 Shuaiqi Liu
Shuaiqi Liu Weijian Peng1,2
Weijian Peng1,2 Wenjing Jiang
Wenjing Jiang Yonggang Su
Yonggang Su- 1College of Electronic and Information Engineering, Hebei University, Baoding, China
- 2Machine Vision Technological Innovation Center of Hebei, Baoding, China
- 3National Laboratory of Pattern Recognition (NLPR), Institute of Automation, Chinese Academy of Sciences, Beijing, China
Introduction
In the past three decades, not only some classical MIF datasets have appeared, but also MIF technology has developed rapidly (Zheng et al., 2020; Zhu et al., 2021). The existing MIF datasets can be divided into two categories, namely, the simulated image dataset obtained by applying Gaussian blur to the existing image dataset and the benchmark image dataset captured by the professional camera. The source image after Gaussian blurring in the multi-focus simulated image dataset are difficult to reflect the information of focused and unfocused objects in the real environment. The benchmark image dataset also has imaging equipment limited to professional cameras. Both of them are difficult to achieve the application of MIF technology in the real environment.
MIF algorithms can be classified into three categories i.e., spatial domain fusion algorithms, transform domain fusion algorithms, and fusion algorithms based on deep learning (Liu et al., 2021). The spatial domain fusion algorithms mainly take pixel-level gradient information or image blocks for fusion. Bouzos et al. (2019) presented a MIF algorithm based on conditional random field optimization. Xiao et al. (2020) presented a MIF algorithm based on Hessian matrix. The transform domain fusion algorithms consist of three processes: image transformation, coefficient fusion and inverse transformation. Liu et al. (2019) proposed a MIF algorithm based on an adaptive dual-channel impulse cortical model and differential images in non-subsampled Shearlet transform (NSST) domain. In recent years, the fusion algorithms based on deep learning have become a research hotspot in the field of multi-focused image fusion. Zhang et al. (2020) proposed an image fusion framework based on convolutional neural network, which utilizes two convolutional layers to extract salient features from source images. Liu et al. (2022) proposed a MIF algorithm based on low vision image reconstruction and focus feature extraction. Although these MIF algorithms have achieved good image fusion results among these public datasets, the image fusion databases used by these algorithms are all data taken by professional cameras or synthetic data, which cannot reflect the fusion performance of the fusion algorithm in the real environment.
As mentioned above, in the past few years, a series of MIF algorithms have been developed by scholars from various countries. To test the performance of these algorithms, some classic public MIF datasets have occurred. Currently, the commonly used datasets include Multi Focus-Photography Contest dataset (http://www.pxleyes.com/photography-contest/19726), Lytro color multi-focus image dataset (Nejati et al., 2015), Savic dataset (http://dsp.etfbl.net/mif/) and Aymaz dataset (https://github.com/sametymaz/Multi-focus-Image-Fusion-Dataset), etc. Some of these datasets were captured by professional cameras, and others were obtained by applying Gaussian blur to existing image datasets. The Multi Focus-Photography Contest dataset is an image photography competition held by the Photography Contest website. It contains 27 pairs of multi-focus images. Images in Lytro multi-focus dataset were acquired by the Lytro camera which is an all-optical camera whose imaging system employs a microlens array focused on the focal plane of the camera's main lens. The Lytro multi-focus dataset includes 20 groups of color multi-focus images and four sets of multi-source focus images. The image resolution is and the image format is jpg. The Savic dataset is collected by Nikon D5000 camera and contains 27 pairs of images. In Savic dataset, 21 pairs of images with format jpg are taken indoors, and 6 pairs of images with format bmp are used for MIF algorithm testing. In Aymaz dataset, the 150 multi-focus images are obtained by using the Gaussian blur function to locally blur some common image datasets. This dataset also contains some multiple source images of the same scene with different focal points. In addition to color multi-focus datasets, there are also some grayscale multi-focus datasets, and some images in grayscale multi-focus datasets.
