 Song Zhang
Song Zhang Jiewei Lu1,2†
Jiewei Lu1,2† Ningbo Yu
Ningbo Yu
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neurorobot. , 25 October 2022
Volume 16 - 2022 | https://doi.org/10.3389/fnbot.2022.978014
This article is part of the Research Topic Advanced Planning, Control, and Signal Processing Methods and Applications in Robotic Systems Volume II View all 14 articles
Estimating human motion intention, such as intent joint torque and movement, plays a crucial role in assistive robotics for ensuring efficient and safe human-robot interaction. For coupled human-robot systems, surface electromyography (sEMG) signal has been proven as an effective means for estimating human's intended movements. Usually, joint movement estimation uses sEMG signals measured from multiple muscles and needs many sEMG sensors placed on the human body, which may cause discomfort or result in mechanical/signal interference from wearable robots/environment during long-term routine use. Although the muscle synergy principle implies that it is possible to estimate human motion using sEMG signals from even one signal muscle, few studies investigated the feasibility of continuous motion estimation based on single-channel sEMG. In this study, a feature-guided convolutional neural network (FG-CNN) has been proposed to estimate human knee joint movement using single-channel sEMG. In the proposed FG-CNN, several handcrafted features have been fused into a CNN model to guide CNN feature extraction, and both handcrafted and CNN-extracted features were applied to a regression model, i.e., random forest regression, to estimate knee joint movements. Experiments with 8 healthy subjects were carried out, and sEMG signals measured from 6 muscles, i.e., vastus lateralis, vastus medialis, biceps femoris, semitendinosus, lateral or medial gastrocnemius (LG or MG), were separately evaluated for knee joint estimation using the proposed method. The experimental results demonstrated that the proposed FG-CNN method with single-channel sEMG signals from LG or MG can effectively estimate human knee joint movements. The average correlation coefficient between the measured and the estimated knee joint movements is 0.858 ± 0.085 for LG and 0.856 ± 0.057 for MG. Meanwhile, comparative studies showed that the combined handcrafted-CNN features outperform either the handcrafted features or the CNN features; the performance of the proposed signal-channel sEMG-based FG-CNN method is comparable to those of the traditional multi-channel sEMG-based methods. The outcomes of this study enable the possibility of developing a single-channel sEMG-based human-robot interface for knee joint movement estimation, which can facilitate the routine use of assistive robots.
Surface electromyography (sEMG) has been extensively used to ensure accurate and safe human-robot interaction (HRI) in robotic devices for rehabilitation or performance enhancement (Nam et al., 2014; Spanias et al., 2016; Caulcrick et al., 2021). Regarding the sEMG-based HRI, one crucial issue is to estimate human motion intention (e.g., intended joint movements) from the sEMG signals (Ding et al., 2017; Bi et al., 2019; Lu et al., 2019). Due to the sEMG signal with the characteristics of preceding the corresponding motion by 20–100 ms and containing neuromuscular control information, the sEMG-based motion estimation benefits in achieving a more natural and fluent HRI and can differentiate how much of the motion is caused by muscles: a unique advantage compared with the inertial measurement unit (IMU)/optical-based method (Xiong et al., 2021). Recently, many approaches have been proposed to estimate the human joint movements based on multi-channel sEMG signals, such as adaptive hybrid classifier for hand gesture recognition (Ding et al., 2019) and Hill-based method or deep learning method for joint movement prediction (Fleischer and Hommel, 2008; Wang et al., 2021; Zhong et al., 2022).
Although multi-channel sEMG signals can provide rich information and contribute to estimate the corresponding joint movement accurately, using multi-channel sEMG has some practical limitations: first, collecting multi-channel sEMG subjects is subject to some limitations, such as weakness or spasticity of one or more specific muscles and mechanical/signal interference between sEMG sensors and wearable robots/environment (e.g., sitting on a chair); second, increasing the number of physical channels would increase the system complexity, making it difficult to deploy, as well as increase the power consumption (He et al., 2019). The above drawbacks limit the routine use of sEMG-based assistive robots. Therefore, it is important to investigate the estimation of human motion using sEMG signals from fewer muscles or even a single muscle.
Recently, some related studies on hand gesture identification (Kumar et al., 2013), upper limb movement recognition (Shao et al., 2020), terrain identification (Gupta and Agarwal, 2019), and lower limb movement recognition (Wei et al., 2022) used single-channel sEMG signals. However, the existing studies mainly focused on recognizing discrete motion modes rather than estimating continuous joint movements. Compared with discrete modes, continuous joint movements can enable simultaneous and proportional control (Bao et al., 2021), realizing more effective and safer HRI for rehabilitation and assistive robots and orthoses. To the best of our knowledge, few studies demonstrated an accurate joint movement estimation method based on single-channel sEMG. According to the muscle synergy principle, which is widely accepted as a constitutional function unit of the central neural systems that control muscles in groups (d'Avella et al., 2003; Jiang et al., 2014; Dwivedi et al., 2020; Kubota et al., 2021), a group of related muscles' activities have certain common components or patterns, which enables the possibility of estimating joint movements using sEMG signals from one or fewer muscles. Therefore, developing a single-channel sEMG-based continuous joint movement estimation method has great potential for facilitating the routine use of assistive robots.
Compared to recognizing motion modes, it is more challenging to accurately estimate continuous joint movements using single-channel sEMG signals due to the limited muscular information. To guarantee an accurate and robust estimation of human joint movement, it is crucial to extract muscular information from single-channel sEMG signals adequately. There are two main ways of extracting muscular information: One is directly computing handcrafted features using mathematical equations (Phinyomark et al., 2012; Thongpanja et al., 2016) and another one is to extract learning features by deep learning, e.g., convolutional neural network (CNN). The learning features may complement the handcrafted features (Atzori et al., 2016; Phinyomark and Scheme, 2018; Côté-Allard et al., 2020). Therefore, it is possible to obtain relatively adequate muscular information from single-channel sEMG by fusing the handcrafted and learning features.
