
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neurorobot. , 22 October 2020
Volume 14 - 2020 | https://doi.org/10.3389/fnbot.2020.00047
This article is part of the Research Topic Neurorobotics and Strategies for Adaptive Human-machine Interaction View all 9 articles
 Dongfang Xu1,2
Dongfang Xu1,2 Qining Wang1,2,3*
Qining Wang1,2,3*The paper puts forward an on-board strategy for a training model and develops a real-time human locomotion mode recognition study based on a trained model utilizing two inertial measurement units (IMUs) of robotic transtibial prosthesis. Three transtibial amputees were recruited as subjects in this study to finish five locomotion modes (level ground walking, stair ascending, stair descending, ramp ascending, and ramp descending) with robotic prostheses. An interaction interface was designed to collect sensors' data and instruct to train model and recognition. In this study, the analysis of variance ratio (no more than 0.05) reflects the good repeatability of gait. The on-board training time for SVM (Support Vector Machines), QDA (Quadratic Discriminant Analysis), and LDA (Linear discriminant analysis) are 89, 25, and 10 s based on a 10,000 × 80 training data set, respectively. It costs about 13.4, 5.36, and 0.067 ms for SVM, QDA, and LDA for each recognition process. Taking the recognition accuracy of some previous studies and time consumption into consideration, we choose QDA for real-time recognition study. The real-time recognition accuracies are 97.19 ± 0.36% based on QDA, and we can achieve more than 95% recognition accuracy for each locomotion mode. The receiver operating characteristic also shows the good quality of QDA classifiers. This study provides a preliminary interaction design for human–machine prosthetics in future clinical application. This study just adopts two IMUs not multi-type sensors fusion to improve the integration and wearing convenience, and it maintains comparable recognition accuracy with multi-type sensors fusion at the same time.
Robotic prosthetics plays an important role in assisting with the daily walking of lower-limb amputees. It can restore the functions of missed limb(s) and help to improve an amputee's balance and reduce the walking metabolic by adopting different control strategies (Au et al., 2009; Shultz et al., 2016; Feng and Wang, 2017; Kim and Collins, 2017). As the control strategies of robotic prosthetics depend on different locomotion modes or terrains, it is important to know the human locomotion mode accurately and efficiently. The question as to how we can acquire a locomotion mode has attracted a lot of attention over these years (Yuan et al., 2015; Zheng and Wang, 2016; Liu et al., 2017; Godiyal et al., 2018).
For lower-limb locomotion mode recognition, a surface electromyogram (sEMG) can record electrical potential generated by muscle cells and can be used to detect human locomotion intents, and this area has attracted plenty of attention and spurred much progress (Kim et al., 2013; Hargrove et al., 2015; Joshi et al., 2015; Afzal et al., 2016; Gupta and Agarwal, 2018). A mechanical sensor is also widely used in locomotion mode recognition. For example, the Inertial Measurement Unit (IMU) can provide position information (Ahmad et al., 2013; Young et al., 2014b; Bartlett and Goldfarb, 2018; Martinez-Hernandez and Dehghani-Sanij, 2018). Besides, a mechanical sensor is easily integrated with prosthetics. In addition, a capacitive sensing method has been applied in human locomotion mode recognition since it can measure muscle contraction and relaxation information directly (Zheng et al., 2014, 2017). Recently, some studies tend to fuse different sensor signals together to recognize locomotion intents and realize control (Novak and Riener, 2015) [e.g., sEMG signals and mechanical signals (Young et al., 2014a; Joshi and Hahn, 2016), mechanical signals and capacitive signals (Zheng and Wang, 2016), etc.].
Based on the sensing methods, studies about online locomotion mode recognition have been conducted (Elhoushi et al., 2017). Huang's research group has developed the locomotion modes recognition with four amputees wearing a hydraulic passive knee by fusing sEMG and mechanical signals, they and achieved 95% accuracy for recognizing seven tasks in real time (on Matlab) based on off-line model training (Zhang and Huang, 2013). Furthermore, they tried on-line recognition (on Matlab) based on sEMG and mechanical sensors with powered prosthetics (Zhang et al., 2015). Hargrove et al. have also developed on-line recognition by fusing sEMG and mechanical sensors (Spanias et al., 2016, 2018). We have also developed real-time on-board recognition of continuous locomotion modes for amputees with robotic transtibial prostheses and got more than 93% recognition accuracy with just two IMUs (Xu et al., 2018).
Though much progress has been made in on-line locomotion mode recognition, there still exist some problems to be solved. As is known, real-time recognition based on the off-line trained models is meaningful for the on-line control; however, off-line training brings a series of disadvantages for real-time recognition. Off-line training means bringing in other devices (e.g., a computer) to train the model, which is not convenient in integration with robotic prosthetics (Zhang et al., 2015; Xu et al., 2018). To improve the problem, Spanias et al. (2018) conducted a model updated on an embedded micro-controller based on mechanical sensor and sEMG. However, the multi-type sensors fusion method may bring wearing difficulty for amputees and integration difficulty for the prosthesis.
In this study, we put forward an on-board training model strategy for real-time recognition based on the robotic transtibial prosthesis using IMUs (IMUs are easily integrated with prosthesis) and develop a study of human locomotion mode recognition. This study is designed to recognize five locomotion modes [Level Ground walking (LG), Stair Ascending (SA), Stair Descending (SD), Ramp Ascending (RA), and Ramp Descending (RD)] based on the on-board trained model. A human–machine (prosthesis) interaction interface is designed to instruct to train model and recognize locomotion modes. The repeatability of gait signals, on-board training time, and recognition time are used to evaluate the performances based on different algorithms [Support Vector Machine (SVM), Quadratic Discriminant Analysis (QDA), and Linear Discriminant Analysis (LDA)]. Real-time recognition was conducted based on QDA.
A commercialized version robotic prosthesis was used in this study (produced by SpeedSmart, a spin-off company of Peking University), as shown in Figure 1. The prosthesis model and other details can be seen in our previous studies (Wang et al., 2015; Feng and Wang, 2017). The prosthesis was comprised of one full bridge of strain gauge, one angle sensor, and two IMUs. One full bridge of strain gauge could reflect the deformation of the carbon-fiber foot, and the stance phase and swing phase could be detected based on the deformation information. Control strategies were performed based on the detected gait phases (Wang et al., 2015; Feng and Wang, 2017). One angle sensor was placed at the ankle of prosthesis to measure ankle's rotation with a 0–360° measurement range and a 12-bit resolution. Two IMUs were integrated on the prosthetic shank and foot. Each IMU included a triple-axis gyroscope (a measurement range of 0–2,000° with a resolution of 0.06°/s), a triple-axis accelerometer (a measurement range of 0–157 m/s2 with a resolution of 0.005 m/s2), and a triple-axis MEMS magnetometer (a measurement range of −4,800–4,800 μT with a resolution of 0.6 μT/LSB). IMU could provide the inclination angles (yaw, pitch, and roll), tri-axis acceleration, and tri-axis angular velocity information.