The above-mentioned datasets can well reflect the performance of the fusion algorithms to some extent. However, these datasets can hardly reflect the application of MIF techniques in real environment. At present, the most commonly used camera device in daily life is the smartphone. With the continuous development of the imaging technology, the smartphone photography is more and more recognized by people. Therefore, it is necessary to try to construct a real-environment dataset by using different smartphones. In order to better build the database and collect images of the real environment more widely, we selected five mobile phones that were among the top ten in sales nationwide at that time for data collection such as HUAWEI Mate 30, OPPO Reno Z, Honor30 Pro+, Honor V30 Pro and iPhone XR to collect the multi-focus images in HBU-CVMDSP dataset. There are some unavoidable problems in collecting images with mobile phones, such as jitter, not completely overlapped and brightness. To address these issues, the proposed dataset is pre-processed after acquisition with image cropping, standardization of basic image attributes and image alignment. The contributions of this paper are as follows: In this paper, we construct a real-environment dataset named as HBU-CVMDSP, which includes 66 groups of multi-focus images. we give the detail of how to pre-process the raw data of the real-environment dataset, and the experiments prove that it is effectively for testing the fusion algorithms. We also test the performance of some existing image fusion algorithms on the HBU-CVMDSP dataset.
Collection and construction of the dataset
Due to the variability of image effects from different smartphones, five different models of smartphones shown in Table 1 are used for image collection in this paper.

Table 1. Acquisition equipment.
In this paper, the constructed real-environment multi-focus image dataset is named as HBU-CVMDSP. There are two kinds of sceneries i.e., natural scenery and artificial scenery in HBU-CVMDSP dataset, and these sceneries are selected from the laboratory, campus, gymnasium, and shopping mall, respectively. The HBU-CVMDSP dataset contains 66 groups of multi-focus images with jpg format. The image size is uniformly cropped to 512 × 512 to ensure the efficient execution of the experiment. Figure 1 shows some images in HBU-CVMDSP dataset.

Figure 1. Some images selected from the HBU-CVMDSP dataset. (A1–F1) are the foreground focused image in a group of multi focus images. (A2–F2) are the background focused image in a group of multi focus images.
Image preprocessing
In order to solve these unavoidable problems when capturing images with mobile phones, the proposed dataset is preprocessed by image clipping, standardization of basic image attributes and image registration after acquisition, such as Figure 2.

Figure 2. Schematic diagram of Image preprocessing.
To further illustrate the necessity of image preprocessing, before the dataset is preprocessed, we use dense scale-invariant feature transform (DSIFT) (Liu et al., 2015) and CNN (Liu et al., 2017) based image fusion algorithms to examine the dataset. The partial fusion results of the DSIFT and CNN can be found in https://www.researchgate.net/publication/359468841.
It can be seen from the above results that the fusion effects are not visually satisfactory. The ghosting at the image edges is mainly due to the misregistration of the images in the dataset, while the blocking and distortion in the images are due to the inconsistency of the brightness between the two source images in the dataset. Therefore, we conduct image cropping, standardization of basic attributes and registration processing on the dataset to ameliorate the quality of the fused images. If the mobile phone device shoots scenes with different focus areas, the obtained image field of view will be different. When the image background information is clear, the field of view is wider, and when the image near field information is clear, the view is narrower. Therefore, if two images with different focal points have the same size, the field of view of the two images will be different, and the ghosting will appear during the fusion process. In addition, the slight jitter when taking pictures will also lead to a slight gap in the field of view of two images. The images in HBU-CVMDSP dataset are cropped using the nearest neighbor interpolation algorithm. The details be found in https://www.researchgate.net/publication/359468841.
When smartphones collect a foreground and background focused image, due to the different depth of field, the attributes such as brightness and contrast of the image will be different. A group of images with different attributes will affect the matching of feature points in the image registration process, and the fusion image will appear block effect, resulting in unsatisfactory fusion result. In this paper, we standardize the basic attributes of color images using the SHINE_color toolbox (Willenbockel et al., 2010). When standardizing the basic attributes of images, we designate one image in the image group as the source image and the other image as the target image. Firstly, the source image and target image are transformed from RGB space to HSV space. Then the chroma, saturation and luminance are separated, the standardization of the basic attributes of the images is accomplished by adjusting the luminance channel of the source image and the target image to be equal in spatial frequency and direction. In this paper, the SIFT algorithm is used for image registration.