In this study, a new feature extraction method, namely feature-guide convolutional neural network (FG-CNN), was proposed to estimate knee joint movements using single-channel sEMG signals. In the proposed FG-CNN, 14 handcrafted features (Wei et al., 2019) were first fed into a fusion layer to guide a traditional CNN in extracting 14 implicit features (i.e., CNN extracted features). The 28 FG-CNN features containing 14 handcrafted features and 14 CNN features were applied to a regression model, e.g., random forest regression, to estimate continuous knee joint movements. To verify the effectiveness of the FG-CNN, the proposed method was respectively evaluated on six kinds of single-channel sEMG signals measured from vastus lateralis (VL), vastus medialis (VM), biceps femoris (BF), semitendinosus (ST), lateral and medial gastrocnemius (LG and MG) for estimating the movements. Meanwhile, the 28 FG-CNN features were respectively compared to 14 handcrafted features and 28 CNN features (extracted by the traditional CNN) on the same regression model. The experimental results show that the proposed FG-CNN method with single-channel sEMG signals from LG or MG can effectively estimate the movement. The FG-CNN features outperform the handcrafted features and CNN features on single-channel sEMG-based movement estimation, suggesting that the FG-CNN features contain more muscular information.
The main contributions of this study are as follows:
1) This is the first study, to our knowledge, to investigate the feasibility of using single-channel sEMG signals to estimate the human knee angles.
2) A new feature extraction algorithm has been developed to extract muscular information from single-channel sEMG adequately and a new scheme is proposed to estimate knee joint angles based on single-channel sEMG signals using FG-CNN and regression models.
3) The effectiveness of the proposed method has been evaluated via experiments with eight subjects during walking. sEMG signals from a single muscle, LG or MG, can be used to improve the estimation performance with the proposed method.
The proposed FG-CNN was depicted in Figure 1. In the FG-CCN, 14 typical sEMG features, i.e., the handcrafted features, were extracted from the raw sEMG data and fed into a fusion layer of a CNN to guide the CNN in extracting implicit muscular information. Furthermore, both the handcrafted features and the CNN extracted features were connected and used to estimate knee joint movements using a regression model, e.g., random forest regression (RF) and light gradient boosting machine (LGBM).
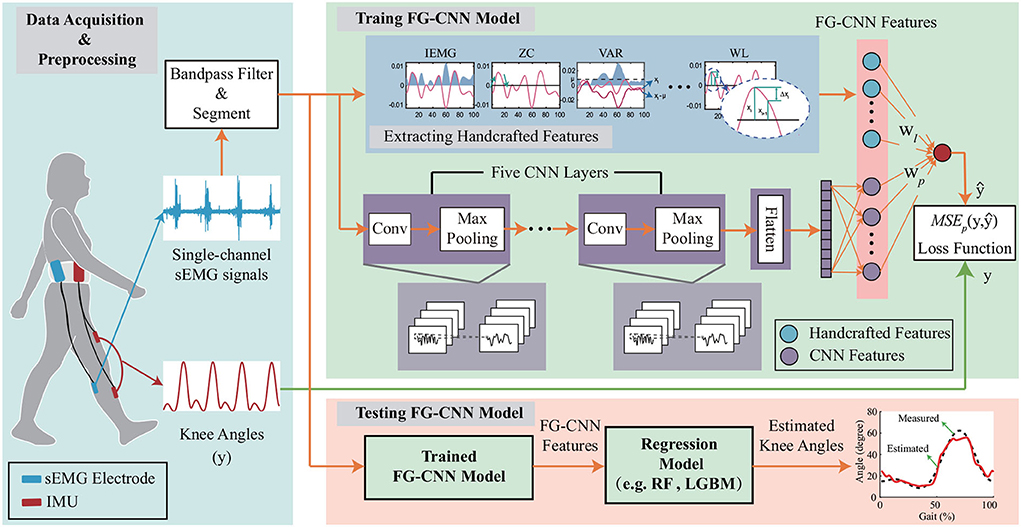
Figure 1. The overall framework of the FG-CNN-based motion estimation. The FG-CNN consists of the operation of extracting handcrafted features, five CNN layers, one flatten layer, and one fusion layer for fusing CNN features and handcrafted features. IMU represents the inertial measurement unit; Conv denotes the convolutional layers; IEMG, VAR, ZC, and WL represent the handcrafted features. The symbols wl and wp, respectively, represent the weights of the handcrafted and CNN features in the fusion layer. RF and LGBM represent the random forest model and light gradient boosting machine, respectively.
A method called overlapping analysis windows with a window length of 50 ms and an increment of 20 ms was used to segment the sEMG signals. The vector x = {x1, x2, …, xn} represents sEMG signal in a window, where n is the length of x. 14 handcrafted features, including integrated EMG (IEMG), mean absolute value (MAV), mean, root mean square (RMS), variance (VAR), Kurtosis, skewness, zero crossing (ZC), slop sign change (SSC), waveform length (WL), and four auto-regressive (AR) model coefficients are calculated using the overlapping analysis windows (Wei et al., 2019). The above 14 handcrafted features are concatenated as a vector (p = {IEMG, MAV, …, AR4}) fused into a CNN to extract CNN features.
The CNN feature extraction (see Figure 1) is used to extract implicit muscular information from the input sEMG signal vector x. In the CNN structure, five convolution layers had 2, 4, 8, 16, and 32 filters, respectively, where the filters were 5 × 1, 4 × 1, 3 × 1, 2 × 1, and 1 × 1. Max pooling was conducted on 2 × 1 area with a stride of 1. The two fully-connected layers contain 192 and 14 neurons. For each convolutional layer, x ∈ ℝL′ × D′ is defined as the input, where the L′ and D′ denote the length and the number of channels. Assuming the D convolutional kernels k, the output of the convolutional layer y ∈ ℝL×D is described as:
where f represents an activation function, w is a bias parameter vector, and * denotes convolution.
The LeakyReLU nonlinearity (Maas et al., 2013) is applied as the activation function of convolutional layers mentioned in (1), which is defined as:
where a is a learnable parameter.
To avoid overfitting the model, batch normalization (BN) (Ioffe and Szegedy, 2015) is applied after each convolutional layer. The convolutional layer is followed by a max-pooling layer with a length of 2, which transforms the outputs of multiple neurons in one layer into a single neuron in the next layer. The input of the pooling layer is the output of the convolutional layer before it, i.e., y ∈ ℝL×D. The output of each pooling layer is described as:
where , j = 1, 2, …D.
The output of the last pooling layer is then flattened into a vector, l ∈ ℝ14 × 1, which is called CNN features.
