.
Simulations were all performed using Neuron v.7.6 (Carnevale and Hines, 1997; Hines et al., 2009) running on a multi-core cluster computer with 3,140 logical cores; the number of available cores varied depending on other jobs being run on the cluster. Each trial of the learning algorithm was run on a separate core; neither the learning or the cell simulation was mutli-threaded. The average simulation time for a complete run of the learning algorithm for the generalization task (i.e., 5 epochs) was several minutes.
In the simulations described above, we have demonstrated that the perceptron learning algorithm can indeed be implemented in a detailed biophysical model of L5 pyramidal cell with conductance-based synapses and active dendrites. This is despite the fact that the perceptron learning algorithm traditionally assumes a cell which integrates its inputs linearly, which is not the case for detailed biophysical neurons with a variety of non-linear active and passive properties and conductance-based synapses. That being said, the ability of a biophysical perceptron to distinguish between different patterns of excitatory synaptic input does depend on the location of the relevant synapses. Specifically, if all the synapses are located proximally to the soma, such as on the proximal basal tree, the cell has a classification capacity similar to that of the M&P perceptron. However, for activation patterns consisting of more distal synaptic inputs, such as those on the apical tuft, the classification capacity of the BP is reduced. We showed that this is due to the reduced effectiveness of distal synapses due to cable filtering and synaptic saturation in the presence of other synaptic inputs, which limits the parameter space of the learning algorithm and thus hampers classification capacity. We also demonstrated that the diminished classification capacity in the apical tuft is negligible in a generalization task. This indicates that, while the maximum effective synaptic weights of the apical tuft may be somewhat limiting for its classification capacity, they do not hamper the apical tuft's robustness to noise.
The above discussion considers that the pyramidal cell separately classifies inputs that synapse onto different regions of its dendrites (such as the apical tuft and the basal tree) and that it does not simultaneously integrate all the synaptic input impinging on the cell. This decision was motivated by a growing body of evidence that different parts of the dendritic tree may play separate roles in shaping the neuron's output. From anatomical studies, it is known that axons from different brain regions preferentially synapse onto particular regions of layer 5 pyramidal cells. For example, basal dendrites tend to receive local inputs whereas the apical tuft receives long-range cortical inputs (Crick and Asanuma, 1986; Budd, 1998; Spratling, 2002; Spruston, 2008). This has led to theories of neuronal integration for layer 5 pyramidal cells that involve a “bottom-up” stream of information entering the basal dendrites and “top-down” signals coming to the apical tuft (Siegel et al., 2000; Larkum, 2013; Manita et al., 2015). Moreover, it has recently been shown experimentally that when experiencing somatosensory stimulation, layer 5 pyramidal cells in S1 first exhibit an increase in firing rate corresponding to the bottom-up sensory input (ostensibly to the basal tree), and then, 30 ms later, receive top-down input to the apical tuft from M2 (Manita et al., 2015). This indicates the presence of temporally segregated time windows in which the cell separately integrates input from the apical and basal tree. There is also work suggesting that plasticity rules may function differently in different regions of the cell (Gordon et al., 2006), again indicating that different regions of the cell might serve as input regions to distinct information pathways, and, as such, may have different priorities underlying the decision of when the cell will or will not fire. Taken together, the above studies strongly suggest that the apical tuft and basal dendrites can and should be studied as independent integration units.
Our study made several simplifications to the learning and plasticity processes found in biology. Critically, our plasticity algorithm utilized only excitatory synapses and did not consider the effect of inhibition on learning. This is not because we believe that inhibition does not play a role in learning; on the contrary, inhibitory synapses are essential both for the learning process and in defining the input-output function of the cell (Wulff et al., 2009; Kullmann et al., 2012; Müllner et al., 2015). However, by restricting ourselves to excitatory synapses, we were able to isolate important biophysical properties of excitatory synapses—namely the impact of synaptic saturation (the bgMESWs) that might have been masked in the presence of inhibition. Future work on the “biophysical perceptron” will include the role of inhibitory synapses; in this case special care must be taken to understand how inhibitory inputs interact with excitatory inputs on different locations of the cell (Gidon and Segev, 2012; Doron et al., 2017). The addition of synaptic inhibition has the potential to increase the classification capacity of the cell (Chapeton et al., 2012), and localized inhibition may allow for additional forms of compartmentalized computation at the dendritic level.