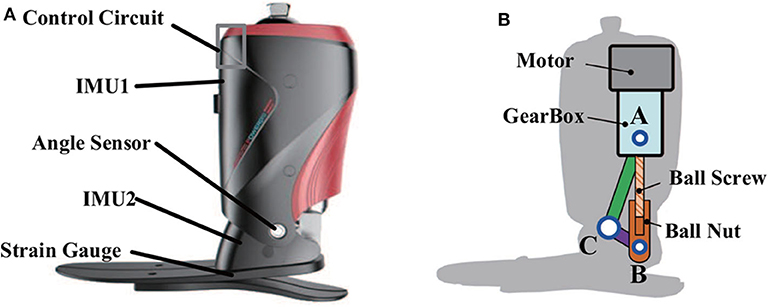
Figure 1. (A) The robotic transtibial prosthesis. (B) The three-bar ankle model: three bars (AB, BC, and AC) and three hinges (A, B, and C).
The control circuit of prosthesis consisted of a Micro Controller Unit (MCU) and an Application Processor Unit (APU), as shown in Figure 2. The MCU was based on a 216 MHz Cortex-M7 processer. The APU was constructed with an integrated programmable SoC chip, which consisted of two parts: a 667 MHz Cortex-A9 MPCore-based processing system (PS) and an FPGA-based programmable logic (PL) circuits. The MCU was used to collect and synchronize the prosthesis sensors signals, and it then packed them to the APU via Universal Asynchronous Receiver/Transmitter (UART). In addition, the MCU would send program instructions to the other prosthetic units. The APU was designed to execute on-board training and real-time recognition. APU would receive sensor data transmitted from the MCU by UART, and a micro SD card would be used to store data and trained model. The recognition results were packed together with sensor signals and then transmitted to a computer for further analysis in a wireless way.
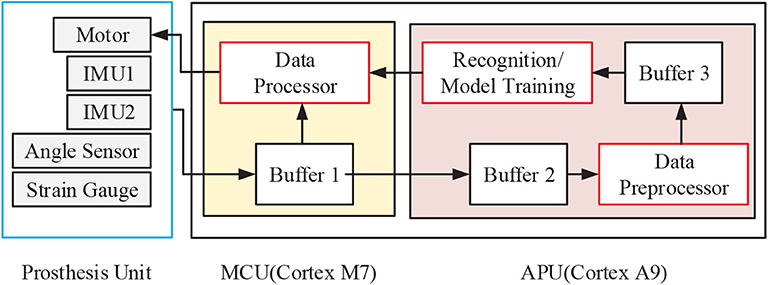
Figure 2. The control circuit of robotic transtibial prosthesis.
In this study, three transtibial amputees (Mean ± Standard Deviation, age: 45 ± 11.4 years, height: 170.3 ± 0.5 cm, and weight: 77 ± 5 kg) were recruited as subjects to finish the designed experimental tasks (S1, S2, and S3 represented the number of subjects). All subjects provided written informed consent forms. The experiments were approved by the Local Ethics Committee of Peking University.
In the experiments, each subject lived with a prosthetic socket that would be mounted on the designed robotic prosthesis by adapter. To gain familiarity with and adapt to the new prosthesis and subsequent experimental tasks, all subjects would do some walking exercises before the experiments. The control parameters were adjusted according to the feedback of each subject ahead of the experiment.
In this study, we first designed a preliminary interaction interface for the experiments as shown in Figure 3A. The interaction interface could send instructions to the prosthesis, and the prosthesis would return results to the interaction interface in a wireless way. The interaction interface included five parts. (1) The wireless connection with prosthesis to communicate with prosthesis. (2) Choosing signal channel(s) to plot signal curve(s). (3) Recording and saving raw data locally. (4) Signal display corresponding to the chosen channel in (2). (5) The interactive operation for experimenter. Figure 3B is a diagram of one amputee wearing a robotic prosthesis in the experiment.
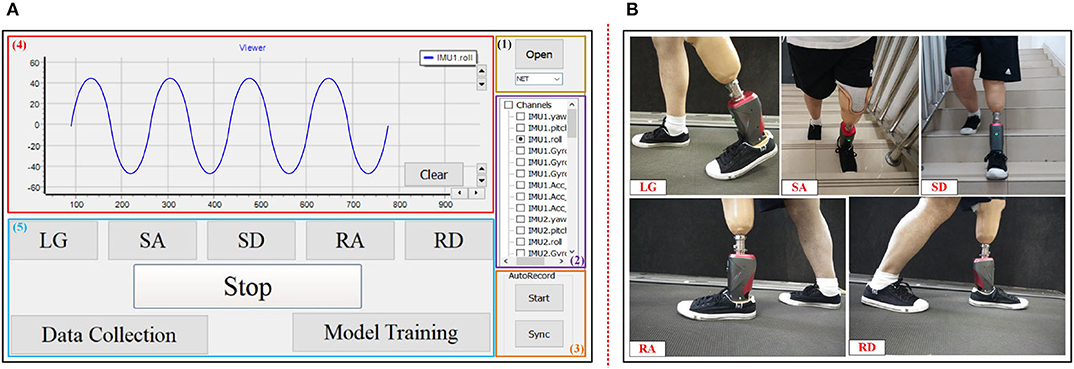
Figure 3. The designed interaction platform and experimental task of the study. (A) The designed interaction interface for the study. (1) Wireless connection option with prosthesis. (2) Signal channel. (3) Raw data recording. (4) Signal display. (5) Interactive operation for experimenter. (B) Subject wears the robotic prosthesis to finish five locomotion modes: LG, SA, SD, RA, and RD.
The experiment could be divided into two sessions: (1) an on-board training session and (2) a real-time recognition session. The experimental duration was about 2 h for each subject. In the on-board training session, each subject was instructed to accomplish the five modes, including the LG, RA, RD, SA, and SD in sequence. All subjects were asked to walk on the treadmill at their self-selected speeds for collecting data on the LG mode. For the RA and RD, the subjects would walk on the treadmill at an incline of 10° at their self-selected speeds. The subjects accomplished SA and SD on the stairs with a height of 16 cm and a length of 28 cm at their normal walking speeds. For each locomotion mode, 20 s of data were collected in the training session for training model. The real-time recognition experiment in session (2) was conducted based on the trained model in session (1).
