 Arpita Bose1*
Arpita Bose1* Niladri S. Dash2
Niladri S. Dash2 Samrah Ahmed1,3
Samrah Ahmed1,3 Manaswita Dutta4
Manaswita Dutta4 Aparna Dutt5
Aparna Dutt5 Ranita Nandi5Yesi Cheng1Tina M. D. Mello1
Ranita Nandi5Yesi Cheng1Tina M. D. Mello1- 1School of Psychology and Clinical Language Sciences, University of Reading, Reading, United Kingdom
- 2Linguistic Research Unit, Indian Statistical Institute, Kolkata, India
- 3Nuffield Department of Clinical Neurosciences, University of Oxford, Oxford, United Kingdom
- 4Department of Communication Disorders and Sciences, Rush University, Chicago, IL, United States
- 5Neuropsychology and Clinical Psychology Unit, Duttanagar Mental Health Centre, Kolkata, India
Background and aim: Speech and language characteristics of connected speech provide a valuable tool for identifying, diagnosing and monitoring progression in Alzheimer's Disease (AD). Our knowledge of linguistic features of connected speech in AD is primarily derived from English speakers; very little is known regarding patterns of linguistic deficits in speakers of other languages, such as Bengali. Bengali is a highly inflected pro-drop language from the Indo-Aryan language family. It is the seventh most spoken language in the world, yet to date, no studies have investigated the profile of linguistic impairments in Bengali speakers with AD. The aim of this study was to characterize connected speech production and identify the linguistic features affected in Bengali speakers with AD.
Methods: Participants were six Bengali speaking AD patients and eight matched controls from the urban metropolis, Kolkata, India. Narrative samples were elicited in Bengali using the Frog Story. Samples were analyzed using the Quantitative Production Analysis and the Correct Information Unit analyses to quantify six different aspects of speech production: speech rate, structural and syntactic measures, lexical measures, morphological and inflectional measures, semantic measures and measure of spontaneity and fluency disruptions.
Results and conclusions: In line with the extant literature from English speakers, the Bengali AD participants demonstrated decreased speech rate, simplicity of sentence forms and structures, and reduced semantic content. Critically, differences with English speakers' literature emerged in the domains of Bengali specific linguistic features, such as the pro-drop nature of Bengali and its inflectional properties of nominal and verbal systems. Bengali AD participants produced fewer pronouns, which is in direct contrast with the overuse of pronouns by English AD participants. No obvious difficulty in producing nominal and verbal inflections was evident. However, differences in the type of noun inflections were evident; these were characterized by simpler inflectional features used by AD speakers. This study represents the first of its kind to characterize connected speech production in Bengali AD participants and is a significant step forward toward the development of language-specific clinical markers in AD. It also provides a framework for cross-linguistic comparisons across structurally distinct and under-explored languages.
Introduction
Language assessment has a crucial role in the clinical diagnosis of several forms of dementia (Taler and Philips, 2008; Macoir et al., 2015). In Alzheimer's Disease (AD) language has been shown to decline in the pre-symptomatic stages (Snowdon et al., 1996; Ahmed et al., 2013); it is the central feature of primary progressive aphasias (Gorno-Tempini et al., 2011; Grossman, 2012), and acts as a supplementary marker in young onset AD (Crutch et al., 2013). As such, clinical assessment of language has become routine in the diagnostic workup; which commonly use assessment of confrontation naming, verbal fluency; and analysis of spontaneous or connected speech. Connected speech samples elicited via picture descriptions, narratives, or interviews have been proven to be better ecological approximations of language production in everyday context. Connected speech goes beyond single-word productions and involves ongoing interactions among diverse cognitive processes including semantic storage and retrieval, executive functions, and memory processes (Ahmed et al., 2013; Mueller et al., 2018; Slegers et al., 2018). Importantly, connected speech samples provide detailed information about processing at several linguistic levels, such as phonetic, phonological, lexico-semantic, syntactic, and discourse-pragmatic; allowing deeper analysis of domains of interest (Boschi et al., 2017).
Recent literature reviews on the linguistic characteristics of connected speech in AD point to a pattern of deficit in several domains including speech rate, syntactic structure and complexity, lexical content, semantic content and efficiency, as well as spontaneity and fluency of speech (Boschi et al., 2017; Mueller et al., 2018; Slegers et al., 2018; Filiou et al., 2020). Specifically, the key features that distinguish AD from healthy control participants are: reduced speech rate and spontaneity including increased repetitions and revisions; simplified syntax and sentence structures including shorter and grammatically simpler sentences; word finding difficulties and increased use of pronouns; inflectional errors in nouns and verbs; and reduced semantic content of speech and uninformative speech with low idea density and efficiency.
With the advantages of quick administration, relatively low burden on the participant, ability to distinguish amongst dementia pathologies, and its use as a marker for disease progression, the evaluation and identification of connected speech characteristics has generated intense interest in dementia research (Gorno-Tempini et al., 2011; Ahmed et al., 2013; Boschi et al., 2017; Mueller et al., 2018; Slegers et al., 2018; Filiou et al., 2020). The progress in the field is encouraging, however, a significant drawback remains with regard to the diversity of languages studied, and how fragmentation of linguistic features differs across different languages (Beveridge and Bak, 2011). Our understanding of linguistic breakdown in dementia is, therefore, limited as the vast majority of studies have been conducted in English speaking participants, with only a few studies in French, Spanish, Brazilian Portuguese, Chinese, Japanese, Hebrew, Iranian, Finnish, Italian, and German (Boschi et al., 2017; Filiou et al., 2020). However, it is well-known from research in language impairments and neurological diseases that language impairments depend on how the system can break down, which in turn is determined by the structure of the language system (Paradis, 1988). For example, syntactic disorders apparent at the surface of a speaker's grammar are dependent on the underlying structure of the specific language. Languages, such as Italian, Spanish, and Bengali are pro-drop languages, that is, they allow speakers to “drop” the subject pronoun if the subject can be inferred from the context. To illustrate, if a Bengali speaker stated, “āmār mā bijñāni” (“My mother is a scientist”), his or her next sentence could be “iunivārsitite kāj karen” (“Works at the university”) in which the pronoun “she” is excluded. Conversely, English, is a non-pro-drop language, that is, speakers must use the subject regardless of the availability of the referent in the context.
This feature becomes all the more important given that one salient marker of language breakdown in AD is the over production of pronouns, such as he, she, they, it, rather than use of the specific name or nouns (March et al., 2006; Ahmed et al., 2013; Jarrold et al., 2014; Fraser et al., 2016 for English; Kavé and Levy, 2003; Kavé and Goral, 2016, for Hebrew). However, it remains to be determined if in pro-drop languages individuals with AD would show a similar over production of pronouns or a different pattern might emerge, given that a pronoun is not essential for correct and grammatical production of sentences.
Another feature of note is inflection abilities in AD. Whilst many studies with English speaking AD individuals have shown difficulty with verb inflections in connected speech (e.g., Sajjadi et al., 2012; Ahmed et al., 2013); other studies in English and other languages have not shown difficulty in inflectional morphology for individuals with AD [e.g., Kavé and Levy, 2003; see Auclair-Ouellet (2015) for a review of inflectional morphology in dementia].
There is a critical need to determine language-specific features to accurately describe and understand the linguistic impairments of individuals with AD across different languages. These lines of research will inform assessment procedures, which in turn would lead to more accurate clinical diagnosis of these language users. Compared to English and some European languages, there remains a distinct absence of research evidence documenting the markers associated with language decline in South Asian languages (e.g., Bengali, Urdu, Hindi, Punjabi, Nepalese, and Tamil). The expected growth in neurodegenerative diseases, such as AD will be in low and middle income South Asian and Western Pacific countries including China and India (Prince et al., 2015; Alzheimer's Disease International, 2021). English is not the primary language of use in these countries. Therefore, it is important to identify, characterize, and analyze the linguistic features of connected speech among individuals with dementia from non-English speaking populations. Evaluation of the linguistic profiles of individuals with AD who speak different languages is also key to improve our core theoretical understanding of linguistic impairments across different dementia pathologies. Furthermore, this knowledge has the potential to inform the development and provision of equitable clinical services for the assessment, diagnosis and management for these individuals. The current study fills a significant gap in the research literature and aims to identify and characterize linguistic features of connected speech in Bengali speakers with a clinical diagnosis of AD.
Bengali (also known as Bangla) belongs to the Aryan branch of the Indo-Iranian of the Indo-European group of languages. It is the national language of Bangladesh (first language of 142 million speakers, 98.8% of the total population, Bangladesh Census, 2011) and the official language of three states of India, West Bengal, Tripura, and Assam (first language of 97 million speakers, 8.3% of the total population, India Census, 2011). Bengali is also spoken by the significant global Bengali diaspora (Indian and Bangladeshi) in the United States, the United Kingdom, the Middle East and many Western countries. Bengali is currently ranked as the seventh most spoken language in the world; more than 265 million people speak Bengali as their first or second language in their everyday life. Despite the large number of Bengali speakers there are only handful of studies involving Bengali speakers with neurological impairments (e.g., Lahiri et al., 2019; Patra et al., 2020), and remains one of the under-represented and under-explored world languages in neurological research (Beveridge and Bak, 2011).
In the following section, we highlight the features of Bengali that are relevant for characterization of connected speech production in AD in the domains of syntax, lexicon, and morphology. Table 1 provides a summary of these features and draws attention to the specific differences with English. This table is not intended to include an exhaustive account of all aspects of Bengali, but provides relevant information for characterizing connected speech in the context of AD.
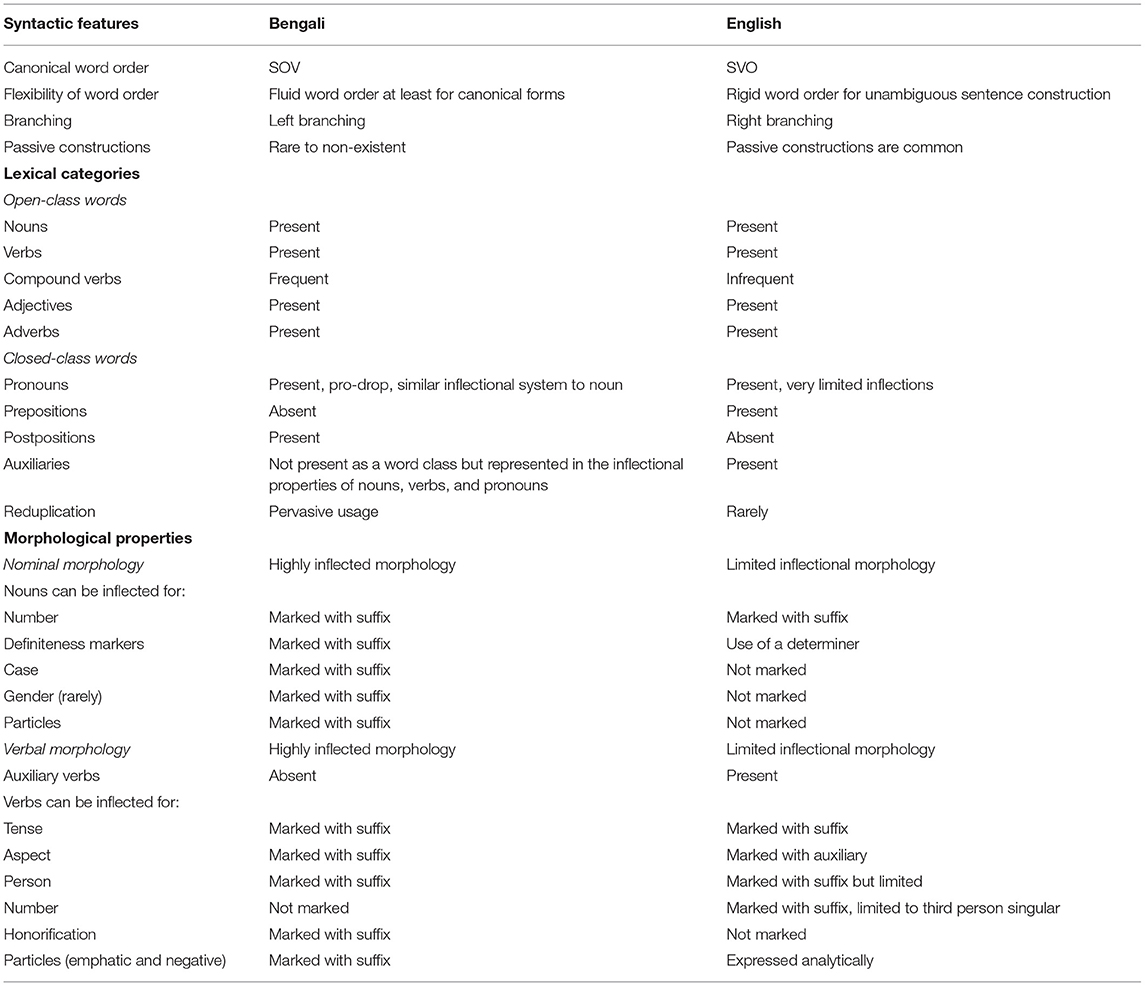
Table 1. Summary of relevant linguistic features (syntactic, lexical, and morphology) for Bengali and its contrast with English.