The focus on excitatory synapses also enables our work to be directly compared to studies of excitatory perceptron-like learning done on Purkinje cells—which have been classically conceived of as perceptrons (Marr, 1969; Albus, 1971)—, such as the work of Brunel et al. (2004), Steuber et al. (2007), and Safaryan et al. (2017). These studies demonstrated that detailed models of Purkinje cells can learn to discriminate between different patterns of input from the parallel fibers (PF) via a perceptron-like usage of long-term depression (LTD), which is known to occur in PF-Purkinje synapses. Crucially, the difference between the Purkinje cell's responses to learned vs. unlearned patterns was the duration of the pause between spikes in the Purkinje cell's output subsequent to the presentation of PF input. Steuber et al. (2007) argue that this pause duration-based learning depends on the modulation of calcium concentrations inside the cell. This is different from the more direct M&P-like mechanism, used in the present study, of synapses being weighted such that only certain input patterns will reach the cell's spiking threshold.
Our focus on perceptron-like learning constitutes an additional simplification, as perceptron learning ignores how dendritic non-linearities such as local NMDA spikes (Schiller et al., 2000; Polsky et al., 2004), dendritic Na+ spikes (Golding and Spruston, 1998; Sun et al., 2014), and dendritic Ca2+ spikes (Magee and Johnston, 1995; Kampa et al., 2006; Cichon and Gan, 2015) may impact learning in classification tasks. Although a variety of dendritic non-linearities are present in our L5 pyramidal cell model, we did not make explicit use of them in our plasticity rule. Indeed, some models of dendritic integration such as the Clusteron (Mel, 1991, 1992) and the two-layer model (Poirazi and Mel, 2001) treat the NMDA spike as critical for dendritic computation. In particular, these models treat clustering of nearby synapses, and “structural plasticity,” or the relocation of synaptic inputs within and between branches as crucial for learning (Trachtenberg et al., 2002; Larkum and Nevian, 2008; Losonczy et al., 2008; Kastellakis et al., 2015; Weber et al., 2016; Mel et al., 2017). The present study did not address the role of synaptic clustering in learning; a promising future direction would be to combine the weight-based learning rules used in our study with the structural plasticity algorithm as discussed in Mel (1992).
There are several other models of learning and plasticity that make use of neuronal biophysics and constitute promising opportunities for improving the learning ability of pyramidal cell models in a biologically plausible way. The calcium-based plasticity rule of Graupner and Brunel (2012) presents an exciting possibility for implementing perceptron-like learning in a more biological manner by making direct use of the experimentally observed mechanisms of plasticity in neurons. Because neurons exhibit some properties of multi-layered networks (Poirazi et al., 2003; Beniaguev et al., 2019), it would also be valuable to explore more powerful learning algorithms that make use of the dendrites as a second (or higher) layer of computation as in Schiess et al. (2016). Alternatively, it may make sense to consider a different paradigm of dendritic learning, where the dendrites attempt to “predict” the somatic output, allowing for forms of both supervised and unsupervised learning (Urbanczik and Senn, 2014). Variants of the perceptron rule, such as the three-threshold learning rule (Alemi et al., 2015) may also be valuable to explore the ability of biophysical cells to solve pattern-completion tasks.
Another crucial element that remains to be studied in detailed biophysical models is the role of the timing of both the input and output of pyramidal cells in learning and computation. Regarding input timing, some theoretical work has been done on the M&P perceptron, which has been extended in a variety of ways to take into account several components of real neurons. One such extension is the tempotron, which uses a leaky integrate and fire mechanism (Gütig and Sompolinsky, 2006) and can make use of conductance-based synapses (Gütig and Sompolinsky, 2009) to classify spatiotemporal input patterns. Regarding output timing and firing rate, learning rules like the one from Gutig (2016) can learn to solve the temporal credit-assignment by producing different spike rates for different inputs. Similarly, the Chronotron (Florian, 2012) considers learning rules that generate precisely timed output spikes. It is not clear to what extent these particular plasticity algorithms are truly “biological,” but there is no question that temporal sequence learning is an essential feature of the brain (Aslin et al., 1998; Xu et al., 2012; Moldwin et al., 2017). The addition of a temporal dimension increases the classification capacity of the cell, as discussed in Gütig and Sompolinsky (2009).
The present study shows that, by implementing the perceptron learning rule, layer 5 cortical pyramidal cells are powerful learning and generalization units, comparable—at the very least—to the abstract M&P perceptron. Other plasticity rules, which take into account synaptic clustering, input and output timing, and interaction between the apical and basal regions of pyramidal cells will be explored in further studies in detailed biophysical models in order to determine their biological plausibility and classification capacity. Until then, our study should be viewed as a baseline for comparison of any future work implementing learning algorithms in detailed biophysical models of neurons.