In the experiment, we could perform data collection for training models with corresponding modes (i.e., label) by use of the interaction operation. When the experiment started, the subject would walk in a steady locomotion mode (for example LG), and we clicked the corresponding mode (corresponding to “LG”) and then clicked “Data Collection” in (5) of Figure 3A to collect sensor signals with labels as training data. After finishing data collection, we clicked the “Stop” option and finished training data collection. Then “Model Training” was clicked to send instructions to the on-board system (i.e., control circuit) of the prosthesis to start on-board training of the model. The real-time recognition would start as soon as the on-board training was finished. During real-time recognition, the recognition tasks were the same as the training tasks, namely, finishing the five locomotion modes: LG, SA, SD, RA, and RD.
Signal processing is important to the on-board training and recognition. The main procedures of on-board training and recognition could be seen in Figure 4. For both training and recognition, raw signals needed to be processed to extract features. Feature extracting was performed based on raw signal data by sliding window. For on-board training, feature vectors and labels formed a training data set and were then used for the training mode. After on-board training was finished, the continuous feature vectors were fed into the model for recognition one by one in time sequence. The feature extracting method and recognition algorithm could been seen as follows.
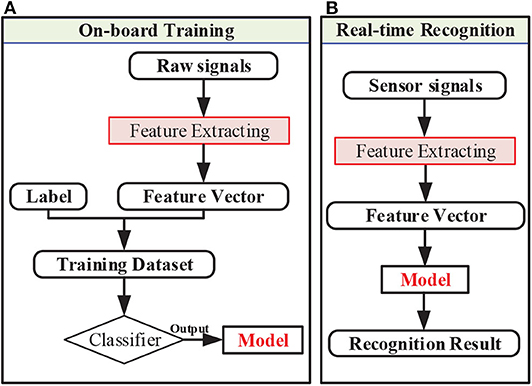
Figure 4. The procedures of signal processing for (A) on-board training and (B) real-time recognition.
Two IMUs were integrated in the robotic prosthetic shank and foot. IMU could provide the raw signals of nine channels as mentioned: inclination angles (yaw, pitch, and roll), tri-axis acceleration, and tri-axis angular velocity signals. The sample frequency was 100 Hz. The pitch and roll angle of IMU can be calculated according accelerometer, and the yaw angle can be calculated according the MEMS magnetometer and accelerometer, but it needs static calibration to remove the drift. We chose IMU information from eight channels (angles from two channels, triple-axis acceleration, and triple-axis angular velocity), excluding yaw angle information. A sliding window was selected to extract features of raw signals. Each window's length was 250 ms and the sliding increment was 10 ms (Zheng and Wang, 2016; Xu et al., 2018). Five time domain features were selected for this study. These features were f1 = mean(Y), f2 = std(Y), f3 = max(Y), f4 = min(Y), and f5 = sum(abs(diff(Y))), where Y was the data matrix of one sliding window, and the data sizes of one sliding window were 25 (250 ms' length) by 16 (16 channels in total). The mean(Y) and std(Y) were the average value and the standard deviation of each channel in Y, respectively. The max(Y) and min(Y) were the maximum and minimum of each channel in Y, respectively. The diff(Y) was the difference value of adjacent two elements of each channel in Y. The sum(Y) was the summation of each channel in Y. The abs(Y) was the absolute value. All these feature values were concatenated together to be a feature vector (we did not conduct a feature vector dimension reduction). Feature vectors with labels constituted a training data set, and the model was trained based on the training data set. For recognition, the raw IMU signals were also processed following the same processing procedures and one feature vector was generated each time. The continuous feature vectors were fed into the trained model and then we could get the recognition results.
Recognition algorithms directly affect the recognition accuracy. SVM, QDA, and LDA were widely used in locomotion mode recognition (Liu et al., 2017). In the previous study, we have compared the on-board recognition performances of different algorithms (SVM, QDA, and LDA) (Xu et al., 2018). SVM algorithm could achieve high recognition accuracy, LDA could achieve good recognition time performance, and QDA could take count of accuracy and recognition time performance (Xu et al., 2018). For multi-class (five locomotion modes in this study) recognition, a one vs. one strategy was adopted. Here we conducted this study based on the three algorithms.
The core of SVM is to construct an optimal hyperplane to separate the data belonging to different classes. The hyperplane equation is as follows:
where w is the weight vector, b is the constant item (bias), and x is the input vector (i.e., feature vector). To construct this hyperplane, we need to optimize the objective function, and the objective function is as follows:
where C is the penalty parameter (the default of C is 1) that represents penalty for misclassification, and its function is adjusting the confidence interval range. N is the number of training data samples, ξi is the relaxation factor corresponding to the ith training data sample (xi). yi (yi = 1 or −1) is the label corresponding to xi. Its discriminant function can be seen as follows (Vapnik and Hervonenkis, 1974):
where αi, xi, and b mainly construct the SVM model for the study, which need to be trained on board, and they denote coefficient, support vector, and constant terms, respectively. K(xi, x) is the kernel function of SVM. In our study, a radial basis function is chosen as the kernel function of SVM to realize on-board training and recognition. It is shown as follows:
where γ is a coefficient that determines the distribution of data mapped to a new feature space, and its function is adjusting the effect of each sample on the classification hyperplane [γ = 1/n (default), where n is the feature vector's dimension, n = 80].
QDA and LDA are based on normal distribution hypothesis (Friedman, 1989). It is assumed that the feature vectors are multivariate normally distributed with estimated specific mean vector μ, and covariance matrix Σ of each class data for QDA. In this study, the number of class (locomotion modes) is five. For the QDA algorithm, its discriminant function is
Here, W, w, and w0 construct the QDA model, and they are the functions of the estimated specific mean vector and covariance matrix of each class, which could be denoted as
Here, Σi, μi, Σj, and μj are the estimated specific mean vector and covariance matrix corresponding to class i and class j, respectively. |Σi| and |Σj| are the determinants of Σi and Σj. In the study, all these parameters are estimated on board to construct QDA model.
For LDA, it is assumed that the feature vectors are multivariate, normally distributed with an estimated mean vector of each class data and common covariance matrices (Σ1 = Σ2 = …= Σ) for LDA (Friedman, 1989). Σ can be denoted as
where C is the number of classes, Ni is the number of feature vectors of class i, and N is the number of total feature vectors (N = N1 + N2 + … + Ni + NC). The discriminant function of LDA can be denoted as
Here, w and w0 could be denoted as
The LDA model is constructed of w and w0 without W compared with QDA and it is a linear function of x, which is trained on board with a lower computation amount than QDA model in the study.