To understand the linguistic characteristics of a language, it is useful to consider language typology. It has been shown that word order patterns, such as SOV (Subject Object Verb, in Bengali, Farsi, Hindi, Sanskrit, Latin, and Japanese) or patterns such as SVO (English, Dutch, Italian, Spanish, and Russian) may go hand-in-hand with other language features, such as the existence of pre- or postpositions, the placing of determiners before or after nouns, the presence or absence of pro-drop and of dative subjects, although the clustering of language features is highly complex (Thompson, 2010). Another classifying distinction between languages, which links in with the word order system, is the amount of grammatical inflection. Modern English is predominantly an analytic language, which means that it is made up mainly of free lexical units and there is little remaining inflection. Bengali is a highly inflected language with verbal conjugation according to person, tense, aspect, auxiliary marker, honorification, and particles; and number, particle, and case marking for nouns and pronouns (Dash, 2005, 2015). The inflectional nature of words determines the syntactic roles of the constituents of a sentence. The extent of inflection in a language is usually related to the flexibility of word order. Therefore, in Bengali the SOV order is not mandatory and word order is not rigid. In contrast, English follows a relatively rigid word order.
As mentioned earlier, Bengali is a pro-drop language, allowing omission of personal pronouns in the subject position. Pro-drop occurs in languages with unambiguous conjugational systems where person information is given in the verb inflection. The rules for pro-drop occurrence are context-based. Where the referent is clear from the context, subjects can be dropped. The following are examples of pro-drop sentences produced by participants of this current research:
Example 1:‘tār nām chhila phreṭi’ “His name was Freddy”
‘khub bhālobāsto or dui peṭke’ “Deeply loved his two pets”: Subject dropped
Example 2: ‘maumāchhi tāder tāṛā kare’ “Bees attack them”
‘gāchher guṛite uṭhe paṭe’ “Climb up on a log”: Subject dropped
This pro-drop property of Bengali has important consequences for the amount of pronouns that are produced by speakers in their connected speech.
In terms of lexical distribution, Bengali words belong to seven parts-of-speech: nouns, verbs, adjectives, adverbs, pronouns, postpositions and indeclinables. These grammatical classes can be also organized in terms of open class words (i.e., nouns, verb, adjective, and adverb) and closed class words (i.e., pronoun, postpositions, and indeclinable). Nouns, pronouns, adjectives, verbs and adverbs are inflected in Bengali, whilst indeclinables and postpositions are not.
Bengali nouns are inflected for number, definiteness, gender (rarely), case, and particles. The inflections are tagged in an ordered agglutinative manner to the right side of the nouns to generate the final form.
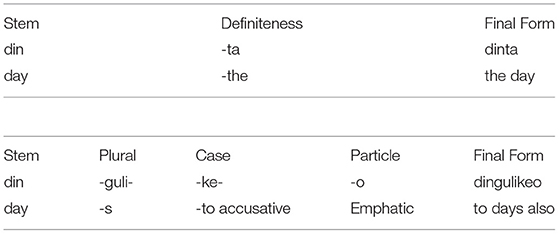
For the inflected noun “dingulikeo”, there are three inflections. These three inflections have a fixed order dingulikeo (< din + -guli + -ke + -o) and using them in different orders (e.g., < din +-ke + -o+ guli, or < din -o+ +-ke + guli) will generate erroneous forms. Pronouns use a similar set of inflections to nouns.
Bengali verb morphology is extensive and complex, verbs can be inflected for person, tense, aspect, honorification, and particles. In Bengali verbs, person, tense and aspect information are mandatory, whilst honorification and particles can also be added. However, verb inflections do not change with the number and gender of the subject. In contrast to English, Bengali does not have the word classes of auxiliaries, modals, and aspect markers as lexical entities but these are incorporated as inflections on the verbs. To illustrate, the English phrase He/She/They has/have been writing is expressed by a single conjugated form /likhechhe/ in Bengali. Similar to nouns, the inflections are added in a specific order with the verb root to generate the final conjugated form. These conjugated forms generate a complete sense of action as well as aspectual, temporal, and spatial information within the form. Due to the composite nature of inflected Bengali verbs, there is no possibility of dropping a part of an inflection as this will generate an invalid form.
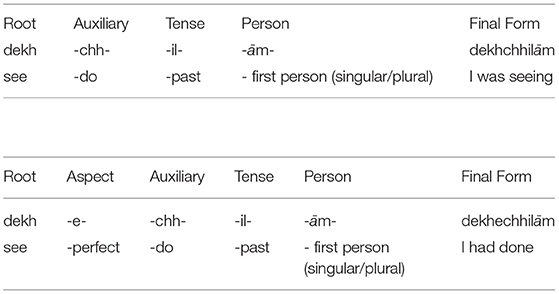
Bengali has a high occurrence of compound verbs, which is also a prominent feature in many South Asian languages, such as Hindi (Koul, 2008). A compound verb is a two or multiword compound formed by combining a sequence of two or more verbs to act as a single verb to express a single sense or meaning (e.g., dhare rākh “catch”, uṭhe paṛ “rise”, śuye paṛ “lie down”, bale phel “speak”).
In contrast to English, Bengali has fewer word classes within the closed-class category (Bengali: pronouns, postpositions, indeclinables vs. English: prepositions, determiners, pronouns, conjunctions, modals, auxiliaries). Bengali postpositions are similar to prepositions in English. Postpositions occur immediately after a noun or a pronoun to denote spatial, temporal, situational, locational, directional, and conditional information with other words used in a sentence (e.g., bābār kāchhe “near father”, gharer madhye “in house”, hāt diye “by hand”, dupurer pare “after noon”, rāstār dhāre “beside road”). Akin to English word classes of conjunctions and disjunctions, Bengali has a lexical category collectively known as indeclinables ‘abyay’ which are, in principle, not capable of being inflected (e.g., ār “and”, ebaṃ “and”, bā “or”, kintu “but”, athabā “or”).
A frequent feature of Bengali and in many Indian languages is reduplication. Reduplication is a process by which a word is duplicated—wholly or partially—to generate a new word that is different in form and adds new sense in meaning. Reduplication serves multiple semantic functions, such as sense of multiplicity, continuation of action, recurrence of an event or emotional state (e.g., hāśi “smile” → hāśihāśi “smiling”; ghuṭ “dark” → ghuṭghuṭe “pitch dark”; → ghar “house” ghar ghar “in every house”; din “day” → din din “day by day”). Reduplication can happen to words of all parts-of-speech, although it is more common for open class words.
As can be seen from the above mentioned linguistic features of Bengali, there are distinct differences from English, which can impact manifestation of linguistic impairments in AD. Despite recognition that linguistic impairments are important markers for AD, very little is known regarding patterns of linguistic deficits in speakers of languages other than English. The literature is non-existent with this regard in South Asian languages (e.g., Bengali, Hindi, Urdu, and Punjabi). This research fills a significant gap in the literature and aims to identify linguistic features of connected speech in Bengali speakers with a clinical diagnosis of AD. We used the Frog Story narrative task (“Frog, Where are You?,” Mayer, 1969) to elicit connected speech samples from Bengali AD and matched healthy controls. The multidimensional nature of connected speech and the large number of different variables for analysis that are reported in the literature makes it challenging to decide the best variables to choose to characterize production. The most often used multidimensional analysis framework has been a variant of the Quantitative Production Analysis (QPA; Berndt et al., 2000). In addition, researchers have augmented the QPA with other measures, such as semantic content analysis to capture the semantic breakdown (e.g., Croisile et al., 1996; Ahmed et al., 2013). We implemented and adapted the QPA analysis framework for Bengali as well as used semantic content analysis using the Correct Information Unit analyses (CIU; Nicholas and Brookshire, 1993). As detailed linguistic analysis in Bengali has not yet been reported in connected speech data from neurological impairments, we saw value in covering an exhaustive range of variables in relevant domains to ensure broad range of linguistic features of Bengali are explored. To capture linguistic features specific to Bengali, we supplemented the QPA by adding additional variables (e.g., elaboration of the inflectional morphology for nouns and verbs, inclusion of lexical categories, such as postpositions).
The main objective of the present study was to identify the features of connected speech in the domains of—speech rate, syntactic and grammatical parameters, lexical content, morphological features, semantic content and disruption to fluency and spontaneity—that may be affected in Bengali speakers with AD.
Materials and Methods
Ethics Statement
This study was carried out with ethical clearance from the School of Psychology and Clinical Language Sciences, University of Reading (Ref: 2017-035-AB). Participation was voluntary and written consent was obtained from all participants prior to commencement of the study. For participants with AD, consent and information forms were adapted to facilitate comprehension. All participants were able to self-consent to the study.
Participants
Participants were six right-handed Bengali speaking adults with a clinical diagnosis of AD and eight age-, gender-, education-, and language-matched healthy control participants (HC). Participants were recruited from the Neuropsychology and Clinical Psychology Unit, Duttanagar Mental Health Centre, Kolkata, India. Control participants were recruited from a volunteer participant pool. Exclusion criteria for both groups included a known history of alcohol or drug abuse, or a history of other neurological or psychiatric illness, or <10 years of education.
Background assessments. For each participant detailed demographic information was obtained. The level of general cognitive functioning was measured using the adapted Kolkata Cognitive Screening Battery, an adapted Bengali version of Mini-Mental State Examination (BMSE; Das et al., 2006), the Bengali adapted version of Addenbrooke's Cognitive Examination (ACE)-III (Hsieh et al., 2013) and the Clinical Dementia Rating Scale (CDR; Morris, 1993). The CDR is a measure of dementia severity based on the individual's cognitive and daily functions across six domains, which included memory, orientation, judgement and problem solving, community affairs, home and hobbies, and personal care. In addition, the Instrumental Activities of Daily Living Scale for Elderly (IADL-EDR; Mathuranath et al., 2005) assessed patient's ability to undertake day-to-day activities which include cognitive activities (e.g., managing finances, taking medication), social and recreational activities (e.g., looking after grandchildren, pursuing hobbies), community activities (e.g., shopping, travel), household activities (e.g., meal preparation, laundry) and self-care activities (e.g., shaving, personal care). There were 11 items in this scale which were rated for their relevance, levels of impairment, and whether difficulties were caused by cognitive or physical problems. Subsequently, a composite score is derived which indicates the overall physical and cognitive disability. All HC were free of cognitive symptoms or neurological illnesses, and performed within the normal range in KCSB, ACE-III, CDR, and IALD-EDR.
