 Pierluigi Polese
Pierluigi Polese Manuela Del Torre
Manuela Del Torre Mara Lucia Stecchini
Mara Lucia Stecchini- 1Polytechnic Department of Engineering and Architecture, University of Udine, Udine, Italy
- 2Department of Agricultural, Food, Environmental and Animal Sciences, University of Udine, Udine, Italy
Controlling harmful microorganisms, such as Listeria monocytogenes, can require reliable inactivation steps, including those providing conditions (e.g., using high salt content) in which the pathogen could be progressively inactivated. Exposure to osmotic stress could result, however, in variation in the number of survivors, which needs to be carefully considered through appropriate dispersion measures for its impact on intervention practices. Variation in the experimental observations is due to uncertainty and biological variability in the microbial response. The Poisson distribution is suitable for modeling the variation of equi-dispersed count data when the naturally occurring randomness in bacterial numbers it is assumed. However, violation of equi-dispersion is quite often evident, leading to over-dispersion, i.e., non-randomness. This article proposes a statistical modeling approach for describing variation in osmotic inactivation of L. monocytogenes Scott A at different initial cell levels. The change of survivors over inactivation time was described as an exponential function in both the Poisson and in the Conway-Maxwell Poisson (COM-Poisson) processes, with the latter dealing with over-dispersion through a dispersion parameter. This parameter was modeled to describe the occurrence of non-randomness in the population distribution, even the one emerging with the osmotic treatment. The results revealed that the contribution of randomness to the total variance was dominant only on the lower-count survivors, while at higher counts the non-randomness contribution to the variance was shown to increase the total variance above the Poisson distribution. When the inactivation model was compared with random numbers generated in computer simulation, a good concordance between the experimental and the modeled data was obtained in the COM-Poisson process.
Introduction
Providing an easy way to access prediction, the deterministic approach to the description of microbial populations has long been successful in managing food safety. Process and formulation of foods have long benefited from non-thermal inactivation (NTI) models, which represent valuable tools for controlling pathogens (Lindqvist and Lindblad, 2009). However, the point estimates provided by the deterministic models, which do not take into account variability and uncertainty, may be insufficient for a more realistic estimation of microbial behavior (Membré et al., 2006; Koutsoumanis and Angelidis, 2007; Couvert et al., 2010; Augustin et al., 2011). The European Food Safety Authority defines uncertainty as variation associated with the lack of knowledge or the use of imprecise data, and variability as variation in the response of the individual cells within the population, which cannot be reduced based on knowledge [European Food Safety Authority (EFSA) Scientific Committee, Benford et al., 2018; Schendel et al., 2018]. Numerical estimation of microorganisms can be affected by different sources of uncertainty introduced by the experimental procedures, which can include serial dilution and viable cell enumeration (Garre et al., 2019). Likewise, there are numerous sources of variability, which are associated to both the microorganism and the environment, affecting microbial behavior (Koutsoumanis et al., 2016; Koyama et al., 2016; Koutsoumanis and Aspridou, 2017; Aspridou et al., 2019).
The importance of the separation of variability and uncertainty has long been recognized for quantitative microbial risk assessment (QMRA) purposes (Nauta, 2000; den Besten et al., 2018), but the combined description of variability and uncertainty can also play an important role in the valid prediction of bacterial behavior, which is crucial for management interventions (Aguirre et al., 2009; Membré and van Zuijlen, 2011; Aspridou and Koutsoumanis, 2015; Zwietering, 2015; Koyama et al., 2019).
Poisson distribution or the Poisson stochastic process, which refers to the Poisson distribution, have been applied to describe variation in the number of survivors in thermal and non-thermal processes (Aguirre et al., 2009; Koyama et al., 2017). A major assumption of the Poisson model is that the variance is equal to the mean. This assumption is violated if the variance is greater or lower than the mean and, therefore, there is evidence of over or under-dispersion, respectively (Jarvis, 2016).
Over-dispersion is defined as the extra variation occurring in count data modeling which is not explained by the Poisson distribution alone (Rigby et al., 2008). As summarized by Payne et al. (2017) over-dispersion is a common feature in real count data and may occur due to population heterogeneity, correlation, omission of important covariates in the model, the presence of outliers, zero inflation, or other reasons. Under-dispersion may also be encountered in real applications and can be caused by model-overfitting or seen in datasets with small sample values (Sellers and Morris, 2017). Under-dispersion can also be associated with the presence of zero counts in a data set (Sellers and Raim, 2016; Tin, 2008).
Naturally occurring bacteria often exist as social communities and live in spatially structured habitats where spatial heterogeneity is generated (Eriksen et al., 2020). The under-dispersion pattern is characterized by a regular spatial distribution, indicating repulsion, while over-dispersion reflects clustering, indicating aggregation, and both can result from microbial growth or inactivation (Lynch et al., 2014; Jongenburger et al., 2012b; Jarvis, 2016).
Over and under-dispersion, unless properly handled, can lead to biased inferences (Payne et al., 2017; Sellers and Morris, 2017).
The context of this study is a planktonic culture and not a solid or a gelled system where the immobilization of bacteria has an effect on their distribution (Baka et al., 2016, 2017; Jeanson et al., 2011, 2015). However, even the planktonic-cell spatial distribution can show heterogeneity, as happens in the case of aggregate formation. In fact, the assumption that planktonic bacterial cells are by definition not aggregated has been challenged and evidence has been provided of mechanical connections between bacterial cells in diluted planktonic suspensions (Sretenovic et al., 2017). Thus, when randomly distributed cells form aggregates a clustered distribution (over-dispersion) can be generated (Gao et al., 2016).
In this study, the random component of the total variation, which can be represented by the Poisson distribution was referred to as randomness (Lynch et al., 2014; Koyama et al., 2017), whereas the unexplained part of variation (over or under-dispersion), which represents the departure from randomness was referred to as non-randomness (Hui et al., 2010).
When the dispersion pattern of cells deviated from the homogeneous Poisson process other models could be applied to capture count dispersion. For example, the Poisson-Lognormal distribution was found appropriate for the representation of high microbial counts, while the Poisson-gamma (or negative binomial) distribution was better for the characterisation of low microbial counts and for highly clustered microbial data, but both can cope only with over-dispersion (Gonzales-Barron et al., 2010, 2014; Gonzales-Barron and Butler, 2011; Jongenburger et al., 2012b).
When dealing with pathogenic bacteria, variability in concentration of the raw material can be high (European Food Safety Authority (EFSA), 2012). By applying an inactivation process it is likely to result in low and zero counts (European Food Safety Authority (EFSA), 2018). It follows that distributions flexible enough to deal with low, medium or higher counts and suitable for over and under-dispersed data could be more appropriate. The Conway–Maxwell-Poisson (COM-Poisson) (Conway and Maxwell, 1962) distribution, which is a two-parameter generalization of the Poisson distribution, proved to be a useful and elegant model for fitting count data ranging from high to low, including zero, with an unlimited range of dispersion (Sellers and Shmueli, 2010; Francis et al., 2012; Gupta et al., 2014). A more detailed overview of the history, features and applications of COM-Poisson distribution is in Shmueli et al. (2005).
Therefore, in consideration of the variation of the numbers of pathogens usually occurring in food during processing, it would be of importance to derive a statistical model from different population size experiments, to capture the variation in the response of a pathogen, such as Listeria monocytogenes, in an osmotic inactivation process, such as that used for processed meat products. For these products, the micro-organisms of concern are both Salmonella spp. and L. monocytogenes. However, L. monocytogenes proved to be less susceptible to manufacturing processes than Salmonella, with water activity (aw) being a key factor in the survival of the pathogen (Mataragas et al., 2015; Nightingale et al., 2006). Indeed, the severity of Listeria illness and the possibility of infection from low doses underlines the necessity to control not only its frequency but also its different levels of contamination (Buchanan et al., 2017; Polese et al., 2017; Radoshevich and Cossart, 2018).
The main objective of the present study was to propose a regression model able to deal with a wide range of dispersion levels, in order to describe the variation in osmotic inactivation of L. monocytogenes Scott A at different initial cell levels. To achieve this goal, we investigated whether the variation in survival of Listeria numbers followed the theoretical COM-Poisson distribution, which extends the Poisson distribution by adding a parameter to model over- and under-dispersion. This fitting procedure provided a framework able to incorporate the randomness and non-randomness contributors to variation allowing for a more accurate quantification of the survivor dispersion.
Materials and Methods
Preparation of L. monocytogenes Cells
Listeria monocytogenes strain Scott A, serotype 4b, a virulent clinical isolate from a food-borne listeriosis outbreak in 1983 (Briers et al., 2011) was used in this study. This strain was selected for its tolerance to stress conditions encountered in food, which included exposure to conditions of high osmolarity (Becker et al., 1998; Bucur et al., 2018; Durack et al., 2013). The L. monocytogenes strain was taken from porous cryobeads (MicrobankTM, Pro-Lab Diagnostic, Richmond Hill, ON, Canada) that had been stored at −30°C. The strain was cultured in 10 mL Brain Heart Infusion (BHI, Oxoid Ltd., Hampshire, United Kingdom) broth incubated overnight at 30°C. No osmotic adaptation was adopted that could have increased phenotypic heterogeneity (Kapetanakou et al., 2019). This first inoculum of approximately 4.3 × 109 CFU/mL was thoroughly vortexed (Vortex mixer, Velp Scientifica, Usmate, Italy) and then diluted in saline/peptone water [8.5 g L–1 NaCl (J.T. BakerTM, Baker analyzed® A.C.S, Thermo Fisher Scientific, Waltham, MA, United States) and 1 g L–1 Bacteriological Peptone (Oxoid Ltd)] to attain different sub-inoculum levels of approximately 2.2 × 105 CFU/mL, 2.2 × 104 CFU/mL and 2.2 × 103 CFU/mL. Aliquots of 0.07 or 0.14 mL of the latter inoculum solutions were further diluted in the osmotic challenge medium (see section “Osmotic Inactivation Trials”) to obtain final Listeria concentrations of approximately 2 × 10 CFU/mL (low inoculum: L), 102 CFU/mL (medium inoculum: M) and 103 CFU/mL (high inoculum: H).
Osmotic Inactivation Trials
The osmotic challenge medium used was BHI broth supplemented with 134 g L–1 NaCl to produce a reduction of the aw that mimicked a representative condition of processed meat products subjected to salt treatment. The aw was assessed using an Aqua Lab CX2 instrument (Decagon Devices, Inc., Pullman, Washington, United States) and the measured aw value was 0.913 ± 0.001. The pH was adjusted to 6.6 with HCl 1M (Carlo Erba Reagents, Val-de-Reuil, France) using an HI1131B (Hanna instruments, Verona, Italy) electrode and an HI5221 pH-meter (Hanna Instruments, Verona, Italy), equipped with a temperature probe. BHI broth supplemented with NaCl was sterilized by filtration (Nalgene Rapid-Flow 0.2 μm aPES membrane, Thermo Fisher Scientific, Waltham, MA, United States), poured in 15 mL aliquots in sterile tubes and stored at 4°C until use. Prior to inoculation, the osmotic challenge medium was pre-warmed at 30°C, with this temperature being maintained throughout the trials. Samples from bacterial suspensions were thoroughly vortexed (Vortex mixer, Velp Scientifica, Usmate, Italy) before taking samples at time intervals (0, 3, 6, 10, 13, and 18 days). The cell density in each solution was determined by surface plating 0.2 mL solution onto BHI (BHI, Oxoid Ltd., Hampshire, United Kingdom) agar plates (five plates for each sample). The colonies were counted after 48 h incubation at 30°C. The enumeration process was conducted omitting serial dilutions for reducing the impact of uncertainty (Garre et al., 2019). The data were expressed as the mean value (CFU in 0.2 mL or Ln CFU in 0.2 mL) for the five replicates of plate counts. Three independent trials were conducted for each Listeria concentration tested.
