 Shahbaz Ahmed1
Shahbaz Ahmed1 Raghavan Varadarajan
Raghavan Varadarajan
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Mol. Biosci. , 21 January 2022
Sec. Biological Modeling and Simulation
Volume 8 - 2021 | https://doi.org/10.3389/fmolb.2021.800819
This article is part of the Research Topic Integrative Structural Biology of Proteins and Macromolecular Assemblies: Bridging Experiments and Simulations View all 10 articles
Accurate prediction of residue burial as well as quantitative prediction of residue-specific contributions to protein stability and activity is challenging, especially in the absence of experimental structural information. This is important for prediction and understanding of disease causing mutations, and for protein stabilization and design. Using yeast surface display of a saturation mutagenesis library of the bacterial toxin CcdB, we probe the relationship between ligand binding and expression level of displayed protein, with in vivo solubility in E. coli and in vitro thermal stability. We find that both the stability and solubility correlate well with the total amount of active protein on the yeast cell surface but not with total amount of expressed protein. We coupled FACS and deep sequencing to reconstruct the binding and expression mean fluorescent intensity of each mutant. The reconstructed mean fluorescence intensity (MFIseq) was used to differentiate between buried site, exposed non active-site and exposed active-site positions with high accuracy. The MFIseq was also used as a criterion to identify destabilized as well as stabilized mutants in the library, and to predict the melting temperatures of destabilized mutants. These predictions were experimentally validated and were more accurate than those of various computational predictors. The approach was extended to successfully identify buried and active-site residues in the receptor binding domain of the spike protein of SARS-CoV-2, suggesting it has general applicability.
Mutagenesis is often used to generate variants of proteins with improved biophysical properties such as solubility and activity and to understand protein function. The advancement of high-throughput mutagenesis techniques has enabled the generation of a large number of variants of a protein in a short span of time, in a massively parallelizable manner (Zheng et al., 2004; Jain and Varadarajan, 2014; Wrenbeck et al., 2016). If an appropriate functional assay to score protein activity in vivo exist, it is possible to infer the relative activity of each variant in the library, through library screening coupled to next generation sequencing (Fowler et al., 2010; Adkar et al., 2012; Matreyek et al., 2018). However, there is a dearth of efficient, high-throughput methods to measure the solubility and stability of multiple protein variants in parallel, and to discriminate between buried and active-site residues solely using mutational data (Bhasin and Varadarajan, 2021).
Yeast surface display (YSD) is commonly used as a tool to identify protein variants with improved biophysical properties (Schweickhardt et al., 2003; Jones et al., 2006). YSD is preferable to bacterial expression for disulfide containing or glycosylated proteins. Agglutinin based Aga2p is the most widely used system to display proteins on the yeast cell surface (Shusta et al., 2008). Aga2p is a small protein (7.5 kDa), covalently linked via disulphide linkages to the yeast cell surface protein Aga1p (Boder and Wittrup, 1997). Previous studies have shown that the amount of protein displayed on the yeast cell surface is directly correlated to the amount of protein secreted by the cells, as well as the thermal stability of the protein (Shusta et al., 1999). However, in other studies where the secretion efficiency (Hagihara and Kim, 2002) or yeast cell surface expression of proteins was measured, no such correlation was observed (Park et al., 2006; Piatesi et al., 2006). Proteolysis of yeast surface displayed proteins has also been used to differentiate properly folded, stable variants from unstructured variants or molten globules, as a proxy for stabilization (Chevalier et al., 2017; Rocklin et al., 2017; Basanta et al., 2020). However, this has primarily been applied to relatively small proteins (Chevalier et al., 2017; Rocklin et al., 2017; Dou et al., 2018; Basanta et al., 2020).
A previous study which showed correlation between stability and expression levels was carried out on a limited number of mutants, that were studied individually. In addition, the WT protein itself had a very low Tm (Shusta et al., 1999). It has also been suggested that if the stability of a protein crosses a certain threshold, its expression does not increase linearly with increase in stability and it is therefore difficult to distinguish stable mutants from less stable ones, using only expression as the criterion (Traxlmayr and Shusta, 2017). With a very high level of yeast surface expression for unstable variants, the yeast quality control system may not be able to differentiate between properly folded, unfolded or molten globule like proteins. However, once displayed on the yeast cell surface such mutants may unfold or aggregate and hence will not bind to a tertiary structure specific ligand or cognate partner.
To verify the above hypothesis, we used Escherichia. coli (E.coli) CcdB as a model protein. CcdB is the toxin component of the CcdAB toxin-antitoxin (TA) module which binds both free DNA Gyrase and the DNA Gyrase-DNA complex, these are referred to as inhibition and poisoning respectively. Formation of the poisoned CcdB:DNA Gyrase:DNA ternary complex stalls replication and causes cell death (Bernard and Couturier, 1992). The other component of this TA module codes for an antitoxin CcdA, which neutralizes the toxicity of the CcdB toxin upon binding to CcdB. A mutation of Arginine to Cysteine in the DNA Gyrase subunit A (GyrA) at residue 462 can abolish the binding of Gyrase to CcdB (Bernard and Couturier, 1992). The CSH501 E. coli strain carries this mutation in the gene of the gyrA subunit which makes it insensitive to CcdB (Bajaj et al., 2008). In a previous study, a single-site saturation mutagenesis library of CcdB was generated and the mutants were scored based on their in vivo growth phenotype (MSseq score) (Adkar et al., 2012). In E. coli, a good correlation was found between the MSseq score of ∼70 mutants with either ΔTm of purified protein (r = 0.65) or in vivo solubility in E. coli (r = 0.69) (Tripathi et al., 2016). In contrast to plate based phenotypes, YSD provides greater flexibility and improved quantitation. We therefore wished to explore the correlation between the amount of surface expression or ligand binding seen with YSD, with thermal stability and E. coli in vivo solubility using this large set of characterized mutants, which had a range of in vitro thermal stability and in vivo solubility.
We initially examined 30 different variants of CcdB. Mutants were chosen so as to have varying solubility (when expressed in E. coli), in vitro thermal stability, accessibility and residue depth. Fewer mutants were chosen for exposed residues, where most mutants are tolerated. Residue V18 is one of the most highly buried residues in CcdB and several mutants which span a range of thermal stability and in vivo solubility were chosen at this position. The in vivo solubility of these mutants ranged from completely soluble to insoluble. We did not find a good correlation between total expressed protein amount on the yeast cell surface and either in vivo solubility in E. coli, or in vitro determined thermal stability. However, a better correlation was observed between the amount of active protein on the yeast cell surface (i.e., the amount of bound ligand) with in vivo solubility/thermal stability. In the yeast cell surface display system (Chao et al., 2006), activity was monitored by measuring the extent of binding of yeast cell surface displayed CcdB to a FLAG tagged fragment of GyrA14 as described previously (Sahoo et al., 2015).
Multiple rounds of sorting enrich mutants which have the highest expression and binding on the yeast cell surface. Sorting in such a way may lead to the identification of mutants with better biophysical properties, however, it does not give any information about the relative activity of all the mutants in a library. We coupled FACS and deep sequencing to reconstruct the MFI (MFIseq) of each mutant in the Site Saturation Mutagenesis (SSM) library of CcdB, using single round FACS sorting methodology. We use this parameter MFIseq, to rank all the mutants based on their activity to generate the mutational landscape or distribution of fitness effects (DFE). We found that the DFE generated using binding was more accurate than the DFE generated using expression. Overall, our MFIseq scoring parameter could readily discriminate between stable and destabilized mutants of CcdB in a highly multiplexed manner.
It is well known that mutations that affect activity occur primarily at either surface exposed residues directly involved in binding or catalysis or at buried residues important for folding and stability. It has been difficult to distinguish between these two classes of residues, solely from mutational data (Bhasin and Varadarajan, 2021). We show here that by examining the effects of charged substitution on surface expression we can discriminate between the two classes of residues. To further validate the approach described above, we analyzed previously published saturation mutagenesis YSD expression and binding data for the receptor binding domain (RBD) of SARS-CoV-2 to its ligand ACE-2 (Starr et al., 2020). We could successfully predict both binding-site and buried residues solely from the mutational data in this system as well.
E.coli CSH501 strain carries a mutation in the gyrA gene which abolishes inhibition and poisoning by CcdB (Bajaj et al., 2008). The EBY100 strain of Saccharomyces cerevisiae has the aga1 gene under the Gal1 promoter for inducible expression and a TRP1 auxotrophic mutation. The strain lacks the aga2 gene, so only Aga2p fused protein expressed from the plasmid, will form a complex with the Aga1p for yeast cell surface display (Boder and Wittrup, 2000). The ccdB gene was cloned in the pBAD24 plasmid for controllable expression in E. coli. ccdB mutants were cloned in the pPNLS shuttle vector for yeast cell surface expression (Najar et al., 2017).
ccdB mutants in pBAD24 were generated using three fragment Gibson assembly. Briefly, ccdB was amplified in two fragments using two sets of oligos. For each fragment one of the oligos binds to the vector and the other binds to the gene. The primer of both fragments which bind to the gene were completely overlapping and contained the desired mutation. The fragments were gel extracted and Gibson assembled with NdeI and HindIII digested pBAD24 vector. The Gibson assembled product was electroporated in E. coli CSH501 strain and positive transformants were selected on LB agar media containing ampicillin (100 μg/ml). The sequence was confirmed by Sanger sequencing. Sequence confirmed WT or mutant ccdB in pBAD24 vector was used as a template for PCR to amplify the ccdB gene by Vent DNA polymerase. The PCR amplified product was co-transformed with SfiI digested pPNLS vector in the EBY100 strain of Saccharomyces cerevisiae using LiAc/SS carrier DNA/PEG method for in vivo recombination (Gietz and Schiestl, 2007). Positive transformants were selected on SDCAA Tryptophan dropout media plates and the sequence was confirmed by Sanger sequencing.
WT and mutant CcdB was purified as described previously (Chattopadhyay and Varadarajan, 2019). Briefly, an overnight culture was diluted 100-fold in LB media containing ampicillin (100 μg/ml) and induced with L-arabinose (0.2% w/v) at an OD600 of ∼0.5. Following induction for 3 h, cells were harvested and lysed by sonication. The soluble fraction was separated using centrifugation and incubated with CcdA peptide (residues 45–72nd) coupled to Affigel-15 at 4°C. The unbound fraction was removed and the column was washed with bicarbonate buffer (50 mM NaHCO3, 500 mM NaCl, pH 8.5). The bound protein was eluted with 200 mM glycine (pH 2.5) and collected in an equal volume of 400 mM HEPES buffer (pH 8) to neutralize the acidity of glycine.