Participants with AD (AD01, AD03, AD04, AD06, AD07, and AD09) were diagnosed by experienced behavioral neurologist and neuropsychologists (fifth and sixth author; AD, RN) using the NINCDS/ADRAA criteria (Mckhann et al., 1984; McKhann et al., 2011). Table 2 provides both AD and HC participants' demographic details and the results of the neuropsychological tests. All participants were Bengali-English sequential bilinguals. They were all native speakers of Bengali and were living in a predominantly Bengali speaking context, using Bengali at home and at work. They were professionally engaged prior to the onset of AD: AD01 was a retired clerk in insurance company; AD03 was a retired electrical supervisor; AD04 managed a farming business; AD06 was a retired tax consultant; AD07 was a homemaker; AD09 was a retired high school teacher. With the exception of AD07 with moderate dementia (i.e., CDR global score of 2), all other AD participants had mild dementia (i.e., CDR global score of 1). At the time of the study, all participants were living with their families in the urban metropolis of Kolkata in eastern India.
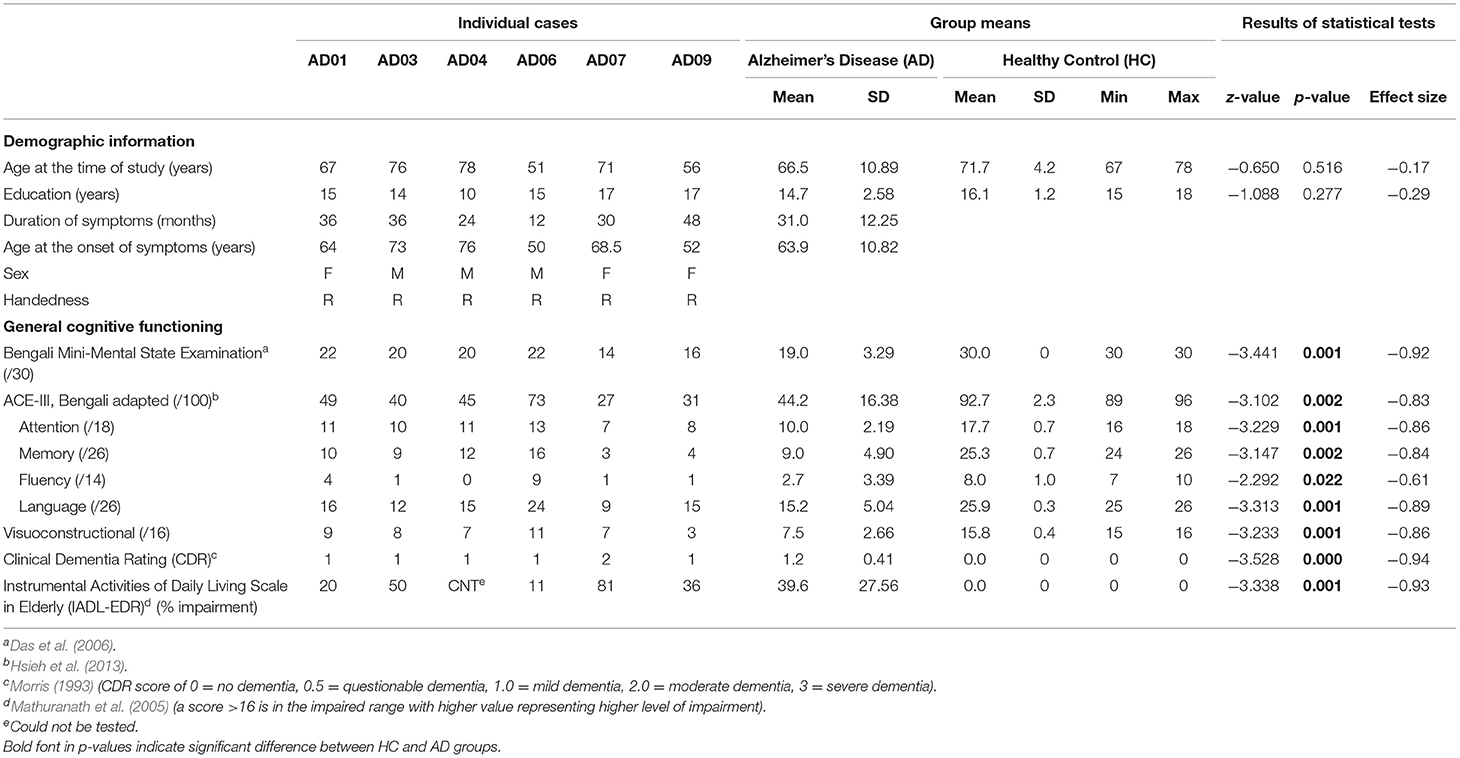
Table 2. Demographic characteristics and neuropsychological data on the various background measures for each individual with Alzheimer's Disease (AD) as well as Mean and SD of AD and Healthy Controls (HC) groups.
Experimental Task
A narrative sample in Bengali was elicited using the story book: “Frog, Where Are you?” (Mayer, 1969). Most literature in English speakers with dementias have been elicited using the Cinderella Story retelling narrative task (Kavé et al., 2007; Fraser et al., 2014); whilst the Frog Story has been used by few researchers (e.g., Ash et al., 2007; Ash and Grossman, 2015). For Bengali speakers living in Kolkata, India, it was unlikely that they would know all details of the Cinderella story even if they knew the broad idea of the story. The story of Cinderella is not ingrained in their cultural repertoire as in English speaking or Western countries. We used the Frog Story because we wanted to use a task that would capture relevant and appropriate concepts, and be also culturally acceptable. The stimulus has been successfully used with different types of dementias (Ash et al., 2007).
Prior to administering the narrative task, participants were given a brief background about the story and were told that the main characters of the story are a boy, his dog, and a frog. The story is about a boy who is searching for his missing frog along with his dog. Participants were instructed to look through the picture book and then asked to narrate a story based on the picture book using sentences. Participants could keep the book with them while narrating the story. Tester interruptions were kept to a minimum, other than occasional prompts and generic encouragement. No feedback was provided during the elicitation. Instructions for testing and feedback where written down for the tester to ensure consistency in instruction across participants. The narrative productions were recorded using the digital audio recorder Olympus voice recorder WS-833 for subsequent verbatim orthographic transcription. Excerpts of transcripts from two AD participants (AD03 and AD09) and two HC participants are provided in the Table 3.
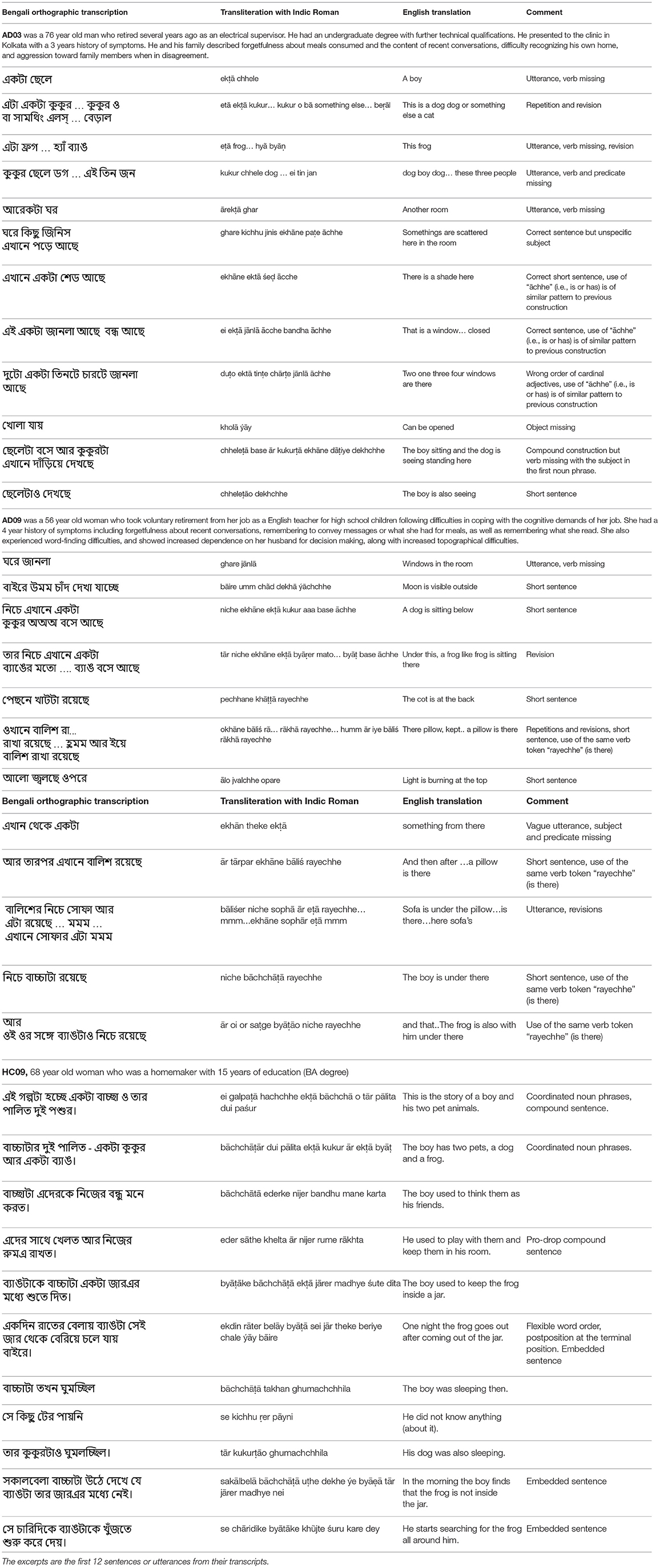
Table 3. Illustrative samples of the Frog Story narration by two individuals with Alzheimer's Disease (AD) and one Healthy Controls (HC).
Quantitative Analysis of Narrative Speech
Using the QPA and the CIU analyses we calculated a set of measures for each narrative sample. CIUs are a widely used metric in narrative analysis that assesses the informativeness and efficiency of information conveyed through connected speech (e.g., Carlomagno et al., 2005). The multidimensional nature of connected speech analysis and the large number of different variables used by researchers makes the choosing of appropriate variables to report a challenging task. The measures for this research were in keeping with the recommendations from recent reviews for domains that are essential for characterizing AD speech (Slegers et al., 2018; Filiou et al., 2020). They aimed at quantifying six different aspects of speech production: 1. speech rate; 2. structural and syntactic measures; 3. lexical measures; 4. morphological and inflectional measures; 5. semantic measures (CIU analysis); and 6. measure of spontaneity and fluency disruptions (Wilson et al., 2010; Ahmed et al., 2013; Fraser et al., 2016; Boschi et al., 2017; Slegers et al., 2018; Filiou et al., 2020).
To derive these measures, the narrative samples were transcribed verbatim, segmented and analyzed in accordance with the procedures identical to those used in the QPA (Berndt et al., 2000). As in the original QPA, utterances were defined as segments of running speech that were syntactically and/or prosodically coherent. Placement of sentence boundaries was guided by semantic, syntactic and prosodic features. An utterance did not have to constitute a fully grammatical sentence. Using the QPA rules of extracting the narrative core, words that did not contribute to the narrative were removed, that is, repetitions, repairs, examiner's prompts, discourse markers, non-words (Rochon et al., 2000 for specific steps in extracting the narrative words; please see Berndt et al., 2000). Both the first and second author performed the narrative core extraction individually for all the 14 speech samples. Consensus for any disagreements in narrative core extraction and utterance segmentation were achieved through review of the QPA rules, and re-listening of the audio samples.