A fusion layer is introduced to combine the extracted handcrafted features (p) and the CNN extracted features (l). In the fusion scheme, both the handcrafted and CNN extracted features are fed into the last fully connected layer to estimate the joint motion () (see Figure 1). Instead of using the LeakyReLU, the tanh function, which normalizes fused features to [-1,1], is chosen to avoid the blow-up phenomenon. The fusion scheme is defined as follows:
where wp and wl refer to the connection weights.
The built FG-CNN model is trained using a mean squared error function (MSEp) as follows:
where y and denote the measured and estimated knee joint movements, respectively. N is the total number of samples.
During the training, Adam algorithm (Diederik and Jimmy, 2015) is utilized to update the weights. Unlike the traditional CNN, the proposed FG-CNN includes the handcrafted features in the weight updating process to guide the CNN to extract features. Correspondingly, the weights of the fusion layer of the FG-CNN are updated in the following steps.
Step 1: Compute the gradients:
Step 2: Update the weights:
where ϵ denotes the constant, ϵ = 10−8. ap, al, b, cp, cl, and d are given as follows:
where sp and sl denote the first and second order moment vector of handcrafted features, rp and rl denote the first and second order moment vector of FG-CNN features, and β1, , β2, are the exponential decay rates for the moment estimations. α denotes the step-size.
As seen in Equation (7), the updated weights of the fusion layer are updated using both handcrafted and CNN extracted features. With a learning rate of 0.001, the FG-CNN was trained on NVIDIA Quadro P5000 GPU by using the Adam algorithm for 50 epochs in our experiments.
Eight healthy subjects (six men and two women, aged 25.13 ± 3.27 years old) participated in the experiments. All experiments were conducted in accordance with the ethical standards encoded in the latest Declaration of Helsinki. Before the experiments, each participant was fully informed of the experimental purpose and procedures and provided their written consent to participate in this study. The experiments were proved by the local ethics committee of Nankai University.
The experiment scheme is shown in Figure 2. Six channels of sEMG electrodes were respectively placed on six muscles, namely, vastus lateralis (VL), vastus medialis (VM), biceps femoris (BF), semitendinosus (ST), lateral gastrocnemius (LG), and medial gastrocnemius (MG) (Lu et al., 2021), which are relative to the knee joint motion. The data of sEMG were obtained by an acquisition system (Bagnoli, Delsys, MA, USA) under the sampling rate of 5 kHz. At the same time, the data of knee joint angles were also measured using two IMUs with the sampling rate of 100 Hz. Each subject was asked to walk for 1 min with a velocity of 1.25 m/s on the treadmill per trial and perform 11 trials in total with a 3-min rest in between to avoid muscle fatigue. The raw sEMG signals were pre-processed using a Butterworth bandpass filter with cutoff frequencies of 10 Hz and 500 Hz. The sEMG signals measured from the six muscles were tested separately to estimate the knee joint movements. Five cross-validations were used to split the dataset into training data and testing data that are independent of each other. For each time, the proposed FG-CNN model was trained on 80% of data and evaluated on 20% of data.
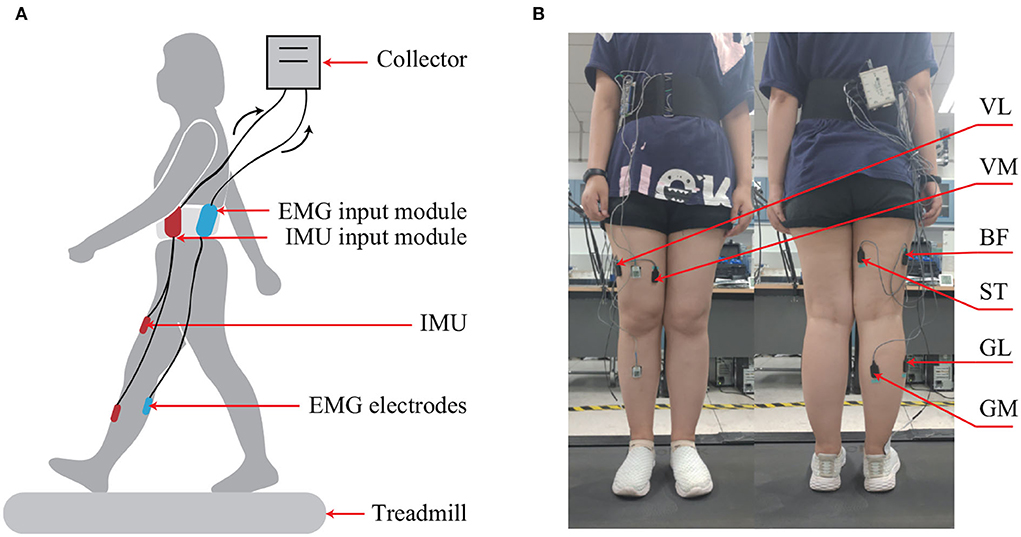
Figure 2. The experimental setup. (A) Schematic diagram of the experimental setup. (B) The locations of sEMG electrodes.
The estimation performance of the trained FG-CNN was evaluated by using two indicators: normal root-mean-squared error (NRMSE) and correlation coefficients (CC), respectively (Kwon and Kim, 2011; Qing et al., 2022). The NRMSE is used to reflect the deviation between the measured and estimated knee joint angles, in percentage (%) (Zhu et al., 2022). The CC value can reflect the strength of the correlation between the measured and estimated knee joint angles, which is close to 1, which indicates meaning a good match between the measurement and the estimation.
The NRMSE is defined as
where yi and ŷi are the measured and estimated knee joint angles, respectively, n denotes the total number of samples, and ymax and ymin are the maximum and minimum values of the measured angles, respectively.
CC is defined as
where Cyŷ denotes the covariance between the measured and estimated angles and σy and σŷ represent the standard deviation of measured and estimated angles, respectively.
Statistical analyses were performed to compare the estimation performances between the proposed FG-CNN and the other compared methods. As the evaluation indicators were not normally distributed, the Kruskal-Wallis test was conducted to compare the different estimation methods with the FG-CNN to identify differences in NRMSE and CC. For all tests, the significance level was set at a p < 0.05. Statistical analyses were conducted with MATLAB (MathWorks, Natick, MA, USA).
To verify the effectiveness of the proposed method in extracting implicit features from single-channel sEMG signals, a comparison study was carried out, in which the handcrafted features, the CNN features, and the FG-CNN features were separately used to estimate the knee joint movements via a random forest (RF) regression model (see Figure 1).
