 Yilin Zhu
Yilin Zhu Jiayu Shang
Jiayu Shang Cheng Peng
Cheng Peng Yanni Sun
Yanni Sun
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Microbiol., 16 December 2022
Sec. Phage Biology
Volume 13 - 2022 | https://doi.org/10.3389/fmicb.2022.1032186
This article is part of the Research TopicAdvances in Viromics: New Tools, Challenges, and Data towards Characterizing Human and Environmental ViromesView all 6 articles
Bacteriophages, which are viruses infecting bacteria, are the most ubiquitous and diverse entities in the biosphere. There is accumulating evidence revealing their important roles in shaping the structure of various microbiomes. Thanks to (viral) metagenomic sequencing, a large number of new bacteriophages have been discovered. However, lacking a standard and automatic virus classification pipeline, the taxonomic characterization of new viruses seriously lag behind the sequencing efforts. In particular, according to the latest version of ICTV, several large phage families in the previous classification system are removed. Therefore, a comprehensive review and comparison of taxonomic classification tools under the new standard are needed to establish the state-of-the-art. In this work, we retrained and tested four recently published tools on newly labeled databases. We demonstrated their utilities and tested them on multiple datasets, including the RefSeq, short contigs, simulated metagenomic datasets, and low-similarity datasets. This study provides a comprehensive review of phage family classification in different scenarios and a practical guidance for choosing appropriate taxonomic classification pipelines. To our best knowledge, this is the first review conducted under the new ICTV classification framework. The results show that the new family classification framework overall leads to better conserved groups and thus makes family-level classification more feasible.
Bacteriophages (aka phages) are viruses that infect bacteria (McGrath and van Sinderen, 2007). Phages are the most abundant biological entities on Earth. It is estimated that there are more than 1031 bacteriophages on the planet, outnumbering every other organism on Earth combined (Suttle, 2005; LaFee and Buschman, 2017). In most microbial communities, phages play a crucial role by shaping and maintaining microbial ecology (Thingstad, 2000; Koskella and Meaden, 2013), facilitating co-evolutionary relationships (Hoyles et al., 2014; Cobián Güemes et al., 2016; Silveira and Rohwer, 2016), and promoting microbial evolution through horizontal gene transfer (Brown-Jaque et al., 2015; Chiang et al., 2019).
Phages are diverse in size, morphology, and genomic organization (Ackermann, 2006; Chow and Suttle, 2015). They have a variety of structural morphologies, among which tailed double-stranded DNA (dsDNA) phages (Brum et al., 2013; Kauffman et al., 2018) are the most abundant. Besides dsDNA phages, there are also phages with single-stranded DNA (ssDNA) (Lim et al., 2015), single-stranded RNA (ssRNA) (Loeb and Zinder, 1961) or double-stranded RNA (dsRNA) (Mertens, 2004). Phages also have a wide range of genome sizes. Recently, an increasing number of megaphages (>200 kbp) have been sequenced, demonstrating unique genomic features (Yuan and Gao, 2017). Because of the high diversity of genomes, phages infecting different hosts typically have a low similarity. However, phages that infect the same host may also have considerable differences in their genomes (Hatfull, 2008; Krupovic et al., 2011).
It is now demonstrated that phages can be found in a wide variety of environments, including aquatic ecosystems (Paul et al., 2002; Guttman et al., 2005), human gut (Manrique et al., 2017; Sutton and Hill, 2019), and soil (Chow and Suttle, 2015; Williamson et al., 2017). The first viral metagenome of uncultured marine viral communities was published in 2002 (Breitbart et al., 2002). Phages can shape the composition and function of underlying ecosystems through two different lifestyles: temperate and virulent. Temperate phages will integrate their genomes into bacterial chromosomes and replicate with their host. They will maintain this state, which is also called prophages, until being induced by the environment's condition, such as appropriate temperature and pH value. Then, temperate phages will enter the lytic cycle to kill the host (Campbell, 2003; Howard-Varona et al., 2017). In contrast, virulent phages do not integrate their genomes into the hosts. They stay in the lytic cycle and kill the hosts after replicating themselves (Hobbs and Abedon, 2016).
The unique properties and life styles make phages key players in multiple applications. For example, phage therapy is a promising strategy for treating bacterial infections, particularly those with antibiotic-resistant bacteria. It has been found that intravenous phage preparations could treat Staphylococcus aureus that induced pneumonia in mice (Saussereau and Debarbieux, 2012; Oduor et al., 2016). In addition, phages can be used to treat gastrointestinal infections. It has been demonstrated that phages are effective in reducing intestinal pathogens and have less impact on the composition of the intestinal microbiota compared to antibiotics (Jaiswal et al., 2013; Galtier et al., 2016; Nale et al., 2016; Gutiérrez and Domingo-Calap, 2020). Moreover, phages are important in food safety. The use of specific phage treatments in the food industry can prevent product spoilage and limit the spread of bacteria, providing a safe environment for animal and plant food production (Garcia et al., 2008; Coffey et al., 2010; Sillankorva et al., 2012; Gutiérrez et al., 2017).
However, despite the abundance and importance of phages in various ecosystems, our understanding of phages is still very limited. According to the database supported by the National Center for Biotechnology Information (NCBI), the number of identified phages in class Caudoviricetes changed from 1,359 in 2015 to 4,483 in 2022 in the RefSeq database, which is tripled in size. Besides the reference genomes, there are roughly 63,588 assembled phages belonging to Class Caudoviricetes in the Genbank database in 2022, an almost five fold increase compared to 2015 (16,232). However, the characterization of phages cannot keep pace with the fast increase of the sequencing data.
Assigning phages into different taxonomic groups is a fundamental step following phage discovery. The official taxonomy was established by the International Committee on Taxonomy of Viruses (ICTV) (Adams et al., 2017), which organizes viruses in several taxonomic levels, including class, order, family, subfamily, genus, and so on. Within the ICTV, the Bacterial and Archaeal Viruses Subcommittee (BAVS) is responsible for the phages' taxa. BAVS classifies phages based on a variety of phage properties, including the molecular composition of the genome (ss/ds, DNA, or RNA), the morphology, the structure of the capsid, and the host range (Dion et al., 2020). Recently, with the increasing availability of viral genomes, using genomes for taxonomic classification has become more widely accepted (Lefkowitz et al., 2018). Due to the extensive sequencing efforts for virus discovery, ICTV cannot catch up with the sheer number of newly identified phages, and thus many viruses are still not classified. One challenge behind this delay is the lack of standard, accurate, and comprehensive taxonomic classification tools for phages. Indeed, phage classification is not a trivial problem. The taxonomic standard in ICTV is constantly changing as new phages are discovered. Recently, ICTV updated the phage classification system in August 2022, in which several major families in the previous ICTV system are removed, such as Siphoviridae, Podoviridae, and Myoviridae. These changes can significantly affect the performance of family classification. To our best knowledge, no quantitative evaluations of the performance change have been conducted. Table 1 shows the average similarity (calculated by Dashing; Baker and Langmead, 2019) of the largest four families in the old and new ICTV taxonomy classification systems. The updated families are more conserved as shown by the increased average similarity, making family-level classification more feasible.

Table 1. The average pairwise Dashing similarity of the four largest phage families under Caudoviricetes.
Available taxonomic classification tools often have different designs and were tested on different datasets by their authors. Without a comprehensive comparison on the same training/reference data set and test set, it is difficult for users to choose the most appropriate solution for their needs. This paper presents a comprehensive benchmark of the main players in phage taxonomic classification under the latest ICTV standard. The remaining of this review is organized as follows. First, we will describe the main methods/models for existing phage taxonomic classification approaches and discuss whether they can be retrained/used under the new ICTV taxonomy standard. Then, we evaluate the four representative approaches that can be retrained by newly labeled sequences in different usage scenarios. In particular, we tested these tools on complete virus genomes, short contigs, simulated metagenomic datasets, and low-similarity datasets. In addition, we conducted a leave-one-family-out experiment to test whether these tools can recognize out-of-distribution sequences. By comparing their performance and analyzing the underlying reasons, we draw conclusions and provide guidance for users about choosing the most appropriate tools for different scenarios.