GyrA14 was purified as described previously (Dao-Thi et al., 2004). Briefly, an overnight culture was diluted 100-fold in LB media containing ampicillin (100 μg/ml) and induced with IPTG (1 mM) at an OD600 of ∼0.5. Following induction for 3 h, cells were harvested and resuspended in TES buffer (0.2 M Tris, pH 7.5, 0.5 mM EDTA, 0.5 M sucrose and 1 mM PMSF). Cells were lysed and the soluble fraction was separated using centrifugation. The soluble fraction was incubated with pre-equilibrated Ni-NTA beads for 2 h at 4°C. The unbound fraction was removed, and the column was washed with 100 column volumes of wash buffer (50 mM imidazole in 0.05 M Tris, pH 8, 0.5 M NaCl). The protein was eluted with 500 mM imidazole in 0.05 M Tris, pH 8, 0.5 M NaCl and dialysed against 1x PBS.
E.coli CSH501 strain, transformed with pBAD24 plasmid containing WT or mutant ccdB, was grown in media containing ampicillin for 16 h at 37°C and 180 RPM. A secondary culture was grown by diluting overnight grown culture 100-fold. Upon reaching an OD600 of 0.4–0.5, CcdB variants were induced with Arabinose at a final concentration of 0.2% (w/v) for 3 h. The cells were harvested from 1.5 ml culture and lysed in 500 µl 1X PBS, using sonication. Supernatant and pellet fractions were separated by centrifugation at 13,000 RPM at 4°C. The pellet fraction was resuspended in 500 µl 1X PBS and equal volumes of pellet and supernatant fractions were loaded on Tricine-SDS-PAGE to measure the relative amounts of protein in each fraction.
The thermal shift assay was conducted in an iCycle iQ5 Real Time Detection System (Bio-Rad, Hercules, CA). A solution of total volume 20 μl containing 10 μM of the purified CcdB protein and 2.5X Sypro orange dye in suitable buffer (200 mM HEPES, 100 mM glycine), pH 7.5 was added to a well of a 96-well iCycler iQ PCR plate. The plate was heated from 15°C to 90°C with a 0.5°C increment every 30 s. The normalized fluorescence data was plotted against temperature and Tm measured as described (Niesen et al., 2007; Tripathi et al., 2016).
Saccharomyces cerevisiae EBY100 cells containing WT ccdB or mutant in pPNLS plasmids were grown in 3 ml SDCAA media (glucose 20 g/L, yeast nitrogen base 6.7 g/L, casamino acid 5 g/L, citrate 4.3 g/L, sodium citrate dihydrate 14.3 g/L) for 16 hours. Grown cells were diluted to an OD600 of 0.2 in 3 ml SDCAA media and grown till the OD600 reached two. Thirty million cells were harvested using centrifugation and resuspended in 3 ml SGCAA induction media (galactose 20 g/L, yeast nitrogen base 6.7 g/L, casamino acid 5 g/L, citrate 4.3 g/L, sodium citrate dihydrate 14.3 g/L) for 16 hours at 30°C, 250 RPM (Chao et al., 2006). One million cells were used for flow cytometric analysis. The amount of total protein expressed on the yeast cell surface was estimated by incubating the induced cells in 20 μl FACS buffer (1X PBS and 0.5% BSA), containing chicken anti-HA antibodies from Bethyl labs (1:600 dilution) for 30 min at 4°C. This was followed by washing the cells twice with 100 μl FACS buffer at 4°C. Washed cells were incubated with 20 µL FACS buffer containing goat anti-chicken antibodies conjugated to Alexa Fluor 488 (1:300 dilution), for 20 min at 4°C. Fluorescence of yeast cells was measured by flow-cytometric analysis. The total amount of active protein on the yeast cell surface was estimated by incubating the induced cells in 20 μl FACS buffer containing 100 nM GyrA14 for 45 min at 4°C. Cells were washed and incubated with 20 µl mouse anti-FLAG antibodies (1:300). This was followed by washing the cells twice with FACS buffer, followed by incubating with 20 µl rabbit anti-mouse antibodies conjugated to Alexa Fluor 633 (1:1,600 dilution). The flow-cytometric analysis was carried out on BD Accuri or BD Aria III instruments.
Previously, an SSM library of ccdB was generated in the pBAD24 vector (Adkar et al., 2012; Tripathi et al., 2016). The library was PCR amplified using primers having homology to the pPNLS vector. The PCR amplified library was gel extracted and cloned in pPNLS vector using yeast in vivo recombination.
A similar protocol was used for sample preparation of the library for FACS as described above for the single mutants with slight modifications. Briefly, ten million cells were taken for FACS sample preparation and the reagents were used in 10X higher volumes compared to the earlier flowcytometric analysis. Two different concentrations of GyrA14 (100 nM, 5 nM) were used for sorting CcdB mutants based on the binding in the 1D histogram. The cells were sorted in 11 and 10 different populations (bins) in case of binding with GyrA14 at concentrations of 100 and 5 nM respectively. Additionally, 11 different populations (bins) were sorted from the expression histogram. The experiment was repeated in a biological replicate. The sorting of CcdB libraries was performed using a BD Aria III cell sorter.
Sorted populations were grown on SDCAA agar plates for 48 h. Colonies were scraped and plasmids were extracted from the cells. The ccdB gene was PCR amplified using primers which bind upstream and downstream of the ccdB sequence and had multiplex identifier (MID) sequence to segregate the reads from different sorted bins. The DNA was amplified for 15 cycles using PCR and the amplified product was gel extracted and purified. Equal amounts of DNA from each sorted population were pooled, and the library was generated using the TruSeq™ DNA PCR-Free kit from Illumina. The sequencing was done on an Illumina HiSeq 2,500 250 PE platform at Macrogen, South Korea after incorporating 20% ϕX174 DNA in the library.
Deep sequencing data for the ccdB mutants obtained from the Hiseq 2,500 platform was processed using a pipeline developed by adopting certain aspects from an already existing in-house protocol (https://github.com/skshrutikhare/cys_library_analysis). The latter method involved the alignment with wild type sequence followed by merging of the paired-end reads, while in the modified protocol, the reads are first merged and then aligned with the wild-type sequence. The present methodology consists of the following steps: assembling the paired end reads, quality filtering, binning, alignment and mutant identification. All these steps were incorporated in a pipeline and made executable from a single command using a parameter file unique to a given data-set. In the first step, paired end reads were assembled using the PEAR v0.9.6 (Paired-End Read Merger) tool (Zhang et al., 2014). The “quality filtering” step involved deletion of terminal “NNN” residues in the reads, and removal of reads, not containing the relevant MID and/or primers, along with the reads having mismatched MID’s. Finally, only those reads having bases with Phred score ≥20 are retained. A binning step involved further filtering, which eliminated all those reads having incorrectly placed primers, truncated MIDs/primers (due to quality filtering) and shorter/longer sequences than the length of the wild type sequences. The remaining reads were binned according to the respective MIDs. In the alignment step, reads were aligned with the wild type ccdB sequence using the Water v6.4.0.0 program (Smith and Waterman, 1981) and reformatted. The default values of all parameters, except the gap opening penalty, which was changed to 20, was used. In the final step of “substitution”, reads were classified based on insertions, deletions and substitutions (single, double etc mutants).
Reads of each mutant were normalized across different bins individually (Equation 1), and the fraction of each mutant (Xi) distributed amongst the different bins was calculated (Equation 2). The reconstructed MFI for an individual mutant was calculated by the summation of the product, obtained upon multiplying the fraction (Xi) of the mutant in a particular bin 1) with the MFI of the corresponding bin obtained from the FACS experiment (Fi), across the various bins populated by the respective mutant (Equation 3).
The MFIseq of the biological replicates were different so the MFIseq of one of the replicates was adjusted using “m” and “c” obtained from the correlation between the replicates and then averaged.
Reads of each mutant were normalized within and across the bins. The fraction of each mutant (Xi), distributed amongst the different bins, was calculated as explained in the above section. The fraction (Xi) was multiplied with a scaling factor to convert the data into integers as this is required by the package below. The mlMFI was calculated using a maximum likelihood method using the fitdistrplus R package as explained earlier (Starr et al., 2020). The “fitdistcens” function in the fitdistplus R package helps in the estimation of fluorescence values for such observations using a maximum likelihood approach, where the values are transformed into a data frame of two columns left and right, describing each observed value as an interval and assuming a normal distribution of values. The left column contains the left bound of the interval and the right column contains the right bound of the interval for interval-censored observations, based on the fluorescence boundaries of each bin. The maximum likelihood approach was used to estimate the MFI of binding and expression for each mutant, based on its distribution of reads across the sorted bins, and the fluorescence boundaries of each sorted bin.
The bins were merged following which mlMFI amd MFIseq were calculated for GyrA14 binding (100 nM) for replicate 1. The fraction of each mutant in each bin was calculated as explained in the earlier sections. To merge bins for a given mutant, fractions present in each of the bins to be merged were added arithmetically. For mlMFA calculation, the minimum and maximum fluorescent boundary of the merged bin was set at the lowest and highest value of the fluorescent boundary for that set of bins. The mlMFI of CcdB mutants was calculated as explained above. In the case of MFIseq, the mean fluorescent intensity of merged bins was determined by making a new bin spanning the set of merged bins. The MFIseq of CcdB mutants was then calculated as explained above.
Depth was calculated using the server DEPTH (Chakravarty and Varadarajan, 1999; Tan et al., 2011). Accessibility was calculated using the program NACCESS (Hubbard SJ, 1993). In both cases, the input co-ordinates were homodimeric CcdB (PDB ID 3VUB). RankScore and MSseq are measures of mutational sensitivity in E. coli. Values were obtained from Adkar et al. (Adkar et al., 2012). Buried residues were those with <10% accessibility in 3VUB. Active-site residues were those with ΔASA>0. ΔASA difference between the solvent accessible surface area of CcdB residues in the free (3VUB) and GyrA14-bound forms (1X75) respectively (Aghera et al., 2020).
The deep mutational scanning data was taken from a recent report (Starr et al., 2020) in which two independent libraries of RBD were generated and sorted in four different bins based on expression or binding to ACE-2. In the MFI of binding and expression for individual mutants was reconstructed in that study using a maximum likelihood method using fitdistrplus R package. The expression MFI [Sortseq (expr)] data was shared by the authors in a repository (https://github.com/jbloomlab/SARS-CoV-2-RBD_DMS). We reconstructed the binding MFI [Sortseq (bind)] at an ACE-2 concentration of 100 pM (TiteSeq_09). For Sortseq (bind) estimation we used the script provided by the authors (https://github.com/jbloomlab/SARS-CoV-2-RBD_DMS/blob/master/results/summary/compute_expression_meanF.md). The authors used data from both single and multiple mutants, together with a model to account for epistatic effects to infer the MFI values for individual mutants. We modified the script to change the input data required to calculate Sortseq (bind). For both Sortseq (bind) and Sortseq (expr), we analyzed only single mutant data to avoid any artifacts that might arise from the epistatic model and took the average of delta Sortseq MFI {log (Sortseq (WT))—log [Sortseq (mutant)]} of mutants which had multiple barcodes. The Sortseq MFI values of mutants were averaged between the two libraries and the antilog was calculated for delta Sortseq MFI to analyse the ratio of Sortseq (bind) or Sortseq (expr) of mutants with respect to WT.