The code used for the biophysical model (including the hoc files for the pyramidal cell model) and the M&P model, as well as the code used to generate the input patterns, can be found at https://github.com/tmoldwin/BiophysicalPerceptron.
TM and IS designed the research. TM implemented the simulation, analyzed the results, and created the figures. IS supervised the research and contributed to the development of the theoretical and biophysical aspects of the study.
This work was supported by the Drahi family foundation, the EU Horizon 2020 program (720270, Human Brain Project), a grant from Huawei Technologies Co., Ltd., and by a grant from the Gatsby Charitable Foundation, the ETH domain for the Blue Brain Project (BBP), and from the NIH Grant Agreement U01MH114812.
The authors declare that this study received funding from Huawei Technologies Co., Ltd. The funder was not involved in the study design, collection, analysis, interpretation of data, the writing of this article or the decision to submit it for publication.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
We would like to thank Oren Amsalem for his assistance in many aspects of this work, particularly his help with the use of the NEURON software. We also would like to thank David Beniaguev, Guy Eyal, and Michael Doron for their insightful discussions about machine learning and neuronal biophysics. Itamar Landau provided several useful comments to an early version of this work, inspiring important revisions. Additionally, we appreciate Nizar Abed's support in maintaining the computer systems used to perform our simulations and data analysis. This manuscript has been released as a pre-print at BioRxiv (Moldwin and Segev, 2018).
Alemi, A., Baldassi, C., Brunel, N., and Zecchina, R. (2015). A three-threshold learning rule approaches the maximal capacity of recurrent neural networks. PLoS Comput. Biol. 11, 1–23. doi: 10.1371/journal.pcbi.1004439
Amit, D. J., Wong, K. Y. M., and Campbell, C. (1999). Perceptron learning with sign-constrained weights. J. Phys. A 22, 2039–2045. doi: 10.1088/0305-4470/22/12/009
Aslin, R. N., Saffran, J. R., and Newport, E. L. (1998). Computation of conditional probability statistics by 8-month-old. Infants. 9, 321–324.
Beniaguev, D., Segev, I., and London, M. (2019). Single cortical neurons as deep artificial neural networks. bioRxiv 613141. doi: 10.1101/613141
Brunel, N., Hakim, V., Isope, P., Nadal, J.-P., and Barbour, B. (2004). Optimal information storage and the distribution of synaptic weights: perceptron versus Purkinje cell. Neuron 43, 745–757. doi: 10.1016/j.neuron.2004.08.023
Budd, J. M. L. (1998). Extrastriate feedback to primary visual cortex in primates: a quantitative analysis of connectivity. Proc. R. Soc. B Biol. Sci. 265, 1037–1044. doi: 10.1098/rspb.1998.0396
Carnevale, N. T., and Hines, M. L. (1997). The neuron simulation environment. Neural Comput. 1209, 1–26.
Chapeton, J., Fares, T., Lasota, D., and Stepanyants, A. (2012). Efficient associative memory storage in cortical circuits of inhibitory and excitatory neurons. Proc. Natl. Acad. Sci. U.S. Am. 109, E3614–E3622. doi: 10.1073/pnas.1211467109
Cichon, J., and Gan, W.-B. (2015). Branch-specific dendritic Ca2+ spikes cause persistent synaptic plasticity. Nature 520, 180–185. doi: 10.1038/nature14251
Crick, F., and Asanuma, C. (1986). “Certain aspects of the anatomy and physiology of the cerebral cortex,” in Parallel Distributed Processing: Explorations in the Microstructures of Cognition. Volume 2: Psychological and Biological Models. eds D. E. Rumelhart, J. L. McClelland, and PDP Research Group (Cambridge, MA: MIT Press), 333–371.