In this study, the repeatability of gait signals was analyzed. The time performance, recognition accuracy, and classifier quality were also evaluated.
The movement of the lower limb is periodical or quasi-periodical. The repeatability of signals can reflect the repeatability of gait waveforms over gait cycles (Godiyal et al., 2018). The variance ratio (VR) is a widely used metric to analyze the repeatability of signals (Erni and Colombo, 1998; Hwang et al., 2003; Godiyal et al., 2018). VR is expressed as follows (Hershler and Milner, 1978):
where N denotes the number of gait cycles. For each gait cycle, signals is normalized by interpolation and has a fixed length, namely, n (n is 1,000 in the study). Xij is the ith shank angle signal value in jth gait cycle. is the mean of signals at ith data point over N gait cycles, and is the mean of over the gait cycle. and are formulated as
VR can measure the degree of dispersion of data, and it varies from 0 to 1. When VR is close to 0 in the study, it means high repeatability of the IMU signals, which reflects the repeatability of gait.
The training process started as the experimenter pressed the “Model training” button (as shown in Figure 3A) and ended with model saving. The training time consisted of model generating and saving time. After the training process ended and the model was generated and saved, the real-time recognition started to run based on the trained model. Recognition was continuous and multiple based on various feature vectors streams. For each recognition, the recognition process was that one feature vector was fed into the trained model, and the recognition result was then outputted. The recognition decision consist of collections of the data, preparation of the feature vector, and the recognition process. The time to execute the recognition decision was recorded as recognition time.
Recognition accuracy was an important metric to evaluate the recognition performance. The recognition accuracy for each locomotion mode could be denoted as follows:
where nij was the number that test samples (belonging to mode i) were recognized as mode j, and ni was the number of the total test samples belonging to mode i. The confusion matrix (CM) was also used to evaluate the recognition performance for each mode in detail, which is shown as follows:
The m denotes the number of locomotion modes. The elementcij in confusion matrix CM is shown in Equation (16). The diagonal elements in CM denoted the recognition accuracy of each mode.
The receiver operating characteristic (ROC) could check the quality of classifiers and was used to evaluate the locomotion mode recognition in this study. For each class of a classifier, the ROC applies threshold values across the interval [0,1] to outputs. For each threshold, two values [the True Positive Ratio (TPR) and the False Positive Ratio (FPR)] were calculated. TPR is the predict/recognition accuracy for class i (i.e., locomotion mode i), and FPR is the number of samples whose actual class is not class i, but predicted to be class i, divided by the number of outputs whose predicted class is not class i. Then we can get a series of TPR and FPR pairs, which forms the ROC curve. The more each curve hugs the left and top edges of the plot, i.e., the bigger the area under the ROC curve (AUC) the better the classification.
The normalized shank angle of prosthesis relative to the perpendicular to the ground was shown in Figure 5. The solid line shows the mean, and the shaded area represents the standard deviation (SD) of the signal. The mean and standard deviation showed the quasi-periodicity of lower-limb movement. From Figure 5, it could be seen that each subject had their specific signal feature.
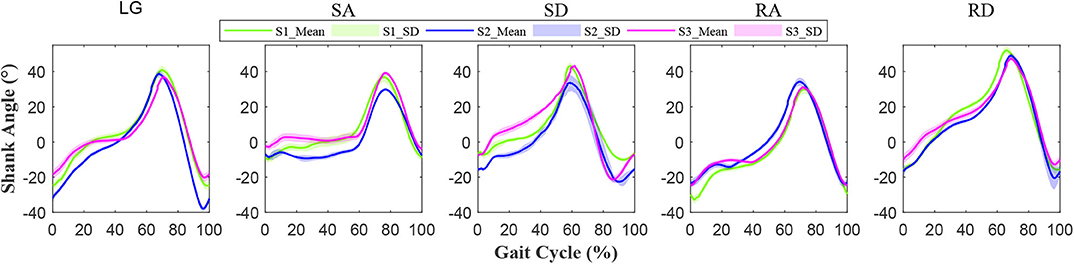
Figure 5. Normalized angle signals of the prosthetic shank. The horizontal axis represents the gait cycle. One gait cycle is from heel strike to toe off and ends at the next heel strike of the prosthesis. The vertical axis denotes the shank angle of prosthesis relative to the vertical direction. The solid line shows the mean and the shaded area represents the standard deviation (SD) of the signal. The different colors represent different subjects (S1, S2, and S3), as shown in the legend.
The repeatability of gait signals (waveforms) over gait cycles was analyzed based on variance ratio, as listed in Table 1. For LG and SA, the shaded area corresponding to S2 (in Figure 5) was smaller on the whole, and S2 could achieve smaller variance ratio values (0.006 and 0.01), as shown in Table 1, which indicated better repeatability than S1 and S3. For SD, RA, and RD, S2 could achieve bigger variance ratio values (0.051, 0.015, and 0.021), and its shaded area (in Figure 5) was bigger; S1 and S3 thus achieved better repeatability than S2.
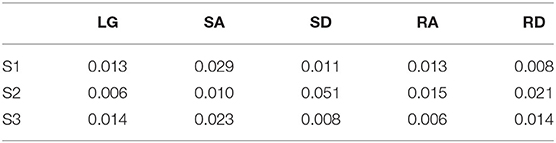
Table 1. The repeatability of gait signals (waveforms) of subjects based on variance ratio analysis.
The APU of prosthesis control circuit was designed to execute on-board training and real-time recognition. The on-board training and recognition times based on the APU are shown in Figure 6. On-board training time was related to the size of training data set. The acquisition of training data set was as follow. For each sampling, we could get one feature vector and each vector contained 80 values (two IMUs, eight channels of each IMU, and five feature values of each channel's signal, 2 × 8 × 5 = 80). In this study, we asked each subject to finish the five locomotion modes (LG, SA, SD, RA, and RD), and collected 2,000 feature vectors for each locomotion modes. After this, we could get 10,000 feature vectors corresponding five locomotion modes. The training data set consisted of a matrix and its size was 10,000 × 80. The training time consisted of model generating and saving time, which were 89, 25, and 10 s for SVM, QDA, and LDA, respectively, as shown in Figure 6A.