The details are given as follows:
1) HF-RF: Fourteen handcrafted features were fed into the RF regression.
2) CNN-RF: Twenty-eight CNN features were used as the inputs of the RF regression.
3) FG-CNN-RF: Twenty-eight FG-CNN features were fed into the RF regression.
Figure 3 shows the knee joint angles measured using the IMUs (i.e., the reference) and the ones estimated using the HF-RF, CNN-RF, and FG-CNN-RF. For all approaches, the estimated angles from FG-CNN-RF are closer to the reference than those from HF-RF and CNN-RF. For all muscles, it can also be seen that the estimated knee joint angles using single-channel sEMG signals measured from LG or MG are more accurate than those estimated using sEMG signals from VL, VM, BF, or ST.
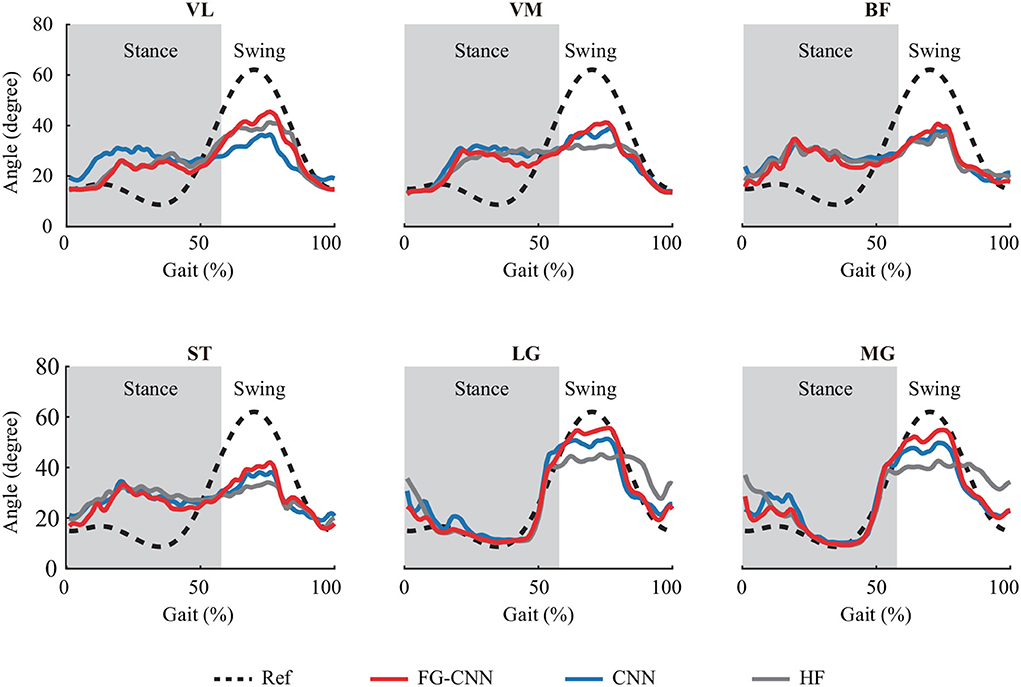
Figure 3. Knee joint angles profiles averaged across 57 strides with subject 2. Dashed and solid lines are reference angles measured by IMUs and estimated angles by FG-CNN-RF, CNN-RF, and HF-RF, using single-channel sEMG signals. The gray shaded area indicates the stance phase.
Meanwhile, to quantitatively evaluate the estimation results, the indicators of NRMSE and CC were used. The NRMSE values using the LG and MG from the FG-CNN-RF were, respectively, 15.2±3.5% (LG) and 15.7±3.1% (MG), and the CC values were, respectively, 0.858 ± 0.085 (LG) and 0.856 ± 0.057 (MG). Although the estimation performance obtained from single-channel sEMG signals (LG or MG) is slightly lower than that from six-channel signals (NRMSE: 10.2±1.4%; CC: 0.948±0.013, shown in Figure 4), the estimation accuracy using the proposed single-channel based method is comparable to the that using six-channel sEMG. The results can be explained by the muscle synergy analysis, in which the muscles are controlled in groups to generate a desired joint movement, and all relevant muscles share some common components.
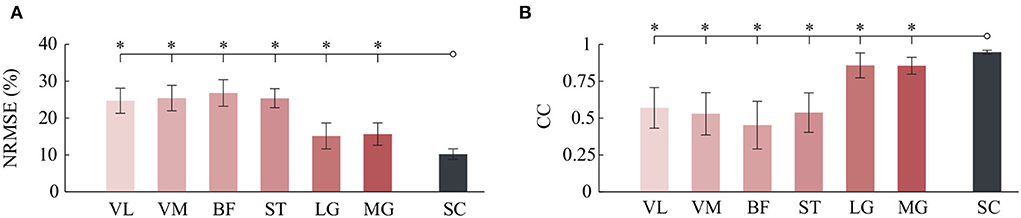
Figure 4. Comparison of angle estimation accuracy between six kinds of single-channel sEMG and six-channel sEMG (SC). (A) Comparison of NRMSE. (B) Comparison of CC. Bars are means, error bars are standard error of the mean (SEM), and asterisks denote statistically significant differences with respect to the six-channel sEMG (P < 0.05).
For each muscle, the mean NRMSE values of the FG-CNN-RF were lowest and decreased by 15% (VL), 19.2% (VM), 8.1% (BF), 13.3% (ST), 37.6% (LG), and 39.4% (MG) compared to those of the HF-RF and by 11.3% (VL), 9% (VM), 8.6% (BF), 12.1% (ST), 18.8% (LG), and 19.2% (MG) compared to those of the CNN-RF (shown in Figure 5A). The average CC values of FG-CNN-RF were highest, which were increased by 33.4% (VL), 59.3% (VM), 42.4% (BF), 51.7% (ST), 27.3% (LG), and 33.8% (MG) compared to those of the HF-RF, and increased by 32.2% (VL), 24.8% (VM), 34.1% (BF), 42.8% (ST), 7.9% (LG), and 9.8% (MG) compared to those of the CNN-RF (see Figure 5B).