Doron, M., Chindemi, G., Muller, E., Markram, H., and Segev, I., et al. (2017). Timed synaptic inhibition shapes NMDA spikes, influencing local dendritic processing and global I/O properties of cortical neurons. Cell Rep. 21, 1550–1561. doi: 10.1016/j.celrep.2017.10.035
Eyal, G., Verhoog, M. B., Testa-Silva, G., Deitcher, Y., Benavides-Piccione, R., DeFelipe, J., et al. (2018). Human cortical pyramidal neurons: from spines to spikes via models. Front. Cell. Neurosci. 12:181. doi: 10.3389/fncel.2018.00181
Florian, R. V. (2012). The chronotron: a neuron that learns to fire temporally precise spike patterns. PLoS ONE 7:e040233. doi: 10.1371/journal.pone.0040233
Gidon, A., and Segev, I. (2009). Spike-timing–dependent synaptic plasticity and synaptic democracy in dendrites. J. Neurophysiol. 101, 3226–3234. doi: 10.1152/jn.91349.2008
Gidon, A., and Segev, I. (2012). Principles governing the operation of synaptic inhibition in dendrites. Neuron 75, 330–341. doi: 10.1016/j.neuron.2012.05.015
Golding, N. L., and Spruston, N. (1998). Dendritic sodium spikes are variable triggers of axonal action potentials in hippocampal CA1 pyramidal neurons. Neuron 21, 1189–1200. doi: 10.1016/S0896-6273(00)80635-2
Gordon, U., Polsky, A., and Schiller, J. (2006). Plasticity compartments in basal dendrites of neocortical pyramidal neurons. J. Neurosci. 26, 12717–12726. doi: 10.1523/JNEUROSCI.3502-06.2006
Graupner, M., and Brunel, N. (2012). Calcium-based plasticity model explains sensitivity of synaptic changes to spike pattern, rate, and dendritic location.. Proc. Natl. Acad. Sci. U.S.A. 109, 3991–3996. doi: 10.1073/pnas.1109359109
Gutig, R. (2016). Spiking neurons can discover predictive features by aggregate-label learning. Science 351:aab4113. doi: 10.1126/science.aab4113
Gütig, R., and Sompolinsky, H. (2006). The tempotron: a neuron that learns spike timing-based decisions. Nat. Neurosci. 9, 420–428. doi: 10.1038/nn1643
Gütig, R., and Sompolinsky, H. (2009). Time-warp-invariant neuronal processing. PLoS Biology. 7:e1000141. doi: 10.1371/journal.pbio.1000141
Häusser, M. (2001). Synaptic function: dendritic democracy. Curr. Biol. 11, 10–12. doi: 10.1016/S0960-9822(00)00034-8
Hay, E., Hill, S., Schürmann, F., Markram, H., and Segev, I. (2011). Models of neocortical layer 5b pyramidal cells capturing a wide range of dendritic and perisomatic active properties. PLoS Comput. Biol. 7:e1002107. doi: 10.1371/journal.pcbi.1002107
Heimel, J. A., Van Hooser, S. D., and Nelson, S. B. (2005). Laminar organization of response properties in primary visual cortex of the gray squirrel (Sciurus carolinensis). J. Neurophysiol. 94, 3538–3554. doi: 10.1152/jn.00106.2005
Hengen, K. B., Lambo, M. E., Van Hooser, S. D., Katz, D. B., and Turrigiano, G. G. (2013). Firing rate homeostasis in visual cortex of freely behaving rodents. Neuron 80, 335–342. doi: 10.1038/jid.2014.371
Hines, M. L., Davison, A. P., and Muller, E. (2009). NEURON and python. Front. Neuroinformatics 3:1. doi: 10.3389/neuro.11.001.2009
Jahr, C. E., and Stevens, C. F. (1990). Voltage dependence of NMDA-activated predicted by single-channel kinetics. J. Neurosci. 10, 3178–3182.
Kampa, B. M., Letzkus, J. J., and Stuart, G. J. (2006). Requirement of dendritic calcium spikes for induction of spike-timing-dependent synaptic plasticity. J. Physiol. 574, 283–290. doi: 10.1113/jphysiol.2006.111062
Kastellakis, G., Cai, D. J., Mednick, S. C., Silva, A. J., and Poirazi, P. (2015). Synaptic clustering within dendrites: an emerging theory of memory formation. Prog. Neurobiol. 126, 19–35. doi: 10.1016/j.pneurobio.2014.12.002
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). “ImageNet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems, 1097–1105.