Most phage taxonomic classification approaches can output classification results in different ranks, such as order, family, and genus. In this review, we focus on comparing different tools' performance at the family level because of the following reasons. First, the taxonomy by ICTV is under constant changes, which affects the total genus number significantly. For example, there are 735 genera in the ICTV database released in 2016. However, the number of genera increased to 2,224 in 2020. The overhaul of the genus-level taxonomy can make the definition of “ground truth” ambiguous. In addition, hundreds of rare genera only contain one phage, making the construction of reference and test set difficult. Second, classification at higher taxonomic ranks is usually easier than at lower ranks due to the smaller inter-class similarities and more abundant sequences in each class. Thus classification at order or above is not as challenging as family classification. Caudoviricetes, a class of phage known as the tailed phages whose hosts are phage and archaea, contains the majority of the total phage sequences and can be classified by almost all of the tools mentioned above, we thus focus on the classification of the families under Caudoviricetes in this work.
The phage taxonomic classification methods are summarized in Table 2 following the chronological order, which includes a brief description, publication year, required input data type, and the lowest predicted level of each tool. A majority of these tools conduct phage taxonomic classification based on sequence comparison, utilizing nucleotide-level or protein-level similarity between a query virus and the reference database. The comparison-based methods differ in their constructed reference database, the alignment method, and how they utilize these alignments. Both pairwise sequence alignment and hidden Markov model (HMM)-based profile alignments are commonly used. Multiple tools construct virus protein families and use them as marker genes. Using markers usually incurs less memory usage than using all phage genomes. But newly sequenced phages with novel genes may not be aligned to any marker gene families and thus cannot be assigned to a known class. Learning-based models have also been applied to phage classification. Learning models can automatically infer the sequence patterns in phage genomes of different families and use the learned features for automatic classification. A more detailed description of these tools is provided below.
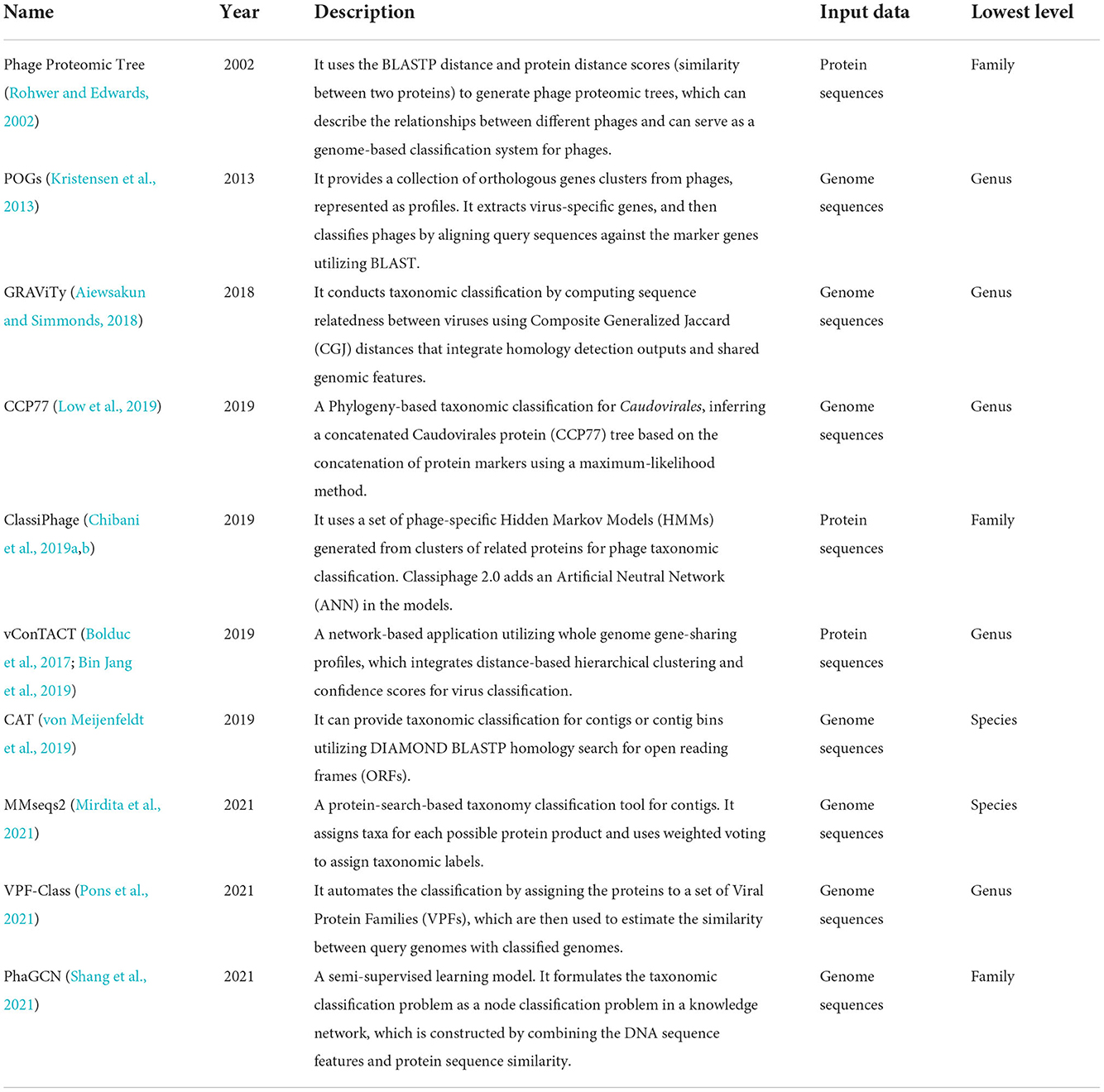
Table 2. Overview of bioinformatic approaches used for phage taxonomic classification.
Phage Proteomic Tree (Rohwer and Edwards, 2002; Nishimura et al., 2017) is a relatively early program providing phage genome classification down to the family level. It extracts protein sequences from virus genomes and clusters these sequences using BLASTP (Altschul et al., 1997). Then the clusters in Phage Proteomic Tree are refined and scored. Finally, the alignment scores are converted to distances, which were used to generate the final tree using the neighbor-joining algorithm.
Taxon-specific signature genes can be identified in most virus taxa. POGs (Phage Orthologous Groups) (Kristensen et al., 2013) is a collection of clusters of orthologous genes from phages, presented as profiles (multiple sequence alignment). The viral families of POGs are filtered as “Viruses[Organism] NOT cellular organisms [ORGN] NOT srcdb_refseq[PROP] AND vhost bacteria[filter] AND ‘complete genome’ [All Fields]” in NCBI. Signatures are extracted for each taxon, and we can use BLASTP to search for matches among the viral protein sequences. POGs are designed to be well-suited for defining taxon-specific signature genes, and the profiles built from POGs are more sensitive and specific to search for signature genes in a given dataset.
GRAViTy (Aiewsakun and Simmonds, 2018) also extracts protein sequences from virus genomes and cluster these sequences using BLASTP (Altschul et al., 1997). GRAViTy generates protein profile hidden Markov models (PPHMMs) and genomic organization models (GOMs) based on the sequences from BLASTP-based clustering. Then it computes Composite Generalized Jaccard (CGJ) similarity scores (a geometric mean of the two generalized Jaccard scores computed for a pair of PPHMM signatures and a pair of GOM signatures) between each sequence pair to construct the heat map and dendrogram and estimate sequences' relatedness. GRAViTy requires users to choose reference database freely but need sequences in GenBank format as input.
CCP77 (Low et al., 2019) applies a concatenated protein phylogeny for the classification of tailed dsDNA viruses belonging to the specific order Caudovirales. Classiphage (Chibani et al., 2019a,b) uses phage-specific Hidden Markov Models (HMMs) (Eddy, 2011) profiles generated from clusters of related proteins for classification. The HMM profiles are built using the produced multi-sequence alignment files by the “hmmbuild” command. Classiphage 2.0 additionally trains an Artificial Neutral Network (ANN) using phage family-proteome to phage-derived HMMs scoring matrix, which can classify more phage families and include more features than its previous version.
vConTACT (Bolduc et al., 2017; Bin Jang et al., 2019) is a high-throughput network-based approach utilizing whole-genome gene-sharing profiles. It clusters the input viral genomes together with characterized genomes. The genomes in the same cluster indicate the same family or genus, and the predicted family can be inferred if there are characterized genomes in the same cluster.
CAT (von Meijenfeldt et al., 2019) provides taxonomic classification using homology searches. It uses DIAMOND BLASTP to identify homologous sequences and then assigns query sequences into taxa with a voting approach. The authors of CAT show that using the best hit strategy can lead to low specificity and thus design a more robust strategy based on multiple hits. Users can select the reference database and tune the setting, which is more flexible than some other tools. Moreover, it has a very low memory usage.
MMseqs2 (Mirdita et al., 2021) is a fast contig taxonomic assignment tool. Similar to CAT, it conducts protein homology search against reference sequences and uses majority vote to assign the most specific taxon for a contig. With some optimizations and adoption of 2bLCA (Hingamp et al., 2013), MMseqs2 circumvents the need of adjusting a parameter in CAT and achieves faster speed on the tested bacterial and eukaryotic datasets. It allows users to supply a customized reference database.