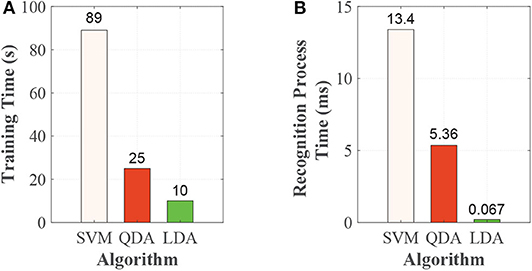
Figure 6. The time performances based on SVM, QDA, and LDA. (A) Training time and (B) Recognition process time.
The recognition decision was comprised of data collection, feature vector preparation, and the recognition process. It took <1 μs for data collection and 0.146 ms for preparation of feature vector each time. The data collection and preparation times of the feature vector were the same for SVM, QDA, and LDA. For recognition, when the each subject walked, we could get one feature vector for each sampling, and each feature vector contained 80 values. By feeding the feature vector streams into the trained model, we could get the continuous recognition results. The recognition process was from one feature vector fed into the model to output the result. The recognition process time were 13.4, 5.36, and 0.076 ms, corresponding to SVM, QDA, and LDA, respectively, as shown in Figure 6B.
The real-time recognition was conducted based on QDA and the off-line recognition was conducted based on LDA and SVM. Real-time recognition and off-line recognition are conducted using the same training data and test data. The total real-time recognition accuracies for the three subjects were 96.51, 97.33, and 97.73%, and the mean accuracy and SEM (standard error of mistake) was 97.19 ± 0.36% based on QDA, as shown in Table 2. The off-line recognition accuracies and SEMs (standard error of mistake) were 89.96 ± 0.48%, and 97.11 ± 0.93% based on LDA and SVM, as shown in Table 2, respectively.
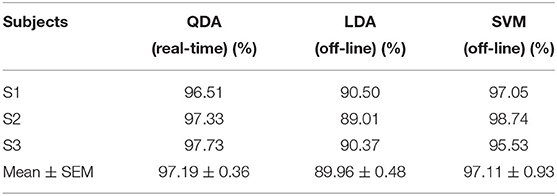
Table 2. Recognition accuracy (mean ± SEM) based on QDA, LDA, and SVM.
For each locomotion mode, it could be recognized with more than 92% accuracy for each subject, as shown in Figure 7. For S1 and S2, this study could achieve the highest recognition accuracies (99.78 and 99.71%, respectively) in RD and lowest recognition accuracies in SA (92.31%) and RA (95.27%). For S3, it could achieve the highest recognition accuracy in RA (99.94%) and the lowest recognition accuracy in RD (96.28%). There were some differences among the subjects for each locomotion mode.
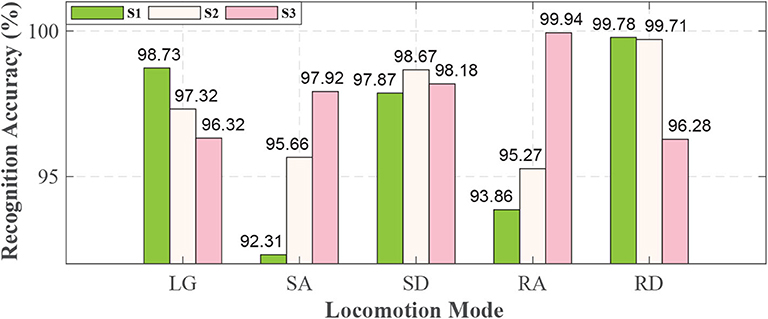
Figure 7. Real-time recognition result for each locomotion mode based on QDA algorithm. The height of the bar denotes the recognition accuracy. The different colors of bars denote subjects as the legend shows.
A confusion matrix (mean ± SEM) was used to evaluate the recognition performance for each locomotion mode, as listed in Table 3. In Table 3, we could see that each locomotion mode could be recognized with quite high accuracy, and the SEM is no more than 2%. The highest accuracy was achieved in recognizing RD (98.59 ± 1.16%), and the lowest was achieved in recognizing SA (95.30 ± 1.63%). From Table 3, we could see that LG was mistakenly recognized as RD (1.87 ± 0.57%), SA was mistakenly recognized as SD (3.64 ± 1.61%), SD was mistakenly recognized as RD (1.05 ± 0.54%), RA was mistakenly recognized as LG (2.64 ± 1.82%), and RD was mistakenly recognized as SD (1.34 ± 1.19%).
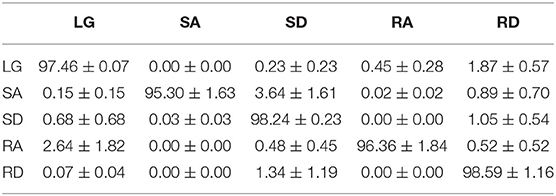
Table 3. Recognition confusion matrix (mean ± SEM) based on QDA (%).
The ROC curves can be seen in Figure 8. We could see that each curve hugs the left and top edges of the plot. The AUC for each subject and for the five locomotion modes (LG, SA, SD, RA, and RD) can be seen in Table 4. For S1, the AUCs for SA were 0.9865 and 0.9957, 0.9915, 0.9991, and 0.9996, for LG, SD, RA, and RD, respectively. For S2 and S2, the AUCs were more than 0.99 for each locomotion mode, as shown in Table 4. The maximum AUC was 0.9865 (S1, LG) and the maximum AUC was 1.0 (S3, RA).
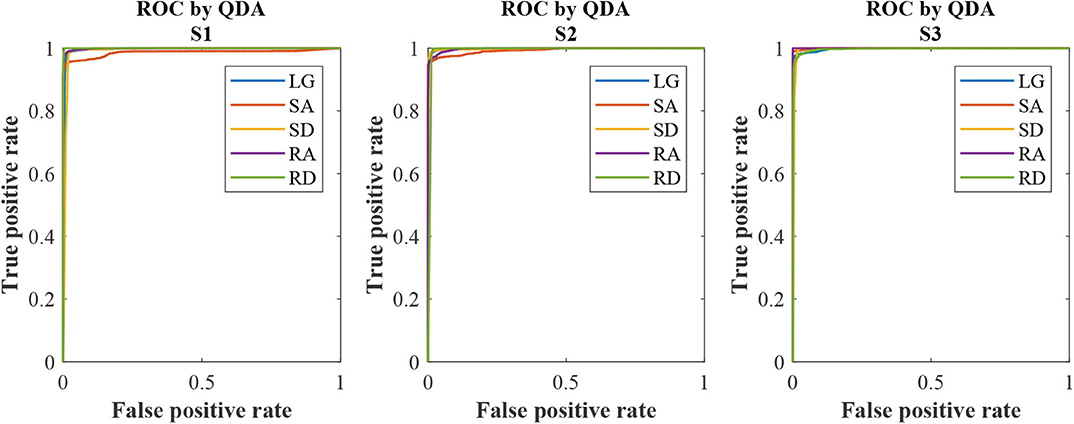
Figure 8. ROC curves for the subjects (S1, S2, and S3) based on QDA. The color of solid line denotes locomotion mode as the legend shows.