The correlations and p values for its significance were calculated using the GraphPad Prism software 9.0.0 (* indicates p < 0.05, ** indicates p < 0.01, **** indicates p < 0.0001). The weighted correlations were calculated using the weights function of R. For the computation of weighted correlation, a weight of 1/(σ/µ) was used on the mean values of replicates.
Yeast surface display (YSD) has become an increasingly popular tool for protein engineering and library screening applications (Pepper et al., 2008). Aga2p mating adhesion receptor of Saccharomyces cerevisiae is used as a fusion protein for yeast surface display. For surface expression, we used a vector in which CcdB is fused at the C-terminus of Aga2 (Sahoo et al., 2015). We generated (Supplementary Figure S1) and individually characterized 30 CcdB variants on the yeast cell surface. Most CcdB mutants had similar levels of expression to the WT protein (Figure 1A). However, the mutants showed different amounts of active protein as assayed by binding to the FLAG tagged GyrA14 compared to the WT protein (Figure 1B). Previously, we have characterized the in vitro thermal stability and in vivo solubility of several CcdB mutants (Tripathi et al., 2016). The amounts of total and active protein were estimated using antibodies against the HA-tag at the N-terminal of the yeast surface displayed CcdB and the C-terminal FLAG tag of GyrA14 respectively. The correlation coefficient (r) between amount of total protein on the yeast cell surface with in vivo solubility or Tm of the corresponding purified protein were 0.31 and 0.70 respectively (Figures 2A,B). It is unclear why mutants which have very low solubility in E. coli are highly expressed on the yeast cell surface. It was previously hypothesized that the protein folding quality control system in yeast is not as effective as in mammalian systems, therefore partially folded/molten globule/aggregated protein may exist on the surface of yeast (Park et al., 2006). A correlation of r = 0.80 was found between the amount of active protein on the yeast cell surface with its in vivo solubility determined in E. coli (Figure 2C). We also found a better correlation (r = 0.90) between amount of active CcdB protein on the yeast cell surface and its in vitro thermal stability (Figure 2D), compared to that between total CcdB protein on the yeast cell surface and thermal stability.
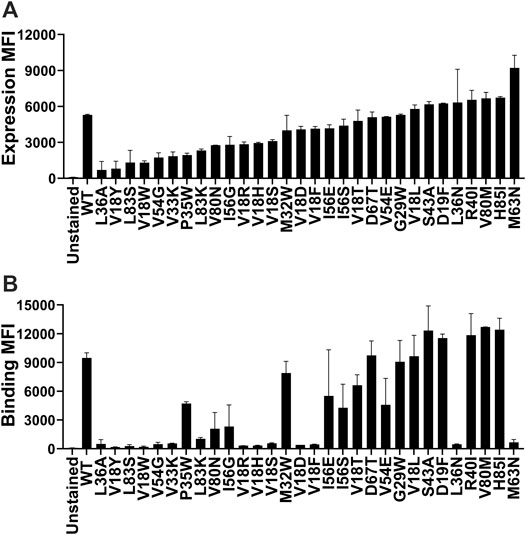
FIGURE 1. Comparison of the level of expression and binding of CcdB mutants on the yeast cell surface. (A) The expression and (B) binding to GyrA14 of individual mutants. Errors are calculated from two biological replicates. Most mutants expressed at high levels, however, the amount of active protein varied widely. A few mutants which showed a high level of expression did not show any binding to GyrA14. In both panels, mutants are arranged in order of increasing expression level.
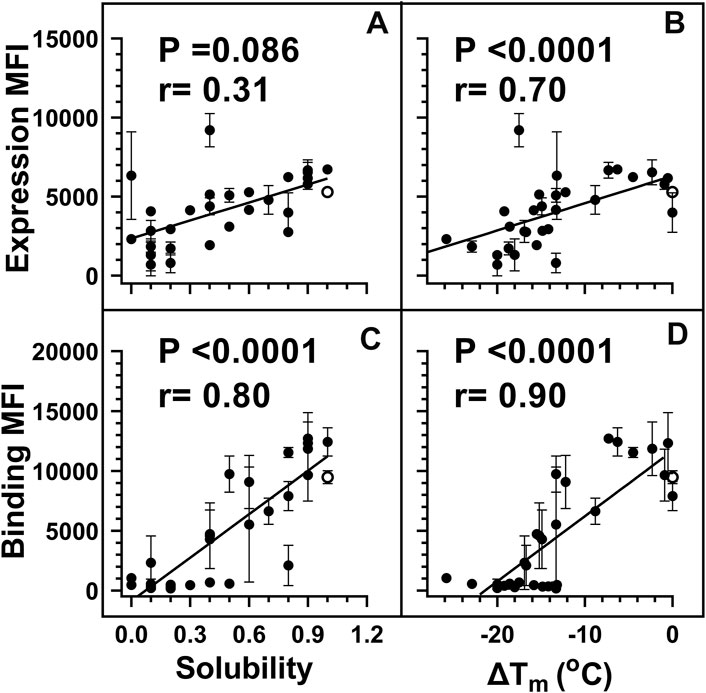
FIGURE 2. Weighted correlations of E. coli in vivo solubility and in vitro thermal stability with the amount of total and active protein respectively, on the yeast cell surface. For individual mutants, MFI’s of expression and binding were estimated by probing the HA tag on surface expressed protein and the FLAG tag on cell surface bound GyrA14 respectively. For weighted correlation calculation, a weight of 1/(σ/µ) was used. Here σ and µ represent the standard deviation and mean values for each point respectively. Weighted correlation of the total amount of protein (Expression MFI) displayed on the yeast cell surface with (A) in vivo solubility and (B) ΔTm [Tm (mutant)-Tm (WT)] of CcdB mutants. Weighted correlation of the amount of active protein (Binding MFI) on the yeast cell surface with (C) E. coli in vivo solubility and (D) ΔTm of CcdB mutants. A better correlation was observed between biophysical parameters with binding MFI rather than expression MFI. In the figure, the ΔTm of WT was increased by 1°C to remove overlap with another point. Data for E. coli in vivo solubility and thermal stability was taken from Tripathi et al. (Tripathi et al., 2016). WT data is shown in open circles. p values indicate the significance for non-zero slope values in all the correlations.
To extend these results, an SSM library of ccdB was expressed on the yeast cell surface. Different populations based on extent of binding to gyrase or cell surface expression were sorted. A total of 32 different populations were sorted at two different concentrations of GyrA14 (100 nM, 5 nM) as a function of either surface expression level or the extent of binding to GyrA14 (Supplementary Figure S2). The lower concentration of GyrA14 was chosen to be around the KD of CcdB-GyrA binding (Supplementary Figure S3), the higher concentration was one where WT CcdB approaches saturation in binding with GyrA14 on the yeast cell surface. We hypothesized that at lower concentrations of GyrA14, the binding on the yeast cell surface will be a function of both stability as well as binding affinity. However, at saturating concentration of GyrA14, the binding on the yeast cell surface will largely be a function of amount of correctly folded protein that in turn might be a function of protein stability, rather than the Kd of the mutant(s). MFI was calculated for each mutant as explained in the Methods section. The MFI was calculated at different stringencies (where the stringency refers to the sum of reads for a given mutant over each gate of the histogram), namely 25, 50, 100, 150, and 200 reads. All mutants with a total read number less than the stringency value were removed from the analysis. As the stringency increased, the pairwise correlation between the biological replicates increased (Supplementary Figure S4, Supplementary Table S1). The data was analysed with a stringency of 50 reads, since at higher stringencies, correlation did not improve significantly, but the number of mutants reduced. Reconstructed Binding and Expression MFI from deep sequencing data are hereafter referred to as MFIseq (bind) and MFIseq (expr) respectively.
A few published studies have described estimation of MFI values using deep sequencing of sorted populations and are therefore similar to our experimental strategy. However, the procedure for MFI reconstruction in these reports was relatively complicated compared to that used here (Sharon et al., 2012; Noderer et al., 2014; Peterman and Levine, 2016; Cambray et al., 2018). In those studies, the fractions of reads were calculated in each bin for all the mutants and MFI (mlMFI) of mutants were calculated by fitting the data to a maximum likelihood distribution of the histogram. We found that if mutants are present in only one bin (highly destabilized or nonsense mutants) then this method is unable to perform the MFI calculation (Starr et al., 2020). For the remaining mutants we found a good correlation between MFIseq and mlMFI for binding at 5 and 100 nM GyrA14, and for expression (Supplementary Figure S5). For mutants with over 50 reads, we could calculate the MFI of 11,153 mutants using the maximum likelihood method and 11,436 mutants using our method. We also found that progressively reducing the number of bins from eleven to six, does not significantly affect the estimated MFI values, however a further reduction to four bins results in a noticeable change in the estimated values using either method (Supplementary Figure S6). A good correlation was also found between the MFI of individually analysed mutants and their corresponding MFIseq values, validating our approach of MFI reconstruction (Supplementary Figure S7A, 7B). Individually analysed mutants showed a good correlation between the amount of active protein on the cell surface and in vitro measured thermal stability of the purified protein. Similarly, we also found a good correlation between MFIseq (bind) of mutants inferred from deep sequencing, and thermal stability as well as in vivo solubility for the selected mutants (Supplementary Figure S7C, 7D).