Experimental results and analysis
Experiment and analysis
In this experiment, we use the following nine metrics to quantitatively evaluate the performance of the image fusion algorithms: (1) Normalized mutual information (NMI), which can effectively improve the stability of the MI (Liu et al., 2020). (2) Nonlinear correlation information entropy (NCIE), which is a metric used to evaluate the quality of the fusion image (Su et al., 2022). (3) Gradient-based evaluation metric QG (Liu et al., 2020), which is used to evaluate the gradient information of the source image retained in the fused image. (4) Phase consistency based evaluation metric was proposed in Liu et al. (2020). (5) Structural similarity based evaluation metric QS, which is an image quality evaluation metric based on the universal quality index (Liu et al., 2020). (6) Structural similarity based evaluation metric QY (Liu et al., 2020). (7) Human perception based evaluation metric QCB, which can be used to evaluate the contrast information between images (Liu et al., 2020). (8) Human perception based evaluation metric QCV, which is an image fusion evaluation metric based on human visual perception (Liu et al., 2020). (9) Tsallis entropy is a generalization of Shannon entropy, which can be used to evaluate the retentive information between the source image and the fusion image. For QMI, QNCIE, QG, QP, QS, QY, QCB, and QTE, the higher the value of them is, the better the fusion result will be. And for the QCV, the smaller the value is, the better the fusion result will be.
Ablation experiment
To validate the importance of the pre-processing of the dataset, we use DSIFT and CNN fusion algorithms to conduct the fusion experiments on the dataset before and after image registration, and compare the subjective and objective fusion results of the two fusion algorithms. The experiments are completed by a PC with Intel core i5-10500, 3.10 GHz CPU, 8GB RAM memory, and NVIDIA GeForce GTX 1660 SUPER GPU. Due to space limitation, we only give the experimental results of the DSIFT algorithm. The experimental results of the CNN algorithm are shown in https://www.researchgate.net/publication/359468841.
The fusion results of the DSIFT algorithm are shown in Figure 3. The first row and second row in Figure 3 are the fusion results corresponding to the dataset before image registration and the dataset after image registration, respectively. Obviously, after image registration, the visual effects of the fused images in the second row have been significantly improved.

Figure 3. The fusion results before and after image registration. (A1–D1) are the fused images for the multi focus image pair without registration processing. (A2–D2) are the fused images by registration images.
In addition, we calculate the values of QMI, QTE, QNCIE, QG, QP, QS, QY, QCV, and QCB of the fused images obtained by DSIFT algorithm on the dataset before and after image registration, respectively. The values of the nine metrics are shown in Table 2, respectively, from which one can find that in addition to the decrease of the QCV value, the QMI, QTE, QNCIE, QG, QP, QS, QY, and QCB values of the fused images obtained by the DSIFT on the dataset after image registration are all increased. Therefore, conducting the image registration process on the dataset can effectively improve the performance of the fusion algorithms both in subjective vision and objective evaluation.
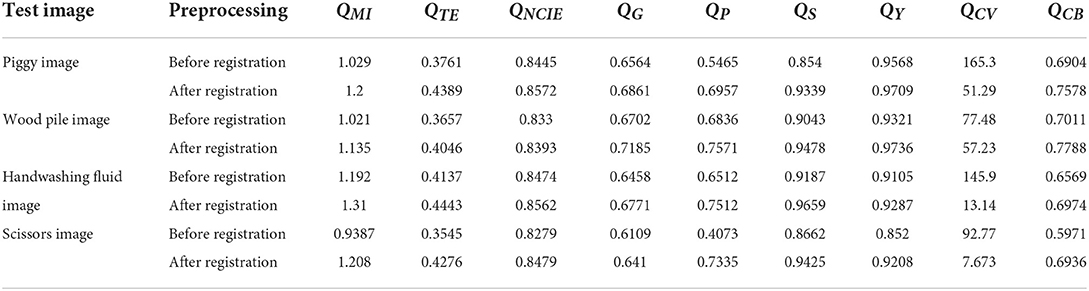
Table 2. The nine metrics' values of the fused images before and after image registration.
The fusion results of the DSIFT algorithm on the dataset before and after standardizing the basic attributes of images are shown in the first row and second row of the Figure 4, respectively. After the standardization of the image basic attribute, the visual effects of the fused images shown in the second row of the Figure 4 have been significantly improved.

Figure 4. The fusion results before and after standardization of the image basic attribute. (A1–C1) are the fused images for the multi focus image pair without image basic attribute standardization processing. (A2–C2) are the fused images by image basic attribute standardization processing.
Furthermore, we also calculate the values of QMI, QTE, QNCIE, QG, QP, QS, QY, QCV, and QCB of the fused images obtained by DSIFT algorithm on the dataset before and after standardization of the image basic attribute. The calculated results of the nine metrics are shown in Table 3, respectively. From which one can find that in addition to the decrease of the value, the values of QMI, QTE, QNCIE, QG, QP, QS, QY, and QCB of the fused images obtained by the DSIFT algorithm on the dataset after the standardization of the image basic attribute are all increased. Therefore, after the dataset is standardized by the image basic attribute, both the subjective vision and the objective evaluation are all improved.