The total narrative duration and total number of words produced by each participant were recorded. The minimum length of speech sample for obtaining meaningful results from a narrative production has been widely debated (e.g., Berndt et al., 2000; Sajjadi et al., 2012). The QPA analysis protocol recommends a corpus of 150 words for obtaining meaningful results (Saffran et al., 1989; Berndt et al., 2000). Previous research with different sample lengths have shown that a 150 narrative word corpus produced an adequate and reliable analysis (Sajjadi et al., 2012). To ensure that sample length would not influence the results, we performed our planned analyses using the full sample and ~150-word sample for two AD and two HC participants. The proportional variables on QPA and CIU analyses showed similar, if not identical values for the two sample lengths. Therefore, following recommendation from the literature and to keep the sample length consistent across participants, we derived the measures after extracting 150 ± 10 narrative words.
Using the QPA analysis framework, the narrative samples were analyzed for various measures: structural and syntactic, lexical, and morphological measures (Berndt et al., 2000). Specific linguistic features of Bengali (e.g., postpositions, number of reduplications, number of verbal compounds, verbal, and nominal morphology) were captured by including additional variables to the analysis scheme (see Table 4). We followed the QPA rules for deriving each of these variables; any exception made to the QPA rules to accommodate the characteristics of Bengali is indicated. Semantic content was analyzed using the CIU analyses. The complete list of different variables derived from the analyses is presented in Table 4. The following section provides a brief description of the domains used for characterizing the speech samples between the two groups.

Table 4. Summary of the variables that were derived from the narrative production across the six domains of speech production.
Speech rate (words per minute). Speech rate was defined as the number of words per minute. That is, the total number of words produced in the narrative divided by the total duration of the narrative.
Structural and syntactic measures. This domain measured length, complexity and grammaticality of sentences to capture the structural and syntactic aspects of speech production. Four measures were drawn from various raw structural and syntactic measures (i.e., proportion of words in sentences, mean sentence length, proportion of well-formed sentences, embedding index).
Lexical measures. This domain captured subjects' production of various types of lexical items across the entire extracted narrative words, independent of utterance type. These measures included: number of narrative words (NW), number of open class, closed class words, number of nouns (N), verbs (V), compound verbs (CV), non-finite verbs (NF), matrix verbs (MV), adjectives, adverbs, personal pronouns (P), postpositions (PP), and reduplications. A wide range of proportional measures were generated on the basis of these counts of lexical items; full range reported in the Table 4. For this study, we limit reporting and analyzing to a set of variables indicated by check mark () in Table 4. The choice for these variables were motivated by findings in the literature that have been shown to demonstrate dependable differences in connected speech between AD and healthy controls (Slegers et al., 2018; Filiou et al., 2020).
Morphological and inflectional measures. To capture the richness and intricacies of the noun and verb inflectional system in Bengali, we generated measures described below. For nominal inflections, we determined the total number of nouns, number of nouns in their base form (i.e., uninflected forms), number of nouns that are possible to be inflected, and number of nouns with appropriate inflections. Additionally, we counted the number of inflections on each noun (i.e., one, two, >two) and the type of those inflections (i.e., definiteness markers vs. case markers, including accusative, genitive, locative). From these count measures, we derived six variables for noun inflections as indicated in Table 4. For verbs, we determined the total number of verbs, number of inflectable verbs, number of inflected verbs with appropriate inflections, and inflection score. From these count measures, verb inflection index and inflection complexity score were calculated to capture inflectional properties of the verbs.
Semantic measures (CIU analysis). Semantic content of the narrative samples was quantified separately using the CIU measures. Words and CIUs were identified from each narrative sample following the procedures outlined by Nicholas and Brookshire (1993). For CIU analysis we used the length of the sample that were used for QPA analysis, rather than the whole sample. Three measures were derived from the CIU analysis: number of CIUs, idea density and idea efficiency.
Measures of spontaneity and fluency disruptions. Given that difficulties with fluency and spontaneity have been identified as a salient measure to capture characteristics of AD speech output (Croisile et al., 1996; Ehrlich et al., 1997; De Lira et al., 2011; Slegers et al., 2018), we included a measure called total count of disruption to spontaneity and fluency. This measure included the total number of repetitions, revisions, and reformulations in the narrative sample.
Statistical Analysis
We approached the analysis in two ways: group and case-series analyses. This is a new set of data in a language that has not been investigated before, thus it is important to capture both group level as well as individual level performance. For the group comparisons, non-parametric versions of independent samples t-test (Mann-Whitney U-test) were used for the selected variables. Given the explorative nature of this study and that finding might be informative for under-researched clinical population and potential for future larger scale studies in this area (Perneger, 1998; Feise, 2002), we report findings with exact p-values (both at p ≤ 0.01 and p ≤ 0.05) and effect sizes for readers to appreciate the strength of these effects. It has been suggested that over-correction of alpha level risks the chance of increasing type II errors (i.e., rejecting significant findings) especially for under-represented clinical populations and hard to recruit populations (Feise, 2002; Streiner, 2009; Streiner and Norman, 2011). Perneger (1998) maintains that over correction leads to a situation where “The likelihood of type II errors is increased, so that truly important differences are deemed non-significant” (p. 1237).
For this research to achieve a balance between Type I and Type II errors (Perneger, 1998; Feise, 2002), and to be erring on caution, we corrected the p-value by four (p ≤ 0.05/4 = 0.012) for family wise multiple comparisons. The determination of what makes a family for multiple comparison is difficult and ambiguous (Perneger, 1998), especially in a multidimensional phenomenon such as connected speech. The denominator of four is based on the aspects captured by each linguistic domain of the connected speech (i.e., speech rate and spontaneity; structural, syntactic and morphosyntactic measures; lexical measures; and semantic content). Based on the linguistic theories independence across various linguistic domains can be robustly debated, for example, modularity between semantics-syntax, or between semantic-conceptual (Jackendoff, 1972; Caramazza and Zurif, 1976; Moscovitch and Umilta, 1990). Given the inter-correlation of variables amongst linguistic domains, we use four broad domains as family to strike balance between caution and overly conservative interrogation of data.
We implemented Crawford and colleague's single-subject statistical method of comparing a single case to a small control group (at least five) to identify differences between each AD participant and controls (e.g., Crawford and Garthwaite, 2002, 2006; Crawford et al., 2010). This was motivated to facilitate understanding of individual variation and to capture the heterogeneity of the AD population.
Results
Table 5 provides the mean group data from AD and HC participants; individual data for all six AD participants across different variables; results of group statistics (p-values and effect sizes); and results of the single-subject statistics. The readers are encouraged to review Table 3 of illustrative examples of narrative production of AD and HC participants. Table 6 provides the summary of the key findings across the six domains of speech and language production, and information on the proportion of AD individuals who showed similar results to the group differences (i.e., proportion of AD individuals who were significantly different from the controls).
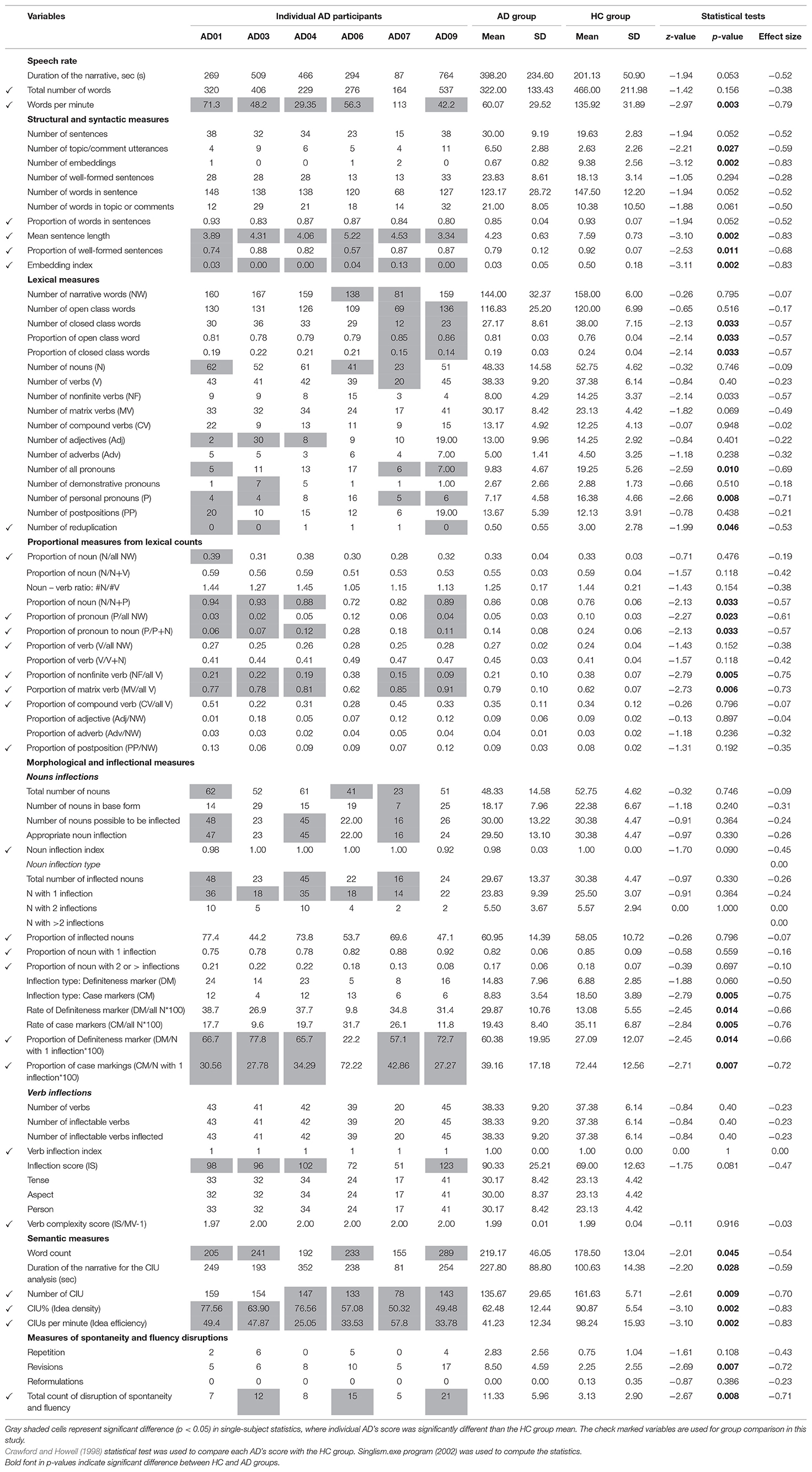
Table 5. Individual raw scores for each AD participant, and mean group data from Alzheimer's Disease (AD) and Healthy Controls (HC) across all the connected speech variables along with the results of statistical analysis.