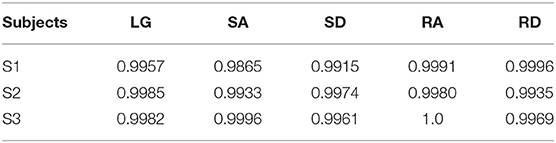
Table 4. The AUC for each locomotion mode and each subject based on QDA.
We conducted a robustness analysis of recognition, which was done by adding some white noise artificially to the data and running the experiments in off-line mode. The signal noise ratios were 100 : 0.1, 100 : 0.25, 100 : 0.5, 100 : 0.75, 100 : 1, and 100 : 1.25. To make comparisons, we conducted recognition analysis in the off-line mode, and the off-line results combined with real-time recognition accuracy can be seen in Figure 9. Real-time recognition based original signals without added noise was 97.18% (as mentioned above). The off-line recognition results with added noise were 97.06, 97.07, 96.96, 96.13, 88.74, and 70.83%, corresponding to different signal noise ratios (100 : 0.1, 100 : 0.25, 100 : 0.5, 100 : 0.75, 100 : 1, and 100 : 1.25, respectively). When the signal noise ratio was no <100 : 0.75, the recognition accuracy was more than 96.0%.
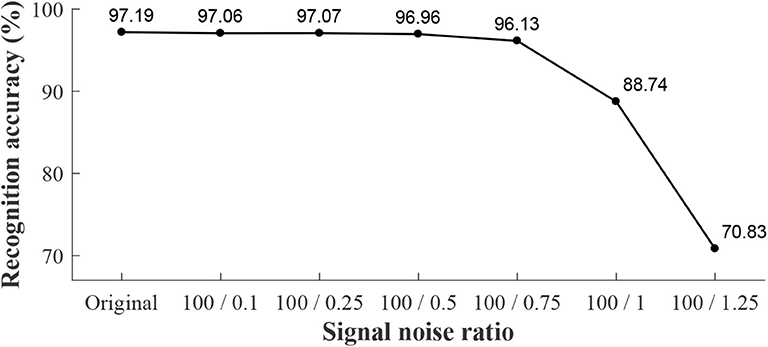
Figure 9. Robustness analysis (off-line) of recognition for locomotion modes. The horizontal axis denotes the signal noise ratio, which represents the noise added by manual into original data. Here, “Original” denotes the original data without added noise. The text in this figure denotes the recognition accuracy.
Most of the current locomotion modes recognition is based on off-line trained model. Off-line training will bring other devices (e.g., a computer) to the training model, which is not convenient to integrate with robotic prosthesis. In addition to the off-line problem, some multi-type sensors fusion method for improving locomotion mode accuracy may bring wearing and integration difficulties. In this paper, on-board training and real-time locomotion modes recognition has been conducted using two IMUs of robotic transtibial prostheses. We have design an interactive interface to execute the on-board training and recognition.
The repeatability of signals can reflect gait features, and it is affected by a lot of factors, such as sensor types, movement regularity of different subjects, and so on (Hwang et al., 2003; Godiyal et al., 2018). Compared with force myography and sEMG signals (Hwang et al., 2003; Godiyal et al., 2018), the shank angle (IMU signals) of prosthesis relative to perpendicular to the ground are used to evaluate the repeatability of lower-limb movement. Figure 5 and Table 1 show how all the locomotion modes show good repeatability (VR is no more than 0.051), which is comparable to (and even better than) the other research (Godiyal et al., 2018). The repeatability of signal waveforms is important for training and recognition. Good repeatability of signals may reduce the amount of training data and provide supports for locomotion recognition or gait prediction.
The on-board training time and recognition decision time are affected by the performances of hardware, algorithm, and so on. In this study, we conducted the experiment to analyze the performances of different algorithms (SVM, QDA, and LDA) based the same on-board hardware system and experimental training and test data. The time performance can reflect the computation efficiency of system and the complexity of algorithms. The training time in our study are 89 s for SVM, 25 s for QDA, and 10 s for LDA. For SVM, model training requires continuous iterative optimization, which is very time consuming. Training with SVM requires more time than QDA and LDA due to its complexity. For QDA, the mean vector and covariance matrix of training data are evaluated, and the inverse matrix and determinant of covariance matrix are computed in the training process. Training with LDA need less time for its lower algorithm complexity compare with QDA, as shown in Equations (11) and (12). The recognition decision process was comprised of collection of the data, preparation of the feature vector and the recognition process. It took <1 μs for data collection and 0.146 ms for preparation of the feature vector each time. Data collection time and preparation time of feature vector were same for SVM, QDA, and LDA. The recognition process time are 13.4, 5.36, and 0.067 ms, corresponding to SVM, QDA, and LDA. For locomotion mode recognition, the recognition process time should be less than sliding window increment (Englehart and Hudgins, 2003), which can void data collision and leave time for subsequent process. In our experiments, the sliding window increment is 10 ms, which means the recognition decision must be finished within 10 ms, and QDA and LDA are thus better than SVM. Our previous study has used QDA taking count of accuracy and recognition time performance (Xu et al., 2018). In this study, we also use QDA in recognition study.
The real-time recognition accuracy (based on QDA) and the off-line recognition accuracy (based on LDA and SVM) are conducted. The results show that we can get high accuracy (more than 97%) when using QDA and SVM. While using LDA, the accuracy is no more than 90%. The mean real-time recognition accuracies for each locomotion mode are more than 95% and the standard error of mistakes are no more than 2%, as seen in Table 3, which is comparable with current online recognition studies (Zhang et al., 2015; Spanias et al., 2018; Xu et al., 2018). Besides, the high accuracy and low standard error of mistake show the feasibility of this study.