Autoaggregation Assay
The ability of L. monocytogenes to autoaggregate was measured in phosphate buffered saline (PBS) after 20 h culture in BHI, according to the method described by Collado et al. (2008), with some modifications. Listeria cultures were harvested by centrifugation, washed twice in PBS, pH 7.1 (10 mM Na2HPO4, 1 mM KH2PO4, 140 mM NaCl, 3 mM KCl) and suspended in the same buffer or in the same buffer supplemented with further NaCl to produce aw of 0.913 ± 0.001. The optical density (OD600 nm) of the homogenized bacterial suspensions were adjusted to 0.3 ± 0.05 with the same buffers listed above. In addition, the dependence on the concentration was tested adjusting the initial OD of the osmotic medium from 0.2 ± 0.05 up to 0.6 ± 0.05. To determine percentage autoaggregation, suspensions were incubated in aliquots at 30°C without vortexing and monitored (OD600 nm) at 24 and 72 h. Autoaggregation was assessed by a decrease in the OD600 indicating an increase in bacterial sediments that settle at the bottom of culture tubes. The aggregation percentage was expressed as [(1 – (ODTime/OD0)) × 100] where ODTime represents the optical density of the mixture at the different incubation times, i.e., at 24 h and at 72 h, while OD0 is the optical density at time 0 h.
The NTI Models
The change of survivors over inactivation time was described as an exponential function (1):
where μt is the centering parameter of the Poisson (i.e., the mean number of survivors at time t) or the COM-Poisson distribution (Shmueli et al., 2005; Guikema and Goffelt, 2008; Sellers and Shmueli, 2010; Supplementary Box 1); a is a regression parameter, which corresponds to LnN0; b represents the inactivation rate (day–1); t (day) is the time of the osmotic treatment.
Equations (2, 3) were used for the Poisson and COM-Poisson processes, respectively:
where Nt (the observed value) is the realization of μt; ∼ is the tilde symbol which means: has the distribution of; ν denotes the COM–Poisson dispersion parameter.
In the COM-Poisson distribution model the mean E[Nt] and the variance VAR[Nt] of Nt can be approximated by eqs. (4a,b) as follows:
where E[Nt] is the mean of survivors at time t; μt is the centering parameter of the COM-Poisson distribution (Supplementary Box 1); VAR[Nt] is the variance of Nt; ν is the COM–Poisson dispersion parameter.
Equation (4b) becomes eq. (5):
Thus, eq. (4a) can be rewritten as (6):
To produce a framework for the variance of Nt, it is assumed, as in the negative binomial distribution, that the total population variance is represented by the combination of the randomness and the non-randomness components. The first component corresponds to complete homogeneity and can be represented by the mean, whereas the second component represents the non-random variation and is given by a quadratic function of the mean (El-Shaarawi et al., 1981). Therefore, let the randomness component having a Poisson distribution be equal to the mean E[Nt] and assume the non-randomness component (corresponding to c0E[Nt]2) to be a quadratic function of the mean (El-Shaarawi et al., 1981; Gonzales-Barron et al., 2010; Gonzales-Barron and Butler, 2011), it follows that (Eq. 7):
where VAR[Nt] is the variance of Nt; E[Nt] is the mean number of survivors at time t; c0 is the non-randomness variance parameter.
Equation (6) becomes (8) as follows:
For low values of E[Nt], ν is close to 1, giving the Poisson; while for high values of E[Nt] (Supplementary Box 2) Eq. (8) is reduced to Eq. (9):
Thus, the COM-Poisson dispersion parameter ν, was expressed by Eq. (10) which describes the effect of E[Nt] on this parameter:
The COM-Poisson dispersion parameter ν represents, therefore, the inverse of the variance over mean ratio. From eq. (10), as Nt → ∞, ν converges to 0.
For a population subjected to osmotic stress, which can facilitate aggregation (Jensen et al., 2007; Schmid et al., 2009; Eshwar et al., 2017) and hence the production of clustered count data that result in over-dispersion (Jongenburger et al., 2012b), an additional non-randomness term occurring over time in response to the osmotic treatment contributed to the total variance (see section “Results”). Since no extensive literature exists on the non-randomness variance, this additional contribution, which was obtained balancing the number of survivors with the initial number of cells, can be regarded as an empirical term. To describe this additional contribution, a number of empirical equations were developed (Supplementary Box 3) and the Akaike information criterion (AIC) (Vrieze, 2012) was used to select the best-fit model under parsimony, which resulted in (11):
where εt is the additional non-randomness variance parameter; E[Nt] is the mean number of survivors at time t.
Including the non-randomness contribution, we can write (12):
where VAR[Nt] is the variance of Nt; c0E[Nt]2 is the non-randomness contribution to the variance; εtt E[Nt]2/E[N0]1/2 is the additional non-randomness contribution to the variance occurring over the treatment time, and εt is the additional non-randomness variance parameter.
For a population subjected to osmotic inactivation, ν can therefore be expressed as (13):
where E[Nt], c0E[Nt]2 and εtt E[Nt]2/E[N0]1/2 are as above.
The final NTI model in the Poisson process was obtained using Eqs. (1, 2), whereas the model in the COM-Poisson process was obtained using Eqs (1, 3, and 13).
For providing an estimation of c0 and εt within the COM-Poisson process, a maximum- likelihood regression on all the survival data was conducted (for details, see section “Stochastic Processes and Statistical Tests”). For practical reasons (too time-consuming calculations), the estimation was limited to the shape function (ν), holding the centering function (μ) fixed to the previously estimated regression values (LnN0 and b values of each trial).
Stochastic Processes and Statistical Tests
The Poisson and the COM-Poisson (Shmueli et al., 2005; Guikema and Goffelt, 2008; Sellers and Shmueli, 2010) distributions (Supplementary Box 1) were fitted to the Listeria initial counts (178 data, Supplementary Table 1) and to the survival data over time (993 data, Supplementary Table 1), and the parameters of the cell counts distributions were estimated using the maximum-likelihood method (Nelder and Wedderburn, 1972).
The maximum-likelihood coefficient estimates of the Poisson and the COM-Poisson frameworks were obtained from regression by maximizing equation (S6) (Supplementary Box 1) under the constraint ν ≥ 0, using Excel Solver add-in (Microsoft Office Excel 2007, v12.0.6611.1000) as a nonlinear optimization tool. The COM-Poisson equations were coded adapting the algorithm proposed by Huntley (2005), in Visual Basic for Application (VBA) and used in Excel workbooks (Supplementary Table 2). Regression parameters, standard errors and related goodness of fit tests were obtained through SolverStat add-in (Comuzzi et al., 2003) by using Fisher Information Matrix and bootstrap (Sellers and Shmueli, 2010). All other used statistical analyses [Log-likelihood (LL) value, likelihood ratio (LR) test (Santner and Duffy, 1989), AIC (Vrieze, 2012), variance-to-mean ratio, ANOVA, mean, variances, standard deviations] were conducted in Excel. The LR test was computed by taking twice the difference in negative log-likelihoods between the full model (COM-Poisson) and the reduced model (Poisson). The parsimony principle, which is not considered by the LR and LL tests, is included by using the AIC method.
Analysis of deviance for generalized linear regression models (Hardin and Hilbe, 2018) was carried out by using Excel from the deviance values obtained with SolverStat add-in (Comuzzi et al., 2003).
Comparison between the observed variances in the number of surviving Listeria cells and the predicted variances in the Poisson and the COM-Poisson distributions was also carried out using Excel. The standard error of the experimental variance was calculated as sqrt[2/(n–1)] VAR[Nt] (Harding et al., 2014). The variance estimated under the Poisson assumption was the mean, while the COM-Poisson variance was the mean divided by ν.
Simulation via Random Number Generation
To predict the Listeria inactivation over time a basic Monte Carlo (MC) random sampling with random seed to simulate random numbers from user-provided functions was used (Thomopoulos, 2013). Normal deviates (used to introduce variability in the parameters N0, b, c0, and εt) are generated using the Box-Muller Algorithm (Press et al., 1997). Poisson random numbers were generated using the algorithm proposed by Knuth (1997). The COM-Poisson random numbers were generated by the inversion method (Minka et al., 2003). For the expected values ≥200 a normal approximation was used and bounded to integers between 0 and ∞ (Supplementary Table 3). As above reported, the COM-Poisson equations used in random numbers generation were coded, adapting the algorithm proposed by Huntley (2005), in Excel Visual Basic for Application (VBA) (Supplementary Table 3). Inactivation was simulated (Figures 1A,B and Supplementary Table 3) using dispersion of survivors described as randomness in the Poisson process, while randomness, non-randomness and additional non-randomness over time in the COM-Poisson process. For each MC simulation cycle i, a randomly selected inoculum level (N0i) and a normal random parameter bi was assigned, and at each selected j-th time tj the centering parameter μij was estimated using Eq. (1) used for inactivation. In the COM-Poisson model νij was calculated as a random parameter by applying Eq. (13). Finally, the generation of Ntij as random numbers was achieved using Eqs (2) or (3), for the Poisson or COM-Poisson process, respectively.