VPF-Class (Pons et al., 2021) provides both taxonomic classification and host prediction for input viral genomes. It compares predicted proteins against the set of constructed Viral Protein Families (VPFs) (from the IMG/VR system). Then it derives taxonomic classifications and confidence scores from the list of VPFs detected on each query genome. However, VPF-Class does not require users to download and select the reference datasets.
PhaGCN (Shang et al., 2021) is a semi-supervised learning model for phage taxonomic classification developed by our team. This model constructs a knowledge graph by combining the DNA sequence features learned by Convolutional Neural Networks (CNN) and protein sequence similarity gained from the gene-sharing network. The learning model can incorporate the automatically learned features for each contig. However, unlike sequence comparison-based approaches, PhaGCN only accepts phage-like sequences as input. Thus, a pre-processing step is needed for detecting those contigs from metagenomic data. A number of tools, such as VirFinder (Ren et al., 2020), Seeker (Auslander et al., 2020), and PhaMer (Shang et al., 2022) can be applied in the pre-processing step.
Because of the changes in the ICTV classification system, the models/reference databases need to be updated using the latest labeled sequences. However, not all the tools in Table 2 can be updated easily. Among them, only CAT, GRAViTy, PhaGCN, MMseqs2, and vConTACT 2.0 allow users to change their reference databases or retrain the models with reasonable efforts. The others do not specify the feasibility of changing models or reference databases in the descriptions. The source code of CCP77 is only available on request but not to the public. The code of GRAViTy released at GitHub is the alpha version and the author mentioned that they are currently working on a new and improved version that is more user-friendly and written in python3. Nevertheless, we downloaded and installed the alpha version of GRAViTy. The alpha version is computationally expensive and requires 30 h to build a reference database with about 1200 genomes and another 25 h to process just 300 queries. Therefore, we focus on evaluating the performance of the four tools: PhaGCN, vConTACT 2.0, CAT, and MMseqs2. These tools were recently published and demonstrated good performance in their own or others' tests. In addition, the corresponding codes and tools are still under maintenance. None of them requires an internet connection or a web server. To mimic the scenario of applying these tools to datasets without known taxonomic composition, we apply all these tools with their default parameters, which are optimized by the authors. The commands for running all these tools are available in the Supplementary material. All the tools were run on IntelVRⓇXeonVRⓇ Gold 6258 R CPU with 8 cores.
We rigorously evaluated these phages taxonomic classification tools on multiple datasets. The detailed information is listed below.
• The RefSeq dataset RefSeq is a widely used benchmark dataset in phage classification tasks. By October 2022, there are 1,826 complete sequences with family-label under Class Caudoviricetes in the RefSeq database. In this paper, we only focus on the phages infecting bacteria. After filtering out the families that infect archaea or contain sequences less than 6, there are 19 families (including 1460 complete sequences) we can use in our experiments. Table 3 shows the number of sequences within the 19 families under class Caudoviricetes, among which Autographiviridae contains the largest number of sequences. For the tools that require protein sequences, we used Prodigal (Hyatt et al., 2010) to predict and translate the nucleotide sequence into the proteins.
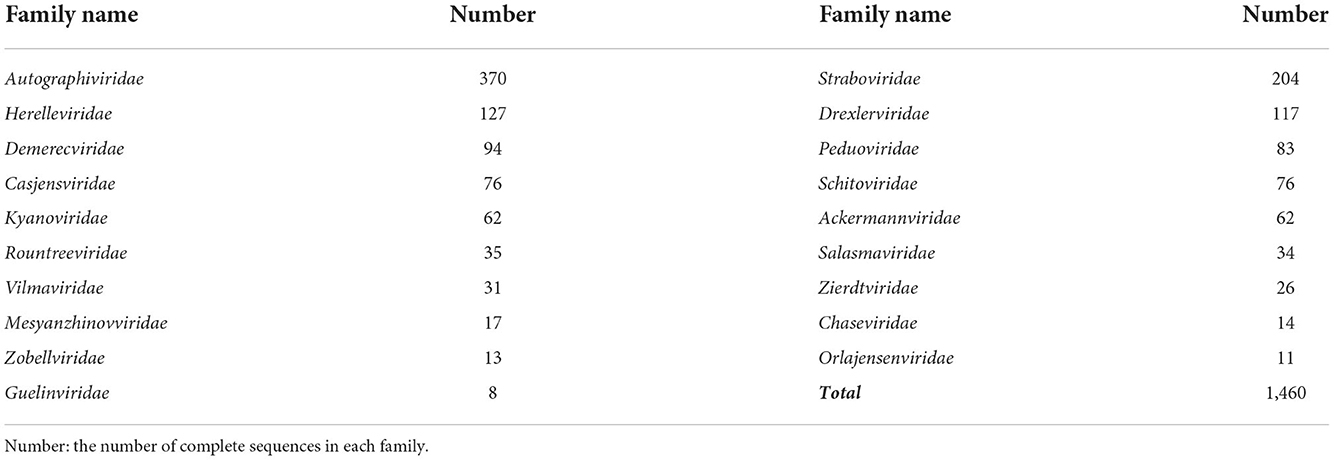
Table 3. The 19 families under class Caudoviricetes from the RefSeq database we used in the experiments.
We sorted the sequence by their release time at RefSeq. Then, we used the first 80% of the labeled complete sequences from each family as the training set/reference database to retrain/update the four tools, and the rest 20% as test set. Because we split the data in chronological order, the data in the test set are more recent (almost all were released in 2020 or after).
• Short contigs dataset This dataset contains segments with different lengths, including 500, 1,000, 3,000, 5,000, 10,000, and 15,000 bp. We randomly generated the segments from the 20% RefSeq dataset (293 sequences) mentioned above. For each length, we cut ten segments from each phage genome by selecting a random start position. Finally, we had 2,930 phage contigs for each length and 29,300 for all different lengths. Then, we used these segments to evaluate the performance of the four tools on short contigs.
• Simulated metagenomic dataset We used a simulated metagenomic dataset generated by six common bacteria living in human gut (Shang et al., 2022). We first utilized metaSPAdes (Nurk et al., 2017) to assemble the reads into contigs. Then PhaMer (Shang et al., 2022) was applied to identify bacteriophages from metagenomic data, and the labels of the contigs were determined using BLAST (Camacho et al., 2009). Eventually, 37 contigs were used in the experiments. More details about this dataset will be provided in the section of Experiment 4.
• Low-similarity dataset To test the tools' performance on classifying highly diverged phages, we constructed a hard case where the test sequences share low similarity with the reference database/training data. Specifically, we calculated the Dashing pairwise similarity of the sequences in each family and then used the approach in Petti and Eddy (2022) to partition the data into two parts with specified maximum similarity. With this method, we got 264 and 45 genomes for training and test, where each test genome has at most 0.015 Dashing similarity with any reference genome. Then we randomly cut 15 contigs with a length of 3,000 and 5,000 bp, respectively, from each testing genome. Finally, there are 675 contigs for each length in the test set.
An ideal phage classification tool should assign correct labels for as many inputs as possible. Nevertheless, there is usually a tradeoff between the percentage of prediction and the accuracy of the prediction. Some tools may sacrifice the percentage of prediction in order to achieve high specificity and accuracy, while others may predict more with lower accuracy. Thus the first metric is prediction rate, which is the ratio of outputs with prediction results (Npred in Equation 1) to the total input (Nall in Equation 1). Because some tools only provide a family name as output, commonly used metrics such as AUROC cannot be computed. In this work, we calculated accuracy, recall, and precision for each tool (Equations 2–4). Ncorrect is the number of sequences with correct predictions in output. Ntotal is the total number of sequences used to evaluate, which can be Nall or Npred when we report accuracy for all input phage sequences (Nall) or only for sequences with predictions in output (Npred), respectively. Providing accuracy for all input sequences has the advantage of using the same denominator (i.e., Nall) for all tools. But it penalizes the tools of low prediction rate twice. On the other hand, reporting accuracy for only sequences with predictions removes the impact of prediction rate but may favor tools with low prediction rate (i.e., small Npred). Thus, reporting both can provide a more comprehensive evaluation for users. For example, if there are 293 (Nall) sequences input, among which 290 sequences have classification prediction results (Npred), and 285 of them have correct results (Ncorrect), the accuracy on all input will be 285/293 = 0.973, and the accuracy on predicted sequences will be 285/290 = 0.983. We only calculate the recall and precision of each family (Precisioni and Recalli) to check the performance on different families. TPi, FPi, and FNi are the true positive, false positive, and false negative for family i, respectively.