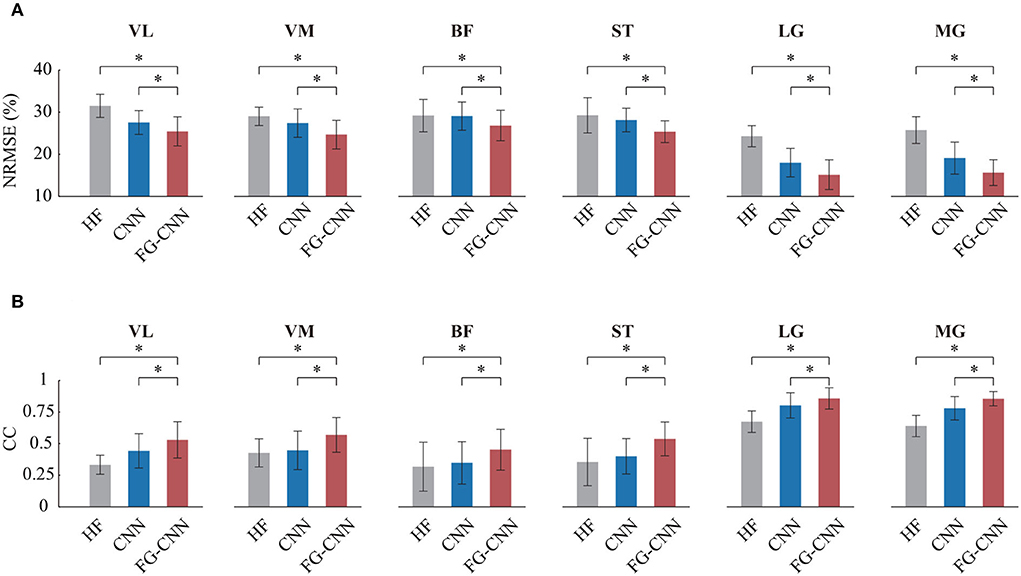
Figure 5. Comparison of angle estimation accuracy by HF, CNN, and FG-CNN. (A) Comparison of NRMSE. (B) Comparison of CC. Bars are means, error bars are standard error of the mean (SEM), and asterisks denote statistical significance (P < 0.05).
The Kruskal-Wallis test was conducted to identify differences in NRMSE and CC between the case using FG-CNN features and the cases using the other two kinds of features (handcrafted features and CNN features). Both the NRMSE and CC values of FG-CNN had statistically significant differences with respect to handcrafted features and CNN features (see Figure 5). The above results implies that the FG-CNN features contain more muscular information than the handcrafted features or CNN features for ensuring a more accurate estimation of knee joint movement.
To further test the effectiveness of the FG-CNN features, five difference regression models were used, including RF regression, light gradient boosting machine (LightGBM), multilayer perceptron (MLP), support vector regression (SVR), and k-nearest neighbors (KNN) regression. The inputs of the five models were FG-CNN features. Figure 6 shows the NRMSE and CC values for knee joint movement estimation using the five regression models. The regression models of RF, LightGBM, and MLP have similar estimation performance with lower NRMSE and greater CC values than the other two models.
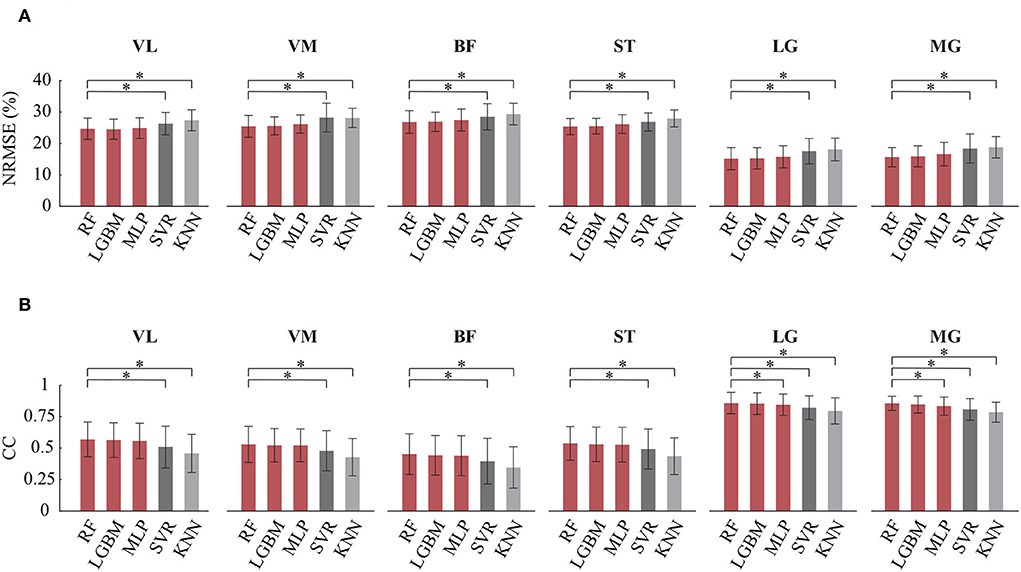
Figure 6. Comparison of angle estimation accuracy on different regression models. RF, random forest regression; LGBM, gradient boosting machine; MLP, multilayer perceptron (MLP); SVR, support vector regression; KNN, k-nearest neighbors regression. (A) Comparison of NRMSE. (B) Comparison of CC. Bars are means, error bars are standard error of the mean (SEM), and asterisks denote statistically significant differences with respect to the RF (P < 0.05).
The Kruskal-Wallis test was also used to determine if there were differences between the RF and the other four regression models. Table 1 showed the statistical analysis results on CC and NRMSE. For each single-channel sEMG, the NRMSE values of RF significantly decreased compared to these of SVR and KNN. Meanwhile, the CC values of RF significantly increased compared to those of SVR and KNN. The CC values of MLP from LG and MG were different compared to that from the RF (LG: P = 0.015; MG: P = 0.0015), while no significant differences were found between RF and the other two models (LightGBM and MLP) on NRMSE and CC.
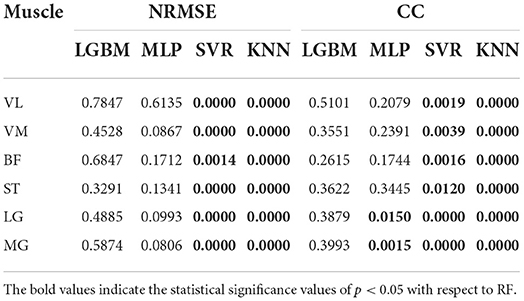
Table 1. Statistical analysis results between RF and the other regression models (including LGBM, MLP, SVR, and KNN) on NRMSE and CC.