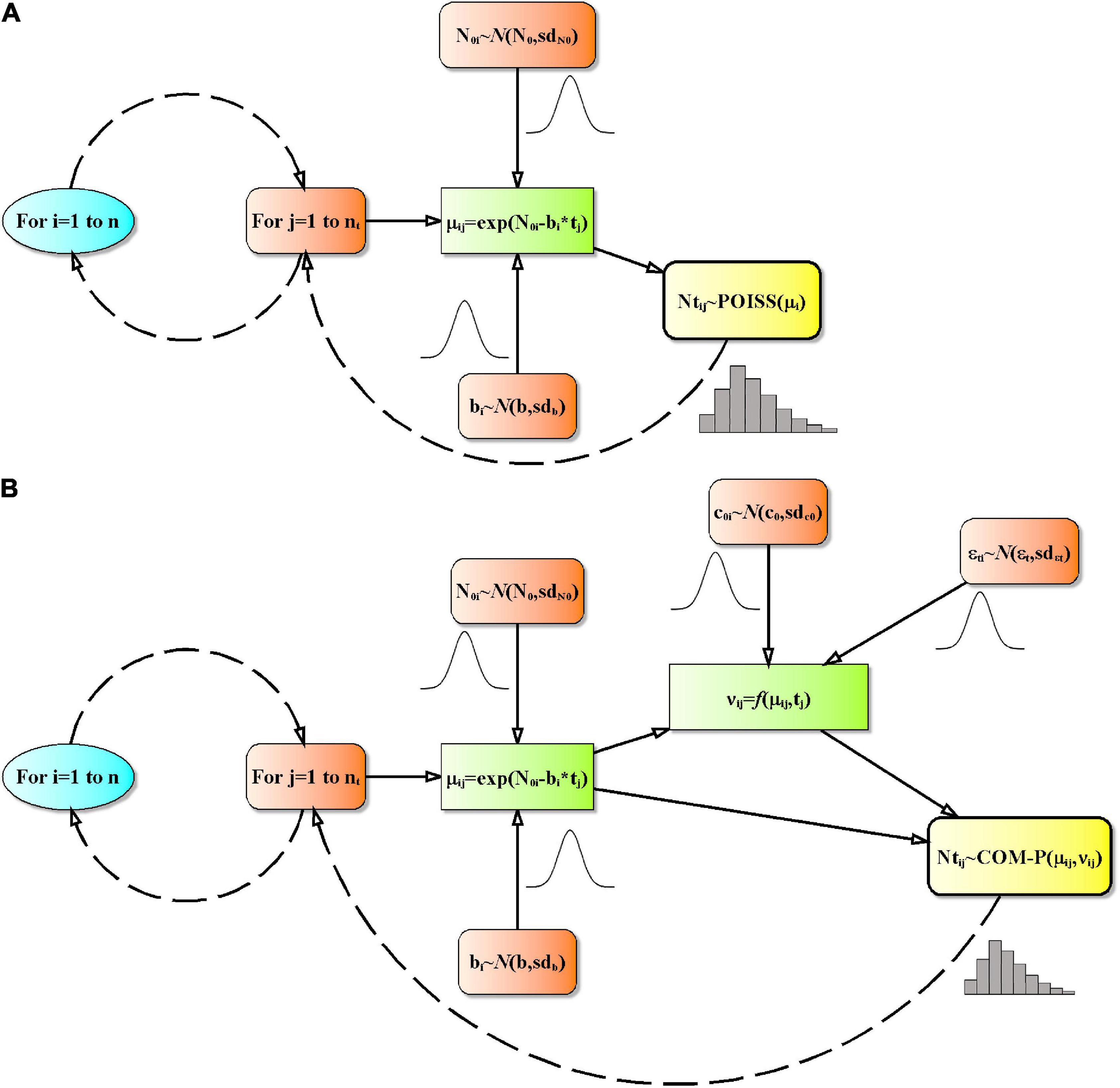
Figure 1. Flowcharts of the computer modeling in the Poisson (A) and in the COM-Poisson process (down) (B). Prediction was by Monte Carlo simulation. n: number of simulations; tj, time; nt, number of experimental times; N0i: realization of initial count characterized by a normal distribution with mean N0 and standard deviation sdN0; bi, realization of survival rate characterized by a normal distribution with mean b and standard deviation sdb; μij, centering parameter of the Poisson or COM-Poisson distribution; Ntj, realization of μij, i.e., the number of survivors; POISS(): Poisson distributed random numbers; νij, COM-Poisson dispersion parameter; CMP(): COM-Poisson distributed random numbers; c0i, realization of the non-randomness variance parameter characterized by a normal distribution with mean c0 and standard deviation sdc0; εtij, realization of the additional non-randomness variance parameter characterized by a normal distribution with mean εt and standard deviation sdεt.
The number of iterations required to achieve a percentage error of the mean equal to 5% with a 95% level of confidence, was determined by applying MC guidelines (Hahn, 1972; Oberle, 2015). To fulfill these requirements at least 2,300 iterations were required. Monte Carlo simulations, which were recorded by using the mcmon utility in SolverStat (Comuzzi et al., 2003) in Excel, were repeated 5,000 times for each experimental time, assigning 30,000 survival values for each inoculum level assayed. The convergence was assessed by computing confidence intervals on variables of interest (Ballio and Guadagnini, 2004), running in triplicate the MC simulations for different values of the seed of the pseudorandom number generator.
Results
Variation in the Initial Cell Number
The initial Listeria cell data (N0), in consonance with event data, were modelled by both the Poisson and the COM-Poisson distributions (see Supplementary Box 1 for the COM-Poisson regression) and their estimated parameters a (aP and aCOM) and ν are shown, for each trial, in Table 1. As expected, a values were almost identical, at the different initial cell levels in the Poisson and in the COM-Poisson distributions. At the higher counts when N0 was around 185/0.2 mL (H samples), the COM dispersion parameter ν was < 1, revealing over-dispersion. Accordingly, at these high counts the AIC, which is designed to pick the model that minimizes the information loss, was substantially lower at the higher counts in two trials out of three, while the variance over mean ratios were largely >1 (Table 2). In addition, the p-values of the likelihood ratio test (P-LR) were <0.05 in two trials out of three. Likewise, the log-likelihood value (LL), which expresses how many times more likely the data are under one model than the other, was higher at the higher counts in two trials out of three. All these statistics indicated a better fit for the COM-Poisson at the higher counts in two trials out of three assayed. When N0 was around 5–20 CFU/0.2 mL (L and M samples), the p-values of the likelihood ratio test were larger than 0.05, and LL and AIC were similar in the Poisson and in the COM-Poisson processes (Table 2). In addition, the mean values and variances were similar (the ratios were around 1), showing that for these populations the experimentally obtained counts followed the Poisson distribution.
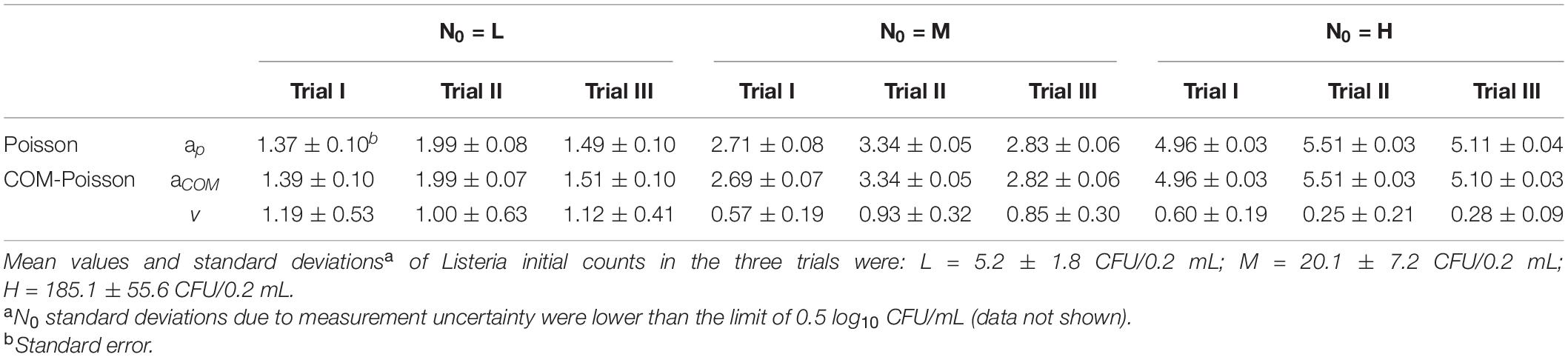
Table 1. The Poisson and the COM-Poisson distribution parameters (aP, Poisson; aCOM, COM-Poisson, ν COM-Poisson) of the observed initial bacterial cell counts (LnN0: Ln CFU/0.2 mL) in the three trials.
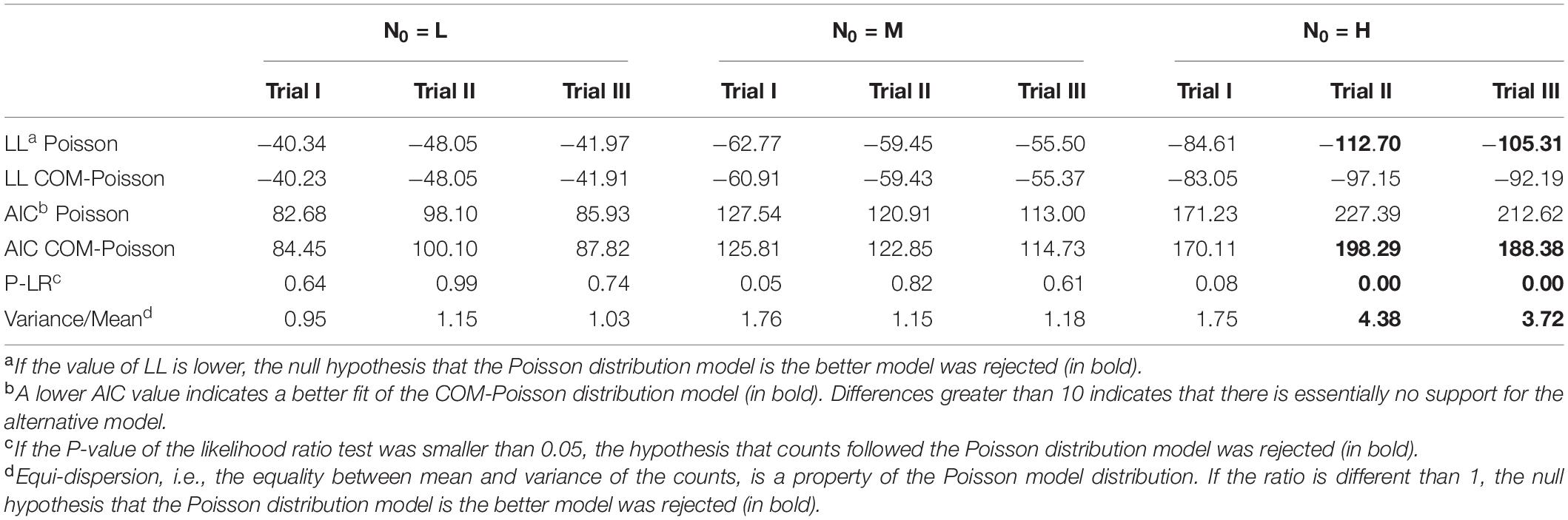
Table 2. Log-likelihood (LL) value, P of likelihood ratio test (P-LR), Akaike information criterion (AIC) and variance-to-mean ratio to determine the better-fitted distribution for the initial observed L. monocytogenes counts (LnN0: Ln CFU/0.2 mL) in each of the three trials, starting with different initial cells (L, low inoculum; M, medium inoculum; H, high inoculum).
Variation in Survivors Over Time
In our study, osmotic inactivation was through an osmotic stress and the resulting L. monocytogenes survival data at the different N0 in BHI broth at aw of 0.913 are shown in Figure 2 and Supplementary Table 1. To describe the variation in the number of surviving cells, both the Poisson and the COM-Poisson regressions (see Supplementary Box 1 for the COM-Poisson regression) were applied to the survival Listeria data over time keeping, at this step, ν constant for each regression. The trends of the experimental and predicted data variances were then visualized using the mean variance over time at the different N0 (Figure 3) to provide visual evidence of the scattering of the mean experimental points and how the COM-Poisson distribution could improve the interpretation of the observed data, at least at the medium and higher counts. This was confirmed by goodness of fit statistics used to determine the better-fitted distribution for L. monocytogenes observed survivors in each of the three osmotic inactivation trials, starting with different initial cell levels (Table 3). Starting from the higher count (H) and according to the AIC method the hypothesis that bacterial survivors follow the Poisson distribution was rejected in all the three trials. The LL values and the p-values of the LR test (Table 3) confirmed that the COM-Poisson better fit the data in the H samples. The better fit of the COM-Poisson was also observed in two trials out of three of the M samples (II and III). The Poisson model, in which the complexity of computation is reduced, could be appropriate for fitting regression data from the lower count samples (L samples). However, it is not a good choice for data sets where the Poisson assumptions are not met.