For the exposed residues (>10% accessibility) (Supplementary Figure S8), mutations did not affect the degree of surface expression and binding to GyrA14 (Figures 3A,B). Expression was also unaffected by mutations in the active-site residues (identified from PDB ID:1X75) (Figure 3C, Supplementary Figure S8). However, many buried site mutants showed very low expression, possibly because of aggregation and degradation inside cells or during export (Figure 3C). In the case of binding for buried and active-site residues, a very high mutational sensitivity was found (Figure 3D) similar to the previous report of CcdB mutants in E. coli (Tripathi et al., 2016). We also found a very high mutational sensitivity of binding for a few non-interacting residues in the loop connecting beta strands S2 and S3 at both 5 and 100 nM GyrA14 concentration (Supplementary Figure S9). The residues I24, I25 and D26 in this loop are directly involved in interacting with Gyrase and mutation at non-interacting residues (22, 23 and 27) in the loop might restrict or alter the conformation of the loop, thus reducing the affinity of CcdB mutants to GyrA14. However, there was no effect on the expression of the mutants in this loop, indicating that the mutant proteins are not destabilized (Supplementary Figure S9). We did not find a high correlation between MFIseq (bind) and either accessibility or depth, because many mutations at both buried and active-site residues have high mutational sensitivity (Supplementary Table S2). The previously described parameter RankScore, is a measure of mutant activity in E. coli (Adkar et al., 2012) with high RankScore denoting lower activity. We found a poor correlation between the MFIseq (bind) values of CcdB mutants at both exposed non active-site as well as active-site residues, and RankScore. In E. coli, most of the exposed non active-site residues do not show any mutational sensitivity, i.e., they have the same RankScore values as WT. However, in the present case many such CcdB mutants show lower binding to GyrA14 compared to WT. The loss of binding could be attributed to the decrease in the affinity between CcdB and Gyrase, or destabilization due to mutation. We defined a new parameter MrMFI (mean residue MFI) which is the mean of the MFI values of all the mutants at a certain position. MrMFI (expr) and MrMFI (bind) at 100 nM GyrA14, show a good correlation with RankScore (Supplementary Table S2). MrMFI (expr) also showed good correlation with Depth which is a structural measure of residue burial (Chakravarty and Varadarajan, 1999). However, in the case of binding at 5 nM, a weaker correlation of MrMFI (bind) with the aforementioned parameters was observed (Supplementary Table S2). In previous studies, identification of the active-site residues solely from the deep sequencing data was not very efficient (Adkar et al., 2012; Bhasin and Varadarajan, 2021), this is presumably because in vivo activity is often governed by threshold effects, and because mutations at buried residues also affect activity. The current methodology removes such drawbacks. We could distinguish between buried and active-site residues by comparing the MFIseq (bind) and MFIseq (expr). Most buried site residues showed low values of both MFIseq (bind) and MFIseq (expr) compared to WT. However, the active-site residues showed low MFIseq (bind) but similar MFIseq (expr) compared to WT. We found that the average MFIseq values of charged residues are a good predictor to discriminate between buried and active-site residues. For calculating MrMFIcharged of charged WT residues, we only consider mutants with opposite charge. For some mutants at buried positions, we found a very low MrMFIcharged (expr) but the mutants were absent in MrMFIcharged (bind). We found that such mutants had very high reads, suggesting that the values of MrMFIcharged (expr) are correct. We anticipated that such mutants lack binding and are therefore present only in the bin which had a background level of binding signal, the presence of mutant in only that gate led to the removal of such mutants due to the stringency set for the analysis. Hence, such mutants were assigned a MrMFIcharged (bind) similar to other buried positions. MrMFIcharged had a bimodal distribution (Supplementary Figure S10), so k-means clustering was performed to identify the mean (µ) and standard deviation (σ) of each distribution. The distributions were named D1 (higher MrMFIcharged) and D2 (lower MrMFI charged). Buried site residues were assigned to be those which have MrMFIcharged (bind) and MFIseq (expr) less than the set threshold (µ+0.5*σ) for distribution D2. Active-site residues were assigned as those which had MrMFIcharged (bind) less than (µ+σ) of the D2 distribution and MFIseq (expr) higher than (µ−2*σ) of distribution D1 (Figure 4). The accuracy, specificity and sensitivity of prediction of exposed non active-site, buried and exposed active-site residues are mentioned in Supplementary Table S3. We also compared our prediction results derived from saturation mutagenesis phenotypes with those of an in silico predictor, PROF (Rost and Sander, 1994). For a residue to be classified as buried by PROF, the relative solvent accessibility cut-off used is < 12. We observed a slightly lower specificity and accuracy for CcdB, and lower sensitivity in the case of RBD when predictions were made using PROF (Supplementary Table S4), relative to our predictions. We also examined the performance of PROF with other proteins and found that the specificity of the predictions was higher than 0.8 in all the cases except for CcdB. However, the sensitivity of the predictions was lower than 0.8 in all the cases except for CcdB, Gal4 and Ubiquitin. The accuracy for the PROF prediction was 0.77 and 0.78 for CcdB and RBD respectively, comparable but slightly lower than the corresponding values of 0.92 and 0.8 for CcdB and RBD respectively, from the saturation mutagenesis predictions in this work.
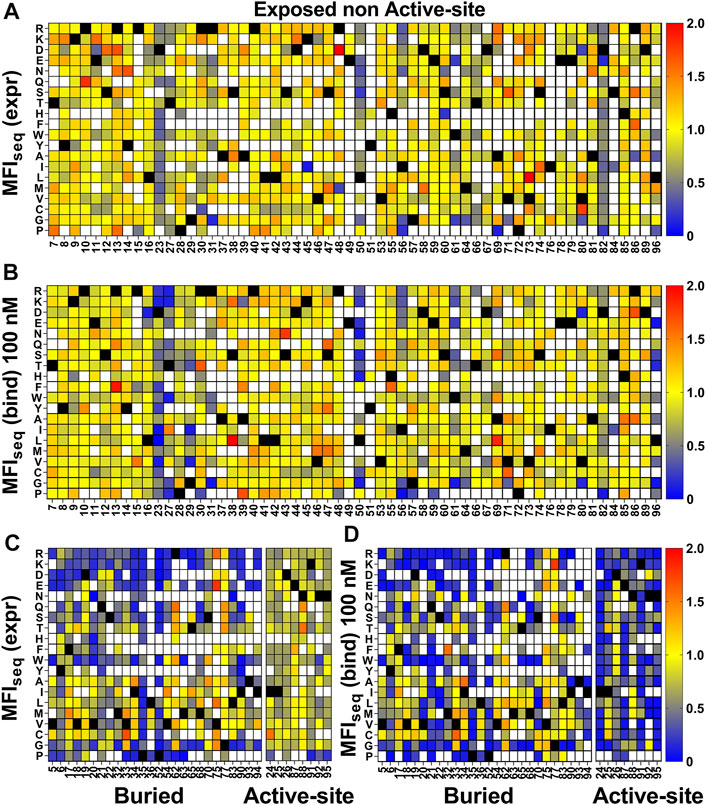
FIGURE 3. Heatmap of normalized MFIseq values for CcdB mutants. MFIseq value of mutant was divided by the MFIseq value of WT to normalize it. (A) MFIseq (expr) and (B) MFIseq (bind) at 100 nM GyrA14 for exposed non active-site residues. (C) MFIseq (expr) and (D) MFIseq (bind) for buried and active-site residues. Exposed, buried (PDB ID:3VUB) and active-site (PDB ID:1X75) residues are segregated based on the crystal structure. Residues which had accessibility greater than 10% were considered exposed, all remaining residues were considered buried, and active-site mutants in contact with GyrA14 were identified as explained the Methods section. Blue to red colour represents increasing normalized MFIseq values, black colour shows the WT residue at the corresponding position. White colour indicates that the mutant is not available. The buried site residues have very high mutational sensitivity both in case of expression and binding. The active-site residues show mutational sensitivity only with respect to Gyrase binding. Information about the mutational sensitivity of expression and binding can be used to differentiate exposed, buried and active-site residues.

FIGURE 4. Identification of buried and active-site residues from MrMFIcharged (bind) and MrMFIcharged (expr). Side chain accessibilities in dimeric CcdB (PDB: 3VUB), darker to lighter shade indicate increasing accessibility, accessibility is reported as log accessibility. The mutants were clustered into two bins based on the distribution of MrMFIcharged and k-means and standard deviations were calculated for both distributions. The distributions were named D1 (higher MrMFIcharged) and D2 (lower MrMFIcharged). Residues which had MrMFIcharged (binding) and MrMFIcharged (expr) lower than (µ+0.5*σ) of distribution D2 were characterized as buried. The false negatives were Y6, D19, Q21, S22, S70, V75 and G77, the polar side chains of these residues are pointing towards the surface. Active-site residues were identified as those in contact with GyyrA14 (PDB ID 1X75). Residues which had MrMFIcharged (binding) less than (µ+σ) of D2 distribution and MrMFIcharged (expr) higher than (µ-2*σ) of distribution D1 were predicted as active-site. We obtained a few putative false positives. However, these residues are likely involved in functional aspects of activity that cannot be inferred from the CcdB:GyrA14 crystal structure. The same residues were seen to be important for CcdB activity in vivo in E. coli (Tripathi et al., 2016). Some positions could not be categorized due to lack of reads, such positions are indicated with an ‘X’. Positions indicated with ‘*’ are the ones where MrMFIcharged (expr) was observed and the mutants had high read counts but the mutants were absent in MrMFIcharged (bind), such positions were assigned MrMFIcharged (bind) values similar to other buried positions.
In the previous section, we discussed the correlation between protein biophysical properties such as thermal stability and in vivo solubility with either the amount of active protein or the ratio of active protein to total protein on the yeast cell surface for a few (30) mutants. However, most of these mutants were destabilized with respect to the WT protein. To confirm whether this correlation also holds for mutants that have stability similar or greater than WT, we selected a few CcdB mutants based on either the MFIseq (bind) or MFIseq (ratio) [MFIseq (bind)/MFIseq (expr)] for in vitro characterization of thermal stability. We examined the average and standard deviation of expression for all mutants and selected only those mutants based on MFIseq (ratio) which cross a minimum cut-off (µ+0.5*σ) for MFIseq (expr) to remove the bias created by mutants which have very low expression. No threshold for expression was set for selection of mutants based on their MFIseq (bind). No selection of the mutants was performed based solely on the MFIseq (expr).
Six mutants were characterized using the criteria MFIseq (bind) at 5 nM GyrA14, none of them showed a higher Tm than WT (Figure 5A); whereas two of the mutants selected on the basis of MFIseq (ratio) showed a significantly higher Tm than WT (Figure 5B). A subset of seven mutants was selected based on MFIseq (bind) at 100 nM GyrA14, none of the mutants showed higher stability than WT CcdB (Figure 5C). Ten mutants were selected based on MFIseq (ratio) and characterized, four showed higher stability, two mutants were similar to WT and the remaining four were less stable than WT CcdB (Figure 5D). We therefore hypothesize that if the stability of a mutant crosses a threshold then its expression will not increase further. To confirm this hypothesis, we measured the amount of active protein on the yeast cell surface for seven individual mutants which had Tm’s ranging from 60°C to 70°C, and found that the expression and binding for these mutants are similar to each other and to WT (Supplementary Figure S11).