Human joint movement estimation using multi-channel sEMG signals has been widely used to enable HRI systems' intuitive and voluntary control. However, some issues have inhibited the collection of high-quality sEMG signals from all relevant muscles, such as weakness or spasticity of one or more specific muscles, mechanical/signal interference between EMG sensors and wearable robots/environment, discomfort for long-term use, etc. Therefore, using fewer channels or single-channel sEMG signals is of practical importance. It remains unknown whether the continuous knee joint movement can be estimated using single-channel sEMG signals. In addition, it is a challenge to ensure high estimation accuracy using only single-channel sEMG signals. This study verified the feasibility of continuous joint movement estimation only using single-channel sEMG signals and proposed a new feature extraction scheme, namely FG-CNN, to improve the estimation performance effectively.
The main advantage of FG-CNN is that it contains both handcrafted features and CNN features, which can improve the motion estimation performance just by using single-channel sEMG signals (as shown in Figure 5). When multi-channel sEMG signals were used, the handcrafted features or CNN features contained enough muscular information and could be successfully adopted in motion estimation. However, with the number of channels decreasing, the muscular information in the handcrafted features or CNN features will not be sufficient. To further extract implicit features, this study fed the handcrafted features into a fusion layer to guide the extraction of CNN features. Compared with both the handcrafted features and CNN features, the FG-CNN features can ensure a more accurate joint movement estimation, which implies that the FG-CNN features contained more muscular information.
Based on the single-channel sEMG signals of LG or MG, the estimated angle profiles were similar to the reference during the gait cycle, as shown in Figure 3. On the contrary, for single-channel sEMG of VL, VM, BF, or ST, the trends of estimated angles profiles were reversed, especially at the stance phase. In this study, the used estimation methods, such as random forest regression and light gradient boosting machine, directly mapped the sEMG features to knee angles without any biomechanics. The estimation performance was influenced by the correlation between inputs (sEMG features) and outputs (knee angles). In a gait cycle, compared to the other four muscle activity profiles, the correlation between the gastrocnemius activity profiles and the knee angle profiles was stronger (shown in Figure 7). This can explain why the estimation accuracy from LG or MG is highest.
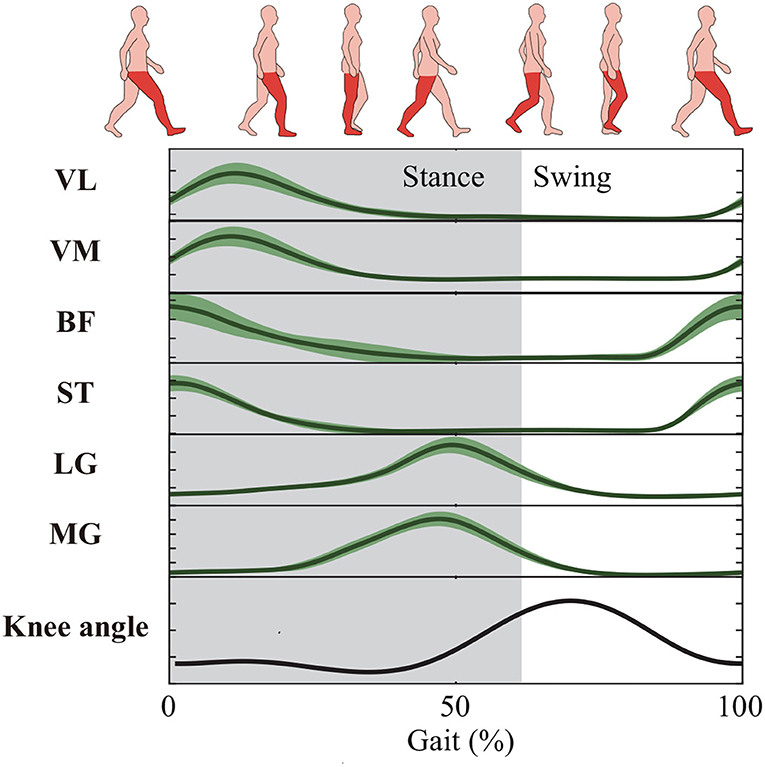
Figure 7. Muscle activity profiles and knee angle profiles during the gait cycle.
sEMG will be changed on different days and subjects due to the changing skin impedance, which is affected by physiological factors such as subcutaneous tissue, the physiological cross-sectional area of the muscle, or dynamic factors such as sweat. It is a complex and significant issue need to be addressed in practical application. To date, some studies made efforts to address this issue. Bao et al. established a two-stream CNN with shared weights to enhance inter-subject performances in the wrist kinematics estimation (Bao et al., 2021). The results showed that the NRMSE and CC values were 22% and 0.67, respectively, which outperformed a state-of-the-art transfer learning method. Dantas et al. demonstrated that the CNN decoder performed significantly better than polynomial Kalman filters in most analyzed cases of temporal separations (0–150 days) between the acquisition of the training and testing datasets (Dantas et al., 2019). The above studies demonstrated the potential for the utilization of CNN to address the limitations of using sEMG on different days and subjects. Therefore, although the proposed FG-CNN degrades its estimation performance using sEMG from different subjects or days, it is possible not to degrade too much. Future studies should advance in this direction.
In comparison with the previous studies, the main advantage of the proposed method is to achieve good estimation performance using single-channel sEMG signals rather than the multi-channels, which can be used to improve the usability of low limb wearable robotics in weakness or spasticity of one or more specific muscles (Wei et al., 2022). Although the mean CC values of the proposed FG-CNN with single-channel EMG signals were slightly lower than the CC values of the state-of-the-art studies with multi-channel sEMG (shown in Table 2), the mean CC values of the proposed FG-CNN is around 0.85, which suggests the strong correlation strength between the estimated and the measured.
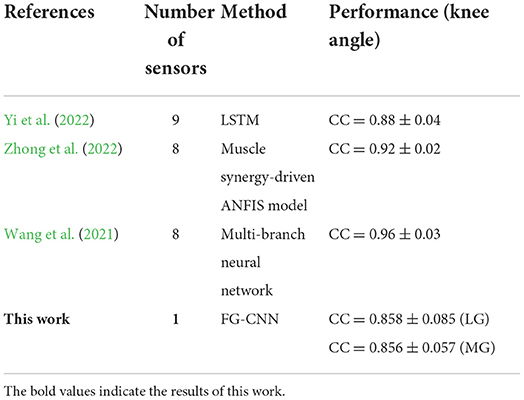
Table 2. Comparison with related research.