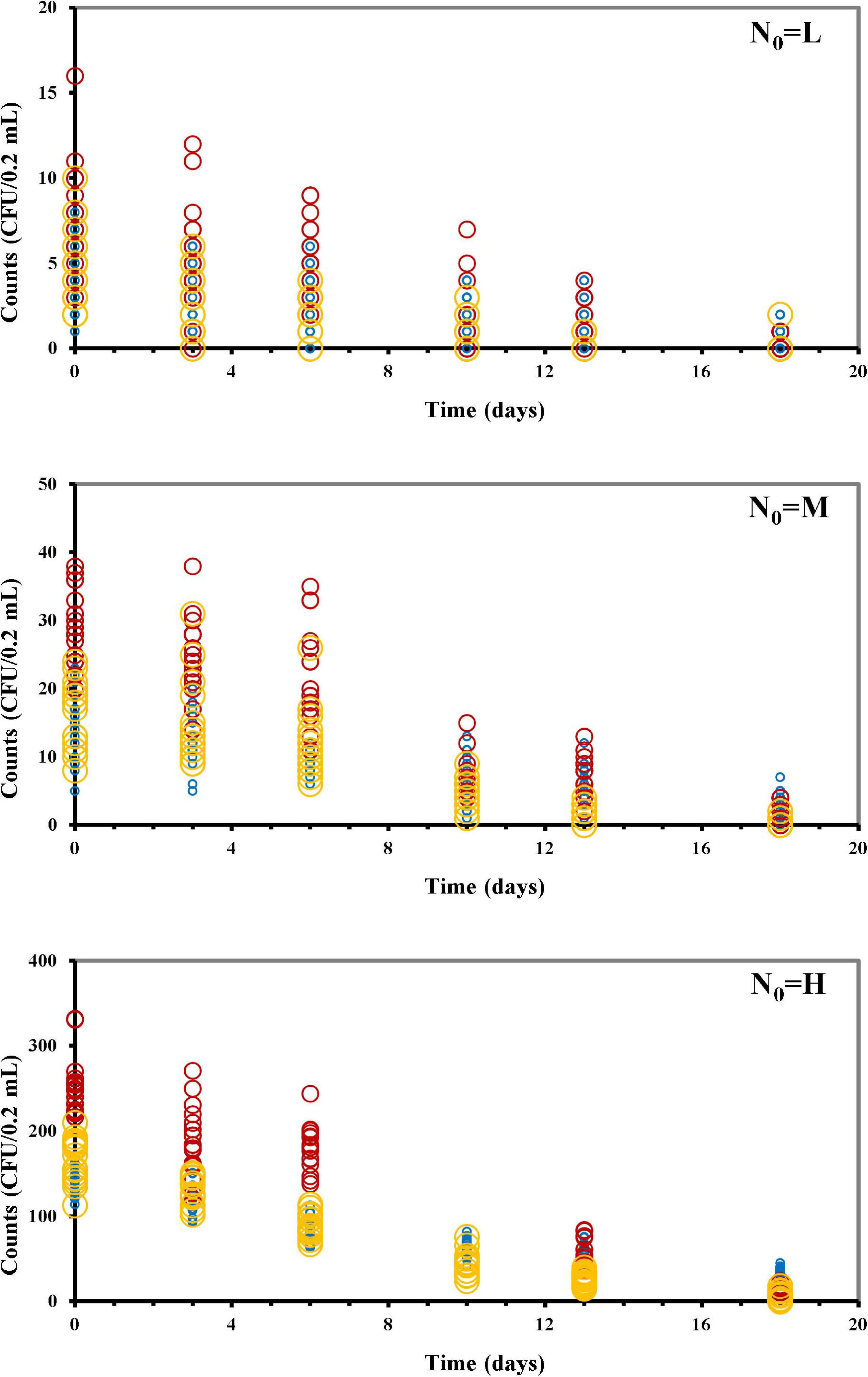
Figure 2. Listeria monocytogenes survivors during the osmotic treatment, starting with different initial cells (N0: CFU/0.2 mL) (L, low inoculum; M, medium inoculum; H, high inoculum). Trial I, blue circles; trial II, red circles; trial III, yellow circles.
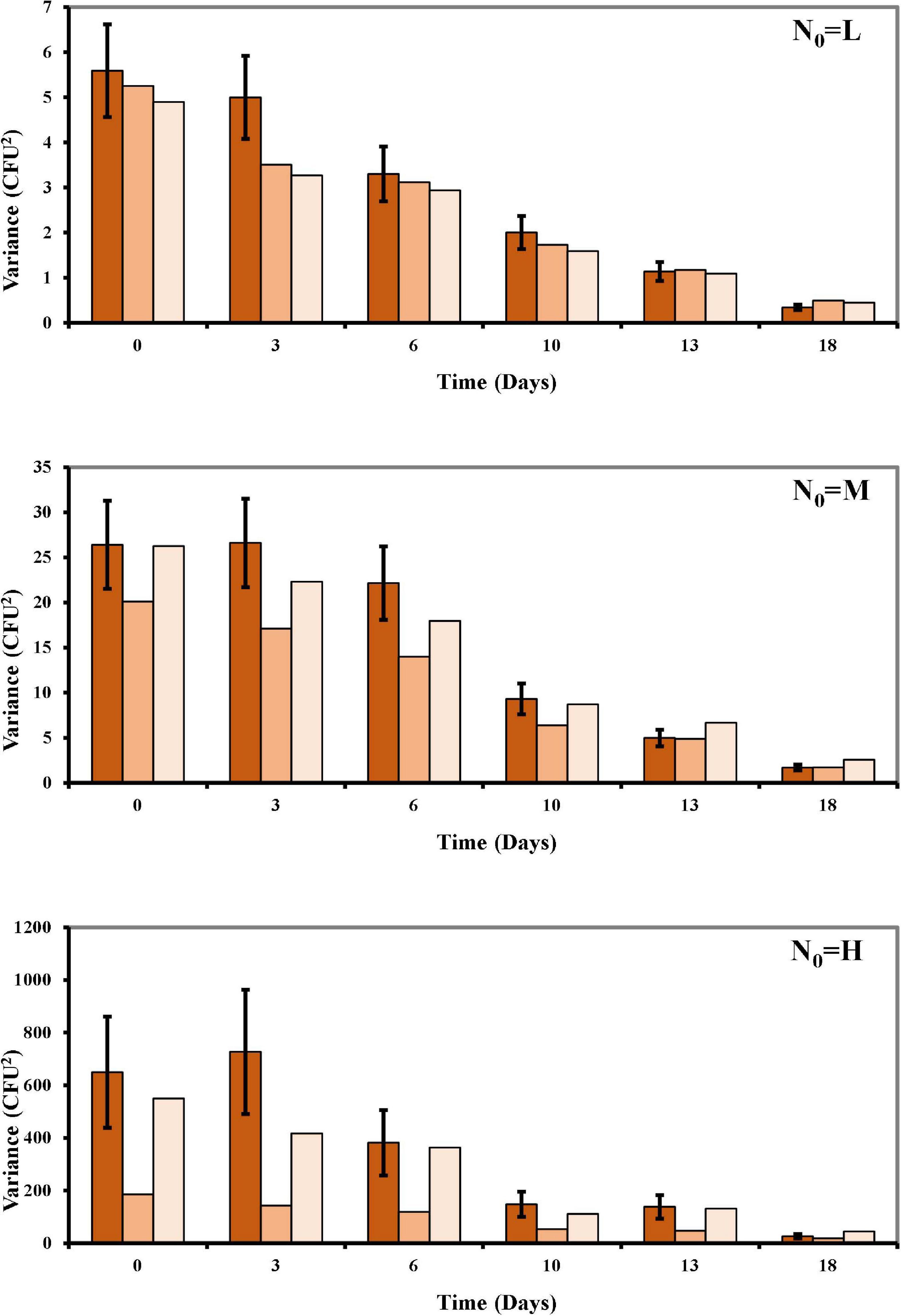
Figure 3. Mean of the variances over time of the observed survival Listeria data compared to the Poisson and the COM-Poisson (Supplementary Box 1) distributions fitted to the experimental data points at the different N0 (L, low inoculum; M, medium inoculum; H, high inoculum). Observed variances: dark orange columns; Poisson distribution variances: orange columns; COM-Poisson distribution variances: light orange columns; bars are standard errors.
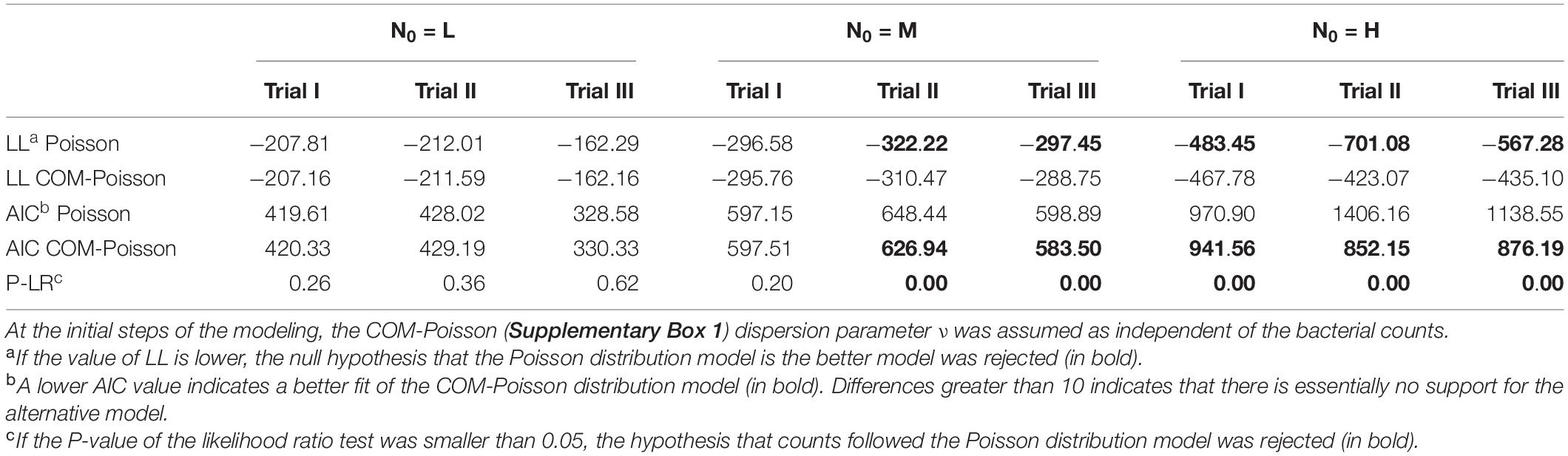
Table 3. Log-likelihood value (LL), P of likelihood ratio test (P-LR) and Akaike information criterion (AIC) to determine the better-fitted distribution for L. monocytogenes observed survivors in each of the three osmotic non-thermal inactivation trials, starting with different initial cells (L, low inoculum; M, medium inoculum; H, high inoculum).
The Poisson and the COM-Poisson inactivation rate parameters (b) and their associated statistics were calculated and reported in Table 4, along with the COM-Poisson dispersion parameter ν which is assumed, at this step, as independent of the microbial counts. The inactivation parameters (mean values from the 9 trials: −0.120 ± 0.035 day–1 and −0.125 ± 0.035 day–1 for the Poisson and COM-Poisson, respectively) were not affected (p > 0.05) by the initial cell numbers, but by the trials (p < 0.05), indicating the relevance of variability in population dynamics in the case of microbial inactivation. For this reason, in the stochastic inactivation model (see section “Stochastic Inactivation Modeling and Comparison With Random Numbers Generated in a Computer Simulation”) normal distributions with their parameters (mean and standard deviations as reported above) were used to describe the variation of the inactivation rates. For each trial the degree of dispersion of the inactivation parameters, expressed as standard error, decreased as the initial population increased. It therefore appeared that the smaller the population, the more spread out the linear rate of inactivation was, due to stochastic variation. On the other hand, the cells that survived the osmotic treatment starting from the highest values and the medium initial counts (H and M samples) showed most of the values of the COM-Poisson dispersion parameter ν < 1, revealing over-dispersion. The ν decline was similar (data not shown) when testing much higher initial cell levels, which, however, required serial dilutions to perform the experiments (Supplementary Table 1, HH data).