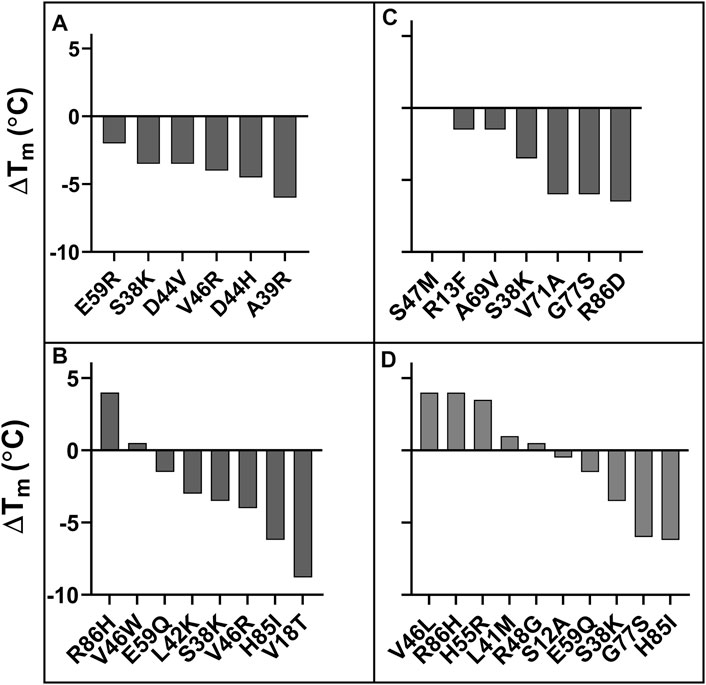
FIGURE 5. ΔTm of putative stabilized CcdB mutants. Mutants were identified from (A) MFIseq (bind) at 5 nM GyrA14, (B) MFIseq (ratio) at 5 nM GyrA14, (C) MFIseq (bind) at 100 nM GyrA14, (D) MFIseq (ratio) at 100 nM GyrA14. The mutants were randomly selected from a subset of forty mutants which showed the highest MFIseq (bind) or the highest MFIseq (ratio) and had MFIseq (expr) > 6,672.
For destabilized mutants we observed a good correlation between MFIseq (bind) and Tm of individual mutants (Supplementary Figure S7D). Using this correlation, we next predicted the Tm of each mutant for an additional set of (n = 28) previously described CcdB mutants (Tripathi et al., 2016) based on their MFIseq (bind). We found a good correlation (r = 0.82) between predicted and in vitro measured Tm for this set of CcdB mutants as well (Supplementary Figure S12A). This now allows us to identify putative destabilized mutants and accurately predict the extent of destabilization for all such mutants in the CcdB YSD library. We also predicted the thermal stability of CcdB mutants using the in silico predictor, HoTMuSiCv1.0 (Pucci et al., 2020), however, we did not find a good correlation between measured and predicted Tm (Supplementary Figure S12B). It has been shown that in vitro protein thermal stability and free energy of unfolding are correlated (Chen et al., 2000; Prajapati et al., 2007; Tripathi et al., 2016). We therefore predicted the free energy of unfolding for CcdB mutants using SDM (Pandurangan et al., 2017), mCSM (Pires et al., 2014b), PoPMuSiC (Dehouck et al., 2011), DynaMut (Rodrigues et al., 2018), DUET (Pires et al., 2014a), MAESTROweb (Laimer et al., 2016), DeepDDG (Cao et al., 2019), CUPSAT (Parthiban et al., 2006), PremPS (Chen et al., 2020) and INPS-MD (Savojardo et al., 2016). We found moderate correlations, with DeepDDG performing the best (r = 0.59), but still poorer compared to our prediction from YSD data (r = 0.82). For a more detailed comparison we analysed the predictions of stability by DeepDDG, since this showed the highest correlation with measured stability of individual mutants at non active-site residues. We excluded residues 21, 22, 23 and 27 as these positions behaved like active-site residues. We found that trends for ΔΔG predicted by DeepDDG for exposed non active-site residues are similar to those obtained from MFIseq (bind) (Figures 6A,B). However, we observed some mutant specific differences at residues 8, 16, 50, 53 and 96. Mutations at residues 50 and 96 have highly deleterious effects which reduced GyrA14 binding to yeast surface displayed protein, these are only partially predicted by DeepDDG. In the case of charged and polar mutations at residue 8, 16 and 53 we did not observe a reduction in binding, but the software predicted them to be destabilizing. In the case of buried positions, we found mutation specific effects at 35, 52 and 94 where DeepDDG predicted changes were significantly smaller than the experimentally observed ones. We also found that most of the phenylalanine, tryptophan and arginine mutations were highly destabilizing and the mutants did not bind to GyrA14, however the software gave a lower stability penalty for these substitutions (Figures 6C,D). Our MFI based measurements suggested greater destabilization for several mutants relative to DeepDDG prediction. While the overall trends were similar, as discussed above, there are several differences between MFI based and DeepDDG based stability predictions.
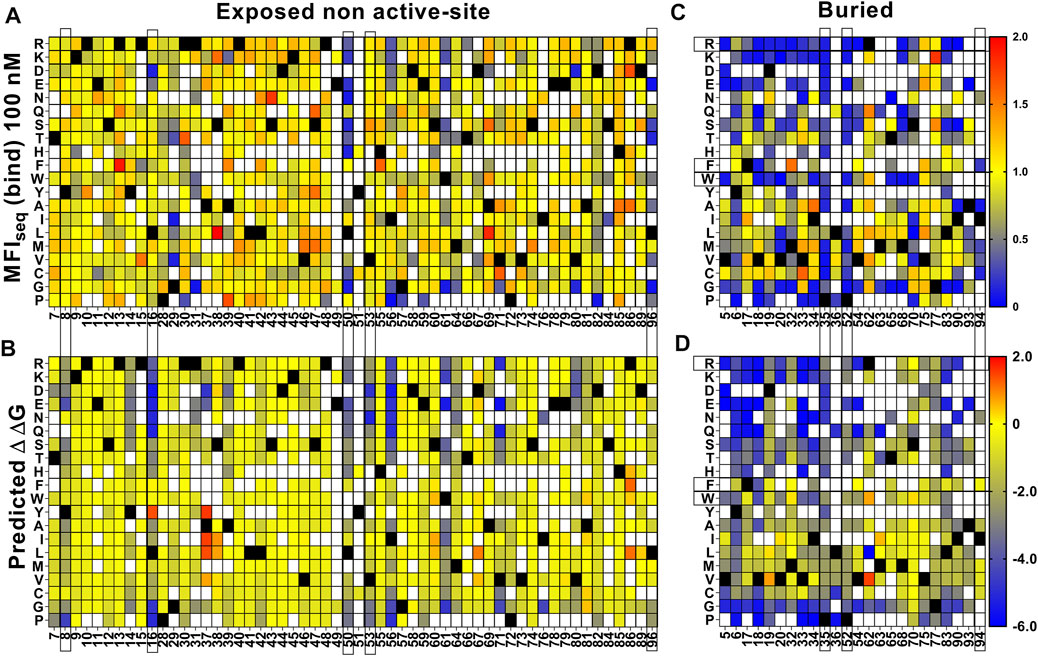
FIGURE 6. Comparison of stabilities estimated by DeepDDG and yeast surface display. Heat maps for (A,C) MFIseq (bind) normalized to WT and (B,D) ΔΔG predicted by DeepDDG. Residue positions or specific amino acid mutations showing significantly different predicted stabilities by the two methods are highlighted by a box. Blue to red colour corresponds to increasing stability.
To examine the generality of our approach, we also analyzed recently reported deep mutational scanning data of the SARS-CoV-2 receptor binding domain (Starr et al., 2020). In this study two separate libraries were generated and individually sorted based on expression and binding to ACE-2. The binding [Sortseq (bind)] or expression [Sortseq (expr]) MFIs relative to WT for barcoded mutants were calculated from the deposited NGS data as explained in the Methods section. Additionally, we analyzed binding at only one concentration of ACE-2 (100 pM, TiteSeq_09) at which the binding started to saturate. Buried residues were those with <10% side chain accessibility in chain C of PDB ID 7KMH (Jones B. E. et al., 2020). ACE-2 binding (active-site) residues were assigned as those contacting ACE-2 (Malladi et al., 2021). To identify the active-site and buried residues from Sortseq data, we calculated the MrMFIcharged for each position. Similar to CcdB, we observed a bimodal distribution for both MrMFIcharged (bind) and MrMFIcharged (expr) (Supplementary Figure S13) and k-means and standard deviation were calculated for both the distribution D1 (higher MrMFIcharged) and D2 (lower MrMFIcharged). As described above for CcdB, buried residues were identified as those which had MrMFIcharged (bind) and MrMFIcharged (expr) less than the set threshold (µ+0.5*σ) for distribution D2. The active-site positions were identified as those which had MrMFIcharged (bind) lower than the set threshold (µ+σ) for population D2 and MrMFIcharged (expr) values higher then (µ-2*σ) for population D1. We accurately identified most of the buried residues, however there were some false positive and false negative predictions relative to the crystal structure information (Figure 7). We found 21 positions to be false negative buried positions. We categorized these false negatives into two categories, namely, glycine and the side chains which are pointing towards the surface. The accessibility calculated by DEPTH server for glycine was zero and we therefore expected glycine to fall into the false negative buried category. Thirteen positions out of twenty-one false negative were glycine. Another six positions, 336, 348, 361, 443 and 480 had their side chains pointing towards the protein surface. We also found similar false negative buried residues in CcdB where the side chain hydrophilic group was pointing towards the protein surface. Position 363 and 365 in RBD had accessibility <10% and were pointing towards the core of the protein in the PDB (7KMH) used to calculate accessibility. However, we found that these positions have high accessibility (>30%) in another structure (PDB ID 7D2Z). All the available RBD structures are in complex with other molecules, this might be responsible for variation in the accessibility of residues in different RBD structures. We found 17 false positive buried residue predictions, seven of them were aromatic, seven are charged or polar, two are prolines and one is an aliphatic residue. These positions have both reduced expression and binding for charged residue substitutions (Supplementary Figure S14A, 14D) similar to the buried residues (Supplementary Figure S14B, 14E). The specificity, sensitivity and accuracy of prediction is mentioned in Supplementary Table S3. Active site residues were identified with very high accuracy (Supplementary Table S3), though there were a few false negative and false positive predictions. Additionally, we found several positions which had Sortseq (expr) like WT, however, they had very low Sortseq (bind) (Supplementary Figure S14A, 14D). We hypothesize that these positions are also assisting in the maintenance of proper RBM conformation and enabling its binding to ACE-2. Residues 447, 448, 473 and 476 which gave false positive results, 447 and 476 are part of the receptor binding motif (RBM) and contain glycine in a conformation which is available only for glycine. Hence mutation to a non-Gly residue will likely disrupt the conformation of the RBM thus decreasing binding to ACE-2. Mutations at positions 446, 453, 493 and 498 gave false negative results. Of these false negative positions, 446 is again glycine. We found that the Arg mutants at N493 and N498 positions have very little effect on expression and binding (Supplementary Figure S14C, 14F). We hypothesized that these positions may not have the most optimal WT residue, or they may show no mutational penalty for binding to ACE-2. A recent report showed that the affinity of Q498R to ACE-2 is higher than WT RBD (Xue et al., 2020) and was enriched as double mutant Q498R/N501Y when selection was performed for RBD mutants having high affinity towards ACE-2 (Zahradník et al., 2021). It has also been reported that when chimeric virus evolved in the presence of neutralizing antibodies C121 and C141, this enriched for the Q493R mutation. The mutant virus grows to high PFU titers similar to WT, and infectivity is also inhibited by a chimeric ACE-2 analog, similar to WT (Weisblum et al., 2020). The specificity, sensitivity and accuracy of prediction is mentioned in Supplementary Table S3.