Because the output format of each tool is different, we will describe how we process the output and calculate the metrics in detail.
vConTACT 2.0 can output the result of each sequence and assign it a “VC State”, including “Singleton”, ‘Outlier”, or “Clustered”. In addition, the sequences with a “Clustered” state will be assigned to a VC cluster/subcluster. When the query sequence is within the same VC cluster as a reference genome, the taxonomic labels can be assigned based on the known labels. However, some sequences are clustered but have no reference genome in the same VC cluster, so they can not be assigned with a known label. Therefore, we treat the sequence with VC state of “Singleton”, “Outlier”, and “Clustered” but no reference genome in the same clusters, as “no prediction”. In other words, Npred of vConTACT 2.0 refers to the number of the sequences that are clustered with reference genomes.
PhaGCN will not output the classification results for the sequences they can not classify, so Npred of PhaGCN is the number of sequences that can be predicted.
MMseqs2 and CAT will not output any prediction result for the sequences they cannot classify. The classification result of MMseqs2 and CAT can be a label at different ranks. If the prediction at the lowest rank is above family, we also treat this sequence as “no prediction” for the family level. The number of the rest sequences is Npred of MMseqs2/CAT.
The constant change of ICTV underscores a need for classification tools to recognize the sequences that are not part of the current classification system. For example, the three largest families, Siphoviridae, Podoviridae, and Myoviridae, were largely removed from the current ICTV system. Some of the sequences that belonged to these three families are not part of any existing family. Thus, the classification tools need to handle these out-of-distribution sequences by providing a signal for users.
To examine whether the tested tools can single out those out-of-distribution sequences, we removed all the phages in one family from the training data and retrained the models. Then the retrained models are applied to the removed family members. Ideally, the test sequences in this removed family should not be classified into any existing family labels.
At first, we conducted the experiments on a small and a relatively large family: Guelinviridae and Rountreeviridae. The classification results are plotted in Figures 1, 2, which show that PhaGCN assigned all of the query genomes to one of the other families in the training set, while CAT and MMseqs2 can correctly recognize a few sequences as “no family label”. However, vConTACT 2.0 can assign all sequences to “Outlier/Singleton” or a “VC cluster” without reference genomes.
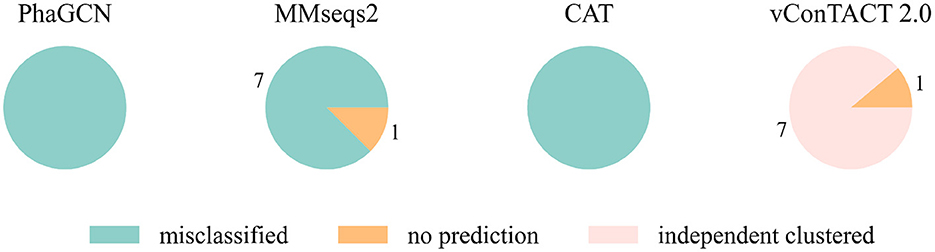
Figure 1. The classification result of Guelinviridae sequences in tools that are retrained by removing all Guelinviridae sequences. “independent clustered”: The sequences are in a VC cluster without any reference genome.
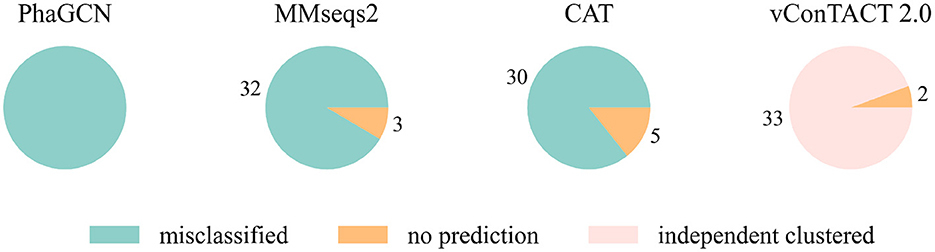
Figure 2. The classification result of Rountreeviridae sequences in tools that are retrained by removing all Rountreeviridae sequences. “independent clustered”: The sequences are in a VC cluster without any reference genome.
We then extended the experiment to each family. Because the current version of PhaGCN is not designed to handle out-of-distribution sequences, we only show the results for CAT, MMseqs2, and vConTACT 2.0 in Table 4. The output of these three tools for the test sequences are divided into two parts: those that did not output a family label (“no prediction”, defined in the Section 3.2.2), and those that can output a family label from the training data (i.e., a misclassification in this experiment). Table 4 shows the misclassification rate of each tool. CAT and MMseqs2 assign more test sequences to other families in the reference database. In contrast, vConTACT 2.0 can assign almost all sequences of each family to “Outlier/Singleton” labels or “VC cluster” without reference genomes. The misclassification rates of CAT and MMseqs2 vary widely across different families, with the ranges 0–1 and 0–0.92, respectively. A closer look at those results reveals that the misclassified phages tend to distribute in a small set of families. For example, almost all sequences belonging to Guelinviridae are classified into Salasmaviridae by CAT, which is likely due to the higher inter-family similarity between them. Specifically, 29.6% proteins of Guelinviridae can align with Salasmaviridae using BLASTP. Similarly, sequences from Zobellviridae tend to be classified into family Autographiviridae because they share about 16.9% proteins. Therefore, the inter-family similarity is an essential factor leading to misclassification. Overall, the misclassification results of MMseqs2 are more divergent than CAT. For example, CAT will classify Autographiviridae genomes into 4 other families, while MMseqs2 will assign them into 8 families (including the 4 families in CAT).
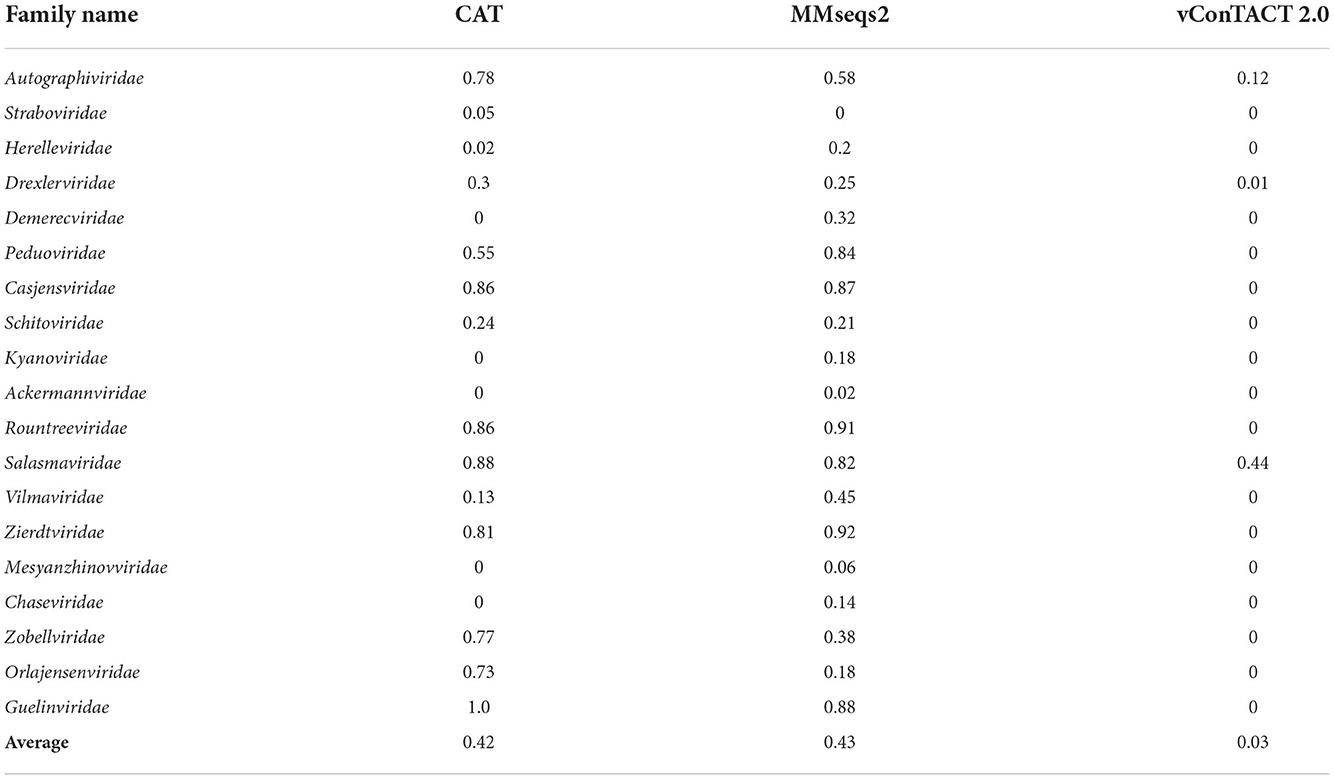
Table 4. The percentage of misclassified sequences in leave-one-family-out experiment for each family.