Table 4. Osmotic inactivation rate (b) (day–1) parameters of L. monocytogenes at different initial cells (L, low inoculum; M, medium inoculum; H, high inoculum) and the COM-Poisson (Supplementary Box 1) dispersion parameter ν (assumed, at this step, as independent of the bacterial counts) obtained by the Poisson and COM-Poisson regressions.
The aggregation assay, which is based on bacterial sedimentation, was performed by measuring the optical absorbance of culture supernatant. With this assay, the aggregative ability of L. monocytogenes (Travier et al., 2013; Eshwar et al., 2017) was substantiated in the presence of salt and over time and enhanced (p < 0.05) in the osmotic medium (Supplementary Figure 1A). In the latter, the aggregative ability increased proportionally to the cell density (Supplementary Figure 1B). Although cell densities required for measuring auto-aggregation through the culture absorbance shift were higher than those used in our modeling experiments, these results supported the idea that aggregation during osmotic stress occurred in a concentration-dependent manner. Since aggregation can result in a clustered distribution with variance greater than its mean (over-dispersion), it is conceivable to hypothesize a role of cell-density mediated aggregation in over-dispersion, which was more relevant at the highest counts (H samples).
Stochastic Modeling of Dispersion
To quantify the variance contributors producing over-dispersion, we developed a model for ν [see section “Materials and Methods”: Eq. (13)] that through the c0 and εt parameters (Table 5) estimated the total variance and distinguished its contributors in terms of randomness, non-randomness, and an additional non-randomness arising during the osmotic treatment. This modeling approach allowed us to integrate and distinguish these different components of variation into simulations that are shown in Figure 4. The contribution of randomness to the total variance was confirmed to be dominant in the lower count (L samples) survivors of the osmotic inactivation procedure, where the non-randomness contribution to the variance, even that due to the osmotic treatment, was almost irrelevant. In the medium count survivors (M samples) the randomness contribution to variance was always dominant, but non-randomness, even that due to the osmotic treatment, was larger than in the L survivors. For both L and M samples the variance-to-mean ratios were around one. At the higher counts (H samples) the non-randomness increased the total variance above the Poisson distribution, making the osmotic non-randomness contribution more relevant. On the other hand, during the osmotic treatment, along with the decreasing number of survivors, the randomness tended to overtake the non-randomness contribution with the duration of the treatment. In these H samples the variance-to-mean ratio, initially predicted about four times larger than the mean, tended to be closer to the mean.

Table 5. Estimation and related regression statistics of ν model (Eq. 13) parameters.
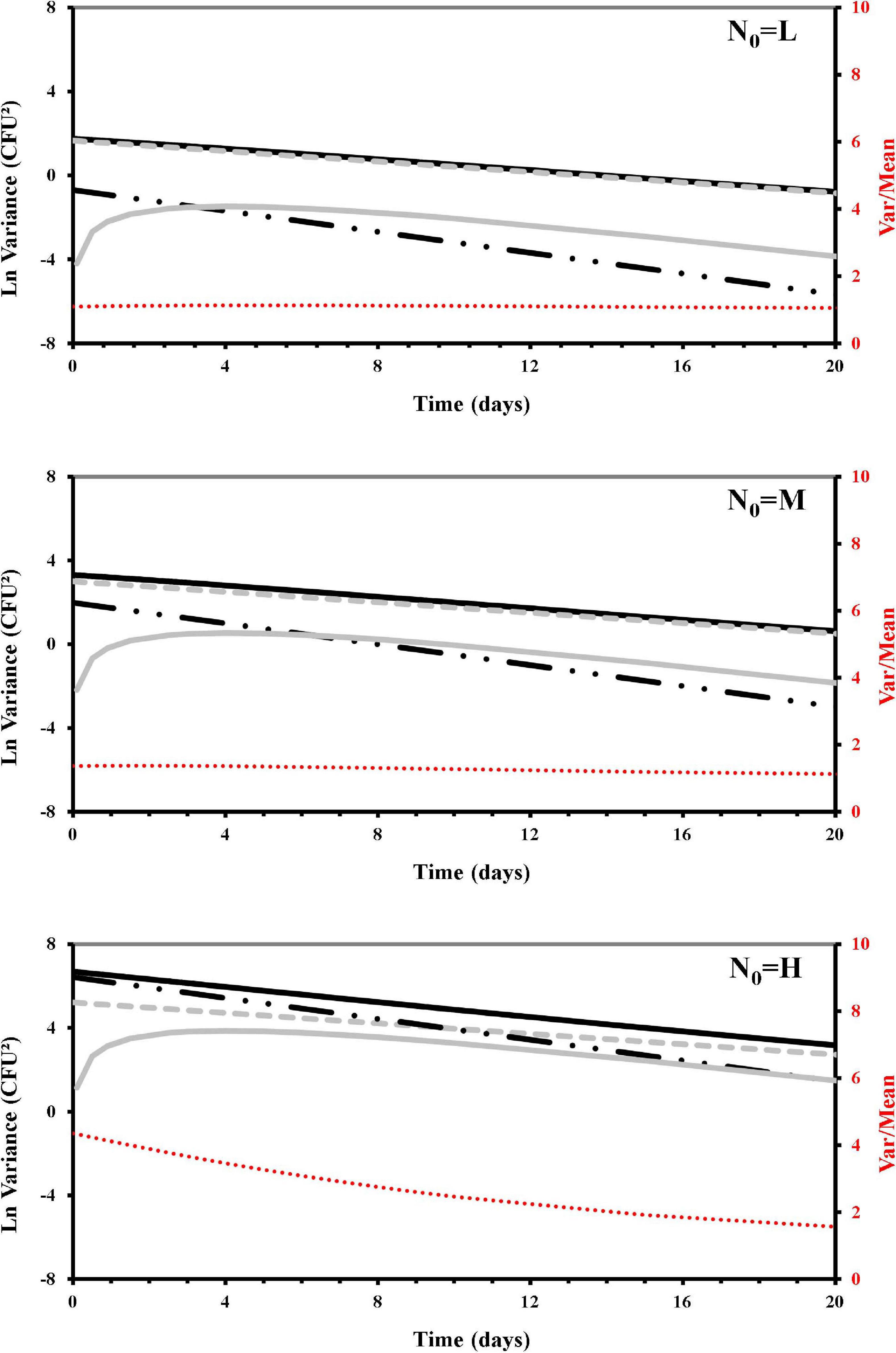
Figure 4. Simulated contributors to variance of Listeria monocytogenes survivors during the osmotic treatment, starting with different initial cells (L, low cell density; M, medium cell density; H, high cell density). Total variance (Var[Nt]): black solid line; Poisson variance E[Nt]: dashed gray line; non-randomness c0E[Nt]2: dashed black line; additional contribution (due to the osmotic treatment) to non-randomness εtt E[Nt]2/E[N0]1/2: gray solid line; variance over mean (secondary axis): dashed red line.
From the goodness of fit results (Table 6), it was evident that the Poisson and the COM-Poisson processes were quite distinct in terms of their ability to capture variance. The COM-Poisson overall performance, which was better than the Poisson, could be attributable to its ability to deal with over-dispersion exhibited by the higher counts.
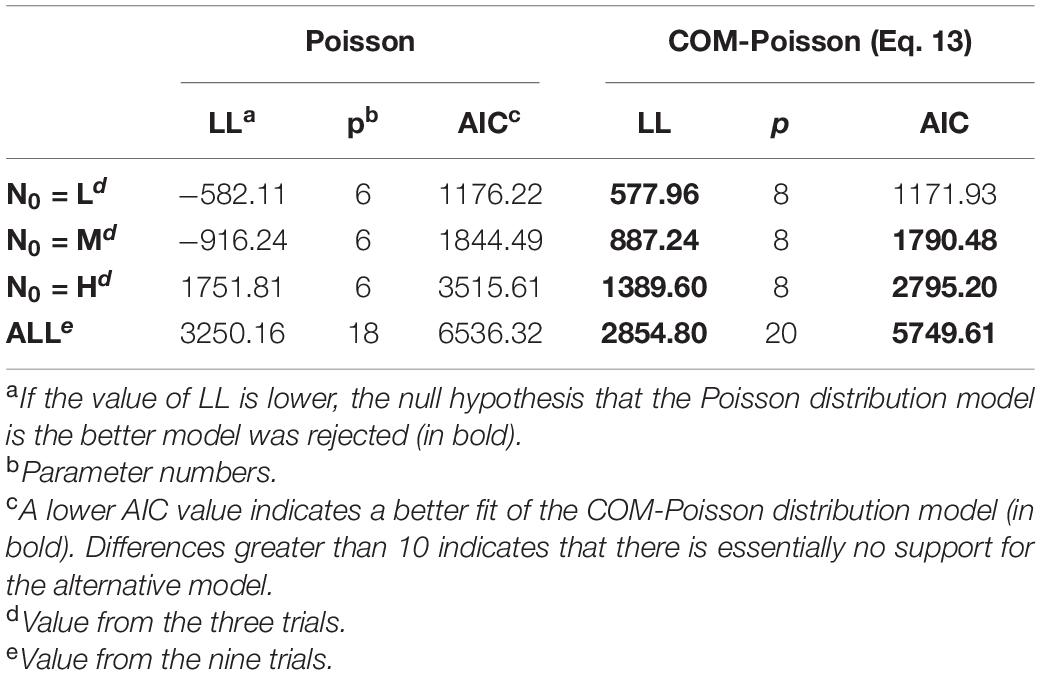
Table 6. Log-likelihood value (LL) and Akaike information criterion (AIC) values to determine the better-fitted distribution between the Poisson and the COM-Poisson (eq. 13) processes for L. monocytogenes observed survivors starting with different initial cells (L, low inoculum; M, medium inoculum; H, high inoculum).
Further diagnostic analysis of the COM-Poisson and Poisson processes was done applying the regression residual deviance. The null deviance, referred to the null model, which shows how well the response variable is predicted by a model including only the intercept, amounted to 69020.53 on 992 degrees of freedom (DF). Adding the variance components that are comprised in the Poisson and COM-Poisson frameworks the residual deviance, which represents the quantity of variation unexplained by the model, significantly decreased to 2604.10 (on 975 DF) and 1813.39 (on 973 DF), respectively. Hence, taking into account variation in the number of survivors, which were assigned to a combination of biological variability and uncertainty, the explanatory power of the processes increased, with the COM-Poisson providing a better description of the variance. It is worth noticing that the quantity of variation explained by the COM-Poisson process also encompassed over-dispersion.