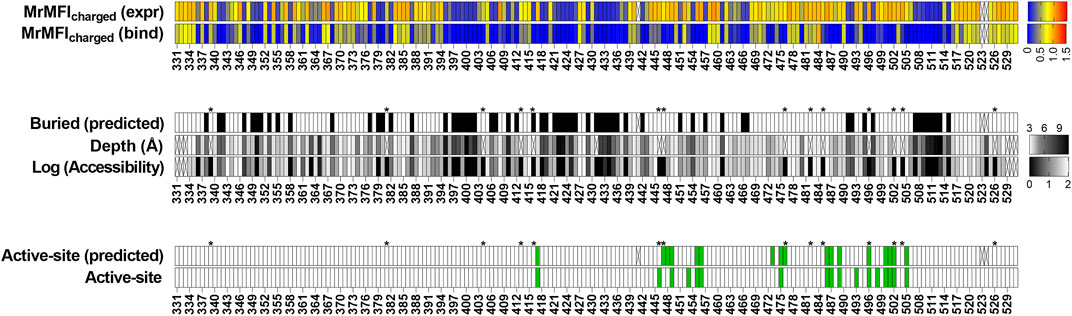
FIGURE 7. Prediction of buried and active-site positions in SARS-CoV-2 RBD from Sortseq data. Buried residues were identified from chain C of PDB ID 7KMH, residues which had <10% side chain accessibility were categorized as buried. The accessibility and depth was calculated using DEPTH server (Tan et al., 2011). Active-site residues were identified from PDB ID 6M0J as explained earlier (Malladi et al., 2021). Criteria used to predict buried and active-site positions from MFI data were identical to those used for CcdB. Positions which did not have MrMFI data or could not be assigned to either buried or active-site categories are highlighted with “X”. Accessibility calculated by DEPTH server for glycine is zero and these are marked with a “*”.
With the advancement of mutagenesis and directed evolution methodologies, proteins with modified traits and function can be developed in a relatively short duration of time (Chen and Arnold, 1991; Winter et al., 1994; Bornscheuer et al., 2019). E. coli remains an expression host of choice for many proteins and high level, soluble E. coli expression is a desirable attribute. When eukaryotic or unstable prokaryotic proteins are overexpressed in bacteria, they often tend to form insoluble aggregates called inclusion bodies (IB). Formation of IBs often results in low yields of purified soluble protein. Designing improved variants of a protein by increasing half-life, stability and activity is an ongoing requirement of most pharmaceutical and biotechnology industries. However, a reliable, high-throughput, efficient and rapid method is required for solubility and stability analysis of engineered proteins. Previously, several high-throughput methods to select for soluble expression have been developed based on fusion to a reporter protein. These rely on the reporter activity, which is perturbed if an aggregation prone protein is fused (Maxwell et al., 1999; Waldo et al., 1999; Wigley et al., 2001; Fisher, 2006). These methods can be used to isolate protein variants with enhanced solubility but cannot reveal if the fused protein is properly folded. In some cases, such unstable proteins may also form soluble aggregates (Tripathi et al., 2016). Since many of these reporter screens employ cytoplasmic expression and use bacterial hosts, disulphide rich or glycosylated proteins, or those binding to complex ligands cannot be studied. Yeast surface display coupled to FACS, has been widely used to evolve such targets. Typically, populations are sorted for multiple rounds to enrich for stable binders to a target of interest (Kieke et al., 1999; Esteban and Zhao, 2004; Kim et al., 2006; Traxlmayr and Obinger, 2012). While this approach readily selects for high affinity binders, selecting for stable proteins is more difficult. In some cases, this methodology has also been used to isolate stable variants of proteins (Pepper et al., 2008) and a good correlation was observed between surface expression and improved biophysical parameters. However, other studies in different systems did not find such a correlation (Park et al., 2006; Piatesi et al., 2006).
In the present work we utilize YSD to measure the amount of total protein as well as total active protein displayed on the yeast cell surface. A good correlation was found between the amount of active CcdB mutant on the yeast surface and corresponding in vivo solubility in E. coli (r = 0.85) or Tm (r = 0.80). A recent report also suggests that the amount of active protein on the yeast cell surface can be used as a criterion to isolate stable mutants (Traxlmayr and Shusta, 2017). In the present study, no correlation was found between the amount of total protein on the yeast cell surface and the biophysical properties of mutants. A few mutants which have very low solubility in E. coli showed very high expression, but there was a negligible amount of active protein on the yeast surface. It has been previously suggested that the quality control system in yeast is not able to discriminate these mutants from properly folded ones or alternatively that the folded conformation is maintained by chaperones in the ER (Park et al., 2006). Once these mutants are exported to the cell surface they may start to unfold. This could be one reason why some groups including ours did not find a good correlation of surface expression with the stability or solubility of these proteins. In previous studies (Shusta et al., 1999), a very limited number of proteins were used for surface expression studies, it is possible that in this small number, mutants which had high surface expression or secretion but lower stability than WT were not observed.
Yeast surface display coupled to FACS typically requires multiple rounds of sorting to enrich variants with desired activity and phenotype. Here, we have performed a single round of sorting and developed a rapid, uncomplicated procedure of estimating MFI’s of individual mutants of CcdB combining FACS and deep sequencing. This MFIseq was shown to correlate well with the corresponding experimentally measured MFIs for several individual mutants. The MFIseq was used to generate the mutational landscape of expression and binding of a mutant library. We showed that such data can be used to accurately discriminate between buried, exposed non active-site and exposed active-site residues both for CcdB and an unrelated protein, RBD of the spike protein of SARS-CoV-2. Highly destabilizing charged mutations in the core of the protein decreased both expression and binding, while the active-site residues showed reduction in binding alone for charged mutations. Relative to an earlier study which assayed in vivo activity in E. coli (Adkar et al., 2012), the present methodology is better able to identify and distinguish between the two categories of mutationally sensitive residues, namely buried and exposed, active-site residues. Identification of active-site residues of interacting partners through charged mutation scanning provides a better alternative to alanine and cysteine scanning mutagenesis. In general, mutations that affect total activity in vivo can do so by affecting specific activity without changing the amount of folded protein, decrease the amount of folded protein without affecting specific activity or a combination of the above. The present analysis distinguishes between the above possibilities, and is therefore able to distinguish buried from exposed, active-site positions. This is useful for applications that attempt to use saturation mutagenesis data for protein model discrimination and structure prediction (Khare et al., 2019; Jones E. M. et al., 2020) as well as interpreting clinical data on disease causing mutations (Findlay et al., 2018; Livesey and Marsh, 2020).
MFIseq (bind) was also used to predict the Tm of CcdB mutants. We found a good correlation between predicted and measured ΔTm for a subset of CcdB mutants. We also compared the accuracy of in silico approaches used to predict the stability of mutants and found that these predictors had lower accuracy relative to our approach. We used experimental stability measurements for a small number of destabilized mutations, combined with MFIseq measurement to predict stabilities of all destabilized mutants in the saturation mutagenesis library. We could readily identify destabilized mutants of CcdB, however, the recovery of mutants more stable than WT was lower, but still significant, considering the rarity of such mutations. This is likely due to the possibility that if the stability of the protein crosses a threshold, additional increments in stability do not result in enhanced expression or binding.
A limitation of the present approach is that it requires an epitope tagged or fluorescently labelled conformation specific binding partner. Another limitation could be differential relative stability of proteins upon yeast cell surface display compared to expression in the native host and/or intracellular expression. For glycosylated proteins, the stability of mutants may also be altered because of hyper glycosylation of protein on the yeast cell surface compared to proteins expressed in mammalian systems or prokaryotic systems where glycosylation is absent. The presence of glycosylation may also affect the binding to a cognate partner which in turn may give rise to false results. This does not appear to be the case for the SARS-CoV-2 RBD which contains two glycans at residues 331 and 343, but may be an issue for proteins with multiple glycosylation sites. We are examining these possibilities in ongoing studies. Despite these caveats, the present study suggests that the proposed methodology can accurately distinguish buried from active-site residues, quantitatively estimate thermal stabilities of destabilized mutants in large libraries, and also be used with moderate accuracy to identify stabilized mutants.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found in the article/Supplementary Material.
RV and SA designed the experiments. SA performed all the experiments, RV and SA analyzed all the data. KM wrote the software and carried out the processing of the deep sequencing data. MB calculated the MFI of CcdB mutants using maximum likelihood method. RV and SA wrote most of the manuscript.
This work was funded by grants to RV from the Department of Science and Technology, grant number-EMR/2017/004054, DT.December 15, 2018), Government of India, Department of Biotechnology, grant no. BT/COE/34/SP15219/2015 DT. November 20, 2015, Ministry of Science and Technology, Government of India and Bill and Melinda Gates Foundation (United States) (INV-005948). We also acknowledge funding for infrastructural support from the following programs of the Government of India: DST FIST, UGC Centre for Advanced study, Ministry of Human Resource Development (MHRD), and the DBT IISc Partnership Program. The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
SA acknowledges Council of Scientific and Industrial Research for his fellowship (SPM-07/079(0218)/2015-EMR-I). KM is thankful to Department of Science and Technology (DST) Science and Engineering Research Board for financial support, sanction order no: PDF/2017/002641. MB acknowledges Council of Scientific and Industrial Research for her fellowship (SRF-09/079(2766)/2017-EMR-I). RV is a J. C. Bose Fellow of DST. Aparna Asok is duly acknowledged for FACS.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmolb.2021.800819/full#supplementary-material
YSD, yeast surface display; SSM, site saturation mutagenesis; FACS, fluorescence-activated cell sorting; DFE, distribution of fitness effects; RBD, receptor binding domain; SARS-CoV-2, severe acute respiratory syndrome coronavirus 2; ACE-2, angiotensin-converting enzyme 2.