Then we extended the experiment to the genomes that are unclassified at the family level in the RefSeq database under class Caudoviricetes. Because the three largest families Myoviridae, Siphoviridae and Podoviridae were removed, we used the genome sequences that initially belonged to these three families but now no longer have a family label as the test data. There are 2445 of them, and the classification result is shown in Figure 3. MMseqs2 and CAT misclassified about 65% of the input sequences. vConTACT 2.0 can identify 98% unclassified sequences by assigning them in independent clusters or outputting a “Singleton/Outlier” label and only misclassified 2% sequences. In conclusion, vConTACT 2.0 performs better in identifying novel phages than the other three tools.
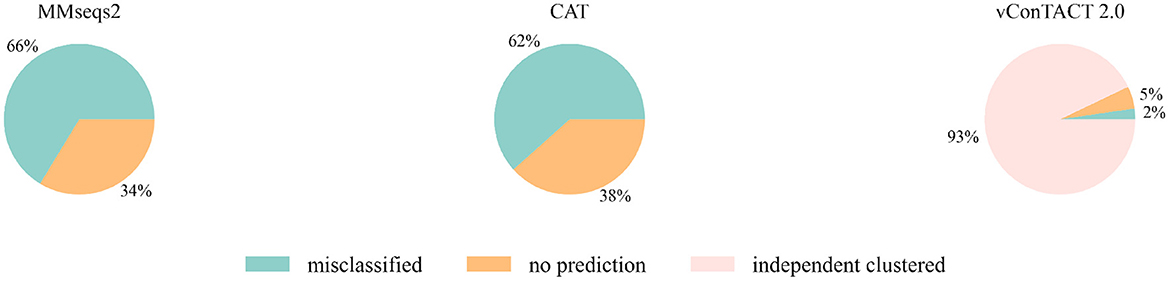
Figure 3. The classification result of 2,445 unclassified sequences. “independent clustered”: The sequences are in a VC cluster without any reference genome.
As we described in Section “Dataset”, we used 20% (293) of the complete sequences from the RefSeq database as the test set, and the other 80% as the reference/training set. To mimic metagenomic assembled contigs, we generated six sets of segments of different lengths for comparison, including 500, 1,000, 3,000, 5,000, 10,000, and 15,000 bp. We randomly selected the start positions for each length and cut ten segments from each complete sequence. Finally, we had 2,930 phage fragments for each length and 29,593 for all different lengths as the test data (293 complete sequences + 2930 * 10 short fragments).
A good taxonomic classification tool should have a high prediction rate and high accuracy. First, we recorded the prediction rate of each tool on different lengths. Because PhaGCN only accepts contigs longer than 2,000 bp, we do not show its results on 500 and 1,000 bp in Figure 4. The prediction rate (Figure 4A) of all tools becomes higher with the increase in sequence length. This is expected because longer sequences usually provide more information for classification. Almost all pipelines can maintain a high prediction rate (>80%) on short sequences except vConTACT 2.0. PhaGCN has the highest prediction rate if the inputs are longer than 5,000 bp, while CAT is slightly lower. vConTACT 2.0 is mainly designed for complete or long sequences, and its prediction rate drops sharply when the inputs are shorter than 15,000 bp. All four can handle more than 95% of complete sequences, among which PhaGCN can predict all of them (100%), and the prediction rates of MMseqs2, CAT, and vConTACT 2.0 are 99.3, 97.9, and 95.1%, respectively.
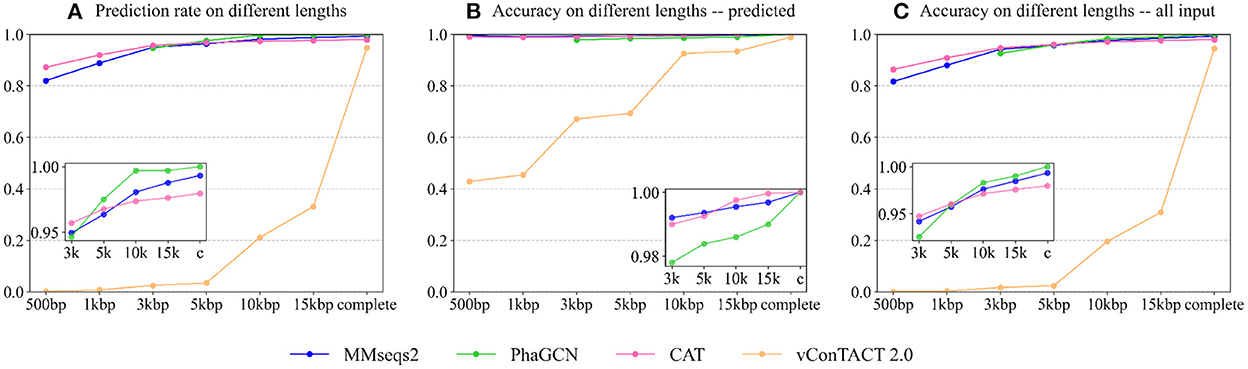
Figure 4. The performance of each tool on contigs from the RefSeq. (A) The prediction rate of four tools on different lengths. (B) The accuracy of four tools on phage contigs with predictions. (C) The accuracy of four tools on all input phage contigs. X-axis: The lengths Y-axis: The values.
Figure 4B shows the accuracy of the four tools on phage sequences with predictions (Npred in Equation 1). Similar to the prediction rates above, the accuracy of these approaches becomes better as the sequence lengths increase. The classification ability of CAT, PhaGCN, and MMseqs2 are not significantly affected by the change of contig lengths. On incomplete contigs, the accuracy of vConTACT 2.0 has an obvious upward trend when length increases. CAT gains the best prediction accuracy for contigs longer than 5,000 bp. Combined with the slightly lower prediction rate of CAT mentioned above, we can conclude that there is a tradeoff between the prediction rate and the accuracy of CAT. The accuracy of PhaGCN is slightly lower than the other two on contigs, and all three tools reach a high accuracy (100%) for all complete sequences with predictions.
Figure 4C shows the accuracy of the four tools on all input phage contigs (Nall in Equation 1), which combines the results in Figures 4A,B in order to display the overall performance of each tool. It reveals that PhaGCN keeps the best performance on contigs longer than 5,000 bp and reaches 100% accuracy on complete genomes because it gains 100% accuracy and prediction rate in Figures 4A,B, respectively. It is worth noting that the other three tools all have a less than 100% recall on Autographiviridae, most likely due to the lower pairwise similarity in Autographiviridae (Table 1). Due to the length limitation of PhaGCN, it is not suitable for classifying contigs shorter than 2,000 bp. When classifying contigs longer than 2,000 bp, PhaGCN and MMseqs2 are recommended for obtaining high prediction rates. Otherwise, CAT is a better choice if precision is the primary consideration.
Being a learning-based classification tool, PhaGCN can be affected by training data size. To test whether PhaGCN and other alignment-based tools suffer from reduced training data/reference database, we used 80% (the same as Experiment 2), 60%, and 50% of the RefSeq databases as the reference database for these tools, respectively. Then we tested them on the same test set as in Experiment 2. As shown in Figure 5A, the prediction rates of PhaGCN with different reference databases have no obvious differences. There is a slight change in the prediction rate of CAT, MMseqs2, and vConTACT 2.0, but the differences do not exceed 0.2%. In addition, the accuracy of these tools shown in Figure 5B are almost identical and are less affected than the prediction rate.