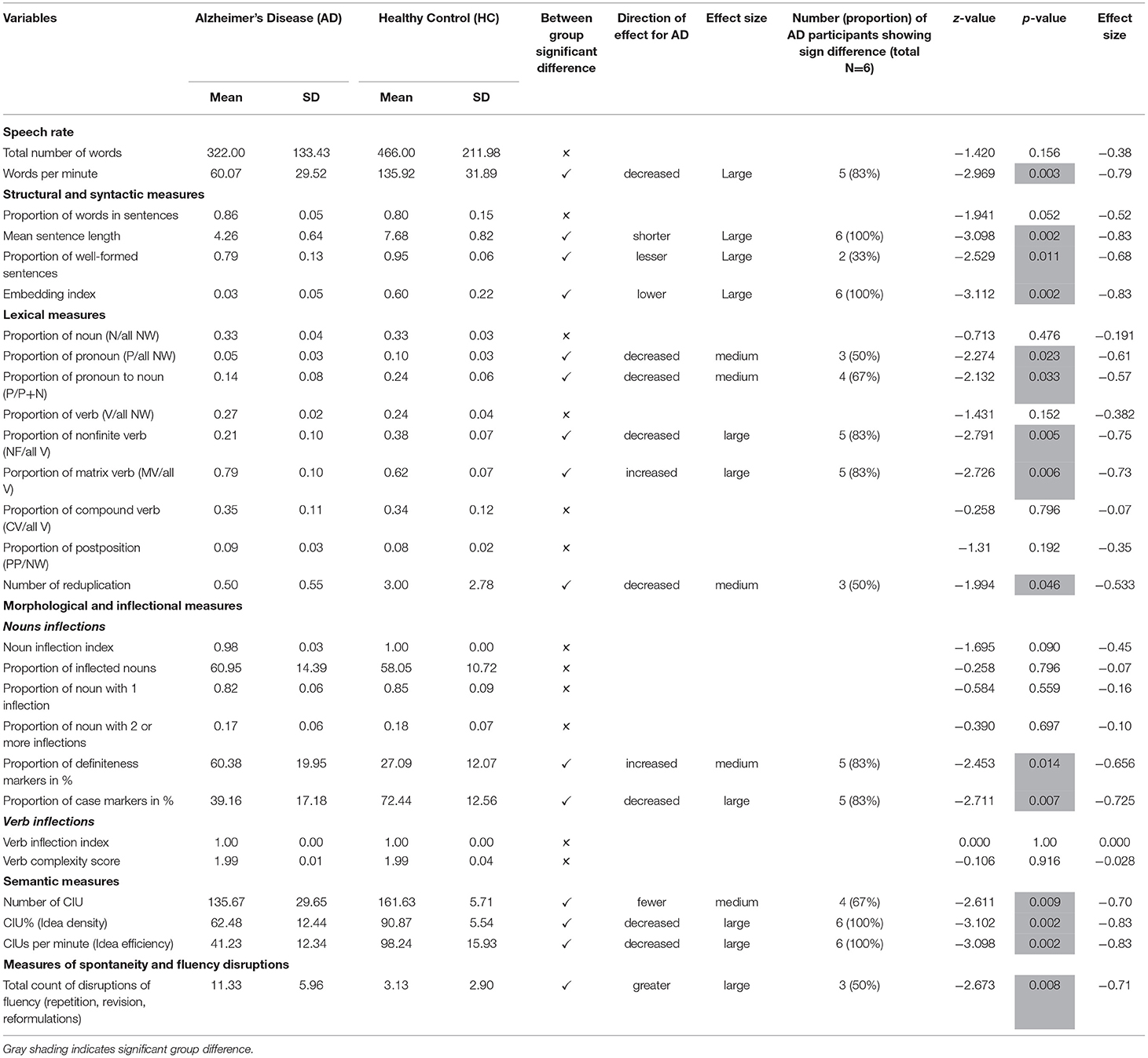
Table 6. Summary of the key findings across the six domains of speech and language production, and information on the proportion of AD individuals who showed similar results to the group differences.
In terms of rate and spontaneity of speech, compared to the HC, AD individuals produced a slower rate of speech with higher number of disruptions to spontaneity and fluency of speech. Table 5 indicates that revisions caused the most common type of disruption to the spontaneity of speech. Individual level analyses revealed that slow speech rate was observed in majority of AD participants (five out of six) and disrupted spontaneity was evident for three out of six participants.
In terms of syntactic and structural features, compared to the HC, AD individuals produced shorter (smaller mean sentence length), grammatically simpler (lower embedding indexes), and less well-formed sentences. Individual level analyses revealed that shorter length and lower embedding index was present in all of our AD participants. In contrast, ill-formed sentences were observed only in two of the six participants. Some sources of ill-formedness of the sentences were: Unclear or missing subjects, despite pro-drop being allowed in Bengali; incomplete sentences; missing coordinating conjuncts; correct but overuse of a specific marker; subject, object or verb on some occasions replaced by fillers or particles. Table 3 provides illustrative examples of these errors.
In the domain of lexical measures, compared to the HC, AD individuals showed reduced proportion of pronouns, decreased proportion of nonfinite verbs, increased proportion of matrix verbs, and fewer reduplications. All other distributions and proportions of lexical items were comparable between the two groups. Individual level analyses revealed change in the proportion of pronouns (four out of six), matrix verbs (five out of six), and nonfinite verbs (five out of six) in majority of the AD participants (see Table 5).
For the morphological and inflectional measures, AD and HC participants demonstrated equivalent inflectional indices both for nouns and verbs. This implies that AD participants were able to provide correct and appropriate inflections for the nouns and verbs they produced. Further, AD participants could also produce similar proportion of inflected nouns and similar proportion of nouns with one or two inflections (see Table 5). However, contrast could be observed between the two groups in terms of the type of noun inflections: AD participants produced higher proportion of definiteness markers, whilst HC produced greater proportion of case markings. The pattern of higher proportion of definiteness markers for nouns and lower proportion of case markers were observed for five out six AD participants. AD participants did not show any difference in the inflectional complexity scores for verbs, indicating that they could produce similar quantity of inflections compared to the controls. In the domain of semantic content and CIU analyses, compared to the HC, AD individuals showed fewer CIUs, lower idea density and idea efficiency. Individual level analyses revealed every AD participant had lower idea density and efficiency (six out of six). It is worth noting that the relationship between overall dementia severity and deficits in connected speech is far from straightforward. With the exception of one AD participant, AD07, who had a dementia rating of two, all other five participants evidenced a severity rating of one (i.e., mild). Despite AD07 demonstrating more severe dementia compared to the others in the group, she did not necessarily show more severe deficits on connected speech variables.
In summary, from Table 6 we can see that the parameters which most prominently distinguished AD from the HC with large effect sizes and were impaired in majority of AD participants (at least four out of six) include: slowed speech rate; shorter sentence length; fewer embeddings; decreased proportion of pronouns; increased proportion of matrix verb with decreased proportion of non-finite verbs; decreased proportion of case marking for nouns with increased proportion of definiteness markers; and semantically reduced idea density and idea efficiency. In addition, disruption in spontaneity and fluency, decreased numbers of reduplications, and decreased proportion of well-formed sentences showed significant group differences with fewer AD participants.
Discussion
We undertook this research to characterize connected speech production and identify linguistic features of Bengali AD participants. The impetus for this work was driven by the fact that an accumulating body of research has shown that speech and language characteristics of connected speech provide a valuable tool for identifying, diagnosing and monitoring progression in AD. However, our knowledge of linguistic features of connected speech in AD is primarily derived from English speakers. This is a problematic situation. The world is full of languages that are linguistically different from English. In fact, the majority of world's population do not speak English as their primary language. Therefore, there is an urgent need to investigate whether linguistic features that are used for characterizing AD in English will be relevant for structurally distinct languages. This is what we set out to find in speakers of Bengali, a pro-drop, Indo-Aryan language, and which is the seventh most spoken language in the world.
The key findings indicate that Bengali AD participants showed both similarities to findings reported from English speaking AD subjects as well as language specific differences from English. Similarities with English speaking literature were decreased speech rate, simplicity of sentence forms and structures, and reduced semantic content.
Critically, differences with English speakers' literature emerged in the domains of linguistic features where Bengali differs, such as pro-drop nature of the language and inflectional properties of nominal and verbal systems. Specifically, Bengali AD participants produced fewer pronouns, which is in contrast with a key feature of English AD speakers who produce an abundance of pronouns in connected speech. Despite Bengali being a highly inflected language, our AD participants showed a similar amount of noun and verb inflections without any obvious difficulties. However, differences did appear in the type of noun inflections that the AD speakers used, in most instances choosing simpler inflectional features.
Overall, connected speech production in these AD participants was characterized by the use of simpler, less complex and operationally less demanding options, with impoverished semantic content. They used shorter and simpler sentences with reduced rate of speech and reduced spontaneity, using fewer pronouns, fewer reduplications, and demonstrated a lack of difficulty with the quantity of noun and verb inflections produced but using inflections that are simpler. In the following paragraphs, we discuss the findings in detail and highlight how this research provides seminal evidence to build future research with different languages.
The finding that our AD participants produced a slower rate with higher number of disruptions to spontaneity because of revisions corroborates existing literature (Sajjadi et al., 2012; Forbes-McKay et al., 2013; Ash and Grossman, 2015). They produced significantly shorter sentences, which were grammatically simpler with minimal embeddings, and at times also fewer well-formed sentences. The majority of AD participants in our study showed difficulty with speech rate (5/6), shorter MLU (6/6), and fewer sentence embeddings (6/6) highlighting the consistency of these features across AD patients. Although poorly formed sentences showed a significant group difference, it arose from only two of the six participants (AD01, AD06). The reason for less well-formed sentences was because the sentences had missing or under specified lexical items, mostly objects or subjects but at times even verbs resulting in incomplete sentences. Recall that unlike English, Bengali allows a more flexible word order, it permits greater leeway to formulate grammatically correct and well-formed sentences. Despite this feature two of the AD participants produced significantly fewer well-formed sentences. These findings of simplified syntactic production are in concordance with AD connected speech literature (Ash et al., 2007; Cuetos et al., 2007; De Lira et al., 2011; Sajjadi et al., 2012; Ahmed et al., 2013; Forbes-McKay et al., 2013; Ash and Grossman, 2015; Fraser et al., 2016).
An interesting question arises as to why these AD participants were producing syntactically and grammatically simpler sentences. Prior AD literature suggests that participants have significant impairments in their memory processes, which contributes to their difficulty in syntactic operations (e.g., Waters et al., 1998). This could indeed be a possibility in our data as most of our participants have lower scores on background memory measures. Another contending explanation is that our AD participants demonstrated grammatical difficulty as noted by other authors (e.g., Fraser et al., 2016). Fraser et al. (2016) noted that the syntactic impairments in their AD participants' picture description had features similar to Broca's aphasia, but commented that “while these deficits resemble Broca's aphasia and progressive nonfluent aphasia in their form, they are less severe, seldom reaching the point of frank agrammatism or telegraphic speech seen in those disorders” (p. 414). The difficulty with syntax and grammar is evident in our participants if we carefully consider the lexical distribution of types of verbs in the narratives. The findings of fewer nonfinite verbs produced by the AD participants correspond to the associated lack of complexity and embedding of their sentences. However, when the embedded clauses were indeed produced, the verbs were appropriately marked for agreement. This suggests that the difficulty was is in the structural complexity of the sentence rather than in inflectional morphology. This is consistent with previous studies in languages with high inflectional morphology, in that, the inflectional morphology is spared in cases of language impairments (Leonard, 2000; Penke, 2009; Auclair-Ouellet et al., 2019). Instead, the participants with AD in our study produced shorter sentences with single matrix verbs. Individual level analyses revealed an increase in the proportion of matrix verb with a corresponding decrease in nonfinite verbs in the majority of the AD participants (see Table 5). Future research using sentence production and comprehension tasks, with different sentence types and varying syntactic complexity would be important to understand the mechanism that is underplaying in the production of syntactically simplified connected speech in AD.
In terms of lexical measures and distribution of various lexical classes, the most salient finding from this research is that Bengali speaking AD showed a reduced proportion of pronouns in their narrative samples. As a group, AD participants produced fewer pronouns; four of the six participants produced significantly fewer pronouns compared to the controls; two produced similar number of pronouns to the controls. Importantly, none of them over produced pronouns. This finding is in stark contrast with the findings from English speaking AD participants where over production of pronouns is a distinctive feature (March et al., 2006; Ahmed et al., 2013; Jarrold et al., 2014; Fraser et al., 2016). Increased production of pronouns has also been reported from AD speakers of Hebrew (Kavé and Levy, 2003; Kavé and Goral, 2016). Recall that Bengali is a pro-drop language and allows dropping of the subject; the subject could be inferred from the other inflected parts of speech. Pro-drop is more common with inflectionally rich languages, where inflectional morphology could be used to infer the referent. In languages where subjects are obligatorily spelled out, such as in English, dropping the subject is not an option. Therefore, AD individuals of those languages such as English, will prefer pronouns over nouns as the former is semantically vague, more frequent in use and thus might be easier to retrieve. In contrast, Bengali allows null-subject (i.e., dropped subject). Participants can drop the subject as null subject is cognitively less costly (Bloom, 1990). However, in English when one has to produce something, a less costly option is usually opted for, which is over-producing the pronoun (Almor et al., 1999). One simple deduction can be drawn from this cross-linguistic observation: when a language allows the avoidance of a linguistic feature or structure, such as subject drop in Bengali, AD participants will avoid it as retrieving and producing the subjects is more demanding. In contrast, when a language does not allow the avoidance of a linguistic feature, such as the obligatory use of a subject in English, AD participants will opt for a cognitively less costly option, that is, the replacement of nouns with pronouns. The important implication for this finding is that over-production of pronouns, which is a characteristic feature in English, might not be a relevant linguistic marker for a pro-drop language, such as Bengali. Research investigating pronoun usage for AD speakers in other pro-drop languages will be of great importance to determine if this pattern holds true across languages.