Stochastic Inactivation Modeling and Comparison With Random Numbers Generated in a Computer Simulation
Monte Carlo, which is a common method to approximate the distribution of a model output, has been successfully used to describe variability and uncertainty in survival numbers (Akkermans et al., 2018; Abe et al., 2019; Garre et al., 2019). MC simulations were then used to model the variation in survivors at various initial cell counts in both the Poisson and the COM-Poisson frameworks (MC-Poisson and MC-COM), with the latter including the dispersion parameter ν (Table 7). Most of the observed values were within the MC estimated-ranges of the counts predicted in both processes. It is worth noticing that in the MC-COM the variations estimated at the higher counts were larger than those estimated in the MC-Poisson framework, which assumes only randomness. Since the dispersion parameter was successfully predicted by MC simulations, it could be inferred that other contributors to variance, i.e., non-randomness and an additional non-randomness emerging during the osmotic treatment, could have contributed to the observed differences in variations (Table 7). Therefore, the additional variance components in the observed values could be substantiated by the Monte Carlo within the COM-Poisson framework, which was able to describe the randomness and non-randomness bacterial behavior.
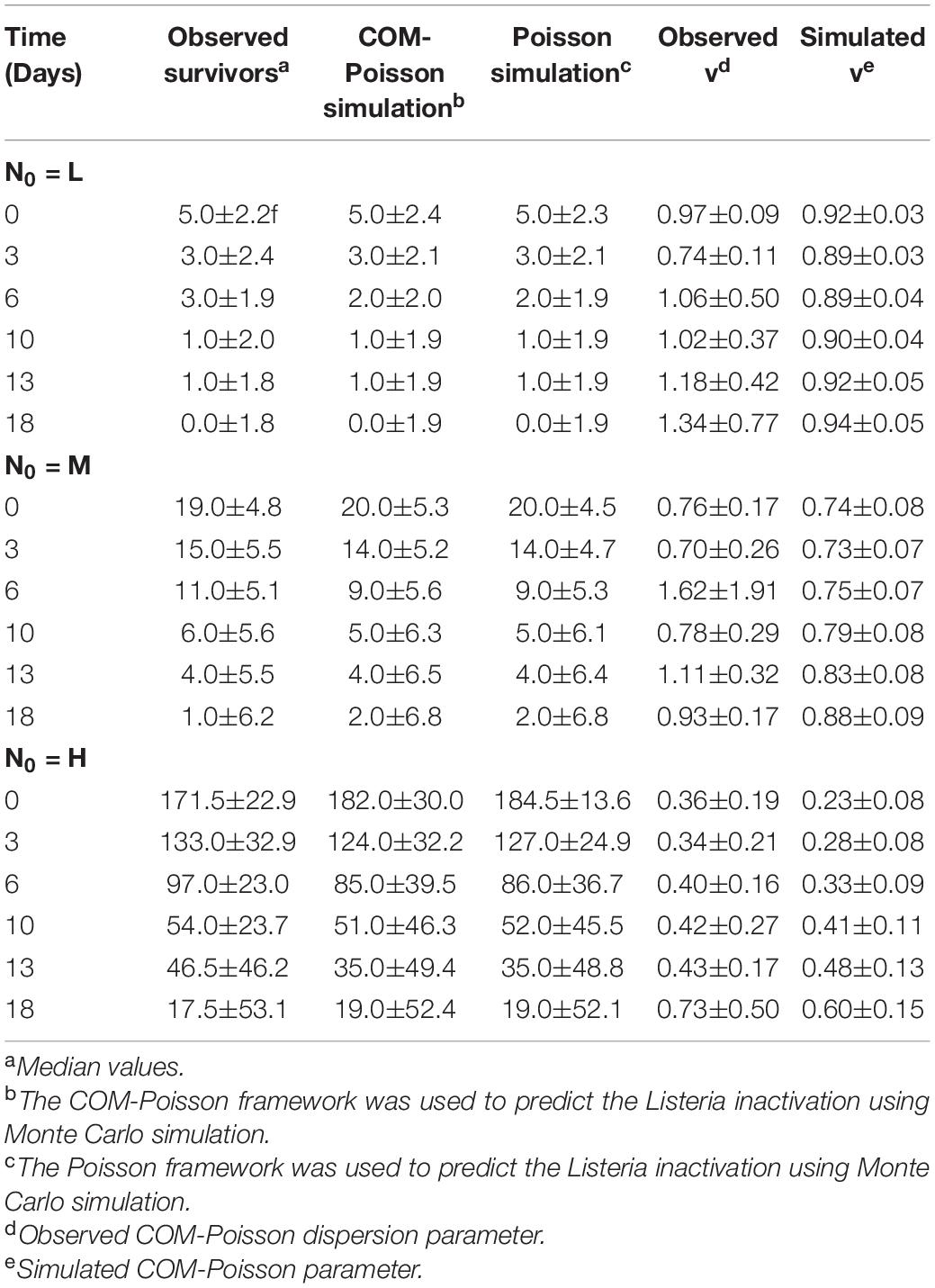
Table 7. Observed and Monte Carlo simulation results for osmotic inactivation of L. monocytogenes starting with different initial cells (L: low inoculum, M: medium inoculum, H: high inoculum).
Discussion
Dispersion of pathogenic microorganisms in food has a strong impact on public health (Jongenburger et al., 2012a). It is therefore of importance to provide a framework that can be used to represent and distinguish the randomness and the non-randomness components of variation. The COM-Poisson process, which refers to COM-Poisson distribution, can be a good candidate. In fact, the two-parameter COM-Poisson distribution, which has the Poisson distribution as a special case, can deal with both the over-dispersed (ν < 1) and under-dispersed (ν > 1) count data (Sellers and Shmueli, 2010; Francis et al., 2012), whereas the Poisson distribution has only one parameter, which represents both the expectations and variance of the count random variable. In addition, unlike the Poisson model where the conditional mean is central to interpretation, the COM-Poisson distribution, taking into account the complete conditional fitted distribution, uses a more general function of the response distribution (Sellers and Shmueli, 2010).
According to our results, and as reported by others (Koyama et al., 2016, 2019), initial small cell numbers followed the Poisson distribution, indicating that they exhibited naturally occurring randomness. On the other hand, larger amounts of cells mostly followed the COM-Poisson distribution, revealing over-dispersion. It is well known that only for low-density populations the cells can be randomly spread, whereas the frequent presence of clumps and aggregates in larger populations could result in the detection of over-dispersed data. However, in this context, it can be more accurate to model the over-dispersed microbial data under the theoretical interpretation of independent events and not to follow a true contagious process of non-independent events (Gonzales-Barron and Butler, 2011). Dispersion was then confirmed to be dependent on the initial number of cells, i.e., as the number of initial cells increased, the randomness contribution to the variance decreased, while over-dispersion increased.
Similarly to what was observed by others (Aspridou and Koutsoumanis, 2015), in the experiments conducted to generate the osmotic inactivation rates, number of cells, had no significant effect on the inactivation rates, possibly due to the lack of a cooperative behavior (García and Cabo, 2018). On the other hand, a trial effect was observed, suggesting that such effect could depend on each baseline population history, which determines both regulatory and mutational responses to new environments (Ryall et al., 2012). The biological individuality, which refers also to cell to cell variations from a given species, is therefore of great importance in the case of microbial inactivation (Aspridou and Koutsoumanis, 2015, 2020). Unlike what was observed for the rate of inactivation, the dispersion parameter ν did not respond to determinants other than the cell levels, reinforcing the view of the importance of the number of cells as effectors of over-dispersion.
Following inactivation, the stochastic variation dominated in the smaller populations. However, even randomly dispersed populations may allow for the survival of over-dispersed cell populations. Thus, the results on the survival Listeria cells ultimately justified the use of the COM-Poisson over the Poisson distribution in its ability to fit differently dispersed count data and sustained the idea that when an osmotic treatment is applied it allows for the survival of over-dispersed cell populations. This additional contribution to the total variance in terms of non-randomness, noticed in the populations following the osmotic stress, is consistent with the hypothesis that over-dispersion could be due to aggregation. L. monocytogenes aggregation is mediated by key virulence determinants and can represent a strategy for surviving in inimical environments as those at high NaCl concentration (Jensen et al., 2007; Travier et al., 2013; Eshwar et al., 2017). Hence, the non-randomness, attributable to bacterial abundance, could also arise following an osmotic stress that can contribute to cell aggregation (Schmid et al., 2009).
Quantification of the variance contributors of over-dispersion through the ν (dispersion) model allowed us to integrate the different components of variation into the COM-Poisson inactivation process. This latter process enabled the description of the survival of different-sized populations by introducing the COM-Poisson distribution for survivors along with the modelled COM-Poisson dispersion parameter (ν). Although a number of stochastic models describing the population randomness under inactivation have been developed (Aguirre et al., 2009; Koyama et al., 2017; Abe et al., 2019; Hiura et al., 2020), less attention has been paid to modeling other variance components, such as the non-randomness (Reinders et al., 2003, 2004; Gonzales-Barron and Butler, 2011). Thus, we proposed a statistical modeling approach, suitable for count data, for accurately estimating the variation in microbial response to an osmotic inactivation and to capture the randomness and non-randomness contributions to the total variance that can have practical implications when dealing with intervention strategies capable of controlling pathogens. The suitability of the approach was demonstrated by its flexibility in handling different dispersion types addressing the variance contributors in different-sized populations. The variation in bacterial numbers, as defined in this study in the context of osmotic stress, and the notions of the random and non-random occurrence of surviving bacteria, could be applied to other hurdles or processes, i.e., thermal processing, used to inactivate bacteria for managing food safety in more realistic conditions.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author/s.
Author Contributions
MS and PP: conception and design of the study. MD: acquisition, analyses, and interpretation of data. MS: drafting of manuscript. MS, MD, and PP: critical revision and final approval of the version to be submitted. All authors contributed to the article and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We sincerely thank Cristina Presacco for her excellent technical contribution.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmicb.2021.681468/full#supplementary-material
Supplementary Figure 1 | Quantification of the autoaggregation ability (%) of L. monocytogenes in PBS and in osmotic PBS: (A) effect of salt; (B) effect of initial optical density.
Supplementary Table 1 | Excel workbook containing observed count data.
Supplementary Table 2 | Excel workbook containing Poisson and COM-Poisson regressions as examples.
Supplementary Table 3 | Excel workbook containing Poisson and COM-Poisson random numbers routines.
Supplementary Box 1 | Conway-Maxwell-Poisson Regression.
Supplementary Box 2 | Equation (8, 9) in the text.
Supplementary Box 3 | Empirical approach for selecting the additional non-randomness model component.
Abbreviations
AIC, Akaike information criterion; aw, water activity; CFU, colony forming units; COM-Poisson, Conway-Maxwell Poisson; DF, degrees of freedom; H, high inoculum; L, low inoculum; LL, log- likelihood; LR, likelihood ratio; M, medium inoculum; MC, Monte Carlo; NTI, non-thermal inactivation; OD, optical density; P-LR, p-values of the likelihood ratio; QMRA, quantitative microbial risk assessment.