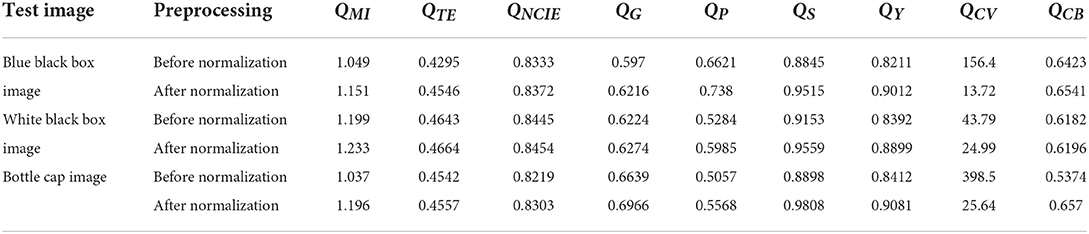
Table 3. The nine metrics' values of the fused images before and after standardization of the image basic attribute.
Test of existing image fusion algorithms
In this subsection, we test the performance of some existing image fusion algorithms on the HBU-CVMDSP dataset. The multi-focus image fusion algorithms used in the test include multi-scale guided filtering algorithm (MGF) (Bavirisetti et al., 2019), dense scale-invariant feature transformation algorithm (DSIFT) (Liu et al., 2015), a general image fusion algorithm based on convolutional neural network (IFCNN) (Zhang et al., 2020), MIF algorithm based on convolutional neural network (CNN) (Liu et al., 2017), and unsupervised depth model for MIF (SESF) (Ma et al., 2020). We select six pairs of images from the HBU-CVMDSP dataset to test the above algorithms, and the selected images are shown in Figure 1. Figure 5 shows the fusion results of different algorithms on the selected images. In order to better show the visual effects of different fusion algorithms, the image of the red rectangular area in the figure is enlarged in this paper. From the Figure 5, it can be found that the fused image obtained all the fusion methods are all kinds of problems, such as block effect, unfocused pixels on the edge, blurred edges, the detailed information lost, the boundary too smooth, artificial artifacts, misclassification of focused pixels, distorted, and poor spatial consistency.

Figure 5. Fusion results of different algorithms. (A–F) are the fusion results of MGF, DSIFT, IFCNN, CNN, and SESF, respectively.
The nine metrics' values of the fused images in Figure 5 are shown in Table 4, in which the best result of each group of fused images is bolded. As can be seen from the Table 4, in the objective evaluation of the fusion results of MGF, DSIFT, IFCNN, CNN and SESF in the real environment, no fusion algorithm has competitive performance compared with other comparison algorithms, which indicates that the multi focus image dataset in the real environment can reflect that the existing fusion algorithms cannot meet the application of MIF technology in the real environment. In addition, due to the limited generalization ability, these existing fusion algorithms all transfer specific prior knowledge to the model, and then perform image fusion. However, images in the real world are very complex, and cannot be achieved only through the prior knowledge of inherent images. Therefore, the HBU-CVMDSP dataset can be used as a new test set to promote the development of the field of MIF and narrow the gap between the theoretical and real environmental data of image fusion algorithms.