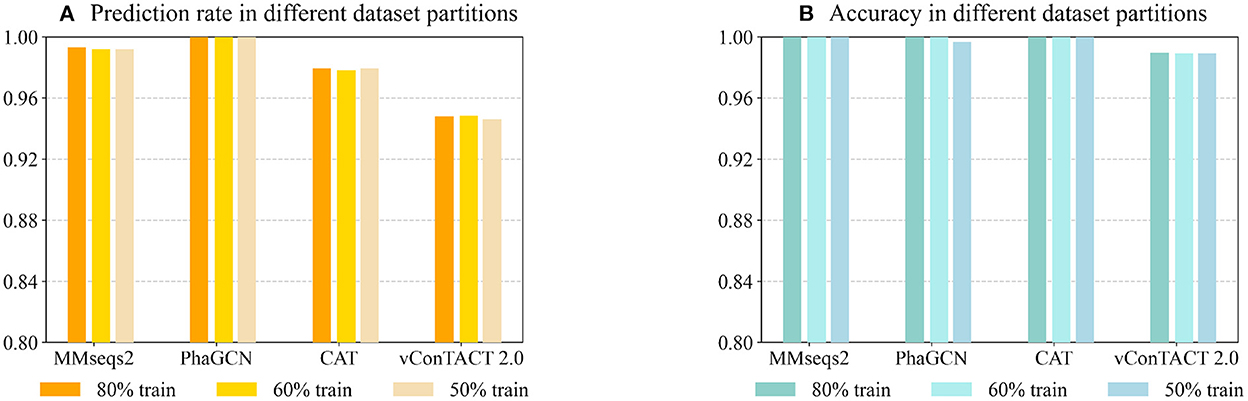
Figure 5. (A) The prediction rate of four tools with reduced reference datasets. (B) The corresponding accuracy on sequences with predictions. X-axis: The tools and training data partitions Y-axis: The values.
In this experiment, we used the simulated metagenomic dataset provided in PhaMer (Shang et al., 2022). The dataset is a small-scale metagenomic dataset simulated by CAMISIM (Fritz et al., 2019) using the commonly seen bacteria living in the human gut and the phages that infect these bacteria. The reads were assembled into contigs using metaSPAdes (Nurk et al., 2017).
We kept contigs of size above 3,000 bp. To assign labels to the contigs, we used BLAST (Camacho et al., 2009) to map contigs to reference genomes and calculated the coverage. Only the contigs with at least 90% of the sequence aligning to a reference genome were kept. Others are likely chimeric contigs due to assembly errors and thus are not used for testing. Finally, the number of contigs we could use in the experiment is 37. The name of the families and the number of genomes within each family are listed in Table 5. Compared to Table 3, this test set contains a different abundance distribution for the component families, which can thus change the performance of these tools.

Table 5. Family composition of the simulated metagenomic dataset.
As shown in Figure 6A, PhaGCN, MMseqs2, and CAT can classify all the simulated sequences correctly, which is slightly higher than that on the RefSeq data in Experiment 2. A plausible reason is that most of the sequences in this simulated dataset belong to Straboviridae and Ackermannviridae, which make up a large part of the reference database according to Table 3 (14% and 4%). In addition, they have greater intra-family similarities. The performance of vConTACT 2.0 is lower than the other three tools because the assembled contigs are short. This experiment shows that PhaGCN, MMseqs2, and CAT can process assembled contigs with different lengths.
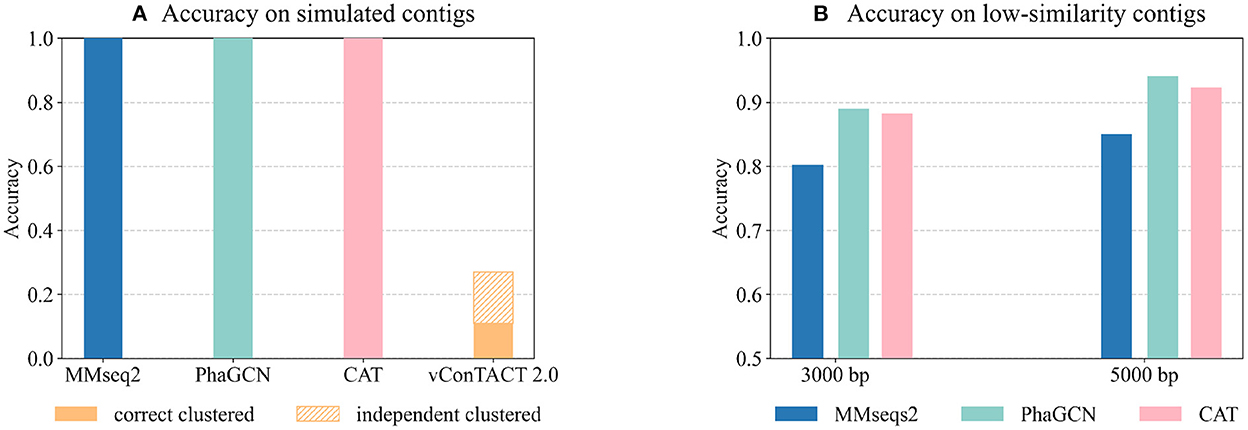
Figure 6. (A) The performance of the four tools on the simulated metagenomic dataset. The bars show the accuracy on all inputs. The top part with patterns in vConTACT 2.0 shows the percentage of contigs that are not clustered with any reference genome. (B) The performance of each tool on the two low-similarity datasets. Each bar shows the tools' accuracy on all input contigs.
Although the updated families under the new ICTV standard exhibit higher pairwise sequence similarity, there are still some diverged members. The diverged members may appear more often when sequencing new or underrepresented ecosystems. Thus, we test these tools' performance on predicting highly diverged sequences using the “low similarity dataset”. There are 45 genomes in the test set with the maximum Dashing similarity of 0.015 with any reference genome. Then we randomly cut 15 contigs with a length of 3,000 bp and 5,000 bp from each test genome, leading to 1,350 contigs in total. Figure 6B shows the accuracy of all inputs. Because vConTACT 2.0 can not handle short contigs, we exclude it from this experiment.
Figure 6B reveals that the accuracy of MMseqs2 decreases by more than 10% compared to Figure 4C from Experiment 2. And the accuracy drop in CAT (6%, 5.2%) are greater than PhaGCN (3.3%, 2%) on the contigs of the same lengths. Therefore, the increased divergence between test and training data has a greater impact on alignment-based tools than PhaGCN in this experiment.
Running time is also an essential factor to consider for practical usage. Table 6 shows the running time of the tools for processing 500 complete sequences in RefSeq when using a different number of CPUs. Users can save more time by increasing the number of CPUs. The table also shows that CAT and MMseqs2 take the least time to process 500 complete phages.

Table 6. The total running time of tools for classifying 500 genomes using a different number of CPUs.
This work presents a review of taxonomic classification tools on phage family classification under Caudoviricetes. To our best knowledge, this is the first review under the new ICTV standard released in August 2022. Compared to the previous version of ICTV, the updated families in the latest system are more conserved, which warrants a high prediction rate and accuracy of alignment-based tools. For example, the prediction rate of CAT and vConTACT 2.0 were 62 and 92% on the data in the previous ICTV system, respectively. And their accuracy on complete genomes were only 61.7 and 86%. However, their prediction rate and accuracy are significantly better under the new classification system.
The constant change of the taxonomic classification system by ICTV emphasizes the need for a tool to provide database updating or model retraining. Tools without these utilities can return obsolete or even wrong labels, making their practical usage limited. Many of these tools in Table 2 either lack this option or need excessive efforts to retrain.
Despite great efforts, the current classification system by ICTV is not complete. New families can appear with new viruses sequenced and discovered, particularly those from underrepresented ecosystems. Thus, it is desired that a classification tool can handle out-of-distribution inputs, which are not part of any existing families. Based on our leave-one-family-out experiment, vConTACT 2.0 is more sensitive to those out-of-distribution sequences than others. However, a price paid by vConTACT 2.0 is its low prediction rate on short contigs, which is likely caused by the low gene sharing significance score between the query and the reference. Other tools perform better on short contigs, which is important for virus composition analysis in metagenomic data.
PhaGCN can only classify sequences on the family level. The lowest levels that the other three tools can classify are genus level or below. The experimental results show that all of them can perform well on complete genomes from the RefSeq database after retraining. PhaGCN has the highest prediction rate when classifying short contigs (>3,000 bp), and CAT gains a higher accuracy with a slightly lower prediction rate. Therefore, when classifying incomplete contigs larger than 3,000 bp, PhaGCN, CAT, and MMseqs2 can all be considered, but PhaGCN has a better overall performance. In addition, CAT and MMseqs2 can be used to classify contigs shorter than 2,000 bp because PhaGCN can not handle that length. All these four tools are robust against the size reduction of the reference database/training data. The performance of PhaGCN is less affected in classifying highly diverged sequences that share low similarity with the reference genomes.
The focus of this review is family-level classification. While the current families annotated by ICTV usually contain multiple phages per family, the genus size distribution exhibits a much more skewed distribution with many genera only containing one phage genome. It is not trivial to create appropriate reference database/training data vs. test data with hundreds of rare genera. It is our future work to examine the impact of the long tail distribution on current classification tools.