References
Abe, H., Koyama, K., Kawamura, S., and Koseki, S. (2019). Stochastic modeling of variability in survival behavior of Bacillus simplex spore population during isothermal inactivation at the single cell level using a Monte Carlo simulation. Food Microbiol. 82, 436–444. doi: 10.1016/j.fm.2019.03.005
Aguirre, J. S., Pin, C., Rodríguez, M. R., and García de Fernando, G. D. (2009). Analysis of the variability in the number of viable bacteria after mild heat treatment of food. Appl. Environ. Microb. 75, 6992–6997. doi: 10.1128/AEM.00452-09
Akkermans, S., Nimmegeers, P., and Van Impe, J. F. (2018). A tutorial on uncertainty propagation techniques for predictive microbiology models: a critical analysis of state-of-the-art techniques. Int. J. Food Microbiol. 282, 1–8. doi: 10.1016/j.ijfoodmicro.2018.05.027
Aspridou, Z., Balomenos, A., Tsakanikas, P., Manolakos, E., and Koutsoumanis, K. P. (2019). Heterogeneity of single cell inactivation: assessment of the individual cell time to death and implications in population behavior. Food Microbiol. 80, 85–92. doi: 10.1016/j.fm.2018.12.011
Aspridou, Z., and Koutsoumanis, K. P. (2015). Individual cell heterogeneity as variability source in population dynamics of microbial inactivation. Food Microbiol. 45, 216–221. doi: 10.1016/j.fm.2014.04.008
Aspridou, Z., and Koutsoumanis, K. P. (2020). Variability in microbial inactivation: from deterministic Bigelow model to probability distribution of single cell inactivation times. Food Res. Int. 137:109579. doi: 10.1016/j.foodres.2020.109579
Augustin, J.-C., Bergis, H., Midelet-Bourdin, G., Cornu, M., Couvert, O., Denis, C., et al. (2011). Design of challenge testing experiments to assess the variability of Listeria monocytogenes growth in foods. Food Microbiol. 28, 746–754. doi: 10.1016/j.fm.2010.05.028
Baka, M., Noriega, S., Van Langendonck, K., and Van Impe, J. F. (2016). Influence of food intrinsic complexity on Listeria monocytogenes growth in/on vacuum-packed model systems at suboptimal temperatures. Int. J. Food Microbiol. 235, 17–27. doi: 10.1016/j.ijfodmicro.2016.06.029
Baka, M., Vercruyssen, S., Cornette, N., and Van Impe, J. F. (2017). Dynamics of Listeria monocytogenes at suboptimal temperatures in/on fish-protein based model systems: effect of (micro)structure and microbial distribution. Food Control 73, 43–50. doi: 10.1016/j.foodcont.2016.06.031
Ballio, F., and Guadagnini, A. (2004). Convergence assessment of numerical Monte Carlo simulations in groundwater hydrology. Water Resour. Res. 40:W04603. doi: 10.1029/2003WR002876
Becker, L. A., Cetin, M. S., Hutkins, R. W., and Benson, A. K. (1998). Identification of the gene encoding the alternative sigma factor sigmaB from Listeria monocytogenes and its role in osmotolerance. J. Bacteriol. 180, 4547–4554. doi: 10.1128/JB.180.17.4547-4554
Briers, Y., Klumpp, J., Schuppler, M., and Loessner, M. J. (2011). Genome sequence of Listeria monocytogenes Scott A, a clinical isolate from a food-borne listeriosis outbreak. J. Bacteriol. 193, 4284–4285. doi: 10.1128/JB.05328-11
Buchanan, R. L., Gorris, L. G. M., Hayman, M. M., Jackson, T. C., and Whiting, R. C. (2017). A review of Listeria monocytogenes: an update on outbreaks, virulence, dose-response, ecology, and risk assessments. Food Control 75, 1–13. doi: 10.1016/j.foodcont.2016.12.016
Bucur, F. I., Grigore-Gurgu, L., Crauwels, P., Riedel, C. U., and Nicolau, A. I. (2018). Resistance of Listeria monocytogenes to stress conditions encountered in food and food processing environments. Front. Microbiol. 9:2700. doi: 10.3389/fmicb.2018.02700
Collado, M. C., Meriluoto, J., and Salminen, S. (2008). Adhesion and aggregation properties of probiotic and pathogen strains. Eur. Food Res. Technol. 22, 1065–1073. doi: 10.1007/s00217-007-0632-x
Comuzzi, C., Polese, P., Melchior, A., Portanova, R., and Tolazzi, M. (2003). SOLVERSTAT: a new utility for multipurpose analysis. An application to the investigation of dioxygenated Co(II) complex formation in dimethylsulfoxide solution. Talanta 59, 67–80. doi: 10.1016/s0039-9140(02)00457-5
Conway, R. W., and Maxwell, W. L. (1962). A queueing model with state dependent service rate. J. Indstrl. Engn. 12, 132–136.
Couvert, O., Pinon, A., Bergis, H., Bourdichon, F., Carlin, F., Cornu, M., et al. (2010). Validation of a stochastic modelling approach for Listeria monocytogenes growth in refrigerated foods. Int. J. Food Microbiol. 144, 236–242. doi: 10.1016/j.ijfoodmicro.2010.09.024
den Besten, H. M. W., Amézquita, A., Bover-Cid, S., Dagnas, S., Ellouzee, M., Guillou, S., et al. (2018). Next generation of microbiological risk assessment: potential of omics data for exposure assessment. Int. J. Food Microbiol. 287, 18–27. doi: 10.1016/j.ijfoodmicro.2017.10.006
Durack, J., Ross, T., and Bowman, J. P. (2013). Characterisation of the transcriptomes of genetically diverse Listeria monocytogenes exposed to hyperosmotic and low temperature conditions reveal global stress-adaptation mechanisms. PLoS One 8:e73603. doi: 10.1371/journal.pone.0073603
El-Shaarawi, A. H., Esterby, S. R., and Dutka, B. J. (1981). Bacterial density in water determined by Poisson or negative binomial distributions. Appl. Environ. Microb. 41, 107–116.
Eriksen, R. S., Mitarai, N., and Sneppen, K. (2020). Sustainability of spatially distributed bacteria-phage systems. Sci. Rep. 10:, 3154. doi: 10.1038/s41598-020-59635-7
Eshwar, A. K., Guldimann, C., Oevermann, A., and Tasara, T. (2017). Cold-shock domain family proteins (Csps) are involved in regulation of virulence, cellular aggregation, and flagella-based motility in Listeria monocytogenes. Front. Cell Infect. Microbiol. 7:453. doi: 10.3389/fcimb.2017.00453
European Food Safety Authority (EFSA) (2012). Scientific opinion on public health risks represented by certain composite products containing food of animal origin. EFSA J. 10:2662. doi: 10.2903/j.efsa.2012.2662
European Food Safety Authority (EFSA) (2018). Listeria monocytogenes contamination of ready-to-eat foods and the risk for human health in the EU. EFSA J. 16:5134. doi: 10.2903/j.efsa.2018.5134
European Food Safety Authority (EFSA) Scientific Committee, Benford, D., Halldorsson, T., Jeger, M. J., Knutsen, H. K., More, S., et al. (2018). Guidance on uncertainty analysis in scientific assessments. EFSA J. 16:5123. doi: 10.2903/j.efsa.2018.5123
Francis, R. A., Geedipally, S. R., Guikema, S. D., Dhavala, S. S., Lord, D., and LaRocca, S. (2012). Characterizing the performance of the Conway-Maxwell Poisson generalized linear model. Risk Anal. 32, 167–183. doi: 10.1111/j.1539-6924.2011.01659.x
Gao, M., Zheng, H., Ren, Y., Lou, R., Wu, F., Yu, W., et al. (2016). A crucial role for spatial distribution in bacterial quorum sensing. Sci. Rep. 6: 34695. doi: 10.1038/srep34695
García, M. R., and Cabo, M. L. (2018). Optimization of E. coli inactivation by benzalkonium chloride reveals the importance of quantifying the inoculum effect on chemical disinfection. Front. Microbiol. 9:1259. doi: 10.3389/fmicb.2018.01259
Garre, A., Egea, J. A., Esnoz, A., Palop, A., and Fernandez, P. S. (2019). Tail or artefact? Illustration of the impact that uncertainty of the serial dilution and cell enumeration methods has on microbial inactivation. Food Res. Int. 119, 76–83. doi: 10.1016/j.foodres.2019.01.059
Gonzales-Barron, U., and Butler, B. (2011). A comparison between the discrete Poisson-gamma and Poisson-lognormal distributions to characterise microbial counts in foods. Food Control 22, 1279–1286. doi: 10.1016/j.foodcont.2011.01.029
Gonzales-Barron, U., Cadavez, V., and Butler, B. (2014). Conducting inferential statistics for low microbial counts in foods using the Poisson-gamma regression. Food Control 37, 385–394. doi: 10.1016/j.foodcont.2013.09.032
Gonzales-Barron, U., Kerr, M., Sheridan, J. J., and Butler, B. (2010). Count data distributions and their zero-modified equivalents as a framework for modelling microbial data with a relatively high occurrence of zero counts. Int. J. Food Microbiol. 136, 268–277. doi: 10.1016/j.ijfoodmicro.2009.10.016
Guikema, S. D., and Goffelt, J. P. (2008). A flexible count data regression model for risk analysis. Risk Anal. 28, 213–223. doi: 10.1111/j.1539-6924.2008.01014.x
Gupta, R. C., Sim, S. Z., and Ong, S. H. (2014). Analysis of discrete data by Conway–Maxwell Poisson distribution. Adv. Stat. Anal. 98, 327–343. doi: 10.1007/s10182-014-0226-4
Hahn, G. J. (1972). Sample sizes for Monte Carlo simulation. IEEE Syst. Man Cybern. Soc. 5, 678–680.
Hardin, J. H., and Hilbe, J. M. (2018). Generalized Linear Models and Extensions. College Station, TX: Stata Press.
Harding, B., Tremblay, C., and Cousineau, D. (2014). Standard errors: a review and evaluation of standard error estimators using Monte Carlo simulations. Quant. Method Psychol. 10, 107–123. doi: 10.20982/tqmp.10.2.p107
Hiura, S., Abe, H., Koyama, K., and Koseki, S. (2020). Transforming kinetic model into a stochastic inactivation model: statistical evaluation of stochastic inactivation of individual cells in a bacterial population. Food Microbiol. 91:103508. doi: 10.1016/j.fm.2020.103508
Hui, C., Veldtman, R., and McGeoch, M. A. (2010). Measures, perceptions and scaling patterns of aggregated species distributions. Ecography 33, 95–102. doi: 10.1111/j.1600-0587.2009.05997.x
Huntley, J. (2005). Generation of Random Variates version 1.0, MatLab Central. Available online at: https://www.mathworks.com/matlabcentral/fileexchange/35008-generation-of-random-variates/ (accessed October 2, 2019).
Jarvis, B. (2016). “The distribution of microorganisms in foods in relation to sampling,” in Statistical Aspects of the Microbiological Examination of Foods, ed. B. Jarvis (London: Elsevier Academic Press), 45–69.
Jeanson, S., Chadoeuf, J., Madec, M.-N., Aly, S., Floury, J., Brocklehurst, T. F., et al. (2011). Spatial distribution of bacterial colonies in amodel cheese. Appl. Environ. Microbiol. 77, 1493–1500. doi: 10.1128/AEM.02233-10
Jeanson, S., Floury, J., Gagnaire, V., Lortal, S., and Thierry, A. (2015). Bacterial colonies in solid media and foods: a review on their growth and interactions with the micro-environment. Front. Microbiol. 6:1284. doi: 10.3389/fmicb.2015.01284
Jensen, A., Larsen, M. H., Ingmer, H., Vogel, B. F., and Gram, L. (2007). Sodium chloride enhances adherence and aggregation and strain variation influences invasiveness of Listeria monocytogenes strains. J. Food Prot. 70, 592–599. doi: 10.4315/0362-028X-70.3.592
Jongenburger, I., Bassett, J., Jackson, T., Gorris, L. G. M., Jewell, K., and Zwietering, M. H. (2012a). Impact of microbial distributions on food safety II. Quantifying impacts on public health and sampling. Food Control 26, 546–554. doi: 10.1016/j.foodcont.2012.01.064
Jongenburger, I., Bassett, J., Jackson, T., Gorris, L. G. M., Zwietering, M. H., and Jewell, K. (2012b). Impact of microbial distributions on food safety I. Factors influencing microbial distributions and modelling aspects. Food Control 26, 601–609. doi: 10.1016/j.foodcont.2012.02.004
Kapetanakou, A. E., Makariti, I. P., Nazou, E. N., Manios, S. G., Karavasilis, K., and Skandamis, P. N. (2019). Modelling the effect of osmotic adaptation and temperature on the non–thermal inactivation of Salmonella spp. on brioche-type products. Int. J. Food Microbiol. 296, 48–57. doi: 10.1016/j.ijfoodmicro.2019.02.010
Knuth, D. E. (1997). The Art of Computer Programming, vol. 2 Seminumerical Algorithms. Boston, MA: Addison-Wesley Longman Publishing Co.