From the Table 3, LG is mistakenly recognized as RD with 1.87% error, and RA is mistakenly recognized as LG with 2.64% error, which shows some confusion trends among the three locomotion modes (LG, RA, and RD). As is known, level ground and ramps are even terrains, and the similarities between the terrains may cause confusion when it comes to recognizing the three locomotion modes (LG, RA, and RD) (Spanias et al., 2018). We also note that SA is mistakenly recognized as SD with 3.64% error because of the similarity between the terrains (stairs). In Table 3, it also shows SD is recognized as RD with 1.05% error, and RD is recognized as SD with 1.34% error. As we know, the subject is in downward ambulation direction no matter he is in SD or RD, so there are some recognition errors between SD and RD. Spanias et al. (2018) conducted model updating on an embedded micro-controller based on a mechanical sensor and sEMG, and they view LG and SA as one class. Compare with the study, we made progress in terms of integration and recognition accuracy. In this study, just two IMUs are adopted, because IMU is more easily integrated with prosthesis. Besides, our study can discriminate LG and SA and also achieve comparable effect with some other studies (Zhang et al., 2015; Xu et al., 2018).
We have used ROC and AUC to check the quality of QDA classification algorithm. Each ROC curve (in Figure 8) hugs the left and top edges of the plot and the AUCs (in Table 4) for each subject and each locomotion mode are more than 0.98. The ROC and the AUC reflect the good quality of QDA classifier. Robustness analysis of recognition is also conducted by adding some white noise artificially to the data and running the experiments in off-line mode. The recognition accuracy decreases when added noise into original data. When the signal noise ratio is no <100 : 0.75, the recognition accuracy is more than 96.0%, which is compared with real-time recognition with original data and without added noise. In conclusion, the recognition has robustness, when there is some noise (signal noise ratio ⩾ 100 : 0.75), according to this study. The contributions of the study are as follows. (1) In terms of a sensor, using just IMUs not multi-type sensors (for example sEMG and Mechanical sensor) fusion improves the integration and wearing convenience and maintain comparable recognition accuracy with multi-type sensors fusion at the same time. (2) On-board training solves algorithm integration problem with prosthetics. In addition, on-board training of model will lay a preliminary foundation for the model updating automatically which will make preparation for future recognition adaptation study.
This study still need improvements in the further study. First, the on-board training time and recognition time are affected by the hardware performance and algorithm complexity. Higher performance processor, hardware acceleration, and new algorithms can be effective ways to decrease the training time and improve efficiency. Secondly, the recognition accuracy for locomotion modes still needs much improvement. This study focused more on the on-board training for real-time recognition, and we therefore have not conducted a transition study. Recognition delay for transition between various locomotion modes is an important parameter, and this was the subject of our previous study (Xu et al., 2018). In addition, this study is conducted in structured environment, which make good gait repeatability of prosthesis users. We need to explore whether and how the accuracy would be affected if the repeatability decreases. We should also combine the recognition with the prosthesis control to realize the better assistance for amputee in different locomotion modes in the future.
The paper puts forward an on-board training based on robotic transtibial prosthesis and develops the real-time human locomotion mode recognition based on the trained model. An interaction interface is designed for the study to collect sensor data, train models, and conduct recognition. The IMUs signals shows good gait repeatability. The on-board training time and recognition process time of three algorithms (SVM, QDA, and LDA) are used to evaluate the time performance. The real-time recognition accuracy based on QDA are 97.19 ± 0.36%. The study also achieves more than 95% recognition accuracy for each locomotion mode. The results show the on-board training is feasible and effective to recognize the amputee's locomotion mode with robotic transtibial prosthesis. Our study improves the integration and wearing convenience by just IMUs and maintains comparable recognition accuracy with multi-type sensors fusion at the same time and also solves algorithm integration problem with prosthetics.
The datasets generated for this study are available on request to the corresponding author.
The studies involving human participants were reviewed and approved by the Local Ethics Committee of Peking University. The patients/participants provided their written informed consent to participate in this study.
DX and QW designed the research and wrote the paper. DX performed research and analyzed the data. All authors contributed to the article and approved the submitted version.
This work was supported by the National Key R&D Program of China (No. 2018YFB1307302), the National Natural Science Foundation of China (Nos. 91648207, 61533001, 91948302), the Beijing Natural Science Foundation (No. L182001), and the Beijing Municipal Science and Technology Project (No. Z181100009218007).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
They would also like to thank S. Zhang and J. Mai for their contributions in experiments.
Afzal, T., Iqbal, K., White, G., and Wright, A. B. (2016). A method for locomotion mode identification using muscle synergies. IEEE Trans. Neural Syst. Rehabil. Eng. 25, 608–617. doi: 10.1109/TNSRE.2016.2585962
Ahmad, N., Ghazilla, R. A. R., Khairi, N. M., and Kasi, V. (2013). Reviews on various inertial measurement unit (IMU) sensor applications. Int. J. Signal Process Syst. 1, 256–262. doi: 10.12720/ijsps.1.2.256-262
Au, S. K., Weber, J., and Herr, H. (2009). Powered ankle-foot prosthesis improves walking metabolic economy. IEEE Trans. Robot. 25, 51–66. doi: 10.1109/TRO.2008.2008747
Bartlett, H. L., and Goldfarb, M. (2018). A phase variable approach for imu-based locomotion activity recognition. IEEE Trans. Biomed. Eng. 65, 1330–1338. doi: 10.1109/TBME.2017.2750139
Elhoushi, M., Georgy, J., Noureldin, A., and Korenberg, M. J. (2017). A survey on approaches of motion mode recognition using sensors. IEEE Trans. Intell. Transp. Syst. 18, 1662–1686. doi: 10.1109/TITS.2016.2617200