Reduplication is a frequent lexical feature in Bengali which is employed by speakers to enhance senses of multiplicity, continuation of action, recurrent happening of an event, or emotional state. In a sense, it serves a semantic function but requires word formation processes to generate the reduplicated forms. Using reduplication allows the expression of a richer and enhanced sense of the concept or event; however, lack of use of reduplication is not a linguistic deficit. AD participants' use of fewer reduplications could be further evidence of their difficulty in using complex linguistic operations, in this case, the word formation processes. This could indicate that AD participants have difficulty with complex word formation processes. Reduced reduplication has been reported in individuals with aphasia speaking standard Indonesian (Anjarningsih et al., 2012).
In the context of semantic content analysis—idea density and idea efficiency—reflect the ability to produce relevant content efficiently at a discourse level. Unsurprisingly, results reveal that our AD participants generated less concise information as noted by reduced idea density indicating they needed more words to convey ideas. This resulted in characteristic features of “empty speech” and “non-specificity” of discourse in AD reported in the literature (e.g., Nicholas et al., 1985). Some of these features include empty phrases (e.g., mane hacche “it seems”), deictic terms (e.g., edik odik “this side that side”, tār pare “then”), indefinite terms (e.g., ekṭā “one”, iye “something”), and repetitions (e.g., eṭā ekṭā kukur… kukur “this one is dog…dog”). Along with reduced idea density, AD participants evidenced reduced rate at which meaningful information is conveyed over time, that is, reduced idea efficiency. All of our AD participants (six out of six) showed reduced idea density and idea efficiency in their narrative samples. Reduced information content resulting in limited idea density and idea efficiency is a consistent finding across AD connected speech studies (Nicholas et al., 1985; Croisile et al., 1996; Forbes-McKay and Venneri, 2005; Sajjadi et al., 2012; Ahmed et al., 2013; Forbes-McKay et al., 2013). This highlights the fact that irrespective of the language spoken by AD participants, difficulties in conveying ideas concisely and efficiently are a pervasive difficulty as noted across various production tasks such as conversations (e.g., Dijkstra et al., 2004); picture description (e.g., Ahmed et al., 2013), and interviews (Sajjadi et al., 2012).
Studies investigating morphosyntactic characteristics of connected speech by measuring differences in inflectional properties between AD and controls have been reported from English speakers [see Auclair-Ouellet (2015) for a systematic review of inflectional morphology in primary progressive aphasia and AD]. As English is not an inflectionally rich language, it offers limited opportunity to test morphosyntactic differences between control and AD. In contrast, Bengali has a rich inflectional system for nouns and verbs. The findings from this study show that AD participants and the controls produced comparable proportion of inflected nouns, as noted by the similar noun inflection index as well as comparable proportion of nouns with one and two inflections. This highlights that AD participants were able to produce noun inflections in similar quantity to the controls. This is in contrast with findings from English speaking subjects from the literature who have been reported to have difficulties with nouns with determiners (e.g., Ahmed et al., 2013). This finding is not surprising when viewed with the lens of the literature on acquisition of morphological markers in morphologically rich languages (e.g., Penke, 2012). It has been proposed that morphologically rich and agglutinative systems generally display a greater morphological transparency compared to inflection systems where the inflection is associated with changes to the stem. As such, in these morphologically richer languages, inflectional morphology is acquired earlier in comparison to languages with sparse inflectional morphology (Bates and MacWhinney, 1987; Dressler, 2010). Therefore, in our data preservation of inflectional abilities in AD participants could be a reflection of the stability of these patterns as they might have been acquired earlier.
Distinct differences do appear between the two groups when type of noun inflections was explored in detail (see Figure 1). In AD, definiteness markers were more prevalent in nouns; whilst case marking was under-used (e.g., case-marking jāre “in the jar”; kukurke “to the dog”; definiteness marking jāta “the jar”; kukurta “the dog”). Case marking is grammatical in nature and use of appropriate case markers requires complex morphosyntactic operations. The difficulty with case marking is an indication that AD participants' difficulties in production could be in using complex grammatical operations as use of appropriate case marking requires complex morphosyntactic processes. In contrast, definiteness marker is more semantic in nature and is used as a tool for over specifying a subject or object. This finding highlights the importance of digging deeper into the morphosyntax of languages to understand the core linguistic difficulties across languages, which has the potential to inform about underlying processes as well as aid in developing specific clinical markers for diagnosis.
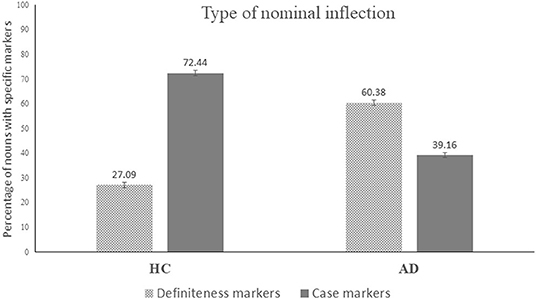
Figure 1. Mean proportion of nouns with definiteness vs. case markers for Alzheimer's Disease (AD) and Healthy Controls (HC). Error bars represent standard error of mean.
In terms of verbal inflections, our AD participants showed no difficulty with generating appropriate inflections for verbs, as noted by verb inflection index and verb complexity score. Any verb they produced was correctly inflected for tense, aspect, and person. Qualitatively, they produced fewer variations in these features (see illustrative examples in Table 3) but overall, they could produce correctly inflected verbs. Research from German speakers with AD (Blanken et al., 1987) and Hebrew speakers with AD (Kavé and Levy, 2003) found no difference between AD and their control groups on verb inflectional abilities. This is in contrast with the greater number of inflectional errors in English-speaking AD patients (Altmann et al., 2001; Sajjadi et al., 2012; Ahmed et al., 2013), difficulty with inflected verbs, auxiliary verbs, gerunds or participles (Fraser et al., 2016); difficulty with verb tense use (Dijkstra et al., 2004) and difficulty with subject verb agreement (Kaprinis and Stavrakaki, 2007). This is an interesting point of discussion as languages such as Bengali, German, Hebrew, who have a more complex and richer verbal inflectional system than English was not precipitating more inflectional errors in AD speakers. The answer could be found in thinking about the nature of this complexity. In these languages, the verbal inflectional system is complex but regular and systematic. That complexity does not equate to difficulty has been shown in morphologically richer languages even in child acquisition literature (e.g., Penke, 2012). As argued earlier, the complex morphological structures that are acquired earlier might have been better preserved. We believe that a future line of research which systematically compares inflectional morphology and its breakdown across different languages stands to inform our understanding of core linguistic deficits across various dementia syndromes.
Considerations for Future Research and Limitations
In this section, we share our experiences and “lessons learnt” from embarking on connected speech research in an unexplored language, especially in determining an appropriate task and linguistic analysis framework for the data. Given that research is a resource intensive enterprise, we believe that documenting these observations would be useful for future researchers interested in similar research in neurological impairments in languages that have not yet been studied. We also highlight limitations of our current study and suggest future research directions.
First, if one is interested in characterizing linguistic patterns of connected speech in AD in a language, which has yet not been documented, the choice of task has important implications for the conclusions that could be drawn based on the findings. Picture description is quick and easy to administer. However, several studies with neurological impairments have reported that picture description often generates impoverished speech with limited types of sentence production, and patients often default to listing of the elements in the picture rather than producing “connected” speech per se (e.g., Olness, 2006; Armstrong et al., 2013). Interviews on the other hand are time-consuming and lack consistency across participants. It is ideal to use a linguistic task, which allows the person to generate connected speech samples with a story line (e.g., narrative story retell tasks). Grossman (2012) noted that connected speech features in dementia “are best quantified by a semi-structured protocol that is long enough to show the variety of utterances that can occur in spontaneous speech, yet is standardized enough so that all participants have an opportunity to produce speech prompted by the same content” (p. 546). The type of data generated in story narratives, such as Cinderella or Frog Story, affords opportunities to analyze connected speech both at micro- and macro-linguistic levels. It has also been suggested that it is prudent to use multiple elicitation methods in research studies to fully capture production differences across tasks (Boyle, 2015; Stark, 2019), which in turn can help decide the best task for clinical use. For our study, we used the Frog story as it allowed richer output and was culturally appropriate for our participants. Once a baseline of deficits is established in a new language using a semi-structured task, further research could be conducted to compare language production across different tasks (e.g., story narrative, picture description). Our current research focused on the micro-linguistic structures of production; macro-linguistic analysis of narratives remains a productive area of research in AD. Future research using multi-level analyses of micro-and macro-linguistic structures will further improve our understanding of connected speech profiles in AD.
Second, having an excellent team with interdisciplinary expertise is important. Critically, in-depth knowledge and understanding of linguistics of the language studied is essential. Without the linguistic expertise, it is possible to miss important features of the language that could serve as linguistic markers of the impairments. As illustrated from the current research, the differences between AD and controls in the type of nominal inflections used highlights specific linguistic differences between the two groups; whilst restricting our analysis to overall noun inflection index would not have revealed the true nature of the deficits in AD participants. Future research that aims to characterize impairments in languages that have not been studied should strive to provide an exhaustive characterization of the linguistic features as these documentations over time could lead to a greater understanding of how different languages breakdown in AD.
Third, linked with the linguistic knowledge is the choice of analysis framework. We used the well-tested multidimensional analysis system of the QPA and augmented the framework with additional measures to capture Bengali specific linguistic features, as well as semantic content analysis. We found this approach useful, as it remained in line with the analysis framework that most researchers in this field are using (Slegers et al., 2018). Using a well-established method for analyzing and reporting data that is accessible to readers in the field would be an important consideration for future researchers. This will ensure that research findings from new languages remain comprehensible for readers who are non-speakers of those languages. We are happy to discuss and share with interested researchers the steps we followed in augmenting the QPA to suit the needs for Bengali.
Fourth, although it might be obvious, we emphasize the importance of clear task instructions and well-documented administration protocol especially for testing linguistically and culturally diverse populations. For example, bilingual clients who are proficient in both languages and in their naturalistic speech might code-switch effortlessly. In these instances, it will be beneficial to mention if the testing was conducted in bilingual vs. monolingual mode and how strictly those modes were followed. The corpus of language output, its analysis and interpretation would be different when bilinguals are allowed to use bilingual mode instead of monolingual mode. Future research with bilingual clients including various modes of elicitation stands to inform language processing and language control in them, and whether bilinguals can harness the power of two languages to provide a more productive output.
Fifth, recruiting a large sample of well-controlled and well-characterized clinical group remains a perennial difficulty for researchers. For this research we had six AD participants. A larger sample of AD participants would, of course, be desirable, although such number is not unusual in clinical studies particularly where participants belong to an under-represented group. The methodology was selected to mitigate challenges of generalization. As such, statistical analysis captured findings at both the group and individual levels, offering a comprehensive, detailed and nuanced approach to the profiling of linguistic impairments in a language which has not yet been linguistically studied in depth in neurological impairments. Future research with larger sample sizes with varying severity is desirable. As seen amongst the AD participants in this research that higher overall dementia severity did not necessarily reflect most difficulties in linguistic features. We urge caution in establishing direct link with overall dementia severity to the linguistic profiles of AD participants. In addition, consorted efforts for data sharing and data deposits amongst researchers and clinicians would enable collection of larger datasets.