Koutsoumanis, K. P., and Angelidis, A. S. (2007). Probabilistic modeling approach for evaluating the compliance of ready -to- eat foods with new European Union safety criteria for Listeria monocytogenes. Appl. Environ. Microb. 73, 4996–5004. doi: 10.1128/AEM.00245-07
Koutsoumanis, K. P., and Aspridou, Z. (2017). Individual cell heterogeneity in predictive food microbiology: challenges in predicting a “noisy” world. Int. J. Food Microbiol. 240, 3–10. doi: 10.1016/j.ijfoodmicro.2016.06.021
Koutsoumanis, K. P., Lianou, A., and Gougouli, M. (2016). Latest developments in foodborne pathogens modelling. Curr. Opin. Food Sci. 8, 89–98. doi: 10.1016/j.cofs.2016.04.006
Koyama, K., Abe, H., Kawamura, S., and Koseki, S. (2019). Stochastic simulation for death probability of bacterial population considering variability in individual cell inactivation time and initial number of cells. Int. J. Food Microbiol. 290, 125–131. doi: 10.1016/j.ijfoodmicro.2018.10.009
Koyama, K., Hokunan, H., Hasegawa, M., Kawamura, S., and Koseki, S. (2016). Do bacterial cell numbers follow a theoretical Poisson distribution? Comparison of experimentally obtained numbers of single cells with random number generation via computer simulation. Food Microbiol. 60, 49–53. doi: 10.1016/j.fm.2016.05.019
Koyama, K., Hokunan, H., Hasegawa, M., Kawamura, S., and Koseki, S. (2017). Modeling stochastic variability in the numbers of surviving Salmonella enterica, enterohemorrhagic Escherichia coli, and Listeria monocytogenes cells at the single-cell level in a desiccated environment. Appl. Environ. Microb. 83, e2974–e2916. doi: 10.1128/AEM.02974-16
Lindqvist, R., and Lindblad, M. (2009). Inactivation of Escherichia coli, Listeria monocytogenes and Yersinia enterocolitica in fermented sausages during maturation/storage. Int. J. Food Microbiol. 129, 59–67. doi: 10.1016/j.ijfoodmicro.2008.11.011
Lynch, H. J., Thorson, J. T., and Shelton, A. O. (2014). Dealing with under- and over-dispersed count data in life history, spatial, and community ecology. Ecology 95, 3173–3180. doi: 10.1890/13-1912.1
Mataragas, M., Bellio, A., Rovetto, F., Astegiano, S., Greci, C., Hertel, C., et al. (2015). Quantification of persistence of the food-borne pathogens Listeria monocytogenes and Salmonella enterica during manufacture of Italian fermented sausages. Food Control 47, 552–559. doi: 10.1016/j.foodcont.2014.07.058
Membré, J. M., and van Zuijlen, A. (2011). A probabilistic approach to determine thermal process setting parameters: application for commercial sterility of products. Int. J. Food Microbiol. 144, 413–420. doi: 10.1016/j.ijfoodmicro.2010.10.028
Membré, J. M., Ameìzquita, A., Bassett, J., Giavedoni, P., Blackburn, C., de, W., et al. (2006). A probabilistic modeling approach in thermal inactivation: estimation of postprocess Bacillus cereus spore prevalence and concentration. J. Food Prot. 69, 118–129. doi: 10.4315/0362-028x-69.1.118
Minka, T. P., Shmueli, G., Kadane, J. B., Borle, S., and Boatwright, P. (2003). Computing with the COM-Poisson distribution. Technical Report 775. Pittsburgh, PA: Department of Statistics, Carnegie Mellon University.
Nauta, M. J. (2000). Separation of uncertainty and variability in quantitative microbial risk assessment models. Int. J. Food Microbiol. 57, 9–18. doi: 10.1016/S0168-1605(00)00225-7
Nelder, J., and Wedderburn, R. (1972). Generalized linear models. J. R. Stat. Soc. A Stat. 135, 370–384.
Nightingale, K. K., Thippareddi, H., Phebus, R. K., Marsden, J. L., and Nutsch, A. L. (2006). Validation of a traditional Italian-style salami manufacturing process for control of Salmonella and Listeria monocytogenes. J. Food Prot. 69, 794–800. doi: 10.4315/0362-028x-69.4.794
Oberle, W. (2015). Monte Carlo Simulations: Number of Iterations and Accuracy. Technical note: US Army Research Laboratory. ARL-TN-0684. Aberdeen Proving Ground, MD: US Army Research Laboratory.
Payne, E. H., Hardin, J. H., Egede, L. E., Ramakrishnan, V., Selassie, A., and Gebregziabher, M. (2017). Approaches for dealing with various sources of overdispersion in modeling count data: scale adjustment versus modelling. Stat. Methods Med. Res. 26, 1802–1823. doi: 10.1177/0962280215588569
Polese, P., Del Torre, M., and Stecchini, M. L. (2017). Prediction of the impact of processing critical conditions for Listeria monocytogenes growth in artisanal dry-fermented sausages (salami) through a growth/no growth model applicable to time-dependent conditions. Food Control 75, 167–180. doi: 10.1016/j.foodcont.2016.12.002
Press, W. H., Teukolsky, S. A., Vetterling, W. T., and Flannery, B. P. (1997). Numerical Recipes in C, The Art of Scientific Computing. Cambridge: Cambridge University Press.
Radoshevich, L., and Cossart, P. (2018). Listeria monocytogenes: towards a complete picture of its physiology and pathogenesis. Nat. Rev. Microbiol. 16, 32–46. doi: 10.1038/nrmicro.2017.126
Reinders, R. D., De Jonge, R., and Evers, E. G. (2003). A statistical method to determine whether micro-organisms are randomly distributed in a food matrix, applied to coliforms and Escherichia coli O157 in minced beef. Food Microbiol. 20, 297–303. doi: 10.1016/S0740-0020(02)00134-X
Reinders, R. D., De Jonge, R., and Evers, E. G. (2004). Corrigendum to: “a statistical method to determine whether micro-organisms are randomly distributed in a food matrix, applied to coliforms and Escherichia coli O157 in minced beef”. Food Microbiol. 21:819.
Rigby, R. A., Stasinopoulos, D. M., and Akantziliotou, C. (2008). A framework for modelling overdispersed count data, including the Poisson-shifted generalized inverse Gaussian distribution. Comput. Stat. Data Anal. 53, 381–393. doi: 10.1016/j.csda.2008.07.043
Ryall, B., Eydallin, G., and Ferenci, T. (2012). Culture history and population heterogeneity as determinants of bacterial adaptation: the adaptomics of a single environmental transition. Microbiol. Rev. 76, 597–625. doi: 10.1128/mmbr.05028-11
Santner, T. J., and Duffy, D. E. (1989). The Statistical Analysis of Discrete Data. New York, NY: Springer-Verlag.
Schendel, T., Jung, C., Lindtner, O., and Greiner, M. (2018). Guidelines for uncertainty Analysis: Application of the Respective Documents of EFSA and BfR for Exposure Assessments. EFSA Supporting Publication 2018: EN-1472. Parma: European Food Safety Authority, doi: 10.2903/sp.efsa.2018.EN-1472
Schmid, B., Klumpp, J., Raimann, E., Loessner, M. J., Stephan, R., and Tasara, T. (2009). Role of cold shock proteins in growth of Listeria monocytogenes under cold and osmotic stress conditions. Appl. Environ. Microb. 75, 1621–1627. doi: 10.1128/aem.02154-08
Sellers, K. F., and Morris, D. S. (2017). Underdispersion models: models that are “under the radar”. Commun. Stat. Theory Methods 46, 12075–12086. doi: 10.1080/03610926.2017.1291976
Sellers, K. F., and Raim, A. (2016). A flexible zero-inflated model to address data dispersion. Comput. Stat. Data Anal. 99, 68–80. doi: 10.1016/j.csda.2016.01.007
Sellers, K. F., and Shmueli, G. (2010). A flexible regression model for count data. Ann. Appl. Stat. 4, 943–961. doi: 10.1214/09-AOAS306
Shmueli, G., Minka, T. P., Kadane, J. B., Borle, S., and Boatwright, P. (2005). A useful distribution for fitting discrete data: revival of the Conway–Maxwell–Poisson distribution. J. R. Stat. Soc. Ser. C Appl. Stat. 54, 127–142. doi: 10.1111/j.1467-9876.2005.00474.x
Sretenovic, S., Stojković, B., Dogsa, I., Kostanjsek, R., Poberaj, I., and Stopar, D. (2017). An early mechanical coupling of planktonic bacteria in dilute suspensions. Nat. Commun. 8:213. doi: 10.1038/s41467-017-00295-z
Thomopoulos, N. T. (2013). Essentials of Monte Carlo Simulation, Statistical Methods for Building Simulation Models. New York, NY: Springer-Verlag.
Tin, A. (2008). Modeling Zero-Inflated Count Data With Underdispersion and Overdispersion. SAS Global Forum 2008. SAS Global Forum 2008: Statistics and Data Analysis. Available online at: http://www2.sas.com/proceedings/forum2008/372-2008 (accessed September 16, 2020).
Travier, L., Guadagnini, S., Gouin, E., Dufour, A., Chenal-Francisque, V., Cossart, P., et al. (2013). ActA promotes Listeria monocytogenes aggregation, intestinal colonization and carriage. PLoS Pathog. 9:e1003131. doi: 10.1371/journal.ppat.1003131
Vrieze, S. I. (2012). Model selection and psychological theory: a discussion of the differences between the akaike information criterion (AIC) and the bayesian information criterion (BIC). Psychol. Methods 17, 228–243. doi: 10.1037/a00227127
Keywords: Listeria monocytogenes, osmotic inactivation, modeling, variation, Poisson, Conway-Maxwell-Poisson, population levels, Monte Carlo
Citation: Polese P, Del Torre M and Stecchini ML (2021) The COM-Poisson Process for Stochastic Modeling of Osmotic Inactivation Dynamics of Listeria monocytogenes. Front. Microbiol. 12:681468. doi: 10.3389/fmicb.2021.681468
Received: 16 March 2021; Accepted: 31 May 2021;
Published: 09 July 2021.
Edited by:
Lin Lin, Jiangsu University, ChinaReviewed by:
Lina Sheng, University of California, Davis, United StatesBeatrix Stessl, University of Veterinary Medicine Vienna, Austria
Davy Verheyen, KU Leuven, Belgium
Copyright © 2021 Polese, Del Torre and Stecchini. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mara Lucia Stecchini, bWFyYS5zdGVjY2hpbmlAdW5pdWQuaXQ=