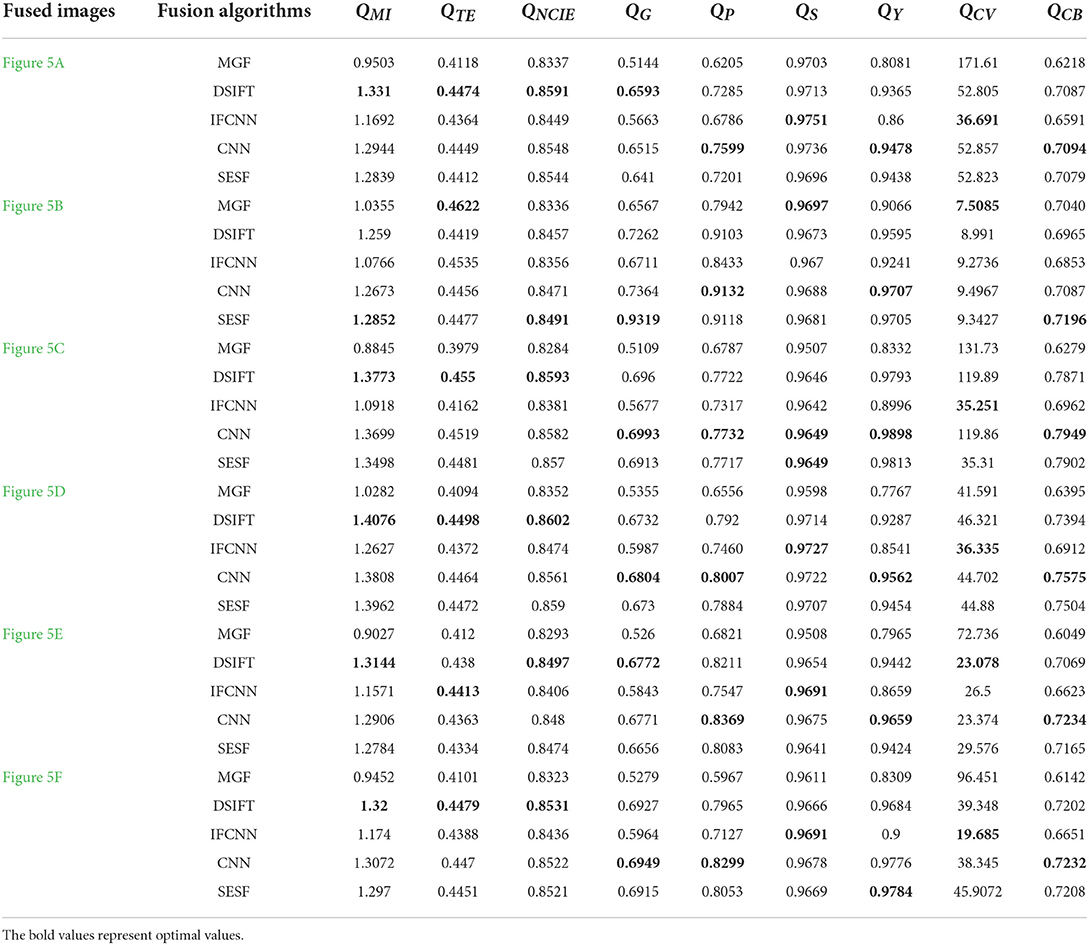
Table 4. The nine metrics' values of the fused images obtained by different fusion algorithms.
Conclusion
Due to the existing MIF datasets cannot reflect the image registration caused by physical movement or camera shake, and the brightness differences caused by illumination in real life, we proposed a new MIF dataset i.e., the HBU-CVMDSP dataset. Images in this dataset are captured by smartphone, and can truly reflect the real-world scene. In addition, we test the performance of some existing fusion algorithms on the proposed dataset. The results indicate that the performance of these algorithms on the proposed dataset has much room for improvement. Therefore, the HBU-CVMDSP dataset can better promote the research of the MIF algorithms.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://www.researchgate.net/publication/359468841.
Author contributions
WP and YY performed the computer simulations. SL, WJ, and JZ analyzed the data. SL, WP, and YY wrote the original draft. WJ, YS, and JZ revised and edited the manuscript. YS polished the manuscript. All authors confirmed the submitted version.
Funding
This work was supported in part by National Natural Science Foundation of China under Grant No. 62172139, Natural Science Foundation of Hebei Province under Grant No. F2022201055, Project Funded by China Postdoctoral under Grant No. 2022M713361, Science Research Project of Hebei Province under Grant No. BJ2020030, Natural Science Interdisciplinary Research Program of Hebei University under Grant No. DXK202102, Open Project Program of the National Laboratory of Pattern Recognition (NLPR) under Grant No. 202200007, Foundation of President of Hebei University under Grant No. XZJJ201909, Research Project of Hebei University Intelligent Financial Application Technology R&D Center under Grant No. XGZJ2022022, and Open Foundation of Guangdong Key Laboratory of Digital Signal and Image Processing Technology under Grant No. 2020GDDSIPL-04.