Kullmann, D. M., Moreau, A. W., Bakiri, Y., and Nicholson, E. (2012). Plasticity of inhibition. Neuron 75, 951–962. doi: 10.1016/j.neuron.2012.07.030
Larkum, M. (2013). A cellular mechanism for cortical associations: an organizing principle for the cerebral cortex. Trends Neurosci. 36, 141–151. doi: 10.1016/j.tins.2012.11.006
Larkum, M. E., and Nevian, T. (2008). Synaptic clustering by dendritic signalling mechanisms. Curr. Opin. Neurobiol. 18, 321–331. doi: 10.1016/j.conb.2008.08.013
Losonczy, A., Makara, J. K., and Magee, J. C. (2008). Compartmentalized dendritic plasticity and input feature storage in neurons. Nature 452, 436–441. doi: 10.1038/nature06725
Magee, J. C., and Johnston, D. (1995). Characterization of single voltage-gated Na+ and Ca2+ channels in apical dendrites of rat {CA1} pyramidal neurons. J. Physiol. 481, 67–90.
Manita, S., Suzuki, T., Homma, C., Matsumoto, T., Odagawa, M., Yamada, K., et al. (2015). A top-down cortical circuit for accurate sensory perception. Neuron. 86, 1304–1316. doi: 10.1016/j.neuron.2015.05.006
McCulloch, W. S., and Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 5, 115–133. doi: 10.1007/BF02478259
Megías, M., Emri, Z., Freund, T. F., and Gulyás, A. I. (2001). Total number and distribution of inhibitory and excitatory synapses on hippocampal CA1 pyramidal cells. Neuroscience 102, 527–540. doi: 10.1016/S0306-4522(00)00496-6
Mel, B. W. (1992). NMDA-based pattern discrimination in a modeled cortical neuron. Neural Comput. 4, 502–517. doi: 10.1162/neco.1992.4.4.502
Mel, B. W., Schiller, J., and Poirazi, P. (2017). Synaptic plasticity in dendrites: complications and coping strategies. Curr. Opin. Neurobiol. 43, 177–186. doi: 10.1016/j.conb.2017.03.012
Moldwin, T., Schwartz, O., and Sussman, E. S. (2017). Statistical learning of melodic patterns influences the Brain's response to wrong notes. J. Cogn. Neurosci. 29, 2114–2122. doi: 10.1162/jocn_a_01181
Moldwin, T., and Segev, I. (2018). Perceptron learning and classification in a modeled cortical pyramidal cell. bioRxiv 464826. doi: 10.1101/464826
Muller, E., and Reimann, M. S. R. (2011). Modification of ProbAMPANMDA: 2-State model'. Available online at: https://github.com/BlueBrain/BluePyOpt/blob/master/examples/l5pc/mechanisms/ProbAMPANMDA_EMS.mod
Müllner, F. E., Wierenga, C. J., and Bonhoeffer, T. (2015). Precision of inhibition: dendritic inhibition by individual GABAergic synapses on hippocampal pyramidal cells is confined in space and time. Neuron 87, 576–589. doi: 10.1016/j.neuron.2015.07.003
Poirazi, P., Brannon, T., and Mel, B. W. (2003). Pyramidal neuron as two-layer neural network. Neuron 37, 989–999. doi: 10.1016/S0896-6273(03)00149-1
Poirazi, P., and Mel, B. W. (2001). Impact of active dendrites and structural plasticity on the memory capacity of neural tissue. Neuron 29, 779–796. doi: 10.1016/S0896-6273(01)00252-5
Polsky, A., Mel, B. W., and Schiller, J. (2004). Computational subunits in thin dendrites of pyramidal cells. Nat. Neurosci. 7, 621–627. doi: 10.1038/nn1253
Quiroga, R. Q., Kreiman, G., Koch, C., and Fried, I. (2008). Sparse but not “Grandmother-cell” coding in the medial temporal lobe. Trends Cogn. Sci. 12, 87–91. doi: 10.1016/j.tics.2007.12.003
Quiroga, R. Q., Reddy, L., Kreiman, G., Koch, C., and Fried, I. (2005). Invariant visual representation by single neurons in the human brain. Nature 435, 1102–1107. doi: 10.1038/nature03687
Rall, W. (1967). Distinguishing theoretical synaptic potentials computed for different soma-dendritic distributions of synaptic input. J Neurophysiol. 30, 1138–1168.