Englehart, K., and Hudgins, B. (2003). A robust, real-time control scheme for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 50, 848–854. doi: 10.1109/TBME.2003.813539
Erni, T., and Colombo, G. (1998). Locomotor training in paraplegic patients: a new approach to assess changes in leg muscle EMG patterns. Electroencephalog. Clin. Neurophysiol. 109, 135–139. doi: 10.1016/S0924-980X(98)00005-8
Feng, Y., and Wang, Q. (2017). Combining push-off power and nonlinear damping behaviors for a lightweight motor-driven transtibial prosthesis. IEEE/ASME Trans. Mechatron. 22, 2512–2523. doi: 10.1109/TMECH.2017.2766205
Friedman, J. H. (1989). Regularized discriminant analysis. J. Am. Stat. Assoc. 84, 165–175. doi: 10.1080/01621459.1989.10478752
Godiyal, A. K., Mondal, M., Joshi, S. D., and Joshi, D. (2018). Force myography based novel strategy for locomotion classification. IEEE Trans. Hum. Mach. Syst. 48, 648–657. doi: 10.1109/THMS.2018.2860598
Gupta, R., and Agarwal, R. (2018). Continuous human locomotion identification for lower limb prosthesis control. CSI Trans. ICT 6, 17–31. doi: 10.1007/s40012-017-0178-4
Hargrove, L. J., Young, A. J., and Simon, A. M. (2015). Intuitive control of a powered prosthetic leg during ambulation: a randomized clinical trial. J. Am. Med. Assoc. 313, 2244–2252. doi: 10.1001/jama.2015.4527
Hershler, C., and Milner, M. (1978). An optimality criterion for processing electromyographic (EMG) signals relating to human locomotion. IEEE Trans. Biomed. Eng. 25, 413–420. doi: 10.1109/TBME.1978.326338
Hwang, I. S., Lee, H. M., Cherng, R. J., and Chen, J. J. (2003). Electromyographic analysis of locomotion for healthy and hemiparetic subjects-study of performance variability and rail effect on treadmill. Gait Posture 18, 1–12. doi: 10.1016/S0966-6362(02)00071-1
Joshi, D., and Hahn, M. E. (2016). Terrain and direction classification of locomotion transitions using neuromuscular and mechanical input. Ann. Biomed. Eng. 44, 1275–1284. doi: 10.1007/s10439-015-1407-3
Joshi, D., Nakamura, B. H., and Hahn, M. E. (2015). High energy spectrogram with integrated prior knowledge for emg-based locomotion classification. Med. Eng. Phys. 37, 518–524. doi: 10.1016/j.medengphy.2015.03.001
Kim, D. H., Cho, C. Y., and Ryu, J. H. (2013). Real-time locomotion mode recognition employing correlation feature analysis using EMG pattern. ETRI J. 36, 99–105. doi: 10.4218/etrij.14.0113.0064
Kim, M., and Collins, S. H. (2017). Once-per-step control of ankle push-off work improves balance in a three-dimensional simulation of bipedal walking. IEEE Trans. Robot. 33, 406–418. doi: 10.1109/TRO.2016.2636297
Liu, M., Zhang, F., and Huang, H. (2017). An adaptive classification strategy for reliable locomotion mode recognition. Sensors 17:2020. doi: 10.3390/s17092020
Martinez-Hernandez, U., and Dehghani-Sanij, A. A. (2018). Adaptive bayesian inference system for recognition of walking activities and prediction of gait events using wearable sensors. Neural Netw. 102, 107–119. doi: 10.1016/j.neunet.2018.02.017
Novak, D., and Riener, R. (2015). A survey of sensor fusion methods in wearable robotics. Robot. Auton. Syst. 73, 155–170. doi: 10.1016/j.robot.2014.08.012
Shultz, A. H., Lawson, B. E., and Goldfarb, M. (2016). Variable cadence walking and ground adaptive standing with a powered ankle prosthesis. IEEE Trans. Neural Syst. Rehabil. Eng. 24, 495–505. doi: 10.1109/TNSRE.2015.2428196
Spanias, J. A., Perreault, E. J., and Hargrove, L. J. (2016). Detection of and compensation for EMG disturbances for powered lower limb prosthesis control. IEEE Trans. Neural Syst. Rehabil. Eng. 24, 226–234. doi: 10.1109/TNSRE.2015.2413393
Spanias, J. A., Simon, A. M., Finucane, S. B., Perreault, E. J., and Hargrove, L. J. (2018). Online adaptive neural control of a robotic lower limb prosthesis. J. Neural Eng. 15:016015. doi: 10.1088/1741-2552/aa92a8
Wang, Q., Yuan, K., Zhu, J., and Wang, L. (2015). Walk the walk: a lightweight active transtibial prosthesis. IEEE Robot. Autom. Mag. 22, 80–89. doi: 10.1109/MRA.2015.2408791
Xu, D., Feng, Y., Mai, J., and Wang, Q. (2018). Real-time on-board recognition of continuous locomotion modes for amputees with robotic transtibial prostheses. IEEE Trans. Neural Syst. Rehabil. Eng. 26, 2015–2025. doi: 10.1109/TNSRE.2018.2870152
Young, A. J., Kuiken, T. A., and Hargrove, L. J. (2014a). Analysis of using emg and mechanical sensors to enhance intent recognition in powered lower limb prostheses. J. Neural Eng. 11:056021. doi: 10.1088/1741-2560/11/5/056021
Young, A. J., Simon, A. M., and Hargrove, L. J. (2014b). A training method for locomotion mode prediction using powered lower limb prostheses. IEEE Trans. Neural Syst. Rehabil. Eng. 22, 671–677. doi: 10.1109/TNSRE.2013.2285101
Yuan, K., Wang, Q., and Wang, L. (2015). Fuzzy-logic-based terrain identification with multisensor fusion for transtibial amputees. IEEE/ASME Trans. Mechatron. 20, 618–630. doi: 10.1109/TMECH.2014.2309708
Zhang, F., and Huang, H. (2013). Source selection for real-time user intent recognition toward volitional control of artificial legs. IEEE J. Biomed. Health Inform. 17, 907–914. doi: 10.1109/JBHI.2012.2236563
Zhang, F., Liu, M., and Huang, H. (2015). Effects of locomotion mode recognition errors on volitional control of powered above-knee prostheses. IEEE Trans. Neural Syst. Rehabil. Eng. 23, 64–72. doi: 10.1109/TNSRE.2014.2327230
Zheng, E., Manca, S., Yan, T., Parri, A., Vitiello, N., and Wang, Q. (2017). Gait phase estimation based on noncontact capacitive sensing and adaptive oscillators. IEEE Trans. Biomed. Eng. 64, 2419–2430. doi: 10.1109/TBME.2017.2672720
Zheng, E., Wang, L., and Wei, K. (2014). A noncontact capacitive sensing system for recognizing motion modes of transtibial amputees. IEEE Trans. Biomed. Eng. 61, 2911–2920. doi: 10.1109/TBME.2014.2334316
Keywords: robotic transtibial prosthesis, inertial measurement unit, on-board training, real-time recognition, human-machine interaction
Citation: Xu D and Wang Q (2020) On-board Training Strategy for IMU-Based Real-Time Locomotion Recognition of Transtibial Amputees With Robotic Prostheses. Front. Neurorobot. 14:47. doi: 10.3389/fnbot.2020.00047
Received: 27 October 2019; Accepted: 12 June 2020;
Published: 22 October 2020.
Edited by:
Loredana Zollo, Campus Bio-Medico University, ItalyReviewed by:
Uriel Martinez-Hernandez, University of Bath, United KingdomCopyright © 2020 Xu and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Qining Wang, cWluaW5nd2FuZ0Bwa3UuZWR1LmNu
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.