It is worth noting that the proposed methods have limitations. One method is that the sEMG data from each subject were recorded on the same day and the proposed FG-CNN was trained and tested on the same subject. This study did not consider the influence of sEMG changes on different days and subjects. Future studies should advance in this direction. Another method is that the estimation performance still has room for improvement. Future studies would be required to recruit more subjects and further to improve the accuracy of knee joint estimation by advanced single-channel sEMG-based methods.
In this study, a new feature extraction method, namely FG-CNN, was proposed to estimate human knee joint movement using single-channel sEMG signals. To verify the effectiveness of this method, sEMG signals measured from six muscles, including the vastus lateralis, the vastus medialis, the biceps femoris, the semitendinosus, the lateral or medial gastrocnemius (LG or MG), were separately evaluated for estimating knee joint movements using the proposed FG-CNN. The experimental results showed that combined handcrafted-CNN features outperform either the handcrafted features or the CNN features. In addition, the results demonstrated that the proposed FG-CNN method with sEMG signals from LG or MG can effectively estimate the movements with average NRMSE values of 15.2 ± 3.5% (LG) and 15.7 ± 3.1% (MG) and average CC values of 0.858 ± 0.085 (LG) and 0.856 ± 0.057 (MG). The performance of the proposed signal-channel sEMG-based FG-CNN method was comparable to those of traditional multi-channel sEMG-based methods. The proposed FG-CNN have the potential to provide an alternative means for knee joint movement estimation to overcome the aforementioned limitations faced by the traditional multi-channel sEMG-based methods.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by the local Ethics Committee of Nankai University. The patients/participants provided their written informed consent to participate in this study.
WH, NY, and JH initiated and supervised the research project. SZ and JL carried out the research. SZ analyzed the data. SZ, JL, WH, NY, and JH interpreted the data and drafted and revised the manuscript. All authors read and approved the final manuscript.
This work was supported by the National Natural Science Foundation of China (U1913208, 61873135, and 61720106012).
The authors are grateful to all participants in experiments.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Atzori, M., Cognolato, M., and Mller, H. (2016). Deep learning with convolutional neural networks applied to electromyography data: a resource for the classification of movements for prosthetic hands. Front. Neurorobot. 10, 9. doi: 10.3389/fnbot.2016.00009
Bao, T., Zaidi, S. A. R., Xie, S., Yang, P., and Zhang, Z. Q. (2021). Inter-subject domain adaptation for cnn-based wrist kinematics estimation using semg. IEEE Trans. Neural. Syst. Rehabil. Eng. 29, 1068–1078. doi: 10.1109/TNSRE.2021.3086401
Bi, L., Feleke, A. G., and Guan, C. (2019). A review on emg-based motor intention prediction of continuous human upper limb motion for human-robot collaboration. Biomed. Signal Process. Control 51, 113–127. doi: 10.1016/j.bspc.2019.02.011
Caulcrick, C., Huo, W., Hoult, W., and Vaidyanathan, R. (2021). Human joint torque modelling with mmg and emg during lower limb human-exoskeleton interaction. IEEE Robot. Automat. Lett. 6, 7185–7192. doi: 10.1109/LRA.2021.3097832
Côté-Allard, U., Campbell, E., Phinyomark, A., Laviolette, F., Gosselin, B., and Scheme, E. (2020). Interpreting deep learning features for myoelectric control: a comparison with handcrafted features. Front. Bioeng. Biotechnol. 8, 158. doi: 10.3389/fbioe.2020.00158
Dantas, H., Warren, D. J., Wendelken, S. M., Davis, T. S., Clark, G. A., and Mathews, V. J. (2019). Deep learning movement intent decoders trained with dataset aggregation for prosthetic limb control. IEEE Trans. Biomed. Eng. 66, 3192–3203. doi: 10.1109/TBME.2019.2901882
d'Avella, A., Saltiel, P., and Bizzi, E. (2003). Combinations of muscle synergies in the construction of a natural motor behavior. Nat. Neurosci. 6, 300–308. doi: 10.1038/nn1010
Diederik, P. K., and Jimmy, L. B. (2015). “Adam: a method for stochastic optimization,” in International Conference on Learning Representations (ICLR) (San Diego, CA).
Ding, Q., Han, J., and Zhao, X. (2017). Continuous estimation of human multi-joint angles from semg using a state-space model. IEEE Trans. Neural. Syst. Rehabil. Eng. 25, 1518–1528. doi: 10.1109/TNSRE.2016.2639527
Ding, Q., Zhao, X., Han, J., Bu, C., and Wu, C. (2019). Adaptive hybrid classifier for myoelectric pattern recognition against the interferences of uutlier motion, muscle fatigue, and electrode doffing. IEEE Trans. Neural. Syst. Rehabil. Eng. 27, 1071–1080. doi: 10.1109/TNSRE.2019.2911316
Dwivedi, S. K., Ngeo, J., and Shibata, T. (2020). Extraction of nonlinear synergies for proportional and simultaneous estimation of finger kinematics. IEEE Trans. Biomed. Eng. 67, 2646–2658. doi: 10.1109/TBME.2020.2967154
Fleischer, C., and Hommel, G. (2008). A human-exoskeleton interface utilizing electromyography. IEEE Trans. Robot. 24, 872–882. doi: 10.1109/TRO.2008.926860
Gupta, R., and Agarwal, R. (2019). Single channel emg-based continuous terrain identification with simple classifier for lower limb prosthesis. Biocybern. Biomed. Eng. 39, 775–788. doi: 10.1016/j.bbe.2019.07.002
He, J., Sheng, J., Zhu, X., Jiang, C., and Jiang, N. (2019). Spatial information enhances myoelectric control performance with only two channels. IEEE Trans. Ind. Inf. 15, 1226–1233. doi: 10.1109/TII.2018.2869394
Ioffe, S., and Szegedy, C. (2015). “Batch normalization: accelerating deep network training by reducing internal covariate shift,” in International Conference on Machine Learning (Lille), 448–456.