Acknowledgments
Thanks for supporting by the High-Performance Computing Center of Hebei University.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Bavirisetti, D. P., Xiao, G., Zhao, J., Dhuli, R., and Liu, G. (2019). Multi-scale Guided image and video fusion: a fast and efficient approach. Circ. Syst. Signal Proc. 38, 5576–5605. doi: 10.1007/s00034-019-01131-z
Bouzos, O., Andreadis, I., and Mitianoudis, N. (2019). Conditional random field model for robust multi-focus image fusion. IEEE Trans. Image Proc. 28, 5636–5648. doi: 10.1109/TIP.2019.2922097
Liu, S., Ma, J., Yang, Y., Qiu, T., Li, H., Hu, S., et al. (2022). A multi-focus color image fusion algorithm based on low vision image reconstruction and focused feature extraction. Signal Proc. Image Commun. 100, 116533. doi: 10.1016/j.image.2021.116533
Liu, S., Ma, J., Yin, L., Li, H., Cong, S., Ma, X., et al. (2020). Multi-focus color image fusion algorithm based on super-resolution reconstruction and focused area detection. IEEE Access 8, 90760–90778. doi: 10.1109/ACCESS.2020.2993404
Liu, S., Miao, S., and Su, J. (2021). UMAG-Net: A new unsupervised multiattention-guided network for hyperspectral and multispectral image fusion. IEEE J. Select. Top. Appl. Earth Observat. Remote Sens. 14, 7373–7385. doi: 10.1109/JSTARS.2021.3097178
Liu, S., Wang, J., Lu, Y., Li, H., Zhao, J., and Zhu, Z. (2019). Multi-focus image fusion based on adaptive dual-channel spiking cortical model in non-subsampled shearlet domain. IEEE Access 7, 56367–56388. doi: 10.1109/ACCESS.2019.2900376
Liu, Y., Chen, X., Peng, H., and Wang, Z. (2017). Multi-focus image fusion with a deep convolutional neural network. Informat. Fusion 36, 191–207. doi: 10.1016/j.inffus.2016.12.001
Liu, Y., Liu, S., and Wang, Z. (2015). Multi-focus image fusion with dense SIFT. Inf. Fusion 23, 139–155. doi: 10.1016/j.inffus.2014.05.004
Ma, B., Zhu, Y., Yin, X., Ban, X., Huang, H., and Mukeshimana, M. (2020). SESF-Fuse: an unsupervised deep model for multi-focus image fusion. Neural Comput. Appl. 33, 5793–5804. doi: 10.1007/s00521-020-05358-9
Nejati, M., Samavi, S., and Shirani, S. (2015). Multi-focus image fusion using dictionary-based sparse representation. Inf. Fusion 25, 72–84. doi: 10.1016/j.inffus.2014.10.004
Su, X., Li, J., and Hua, Z. (2022). Transformer-based regression network for pansharpening remote sensing images. IEEE Trans. Geosci. Remote Sens. 60, 5407423. doi: 10.1109/TGRS.2022.3152425
Willenbockel, V., Sadr, J., Fiset, D., Horne, G. O., Gosselin, F., and Tanaka, J. W. (2010). Controlling low-level image properties: the SHINE toolbox. Behav. Res. Methods 42, 671–684. doi: 10.3758/BRM.42.3.671
Xiao, B., Ou, G., Tang, H., Bi, X., and Li, W. (2020). Multi-focus image fusion by hessian matrix based decomposition. IEEE Trans. Multimedia 22, 285–297. doi: 10.1109/TMM.2019.2928516
Zhang, Y., Liu, Y., Sun, P., Yan, H., Zhao, X., and Zhang, L. (2020). IFCNN: a general image fusion framework based on convolutional neural network. Inf. Fusion 54, 99–118. doi: 10.1016/j.inffus.2019.07.011
Zheng, M., Qi, G., Zhu, Z., Li, Y., Wei, H., and Liu, Y. (2020). Image dehazing by an artificial image fusion method based on adaptive structure decomposition. IEEE Sens. J. 20, 8062–8072. doi: 10.1109/JSEN.2020.2981719
Keywords: image fusion, multi-focus image fusion dataset, image preprocessing, multi-focus image fusion algorithm test, real environment
Citation: Liu S, Peng W, Jiang W, Yang Y, Zhao J and Su Y (2022) Multi-focus image fusion dataset and algorithm test in real environment. Front. Neurorobot. 16:1024742. doi: 10.3389/fnbot.2022.1024742
Received: 22 August 2022; Accepted: 09 September 2022;
Published: 18 October 2022.
Edited by:
Xin Jin, Yunnan University, ChinaReviewed by:
JInjiang Li, Shandong Institute of Business and Technology, ChinaZhiqin Zhu, Chongqing University of Posts and Telecommunications, China
Copyright © 2022 Liu, Peng, Jiang, Yang, Zhao and Su. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yonggang Su, eWdzdTA3MjZAMTYzLmNvbQ==