Adkar, B. V., Tripathi, A., Sahoo, A., Bajaj, K., Goswami, D., Chakrabarti, P., et al. (2012). Protein Model Discrimination Using Mutational Sensitivity Derived from Deep Sequencing. Structure 20, 371–381. doi:10.1016/j.str.2011.11.021
Aghera, N. K., Prabha, J., Tandon, H., Chattopadhyay, G., Vishwanath, S., Srinivasan, N., et al. (2020). Mechanism of CcdA-Mediated Rejuvenation of DNA Gyrase. Structure 28, 562–572.e4. doi:10.1016/j.str.2020.03.006
Bajaj, K., Dewan, P. C., Chakrabarti, P., Goswami, D., Barua, B., Baliga, C., et al. (2008). Structural Correlates of the Temperature Sensitive Phenotype Derived from Saturation Mutagenesis Studies of CcdB. Biochemistry 47, 12964–12973. doi:10.1021/bi8014345
Basanta, B., Bick, M. J., Bera, A. K., Norn, C., Chow, C. M., Carter, L. P., et al. (2020). An Enumerative Algorithm for De Novo Design of Proteins with Diverse Pocket Structures. Proc. Natl. Acad. Sci. USA 117, 22135–22145. doi:10.1073/pnas.2005412117
Bernard, P., and Couturier, M. (1992). Cell Killing by the F Plasmid CcdB Protein Involves Poisoning of DNA-Topoisomerase II Complexes. J. Mol. Biol. 226, 735–745. doi:10.1016/0022-2836(92)90629-X
Bhasin, M., and Varadarajan, R. (2021). Prediction of Function Determining and Buried Residues through Analysis of Saturation Mutagenesis Datasets. Front. Mol. Biosci. 8, 635425. doi:10.3389/fmolb.2021.635425
Boder, E. T., and Wittrup, K. D. (1997). Yeast Surface Display for Screening Combinatorial Polypeptide Libraries. Nat. Biotechnol. 15, 553–557. doi:10.1038/nbt0697-553
Boder, E. T., and Wittrup, K. D. (2000). [25] Yeast Surface Display for Directed Evolution of Protein Expression, Affinity, and Stability. Meth. Enzym. 328, 430–444. doi:10.1016/s0076-6879(00)28410-3
Bornscheuer, U. T., Hauer, B., Jaeger, K. E., and Schwaneberg, U. (2019). Directed Evolution Empowered Redesign of Natural Proteins for the Sustainable Production of Chemicals and Pharmaceuticals. Angew. Chem. Int. Ed. 58, 36–40. doi:10.1002/anie.201812717
Cambray, G., Guimaraes, J. C., and Arkin, A. P. (2018). Evaluation of 244,000 Synthetic Sequences Reveals Design Principles to Optimize Translation in Escherichia coli. Nat. Biotechnol. 36, 1005–1015. doi:10.1038/nbt.4238
Cao, H., Wang, J., He, L., Qi, Y., and Zhang, J. Z. (2019). DeepDDG: Predicting the Stability Change of Protein Point Mutations Using Neural Networks. J. Chem. Inf. Model. 59, 1508–1514. doi:10.1021/acs.jcim.8b00697
Chakravarty, S., and Varadarajan, R. (1999). Residue Depth: a Novel Parameter for the Analysis of Protein Structure and Stability. Structure 7, 723–732. doi:10.1016/s0969-2126(99)80097-5
Chao, G., Lau, W. L., Hackel, B. J., Sazinsky, S. L., Lippow, S. M., and Wittrup, K. D. (2006). Isolating and Engineering Human Antibodies Using Yeast Surface Display. Nat. Protoc. 1, 755–768. doi:10.1038/nprot.2006.94
Chattopadhyay, G., and Varadarajan, R. (2019). Facile Measurement of Protein Stability and Folding Kinetics Using a Nano Differential Scanning Fluorimeter. Protein Sci. 28, 1127–1134. doi:10.1002/pro.3622
Chen, K., and Arnold, F. H. (1991). Enzyme Engineering for Nonaqueous Solvents: Random Mutagenesis to Enhance Activity of Subtilisin E in Polar Organic Media. Nat. Biotechnol. 9, 1073–1077. doi:10.1038/nbt1191-1073
Chen, J., Lu, Z., Sakon, J., and Stites, W. E. (2000). Increasing the Thermostability of Staphylococcal Nuclease: Implications for the Origin of Protein Thermostability. J. Mol. Biol. 303, 125–130. doi:10.1006/jmbi.2000.4140
Chen, Y., Lu, H., Zhang, N., Zhu, Z., Wang, S., and Li, M. (2020). PremPS: Predicting the Impact of Missense Mutations on Protein Stability. PLOS Comput. Biol. 16, e1008543. doi:10.1371/journal.pcbi.1008543
Chevalier, A., Silva, D.-A., Rocklin, G. J., Hicks, D. R., Vergara, R., Murapa, P., et al. (2017). Massively Parallel De Novo Protein Design for Targeted Therapeutics. Nature 550, 74–79. doi:10.1038/nature23912
Dao-Thi, M.-H., Van Melderen, L., De Genst, E., Buts, L., Ranquin, A., Wyns, L., et al. (2004). Crystallization of CcdB in Complex with a GyrA Fragment. Acta Crystallogr. D Biol. Cryst. 60, 1132–1134. doi:10.1107/S0907444904007814
Dehouck, Y., Kwasigroch, J. M., Gilis, D., and Rooman, M. (2011). PoPMuSiC 2.1: A Web Server for the Estimation of Protein Stability Changes upon Mutation and Sequence Optimality. BMC Bioinformatics 12, 151. doi:10.1186/1471-2105-12-151
Dou, J., Vorobieva, A. A., Sheffler, W., Doyle, L. A., Park, H., Bick, M. J., et al. (2018). De Novo design of a Fluorescence-Activating β-barrel. Nature 561, 485–491. doi:10.1038/s41586-018-0509-0
Esteban, O., and Zhao, H. (2004). Directed Evolution of Soluble Single-Chain Human Class II MHC Molecules. J. Mol. Biol. 340, 81–95. doi:10.1016/j.jmb.2004.04.054
Findlay, G. M., Daza, R. M., Martin, B., Zhang, M. D., Leith, A. P., Gasperini, M., et al. (2018). Accurate Classification of BRCA1 Variants with Saturation Genome Editing. Nature 562, 217–222. doi:10.1038/s41586-018-0461-z
Fisher, A. C. (2006). Genetic Selection for Protein Solubility Enabled by the Folding Quality Control Feature of the Twin-Arginine Translocation Pathway. Protein Sci. 15, 449–458. doi:10.1110/ps.051902606
Fowler, D. M., Araya, C. L., Fleishman, S. J., Kellogg, E. H., Stephany, J. J., Baker, D., et al. (2010). High-resolution Mapping of Protein Sequence-Function Relationships. Nat. Methods 7, 741–746. doi:10.1038/nmeth.1492
Gietz, R. D., and Schiestl, R. H. (2007). High-efficiency Yeast Transformation Using the LiAc/SS Carrier DNA/PEG Method. Nat. Protoc. 2, 31–34. doi:10.1038/nprot.2007.13
Hagihara, Y., and Kim, P. S. (2002). Toward Development of a Screen to Identify Randomly Encoded, Foldable Sequences. Proc. Natl. Acad. Sci. 99, 6619–6624. doi:10.1073/pnas.102172099
Jain, P. C., and Varadarajan, R. (2014). A Rapid, Efficient, and Economical Inverse Polymerase Chain Reaction-Based Method for Generating a Site Saturation Mutant Library. Anal. Biochem. 449, 90–98. doi:10.1016/j.ab.2013.12.002
Jones, L. L., Brophy, S. E., Bankovich, A. J., Colf, L. A., Hanick, N. A., Garcia, K. C., et al. (2006). Engineering and Characterization of a Stabilized α1/α2 Module of the Class I Major Histocompatibility Complex Product Ld. J. Biol. Chem. 281, 25734–25744. doi:10.1074/jbc.M604343200
Jones, B. E., Brown-Augsburger, P. L., Corbett, K. S., Westendorf, K., Davies, J., Cujec, T. P., et al. (2020a). LY-CoV555, a Rapidly Isolated Potent Neutralizing Antibody, Provides protection in a Non-human Primate Model of SARS-CoV-2 Infection. Biorxiv Prepr. Serv. Biol. doi:10.1101/2020.09.30.318972
Jones, E. M., Lubock, N. B., Venkatakrishnan, A., Wang, J., Tseng, A. M., Paggi, J. M., et al. (2020b). Structural and Functional Characterization of G Protein-Coupled Receptors with Deep Mutational Scanning. Elife 9, e61312. doi:10.7554/eLife.54895
Khare, S., Bhasin, M., Sahoo, A., and Varadarajan, R. (2019). Protein Model Discrimination Attempts Using Mutational Sensitivity, Predicted Secondary Structure, and Model Quality Information. Proteins 87, 326–336. doi:10.1002/prot.25654
Kieke, M. C., Shusta, E. V., Boder, E. T., Teyton, L., Wittrup, K. D., and Kranz, D. M. (1999). Selection of Functional T Cell Receptor Mutants from a Yeast Surface-Display Library. Proc. Natl. Acad. Sci. 96, 5651–5656. Availableat: http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=21915&tool=pmcentrez&rendertype=abstract. doi:10.1073/pnas.96.10.5651
Kim, Y.-S., Bhandari, R., Cochran, J. R., Kuriyan, J., and Wittrup, K. D. (2006). Directed Evolution of the Epidermal Growth Factor Receptor Extracellular Domain for Expression in Yeast. Proteins 62, 1026–1035. doi:10.1002/prot.20618
Laimer, J., Hiebl-Flach, J., Lengauer, D., and Lackner, P. (2016). MAESTROweb: a Web Server for Structure-Based Protein Stability Prediction. Bioinformatics 32, 1414–1416. doi:10.1093/bioinformatics/btv769
Livesey, B. J., and Marsh, J. A. (2020). Using Deep Mutational Scanning to Benchmark Variant Effect Predictors and Identify Disease Mutations. Mol. Syst. Biol. 16, e9380. doi:10.15252/msb.20199380
Malladi, S. K., Singh, R., Pandey, S., Gayathri, S., Kanjo, K., Ahmed, S., et al. (2021). Design of a Highly Thermotolerant, Immunogenic SARS-CoV-2 Spike Fragment. J. Biol. Chem. 296, 100025. doi:10.1074/jbc.RA120.016284
Matreyek, K. A., Starita, L. M., Stephany, J. J., Martin, B., Chiasson, M. A., Gray, V. E., et al. (2018). Multiplex Assessment of Protein Variant Abundance by Massively Parallel Sequencing. Nat. Genet. 50, 874–882. doi:10.1038/s41588-018-0122-z
Maxwell, K. L., Mittermaier, A. K., Forman-Kay, J. D., and Davidson, A. R. (1999). A Simple In Vivo Assay for Increased Protein Solubility. Protein Sci. 8, 1908–1911. doi:10.1110/ps.8.9.1908