Jiang, N., Rehbaum, H., Vujaklija, I., Graimann, B., and Farina, D. (2014). Intuitive, online, simultaneous, and proportional myoelectric control over two degrees-of-freedom in upper limb amputees. IEEE Trans. Neural. Syst. Rehabil. Eng. 22, 501–510. doi: 10.1109/TNSRE.2013.2278411
Kubota, K., Hanawa, H., Yokoyama, M., Kita, S., Hirata, K., Fujino, T., et al. (2021). Usefulness of muscle synergy analysis in individuals with knee osteoarthritis during gait. IEEE Trans. Neural. Syst. Rehabil. Eng. 29, 239–248. doi: 10.1109/TNSRE.2020.3043831
Kumar, D. K., Arjunan, S. P., and Singh, V. P. (2013). Towards identification of finger flexions using single channel surface electromyography able bodied and amputee subjects. J. Neuroeng. Rehabil. 10, 50. doi: 10.1186/1743-0003-10-50
Kwon, S., and Kim, J. (2011). Real-time upper limb motion estimation from surface electromyography and joint angular velocities using an artificial neural network for human-machine cooperation. IEEE Trans. Inform. Tech. Biomed. 15, 522–530. doi: 10.1109/TITB.2011.2151869
Lu, Y., Wang, H., Hu, F., Zhou, B., and Xi, H. (2021). Effective recognition of human lower limb jump locomotion phases based on multi-sensor information fusion and machine learning. Med. Biol. Eng. Comput. 59, 883–899. doi: 10.1007/s11517-021-02335-9
Lu, Z., Stampas, A., Francisco, G. E., and Zhou, P. (2019). Offline and online myoelectric pattern recognition analysis and real-time control of a robotic hand after spinal cord injury. J. Neural Eng.,16, 036018. doi: 10.1088/1741-2552/ab0cf0
Maas, A. L., Hannun, A. Y., and Ng, A. Y. (2013). “Rectifier nonlinearities improve neural network acoustic models,” in International Conference on Machine Learning.
Nam, Y., Koo, B., Cichocki, C., and Choi, S. (2014). Gom-face: Gkp, eog, and emg-based multi-modal interface with application to humanoid robot control. IEEE Trans. Biomed. Eng. 61, 453–462. doi: 10.1109/TBME.2013.2280900
Phinyomark, A., Phukpattaranont, P., and Limsakul, C. (2012). Feature reduction and selection for emg signal classification. Expert Syst. Appl. 39, 7420–7431. doi: 10.1016/j.eswa.2012.01.102
Phinyomark, A., and Scheme, E. (2018). Emg pattern recognition in the era of big data and deep learning. Big Data Cogn. Comput. 2, 21. doi: 10.3390/bdcc2030021
Qing, Z., Lu, Z., Liu, Z., Cai, Y., Cai, S., He, B., et al. (2022). A simultaneous gesture classification and force estimation strategy based on wearable a mode ultrasound and cascade model. IEEE Trans. Neural Syst. Rehabil. Eng. 30, 2301–2311. doi: 10.1109/TNSRE.2022.3196926
Shao, J., Niu, Y., Xue, C., Wu, Q., Zhou, X., Xie, Y., et al. (2020). Single-channel semg using wavelet deep belief networks for upper limb motion recognition. Int. J. Ind. Ergon. 76, 102905. doi: 10.1016/j.ergon.2019.102905
Spanias, J. A., Perreault, E. J., and Perreault, L. J. (2016). Detection of and compensation for emg disturbances for powered lower limb prosthesis control. IEEE Trans. Neural Syst. Rehabil. Eng. 24, 226–234. doi: 10.1109/TNSRE.2015.2413393
Thongpanja, S., Phinyomark, A., Quaine, F., Laurillau, Y., Limsakul, C., and Phukpattaranont, P. (2016). Probability density functions of stationary surface emg signals in noisy environments. IEEE Trans. Instr. Meas. 65, 1547–1557. doi: 10.1109/TIM.2016.2534378
Wang, X., Dong, D., Chi, X., Wang, S., Miao, Y., An, M., et al. (2021). semg-based consecutive estimation of human lower limb movement by using multi-branch neural network. Biomed. Signal Process. Control 68, 102781. doi: 10.1016/j.bspc.2021.102781
Wei, C., Wang, H., Hu, F., Zhou, B., Feng, N., Lu, Y., et al. (2022). Single-channel surface electromyography signal classification with variational mode decomposition and entropy feature for lower limb movements recognition. Biomed. Signal Process. Control 74, 103487. doi: 10.1016/j.bspc.2022.103487
Wei, W., Dai, Q., Wong, Y., Hu, Y., Kankanhalli, M., and Geng, W. (2019). Surface-electromyography-based gesture recognition by multi-view deep learning. IEEE Trans. Biomed. Eng. 66, 2964–2973. doi: 10.1109/TBME.2019.2899222
Xiong, D., Zhang, D., Zhao, X., and Zhao, Y. (2021). Deep learning for emg-based human-machine interaction: a review. IEEE/CAA J. Autom. Sin. 8, 512–533. doi: 10.1109/JAS.2021.1003865
Yi, C., Jing, F., Zhang, S., Guo, H., Yang, C., Ding, Z., et al. (2022). Continuous prediction of lower-limb kinematics from multi-modal biomedical signals. IEEE Trans. Circuits Syst. 32, 2592–2605. doi: 10.1109/TCSVT.2021.3071461
Zhong, W., Fu, X., and Zhang, M. (2022). A muscle synergy-driven anfis approach to predict continuous knee joint movement. IEEE Trans. Fuzzy Syst. 30, 1553–1563. doi: 10.1109/TFUZZ.2022.3158727
Keywords: single-channel sEMG signals, human-robot interaction, joint movement estimation, level walking, feature-guided convolutional neural network (FG-CNN)
Citation: Zhang S, Lu J, Huo W, Yu N and Han J (2022) Estimation of knee joint movement using single-channel sEMG signals with a feature-guided convolutional neural network. Front. Neurorobot. 16:978014. doi: 10.3389/fnbot.2022.978014
Received: 25 June 2022; Accepted: 28 September 2022;
Published: 25 October 2022.
Edited by:
Zhan Li, Swansea University, United KingdomReviewed by:
Hui Zhou, Nanjing University of Science and Technology, ChinaCopyright © 2022 Zhang, Lu, Huo, Yu and Han. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ningbo Yu, bnl1QG5hbmthaS5lZHUuY24=; Weiguang Huo, d2VpZ3VhbmcuaHVvQG5hbmthaS5lZHUuY24=
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.