Sixth, it is likely that non-English speakers would come from culturally diverse populations and perhaps from non-Western countries. In such situations the challenges of undertaking cross-cultural neuropsychological and neurolinguistic research should be acknowledged with clear mention of how tasks and tools used for profiling a client are appropriate and reliable. For instance, a published version of ACE for Bengali does not yet exist. Accordingly, the adapted version was used for this research, reliably adapted at the regional center we recruited from. Moreover, the population we recruited were highly educated pre-morbidly, and most were working professionally. Therefore, we did not face the typical challenges of testing lower literacy populations. However, going forward, having protocols and training in place to ensure reliability of methods for generating quality data will be of utmost importance.
Summary and Conclusions
In summary, in this research we characterize connected speech production in Bengali AD participants. Our research is the first of its kind to provide a comprehensive and detailed characterization of linguistic features in Bengali speaking AD individuals. Such detailed characterization in South Asian languages is currently non-existent. The findings highlight that Bengali AD participants showed both similarities to findings reported from English speaking AD subjects as well as language specific differences compared to English. Similarities with English speaking literature gravitated toward decreased speech rate, simplicity of sentence forms and structures, and reduced semantic content. Critically, differences with English speakers' literature emerged in the domains of Bengali specific linguistic features; fewer pronouns, fewer reduplications and a similar quantity of noun and verb inflections without obvious errors. Specifically, connected speech productions of Bengali AD participants were characterized by: impoverished semantic content with higher rate of disruption to spontaneity of speech and slower rate of speech; use of simpler, shorter and grammatically less complex sentences with limited embeddings; use of fewer pronouns and fewer reduplications; similar level of noun and verb inflections, but using inflections that are operationally simpler such as definiteness markers in nouns instead of case markers. This paints the picture of semantic difficulties along with differences in grammaticality of production where AD individuals choose simpler and operationally less demanding options.
This study is a significant step forward for improving both our theoretical understanding of linguistic deficits in AD and clinical implications of implementing these for improving diagnosis and monitoring progress in AD. Theoretically, this research contributes to the understanding of language impairments in neurodegenerative diseases; this could ultimately identify the core underlying impairments that result in specific linguistic profiles. The study also provides a framework for cross-linguistic comparisons across structurally distinct and under-explored languages, and also challenges the notion that more complex morphology is more difficult for AD. This research begins to address the urgent need to develop language specific linguistic markers for AD, which in turn can aid in creating clinical guidance for assessment of this community of patients in dementia services to help with sensitive and, importantly specific diagnosis of dementia disorders.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics Statement
The studies involving human participants were reviewed and approved by University of Reading (Ref: 2017-035-AB). The patients/participants provided their written informed consent to participate in this study.
Author Contributions
AB, AD, and SA: conceptualization. AD and RN: participant recruitment and data collection. AB, ND, and MD: linguistic framework development. AD, RN, AB, and SA: neuropsychological data coding and interpretation. AB, ND, MD, TD, YC, and SA: linguistic data coding and analysis. AB, YC, and TD: statistical analysis. AB, ND, SA, and MD: writing and critical review. All authors contributed to the article and approved the submitted version.
Funding
AB was supported by the Centre of Literacy and Multilingualism (CELM) pump priming grant from the University of Reading. ND was supported by the British Academy International Visiting Fellowship Grant (VF1/103620; Visiting Fellowships Programme 2018). TD was supported by the University of Reading's 2020 UROP summer studentship.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We are indebted to all our participants for their enthusiasm and time for participation in this research. We are grateful to the funding bodies for supporting this research. We thank Theodoros Marinis, George Pontikas, Vesna Stojanovik, Doug Saddy, and Elizabeth Rochon for productive and insightful discussions regarding the linguistic interpretation of the data. We also thank Mousumi Chatterjee and Anisha Sinha for assistance with Bengali transcriptions.
References
Ahmed, S., Haigh, A. M. F., de Jager, C. A., and Garrard, P. (2013). Connected speech as a marker of disease progression in autopsy-proven Alzheimer's disease. Brain 136, 3727–3737. doi: 10.1093/brain/awt269
Almor, A., Kempler, D., MacDonald, M. C., Andersen, E. S., and Tyler, L. K. (1999). Why do Alzheimer patients have difficulty with pronouns? Working memory, semantics, and reference in comprehension and production in Alzheimer's disease. Brain Lang. 67, 202–227. doi: 10.1006/brln.1999.2055
Altmann, L., Kempler, D., and Andersen, E. S. (2001). Speech errors in Alzheimer's disease: reevaluating morphosyntactic preservation. J. Speech Lang. Hear. Res. 44, 1069–1082. doi: 10.1044/1092-4388(2001/085)
Alzheimer's Disease International (2021). Dementia Statistics. Available online at: https://www.alzint.org/about/dementia-facts-figures/dementia-statistics/ (accessed March 2, 2021).
Anjarningsih, H. Y., Haryadi-Soebadi, R. D., Gofir, A., and Bastiaanse, R. (2012). Characterising agrammatism in standard Indonesian. Aphasiology 26, 757–784. doi: 10.1080/02687038.2011.648370
Armstrong, E., Ferguson, A., and Simmons-Mackie, N. (2013). “Discourse and functional approaches to aphasia,” in Aphasia and Related Neurogenic Communication Disorders, eds I. Papathanasiou, P. Coppens, and C. Potagas (Boston, MA: Jones and Bartlett Publishers), 217–232.
Ash, S., and Grossman, M. (2015). “Why study connected speech production?,” in Cognitive Neuroscience of Natural Language Use, ed R. M. Willems (Cambridge: Cambridge University Press), 29–58. doi: 10.1017/CBO9781107323667.003
Ash, S., Moore, P., Vesely, L., and Grossman, M. (2007). The decline of narrative discourse in Alzheimer's disease. Brain Lang. 103, 181–182. doi: 10.1016/j.bandl.2007.07.105
Auclair-Ouellet, N. (2015). Inflectional morphology in primary progressive aphasia and Alzheimer's disease: a systematic review. J. Neurolinguist. 34, 41–64. doi: 10.1016/j.jneuroling.2014.12.002
Auclair-Ouellet, N., Pythoud, P., Koenig-Bruhin, M., and Fossard, M. (2019). Inflectional morphology in fluent aphasia: a case study in a highly inflected language. Lang. Speech 62, 250–259. doi: 10.1177/0023830918765897
Bates, E., and MacWhinney, B. (1987). “Competition, variation, and language learning,” in Mechanisms of Language Acquisition, ed B. MacWhinney (Mahwah, NJ: Lawrence Erlbaum Associates, Inc), 157–193.
Berndt, R. S., Wayland, S., Rochon, E., Saffran, E., and Schwartz, M. (2000). Quantitative Production Analysis: A Training Manual for the Analysis of Aphasic Sentence Production. Hove: Psychology Press.
Beveridge, M. E., and Bak, T. H. (2011). The languages of aphasia research: bias and diversity. Aphasiology 25, 1451–1468. doi: 10.1080/02687038.2011.624165
Blanken, G., Dittmann, J., Haas, J. C., and Wallesch, C. W. (1987). Spontaneous speech in senile dementia and aphasia: implications for a neurolinguistic model of language production. Cognition 27, 247–274. doi: 10.1016/S0010-0277(87)80011-2
Boschi, V., Catricala, E., Consonni, M., Chesi, C., Moro, A., and Cappa, S. F. (2017). Connected speech in neurodegenerative language disorders: a review. Front. Psychol. 8:269. doi: 10.3389/fpsyg.2017.00269
Boyle, M. (2015). Stability of word-retrieval errors with the AphasiaBank stimuli. Am. J. Speech Lang. Pathol. 24, S953–S960. doi: 10.1044/2015_AJSLP-14-0152
Caramazza, A., and Zurif, E. B. (1976). Dissociation of algorithmic and heuristic processes in language comprehension: evidence from aphasia. Brain Lang. 3, 572–582. doi: 10.1016/0093-934X(76)90048-1
Carlomagno, S., Santoro, A., Menditti, A., Pandolfi, M., and Marini, A. (2005). Referential communication in Alzheimer's type dementia. Cortex 41, 520–534. doi: 10.1016/S0010-9452(08)70192-8
Crawford, J. R., and Garthwaite, P. H. (2002). Investigation of the single case in neuropsychology: confidence limits on the abnormality of test scores and test score differences. Neuropsychologia 40, 1196–1208. doi: 10.1016/S0028-3932(01)00224-X
Crawford, J. R., and Garthwaite, P. H. (2006). Methods of testing for a deficit in single-case studies: evaluation of statistical power by Monte Carlo simulation. Cogn. Neuropsychol. 23, 877–904. doi: 10.1080/02643290500538372
Crawford, J. R., Garthwaite, P. H., and Porter, S. (2010). Point and interval estimates of effect sizes for the case-controls design in neuropsychology: rationale, methods, implementations, and proposed reporting standards. Cogn. Neuropsychol. 27, 245–260. doi: 10.1080/02643294.2010.513967
Crawford, J. R., and Howell, D. C. (1998). Comparing an individual's test score against norms derived from small samples. Clin. Neuropsychol. 12, 482–486. doi: 10.1076/clin.12.4.482.7241
Croisile, B., Ska, B., Brabant, M. J., Duchene, A., Lepage, Y., Aimard, G., et al. (1996). Comparative study of oral and written picture description in patients with Alzheimer's disease. Brain Lang. 53, 1–19. doi: 10.1006/brln.1996.0033
Crutch, S. J., Lehmann, M., Warren, J. D., and Rohrer, J. D. (2013). The language profile of posterior cortical atrophy. J. Neurol. Neurosurg. Psychiatr. 84, 460–466. doi: 10.1136/jnnp-2012-303309
Cuetos, F., Arango-Lasprilla, J. C., Uribe, C., Valencia, C., and Lopera, F. (2007). Linguistic changes in verbal expression: a preclinical marker of Alzheimer's disease. J. Int. Neuropsychol. Soc. 13, 433–439. doi: 10.1017/S1355617707070609
Das, S. K., Banerjee, T. K., Mukherjee, C. S., Bose, P., Biswas, A., Hazra, A., et al. (2006). An urban community-based study of cognitive function among non-demented elderly population in India. Neurol. Asia 11, 37–48.