YZ, JS, and YS designed the experiments. YZ and JS conducted the experiments. CP helped additional experiments for addressing reviewers' questions. YZ, JS, and YS contributed to the manuscript. All authors read and approved the manuscript.
This work was supported by City University of Hong Kong (Project 9678241 and 7005453) and the Hong Kong Innovation and Technology Commission (InnoHK Project CIMDA).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmicb.2022.1032186/full#supplementary-material
Ackermann, H.-W. (2006). Classification of bacteriophages. The Bacteriophages 2, 8–16. doi: 10.1002/9780470015902.a0000782.pub2
Adams, M. J., Lefkowitz, E. J., King, A. M., Harrach, B., Harrison, R. L., Knowles, N. J., et al. (2017). 50 years of the International Committee on Taxonomy of Viruses: progress and prospects. Arch. Virol. 162, 1441–1446. doi: 10.1007/s00705-016-3215-y
Aiewsakun, P., and Simmonds, P. (2018). The genomic underpinnings of eukaryotic virus taxonomy: creating a sequence-based framework for family-level virus classification. Microbiome 6, 1–24. doi: 10.1186/s40168-018-0422-7
Altschul, S. F., Madden, T. L., Schäffer, A. A., Zhang, J., Zhang, Z., Miller, W., et al. (1997). Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Res. 25, 3389–3402. doi: 10.1093/nar/25.17.3389
Auslander, N., Gussow, A. B., Benler, S., Wolf, Y. I., and Koonin, E. V. (2020). Seeker: alignment-free identification of bacteriophage genomes by deep learning. Nucleic Acids Res. 48, e121. doi: 10.1093/nar/gkaa856
Baker, D. N., and Langmead, B. (2019). Dashing: fast and accurate genomic distances with HyperLogLog. Genome Biol. 20, 1–12. doi: 10.1186/s13059-019-1875-0
Bin Jang, H., Bolduc, B., Zablocki, O., Kuhn, J. H., Roux, S., Adriaenssens, E. M., et al. (2019). Taxonomic assignment of uncultivated prokaryotic virus genomes is enabled by gene-sharing networks. Nat. Biotechnol. 37, 632–639. doi: 10.1038/s41587-019-0100-8
Bolduc, B., Jang, H. B., Doulcier, G., You, Z.-Q., Roux, S., and Sullivan, M. B. (2017). vConTACT: an iVirus tool to classify double-stranded DNA viruses that infect Archaea and Bacteria. PeerJ 5, e3243. doi: 10.7717/peerj.3243
Breitbart, M., Salamon, P., Andresen, B., Mahaffy, J. M., Segall, A. M., Mead, D., et al. (2002). Genomic analysis of uncultured marine viral communities. Proc. Natl. Acad. Sci. U.S.A. 99, 14250–14255. doi: 10.1073/pnas.202488399
Brown-Jaque, M., Calero-Cáceres, W., and Muniesa, M. (2015). Transfer of antibiotic-resistance genes via phage-related mobile elements. Plasmid 79, 1–7. doi: 10.1016/j.plasmid.2015.01.001
Brum, J. R., Schenck, R. O., and Sullivan, M. B. (2013). Global morphological analysis of marine viruses shows minimal regional variation and dominance of non-tailed viruses. ISME J. 7, 1738–1751. doi: 10.1038/ismej.2013.67
Camacho, C., Coulouris, G., Avagyan, V., Ma, N., Papadopoulos, J., Bealer, K., and Madden, T. L. (2009). BLAST+: architecture and applications. BMC Bioinformatics 10, 421. doi: 10.1186/1471-2105-10-421
Campbell, A. (2003). The future of bacteriophage biology. Nat. Rev. Genet. 4, 471–477. doi: 10.1038/nrg1089
Chiang, Y. N., Penadés, J. R., and Chen, J. (2019). Genetic transduction by phages and chromosomal islands: the new and noncanonical. PLoS Pathog. 15, e1007878. doi: 10.1371/journal.ppat.1007878
Chibani, C. M., Farr, A., Klama, S., Dietrich, S., and Liesegang, H. (2019a). Classifying the unclassified: a phage classification method. Viruses 11, 195. doi: 10.3390/v11020195
Chibani, C. M., Meinecke, F., Farr, A., Dietrich, S., and Liesegang, H. (2019b). Classiphages 2.0: sequence-based classification of phages using artificial neural networks. bioRxiv 558171. doi: 10.1101/558171
Chow, C.-E. T., and Suttle, C. A. (2015). Biogeography of viruses in the sea. Annu. Rev. Virol. 2, 41–66. doi: 10.1146/annurev-virology-031413-085540
Cobián Güemes, A. G., Youle, M., Cantú, V. A., Felts, B., Nulton, J., and Rohwer, F. (2016). Viruses as winners in the game of life. Annu. Rev. Virol. 3, 197–214. doi: 10.1146/annurev-virology-100114-054952
Coffey, B., Mills, S., Coffey, A., McAuliffe, O., and Ross, R. P. (2010). Phage and their lysins as biocontrol agents for food safety applications. Annu. Rev. Food Sci. Technol. 1, 449–468. doi: 10.1146/annurev.food.102308.124046
Dion, M. B., Oechslin, F., and Moineau, S. (2020). Phage diversity, genomics and phylogeny. Nat. Rev. Microbiol. 18, 125–138. doi: 10.1038/s41579-019-0311-5
Eddy, S. R. (2011). Accelerated profile HMM searches. PLoS Comput. Biol. 7, e1002195. doi: 10.1371/journal.pcbi.1002195
Fritz, A., Hofmann, P., Majda, S., Dahms, E., Dröge, J., Fiedler, J., et al. (2019). CAMISIM: simulating metagenomes and microbial communities. Microbiome 7, 1–12. doi: 10.1186/s40168-019-0633-6
Galtier, M., De Sordi, L., Maura, D., Arachchi, H., Volant, S., Dillies, M.-A., et al. (2016). Bacteriophages to reduce gut carriage of antibiotic resistant uropathogens with low impact on microbiota composition. Environ. Microbiol. 18, 2237–2245. doi: 10.1111/1462-2920.13284
Garcia, P., Martinez, B., Obeso, J., and Rodriguez, A. (2008). Bacteriophages and their application in food safety. Lett. Appl. Microbiol. 47, 479–485. doi: 10.1111/j.1472-765X.2008.02458.x
Gutiérrez, B., and Domingo-Calap, P. (2020). Phage therapy in gastrointestinal diseases. Microorganisms 8, 1420. doi: 10.3390/microorganisms8091420
Gutiérrez, D., Rodríguez-Rubio, L., Fernández, L., Martínez, B., Rodríguez, A., and García, P. (2017). Applicability of commercial phage-based products against Listeria monocytogenes for improvement of food safety in Spanish dry-cured ham and food contact surfaces. Food Control 73, 1474–1482. doi: 10.1016/j.foodcont.2016.11.007
Guttman, B., Raya, R., and Kutter, E. (2005). Basic phage biology. Bacteriophages Biol. Appl. 4, 30–63. doi: 10.1201/9780203491751.ch3
Hatfull, G. F. (2008). Bacteriophage genomics. Curr. Opin. Microbiol. 11, 447–453. doi: 10.1016/j.mib.2008.09.004
Hingamp, P., Grimsley, N., Acinas, S. G., Clerissi, C., Subirana, L., Poulain, J., et al. (2013). Exploring nucleo-cytoplasmic large DNA viruses in tara oceans microbial metagenomes. ISME J. 7, 1678–1695. doi: 10.1038/ismej.2013.59
Hobbs, Z., and Abedon, S. T. (2016). Diversity of phage infection types and associated terminology: the problem with “Lytic or lysogenic”. FEMS Microbiol. Lett. 363, fnw047. doi: 10.1093/femsle/fnw047
Howard-Varona, C., Hargreaves, K. R., Abedon, S. T., and Sullivan, M. B. (2017). Lysogeny in nature: mechanisms, impact and ecology of temperate phages. ISME J. 11, 1511–1520. doi: 10.1038/ismej.2017.16
Hoyles, L., McCartney, A. L., Neve, H., Gibson, G. R., Sanderson, J. D., Heller, K. J., et al. (2014). Characterization of virus-like particles associated with the human faecal and caecal microbiota. Res. Microbiol. 165, 803–812. doi: 10.1016/j.resmic.2014.10.006
Hyatt, D., Chen, G.-L., LoCascio, P. F., Land, M. L., Larimer, F. W., and Hauser, L. J. (2010). Prodigal: prokaryotic gene recognition and translation initiation site identification. BMC Bioinformatics 11, 119. doi: 10.1186/1471-2105-11-119
Jaiswal, A., Koley, H., Ghosh, A., Palit, A., and Sarkar, B. (2013). Efficacy of cocktail phage therapy in treating Vibrio cholerae infection in rabbit model. Microb. Infect. 15, 152–156. doi: 10.1016/j.micinf.2012.11.002
Kauffman, K. M., Hussain, F. A., Yang, J., Arevalo, P., Brown, J. M., Chang, W. K., et al. (2018). A major lineage of non-tailed dsDNA viruses as unrecognized killers of marine bacteria. Nature 554, 118–122. doi: 10.1038/nature25474
Koskella, B., and Meaden, S. (2013). Understanding bacteriophage specificity in natural microbial communities. Viruses 5, 806–823. doi: 10.3390/v5030806
Kristensen, D. M., Waller, A. S., Yamada, T., Bork, P., Mushegian, A. R., and Koonin, E. V. (2013). Orthologous gene clusters and taxon signature genes for viruses of prokaryotes. J. Bacteriol. 195, 941–950. doi: 10.1128/JB.01801-12
Krupovic, M., Prangishvili, D., Hendrix, R. W., and Bamford, D. H. (2011). Genomics of bacterial and archaeal viruses: dynamics within the prokaryotic virosphere. Microbiol. Mol. Biol. Rev. 75, 610–635. doi: 10.1128/MMBR.00011-11
LaFee, S., and Buschman, H. (2017). Novel Phage Therapy Saves Patient with Multidrug-Resistant Bacterial Infection. UC San Diego News Center, University of California.