Rhodes, P. (2006). The properties and implications of NMDA spikes in neocortical pyramidal cells. J. Neurosci. 26, 6704–6715. doi: 10.1523/JNEUROSCI.3791-05.2006
Rosenblatt, F. (1958). The perceptron: a probabilistic model for information storage and organization in the brain. Psychol. Rev. 65, 386–408. doi: 10.1037/h0042519
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1986). Learning representations by back-propagating errors. Nature 323, 533–536. doi: 10.1038/323533a0
Rumsey, C. C., and Abbott, L. F. (2006). Synaptic democracy in active dendrites. J. Neurophysiol. 96, 2307–2318. doi: 10.1152/jn.00149.2006
Safaryan, K., Maex, R., Maex, N., Adams, R., and Steuber, V. (2017). Nonspecific synaptic plasticity improves the recognition of sparse patterns degraded by local noise. Sci. Rep. 7:46550. doi: 10.1038/srep46550
Sarid, L., Bruno, R., Sakmann, B., Segev, I., and Feldmeyer, D. (2007). Modeling a layer 4-to-layer 2/3 module of a single column in rat neocortex: interweaving in vitro and in vivo experimental observations. Proc. Natl. Acad. Sci.U.S.A. 104, 16353–16358. doi: 10.1073/pnas.0707853104
Schiess, M., Urbanczik, R., and Senn, W. (2016). Somato-dendritic synaptic plasticity and error-backpropagation in active dendrites. PLoS Comput. Biol. 12:e1004638. doi: 10.1371/journal.pcbi.1004638
Schiller, J., Bruno, R., Bruno, B., Segev, I., and Feldmeyer, D. (2000). NMDA spikes in basal dendrites of cortical pyramidal neurons. Nature 404, 285–289. doi: 10.1038/35005094
Siegel, M., Körding, K. P., and König, P. (2000). Integrating top-down and bottom-up sensory processing by somato-dendritic interactions. J. Comput. Neurosci. 8, 161–173. doi: 10.1023/A:1008973215925
Spratling, M. W. (2002). Cortical region interactions and the functional role of apical dendrites. Behav. Cogn. Neurosci. Rev. 1, 219–228. doi: 10.1177/1534582302001003003
Spruston, N. (2008). Pyramidal neurons: dendritic structure and synaptic integration. Nat. Rev. Neurosci. 9, 206–221. doi: 10.1038/nrn2286
Steuber, V., Mittmann, W., Hoebeek, F. E., Silver, R. A., De Zeeuw, C. I., Häusser, M., et al. (2007). Cerebellar LTD and pattern recognition by purkinje cells. Neuron 54, 121–136. doi: 10.1016/j.neuron.2007.03.015
Stuart, G., and Spruston, N. (1998). Determinants of voltage attenuation in neocortical pyramidal neuron dendrites. J. Neurosci. 18, 3501–10.
Sun, Q., Srinivas, K. V., Sotayo, A., and Siegelbaum, S. A. (2014). Dendritic Na(+) spikes enable cortical input to drive action potential output from hippocampal CA2 pyramidal neurons. eLife 3, 1–24. doi: 10.7554/eLife.04551
Trachtenberg, J. T., Chen, B. E., Knott, G. W., Feng, G., Sanes, G. R., Welker, E., et al. (2002). Long-term in vivo imaging of experience-dependent synaptic plasticity in adult cortex. Nature 420, 789–794. doi: 10.1111/j.1528-1157.1986.tb03495.x
Urbanczik, R., and Senn, W. (2014). Learning by the dendritic prediction of somatic spiking. Neuron 81, 521–528. doi: 10.1016/j.neuron.2013.11.030
Weber, J. P., Ujfalussy, B. B., and Makara, J. K. (2016). Location-dependent synaptic plasticity rules by dendritic spine cooperativity. Nat. Commun. 7:11380. doi: 10.1038/ncomms11380
Wulff, P., Schonewille, M., Renzi, M., Viltono, L., Sassoè-Pognetto, M., Badura, A., et al. (2009). Synaptic inhibition of Purkinje cells mediates consolidation of vestibulo-cerebellar motor learning. Nat. Neurosci. 12, 1042–1049. doi: 10.1038/nn.2348
Keywords: compartmental modeling, non-linear dendrites, cortical excitatory synapses, single neuron computation, machine learning, synaptic weights, dendritic voltage attenuation, perceptron
Citation: Moldwin T and Segev I (2020) Perceptron Learning and Classification in a Modeled Cortical Pyramidal Cell. Front. Comput. Neurosci. 14:33. doi: 10.3389/fncom.2020.00033
Received: 24 September 2019; Accepted: 25 March 2020;
Published: 24 April 2020.
Edited by:
Yilei Zhang, Nanyang Technological University, SingaporeReviewed by:
Salvador Dura-Bernal, SUNY Downstate Medical Center, United StatesCopyright © 2020 Moldwin and Segev. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Toviah Moldwin, dG92aWFoLm1vbGR3aW5AbWFpbC5odWppLmFjLmls
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.