Dash, N. S. (2015). A Descriptive Study of Bengali Words. New Delhi: Cambridge University Press. doi: 10.1017/CBO9781107585706
De Lira, J. O., Ortiz, K. Z., Campanha, A. C., Bertolucci, P. H. F., and Minett, T. S. C. (2011). Microlinguistic aspects of the oral narrative in patients with Alzheimer's disease. Int. Psychogeriatr. 23, 404–412. doi: 10.1017/S1041610210001092
Dijkstra, K., Bourgeois, M. S., Allen, R. S., and Burgio, L. D. (2004). Conversational coherence: discourse analysis of older adults with and without dementia. J. Neurolinguist. 17, 263–283. doi: 10.1016/S0911-6044(03)00048-4
Dressler, W. U. (2010). A typological approach to first language acquisition. Lang. Acquisit. Across Linguist. Cogn. Syst. 52, 109–123. doi: 10.1075/lald.52.09dre
Ehrlich, J. S., Obler, L. K., and Clark, L. (1997). Ideational and semantic contributions to narrative production in adults with dementia of the Alzheimer's type. J. Commun. Disord. 30, 79–99. doi: 10.1016/0021-9924(95)00053-4
Feise, R. J. (2002). Do multiple outcome measures require p-value adjustment? BMC Med. Res. Methodol. 2, 1–4. doi: 10.1186/1471-2288-2-8
Filiou, R. P., Bier, N., Slegers, A., Houzé, B., Belchior, P., and Brambati, S. M. (2020). Connected speech assessment in the early detection of Alzheimer's disease and mild cognitive impairment: a scoping review. Aphasiology 34, 723–755. doi: 10.1080/02687038.2019.1608502
Forbes-McKay, K., Shanks, M. F., and Venneri, A. (2013). Profiling spontaneous speech decline in Alzheimer's disease: a longitudinal study. Acta Neuropsychiatr. 25, 320–327. doi: 10.1017/neu.2013.16
Forbes-McKay, K. E., and Venneri, A. (2005). Detecting subtle spontaneous language decline in early Alzheimer's disease with a picture description task. Neurol. Sci. 26, 243–254. doi: 10.1007/s10072-005-0467-9
Fraser, K. C., Meltzer, J. A., Graham, N. L., Leonard, C., Hirst, G., Black, S. E., et al. (2014). Automated classification of primary progressive aphasia subtypes from narrative speech transcripts. Cortex 55, 43–60. doi: 10.1016/j.cortex.2012.12.006
Fraser, K. C., Meltzer, J. A., and Rudzicz, F. (2016). Linguistic features identify Alzheimer's disease in narrative speech. J. Alzheimer's Dis. 49, 407–422. doi: 10.3233/JAD-150520
Gorno-Tempini, M. L., Hillis, A. E., Weintraub, S., Kertesz, A., Mendez, M., Cappa, S. E. E. A., et al. (2011). Classification of primary progressive aphasia and its variants. Neurology 76, 1006–1014. doi: 10.1212/WNL.0b013e31821103e6
Grossman, M. (2012). The non-fluent/agrammatic variant of primary progressive aphasia. Lancet Neurol. 11, 545–555. doi: 10.1016/S1474-4422(12)70099-6
Hsieh, S., Schubert, S., Hoon, C., Mioshi, E., and Hodges, J. R. (2013). Validation of the Addenbrooke's Cognitive Examination III in frontotemporal dementia and Alzheimer's disease. Dement. Geriatr. Cogn. Disord. 36, 242–250. doi: 10.1159/000351671
Jarrold, W., Peintner, B., Wilkins, D., Vergryi, D., Richey, C., Gorno-Tempini, M. L., et al. (2014). “Aided diagnosis of dementia type through computerbased analysis of spontaneous speech,” in Proceedings of the Workshop on Computational Linguistics and Clinical Psychology, ACL (Baltimore, MD), 27–37. doi: 10.3115/v1/W14-3204
Kaprinis, S., and Stavrakaki, S. (2007). Morphological and syntactic abilities in patients with Alzheimer's disease. Brain Lang. 1, 59–60. doi: 10.1016/j.bandl.2007.07.044
Kavé, G., and Goral, M. (2016). Word retrieval in picture descriptions produced by individuals with Alzheimer's disease. J. Clin. Exp. Neuropsychol. 38, 958–966. doi: 10.1080/13803395.2016.1179266
Kavé, G., Leonard, C., Cupit, J., and Rochon, E. (2007). Structurally well-formed narrative production in the face of severe conceptual deterioration: a longitudinal case study of a woman with semantic dementia. J. Neurolinguist. 161–177. doi: 10.1016/j.jneuroling.2006.06.003
Kavé, G., and Levy, Y. (2003). Morphology in picture descriptions provided by persons with Alzheimer's disease. J. Speech Lang. Hear. Res. 46, 341–352. doi: 10.1044/1092-4388(2003/027)
Lahiri, D., Dubey, S., Ardila, A., Sawale, V. M., Das, G., and Ray, B. K. (2019). Lesion-aphasia discordance in acute stroke among Bengali-speaking patients: frequency, pattern, and effect on aphasia recovery. J. Neurolinguist. 52:100859. doi: 10.1016/j.jneuroling.2019.100859
Leonard, L. B. (2000). “Specific language impairment across languages,” in Speech and Language Impairments in Children: Causes, Characteristics, Intervention and Outcome, eds D. V. M. Bishop and L. B. Leonard (Hove: Psychology Press), 115–129.
Macoir, J., Turgeon, Y., and Laforce, R. J. (2015). “Language processes in delirium and dementia,” in International Encyclopedia of the Social & Behavioral Sciences, Vol 13, 2nd Edn, J. D. Wright (Oxford: Elsevier), 360–367. doi: 10.1016/B978-0-08-097086-8.54031-8
March, E. G., Wales, R., and Pattison, P. (2006). The uses of nouns and deixis in discourse production in Alzheimer's disease. J. Neurolinguist. 19, 311–340. doi: 10.1016/j.jneuroling.2006.01.001
Mathuranath, P., George, A., Cherian, P., Mathew, R., and Sarma, P. (2005). Instrumental activities of daily living scale for dementia screening in elderly people. Int. Psychogeriatr. 17, 461–474. doi: 10.1017/S1041610205001547
Mckhann, G., Drachman, D., Folstein, M., Katzman, R., Price, D., and Stadlan, E. M. (1984). Clinical diagnosis of Alzheimer's disease: report of the NINCDS-ADRDA Work Group under the auspices of Department of Health and Human Services Task Force on Alzheimer's Disease. Neurology 34, 939–944. doi: 10.1212/WNL.34.7.939
McKhann, G. M., Knopman, D. S., Chertkow, H., Hyman, B. T., Jack, C. R. J.r, et al. (2011). The diagnosis of dementia due to Alzheimer's disease: recommendations from the National Institute on Aging-Alzheimer's Association workgroups on diagnostic guidelines for Alzheimer's disease. Alzheimer's Dement. 7, 263–269. doi: 10.1016/j.jalz.2011.03.005
Morris, J. C. (1993). The Clinical Dementia Rating (CDR): current version and scoring rules. Neurology 43, 2412–2414. doi: 10.1212/WNL.43.11.2412-a
Moscovitch, M., and Umilta, C. (1990). “Modularity and neuropsychology: modules and central processes in attention and memory,” in Modular Deficits in Alzheimer-Type Dementia, ed M. F. Schwartz (Cambridge, MA: MIT Press), 1–58.
Mueller, K. D., Hermann, B., Mecollari, J., and Turkstra, L. S. (2018). Connected speech and language in mild cognitive impairment and Alzheimer's disease: a review of picture description tasks. J. Clin. Exp. Neuropsychol. 40, 917–939. doi: 10.1080/13803395.2018.1446513
Nicholas, L. E., and Brookshire, R. H. (1993). A system for quantifying the informativeness and efficiency of the connected speech of adults with aphasia. J. Speech Lang. Hear. Res. 36, 338–350. doi: 10.1044/jshr.3602.338
Nicholas, M., Obler, L. K., Albert, M. L., and Helm-Estabrooks, N. (1985). Empty speech in Alzheimer's disease and fluent aphasia. J. Speech Lang. Hear. Res. 28, 405–410. doi: 10.1044/jshr.2803.405
Olness, G. S. (2006). Genre, verb, and coherence in picture-elicited discourse of adults with aphasia. Aphasiology 20, 175–187. doi: 10.1080/02687030500472710
Paradis, M. (1988). Recent developments in the study of agrammatism: their import for the assessment of bilingual aphasia. J. Neurolinguist. 3, 127–160. doi: 10.1016/0911-6044(88)90012-7
Patra, A., Bose, A., and Marinis, T. (2020). Lexical and cognitive underpinnings of verbal fluency: evidence from Bengali-English Bilingual Aphasia. Behav. Sci. 10:155. doi: 10.3390/bs10100155
Penke, M. (2009). Morphology and language disorder. Handb. Clin. Linguist. 56:212. doi: 10.1002/9781444301007.ch13
Penke, M. (2012). “The acquisition of inflectional morphology,” in The Handbook of Morphology, eds A. Spencer and A. Zwicky (Oxford: Blackwell). Available online at: https://www.hf.uni-koeln.de/34653 (accessed April 2, 2021).
Perneger, T. V. (1998). What's wrong with Bonferroni adjustments. BMJ 316, 1236–1238. doi: 10.1136/bmj.316.7139.1236
Prince, M., Wimo, A., Guerchet, M., Ali, G.-C., Wu, Y.-T., and Prina, M. (2015). World Alzheimer Report 2015. The Global Impact of Dementia: An Analysis of Prevalence, Incidence, Costs and Trends. London: Alzheimer's Disease International.
Rochon, E., Saffran, E. M., Berndt, R. S., and Schwartz, M. F. (2000). Quantitative analysis of aphasic sentence production: further development and new data. Brain Lang. 72, 193–218. doi: 10.1006/brln.1999.2285
Saffran, E. M., Berndt, R. S., and Schwartz, M. F. (1989). The quantitative analysis of agrammatic production: procedure and data. Brain Lang. 37, 440–479. doi: 10.1016/0093-934X(89)90030-8
Sajjadi, S. A., Patterson, K., Tomek, M., and Nestor, P. J. (2012). Abnormalities of connected speech in semantic dementia vs. Alzheimer's disease. Aphasiology 26, 847–866. doi: 10.1080/02687038.2012.654933
Slegers, A., Filiou, R. P., Montembeault, M., and Brambati, S. M. (2018). Connected speech features from picture description in Alzheimer's disease: a systematic review. J. Alzheimer's Dis. 65, 519–542. doi: 10.3233/JAD-170881
Snowdon, D. A., Kemper, S. J., Mortimer, J. A., Greiner, L. H., Wekstein, D. R., and Markesbery, W. R. (1996). Linguistic ability in early life and cognitive function and Alzheimer's disease in late life: findings from the Nun Study. J. Am. Med. Assoc. 275, 528–532. doi: 10.1001/jama.1996.03530310034029
Stark, B. C. (2019). A comparison of three discourse elicitation methods in aphasia and age-matched adults: implications for language assessment and outcome. Ame. J. Speech Lang. Pathol. 28, 1067–1083. doi: 10.1044/2019_AJSLP-18-0265
Streiner, D. L. (2009). From the corrections officer: why we correct for multiple tests. Can. J. Psychiatr. 54, 351–352. doi: 10.1177/070674370905400601
Streiner, D. L., and Norman, G. R. (2011). Correction for multiple testing: is there a resolution? Chest 140, 16–18. doi: 10.1378/chest.11-0523
Taler, V., and Philips, N. A. (2008). Language performance in Alzheimer's disease and mild cognitive impairment: a comparative review. J. Clin. Exp. Neuropsychol. 30, 501–556. doi: 10.1080/13803390701550128
Waters, G. S., Rochon, E., and Caplan, D. (1998). Task demands and sentence comprehension in patients with dementia of the Alzheimer's type. Brain Lang. 62, 361–397. doi: 10.1006/brln.1997.1880
Keywords: speech analysis, Bengali, pronoun, semantic, Alzheimer's disease, connected speech, syntax, micro-linguistics
Citation: Bose A, Dash NS, Ahmed S, Dutta M, Dutt A, Nandi R, Cheng Y and D. Mello TM (2021) Connected Speech Characteristics of Bengali Speakers With Alzheimer's Disease: Evidence for Language-Specific Diagnostic Markers. Front. Aging Neurosci. 13:707628. doi: 10.3389/fnagi.2021.707628
Received: 10 May 2021; Accepted: 28 July 2021;
Published: 07 September 2021.
Edited by:
Adolfo M. García, Universidad de San Andrés, ArgentinaReviewed by:
Mira Goral, The City University of New York, United StatesFacundo Carrillo, University of Buenos Aires, Argentina
Copyright © 2021 Bose, Dash, Ahmed, Dutta, Dutt, Nandi, Cheng and D. Mello. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Arpita Bose, YS5ib3NlQHJlYWRpbmcuYWMudWs=