Lefkowitz, E. J., Dempsey, D. M., Hendrickson, R. C., Orton, R. J., Siddell, S. G., et al. (2018). Virus taxonomy: the database of the International Committee on Taxonomy of Viruses (ICTV). Nucleic Acids Res. 46, D708–D717. doi: 10.1093/nar/gkx932
Lim, E. S., Zhou, Y., Zhao, G., Bauer, I. K., Droit, L., Ndao, I. M., et al. (2015). Early life dynamics of the human gut virome and bacterial microbiome in infants. Nat. Med. 21, 1228–1234. doi: 10.1038/nm.3950
Loeb, T., and Zinder, N. D. (1961). A bacteriophage containing RNA. Proc. Natl. Acad. Sci. U.S.A. 47, 282–289. doi: 10.1073/pnas.47.3.282
Low, S. J., Džunková, M., Chaumeil, P.-A., Parks, D. H., and Hugenholtz, P. (2019). Evaluation of a concatenated protein phylogeny for classification of tailed double-stranded DNA viruses belonging to the order Caudovirales. Nat. Microbiol. 4, 1306–1315. doi: 10.1038/s41564-019-0448-z
Manrique, P., Dills, M., and Young, M. J. (2017). The human gut phage community and its implications for health and disease. Viruses 9, 141. doi: 10.3390/v9060141
McGrath, S., and van Sinderen, D. (2007). Bacteriophage: Genetics and Molecular Biology. Poole, UK: Caister Academic Press.
Mirdita, M., Steinegger, M., Breitwieser, F., Söding, J., and Levy Karin, E. (2021). Fast and sensitive taxonomic assignment to metagenomic contigs. Bioinformatics 37, 3029–3031. doi: 10.1093/bioinformatics/btab184
Nale, J. Y., Spencer, J., Hargreaves, K. R., Buckley, A. M., Trzepiński, P., Douce, G. R., et al. (2016). Bacteriophage combinations significantly reduce Clostridium difficile growth in vitro and proliferation in vivo. Antimicrob. Agents Chemother. 60, 968–981. doi: 10.1128/AAC.01774-15
Nishimura, Y., Yoshida, T., Kuronishi, M., Uehara, H., Ogata, H., and Goto, S. (2017). Viptree: the viral proteomic tree server. Bioinformatics 33, 2379–2380. doi: 10.1093/bioinformatics/btx157
Nurk, S., Meleshko, D., Korobeynikov, A., and Pevzner, P. A. (2017). metaSPAdes: a new versatile metagenomic assembler. Genome Res. 27, 824–834. doi: 10.1101/gr.213959.116
Oduor, J. M. O., Onkoba, N., Maloba, F., and Nyachieo, A. (2016). Experimental phage therapy against haematogenous multi-drug resistant Staphylococcus aureus pneumonia in mice. Afr. J. Lab. Med. 5, 1–7. doi: 10.4102/ajlm.v5i1.435
Paul, J. H., Sullivan, M. B., Segall, A. M., and Rohwer, F. (2002). Marine phage genomics. Comp. Biochem. Physiol. B Biochem. Mol. Biol. 133, 463–476. doi: 10.1016/S1096-4959(02)00168-9
Petti, S., and Eddy, S. R. (2022). Constructing benchmark test sets for biological sequence analysis using independent set algorithms. PLoS Comput. Biol. 18, e1009492. doi: 10.1371/journal.pcbi.1009492
Pons, J. C., Paez-Espino, D., Riera, G., Ivanova, N., Kyrpides, N. C., and Llabrés, M. (2021). VPF-Class: taxonomic assignment and host prediction of uncultivated viruses based on viral protein families. Bioinformatics 37, 1805–1813. doi: 10.1093/bioinformatics/btab026
Ren, J., Song, K., Deng, C., Ahlgren, N. A., Fuhrman, J. A., Li, Y., et al. (2020). Identifying viruses from metagenomic data using deep learning. Quant. Biol. 8, 64–77. doi: 10.1007/s40484-019-0187-4
Rohwer, F., and Edwards, R. (2002). The Phage Proteomic Tree: a genome-based taxonomy for phage. J. Bacteriol. 184, 4529–4535. doi: 10.1128/JB.184.16.4529-4535.2002
Saussereau, E., and Debarbieux, L. (2012). Bacteriophages in the experimental treatment of Pseudomonas aeruginosa infections in mice. Adv. Virus Res. 83, 123–141. doi: 10.1016/B978-0-12-394438-2.00004-9
Shang, J., Jiang, J., and Sun, Y. (2021). Bacteriophage classification for assembled contigs using graph convolutional network. Bioinformatics 37(Suppl. _1), i25–i33. doi: 10.1093/bioinformatics/btab293
Shang, J., Tang, X., Guo, R., and Sun, Y. (2022). Accurate identification of bacteriophages from metagenomic data using transformer. Brief. Bioinform. 23, bbac258. doi: 10.1093/bib/bbac258
Sillankorva, S. M., Oliveira, H., and Azeredo, J. (2012). Bacteriophages and their role in food safety. Int. J. Microbiol. 2012, 863945. doi: 10.1155/2012/863945
Silveira, C. B., and Rohwer, F. L. (2016). Piggyback-the-winner in host-associated microbial communities. NPJ Biofilms Microb. 2, 1–5. doi: 10.1038/npjbiofilms.2016.10
Sutton, T. D., and Hill, C. (2019). Gut bacteriophage: current understanding and challenges. Front. Endocrinol. 10, 784. doi: 10.3389/fendo.2019.00784
Thingstad, T. F. (2000). Elements of a theory for the mechanisms controlling abundance, diversity, and biogeochemical role of lytic bacterial viruses in aquatic systems. Limnol. Oceanogr. 45, 1320–1328. doi: 10.4319/lo.2000.45.6.1320
von Meijenfeldt, F., Arkhipova, K., Cambuy, D. D., Coutinho, F. H., and Dutilh, B. E. (2019). Robust taxonomic classification of uncharted microbial sequences and bins with CAT and BAT. Genome Biol. 20, 1–14. doi: 10.1101/530188
Williamson, K. E., Fuhrmann, J. J., Wommack, K. E., and Radosevich, M. (2017). Viruses in soil ecosystems: an unknown quantity within an unexplored territory. Annu. Rev. Virol. 4, 201–219. doi: 10.1146/annurev-virology-101416-041639
Keywords: bacteriophage, taxonomic classification tools, viral metagenomic data, review of tools, Caudoviricetes
Citation: Zhu Y, Shang J, Peng C and Sun Y (2022) Phage family classification under Caudoviricetes: A review of current tools using the latest ICTV classification framework. Front. Microbiol. 13:1032186. doi: 10.3389/fmicb.2022.1032186
Received: 30 August 2022; Accepted: 29 November 2022;
Published: 16 December 2022.
Edited by:
Cristina Moraru, University of Oldenburg, GermanyReviewed by:
Stephen Nayfach, Berkeley Lab (DOE), United StatesCopyright © 2022 Zhu, Shang, Peng and Sun. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yanni Sun, eWFubmlzdW5AY2l0eXUuZWR1Lmhr
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.