Najar, T. A., Khare, S., Pandey, R., Gupta, S. K., and Varadarajan, R. (2017). Mapping Protein Binding Sites and Conformational Epitopes Using Cysteine Labeling and Yeast Surface Display. Structure 25, 395–406. doi:10.1016/j.str.2016.12.016
Niesen, F. H., Berglund, H., and Vedadi, M. (2007). The Use of Differential Scanning Fluorimetry to Detect Ligand Interactions that Promote Protein Stability. Nat. Protoc. 2, 2212–2221. doi:10.1038/nprot.2007.321
Noderer, W. L., Flockhart, R. J., Bhaduri, A., Diaz de Arce, A. J., Zhang, J., Khavari, P. A., et al. (2014). Quantitative Analysis of Mammalian Translation Initiation Sites by FACS ‐seq. Mol. Syst. Biol. 10, 748. doi:10.15252/msb.20145136
Pandurangan, A. P., Ochoa-Montaño, B., Ascher, D. B., and Blundell, T. L. (2017). SDM: A Server for Predicting Effects of Mutations on Protein Stability. Nucleic Acids Res. 45, W229–W235. doi:10.1093/nar/gkx439
Park, S., Xu, Y., Stowell, X. F., Gai, F., Saven, J. G., and Boder, E. T. (2006). Limitations of Yeast Surface Display in Engineering Proteins of High Thermostability. Protein Eng. Des. Sel. 19, 211–217. doi:10.1093/protein/gzl003
Parthiban, V., Gromiha, M. M., and Schomburg, D. (2006). CUPSAT: Prediction of Protein Stability upon point Mutations. Nucleic Acids Res. 34, W239–W242. doi:10.1093/nar/gkl190
Pepper, L., Cho, Y., Boder, E. T., and Shusta, E.V. (2008). A Decade of Yeast Surface Display Technology: where Are We Now? Cchts 11, 127–134. doi:10.2174/138620708783744516
Peterman, N., and Levine, E. (2016). Sort-seq under the Hood: Implications of Design Choices on Large-Scale Characterization of Sequence-Function Relations. BMC Genomics 17, 206. doi:10.1186/s12864-016-2533-5
Piatesi, A., Howland, S. W., Rakestraw, J. A., Renner, C., Robson, N., Cebon, J., et al. (2006). Directed Evolution for Improved Secretion of Cancer-Testis Antigen NY-ESO-1 from Yeast. Protein Expr. Purif. 48, 232–242. doi:10.1016/j.pep.2006.01.026
Pires, D. E. V., Ascher, D. B., and Blundell, T. L. (2014a). DUET: A Server for Predicting Effects of Mutations on Protein Stability Using an Integrated Computational Approach. Nucleic Acids Res. 42, W314–W319. doi:10.1093/nar/gku411
Pires, D. E. V., Ascher, D. B., and Blundell, T. L. (2014b). MCSM: Predicting the Effects of Mutations in Proteins Using Graph-Based Signatures. Bioinformatics 30, 335–342. doi:10.1093/bioinformatics/btt691
Prajapati, R. S., Das, M., Sreeramulu, S., Sirajuddin, M., Srinivasan, S., Krishnamurthy, V., et al. (2007). Thermodynamic Effects of Proline Introduction on Protein Stability. Proteins 66, 480–491. doi:10.1002/prot.21215
Pucci, F., Kwasigroch, J. M., and Rooman, M. (2020). Protein Thermal Stability Engineering Using HoTMuSiC. Methods Mol. Biol. 2112, 59–73. doi:10.1007/978-1-0716-0270-6_5
Rocklin, G. J., Chidyausiku, T. M., Goreshnik, I., Ford, A., Houliston, S., Lemak, A., et al. (2017). Global Analysis of Protein Folding Using Massively Parallel Design, Synthesis, and Testing. Science 357, 168–175. doi:10.1126/science.aan0693
Rodrigues, C. H., Pires, D. E., and Ascher, D. B. (2018). DynaMut: Predicting the Impact of Mutations on Protein Conformation, Flexibility and Stability. Nucleic Acids Res. 46, W350–W355. doi:10.1093/nar/gky300
Rost, B., and Sander, C. (1994). Combining Evolutionary Information and Neural Networks to Predict Protein Secondary Structure. Proteins 19, 55–72. doi:10.1002/prot.340190108
Sahoo, A., Khare, S., Devanarayanan, S., Jain, P. C., and Varadarajan, R. (2015). Residue Proximity Information and Protein Model Discrimination Using Saturation-Suppressor Mutagenesis. Elife 4, e09532. doi:10.7554/eLife.09532
Savojardo, C., Fariselli, P., Martelli, P. L., and Casadio, R. (2016). INPS-MD: a Web Server to Predict Stability of Protein Variants from Sequence and Structure. Bioinformatics 32, 2542–2544. doi:10.1093/bioinformatics/btw192
Schweickhardt, R. L., Jiang, X., Garone, L. M., and Brondyk, W. H. (2003). Structure-expression Relationship of Tumor Necrosis Factor Receptor Mutants that Increase Expression. J. Biol. Chem. 278, 28961–28967. doi:10.1074/jbc.M212019200
Sharon, E., Kalma, Y., Sharp, A., Raveh-Sadka, T., Levo, M., Zeevi, D., et al. (2012). Inferring Gene Regulatory Logic from High-Throughput Measurements of Thousands of Systematically Designed Promoters. Nat. Biotechnol. 30, 521–530. doi:10.1038/nbt.2205
Shusta, E. V., Kieke, M. C., Parke, E., Kranz, D. M., and Wittrup, K. D. (1999). Yeast Polypeptide Fusion Surface Display Levels Predict thermal Stability and Soluble Secretion Efficiency 1 1Edited by J. A. Wells. J. Mol. Biol. 292, 949–956. doi:10.1006/jmbi.1999.3130
Shusta, E., Pepper, L., Cho, Y., and Boder, E. (2008). A Decade of Yeast Surface Display Technology: Where Are We Now? Cchts 11, 127–134. doi:10.2174/138620708783744516
Smith, T. F., and Waterman, M. S. (1981). Identification of Common Molecular Subsequences. J. Mol. Biol. 147, 195–197. doi:10.1016/0022-2836(81)90087-5
Starr, T. N., Greaney, A. J., Hilton, S. K., Ellis, D., Crawford, K. H. D., Dingens, A. S., et al. (2020). Deep Mutational Scanning of SARS-CoV-2 Receptor Binding Domain Reveals Constraints on Folding and ACE2 Binding. Cell 182, 1295–1310.e20. doi:10.1016/j.cell.2020.08.012
Tan, K. P., Varadarajan, R., and Madhusudhan, M. S. (2011). DEPTH: a Web Server to Compute Depth and Predict Small-Molecule Binding Cavities in Proteins. Nucleic Acids Res. 39, W242–W248. doi:10.1093/nar/gkr356
Traxlmayr, M. W., and Obinger, C. (2012). Directed Evolution of Proteins for Increased Stability and Expression Using Yeast Display. Arch. Biochem. Biophys. 526, 174–180. doi:10.1016/j.abb.2012.04.022
Traxlmayr, M. W., and Shusta, E. V. (2017). “Directed Evolution of Protein thermal Stability Using Yeast Surface Display,” in Methods in Molecular Biology (New York, NY: Humana Press), 45–65. doi:10.1007/978-1-4939-6857-2_4
Tripathi, A., Gupta, K., Khare, S., Jain, P. C., Patel, S., Kumar, P., et al. (2016). Molecular Determinants of Mutant Phenotypes, Inferred from Saturation Mutagenesis Data. Mol. Biol. Evol. 33, 2960–2975. doi:10.1093/molbev/msw182
Waldo, G. S., Standish, B. M., Berendzen, J., and Terwilliger, T. C. (1999). Rapid Protein-Folding Assay Using green Fluorescent Protein. Nat. Biotechnol. 17, 691–695. doi:10.1038/10904
Weisblum, Y., Schmidt, F., Zhang, F., DaSilva, J., Poston, D., Lorenzi, J. C., et al. (2020). Escape from Neutralizing Antibodies by SARS-CoV-2 Spike Protein Variants. Elife 9, e61312. doi:10.7554/eLife.61312
Wigley, W. C., Stidham, R. D., Smith, N. M., Hunt, J. F., and Thomas, P. J. (2001). Protein Solubility and Folding Monitored In Vivo by Structural Complementation of a Genetic Marker Protein. Nat. Biotechnol. 19, 131–136. doi:10.1038/84389
Winter, G., Griffiths, A. D., Hawkins, R. E., and Hoogenboom, H. R. (1994). Making Antibodies by Phage Display Technology. Annu. Rev. Immunol. 12, 433–455. doi:10.1146/annurev.iy.12.040194.002245
Wrenbeck, E. E., Klesmith, J. R., Stapleton, J. A., Adeniran, A., Tyo, K. E. J., and Whitehead, T. A. (2016). Plasmid-based One-Pot Saturation Mutagenesis. Nat. Methods 13, 928–930. doi:10.1038/nmeth.4029
Xue, T., Wu, W., Guo, N., Wu, C., Huang, J., Lai, L., et al. (2020). Single point Mutations Can Potentially Enhance Infectivity of SARS-CoV-2 Revealed by In Silico Affinity Maturation and SPR Assay. bioRxiv. doi:10.1101/2020.12.24.424245
Zahradník, J., Marciano, S., Shemesh, M., Zoler, E., Chiaravalli, J., Meyer, B., et al. (2021). SARS-CoV-2 RBD In Vitro Evolution Follows Contagious Mutation Spread, yet Generates an Able Infection Inhibitor. bioRxiv. doi:10.1101/2021.01.06.425392
Zhang, J., Kobert, K., Flouri, T., and Stamatakis, A. (2014). PEAR: A Fast and Accurate Illumina Paired-End reAd mergeR. Bioinformatics 30, 614–620. doi:10.1093/bioinformatics/btt593
Keywords: mutational scanning, residue burial, saturation mutagenesis, free energy, protein stability
Citation: Ahmed S, Bhasin M, Manjunath K and Varadarajan R (2022) Prediction of Residue-specific Contributions to Binding and Thermal Stability Using Yeast Surface Display. Front. Mol. Biosci. 8:800819. doi: 10.3389/fmolb.2021.800819
Received: 24 October 2021; Accepted: 14 December 2021;
Published: 21 January 2022.
Edited by:
Paulo Ricardo Batista, Oswaldo Cruz Foundation (Fiocruz), BrazilReviewed by:
Mattia Miotto, Sapienza University of Rome, ItalyCopyright © 2022 Ahmed, Bhasin, Manjunath and Varadarajan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Raghavan Varadarajan, dmFyYWRhckBpaXNjLmFjLmlu
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.